Embed Size (px)
Citation preview

IEEE TRANSACTIONS ON CYBERNETICS, VOL. 50, NO. 3, MARCH 2020 1047
MHTN: Modal-Adversarial Hybrid TransferNetwork for Cross-Modal Retrieval
Xin Huang, Yuxin Peng , and Mingkuan Yuan
Abstract—Cross-modal retrieval has drawn wide interest forretrieval across different modalities (such as text, image, video,audio, and 3-D model). However, existing methods based on adeep neural network often face the challenge of insufficient cross-modal training data, which limits the training effectiveness andeasily leads to overfitting. Transfer learning is usually adopted forrelieving the problem of insufficient training data, but it mainlyfocuses on knowledge transfer only from large-scale datasets as asingle-modal source domain (such as ImageNet) to a single-modaltarget domain. In fact, such large-scale single-modal datasets alsocontain rich modal-independent semantic knowledge that canbe shared across different modalities. Besides, large-scale cross-modal datasets are very labor-consuming to collect and label,so it is significant to fully exploit the knowledge in single-modaldatasets for boosting cross-modal retrieval. To achieve the abovegoal, this paper proposes a modal-adversarial hybrid transfernetwork (MHTN), which aims to realize knowledge transfer froma single-modal source domain to a cross-modal target domain andlearn cross-modal common representation. It is an end-to-endarchitecture with two subnetworks. First, a modal-sharing knowl-edge transfer subnetwork is proposed to jointly transfer knowledgefrom a single modality in the source domain to all modalitiesin the target domain with a star network structure, which dis-tills modal-independent supplementary knowledge for promotingcross-modal common representation learning. Second, a modal-adversarial semantic learning subnetwork is proposed to constructan adversarial training mechanism between the common rep-resentation generator and modality discriminator, making thecommon representation discriminative for semantics but indiscrim-inative for modalities to enhance cross-modal semantic consistencyduring the transfer process. Comprehensive experiments on fourwidely used datasets show the effectiveness of MHTN.
Index Terms—Adversarial training, cross-modal retrieval,hybrid transfer network, knowledge transfer, modal-adversarial.
I. INTRODUCTION
IN THE era of big data, digital media content can be gener-ated and found everywhere. Multimodal data such as text,
image, video, audio, and 3-D model have become the mainform of information acquisition and dissemination. Underthis situation, cross-modal retrieval [1] becomes a highlighted
Manuscript received August 7, 2017; revised April 8, 2018 and July 7,2018; accepted November 1, 2018. Date of publication December 5, 2018;date of current version January 21, 2020. This work was supported by theNational Natural Science Foundation of China under Grant 61771025 andGrant 61532005. This paper was recommended by Associate Editor M. Zhang.(Corresponding author: Yuxin Peng.)
The authors are with the Institute of Computer Science and Technology,Peking University, Beijing 100871, China (e-mail: [email protected]).
Color versions of one or more of the figures in this paper are availableonline at http://ieeexplore.ieee.org.
Digital Object Identifier 10.1109/TCYB.2018.2879846
Fig. 1. Examples of cross-modal retrieval, which can provide retrieval resultswith different modalities by a query of any modality.
research topic to perform retrieval across various modalities.The essential difference between the cross-modal retrieval andtraditional single-modal retrieval is that cross-modal retrievalallows the modalities of query and retrieval results to be dif-ferent, as shown in Fig. 1. As a novel retrieval paradigm,cross-modal retrieval has wide application prospects, such asintelligent search engine and multimedia data management.However, it is a challenging problem due to the “heterogeneitygap,” which means that the representation forms of differ-ent modalities are inconsistent, so the cross-modal similaritycannot be directly calculated.
