Embed Size (px)
Citation preview

The EXPO Ontology:Describing Scientific Experiments
Ross D. King
Department of Computer Science
University of Wales, Aberystwyth

What is e-Science? E-science is computationally intensive science. It is
also the type of science that is carried out in highly distributed network environments, or science that uses immense data sets that require grid computing. Examples of this include social simulations, particle physics, earth sciences and bio-informatics. ...wikipedia. I DISAGREE
“eScience is about global collaboration in key areas of science and the next generation of infrastructure that will enable it.” John Taylor (UK e-Science) I AGREE

Standard e-Science Vision
Research is done in Lab X.– All results, metadata, programs, etc. are stored
electronically in an internationally agreed standard format, and openly published.
– An open access paper is published with links to the results, metadata, programs, etc.
Research lab Y wishes to replicate/build-on the published work of Lab X.– This is easy because all the results, metadata,
programs, etc. are publicly available.

Standard e-Science Projects
Most e-Science is based around building software infrastructure.– Software: “web services”– Databases: digital archiving, standards, etc.– GRID computing: Globus, Condor– Communication: Access Grid– Open Access publishing: UK, NIH, etc.– Services: Text mining, Bioinformatic, etc.

My View of e-Science
I am interested in the formalisation and automation of scientific research.
I and my colleagues have two related projects in this area:
– EXPO an ontology of scientific experiments.
– The Robot Scientist Project.

Formalization of Science
The goal of science is to increase our knowledge of the natural world through the performance of experiments.
This knowledge should, ideally, be expressed in a formal logical language.
Formal languages promote semantic clarity, which in turn supports the free exchange of scientific knowledge and simplifies scientific reasoning.

Motivation
The formal description of experiments for efficient analysis, annotation, and sharing of results is a fundamental objective of science.
Ontologies are required to achieve this goal. A few subject-specific ontologies of experiments
currently exist. However, despite the unity of science, there is no general ontology of scientific experiments.
We propose the ontology EXPO to meet this need.

Ontologies
An ontology is “a concise and unambiguous description of what principal entities are relevant to an application domain and the relationship between them”*.
*Schulze-Kremer, S., 2001, Computer and Information Sci. 6(21)

The Unity of Science We aim to formalise generic knowledge about
scientific experimental design, methodology, and results representation.
Such a common ontology is both feasible and desirable because all the sciences follow the same experimental principles.
Despite their different subject matters, they all organise, execute, and analyse experiments in similar ways.
They use related instruments and materials; they describe experimental results in identical formats, dimensional units, etc.

Ontologies for Experiments The formal description of experiments for efficient
analysis, annotation, and sharing of results is a fundamental objective of science.
Ontologies are required to achieve this goal.
A few subject-specific ontologies of experiments currently exist. The most notable of these is the MGED Ontology (MO). It was designed to provide descriptors required by MIAME (Minimum Information About a Microarray Experiment)
We have developed the ontology EXPO to meet this need.
Soldatova & King (2005) Nature BiotechnologySoldatova & King (2006) Royal Society Interface

Advantages of Ontologies
The utilisation of a common standard ontology for the annotation of scientific experiments would:– Make scientific knowledge more explicit.– Help detect errors.– Enable the sharing and reuse of common
knowledge.– Remove redundancies in domain-specific
ontologies.– Promote the interchange and reliability of
experimental methods and conclusions.

Our Approach to Ontology Building
Explicitly list the principles of an ontology's design, its constraints, along with definitions and axioms.
Provide compliance with a standard upper ontology (SUO) developed by IEEE P1600.1.
Keep separately domain-dependent and domain-independent knowledge, as well as declarative and procedural knowledge.
Build ontologies so that they are purpose-independent and therefore are future-proof.

