Embed Size (px)
Citation preview

PODSTAWY STATYSTYKISEMINARIUM 1
! UWAGA !
SLAJDY WYBRANE I ZMODYFIKOWANE
POD KĄTEM PREZENTACJI W INTERNECIE
Jan E. Zejda
Katedra Epidemiologii – WLK, SUM
STUDIUM DOKTORANCKIE WLK

TREŚĆ SEMINARIUM 1
• Rola biostatystyki w medycznych badaniach naukowych
• Baza danych
• Zmienne
• Statystyka opisowa
• Szacowanie

TREŚĆ SEMINARIUM 1
• Rola biostatystyki w medycznych badaniach naukowych
• Baza danych
• Zmienne
• Statystyka opisowa
• Szacowanie
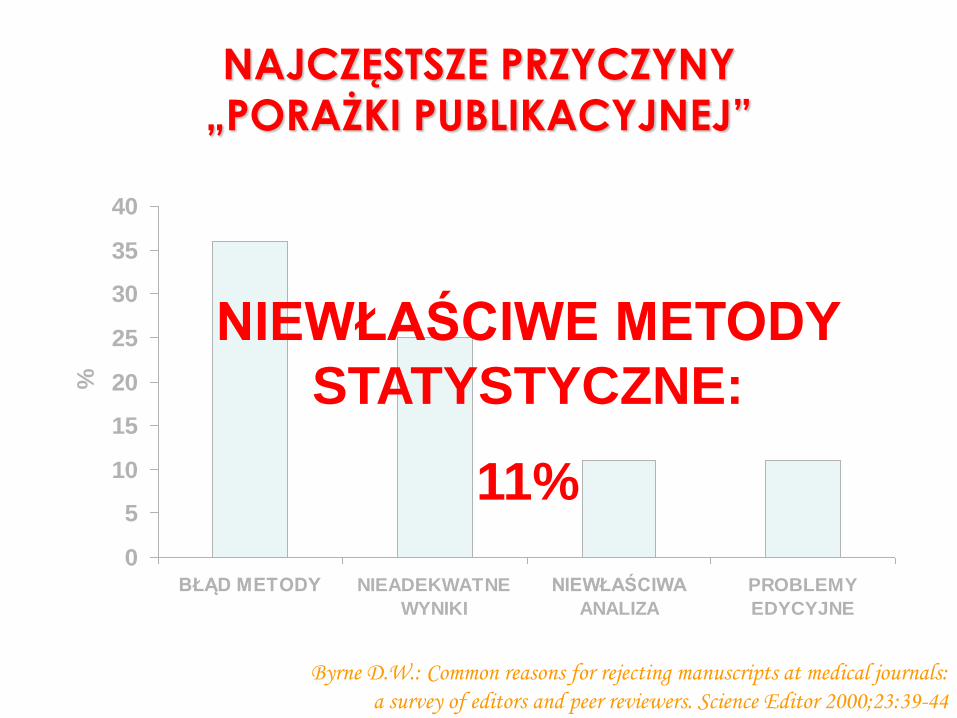
NAJCZĘSTSZE PRZYCZYNY
„PORAŻKI PUBLIKACYJNEJ”
0
5
10
15
20
25
30
35
40
BŁĄD METODY NIEADEKWATNE
WYNIKI
NIEWŁAŚCIWA
ANALIZA
PROBLEMY
EDYCYJNE
%
Byrne D.W.: Common reasons for rejecting manuscripts at medical journals:
a survey of editors and peer reviewers. Science Editor 2000;23:39-44
NIEWŁAŚCIWE METODY
STATYSTYCZNE:
11%

STATYSTYKA
Dyscyplina nauki zajmująca się formułowaniem metod liczbowego
przetwarzania indywidualnych informacji statystycznych w celu
opisu i wnioskowania statystycznego
Nowa Encyklopedia Powszechna PWN, 1997
informacje o zjawiskach biologicznych
Pojęcie „statystyka” posiada więcej znaczeń
1) Nauka zajmująca się zbieraniem, analizą i interpretacją w/w danych
2) Numeryczne dane dotyczące agregatów złożonych z pewnych jednostek - zagregowaną,
charakteryzującą więcej niż 1 jednostkę daną jest np. średnia masa ciała 10 dziewcząt (jedna liczba
dla opisu zjawiska pochodzącego z 10 obserwacji), wartość odchylenia standardowego, częstość,
różnica pomiędzy dwoma wartościami średnimi
Statystyką nazywamy także liczbę reprezentującą wynik testu statystycznej znamienności – np.
statystyka ‘t’ lub statystyka ‘chi-kwadrat’

STATYSTYKA
W PRAKTYCE
albo opis
albo szacowanie
albo testowanie hipotez*
* - hipotezy odnośnie różnic lub zależności

BIOSTATYSTYKA
Biostatystyka jest to gałąź statystyki uwzględniająca specyfikę
zjawisk biologicznych, a w szczególności skutki zmienności
biologicznej stanowiącej przejaw zróżnicowania procesów
fizjologicznych i patologicznych, charakteryzujących stan zdrowia
i choroby.

