Embed Size (px)
Citation preview

STATISTIKA
1. Osnovni pojmovi
Matematicka statistika se bavi proucavanjem skupova sa velikim brojem elemenata, koji su jednorodniu odnosu na jedno ili vise zajednickih kvalitatitvnih ili kvantitativnih svojstava. Kako individualnislucajevi mogu pokazivati manja ili veca odstupanja od prosecnog ili tipicnog, to je neophodno da seposmatraju u velikom broju, u masi, da bi se otkrilo ono sto je njima opste i zakonito - jer se zakonitostispoljava u masi.
Predmet ispitivanja Matematicke statistike su skupovi (populacije, mase) ciji su elementi objekti ipojave raznolikog karaktera. Skip elemenata koji posmatramo zove se populacija (ili generalni skup, iliprostor uzoraka). Kod svakog elementa (statisticke jedinice) posmatramo njegovu odredenu numerickukarakteristiku X, koju nazivamo obelezjem. Ako populaciju posmatramo kao skup Ω elementarnihdogadaja ω, onda je obelezje X = X(ω) numericka funkcija definisana nad Ω.
Primer 1. Kutija sadrezi N kuglica od kojih N · p belih i N · q crnih (p + q = 1). Tih N kuglica u
kutiji cini jednu populaciju. Kao obelezje svakog elementa (kuglice) uzecemo njenu boju. To nije numericka
karakteristika, ali moze se lalo svesti na takvu. Na primer, stavimo da je obelezje 1 ako je kuglica bela i 0 ako je
crna (kodiranje).
Primer 2. Skup svih seoskih domacinstva neke zemlje cini jednu populaciju. Obelezje svakog domacinstva
moze da bude velicina poseda, broj konja, prinos psenice, itd.
Primer 3. Celokupna proizvodnja fabrike sijalica cini jednu populaciju. Obelezje svake sijalice moze, na
primer, da bude ,,duzina zivota” izrazena u casovima.
Broj elemenata populacije moze da bude konacan ili beskonacan (prebrojiv ili neprebrojiv). Primetimoda kod svakog elementa mozemo da posmatramo ne samo jedno obelezje, vec dva ili vise istovremeno(Primer 2). U tom slucaju ponekad je od interesa posmatrati njihovu meduzavisnost.
Osnovni problem kojim se Matematicka statistika bavi sastoji se u sledecem: za datu populacijunaci raspodelu datog obelezja na njenim elementima. U toku statistickog proucavanja mogu serazlikovati tri etape:
1) statisticko posmatranje;
2) grupisanje i sredivanje podataka;
3) obrada sa naucnom analizom rezultata.
Primer 1’. Zamislimo da nam je nepoznat broj belih i crnih kuglica. Raspodelu obelezja znacemo ako
oderdimo broj p jer tada imamo Np belih i N −Np = Nq crnih kuglica.
Primer 2’. Ako je obelezje velicina poseda, raspodelu tog obelezja imamo ako znamo koliko je poseda od 0
do 1 hektara, 1–2 hektara, itd.
Primer 3’. Raspodelu ,,duzine zivota” znamo ako nam je poznat procenat proizvedenih sijalica cija je ,,duzina
zivota” u odredenim granica [a, b] za svako a, b (a < b).
Statisticka ispitivanja mogu se podeliti na dve vrste:
1

2
1) potpuna ispitivanja celokupne populacije;
2) delimicna ispitivanja, odnosno ispitivanje jednog dela populacije (uzorka).
Prva vrsta ispitivanja je vrlo retka u praksi. U ogromnoj vecini slucajeva koje srecemo u primenamanije moguce dobiti kompletnu informaciju o raspodeli obelezja u celoj populaciji. Razlog moze da leziu brojnosti populacije, u velikim troskovima vezanim sa registrovanjem obelezja kod svakog elementa,velikim gubitkom vremena, unistavanju elemenata populacije (Primer 3), itd.
Zbog navedenih teskoca, po pravilu se iz cele populacije uzima jedan deo i to konacan i on se izucava.Taj deo se zove uzorak. Broj elemenata u uzorku je konacan i zove se obim uzorka. Na izabranomuzorku regustruje se obelezje kod svakog elementa a zatim se vrsi ekstrapolacija na celu populaciju, tj.dobijena raspodela obelezja prosiruje se sa uzorka na ceo skup. Odmah se namece pitanje tzv. reprezen-tativnosti takvog uzorka. Bez matematicke rigoroznosti mozemo reci da je neki metod uzimanja delapopulacije reprezentativan, ako je kriterijum po kome se uzima taj deo nezavisan od obelezja koje pos-matramo. Jedan od nacina postizanja reprezentativnosti je da taj deo izaberemo slucajno.
Metod slucajnog uzorka sastoji se u tome da se slucajno bira element ω iz Ω i registruje njegovoobelezje X = X(ω). Dakle, obelezje X je slucajna promenljiva i neka je F (x) njena funkcija raspodele.Ako vrsimo n takvih biranja elemenata, odnosno registrovanja obelezja X, imamo uzorak obima n, tj.n-dimenzionalnu slucajnu promenljivu (X1, . . . , Xn), gde je Xi (i = 1, . . . , n) obelezje X u i-tom biranju.
Prost slucajni uzorak je uzorak kod koga su slucajne promenljive Xi (i = 1, . . . , n) nezavisnei imaju istu raspodelu kao X. Odredene numericke vrednosti kojima registrujemo slucajne promenljiveXi (i = 1, . . . , n) obelezavamo malim slovima xi. n-dimenzionalni vektor (x1, . . . , xn) baziva se realizo-van uzorak.
Ocena generalnog skupa (populacije) na osnovu podataka iz uzorka, predstavlja oblik induktivnoguopstavanja: osobine ispitanog dela pripisuju se celini iz koje je uzet. Da bi uzorak dobro reprezentovaogeneralni skup, mora da budu ispunjeni sledeci uslovi:
1) svaki element generalnog skupa mora da ima jednaku sansu da ude u uzorak;
2) uzorak mora da bude dovoljno brojan.
Osnovni zadatak Matematicke statistike jeste da pomocu uzorka (X1, . . . , Xn) odredi raspodelu F (x)obelezja X. Da je to moguce tvrdi centralna teorema statistike (o kojoj ce biti reci kasnije) poduslovom da je n vrlo veliko. Kako u primenama radimo samo sa konacnim obimom uzorka, raspodeluza X mozemo da odredimo samo priblizno, utoliko tacnije ukoliko je n vece. U resavanju postavljenogproblema radimo sa funkcijama slucajnog uzorka (X1, . . . , Xn).
Definicija 1. Za dati prost uzorak (X1, . . . , Xn), empirijska funkcija raspodele definise se, zasvako x ∈ R, sa Sn(x) = k/n, gde je k broj elemenata iz uzorka koji nisu veci od x.
Neka jeX(1), X(2), . . . , X(n) varijacioni niz, koji cine vrednosti slucajnih promenljivihX1, X2, . . . , Xn
uredene po velicini od najmanje do najvece. Tada se empirijska raspodela moze odrediti pomocu
Sn(x) =
0, ako je x < X(1),
k
n, ako je X(k) ≤ x ≤ X(k+1), 1 ≤ k ≤ n− 1,
1, ako je x ≥ X(n).
(1)
Primer 4. U eksperimentu su dobijene sledece brojne vrednosti uzorka obima n = 10 : 9, 15, 7, 11, 17, 9, 7,
12, 7, 15. Varijacioni niz je 7, 7, 7, 9, 9, 11, 12, 15, 15, 17. Iz jednakosti (1) ili direktno iz Definicije 1 nalazimo
da je

3
Sn(x) =
0, x < 7,310 , 7 ≤ x < 9,510 , 9 ≤ x < 11,610 , 11 ≤ x < 12,710 , 12 ≤ x < 15,910 , 15 ≤ x < 17,
1, x ≥ 17.
Stepenasta kriva empirijske funkcije raspodele Sn(x) prikazana je na gornjoj slici desno.
Neka je X ∈ R fiksirano. Definisimo Yi = 1 ako je Xi ≤ x i Yi = 0 ako je Xi > x. Tada zbir Y1+· · ·+Yn
predstavlja broj onih slucajnih promenljivih iz uzorka X1, . . . , Xn cije su vrednosti ≤ x, pa je
Sn(x) =Y1 + · · ·+ Yn
n.
Prema zakonu velikih brojeva za svako fiksirano x ∈ R vazi
P(
limn→+∞
Sn(x) = F (x))
= 1. (2)
Ovaj rezultat opravdava aproksimaciju funkcije raspodele njenom empirijskom raspodelom dobijenomiz uzorka. Sledeca teorema, poznata i pod nazivom centralna teorema statistike, tvrdi da je taaproksimacija uniformna po x :
Teorema 1 (Glivenko-Kantelijeva teorema). Ako je F (x) funkcija raspodele slucajne promenljiveX i Sn empirijska funcija raspodele dobijena iz prostog uzorka (X1, . . . , Xn) obima n, tada je
P(
supx∈R
|Sn(x)− F (x)| → 0, kada n→ +∞)
= 1.
Smisao ove teoreme je sledeci: kada je uzorak dovoljno brojan, tada sa verovatnocom bliskom jediniciempirijska raspodela se malo razlikuje od teorijske, drugim recima, ukoliko je uzorak brojniji, utolikobolje reprezentuje celokupnost.
2. Prikazivanje statistickih podataka iz uzorka
Eksperimentalni podaci se, radi statisticke obrade, predstavljaju na dva osnovna nacina: tablicno igraficki. Tablicni metod daje podatke u obliku tabele, cesto poredane u rastucem poretku dajuci tzv.varijacioni niz obelezja. On pruza osnovu za dalja razmatranja u vezi sa raspodelom.
Primer 5. U 20 odeljenja osnovne skole registrovan je broj ucenika sa natprosecnim sposobnostima: 5, 6, 8,
10, 9, 8, 4, 7, 7, 3, 6, 4, 8, 7, 6, 6, 5, 3, 6, 6. Varijacioni niz uzorka je: 3, 3, 4, 4, 5, 5, 6, 6, 6, 6, 6, 6, 7, 7, 7, 8, 8,
8, 9, 10. Za odredivanje raspodele obelezja koristi se sledeca tabela:
Tabela 1

4
U tabeli su koriscene oznake: k–broj odeljenja sa posmatranim brojem natprosecnih ucenika, f–apsolutna
ucestanost, f∗–relativna ucestanost, nx–broj odeljenja sa ne vise od x natprosecnih ucenika,∑f–zbirna (kumu-
lativna) ucestanost,∑f∗–zbirna relativna ucestanost.
Od posebnog interesa su zbirne relativne ucestanosti Sn(x) = nx/n, gde je nx, zapravo, slucajnavelicina. Kao sto smo ranije videli, a sto se moze zapaziti i iz tabele X, funkcijom Sn(x) = nx/n jeodredena empirijska funkcija raspodele obelezja X (broj natprosecnih ucenika u pojedinim odelje-njima u Primeru X.)
Kod obelezja apsolutno neprekidnog tipa podaci u tabeli se sreduju po unapred odabranim intervalima(klasama). Broj i raspored intervala zavisi od broja podataka i samog obelezja. Strogog pravila za izborbroja i duzine intervala nema, ali se u praksi preporucuje da broj intervala k zadovolji nejednakosti
1 + 3.322 log10 n = 1 + log2 n ≤ k ≤ 5 · log10 n
za obim uzoraka n. Broj intervala k se moze odrediti i na jedan od sledecih nacina: k =√n, k = 2n1/3
ili k = 5 log10 n.
Duzine intervala se odreduju na sledeci nacin: Odreduju se najmanja xmin i najveca xmax vrednost urealizovanom uzorku (x1, . . . , xn), a zatim se duzina intervala racuna po formuli
h =xmax − xmin
k,
pri cemu se vodi racuna da su granice intervala jednostavne za rad (celi brojevi, brojevi deljivi sa 5 islicno).
Raspodela obelezja graficki se prikazuje preko ucestanosti, zbirnih ucestanosti ili zbirnih relativnihucestanosti, tj. emprijiske funkcije raspodele. Graficki metodi prikaza su najcesce poligon, kumulativnakriva, razni dijagrami, histogram (iskljucivo za obelezje apsolutno neprekidnog tipa) i slicno.
Na slikama od 1 do 3 prikazani su podaci koji se odnose na Primer 5. Figure na slikama 1a i 1b supoligoni, a na slikama 2 i 3b su trakasti dijagrami. Kumulativna kriva relativnih ucestanosti sa slike 3aprikazuje emprijsku funkciju raspodele.
Sl. 1 Poligoni: a) apsolutnih ucestanosti; b) relativnih ucestanosti u % (Primer 5)

5
Sl. 2 Trakasti dijagram apsolutnih usetanosti (Primer 5)
Sl. 3 a) Kumulativna kriva relativnih ucestanosti; b) trakasti dijagram zbirnih ucestanosti (Primer 5)
Primer 6. Testom za proveru motornih sposobnosti je meren nivo sposobnosti ucenika jednog odeljenja i
dobijeni rezultati su svrstani u tri kategorije: nizak (n), srednji (s) i visok (v) nivo sposobnosti. U odeljenju je
registrovan sledeci niz podataka: n, n, s, v, s, s, s, n, v, v, s, s, s, n, v, v, v, s, v, n, n, s, v, s. Na osnovu niza
realizacija dobijena je tabela
Tabela 2
Prilikom grafickog prikaza kvalitativnih obelezja, vrednosti obelezja se mogu proizvoljno poredati,recimo prema rascenju ili opadanju ucestanosti, azbucnom redu, itd. Na slikama 4 i 5 prikazana su cetirikarakteristicna nacina ilustracije apsolutne ucestanosti kod kvalitativnih obelezja (za Primer 6).

