Embed Size (px)
Citation preview

Noname manuscript No.(will be inserted by the editor)
Signer Independent Isolated Italian Sign RecognitionBased on Hidden Markov Models
Marco Fagiani · Emanuele Principi ·Stefano Squartini · Francesco Piazza
Received: date / Accepted: date
Abstract Sign languages represent the most natural way to communicate fordeaf and hard of hearing. However, there are often barriers between peopleusing this kind of languages and hearing people, typically oriented to expressthemselves by means of oral languages. In order to facilitate the social inclu-siveness in everyday life for deaf minorities, technology can play an impor-tant role. Indeed many attempts have been recently made by the scientificcommunity to develop automatic translation tools. Unfortunately, not manysolutions are actually available for the Italian Sign Language (Lingua Italianadei Segni - LIS) case study, specially for what concerns the recognition task.In this paper the authors want to face such a lack, in particular addressingthe signer-independent case study, i.e., when the signers in the testing set areto included in the training set. From this perspective, the proposed algorithmrepresents the first real attempt in the LIS case. The automatic recognizeris based on Hidden Markov Models (HMMs) and video features have beenextracted by using the OpenCV open source library. The effectiveness of theHMM system is validated by a comparative evaluation with Support VectorMachine approach. The video material used to train the recognizer and testingits performance consists in a database that the authors have deliberately cre-ated by involving ten signers and 147 isolated-sign videos for each signer. Thedatabase is publicly available. Computer simulations have shown the effective-ness of the adopted methodology, with recognition accuracies comparable tothose obtained by the automatic tools developed for other sign languages.
Keywords Italian Sign Language (LIS) · Automatic Sign Recognition ·Video Feature Extraction · Hidden Markov Models
E. PrincipiDepartment of Information Engineering, Universita Politecnica delle MarcheVia Brecce Bianche 1, 60131, Ancona, ItalyE-mail: [email protected]

2 M. Fagiani, et al.
1 Introduction
Deaf and hard of hearing widely use sign languages to communicate [32]. Theselanguages have arisen spontaneously and evolved rapidly, all over the globe.As widely accepted by the scientific community, they are characterized by arelevant relationship with the geographic location where they are used andby a strong independence on the oral languages diffused in the same region.It follows that different sign languages have arisen and have been officiallyrecognized in most countries, like United States, United Kingdom, Germany,China.
As for the oral case, a large variety of dialects can be found within thearea of influence of the “official” sign language and this can give origin tomisunderstanding problems among people living in different places in thatarea. Beside this aspect, the communication between deaf and hearing peopleis most of the time troublesome, because people using oral languages are nottypically well disposed to learn a sign language, even recognizing that thiscould represent an effective way to enrich their communication capabilities.This inevitably induces the establishment of social inclusion barriers, whichthe entire population is called to face and likely overcome. The impact of theseproblems increases considering that the interpreters, with their indispensablework, cannot be always present and that less of the 0.1% of total populationbelong to deaf community.
Scientists and technicians from all over the world have recently addressedthe issue and several solutions have been proposed to facilitate the usage ofsign languages to deaf and also the interaction among them and hearing peo-ple in different communication scenarios. Many automatic translation systems(Sign-to-Sign, Sign-to-Oral or Oral-to-Sign) have been developed, taking thespecificity of the examined languages into account. Typically, these systemsrequire two separate tasks: recognition and synthesis. In this work, the focus isspecifically on the former and a brief state of the art of existing methodologiesfor automatic recognition of sign languages and related databases is providedin the following, first from an international perspective and then looking closerat the Italian context.
In the international scenario many research projects can be found. Starner& Pentland [35] have been the first to propose a system based on HiddenMarkov Models (HMM) for sign language recognition. The approach is capa-ble of performing real-time sentence recognition of the America Sign Language(ASL) using only hands information such as position, angle of axis of least in-ertia and eccentricity of bounding ellipse. In a later study [36], the authorspresented a real-time continuous sentence-level recognition based on two dif-ferent point of view for the camera: a desk-based and a cap-mounted. In [2]a sign recognition system in signer-independent and signer-dependent condi-tions has been investigated. Both hands-related features, based on a multiplehypotheses tracking approach, and face-related features, based on an activeappearance model, are robustly extracted. The classification stage is based onHMM and is designed for the recognition of both isolated and continuous signs.

Signer Independent Isolated Italian Sign Recognition Based on HMMs 3
The work in [37] proposed a so-called product HMM for efficient multi-streamfusion, while [27] discussed the optimal number of the states and mixtures toobtain the best accuracy.
SignSpeak [14] is one of the first European funded projects that tackles theproblem of automatic recognition and translation of continuous sign languages.Among the works of the project, Dreuw and colleagues in [11–13] introducedimportant innovations: they used a tracking adaptation method to obtain ahand tracking path with optimized tracking position, and they trained robustmodels through visual signer alignments and virtual training samples.
In [42], Zaki & Shaheen presented a new combination of appearance basedfeatures obtained by using Principal Component Analysis (PCA), the kurtosisposition and Motion Chain Code (MCC). First of all, they detect the dominanthand by using a skin colour detection algorithm that is then tracked by aconnected component labelling. After that, PCA provides a measure for thehand configuration and orientation, kurtosis position is used for measuringthe edge which denotes the place of articulation and MCC represents thehand movement. Several combinations of the proposed features are tested andevaluated, and an HMM classifier is used to recognize signs. Experiments areperformed using the RWTH-BOSTON-50 database of isolated signs [41]. In[25, 28] two approaches based on Support Vector Machines (SVM) for therecognition of the sole hand gesture have been proposed. In the first, a multi-feature classifier combined with spatio-temporal characteristics has been usedto realize an automatic recognizer of sign language letters. In the second, acombination of ad-hoc weight eigenspace Size Function and Hu moments hasbeen used.
Taking a closer look at the databases for international sign languages, in[41], as mentioned above, and [15] two free automatic sign language databasesare presented, both created as subset of the general database recorded at theBoston University1. The video sequences have been recorded at 30 frames persecond (fps) with a resolution of 312×242 pixels. Sentences have been executedby three different people, two men and one woman, all dressed differently andwith different brightness of the clothes. The first database, RWTH-BOSTON-50, is made of 483 utterances of 50 signs, with each utterance stored in aseparate video file in order to create a video collection of isolated signs. Thesecond corpus, RWTH-BOSTON-104, is made of 201 sentences (161 for train-ing and 40 for testing) and the dictionary contains 104 different signs. Unlikethe first one, each video contains a sequence of signs. The SIGNUM [1] corpusis composed both of isolated sign and of sign sequences executed by 25 persons,and recordings have been conducted in controlled conditions, to facilitate thevideo feature extraction. The videos have been recorded with a resolution of780× 580 pixels at 30 fps. The dictionary is made of 450 DGS sign composinga total of 780 sentences with sign sequences.
Regarding the Italian scenario, Infantino et al. [24] presented a signer-dependent recognition framework applied to Italian sign language (in Italian
1 http://www.bu.edu/asllrp/ncslgr.html

4 M. Fagiani, et al.
Lingua Italiana Segni, LIS). Features are composed of centroid coordinates ofthe hands and classification is based on a self-organizing map (SOM) neuralnetwork. In addition, the framework integrates a common-sense engine thatselects the right meaning depending on the context of the whole sentence. Upto the authors’ knowledge, this is the only work appeared in the literature sofar that deals with the Italian sign language recognition. For what concernthe LIS databases, an interesting work has been recently presented within theATLAS2 project [4], that describes the development of a tri-lingual corpusof the Italian sign language. The database will be used to realize a virtualinterpreter, which automatically translates an Italian text into LIS, and itis publicly available to the community. Actually, no information about thenumber of signers, recording conditions, video properties and signs dictionaryare provided. As stated by [4], it includes many recordings with thousands ofsigns, but they are executed by single signers thus representing a limitation inthe development of automatic sign recognition systems.
The objective of this work is proposing an automatic recognition systemof isolated LIS signs. Differently from [24], the system operates independentlyfrom the signer, i.e., it is able to deal with signers not included in the train-ing phase. An HMM approach has been employed on purpose, inspired toother existing tools for oral languages and also for some international sign lan-guages, as mentioned above. The isolated sign case study has been addressed.Due to the lack of a suitable database to train and evaluate the system, aspecific LIS database has been created in collaboration with the local officeof the Deaf People National Institute (Ente Nazione dei Sordi - ENS). Thedatabase, namely A3LIS-147, is composed of more than 1400 signs performedby 10 different signers and it is publicly available. The proposed recognizer hasbeen partially presented in [17], and here a more detailed description of therelated algorithms and insights on the attainable performance are provided.In particular, here the algorithm parameters have been optimized in order tofurther improve the recognition performance, and for an additional validationthe approach has been also compared to a Support Vector Machine recognizer.In addition, each sign of the corpus has been transcribed to the HamNoSystranscription system and a thorough discussion on the correlation between theedit distance of the signs transcriptions and the error rates has been provided.As pointed out in the following sections, the obtained recognition accuracy(superior to 48%) is consistent with the results obtained by alternative tech-niques related to other Sign Languages, thus proving the effectiveness of theapproach.
This is the paper outline. In Section 2 the main characteristics of theA3LIS-147 Database are reviewed. Section 3 reports the algorithms in thetwo stages composing the automatic LIS recognition system, i.e., the FeatureExtractor and the HMM-based recognizer, whereas in Section 4 the experimen-tal tests are described and related results are commented. Section 5 presents
2 http://www.atlas.polito.it/index.php/en/home