SPECYFIKA BIOSTATYSTYKI
Zmienność biologiczna w zakresie:
• narażenia;
• podatności;
• odpowiedzi biologicznej;
• wywiadu chorobowego;
• etc.
zidentyfikować i kontrolować źródła zmienności

KLASYFIKACJA ZMIENNOŚCI
BIOLOGICZNEJ
• Zmienność międzyosobnicza: np. skurczowe ciśnienie tętnicze krwi u 10 zdrowych studentów w wieku 24-25 lat
• Zmienność wewnątrzosobnicza: np. skurczowe ciśnienie tętnicze krwi u 1 zdrowego studenta, zmierzone codziennie o godzinie 8:00 przez 7 dni

SYGNAŁ vs SZUM
Gdy istnieje duży sygnał jest on widoczny (ergo: wykrywalny)
nawet w obecności dużego szumu
Niewielki sygnał „tonie” w szumie
Sposoby kontroli szumu
- Model badania (np. restrykcja wieku, płci, narażenia na tzw.
czynniki zakłócające)
- Analiza danych (stratyfikacja w zakresie czynników
zakłócających, statystyczna kontrola szumu)
Co jest sygnałem, co jest szumem ?

Identyfikacja i pomiar sygnału wymaga wiedzy
na temat potencjalnych źródeł szumu,
umiejętności wykazania jego obecności,
kontroli jego maskującego wpływu
Biostatystyka raz jeszcze
ale
Biostatystyka to nie panaceum – to tylko
narzędzie
Przede wszystkim METODOLOGIA !!

TREŚĆ SEMINARIUM 1
• Rola biostatystyki w medycznych badaniach naukowych
• Baza danych
• Zmienne
• Statystyka opisowa
• Szacowanie

AMATORSKA BAZA DANYCH
Nazwisko Płeć Masa Mała masa
urodzeniowa
Apgar w 5
i 10 min.
Rodzaj Leku USG Głowy Antybiotyk
Grupa 1
Abeski N. c. 2,78 Nie 5 -7 Dexametzaon IVHI Nie
Adam Beski C 3500 Nie 8 Deksamet. IVH I Vankomycyna
S. Ceski M 4100 Nie 9 Celeston IVH 1 Ampicylin
z. Dada D 2 950 Nie 6, 7 Dexaren IVH II Wankomycina
Efeska Ż 3,540 Nie IVH I Nie
Fafka A. D 3100 Nie 7 Dexametazon -
Grupa 2
Goga Anna D 2,58? Nie 4 (7) Dexametazon IVH 2 Ampicylina
Hawil D. C 2300 Tak 6 Celeston Ivh I -
T. Iwak M 4320 nie 10 Celeston Nie
w. Jutul M 2,8 Nie 6 - IVH nie Nie
Grupa 3
Celski S. M 3850 + - norma -

PROFESJONALNA BAZA DANYCH
NR GRUPA PLEC MASA APGAR5 APGAR10 LEK1 USGGL LEK2
1 1 1 2780 5 7 1 1 0
2 1 1 3500 8 1 1 1
3 1 2 4100 9 2 1 2
4 1 2 2950 6 7 3 2 1
5 1 2 3540 0 1 0
6 1 2 3100 7 1
7 2 2 2580 4 8 1 2 2
8 2 1 2300 6 2 1
9 2 1 4320 10 2 0
10 2 1 2800 6 0 1 0
! SŁOWNICZEK !
Np. LEK2 – Antybiotyk w pierwszych trzech dobach: 0=nie, 1=wankomycyna, 2=ampicylina, ‘ ‘ = brak danych

PODSTAWOWE ZASADY TWORZENIA BAZY DANYCH*
“DZIESIĘĆ PRZYKAZAŃ”
1. Wprowadź dane jako zmienne liczbowe (np.: tak=1, nie=2; płeć męska=1, płeć żeńska=2). Unikaj
liter, skrótów, jednostek pomiaru (np.: b.d.; 15%, <2500). Wszystkim kolumnom (np. w bazie Excel)
powinien być nadany format liczbowy.
2. Stosuj proste nazwy zmiennych (np.: kliniczny stopień duszności = KSD; płeć dziecka = PLEC;
stężenie bilirubiny = BILIRUB). Unikaj „polskich liter” i nie przekraczaj 8 znaków w nazwie zmiennej
3. Dla jednej zmiennej przeznacz tylko jedną kolumnę
4. Wprowadź dane każdego pacjenta w tej samej kolejności, z konsekwentnym sposobem zapisu
brakujących danych
5. Nadaj każdemu pacjentowi jego własny, niepowtarzalny numer identyfikacyjny. Nie wpisuj
informacji identyfikujących (np. nazwisko lub inicjały, numer historii choroby).
6. Wprowadź wszystkich pacjentów, niezależnie do ich grupowej przynależności (np. grupa
terapeutyczna lub kontrolna) do jednej bazy danych. Kolejność wprowadzania nie ma znaczenia.
Zastosuj zmienną identyfikującą grupę (np. grupa = 1 lub 2).
7. Wprowadzaj źródłowe zmienne ilościowe – transformacja do zmiennych jakościowych lub
pochodnych nastąpi podczas analizy danych (np. wysokość ciała w cm da się „przetłumaczyć” na
niski, średni lub wysoki wzrost; wartość BMI da się obliczyć na podstawie dwóch oryginalnych
danych; obecność hiperglikemii da się zidentyfikować na podstawie wartości ilościowej glikemii)
8. Stwórz kompletny „słowniczek” zawierający tłumaczenie kodów zmiennych, definicję wartości
zmiennych (np. tak=1; nie = 2), informację na temat postępowania z brakującymi danymi
9. Twórz bazę danych mając na uwadze cel i sposób późniejszej ich analizy
10. Skonsultuj pomysł na bazę danych z biostatystykiem i uczyń to ponownie po wprowadzeniu
informacji pochodzących od pierwszych 10 pacjentów.
*- na podstawie propozycji opracowanej przez D.W. Byrne