6
Sl. 4 a) Vertikalni i b) horizontalni trakasti dijagram (Primer 6)
Sl. 5 Podela a) kruga (,,pita”, ,,kolac”) i b) pravougaonika za prikazivanje ucestanosti u uzorku (Primer 6)
Definicija 2. Statistika Z je funkcija uzorka Z = f(X1, . . . , Xn) koja ne zavisi eksplicitno odnepoznatih parametara.
Statistika je slucajna promenljiva koja opisuje empirijsku raspodelu obelezja X. Neke vaznije statistikesu
1. Xmin – minimum uzorka ili najmanja vrednost uzorka;
2. Xmax – maksimum uzorka ili najveca vrednost uzorka;
3. R = Xmax −Xmin – raspon uzorka;
4. Xn = 1n
n∑
k=1
Xk – sredina uzorka;
5. S2
n = 1n
n∑
k=1
(Xk −Xn)2) – disperzija uzorka;
6. S2n = 1
n−1
n∑
k=1
(Xk −Xn)2 – popravljena disperzija uzorka;
7. Sn =
√S
2
n – standardno odstupanje uzorka;
8. Tn =n∑
k=1
Xk – total uzorka;

7
9. koeficijent korelacije uzorka
RX,Y =
1
n
n∑
i=1
XiYi −XnY n
SXSY
,
gde je SX =
√√√√ 1
n
n∑
k=1
X2k − (Xn)2, SY =
√√√√ 1
n
n∑
k=1
Y 2k − (Y n)2 .
Napomena 1. Disperzija uzorka S2
n se jednostavnije racuna po formuli
S2
n =1
n
n∑
k=1
X2k −X
2
n.
Zaista, imamo
S2
n =1
n
n∑
k=1
(Xk −Xn)2) =1
n
n∑
k=1
(X2k − 2XnXk +X
2
n)
=1
n
n∑
k=1
X2k − 2
1
nXn
n∑
k=1
Xk +X2
n =1
n
n∑
k=1
X2k −X
2
n.
Primer 7. U Primeru 1 obelezje X uzima dve vrednosti: 1 ako je kuglica bela i 0 ako je kuglica crna.
Slucajna promenljiva X ima Bernulijevu raspodelu verovatnoca
X :
(1 0p q
).
Prost slucajan uzorak obezbedujemo ako kuglice izvlacimo jednu po jednu i posto kod svake registrujemo njenu
boju vracamo je u kutiju pre sledeceg izvlacenja. Raspodela obelezja X potpuno je odredena parametrom p.Izmenimo oznake tako sto cemo uzorak (X1, . . . , Xn) preimenovati u (I1, . . . , In), gde je Ik (k = 1, . . . , n) u
stvari indikator dogadaja da u k-tom izvlacenju kuglica bude bele boje. Tada je slucajna promenljiva
Sn = I1 + I2 + · · ·+ In
jedna statistika koja predstavlja broj izvucenih belih kuglica. Opisani eksperiment sa Bernulijevom raspodelom
duzine n definise binomnu raspodelu Sn : B(n, p) za koju znamo da je E(Sn) = np i σ2(Sn) = npq. Uvedimo
statistiku
Xn =Sn
n=X1 + · · ·+Xn
n.
Kako je E(Xn) = 1nE(Sn) = p, na osnovu zakona velikih brojeva sledi P
(|Xn − p| ≥ ε
)→ 0 kad
n → ∞, tj. statistika Xn sve je bliza nepoznatom parametru p sa porastom obima uzorka n. Na osnovu
centralne granicne teoreme mozemo vise da kazemo o ovoj pribliznosti i da je ocenimo. Kako Sn ima priblizno
raspodelu N (np, npq), sledi da Xn = Sn/n takode ima priblizno normalnu raspodelu sa parametrima E(Xn) =
p, σ2(Xn) = 1n2σ
2(Sn) =pq
n.
Primetimo da pq = p(1 − p) = p − p2 za 0 < p < 1 nije vece od 1/4. Dakle, σ2(Xn) ≤ 14n . Na primer, za
n = 100 raspodela za X100 je priblizno N(p,
pq
100
)i disperzija nije veca od 1/400. Gustina raspodele skicirana

8
je na slici 6. Vidimo da su verovatnoce odstupanja Xn od nepoznatog parametra p vrlo male. Na primer
P(|X100 − p| < 0.1
)= P
(∣∣∣S100
100− p∣∣∣ < 0.1
)= P
(|S100 − 100p| < 10
)
= P(∣∣∣S100 − 100p√
100pq
∣∣∣ < 10√100pq
)= P
(∣∣∣S100 − 100p√100pq
∣∣∣ < 1√pq
)
≈ P(|Z∗| < 1√
pq
)≥ P
(|Z∗| < 2
)= 2Φ(2) = 2 · 0.47725 = 0.9555.
Sl. 6
Dakle, ,,sanse” da X100 odstupi od nepoznatog parametra p vise od 0.1 manje su od 5%.
3. Neke raspodele vazne u statistici
Hi kvadrat raspodela
U Teoriji verovatnoce, razmatrajuci raspodele neprekidnih slucajnih promenljivih, definisali smo Gamaraspodelu sa parametrima α i λ, u oznaci Γ(α, λ). Za ovu raspodelu je
f(x) =λαe−λxxα−1
Γ(α), E(X) =
α
λ, D(X) =
α
λ2, ϕ(t) =
λα
(λ− it)α. (3)
Poseban slucaj ove raspodele, Γ(n2 ,
12 ) ima vazne primene u verovatnoci i statistici.
Definicija 3. Raspodelu definisanu gustinom
f(x) =1
2n/2Γ(n2 )x
n
2−1e−
x
2 , (x > 0)
nazivamo hi kvadrat raspodelom sa n stepeni slobode, u oznaci χ2(n). Broj n moze biti proizvoljanpozitivan broj, ali je u primenama vazan slucaj kada je n prirodan broj. Za n = 2 dobija se E(1/2)raspodela.
Na sl. 7 prikazana je gustina funkcije za nekoliko stepeni slobode.

9
Sl. 7 Gustine hi kvadrat raspodele
Na osnovu izraza za karakteristicnu funkciju Gama raspodele (3), u specijalnom slucaju za α = n/2 iλ = 1/2 dobijamo karakteristicnu funkciju χ2(n) raspodele
ϕ(t) =1
(1− 2it)n/2. (4)
Teorema 2. Neka su X1, . . . , Xn nezavisne slucajne promenljive sa N (0, 1) raspodelom i neka je
V = X21 + · · ·+X2
n, n ∈ N.
Slucajna promenljiva V ima χ2(n) raspodelu.
Dokaz. Slucajna promenljiva V je zbir n nezavisnih slucajnih promenljivih sa istom raspodelom.Karakteristicna funkcija svakog sabirka je
ϕ0 = E(eitX2
), X ∼ N (0, 1),
odnosno,
ϕ0(t) =1√2π
∫ +∞
−∞
eitx2 · e−x2/2dx =1√2π
∫ +∞
−∞
exp(−x
2(1− 2it)
2
)dx =
1√1− 2it
.
Poredenjem sa (4) vidimo da svaka od nezavisnih slucajnih promenljivih X2i (i = 1, . . . , n) ima χ2(1)
raspodelu. S obzirom da su X1, . . . , Xn nezavisne sluacjne promenljive, karakteristicna funkcija njihovogzbira je
ϕ(t) =(ϕ0(t)
)n
= (1− 2it)−n/2,
a ovo je karakteristicna funkcija χ2(n) raspodele. Time je dokaz zavrsen.
Da bismo istakli da slucajna promenljiva V ima χ2(n) raspodelu, u nastavku cemo umesto V pisatiχ2
n. Iz (3) (za α = n/2 i λ = 1/2) dobijamo
E(χ2n) = n, D(χ2
n) = 2n. (5)
Iz oblika karakteristicne funkcije (4) vidimo da zbir nezavisnih slucajnih promenljivih sa χ2(ni)raspodelom (i = 1, . . . , k) ima χ2(n1 + · · ·+ nk) raspodelu. Naziv ,,broj stepeni slobode”, koji se koristiza parametar hi kvadrat raspodele, potice uglavnom od ove osobine. Sustinski, broj stepeni slobodeoznacava broj linearno nezavisnih slucajnih promenljivih medu X1, X2, . . . , Xn u izrazu za χ2
n. Ako bi,

10
na primer, medu X1, X2, . . . , Xn postojala jedna linearna veza, recimo X1 + X2 + · · · + Xn = 0, tadabismo imali
χ2n−1 = X2
1 +X22 + · · ·+X2
n,
dakle, broj stepeni slobode je umanjen za 1.
Koristeci osobinu karakteristicne funkcije nezavisno promenljivih, lako se dokazuje sledeca teorema.
Teorema 3. Ako su X i Y nezavisne slucajne promenljive takve da X ima χ2(n)raspodelu a Y χ2(r)raspodelu, tada X + Y ima χ2(n+ r) raspodelu.
Dokaz. Kako je ϕX(t) = (1− 2it)−n/2 i ϕY (t) = (1− 2it)−r/2, iz nezavisnosti X i Y sledi ϕX+Y (t) =ϕX(t)ϕY (t), tj.
ϕX+Y (t) = (1− 2it)−n/2(1− 2it)−r/2 = (1− 2it)−n+r
2 ,
a to je karakteristicna funkcija χ2(n+ r) raspodele.
Verovatnoce vezane za hi kvadrat raspodelu daju se tabelarno (videti Tabelu II). S obzirom na najcescuprimenu u Matematickoj statistici te tablice su tako sacinjene da za dati stepen slobode n (obicnon = 1, 2, . . . , 30) i dati broj α (0 < α < 1) (obicno α = 0.01, 0.05, . . . , 0.80) u tablici citamo broj χ2
n;α
(ovo nije slucajna promenljiva, za razliku od χ2n) takav da je
P (χ2n ≥ χ2
n;α) = α.
Sl. 8
Na sl. 8 prikazana je jedna hi kvadrat gustina , broj χ2n;α i broj α koji (kao verovatnoca) predstavlja
povrsinu izmedu x-ose i krive gustine za x > χ2n;α.
U tablicama se broj stepeni slobode n obicno ne daje za n ≥ 30. Za n ≥ 30 na osnovu centralnegranicne teoreme χ2
n ima priblizno (i to za primene sasvim zadovoljavajuce tacno) normalnu raspodelu.Kako je E(χ2
n) = n i D(χ2n) = 2n, znaci da χ2
n ima problizno N (n, 2n) raspodelu. Preciznije, vaziteorema.
Teorema 4. Kada n→ +∞, funkcija raspodele sluajne promenljive
χ2n − n√
2n
konvergira funkciji raspodele N (0, 1).
Raspodela matematickog ocekivanja µ i sredine Xn = (X1 + · · · + Xn)/n je razmatrana u sledecojteoremi.