Signer Independent Isolated Italian Sign Recognition Based on HMMs 5
Table 1 The proposed real-life scenarios, number of signs per scenario and vocabularyexamples.
Scenario Signs per scenario Vocabulary examplesPublic Institute 39 Employee, Municipality, Timetable.Railway station 35 Train, Ticket, Departure.
Hospital 19 Emergency, Doctor, Pain.Highway 8 Traffic, Toll Booth, Delays.
Common life 16 Water, Telephone, Rent.Education 30 School, Teacher, Exam.
a comparison between the proposed approach and the SVM method. Section6 concludes the paper providing also some future works highlights.
2 A3LIS-147: Italian Sign Language Database
The creation of a signer-independent automatic sign recognition system re-quires a suitable corpus for training its parameters and assessing its perfor-mance. For the isolated sign recognition task, the corpus should contain videoswith many different signs executed by multiple signers. The lack of a well-suited corpus for the Italian sign language led the authors to create a new onefrom scratch.
The database, A3LIS-147, is freely available3 and has been presented in[16]. It consists of 147 distinct isolated signs executed by 10 different persons(7 males and 3 females). Each signer executed all the 147 signs, for a total of1470 recorded videos. The ENS4 supported the authors of this work to suit-ably pre-train the subjects and to choose a meaningful and unambiguous setof signs to be executed. In A3LIS-147, signs are divided in six categories, eachrelated to different real-life scenarios (Table 1): public institute (e.g., “em-ployee”), railway station (e.g., “train”), hospital (e.g., “emergency”), highway(e.g., “traffic”), common life (e.g., “water”) and education (e.g., “school”). Ineach video, the person executes a single sign, preceded and ensued by the “si-lence” sign shown in Fig. 1. This sign has been chosen in agreement with theENS, since it represents a common “rest” position in every-day conversations.Recordings have been supported by a sequence of slides projected in front ofthe person executing the sign. Each slide shows the text and the picture ofthe current sign as well as a timer to discriminate the three phases of theexecution: silence, sign execution, silence.
Recordings have been performed in controlled conditions: as Fig. 1 shows,the signers wear dark long-sleeved shirts, a green chroma-key background isplaced behind them, and uniform lighting is provided by two diffuse lights.Videos have been captured at 25 frames per second with a resolution of 720×576 pixel and stored in Digital Video format. For additional details on A3LIS-147, please refer to [16].
3 http://www.a3lab.dii.univpm.it/projects/a3lis4 http://www.ensancona.it

6 M. Fagiani, et al.
Fig. 1 The “silence” position.
3 Description of the proposed system
The structure of the proposed system is shown in Fig. 2. Similarly to the“isolated word recognition” task in speech recognition, the system performsisolated sign recognition, i.e., it recognizes a single sign present in a inputvideo. The main processing blocks of the system are: Face and Hands Detection(FHD), Features Extraction (FE), and Sign Recognition (SR).
The FHD block discriminates the regions of interest in each video frame.The regions are represented by the hands and the face of a person, sincethey convey the information needed to discriminate signs. Features are thenextracted in the FE stage from the pixels belonging to these areas, and foreach input frame a single feature vector is created. The classification stageis based on HMM. For each sign, an HMM is created in the training phaseusing signs executed by different persons. The SR phase operates calculatingthe output probabilities for each model, and then selecting the model whichscored best.
3.1 Face and Hands Detection
The detection of hands and face areas is performed on each input frame usinga skin detection algorithm. This operates on the YCbCr colour space since itgives better performance respect to the Red Green Blue (RGB) colour space[19]. A pixel whose coordinates are (Y,Cb, Cr) belongs to the skin region ifY > 80, 85 < Cb < 135 and 135 < Cr < 180 with Y , Cb, Cr ∈ [0, 255] [26].Pixels that satisfy this condition are included in the skin mask image.

Signer Independent Isolated Italian Sign Recognition Based on HMMs 7
������
�����
��
���������������
���������������
��������������������
��
����������
�����
������
Fig. 2 The proposed isolated sign recognition system.
Face and hands are then determined choosing the regions with largestareas (Fig. 3(b)). These areas can be inhomogeneous, so they are merged bymeans of “morphological transformations”. Notice that here “morphologicaltransformations” refer to image processing operations, and they must not beconfused with the sign language morphology. These operations consist in aclosing operation, that is produced by the combination of the dilation anderosion operators [7,34]. Dilation consists of the convolution of an image witha kernel (e.g., a small solid square or disk with the anchor point at its center)which acts as a local maximum operator. The effect is that bright regions of animage widen. Erosion is the converse operation and has the effect of reducingthe area of bright regions. The closing operation employed here is producedfirst dilating and then eroding the areas detected as skin. The final effect isthe removal of areas that arise from noise, and the union of nearby areas thatbelong to the same region of interest.
The overlap of two or more regions of interest results in loss of information.If one hand overlaps with the other or with the face, it can be difficult todetermine its position. This is why such situation has to be carefully detectedand handled. In this work, the distance between the camera and the signer

8 M. Fagiani, et al.
Fig. 3 A frame of the sign “casa”. (a): the original video frame. (b): the detected skinregions. (c): the skin regions as modified after the morphological transformation.
Fig. 4 Contours detection from the skin regions (a). Bounding rectangle of hands skin zones(b). The hands edge obtained by the Canny algorithm (c).
is supposed to vary by a small percentage from frame to frame. Consideringalso that the skin mask contains three areas when overlap does not occur, anoverlap can be detected following these rules:
1. if only one skin region is present in the skin mask, a face-hands overlap isdetected;
2. otherwise, if two regions are present and the face area increased by a certainpercentage respect to the previous frame, a face-hand overlap is detected;
3. otherwise, if two regions are present and the face area did not increase, ahand-hand overlap is detected;
4. otherwise, if three regions are present, no overlap is detected.
When a hand-hand overlap is detected, the system assigns the same areato both hands, whereas, in the event of a face-hand overlap, it assigns the facearea to the overlapped hand. Whenever a face-hands overlap is detected, bothhands areas coincide with the face one.
3.2 Feature Extraction
Table 2 shows the entire feature set calculated from the regions of interest.The set can be divided in two different subsets: the first comprises features1–8 and includes the centroid coordinates of the hands respect to the face,their derivatives and the distance between the two hands. The second subset

Signer Independent Isolated Italian Sign Recognition Based on HMMs 9
Table 2 The entire feature set. “Canny-Filter” indicates that features have been calculatedafter applying the Canny algorithm to the detected regions.
Features1 Hands centroid normalized respect face region width (Canny-Filter)2 Derivatives of feature 13 Normalized hands centroid distance (Canny-Filter)
4 Hands centroid normalized respect face region width5 Derivatives of feature 46 Normalized hands centroid distance
7 Hands centroid referred to the face centroid8 Derivatives of feature 7
9 Face and hands Hu-moments (Canny-Filter)10 Face and hands Hu-moments
11 Hands area normalized respect to the face area12 Derivatives of feature 11
13 Face and hands compactness 114 Face and hands eccentricity 1
15 Face and hands compactness 216 Face and hands eccentricity 217 Hands orientation
comprises features 9–17 and represents the general characteristics of the re-gions, such as the area, the shape type and the 2-D spatial orientation of thehands.
Features 1–3 and features 4–5 as well as features 9 and 10 differ for theregion of interest employed in their computation: features 1–3 and feature9 exploit the Canny algorithm [8] applied within the bounding rectangle ofthe hands. Features 4–8 and feature 10 use directly the contours segmentedfrom the skin mask. Fig. 4 shows an example extracted from the A3LIS-147database, where the detected area rectangles and the obtained contours aredisplayed. The contours are then used to calculate the regions centroid andthe central moments. The centroid is calculated as follows:
x =m10
m00, (1)
y =m01
m00, (2)
where mij are the spatial moments defined from the pixel intensities I(x, y)as:
mij =∑x
∑y
I(x, y)xiyj . (3)
In the equation, x and y are the pixel abscissa and ordinate and I(·, ·) ∈[0, 255]. The central moments µi,j are defined as:
µij =∑x
∑y
I(x, y)(x− x)i(y − y)j . (4)

