Embed Size (px)
DESCRIPTION
Statistika (II Deo) - PMF Novi Sad
Citation preview

Д .ЧзТ еХМ '• У ^ у а м \ п ^ \ ^ ^ ~ ^ _
ДЕО II
СТАТИСТИЧКОЗАКЉ^ЧИВАЊЕ

ЛА ВА 4ОсноШ ЈГстатистички појмови
Потреба за упознавањем са процедурама статистичког закљу- чивања од стране' оних чије је стручно интересовање везано за географију је прилично очигледно.
Друштвсна географија је нераскидиво везана са статистичким анализама. Штавише, први евидентирани статистички поступци познати у историји били су пописи становништва у старом Египту. Међутим, савремена физичка географија се такође не може за- мислити без примене статистичких поступака у својим истражи- вањима.
Где би било место статистичком закључивању у оквиру физичке географије? Почнимо од кретања небеских тела. Све што је данас исказано у форми закона о кретању небеских тела настало је на основу статистичких посматрања и закључивања. Даље, рудна на- лазишта, квалитет руде и предвиђања у вези са веком експлоата- ције такође су производ статистичког посматрања и закључивања. Затим, клима, састав тла, квалитет вода, салинитет мора и тако даље су предмет проучавања физичке географије, а методологија изучавања подразумева између осталог и статистичке поступке.
4.1 Популација, обележје, узорак1••
Статистика је наука која се бави проучавањем скуцова са ве- ликим бројем елемената, који су једноЈзодни у односу на једно или више својстава. Основни појам статистике је популација. Попула- ција је скуп елемената чија заједничка својства проучавамо статис- тичким методама. Популацију могу чинити сви. становници С.рбије, све реке одређеног слива, сви студенти Природно-математичког фа-
67

68 СТАТИСТИКА
култета у Нишу, календарске године од интереса за анализу, насеља V Србији итд.
Посматрано заједничко својство елемената популације зове се обележје. На једној популацији, тј. на сваком њеном елементу, може се посматрати једно својство, али се могу посматрати и више својстава истовремено. Уколико се посматра само једно својство, онда се каже да је реч о једнодимензионалном обележју. У слу- чају да се посматрају два или више својстава истовремено, онда се за обележје каже да је вишедимензионално.
Неке популације и обележја посматрана на њима дата су следе- ћим примерима.
П ример 33. Популацију чини сви становници Србије. Могу се посматрати следећа обележја: пол, стручна спрема, брачни статус, старост итд. □
П ример 34. Популацију чине све реке црноморског слива. Посматрана обележја могу бити: водостај, дужина реке, темпера- тура воде, протицај, електропроводљивост итд. □
П ример 35. Популацију чине сви туристички објекти у Србији. Могу се посматрати следећа обележја: врста туристичког објекта, број туриста који су посетили туристички објекат у одређеиом вре- менском периоду, капацитет туристичког објекта, квалитет пруже- не услуге итд. □
П ример 36. Ако популацију чине насеља у Србији, тада се могу посматрати следећа обележја: број становника, тип насеља, повр- шина подручја итд. □
Пример 37. Популацију чине сви рудници угља у Србији. Обе- лежја од интереса за проучавање би била: врста угља, залихе угља, тј. количина угља на геолошком локалитету сваког појединачног рудника, минимална дубина на којој се налази угљени слој, про- ■ цењен век експлоатације и слично. □
У зависности од тога како се региструју вредности обележја, обележја могу бити квантитативна и квалитативна. Вредности

ПОПУЛАЦИЈЕ, ОЕЕЛЕЖ ЈЕ, УЗОРАК 69
квантитативних обележја се региструју као бројеви, тако да се ова ■обележја називају још и нумеричким обележјима. Примери квантитативних обележја су: водостај реке, старост становника, температура воде, број туриста итд. Вредности квалитатитивних обележја се региструју као ненумерички подади, те се ова обе- лежја називају и ненумеричким обележјима или атрибутима, односно атрибутивним обележјима. Примери квалитативних обележја су: пол становника, брачно стаље, школска спрема, врста туристичког објекта, врста угља итд. Иако су квалитативна обе- лежја по својој природи ненумеричка, она се могу регистровати као бројеви и такав поступак се зове кодираиве. Значи, кодирање би био поступак превођења вредности ненумеричког обележја у бро- јеве. Кодирање се може вршити на разне начине, тј. придружи- вањем различитих бројева квалитативним својствима. На пример, пол становника има две могуће вредности: мушки и женски. Један од начина кодирања би могао да буде да се особи мушког пола до- дели број 1, а особи женског пола број 2. Међутим, исти поступак би се могао спровести и применом бројева 0 и 1 редом, или неких других. Дакле, кодирање ненумеричких обележја бројевима, по правилу, нема суштинске везе са вредностима обележја.
Према броју различитих вредности које могу имати, обележја могу бити такође различита. Проучаваћемо дискретна и апсо- лутно непрекидна обележја. Дискретна обележја узимају ко- начно много или пребројиво бесконачно много вредности, док.апсолутно непрекидна обележја узимају непребројиво беско- начно много вредности. Ненумеричка обележја су, по правилу, дискретна, док нумеричка обележја могу једнако бити и дискретна и апсолутно непрекидна. Тако на пример, обележја дискретног типа су пол испитаника, врста угља, стручна спрема, број сун- чаних дана у току посматране године, док су обележја апсолутно непрекидног типа температура воде, водостај, количина падавина, висина снежног покривача итд.
Основни задатак статистике је: за дату популацију наћи расподелу посматраног обележ ја на њеним елементима. Међутим, ово најчешће није једноставно, а некад за проучавање популације према одређеном обележју и није неопходно знати тачну

расподелу обележја, већ је довољно знати само нска њена својства. По правилу не проучава се дела популација, тј. ке. посматрају се сви елементи популације да би се одредила расподела обележја. Наиме, популација може бити велика, тако да би проучшзање свих. њених елемената захтевало доста времена и новца илИ непребро- јива па би то било немогуће (на пример вода у реци, сливу, језеру итд) или би утврђивањем вредности обележја на свим елементима популације дошло до уништења популације (нпр. ако би се посма- трао животни век произведених сијалица). Зато се из популацијо на случајан начин издваја један њен део који ее даље проучава и на основу њега се доноси закључак за целу популацију. Издпојепп део зове се узорак. Уколико је узорак такав да се па основу њега може донети закључак за целу популацију, онда је он: репрезен-. тативан. Издвојени узорак увек има коначан број елемената п тај 'број елемената се зове обим узорка. .
70 СТАТИСТИКА •
4.2 Стратегије избора узорка
Раније смо рекли да из популације издвајамо један њеп део који смо назвали узорком. Сам узорак се можс. на више начипа издвојити из популације. Начин издвајања узорка из популације се зовс стратегија избора узорка. Постоји више стратегија избора узорка. Најчешће примењиване стратегијс су: случајни, пери- одични, стратификовани, групни и вишеетапни узорак.
4.2.1 Случајни узорак
Случајни узорак се формира помоћу таблице случајних бро- јева. Таблицу случајних бројева чине декадие цифрс порсђане у низ, које су добијене разним техникама које гарантују случајпост, нпр. рулетом. Цифре су у таблици груписане обично по дпс или пст заједно, ради лакшег читања. Читање из таблице се мбжо вршнтп на више нанина, с лева на десно, с десна на лево, иашмпс, иапижс или слично, али унапред одређеним поступком. Једап Део таГхчпцс случајних бројева приказаи је у табели 4.1.
Таблица случајних бројева може да се користи само ако се зиа

СЛУЧАЈНИ УЗОРАК 71
број елемената популације, односно ако је популација коначна. У том случају се популација најпре уреди тако што се сваком еле- менту популације додељује тачно један природан број. Једна при- ме.на таблица случајних бројева дата је иримером 38.
.51772 74640 42331 29044 4662124033 23491 83587 06568 2196045939 60173 52078 25424 1164530586 02133 75797 45406 3104103585 79353 81938 82322 9679964937 03355 98683 20790 6530415630 64759 51135 98527 6258609448 56301 57683 30277 9402321631 91157 77331 60710 5229091097 17480 29414 06829 87843
Табела 4.1: Део таблице случајиих бројева.
П ример 38. Посматра се популација од 100 елемената н треба формирати случајни узорак од 5 елемсиата. За формирап.е с-лучај- ног узорка користићемо таблицу случајних бројева. Довољпо јс да читамо по две цифре и оне ће представљати редии број елсмспта популације. При томе, ако се јави 00, онда ћемо узети- 100-тн слс- мент популације у узорак, ако се јави 01, узећемо први елсм!!пт. ако се јави 10, узећемо десети елемент итд. Рецимо да узимамо бројсмс из првог реда и то с лева на десно. Тада добијамо слсдећс бројено 51, 77, 27, 46 и 40. Прематоме, из популације узимамо сломсптс са редним бројевима 51, 77, 27, 46 и 40, и од њих формирамо случајпп узорак обима 5. □
П ример 39. Број домаћинстава (у хиљ.) 1971. године■за општппс са уже територије Србије (50 општина) био је: 5, 33, 9, 13, 13, 3(1. 15, 42, 16, 23, 5, 8, 2, 29, 5, 3, 10, 9, 5, 5, 5, 4, 8, 3, 5, 4, 4, 5, 17, 56, 8, 19, 9, 7, 29, 19, 8, 2, 13, 5, 6, 33, 44, 32, 45, 41, 7, 14, 12, 5 (Извор: Стат. год. Југ.; 1976., стр. 564). Користећи бројсис ич

72 СТАТИСТИКА
таблице случајних бројева, почевши од првог реда с лева на десио. формирати случајни узорак обима 6.
Решење. Популација има укупно 50 елемената. Довољно је да читамо по две цифре, али при читању нећемо узимати у обзир бројеве 00, 51, 52, ..., 99.. Читањем цифара из таблице случајпих бројева добијамо следећи низ бројева: 51 (одбацује се), 77 (одбацује се), 27, 46, 40, 42, 33 и 12. Тако из популације узимамо елементе са редним бројевима 27, 46, 40, 42, 33 и 12 и од елемената формирамо узорак. Добијени случајни узорак обима 6 је 4, 41, 5, 33, 9, 8. □
Случајни узорак се може остварити на два начина:
1. Извуче се један елемент из популације, бележи се вредност посматраног обележја на њему, а затим се враћа назад у скуп. Овако формирани случајни узорак се зове случајни узорак са враћањ ем. Карактеристика оваквог узоркГјГтаптГсе Један исти елемент популације може више пута појавити као елемент једног истог узорка.
2. Извуче се један елемент из популације, бележи се врсдност обележја на њему, али се сада овај елемент не враћа у ос- новни скуп. Овако формирани узорак се зове случајни у з о -
,.вра1јан.а. Поступак формирања случајиог узорка без враћања обима п је еквивалентан истовременом извлачењу свих п елемената популације у узорак.
4.2.2 Периодични узорак
Периодични узорак такође захтева уређеиост еле.меиата попу- лације и из низа се бирају елементи на истом размаку, ппр с-вакн пети, десети итд. Избор елемената зависи од броја елемеиата поп\- лације и обима узорка. На пример, посматра се популацнја од Ш елемената и формира се узорак од 15 елемената. С обзнром да је 114 : 15 = 7,6, то се може бирати сваки осми елемеит поихлације лоче-ши од првог или евентуално од другог да би се добило тачко 15 елемената у узорку. Периодични узорак има одређепе предиостп у односу на случајни узорак. Прво, једноставно се формира и за њо- гово формирање није потребна таблица случајних бројева. Д ј,Уго,

СТРАТИФИКОВАНИ УЗОРАК 73
ом је равномерно распоређен по популацији. Међутим. он пеће бити репрезентативан уколико је уређење елемената популацнје у вези са посматраним обележјем.
Пример 40. Посматра се група студената треће године и бележи се колико година имају. Добијене године старости су: 22, 21, 20, 23. 22, 24, 25, 21, 22, 23, 21, 22, 21, 23, 22, 22, 21, 25, 21, 26, 23, 21, 22, 21, 21. Формирати периодични узорак обима 6 узимајући сваки четврти елемент почевши од: а) првог, б) трећег елемента популације.
Решење. (а) Почињемо од првог елемента и узимамо свакпчетврти елемент [22], 21, 20, 23, [22], 24, 25, 21, [22], 23, 21, 22, [ГГ].23, 22, 22,1211, 25, 21, 26, 23 |, 21, 22, 21, 21. У том случа.ју добијепп учорак обима 6 је 22, 22, 22, 21, 21, 23.
(б) Почињемо од трећег елемента и поново узимамо сваки четнр- ти елемент 22, 21, ПГсП, 23, 22, 24, [25], 21, 22, 23, [ГП 22, 21, 23,221, 22, 21, 25, 211, 26, 23, 21, 22 21, 21. У том случају добијенн
узорак обима 6 је 20, 25, 21, 22, 21, 22. □
4.2.3 Стратификовани (слојевит) узорак
Код стратификованог узорка популација се дели на дисјупк- тне делове по неком правилу које олакшава испитивање. Тнчннје. тако да део популације унутар сваког слоја буде хомоген по поком својству. На пример, становници се могу поделити према томе дн ли живе у граду или у селу, путеви према значају, л>уди п|н>мн полу, рудници угља према врсти угља итд. Овако пасталп .целопп популације зову се стратуми или слојеви. Из сваког стратума се на с-лучајан начин бира унапред предвиђени број е.не.мспатп п тако се формира стратификовани узорак. У зависностп од тога ко- лико се елемената бира из сваког стратума, разликују се два тппа стратификованог узорка: равномерни и пропорционални. Код равномерног стратификованог узорка се из сваког стратума бпрп исти број елемената (уколико то није могуће, онда се узима прп- ближно једнак број елемената), док се код пропорционалног стра- тификованог узорка из сваког стратума узима број елемепата стра- тума који је пропорционалан величини стратума.

74 СТАТИСТИКА
П ример 41. Међу становницима једног града се врпги апкста о томе колико су задовољни условима живота. Грађани Су иодсл,еии У ТРИ гР7пе према дужини живота у граду, и на основу псп.гтвања се зна да 15% грађана живи у граду до 5 година, 25% живи више од 5, а мање од 10 година, док 60% живи 10 или више година у граду. Треба формирати узорак обима 300. Уколико желимој да"форми- рамо равномерни стратификовани узорак, тада ћемо из сваког стра- тума узима по исти број елемената, тачније 100 елемената (обим узорка делимо бројем стратума). Уколико желимо да формирамо пропорционални стратификовани узорак, тада ћемо из првог стра- тума узети 300 ■ 0,15 = 45 елемената, из другог 300 • 0,25 = 75, а из трећег стратума узећемо 300 • 0,6 = 180 елемената. □
4 .2 .4 Г руш ш узор ак
Групни узорак такође захтева могућност поделе популације на дисјунктне делове, али не захтева да делови .буду хомогени по било ком својству. Дисјунктни делови популације се у овом случају зову групе. За разлику од стратификованог узорка код кога је из сваког стратума узиман одређеи број елемената, код групног узорка се не узимају све групе, већ се бира само одређени број група и то на случајан начин, па се из изабраних група узимају сви елементи (видети слику 4.1). Предност групног узорка у односу на страти- фиковани узорак је та што се групни узорак дббија једноставније и брже, док је предност стратификованог та што стратификовани узорак даје бољу слику о.популацији.
П рр р п-----___ *3•6 7|01 ..__ ’Ј_ Ј>__ __ ______• П •!« •и.и*|(‘П•» 1-И .1.1 • 1» ц , .
Стратификовани Групвиузорак узорак
Слика 4.1: Пример стратификованог и групног узорка.
Н 1*
•3
4«
‘ 5
• 6 7 .
•» *9
«1» ,II
12-
• » . 1 4 • 15
•И* .17
Популација
.1 2* •3
•» М4• 15• 16 .Ј7:!1_њ
Групниузорак

ВИШЕЕТАПНИ УЗОРАК
4.2.5 Вишеетапни узорак
Вишеетапии узорак се креира у више етапа. Популација се дели па отратуме. ови на нодделове и тако редом зависно од снтуације. На пример, град се дели на општине, општине на месне заједнице, месне заједнице на улице, улице на куће итд. Пример вишеетапног узорка је следећи двоетапни узорак. У првој етапи двоетапног узорка бира се одређени број група, а затим у другој етапи из ода- браних група бира се само одређени број елемената па елучајан пачин. Вишеетаини узорак се користи у ситуацијама када стра- туми имају велики број елемената.
4.3 Избор тачака са тла у узоракКод анализе сливова, путне мреже, неких геолошких иетра-
живаља и сличио, иотребан је избор тачака са тла. тј. са нског дела површине Земље. То значи да је потребно пзвршити избор узорка из дводимензионалНог простора. Избор тачака може бити случајан, периодични, стратификовани и групни. У свим елучајсвнма ее посматрана област са тла прекрије. минималннм правоугаоником, а затим се врши избор тачака унутар тог пра- воугаоника. По правилу посматрана област није правоугаона. У том случају треба водити рачуна да се у узорак узимају само оие случајно изабране тачке правоугаоника које припадају посматрапој области. -
Случајни избор тачака може да се симулнра таблпцом с.пу- чајних бројева. То се постиже натај начин што се парови изабраппх случајиих бројева користе као координате тачака са тла.
Пример 42. Ради испитивања нафтног богатства једне маље пуе- тињске регије планира се отварање бушотина за нафту па 8 елу- чајно одабраних тачака неиспитаног земљишта. Свака тачка се па карти представља својим координатама (мереним од дољег леиог угла). Прецизност мерења је до 10т, а област је облика квадрнтн педпчинеШ)ктх100кт. те је укунап број тачака (обим попудацпје) у којима би се могле наћи бушотине 108. Заиста, доња ивнци је жине 100А"т,, а на сваких 10тп налази се један елемент популацпје х
/■I

76 СТАТИСТИКА
координата, те је укупан број елемената популације х координата100кт 10 т
100 • 1000т 10т = 10000.
На иети начин популација у координата има такође 10000 елеме- ната. Сада из таблице случајних бројева формирамо групе од по 4 цифре које ће представљати х-координате (ако се појави 0000, то ће т координата бита.ОЛш, ако се појави 1045, то ће х координата бити 10,45А:т итд.) и добијамо следеће координате: 51,77; 27,46; 40,46; 33,12; 90,44; 46,62; 12,40 и 33,23. Настављамо узимање случајних бројева, али-..с .да..од њих формирамо у коордипате: 49,18; 35,87: 06,о6, 82,19, (бц,/|5;. 93,96; 01,73 и 52,07. Тако емо добили следећг тамке (т.јј):
тачка 1 2 3 4 5 0 7 8X ‘ V
51,7749,18
27,4635,87
40,4606,56
33,1282,19
90,4460,45.
46,6293,96
12,4001,73
33,2352,07
Распоред тачака приказан је на слици 4.2. □
100
80
60
40
20
0 20 40 60 80 100 *
.4“6
5
• 8
•2
,7 • 3
Слика 4.2: Случајно одабрапе тачке.
Пример 43. На случајан начин бирамо 5 тачака из облцетп иа сли- ци 4.3. Употребимо двоцифрене бројеве редом нз 6. врсте таблпцс на стр. 71 за формирање х координата, при чему Гш 24 ирсдсгпш- ■љати број 2,4, 37 број 3,7 итд., и двоцифреме бројеш« пч 8. нрстс таолице за формирање у координата. Добијамо сшедеће тачке:

ИЗБОР ТАЧАКА СА ТЛА У УЗОРАК
тачка ± 5 6 7 8 9х 6,4 9,3 7,0 3,3 5,5 9,8 6,8 3,2 0,7
Л 0,9 4,4 8,5 6,3 0,1 5,7 6,8 3,3 0,2
Тачко са редним бројевима 1, 2, 3 и 5 се одбацују, јер не припадају шрафираној области. □
10
8
6
4
2
0 2 4
Слика 4.3: Случајно одабране тачке из области која инје квадратнд,
Случајни избор тачака може се остварити и на следећи начнп. Најпре се врши случајан избор тачака на страницама квадрата плп правоугаоника. Затим се од сваке две случајно изнбране тачке са различитих ивица формирају линије унутар квадрата. На крају с<«о.ч нресечпих тачака линија формира узорак (слика 4.4).
Слика 4.4: Случајни избор линија.
Периодични избор тачака се успешно примењује за пчбир тачака 'по квадратној мрежи. Тачке се М01’у бирати на чворшшма

78 СТАТИСТИКА
мреже (слика 4.5а), или се координате једне тачке одређују преко таблице случајних бројева, а остале се узимају иа истом размаку (слика 4.56).
Слика 4.5: Периодични избор тачака.
С тратиф иковани избор тачака остварује се иа следећи на- чин. Посматрана област се дели на мање целине хомогејне по неком својству (врста земљишта, надморска висина и слично) из којих се на случајан начин бира одређени број тачака у узорак. Страти- фиковани избор тачака подразумева избор одређеног броја тачака из сваког стратума, те омогућава равномерну расподелу узорка по ЖЈС.матрапом дслу тла (слика 4.0). ;
Слика 4.6: Стратификовани избор тачака.
Групни избор тачака се остварује на следећи начин. Посма- трана област се дели на мање целине, најчешће правилног облика. рецимо квадрата или правоугаоника истих димензија који имају улогу група. Узорак се формира тако што се иа случајан начин изабере одређен број група, а затим се из сваке групе узимају сви елементи, тј. цео део тла обухваћен изабраном групом. .