SUMO
MSIChEBI
Upper level
Generic level
Domain level
EXPO
SubjectOfExp. ObjectOfExp.
Domain Model
FuGO
PSI
Measurement ontology
Bibliographic Data Ontology
BiblioReference Mes.Unit
MOPlant
ontology
The Position of EXPO

Small Section of EXPO

Generic ontology of experiments
e-Science
Ontology of science(formalization of scientific
methods, technologies, infrastructure of science)
EXPOOntology of
scientific experimentsconcepts: 218language: OWL
Classification of experiments
• Controlled vocabulary of scientific experiments;
• Formalized electronic representation of scientific experiments;
• Unified standards for representation, annotation, storage, and access to experimental results;
• Reasoning over experimental data and conclusions.
Admin info about experiment
Scientific Experiment
Experimental goal
Experimental design
Experimental object
Experimental action
Experimental results
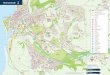
EXPO descriptionEXPO v.1
Concepts: ~200 Language: OWLTool: Hozo Ontology Editor

Scientific Publication 1
The traditional way of presenting scientific knowledge in scientific papers has many limitations.
The most important and obvious of these is the use of natural language to describe knowledge - albeit augmented by various formalisms and mathematics.
This is problematic because natural language is notorious for its imprecision and ambiguity.

Scientific Publication 2
Use of Natural Language is a great hindrance when using computers to store and analyse data – hence the growing importance of text-mining.
We argue that the content of scientific papers should increasingly be expressed in formal languages.
Is writing a scientific paper closer to writing poetry or a computer program?

Applications of EXPO
Phylogentics
Particle Physics
Structural Biology
Drug Screening and Design
Physical Chemistry
Robot Scientist

Solenodons
Solenodons are endangered insectivores from Hispaniola and Cuba.

Phylogenetic Example Random paper selected from Nature: Roca, A.L.,
Bar-Gal, G.K., Eizirik, E., Helgen, M.K., Maria, R. Mesozoic origin for West Indian insectivores. Nature, 429, 649-651 (2004).
Paper investigates the phylogenetic status of the mammalian species Solenodon cubanus and Solenodon paradoxus. i.e. the evolutionary relationship of these animals with all others.
Conclusion - Solenodons diverged in the Cretaceous.

Scientific Experiment: Hypothesis-forming, Hypothesis-drivenAdmin info about experiment:Title: Mesozoic Origin of West Indian InsectivoresAuthor: Roca, A.L., Bar-Gal, G.K., Eizirik, E., Helgen, M.K.,……………… Organisation: 1. National Cancer Institute, Frederick, USA ………………Status: public academic Reference: Roca, A.L., Bar-Gal, G.K., Eizirik, E., Helgen, M.K., Maria, R.
at all. Mesozoic origin for West Indian insectivores. Nature, 429, 649-651 (2004).
Classification of experiment:Taxonomy DDC(Dewey): 575 Evolution and Genetics
Library of Congress: QH 367.5 molecular phylogeneticsZoology DDC(Dewey): 599: mammalology
Library of Congress: QL351-QL352 Zoology-ClassificationExperimental goal: To discover the phylogeny of the species: Solenodon paradoxus
and Solenodon cubanusNull hypothesis H01: explicitRepresentation style: textLinguistic expression: natural language“Some have suggested a close relationship to soricids (shrews) but not to talpids”Linguistic expression: arificial language: predicate calculus …………………………experimental action 1.1.1 extraction and purification
object: sample of DNAparent group: DNA from Solenodon paradoxus sampling: random samplinginstrument: Qiagen DNA cleanup kit
experimental action 1.1.2 DNA amplification …………………………Experimental Conclusions (Formed Hypotheses) C1) Hypothesis Representation style: textLinguistic expression: natural language
There existed an mammal that is the ancestor of: Solenodons, Soricoidea, Talpoidea, Erinaceidea, and which is not the ancestor of any other mammal.
Linguistic expression: artificial language: predicate calculus …………………………
Prolog:instantiation(solenodon, So), instantiation(soricoidea, Sh), instantiation(talpoidea, T), instantiation(mammalia, An), shared_ancestor([So, Sh], [T], An).% shared_ancestror(Shared, Not_shared).shared_ancestor([X],[Y], An) :-ancestor(An, X).not ancestor(An, Y).shared_ancestor([X|Lx],[Ly], An) :-shared_ancestor([Lx],[Ly], An).ancestor(An, X).shared_ancestor([Lx],[[Y|Ly], An) :-shared_ancestor([Lx],[Ly], An).not ancestor(An, Y).
Solonedon Annotation
EXPO: A scientific experiment is a research method which permits the investigation of cause-effect relations between known and unknown (target) variables of the field of study (domain). An experimental result cannot be known with certainty in advance.
EXPO: A classification of experiments is a hierarchical system of categories – types of experiments – according to their domains or used models of experiments. EXPO: A null
hypothesis is an experimental hypothesis that states that a known controlled variable or variables does not have a specified effect on the unknown (target) variable or variables of the domain.
XML: </rdfs:Class><rdfs:Class rdf:ID="classification of experiments"> <rdfs:label>classification of experiments</rdfs:label> <rdfs:subClassOf rdf:resource="#classification" /> <rdfs:comment>Def:A classification of experiments is a hierarchical system of categories - types of experiments - according to their domains or used models of experiments.Axiom: </rdfs:comment>