10 M. Fagiani, et al.
Regarding the face centroid (xf , yf ), its position is almost stationary, but anoverlap with the hands can cause incongruous deviations. This effect has beenreduced smoothing the centroid coordinates at frame t as follows:
(x′f , y′f )t = β(xf , yf )t + (1− β)(x′f , y
′f )t−1, (5)
where β ∈ [0, 1] and has been set to 0.1 in the experiments.In features 1–8 centroid coordinates are normalized respect to the face
region width wf so that they are independent of the distance from the cameraand the signer’s height.
Derivatives in features 2 and 5 are calculated as the difference between thecoordinates at frame t and at frame t− 1:
xt = xt − xt−1, (6)
yt = yt − yt−1. (7)
The normalized Euclidean distance between the hands (features 3 and 6)is computed as follows:
d =
√|(xl, yl)− (xr, yr)|2
wf, (8)
where the l and r subscripts denote the centroid coordinates of the left andright hand respectively.
In the computation of feature 7, the origin of the coordinate system is rep-resented by the face area centroid (xf , yf ) and feature 8 is obtained calculatingits derivative as in equation (6).
Regarding the second subset, features 9 and 10 are the Hu moments [23]:these are invariant to translation, changes in scale, and rotation. Both for theface and the hands regions, seven different values are computed:
I1 =µ20 + µ02, (9)
I2 = (µ20 − µ02)2
+ 4µ211, (10)
I3 = (µ30 − 3µ12)2
+ (3µ21 − µ03)2, (11)
I4 = (µ30 + µ12)2
+ (µ21 + µ03)2, (12)
I5 = (µ30 − 3µ12) (µ30 + µ12)[(µ30 + µ12)
2 − 3 (µ21 + µ03)2]
+
+ (3µ21 − µ03) (µ21 + µ03)[3 (µ30 + µ12)
2 − (µ21 + µ03)2], (13)
I6 = (µ20 − µ02)[(µ30 + µ12)
2 − (µ21 + µ03)2]
+
+ 4µ11 (µ30 + µ12) (µ21 + µ03) , (14)
I7 = (3µ21 − µ03) (µ30 + µ12)[(µ30 + µ12)
2 − 3 (µ21 + µ03)2]−
− (µ30 − 3µ12) (µ21 + µ03)[3 (µ30 + µ12)
2 − (µ21 + µ03)2], (15)

Signer Independent Isolated Italian Sign Recognition Based on HMMs 11
In the equations, µij is the respective central moment defined in equation (4),and I7 is useful in distinguishing mirror images.
Feature 11 is obtained calculating the areas of the recognized skin zonesas the total number of pixels detected, and the derivatives (feature 12) arecalculated similarly to equation (6):
At = At −At−1. (16)
where At denotes the area of a region of interest at the time frame t.Compactness c1 (feature 13) and eccentricity e1 (feature 14) of face and
hands have been proposed in [37]. The first is computed as the ratio betweenthe minor (Axismin) and major (Axismax) axis lengths of the rotated rectanglethat inscribe the detected region:
c1 =Axismin
Axismax. (17)
Eccentricity is calculated from the area A and the perimeter P of the regionas follows:
e1 =Anorm
P 2, (18)
where Anorm is obtained dividing the area A by the face area and the perimeterP is the length of the region contour used in the feature 4.
Features 15–17 have been introduced in [2] and are defined as follows:
c2 =(4πAnorm)
P 2, (19)
e2 =(µ20 − µ02)2 + 4µ11
Anorm, (20)
o1 = sin(2α), o2 = cos(α). (21)
Equations (19) and (20) represent alternative definitions of compactness andeccentricity. Equation (21) defines the hand orientation, obtained from thedifference of the angle between the image vertical axis and the main axis ofthe rotated rectangle that inscribe the hand region. In the equation, the angleα ∈ [−90o, 90o] and the orientation is split into o1 and o2 to ensure stabilityat the interval borders.
3.3 Sign Recognition
Let S = {s1, s2, . . . , sN} be the set of signs and N be the total number of signs.Each sign si is modelled with a different HMM λi. In order to capture thesequential nature of a sign execution, a left-right structure has been chosen onpurpose (Fig. 5). State emission probability density functions are representedby mixtures of gaussians with diagonal covariance matrices. In defining thesign model, the number of states and the number of gaussians in the mixture