11
Teorema 5. Neka su X1, . . . , Xn nezavisne slucajne promenljive sa istom raspodelom N (µ, σ2). Tadavazi
11
σ2
n∑
k=1
(Xk − µ)2 ∼ χ2(n),
21
σ2
n∑
k=1
(Xk −Xn)2 ∼ χ2(n− 1).
Napomena 2. U slucaju 2 broj stepeni slobode je n− 1 jer medu slucajnim promenljivim Xk −Xn
postoji jedna linearna vezan∑
k=1
(Xk −Xn) =n∑
k=1
Xk − nXn = 0.
Napomena 3. Posmatrajmo disperziju uzorka iz normalne populacije (tj. populacije cije je obelezjeX ∼ N (µ, σ2))
S2
n =1
n
n∑
k=1
(Xk −Xn)2.
Na osnovu 2 sledi da slucajna promenljivanS
2
n
σ2ima χ2(n− 1) raspodelu.
Primer 8. Neka obelezje X ima E(X) = µ i D(X) = σ2. Ako je obim uzorka (X1, . . . , Xn) veliki (recimo
n ≥ 30), tada na osnovu centralne granicne teoreme sredima uzorka
Xn =X1 + · · ·+Xn
n
ima priblizno normalnu raspodelu. Kako je
E(Xn) = E( 1
n
n∑
k=1
Xk
)=
1
n
n∑
k=1
E(Xk) =1
n· nµ = µ
i
D(Xn) = D( 1
n
n∑
k=1
Xk
)=
1
n2
n∑
k=1
D(Xk) =1
n2· nσ2 =
σ2
n,
sledi da je to normalna raspodela N (µ, σ2/n). Primetimo da smo u gornjem izracunavanju E(Xn) i D(Xn)koristili cinjenicu da je (X1, . . . , Xn) prost uzorak, tj. da su X1, . . . , Xn nezavisne slucajne promenljive i da
svaka ima istu raspodelu kao i obelezje X.
Na osnovu dobijenog rezultata vidimo da standardizovana slucajna promenljivaXn − µ
σ/√n
ima normalnu
raspodelu N (0, 1).
Studentova t raspodela
Neka su X1, . . . , Xn nezavisne slucajne promenljive sa N (µ, σ2) raspodelom. Na osnovu Primera 8sledi da standardizovana slucajna promenljiva
X∗ =Xn − µ
σ/√n

12
ima standardnu normalnu N (0, 1) raspodelu. Medutim, ako σ2 nije poznato, uzima se ocena
s2 =1
n− 1
n∑
k=1
(Xk −Xn)2
i formira se slucajna promenljiva
tn =Xn − µ
s/√n
cija raspodela je poznata pod nazivom t raspodela ili Studentova raspodela. Ovu raspodelu je otkrioi proucavao Vilijam Goset pocetkom dvadesetog veka. On je radio u Guinnessovoj pivari u Dablinu(Irska) i iz poslovnih razloga koristio je pseudonim Student.
Definicija 4. Raspodela definisana funkcijom gustine
f(x) =Γ(
n+12
)√nπ Γ
(n2
)(
1 +x2
n
)−(n+1)/2
, x ∈ R, n > 0
naziva se Studentovom t raspodelom sa n stepeni slobode, u oznaci t(n). Parametar n moze bitiproizvoljan pozitivan broj, ali se ova raspodela uglavnom koristi kada je n ∈ N.
Za veliko n, t(n) raspodela moze se aproksimirati N (0, 1) raspodelom, kao sto se vidi na slici 9.
Sl. 9 Gustine t(n) raspodele za n = 2, 5, 15 u poredenju sa normalnom N (0, 1) raspodelom (isprekidana linija)
Primene t raspodele proizilaze iz sledece teoreme.
Teorema 6. Neka su slucajne promenljive Z∗ ∼ N (0, 1) i χ2n nezavisne. Tada slucajna promenljiva
tn =√nZ∗√χ2
n
ima t(n) raspodelu.
Kao i u slucaju χ2 raspodele, verovatnoce vezane za t raspodelu daju se tablicno (Tabela III). Zaodredeni broj stepeni slobode n i dati broj α (0 < α < 1), iz tablica se cita pozitivan broj tn;α takav daje
P (|tn| ≥ tn;α) = α.

13
Na slici 10 verovatnoca je prikazana kao zbir srafiranih povrsina koje odgovaraju dogadaja tn ≥ tn;α itn ≤ −tn;α. Primetimo da je
P (|tn| ≥ tn;α) = P (tn ≥ tn;α) + P (tn ≤ −tn;α) =α
2+α
2= α.
Sl. 10
Teorema 7. Ako je (X1, . . . , Xn) uzorak iz populacije sa obelezjem X koje ima normalnu raspodeluN (µ, σ2), tada statistika
Xn − µ
Sn
√n− 1
ima Studentovu t(n− 1) raspodelu.
Dokaz. Jednostavnim transformacijama pocetne statistike dobijamo
Xn − µ
Sn
√n− 1 =
(Xn − µ)
√n
σ√S
2
n
n− 1
√n
σ
=
Xn − µ
σ
√n
√nS
2
n
σ2(n− 1)
.
Xn − µ
σ
√n ima standardnu N (0, 1) raspodelu (Primer 8), a
nS2
n
σ2ima χ2(n − 1) raspodelu (Napomena
3). Koristeci Teoremu 6 zakljucujemo daXn − µ
Sn
√n− 1 ima Studentovu t(n− 1) raspodelu.
4. Ocene parametara
Neka je (X1, . . . , Xn) nezavisan uzorak iz neke raspodele. U opstem slucaju ovaj uzorak zavisi odnepoznatog parametra θ, gde θ moze biti vektor (kao u slucaju normalne raspodele, θ = (µ, σ2)) ili skalar(kao kod Puasonove raspodele θ = λ). Skup mogucih (dozvoljenih vrednosti) parametra θ obelezavamosa Θ.
Problem ocene parametara sastoji su u tome da se nade statistika θ = θ(X1, . . . , Xn) kojom ce seoceniti parametar θ. Ta ocena moze biti nadena na dva nacina: kao tackasta ili intervalna ocena.
Ako za ocenu parametra θ u jednom realizovanom uzorku (x1, . . . , xn) uzmemo broj un = θ(x1, . . . , xn),
to je tzv. tackasta ocena. Cilj je odabrati takvu statistiku θ koja daje bliske vrednosti nepoznatomparametru θ koji ocenjujemo.

14
Tackaste ocene
Navescemo neke kriterijume na osnovu kojih procenjujemo koliko je dobra izabrana tackasta ocena.
Definicija 5. Neka je θ = θ(X1, . . . , Xn) statistika koja se koristi kao ocena parametra θ.
• Kazemo da je θ stabilna ili postojana ocena za θ ako θ konvergira u verovatnoci ka θ kadan→ +∞, tj. ako je
limn→+∞
P (|θ − θ| > ε) = 0 za svako θ ∈ Θ i ε > 0.
• Ocena je centrirana ako je
E(θ) = θ za svako θ ∈ Θ.
• Ocena je asimptotski centrirana ako E(θ) → θ kada n→ +∞.
Napomena 4. Svaka stabilna ocena parametra θ je asimptotski centrirana. S druge strane, svakacentrirana ocena nije stabilna.
Primer 9. Neka je (X1, . . . , Xn) nezavisan uzorak iz raspodele sa nepoznatim matematickim ocekivanjem
µ. Ocenimo ovaj parametar pomocu sredine uzorka
Xn =X1 + · · ·+Xn
n.
U Primeru 8 vudeli smo da je E(Xn) = µ. Ocena Xn je centrirana. To znaci da ako ponavljamo ocenjivanje
veliki broj puta, ,,u proseku” dobijamo tacan rezultat µ. Pokazimo da je ocena i stabilna. Na osnovu zakona
velikih brojeva sledi da je
limn→+∞
P(∣∣∣ 1n
n∑
k=1
Xk − µ∣∣∣ ≥ ε
)→ 0,
te je ocena i stabilna (postojana).
Primer 10. Neka je (X1, . . . , Xn) prost uzorak. Ispitajmo da li je disperzija uzorka S2
n centrirana u odnosu
na disperziju σ2. Najpre izracunavamo
E(S2
n) = E( 1
n
n∑
k=1
(Xk −Xn)2)
= E( 1
n
n∑
k=1
X2k −
2
nXn
n∑
k=1
Xk +1
n
n∑
k=1
X2
n
)
= E( 1
n
n∑
k=1
X2k −X
2
n
)=
1
n
n∑
k=1
E(X2k)− E
(X
2
n
)= E(X2)− E(X
2
n).
Kako je
E(X2
n) =1
n2E( n∑
k=1
X2k +
∑
i6=j
XiXj
)=
1
nE(X2) +
n− 1
nE2(X),
imamo da je
E(S2
n) =n− 1
nE(X2)− n− 1
nE2(X) =
n− 1
nσ2. (6)
Na osnovu poslednjeg izraza zaklucujemo da ocene statistike (disperzije uzorka) S2
n za disperziju σ2 obelezja Xnije centrirana. Medutim, kako n−1
n → 1 kada n→ +∞, sledi da je ova ocena asimptotski centrirana.Iz (6) vidimo i kao treba ,,popraviti” ocenu obelezja X : Uocimo tzv. popravljenu disperziju uzorka
S2n =
1
n− 1
n∑
k=1
(Xk −Xn)2.

15
Kako je S2n = n
n−1S2
n, imamo
E(S2n) =
n
n− 1E(S
2
n) =n
n− 1· n− 1
nσ2 = σ2.
Dakle, S2n je centrirana ocena za σ2. Primetimo da ako je n veliko, tada je n
n−1 ≈ 1 tako da kod velikog broja
uzorka nema znacaja da li uzimamo S2
n ili S2n kao ocenu za disperziju.
Centriranost i stabilnost su pozeljne osobine svake ocene. Za kriterijum bliskosti stvarnoj vrednosti
parametra uzima se srednje kvadratno odstupanje, tj., sto je isto, disperzija D(θ) = E((θ − θ)2) kojapredstavla meru rasejavanja.
Definicija 6. • Ocena θ1 je bolja (u smislu srednjeg kvadratnog odstupanja) od ocene θ2 ako je
E((θ1 − θ)2) < E((θ2 − θ)2), (θ ∈ Θ).
• Neka je S dati skup statistika na bazi uzorka (X1, . . . , Xn). Kazemo da je ocena θ∗ najbolja ocena
parametra θ na skupu S ako θ∗ ∈ S i E((θ∗ − θ)2) = minE((θ − θ)2), θ ∈ S
.
Neka su θ1 i θ2 centrirane ocene parametra θ. Iz Definicije 6 proizilazi da je bolja ona ocena koja imamanju disperziju.
Definicija 7. Neka su θ1 i θ2 centrirane ocene parametra θ. Kazemo da je ocena θ1 efikasnija od
ocene θ2 ako je D(θ1) ≤ D(θ2) za svako θ ∈ Θ.
Primer 11. Neka je (X1, X2) nezavisan uzorak iz raspodele sa nepoznatim matematickim ocekivanjem
µ. Svaka statistika oblika µα = αX1 + (1 − α)X2 jeste centrirana ocena parametra µ. Disperzija ove ocene
je α2 + (1 − α)2 i minimalna je za α = 1/2. Prema tome, najbolja (najefikasnija) ocena u skupu µα je
µ1/2 = (X1 +X2)/2.
Od interesa je odrediti donju granicu disperzije svih mogucih centriranih ocena parametra θ. Bezdokaza navodimo sledeci vazan rezultat.
Teorema 8 (Nejednakost Rao-Kramera).a) Ako je obelezje X neprekidnog tipa sa funcijom gustine f(x; θ), tada je
D(θn) = E((θn − θ)2
)≥ 1
n
∫ +∞
−∞
[∂ log f(x; θ)
∂θ
]2f(x; θ)dx
.
b) Ako je obelezje X diskretnog tipa sa skupom vrednosti x1, x2, . . . i ako stavimo pi(θ) = P (X =xi) (i = 1, 2, . . . ), tada je
D(θn) = E((θn − θ)2
)≥ 1
n∑
i
[∂ log pi(θ)
∂θ
]2pi(θ)
.
Definicija 8. Najefikasnija je ona ocena θ∗n za koju je dostignut infimum disperzije a kao meruefikasnosti neke ocene mozemo uzeti
κ =D(θ∗n)
D(θ).