TREŚĆ SEMINARIUM 1
• Rola biostatystyki w medycznych badaniach naukowych
• Baza danych
• Zmienne
• Statystyka opisowa
• Szacowanie

TERMINOLOGIA STOSOWANAW OPISIE BAZY DANYCH
Zmienne
Nr PLEC WZROST KSD FVC FEV1
1 1 178 2 3200 1800
2 1 169 1 3600 2500
3 2 168 5 3450 2040
4 1 175 3 3750 1750
5 2 163 4 3900 1900
Nazwa Zmiennej Wartość Zmiennej
zmienna, albowiem naturalna zmienność wartości
Obserwacje (1 pacjent=1 obserwacja)

RODZAJE ZMIENNYCH
KOMPLETNY PODZIAŁ UWGLĘDNIAJĄCY FORMAT
ZMIENNE
ILOŚCIOWE JAKOŚCIOWE
CIĄGŁE
liczby
(wzrost, masa)
DYSKRETNE
liczebność
(liczba badanych)
NOMINALNE
kategoria
(płeć, rasa)
PORZĄDKOWE
hierarchia
(klin. st. duszności)

RODZAJE ZMIENNYCH
PRAKTYCZNY PODZIAŁ UWGLĘDNIAJĄCY FORMAT
ZMIENNE
ILOŚCIOWE JAKOŚCIOWE
transformacja

RODZAJE ZMIENNYCH
PROSTY PODZIAŁ UWGLĘDNIAJĄCY FUNKCJĘ
Zmienna zależna
(w danej analizie: jedna zmienna)
Zmienne niezależne
(w danej analizie jedna lub więcej zmiennych)
Funkcja zmiennej zależy od celu: np. czy KSD zależy od FEV1?
KSD ~ FEV1
zmienna zależna zmienna niezależna

TREŚĆ SEMINARIUM 1
• Rola biostatystyki w medycznych badaniach naukowych
• Baza danych
• Zmienne
• Statystyka opisowa
• Szacowanie

STATYSTYKA OPISOWA - CEL
Prezentacja danych w postaci tabelarycznej i graficznej
(histogramy, wykresy liniowe, itd.) oraz za pomocą
zintegrowanej formy matematycznej – liczby
(przy pomocy tzw. statystyk – wartość średnia, częstość, itd.)
…………………………………………………………………………….
Częstość (%) poszczególnych klas cholesterolemii w grupie mężczyzn
0
10
20
30
40
175 205 235 265 295 325 355
Cholesterolemia (mg/dl)
(%)
Średnie stężenie cholesterolu w badanej grupie mężczyzn 215 mg/dl

DWA OBSZARY STATYSTYKI
-1- -2-
Statystyka Opisowa Statystyka Analityczna
(ile ?, jak często ?) ↓ ↓(„charakterystyka”) Szacowanie Testowanie Hipotez

STATYSTYKA OPISOWA
PREZENTACJA ZMIENNYCH
ILOŚCIOWYCH
wzrost bilirubinemia
dochód masa ciała
opór dróg oddechowych
glikemia
czas karmienia piersią
stężenie ołowiu w krwi
czas hospitalizacji
obwód talii
ciśnienie tętnicze krwi

JAK OPISAĆ MASĘ CIAŁA NOWORODKÓW
W BADANEJ GRUPIE ?
n = 41
2,2 2,2 2,3 2,3 2,4 2,4 2,4 2,5 2,5 2,5 2,5 2,7 2,7 2,7 2,8 2,8 2,8
2,8 2,9 3,0 3,1 3,1 3,1 3,2 3,2 3,2 3,2 3,2 3,2 3,2 3,5 3,5 3,5 3,6
3,6 3,6 3,6 3,7 3,7 3,8 3,8 3,8 3,8 3,9 3,9 4,0 4,0 4,1 4,2 4,6 3,1
ŚREDNIA ARYTMETYCZNA = 3,1 kg
Zmienna Średnia arytmetyczna
(kg)
Zakres
(kg)
Mediana
(kg)
Modalna
(kg)
Masa 3,1 2,2- 4,6 3,2 3,2
↑ matematyczna prezentacja rozkładu zmiennej „masa ciała” ↑