ПРИКАЗИВАЊЕ ПОДАТАКА 7,9
И код избора тачака са тла може се примењивати вишеетапни узорак.
4,4 Приказивање података
Приказивање података представља другу етапу статистичког проучавања. Прикуцљени подади се представљају на два основна начина: таблично и граф ички . Код табличног метода прику- пљени подаци се сређују и приказују у облику табела, док се код графичког метода прикупљени подаци илуструју разним графико- нима, дијаграмима, картама итд. ПрилиКом графичког прикази- вања узорка најчешће се полази од табела у које је узорак претходно сређен.
4.4.1 Таблични метод приказивањ а података
Као што смо рекли, код табличног метода прикупљени. подаци се приказују у облику табела. Приказивање прикупљених података зависи од броја различитих реализованих вредности обележја. Укб- лико је број различитих реализованих вредности мали, поступак је следећи:
1. Најпре се добијени подаци поређају у варијациони низ, тј. у низ у коме је сваки следећи елемент већи од претходног или м'у је једнак.
: г2. Затим се уоче све различите реализоване вредности и од њих
се формира табела, при чему се реализоване вредности наводе у растућем редоследу.
3. На крају се уочава колико се цута свака вредност јавила и број појављивања сваке вредности се уноси у табелу.
Наведени поступак сређивања података се најчешће користи за сређивање података из узорака дискретних обележја.
Број појављивања неке реализоване вредности је апсолутна учестаност или ф реквенција те вредности. Апсолутна учеста- ност вреДности т,- означава се са /ј. : •

80 СТАТИСТИКА
Претпоставимо да у узорку обима п има к различитих вредности Х/ < Х'2 < ' ■ • < Хк' и нека СУ њихове апсолутне учестаности редом / 1, Ј2, ■ • А- Напоменимо да збир свих апсолутних учестаности мора бити једнак обиму узорка, тј. ако узорак има п елемената и ако у узорку има /с различитих вредности, тада мора бити Д + / 2 +• ■ • + Л = п Табела којом се представљају подаци је облика:
Реализоване вредности обележја Х-г %2 х к УкупноАпсолутне учестаности л 1ч /к п
Осим апсолутних учестаности могу се посматрати и релативне учестаности. Оне се означавају са /* и дефинишу као количник
•/? = - , * = 1 ,2 ,... ,* .п
Према томе, релативне учестаности добијамо тако што сваку апсо- лутну учестаност поделимо обимом узорка. Напоменимо да збир свих релативних учестаности мора бити 1. Релативна учестаност / показује колики део од укупног броја елемената поседује вредност
Постоје и збирне учестаности. Зову се још и кумулативне фреквенције, а могу бити апсолутне и релативне, у зависности од тога к0Је се учестаности посматрају. Апсолутна збирна учеста- ност вредности означава се са Е Л и дефинише се као збир апсо- лутних учестаности Д, / 2, ..., /„ На пример, апсолутна збирна учестаност вредности т 3 једнака је Л + / 2 + / 3. Слично се може дефинисати и релативна збирна учестаност. Релативна збирна уче- станост вредности гг4 се означава са ЕЛ* и дефинише као збир ре- лативних учестаности /*, / 2‘, .. , /*. На пример, релативна збирна } шстаност вредности једнака је /* + /* + /* + /*
Пример 44. Дат је број кишних дана у месецу јулу току 20 година: 5, 6, 8, 10, 9, 8, 4, 7, 7, 3, 6, 4, 8, 7, 6, Формирати табелу -апсолутних, релативних и збирних 11 релативних учестћности броја кишних дана.
у месту А у 6, 5, 3, 6, 6. апсолутних

Решење. Посматрано обележје је број кишних даиа у мес.ецу ЈУЛУ. а посматрано је у току 20 година, те је апсолутна учестаност број година са одређеним бројем кишних дана. Узорак има 20 еле- мената и у узорку има 8 различитих вредности: 3, 4, 5, 6, 7, 8, 9 и 10. Њихове апсолутне учестаности су редом: 2, 2, 2, 6, 3, 3, 1 и 1. Рекли смо да се релативне учестаности добијају тако што се .апсолутне учестаности поделе обимом узорка. У овом примеру обим узорка је 20, те су релативне учестаности редом: 0,1; 0,1; 0,1; 0,3; 0,15; 0,15; 0,05 и 0,05. Збирне апсолутне учестаности су редом:
ТАВЛИЧНИ МЕТОД ПРИКАЗИВАЊА ПОДАТАКА 81
Е / 1 == 2,
Е / 2 == 2 + 2 = 4,
Е / з == 2 + 2 + 2 = 6,
Е / 4 == 2 + 2 + 2 + 6 = 12,
Е / в == 2 + 2 + 2 + 6 + 3 = 15,
Е / е == 2 + 2 + 2 + 6 + 3 + 3 = 18,
Е / ? == 2 + 2 + 2 + 6 + 3 + 3 + 1 = 19,
Е / в == 2 + 2 + 2 + 6 + 3 -4 -3 4 -1 -1 -1 = 20
док су збирне релативне учестаности једнаке:
Е / Г = 0 , 1 ,
Е Л = 0,14-0,1 = 0,2,
Е / з = 0,1 + 0,14-0,1 = 0,3,
Е /4 = 0,14-0,1 + 0,1 + 0,3 = 0,6,
Е / б = 0,1 + 0,1 + 0,1 4- 0 , 3 + 0,15 = 0 , 75 ,
Е / б = 0 ,1+0,1 + 0,1 + 0,3 + 0,15 + 0,15 = 0,9,
Е / Г = 0,1 + 0,1 + 0,1 + 0,3 + 0,15 + 0,15 + 0,05 = 0,95,Е / з = 0.1 + 0,1 + 0,1 + 0,3 + 0,15 + 0,15 + 0,05 + 0.05 = 1.
Сада можемо формирати табелу учестаности броја кишних да-

82 СТАТИСТИКА
Бр. кишних дана 3 4 5 6 7 8 9 10 Т,Л 2 2 2 6 3 3 1 ; 1 20Л* 0,1 0,1 0,1 0,3 0,15 0,15 0,05 0,05 1
л 2 4 6 12; 15 18 19 20 /ЕЛ* 0Д 0,2 0,3 0,6' 0,75 0,9 0,95 1 /
Уколико у узорку постоји велики број различитих вредности, тада се подаци сређују по интервалима. Поступак сређивања пода- така по интервалима се зове интервално сређивање података и састоји се у следећем. Најпре се одређује број интервала. Сам број интервала зависи од броја података и постоји више формула за одређивање броја интервала. На пример, за одређивање броја интервала може се користити следеће правило: препоручује се нај- мање 1 + 3,3221о§10 7г интервала и највише 51о§10п интервала, где је п обим узорка. Значи, ако са к означимо број интервала, тада к задовољава неједначине
1 + 3,322 1о§ 10 п < к < 51о§10 п.
Интервално сређивање података се најчешће користи за сређивање података из узорака обележја апсолутно непрекидног типа.
П ример 45. Посматрамо узорак обима 40 и желимо да одредимо број интервала. Овде је узорак обима п = 40, тако да најмање можемо узети 1 + 3 ,3221о§10 40 = 6,322 интервала, односно нај- мање 7 интервала, а највише 51о§1040 = 8,011 интервала, односно највише 8 интервала. □
Даље се одређује дужина интервала по формули
г %тах %тгп — *— '
где су •^тах 'И ^тгп највећа и најмања вредност у реализованом узорку. На крају се врши пребројавање елемената по интервалима и формира се табела.
П ример 46. У једном граду је у току 40 година мерена средња температура ваздуха у °С у месецу априлу. Добијене су следеће вредности по годинама:

I
ТАБЛИЧНИ МЕТОД ПРИКАЗИВАЊА ПОДАТАКА 83
12,07 13,94 15,00 17,22 18,1012,06 14,21 15,03 16,94 18,4212,00 14,04 15,56 16,96 ■ 19,26
, 12,09 14,07 15,92 17,06 19,31[12,86 13,96 16,07 16,87 19,44
13,81 15,04 15,92 17,54 20,0013,15 14,91 16,01 18,02 14,0813,06 14,94 16,93 18,01 14,04
Интервално средити дате податке.Решење. Узорак има 40 елемената. На основу претходног при-
мера, табела која се формира може имати 7 или 8 интервала. Нека је рецимо број интервала 8 (к = 8). Најнижа средња температура била је 12°С, док је највиша била 20°С. Тада је дужина сваког интервала
, 2 0 -1 2 . к = — — ш 1-
Према томе, формирамо табелу са 8 интервала: [12; 13), [13; 14), [14; 15), [15; 16), [16; 17), [17; 18), [18;-19) и [19; 20]. Интервал [о,6) садржи све бројеве између а и 6, укључујући о, док интервал [о, 6] садржи све бројеве између а и 6, укључујући и а и 6. Пребројава- њем колико се пута у узорку реализовала температура у сваком од дефинисаних интервала добијамо следећу табелу:
Температура [12; 13) [13; 14) [14; 15) [15; 16) [16; 17)Број година Ш -ни- ■ ш Ш \ ШН
/< 5 5 7 6 . 6 ./<* 0,125 0,125 0,175 0,15 • 0,15
Е/< 5 10 17 23 29Е /* 0,125 0,25 0,425 0,575 0,725
Температура [17; 18) [18; 19) [19; 20] ЕБрој година III 1111 1111
/< 3 4 4 40/ ' ' 0,075 0,1 од 1
Е/< 32 36 40 /Е/<* 0,8 0,9 1 /

84 СТАТИСТИКА
_1>валитативна обележја се такође могу табеларно сређивати. Заређивање се гтримењује поступак коришћен код сређивања узорака Ра малим бројем различитих вредности.
П ример 47. За један водоток дефинисани су распони ниских (н) средњих (с) и високих (в) водостаја. У току 24 месеца осматраља водостаја, просечни месечни водостаји регистровани су као следећи низ: н, н, с, в, с, с, с, н, в, в, с, с, с, н, в, в, в, с, в, н, н, с, в, с. Фор,мирати табелу апсолутних и релативних учестаности водостаја.
^еш ењ е. \ узорку постоје три различите вредности н, с и в. Пребројавањем добијамо следећу табелу:
Водостај н с в г.Врој водостаја
и44-14- 1 Тпг 1
6§ §
10Ш III
8 24п 0,25 0,42 0,33 1
Уколико се посматрају два обележја X и У истовремено тј на елементима истог узорка (која су могуће зависна), тада табела може бити облика
Х \У Уг УзXI /п Лз
хг /и /тз
Х \У л лл /и А з
1 г / г ! Јта
првом случају, вредности х,, . ,., хт и уг, ..., у3 су дискретне вред- ности обележЈа X и V, а број /,, је апсолутна учестаност елемента [Х" Уз)- У другом случају, 1Т и Ји .... Ј, Су интервали апсо-лутно непрекидних обележја X и У, а Д, је апсолутна учестаност производа интервала 1г х Ј,. Добијена табела је у литератури позна- та под називом табела контингенције. Сам цоступак формирања табеле је једноставан. Уколико другачије није наглашено, поступак је следећи. Одређују се интервали за свако обележје посебно а за- тим се реализовани узорак групише по добијеним интервалима. У табели контингенције се могу налазити релативне уместо апсолут- них учестаности.

ТАБЛИЧНИ МЕТОД ПРИКАЗИВАЊА ПОДАТАКА 85
Код свих наведених поступака табличног сређивања података често се, уместо релативних учестаности, користе процентуалне. Процентуалне учестаности се добијају на основу реализованих мно- жењем са 100. Дакле, уместо /* користи се 100/* и означава са /;%■
јо/Пример 48. Посматрана територија (слика 4.7) је подељена на 71 Ч квадрат у којима се одређује приеуство или одсуство две културе
А и В. Формирати табелу међусобног односа култура А и В.
Д:,; •./ ХаV V В"X ’ Г / ■'Ји
/ А АВ в :Ма/
М В АВ АВ АА А АВ АВ А АВ
А АВ В А АВ вА АВ А А АВ
АВ АВАВ АВ В А.;' ч в
А А В 4 "у‘г-}уЈ
Слика 4.7: Посматрана територија.
Решење. Посматрају се два обележја Д-присутна култура А и У-присутна култура В са вредностима да и не. Занима нас ме- ђусобни утицај обележја X и У, тако да ћемо посматрати дводи- мензионално обележје (X , У). Ово обелелсје има четири вредности: (да,да)-обе културе су присутне, (да,не)-присутна је само култура Л, (не,да)-присутна је само култура В и (не.не)-одсутне су обе културе. Након пребројавања култура по квадратима добијамо следећу табелу:
ПрисЈ^тна култура А
Присутна култура Вда не
да 14 12не 9 36
□
!
86 СТАТИСТИКА
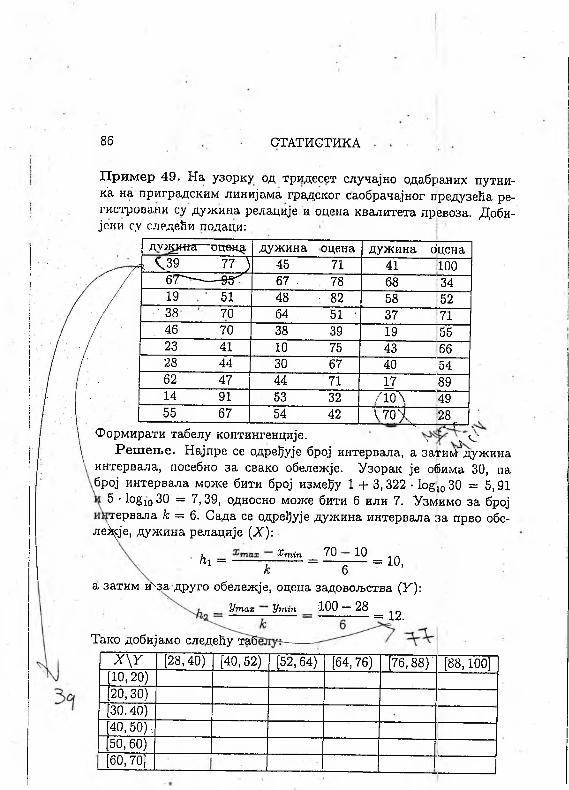
П ример 49. На узорку од тридесет случајно одабраних путни- к'а на приградским линијама градског саобрачајног предузећа ре- гистровани СУ дужина релације и оцена квалитета превоза. Доби- јени су следећи подаци:
ду>Јрдаа""оц&ид дужина оцена ду жина бценач Л 3 9 77 ) 45 71 41 Оог~(
6Г~'------ 95"' 67 ■ 78 68 3419 ' 51 48 : 82 58 52
•• 38 70 64 '51 • 37 7146 70 38 39 19 5523 41 10 : 75 43 6628 44 30 67 40 15462 47 44 71 17 |8914 91 53 32 /10 V 4955 67 54 42 \70у, 28
-----V---------- -г— ЧСФормирати табелу контингенције. ч ^
Реш ењ е. Најпре се одређује број интервала, а затиМ^дужина интервала, посебно за свако обележје. Узорак је обима 30, па број интервала може бити број између 1 + 3,322 • 1одш 30 = 5,91
5 • 1о§1030 = 7,39, односно може бити 6 или 7. Узмимо за број тервала к = 6. Сада се одређује дужина интервала за прво обе-
леЦје, дужина релације (X):^тпгп 70 10 _ п1 = -------------- = ----------= 10,ћт =
к 6а затим ихза друго обележје, оцена задовољства (У):
Утах Утт 100 — 28= 12.
Тако добијамо следећу таб/Г\У [28,40) [40, 52) [52,64) [64,76) [76,88)' [88,100]
[10,20)[20,30)[30.40)[40,50),[50, 60)[60,70]
—
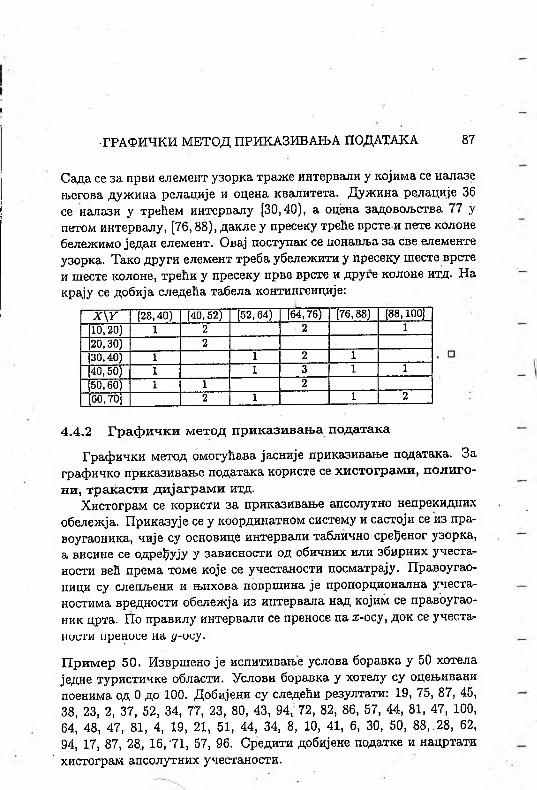
Сада се за први елемент узорка траже интервали у којима се иалазе његова дужина релације и оцена квалитета. Дужииа релације 36 се налази у трећем интервалу [30,40), а оцена задовољства 77 у петом интервалу, [76,88), дакле у пресеку треће врсте и пете колоне бележимо један елемент. Овај поступак се понавља за све елементе узорка. Тако други елемент треба убележити у пресеку шесте врсте и шесте колоне, трећи у пресеку прве врсте и друге колоне итд. На крају се добија следећа табела контингенције:
•ГРАФИЧКИ МЕТОД ПРИКАЗИВАЊА ПОДАТАКА 87
Х \У (28,40) (40,52) [52,64) (64,76) (76,88) (88,100]10,20) 1 2 2 120,30) 230,40) 1 1 2 140,50) 1 1 3 1 150,60) 1 1 260,70]" 2 1 1 2
4.4.2 Граф ички метод приказивањ а података
Графички метод омогућава јасније приказивање података. За графичко приказивање података користе се хистограми, полиго- ни, тракасти дијаграм и итд.
Хистограм се користи за приказивање апсолутно непрекидних обележја. Приказује се у координатном систему и састоји се из пра- воугаоника, чије су основице интервали таблично сређеног узорка, а висине се одређују у зависности од обичних или збирних учеста- ности већ према томе које се учестаности посматрају. Правоугао- ници су слепљени и њихова површина је пропорционална учеста- ностима вредности обележја из интервала над којим се правбугао- ник црта. По правилу интервали се преносе на т-осу, док се учеста- ноеги иреносе на у-осу.
П ример 50. Извршено је испитивање услова боравка у 50 хотела једне туристичке области. Услови боравка у хотелу су оцењивани поенима од 0 до 100. Добијени су следећи резултати: 19, 75, 87, 45, 38, 23, 2, 37, 52, 34, 77, 23, 80, 43, 94, 72, 82, 86, 57, 44, 81, 47, 100, 64, 48, 47, 81, 4, 19, 21, 51, 44, 34, 8, 10, 41, 6, 30, 50, 88,.28, 62, 94, 17, 87, 28, 16, '71, 57, 96. Средити добијене податке и нацртати
' хистограм апсолутних учестаности.

88 СТАТИСТИКА
Решење. Најпре треба интервално средити податке. Како )е ооим узорка п - 50, број интервала може бити 7 или 8. Нека број интервала буде к ~ 7 . Дужина интервала биће
3’тах ЗСтгп. 100 — 2------ — = - 7 - = 14. ' ,
Тако се добија следећа табела апсолутних учестарасти:
Оцена (2Д6) “716.30) (30,44) [44,58) [58,72) 772,86) [86,100]ор. хотеда 5 9 7. 11 3 т , 8
На основу табеле апсолутних учестаности добија се' хистограм прнказан на слици 4.8. □ 1
Слика 4.8: Хистограм апсолутних учестаности.
Код дискретних обележја уместо хистограма користи се тра- касти дијаграм. Његови правоугаоници нису обавезно слепљени а реализована вредност обележја је на средини основице правоугао-
®Редноети обележја могу бити на х или у оси, а површине правоугаоника су сразмерне учестаностима. Код тракастог дија- рама основица правоугаоника је величине јединичне дужи коорди-
натне осе на којој се налази (слика’4.9).
Пример 51. На узорку од 1000 слуИајно изабраних страних ту- под1ц„РеГИСТРОВаН° Ј6 И3 К°је Земље долнзе- Добијени су следећи

ГРАФИЧКИ МЕТОД ПРИКАЗИВАЊА ПОДАТАКА 89
Држава Број туристаНемачка 220Аустрија 320Мађарска 210Шведска 85
Русија 70Остали 95
Приказати заступљеност појединих нација у популацији свих стра- них туриста помоћу тракастог дијаграма процентуалних учеста- ности.
Решење. Табела процентуалних учестаности је:Држава Број туриста %Немачка 220 22%Ауетрија 320 32%Мађарска -210 21%Шведска 85 8,5%
Русија 70 7%Остали 95 9,5%
Тракасти дијаграм је приказан на слици 4.9.
Полигон учестаности је отворена полигонална линија чија су ■емена дефинисана паром бројева (хи &), од којих први број х.

90 СТАТИСТИКА
представља вредност обележја и чита се на х оси, а други број /* је учестаност те вредности обележја и чита се на у оси (слика 4.10). Описани полигон је полигон апсолутних учестаности. Уколико се уместо апсолутних учестаности /< користе релативне учестаности /*, темена полигоналне линије ће бити дефинисана тачкама (жј, /*), а полигон ће се звати полигон релативних учестаности. Код узорка који је сређен интервално за вредност х узима се средина г-тог интервала.
П ример 52. На случајном узорку од тридесет производа испити- вано је колико јединида млечне масти је присутно у 100д једног млечног производа. Добијени су следећи резултати: 325, 313, 322, 319, 296, 290, 311, 303, 331, 313, 330, 323, 308, 335, 299, 321, 308, 347, 311, 328, 327, 326, 311, 323, 314, 350, 333, 316, 305, 301. Нацртати' полигон апсолутних учеста.ности.
Реш ењ е. На основу прикупљених података добија се следећа табела апсолутних учестаности:
Бр. јединица (290,300) [300,-310) (310,320) [320,330)Бр. производа 4 7 6 9
Бр. јединица [330,340) [340,350]Бр. производа 2 2
На х оси се налазе вредности обележја, у овом случају то је број јединица млечне масти, а на у оси се налазе одговарајуће апсолутне учестаности. Изнад средине сваког интервала црта се тачка на висини која одговара учестаности тог интервала. За овај пример, полигонална линија је одређена тачкама (295,4), (305, 7), (315,6), (325,9), (335,2) и (345,2).

ГРАФИЧКИ МЕТОД ПРИКАЗИВАЊА ПОДАТАКА 91
За приказивање квалитативних обележја могу се користити тра- касти дијаграми, али и дијаграми у облику круга (слика 4.11) или правоугаоника.
Остали
Слика 4.11: Питасти дијаграм (Рге — сНаН).


С тати сти чко п роучавањ е. О цењ ивањ е п ар ам етар а расподеле р б е л е ж ја
Статистичко проучавање популације чине три етапе:
1. Прикупљање података. Најпре се дефинише популација која се проучава и обележја која ће се посматрати. Претпоставимо да се посматра једно обележје X. Затим се прелази на форми- рање узорка. Нека се врши п посматрања чији су резул- тати случајне променљиве Х^, Х 2, . .., Х п. Уређена п-торка (Х^. Х 2, ... , Х п) се зове случајни узорак обима п за обе- лежје X. Уколико се посматрају два обележја истовремено (Х,У), резултат посматрања је уређен пар случајних про- менљивих, тако да узорак чини низ парова рб1,У1), (Х2,У2)\ ..., (Х п ,^ ). Узорак мора бити репрезентативан, мора бити одређен обим узорка и начин избора узорка. Затим се одређује тсхиичка нроцедура ирикунљања података. Податке можемо прикупити разним анкетама, интервјуима, попуњавањем раз- них образаца, мерењима итд. На крају се приступа самом прикупљању података.
2. Сређивање и графичко приказивање података. Прикупљени подаци се приказују табелама и. графички.
3. Статистичка обрада података. Сређени подаци се обрађују унапред планираним. статистичким методама и на крају се доносе закључци за целу популацију.
93

94 СТАТИСТИКА
Узорак по својој дефинидији представља случајнју величину, тачније п-димензионални вектор {Хг, Х 2, ■ ■ ■, Х п). После обављеног експеримента или посматрања на располагању је низ конкретних података (т ј , х2, . ■ ■, хп) који се зове реализовани узорак. Реали- зовани узорак се означава малим словима да би се направила ра- злика између њега и случајног узорка. Статистичко закључивање се, по правилу, спроводи.функдијом узорка познатом под називом статистика. Статистика је функција узорка {Хг, Х 2, ■ ■ ■ , Х п) чији апалитички израз пс зависи од непознатих параметара расподеле обележја популације из које је узет. На пример, нека обележје X има нормалну расподелу са параметрима т и сг2 и нека је из популације узет узорак {Хг,Х2, ■ ■ ■ , Х п). Посматрајмо функцију 2
. дефинисану као . __Х„ — т
6 — ---------- I<Ј_ _ п • ј
где је Х п = ^ Е Хг. Уколико су параметри т и а познати, тада*=1
функција 2 представља једну статистику. Уколико.је бар један параметар непознат, тада ова функција није статистика.
Под појмом параметри расподеле обележја или краће параметри обележја, подразумевају се нумеричке карактеристике обележја. Параметри могу бити истакнути у ознаци за расподелу као што је случај код нормалне расподеле случајне променљиве X : /^{т, ст2), где се зна да је т математичко очекивање, тј. т = Е{Х), а а1 дисперзија обележја са наведеном расподелом, тј. сг2 = В{Х). Ме- ђутим, код биномне расподеле В{п,р), тј. случајне променљиве 8п која има В{п,р) расподелу, п и р с е такође називају параметрима, а лако се може показати да је, на пример, р = 1 — -§ ||4 .
Параметри расподеле обележја могу бити познати или непоз- нати. Уколико су параметри расподеле непознати, тада се они про- цењују на бснову реализованог узорка. Када говоримо о оцењи- вању параметара треба истаћи да се ради о оцењивању нумеричких карактеристика обележја као што су математичко очекивање, мод, медијана, дисперзија и слично. При томе постоје о:пште оцене које важе за све расподеле, али такође постоје и оне које се могу применити само код неких расподела. Процењивање непознатих параметара може се вршити конкретним бројем или ивтервалима.