16
Primer 12. Prema teoremi Rao-Kramera, najefikasnija ocena µ∗n parametra µ obelezja X sa normalnom
raspodelom N (µ, σ2) (σ je poznat parametar) ima disperziju
D(µ∗n) =1
n
∫ [∂ log f(x;µ)
∂µ
]2f(x;µ)dx
.
S obzirom da je
f(x;µ) =1
σ√
2πexp(−1
2
(x− µ
σ
)2),
posle kraceg izracunavanja dobijamo
D(µ∗n) =σ2
n.
Kako je D(Xn) = E(X2
n)− E2(Xn), na osnovu Primera 10 i E2(Xn) = E2(X) nalazimo
D(Xn) = −E2(X) +1
nE(X2) +
n− 1
nE2(X) =
1
n
(−E2(X) + E(X2)
)=σ2
n= D(µ∗n).
Dakle, ocena Xn je najefikasnija.
Metod maksimalne verodostojnosti
Metod maksimalne verodostojnosti uveden je u Matematicku statistiku u drugoj deceniji dvadesetogveka. Ideja ovog metoda je da se za ocenu parametra izabere vrednost θ pri kojoj je verovatnoca realizacijedobijenog uzorka najveca. Pokazalo se da ovaj metod daje ocene koje su asimptotski (tj. za veliki uzorak)efikasnije od ocena dobijenih na bilo koji drugi nacin. Medutim, primena tog metoda cesto je vezana zaslozena izracunavanja.
Definicija 9. Neka je (X1, . . . , Xn) prost uzorak obima n i neka je (x1, . . . , xn) realizovan uzorak.Oznacimo sa g(x; θ) gustinu raspodele f(x; θ) obelezjaX ako jeX neprekidnog tipa, a sa P (X = x; θ), x ∈x1, . . . , xn ako je X diskretnog tipa. Funkcija verodostojnosti L(θ) definise se kao
L(θ) = L(x1, x2, . . . , xn; θ) =
g(x1; θ) · g(x2; θ) · · · g(xn; θ), X je neprekidnog tipa,
p(x1; θ) · p(x2; θ) · · · p(xn; θ), X je diskretnog tipa.
Neka je θ = ψ(x1, . . . , xn) vrednost parametra kojim se postize maksimum funkcije L(θ) pri fiksiranimx1, . . . , xn. Statistika
θ = ψ(X1, . . . , Xn)
je ocena maksimalne verodostojnosti parametra θ.
Napomena 5. S obzirom da je logaritamska funkcija monotona, ponekad je lakse naci maksimumresavajuci jednacinu
dL(θ)
dθ= 0.
Primer 13. Za nezavisan uzorak (X1, . . . , Xn) iz Bernilijeve raspodele sa nepoznatim parametrom p,funkcija verodistojnosti je
L(p) = pk(1− p)n−k, k =n∑
j=1
xj .
Iz jednacine
d logL(p)
dp=d(k log p+ (n− k) log(1− p)
)
dp= 0, p ∈ (0, 1)

17
nalazimo da funkcija p 7→ l(p) = logL(p) dostize maksimum za p = k/n. Prema tome, ocena maksimalne
verodostojnosti za p je
p =1
n
n∑
j=1
Xj (= Xn).
Primer 14. Obelezje X ima binomnu raspodelu B(k, p), gde je k ∈ N poznat, a p ∈ (0, 1) nepoznat
parametar. Na osnovu prostog uzorka obima n ocenicemo parametar p metodom maksimalne verodostojnosti.
Funkcija verodostojnosti data je sa
L(p) = L(x1, . . . , xn; p) =n∏
i=1
(k
xi
)pxi(1− p)k−xi .
Maksimum funcije p 7→ l(p) = logL(p) nalazimo polazeci od resenja jednacine
∂ logL(p)
∂p=
1
p
n∑
i=1
xi −1
1− p
n∑
i=1
(k − xi) = 0.
Dobijamo
p =1
k· 1
n
n∑
i=1
xi.
Na osnovu ovog zakljucujemo da je ocena maksimalne verodostojnosti za p data statistikom
p =1
k· 1
n
n∑
i=1
Xi =Xn
k.
Primer 15. Neka obelezje X ima Puasonovu raspodelu P(λ), gde je λ nepoznat parametar. U ovom slucaju
je
f(x;λ) = Pλ(X = λ) =λx
x!e−λ, (x = 0, 1, 2, . . . .)
Uzimajuci da je uzorak (X1, . . . , Xn) prost i, dakle, X1, . . . , Xn nezavisne, dobijamo
L(x1, x2, . . . , xn;λ) =n∏
k=1
f(Xk;λ) =λx1+x2+···+xn
x1!x2! · · ·xn!e−nλ.
Odavde je
logL(x1, x2, . . . , xn;λ) = −nλ+ (x1 + x2 + · · ·+ xn) log λ−n∑
k=1
log xi! .
Izd logL
dλ= −n+
x1 + x2 + · · ·+ xn
λ= 0
nalazimo da funkcija logL(x1, x2, . . . , xn;λ) (pri fiksiranim x1, x2, . . . , xn) dostize maksimum za
λ =x1 + x2 + · · ·+ xn
n.
Odavde zakljucujemo da statistika
λ =X1 +X2 + · · ·+Xn
n(= Xn)
predstavlja ocenu maksimalne verodostojnosti za parametar λ.

18
Primer 16. Neka je (X1, . . . , Xn) prost uzorak iz normalne raspodele sa nepoznatim θ = (µ, σ2). Funkcija
verodostojnosti je
L(µ, σ2) =
n∏
k=1
f(Xk;µ, σ2) =
n∏
k=1
1
(2πσ2)1/2exp(− (xk − µ)2
2σ2
)=
1
(2π)n/2· 1
(σ2)n/2exp(−∑n
k=1(xk − µ)2
2σ2
).
Ocigledno je da konstanta1
(2π)n/2ne utice na polozaj maksimuma, pa se (logaritmovanjem) problem svodi na
oderdivanje maksimuma funkcije
l(µ, σ2) = −n log σ − 1
2σ2
n∑
k=1
(xk − µ)2, (µ ∈ R, σ2 > 0),
gde smatramo da su x1, . . . , xn konstante. Nalazenjem pracijalnih izvoda dobijamo jednacine
∂l
∂µ= − 1
σ2
n∑
k=1
(xk − µ) = 0,
∂l
∂σ2= −n
σ+
1
σ3
n∑
k=1
(xk − µ)2 = 0.
Resenja ovog sistema jednacina su
µ =1
n
n∑
k=1
xk, σ2 =1
n
n∑
k=1
(xk −
1
n
n∑
j=1
xj
)2
.
Dakle, ocene maksimalne verodostojnosti na osnovu nezavisnog uzorka (X1, . . . , Xk) su statistike
µ =1
n
n∑
k=1
Xk (= Xn), σ2 =1
n
n∑
k=1
(Xk − µ)2 =1
n
n∑
k=1
(Xk −Xn)2 (= S2
n).
Primer 17. Neka je (X1, . . . , Xn) prost uzorak iz eksponencijalne raspodele E(λ) sa nepoznatim λ. Funkcija
verodostojnosti je
L(λ) =n∏
k=1
f(Xk;λ) =n∏
k=1
λeλ xk = λne−λ (x1+···+xn).
Posle logaritmovanja problem se svodi na oderdivanje maksimuma funkcije
l(λ) = logL(λ) = n log λ− λ(x1 + · · ·+ xn)
smatrajuci da su x1, . . . , xn konstante. Iz jednacine
∂l
∂λ=n
λ− (x1 + · · ·+ xn) = 0,
nalazimo da funkcija l(λ) dostize maksimum za
λ =n
x1 + · · ·+ xn.

19
Prema tome, ocena maksimalne verodostojnosti na osnovu nezavisnog uzorka (X1, . . . , Xk) data je statistikom
λ =n
X1 + · · ·+Xn=
1
Xn
.
Intervali poverenja
U prethodnom odeljku smo videli na koji nacin se moze vrsiti tackasta ocena nepoznatog parametra θkoji figurise u raspodeli F (x, θ) obelezja X. Ocigledno da zbog prirode postupka i cinjenice da ta ocenapredstavlja slucajnu promenljivu, nije moguce govoriti o gresci u klasicnom smislu. Cesto je zbog togapogodnije koristiti intervalne ocene, tj. nalazenje intervala u kojem se sa nekom verovatnocom nalazinepoznat parametar θ.
Definicija 10. Neka je (X1, . . . , Xn) uzorak obelezja X cija je raspodela F (x, θ) i neka su θ1 =
θ1(X1, . . . , Xn) i θ2 = θ2(X1, . . . , Xn) dve statistike koje ne zavise od nepoznatog parametra θ, takve da
je θ1 ≤ θ2 i da je
P (θ1 < θ < θ2) = β = 1− α,
gde je β unapred zadata verovatnoca. Tada se slucajni interval [θ1, θ2], koji zavisi od uzorka (X1, . . . , Xn),zove interval poverenja za parametar θ, a verovatnoca β novo poverenja.
Prirodno je traziti sto ,,uze” intervale poverenja [θ1, θ2], i sto visi nivo poverenja β; obicno se uzimaβ = 0.95 ili 0.99. Jasno je da su ova dva zahteva, uopste uzev, oprecna. Kao sto teorija i praksa pokazuju,izlaz lezi u povecanju obima uzorka n.
Kada smo uzeli uzorak i dobili brojeve (x1, . . . , xn), tada statistike θ1 = θ1(X1, . . . , Xn) i θ2 =
θ2(X1, . . . , Xn) postaju odredeni brojevi v1 = θ1(x1, . . . , xn) i v2 = θ2(x1, . . . , xn), a slucajni inter-
val [θ1, θ2] postaje odredeni interval [v1, v2]. Pogresno bi bilo smatrati da sa verovatnocom β interval
[v1, v2] sadrzi nepoznati parametar θ; dogadaj θ1 ≤ θ ≤ θ2 je izvestan ili nemoguc dogadaj i njegovaverovatnoca je 1, odnosno 0, a nikako nije β. Verovatnoca β je samo verovatnoca da slucajni interval[v1, v2] prekrije nepoznati broj θ.
Zamislimo da smo ,,uzeli” mnogo serija uzoraka obima n i dobili nizove brojeva (x1, . . . , xn), (x′1, . . . , x′n),
(x′′1 , . . . , x′′n)... i na osnovu njih izracunali intervale poverenja [v1, v2], [v′1, v
′2], [v′′1 , v
′′2 ], ... . Tada se na
te intervale moze gledati kao na realizacije slucajnog intervala [θ1, θ2]. Kako je P (θ1 ≤ θ ≤ θ2) = β itumaceci verovatnocu kao granicnu vrednost relativnih ucestanosti, mozemo reci da priblizno 100β% nu-merickih intervala [v1, v2], [v′1, v
′2], [v′′1 , v
′′2 ], ... pokriva nepoznat broj θ, a ostalih 100(1−β)% ne prekriva
(sl. 11).
q vv1 2
Sl. 11 Pokrivanje parametra θ realizovanim intervalima

20
Intervali poverenja za nepoznatu verovatnocu p.
Kod svakog elementa populacije interesujemo se da li se realizovao dogadaj A. Njegova verovatnocaP (A) = p je nepoznata. Dakle, kao obelezje mozemo da posmatramo indikator dogadaja A : IA = I.Prost uzorak obima n je dakle (I1, I2, . . . , In). Statistika Sn = I1 + I2 + · · ·+ In predstavlja broj kolikose puta u uzorku obima n realizovao dogadaj A.
Na osnovu centralne granicne teoreme (Sn − np)/√npq ima problizno N (0, 1) raspodelu. Za svaki
zadati nivo poverenja β mozemo odrediti broj zβ takav da je
P (|Z∗| ≤ zβ) = β, gde Z∗ ∼ N (0, 1).
Na primer, koristeci se Tablicom I imamo P (|Z∗| ≤ zβ) = 2Φ(zβ) = β. Ako je, recimo, β = 0.95 imamoΦ(z0.95) = 0.475 i iz Tablice I citamo z0.95 = 1.96.
Imamo priblizno
P
(∣∣∣∣∣Sn − np√np(1− p)
∣∣∣ ≤ zβ
)= β.
Dogadaj koji je u pitanju moze se drukcije pisati
P
(∣∣∣∣∣Sn − np√np(1− p)
∣∣∣ ≤ zβ
)= P
(∣∣∣∣∣(Sn − np)2
np(1− p)
∣∣∣ ≤ z2β
)
((n2 + nz2
β)p2 − (2nSn + nz2β)p+ S2
n ≤ 0)
=(p1(Sn) ≤ p ≤ p2(Sn)
),
gde su p1(Sn) i p2(Sn) respektivno manji i veci koren kvadratne jednacine
(n2 + nz2β)p2 − (2nSn + nz2
β)p+ S2n = 0.
[p1(Sn), p2(Sn)] jeste interval poverenja za p sa nivoom poverenja β, jer je
P(p1(Sn) ≤ p ≤ p2(Sn)
)= β.
Eksplicitni oblik za taj interval je
[n
n+ z2β
(Sn
n+z2β
2n− zβ
√Sn(n− Sn)
n+
z2β
4n2
),
n
n+ z2β
(Sn
n+z2β
2n+ zβ
√Sn(n− Sn)
n+
z2β
4n2
)]
Ako smo ,,uzeli” odredeni uzorak (i1, i2, . . . , in) dobili smo odredenu vrednost sn = i1 + i2 + · · ·+ ini interval poverenja je odredeni numericki interval [p1(sn), p2(sn)] koga treba tumaciti onako kako je toucinjeno u diskusiji opsteg slucaja. Primetimo da, iako je nepoznata verovatnoca p sigurno u intervalu[0,1], dobijeni numericki interval poverenja [p1(sn), p2(sn)] za p ne mora da bude sadrzan u [0,1].
Primer 18. U odredenom proizvodnom procesu tokom jednog dana proizvedeno je 79 artikala, medu kojima
su nadena 3 defektna. Naci 95% (β = 0.95) interval poverenja za nepoznatu verovatnocu p = P (,,da je proizvod
defektan”). Ovde je n = 79, s79 = 3 i resenje kvadratne jednacine
(792 + 79× 1.962)p2 − (2× 79× 3 + 79× 1.962)p+ 32 = 0
daje interval poverenja [0.013, 0.106] za p.