12 M. Fagiani, et al.
must be prior set. These parameters have been determined experimentally asdescribed in Section 4.
Denoting with O the observation sequence, sign recognition is performedcalculating the probability P (O|λi) ∀i ∈ {1, 2, . . . , N} through the Viterbialgorithm and then selecting the model whose probability is maximum.
4 Experiments
Video processing has been performed by means of the open source computervision library OpenCV [6]. The aforementioned A3LIS-147 database has beenused both for training the recognizer and for evaluating its performance. TheHMM-based sign recognition stage has been implemented using the HiddenMarkov Model toolkit [40].
The first experiment studies how the number of states and of gaussiansper state in the sign models affects the recognition performance. The secondexperiment analyses the performance of the system for different combinationsof features. The last experiment investigates the optimal number of states andmixtures for the selected features and performs the final test.
All the experiments have been performed following the three-way datasplit approach [31] combined with the K-fold cross-validation method [38].The dataset is split into K = 10 folds, each one composed of all the signsexecuted by the same signer. For each parameters combination, two differentfolds are chosen iteratively as validation and test sets. The remaining K − 2folds form the training set, and the algorithm parameters are determined onthe validation fold. In the features selection, each combination is tested withsame method. The final system performance is evaluated using one fold as test,and the remaining K − 1 folds as training. Note that differently from [24], theindependence between training, validation and test sets is always guaranteed.
The performance have been evaluated using the sign recognition accuracy,defined on the basis of the number of substitution (S), deletion (D) and inser-tion errors (I) as in speech recognition tasks [40]:
Accuracy =(N −D − S − I)
N. (22)
where N is the total number of labels in the reference transcriptions. It isworth pointing out that in the isolated sign recognition task addressed in thiswork only the substitution errors are present.
� � �� �
Fig. 5 A five states left-right Hidden Markov Model. State I and F are non-emitting.
Signer Independent Isolated Italian Sign Recognition Based on HMMs 13
0
5
10
15
20
25
30
35
40
5 10 15 20
Accu
racy
(%)
Number of States
Mixtures:12345678
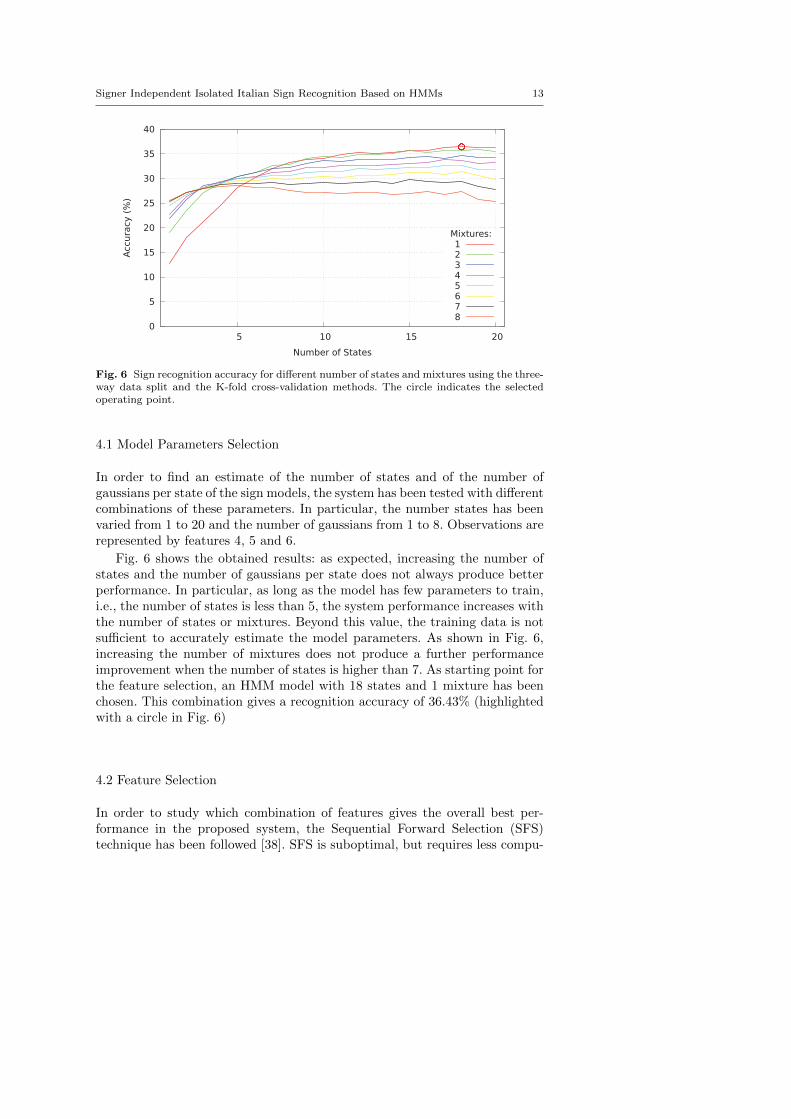
Fig. 6 Sign recognition accuracy for different number of states and mixtures using the three-way data split and the K-fold cross-validation methods. The circle indicates the selectedoperating point.
4.1 Model Parameters Selection
In order to find an estimate of the number of states and of the number ofgaussians per state of the sign models, the system has been tested with differentcombinations of these parameters. In particular, the number states has beenvaried from 1 to 20 and the number of gaussians from 1 to 8. Observations arerepresented by features 4, 5 and 6.
Fig. 6 shows the obtained results: as expected, increasing the number ofstates and the number of gaussians per state does not always produce betterperformance. In particular, as long as the model has few parameters to train,i.e., the number of states is less than 5, the system performance increases withthe number of states or mixtures. Beyond this value, the training data is notsufficient to accurately estimate the model parameters. As shown in Fig. 6,increasing the number of mixtures does not produce a further performanceimprovement when the number of states is higher than 7. As starting point forthe feature selection, an HMM model with 18 states and 1 mixture has beenchosen. This combination gives a recognition accuracy of 36.43% (highlightedwith a circle in Fig. 6)
4.2 Feature Selection
In order to study which combination of features gives the overall best per-formance in the proposed system, the Sequential Forward Selection (SFS)technique has been followed [38]. SFS is suboptimal, but requires less compu-
14 M. Fagiani, et al.
30
32
34
36
38
40
42
44
46
48
50
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
Accu
racy
(%)
SFS Step
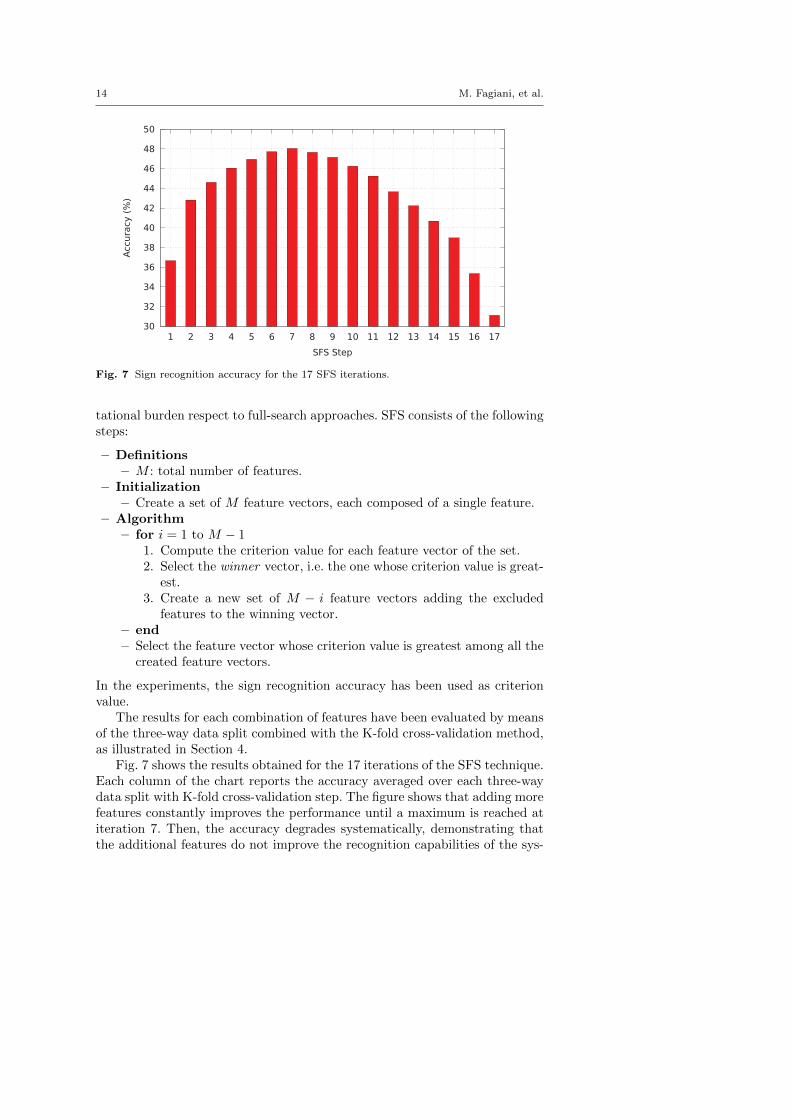
Fig. 7 Sign recognition accuracy for the 17 SFS iterations.
tational burden respect to full-search approaches. SFS consists of the followingsteps:
– Definitions– M : total number of features.
– Initialization– Create a set of M feature vectors, each composed of a single feature.
– Algorithm– for i = 1 to M − 1
1. Compute the criterion value for each feature vector of the set.2. Select the winner vector, i.e. the one whose criterion value is great-
est.3. Create a new set of M − i feature vectors adding the excluded
features to the winning vector.– end– Select the feature vector whose criterion value is greatest among all the
created feature vectors.
In the experiments, the sign recognition accuracy has been used as criterionvalue.
The results for each combination of features have been evaluated by meansof the three-way data split combined with the K-fold cross-validation method,as illustrated in Section 4.
Fig. 7 shows the results obtained for the 17 iterations of the SFS technique.Each column of the chart reports the accuracy averaged over each three-waydata split with K-fold cross-validation step. The figure shows that adding morefeatures constantly improves the performance until a maximum is reached atiteration 7. Then, the accuracy degrades systematically, demonstrating thatthe additional features do not improve the recognition capabilities of the sys-
Signer Independent Isolated Italian Sign Recognition Based on HMMs 15
Table 3 Sign recognition accuracy (%) for each A3LIS-147 signer.
IterationSigner 1 2 3 4 5 6 7FAL 42.76 45.83 47.59 47.44 49.35 51.42 52.03FEF 15.86 23.83 25.06 25.37 26.52 23.30 23.07FSF 26.90 31.34 34.02 35.32 33.71 34.48 34.79MDP 34.03 40.28 44.83 45.99 49.15 52.55 52.39MDQ 41.38 49.35 51.34 51.49 51.65 52.79 53.94MIC 38.39 39.69 40.00 41.76 42.84 45.37 45.98MMR 47.82 52.41 54.94 56.93 54.17 58.70 58.39MRLA 33.57 41.96 45.22 50.35 54.16 50.19 50.35MRLB 43.30 56.93 57.47 57.32 57.09 56.93 57.32MSF 42.68 46.44 45.75 48.58 50.88 51.49 52.34
Average 36.67 42.81 44.62 46.06 46.95 47.72 48.06Std Dev 9.50 9.80 9.68 9.79 9.80 10.88 11.01
Table 4 Average sign recognition accuracy (%) for different number of states and gaussiansusing features 5, 6, 7, 8, 12, 13 and 14.
GaussiansStates 1 2 3 4
15 48.02 47.32 44.49 41.3416 47.69 47.11 44.25 41.0017 47.97 47.20 44.26 40.3518 48.06 47.02 43.81 40.0619 47.98 46.63 43.10 39.6920 46.97 46.31 42.92 38.9221 46.82 44.65 41.06 37.95
tem. The feature vector that gives the overall best accuracy is composed offeatures 5, 6, 7, 8, 12, 13 and 14 for a total of 21 coefficients.
Table 3 shows the detailed results for each signer. As table shows, thebest sign recognition accuracy is obtained by signer MRLB using features 5, 7and 13. As aforementioned, the overall best accuracy is obtained at iterationnumber seven. It is interesting to note the high degree of variability acrossthe signers: the recognition accuracy standard deviation at iteration seven is11.01%, suggesting that further normalization techniques could be employedto improve signer independence.
4.3 Model Parameters Refinement
In order to find the overall best sign recognition accuracy obtainable withthe proposed system, an additional experiment has been performed. Here,the feature set determined in the previous section is employed, and the sameprocedure described in Section 4 has been followed to determine the numberof states and the number of gaussians per state of the HMM sign model. Theresults in Table 4 show that the model with 18 states and 1 mixture per statestill produces the best performance for the selected features.