Ако је процена непознатог параметра конкретан број, тада за такву процену кажемо да је тачкаста оцена непознатог параметра. Уколико је процена интервал, тада такву процену називамо интер- валном оценом непознатог параметра.
5.1 Тачкасте оцене нумеричких карактеристика обелсжја
Као што смо већ рекли, тачкаста оцена параметра расподеле обе- лежја за реализовани узорак је конкретан број. Полази се од узорка (Х 1 , Х 2, . .. , Х п) и формира се статистика 9 = ј ( Х \ , Х 2, ■. • ,Х п). У случају реализованог узорка она постаје конкретан број. Од тачкастих оцена посматраћемо оцене мера центара груписања (узо- рачку средину, мод и медијану), оцене мера растурања (узорачку дисперЗију и стандардну девијацију) и оцену мере повезаности два обележја (узорачки коефицијент корелације).
5.1.1 У зорачка средина
Узорачка средина је најчешће коришћена оцена. Дефинише се на следећи начин. Нека је (Хх, Х 2', ■ ■ -^^Хп) узорак обима п из популације са обележјем X . Статистика Х п дефинисана као
Х п — — (А-! +.Х2 4------ 1- Х п) — — Хј- п п 1=1
иазива сс узорачком средином или средином узорка.Реализована узорачка средина означава се са хп и дефини-
ше се као бројХ,, = — (Х\ -|- “4“ . . . —Ј“ Тп),П
где је (х1 , х2, ... , х„) реализовани узбрак. За разлику од узорачке средине. Х п која представља случајну ■ променљиву, реализована узорачка средина хп је конкретан број.
Пример 53. Бр.ој земљотресау Србијиу периоду 1991-1999. годи- не био је: 26, 10, 11, 6, 5, 10, 26, 103, 81 (Извор: Стат. год. Срб., 33,
ТАЧКАСТЕ ОЦЕНЕ 95

96 СТАТИСТИКА
2000., стр. 24 (извод из табеле)). Колики је био очекивани годишњи број земЈвотреса у Србији у периоду 1991-1999. године?
Решење. Одговор на ово питање добићемо када израчунамо реализовану узорачку средину. Најпре одређујемо укупан број земљотреса у периоду 1991-1999. године, тако што саберемо све бро- јеве друге колоне дате табеле. Добијамо да је укупан број земљо- треса у периоду 1991-1999. године
х > < = 26+ 10 + 11 + 6 + 5 + 10 + 264- 103 + 81 = 278.
Сада можемо да одредимо реализовану узорачку средину тако што ћемо укупан број земљотреса (278) поделити обимом узорка (9). Према томе, узорачка средина једнака је 278/9 = 30,89, што значи да је у периоду 1991-1999. године просечно годишње било 30,89 или приближно 31 земЈнотрес. □ •
Пример 54. Максимални водостај на Дунаву мерен код Бездана у току 1998. године у сантиметрима за сваки месец био је: 199, 88, 337, 230, 188, 335, 320, 187, 417, 300, 563 и 410 (Извор: Стат. год. Југ., 1999., стр. 19 (извод из табеле)). Одредити очекивани месечни максимални водостај на Дунаву мерен код Бездана 1998. године.
Реш ење. Означимо са X обележје које представља максми- мални месечни водостај на Дунаву мерен код Бездана. Тада је просечни максимални водостај на Дунаву мерен код Бездана 1998. године
т ,2 = ^ (1 9 9 + 88 + 337 + 230+ 188 + 335 + 320 + 187 + 417 + 300 + 563 + 410) = 297, 83 ст. □
Уколико је узорак табеларно сређен, тј. облика је
Реализоване вредности обележја X *1 ^2 ДАпсолутне учестаности /, л Л п
где су х г, т2, ..., хк реализоване вредности обележја X , а Д, / 2, ..., /к су апсолутне учестаности такве да је њихов збир једнак обиму

УЗОРДЧКА СРЕДИНА 97
_ 1 • 1 к = - ( / 1 * 1 + / 2т 2 + • • • + ?кхк) = - V / {х{.
п . •Према томе, реализована узорачка средина се израчунава тако што се све реализбване вредности х,-. помноже одговарајућим апсолут- ним учестаностима /,, а затим се збир ових производа подели оби- мом узорка п.
Реализовану узорачку средину можемо једноставно одредити следећом табелом
узорка п , тада се реализована узорачка средина израчунава по фор-мули
Хх /,: Јг&г
Е гг
тако што ћемо добијену суму $2 /»ач поделити обимом узорка п.
Пример 55. За 1100 случајно одабраних жена расподела броја ро- ђене деце је
Број деце 0 1 2 3 4 5 6 7Број жена 232 313 360 130 52 10 2 1
Одредити очекивани број деце по свакој жени.Решење. Нека обележје X представља број деце случајно иза-
бране жене. Помоћна табела је облика
Хг Јг ЈгХг0 232 01 . 313 3132 360 7203 130 3904 52 2085 10 ■506 2 127 1 7Е 1100 1700

98 СТАТИСТИКА
Значи, просечан број деце је 1700/1100 = 1,55 или приближно 2. □
Уколико је узорак интервално сређен, тада је поступак сличан претходном. Једина разлика је у томе што се сада за представнике интервала узимају средине интервала (х() и помоћна табела је тада облика
П ример 56. Број општина у Југославији према % оствареног до- хотка у друштвеном сектору у односу на укупно остварени доходак 1974. године (Извор: Стат. год. Југ., 1976., стр. 552 модификована. табела) дат је следећом табелом
% дохотка [0; 20) [20; 40) [40; 60) [60; 80) [80; 100Број општина 7 41 95 ■ 195 170
Одредити очекивани проценат оствареног дохотка у друштвеном сектору у појединој општини.
Реш ењ е. Узорак је интервално сређен, тако да за представнике интервала узимамо њихове средине. Помоћна табела је
Интервали < Јг ЈЉ[0; 20) 10 7 70
[20; 40) 30 41 1230[40; 60) 50 95 4750[60; 80) 70 195 13650[80; 100] 90 170 15300
Е 508 35000
Према томе, очекивани проценат оствареног дохотка у друштвеном сектору по општинама износи 35000/508 = 68,9%. □
Може се десити да су реализоване вредности велике. У том случају се може извршити трансформација узорка ради лакшег израчунавања узорачке средине. Поступак је следећи. Свака реализована вредност хГ се трансформише у реализовану вредност
Интервали < Јг ЈЉ: :
Е ' п Е Ј<<

УЗОРАЧКИ МОД 99
Уг сменом (/,: = при чему су вредности а и 5 изабране тако да олакшају израчунавање узорачке средине. Сада се узорачка сре- дина израчунава формулом
5 к _Х-п = П + - Ј 2 / гУ г = а + 1>уп,
П <-1где је са уп означена средина реализованог узорка (ух. т/2, • • •. :</„)■
Израчуиајмо сада очекивани проценат оствареног дохотка у друштвеном сектору за податке из претходног примера. Можемб извршити трансформацију узорка сменом
Х'г - 50 ;. * ----- 20“
и тада добијамо трансформисани узорак облика
Уг / г ЈгУг
-2 7 -14-1 41 -41
. 0 95 01 195 1952 170 340Е / 480
Очекивани проценат оствареног дохотка у друштвеном сектору је тада
20 5 20 г 508 = 50 + — Е Ј ш = 50 + — • 480 68, 9 .
5.1.2 У зорачки мод
У зорачки мод или мод узорка је она вредност у узорку која има највећу апсолутну (релативну) учестаност појављивања у сво- јој околини.
Пример 57. Посматрајмо узорак из примера 44 и одредимо узо- рачки мод. Видимо да се вредност 6 највише пута јавља, тачније 6 пута, тако да је узорачки мод броја кишних дана вредност 6 и да других модова нема. □

100 СТАТИСТИКА
Код интервално сређеног узорка најпре се одређује модални интервал. Модални интервал је интервал који има већу апсолутну учестаност од оба своја суседа, тј. и од претходног и од наредног интервала. Уколико више интервала има то својство, онда су сви °ни модални интервали и за узорак се каже да има више узорачких модова. Нека узорак има један модални интервал и означимо га са 1ае- Сада одређујемо мод узоркд. Ма по формули
М0 — а.џ + ћџ ■N2
N 1 + У2 ’
где је а,, доња граница модалног интервала ћџ је дужинамодалног интервала и рачуна се по формули ћџ = 1џ- а џ, N 1 је апсо- лутна учестаност интервала испред модалног, а И2 је апсолутна учестаност интервала иза модалног.
Примедба 1. Може се десити да је модални интервал први или последњи интервал код интервално сређеног узорка. Уколико је модални интервал први интервал, тада испред њега нема интер- вала, те је Иг = 0 и у том случају је мод узорка М0 = ћџ. Уколико Је модални интервал последњи интервал, тада иза њега нема ин- тервала, те је М2 = 0 и у том случају је мод узорка М0 = аџ.
Пример 58 Годишње коришћење шума (у хиљ. т 3) у Србији иЦрно.ј Гори у периоду од 1959-1997. године представљено је следе- ћом табелом:
Искоришћеност шума [2500; 3000) [3000; 3500) [3500; 4000)Број година 2 7 6
Искоришћеност шума [4000; 4500) [4500; 5000) [5000; 5500)Број година
Извор: Стат. гол.15
Туг. гнптл5 4
Одредити мод датог узорка.Решење. Узорак је интервално сређен, тако да је потребно
најпре одредити модални интервал. Највећу апсолутну учестаност има интервал [4000; 4500), тако да је он модални интервал. Доња граница модалног интервала је аџ = 4000, дужина интервала је
I

УЗОРАЧКА МЕДИЈАНА 101
К - 4500-4000 = 500, апсолутна учестаност интервала пре модал- ног износи N 1 = 6, а апсолутна учестаност интервала иза модалног јр Лг2 = 5. Према томе. тражеии мод узорка износи
5т0 = 4000 + 500 • ------= 4227, 27.6 + 5
Међутим, интервал [3000; 3500) има већу апсолутну учестаност и од претходног интервала [2500; 3000) и од наредног [3500; 4000), па се и у њему налази мод. Његова вредност је
т 0 = 3000 + 500 --------= 3375.2 + 6
Према томе, посматрано обележје је бимодално. □
5.1.3 У зорачка медијана
У зорачка медијана или медијана узорка је тачка Ме која дели узорак на два дела, таква да се у сваком од делова налази једнак број елемената узорка. Узорачка медијана се одређује ма следећи начин. Најпре се од елемената узорка формира варија- циони низ Т(1), т (2), ..., т (п), тј. низ вредности које су поређане у неопадајућем редоследу (свака наредна вредност је већа или јед- нака претходној вредности). Затим се посматра обим узорка п. Ако је обим узорка непаран број, узорачка медијана је једнака еле- менту варијационог низа х^п+1у 2)- Уколико је обим узорка паран број, онда је узорачка медијана једнака аритметичкој средини еле- мената ж(п/2) и Т((„/2)+1) варијационог низа, тј. једнака је
Ме + Х(?+') 2
П ример 59. Одредити медијане следећих реализованих а) 7, 6, 6, 8, 9, 4, 3, 7, 8, 5, 3, 6, 8, 3, 4; б) 9, 9, 4, 5, 2, 2, 2, 4, 3, 5, 5, 7.
узорака: 8, 6, 7, 9,
Решење. а) Најпре од датих података формирамо варијациони низ: 3, 3, .3, 4, 4, 5, 6, 6, 6, 7, 7, 8, 8, 8, 9. Укуггио има п = 15 података. Обим узорка је непаран број, те је медијана осми податак
• варијационог низа, тј. медијана датог узорка изноеи 6.

102 СТАТИСТИКА
б) Варијациони низ датог реализованог узорка је 2. 2, 2, 3, 4, 4, 5, 5, 5, 6, 7, 7, 8, 9, 9, 9. Обим узорка је паран број (п = 16), те је медијана аритметичка средина осмог и деветог податка ва- ријационог низа, тј. медијана узорка износи т е — (5 + 5)/2 = 5. □
П ример 60. Број дипломираних студената по календарској годи- ни у централној Србији у периоду 1980-1997. године био је: 10304, 9881, 9984, 9860, 9213, 9019, 8894, 7971, 8004, 8008, 7003, 7825, 7845, 7097, 7433, 8005, 8658 и 7663 (Извор: Стат. год. Југ., 1999., стр. 375 (извод из табеле)). Колика је медијана?
Реш ење. Узорак је обима 18, тако да је медијана аритметичка средина деветог и десетог елемента варијационог низа, тачније
т е 8005 + 8008 2 8006,5. □
Код интервално сређеног узорка најпре се одређује медијански интервал коме, заправо, припада медијана. Медијански интервал је први интервал чија је збирна учестаност већа или једнака п/2, при чему.је п обим узорка. Нека је [ам , &м) медијански интервал. Сада одређујемо медијану узорка по: формули
МЕ = ам + ћм -Д Т , - " , " (5.1)%
где је ам доња граница медијанског интервала [о.л/-Ал/), је ду- жина медијанског интервала и рачуна се као ћм = ђм - ам , №м је апсолутна учестаност медијанског интервала, а Је збирна учестаност интервала испред медијанског интервала.
П ример 61. Расподела општина у СФР Југославији према броју основних школа, стање 1974/75 школске године дата је следећом табелом (Извор: Стат. год. Југ., 1976., стр. 556);
Број .школа [п; 5) [5; 10) [10; 15) [15; 20) [20; 25)Број општина 13 47 75 85 63
Број школа [25; 30) [30; 40) [40; 50) [50; 70)Број општина 57 74 41 53

УЗОРАЧКА ДИСПЕРЗИЈА И СТАНДАРДНА ДЕВИЈАЦИЈА 103
Одредити медијану броја школа.Реш ење. Укупан број општина је 508. Узорак је интервално
сређен, тако да најпре одређујемо медијански интервал. Потребне су нам збирне апсолутне учестаности. Табела са апсолутним и збирним апсолутним учестаностима је следећа
Број школа [0; 5) [5; 10) 10; 15) [15; 20) [20; 25)Број општина 13 47 75 85 . 63Збирне учестаности 13 60 135 220 283Број школа [25; 30) [30; 40) [40; 50) [50; 70)Број општина 57 74 41 53 'Збирне учестаности 340 414 455 508
Тражимо први интервал чија је збирна учестаност већа или јед- нака 508/2 = 254. Из табеле видимо да прва збирна учестаност већа или једнака 254 је 283 и то је збирна апсолутна учестаност интервала [20; 25). Према томе, медијански интервал је интервал [20; 25). Доња граница- медијанског интервала је ад/ = 20, дужина медијанског интервала је ћм = 5, апсолутна учестаност медијан- ског интервала је Лд/ = 63, а збирна апсолутна учестаност интер- вала испред медијанског је Ј2м — 220. Како су нам познати сви подаци, то можемо израчунати медијану узорка
т е — 20 + 5 • 254 - 220 63 = 22, 7. □
Приметимо да се понуђеном статистиком (5.1) за оцену меди- јане не добија средина медијанског интервала. У разлоге за овакав избор оцене за медијану нећемо да улазимо у оквиру овог курса.
5 .1 .4 У зорачка д и сп ер зи ја и стандардна Девцјација
После узорачке средине најчешће коришћена оцена'је узорачкади сп ер зи ја или д и сп ер зи ја узорка. Она представља меру расту-рања података око центра груписања. Дефинише се на следећиначин. Нека је [Х\, Х 2, ... , Х п) узорак обима п > 30 из популације
—2са обележјем X . Статистика 5 п дефинисана као
(5.2)

104 СТАТИСТИКА
назива се узорачком дисперзијом посматраног узорка. Формула (о.2) може се представити у једноставнијем облику за израчуна- вање:
5!
Ако се посматра реализовани узорак, онда се може дефинисати реализована узорачка дисперзија као
4 = ^ Е (** - хп)2 П 1—1
о д н о с н о , к а о ' •
>2 = | Еи 1=1Видимо да је за израчунавање узорачке дисперзије потребно најпре одредити узорачку средину.
Уколико је узорак обима п < 30, тада се уместо узорачке дис- перзије израчунава поправљена узорачка дисперзија 5,2г као
Ова формула се може записати у облику који је једноставнији за израчунавање поправљене узорачке дисперзије:
5 21=1
Уместо обима узорка п, код ових статистика се у индексу може наћи име обележја, дакле и 5% поготову када се посматра више обележја истовремено. , •
Пример 62. Минималне месечне температуре на Дунаву код Зе- муна 1998. године су биле: 3, 2, 6, 7, 13, 19, 19,5, 20,5, 15,11, 4 и 1 (Извор: Стат. год. Југ., 1999., стр. 19 (извод из табеле)). Одредити узорачку федину и дисперзију.

УЗОРАЧКА ДИСПЕРЗИЈА И СТАНДАРДНА ДЕВИЈАЦИЈА 105
Решење. Нека је обележје А минимална месечна температура на Дунаву код Земуна. Збир свих реализованих вредности је
Х ^ = 3 + 2 + 6 + 7 + . . . + 4 + 1 = 121,
док је збир квадрата свих реализованих вредности
Л х * = З2 + 22 + 62 + 72 + . . . + 42 + I2 = 1791, 5.
У том случају, узорачка средина је.
хп = — = 10,08.
С обзиром да је обим узорка 12 < 30, то рачунамо реализовану поправљену узорачку дисперзију и она је једнака
—2 1791,5 12 ,$12 = —^ ------— -(10,08)2 = 52,02. □
/ Пример 63. Годишња производња пшенице (у хиљ. тона) у Срби- Црној Гори у периоду 1965-1997. године била је: 2193, 2750
2945, 2521, 2901, 2213, 3521, 3008, 3040, 3957, 2987, 3765, 3681* 3653, 2729, 3222, 2793, 3205, 3377, 3375, 2911, 2919, 3168, 3939, 3406,’ 3869, 4109, 2101, 3049, 3249, 2949, 1507 и 2920 (Извор: Стат. год! Југ., 1999., стр. 225 (извод из табеле)). Колика је просечна годиш- ња производња пшенице у периоду 1965-1997. године? Колика је узорачка дисперзија?
Решење. Нека обележје X представља годишњу производњу пшенице у хиљ. тона. Збир свих реализованих вредности износи X) т.ј = 101932, и како је узорак обима п = 33, то је просечна годиш- ња производња пшенице једнака
*зз =101932
33 = 3088,85 хиљада тона.
С ДРУ1е схране, узорак је обима већег од 30, тако да у овом примеру рачунамо узорачку дисперзију. Збир квадрата свих реализованих вредности је 325507214, тако да је сада узорачка дисперзија једнака
5зз —325507214
- (3088,85)2 = 8678260,6. □33

106 СТАТИСТИКА
Уколико је узорак табеларно сређен, тада се реализована узо- рачка дисперзија израчунава по формули
П 1=1
ОДНОСНО, 110 ф о р м у л и
^ = - Х > ? - ( * Ј 2 .П 1=1
где је, као што .је објашњено код узорачке средине, /* апсолутнауче- станост реализоване вредности т*. Уколико је узорак обима мањег од 30, тада се поправљена узорачка дисперзија израчунава као
$п = —"ЦТ ^ ~ Хт ’71 1 1=1
односно, као1
п — 1 Е / ^ 1 -1=1 П
Ако је узорак и интервално сређен, тада се за реализоване вред- ности узорка узимају средине тих интервала и даљи поступак је исти као што је управо објашњено..П ример 64. Израчунати узорачку дисперзију података из при- мера 61.
Реш ење. Користимо следећу табелуБрој
општинаСредине
0*) Јг ЈгМ ЈгА[ о; 5) 2.5 13 32,5 81,25[ 5; 10) 7,5 47 352,5 2643,75[10; 15) 12,5 75 937,5 11718,75[15; 20) 17,5 85 1487,5 26031,25[20; 25) 22,5 63. 1417,5 31893,75[25; 30) 27,5 57 1567,5 43106,25[30; 40) 35 74 2590 90650[40; 50) 45 41 1845 83025[50; 70) 60 53 3180 190800
Е 508 13410 479950

УЗОРАЧКИ КОЕФИЦИЈЕНТ КОРЕЛАЦИЈЕ 107
Из табеле добијамо да је узорачка средина једнака 13410/508 = 20,4, док је узорачка диснерзија једнака 479950/508 — (26,4)2 = 247,8. □ "
Помоћу узорачке дисперзије може се дефинисати појам узо- рачке стандардне девијације. Узорачка стандардна девијација означава се са 8„ и дефинише формулом 5„ — у/ з - Такође, може се дефинисати и поправљена узорачка стандардна девијација као 5п = у/§%. За претходна три примера узорачке стандардне де- вијације еу: 7,21 (пример 62), 2945,9 (пример 63) и 15,7 (пример 64).
Ако су реализоване вредности велике, тада се може извршити трансформација узорка да би се лакше израчунала узорачка дис- перзија. • Користи се трансформација т/» = и тада су реали- зоћана узорачка дигпорзија и узорачка стандардна де.вијација ре- дом з'х — V2 • Зу и зх = |6| • зу . Ознаке з'у и зу представља- ју рсализовану узбрачку дисперзију ;и узорачку стандардну деви- јацију трансформисаног узорка {у\,уг, • • •, Уп)-
5.1.5 У зорачки коефицијент корелације
За утврђивање новезаности два обележја X и V кори.сти се узо- рачки коефицијент корелације. За узорак ((АУ.Уј), (Х2, Уг), •••, (Х„, У„)) обима п > 30, узорачки коефицијент корелације једнак је
&х,уЧ (х . - х . ) (у, - у . )
8 х 5 угде су Х„ и У„ узорачке средине обележја X и У, а 8 х и 5У су узо- рачке стандардне девијације обележја X и V. Претходна формула се може записати у облику који је једноставнији за израчунавање
4 ± Х<У{ - Х „ 7 п
■Уколико је узорак мали, тада с.е уместо узорачких стандардних девијација 8х и користе поправљене узорачке стандардне деви- јаЦије З х и З у . . -

108 СТАТИСТИКА
N зорачкп корфпцијсит корелације има исте особине као и ли- неарни коефицијент корелације, тј. узима вредности из интервала [— !]■ једнак је 1 ако између обележја X и У постоји линеарна веза у = аХ + ћ при чему је а > 0, а једнак је -1 ако између X и У поетоји линеарна веза V — аХ + 6 при чему је а < 0. Такође, вред- пост узорачког коефицијента корелације се не мења ако се изврши трапсформаццја узорка, тј. ако је 2 ; = пХГ + ћ и = гУ\ + Л. тада је Кг.ц/ = Кх.у, уколико су а и с истог знака, и К2>\у = - К Ху , уколико су а и с супротног знака.
Слика 5.1: Корелација два обележја.
* пракси се вредност узорачког коефицијента корелације т~ху можо тумачити на више начина. Једно тумачење би било:
- Ако је \гх .у\ < 0,25, тада сматрамо да између обележја X и- У не поетоји линеарна зависност.
- Ако је 0, 25 < |гл-,г| < 0,5, онда између обележја X и V посто- ји сасвим незнатна линеарна повезаност.
Ако је 0,5 < |гх,г1 < 0,7, тада постоји знанајна линеарна повезаност између обележја X и У'.
- Ако је 0,7 < |гХ|У| < 0,9, онда постоји високо значајна пове- заност између обележја X ћ У.
- Ако је 0, 9 < \тх ,у\ < 1, онда је повезаност између обележја X и У практично линеарног облика.