„Liściogram” (stem&leaf)
2 20 21
2 30 33
2 41 44 48
2 50 51 51 52
2 72 75 78
2 80 80 83 84
2 98
3 05
3 10 15 15
3 22 25 25 25 25 25 28
3 50 53 55
3 62 66 68 68
3 70 75
3 82 85 85 85
3 90 95
4 00 50
4 10
4 25
4 60
JAK OPISAĆ MASĘ CIAŁA NOWORODKÓW
W BADANEJ GRUPIE ?
MASA
2,20 i 2,21
2,30 i 2,33
itd.
UWAGA:
brak danych dla klas
2,60-2,69; 3,30 – 3, 49
i 4,30-4,55

0
2
4
6
8
2,2
2,4
2,6
2,8 3
3,2
3,4
3,6
3,8 4
4,2
4,4
4,6
Masa (kg)
n
HISTOGRAM
wartość średnia →
← mediana i modalna

JAK OPISAĆ MASĘ CIAŁA NOWORODKÓW
W BADANEJ DANEJ GRUPIE ?
n = 41
2,2 2,2 2,3 2,3 2,4 2,4 2,4 2,5 2,5 2,5 2,5 2,7 2,7 2,7 2,8 2,8 2,8
2,8 2,9 3,0 3,1 3,1 3,1 3,2 3,2 3,2 3,2 3,2 3,2 3,2 3,5 3,5 3,5 3,6
3,6 3,6 3,6 3,7 3,7 3,8 3,8 3,8 3,8 3,9 3,9 4,0 4,0 4,1 4,2 4,6 3,1
ŚREDNIA ARYTMETYCZNA = 3,1 kg
Zmienna Średnia arytmetyczna
(kg)
Zakres
(kg)
Mediana
(kg)
Modalna
(kg)
Masa 3,1 2,2- 4,6 3,2 3,2
! w konfrontacji z histogramem brakuje jednej ważnej informacji !

MATEMATYCZNY OPIS ROZKŁADU
ZMIENNEJ ILOŚCIOWEJ
uwaga: x = 5,0, gdy [5,5,5,5,5] lub [5,3,7,8,2]
co więcej:
w pierwszym przypadku żadna z indywidualnych wartości nie różni się od w. średniej
w drugim przypadku większość indywidualnych wartości różni się od w. średniej
x
___ n
X = ( Xi) / Ni = 1
wartość średnia
w populacji w grupie
odchylenie wartości zmiennych od wartości średniej określa zmienność zmiennej
(wariancję)
(Xi – X) = Xi - X = Xi – NX = 0, ponieważ X = Xi/N
dlatego wprowadzono „potęgowanie”
zmienność (wariancja) = (Xi – X)2 / N
oczywista niedogodność związana z potęgowaniem, stąd pierwiastkowanie i
odchylenie standardowe = (Xi – X)2 / N

WARIANCJA I ODCHYLENIE STANDARDOWE
Wariancję i odchylenie standardowe rzadko liczymy w całej populacji źródłowej,
zwykle dotyczy to próby, a więc nie N, tylko
n – 1
zapis „n-1” oznacza, że tyle niezależnych względem n-tej wartości
kombinacji odchyleń ma znaczenie dla wielkości rozproszenia
(prymitywne spojrzenie na koncepcję stopni swobody)
Po korekcie: x → X ; x → S,
zmienność = wariancja = s2 = (Xi – X)2 / (n – 1)
odchylenie standardowe = s = (Xi – X)2 / (n – 1)

Wartość średnia i OS opisują rozkład wartości zmiennej ilościowej
0
5
10
15
20
25
30
35
min
x-2S X
x+2S ma
x
%
Rozkład normalny:
68% wszystkich wartości mieści się w przedziale x-1s … x+1s
95% wszystkich wartości mieści się w przedziale x-2s … x+2s
100% wszystkich wartości mieści się w przedziale x-3s … x+3s
WARTOŚĆ ŚREDNIA
I ODCHYLENIE STANDARDOWE

0
5
10
15
20
25
30
35
min
u-2v u
u+2v ma
x
%
x → średnia w populacji; X → średnia w grupie
x → odchylenie standardowe w populacji; SD → odchylenie standardowe w grupie
ROZKŁAD NORMALNY
Standardowa zmienna Z odzwierciedla prawdopodobieństwo,
z jakim występuje wartość X, gdy jej rozkład ma charakter normalny
(całe pole = 100%, reszta w tablicy rozkładu):
Z = (X - x ) / x

