Embed Size (px)
Citation preview

8/3/2019 4093 in Parallel Mag Issue4 090310
http://slidepdf.com/reader/full/4093-in-parallel-mag-issue4-090310 1/15
8/3/2019 4093 in Parallel Mag Issue4 090310
http://slidepdf.com/reader/full/4093-in-parallel-mag-issue4-090310 2/15
© 2010, Intel Corporation. All rights reserved. Intel, the Intel logo,Intel Core, and Intel VTune are trademarks of Intel Corporationin the U.S. and other countries. *Other names and brands may beclaimed as the property of others.
ContentsLetter fr m the E it rBreaking Gr un an Buil ing Trust , by James ReIndeRs Jam R i d r , l ad va g li a d dir c r f I l® s f war D v l pm Pr d c ,addr r c i va i i app a d l , highligh y 2010 mil , a dxpl r wha ’ x i h w y ar a d b y d.
Intel® Parallel Stu i 2011 : Getting Y ur App Rea yf r Multic re Just G t Easier by LeILa chucRIe gi r L ila Ch cri i r d c I l® Parall l s di 2011, xami i g w f a rwi h a y abli g h d v l pm vir m f r m l ic r .
Using Serial M eling T ls t Tamethe Parallel Beast, by John PIePeRAddr i g ma y f h y r a why parall li m i c id r d diffic l , I l® Parall lAdvi r ff r a pr v hr adi g m h d l gy, a d abl parall l a d rial m d li g.
Intel® Cilk Plus, by KRIshna RamKumaRI l® Cil Pl add fi -grai d a parall li m pp r C a d C++, ma i g ia y add parall li m b h w a d xi i g f war , a d ffici ly xpl im l ipl pr c r .
Nine Tips t Parallel Pr gramming Heaven by stePhen b LaIR-chaPPeLLI hi i rvi w, Dr. Ya G la i har wi h hi fav ri ip parall l pr grammi g.th ip ar ba d i v iga iv w r parall l -b dy im la i c d carri d d ri g hi d c ral di .
The W rl ’s First Su ku* “Thirty Niner”
by stePhen b LaIR-chaPPeLLLar P r e dr a d Håvard Graff, w al d gi r fr m o l , har wi h h w h y cr a d wha may b h w rld’ fir s d * p zzl ha ha 39 cl .
© 2010, Intel Corporation. All rights reserved. Intel and the Intel logo are trademarks of Intel Corporation in the U.S. and other countries. *Other names and brands may be claimed as the property of others.
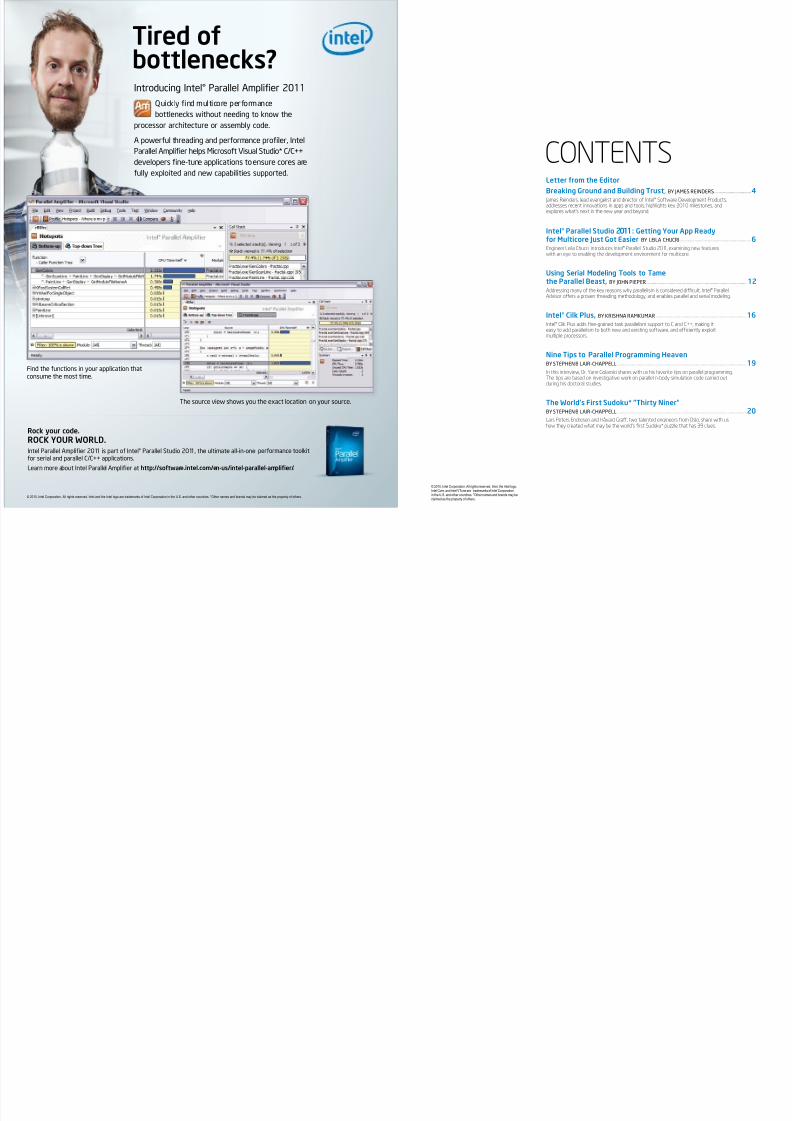
Tire fb ttlenecks?I r i I l® P r ll l a plifi r 2011
Quickly nd multicore performance l k wi i k w
pr r r i r r l .
A powerful threading and performance pro ler, IntelParallel Ampli er helps Microsoft Visual Studio* C/C++developers ne-tune applications toensure cores aref ll xpl i w p ili i pp r .
Fi f i i r ppli i i .
t r vi w w x l i r r .
R ck y ur c e.RoCK YoUR WoRLd.Intel Parallel Ampli er 2011 is part of Intel® Parallel Studio 2011, the ultimate all-in-one p rf r lkifor serial and parallel C/C++ applications. Learn more about Intel Parallel Ampli er at http://software.intel.com/en-us/intel-parallel-ampli er/ .

8/3/2019 4093 in Parallel Mag Issue4 090310
http://slidepdf.com/reader/full/4093-in-parallel-mag-issue4-090310 3/15
Multic re pr cess rs hav br gh parall l c mp i g i hmai r am. s f war d v l p r ar mbraci g parall li m l a dpr grammi g m d l .
I s p mb r 2010, af r a cc f l mm r f b a i g wi hc m r ar d h w rld, w ar i r d ci g I l® Parall l s di2011 ( r i l I l P r ll l s i 2011 i i i ) , which i cl d a ra g f w f a r , i cl di g:
> A c mpr h iv f parall li m d v l pm m d l –I l® Parall l B ildi g Bl c (I l® PBB)
> A i va iv hr adi g a i a – I l® Parall l Advi r 2011
> F ll pp r f r Micr f Vi al s di 2010*, a w ll a 2005a d 2008
> Pr mi r ch ical pp r
B h I l Parall l s di 2011 a d I l PBB b ild pri r pr d c ,pr vid v m r pp r f r parall l pr grammi g, a d ar bac wardc mpa ibl .
Wh w d cid r ly a pr d c , w ar l i g f r ig hait is worthy of our trust. The key for me is guring out the commitmentl v l f h c mpa y b hi d h pr d c , a d f h wh ar alr adyi g i .
I hav a gr a j b b ca I’m w r i g wi h pr d c ha hav ahigh c mmi m l v l fr m I l a d v ry c mmi d c m r .
o r m p p lar parall li m pr j c i I l® thr adi g B ildi gBl c (I l® tBB), which ha b ad p d wid ly. o f h mr c xpr i f r f r I l tBB wa i i cl i i Ad bCr a iv s i 5*. th r liabl p r abili y a d a di g p rf rma cf I l tBB ha pr v val abl f war d v l p r ma yp ra i g y m a d pr c r .
th gr dbr a i g I l® Parall l s di i w d m ra i g
val by h lpi g f war d v l p r Wi d w * ap i h p w rf m l ic r pr c r .I i my di i c pl a r x d r pr d c ba a d
capabili i i a a ral way rv b h c rr a d w c m r .I l PBB a gm h br ad f da i f I l tBB wi h w
bReaKInggRound AnD
BuILDInG tRustLetteR FRom
THE EdIToR
signi cant additions: the compiler-assisted capabilities of Intel® CilkPl a d h phi ica d v c r parall li m capabili i f I l® ArrayB ildi g Bl c (I l® ArBB) ( r i l I l cilk Pl i ii ) . I l tBB c i pply y f c i ali y, i cl di g ahr ad-awar m m ry all ca r, c c rr c ai r , p r abl l ca d a m p ra i , a a - ali g ch d l r, a d a gl bal im r.