УЗОРАЧКИ КОЕФИЦИЈЕНТ КОРЕЛАЦИЈЕ 109
Пример 65. У табели су за период од 1955. до 1964. године дати подаци средњих годишњих протицаја Колубаре код Ваљева и Дра- жевца:
Година Проток код Ваљева Проток код Дражевца1955 8,8 59,61956 5,3 36,31957 5,0 23,21958 4,8 26,81959 4,1 22,21960 3,5 14,51961 2,4 13,41962 4,2 25,91963 2,4 14,11964 2,8 10,6
Одредити узорачки коефицијент корелације између средњих го- дишњих протока код Ваљева и Дражевца.
Решење. Нека је X протицај код Ваљева, а У протицај код Дражевца. Узорачки коефицијент корелације обележја X и У нај- лакше одређујемо помоћу следеће табеле
Г х< У< х< У< х<у<1 8,8 ; 59,6 77,44 3552,16 524,482 5,3 - 36,3 28,09 1317,69 192,393 5,0 23,2 25,00 538,24 116,004 4,8 26,8 23,04 718,24 128,645 4Д 22,2 16,81 492,84 91,026 3,5 14,5 12,25 210,25 50,757 2,4 13,4 5,76 179,56 32,168 4,2 ■ 25,9 17,64 670,81 108,789 2,4 14,1 5,76 198,81 33,8410 2,8 10,6- 7,84 112,36 29,68Д А = 43,3 В = 246,6 С = 219,63 П = 7990,96 1307,74
Узорачке средине обележја X и У су једнаке

110 СТАТИСТИКА
док су одговарајуће узорачке дисперзије
*х = § - (4, ЗЗ)2 = 3, 21, з2 = ^ - (24,66)2
Узорачки коефицијент корелације између X и V је
1190, 98.
г х х =^ ^ - 4 , 3 3 - 2 4 , 6 6
10 - 0,97.У372Т • уТШГЗбВидимо да је узорачки коефицијент корелације између X и У ве- лики, што значи да постоји линеарна веза између об)ележја X и V, тј. да ће повећање протицаја Колубаре код Ваљева довести до повећања протицаја и код Дражевца. Закључак о постојању ли- неарне везе између ова два обележја следи и из графичког приказа парова вредности (хГ, уГ) (слика 5.2). □ .
Слика 5.2: Дражевца.
Графички приказ протицаја Колубаре код Ваљева и
П ример 66. Расподела просечног прихода и броја деце 100 слу- чајно изабраних породица дата је следећом табелом
Број деце-Приход у.хиљ. динара
[0; 10) [10; 20) [20; 30) [30; 40)0 9 14 8 61 11 20 9 42 - 4 7 3 13 1 2 1 0

Одредити узорачки коефицијент корелације између породичног прихода и броја деце.
Решење. Реализоване вредности обележја породични приход су интервално сређене, те је потребно узети средине интервала за представнике интервала. Означимо са У породични приход, X број деце, /„■ апсолутну учестаност пара {х^уј), /*. апсолутну уче- станост податка хи а са /.у апсолутну учестаност податка Уј. Тада су оцене очекиваних вредности и дисперзија обележја X и У редом
8 2х = ± Е Ј и Х ? - ( х п) 2,
Уп = \ Е Ј.ј Уј , 5 2у = А Е /.ј У? - (Уп) 2 •Ј—1 1 = 1 4 7
За израчунавање узорачког коефицијента корелације користимо следећу табелу
УЗОРАЧКИ КОЕФИЦИЈЕНТ КОРЕЛАЦИЈЕ 111
Х \У 5 15 25 35 /<• ®<Е ЈнУј0 9 14 8 6 37 0 0 01 11 20 9 4 44 44 44 7202 4 7 3 1 15 30 60 .4703 1 2 1 0 4 12 36 180
Ј .ј 25 43 21 11 А = 100 5 = 8 6 С =140 5= 1370Ј.јУј 125 645 525 385 5 = 1680Ј .ју1 625 9675 13125 13475 15=36900
Бројеви у последњој колони горње табеле се рачунају на следећи начин:
0 • (9 • 5 + 14 • 15 + 8 ■ 25 + 6 - 35) = 0,1 ■ (11 • 5 + 20 • 15 + 9 • 25 + 4 ■ 35) = 720,.
■2 - (4 - 5 + 7-15 + 3-25 + 1 - 35) = 470,3- ( 1- 5 + 2-15 + 1-25 + 0.-35) = 180.
Ознаке у табели имају следећа значења: А је обим узорка п, В је сума Е /».2+ С је сума Е ћ .х ј , В )е сума Е Ј.јУј, Е је сума Е Ј.јУ2, а Р је сума Е Е ЈгјХ Уј. Из табеле добијамо да је реализована узо- рачка средина обележја X једнака

112 СТАТИСТИКА
реализована узорачка дисперзија за X је
с= -д - (^10о)2 = 0,66,
реализована узорачка средина обележја V је
2/100 — ~д — 16,8,
а реализована узорачка дисперзија обележја У је
ЕЗу = Ј ~ (Уш )2 = 86,76.
За ове вредности добијамо да је узорачки коефицијент корелације) 6 Д Н З .К
ТИГ “ 0,86-16,8Гу у = - <-џо -________ !______ П 1
Вредност узорачког коефицијента корелације је мала, што значи да Је линеарна веза између обележја X и У веома слаба, тј. да породични приходи и број деце у породици нису у линеарној вези.
Интервално оцењивање параметара распо- деле обележја
Д° сада см0 као оц-енУ параметра расподеле обележја користили конкретан број. који је представљао приближну вредност непоз- натог параметра. Међутим, у неким ситуацијама потребна нам је општија информација о вредности непознатог параметра, тј. ин- формација у којим се границама креће права вредност параметра.
отреба за таквом информацијом нас доводи до' интервалног оце- њивања параметара расподеле обележја, Општи поступак је следе- ћн. Посматра се обележје X чија расподела зависи од непознатог параметра в. Потребно је за дати узорак (Хи Х 2, . . . , Х п) обима п

ИНТЕРВАЛНО ОЦЕЊИВАЊЕ
наћи две статистике <Рг{Хи Х 2, . . . , Х а) и ч>г(Хи Х г, .. да је ‘•71Ј -КОК
Р Ш Х г,Х 2, . . . , Х п) < в < њ { Х и Х>,.. . ,! „ )} = 1 - а . (5.3)
Интервал <р2] зове се случајни интервал параметра В нивоа поверења 100(1 - а)% или скраћено, интервал поверења. При- ликом одређивања интервала поверења најчешће се узима висок ииво поверења: 90%, 95%, 99%.
Ако су обе границе интервала поверења случајне променљиве, тада је реч о двостраном интервалу поверења. Ако је само једна граница случајна, тада се ради о једностраном интервалу повере- ња.
Напоменимо да израз (5.3) не значи да је вероватноћа да В упадне у [џ>1 ,џ>2] једнака 1 - а, већ значи да од више интервала који се из више узорака истог обима п добијају, њих 100(1 — а)% захвата праву вредност параметра в.
Сада ћемо посматрати интервалне оцене параметара нормалне расподеле. Нека обележје X има нормалну расподелу Л/(т, а2) и нека је (Хг,Х 2, . . . , Х п) узорак обима п. Посматрајмо најпре пара- метар т. Уколико је параметар сг2 познат, тада је интервал пове- рења за параметар т облика
Јт =
при чему је Х п узорачка средина, а је број који се чита изтаблице нормалне расподеле и задовољава услов Ф Њ - Ј = Пш,Неколико карактеристичних вредности за гња је дато следећом табелом 2
1 — а 0,9 0,95 0,99X1 — а -----2. 1,64 1,96 2,57
Пример 67. Посматрано обележје X, просечне годишње падавине у -фрици, има нормалну расподелу са дисперзијом а2 = 324 и
. непознатим параметром т. Из датог узорка обима 50 реализована

114 СТАТИСТИКА
узорачка средина износи Х50 = 85. Одредити интервал поверења за параметар т за ниво поверења 0,95.
Реш ењ е. Познате су нам све вредности: узорак је обима п = 50, ниво поверења је 1 - а = 0,95, стандардна девијација је а = л/324 = 18, реализована узорачка средина је Зс5ђ = 85, а за дати ниво поверења је = 1, 96. Према томе, тражени интервал поверења за параметар т је
18/7 7 1 -- 85
л/501,96; 85 + 18
л/501,96 [80,01; 89,99]. □
Ако је параметар а2 непознат и узорак је мали (п < 30), тада је интервал поверења за т облика
Ап •Јп ' ^п -1 ;^ (5.4)
где је 5п поправљена узорачка стандардна Девијација,| а 4п_1;1=н је вредност која се чита из таблице Студентове расподеле. Неколико карактеристичних вредности за је дато следећом табелом
1 — а = 0, 9п 5 10 15 20
2,132 1,833 1,761 1,7291 — а = 0,95
п 5 10 15 20*п—1;Ца 2,776 2,262 2,145 2,093
1 — а = 0,99п ■ 5 10 15 20
4,604 3,25 2,977 2,861
Уколико је узорак обима п > 30, тада је интервал поверења за т облика
/ш — Хп ; Хп +
где је 5п узорачка стандардна девијација.

ИНТЕРВАЛНО ОЦЕЊИВАЊЕ 115
Пример 68. У случајном узорку од 10 градова проденти становни- ка старијих од 65 година су: 15,4; 19,7; 24,6; 18,9; 15,2; 19; 21,3; 17,9;15,5 и 16. Одредити 95% интервал поверења очекиваног процента становника старијих од 65 година.
Решење. Означимо са X проценат становника старијих од 65 година. За разлику од претходног примера, овде не постоји никаква претпоставка о дисперзији, што значи да је она непозната. Узорак је мали (10 < 30), тако да користимо формулу (5.4). Узорачка сре- дина је
ххо = — (15,4 + 19,7 + . . . + 15,5 + 16) = 18,35,
а поправљена узорачка дисперзија је
5?0=Л [(15,4 - 18,35)2 + . . . + (16 - 18,35)2] =9,2.
Коначно, интервал поверења за т у случају непознате дисперзијеје
18,35 2’262; 18. 35 + ^ ^ ' 2-26216,06; 20,64]. □
Одредимо сада интервал поверења за параметар сг2 у зависности од параметра т. Поново разликујемо два случаја: када је параме- тар т познат и када је непознат. У случају да је параметар т познат, интервал поверења за с 2 је облика
Е ( Х < - т ) 2Г=1
Е № - т ) 21=1
при чему су Х п ; | и Хп;1 - | вредности које се читају из таблице х 2 расподеле. Неколико карактеристичних вредности за Хп;а и Хн;1 - § .
када је 1 - а — 0,9, је дато следећом табеломп 5 . 10 15 20
1,15 3,94 7,26 10,9
*п;1-* ИД 18,3 25 31,4

116 СТАТИСТИКА
Ако је параметар т непознат, тада је интервал поверења за пара- метар сг2 облика
Поред овог интервала (двостраног), могу се посматрати и једно- страни интервали поверења. Једнострани доњи интервал поверења је облика
Пример 69. Посматрамо обележје X, проценат чистог метала у руди који има нормалну расподелу. Из узорка обима 30 добијена је узорачка дисперзија з |0 = 7, 27. За ниво поверења 0,9 одредити двострани и оба једнострана интервала поверења за параметар сг2.
Решење. Видимо да не постоји никаква претпоставка о пара- метру ?п, што значи да је он непознат. Двострани интервал пове- рења за параметар ст2 је
Једнострани доњи интервал поверења је
а Једнострани горњи интервал поверења је
док Је Једнострани горњи интервал

И Н Т Е Р В А Л Н О О Ц Е Њ И В А 1 -Б Е 117*
Некада је потребно одредити интервале поверења за стандардну девијацију а. Они се једноставно одређују помоћу интервала пове- рења за дисперзију а2. Двострани интервал поверења за а је
Д =п31 п31
N Х п -1 ;1 - § \ Х п - 1 ; |
Једнострани доњи интервал је
1ап з 2п \
N Х п—1;аоо
)док је једнострани горњи интервал
1а
/п ■ п 5 ,211Ј , л
\ 'V2Лп—1;1— а
Тако за претходни пример, двострани интервал поверења нивоа гто- верења 0,9 за стандардну девијацију је 1а = [2,18 ; 3, 69], једностра- ни горњи интервал је 1а = [2,26; оо), а једнострани доњи интервал за стандардну девијацију је 1а = (0; 3,51].

I!

! ' I I! I
I
Тестирање статистичких хипотеза је вид статистичког закљу- чивања који се примењује у ситуацијама када се унапред прет- поставља постојање одређене везе међу изучаваним појавама, и када се претпоставља да посматрано обележје има одређену рас- поделу.
Свака претпоставка која се односи на расподелу обележја зове се статистичка хипотеза. Статистичка хипотеза може бити тачна или погрешна. Она се тестира на основу узорка и доноси се одлука о њеном прихватању или одбацивању. Сам поступак верифико- вања статистичке хипотезе на основу узорка зове се статистички Тест. Статистички тест најчешће користи неку статистику и таква статистика се зове тест статистика.
Сваки статистички тест истовремено посматра две хипотезе које су једна другој супростављене. Ради лакшег рада једна од две хипотезе се узима за полазну или ”нулту” хипотезу и означава се еа # 0. Друга хипотеза се зове алтернативна хипотеза и озна- чава се са Нг или На. По правилу за нулту хипотезу се узима она хипотеза која се лакше верификује.
Статистичка хипотеза може бити проста или сложена. Хи- потеза је проста ако у потпуности одређује расподелу обележја, у супротном је сложена. Примери простих хипотеза биле би хипотезе Н0{т = 10) и #о(<х2 = 4), док би сложене биле Нг(т ф 10) и # 1(сг2 ф 4).
При тестирању статистичких хипотеза по правилу се дефинише скуп С који служи као критеријум за одбацивање, односно прихва- тање нулте хипотезе. Наиме, хипотеза #о се одбацује ако реали- зовани узорак (хх, х2, ... , хп) припада области С, у супротном се
119

120 СТАТИСТИКА
прихвата. Скуп С се зове критична област.Одлуком о прихватању или одбацивању нулте хипотезе могуће је
начинити две грешке: грешку прве и грешку друге врсте. Грешка прве врсте настаје у ситуацијама када је хипотеза Н0 одбачена, а била је фактички тачна. Вероватноћа да се учини грешка прве врсте означава се са а:
а = ^ # 0 { ( ■ '^ 1 > - ^ 2 > • • • > Х п ) 6 С } .
I реш ка друге врсте чини се када се нулта хипотеза прихвати, а заправо није тачна. Вероватноћа да се начини грешка друге врсте означава се са /3:
Р = РнЛ(Х1,Х*;-- : ,Х п) $ С } .
Вероватноћа а се зове и праг значајности теста. За праг значај- ности се најчешће узимају вредности 0, 1 ; 0, 01 и 0,05.
У зависноети од тога да ли расподела тест статистике зависи од расподеле посматраног обележја, статистички тестови могу бити:
1 . параметарски, код којих расподела тест статистике зависи од расподеле посматраног обележја, и
2. непараметарски, код којих расподела тест статистике не зави- си од расподеле посматраног обележја.
6.1 Тестови хипотеза о параметрима
Посматраћемо сада параметарске тестове који се односе на тестирање параметара нормалне расподеле. Ови тестови се користе У ситУаЦиЈама кад имамо 'претходно знање о расподели обележја које испитујемо и то да је та расподела нормална. Најчешће се после извесног времена или неких активности проведених на попу- лацији поставља питање да ли су се параметри посматране нор- малне расподеле променили. У ту сврху се користе тестови за параметре нормалне расподеле. Они спадају у групу параметар- ских тестова, јер расподела тест статистике зависи од нормалне расподеле обележја.

Размотрићемо следеће случајеве тестирања хипотеза које се односе на параметре нормалне расподеле:
1 . тестирање хипотезе о параметру т када је параметар ст2 поз- нат,
2. тестирање хипотезе о параметру т када је параметар а2 не- познат,
3. тестирање хипотезе о параметру п2 када је параметар т поз- нат, и
4. тест-ирање хипотезе о параметру ст2 када је параметар т не- познат.
6 .1.1 Тестирање хипотезе о параметру ?тг када је сг2 познато
Желимо да испитамо да ли је дошло до промене вредности пара- метра т. У том смислу, тестирамо нулту хипотезу Н0(т = ?тг0), где је т 0 конкретан број, против једне од алтернативних Нг(т ^ т 0), Н\(т > т0) или Н\(т < т 0). Претпостављамо да је параметар <х2 познат. Посматра се тест статистика 20 дефинисана као
гу * п т0 ,—2 0 ---------------уп,сг
где је Х п средина посматраног узорка. Под условом да је нулта хипотеза Н0 тачна, тест статистика 20 има стандардну нормалну расподелу. Критичне области С зависе од алтернативних хипотеза и приказане су у табели:
ТЕСТИРАЊЕ ХИПОТЕЗЕ 0 ПАРАМЕТРУ т 121
Н0 Нг Ст ~ т0 т У т 0 N > 20,5-|т = т 0 т > т 0 20 > -го.Б-ат — т 0 т < т 0 гО < — г0,5-с,
Број га је решење једначине Ф(г„) - а и одређује се из таблице нормалне расподеле. На пример, ако је а = 0,475, тада је г0:475 број

122 'СТАТИСТИКА
из таблице који задовољава једначину Ф(20,475) = 0,475, а то је број 1,96. ’
На крају доносимо закључак о одбацивању или неодбацивању нулте хипотезе. Ако реализована вредност г0 упада у критичну. област С, тада одбацујемо нулту хипотезу Н0 и прихва.тамо алтер- нативну Н\ да је дошло до промене вредности параметра т. У супротном, прихватамо нулту'хипотезу Н0, односно можемо сма- трати са прагом значајности а да није дошло до промене вредности параметра т. ■ :
П ример 70. У табели су приказани износи на текућим рачунима 30 случајно одабраних клијената банке:
. У ш т е д а [ - 3 0 0 0 , - 2 0 0 0 ) [ - 2 0 0 0 , - 1 0 0 0 ) [ - 1 0 0 0 , )) [ 0 , 1 0 0 0 )Б р о ј к л и ј е н а т а •1 4 6 7
У ш т е д а [ 1 0 0 0 , 2 0 0 0 ) [ 2 0 0 0 , 3 0 0 0 ) [ 3 0 0 0 , 4 0 0 0 ]Б р о ј к л и ј е н а т а 6 4 2
при чему је дуг посматран као негативна уштеда. Претпостављају- ћи да стање на текућем рачуну клијента има нормалну расподелу АС{т\ 2500), тестирати хипотезу да је: а) очекивана уштеда 500 ди- нара, против алтернативне да није 500 динара, б) већа од 500. ди- нара, против алтернативне да. је мања од или једнака 500 динара. Узети да је праг значајности а — 0,05.
Реш ењ е. Тестирамо хипотезу Н0(т = 500) против једне од ал- тернативних. Познат је обим узорка п = 30, дисперзија сг2 = 2500 и вредност т0 = 500. Одредимо узорачку средину следећом табелом:
Интервал Хг /<[-3000, -2000) -2500 1 -2500[—2000, —1000) -1500 4 -6000
[ - 1000, 0) -500 • 6 -3000[0, 1000) 500 7 3500
[1000, 2000) 1500 6 9000[2000,3000) 2500 4' 10000[3000,4000) 3500 2 7000
Е 30 18000

ТЕСТИРАЊЕ ХИПОТЕЗЕ 0 ПАРАМЕТРУ тп 123.
Према томе, узорачка средина изоси хз0 = 18000/30 = 600. Поз- нате су нам с.ве вредности, тако да можемо одредити реализовану вредност тест статистике: . •
20600 - 500
50 • ^30 = 10,95.
Коначно, остаје да одредимо критичне области. Најпре тестирамо хипотезу да је уштеда 500 динара, тј. Н0(т = 500) против алтер- нативне Нх(т ф 500). Како је 20,475 = 1.96 и 10,95 > 1,96, то одбацујемо нулту хипотезу, тј. закључујемо да висина уштеде није 500 динара. Тестирајмо сада хипотезу да је висина уштеде већа од 500 динара, тј. Н0(т = 500) против алтернативне Н\(т > 500). У том случају је 20,45 = 1,64 и 10,95 > 1,64, тако да одбацујемо нулту хипотезу и закључујемо да је висина уштеде већа од 500 динара. □
Пример 71. Издвојени су подаци о броју становника (у хиљадама) 30 села једног региона. Добијени су следећи подаци: 23, 17, 17, 12,.. 13, 10, 21, 17, 20, 9, 15, 4, 23, 8, 15, 3, 3, 4, 13, 22, 6, 27, 12, 7, 22, 10, 22, 6, 25, 18. Да ли се са прагом значајности 0,05 може рећи да је просечан број становника у селима овог. региона 15, ако је дисперзија броја становника позната и износи 49?
Решење. Тестира се нулта хипотеза Н0(т = 15) против ал- тернативне хипотезе Н\(т ф 15). Најпре треба средити податке интервално. Добија се следећа табела:
Б р о ј с т а н о в н и к а 1 3 ,7 ) [ 7 , 1 1 ) 1 1 1 ,1 5 ) [ 1 5 , 1 9 ) [ 1 9 , 2 3 ) [ 2 3 ,2 7 ]
Б р о ј с е л а 8 4 5 5 6 2
Помоћна табела је облика:
Интервал и[3,7) 5 8 40 .[7,11) 9 4 36
[11,15) 13 5 65[15,19) 17 5 85[19,23) 21 6 126[23,27] 25 2 50
Е 30 402

124 СТАТИСТИКА
Према томе, узорачка средина једнака је т30 = ^ = 13( 4, реали- зована вредност тест статистике је
13,4 - 15л/49
-0,23.
За дати праг значајности је 20,475 = 1, 96 и како је | — 0.23| < 1.96, т° нрихватамо хипотезу Н0, тј. закључујемо да очекивани број становника заиста износи 15. □
6 .1.2 Тестирање хипотезе о параметру т када је а' непознато
Опет испитујемо да ли је дошло до промеие вредности пара- метра т, али сада нам није позната дисперзија. Тестирамо нулту хипотезу Н0(т = т0), где је ш0 конкретан број, против једне од ал- тернативних Н0(т ф т0), Н0(т > т0) или Н0(т < ш0), у случајуда дисперзија није позната. Посматра се тест статистика 4п_ј облика
АГ„ - т 0гп-\ - ----=-‘О п у/п — 1 ,
где је Ап средина узорка, а 5„ .стандардна девијација узорка. Под условом да је хипотеза Н0 тачна, тест статистика 4П_2 има Студен- тову расподелу са п - 1 степени слободе. Уколико је узорак мали, тада се користи тест статистика
где је 5„ поправљена узорачка дисперзија. И ова статистика при тачној нултој хипотези има Студентову расподелу са п - 1 степени слободе. Критичне области С зависе од алтернативних хипотеза и приказане су у табели:
# 0 Н х Ст = ш0 т /= т 0 1^п—11 > ^ « - 1 ; 0 , 5 - §Ш = ш0 т > ш 0 1п-\ > ^ п —1:0.5—п
3 II 3 о т < тО ^ - 1 ^ ~ ^ п - 1 ; 0 , 5 - а