For bridging heterogeneity gap the existing mainstreammethods follow the paradigm of common representationlearning. They take the intuitive idea that there exists anintermediate common semantic space, where data of relevantsemantics can be represented as a similar “feature” and beclose to each other. With this idea, many methods [2]–[5] havebeen proposed to learn a common representation for cross-modal data, and then the cross-modal similarity can be directlycalculated for retrieval. Traditional methods [2], [6] mainlytake linear projections as basic models. However, cross-modalcorrelation is highly complex and hard to be fully captured bylinear projections. Recent years, cross-modal retrieval based onthe deep neural network (DNN) has become an active researchtopic [5], [7]–[9]. These methods exploit DNN’s strong abilityof nonlinear relationship analysis in cross-modal correlation
2168-2267 c© 2018 IEEE. Personal use is permitted, but republication/redistribution requires IEEE permission.See http://www.ieee.org/publications_standards/publications/rights/index.html for more information.

1048 IEEE TRANSACTIONS ON CYBERNETICS, VOL. 50, NO. 3, MARCH 2020
learning and achieve accuracy improvement. Nevertheless,DNN-based methods of cross-modal retrieval often face thechallenge of insufficient training data, which limits the trainingeffectiveness and easily leads to overfitting.
As is known to us, insufficient training data is an impor-tant common challenge for machine learning, especially fordeep learning because it relies heavily on the scale of trainingdata. For cross-modal retrieval, this problem is even greatlyseverer due to the diverse modalities. For example, if wewant to collect training data for “tiger,” we need to see theimages, read the texts, watch the videos, listen to the audio,and even browse the 3-D models, which is extremely labor-consuming. Transfer learning [10]–[12] is usually adoptedfor relieving the problem of insufficient training data, whichtransfers knowledge from large-scale datasets as the sourcedomain for boosting a specific task in the target domain. Somehigh-quality single-modal datasets have been constructed ascommonly used source domains, such as ImageNet [13] forimage and Google News corpus [14] for text. But exist-ing methods of transfer learning mainly focus on knowledgetransfer only from the single-modal source domain to thesingle-modal target domain.
Actually, it is significant to distill the knowledge in theselarge-scale single-modal datasets for cross-modal retrievalbecause of the following.
1) Single-modal datasets can provide considerable sup-plementary information to guide cross-modal retrieval.Besides modal-specific information, single-modaldatasets contain rich modal-independent semanticknowledge. For example, we can analyze the datadistribution of an image dataset to know that tiger isrelevant to “animal,” but irrelevant to “airplane” and“water.” Such general knowledge can be shared acrossdifferent modalities to guide cross-modal retrieval.
2) There are few cross-modal datasets which can be usedas the source domain. It is very hard to construct large-scale cross-modal datasets, which can cover a widerange of common knowledge. Therefore, it would beof great help if the existing large-scale single-modaldatasets can be fully exploited for boosting cross-modalretrieval.
However, it is challenging to transfer useful knowledge fromthe single-modal source domain to the cross-modal targetdomain. On the one hand, due to heterogeneity gap the knowl-edge from the single-modal source domain cannot be directlytransferred to different modalities in the target domain, wherewe need a “bridge” to achieve knowledge sharing. On theother hand, this is an asymmetric transfer paradigm, wherethe source domain contains only one modality. Intuitively,the modality shared in both domains will have higher con-sistency in the transfer process. Such imbalanced informationmay break the inherent correlation in the target domain.Therefore, it is important to ensure the common represen-tations are indiscriminative for different modalities, whichpreserves the inherent cross-modal semantic consistency in thetarget domain.
For addressing the above problems, this paper proposes themodal-adversarial hybrid transfer network (MHTN), which is
an end-to-end architecture with two subnetworks to mutuallyboost and learn the cross-modal common representation.
1) Modal-sharing knowledge transfer subnetworks areproposed to jointly minimize the cross-domain distribu-tion discrepancy and cross-modal pairwise discrepancywith a star network structure, which is a hybrid trans-fer process from the single-modal source domain to thecross-modal target domain. Different from the exist-ing single-modal transfer methods [15]–[17], this hybridtransfer structure can jointly transfer knowledge from alarge-scale single-modal dataset in the source domainto multiple modalities in the target domain, distillingmodal-independent supplementary information to relievethe problem of insufficient cross-modal training data.