I l tBB ha d ill; h la v r i i cl d pp rf r FIFo ch d li g, addi i al pp r f r C++ 0x, a w c ai r(c c rr _ rd r d_map), a “D ig Pa r ” ma al, a dMicr f Vi al s di 2010* pp r . Al availabl i a c mm i ypreview feature called tbb::graph, which is a uni ed approach that letsapplica i graph xpr parall li m. thi i a v r a il f a r
ha ca b d impl m a y hi g fr m impl a ic d p d cygraph c mpl x m ag -pa i g, ac r-li graph . I i a xci i gw f a r ha add b a ial c rdi a i capabili i .
Intel Cilk Plus is ma e up f f ur things: > thr impl b v ry p w rf l yw rd xpr parall li m:
cil _f r, f r parall l l p , a d cil _ paw + cil _ y c f r parall lf c i i v ca i
> A l i , call d hyp r bj c , d al wi h c i f r har dvariabl by r plica i g h m a l cal c pi ma ch a cr a d byh w yw rd , a d pr vidi g f r h ir r d c i bac a har dval a h c cl i f a parall l c mp a i
> Array a i f r da a parall l p ra i array lic , cha a[] = b[] + c[] m w v c r , r a[][1] = qr ( b[][2] )
> Array a i d wi h l m al f c i all wc mp a i ch a __ c_map( axpy, 2.0, x[0: ], y[0: ])
Wi h I l Cil Pl , w hav f c d a c mpil r impl mu li I l tBB, I l Cil Pl i v lv h c mpil r i p imiand managing parallelism. Bene ts include: (1) code th wri a d c mpr h d b ca i i b r i gra d i h
la g ag hr gh f yw rd a d a iv y ax, a d (2) c mp imiza i ha all w f r m r av ida c f da a rac c da d ligh ly b r p rf rma c .
th c mpil r d r a d h f r par f I l Cil Pl , ah r f r abl h lp wi h c mpil - im diag ic , p imiz
and runtime error checking. Intel Cilk Plus has an open h r c mpil r may al impl m h xci i g w C/C
la g ag f a r .
Wi h I l ArBB, w hav f c d ff ri g v ry phi iv c r parall li m capabili i i a a y- -pr gram a d hip r abl fa hi . F a r i cl d h abili y parall li msIMD i r c i , m l ic r , a d ma yc r pr c r . I l ArBff r b il -i pp r f r r g lar, irr g lar, a d par ma ricf a r all w a pr gram wri i ma h ma ical rm haparall li m f r p rf rma c wi h d ff r by h d v l
I l Parall l s di 2011 b ild h rigi al I l Parall(r l a d i May 2009) by a gm i g i wi h I l® Parala d I l PBB ( r i l I l P r ll l a vi r 2011 ii i ) . I l Parall l Advi r h lp f war archi c
diff r p ibl appr ach addi g parall li m a xiapplica i wi h havi g f lly impl m h parall li mgr a ly r d c h im p val a i g impl m a i p i ch i g h righ f r y r applica i .
James Rein erss p mb r 2010
Fi r 1. I l® P r ll l b il i bl k
Fi .2: I l P r ll l s i 2011
James Rein ers i c i f s f w r ev li dir r fs f w r d v l p Pr I l c rp r i . hi r i l
k p r ll li i l Intel Threading Building Blocks: Out tting C++ for Multicore Processor Parallelism .
THE PARATHE PARALLEL UNIVERSE
4 For more information regarding performance and optimization choices in Intel software products, visit http://software.intel.com/en-us/articles/optimization-notice.
d i P b d P Verify Phase t P
INNoVATIVETHREAdINGASSISTANT
CoMPILERANd THREAdEdLIBRARY
MEMoRY ANdTHREAdINGERRoR CHECKER
THREAdINPERFoRMPRoFILER
I nt el ® P ar al le l A v is r I nt el ® P ara ll el C m p se r I nt el ® P ar al le l I ns pe ct r I nt el ® P ar al le l A mp li fi er
t r i i i li plifi , p p r ll lppli i i > I ifi r i
ppli i fi fr p r ll li
> Pr vi p- - p if r r i ppli i
op i izi pil r p rf r rppli i i > C++ Compiler and libraries > c c v r > d r > I l® P r ll l b il i bl k —
s f pr iv p r ll ll pp r l iplw xpl i p r ll li
err r i l i l f ri r r li ili q li > err r i l i l f r
i r r li ili q li > Fi r l k
rr p i > Fi r l k
t i l i f r p i iz l ili > t i l i f r p i iz
l ili > P rf r
l ili l i> L k w i l i

8/3/2019 4093 in Parallel Mag Issue4 090310
http://slidepdf.com/reader/full/4093-in-parallel-mag-issue4-090310 4/15
G i g Y r AppR ady f r M l ic r J G ea i r
I l® P r ll l s i 2011
m l i r : th Gam Cha g r
o c r l ga d a mall ich f p rf rma c -h gry app li gami g, parall l pr grammi gi ma i g p dy i r ad wi h mai r am d v l p r . D ig i g applica i ha xpl i hp rf rma c a d calabili y a rib f m l ic r ch l gy i l g r c id r d “ ic hav ” f c i ali y. t day, v ry d v l p r w ha a h mb r f p r c r c r
i cr a , rial applica i ca l g r r ly h la pr c r chip a ma icallypr vid gr a r h adr m r a b r r xp ri c . Parall l pr grammi g abl applica i f lly iliz m l ic r i va i a d ay c mp i iv . Wh h r p imizi g rial c d r
creating new applications for multicore, parallel programming has evolved to improve pro ciencywith exible design models and tools that make applications reliable and fast.
m ki P r ll l appli i d i – simpl , effici , a d FaOver a year ago, Intel launched the rst product to ease mainstream developers adoptingmulticore. Intel® Parallel Studio was the rst development tool to enable auto-scaling featureshr gh a c mpr h iv f c mpil r , hr ad d librari , m m ry rr r d c i , a da aly i l . Al h gh h r c mpa i hav j mp d hi w d v l pm vir m ,i cl di g Micr f wi h Vi al s di PPL*, I l i i i r l r ip wi i r i f I l® P r ll l s i 2011. The latest edition includes the rst tool to gui de
a developer on where their application can bene t most from m ulticore, plus a new set of taska d da a parall l m d l . thi q ic v rvi w i r d c m f h w r hy w f a rf I l Parall l s di 2011.
I l P r ll l s i 2011R v l
th adva c d l a d m h d l gi f I l Parall l s di 2011 h lp d v l p r hriv i hm l ic r w rld. I abl Micr f Vi al s di 2005*, 2008*, 2010* C/C++ d v l p r easily ramp up to parallelism and achieve the application performance and scalability bene ts ofm l ic r pr c r ch l gy day, a d i h f r .
W ’ n w > exp t r i op i wi I l® P r ll l b il i bl k (I l® Pbb): I l® Parall l B ildi g
Bl c i a c mpr h iv a d c mpl m ary f parall l m d l ha pr vid l i ra gi gfr m g ral-p rp p cializ d parall li m. I abl d v l p r mix a d ma ch parall l m d lwithin an application to suit their speci c environment and needs, providing a simple yet scalable way tod v l p f r m l ic r .
> I l® t r i b il i bl k 3.0: th wid ly ad p d, award-wi i g C++ mpla librarysolution provides exible, cross-platform parallelism solution enabling general parallelism.
> I l® cilk Pl : B il i h I l® C/C++ C mpil r, i pr vid a a y- - , w ll- r c r d m d lthat simpli es parallel development, veri cation, and analysis.
> I l® arr b il i bl k : A API bac d by a phi ica d r im library, i pr vid ag raliz d da a parall l pr grammi g l i ha fr d v l p r fr m d p d ci par ic larl w-l v l parall li m m cha i m r hardwar archi c r . (Availabl i b a a : software.intel.com/en-us/data-parallel/ )
> I l® P r ll l a vi r: An innovative threading guide simpli es and demysti es parallelapplica i d ig
> Microsoft Visual Studio 2010 support
By Leila ChucriPr m rk i ,I l c rp r i
L il c ri i rI l® P r ll l s i 2011 ,x i i w f rwi li v l p vir
f r l i r .
“I l® tBB wa rpri i glya d impl impl m , athe Simul Weather SDK rh I l® C r ™ i7 pr ccl li ar cali g, sim l a d I l’ l p p gr app r i i f r gam d v l i gra dy amic w a h
cl d .”