ТЕСТИРАЊЕ ХИПОТЕЗЕ О ПАРАМЕТРУ т 125
Број 2п_1;а се одређује из таблице Студентове расподеле. На пример, ако је узорак обима 30 и а = 0, 01, тада је г29;0|1 = 0, 256. Закључак је исти као и код претходног тестирања. Једина је разли- ка та што се посматра реализована вредност тест статистике 1п-[,П ример 72. Извршено је 30 мерења процента чистог метала у руди на једном геолошком локалитету. Резултати мерења су дати интервално, са одговарајућим учестаностима:
Проценат метала [0,3; 0,8) [0,8; 1,3) [1,3; 1,8)Учестаности 5 5 4
Проценат метала [1,8; 2,3) [2,3; 2, 8) [2, 8; 3,3)Учестаности 9 5 2
Под претпоставком да проценат метала има нормалну расподелу, тестирати хипотезу да је очекивани проценат 1,75 против алтерна- тивне да је различит од 1,75, са прагом значајности 0,05.
Решење. Тестирамо нулту хипотезу Н0(т = 1,75) против ал- тернативне Нх(т 1,75). Не постоји никаква претпоставка о вредности параметра ст2, тако да је реч о тестирању хипотезе о параметру т када је дисперзија ст2 непозната. Тест статистика је облика
Х п ?710 ,----- —Ч»-1 = — ----- • Нп - 1 .
За сада су нам познати обим узорка п — 30 и вредност т0 = 1,75. Потребно је још да одредимо реализовану узорачку средину хп и реализовану узорачку стандардну девијацију з,г. С обзиром да је узорак интервално сређен, то за' представнике интервала узимамо средине интервала. Као и раније, тако ћемо и сада за израчунавање реализоване узорачке средине и дисперзије користити табелу
Интервали < и к А 4 ~ м ~[0,3; 0,8) 0,55 5 2,75 25 13,75[0,8; 1,3) 1,05 5 5,25 25 26,25[1,3; 1,8) 1,55 4 6,2 16 24,8[1,8; 2,3) 2,05 9 18,45 81 166,05[2,3; 2,8) 2,55 5 12,75 25 63,75[2,8; 3,3) 3,05 2 6,1 4 12,2
Е 51,50 Е ^ 306,8

126 СТАТИСТИКА
Из табеле добијамо да су реализована узорачка средина и дисперзи- ја редом једнаки
= — 51,50 = 1,72,
4 , = • 306,8 — (1,72)2 = 7,268.
У том случају реализована узорачка стандардна девијација је јед- нака 530 = 2,696. Из свега овога добијамо да је реализована вред- ност тест статистике једнака
Остаје још да одредимо критичну област. Читајући из таблице Студентове расподеле добијамо да је 229,0,475 = 2 , 0451 Можемо приметити да је | - 0 ,06| < 2,045, тако да са прагом значајности 0,05 можемо сматрати да је очекивани проценат руде једнак 1,75. □
П ример 73. У једној пољопривредној области је током 10 година мерен укупан принос пшенице (у одговарајућим јединицама). До- бијени су следећи подаци: 40, 34, 40, 29, 23, 32, 22, 24, 34 и 31. Да ли се, ако је праг значајности 0,05, може рећи да просечан принос премашује 25 јединица?
Реш ењ е. Тестира се нулта хипотеза Но(т = 25) прбтив алтер- нативне хипотезе Д Д т > 25). Прво треба израчунати реализовану узорачку средину и реализовану узорачку дисперзију:
х го = -1(40 + 34 + 40 + 29 + 23 + 32 + 22 + 24 + 34 + 31) = 30,9, III ј
5п = — (402 + 342 + 402 + 292 + 232 + 322 + 222 + 242 + 343 +9 10 '
+ 312) - у • (30, 9)2 = 42,1.
Реализована вредност тест статистике једнака је:
30 , 9 -2 59 ~
••N/10 = 2,88.

Како је 2,88 > 1,833, то се прихвата алтернативна хипотеза Нг, тј. закључујемо да просечан принос пшенице премашује 25 јединица. □ •
ТЕСТИРАЊБ ХИПОТЕЗЕ 0 ПАРАМЕТРУ о-2 127
6.1.3 Тестирање хипотезе о а2 када је т непознато
Сада испитујемо да ли је дошло до промене вредности пара- метра а2 у случају када је непозната вредност параметра т. Тести- рамо нулту хипотезу Н0(а2 = а0), где је а2 конкретан број, против једне од алтернативних Н0(а2 ^ а0), Н0(а2 > а0) или Н0(а2 < а0). Тест статистика за узорак обима п > 30 је облика
Хо 0-0
. -р 2где Је 5п дисперзиЈа узорка. тистика је
За узорак обима п < 30, тест ста-
(п — 1)52 —2 >
где је 8 2 поправљена.узорачка дисперзија. У оба случаја, за тачну нулту хипотезу, тест статистика Хо има X2 расподелу са п — 1 сте- пени слободе. Критичне области С зависе од алтернативних хипо- теза и приказане су у табели:
Н 0 Н г с
ео II а2 ф а 2 Хо < Х п - 1;| V Хо > Х п—1;1— ®^ ^ а2 > а0 Хо > Х п—1-,\—а^ = а0 г>: А Хо <
Број Хп- 1 ;а се одређује из таблице х 2 расподеле. На пример, ако је п = 30 и а = 0,01, тада је Хгддог = 14,3. Закључак тестирања је следећи. Ако реализована вредност тест статистике Хо упада у критичну област, тада са прагом значајности а закључујемо да је дошло до промене вредности параметра а2. У супротном, можемо
. сматрати да није дошло до промене вредности параметра а2.

128 СТАТИСТИКА
Пример 74. У случајно узетим узорцима воде из једног језера, ис- питан је садржај Д20з (бор триоксида) и добијени су, у 1 : 100000, резултати: 45, 43, 37, 41, 41, 60, 58, 61, 60, 58, 60, 60, 61 и 58. Претпостављајући да садржај бор триоксида има нормалну рас- поделу, тестирати хипотезу да је дисперзија једнака а 2 = 100 са прагом значајности а = 0, 01.
Решење. Узорак је обима п — 14, тако да је потребно одредити поправљену узорачку дисперзију. Можемо приметити да узорак има мали број различитих вредности, тако да се он може табеларно средити на следећи начин. Помоћна табела је
и 9Х г и г и*{
37 1 1369 37 136941 1 1681 41 168143 2 1849 86 369845 1 2025 45 202558 3 3364 174 1009260 4 3600 240 1440061 2 3721 122 7442Е 14 / 745 40707
Из табеле добијамо да је узорачка средина једнака т 14 — 745/14 = 53,21, а поправљена узорачка дисперзија је
,2 _ 40707 '14~ 13
14Тз
(53,21)'2 = 82,21.
Реализована 100 је
вредност тест статистике при овим вредностима
Хо =13 •82,21
10010,69.
ИСо =
Остаје још да одредимо критичну област. С обзиром да тестирамо нулту хипотезу Н0(а2 — 100) против алтернативне Н ^ а 2 -ф 100), т0 Је Х13;о,оо5 = 3,57, Х13;о,995 = 29,8 и 3, 57 < 10,69 < 29,8, тако да прихвИтамо хипотезу да је дисперзија једнака 100. □
Пример 75. На узорку од 30 парцела једне области, агрономи су посматрали утицај адитива А на принос индустријског биља. До- бијени су следећи приноси: 61, 86, 65, 68, 50, 74, 80, 63, 50, 86, 81,

ТЕСТИРАЊЕ ХИПОТЕЗЕ О ПАРАМЕТРУ а 2 129
69, 67, 61, 70, 58, 82, 54, 71, 85, 85, 60, 84, 86, 51, 64, 63, 64, 64 и 76. Да ли се на основу ових података са прагом значајности 0,05 може рећи да је дисперзија приноса мања од 150?
Решење. Тестира се нулта хипотеза Н0(а2 = 150) против ал- тернативне хипотезе ДДсг2 < 150). Након интервалног сређивања добија се следећа табела:
Принос [50,56) [56,62) [62,68) [68,74) [74,80) [80.86]Бр. парцела 4 6 7 3 3 7
Прво треба израчунати реализовану узорачку средину и реализо- вану узорачку дисперзију. Помоћна табела је:
Интервали < /г №[50,56) 53 4 2809 212 11236[56,62) 59 6 3481 354 20886[62, 68) 65 7 4225 455 29575[68,74) 71 3 5041 213 15123[74, 80) 77 3 5929 231 17787[80,86] 83 7 6889 581 48223
Е 30 / 2046 142830
Тада су узорачка средина и дисперзија редом једнаке:
2зо =
ч2 - *30 —
204630
14283030
= 68-, 2,
- (68,2)2 = 109,76.
Сада се рачуна реализована вредност тест статистике:
2 30 ■ 109.76Хо 150* 21,95.
Како је 21,95 > 17,71, то одбацујемо хипотезу да је дисперзија маља од 150, а прихватамо нулту хипотезу. □

6.1.4 Тестирање хипотезе о сг2 када је т познато
На крају тестирамо хипотезу о промени вредности параметра ст2 у случају када је вредност параметра т позната. Тестирамо нулту хипотезу Н0 (сг2 = а0), где је а\ конкретан број, против једне од алтернативних Н0 (а2 ф а$), Н0(а2 > сг ) или Н0(а2 < а%). За случај познатог т, користи се тест статистика
Е (А Г * -т )2.,„2 —
130 СТАТИСТИКА
која има х 2 расподелу са п степени слободе, па се у том смислу и критичне области разликују од горе наведених, тј. разликују се само у броју степени слободе. Критичне области С зависе од алтернативних хипотеза и приказане су у табели:
Н0 Н\ С.
ч к: II <Ло а2 ф а \ Хо < Х п -Л V Х о > Хп;1-а
сг2 = а 2 а 2 > а20 Хо > Хп;1—а
С) к: II а 2 < а 2 Хо < Х п :а
Закључак тестирања је исти као за претходно тестирање.
П ример 76. Користећи податке из претходног примера и претпо- стављајући да је т = 50, тестирати са прагом значајности а = 0,01, хипотезу да је сг2 = 100.
Реш ењ е. Одредимо суму Е(^» — т ) 2 помоћу следеће табеле:
ХГ и (т.ј. — 50)2 М х<~ 50)237 1 169 16941 1 81 8143 2 49 9845 1 25 2558 3 64 19260 4 100 40061 2 121 242
Е 1207

131ПИРСОНОВ х 2 ТЕСТ
Значи, реализована вредност тест статистике је Хо = 1207/100 = 12,07. Тестирамо хипотезу Но(а2 — 100) против алтернативне # 1(сг2 ф 100). Задати праг значајности је Хгадооб = 4 ,0Т, х?4.о,9д5 =31.3 и 4,07 < 12,07 < 31,3, што значи да прихватамо нулту хипо- тезу да је сг2 = 100. □
Пример 77. Мерен је проценат заступљености минерала А у јед- ној руди. На основу узорка обима 10 дошло се до следећих про- цената заступљености минерала А: 57, 54, 72, 64, 39, 22, 58, 43, 46 и 39. Да ли се на основу ових података са прагом значајности 0,01 може рећи да стандардна девијација процента заступљености износи 15, ако је очекивани проценат познат и износи 50?
Решење. Тестира се нулта хипотеза Н0(<т2 = 152) против ал- тернативне хипотезе Н\(о2 ф 152). Прво треба израчунати реали- зовану вредност тест статистике. Сума у бројиоцу тест статистикеје
Е(х4 - 50)2 = (57 - 50)2 + (54 - 50)2 + (72 - 50)2 + (64 - 50)2 ++ (39 - 50)2 + (22 - 50)2 + (58 - 50)2 + (43 - 50)2 ++ (46 - 50)2 + (39 - 50)2 = 1900,
тако да је реализована вредност тест статистике једнака
2 _ 1900 _ Хо~ 152 8,44.
Како је 3,325 < 8,44 < 16,919, то се прихвата хипотеза Н0, тј. дис- перзија се не разликује значајно од 225, тј. стандардна девијација износи 15.
6.2 Пирсонов х2 тест
Пирсонов х 2 тест је непараметарски тест који се користи за испитивање:
- Сагласности узорка са претпостављеном расподелом: дат је узорак обима п из популације са обележјем X и тестира се хипотеза да обележје X има расподелу чија је функција рас- поделе Р0.

132 СТАТИСТИКА
- Независности два обележја: на основу узорка обима п тести- ра се хипотеза да су два обележја посматрана иа истој попу- лацији међу собом независна.
6.2.1 И спитивање сагласности узорка са претпостављеном расподелом
Тестира се нулта хипотеза да посматрано обележје X има одре- ђену расподелу, чију ће.мо функцију расподеле означнвати са Р0, против алтернативне хипотезе да нема ту расподелу. Поступак тестирања је следећи:
1. У зависности од тога да ли је обележје дискретно или апсо- лутно непрекидно, црта се тракасти дијаграм или хистограм релативних учестаности и на. основу тога се поставља нулта хилотеза И0.
2. Ако изабрана расподела има непознате параметре, тада се они оцењују на основу узорка.
3. Реална права се дели на к дисјунктних интервала 5\, 52, ..., 5к. чија је уни.ја тачно Д, при чему се води рачуна да сваки интервал у себи садржи најмање 5 елемената реализованог узорка. Ако постоје интервали који садрже мање од 5 елеме- иата реализованог узорка, тада се они придружују суседним интервалима.
4. Израчунавају се теоријске вероватноће
Р(и = Рцв{ Х 6 5'.,}, г = 1,2.......к
уз претпоставку да је нулта хипотеза Н0 тачна.
5. Израчунавају се очекиване апсолутне учестаности /, узорка обима п, у сваком интервалу 5 )
/ г ‘П ' V Ог •

ПИРСОНОВ х ' ТЕСТ 133
6. Израчунава се реализована вредност тест статистике
V 2 = V ' ~ Ј Л 'А.0 2—ј ? »Г=1 /г
при чему је /; остварена апсолутна учестаност у интервалу 5). Статистика коју смо управо навели се може записати и у облику који је нешто једноставнији за рачунање:
к г2
хо = Е т ~ п-Г=1 Јг
Тест статистика Хо има X2 расподелу са к — 1 степени слободе. Ако расподела има I непознатих параметара које смо оценили на основу узорка, тада тест статистика има х 2 расподелу са к — I — 1 степени слободе.
7. Одређује се критична област С величине а
Хо > Хк-1;1-а >
при чему се вредност Хк-1;1-а ч и т а из таблице х2 расподеле. У случају I непознатих параметара расподеле Ро(х ), критична ббласт је
X I > х 1 - 1- 1 ;1 - а ■
8. Доноси се закључак о прихватању или одбацивању нулте хи- потезе на основу реализоване вредности тест статистике Хо и добијене критичне области.
Пример 78. (Н ормална расподела) Просечне годишње падави- пс у тт за место у Африци за период 1905-74 дате су следећом табелом
Падавине [40; 50) [50; 60) [60; 70) [70; 80) [80; 90)Бр. година 3 4 7 16 14 .
Падавине [90; 100) [100; 110) [110; 120) [120; 130)Бр. година 11 9 5 1

134 СТАТИСТИКА
Испитати сагласност података са нормалном расподелом са прагом значајности а — 0,05.
Реш ењ е. Означимо са X годишњу количину падавина. Ово обележје је апсолутно непрекидно, тако да је потребно нацртати хистограм релативних учестаности. Из нацртаног хистбграма се за- кључује да се може посматрати нормална расподела (оетављамо чи- таоцу да нацрта хистограм и провери нашу тврдњу). Значи, тести- рамо хипотезу да обележје X има нормалну расподелу« Нормална расподела има два параметра т и ст2, и како не постоји никаква претпоставка о вредностима тих параметара, то сматрамо да су они непознати и треба их оценити. Параметар т се оцењује узо- рачком средином т = Х п, док се параметар <т2 оцењује узорачком дисперзијом <т2 = 5П. За дати узорак добијамо оцене параметара т и сг2:
т = 84,14 о2 = 336,41. •
Према томе, наша нулта хипотеза гласи
Н0(Х има N (84 ,14; 336,41) расподелу).
Следећи корак је подела реалне праве на дисјунктне интервале. Први интервал [40; 50) има учестаност мању од 5, тако да ћемо га придружити наредном интервалу, и тада добијамо интервал 5 г = (-оо; 60) учестаности 7. Следећи интервали су 8 2 = [60; 70), 8 3 = [70; 80), 64 = [80; 90), 65 = [90; 100) и = [100; 110) ^честаности 7, 16, 14, 11 и 9, респективно. Учестаност интервала [120; 130) је мања од 5, тако да ћемо овај интервал придружити претход- ном интервалу и тако добијамо још један интервал 8 7 = [110; оо) учестаности' 6. Значи, реална права је подељена на 7 дисјунк- тних интервала. Одредимо сада теоријске вероватноће догађаја {X Е.Зг}, за г € {1,2,3,4, 5,6,7}. Обележје X има нормалиу рас- ноделу //(84,14; 336,41), тако да је: потребно у току израчунавања вероватноћа извршити стандардизацију
. . . X ~ 84,14 л / 3 3 6 ,41. ' ■

ПИРСОНОВ х 2 ТЕСТ 135
У хом случају обележје X* има стандардиу нормалну расподелу. Прва вероватноћа је једнака
Рох = РНо{Х е 5 г} = Р { Х < 6 0}
= УЈ{А'* < -1 ,3 2 } =0,0У34.
X — 84,14 _ 6 0 -8 4 ,1 4 ] л/336,41 ^ /336,41 Ј
Остале вероватноће су једнаке
Р02
Роз
Р04
Р05
Роб
Р07
= р'{60 < X < 70} = Р |
= 0,1272
= Р{70 < X < 80} = Р |
= 0,1884
= Р{80 < X < 90} = Р |
= 0,2165
= Р{90 < X < 100} = Р
60 - 84,14 ^ 7 0 -8 4 ,1 4 }/336,41 ~ /336,41 ј
70-84 ,14 ^ . 8 0 -8 4 ,1 4 }/336,41 - /336,41 Ј
80-84 ,14 _ 9 0 -8 4 ,1 4 }/336,41 “ ^ /336,41 Ј
Г 90 ~ 84,14 1 0 0 -8 4 ,1 4 }{ /33674Г - /336,41 Ј
= 0,1796
= Р{100 < X
= 0,1156= 1 — (Р01 + Р02 + Роз + Р04 + Р05 + Роб) = 0,0793.
110-84 ,14 /336,41 _
Последња вероватноћа је израчуната тако да збир свих вероватноћа буде 1. Очекиване апсолутне учестаности и реализована вредност
■ тест статистике се добијају из следеће табеле

136 СТАТИСТИКА
5, 1-1 ‘Р0г /: (/, - / ,)2 (А-/0-7[ — ос: 60) 7 0,0934 6,54 0,212 0,032
Г[ 60: 70) 7 0,1272 8,90 3,610 0,406[ 70: 80) 16 0,1884 13,19 7,900 0,599[ 80; 90) 14 0,2165 15,16 1,350 0,089[ 90; 100) 11 0,1796 12,57 2,460 0,196[100; 110) 9 0,1156 8,09 0,830 0,103[110; оо) 6 0,0793 5,55 0,200 0,036
Е 1,461
Нл крају одредимо критичну област. Број интервала је А- = 7. орој^оцењених параметара је 2, а праг значајноети је 0,05, тако да ■Је А7- 2- 1;о,95 — 9,49 И како је 1,461 < 9,49, то прихватамо нулту хмпотезу да су подаци сагласни са нормалном расподелом. □
Пример 79. (Пуасонова расподела) Да ли се са прагом значај- пости о = 0.05 може сматрати да расподела деце из примера 55 има Пуасонову расподелу?
Решење. Нека обележје X представља број деце. Тестирамо хипотезу да обележје X има Пуасонову расподелу. Пуасонова рас- подела има један параметар, А, и у овом примеру он је непознат. Параметар А се оцењује узорачком средином А = Х п. Средина датог узорка је израчуната у примеру и једнака је 1 ,55, тако да је оцсма пара.метра А = 1.55. У том случају, потпуна нудта хипотеза гласи
Но(Х има 1,55) расподелу).
Наредии корак је подела реалне праве на дисјунктне интервале. Водећи рачуна о апсолутним учестаностима интервала, реалну пра- ву поделимо на шест дисјунктних интервала = (—оо; 1), 52 = [!■-). ~ [--^)| 5.[ = [3;4), ,$5 = [4; 5) и 5ц = [5;с»). А честаностинптервала су редом 232, 313, 360, 130, 52 и 13. Одредимо сада теоријске вероватноће догађаја {X € З Ј , за г е {1, 2, 3,4, 5, 6}. Прва вероватноћа је једнака
Р01 = Рн0{Х е 5 Ј = Р {Х < 1} = Р {Х = 0} = 1,55° -1,550! = 0,21.