INNE WAŻNE ROZKŁADY
(W NAUKACH MEDYCZNYCH)
ROZKŁAD DWUMIANOWY (0/1)
NP. ZGON+/ZGON-; KIŁA+/KIŁA-
„0” i „1” to wszystkie możliwe wartości zmiennej dwumianowej.
Zatem gdy prawdopodobieństwo wystąpienia ‘0’ wynosi ‘p’,
to prawdopodobieństwo wystąpienia „1” wynosi ‘q=1-p’ albo ‘q=100%-p’.
Wartość średnia x = p, odchylenie standardowe x = p(1-p)
ROZKŁAD POISSON’A (n)
NP. LICZBA NAPADÓW ASTMY W TYGODNIU
Rozkład Poisson’a jest właściwy dla opisu (i analizy)
liczby zdarzeń w danym przedziale wiekowym

Rozkład prawoskośny (kurtoza >1)
Rozkład lewoskośny (kurtoza < - 1)
0
5
10
15
20
25
30
35
40
min
max
%
CHARAKTER ROZKŁADU
ZMIENNEJ ILOŚCIOWEJ
UWAGA: wartość kurtozy zależy też od wysokości „wybrzuszenia” krzywej
dlatego normalność rozkładu ocenia się testami:
Kołmogorowa-Smirnowa lub Shapiro-Wilka

TRANSFORMACJA ZMIENNYCH(próba przywrócenia normalności)
Gdy wartość średnia <> wartości mediany, lub gdy graficzna prezentacja
rozkładu danych ujawnia odstępstwo od krzywej Gauss’a,
lub gdy statystyczny dowód na takie odstępstwo (np. test Shapiro-Wilk’s):
0
5
10
15
20
25
30
35
min 2 4 6 8 10 12 14 16 18 20
%
Prawoskośny rozkład (bakteriologia, hematologia, toksykologia itp.)
posiada „rytm” naśladujący skalę logarytmiczną:
| | | | | | | |
1 2 3 4 5 6 8

REGUŁA TENDENCJI CENTRALNEJ
Rozkład średniego wieku w dwuosobowej grupie (n=2) wylosowanej z populacji (N=5)
0
1
2
3
4
5
6
5 6 7 8 9 10 11 12 13 14
wiek
n
Niezależnie od rozkładu zmiennej w populacji rozkład tej zmiennej w próbie (z tej populacji)
będzie zbliżony do normalnego, pod warunkiem, że wielkość próby
jest odpowiednio duża
n = 30 (konsensus !)

KANON n ≥ 30
Liczba
obserwacji Próba Komentarz
< 30 „mała” Założenie odstępstwa rozkładu normalnego
30 – 100 „średnia” Konieczne testowanie normalności rozkładu
>100 „duża” Wskazane testowanie normalności rozkładu
Dostępność programów statystycznych rozwiązuje kwestię szybkiej oceny rozkładu

OPIS ZMIENNEJ ILOŚCIOWEJ
MIARY POŁOŻENIA (MIARY TENDECJI CENTRALNEJ)
Średnia arytmetyczna, mediana, modalna
MIARY ROZPROSZENIA
Zakres, zmienność, odchylenie standardowe
X ± SD(„tablica rejestracyjna zmiennej ilościowej”)

X ± SD
Współczynnik Zmienności
„im mniejsza wartość ‘S’ tym mniejsza zmienność”
generalnie TAK, ale rola ‘X’, dlatego:
Współczynnik Zmienności (WZ) = (s / x) * 100%
PRAKTYCZNE ZASTOSOWANIE WZ
porównanie rozkładu jednej zmiennej w dwóch różnych grupach
porównanie rozkładu kilku zmiennych w jednej grupie
odchylenie standardowe ≠ błąd standardowy
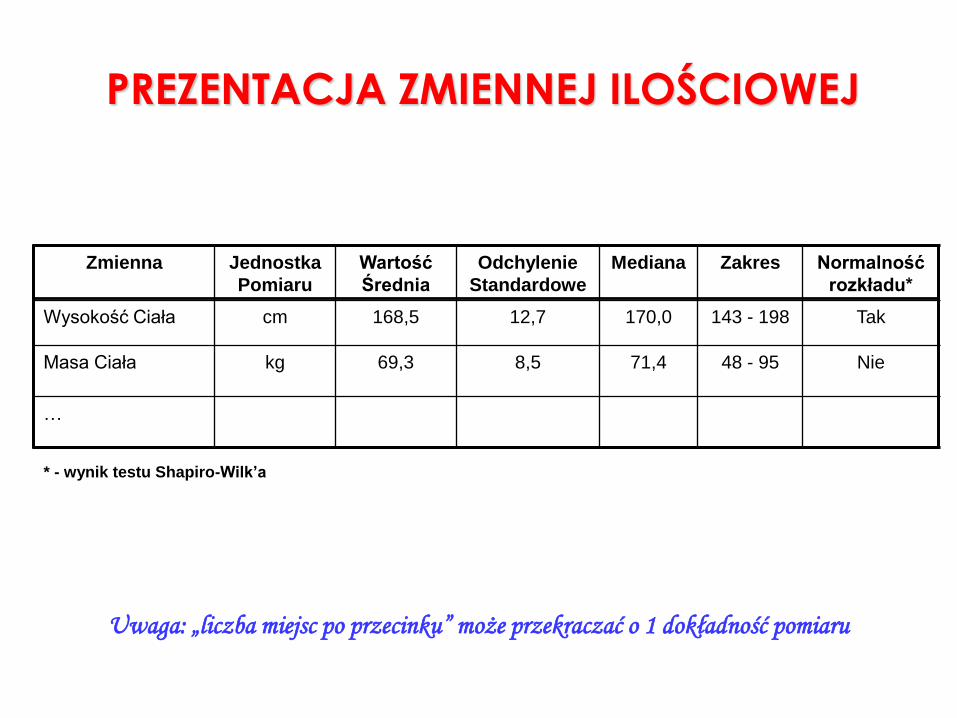
PREZENTACJA ZMIENNEJ ILOŚCIOWEJ
Zmienna Jednostka
Pomiaru
Wartość
Średnia
Odchylenie
Standardowe
Mediana Zakres Normalność
rozkładu*
Wysokość Ciała cm 168,5 12,7 170,0 143 - 198 Tak
Masa Ciała kg 69,3 8,5 71,4 48 - 95 Nie
…
Uwaga: „liczba miejsc po przecinku” może przekraczać o 1 dokładność pomiaru
* - wynik testu Shapiro-Wilk’a