R erick Kenne y,Pri cipal a d f d r f sis f war
THE PARALLEL UNIVERSE THE PAR
6 For more information regarding performance and optimization choices in Intel software products, visit http://software.intel.com/en-us/articles/optimization-notice.

8/3/2019 4093 in Parallel Mag Issue4 090310
http://slidepdf.com/reader/full/4093-in-parallel-mag-issue4-090310 5/15
I l® P r ll l a vi r: A i va iv hr adi g g idimplifi a d d my ifi parall l applica i d ig .
t k p p r ll li wi I l P r ll l a vi r i r p r ll lppli i p i p rf r l ili v f l i r .
Wh h r y ar w parall li m r c rr ly d v l pi g parall l applica i , y willnd Intel® Parallel Advisor an essential tool to use during the design and discovery phase ofparall lizi g c d .
I l Parall l Advi r ff r vi ibili y d v l p r wh r c id r parall li m i C/C++c d ; h lp d v l p r id ify a d xp rim wi h parall l pp r i i ; xp p rf rma cbene ts; identi es how to restructure the application, as well as what time saving tools to
d b g a d h applica i ; a d abl d v l p r val a h r r h iri v m b f r c mmi i g h pr c f parall lizi g h ir applica i .
I l Parall l Advi r giv d v l p r a cl ar r admap f r parall lizi g applica i , wi h
p-by- p g ida c f r hr adi g applica i i g wid ly ad p d, pr v ab rac i f rparall li m; pr vid h p f r a - ri d parall li m; a d arg c ar -grai parall li m.
I l® P r ll l a vi r l z x i ri l pr r
v l p r pr r r l .
> s rv y targ —H lp f c hcall r a d l p a l ca i
xp rim wi h parall li m. > A a s rc —e abl d v l p-
r i r Parall l Advi r a a-i i h ir rc d cribparall l xp rim .
> Ch c s i abili y—H lp val a hp rf rma c f h ir parall l xp ri-m by di playi g h p rf rma cpr j c i f r ach parall l i a dh w ach i ’ p rf rma c impach ir pr gram.
> Ch c C rr c —A i d v l p-r by id ifyi g da a i ch arac i h parall l xp rim .
I l® P r ll l c p r 2011 C/C++ C mpil r b p rf r-ma c wi h librari , parall l m d l , a d d b ggi g capabili i .
I l® Parall l C mp r 2011– C/C++ p imiz d c mpil r wi h I l® I gra d P rf rma cPrimi iv ’ adva c d librari a d I l® Parall l B ildi g Bl c (I l® PBB), a fc mpr h iv parall l d v l pm m d l . t g h r, h l h lp ha c p rf rma ca d r amli parall l applica i d v l pm .
I l Parall l C mp r h lp implify addi g parall li m wi h h w v r i f I l®C mpil r a d librari f r parall li m a d h a d f li f r ady- - c d . s pp rh ir p c r m f parall l xpr i fr m impl c mpl x, da a a , by ff ri g
application-class-speci c, pre-threaded, and thread-safe libraries. Saves time and takesadva ag f m l ic r pr c r wi h a ma ic f c i .
“H r a tradi g sy m Lab, w g a 10% 20% p rf rma c b i h m l im dradi g im la r ha ’ d i r tsL Alg A -D ig Pla f rm by i g h C++c mpil r i I l® Parall l s di . th c mpa ibili y wi h Micr f Vi al C++* i gr a ,a d w ’r l i g f rward i g m r parall li m f a r i Parall l s di .”
Mike Barna,Pr i tr i s L
Buil an debug Phaseop imizi g C mpil r wi h Librari B Applica i P rf rma c
design Phase
“th I l® Parall l Advi r d igappr ach wa i r m al ii r d ci g parall li m i r c d .th rv y f a r h lp d impr vour code by nding areas in our serialc d ha a l f CPu im , a dwhere our code would bene t fromparall li m.”
dr. William orttung ,e ri Pr f r f c i r
“I l® Parall l Advi r r d c hri f addi g parall li m, i c ih lp f c ff r i h righ plac ,av idi g wa d impl m a iff r .”
Matt osterberg,Vickery Research Alliance
“A a Micr f Vi al s di * C++d v l p r f r ma y y ar , a d wi h pr vi xp ri c wi h parall l
pr grammi g, I l® Parall l Advi rpr v d b a maj r b i ma i git easier and ef cient to implementparall li m hr gh h pla i g a dpr d c i pha .”
Brian Reyn l s,bri R l R r
THE PARATHE PARALLEL UNIVERSE
8 For more information regarding performance and optimization choices in Intel software products, visit http://software.intel.com/en-us/articles/optimization-notice.
a v lv r p r ll li r ip , l f r -pr f
l f r r p i iz , v rif , r ppli i f ll
bene ts of the performanl ili ri f l i r
r l . I l P r ll ls i 2011 pr vi v l p rwi ri i l i r
v l p lif l , fri , ,
veri cation, to tuning app rf r r li ili .

8/3/2019 4093 in Parallel Mag Issue4 090310
http://slidepdf.com/reader/full/4093-in-parallel-mag-issue4-090310 6/15
Verify PhaseDy amic A aly i M m ry a d thr adi g Ch c r
I l® P r ll l I p r 2011 wi h m m ry a d hr adi grr r ch c r ha c applica i r liabili y.
Ca chi g f war d f c arly i h d v l pm cycl ca av y im a d c , a di cr a y r RoI. I l® Parall l I p c r pr vid a c mpr h iv l i f r rial a dm l i hr adi g rr r ch c i g. Pi p i m m ry l a a d m m ry c rr p i a w ll ahr ad da a rac a d d adl c .
“The performance bene ts of mul ticore and manycore are critical to SIMULIA’s business.I l® Parall l I p c r pr vid a p w rf l way d v l p parall l c d c mpar d radi i al m h d , which ca b l g hy a d c ly— p cially if h pric f
abl c d i paid by h c m r.”
Matt dunbar, c i f ar i sImuLIa
Tune PhaseThreading and Performance Pro ler
t I l® P r ll l a plif i r 2011 hr adi g a dp rf rma c pr fil r ha c p rf rma c .
By r m vi g h g w r a d a alyzi g p rf rma c b havi r i Wi d w * applica i ,Intel® Parallel Ampli er 2011 provides developers quick access to scaling information for fastera d impr v d d ci i ma i g. Fi - f r p imal p rf rma c , ri g c r ar f llyxpl i d a d w capabili i pp r d.
“Thanks Intel, you guys rock! I decided to give Intel® Parallel Ampli er a run. I was delightedwh i p i d m h righ rc li ha wa a i g m ch f h im . I mad hcha g , a d v ilà, r app i w alm 10 im fa r. th GuI i v ry a y ,i my pi i .”
dat Chu,R r a i c p i l bi i i Lu iv r i f h
THE PARATHE PARALLEL UNIVERSE
10 For more information regarding performance and optimization choices in Intel software products, visit http://software.intel.com/en-us/articles/optimization-notice.

8/3/2019 4093 in Parallel Mag Issue4 090310
http://slidepdf.com/reader/full/4093-in-parallel-mag-issue4-090310 7/15
By J hn Piepers i r s ffs f w r e i r
usIng seRIaL modeLIng tooLs to
A ressing many f the key reas ns why parallelism isc nsi ere ifficult, Intel® Parallel A vis r ffers a pr venthrea ing meth l gy, an enables parallel an serial m eling.
THE
beastPaRaLLeL tame
THE PARALLEL UNIVERSE
12 For more information regarding performance and optimization choices in Intel software products, visit http://software.intel.com/en-us/articles/optimization-notice.

8/3/2019 4093 in Parallel Mag Issue4 090310
http://slidepdf.com/reader/full/4093-in-parallel-mag-issue4-090310 8/15
a l f pr r r i k p r ll l i i r .A quick Internet search will yield several blogs talking about the dif culty of writing parallelpr gram ( r parall lizi g xi i g rial c d ). th r d m b ma y mbli g bl cwai i g rip p h vic . H r ’ a r pr a iv li (ba d by A war Gh l m):
ev lvi ri l p r ll lwi I l P r ll l a vi rI l Parall l Advi r l ad h pr gramm r wi h a pr v hr adi gm h d. thi m h d wa d v l p d by I l gi r v r y arf w r i g wi h c m r hr ad h ir applica i . th y h m h d i c i ly ch c a d r lv pr bl m arly, whill wly v lvi g h c d fr m p r rial, rial b capabl f b i gr i parall l, parall l.