16 M. Fagiani, et al.
0
10
20
30
40
50
60
70
FAL FEF FSF MDP MDQ MIC MMR MRLA MRLB MSF Average
Accu
racy
(%)
Std Dev
55.17
21.38
36.55
53.47 52.41
46.21
63.45
53.8557.93
51.7249.21
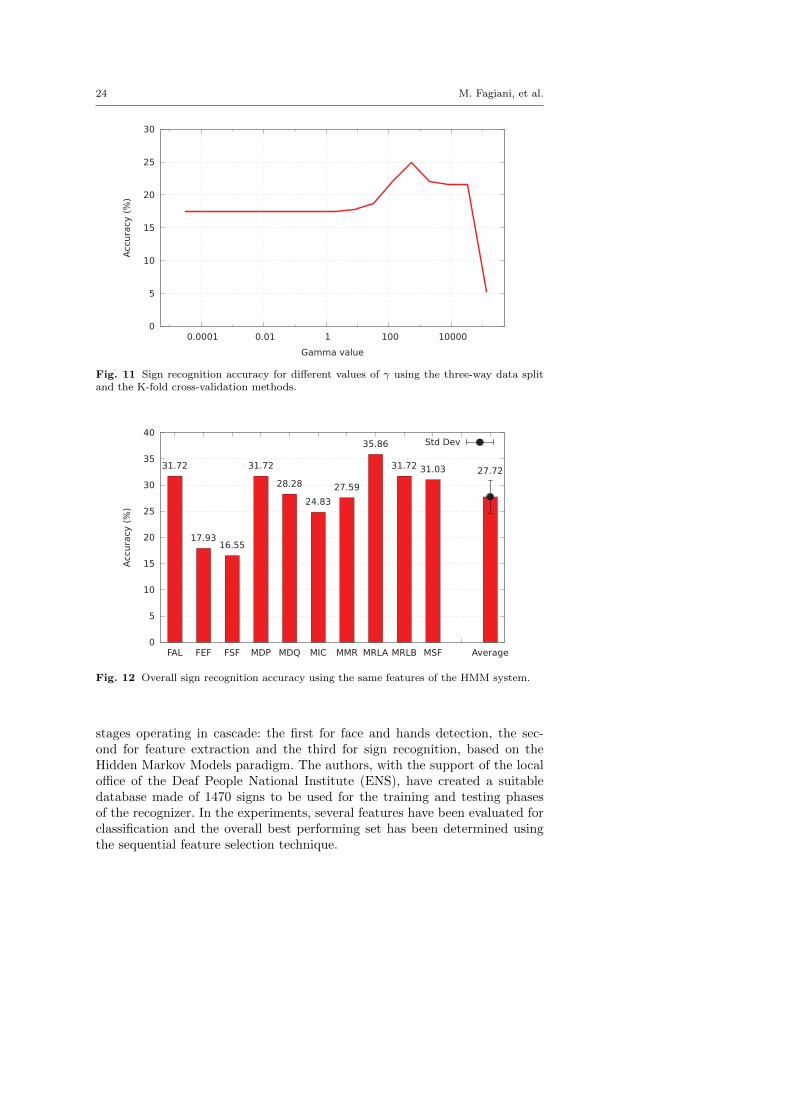
Fig. 8 Overall sign recognition accuracy using 18 states and 1 mixture.
Fig. 8 shows the final results for each signer using the determined model.The final average recognition accuracy of the system is 48.06%.
4.4 Discussion
Better insights on the performance of the HMM-based system can be inferredanalysing the correlation between the edit distances of the signs transcriptionsand the related error rates. Every signs has been transcribed using the Ham-NoSys transcription system [22] (the complete transcriptions are shown in theAppendix), and calculating the edit distance between a pair of signs givesvaluable information about the their confusability. Since HamNoSys describesthe movements of both hands in a single string, each transcription has beendecomposed in two substrings, each related to a different hand. If the sign isexecuted with one hand, an empty string has been assigned to the correspond-ing unused hand. The distance between signs has been computed comparingonly the strings that belong to the same hand, and the resulting edit distanceis given as sum of the values obtained for each hand. The edit distance hasbeen calculated giving an equal cost 1 to characters insertions or deletions andcost 2 to substitutions.
The relationship between the error rate and the edit distance has beenobtained as follows: denoting with D(si, sj) the edit distance between sign siand sj and with
Sd = {(si, sj)|D(si, sj) = d, i = 1, . . . , N, j = 1, . . . , N, i 6= j}, (23)
Signer Independent Isolated Italian Sign Recognition Based on HMMs 17
0%
5%
10%
15%
20%
0 10 20 30 40 50 60
Aver
age
Erro
r Rat
e (E
(d))
Edit Distance (d)
XXX
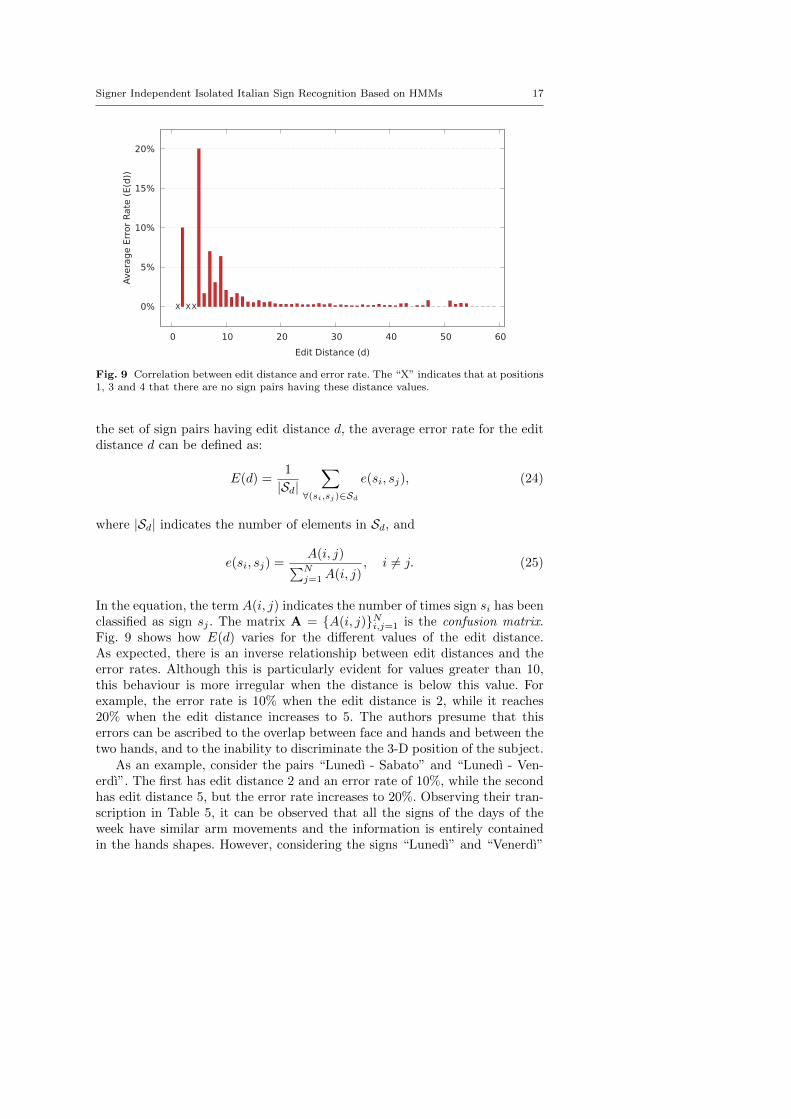
Fig. 9 Correlation between edit distance and error rate. The “X” indicates that at positions1, 3 and 4 that there are no sign pairs having these distance values.
the set of sign pairs having edit distance d, the average error rate for the editdistance d can be defined as:
E(d) =1
|Sd|∑
∀(si,sj)∈Sd
e(si, sj), (24)
where |Sd| indicates the number of elements in Sd, and
e(si, sj) =A(i, j)∑Nj=1A(i, j)
, i 6= j. (25)
In the equation, the term A(i, j) indicates the number of times sign si has beenclassified as sign sj . The matrix A = {A(i, j)}Ni,j=1 is the confusion matrix.Fig. 9 shows how E(d) varies for the different values of the edit distance.As expected, there is an inverse relationship between edit distances and theerror rates. Although this is particularly evident for values greater than 10,this behaviour is more irregular when the distance is below this value. Forexample, the error rate is 10% when the edit distance is 2, while it reaches20% when the edit distance increases to 5. The authors presume that thiserrors can be ascribed to the overlap between face and hands and between thetwo hands, and to the inability to discriminate the 3-D position of the subject.
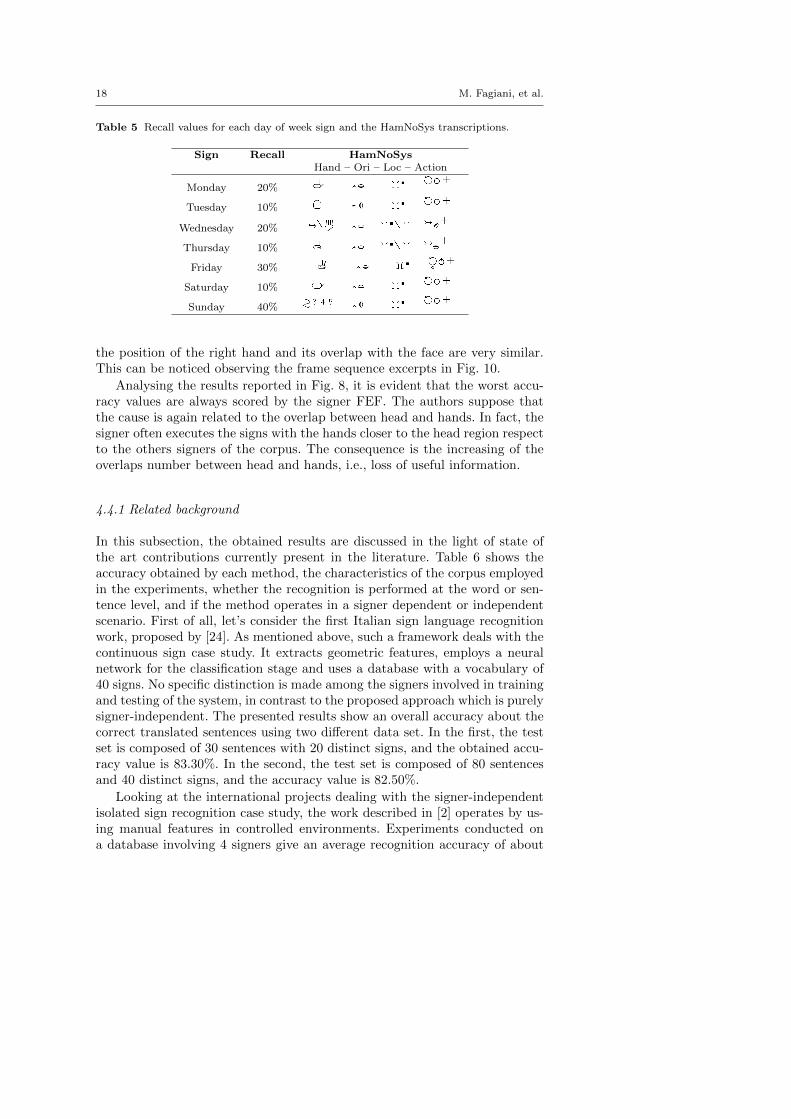
As an example, consider the pairs “Lunedı - Sabato” and “Lunedı - Ven-erdı”. The first has edit distance 2 and an error rate of 10%, while the secondhas edit distance 5, but the error rate increases to 20%. Observing their tran-scription in Table 5, it can be observed that all the signs of the days of theweek have similar arm movements and the information is entirely containedin the hands shapes. However, considering the signs “Lunedı” and “Venerdı”
18 M. Fagiani, et al.
Table 5 Recall values for each day of week sign and the HamNoSys transcriptions.
Sign Recall HamNoSysHand – Ori – Loc – Action
Monday 20%
Tuesday 10%
Wednesday 20%
Thursday 10%
Friday 30%
Saturday 10%
Sunday 40%
the position of the right hand and its overlap with the face are very similar.This can be noticed observing the frame sequence excerpts in Fig. 10.
Analysing the results reported in Fig. 8, it is evident that the worst accu-racy values are always scored by the signer FEF. The authors suppose thatthe cause is again related to the overlap between head and hands. In fact, thesigner often executes the signs with the hands closer to the head region respectto the others signers of the corpus. The consequence is the increasing of theoverlaps number between head and hands, i.e., loss of useful information.
4.4.1 Related background
In this subsection, the obtained results are discussed in the light of state ofthe art contributions currently present in the literature. Table 6 shows theaccuracy obtained by each method, the characteristics of the corpus employedin the experiments, whether the recognition is performed at the word or sen-tence level, and if the method operates in a signer dependent or independentscenario. First of all, let’s consider the first Italian sign language recognitionwork, proposed by [24]. As mentioned above, such a framework deals with thecontinuous sign case study. It extracts geometric features, employs a neuralnetwork for the classification stage and uses a database with a vocabulary of40 signs. No specific distinction is made among the signers involved in trainingand testing of the system, in contrast to the proposed approach which is purelysigner-independent. The presented results show an overall accuracy about thecorrect translated sentences using two different data set. In the first, the testset is composed of 30 sentences with 20 distinct signs, and the obtained accu-racy value is 83.30%. In the second, the test set is composed of 80 sentencesand 40 distinct signs, and the accuracy value is 82.50%.
Looking at the international projects dealing with the signer-independentisolated sign recognition case study, the work described in [2] operates by us-ing manual features in controlled environments. Experiments conducted ona database involving 4 signers give an average recognition accuracy of about