Problems Highlighted by Annotation 1
The use of EXPO makes explicit the different hypotheses described in the paper.
What we have identified in the <research conclusion> are not mentioned as hypotheses in the text.
This contrasts with what we identify as the seven null-hypotheses, which are mentioned explicitly in the main text. – sub-optimal statistically.

Problems Highlighted by Annotation 2
Another aspect of the research which use of EXPO would have highlighted, was that the DNA sequences produced during the experiment were stored in the EMBL database using the taxonomic term “Insectivora”.
This taxon is now generally recognised to be polyphyletic, and its use contradicts the actual conclusions of the paper.

Problems Highlighted by Annotation 3
We formalised the knowledge behind the authors’ argument that “Cuban Solenodons should be classified in a distinct genus, Atopogale”.
Our analysis indicates that it would be more internally consistent for the authors to have classified Cuban Solenodons as a distinct family.
etc…..

High-energy/particle physics
Another random paper selected from same Nature issue: D0 Collaboration. A precision measurement of the mass of the top quark. Nature, 429, 639-642 (2004). (~350 scientists)

Experimental Equipment!

EXPO D0 Example 1<scientific experiment>: <computational experiment>: <simulation><admin info about experiment>:
<title>: A precision measurement of the mass of the top quark<classification by domain>:<domain of experiment>: High Energy Physics / Particle Physics<DDC(Dewey) classification>: 539.7 Atomic and nuclear physics <Library of Congress classification>: QC 770-798 Atomic, Nuclear, Particle Physics <related domain>: Computational Statistics<DDC(Dewey) classification>: 519 Probabilities and Applied Mathematics<Library of Congress classification>: QA 273-274 Probabilities<research hypothesis>: <representation style>: <text><linguistic expression>: <natural language>:
Given the same observed data: use of the new statistical method M1 will produce a more accurate estimate of Mtop than the original method M0.
<linguistic expression>: <artificial language>: M0(∀ D0 observations ∧ ∀ relevant background knowledge) ↦ E0M1(∀ D0 observations ∧ ∀ relevant background knowledge) ↦ E1estimation_error(E0, Mtop) ↦ Error0estimation_error(E1, Mtop) ↦ Error1Error0 > Error1
<alternative hypothesis>: <subject effect>: <experimenter bias>:<linguistic expression>: <artificial language>
P(The Standard Model) is highThe Standard Model → Higgs boson(Mtop = 173.3) → Higgs boson mass best fit mass estimate is experimentally
excluded.∴ Mtop > 173.3

Problems Highlighted by Annotation 1
Poor science, even though published in Nature!
This annotation makes it explicit that the experiment was somewhat unusual in not generating any new observational data. Instead, it presents the results of applying a new statistical analysis method to existing data (a set of putative top quark pair decays events involving e+jets and μ+jets)

Problems Highlighted by Annotation 2
No explicit hypothesis. We argue that the paper’s implicit experimental
hypothesis was: given the same observed data, use of the new statistical method will produce a more accurate estimate of Mtop than the original method.
This is based on the authors’ statement “here we report a technique that extracts more information from each top-quark event and yields a greatly improved precision when compared to previous measurements”.
We prefer the term “accuracy” to “precision”