The rst step is to measure where the application spendsim — ff r p i h ar a will b ff c iv , whil ff r pl wh r i wa d. th x p i i r a a i d crib a p ial parall liza i . th a a i f rm axp rim : what w ul happen if this c e ran in parallel?th a a i d cr a ac al parall li m, b d crib wh r
i h rial pr gram parall li m c ld b i r d. I l Parall l Advi rb rv h x c i f h pr gram wi h a a i , a d hrial b havi r pr dic h p rf rma c a d b g ha migh cc r
if h pr gram ac ally x c d i parall l.I l Parall l Advi r m d l h p rf rma c f h h r ical
parall li m. thi all w h pr gramm r ch c h ff c fv rh ad f parall liza i . Ch c i g arly i h pr c , whilh pr gram i ill rial, r ha im i wa d parall liza i ha ar d m d p r p rf rma c . ei h r ha a i ar cha g d m d l a diff r parall liza i har lv h p rf rma c i r, if al r a iv i prac ical, hprogrammer can focus effort on a more pro table location.
I l Parall l Advi r al m d l h c rr c f h h r icalparall l pr gram d crib d by h a a i . thi l h l d crac c di i a d h r y chr iza i rr r , whil ill r i gh rial pr gram. B ca h pr gram ill r rially, i i a y d b g a d , a d c mp h am r l . th pr gramm r
ca cha g h pr gram— i h r h a a i r h c d i lf—
r lv h p ial rac . Af r ach cha g , h pr gram r maia rial pr gram (wi h a a i ) a d ca b d a d d b gg di g h rmal pr c .
Wh h pr gram ha f lly v lv d, h r l i a c rr c rialpr gram wi h a a i d cribi g a parall liza i wi h wgood performance and no synchronization issues. The nal step inh pr c i c v r h a a i parall l c d . Af r
conversion, the parallel program can undergo nal tuninga d d b ggi g wi h h h r l i I l® Parall l s di .
t v l f I l P r ll l a vi r I l Parall l Advi r addr ma y f h y r a whyparallelism is considered dif cult. Evolving a program m ch a i r ha a mp i g c v r all a c . ta i g malla d i g af r ach cha g all w a m r c mf r abl d v lm d l. I al r d c ri —a a y p i , h parall liza i fb p d d a d r m d la r. th par ially v lv d c d i c rr c rial pr gram. I fac , i ’ f a impl r, a i r- -pr gram, i c h cha g abl parall li m d r g laa d implify h c d .
F c i g h h par f h pr gram r ha im i ff c iv ly. I al c rag h pr gramm r c id r c argrai d a parall li m, which i m r li ly r l i g d
I l Parall l Advi r’ p rf rma c m d l b ild hi appm d li g parall l v rh ad f r a ra g f pr c r , I l ParAdvi r c rag h pr gramm r r lv cali g i a d ig ag .
s rial m d li g giv h pr gramm r h b f b h w rc d r mai rial, c mp h am a w r, a d h amy m, v a i v lv parall li m. th rial m d li g l
the programmer to x problems that might occur in the pwithout the dif culty inherent in non-deterministic execu
W “f il ”A h r adva ag f h I l Parall l Advi r m h d b c mvid wh w c id r wha happ if h parall liza i
fails. If the programmer is unable to nd a correct, highparall liza i , h a a i ca b d l d r c mm d .F r h r, i c h ff r f addi g a a i a d m d li gp rf rma c a d c rr c i m ch l w r ha h ff r fimpl m i g parall li m, h d r l — h rigi al rial pr ach d m ch m r q ic ly wi h I l Parall l Advi r, h“wa d” ff r i mi imiz d. o
o h r r a ha parall l pr grammi g i c id r d hard i cl d h c mpl xi y f h ff r , gh h lp f r d v l p r familiar wi h h ch iq , a d a lac f l f r d ali g
with parallel code. When adding parallelism to existing code, it can also bedif cult to make allh cha g d d add parall li m all a c , a d r ha h r i gh i g limi a imi g- i iv b g .
I l® P r ll l a vi r i a w l f r d v l p r wh d add parall li m xi i g rial c d , a d i h lp addr h pr bl m . I l Parall l Advi r ma i a i r parall liz . I i cr a h pr gramm r’ r r i v m by f c i g ff r wh r
i ma r . I h lp h pr gramm r id ify pr bl m arly, ha li l ff r i wa d pr d c iv dir c i . th y I l Parall l Advi r’ cc i i r lia c a w ll-
pr v m h d f i r d ci g parall li m: rial m d li g.
“b li p r ll lv r f r r fpr r , I l® P r ll la vi r r pr r r r lv
li i i .”
d i i ri fir i wi I l®P r ll l a vi r.Intel Parallel A vis r is available as part f Intel®Parallel Stu i . d wnl a an evaluati n kit, ansee h w easy parallelism can be.
> Fin ing the parallelism: thi ca bdif cult because in tuning code for serialp rf rma c , w f m m ry iway ha limi h availabl parall li m.Simple xes for serial performance oftenc mplica h rigi al alg ri hm a d hidh parall li m ha i pr .
> Av iing the bugs (da a rac , d ad-l c , a d h r y chr iza i pr bl m ):C r ai ly h r i a cla f b g ha af-f c parall l pr gram ha rial pr gramd ’ hav . A d i m , h y arw r , b ca imi g- i iv b g arf hard r pr d c — p cially i ad b gg r.
> Tuning perfrmance (gra lari y,hr ghp , cach iz , m m ry ba d-wid h): s rial pr gramm r hav w rryab m m ry l cali y, b f r parall lpr gram , h pr gramm r al ha c id r h parall l v rh ad , a diq pr bl m li fal hari gf cach li .
> Future proo ng: s rial pr gramm rd ’ w rry ab wh h r h c d h yar wri i g will r w ll x y ar’pr c r —i ’ h j b f h pr c rc mpa i mai ai pward c mpa ibil-i y. B parall l pr gramm r d hiab h w h ir c d will r a widra g f machi , wh h r h r ar
r w , r ma y pr c r . s f war hai d f r day’ q ad-c r pr c rmay ill b r i g cha g d f r16-, 32-, r v 64-c r machi .
> Using m ern pr gramming meth s:obj c - ri d pr grammi g ma im ch l bvi wh r h pr gram ip di g i im .
“W pr r f ll v lv , r l i rrri l pr r wi
i ri i p r ll liz iwi k w p rf r r iz i
i .”
THE PARATHE PARALLEL UNIVERSE
14 For more information regarding performance and optimization choices in Intel software products, visit http://software.intel.com/en-us/articles/optimization-notice.

8/3/2019 4093 in Parallel Mag Issue4 090310
http://slidepdf.com/reader/full/4093-in-parallel-mag-issue4-090310 9/15
InteL®CILk By Krishna Ramkumart i l c l i e i r,I l c rp r i
I l® cilk Pl fi - r itask parallelism support to C and C++, ki i p r ll li w xi i f w r ,
ffi i l xpl i l ipl pr r . PLusparallelism to both new and existing software to ef ciently tap thep ial f m l ipl pr c r .
I l Cil Pl i par ic larly w ll i d f r, b limi d “divida d c q r” alg ri hm . thi ra gy lv pr bl m by br a i gh m i b-pr bl m ( a ) ha ca b lv d i d p d ly a d
h c mbi i g h r l . R c r iv f c i ar f d f rdivid -a d-c q r alg ri hm , a d ar w ll pp r d by I l CilPl . ta ca i h r b f c i r i ra i f a l p. I l Cil Plyw rd id ify f c i call a d l p ha ca r i parall l. th
Intel Cilk Plus runtime schedules these tasks to run ef ciently on theavailabl pr c r .
Fr m a C/C++ d v l p r p r p c iv , i i a impl y p w rf lm d l b ca i add v ry li l v rh ad i ra f rmi g a xi i grial pr gram a parall l impl m a i . thi implici y may m
limiting at rst when compared to OpenMP* or Intel TBB, both of whichc m wi h ma y parall l pr grammi g c r c . H w v r, I l CilPl ha all h f a r d d pp r h impl m a i fparall l alg ri hm . I phi ica i i i i mi imali m.
I l Cil Pl r q ir mi imal i r i i h rc c d ,ma i g a rial pr gram j a f w yw rd away fr m parall li m,h a i g h ra i i parall li m f r pr gramm r rai d lv pr bl m rially. I fac , a pr gram parall liz d (a d which
i rac fr ) i g I l Cil Pl ch l gy ca b i rpr d a a
rial pr gram if h yw rd ar ig r d. thi ma ch a pr grameasy to debug and test. Please refer to the code samples in the nalc i f r a ill ra i h f I l Cil Pl yw rd .