21
Interval poverenja za matematicko ocekivanje µ u slucaju poznate disperzije
Videli smo da kod velikog uzorka sredina uzorka Xn uzima priblizno N (µ, σ2/n) raspodelu. Dakle,
P(∣∣∣Xn − µ
σ/√n
∣∣∣ ≤ zβ
)= β
i
(∣∣∣Xn − µ
σ/√n
∣∣∣ ≤ zβ
)=(|Xn − µ| ≤ zβ
σ√n
)=(−zβ
σ√n≤ Xn − µ ≤ zβ
σ√n
)
=(Xn − zβ
σ√n≤ µ ≤ Xn + zβ
σ√n
),
iliP(Xn − zβ
σ√n≤ µ ≤ Xn + zβ
σ√n
)= β.
Interval poverenja za µ je znaci: [Xn − zβ
σ√n,Xn + zβ
σ√n
].
Primetimo da u ovom slucaju duzina intervala poverenja nije slucajna vec je jednaka 2zβσ√n. Zapaza
se kako se interval suzava sa porastom obima uzorka n.
Primer 19. Pretpostavimo da imamo dovoljno razloga da smatramo da je standardna devijacija visine u
jednoj velikoj ljudskoj grupaciji σ = 16cm. Srednja vrednost visine kod 100 slucajno izabranih ljudi je x100 =175. Odrediti 99% interval poverenja za srednju visinu u celoj grupaciji. Iz Tablice I nalazimo z0.99 = 2.58, te
za 99% interval poverenja imamo
[175− 2.58
15√100
, 175 + 2.5815√100
]≈ [171, 179].
Interval poverenja za matematicko ocekivanje µ kada disperzija σ2 nije poznata
Podsetimo se nekih oznaka uvedenih ranije: t(n) oznacava Studentovu t raspodelu sa n stepeni slobode,dok je tn slucajna promenljiva.
Ranije smo pokazali (Teorema 7) da je
Xn − µ
Sn
√n− 1 ∼ t(n− 1)
i da iz Tablice III citamo broj tn;α takav da
P (|tn| ≥ tn;α) = α ili P (|tn| ≤ tn;α) = 1− α = β.
Za dati nivo poverenja β i statistikuXn − µ
Sn
√n− 1 iz Tablice III mozemo procitati broj tn−1;1−β takav
da jeP (|tn−1| ≤ tn−1;1−β) = β
ili
P(∣∣∣Xn − µ
Sn
√n− 1
∣∣∣ ≤ tn−1;1−β) = β.

22
Odavde, posle izvesnih maipulacija kao u prethodnom slucaju, dobijamo
P(Xn − tn−1;1−β
Sn√n− 1
≤ µ ≤ Xn + tn−1;1−βSn√n− 1
)= β.
Dakle, 100β% interval poverenja je
[Xn − tn−1;1−β
Sn√n− 1
, Xn + tn−1;1−βSn√n− 1
].
Primetimo da je u ovom slucaju duzina intervala 2tn−1;1−βSn√n− 1
slucajna promenljiva, tj. varira od
jednog do drugog realizovanog uzorka.
Primer 20. Pretpostavimo da je godisnji vodeni talog na odredenom lokalitetu slucajna promenljiva X sa
normalnom raspodelom. U toku 8 godina registrovane su sledece vrednosti taloga
34.1, 33.7, 27.4, 31.1, 30.9, 35.2, 28.4, 32.1.
Odrediti 90% interval poverenja za E(X) = µ. Ovde imamo n = 8 i β = 0.9, te iz Tablice III citamo broj
t7;0.1 = 1.89. Odredimo x8 i s8 :
x8 =1
8(34.1 + 33.7 + 27.4 + 31.1 + 30.9 + 35.2 + 28.4 + 32.1) = 31.6,
s8 =1
8
8∑
k=1
x2k − x2
8 =1
8(34.12 + 33.72 + 27.42 + 31.12 + 30.92 + 35.22 + 28.42 + 32.12)− 31.62 = 7.5.
Dakle, 90% interval poverenja za µ je
[31.6− 1.89
√7.5√7, 31.6 + 1.89
√7.5√7
]ili priblizno [29.6, 33.6].
Interval poverenja za nepoznatu disperziju σ2
Disperzija obelezja X meri na neki nacin homogenost tog obelezja u populaciji (meru rasejavanja okoocekivanog rezultata) i u nizu situacija u primenama vazna je samo gornja granica disperzije. Zato jeovde interesantniji tzv. jednostrani interval poverenja, tj. interval cija je jedna krajnja tacka statistika,a druga neslucajan broj. S obzirom na ovo, interval poverenja za disperziju trazicemo u obliku [0, σ2
0 ].
Podsetimo se da je χ2n−1 =
nS2
n
σ2(Teorema 5 i Napomena 3) i da iz Tablice II citamo broj χ2
n;α
takav da je P (χ2n ≥ χ2
n;α) = α. Za dati nivo poverenja β citamo iz Tablice II broj χ2n−1;β takav da je
P (χ2n−1 ≥ χ2
n−1;β) = β ili
P(nS2
n
σ2≥ χ2
n−1;β
)= β.
Odavde odmah dobijamo
P(σ2 ≤ nS
2
n
χ2n−1;β
)= β.

23
Dakle, 100β% jednostrani interval poverenja za disperziju je
[0,
nS2
n
χ2n−1;β
].
Dvostrani interval poverenja za σ2 mozemo da dobijemo na sledeci nacin: za dati nivo poverenja βcitamo iz Tablice II brojeve χ2
n−1;(1+β)/2 i χ2n−1;(1−β)/2 (sl. 12). Na taj nacin je
P(χ2
n−1;(1+β)/2 ≤ χ2n−1 ≤ χ2
n−1;(1−β)/2
)= β,
P(χ2
n−1;(1+β)/2 ≤nS
2
n
σ2≤ χ2
n−1;(1−β)/2
)= β.
Dakle, dvostrani interval poverenja za σ2 je
[nS
2
n
χ2n−1;(1−β)/2
,nS
2
n
χ2n−1;(1+β)/2
].
Sl. 12
Primer 21. Dimenzija nekog proizvoda ima normalnu raspodelu. U uzorku od n = 20 takvih proizvoda
nadeno je x20 = 32.29 mm i 20 · s220 = 2.53 mm2. Naci 96% jednostrani i dvostrani interval poverenja za
nepoznatu disperziju σ2 duzine proizvoda u celokupnoj proizvodnji.
Linearnom ekstrapolacijom vrednosti iz Tablice II dobijamo χ19;0.96 ≈ 11 tako da 96% jednostrani interval
poverenja za σ2 je [0, 2.53/11] ili priblizno [0, 0.23 mm2].
Za dvostrani 96% interval poverenja iz Tablice II citamo χ2n−1;(1−β)/2 = χ2
19;0.02 = 33.69 i linearnom
ekstrapolacijom dobijamo χ2n−1;(1+β)/2 = χ2
19;0.98 ≈ 10.77, tako da je trazeni dvostrani interval
[ 2.53
33.69,
2.53
10.77
]ili priblizno [0.07 mm2, 0.23 mm2].
5. Testiranje statistickih hipoteza
Osnovni problem u Matematickoj statistici je da se na osnovu uzorka oceni kakvu raspodelu u celojpopulaciji ima posmatrano obelezje. U zavisnosti od prirode problema uocava se skup logicki mogucihraspodela (na osnovu histograma, poligona,...), koji se naziva skup dopustivih raspodela. Na primer,X ∼ N (µ, σ2), µ ∈ (150, 180), σ2 ∈ (0, 30).

24
Svaka pretpostavka o konkretnoj raspodeli obelezja X zove se statisticka hipoteza, a postupaknjenog verifikovanja pomocu uzorka (u smislu prihvatanja ili odbacivanja hipoteze) zove se statistickitest. Statistika kojom se sluzimo u tom postupku zove se test statistika.
Ako skup dopustivih raspodela zavisi od nekog parametra θ, F (x, θ), x ∈ R i ako se statisticka hipotezaodnosi na vrednost tog parametra, radi se o parametarskom testu. Ako se statisticka hipoteza odnosina saglasnost statistickog uzorka sa konkretnom raspodelom obelezja X, radi se o neparametarskomtestu.
Statisticka hipoteza je prosta akao je njome potpuno odredena raspodela obelezja, dakle θ = θ0. Usuprotnom, statisticka hipoteza je slozena (na primer, θ ∈ θ1, θ2, θ3).
Test znacajnosti mogao bi se ovako opisati: Neka je F (x, θ) funkcija raspodele obelezja X. Pret-postavlja se hipoteza H(θ = θ0). Vrsi se izbor odgovarajuce statistike U = u(X1, . . . , Xn) i reg-istruje njena vrednost u = u(x1, . . . , xn). Pretpostavljajuci da je hipoteza H(θ = θ0) tacna, nalazimoverovatnocu dobijenog odstupanja statistike U od ocekivane vrednosti. Ako je dobijena verovatnocamanja od ranije usvojenog praga (nivoa) znacajnosti α (obicno 0.05 ili 0.1) hipotezu H(θ = θ0)odbacujemo, jer velicina odstupanja ne moze se objasniti samo slucajnim odstupanjima pod pret-postavkom da je hipoteza tacna, posto bi takva odstupanja imala vrlo malu verovatnocu (manju odα.) Ako je dobijena verovatnoca veca od α, ne mozemo jos zakljuciti da je hipoteza H(θ = θ0) tacna.Testovi znacajnosti ne daju afirmativni odgovor (prihvatanje hipoteze), moze se samo zakljuciti da reg-istrovani uzorak ne protivureci hipotezi. Izbog statistike U i praga znacajnosti α zavisi od konkretnogzadatka.
Hipoteza o verovatnoci p, H(p = p0)
Pretpostavimo da obelezje X ima Bernulijevu raspodelu
X ∼(
0 11− p p
), (0 < p < 1).
Oznacimo sa K broj jedinica u uzorku (X1, . . . , Xn) = (I1, . . . , In) (u stvari, broj realizacija posma-tranog dogadaja). Slucajna promenljiva K ima binomnu raspodelu B(n, p). Neka je k broj jedinica urealizovanom uzorku (x1, . . . , xn). Pod pretpostavkom da je p = p0 nacicemo verovatnocu da odstupanjerelativne ucestanosti K/n od ocekivane vrednosti p0 bude vece nego u realizovanom uzorku. Imamo
P(∣∣∣Kn− p0
∣∣∣ ≥∣∣∣kn− p0
∣∣∣)
= P
(∣∣∣∣∣K − np0√np0(1− p0)
∣∣∣∣∣ ≥∣∣∣∣∣
k − np0√np0(1− p0)
∣∣∣∣∣
).
Na osnovu teoreme Muavra-Laplasa, raspodelu slucajne promenljive (K − np0)/√np0(1− p0) mozemo
aproksimirati N (0, 1) raspodelom, te dobijamo
P(∣∣∣Kn− p0
∣∣∣ ≥∣∣∣kn− p0
∣∣∣)
= 1− 2Φ( k − np0√
np0(1− p0)
)= α∗.
Ako je α∗ < α, gde je α unapred zadat prag znacajnosti, hipotezu odbacujemo, a ako je α∗ ≥ α hipotezune odbacujemo.
Primer 22. Pretpostavimo da smo iz 100 bacanja novcica dobili 36 ,,pisama.” Ovo nije apsolutni dokaz da
novcic nije ,,fer” (homogen i pravilnog oblika), naime nije nemoguce da se takav rezultat dobije sa novcicem kod
koga je hipoteza H(p = 0.5) da padne pismo. Iz iskustva znamo da nam ovakav rezultat eksperimenta daje jake
dokaze protiv hipoteze p = 0.5. Zadatak statisticke teorije testiranja hipoteza jeste da kvantifikuje stepen sumnje
u neku hipotezu. U nasem eksperimentu registrovano je odstupanje |0.5 − 0.36| = 0.14 relativne ucestanosti.