ПИРСОНОВ X2 ТЕСТ 137
Остале вероватноће су једнаке
Р02 = Рн0{Х 6 = Р {Х = 1} =1,551.
1!. е-1.98 == 0, 326
Роз = Рн0{ Х 6 У з} = Р {Х = 2 } = 1,552 2!
. е-1,55 == о, 252
Р04 = Рн0{Х еУ 4} = Р {Х = 3} =1, 553
3!. е~1,55 == о, 13
Р05 = Рн0{Х 6 5б} = Р {Х = 4 } = 1, 554 4! ■ е-1,55 == о, 051
Ров = 1 - (Р01 + Р02 + V оз + .Р04 + Р 0 5 ) — 0, 031.Очекиване апсолутне учестаности и реализована вредност тест
статистике се добијају из следеће табеле
$ и РОг ћ (л - и ? и<-к?п
[—оо;1) 232 0,210 231,0 1,00 0,004[1:2) 313 0,326 358,6 2079,36 5,799[2; 3) 360 0,252 277,2 6855,84 24,732[3; 4) 130 0,130 143,0 169,00 1,182[4; 5) 52 0,051 56,1 16,81 0,300
[5; оо) 13 0,031 34,1 445,21 13,056Е 45,073 .
Одредимо још и критичну област. Број интервала је к = 6, број оцењених параметара је 1, а праг значајности је 0,05, тако да је Хб-1- 1;о,95 = 9,49 и како је 45,073 > 9,49, то одбацујемо нулту хипотезу да су подаци сагласни са Пуасоновом расподелом. □
6.2.2 Испитивање независности два обележја
Пирсонов х2 тест се користи и за испитивање независности два обележја X и У. Нулта хипотеза је
Но{Х и У су независна обележја),а алтернативнаје
Н\{Х и У нису независна обележја).Узорак обима п је задат табелом контингенције

138 СТАТИСТИКА
Х \ У Л ј 2 л Е1 г /и /12 Л ј Л«к /21 / 22 / 2в /г.
1 г /н /г2 /г. /г.Е /•1 /.2 /« П
где с:у Т\, ... , 1Т, Ј и . . Јв конкретни бројеви или интервали, /у је број појављивања пара (Д, Јј) у реализованом узорку, /,. = / а + / г2 + ■ • • + /и и Ј.ј = /у + / у + . . . + / Гј. Тест статистика је облика
хо = Е ЕС=1 ј=1
САј - /»ј);/ц
где је /у очекивани број парова (Д, Јј) и израчунава се по формули
; ■ /;• ■ /«јЛ ј ~ п ;
Статистика Хо има X2 расподелу са (г — 1)(з — 1) степени слободе. Критична облаСт је
2 ч 2Хо — Х(г—1)(«—Г);1—о '
На крају доносимо -закључак о одбацивању или прихватању нулте 'хипотезе.
Тест статистика Хо се може записати у облику- који је једно- ставнији за рачунање:
х 1 = п( г $ (2V1 ~а2_/ Ј—1 с ; ги=1 ј =1 Ј 1 » Ј ч
П ример 80. У узорку од 1000 закључених бракова је било
местовреме закључења брака
пролеће,- лето јесен, зимаград 125 365 •село 175 335

ПИРСОНОВ X2 ТЕСТ 139
Тестирати хипотезу о независности места и времена закључења брака за а = 0,05.
Решење. Тестирамо хипотезу да^су обележја место закључења брака и време закључеља брака независна против алтернативне да су зависна. Табела контингенције је облика
местовреме закључења брака
Епролеће, лето јесен, зимаград 125 365 490село 175 335 510
Е 300 700 1000
Суму
Е Е Јч
најлакше можемо израчунати помоћу следеће табеле:/2/ и /?2
Л ./ .1 Л . / . з/ 21 /22
/а ./«2
За наш пример, помоћна табела је облика
односно
Збир вредности свих ћелија даје тражену суму 1,008. Реализована вредност тест статистике је тада
0,106 0,3880,200 0,314
1253 3652490-300 ’ 490-700
1752 3352510-300 510-700
Хо = 1000 -(1 ,0 0 8 - 1) = 8.
Остаје још да одредимо критичну област и на основу ње да донесе- мо закључак о прихватању или одбацивању нулте хипотезе. Како је т — з = 2, то из таблице х 2 расподеле читамо вредност Х2;о,95- Добијамо да је тра^кена вредност 3,84 и како је 8 > 3,84, то прихва- тамо алтернативну хипотезу, односно закључујемо да су место и време закључења брака зависна обележја. □

140 СТАТИСТИКА
П ример 81. Желимо да тестирамо хипотезу да је марка аутомо- била иезависна од пола власника. У том циљу случајно је изабрано 350 власника и добијена је следећа табела
маркапол А Б Ц
мушки 40 80 30■женски 30 120 50
Да ли се са прагом значајности а = 0,01 може сматрати да је марка аутомобила независна од пола власника?
Реш ење. Тестирамо хипотезу да су обележја марка аутомобила и пол власника независна против алтернативне да су обележја за- висна. Праг значајности износи 0,01, г = 2 и 5 = 3. Табела контин- генције је
маркапол А Б Ц Е
мушки 40 80 30 150женски 30 120 50 200
Е 70 200 80 350
а помоћна табела је
односно
Збир вредности ћелија горње табеле је 1,065, тако да је реали- зована вредност тест статистике једнака
Хо = 350 -(1,065 - 1) = 22,75.
Како је 22,75 > 10,6, то одбацујемо хипотезу о независности марке аутомобила од пола власника. □
0,152 0,213 0,120,064 0,36 0,156
402 802 зо 2150-70 150-200 150-80
,103 1202 502200 70 200-200 200-80

I
ш
•. 'I • 1 •
У великом броју експеримената уочава се веза између две или више променљивих, као на пример, између.степена ерозије и коли- чине падавина, између ширине реке и максималног годишњег про- тицаја, или између броја рођене деце по жени, нивоа образовања и врсте запослења. У таквим случајевима, тражи се функција која ће најбоље представљати ту везу. Проблем се састоји у налажењу везе између посматраних променљивих. Тачније, ако посматрамо обе-лежја Х^, Х-2 , ■ ■., Х р и У, тада тражимо функцију <р(х1:Х2, .......ср)за коју ће бити
У ^< р(Хи Х 2 .......Х р). (7.1)Ј. . ‘1
Функција ср се бира тако да средњеквадратно одступање у озиаци
Е(У -џ>(Хи Х 2 , . . . , Х р ) ) 2 •_/
буде најмање. Добијена функција ц> се зове регресија У по ..Х:иХо, . . ., Хр. 1јЈ‘()
Најједноставнија регресија је једнострука регресија, када се посматрају две променљиве У и X према критеријуму (7.1). Тражи се функција џ> таква да је У « Џ>(Х). Сама функција џ> се бира на следећи начин. Из популације се издваја реализовани узорак ((^пУг), (^2,2/2)1 • • •, (хп,Уп)) и представља се у Декартовој равни. Затим се на основу добијеног дијаграма, који се зове дијаграм растурања, бира фамилија функција са којом ће се радити. И’()'л- мери неких дијаграма растурања представљени су на слициа'к<1“ Према дијаграму'са слике бирамо за случај а) линеарну функцфј'? у — ах + 6, за б) експоНенцијалну функцију у = ае61', док је з1ачв'ј дббро узети логаритамску функцију 'у — а 1о§(ж) + 6. После
•' ’ ’ . ;• ' •'•ННО■ • ' '141 " . ,Јвс;ч
' Н.БС10

142 СТАТИСТИКА
примењујемо критеријум (7.1) да бисмо одредили вредности пара- метара рргрроије а и 6.
7.1 ЈТинеарна регресија
Код неких експеримената се као зависност обележја X и У јавља линеарна функдија у — ах + 6, тј. јавља се зависност облика У = аХ + 6, где су а и 6 непознати параметри који се одређују из услова да је средње-квадратно одсТупање Е(У — аХ — Ц2 најмање. Одене посматраних параметара су:
- = Т.Х јУ ј-$Т .Х јТ .У<тх?-1(т,х<)2 '
I = Уп - а Х п . '
Посматрана линеарна зависност између обележја X и У зове се линеарна регресија прве врсте У по X , односно регресцја случајне променљиве У по случајној променљивој X. Вред- нбст К добијена као У] = аХ^ + 6 је продена вредности УГ на основу вредности Х±. Приликом одређивања линеарне регре- сије прве врсте (и уопште било које регресије)- може се рачунати греш ка оцењивања која садржи информацију о томе колико иза- брана функција добро апроксимира зависност обележја У по X .

Л И Н Е А Р Н А Р Е Г Р Е С И Ј А
Она се означава са $у_у и дефинише као
4 - ? ( « - * ) ’ ■1=1
143
Уколико је узорак мали, тада се рачуна поправљена грешка оце- њивања као
3 У-У = ^ (у* - •
Пример 82. На основу мерења претпролећног минимапног средњемесечног нивоа подземних вода (X), и средњег годишњег нивоа (У) у годинама 1952-1958. добијено је
X 19,51 19,02 19,04 15,80 17,52 15,96 16,31У 17,57' 17,66 18,74 14,48 15,44 13,92 15,22
Одредити праву лииеарне регресије У по X и на основу ње прогнозирати У за изадерену вредност х — 16,9.9 у 1959,. години. Израчунати грешку оцењивања. '
Решење. Потребне суме добијамо из следеће табеле:
- Уг х 'гг ХгУг19,51 17,57 380,64 342,7919,02 17,66 361,76 335,8919,04 18,74 362,52 356,8115,80 14,48 249,64 228,7817,52 15,44 306,95 270,5115,96 13,92 254,72 • 222,1616,31 15,22 266,02 248,24
Е 123,16 113,03. 2182,25 2005,18
Коефицијенти праве линеарне регресије су:
а
' 6
2005,18 - ± • 123,16 • 113,032182,25 - | - (123,16)2 - 1’076’
7 7

144 СТАТИСТИКА
тако да је тражена права линеарне регресије V = 1, 076 • X — 2, 784. На основу праве линеарне регресије процењујемо да је 1959. године средњи годишњи ниво био
1/(16. 99) = 1,076 • 16, 99 - 2,784 = 15,50.
Одредимо још грешку оцењивања следећом табелом
X, 'Уг Т = 1, 076 • хГ - 2, 784 (Уг ~ Уг)~19,51 17,57 18,21 0,409619,02 17,66 17,68 0,000419,04 18,74 17,70 1,081615,80 14,48 14,22 0,067617,52 15,44 16,07 0,396915,96 13,92 14,39 0,220916,31 15,22 . 14,77 0,2025
2,3795
Грешка оцењивања је з\ _ 9 = 2»2р = 0,3966 и како је она мала у односу на вредности обележја У, то закључујемо да смо добро апроксимирали зависност обележја У по X . О
Слика 7.2: Дијаграм растурања из претходног примера и одго- варајуће линеарне регресије.
У неким случајевима је потребно одредити линеарну регреси- ЈУ ^ п0 ^ 4 Она је облика X = сУ + <1, где су с и с1 непознати

ЛИНЕАРНА РЕГРЕСИЈА 145
параметри који се одређују из услова да средњеквадратно одсту- пање Е (Х — сУ — в. )2 буде најмање. Оцене параметара с и в. су тада:
с =Е У' 2 - ± ( Е У ;)2 '
& = Х п - с У п.
И у овом случају се може рачунати грешка оцењивања. Означава се са и дефинише као
4 -* - г ЕГ=1
Наравно, ако је узорак мали тада се рачуна поправљена грешка оцењивања:
5'х - х п У ± ^ - ц г .1 1=1
П ример 83. За претходни пример одредити праву линеарне ре- гресије X по V и израчунати грешку оцењивања.
Решење. Познате су нам све суме, осим суме Е У?- Сабирањем квадрата реализованих вредности обележја У добијамо тражену суму Е у\2 = 1845, 25. Сада можемо одредити коефицијенте с и Л:
с
Л
2005,18 - 1 • 123,16- 113,031845.25 - 1 ■ (113,03)2
123,16 7 ~ - 0,845 113,03 4,
= 0,819,
370.,
Према томе, тражена права линеарне регресије X по V је облика X — 0, 819 ■ V + 4,370. Одредимо још -грешку оцењивања. Поново користимо помоћну.табелу:'

146 СТАТИСТИКА
Уг Тј = 0,819 • у{ + 4,37 (Т{ - Хг) 2
19,51 17,57 18,76 0,562519,02 17,66 18,83 0,036119,04 18,74 19,72 0,462415,8 14,48 16,23 0,1849
17,52 15,44 17,02 0,250015,96 13,92 15,77 0,036116,31 15,22 16,84 . 0,2809
Е 1,8129
Тражена. грешка оцењивања је — ■■'■8ј 2-9- = 0,3022. □
У неким ситуацијама се посматра обележје V које зависи од кон- тролисане, неслучајне, променљиве х. На пример, мери се темпе- ратура воде на одабраним дубинама, прати се прираштај станов- ништва једне регије у зависности од календарске године итд. У таквим ситуацијама, веза између обележја У и контролисане, не- случајне, променљиве х се представља линеарним моделом
У = ах + 6 + е, (7.2)
где је е случајна променљива, која се најчешће идентификује као грешка мерења. За случајну променљиву е се претпоставља да има математичко очекивање 0 (Е(е) = 0) и дисперзију ст2 0 {е) = сг2). Параметри а и 6 су непознати и одређују се тако да је средње- квадратно одступање Е{У — ах - 6)2шајмање:
Е ® ? -* (Е * < )а ’I = Уп — ахп . I
Регресиони модел (7.2) зваћемо линеарна регресија друге врсте V по х, односно регресија случајне променљиве У по контролисаној променљивој х.
П ример 84. Улов морске рибе (у тонама) у нашој земљи у периоду 1994-1998. 'године представљен је следећом табелом:.

ЛИНЕАРНА РЕГРЕСИЈА 147
Година 1994 1995 1996 1997 1998Улов {к) 264 374 383 373 416
Извор: Стат. год. Југ., 1999., стр. 219 (извод из табеле) Одредити линеарну регресију друге врсте улова морске рибе по годинама и израчунати грешку оцењивања. Проценити колики ће бмти улов 2003-. године,
Решење. Као и код линеарне регресије прве врсте, тако и овде користимо помоћну табелу:
Уг Ч ХгУг1994 264 3976036 .5264161995 374 3980025 7461301996 383 3984016 7644681997 373 3988009 7448811998 416 3992004 831168
Е 9980 1810 19920090 3613063
Оцене параметара о. и 6 су тада:
а
6
3613063 - ± 9980 ■ 181019920090 - ±(9980)2 = 30,3
1810 -3 0 ,3 9980 = -60116,8.
Тражена линеарна регресија друге врсте је
У = 30,3 ■ х — 60116,8 4- е.
Грешка оцењива?ва је 52 = 1011,275 и како је она велика уодносу на вредности обележја У, то следи да за ове податке ли- неарна регресија није најбоља прогноза. На основу добијене праве линеарне регресије процењујемо да ће 2003. године бити уловљено
2/(2003) = 30,3 ■ 2003 — 60116,8 = 574,1 тона морске рибе. □
У случају великих вредности променљиве х, као када је реч о го- динама, рачун се може поједноставити увођењем смене г = х - т,
. где је т вредност изабрана тако да поједностави рачун. Тада се

148 СТАТИСТИКА
оцоне параметара а и Ј регресионог модела У = ах + I + е оцењују узорком ((^1, 2/1), . . . , (2п,Уп)) и облика су:
а = ^ уЈ-^гјТ.Уј
6 = Уп — а (гп + т) .
Тако за претходни пример, ако уведемо смену г = х - 1996, доби- ћемо следећу табелу:
Х г Уг 2, + У г1994 264 -2 4 -5281995 374 -1 1 -3741996 383 0 0 01997 373 1 1 3731998 416 2 4 832Е- 1810 0 10 303.
Сада једноставно можемо оценити параметре а и I:
а
I
зоз10
1810= 30,3
-3 0 ,3 '1 9 9 6 = -60116,8.
Добили смо исте оцене као у претходном примеру, тако да је и линеарна регрееија друге врсте иста.
Може се посматрати и зависност једне променљиве У од више променљивих Х^, Х 2, — Таква зависност зове се вишеструка регресија. Пример вишеструке регресије била би линеарна регре- си.ја од две променљиве, тј. линеарна регресија облика
У = аХ + 62 + с.
Непознати параметри а, 6 и с могу се оценити минимизацијом сред- њеквадратног одступања
Е(У — аХ — 62 - с)2.

ЛИНЕАРНА РЕГРЕСИЈА 149
Оцене посматраних параметара се добијају решавањем система нормалних једначина
а Ј 2 Х г + 6 ^ 2 { + с п = ]Г У *
а Е ^ « + * Е ^ 2 + с Е ^ = Е ^
Пример 85. На северозападу Нусије је испитиван предпролећни минимални средњемесечни ниво подземних вода (У) у т испод Иопршиие зсмље, у зависности од средњемесечног нивоа за децсм- бар претходне године (X) и средњемесечне температуре за период децембар-фебруар (2). Из једне бушотине је током времена доби- јено
год. У' X год. У X ' 21958 1,17 0,89 -6 ,7 1964 1,80 1,49 -7 ,21959 1,52 1,39 -6 ,3 1965 2,02 1,86 -6 ,51960 1,94 1,63 -9 ,5 1966 2,42 2,19 -12,01961 1,68 1,54 -2 ,3 1967 1,88 1,74 -10,01962 1,93 1,86 -5 ,6 1968 2,46 1,69 -12 ,01963 1,42 1,05 -10 ,7 1969 2,34 1,45 -9 ,9
Одредити вишеструку регресију V = аХ + д2 + с.Решење. Одговарајуће суме су редом једнаке Е У = 18,78,
Е = ~ 98, 7, Е Уг = 22, 58, Е 4 = 30, 7768, Е -,2 = 906, 07, Е х,т, = — 156.531, Е^«*/; = 36,5449 и Е +Уг — —192,327. Тада је систем нормалних једначина облика
18,78а — 98,76 + 12с = 22,58 30,7768а - 156, 5316 + 18,78с = 36,5449 — 156, 531а + 906, 076 — 98,7с = -192,327
Решења система нормалних једначина су а = 0,792, 6 = -0,053 и с = 0, 208, тако да је вишеструка регресија облика V = 0. 792А' - 0.0532’ +0,208. □

150 СТАТИСТИКА
7.2 Нелинеарни модели зависности
Осим горе описаних најједноставнијих модела регресије који су били линеарни не само по параметрима а и 5, већ и по кон- тролисаном фактору х (регресија друге врсте) или случајном фак- тору X (регресија прве врсте), посматраћемо још неке моделе који се .једноставним трансформацијама могу да сведу на претходне. Такви модели се зову нелинеарни модели зависности,
Од нелинеарних модела зависности посматраћемо оне који се пригодним трансформацијама могу свести на линеарне моделе. Такви су:
- модел линеаран по параметрима,
- стегхени модел, и
- експоненцијални модел.
Нелинеарни модели могу бити прве и друге врсте. Код нели- неарних модела прве врсте посматра се нелинеарна завиСност изме- ђу обележја У и X , док се код модела друге врсте посмјатра нели- неарна зависност између обележја У и контролисане променљиве х. |
7.2.1 .Модел линеаран по параметрима
Модел линеаран по параметрима прве врсте је облика
У = ад(Х) + 5,
где је 'д унапред позната функција од случајне променљиве X , а а и 6 су непознати параметри. Модел се сменом 2 = д(Х) своди на линеаран модел прве врсте
У = а2 + к
Непознати параметри а и 6 се оцењују на основу узорка ((2г, У\), (22, К2), ... , (2п,Уп)) који је добијен трансформацијом 2\ = д(Х{),

•/ = 1 ,2 ,... .п, почетног узорка (№ , У ), (Х2, У2) , . . . , (Хп, Уп)). Оцене параметара а и 6 регресионог модела V = а2 + 6 су:
Е 2 М - ± Е 2 ј - ЕУјЕ 2 ? - 1 ( Е % ) 2 ’
Уп — а ■ 2 п .
У том случају, почетни регресиони модел је облика
V = ад(Х) + к
Може се посматрати и модел регресије друге врсте. Он је облика
У = ад(х) + 6 + е,
где је д унапред позната функција од контролисане случајне про- менљиве х, а и 6 су непознати параметри, а е је грешка мерења. И овде се користи смена г = д(х) и тада се модел своди на ли- неарни модел друге врсте V = аг + 6 + е. Регресиони модел је тада V = ос + I) + г. при чему су а и I оцене параметара а и 6 одређене на следећи начин:
Е г јУ ј -^ Е г ј -Е У ј _ Е г ? - ± ( Е * ) 2 'У п ^ %Т1 ■
МОДЕЛ ЛИНЕАРАН ПО ПАРАМЕТРИМА 151
Пример 86. Одредити регресиону криву У = а 1о§Х+6 везе изме- ђу ширине реке У и максималног годишњег протицаја X (у т 3 /зес), на основу узорка од 10 река:-
макс. протицај 5,7 17 22 31 50 61 85 120 12 19ширина реке 63 260 92 230 720 890 2500 1150 93 210
Решење. Дати модел је линеаран по параметрима. Сменом 2 = 1о§ X своди се на линеаран модел прве врсте У = а2 + 6. Потребно је да одредимо оцене параметара а и 6. Користимо суме Е Е У г, Е +Уг и Е 2%, које најлакше одређујемо из следеће табеле:

152 СТАТИСТИКА
Уг + = 1ое х,- ~гУх .2Л'Г5,7 63 0,756 47,628 0,57217 260 1,230 319,800 1,51322 92 1,342 123,464 1,80131 230 1,491 342,930 2,22350 720 1,699 1223,280 2,88761 890 1,785 1588,650 3,18685 2500 1,929 4822,500 3,721
120 1150 2,079 2390,850 4,32212 93 1,079 100,347 1,16419 210 1,279 268,590 1,636Е 6208 14,669 11228,039 23,025
Узимајући из табеле потребне суме, добијамо да су реализоване вредности оцена. а и к редом:
а
д
1 1 2 2 8 , 0 3 9 - ^ • 1 4 , 6 6 9 • 6 20 8
2 3 , 0 2 5 - ^ • (1 4 , 6 6 9 ) 26208"иГ”- 1407, 739 • 14,669
10
= 1407,739,
1444,21,
тако да је регресиона права између обележја У и 2 облика
У = 1407,739 • 2 — 1444,21.
Коиачно, регресиона крива којом се описује веза између ширине реке и максималног годишњег протицаја је
У = 1407,739 ■ 1о§ X - 1444,21. □
7.2.2 Степени модел
Степени регресиони модел прве врсте је облика
У = дХа,
где су а и 5 константе које треба оценити на основу узорка. Логарит- мовањем леве и десне стране горње једначине, добија се једначина
' . . . 1пК = а.1пХ + 1пК

СТЕПЕНИ МОДЕЛ 153
Ако уведемо смене 2 — 1пАТ, — 1пИ и с = 1п6, тада добијамо линеарни модел прве врсте облика
IV = а2 + с,
којим се описује зависност између обележја V/ и 2 . Оцене параме- тара а и с с е оДређују на основу узорка ((2г, У/{ ),. . . , (2П) \Уп)) који је добијен трансформацијама Д, = 1пХ; и Ж,- = 1пУЈ, г = 1,2.......п.почетног узорка (№ , ) , . . . , (Хп, Кг)):
- = Е 2№ - I Е 2 ј Е 1Уј_ Е Д ^ ( Е Е - ) 2 ’
с = н 7,, - а д п.
На основу оцене параметра с можемо оценити и параметар 6 као 6 = ес. Коначно, тражени регресиони модел је облика
V = 1хћ.Аналогно се може посматрати степени модел регресије друге врсте. Он је облика
V = кха + е,
где су а и 6 константе које треба оценити на основу узорка. Непоз- нати параметри степеног модела друге врсте се оцењују на исти начин као и код модела. прве врсте.
Пример 87. На обали залива се испитује влажност муља (у грами- ма воде на 100 грама суве материје). Из једне бушотине је добијено
дубина (х ) 1,5 3 4,5 6 7,5 9 10,5влажност (у ) 84 50 32 28 24 23 20
Одредити регресиону криву У = Вха + е.Решење. Модел који се посматра је степени модел друге врсте.
Реализоване вредности оцена непознатих параметра добијамо из следеће табеле:

154 СТАТИСТИКА
■X, Уг г, = 1п X, и>г = 1п Уг~2 ггш,-
1,5 84 0,405 4,431 0,164 1,7953 50 1,099 3,912 1,208 4,2994,5 32 1,504 3,466 2,262 5,2136 28 1,792 3,332 3,211 5,9717,5 24 2,015 3,178 4,060 6,4049 23 2,197 3,135 4,827 6,88810,5 20 2,351 2,996 5,527 7,044
Е 11,363 24,45 21,259 37,614
У том случају, реализоване вредности оцена непознатих парамета- ра су
а = 37,614 — | • 11, 363 • 24,45021,259- А (11,363)2
-0,738.
24,450 л 11,363 „с = — '— + 0,738 - - у — = 4,691,
6 = е4,691 = 108,962,
тако да је степени модел друге врсте облика
V = 108,962 • аГ0-738 + е. □
7.2.3 Експоненцијални модел
Експонецијални модел је облика
У — беаХ,
где су а и 6 константе које треба оценити на основу узорка. Ло- гаритмовањем леве и десне стране горње једначине добија се јед- начина облика
■ 1п У = аХ + 1п ђ.
Ако уведемо смене IV = 1пУ и с = 1п6, добићемо линеарни модел прве врсте облика
V/ = аХ + с,