I l Cil Pl ’ ma ic all w y d ig a pr gram wi hp cifyi g h mb r f pr c r which h pr gram will
execute. The runtime scheduler takes care of ef ciently load balancingy r pr gram acr h w v r ma y pr c r ar availabl . Wh ap r i f y r parall l c mp a i x c a i gl pr c r, I l Cil Pl ca x c i j li rdi ary
C c d , a i g f ll adva ag f all h c mpil r p imiza i a druntime ef ciencies that a good C system offers. By starting from goodi gl -c r p rf rma c , I l Cil Pl r ha a pr gram wi h
suf cient parallelism gets good speedup (an increase in performance)wh h r i i r a larg mb r f pr c r r j a f w.
I prac ic , m I l Cil Pl pr gram r q ir f w (if a y) l c .I parall l c r l c r c bvia h d f r h l c hama y h r parall l pr grammi g m d l r q ir f r i r hr adc mm ica i a d y chr iza i . I ma y c mm i a iwh r l c i g w ld m b c ary av id a rac , I l CilPl pr vid hyp r bj c , v l da a r c r ha r lv rac global variables without sacri cing performance or determinism.
By av idi g l c a d i g hyp r bj c , I l Cil Pl id pma y p rf rma c a mali ca d by l c , ch a l cc i , which ca l w d w parall l pr gram ig ifica ly; a dd adl c , which may ca y r applica i fr z . I fac , I lCil Pl d ’ v hav m x l c f i w . Y ca I l tBB l c if y v r d . H w v r, l c i g w r agaiparall li m. I h r w rd , if y r applica i ff r fr m l cc i , h i m a ha y hav r vi i y r alg ri hma d if i i p ibl r r c r y r da a a ma iam abl parall li m.
By i g r d c r , y ly d id ify h gl bal variabl a
r d c r wh r h y ar d clar d. n l gic d b r r c r d.I c ra , m h r c c rr cy pla f rm hav a hard imxpr i g rac -fr parall liza i f hi i d f c d . th r a iha r d c i i m la g ag ar i d a c r l c r c .F r xampl , r d c i i op MP i i d h parall l f r l ppragma. M r v r, h f r d c i i op MP i hardwir d ih la g ag , a d i par ic lar, li app di g i pp r d.
I r iIt has been ve years since we had free lunches. I am r f rri g h l g dary ar icl by Micr f ’ H rb s r h m l ic r
r v l i a d h imp ra iv wri f war ha a adva agf m l ipl x c i i h am chip r di . A s r p i
, hi ail a f dam al r r a paradigm hif i pr grammi gf r h m l ic r ra. Fr m a f war d v l pm p r p c iv , icl arly m a ha d v l p r hav r vi i h i mpl m a i fh ir f war a d “parall liz ” h ir r whil rial applica i . th yhav d c mp h ir applica i i a , a d id ify a haar i d p d f ach h r ha ch a ca b r i “parall l”(y may r ad i a “a h am im ”). Al , wi h hardwar pp r f rvectorization constantly improving, it is de nitely wise to harness dataparall li m i y r pr gram. I rd r a adva ag f m l ic rplatforms with advanced vectorization capabilities, easy and ef cientpr grammi g m d l ar r q ir d r aliz b h a a d da aparall li m, which c ld p ially r l i fa r x c i f c d .
Intel’s software group provides a range of tools speci callyd ig d h lp d v l p r parall liz h ir applica i . I l® Parall lB ildi g Bl c (I l® PBB) i a c mpr h iv a d c mpl m ary
f m d l ha pr vid l i ra gi g fr m g ral p rp p cializ d parall li m, a d i cl d I l® Cil Pl , I l® thr adi gB ildi g Bl c (I l® tBB) a d I l® Array B ildi g Bl c . thi ar icl
f c h c c p a d f a r f I l Cil Pl .
I l® cilk PlI l Cil Pl i a pr grammi g m h d l gy/pla f rm d ig d abl d v l p r a adva ag f day’ m l ic r c mp ry m . I i h r l f arly w d cad f r arch by m fh i d ry’ mar mi d . I l Cil Pl i a ch l gy ha adda a d da a parall li m pp r C a d C++, ma i g i a y add
Relationship/Co-existence with IntelI l tBB i a wid ly d C++ mpla library f r parall lx d C++ by ab rac i g away hr ad ma ag m , h rall wi g raigh f rward parall l pr grammi g. A f ll-bl wf I l tBB i b y d h c p f hi ar icl . th i r d r a
c ld pic p a c py f h b i l d Intel Threadingwri by I l’ Jam R i d r a d p bli h d by o’R illy, c mpr h iv r a m f h c c p a d f a r f I l tBB
th d rlyi g ymm ry i h r im har d by I l Cila d I l tBB i x r m ly f l f r d v l p r . Whil I l CPl i i abl f r b h pr c d ral a w ll a a bj c - ri dc d ba , I l tBB ca al b d parall liz C++ c d wp r abili y -I l c mpil r i r q ir d. I l Cil Pl a dtBB ar diff r i rfac f r imilar d rlyi g hr adi g rimpl m a i . B h impl m w r / a ali g wh r hr im al w r fr m ch ha hav b y w r r a d rh m ch ha hav idl w r r . thi i wha ma f wd v l p d i g I l Cil Pl a d I l tBB calabl .
Wh i c m pr grammi g i parall l, h imp r a cy chr iza i primi iv , hr ad- af c ai r da a r c ra d calabl m m ry all ca r ca b v r mpha iz d. thI l tBB b i g impl m d a a C++ a dard -c mplia library, a pr gram wri i g I l Cil Pl ca all f hf a r , which ar impl m d by I l tBB i a l ga faW alr ady di c d ab v ha I l Cil Pl ca I l tBy chr iza i primi iv if d d. I l Cil Pl ca al tBB’ hr ad- af c ai r a d calabl m m ry all ca r .
THE PARATHE PARALLEL UNIVERSE
16 For more information regarding performance and optimization choices in Intel software products, visit http://software.intel.com/en-us/articles/optimization-notice.

8/3/2019 4093 in Parallel Mag Issue4 090310
http://slidepdf.com/reader/full/4093-in-parallel-mag-issue4-090310 10/15
Li i 2 : ilk_f r
/* The below cilk_for keyword enables parallel loop iterations. If thecilk_for keyword is replaced by for, it is then an ordinary for loop */
cilk_for (int i = begin; i < end; i += 2){
foo(i);}
By Stephen Blair-ChappellI l c pil r L
I i i rvi w, dr. y g l kir wi i f v ri ip p r ll l
pr r i . t ip r i v i ivw rk p r ll l - i l i rri
ri i r l^ i .
Just buy a faster machine. Fir l a h w m ch i will cy ma y r pr gram parall l. If iwill a , ay w m h f c di g, ca y j b y a fa r machi ha will giv yh p d p y wa ? of c r , c yr ach h limi f a machi ’ p d, yar g i g hav d m parall liza i .
Start small. D ’ ry ma v ry hi g parall la c , j w r mall bi f c d .
Starting fr m scratch?Use s me ne else’s wheel. If y ar ar i g fr m cra ch, whah r p pl hav d . L ar fr m h r .
D ’ r i v h wh l.
Fin a way f l gging\ebugging y ur applicati n. Ma r y hav a way f raci g whay r applica i i d i g. If c ary, b ym f war l ha will d h ric .
Pri h ir w will pr bably h lp.
L k at where the c e is struggling.exami h r im b havi r fyour application. Pro le the code withI l®Vt ™ P rf rma c A alyz r.The hotspots you nd should be the
ma parall l.
The F rmati nf Stars
I i h gh ha ar ar f rm dfr m h I r s llar M di m (IsM),a ar a p p la d wi h par icl fpr d mi a ly hydr g a d h li m.Wi hi h IsM, h r ar d cl d .th cl d ar rmally i q ilibri m,b ca c llap if rigg r d by variv .
I h r arch w r d by Dr.G la i, h m d l im la hc llap f h IsM, by di g h IsMwi h c la fr m a p r va.
th c llap i g cl d c ic llap i g il q ilibri m i r ach d.thi cl d i w a a pr llarcl d.
F r h r c rac i a d f i f hpr llar cl d a plac , r l i gi h v al f rma i f a ar.
a l f l i r ll r
to PaRaLLeLPRogRammIng
HEAVEN
1
2
3
4
5
Write a parallel versi nf the alg rithm.
try r wri i g h alg ri hmparall l-fri dly.