25
Ispitajmo kolika je verovatnoca, pretpostavljajuci da je hipoteza H(p = 0.5) tacna, da se pojavi i vece odstupanje
od 0.14.
Prema centralnoj granicnoj teoremi (Muava-Laplasa) slucajna promenljiva sa binomnom raspodelom S100 ∼B(100, 0.5) ima u granicnom slucaju priblizno normalnu raspodelu N
(np, np(1−p)
)= N (50, 52), te je
S100
100∼
N (0.5, 0.052). Primetimo da je u ovom slucaju standardizovana promenljiva S∗ = (S100/100− 0.5)/0.05 i ima
priblizno normalnu raspodelu N (0, 1). Nalazimo
P(∣∣∣S100
100− 0.5
∣∣∣ ≥ 0.14)= P
(∣∣∣∣∣
S100
100− 0.5
0.05
∣∣∣∣∣ ≥ 2.8
)= 1− 2Φ(2.8) = 0.005 (iz Tablice I).
Dakle, pretpostavljajuci da je hipoteza H(p = 0.5) tacna, realizovao se dogadaj cija je verovatnoca bila vrlo mala
(= 0.005). Znaci da treba da odbacimo hipotezu o ,,fer” novcicu, odnosno hipotezu H(p = 0.5).
Hipoteza o matematickom ocekivanju µ, H(µ = µ0), ako je σ poznato
ObelezjeX imaN (µ, σ2) raspodelu sa nepoznatim parametrom µ i poznatom standardnom devijacijomσ. Pretpostavimo da je µ = µ0. Posmatracemo odstupanje aritmeticke sredine Xn uzorka (X1, . . . , Xn)od ocekivane vrednosti µ0. Sa xn cemo oznaciti aritmeticku sredinu realizovanog uzorka (x1, . . . , xn).
Koristicemo cinjenicu da Xn ima N (µ, σ2/n) raspodelu (Primer X), odakle sledi daXn − µ
σ
√n ima
N (0, 1) raspodelu. Tada je
P(|Xn − µ0| ≥ |xn − µ0
)= P
(∣∣∣Xn − µ0
σ
√n∣∣∣ ≥
∣∣∣ xn − µ0
σ
√n∣∣∣)
= 1− 2Φ( xn − µ0
σ
√n)
= α∗.
Ako je α∗ < α hipotezu H(µ = µ0) odbacujemo, a ako je α∗ ≥ α, hipotezu H(µ = µ0) ne odbacujemo.
Primer 23. Neka obelezje X ima normalnu raspodelu N (µ, 1) i neka je sredina uzorka od 25 elemenata
x25 = 50. Testirati hipotezu H(µ = 49.5) za prag znacajnosti α = 0.01. Ovde je
α∗ = 1− 2Φ(50− 49.5
1
√25)
= 1− 2Φ(2.5) = 0.0124.
Kako je α∗ > α, hipotezu ne odbacujemo.
Hipoteza o matematickom ocekivanju µ, H(µ = µ0), ako σ nije poznato
Obelezje X ima N (µ, σ2) raspodelu sa nepoznatim parametrima µ i σ. Postavimo hipotezu H(µ =
µ0). Neka Xn i S2
n oznacavaju sredinu uzorka i disperziju uzorka (X1, . . . , Xn) a xn i s2n vrednost tih
statistika za realizovan uzorak (x1, . . . , xn). Na osnovu Teoreme 7 znamo da statistikaXn − µ0
Sn
√n− 1
ima Studentovu t(n− 1) raspodelu. Imamo
P(∣∣∣Xn − µ0
Sn
√n− 1
∣∣∣ ≥∣∣∣ xn − µ0
sn
√n− 1
∣∣∣)
= α∗.
Vrednost α∗ nalazimo iz tablica za Studentovu t raspodelu. Ako je α∗ < α, gde je α unapred usvojenprag znacajnosti, hipotezu H(µ = µ0) odbacujemo, a ako je α∗ ≥ α, hipotezu H(µ = µ0) ne odbacujemo.
Primer 24. Za obelezje X dobijen je realizovan uzorak (x1, x2, x3, x4, x5) = (1.10, 1.30, 1.20, 1.10, 1.30).Testiracemo hipotezu H(µ = 1) za prag znacajnosti α = 0.1. Najpre izracunavamo x5 = 1.20, s2n = 0.008 i
s5 ≈ 0.09. Kako jexn − µ0
sn
√n− 1 =
1.2− 1
0.09
√4 ≈ 4.45,
iz Tablice III za Studentovu t raspodelu nalazimo α∗ ≈ 0.01. Hipotezu odbacujemo jer je α∗ < α.

26
Hipoteza o disperziji σ2, H(σ2 = σ20)
Obelezje X ima N (µ, σ2) raspodelu sa nepoznatim parametrom σ. Postavljamo hipotezu H(σ2 = σ20).
Ako je S2
n disperzija uzorka (X1, . . . , Xn) a s2n realizovana vrednost disperzije uzorka, tada je
P
(nS
2
n
σ20
≥ ns2nσ2
0
)= α∗.
Znamo danS
2
n
σ20
ima χ2(n− 1) raspodelu (videti Napomenu 3). Verovatnocu α∗ uporedujemo sa unapred
zadatim pragom znacajnosti α i ako je α∗ < α hipotezu H(σ2 = σ20) odbacujemo, u suprotnom je ne
odbacujemo.
Primer 25. Obelezje X ima normalnu raspodelu i disperziju uzorka s230 = 10 za izabrani uzorak od 30
elemenata. Testiracemo hipotezu H(σ2 = 15) za prag znacajnosti α = 0.01. Najpre nalazimo vrednost kolicnika
ns2nσ2
0
=30 · 10
15= 20.
Kako je
P
(nS
2
n
σ20
≥ 20
)= α∗ = 0.9 (procitano iz Tablice II za χ2 raspodelu),
i α∗ > α, hipotezu H(σ2 = 15) ne odbacujemo.
Izbor hipoteza
Izbor izmedu dve hipoteze, nazovimo ih H0–nulta hipoteza i H1–alternativna hipoteza, pojavljujese u razlicitim oblastima primene, u stvari kad god treba dokazati neko tvrdenje ili verifikovati neku novuteoriju, tehnologiju, proizvod. Na primer, ako se pojavi novi proizvod, proizvodac mora dokazati da jeon bolji od postojecih. Da bi dokazao tu hipotezu, on mora da obori suprotnu hipotezu.
Ako zelimo da dokazemo neko tvrdenje, onda suprotno tvrdenje (ili neutralno ili postojece stanje)uzimamo za nultu hipotezu H0, a samo tvrdenje za hipotezu H1. Cilj postupka testiranja je da se ispita,na osnovu rezultata eksperimenta, ima li dokaza protiv hipoteze H0, a u korist hipoteze H1.
Test je odreden ako je definisana statistika U (statistika testa) i skup vrednosti za U za koje odbacu-jemo hipotezu H0 (oblast odbacivanja ili kriticna vrednost. Ako je oblast odbacivanja testa oblikaU > c, U ≥ c, U < c ili U ≤ c, za broj c kazemo da je kriticna vrednost testa. Na primer,ako za statistiku koristimo sredinu uzorka Xn, za dati prag znacajnosti testa α kriticnu vrednost testa codredujemo iz relacije
α = P (Xn < c). (7)
Zakljucak testa moze biti jedan od sledeca dva:
• Odbacujemo H0 jer smo u eksperimentu dobili U u oblasti odbacivanja. Kao objasnjenje nudimohipotezu H1.
• Ne odbacujemo H0 jer je vrednost za U u eksperimentu bila van oblasti odbacivanja. Nemamodokaze protiv H0.
Pri testiranju hipoteza moguce su dve vrste gresaka:
• Greska prve vrste nastaje ako se H0 odbaci kada je H0 tacna.
• Greska druge vrste nastaje ako se H0 ne odbaci kada je H1 tacna.

27
S obzirom na interpretaciju hipoteza H0 i H1, obicno nam je vaznije da ne napravimo gresku prvevrste, jer bismo tim postupkom dokazali tvrdenje koje nije tacno (hipoteza H1). Greska druge vrstenije toliko znacajna, jer ako nemamo dovoljno jakih dokaza protiv H0, a verujemo da je H1 ipak tacna,postupak dokazivanja hipoteze H1 mozemo nastaviti izvodenjem novih obimnijih eksperimenata.
Primer 26. Brasno se prodaje u pakovanjima nominalne mase 1 kg. Na zahtev potrosaca, koji su primetili
da je masa manja od 1 kg, potrebno je izvrsiti proveru na bazi slucajnog uzorka od 25 pakovanja brasna. Poznato
je da masina za punjenje ima standardnu devijaciju σ = 15 g.
U ovom problemu mozemo pretpostaviti da je masa jednog pakovanja brasna normalna slucajna promenljiva
sa matematickim ocekivanjem µ i disperzijom σ2 = 152 = 225. Zadatak je da se testira
H0 : µ = 1000 protiv H1 : µ < 1000.
Uzecemo prag znacajnosti α = 0.05. Statistika testa moze da bude sredina uzorka Xn koja, kao sto znamo,
ima N (µ, σ2/n) raspodelu (Primer 8), gde je n = 25. Manje vrednosti (od 1000) za Xn su dokaz protiv hipoteze
H0; oblast odbacivanja je Xn < c, sa nekim c koje izracunavamo iz nivoa znacajnosti, videti formulu (7).
Statistika Xn pri nultoj hipotezi ima N (1000, 9) raspodelu, tako da je
α = P (Xn < c) = P(Z∗ <
c− 1000
3
)=
1
2+ Φ
(c− 1000
3
).
Odavde za α = 0.05 iz Tablice I (imajuci u vidu da je Φ(−x) = −Φ(x)), nalazimo da je (c− 1000)/3 = −1.64,odakle je c = 995 (zaokruzeno na ceo broj). Prema tome, test sa pragom znacajnosti 0.05, na bazi uzorka
obima 25, ima sledece pravilo odlucivanja: Ako je Xn < 995, hipoteza H0 se odbacuje u korist H1 (tj. u korist
potrosaca); u suprotnom slucaju, hipoteza H0 se ne odbacuje.
Sa pragom znacajnosti α = 0.01 dobija se c = 993, dok se sa α = 0.1 dobija c = 996.
Testiranje neparametarskih hipoteza
Ovim testovima se ispituje saglasnost izmedu hipoteticne (teorijske) raspodele populacije F (x) i empir-ijske raspodele uzorka Sn(x). Ako Sn(x) aproksimira F (x) ,,dovoljno dobro”, onda prihvatamo hipotezuda je F (x) funkcija raspodele populacije iz koje je uzet uzorak. Da bismo doneli ovakvu odluku moramoznati koliko mnogo Sn(x) moze da odstupa od F (x), ako je hipoteza o saglasnosti tacna. Zbog togauvodimo meru odstupanja Sn(x) od F (x) i trazimo raspodelu verovatnoca ove mere, pod pretpostavkomda je hipoteza tacna.
Primer 27. Pretpostavimo da imamo 50 podataka za koje smo izracunali ucestanosti i relativne ucestanosti.
Na osnovu ovog nacrtan je grafik emprijske raspodele (,,stepenasta kriva” na sl. 13) i uporeden sa grafikom
funkcije N (0, 1) raspodele (neprekidna kriva na sl. 13). Na prvi pogled izgleda da empirijska raspodela dobro
aproksimira standardnu normalnu raspodelu, sa izvesnim odstupanjima, medutim to nije dovoljno za prihvatanje
ove hipoteze. Da li, na primer, podaci uzorka i odgovarajuca empirijska raspodela bolje aproksimiraju N (0, 1.2)raspodelu? Da bismo odgovorili na ovo pitanje, potreban nam je neki kriterijum pomocu koga bismo ispitali da
li su odstupanja u dozvoljenim granicama ili nisu.
Sl. 13 Empirijska funcija raspodele u poredenju sa funkcijom raspodele N (0, 1)