Signer Independent Isolated Italian Sign Recognition Based on HMMs 19
Fig. 10 Frame sequence excerpts of words “Lunedı” (left) and “Venerdı” (right).

20 M. Fagiani, et al.
Table 6 Summary of the existing contribution in the state of the art. V/Se/Si indicatesthe vocabulary dimension, the sentences number and the number of signers.
Contr. Accuracy (%) V/Se/Si Rec. Type Signer Device[2] 45.23 ∼220/–/4 Word Independent Camera[18] 88.20 208/4368/7 Word Independent Gloves & Trackers[24] 83.30-82.50 40/30–80/2 Sentence Dependent Camera[42] 89.09 30/110/3 Sentence Dependent Camera[35] 99.20-91.30 40/494/1 Sentence Dependent Camera[36] 91.90-79.50 40/478/1 Sentence Dependent Camera∗
[36] 97.80-96.80 40/478/1 Sentence Dependent Camera∗∗
*: second person view. **: first person view.
45.23%, which is consistent with the performance obtained by the HMM sys-tem proposed in this paper, whose accuracy is 48.06%.
HMM-based recognition applied to sign language has been proposed forthe first time by [35]. In order to obtain a real-time execution, the signer weardistinctly coloured gloves on each hand and the frame were deleted when thetracking of one or both hands was lost. They executed an experiment using 395training sentences and 99 independent test sentences with a vocabulary of 40words. The system achieved an accuracy of 99.2% using a grammar modellingand 91.3% for free grammar. In a successive study [36], the authors introducedtwo different dataset, changed the camera mount point, and recorded the samesentences. For testing purposes, 384 sentences were used for training and 94were reserved for testing. The testing sentences are not used in any portionof the training process. For the second person view, camera mounted on thedesk, the performance reach an accuracy of 91.9%, with grammatical rules,and 79.5% unrestricted. As for the first person view, hat-mounted camera, theobtained accuracy is 97.8%, with grammatical rules, and 96.8% unrestricted.
In [42] a simple features combination has been studied in order to improvethe performance of the recognition system. They have obtained relevant resultswith an overall accuracy of 89.09%, with the combination of PCA, kurtosisposition feature vector and the MCC feature. They also used an HMM clas-sifier, but a comparison between these results and the ones described in thispaper is not feasible because of the wide difference between the used databases.Moreover, it must be observed that, as clearly stated by [42], “the system vo-cabulary is restricted to avoid hand over face occlusion, location interchangeof dominant hand and right hand” in their work, in contrast to what done inthe present contribution where all signs have been considered for training andtesting.
Noteworthy are the studies proposed by [18] and [3], where alternativeacquisition techniques have been investigated. In [18] two CyberGloves andthree Pohelmus 3SPACE-position trackers have been used as input devices.The gloves collect the information about hand shapes, and the trackers collectthe orientation, position and movement trajectory information. The classifi-cation stage is based on a novel combination of HMMs and self-organizingfeature maps (SOFMs) to implement a signer-independent recognizer of Chi-

Signer Independent Isolated Italian Sign Recognition Based on HMMs 21
nese sign language. All the experiments have been conducted on a databasewhere 7 signers have performed 208 signs for 3 times. The tests presented anoverall accuracy of 88.20% for the unregistered test set.
A system for continuous sign language recognition has been introducedin [3]. The main aspect of the proposed approach lies in the acquisition levelwhere an electromyographic (EMG) data-glove has been used. The EMG al-lows a good gesture segmentation, based on muscle activity. The classificationphase is divided in two distinct levels: gesture recognition and language mod-elling. The former one is based on a four channel HMM classifier, where eachchannel identify one gesture articulation: movement, hand shape, orientationand rotation. The latest one uses a single channel HMM classifier to matcha recognized gesture with a model sentence based on language grammar andsemantic. Unfortunately, the system has been tested only on an authors’ owndatabase and no results are reported.
4.5 Computational Complexity
Here a detailed computational complexity analysis of the algorithms of theautomatic LIS recognition system is discussed and the real-time factor relatedto the framework implementation on a common hardware/software platformis provided.
The Face and Hands Detection stage is characterized by two main algo-rithms: skin detection, and morphological smoothing. The Feature Extractionstage is characterized by the Canny edge detector and the operation requiredto calculate the features of Table 2, which are directly performed on the im-age regions determined by the Face and Hands Detection stage on each videoframe. Table 7 reports the number of FLoating point Operations Per Second(FLOPS) of each stage, as well as their time occupancy respect to the totalexecution time. Consider that in calculating the number of FLOPS, multi-plications/divisions and additions/subtractions have been equally weighted.Note also that for those operations it is assumed that the skin regions arecomposed of 30% of the overall amount of image pixels. This value coincideswith the worst case in A3LIS-147 the database. The equivalent time consumedfor each operation is based on the performance achieved on a Toshiba SatellliteL500D-159 laptop equipped with an AMD Athlon II Dual-Core M300x2 run-ning at 2 GHz and with 4 GB of RAM. It is worth reminding that the numberof frame-per-second of the database videos is 25.
Looking at the values reported in Table 7, it is evident that the CannyFilter represents the bottleneck in the Face and Hands Detection and FeatureExtraction stages from the computational complexity perspective, and thatthere is thus space to calculate other feature based on the Canny outcomeand/or evaluating more performing skin detection procedures. Note that alsothe morphological smoothing can induce a certain burden, in dependence onthe size of the structuring element: in the present case studies, its size is

22 M. Fagiani, et al.
equal to 9 and bigger values were not beneficial to improve overall systemperformance.
For what concern the recognition stage, the Viterbi algorithm [30] requiresmost of the computational resources. Indeed, such algorithm is executed foreach sign and to calculate the probability that the input feature vectors aregenerated by the sign model. The computational cost of these operations de-pends on the number of HMM states N , the number of signs in the vocabularyV and the number of frames per second T of the video input to recognize.Moreover it is linearly dependent on the operations needed to calculate theobservation density, i.e. a mixture of G Gaussians whose observation vectorhas size L. As pointed out in [30], the computational cost is given by:
FLOPS ≈ V TN2(6L+ 2)G. (26)
Therefore, assuming N = 18, G = 1, L = 21, (as in best results reportedabove) and V = 147, T = 25 (due to database characteristics), the compu-tational cost is approximatively 152.4 MFLOPS, thus greater than the oneattained in the two former stages.
The computational burden of the recognition process has been evaluatedalso in terms of real-time factor, defined as the ratio between the processingtime and the length of the video sequence. On average, the whole process, in-cluding the features calculation and the Viterbi algorithm for sign recognition,requires about 8 seconds per video segment. This results in a real-time factorof about 2.6, which represents an encouraging result for future real-time de-velopments also on embedded platforms. Indeed, considering that no specificoptimization strategies have been carried out so far, space for improvementscan be foreseen from this perspective.
5 Comparative evaluation with Support Vector Machines
In order to have better insights on the performance of the HMM-based sys-tem, a Support Vector Machines approach has been considered [10]. SVMs arebinary classifiers that discriminate whether an input vector x belongs to class
Table 7 Computational Cost in MFLOPS (Mega-FLOPS) and time consumed for all al-gorithms in the Automatic LIS Recognition tool. The “Feature Operations” includes allformulas appearing in Table 2, the calculation of moments which are used therein and theface smoothing described in 5.
MFLOPS Time occupancy (%)Skin Detector 31.1 10.00Morphological Smoothing 112.0 25.00Canny Filter 134.5 30.00Feature Operations 6.2 1.67Recognition 152.4 33.33