STATYSTYKA OPISOWA
PREZENTACJA ZMIENNYCH
JAKOŚCIOWYCH
hiperglikemia płeć
nadwaga
obturacja jakość życia
kliniczny stopień duszności zawód
wykształcenie
cień okrągły w płucach krwotok
rodzaj porodu
hipercholesterolemia mutacja
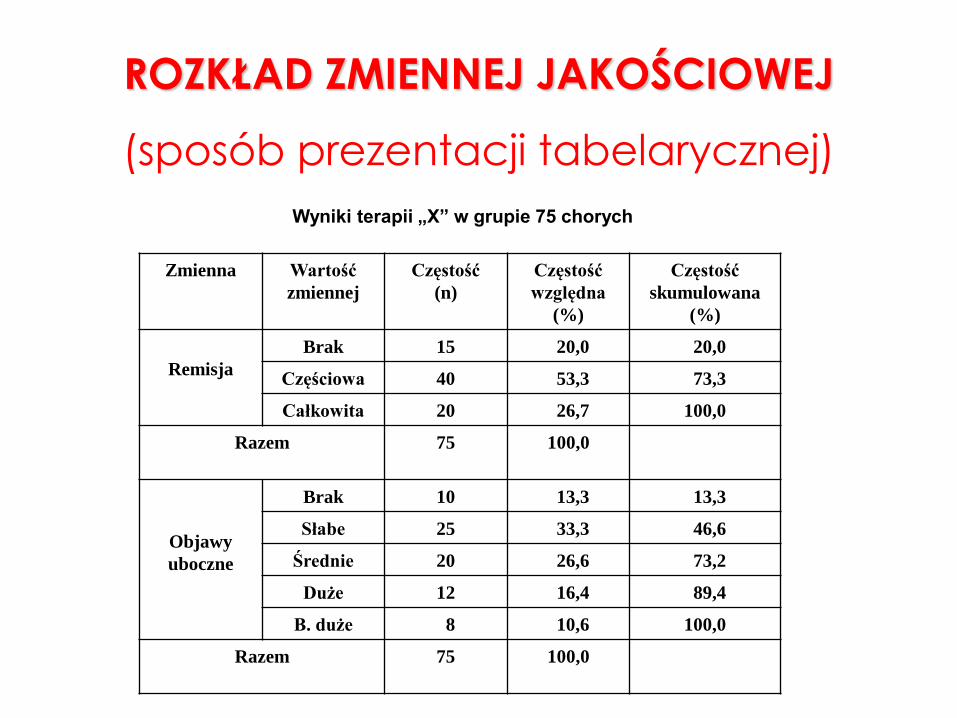
ROZKŁAD ZMIENNEJ JAKOŚCIOWEJ
(sposób prezentacji tabelarycznej)
Wyniki terapii „X” w grupie 75 chorych
Zmienna Wartość
zmiennej
Częstość
(n)
Częstość
względna
(%)
Częstość
skumulowana
(%)
Remisja
Brak 15 20,0 20,0
Częściowa 40 53,3 73,3
Całkowita 20 26,7 100,0
Razem 75 100,0
Objawy
uboczne
Brak 10 13,3 13,3
Słabe 25 33,3 46,6
Średnie 20 26,6 73,2
Duże 12 16,4 89,4
B. duże 8 10,6 100,0
Razem 75 100,0

Zmienna Wartość
zmiennej
Częstość
n %
Remisja
Brak 15 20,0
Częściowa 40 53,3
Całkowita 20 26,7
Objawy
uboczne
Brak 10 13,3
Słabe 25 33,3
Średnie 20 26,6
Duże 12 16,4
B. duże 8 10,6
ROZKŁAD ZMIENNEJ JAKOŚCIOWEJ
(prosty sposób prezentacji tabelarycznej)
Wyniki terapii „X” w grupie 75 chorych
gdy zmienna ma tylko dwie wartości można podać częstość jednej
np. częstość hiperbilirubinemii