28
Za resavanje postavljenog problema izlozicemo neparametarski hi kvadrat test. Ovaj test uveoje u statistiku Karl Pirson (1857–1936) i zato se cesto naziva i Pirsonov test. Danas je to jedan odtestova sa najsirom oblascu primene.
Neka je (X1, . . . , Xn) nezavisan uzorak iz nepoznate raspodele sa funkcijom raspodele F. Zelimo daproverimo da li je F = F0, gde je F0 data funcija raspodele.
Podelimo realnu osu na r disjunktnih intervala Aj = (aj−1, aj ] (j = 1, . . . , r), pri cemu je a0 =−∞, ar = +∞. Ukoliko priroda problema zahteva, granice a0 i ar mogu biti konacne. Kako X1, . . . , Xn
imaju istu raspodelu, verovatnoca da vrednost slucajne promenljive Xi pripada intervalu Aj jednaka je
pj = P (X ∈ Aj) = F (aj)− F (aj−1), (j = 1, . . . , r).
S druge strane, za raspodelu F0, odgovarajuce verovatnoce su
pj0 = F0(aj)− F0(aj−1), (j = 1, . . . , r). (8)
Neparametarsko testiranja hipoteze svodi se na problem testiranja hipoteze
H0 : p1 = p10, . . . , pr = pr0 protiv alternativne hipoteze H1 : (p1, . . . , pr) 6= (p10, . . . , pr0).
Za testiranje nam je potrebna statistika testa i njena raspodela pod nultom hipotezom. Sledeca teoremasugerise jedan izbor.
Teorema 9. Neka je (X1, . . . , Xn) nezavisan uzorak iz raspodele sa funkcijom raspodele F0. Neka jeNj broj onih slucajnih promenljivih iz uzorka slucajnih promenljivih cije se brojne karakteristike nalazeu intervalu Aj . Neka je pj0 definisano sa (8). Statistika
r∑
j=1
(Nj − npj0)2
npj0(9)
ima asimptotsku χ2(r − 1) raspodelu (kad n→ +∞).
Statistika definisana sa (9) naziva se Pirsonov hi kvadrat statistikom i obelezava se sa χ2. Bro-jevi Nj su rezultat posmatranja (stvarno stanje) dok je npj0 matematicko ocekivanje broja slucajnihpromenljivih Xi cije su se vrednosti realizovale u intervalu Aj . Dakle, imamo da je
χ2 =n∑
j=1
(stvarno− ocekivano)2
ocekivano.
Velike vrednosti statistike χ2 ukazuju na veliku razliku izmedu stvarnog i ocekivanog, pa je to indikacijaza odbacivanje hipoteze H0.
Neka je ν broj stepeni slobode χ2 raspodele a α prag (nivo) znacajnosti (ili rizik prihvatanja hipoteze).U Tabeli II se daju vrednosti χ2
ν;α za razne vrednosti ν i α prema relaciji
P(χ2 > χ2
ν;α
)= α.
Verifikacija hipoteze vrsi se na sledeci nacin:
1) Ako je izracunata vrednost χ2 (iz (9)) veca od χ2ν;α, onda hipotezu odbacujemo, smatrajuci da su
odstupanja empirijske raspodele od pretpostavljene raspodele bitna. Kako je u tom slucaju
P(χ2 > χ2
ν;α
)= α,

29
mozemo biti sigurni da su ova odstupanja bitna, jer bi nas zakljucak bio ispravan u oko 95% (= (1−α)·100)odsto slucajeva za α = 0.05.
2) Ako je izracunata vrednost χ2 manja od χ2ν;α, onda nemamo osnovu da odbacujemo hipotezu, sto
jos ne znaci da je hipoteza potpuno tacna. Da bismo prihvatili hipotezu kao tacnu, treba je proveriti nanekoliko drugih uzoraka.
Primer 28. Zelimo da testiramo hipotezu H0 : E(0.005) da duzina ,,zivota” X sijalice ima eksponencijalnu
raspodelu E(0.005). Podsecamo da ova raspodela ima funkciju gustine
f(x) =
λe−λx, x ≥ 0,
0, x < 0
i da se cesto koristi u Teoriji pouzdanosti. U konkretnom slucaju je λ = 0.005.
U uzorku od 150 sijalica dobijeno je da 47 sijalica imaju ,,zivot” u intervalu [0,100] casova, 40 u [100,200], 35 u
[200,300] i 28 traju preko 300 casova. Hipotezu H0 : E(0.005) testiramo primenjujuci Pirsonov χ2 test. Ovde je
r = 4, A1 = [0, 100], A2 = [100, 200], A3 = [200, 300], A4 = [300,+∞].
Za ove intervale nalazimo da je
N1 = 47, N2 = 40, N3 = 35, N4 = 28.
Dalje je
p10 = PH0(0 ≤ X < 100) =
∫ 100
0
f(x)dz =
∫ 100
0
0.005e−0.005xdx = 0.39,
p20 = PH0(100 ≤ X < 200) =
∫ 200
100
0.005e−0.005xdx = 0.24,
p30 = PH0(200 ≤ X < 300) =
∫ 300
200
0.005e−0.005xdx = 0.15,
p40 = PH0(X ≥ 300) =
∫ +∞
300
0.005e−0.005xdx = 0.22.
Prema formuli (9) je
χ24−1 =
4∑
j=1
(Nj − 150pj0)2
150pj0=
(47− 58.5)2
58.5+
(40− 36)2
36+
(35− 22.5)2
22.5+
(28− 33)2
33= 11.56.
Usvojimo α = 0.01 i iz Tablice II citamo kriticnu vrednost χ23;0.01 = 11.34. Kako je χ2
3 > χ23;0.01, odbacujemo
hipotezu H0 : E(0.005).
6. Linearna regresija i korelacija
Rec regresija je dospela u statistiku kada je 1855. gidine Fransis Galton objavio publikaciju u kojojje analizirao visinu sinova u zavisnosti od visine oceva. Zakljucak ove studije bio je da sinovi ekstremnovisokih oceva nisu toliko visoki, dakle, regresiraju.
Promena jednog obelezja statistickog skupa cesto utice na promenu drugih obelezja zbog medusobnepovezanosti. Povezanost izmedu obelezja moze se razlikovati i po smeru i po jacini povezanosti. Najjacaili najuza veza izmedu obelezja je funkcionalna veza, tj. takva veza da svakoj vrednosti jednog obelezjaodgovara tacno odredena vrednost drugog. Labavija veza izmedu obelezja, koja su podlozna manjim ili

30
vecim odstupanjima, naziva se korelativnom (ili stohastickom) vezom. Na primer, povrsina P kruga ipoluprecnik r su u funkcionalnoj vezi (P = r2π) a promenljive velicine koje oznacavaju visinu i tezinuljudi pokazuju izvesnu korelaciju, dok su brojevi tacaka koji se pojavljuju na dvema bacenim kockamanekorelativne velicine. Skup statistickih metoda kojima se proucavaju uzajamne veze statistickih obelezjai pojava (smer, jacina, oblik) naziva se teorijom korelacije, a osnovni pokazatelji korelacionih veza sujednacine regresije i koeficijent korelacije.
U velikom broju istrazivanja ili eksperimenata uocava se veza izmedu dve ili vise promenljivih velicina.Od istrazivaca se u tom slucaju ocekuje da utvrdi da li postoji i kakva je direktna funkcionalna zavisnostmedu tim velicinama. Na primeru dva svojstva X i Y koja se istrazuju na nekom uzorku obima n, kaorezultat posmatranja dobija se n uredenih parova realizacija (x1, y1), (x2, y2), . . . , (xn, yn). Oni se mogupredstaviti u Dekartovoj ravni (slika 14), a graficka reprezentacija koja tom prilikom nastaje naziva sedijagram rasturanja. Ovi dijagrami ilustruju redom pozitivne jace i slabije korelacije, kao i slucajnekorelativnosti.
Sl. 14 Dijagrami rasturanja tacaka
Da bi se na osnovu dijagrama rasturanja odredila funkcionalna zavisnost obelezja X i Y potrebno je,,aproksimirati” dobijeni skup podataka tzv. fitovanom krivom ili krivom regresije koristeci nekiod kriterijuma: zbir kvadrata odstupanja ordinata od krive je minimalan, zbir aposlutnih vrednostiodstupanja je minimalan, itd. Na prikazanim slikama treba proveriti linearnu vezu y = ax+ b na sl. a),logaritamsku vezu y = a log(x + b) na sl. b), dok dijagram pod c) ne ukazuje ni na kakvu funkcionalnuzavisnost. Ako je kriva regresije prava, tada postoji linearna korelacija, a ako je kriva regresije bilokoja druga, onda postoji nelinearna korelacija. U nasem razmatranju bavicemo se samo linearnomregresijom koja se u praksi najcesce pojavljuje.
Korelacija
U Teoriji verovatnoce dokazuje se da za nezavisne slucajne promenljive X i Y vazi da je
E(XY )− E(X)E(Y ) = 0.
Obrnuto, u opstem slucaju, ne vazi. Medutim, pokazuje se da se razlikom E(XY ) − E(X)E(Y ) mozemeriti stepen linearne zavisnosti izmedu X i Y.
Definicija 11. Za slucajne promenljive X i Y definisemo kovarijansu, u oznaci Cov:
Cov(X,Y ) = E(XY )− E(X)E(Y ).
Koristeci osobine matematickog ocekivanja mozemo izvesti i sledecu formulu za kovarijansu:
Cov(X,Y ) = E((X − E(X))(Y − E(Y ))
).

31
Lako se izvode sledece osobine kovarijanse.
Teorema 10. Neka su X i Y slucajne promenljive i neka su a i b realni brojevi.
1 Ako su X i Y nezavisne slucajne promenljive, tada je Cov(X,Y ) = 0. Obrnuto ne mora da vazi.
2 Cov(X,Y ) = Cov(Y,X).
3 Cov(X,X) = D(X).
4 Cov(aX, bY ) = abCov(X,Y ).
5 Cov(X + a, Y + b) = Cov(X,Y ).
Definicija 12. Koeficijent korelacije izmedu slucajnih promenljivih X i Y sa pozitivnim disperzi-jama definise sa
ρ(X,Y ) =Cov(X,Y )√D(X)
√D(Y )
.
Koeficijent korelacije se, u primenama, koristi kao mera linearne zavisnosti dve slucajne promenljive.Opravdanje za to daju tvrdenja sledece teoreme.
Teorema 11. Za slucajne promenljive X i Y sa pozitivnim disperzijama vazi:
1 −1 ≤ ρ(X,Y ) ≤ 1.
2 ρ(X,Y ) = ±1 ako i samo ako je P (Y = aX+b) = 1, a 6= 0, b ∈ R. Drugim recima, ρ(X,Y ) = ±1ako i samo ako je sa verovatnocom 1, Y rastuca (opadajuca) linearna funkcija promenljive X.
Definicija 13. Neka su X i Y slucajne promenljive i neka je ρ(X,Y ) njihov koeficijent korelacije.Kazemo da su X i Y
• nekorelisane ako je ρ(X,Y ) = 0,
• pozutivno korelisane ako je ρ(X,Y ) > 0,
• negativno korelisane ako je ρ(X,Y ) < 0.
Iz Definicije 13 neposredno izlazi da su svake dve nezavisne slucajne promenljive nekorelisane, dokobrnuto, u opstem slucaju, ne mora da vazi. Napominjemo da koeficijent korelacije ukazuje samo nalinearnu vezu; moguce je da bude ρ(X,Y ) = 0 a da, i pored toga, X i Y budu povezane nekom nelinearnomvezom.
Kao empirijsko pravilo prihvata se sledece:
1) |ρ| < 0.3 – postoji sasvim neznatna linearna veza izmedu obelezja i nesigurnog je znacenja, narocitoako je obim uzoraka mali.
2) |ρ| izmedu 0.5 i 0.7 – postoji znacajna linearna veza koja ima prakticnu primenu.
3) 0.7 < |ρ| < 0.9 – pokazuje tesnu (linearnu) vezu.
4) |ρ| > 0.9 – znaci vrlo tesnu vezu.
Ako se koeficijent korelacije odreduje na osnovu uzorka (x1, y1), . . . , (xn, yn), tada se za njegovoizracunavanje koristi formula
ρ =
1
n
n∑
k=1
xkyk − xy
√√√√[
1
n
n∑
k=1
x2k − x2
][1
n
n∑
k=1
y2k − y2
] , x =1
n
n∑
k=1
xk, y =n∑
k=1
yk.