St p when it’s g en ughWh y hi i ’ g d gs p bac , g f r a pi . Hawh y ’v achi v d h m
Trea carefully. Y u are wn eggs, an s me eggs amines. ta car wi h h parall l ci c rr r c ld bl w p pr gram. u a g d l ca y da a rac a d h r pa
Get the l a -balancing rio c y ’v mad y r c d ma r all h hr ad arq al am f w r
The tips were recorded over ameal in the City of York. Bedishes, Dr. Golanski spoke ahe’d give to someone startinan application. At the end ofrestaurant owner asked if wethe restaurant. Well here goein the center of York, look foGoodramgate.
^y. g l ki m. m.W lf . a p r ir i i l i f ll p f
i r ll r i . m l n i R la r i l s i . 320, 1-11 (2001).
t pl , l wi - x pl ,will v il l i WRoX k,with Intel® Parallel Studio . s p bl
a r w s k , Wil P li i I . Isbn978047 08916 50 (m r , 2011)
P r i : nasa, esa, m. Livi h20 a iv r r t (sts I)
6
7
8
9
tIPsnIne
expl i i -p r ll l r w rM r f ha , i f war pr gram ha ma ag a l fda a h r i c p f r pr c i g h da a i parall l wh ham p ra i i b p rf rm d all f h da a. F r a ly,m d r c mp r y m c m wi h addi i al i r c i a da cia d r gi r ha ar capabl f pr c i g p ra i m l ipl pair f p ra d a h am im . thi i call d
v c riza i . th I l® C mpil r a ma ically a alyz a pr grama d g ra v c r c d ha xpl i v c r hardwar capabili i .B id a ma ic v c riza i , i al ha f a r ha l yxplici ly f rc v c riza i i h f rm f c mpil r dir c iv a dC/C++ la g ag x i . th f a r ca b d al g wi ha y pr grammi g pla f rm ch a I l Cil Pl , I l tBB, r op MP,which gives developers a lot more choice and exibility.
th #pragma imd c mpil r dir c iv ca b d f r l pv c riza i . th imd pragma i d g id h c mpil r v c riz a l p. V c riza i i g h imd pragma c mpl m(b d r plac ) h f lly a ma ic appr ach.
th C/C++ la g ag x i (par f I l Cil Pl ) pr vidxplici da a parall l array a i ha h c mpil r ca p rf rm
ex pl ill r i f I l cilk Pl k w r
void mergesort(int a[], int left, int right){
if(left < right){
int mid = (left + right)/2 ;
/* The below calls to the mergesort function are independent of eachother. In other words, they are task parallel. This parallelism caneasily be expressed by using the keyword cilk_spawn as shown below. */
cilk_spawn mergesort(a, left, mid); mergesort(a, mid+1, right);
/* Use of cilk_sync ensures that the threads spawned in thisfunction join at this point. Serial execution resumes after this point */
cilk_sync; merge(a, left, mid, right);
}
}
ra f rma i g ra v c riz d c d . A a xampl , hf ll wi g array a i ca b d if l m -wi m l iplica if array b a d c i b p rf rm d.
a[:] = b[:] * c[:];
t mmariz , I l Cil Pl i a la g ag x i wi h pp rf r a parall li m a ma f ll f m l ipl c r a d da aparall li m ha ca v c riza i capabili i wi hi ach c r .C mbi d, h x i ca har h p w r f m d rmicr pr c r .
I l Cil Pl i par f I l® Parall l C mp r. W c ragy ry I l Cil Pl by d w l adi g I l® Parall l C mp rfr m h f ll wi g li : http://software.intel.com/en-us/articles/intel-software-evaluation-center/ . th d w l ad al i cl dd c m a i ha pr vid d ail d r f r c i f rma i abI l Cil Pl . o
Li i 1 : ilk_ p w ilk_
THE PARATHE PARALLEL UNIVERSE
18 For more information regarding performance and optimization choices in Intel software products, visit http://software.intel.com/en-us/articles/optimization-notice.

8/3/2019 4093 in Parallel Mag Issue4 090310
http://slidepdf.com/reader/full/4093-in-parallel-mag-issue4-090310 11/15
for(int num=0; num < 9; num++){
__m128i xmm0 = _mm_and_si128(BinSmallNum, BinNum[num]);for(int i=0; i < 9; i++){ __m128i BoxSum = _mm_and_si128(BinBox[i], xmm0); __m128i RowSum = _mm_and_si128(BinRow[i], xmm0); __m128i ColumnSum = _mm_and_si128(BinColumn[i], xmm0);
if (ExactlyOneBit(BoxSum)){
int cell=BitToNum(BoxSum);FoundNumber(cell, num);return true;}
}}
Figure 2: u i sse pil r i ri i i pr v p rf r
t n r f c llThere are ver 6 x 10 21 vali Su ku b ar s in a 9x9 gri .u i g br f rc ry all h c mbi a i f mb r i hadif cult a programming exercise, the real challenge is in getting a
pr gram ha will c mpl h calc la i wi hi h lif im fh pr gramm r!
th chall g r gi r q ar d p , wa h w pr d ca p zzl wi h 39 cl , a hir y- igh r havi g alr ady b pr d c dby h r .
a i sse I ri isse i ri ic ar c mpil r-g ra d, a mbl r-c d d f c i haca b call d fr m C\C++ c d a d pr vid l w-l v l acc sIMDf c i ali y wi h h d i li a mbl r. C mpar d i g i li a mbl r, i ri ic ca impr v c d r adabili y, a i
i r c i ch d li g, a d h lp r d c d b ggi g ff r . I ri icpr vid acc i r c i ha ca b g ra d i g ha dard c r c f h C a d C++ la g ag .
th I l® C mpil r pp r a wid ra g f archi c ralx i fr m h arly MMX i r c i h la g ra if sse4.2 i r c i .
th c d i Fi r 2 h w h w 128-bi sse2 r gi r ar d ih s d c d .
The rst version of the Sudoku generator did not use SSEinstructions or intrinsics. Reworking the rst version of the code touse SSE2 registers took a signi cant amount of time. The adding ofsse i ri ic gav a p d p f v ral h dr d.
u i g sse i ri ic d hav i drawbac . Y ca d p l c i gy r impl m a i a par ic lar g ra i f archi c r . thl g am f h sse f c i ca ma y r C++ c d almunreadable, and there is a sig ni cant learning curve the programmerha climb. I h ca f h s d g ra r, h p rf rma cimpr v m far w igh d h x ra ff r ha wa d d.
s p 3: a i P r ll liWe used OpenMP* tasks - which are de ned in the Opea dard. op MP 3.0 i pp r d by h I l® C\C++ C
b gi i g wi h v r i 11. Addi g h parall li m ab w f w r – which f l a l f ff r a h im , b i r la h l g h f h pr j c h im wa fairly h r a d w ll
Fi r 3 giv a xampl f i g op MP a .One of the most dif cult aspects of adding the OpenM
gra p h w variabl w r r a d. Da a i op MP ca b private. The ne-tuning of our code to get the right scopvariabl v ral i ra i . M ch f h im a i addiparall li m wa r w r i g h c d ha h r wa l d har da a b w h diff r r i g a , a d ma i g
r ha h r w r d p d ci b w h diff rl p ha w r parall liz d.
u i I l® cilk R r op mPt day, I l® Parall l s di pp r a mb r f diff r wayparall lizi g a pr gram. th diagram i Fi r 4 h w IB ildi g Bl c , which ff r m l ipl pp r f r parall l pr
A a d arli r, h s d hir y- i r wa parall liz d op MP, i b i g m ch a i r ha a iv hr ad .
By Stephen Blair-Chappell
I l c pil r LL r P r e r håv r gr ff, w l
i r fr o l , r wi w r w w rl ’ fir s k
p zzl 39 l .
th W rld’Fir s d *‘t ir -ni r’
Fi r 1 : cr i w17- l s k
devel ping the C e af r wri i i i i l - p i iz , ww rk p rf r i pr v i r p : > s p 1: Cha gi g h alg ri hm h r c h br
f rc appr ach
> s p 2: op imizi g h rial c d , a i g adva ag fsse i r c i .
> s p 3: Addi g parall li m
t w v l p v r w r , f w rk i - f- ffi r , i 2,000-3,000 pr r i r .
x 0 i k f r llrr f p r i l r r
i i r v r r w, l x
t if x l r i
s p 1: c i al riRa h r ha i g a br f rc m h d cr a all h diff rp ibl l i , w d cid d a a xi i g p zzl , r m v r w cl , a d h a r c r iv lv r pr d c a w p zzl .