ROZKŁAD ZMIENNEJ JAKOŚCIOWEJ
(graficzna prezentacja)
Częstość (%) objawów ubocznych terapii „X” w grupie 75 chorych
0
5
10
15
20
25
30
35
Brak Słabe Średnie Duże B. Duże
Nasilenie Objawów Ubocznych
%

TREŚĆ SEMINARIUM 1
• Rola biostatystyki w medycznych badaniach naukowych
• Baza danych
• Zmienne
• Statystyka opisowa
• Szacowanie

BIOSTATYSTYKA
W PRAKTYCE
albo opis
albo szacowanie
albo testowanie hipotez*
* - hipotezy odnośnie różnic lub zależności
Statystyka
opisowa
Statystyka
analityczna

SZACOWANIE
• wyniki badania sugerują, że częstość astmy u dzieci w wieku 7-10 lat kształtuje się na poziomie 5%
• ryzyko względne zachorowania na cukrzycę związane z przebyciem częstych infekcji wirusowych w młodości wynosi 1,27
• prawdopodobieństwo uzyskania stopnia doktora nauk medycznych w wyniku ukończenia studiów doktoranckich na Wydziale Lekarskim SUM w Katowicach wynosi 100%

SZACOWANIE (ESTYMACJA)
<) ‘x’ w próbie
ESTYMATOR PARAMETR
to mierzę, aby o tym się wypowiedzieć
aby poznać średnią masę ciała donoszonych noworodków matek palących
papierosy nie badam wszystkich dzieci, ale grupę np. 500 dzieci takich matek

BŁĄD W BADANIU EPIDEMIOLOGICZNYM
SYTUACJA IDEALNA
ESTYMATOR = PARAMETR
SYTUACJA REALNA
ESTYMATOR = PARAMETR + BŁĄD
ESTYMATOR = PARAMETR + BŁĄD SYSTEMATYCZNY + BŁĄD PRZYPADKOWY

BŁĄD
PRZYPADKOWY I SYSTEMATYCZNY
• Duży błąd systematyczny → mała trafność
• Duży błąd przypadkowy → mała precyzja
Trafność = stopień, w jakim obserwacja jest zdolna do
pomiaru zjawiska, które jest przedmiotem obserwacji
Precyzja = powtarzalność wyniku obserwacji
PRECYZJA ≠ TRAFNOŚĆ
ale
WIARYGODNOŚĆ = PRECYZJA + TRAFNOŚĆ

# 1: Odchylenie Standardowe (SD)
# 2: Wielkość próby (n)
BŁĄD STANDARDOWY ŚREDNIEJ
(STANDARD ERROR OF MEAN: SE)
SE = SD / √n
DETERMINANTY BŁĘDU PRÓBY
(BŁĘDU PRZYPADKOWEGO)

SZACOWANIE ≡ ESTYMATOR PUNKTOWY + ESTYMATOR ZAKRESU
Estymator punktowy = pojedyncza wartość liczbowa (np. średnia arytm., %) obliczona
w celu oszacowania wartości korespondującego, populacyjnego parametru (prawdziwej
średniej)
Estymator zakresu = dwie wartości liczbowe definiujące zakres przedziału zawierającego
wartość parametru (przedziału ufności – P.U.)
Dolna Wartość P.U. Estymator Punktowy Górna Wartość P.U.
|---------------------------------------•---------------------------------------|
| ←margines błędu (dół) || margines błędu (góra) → |
wąski Przedział Ufności (Confidence Interval – CI) jest sygnałem wysokiej precyzji szacowania
Mały Błąd Standardowy = wąski Przedział Ufności,
ALE …

ILE BŁĘDÓW STANDARDOWYCH W GÓRĘ / DÓŁ ?
“1 SE”
0
5
10
15
20
25
30
35
1SE X
1SE
“1.96 SE”
0
5
10
15
20
25
30
35
2SE X
2SE
Zwykle 1.96 SE → szacowanie na poziomie 95%: 95%PU = Estymator ± 1.96 SE
Gdy reprezentatywna próba pochodzi z populacji
o normalnym rozkładzie parametru wówczas istnieje 95% pewność,
że obliczony 95% PU zawiera prawdziwą wartość szacowanego parametru

95% PU

PRZYKŁAD – ZMIENNA ILOŚCIOWA
Jakie jest rzeczywiste stężenie hemoglobiny u dzieci narażonych na
zanieczyszczenia powietrza atmosferycznego związkami ołowiu,
gdy w próbie 100 dzieci wylosowanych z tej populacji stwierdzono
średnie stężenie hemoglobiny na poziomie 11,5 g/100ml ?
x = 11,5 g/100 ml (estymator punktowy); SD = 2,1 g/100 ml; n=100
cel - uzyskanie wiarygodności na poziomie 95%
SE = SD / √ n = 2,1 / 10 = 0,21
95% PU = 11,5 +/- 1,96 * 0,21
95%PU: 11,1 – 11,9
Rzeczywiste stężenie hemoglobiny w tej populacji wynosi od 11,1 do 11,9 g/100 ml