32
Pod regresijom se u statistici podrazumeva zavisnost jedne slucajne promenljive od druge ili visenjih. Opsti model zavisnosti je
Y = f(X) + ε, (10)
gde je ε ∼ N (0, σ2) slucajna promenljiva nezavisna od X, pri cemu X moze biti skalarna ili vektorskavelicina. f(X) je funkcija kojom se objasnjava zavisnost izmedu X i Y. Slucajna promenljiva X nazivase kontrolisana a Y observirana (ili registrovana) slucajna promenljiva.
Velicina ε je slucajna greska koja nastaje iz raznih razloga (sum u telekomunikasionom prenosu, uticajkapacitivnosti i induktivnosti u elektronskim kolima, nepredvidene oscilacije, itd.) Ona modeluje uticajraznih slucajnih faktora koji se, na osnovu centralne granicne teoreme, moze predstaviti normalnomslucajnom promenljivom ε sa E(ε) = 0 i nepoznatom disperzijom σ2.
+X Yf
e
Sl. 15
Model (10) moze se predstaviti kao na sl. 15. Na ulazu u sistem imamo slucajnu promenljivu X, a naizlazu Y. Samo posmatranjem X i Y treba odrediti karakteristike sistema, tj. funkciju f.
Iz jednakosti (10) sleduje da je E(Y |X) = f(X), odakle se dobija
f(x) = E(Y |X = x). (11)
Funkcija f definisana sa (11) naziva se regresionom funcijom a odgovarajuca kriva krivom regresije.
Na osnovu (11) moglo bi se pretpostaviti da mozemo oceniti E(Y |X = x) tako sto cemo za svakufiksiranu (ulaznu) vrednost X = x meriti izlaz Y dovoljan broj puta. U praksi obicno nemamo uslove zaovakav eksperiment i jedino sto mozemo koristiti su parovi merenih vrednosti (xi, yi). Problem ocenjivanjase moze uprostiti koristeci dodatne pretpostavke koje mozemo svrstati u dve kategorije:
• Pretpostavke o zajednickoj funkciji raspodele za (X,Y ).
• Pretpostavke o obliku zavisnosti f.
Primer 29. U Teoriji verovatnoce se dokazuje da ako slucajni vektor (X,Y ) ima dvodimenzionalnu normalnu
raspodelu sa parametrima µX , µY , σ2X , σ
2Y i koeficijentom korelacije ρ = ρ(X,Y ), tada je
f(x) = E(Y |X = x) = µX + ρσY
σX(x− µx).
Dakle, da bi se ocenila regresiona funkcija (u ovom slucaju regresiona prava), potrebno je oceniti pet nepoznatih
parametara.
Na osnovu Primera 29 i uzimajuci u obzir da se normalna raspodela cesto srece u praksi i da se veomacesto javlja kao (asimptotska) aproksimacija raspodela velikog broja slucajnih promenljivih, zakljucujemoda je regresiona funkcija vrlo cesto javlja u praksi kao linearna funkcija, u kom slucaju imamo linearnuregresiju (korelaciju).
Regresiona prava
Najjednostavniji slucaj regresije je ako se pretpostavi u obliku
f(x) = ax+ b, tj. Y = aX + b+ ε. (12)

33
Koristicemo se sledecim tvrdenjem.
Teorema 12. Neka su X i Y zavisne slucajne promenljive. Tada je
E(Y − E(Y |X))2
)≤ E
(Y − g(X))2
)
za svaku funkciju g za koju postoji matematicko ocekivanje na desnoj strani.
Na osnovu Teoreme 12 i (11) sledi da parametre a i b u (12) treba odrediti iz uslova
R(a, b) = E((Y − aX − b)2
)−→ min.
Ispitajmo kada funkcija R(a, b) dostize minimum. Iz uslova
∂R(a, b)
∂a= E((Y − aX − b)X) = 0
∂R(a, b)
∂b= E(Y − aX − b) = 0,
nalazimo resenja
a =E(XY )− E(X)E(Y )
D(X), b = E(Y )− aE(X). (13)
Prva jednakost u (13) moze se napisati u obliku
a = ρ(X,Y )
√D(X)
D(Y ).
Ako uvedemo oznake µx, µY , σX , σY , ρ, iz (12) i (13) nalazimo da je
f(x) = µX + ρσY
σX(x− µX).
Poredenjem sa rezultatom Primera 29 vidimo da se dobija isti oblik regresione funkcije kao kada sepretpostavi da je zajednicka raspodela normalna. Ovo je vazno svojstvo normalne raspodele:
Teorema 13. Regresiona funkcija je prava (regresiona prava)
E(Y |X = x) = µX + ρσY
σX(x− µX)
ako i samo ako sluacjni vektor (X,Y ) ima zajednicku dvodimenzionalnu normalnu raspodelu.
Regresionu pravu ima smisla konstruisati i ako se zna da zajednicka raspodela nije normalna. Toje onda prava koja od svih pravih linija najbolje opisuje zavisnost izmedu Y i X u smislu srednjegkvadratnog odstupanja. Ocenjena regresiona prava
y = ax+ b
je prava koja, od svih pravih linija, najbolje opisuje zavisnost izmedu X i Y na osnovu datog uzorka.
Da bi se doslo do regresione prave, u praksi se za prost uzorak (X1, . . . , Xn) nalazi realizovan uzorak(x1, . . . , xn). Zatim se svakoj numerickoj vrednosti xk pridruzuje slucajna promenljiva Yk = aXk +bk +εk
obelezja Y. Dakle,(x1, Y1), (x2, Y2), . . . , (xn, Yn)

34
za koji realizovan uzorak ima oblik uredenih parova
(x1, y1), (x2, y2), . . . , (xn, yn).
Kao sto je ranije napomenuto, ovi parovi cine u ravni dijagram rasturanja za koji se ispituje tendencijalinearne zavisnosti.
U opisanom modelu potrebno je odrediti parametre a i b tako da postoji linerna zavisnost izmeduvrednosti realizovanog uzorka, gde je
yk = axk + b+ εk sa E(εk) = 0,
pri cemu su a i b ocene parametara a i b dobijene na osnovu uzorka.
Ideja je jednostavna i moze se jasno sagledati sa sl. 16. Rasipanje ,,roja” tacaka (x1, y1), (x2, y2),. . . , (xn, yn) oko pretpostavljene regresione prave y = ax+b bice najmanje ako je zbir apsolutnih vrednosti,,sumova” ε1, ε2, . . . , εn (ili zbira njihovih kvadrata) minimalno. Drugi pristup je jednostavniji (metodnajmanjih kvadrata) pa, prema tome, parametre a i b cemo odrediti tako da zbir ε2
1 + ε22 + · · ·+ ε2n budeminimalan.
e
e
ee
e
y
xo
y=ax+b
1
1
2
2
3
3
n
n
4
4x x x x x
Sl. 16
Uvedimo funkciju
G(a, b) =n∑
k=1
(yk − axk − b
)2.
Da bismo minimizirali funciju G(a, b) najpre nalazimo resenja sistema jednacina
∂G(a, b)
∂a= 0,
∂G(a, b)
∂b= 0,
koji se svodi na sistem
2n∑
k=1
xk(yk − axk − b) = 0, 2n∑
k=1
(yk − axk − b) = 0. (14)
Uvedimo skracenice
x =1
n
n∑
k=1
xk, y =n∑
k=1
yk.
Tada se sistem (14) svodi na sistem
a1
n
n∑
k=1
x2k + bx =
1
n
n∑
k=1
xkyk, ax+ b = y. (15)

35
Odavde dobijamo ocene a i b koeficijenata a i b :
a =
1
n
n∑
k=1
xkyk − xy
1
n
n∑
k=1
x2k − x2
, b = y − ax. (16)
Koristeci ranije uvedene statistike, formule (16) mogu se napisati u obliku
a =(XY )n −XnY n
S2
n
, b = Y n − aXn.
Primetimo da su formule dobijene na osnovu ocena iz uzorka analogne formulama (13).
Koristeci a i b odredenim formulama (3) dobija se prava linearne regresije
y = ax+ b.
Primer 30. Neka su x1 = 1, x2 = 2, x3 = 4, x4 = 5, x5 = 8 vrednosti kontrolisane promenljive x, a
ogovarajuce registrovane vrednosti za posmatrano obelezje Y su y1 = 3, y2 = 3, y3 = 7, y4 = 6, y5 = 12.Odrediti jednacinu regresione prave.
Izracunavanje koeficijeneta a i b je jednostavnije pomocu sledece tabele:
Σ
xk 1 2 4 5 8 20yk 3 3 7 6 12 31x2
k 1 4 16 25 64 110xkyk 3 6 28 30 96 163
Sistem (15) u ovom slucaju je
110a+ 20b = 163,
20a+ 5b = 31,
sa resenjem a = 1.3, b = 1. Dakle, jednacina regresione prave je y = 1.3x+ 1.
Primer 31. Za nekoliko slucajno odabranih porodica dobijeni su podaci o dnevnoj potrosnji mleka (u `) i
broju clanova porodice (x):
broj clanova porodice (x) 2 4 3 6 3 4 3 4potrosnja mleka u ` 1 3 1 4 2 2 2 3
Odrediti pravu linearne regresije Y na x. Graficki predstaviti podatke i nacrtati pravu linearne regresije.
Proceniti potrosnju mleka u petoclanoj porodici.
Do resenja cemo doci jednostavnije koristeci sledecu tabelu:
Σ
xk 2 4 3 6 3 4 3 4 29yk 1 3 1 4 2 2 2 3 18x2
k 4 16 9 36 9 16 9 16 115xkyk 2 12 3 24 6 8 6 12 73
36
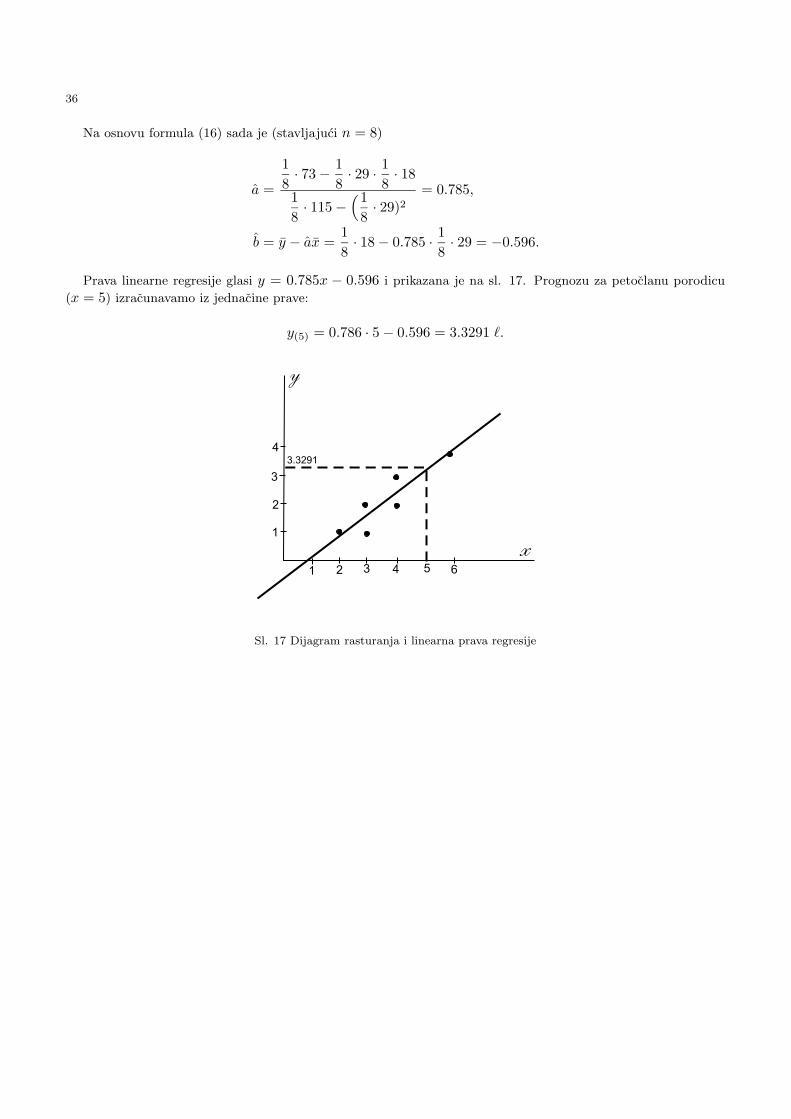
Na osnovu formula (16) sada je (stavljajuci n = 8)
a =
1
8· 73− 1
8· 29 · 1
8· 18
1
8· 115−
(1
8· 29)2
= 0.785,
b = y − ax =1
8· 18− 0.785 · 1
8· 29 = −0.596.
Prava linearne regresije glasi y = 0.785x − 0.596 i prikazana je na sl. 17. Prognozu za petoclanu porodicu
(x = 5) izracunavamo iz jednacine prave:
y(5) = 0.786 · 5− 0.596 = 3.3291 `.
1 2 3 4 6
1
2
3
4
5
3.3291
x
y
Sl. 17 Dijagram rasturanja i linearna prava regresije

37
Tablica I – Normalna raspodela
Laplaceova funkcija Φ(x) =1√2π
x∫
0
e−t2/2dt
Tablice daju vrednost izraza
Φ(x) =1√2π
x∫
0
e−t2/2dt
za vrednost argumenta x izmedu 0 i 3.5. Za negativne vrednosti koristimo relaciju
Φ(−x) = −Φ(x).
Vaze formule P (|X − µ| < ε) = 2Φ( εσ
), P (|X − µ| ≥ ε) = 1− 2Φ
( εσ
).

38
Tablica II - χ2 raspodela P (χ2n ≥ χ2
n;α) = α

39
Tablica III – Studentova t raspodela P (|tn| ≥ tn;α) = α