To nd a new 17-clue puzzle, we start with an 18-clue puzzle,r m v w cl , a d arch f r a y valid l i . s f r xampl ,i h p zzl b l w i Fi r 1 , clues 3 and 9 are rst removed fromc l m 1. th lv r h p p la ach f h lv d c ll wi h ali f valid al r a iv .
The solver then recursively prunes down the alternatives to nd avalid p zzl , a i g car h r ar r d da cl . thi m h d fcr a i g a w p zzl w call h “-2 + 1” alg ri hm.
We use the same technique to nd the ‘thirt y-niner’. Taking anexisting ‘thirty-eighter, we remove one clue and then add two newcl —w call hi a “-1 + 2” alg ri hm.
s p 2: op i izi s ri l cM d r CPu hav i r c i ha ca w r m r ha da ai m a h am im , ha i , si gl I r c i M l ipl Da a (sIMD).R placi g radi i al i r c i wi h sIMD i r c i ca l ad c d ha r m ch fa r. exampl f ch i r c i i cl d
MMX a d h vari s r ami g sIMD ex i (sse, sse2, …) .
THE PARATHE PARALLEL UNIVERSE
20 For more information regarding performance and optimization choices in Intel software products, visit http://software.intel.com/en-us/articles/optimization-notice.

8/3/2019 4093 in Parallel Mag Issue4 090310
http://slidepdf.com/reader/full/4093-in-parallel-mag-issue4-090310 12/15
Fi r 5. t r I l cilk Pl k w r
Fi r 4. I l P r ll lb il i bl k ff rl ipl l
f r p r ll l pr r i .
#include <cilk/cilk.h>void work(int num}{
// add code here}
void func1(){
cilk_spawn work(1); work(2);
cilk_sync;}
void func2(){
cilk_for(int i=0; i<9; i++){
work(3);}
}
cilk_spawn an cilk_sync th li b w cil _ paw a dcil _ y c ar w a h c i a i .th cil _ paw giv p rmi i hr im r w r (1) i parall l wi hh c i a i c d . If h r i a parw r r availabl , h ch d l r al hcontinuation code from the rst workera d a ig i a c d w r r—athe same time the rst worker continuesx c i g w r (1). Af r cil _ y c hc d r v r rial x c i
cilk_f rR plac a a dard C/C++ f r l p.th l p ar har d b w availablw r r . n par ic lar rd r f x c ii g ara d. o c all h l p havb x c d h pr gram c i .If l p d q al am f w r , l adbala ci g will b a car f by hch d l r’ w r - ali g alg ri hm.
#pragma omp parallel{
#pragma omp single nowait{
for( int i=0; i< NUM_NODES -1; i++){
NODE Node1 = pPuzzle ->Nodes [i];if (Node1.number > 0)
{//create copy of the top level node;
memcpy (&gPuzzles[i];pPuzzle, sizeof (SUDOKU));#pragma omp taskprivate (i)GenDoWork (&gPuzzles[i],i;
}}
}}
Fi r 3. c i op mP k
#include <cilk/cilk.h>...cilk_for(int i = 0 ; i < NUM_NODES -1; i++ )
{NODE Node1 = pPuzzle->Nodes[i];
if(Node1.number > 0){
// create a copy of the top level node; memcpy(&gPuzzles[i],pPuzzle,sizeof(SUDOKU));
GenDoWork(&gPuzzles[i],i);}
}
Fi r 6. a i ilk_f r s k
o r x f r l p
If h pr j c wa ar i g agai day, h i g I l® CilPl w ld b a a rac iv ch ic . Cil i f h a i way parall liz a xi i g pr gram. Addi g Cil xi i g C c d ix r m ly a y.
Cil hr y w rd : cil _ paw , cil _ y c, a d cil _f r. o cthe header le cilk.h is included in a le, the key words are available for
. s Fi r 5 .I Cil h pr gramm r d c r l h parall li m f a pr gram
b ra h r xpr i . By placi g Cil yw rd i a pr gram,h d v l p r i givi g p rmi i f r h c d b r i parall l.th d ci i wh h r r r c d i parall l i mad by h Cilch d l r a r im . th I l Cil Pl r im a ma ically acar f l ad bala ci g.
Fi r 6 h w h w h s d c d i mad parall l i g h Cilcil _f r yw rd. th c d i i r d i h am plac a h rigi alop MP a ( Fi r 3) . th l i i mbarra i gly impl !
I l cilk Pl I e i W P r ll liz exi i Pr rWh ma i g c d parall l, h pr gramm r ha b car f l ha
da a rac ar i r d c d. If h r ar a y gl bal variabl hh c d h ld b r w r d ha h c p f h variabl ir ric d—by, f r xampl , i g l cal r a ma ic variabl ra h rha gl bal variabl . If i i imp ibl r m v all gl bal variabl ,h acc ch variabl h ld b pr c d ha ly hr ad a a im ca m dify h m.
I Cil h a i way d al wi h gl bal a d har d variabl i d clar h m b a r d c r. Wh a w r r acc a r d c r
i i giv i w priva vi w ha i ca af ly ma ip la .Vi w ar h la r m rg d i h rial par f h c d by acall g _val (). th c d i Fi r 7 h w h w h gl balgn mCil P zzl s lv d i d clar d b a r d c r_ padd. th call g _val (),which i call d fr m h rial par f h c d , c mbiall h val f h r d c r, h b ai i g h c rr c val .
a p l f r i r r
t i l “f r l p” r r kf r i f g d W rk ()
“W r p i izi ri l r r i w ppli i f rl i r , p r ll l pr r i
evolved to improve pro ciency withexible design models and tools thatk ppli i r li l f .”
THE PARATHE PARALLEL UNIVERSE
22 For more information regarding performance and optimization choices in Intel software products, visit http://software.intel.com/en-us/articles/optimization-notice.

8/3/2019 4093 in Parallel Mag Issue4 090310
http://slidepdf.com/reader/full/4093-in-parallel-mag-issue4-090310 13/15
Fi r 7. Fixi r pr l i I l cilk Pl r r
Fi r 8. Wi p r ll li i pli , r w r r r 100 p r .
Fi r 9. t r 39 i i l l i f i i - -pl - w r
int gNumCilkPuzzlesSolved; // global variable..gNumCilkPuzzlesSolved++; // somewhere in parallel code..int Tmp = gNumCilkPuzzlesSolved; // somewhere in serial code
(a) The global variable gNumCilkPuzzlesSolved is unsafe to use in parallel code.
#include <cilk/reducer_oppad.h>cilk::reducer_opadd<int> gNumCilkPuzzlesSolved;..gNumCilkPuzzlesSolved++; // in parallel code..int Tmp = gNumCilkPuzzlesSolved.get_value();// in serial code
(b) The global variable is declared to be a reducer, making it safe to access.
t R lI r rigi al op MP l i cparall l c d wa add d h pwa r wardi g ha a sMc r —which ca pp r igh hhr ad —all igh hardwar hb y. s Fi r 8 .
La r xp rim a i i g Cha h Cil l i p rf rm d h op MP , a d wa m ch
impl m . Fi r 9 h w h hr w “ hha w r f d i g r s d g ra
Intel® Cilk Plus is ma e upf these main features: > a f k w r , f r xpr i f k
p r ll li
> R r , w i li i i f rr v ri l k i-ll r i vi w f f r k r i k r v l
f r k pl i
> arr i , w i pr vi parallelism for sections of C\C++ notation ip l rr
> el l f i , w i l p r ll li f w l f i r p r -i w i ppli w lr p r f rr r l r
> t i pr , w i l xprv r p r ll li f r ilizi r w rsImd p r ll li w il wri i rcompliant C/C++ code with an Intel®c pil r.
** Lars Peters Endresen andHåvard Graff wrotethe original program usingOpenMP. Thedesignw l r r wri s p bl ir-c pp ll i I l® cilk Pl .
t pl , l wi - x pl , will v il l i WRoXk Parallel Programming with Intel Parallel Studio . s p bl ir-c pp ll a r w s k ,
Wil P li i I . Isbn 9780470891650 (m r 2011)
I l® cilk Pl
THE PARATHE PARALLEL UNIVERSE
24 For more information regarding performance and optimization choices in Intel software products, visit http://software.intel.com/en-us/articles/optimization-notice.