PRZYKŁAD – ZMIENNA JAKOŚCIOWA
Jaka jest rzeczywista częstość astmy w populacji dzieci w wieku 7-9 lat,
gdy w próbie 100 dzieci wylosowanych z tej populacji stwierdzono 5
przypadków astmy ?
p = 5 / 100 = 0,05 (estymator punktowy); n = 100
cel - uzyskanie wiarygodności na poziomie 95%
SE = √ p (1-p) / n = √ 0,05 (1-0,05) / 100 = 0,02
95% PU = 0,05 +/- 1,96 * 0,02
95%PU: 0,01 – 0,09
Rzeczywista częstość astmy w populacji wynosi od 1% do 9%

CO MOŻNA SZACOWAĆ ?
Wszystko, co pozwala się zmierzyć
i przedstawić jako estymator
(X, %, mediana, różnica, ryzyko …)
i błąd standardowy

WALORY 95%PU
‘PU’ jest miarą precyzji szacowania efektu i:
zawiera informację o statystycznej znamienności efektu ( tę
samą, która wynika z ‘p’, przy ‘α’ korespondującym z PU),
ujawnia prawdopodobny rozmiar efektu, z opisem jego
zakresu (ułatwia interpretację wyniku badania);
informuje o mocy badania (identyfikuje m.in. małą moc* badania
jako możliwą przyczynę negatywnego wyniku).
*- moc badania to praawdopodobienstwo wykrycia rzeczywiscie istniejacego efektu

REKOMENDACJA DLA AUTORÓW* Międzynarodowy Komitet Redaktorów
Czasopism Medycznych
(„Vancouver Group” – 1988)
„Gdzie możliwe, podaj zmierzone wielkości efektów i przedstaw je
razem z właściwymi wskaźnikami błędu pomiaru lub niepewności
(takimi jak przedział ufności). Unikaj wyłącznego przytaczania
wyników testowania hipotez, takich jak wartości ‘p’, które nie są
w stanie przekazać ważnej informacji o wielkości efektu”.
*- International Committee of Medicla Journal Editors. Uniform requirements for
manuscripts submitted to biomedicla journals. Strona internetowa: www.icmje.org

/…/
/…/

SZACOWANIE (ESTYMACJA)
<) ‘x’ w próbie
to poznajemy poprzez badanie
Krytyczne znaczenie reprezentatywności
próby, jej wielkości oraz metod pomiaru

Krytyczne znaczenie reprezentatywności
próby, jej wielkości oraz metod pomiaru
REPREZENTATYWNOŚĆ
Zdolność do opisu zjawiska w populacji,
w stopniu najlepiej charakteryzującym jego
rzeczywistą (prawdziwą) naturę

PODSTAWOWE METODY DOBORU
REPREZENTATYWNEJ PRÓBY
Losowanie Proste
Losowanie Systematyczne
Losowanie Warstwowe
Losowanie Zespołowe

Krytyczne znaczenie reprezentatywności
próby, jej wielkości oraz metod pomiaru
MINIMALNA
NIEZBĘDNA
LICZEBNOŚĆ
PRÓBY

OSZACOWANIE WIELKOŚCI PRÓBY
ESTYMATOR ILOŚCIOWY (WARTOŚĆ ŚREDNIA)DODATKOWE NIEZBĘDNE USTALENIA
WYBÓR ZMIENNEJ DECYDUJĄCEJ
Gdy szacowanie dotyczy złożonego parametru (np. niedokrwistość)
należy wybrać jedną zmienną sterującą procedurą (np. stężenie
hemoglobiny, a nie hematokryt, liczbę erytrocytów itd.)
UWGLĘDNIENIE STRUKTURY PRÓBY
Gdy szacowanie dotyczy parametru, który może przybierać różną
wartość w zależności od danej cechy należy obliczyć pożądaną
wielkość próby dla każdej z istotnych warstw, np.
dla obliczenia liczby badanych kobiet i mężczyzn w celu oszacowania
częstości otyłości trzeba przeprowadzić tę procedurę osobno dla
kobiet i osobno dla mężczyzn (ostateczna liczebność to suma dwóch
obliczeń)

FILARY DOBREJ PRAKTYKI
EPIDEMIOLOGICZNEJ
Reprezentatywna i odpowiednio duża
próba to warunki koniecznie (chociaż
niewystarczające) dla uzyskania
wiarygodnych wyników w badaniach
epidemiologicznych
to minimum minimorum dla spełnienia wymogów poprawności badania epidemiologicznego

Krytyczne znaczenie reprezentatywności
próby, jej wielkości oraz metod pomiaru
WSZYSTKO JEST POMIAREM
Odpowiedź na pytanie w kwestionariuszu (tak/nie ~ 1/0)
Obecność cienia okrągłego na zdjęciu rtg płuc (tak/nie ~1/0)
Kliniczny stopień duszności (1/2/3/4/5)
Glikemia (mg%)

ITP …
ITD …





