Problems Highlighted by Annotation 3
The Carnap principle: All relevant knowledge should be used to decide a scientific question:– 91 candidate events were used to calculate the old
value, but only 22 of these were used for the new value!
– The old method estimate of Mtop is: 173.3 ± 5.6 (stat) ± 5.5 (sys) GeV/c2
– The new method estimate of Mtop is: 180.1 ± 3.6 (stat) ± 3.9 (sys) GeV/c2.
– The current (June 2005) best estimate for Mtop is 174.3 ± 3.4 GeV/c2

Problems Highlighted by Annotation 4
The paper concluded that Mtop is higher than previously estimated, which deductively implies a higher mass for the Higgs Boson. As the Higgs Boson has not yet been observed, even at energies above its previously predicted maximum likelihood mass, the newly inferred higher Mtop lent support to the existence of the Higgs Boson.
However, it would have been possible to argue validly the other way: that the Higgs Boson is thought highly likely to exist, therefore its non observation makes more probable a higher value of Mtop.
This argument was not explicit in the paper, but may have existed implicitly as a motivation.
The paper would have benefited from making this argument explicit, even if not used.

An Ontology for Drug Screening & Design
Funded BBSRC project started in April 2007. Extend Expo to formalise meta-data for drug
screening and design. We are developing our own Drug screening and Drug
design “Robot Scientist” - Eve. Collaborating with industry. Working with Pfizer to
develop ontology and experiment annotation system. Especially important in merging data that results from corporate merging.

Structural Biology Structural Biology was once a leader in the
development of standards for the preservation and sharing of data.
This lead has been lost. – The main data standard, mmCIF, does not meet
state-of-the-art standards in biology for ontologies.– The main database, PDB, is not “relational”
although it is meant to be.
We have proposed a way forward using EXPO.
Nature Biotechnology (2007) 25, 437-442

ART
An Ontology Based Tool for the Translation of Papers into Semantic Web Format.
Focussed on physical chemistry – very structured publications.
Funded by JISC, in collaboration with the Royal Society of Chemistry, and UKOLN.

ART 2 Tool to add value to papers and data stored in a
repository. The tool will lead authors through a process where:
experimental goals, hypotheses, methodologies, results, etc. are described and linked to the etx and external data.
The result will be an article in OWL format that can be archived with the original text version.
The OWL version will be more formalised and useful for computer processing, e.g. text mining.
SIG/ISMB07 Ontology Workshop / BMC Bioinformatics
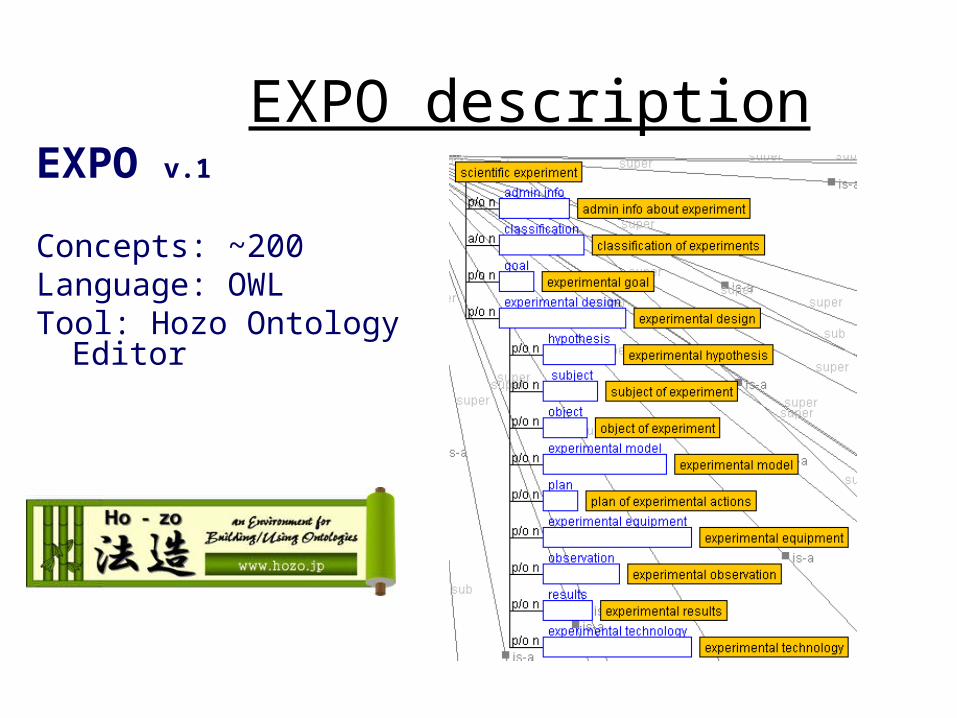
ChEBIFIXREX…
EXPOOBIECO
…
Generate:Summary, RSS feed
Output:xml/ owl article
Named entity recognition
DCPRISM
…
Convert: to SciXML article
Markup: paper metadata(title, author,…)
Markup: domain concepts(molecule, bond,…)
Recognition ofgeneric scientific concepts
(goal, hypothesis,…)
Input:free text article
user
Req
uest
/ Con
firm
/ E
xpla
in
dom
ain
depe
nden
tdo
mai
n in
depe
nden
tdo
mai
n in
depe
nden
t
Markup: generic scientific concepts