ЕКСПОНЕНЦИЈАЛНИ МОДЕЛ 155
којим се изражава зависност између обележја IV и X . Оцене пара- метара линеарног модела прве врсте V/ по X су:
Овим смо оценили непознати параметар а експоненцијалног мо- дела, док се други непознати параметар 6 оцењује помоћу оцене параметра с као 6 = е°.
Може се посматрати и експоненцијални модел друге врсте. Он је облика
У = деах + г,где се параметри а и 6 модела оцењују слично као што су се оцењи- вали параметри експоненцијалног модела прве врсте.
Пример 88. Одредити регресиону криву У = бе®* + е за податкеиз примора 87.
Решење. Дати модел је експоненцијални модел друге врсте и реализоване вредности оцена непознатих параметара се добијају из следеће табеле:
Уг е н 5" 5? ЖјШј1,5 84 4,431 2,25 6,6473 50 3,912 9 11,736
4,5 32 3,466 20,25 15,5976 .28 3,332 36 19,992
7,5 24. 3,178 56,25 23,8359 23 3,135 81 28,215
10,5 20 2,996 110,25 31,458Е '42 / 24,45 315 137,48
Реализоване вреДности су редом137,48 — | • 42 * 24,46 7 315 - | (42)^
-0,146,
с
6
24,457
е4,369 =
+ 0,146 • — = 4,369,
= 78,965,II'

156 СТАТИСТИКА
тако да је тражена регресиона крива облика
V = 78,965 • е-0'1461 + е. □

А н ал и за п р о сто р н о г . расп ореда тачака
Елементе популација као што су градови, рудна налазишта, објекти у оквиру градова, карактерише и положај у посматраној области. Положаји посматраних елемената се представљају тачка- ма (%, у), где х представља прву, а у другу координату. Интересује нас просторни размештај тачака и његове карактеристике. У ту сврху, посматрамо дводимензионално обележје (Х,У), где су X и У координате елемента у посматраној области.
Прво пгто нас интересује је растојање између два елемента. Пос- матраћемо М енхетн и Еуклидово растојање. Менхетн расто- јање се зове још и растојање типа градског блока. Оно пред- ставља дужину најкраћег пута између две тачке у граду чије се улице секу под правим углом. Назив је добило према урбани- стичком решењу острва Менхетн као градске четврти Њујорка. За две тачке А = (х а ,Уа ) и В = (хв ,Ув) Менхетн растојање се дефи- нише као број
&м(А, В) = \хА — хв \.+ \уа ~ Ув\-
Еуклидово растојање представља најкраће растојање између две тачке у равни. За дате тачке А и В, Еуклидово растојање се дефи- нише као број
А А ; В ) - \ Ј ( ха “ х в )2 + (уА ~ УвУ.
Еуклидово растојање заправо представља дужину ваздушне линије између две географски одређене тачке А и В.
*157

158 СТАТИСТИКА
Слика 8.1: Менхетн и Еуклидово растојање између тачака А и В.
Помоћу Менхетн растојања може се дефинисати просечно градско растојање. Нека су дате тачке А х = {хх,ууј, А 2 = (х2, у2),
Ап = (х„,уп), и нека-је А0 — (х0,у0) произвољна тачка у граду. Просечно градско растојање тачке А0 до осталих тачака у граду је број
__ 1 «<%м(Ар) — — Ам(Ај, А0).
71 1=1
Ово растојање је ништа друго до средина Менхетн растојања тачака А 0 и АГ, % = 1, 2 ,.. . ,п.
П ример 89. Нека су дате тачке Аг = (3,7), А 2 = (6,3), Л3 = (4,0), Аа = (2,7) и А 5 = (6, 6). Одредити просечно градско; растојање тачке Л0 = (5,4)' од датих тачака.
Реш ењ е. Најпре одређујемо Менхетн' растојања између тачака А0 и А{, г = 1 ,2 ,. . . ,п: ,
&м(А\, А0) ^ м ( А 2, А 0 )
Фи(Л3, Л0)<м (Аа, А0) < м ( А 5 , А0)
= |3 - 5 | + |7 - 4 |= '5 ,= Јб. — 5| + |3 — 4| = 2,= • |4-5| + Ј0 —4| = 5, . •= |2 — 5| + |7 — 4| = 6,= |6 — 5| + |6 — 4| = 3.

Тако добијамо да је просечно градско растојање тачке А 0 до осталих тачака у граду ■
д-м(Ао) — —(5 + 2 + 5 + 6 + 3) = 4,2. □о
8.1 Мере централне тенденције
Посматра се дводимензионално обележје (X, V) које представља положај елемента популације у посматраној области. Наш задатак је да нађемо тачку која ће бити карактеристична за читаво дводи- мензионалио обележје. Постоји више таквих тачака у зависности од захтева.
Једна од тачака које се посматрају је медијански центар и разликујемо два медијанска центра, у зависности од тога које расто- јање посматрамо.
Д еф иниција 18. Нека је п тачака нанесено на карту и нека је ' Мх медијана за прве, а Му медијана за друге координате тачака. Медијански центар је тачка Мх,у — (М х ,М у ).
Ако посматрамо тачке из претходног примера, тада је медијана првих координата Мх = 4, других координата је Му = 6, тако да је медијански центар тачка Мх ,у = (4,6).
Може се успоставити веза између овако дефинисаног медијан- ског центра и просечног градског растојања. Наиме, медијански центар ј'е тачка са најмањим просечним Менхетн растојањем до тачака А и А 2 , . . . , А п.
Ако се посматра Еуклидово растојање, тада се медијански цен- тар дефинише као тачка са најкраћим (ваздушним) путем до скупа тачака А г, Л2, . . . , Ап, тј. као тачка М за коју важи:
Е а ( А и М ) < ј Г д ( А иА),1=1 1=1
где је А произвољна тачка. Само одређивање тачке М је иначе доста компликовано,. тако да нећемо дати пример за њено одређи- вање.
МЕРЕ ЦЕНТРАЛНЕ ТЕНДЕНЦИЈЕ 159

160 СТАТИСТИКА
Следећа тачка која ее може посматрати је центар средњих. Шначава се^са т х у и дефинише као тачка са координатама (хП) 1Јп ), где су хп и уп узорачке средине првих и других координата тачака. Иа тачке из примера 89, центар средњих је тачка т х у =(4. 2 :4 ,6 ) .
Ако тачке Ах, Л2, ..., Ак представљају градове, тада с-е може одредити просторни или гравитациони центар за становниш- тво. Нека посматрани градови имају / х, / 2, ... , / , становника и нека Јв п укупан број становника у свим градовима. Тада се про- сторни центар дефинише као тачка која се најчешће означава са т х,У\ а координате су јој
т 'Х ,У . п* 1 к \
5 2 /&и ~12/гУг) • 1 -1 П
Пример 90. Нека тачке из примера 89 представљају градове кош редом имају 60, 300, 30, 40 и 70 хиљада становника. Одредимо просторни центар. Координате просторног центра су
т х
т «
1500
1500
(60-3 -1- 300 • 6 + 30 • 4 + 40 ■ 2 + 70 ■ 6) = 5 , 2 ,
(60 ■ 7 + 300 : 3 + 30 ■ 0 + 40 • 7 + 70 • 6) = 4,04.
Према томе, просторни центар је тачка (5,2; 4, 04). □
За просторни центар је карактеристично то да се помера ка густо настањеним подручјима. Ј
Као мера. концентрације тачака око центра средњих узима се средње-квадратно одстојање тачака до центра средњих у ознаци' аЂ дефинисано на следећи начин
о 1 п 1 п= -7 22(х< - т х ? + - - т у ) 2
г=1 П ■ .П1=1
и стандардно одстојање = ^ . За пример 89, средњеквадратно одстојање износи 10, док је стандардно одстојање 3,6.

ТЕСТИРАЊЕ ПРОСТОРНОГ РАСПОРЕДА ТАЧАКА 161
8.2 Тестирање просторног распореда тачакаПоново посматрамо дводимензионално. обележје (X, V) које
представља положај тачака у посматраној области и нека је тдт реализовани узорак ((хи У1), (х2, у2) , . . . , (хп, уп)) из популације са посматраним обележјем. Испитујемо да ли су посматране тачке случајно распоређене по области. Испитивање случајности тачака спроводимо тестирањем хипотеза о случајности распореда тачака. Тестирамо нулту хипотезу Д0(распоред тачака је случајан) против једне од алтернативних:
#1 (распоред тачака није случајан),ДДраспоред тачака је правилан),ДДтачке се групишу).
Случајан распоред тачака и неслучајни распореди наведеии у алтернативним хипотезама приказана су на следећој слици.
С л у ч а ј а п р а с п о р е д П р а в и л а н р а с п о р е д
• • , ® о
® е е ® о ©
Г р у п и с а н е
т а ч к е
Слика 8.2: Распоред тачака.
Разликујемо два метода тестирања случајности распореда та- чака по области: метод квадрата и метод најближег суседа. Код метода квадрата посматрана област је подељена. на к једнаких квадрата у коме је смештено / и / 2, .... Д тачака редом. Укупан броЈ тачака је п. Уколико је нулта хипотеза тачна, тада се очекује приближно исти број тачака по квадратима, тј. очекује се при- ближно | тачака у сваком квадрату. Тест статистика је
х 1 =I , (Л - ?)’

162 СТАТИСТИКА
и ова статистика има х 2 расподелу са А; — 1 степени слободе. Кри- тична област зависи од алтернативне хипотезе и могуће критичне ббЛасти су:
Ш:Н о Н г С '
случајанраспоредтачака
није. случајан Хо — Хк—1,а/2 V Хо > Х1-Х З - а /2правилан Хо < Хк—1 .а
груписање Хо > Х к - 1 .1 - а
На крају се доноси закључак о прихватању или одбацивању хипотезе на основу реализоване вредности тест статистике и одго-' варајуће критичне области.
Област при овом тестираљу не мора обавезно бити подељена на квадрате. Уколико су делови поделе неједнаки, тада се очекивана адсолутна учестаност одређује сразмерно површини посматраног дела. Ако је Р површина'целе области, а Р\, Р%, . . . , Рк површине делова, тада је очекивани број тачака у г-том..делу
РР
п.
Тест статистика је тада
Хо =Е (/ј-9-п)
пр п
и она има х2 расподелу са к — 1 степени слободе. Надаље! поступак је исти као у случају поделе области на квадрате.
П рим ер 91. На једној каменој плочи 80 х 100с77г2'посматрани су положаји кристала магнетита којих :је избројано 47. У следећој табели су дате координате кристала, у ст од доњег левог угла плоче
■ *х 1 2 4 4 8 9 7 8 10 12 14 22 (21 22У 86 41 3 15 95 13 35 44 58 88 2 2 56 53
24 27 .27 28 37 37 27, .11 15 35 38 38 41 46 4731 12 34 76 14 61 85 25 15 93 25 7 51 2 12

ТЕСТИРАЊЕ ПРОСТОРНОГ РАСПОРЕДА ТАЧАКА 163
45 50 49 50- 51 56 58 59 60 62 66 66 65 69 6982 83 96 13 25 12 40 28 61' 70 0 15 75 38 83
71 76 7727 1 4
Плоча јс иодслзопа на 8 једпаких правоугаоника и број тачака у сваком од њих је. 11, 9, 5, 5, 4, 4, 6 и 4. Тестирати са прагом значајности а = 0,05 хипотезу да је распоред кристала случајан против алтернативне да није случајан.
Решење. У сваком правоугаонику се очекује по 47/8 = 5,875 тачака. Реализована вредност тест статистике је
х 1 = ± [(Ц - 5 ,875)2Ч- • ■ ■ + (4 - 5,875)2] = 8,191.
Како је' 1,69 < 8,191 < 16, то прихватамо нулту хипотезу да је распоред кристала случајан. □
Други метод, метод најближег суседа, се заснива на мерењу Еуклидовог растојања међу тачкама. Уколико је распоред тачака случајан, тада је очекивано растојање између једне тачке и њој нај- ближег суседа ^
^ = 2Т±о'где је А0 = ђ број тачака узорка по јединици површине. Тестстатистика Је
До =Д - 10,523 \/п,
гдр је П индекс најближ ег суседа и израчунава се као количник просечног растојања до најближег суседа &п и очекиваног растојања а!о, тј. као _
ОоИндекс најближег суседа узима следеће вредности:
О = 1 за случајни распоред тачака,

164 СТАТИСТИКА
п < О < 1 за груписање тачака, и
1 < п < 2,15 за правилан распоред тачака.
I!наме, максимална вредност индекса најближег суседа је управо 2,1о. ^ елучају да је нулта хипотеза тачна, тест статистика 2 0 има стандардну нормалну расподелу. Одговарајуће критичне областису:
Н0 Нг Сслучајанраспоредтачака
није случајан сч1тА1
Ј?
правилан ~0 > ~ 0 ,5 - пгруписање ^ -2-0,5—л
Пример 92. Одредити индекс најближег суседа за кристале маг- нртита из примера 91, а затим са прагом значајности тестирати нулту хипотезу да је распоред кристала случајан против алтерна- тивне да распоред кристала магнетита није случајаи.
Реш ење. Кристали магнетита су нумерисани и мерењем расто- јања је добијено (у ст)
Кристал 1 2 3 4 5 6 7 8Најближи сусед 10 8 11 6 10 4 2 2Растојање 11,18 6,71 10,05 5,39 8,06 5,39 7,81 6,71
9 10 11 12 13 ■14 15 16 17 18 1913 5 12 11 14 13 17 19 15 21 26
11,18 8,06 8,0 8,0 3,16 3,16 4,24 10,20 4,24 9,06 7,0720 21 22 23 24 25 26 27 28 2927 18 7 6 21 19 19 20 26 33
10,77 9,06 10,77 6,32 11,31 11,05 7,07 10,77 9,43 3,1630 31 32 33 34 35 36 37 38 39 4031 30 31 29 37 33 43 34 39 42 46
ј , 1 0 о.Ш 13,04 3,16 8,54 6,08 11,18 8,54 9,22 5,83 10,0541 42 43 44 45 46 4735 39 36 42 43 47 46
10,44 5,83 11,18 8,94 11,18 3,16 3,16
Тада је просечно растојање до најближег суседа = 7,811. Повр- шина области је Р = 80 ст ■ 100 ст = 8000 а п \ а густина кристала магнетита по јединици површине је А0 = 47/8000 = 0,005875. На

ТЕСТИРАЊЕ ПРОСТОРНОГ РАСПОРЕДА ТАЧАКА 165
основу тога је а(0 = 1/ (2 • л/0, 005875) = 6,523, тако да је индекссуседства Ј = 7,811/6,523 = 1,197. Реализована вредност тест статистике је
1 .1 9 7 - 1 г -
28 = " 0 ^ 2 3 - ^ = 2' Ж 'За дати праг значајности добијамо да је 2,582 > 1,96, што значи да одбацујемо нулту хипотезу да је распоред кристала магнетита случајан. □

I

Г Л А В А 9Временски низови
Мншч; прсмсиске ситуације, као што су сунчано, облачно, кишо- вито, могу се посматрати као функције времена I. С друге стране, ове и друге временске ситуације се могу посматрати као случајне променљиве, тј.. као функције случајног исхода ш. Рецимо, уоби- чајено је говорити или чути: ”Јуче је у јутарњим часовима било претежно сунчано,.око подне је настала потпуна облачност, а у ве- черњим часовима је падала киша”. С друге стране, у фиксираном временском тренутку у току дана временска ситуација се може пос- матрати као случајни исход. Да ли ће у 12/г бити сунчано, облачно и суво или облачно са падавина је ствар случајности. Дакле, ако сунчано означимо са 1, облачно и суво са 2 и, најзад, облачно са па- давинама са 3, дефинисаћемо једну случајну променљиву. Према томе, временске ситуације представљају функције две променљиве. На основу овога долазимо до појма случајног процеса.
Д еф иниција 19. Нека је П простор свих елементарних исхода и нека је Т С Н интервал. Скуп ој € п , I е Т}, г<?е Х(ш ,1 )■прггликава П х Т у с.куп реалних бројева тако да је за, свако фикси- рано I функција X (со, I). случајна променљива, и за свако фиксирано и> је реална функција, зове се случајни процес са непрекидним вре- меном.
У дефиницији се термин ”време" користи из традионалних разлога, јер је то најчешћи физички смисао елемената скупа Т. Међутим, та променљива може представљати и надморску висину, дубину мора и слично.
Реална функција реалне променљиве која настаје када се слу- чајпом процесу фиксира елемеитарии исход ој зове се реализација
167

168 СТАТИСТИКА
случајног процеса или трајекторија. Најчешће се уместо ознаке Х{цј, 1 ) користи ознака Х г(ш) или чак само Х Г. Посматрани скуп Т зове се параметарски скуп. Скуп Т може бити и дискретан скуп тачака. У том случају, скуп {Х(, 1 6 Т} зове се случајни низ шти случајни процес са дискретним временом или временски низ.
П ример 93. Као пример случајног процеса могли би да посма- трамо температуру ваздуха, рецимо на следећи начин. Наиме, температура ваздуха је случајна променљива, на коју осим слу- чајних фактора утиче и надморска висина места на коме се темпе- ратура ваздуха мери. Дакле, посматраћемо температуру ваздуха у фиксираном временском тренутку на различитим надморским висинама. Овде је надморска висина неслучајна променљива.
Температура ваздуха може да буде случајни процес и као функ- ција заиста од времена. Заиста, ако бисмо на једном месту мери- ли температуру ваздуха у току неког временског периода, реци- мо јсдпс године, дефшшсали бисмо другачији случајни процес од претходно описаног. □
Као што смо већ истакли, случајни процес { ХГ, 'I е Т} се у спаком поједмном тренутку времена посматра као случајна промен- љива. Отуда се могу дефинисати нумеричке карактеристике ових случајних променљивих. Међутим, како се ове карактеристике дефинишу за сваки поједини тренутак времена, са променом вре- мена, тј. вредности параметарског скупа Т, и оне ће се мењати. Дакле, и саме су функције од времена. На тај начин долазимо до функција као што су средња вредност, коваријансна функција и аутокорелациона ф ункција случајног процеса које ћемо.нада- ље дефинисати. .
Д еф иниција 20. Средња вредност слунајног процеса { ХГ, I 6 Т) ј е н е с л у н а јн а ф у н к ц и ја т(1 ) д е ф и н и с а н а к а о т{к) = Е ( Х%).
Слично појму математичког очекивања случајне променљиве, средња вредност тЏ) случајног процеса {.Х%, I 6 Т} била би некасредња функција” око које би се груписале реализације случајног
процеса. ,

ВРЕМЕНСКИ НИЗОВИ 169
Д еф иниција 21. Коваријансна функција случајног процеса {Д , '/■ Е Т}, у ознаци К ( 1 ,з), је функција
Уколико је 2 = 3, тада се уместо термина коваријансна функција користи термин дисперзија случајног процеса. Према томе, фуикција П(Х() = К ( 1 , 1 ) зове се дисперзија елучајног процеса {Хј. г € Т).
Д еф иниција 22. Аутокорелациона функција случајног проиеса {Хи I 6 Т}, у ознаци р(1 ,з),.је функција
V зависности од вредности коваријансне функције могу се дефи- нисати специјални типови случајних процеса. Уколико је ковари- јансна функција К( 1,з) једнака 0 за свако I ^ з, тада за случајни процес {XI, 4 6 Т} кажемо да је случајни процес са неко- релисаним вредностима. Ако је случајни процес {X (, I 6 Т} такав да има константну средњу вредност ш(ф за свако I, има коначан момент другог реда за свако I и ако је коваријансна функ- ција К( г, з) функција разлике Г — з, за свако I, $, тада за такав случајни процес кажемо да је стационаран. Може се посматрати и ергодичан процес. Наиме, за неки процес кажемо да је ер- годичан, уколико се средња вредност процеса може бценити среди- ном реализованог узорка који је део једне. једине реализације: гсј. т 2, ..., хп.
Наведене дефиниције неслучајних функција средње вредности, коваријансне функције, дисперзије и аутокорелационе функције случајних процеса, односе се и на случајне низове. Једина разлика је У томе што је Т неки подскуп скупа целих бројева, а не интервал. То ће, међутим, произвести последицу да ће графици ових случај- них функција за низове бити скуп дискретних тачака (а не линије). Ове тачке се по традицији користе као темена линијског дијаграма којим се реализација временског низа представља. Надаље ћемо се задржати на временским низовима.
К(фз) = Сои(ХиХе) = Е [(Хг - т(Г))(Х. - т(з))].

170 СТАТИСТИКА
Видели смо раније да временски низ зависи од случајног и не- случајног аргумента. Облик ове зависности, међутим,ј је један од најважнијих аспеката истраживања у овој области. Проучавање иде у правцу откривања тзв. неслучајних компоненти. Ниже ћемо навести један од начина на који се представљају елементи вре- менског низа са неслучајним компонентама. Неслучајне компо- ненте се сврставају у три групе: тренд, сезонска компонента и циклична компонента. Тренд се означава са Т* и представља систематску компоненту дугорочног развоја. Друга неслучајна компонента је сезонска компонента. Она се означава са! 5) и резул- тат је дејства фактора који се јављају периодично, п:о сезонама једне године. Пример случајног низа са сезонском компонентом била би температура ваздуха мерена на једном месту. I Код неких случајних низова, периодичност се може јавити у перИодима кра- ћим или дужим од једне године. У том случају, реч је о цикличнОј компоненти. Она се означава са С%. Пример случајногјпроцеса са цикличном компонентом био би низ океанских плима. Случајна компонента се означава са и она се добија када се из временског низа одстране све неслучајне компоненте.
Временски низ {Хг, / € Т} се често може да представи у облику суме неслучајних компонената и случајне компоненте као
— Т( + + С ј + Е{, 4 6 Т .
У неким случајевима, сезонска и циклична компонента се пред- стављају једним сабирком, јер обе одражавају периодично понаша- ње низа.
Уколико је из временског низа узет реализовани узорак, тада је потребно испитати да ли временски низ има неслучајних ком- поненти. Тај поступак се спроводи тестирањем нулте хипотезе 7/о(временски низ из кога је узет узорак је.случајан), прбтив алтер- нативне хипотезе Нг (у временском низу из кога је узет реализовани узорак постоји неслучајна компонента). Уколико се .деси да треба прихватити алтернативну хипотезу Нх, тада се накнадно провера- ва о којој неслучајној компоненти је реч, тј. да ли је реч о тренду, сезонској или цикличној компоненти.

ВРЕМЕНСКИ НИЗОВИ 171
У крајњем, у анализи временских низова важно је утврдити да ли иостоје или не неслучајне компоненте, а затим се врши њихово уклањање из података ради утврђивања расподеле и других статис- тичких својстава временског низа.