Signer Independent Isolated Italian Sign Recognition Based on HMMs 23
+1 or to class −1 based on the following discriminant function:
f(x) =
N∑i=1
αitiK(x,xi) + d, (27)
where ti ∈ {+1,−1}, αi > 0 and∑N
i=1 αiti = 0. The terms xi are the “supportvectors” and d is a bias term that together with the αi are determined duringthe training process of the SVM. The input vector x is classified as +1 iff(x) ≥ 0 and −1 if f(x) < 0. The kernel function K(·, ·) can assume differentforms [5]. Regardless the kernel, the basic assumption is that all the inputvectors are of the same dimension. However, in the sign recognition scenario,the video sequences are composed of a varying number of frames, thus thenumber of feature vectors changes from video to video. A popular approachto deal with the problem is using the so called alignment kernels.
In this work, the Gaussian Dynamic Time Warping kernel (GDTW) [21]has been employed. The kernel assumes the form:
K(x,xj) = exp(−γDTW(x,xj)), γ > 0, (28)
Notice that GDTW is a variant of the radial basis function kernel K(x,xi) =exp(−γ‖x− xi‖2), where the term ‖x− xi‖2 is replaced with Dynamic TimeWarping [29], thus able to deal with variable length sequences.
Since SVMs are binary classifiers, the multiclass problem has been ad-dressed using the “one versus all” strategy. All the experiments have beenperformed using LIBSVM (a library for Support Vector Machines) [9].
As for the HMM model parameters selection illustrated in Section 4.1, thefirst test aims at evaluate the best γ value to use for the feature selectiontests. Fig. 11 shows the obtained results varying γ from 2−15 to 217. Thebest accuracy, 24.93%, is reached for γ = 29. All the test have been executedfollowing the three-way data split method combined with the 10-fold crossvalidation as for the HMM-based system.
Fig. 12 shows the final performance obtained using the same features ofthe HMM approach: the resulting accuracy is 21.49% below the one obtainedwith the HMM system.
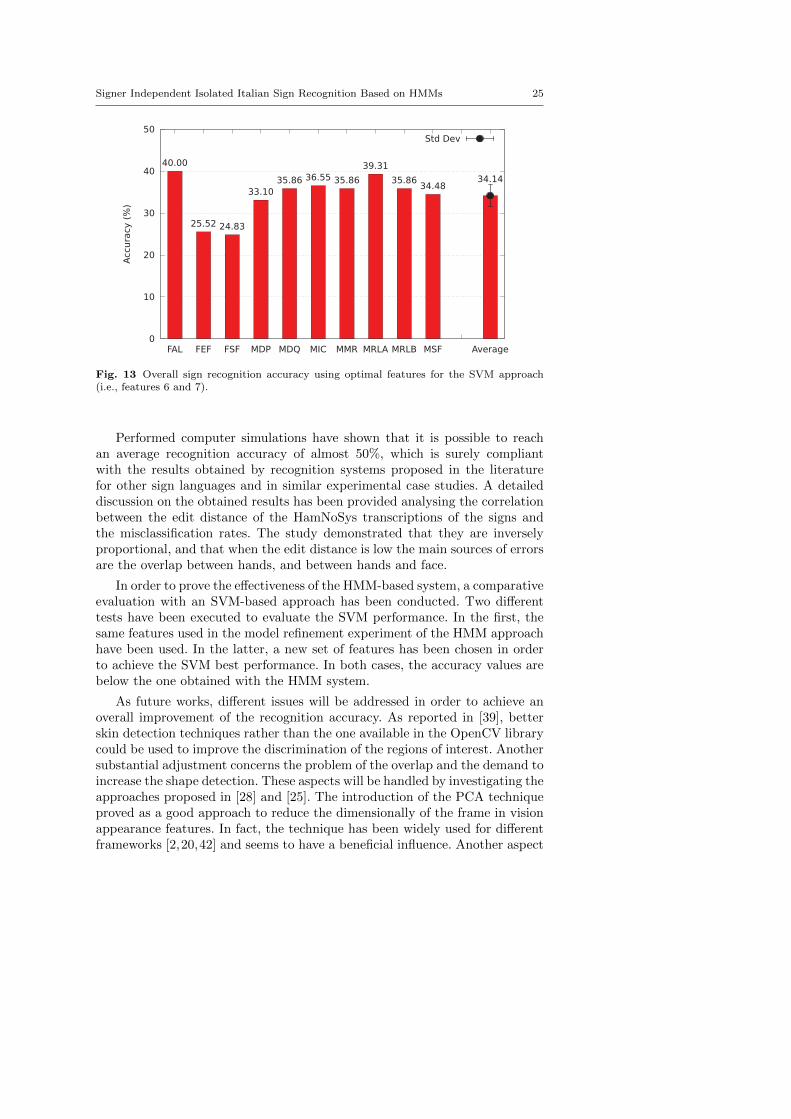
Since the adopted SFS procedure depends on the classifier, it has beenrepeated for the SVM approach in order to find the best performing features.The resulting features for SVM are the normalized hands centroid distance andthe hands centroid referred to the face centroid. Fig. 13 shows the obtainedresults: the average accuracy of the SVM improves to 34.14%, however it isstill below the one obtained with the HMM approach, 48.06%.
6 Conclusion
In this work, a system for the automatic recognition of isolated signs of theItalian sign language has been described and evaluated. The approach oper-ates independently of the signer, and it is based on three distinct algorithmic
24 M. Fagiani, et al.
0
5
10
15
20
25
30
0.0001 0.01 1 100 10000
Accu
racy
(%)
Gamma value
Fig. 11 Sign recognition accuracy for different values of γ using the three-way data splitand the K-fold cross-validation methods.
0
5
10
15
20
25
30
35
40
FAL FEF FSF MDP MDQ MIC MMR MRLA MRLB MSF Average
Accu
racy
(%)
Std Dev
31.72
17.9316.55
31.72
28.28
24.8327.59
35.86
31.72 31.03 27.72
Fig. 12 Overall sign recognition accuracy using the same features of the HMM system.
stages operating in cascade: the first for face and hands detection, the sec-ond for feature extraction and the third for sign recognition, based on theHidden Markov Models paradigm. The authors, with the support of the localoffice of the Deaf People National Institute (ENS), have created a suitabledatabase made of 1470 signs to be used for the training and testing phasesof the recognizer. In the experiments, several features have been evaluated forclassification and the overall best performing set has been determined usingthe sequential feature selection technique.
Signer Independent Isolated Italian Sign Recognition Based on HMMs 25
0
10
20
30
40
50
FAL FEF FSF MDP MDQ MIC MMR MRLA MRLB MSF Average
Accu
racy
(%)
Std Dev
40.00
25.52 24.83
33.1035.86 36.55 35.86
39.3135.86 34.48 34.14
Fig. 13 Overall sign recognition accuracy using optimal features for the SVM approach(i.e., features 6 and 7).
Performed computer simulations have shown that it is possible to reachan average recognition accuracy of almost 50%, which is surely compliantwith the results obtained by recognition systems proposed in the literaturefor other sign languages and in similar experimental case studies. A detaileddiscussion on the obtained results has been provided analysing the correlationbetween the edit distance of the HamNoSys transcriptions of the signs andthe misclassification rates. The study demonstrated that they are inverselyproportional, and that when the edit distance is low the main sources of errorsare the overlap between hands, and between hands and face.
In order to prove the effectiveness of the HMM-based system, a comparativeevaluation with an SVM-based approach has been conducted. Two differenttests have been executed to evaluate the SVM performance. In the first, thesame features used in the model refinement experiment of the HMM approachhave been used. In the latter, a new set of features has been chosen in orderto achieve the SVM best performance. In both cases, the accuracy values arebelow the one obtained with the HMM system.
As future works, different issues will be addressed in order to achieve anoverall improvement of the recognition accuracy. As reported in [39], betterskin detection techniques rather than the one available in the OpenCV librarycould be used to improve the discrimination of the regions of interest. Anothersubstantial adjustment concerns the problem of the overlap and the demand toincrease the shape detection. These aspects will be handled by investigating theapproaches proposed in [28] and [25]. The introduction of the PCA techniqueproved as a good approach to reduce the dimensionally of the frame in visionappearance features. In fact, the technique has been widely used for differentframeworks [2,20,42] and seems to have a beneficial influence. Another aspect