8/3/2019 4093 in Parallel Mag Issue4 090310
http://slidepdf.com/reader/full/4093-in-parallel-mag-issue4-090310 14/15
WHICH CoMES FIRST: p r ll l l r p r ll lpr r i p r ?CLAY BRESHEARS,CoURSEWARE ARCHITECT/INSTRUCToR,INTEL CoRPoRATIoN
o h h l h r c uPCRC (u iv r al Parall lC mp a i R arch C r) A al s mmi m i g h Micr f * camp i R dm d, WA, I wa li i g i
a di c i ab parall l pr grammi g pa r . B -i g a parall l pr gramm r, I wa i r d i wha p pl(a d h w r m f h xp r i h fi ld) had ay ab parall l pr grammi g pa r , h w h y arv lvi g, a d h w h y will impac f r parall l c d r .
th di c i r d wh h r pa r w ld aff cpr grammi g la g ag dir c ly r r mai m hi g haw ld b c r c d fr m a m f h la g ag . Ihi I’m i h f rm r camp. h r ’ w .
F r h f ha w r pr grammi g wh elvi waill aliv , hi bac wri i g wi h a mbly la g ag .
F r h m par , h r w r i r c i f r L ad, s r ,Add, C mpar , J mp, pl m varia i h a dh r mi c lla i r c i . t impl m a c i g/
i d xi g l p y w ld m hi g li h f ll wi g:
Initialize counter
LOOP: test end condition,goto EXIT if done
Loop Bodyincrement countergoto LOOPEXIT: next statement
thi i a pr grammi g pa r . (s rpri d?) Wi h hpr p r c di i al i g a d j mpi g (g ) i r c iwi hi h pr grammi g la g ag , hi pa r ca bimpl m d i a y imp ra iv la g ag .
si c hi pa r pr v d b f l a d p rva iv ih c mp a i b i g wri , pr grammi g la g ag
d ig r add d y ax “a ma ” h p ab v .F r xampl , h f r-l p i C.
for (i = 0; i < N; ++i) {Loop Body}
o c w had hr ad a d h pp r i g librari cr a a d ma ag hr ad , parall l c di g i har dm m ry wa f a ibl , b a a pr y cr d l v l i c hpr gramm r had b r h c d ha dl d v ry hi gxplici ly. F r xampl , dividi g h l p i ra i am ghr ad ca b d wi h ach hr ad x c i g c dha l m hi g li hi :
start = (N/num_threads) * (myid)end =(N/num_threads) * (myid + 1)if (myid == LAST) end = Nfor (i = start; i < end; ++i) {Loop Body}
Parall l pr grammi g pa r will b ab rac i haca b “cr d ly” impl m d i c rr la g ag a dparall l librari , li h p d c d ab v . n w la -g ag ( r la g ag x i ) will ma pr grammi gparall l pa r a i r a d l rr r pr . Fr m hxampl ab v , op MP* ha h y ax d hi , b ily a a i gl li add d h rial c d :
#pragma omp forfor (i = 0; i < N; ++i) {Loop Body}
Fr m h vid c ab v , I hi f r parall l pr grammi gla g ag r la g ag x i pp r i g parall li mwill be in uenced by the parallel programming patterns wede ne and use today. And nothing will remain static. Ralph J h (D ig Pa r ), d ri g hi pr a i , r mar dha m f h rigi al pa r aw arly , b hi ha lac d ff. tw r a h d f r hi wa ham f h pa r c ld ’ a ily b impl m d i Java*
a d m d r oo la g ag had b r way acc mpli hh am a —m li ly h w la g ag f di pira i fr m h pa r a d h ir ag .
F r a a w r h q i p d i h i l , i b ild w ( p i d d) h ld chic -a d- ggparad x. th r w r alg ri hm (pa r ) d c m-p a i b f r h r w r c mp r ; pri r ha ,h alg ri hm w r m difica i f pr vi alg -
ri hm i fl c d by h l availabl . L i g f rward,h gh, w ’r ill i h r la iv ag f i fa cy f r
pr grammi g, l al parall l pr grammi g. Cl arly, hx g ra i f parall l pr grammi g la g ag r
librari r x i b l d rial la g ag will
b i fl c d by h pa r w w f r p cifyi gparall l c mp a i .
Visit G -Parallel.c mbr w r l xpl ri r f r l
j g P r ll l: tr l i m l i rP w r i appli i P rf r .
For more information regarding performance and optimization choices in Intel software products, visit http://software.intel.com/en-us/articles/optimization-notice.
Struggling tsee clearly?I r i I l® P r ll l a vi r 2011
Pi p i w r r ppli i fi fr r i — f r
j r ff r i .
I l P r ll l a vi r i l p- - pguide available for Microsoft Visual Studio* C/C++ developers who want to add threading to xi i ri l r p r ll l ppli i .
© 2010, Intel Corporation. All rights reserved. Intel and the Intel logo are trademarks of Intel Corporation in the U.S. and other countries. *Other names and brands may be claimed as the property of others.
R ck y ur c e.RoCK YoUR WoRLd.I l P r ll l a vi r 2011 i p r f I l® P r ll l s i 2011, l i ll-i - p rf r lkifor serial and parallel C/C++ applications.L r r I l P r ll l a vi r http://s ftware.intel.c m/en-us/intel-parallel-a vis r/ .
F ll w p f r k- ri p r ll li r r - r i p r ll li .
a w rkr
l ,I l P r ll l
a vi r l z x i
ri l pr r .

8/3/2019 4093 in Parallel Mag Issue4 090310
http://slidepdf.com/reader/full/4093-in-parallel-mag-issue4-090310 15/15
28 For more information regarding performance and optimization choices in Intel software products, visit http://software.intel.com/en-us/articles/optimization-notice.
Optimization Notice
Intel ® compilers, associated libraries and associated development tools may include or utilize options that optimizefor instruction sets that are available in both Intel ® and non-Intel microprocessors (for example SIMD instructionsets), but do not optimize equally for non-Intel microprocessors. In addition, certain compiler options for Intelcompilers, including some that are not speci c to Intel micro-architecture, are reserved for Intel microprocessors.For a detailed description of Intel compiler options, including the instruction sets and speci c microprocessors theyimplicate, please refer to the “Intel ® Compiler User and Reference Guides” under “Compiler Options.” Many libraryroutines that are part of Intel ® compiler products are more highly optimized for Intel microprocessors than for other microprocessors. While the compilers and libraries in Intel ® compiler products offer optimizations for both Intel and
Intel-compatible microprocessors, depending on the options you select, your code and other factors, you likely willget extra performance on Intel microprocessors.
Intel ® compilers, associated libraries and associated development tools may or may not optimize to the same degreefor non-Intel microprocessors for optimizations that are not unique to Intel microprocessors. These optimizationsinclude Intel ® Streaming SIMD Extensions 2 (Intel ® SSE2), Intel ® Streaming SIMD Extensions 3 (Intel ® SSE3), andSupplemental Streaming SIMD Extensions 3 (Intel ® SSSE3) instruction sets and other optimizations. Intel does notguarantee the availability, functionality, or effectiveness of any optimization on microprocessors not manufactured byIntel. Microprocessor-dependent optimizations in this product are intended for use with Intel microprocessors.
While Intel believes our compilers and libraries are excellent choices to assist in obtaining the best performance onIntel ® and non-Intel microprocessors, Intel recommends that you evaluate other compilers and libraries to determinewhich best meet your requirements. We hope to win your business by striving to offer the best performance of anycompiler or library; please let us know if you nd we do not.
Notice revision #20101101
The Ultimate All-in-onePerf rmance T lkitI r i I l® P r ll l s i 2011Intel® Parallel Studio 2011 simpli es and speeds the analysis, compiling, debugging, error-checking,
i f r ri l p r ll l pp . Wi I l P r ll l s i , v r i p i iz l ri l , xpl i l i r , l f r r .
INTEL® PARALLEL STUdIo CoMPoNENTSI l P r ll l s i pp r v r f v l p lif l .
Inn vative threa ing assistant
I l® P r ll l a vi r 2011: F ll w p f r k- rip r ll li r r - r i p r ll li .
Mem ry an threa ingerr r checker
I l® P r ll l I p r 2011: Quickly nd memory errors inr i l l i r ppli i .
optimizing c mpiler anthrea e libraries
I l® P r ll l c p r 2011: a i pl r pil wiI l P r ll l c p r i l r p rf r .
Threa ing anperformance pro ler
Intel® Parallel Ampli er 2011: Fi f i i rppli i i .
© 2010, Intel Corporation. All rights reserved. Intel and the Intel logo are trademarks of Intel Corporation in the U.S. and other countries. *Other names and may be claimed as the property of others.
R ck y ur c e.RoCK YoUR WoRLd.If w ri i l I l P r ll l s i , p r f r fr . L r r k w ’new in Intel Parallel Studio 2011 at http://software.intel.com/en-us/intel-parallel-studio-home/ .





