The Concept of a Robot Scientist
Background Knowledge
Analysis
Consistent
Hypotheses
Final Theory Experiment selection Robot
ExperimentResults
Interpretation
We have developed the first computer system that is capable of originating its own experiments, physically doing them, interpreting the results, and then repeating the cycle*.
Hypothesis Formation
*King et al. (2004) Nature, 427, 247-252.

Motivation 1: Philosophical
What is Science?
The question whether it is possible to automate the scientific discovery process seems to me central to understanding science.
There is a strong philosophical position which holds that we do not fully understand a phenomenon unless we can make a machine which reproduces it.

Motivation 2: Technological
In many areas of science our ability to generate data is outstripping our ability to analyse the data.
One scientific area where this is true is functional genomics, where data is now being generated on an industrial scale.
The analysis of scientific data needs to become as industrialised as its generation.

The Application Domain Systems Biology
Yeast (S. cerevisiae) – best understood eukaryotic organism.
Strain libraries, e.g. EUROFAN 2 has knocked out each of the 6,000 genes.
Task to learn models of yeast metabolism using selected mutant strains and quantitative growth experiments.

Movie

Some Example Growth Curves
Soldatova et al., CS Dept., Aberystwyth, UK

The need for a Robot Scientist ontology (EXPO-RS)
The robot requires detailed and formalized description: domains, background knowledge, experiment methods, technologies, hypotheses formation and experiment designing rules, etc.
Integrity of data and metadata.
Open access of the RS experimental data and metadata to the scientific community.
Soldatova, Sparkes, Clare, & King (2006) Bioinformatics

EXPO-RS Formalization of the entities involved in Robot Scientist
experiments.
A controlled vocabulary for all the participants of the project.
Identification of metadata essential for the experiment's description and repeatability.
Coordination of the planning of experiments, their execution, access to the results, technical support of the robot, etc.
Modelling a database for the storage of experiment data and track experiment execution.

Conclusions The unity of science implies that an accepted general
ontology of experiments is both possible and desirable. Such an ontology would promote the sharing of results
within and between subjects, reducing both the duplication and loss of knowledge.
It is also an essential step in formalising science, and fully exploiting computer reasoning in science.
We propose EXPO as a general ontology for scientific experiments.
We have demonstrated the utility of EXPO on applications in phylogenetics, high-energy physics, chemistry, and high-throughput Systems Biology.
Acknowledgements Larisa Soldatova Aberystwyth Amanda Schierz Aberystwyth
Ken Whelan Aberystwyth Amanda Clare Aberystwyth Mike Young Aberystwyth Jem Rowland Aberystwyth Andrew Sparkes Aberystwyth Wayne Aubrey Aberystwyth Emma Byrne Aberystwyth Larisa Soldatova Aberystwyth Magda Markham Aberystwyth
Steve Oliver Manchester Riichiro Mizoguchi Osaka
BBSRC, JISC










![OPM: An ontology for describing properties that …...GoodRelations ontology [4], one of the main ontologies regarding e-commerce, which is now deprecated. schema.org allows to define](https://img.dokumen.tips/doc/110x75/5f5108b817b17f5ebb77439c/opm-an-ontology-for-describing-properties-that-goodrelations-ontology-4.jpg)