26 M. Fagiani, et al.
to investigate could be the introduction of different hands tracker, like thoseproposed by [3, 18].
Moreover, the development of a new sign database including audio andspatial information (e.g., using multiple cameras, or Microsoft KinectTM) toaugment the feature set and reduce errors due to overlapping and wrong spatialdetection of the subject is actually under investigation. Clearly, in the newdatabase it will be necessary to increase the number of vocabulary signs andto introduce more realizations of each sign per signer. The proposed approachwill be also assessed using on sign corpora in order to compare the results withalternative techniques, and to verify the performance on different scenarios.
Finally, the authors have been also directing their efforts in extending theusability of the tool to the continuous sign case study, which requires theintroduction of a suitable language model within the recognizer stage. TheHMM based approach used in the proposed framework surely represents a goodchoice from this perspective, as effectively demonstrated by many continuousspeech recognition applications [33,35,36].
References
1. von Agris, U., Kraiss, K.F.: Towards a Video Corpus for Signer-Independent ContinuousSign Language Recognition. In: Proc. of the International Workshop on Gesture inHuman-Computer Interaction and Simulation. Lisbon (2007)
2. von Agris, U., Zieren, J., Canzler, U., Bauer, B., Kraiss, K.F.: Recent Developments inVisual Sign Language Recognition. Univers. Access in the Inf. Society 6(4), 323–362(2008)
3. Al-Ahdal, M., Tahir, N.: Review in Sign Language Recognition Systems. In: Proc. ofIEEE Symposium on Computers Informatics, pp. 52–57 (2012)
4. Bertoldi, N., Tiotto, G., Prinetto, P., Piccolo, E., Nunnari, F., Lombardo, V., Mazzei,A., Damiano, R., Lesmo, L., Del Principe, A.: On the Creation and the Annotation ofa Large-Scale Italian-LIS Parallel Corpus. In: Proc. of the International Conference onLanguage Resources and Evaluation, pp. 19–22 (2010)
5. Bishop, C.: Pattern Recognition and Machine Learning. Springer Science+BusinessMedia, LLC, New York (2006)
6. Bradski, G.: The OpenCV Library. Dr. Dobb’s J. of Softw. Tools 25(11), 120, 122–125(2000)
7. Bradski, G., Kaehler, A.: Learning OpenCV: Computer Vision with the OpenCV Li-brary. O’Reilly Media, Inc., Sebastopol (2008)
8. Canny, J.: A Computational Approach to Edge Detection. IEEE Trans. Pattern Anal.Machine Intell. 8(6), 679–698 (1986)
9. Chang, C.C., Lin, C.J.: LIBSVM: A library for support vector machines. ACM Trans-actions on Intelligent Systems and Technology 2, 1–27 (2011)
10. Cortes, C., Vapnik, V.: Support-Vector Networks. In: Machine Learning, pp. 273–297(1995)
11. Dreuw, P., Forster, J., Deselaers, T., Ney, H.: Efficient Approximations to Model-BasedJoint Tracking and Recognition of Continuous Sign Language. In: Proc. of the IEEEInternational Conference on Automatic Face Gesture Recognition, pp. 1–6. Los Alamitos(2008)
12. Dreuw, P., Neidle, C., Sclaroff, V.A.S., Ney, H.: Benchmark Databases for Video-BasedAutomatic Sign Language Recognition. In: Proc. of the International Conference onLanguage Resources and Evaluation. European Language Resources Association, Mar-rakech (2008)
13. Dreuw, P., Ney, H.: Visual Modeling and Feature Adaptation in Sign Language Recog-nition. ITG Conf. on Voice Commun. (SprachKommunikation) pp. 1–4 (2008)

Signer Independent Isolated Italian Sign Recognition Based on HMMs 27
14. Dreuw, P., Ney, H., Martinez, G., Crasborn, O., Piater, J., Moya, J.M., Wheatley, M.:The SignSpeak Project - Bridging the Gap Between Signers and Speakers. In: Proc. ofthe International Conference on Language Resources and Evaluation. Valletta, Malta(2010)
15. Dreuw, P., Rybach, D., Deselaers, T., Zahedi, M., Ney, H.: Speech Recognition Tech-niques for a Sign Language Recognition System. In: Proc. of Interspeech, pp. 2513–2516(2007)
16. Fagiani, M., Principi, E., Squartini, S., Piazza, F.: A New Italian Sign LanguageDatabase. In: H. Zhang, A. Hussain, D. Liu, Z. Wang (eds.) Advances in Brain In-spired Cognitive Systems, Lecture Notes in Computer Science, vol. 7366, pp. 164–173.Springer (2012)
17. Fagiani, M., Principi, E., Squartini, S., Piazza, F.: A New System for Automatic Recog-nition of Italian Sign Language. In: B. Apolloni, S. Bassis, A. Esposito, F.C. Morabito(eds.) Neural Nets and Surroundings, Smart Innovation, Systems and Technologies,vol. 19, pp. 69–79. Springer Berlin Heidelberg (2013)
18. Fang, G., Gao, W., Ma, J.: Signer-Independent Sign Language Recognition Based onSOFM/HMM. In: Proc. of the IEEE ICCV Workshop on Recognition, Analysis, andTracking of Faces and Gestures in Real-Time Systems, pp. 90–95 (2001)
19. Gonzalez, R.C., Woods, R.E.: Digital Image Processing, third edn. Prentice Hall (2007)20. Gweth, Y., Plahl, C., Ney, H.: Enhanced Continuous Sign Language Recognition Using
PCA and Neural Network Features. In: Proc. of the Computer Vision and PatternRecognition Workshops, pp. 55–60 (2012)
21. Haasdonk, B., Bahlmann, C.: Learning with Distance Substitution Kernels. In: C. Ras-mussen, H.H. Bulthoff, B. Scholkopf, M.A. Giese (eds.) Pattern Recognition, LectureNotes in Computer Science, vol. 3175, pp. 220–227. Springer Berlin Heidelberg (2004)
22. Hanke, T.: HamNoSys-representing Sign Language Data in Language Resources andLanguage Processing Contexts. In: Proc. of LREC, pp. 1–6 (2004)
23. Hu, M.K.: Visual Pattern Recognition by Moment Invariants. IRE Trans. on Inf. Theory8(2), 179–187 (1962)
24. Infantino, I., Rizzo, R., Gaglio, S.: A Framework for Sign Language Sentence Recognitionby Commonsense Context. IEEE Trans. Syst., Man, Cybern. C, Appl. Rev. 37(5), 1034–1039 (2007)
25. Kelly, D., McDonald, J., Markham, C.: A Person Independent System for Recognition ofHand Postures Used in Sign Language. Pattern Recognition Letters 31(11), 1359–1368(2010)
26. Kukharev, G., Nowosielski, A.: Visitor Identification - Elaborating Real Time FaceRecognition System. In: Proc. of the International Conference on Computer Graphics,Visualization and Computer Vision, pp. 157–164. UNION Agency, Plzen (2004)
27. Maebatake, M., Suzuki, I., Nishida, M., Horiuchi, Y., Kuroiwa, S.: Sign Language Recog-nition Based on Position and Movement Using Multi-Stream HMM. In: Proc. of the In-ternational Symposium on Universal Communication, pp. 478–481. Los Alamitos (2008)
28. Quan, Y.: Chinese Sign Language Recognition Based on Video Sequence AppearanceModeling. In: Proc. of the IEEE Conference on Industrial Electronics and Applications,pp. 1537–1542 (2010)
29. Rabiner, L., Juang, B.H.: Fundamentals of Speech Recognition. Prentice-Hall, Inc.,Upper Saddle River, NJ, USA (1993)
30. Rabiner, L.R.: A Tutorial on Hidden Markov Models and Selected Applications inSpeech Recognition. Proceedings of the IEEE 77(62), 257–286 (1989)
31. Ripley, B.D.: Pattern Recognition and Neural Networks. Cambridge University Press,Cambridge (1996)
32. Sandler, W., Lillo-Martin, D.: Sign Language and Linguistic Universals. CambridgeUniversity Press, Cambridge (2006)
33. Saon, G., Chien, J.T.: Large-Vocabulary Continuous Speech Recognition Systems: ALook at Some Recent Advances. IEEE Signal Processing Mag. 29(6), 18–33 (2012)
34. Serra, J.: Image Analysis and Mathematical Morphology. Academic Press, Inc., Orlando(1983)
35. Starner, T., Pentland, A.: Real-time American Sign Language Recognition from VideoUsing Hidden Markov Models. In: Proc. of the International Symposium on ComputerVision, pp. 265–270 (1995)

28 M. Fagiani, et al.
36. Starner, T., Weaver, J., Pentland, A.: Real-time American Sign Language RecognitionUsing Desk and Wearable Computer Based Video. IEEE Transactions on Pattern Anal-ysis and Machine Intelligence 20(12), 1371–1375 (1998)
37. Theodorakis, S., Katsamanis, A., Maragos, P.: Product-HMMs for Automatic Sign Lan-guage Recognition. In: Proc. of the International Conference on Acoustics, Speech andSignal Processing, pp. 1601–1604. Taipei, Taiwan (2009)
38. Theodoridis, S., Koutroumbas, K.: Pattern Recognition, Fourth Edition. AcademicPress, Burlington (2008)
39. Vezhnevets, V., Sazonov, V., Andreeva, A.: A Survey on Pixel-Based Skin Color Detec-tion Techniques. In: Proc. of GraphiCon, pp. 85–92 (2003)
40. Young, S.J., Evermann, G., Gales, M.J.F., Hain, T., Kershaw, D., Moore, G., Odell,J., Ollason, D., Povey, D., Valtchev, V., Woodland, P.C.: The HTK Book, version 3.4.Cambridge University Press, Cambridge (2006)
41. Zahedi, M., Keysers, D., Deselaers, T., Ney, H.: Combination of Tangent Distance andan Image Distortion Model for Appearance-Based Sign Language Recognition. In:W. Kropatsch, R. Sablatnig, A. Hanbury (eds.) Pattern Recognition, Lecture Notesin Computer Science, vol. 3663, pp. 401–408. Springer Berlin Heidelberg (2005)
42. Zaki, M.M., Shaheen, S.I.: Sign Language Recognition Using a Combination of NewVision Based Features. Pattern Recognition Letters 32(4), 572–577 (2011)

Signer Independent Isolated Italian Sign Recognition Based on HMMs 29
A Appendix: HamNoSys Sign Transcription

30 M. Fagiani, et al.

Signer Independent Isolated Italian Sign Recognition Based on HMMs 31





