Статистичке таблице

СТАТИСТИЧКЕ ТАБЛИЦЕ 175
1. С тандардна норм ална расподела
2 0 1 2 3 4 5 6 7 8 90.0 .0000 .0040 .0080 .0120 .0160 .0199 .0239 .0279 .0319 .03590.1 .0398 .0438 .0478 .0517 .0557 .0596 .0636 .0675 .0714 .07540.2 .0793 .0832 .0871 .0910 .0948 .0987 .1026 .1064 .1103 .11410.3 .1179 .1217 .1255 .1293 .1331 .1368 .1406 .1443 .1480 .15170.4 .1554 .1591 .1628 .1664 .1700 .1736 .1772 .1808 .1844 .18790.5 .1915 .1950 .1985 .2019 .2054 .2088 .2123 .2157 .2190 .22240.6 .2258 .2291 .2324 .2357 .2389 .2422 .2454 .2486 .2518 .25490.7 .2580 .2612 .2642 .2673 .2704 .2734 .2764 .2794 .2823 .28520.8 .2881 .2910 .2939 .2967 .2996 .3023 .3051 .3078 .3106 .3133 !0.9 .3159 .3186 .3212 .3238 .3264 .3289 .3315 .3340 .3365 .33891.0 .3413 .3438 .3461 .3485 .3508 .3531 .3554 .3577 .3599 .36211.1 .3643 .3665 .3686 .3708 .3729 .3749 .3770 .3790 .3810 .38301.2 .3849 .3869 .3888 .3907 .3925 .3944 .3962 .3980 .3997 .40151.3 .4032 .4049 .4066 .4082 .4099 .4115 .4131' .4147 .4162 .4177 :1.4 .4192 .4207 .4222 .4236 .4251 .4265 .4279 .4292 .4306 .43191.5. .4332 .4345 .4357 .4370 .4382 .4394 .4406 .4418 .4429 .44411.6 .4452 .4463 .4474 .4484 .4495 .4505 .4515 .4525 .4535 .45451.7 .4554 .4564 .4573 .4582 .4591 .4599 .4608 .4616 .4625 .46331.8 .4641 .4649 .4656 .4664 .4671 .4678 .4686 .4693 .4699 .47061.9 .4713 .4719 .4726 .4732 .4738 .4744 .4750 .4756 .4761 .47672.0 .4772 .4778 .4783 .4788 .4793 .4798 .4803 .4808 .4812 .48172.1 .4821 .4826 .4830 .4834 .4838 .4842 .4846 .4850 .4854 .48572.2 .4861 .4864 .4868 .4871 .4875 .4878 .4881 .4884 .4887 .48902.3 .4893 .4896 .4898 .4901 .4904 .4906 .4909 .4911 .4913 • .49162.4 .4918 .4920 .4922 .4925 .4927 .4929 .4931 .4932 .4934 .49362.5 .4938 .4940 .4941 .4943 .4945 .4946 .4948 .4949 .4951 .49522.6 .4953 .4955 .4956 .4957 .4959 .4960 .4961 .4962 .4963: .49642.7 .4965 .4966 .4967 .4968 .4969 .4970 .4971 .4972 .4973 .49742.8 .4974 .4975 .4976 .4977 .4977 .4978 .4979 .4979 .4980 .49812.9 .4981 .4982 .4982 .4983 .4984 .4984 .4985 .4985 .4986 .49863.0 .4987 .4987 .4987 .4988 .4988 .4989 .4989 .4989 .4990 .49903.1 .4990 .4991 .4991 .4991 .4992 .4992 .4992 .4992 .4993 .49933.2 .4993 .4993 .4994 .4994 .4994 .4994 .4994 .4995 .4995 .49953.3 .4995 .4995 .4995 .4996 .4996 .4996 .4996 .4996 .4996 .49973.4 .4997 .4997 .4997 .4997 .4997 .4997 .4997 .4997 .4997 .49983.5 .4998 .4998 .4998 .4998 .4998 .4998 .4998 .4998 .4998 .49983.6 .4998 ■ .4998 .4999 .4999 .4999 .4999 .4999 .4999 .4999 .49993.7 .4998 .4998 .4999 .4999 .4999 .4999 .4999 .4999 .4999 .49993.8 .4998 .4998 .4999 .4999 .4999 .4999 .4999 .4999 .4999 .49993.9 .5000 .5000 .5000 .5000 .5000 .5000 .5000 .5000 .5000 .5000

176 СТАТИСТИКА
2. Студентова расподела
п\р 0 .1 0 0 0 .2 0 0 0 .3 0 0 0 .4 0 0 0 .4 5 0 0 .4 7 5 0 .4 9 0 0 .4 9 51 .3 2 5 .7 2 7 1 .3 7 6 3 .0 7 8 6 .3 1 4 1 2 .7 0 6 3 1 .8 2 1 6 3 .6 5 72 .2 8 9 .6 1 7 1 .0 6 1 1 .8 8 6 2 .9 2 0 4 .3 0 3 6 .9 6 5 9 .9 2 53 .2 7 7 .5 8 4 .9 7 8 1 .6 3 8 2 .3 5 3 3 .1 8 2 4 .5 4 1 5 .8 4 14 .2 7 1 .5 6 9 .9 4 1 1 .5 3 3 2 .1 3 2 2 .7 7 6 3 .7 4 7 4 .6 0 45 .2 6 7 .5 5 9 .9 2 0 1 .4 7 6 2 .0 1 5 2 .5 7 1 3 .3 6 5 4 .0 3 26 .2 6 5 .5 5 3 .9 0 6 .1 .4 4 0 1 .9 4 3 2 .4 4 7 3 .1 4 3 3 .7 0 77 .2 6 3 .5 4 9 .8 9 6 1 .4 1 5 1 .8 9 5 2 .3 6 5 2 .9 9 8 3 .4 9 98 .2 6 2 .5 4 6 .8 8 9 1 .3 9 7 1 .8 6 0 2 .3 0 6 2 .8 9 6 3 .3 5 59 .2 6 1 .5 4 3 .8 8 3 1 .3 8 3 1 .8 3 3 2 .2 6 2 2 .8 2 1 3 .2 5 0
10 .2 6 0 .5 4 2 .8 7 9 1 .3 7 2 1 .8 1 2 2 .2 2 8 2 .7 6 4 3 .1 6 911 .2 6 0 - .5 4 0 .8 7 6 1 .3 6 3 1 .7 9 6 2 .2 0 1 2 .7 1 8 3 .1 0 612 .2 5 9 .5 3 9 .8 7 3 1 .3 5 6 1 .7 8 2 2 .1 7 9 2 .6 8 1 3 .0 5 513 .2 5 9 .5 3 8 .8 7 0 ‘ 1 .3 5 0 1 .7 7 1 2 .1 6 0 2 .6 5 0 3 .0 1 214 .2 5 8 .5 3 7 .8 6 8 1 .3 4 5 1 .7 6 1 2 .1 4 5 2 .6 2 4 2 .9 7 715 .2 5 8 .5 3 6 .8 6 6 1 .3 4 1 1 .7 5 3 2 .1 3 1 2 .6 0 2 2 .9 4 716 .2 5 8 .5 3 5 .8 6 5 1 .3 3 7 1 .7 4 6 2 .1 2 0 2 .5 8 3 2 .9 2 117 .2 5 7 .5 3 4 .8 6 3 1 .1 3 3 1 .7 4 0 2 .1 1 0 2 .5 6 7 2 .8 9 818 .2 5 7 .5 3 4 .8 6 2 1 .3 3 0 1 .7 3 4 2 .1 0 1 2 .5 5 2 2 .8 7 8 •19 .2 5 7 .5 3 3 .8 6 1 1 .3 2 8 1 .7 2 9 2 .0 9 3 2 .5 3 9 2 .8 6 12 0 .2 5 7 .5 3 3 .8 6 0 1 .3 2 5 1 .7 2 5 2 .0 8 6 2 .5 2 8 2 .8 4 521 .2 5 7 .5 3 2 .8 5 9 1 .3 2 3 1 .7 2 1 2 .0 8 0 2 .5 1 8 2 .8 3 12 2 .2 5 6 .5 3 2 .8 5 8 1 .3 2 1 1 .7 1 7 2 .0 7 4 2 .5 0 8 2 .8 1 92 3 .2 5 6 .5 3 2 .8 5 8 1 .3 1 9 1 .7 1 4 2 .0 6 9 2 .5 0 0 2 . 8 0 72 4 .2 5 6 .5 3 1 .8 5 7 1 .3 1 8 1 .7 1 1 2 .0 6 4 2 .4 9 2 2 .7 9 72 5 .2 5 6 .5 3 1 .8 5 6 1 .3 1 6 1 .7 0 8 2 .0 6 0 2 .4 8 5 2 .7 8 72 6 .2 5 6 .5 3 1 .8 5 6 1 .3 1 5 1 .7 0 6 2 .0 5 6 2 .4 7 9 2 .7 7 92 7 .2 5 6 .5 3 1 .8 5 5 1 .3 1 4 1 .7 0 3 2 .0 5 2 2 .4 7 3 2 .7 7 12 8 .2 5 6 .5 3 0 .8 5 5 1 .3 1 3 1 .7 0 1 2 .0 4 8 2 .4 6 7 2 .7 6 32 9 .2 5 6 .5 3 0 .8 5 4 1 .3 1 1 1 .6 9 9 2 .0 4 5 2 .0 4 5 2 .4 6 23 0 .2 5 6 .5 3 0 .8 5 4 1 .3 1 0 1 .6 9 7 2 .0 4 2 2 .4 5 7 2 .7 5 04 0 .2 5 5 .5 2 9 .8 5 1 1 .3 0 3 1 .6 8 4 2 .0 2 1 2 .4 2 3 2 .7 0 46 0 .2 5 4 .5 2 7 .8 4 8 1 .2 9 6 1 .6 7 1 2 .0 0 0 2 .3 9 0 2 .6 6 01 2 0 .2 5 4 .5 2 6 .8 4 5 1 .2 8 9 1 .6 5 8 1 .9 8 0 2 .3 5 8 2 .6 1 7оо .2 5 3 .5 2 4 .8 4 2 1 .2 8 2 1 .6 4 5 1 .9 6 0 2 .3 2 6 2 .5 7 6
СТАТИСТИЧКЕ ТАВЛИЦЕ 177
. а:2 расподела
п\р 0 .0 0 5 0.010 0 .0 2 5 0 .0 5 0 0 .9 5 0 .9 7 5 0 .9 9 0 0 .9 9 51 .0000 .0002 .0010 .0 0 3 9 3 ,8 4 5 .0 2 6 ,6 3 7 .8 8.0100 .0201 . 0 5 0 6 .1 0 3 5 .9 9 7 .3 8 9 .2 1 10.63 .0 7 1 7 .1 1 5 .2 1 6 .3 5 2 7 .8 1 9 .3 5 1 1 .3 12.84 .2 0 7 .2 9 7 .4 8 4 .7 1 1 9 .4 9 11.1 1 3 .3 1 4 .95 .4 1 2 .5 5 4 .8 3 1 1 .1 5 11.1 12.8 1 5 .1 1 6 .76 .6 7 6 .8 7 2 1 .2 4 1 .6 4 12.6 1 4 .4 1 6 .8 1 8 .57 .9 8 9 1 .2 4 1 .6 9 2 .1 7 1 4 .1 1 6 .0 1 8 .5 2 0 .38 1 .3 4 1 .6 5 2 .1 8 2 .7 3 1 5 .5 1 7 .5 20.1 22.09 1 .7 3 2 .0 9 2 .7 0 3 .3 3 1 6 .9 1 9 .0 2 1 .7 2 3 .610 2 .1 6 2 .5 6 3 .2 5 3 .9 4 1 8 .3 2 0 .5 2 3 .2 2 5 .211 2 .6 0 3 .0 5 3 .8 2 4 .5 7 1 9 .7 2 1 .9 2 4 .7 2 6 .812 3 .0 7 3 .5 7 4 .4 0 5 .2 3 21.0 2 3 .3 2 6 .2 2 8 .313 3 .5 7 4 .1 1 5 .0 1 5 .8 9 2 2 .4 2 4 .7 2 7 .7 2 9 .814 4 .0 7 4 .6 6 5 .6 3 6 .5 7 2 3 .7 2 6 .1 2 9 .1 3 1 .3
15 4 .6 0 5 .2 3 6 .2 6 7 .2 6 2 5 .0 2 7 .5 3 0 .6 3 2 .816 5 .1 4 5 .8 1 6 .9 1 7 .9 6 2 6 .3 2 8 .8 3 2 .0 3 4 .31 7 5 .7 0 6 .4 1 7 .5 6 8 .6 7 2 7 .6 3 0 .2 3 3 .4 3 5 .718 6 .2 6 7 .0 1 8 .2 3 9 .3 9 2 8 .9 3 7 .5 3 4 .8 3 7 .219 6 .8 4 7 .6 3 8 .9 1 10.1 3 0 .1 3 2 .9 3 6 .2 3 8 .620 7 .4 3 8 .2 6 9 .5 9 1 0 .9 3 1 .4 3 4 .2 3 7 .6 4 0 .021 8 .0 3 8 .9 0 1 0 .3 11.6 3 2 .7 3 5 .5 3 8 .9 4 1 .422 8 .6 4 9 .5 4 11.0 1 2 .3 3 3 .9 3 6 .8 4 0 .3 4 2 .8, 23 9 .2 6 10.2 1 1 .7 1 3 .1 3 5 .2 3 8 .1 4 1 .6 4 4 .22 4 9 .8 9 1 0 .9 1 2 .4 1 3 .8 3 6 .4 3 9 .4 4 3 .0 4 5 .62 5 1 0 .5 1 1 .5 1 3 .1 1 4 .6 3 7 .7 4 0 .6 4 4 .3 4 6 .9
2 6 11.2 12.2 1 3 .8 1 5 .4 3 8 .9 4 1 .9 4 5 .6 4 8 .32 7 11.8 1 2 .9 1 4 .6 1 6 .2 4 0 .1 4 3 .2 4 7 .0 4 9 .62 8 1 2 .5 1 3 .6 1 5 .3 1 6 .9 4 1 .3 4 4 .5 4 8 .3 5 1 .02 9 1 3 .1 1 4 .3 1 6 .0 1 7 .7 4 2 .6 4 5 .7 4 9 .6 5 2 .33 0 1 3 .8 1 5 .0 1 6 .8 1 8 .5 4 3 .8 4 7 .0 5 0 .9 5 3 .74 0 2 0 .7 22.2 2 4 .4 2 6 .5 5 5 .8 5 9 .3 6 3 .7 66.85 0 2 8 .0 2 9 .7 3 2 .4 3 4 .8 6 7 .5 7 1 .4 7 6 .2 7 9 .56 0 3 5 .5 3 7 .5 4 0 .5 4 3 .2 7 9 .1 8 3 .3 8 8 .4 9 2 .07 0 4 3 .3 4 5 .4 4 8 .8 5 1 .7 9 0 .5 9 5 .0 100 1 0 48 0 5 1 .2 5 3 .5 5 7 .2 6 0 .4 102 1 0 7 112 1 1 6
5 9 .2 6 1 .8 6 5 .6 6 9 .1 1 1 3 1 1 8 1 24 198100 6 7 .3 7 0 .1 7 4 .2 7 7 .9 1 2 4 1 3 0 1 3 6 1 4 0

178 СТАТИСТИКА
4. С лучајни бројеви
51772 74640 42331 29044 4662124033 23491 83587 06568 2196045933 60173 52078 25424 1164530586 02133 75797 45406 3104103585 79353 81938 82322 9679964937 '03355 98683 20790 6530415630 64759 51135 98527 6258609448 56301 57683 30277 9462321631 91157 77331 60710 5229091097 17480 29414 06829 8784362898 93582 04186 19640 8705621387 75105 10863 97453 9058155870 56974 37428 93507 9427186707 12973 17169 88116 4218785659 36081 50884 14070 7495055189 00745 65253 11822 1580441889 25439 88036: 24034 6728385418 68829 06652 41982 4915916835 48653 71590 16159 1467628195 27279 47152: 35683 47280

Литература
1. Бањевић Д.: М атематичка статистика, ПМФ Универзите- та у Београду, Београд 1985.
2. Ивковић 3.: М атем атичка статистика, Научна књига, Бео- град, 1975.
3. Ивковић 3., Бањевић Д., Перуничић, П., Глишић, 3.: Статис- тика за I V разред усмереног образовања, Научна књига, Београд, 1980.
4. Југовић-Стојановић Д., Јевремовић В., Марић-Дедијер М.: Збирка задатака из теорије вероватноће и матема- тичке статистике, Научна књига, Београд, 1992.
5. Поповић Б., Благојевић Б.: М атематичка статистика са применама у хидротехници, Универзитет у Нишу, Ниш, 1997, 1999, 2003.
6. Поповић Б., Ристић М.: Статистика у психологији, Мр- љеш, Београд, 2001.
7. Статистички годиш њ ак Југославије, 1976.
8. Статистички годиш њ ак Југославије, 1999.
9. Статистички годиш њ ак Југославцје, 2000.
179


Индекс појмова
аутокорелациона функција случај- иог процеса 169
В
Вернулијева шема 25
В
варијациони низ 79, 101 вероватвдђа 8
- класична дефиниција 8- сг-адитивност 9- ненегативност 9- нормираност 9- особине 9- савремена дефиниција 9
временски низ 168 временски низови 167
гравитациоии центар 160 графички метод приказивања пода-
така 87грешка
- друге врсте 120- прве врсте 120
грешка оцењивања 142 групе 74густина расподеле 17
дискретне расподеле 25 дисперзија случајне променљиве 53 дисперзија случајног процеса 169 догађај
- апсолутна учестаност 8- вероватноћа 8- известан 5- немогућ 5- реализација 4- сигуран 5- случајан 4- супротал 6
догађаји- дисјунктни 6- зависни 10- збир 7- импликација 5- независни 10- пресек 6- разлика 7- унија 7- узајамно искључиви 6
Е
експеримент- детерминистички 3- лабораторијски 3- случајан 3
експоненцијални модел 154 ергодичан процес 169
Д з
дијаграм растурања 141 закон расподеле 13
181

182 СТАТИСТИКА
И
интервал поверења 113- двострани 113 - једнострани 113
интервал поверења за параметар сг2 115
интервал поверења за параметар тп 113, 114
интервална оцена 95 интервално оцењивање 112 интервално сређивање података 82 исход 4
- елементаран 4- атрибутивни 11- ненумерички 11- нумерички 11
избор тачака- случајан 75- периодични 77- групни 78- стратификовани 78
Ј
једнострука регресија 141
К
кодирање 11, 69 коефицијент асиметрије 58 коефицијент ексцеса 59 коефицијент корелације 60 коефицијент спљоштености 59 коефицијент варијације 57 коваријансна функција случајног
процеса 169 критична област 120
М
маргинална- расподела 21- вероватноћа 21- густина 22
- расподела 22 математичко очекивање 45 медијана 51 медијански центар 159 медијански интервал 102 мере централне тенденције 159 метод квадрата 161 метод најближег суОеда 161 мод 50модални интервал 100 модел линеаран по параметрима
150моменти 48
И
нелинеарни модели Зависности 150 независне случајне променљиве 22 независност догађаја 10
оележје 68- једнодимензионално 68- квалитативно 68- квантитативно 68- вишедимензиОнално 68- апсолутно непрекидно 69- атрибутивно 69- дискретно 69 ј- ненумеричко 69- нумеричко 69
оим узорка 70
П
параметарски скуп 168 параметри обележја|94 Пирсонов х 2 тест 131 питасти дијаграм 91 полигон учестаности 89
- алсолутних 90- релативних 90
поправљена узорачка дисперзија 104

ИНДЕКС ПОЈМОВА 183
популација 67 потпун систем догађаја 7 праг значајности теста 120 процена вредности 142 просечно градско растојање 158 просторни центар 160
Р
расподела.- X2 40- биномна 25, 26- дискретне случајне
променљиве 25- биномна 26- Пуасонова 27, 28-- униформна дискретна 30- апсолутно непрекидне
случајне променљиве 31- равномерна 32- униформна 32- Гаусова 34- нормална 34- стандардна нормалиа 35- Студентова 42
растојање- Еуклидово 157- Менхетн 157- типа градског блока 157 .
реализација случајног процеса 168 реализована узорачка дисперзија
104 •регресија 141 .
- линеарна 142- случајне променљиве по
случајној променљивој 142- случајне променљиве по
контролисаној променљивој 146
- вишеструка 148
С
сезонска компонента 170 ’ скуп могућих исхода 4
- бесконачно пребројив 4- коначан 4- непребројив 4
слојеви 73случајна променљива 11
- реализације 11- скуп реализација 11- апсолутно непрекидна 12- дискретна 12- апсолутно непрекидна 16- дводимензионална 18- једнодимензионална 17- вишедимензионална 18- математичко очекивање 45- нумеричке карактеристике 45- моменти 48- мод 50- медијана 51- дисперзцја 53- стандардна девијација 53- централни моменти 55- стандардна девијација 55- стандардно одступање 55
случајни интервал 113 случајни низ 168случајни процес са дискретним вре-
меном 168случајни процес са некорелисаним
вредностима 169 случајни процес са непрекидним
временом 167 случајии узорак 93 средина узорка 95 средња вредност случајног процеса
168стационаран процес 169 стандардизација 38 стандардна девијаццја 53, 55 стандардно одступање 55 статистичка хипотеза 119 статистички тест 119 статистика 67, 94 степени модел 152 стратегија избора узорка 70

184 СТАТИСТИКА
стратуми 73
Т
табела коитингенције 19 таблица случајних бројева 70 таблични метод 79 тачкаста оцена 95 тест статистика. 119 тестирање статистичких хипотеза
119ТРСТОВИ
- иепараметарски 120- параметарскн 120
трајекторија 168 тракастм дијаграм 88 тренд 170
У
учестаност- апсолутна 79- релативна 80- збирна 80” процентуална 85
узорачка дисперзија 103 узорачка медијана 101 узорачка средина 95
- реализована 95узорачка стандардна девијација 103 узорачки коефицијент корелације
107узорачкн мод 99 узорак 70
- репрезентативан 70- случајан 70- периодичан 72- слојевит 73- стратификован 73- групни 74- вишеетапни 75- двоетапни 75- реализовани 94
фреквенција 79- кумулативиа 80
функција расподеле 15- особиие 15
X
хипотеза- алтернативна 119- нулта 119- полазиа 119- проста 119- сложена 119
хистограм 87
ц
центар средњих 160 централни моменти 55 циклична компонента 170

Аутори:Др Мирослав М. Ристић, доцент Природно-математичког факултета у Нишу, Др Биљана Ч. Поповић, редовни професор Природно-математичког факултета у Нишу,Миодраг С. Ђорђевић, асистент-приправник Природно-математичког факултета у Нишу
СТАТИСТИКА ЗА СТУДЕНТЕ ГЕОГРАФШЕ Рецензенти:Др Милан Меркле, редовни професор Електротехничког факултета у Београду,Др Слободан Јанковић, ванредни професор Природно-математичког факултета у Нишу
Одлуком Научно-наставног већа Природно-математичког факултета у Нишу, број 93/1-01 од 7. фебруара 2006. године, рукопис је одобрен за штампу ка'оуниверзитетски уџбеник._____________Издавач:Природно-математички факултет, Ниш
Ш тампа:ДП „Вук Караџић”, Ниш
Тираж:200 примерака
13ВМ: 86-83481-32-8
С1Р - Каталогизација у публикацији Народна библиотека Србије, Београд
519.2(075.8)
Ристић, Мирослав М.Статистика за студенте географије /
Мирослав М. Ристић, Биљана Ч. Поповић,МИодраг Ђорђевић, - Ниш:Природно-математички факултет, 2006 (Ниш:”Вук Караџић”). - 184 стр. : граф. прикази, табеле; 24 сш
Тираж 200. - Библиографија: цтр. 179. - Регистар.
15814: 86-83481-32-8 1. Поповић, Биљана Ч. 2. Ђорђевић,Миодрага) Математичка статистика б) Теорија вероватноћеСОВ155.5К-ГО 129572364





