2) Modal-adversarial semantic learning subnetworks areproposed to construct an adversarial training mecha-nism between the common representation generator andmodality discriminator for driving the transfer process.The former aims to generate semantic representation tobe indiscriminative for modalities, while the latter triesto distinguish the modalities of the common represen-tation, which compete each other to mutually boost. Itmakes the learned common representation discriminativefor semantics but indiscriminative for modalities, thuseffectively enhances cross-modal semantic consistencyto improve retrieval accuracy.
Extensive experiments compared with 13 existing meth-ods on four widely used datasets show the effectiveness ofour MHTN approach, including the challenging PKU XMediadataset with up to five modalities. Compared with our previousconference paper [18], there are two major aspects of newlyadded contributions.
1) This paper newly proposes the modal-adversarial train-ing strategy. A modality discriminator competes againstthe common representation generator during the transferprocess. This aims to address the problem of imbalancedinformation from the asymmetric transfer paradigm andenhance the cross-modal semantic consistency in thetarget domain.
2) This paper newly proposes the five-pathway star networkstructure, which can perform knowledge transfer andcommon representation learning for up to five modal-ities (text, image, video, audio, and 3-D model) so thatthey can naturally align with each other by joint transfer.This improves the width of knowledge transfer com-pared with [18], which can only perform knowledgetransfer to two modalities (image and text).
The rest of this paper is organized as follows. Section IIpresents a brief review of related work. Section III intro-duces our proposed MHTN approach. Section IV presents thecomparison experiments, and Section V concludes this paper.
II. RELATED WORK
A. Cross-Modal Retrieval
Cross-modal retrieval is proposed to perform a retrieval taskacross different modalities. The key challenge of cross-modal

HUANG et al.: MHTN NETWORK FOR CROSS-MODAL RETRIEVAL 1049
retrieval is the heterogeneity gap and the mainstream of cross-modal retrieval is to represent data of different modalities witha common representation. Then the cross-modal retrieval canbe performed in the same common space by a commonly useddistance metric, such as the Euclidean distance and cosinedistance. Existing methods can be classified into traditionalmethods and DNN-based methods.
Traditional methods mainly convert cross-modal data intocommon representation by linear projections. For example,canonical correlation analysis (CCA) [2] learns linear projec-tion matrices by maximizing pairwise correlation of cross-modal data, which has many extensions as [3] and [6].Cross-modal factor analysis (CFA) [19] directly minimizesthe Frobenius norm between the common representation ofpairwise data. Recently, a few studies have been proposedfor incorporating various information into common repre-sentation learning, such as semi-supervised and sparse reg-ularizations [4], local group-based priori [20], and semantichierarchy [21]. Inspired by the considerable improvement bythe DNN in many single-modal tasks such as image classifica-tion [13] and object recognition [22], researchers have madegreat efforts to apply the DNN to the cross-modal retrievalas [5], [7] and [23]. For example, Ngiam et al. [7] proposeda bimodal deep autoencoder, which is an extension of therestricted Boltzmann machine. Data of two modalities passthrough a shared code layer, in order to learn the cross-modalcorrelations as well as preserve the reconstruction information.
Deep CCA (DCCA) [24] is a nonlinear extension of CCAand can learn the complex nonlinear transformations for twomodalities. Peng et al. [5] proposed cross-media multiple deepnetworks (CMDNs), which jointly preserve the intramodalityand intermodality information to generate complementary sep-arate representations and then hierarchically combine them forimproving the retrieval accuracy. Wang et al. [25] adoptedthe idea of adversarial learning and triplet constraints, togenerate modality-invariant representations in the commonsubspace. Mandal et al. [26] proposed a generalized hash-ing framework, which can preserve the semantic distanceunder single-label or multilabel settings, whether there existsone-to-one correspondence information or not.
However, most of the existing studies as [5] and [9] onlyperform model training with the cross-modal datasets. Becausetraining data play a key role in the performance of DNN-basedmethods, they often face the challenge of insufficient trainingdata, which limits the training effectiveness and easily leadsto overfitting. Some recent works take auxiliary single-modaldatasets to directly pretrain the network component for onlyone modality as [23]. For example, ImageNet is adopted asan auxiliary dataset in the work of [23] to pretrain a convo-lutional neural network (CNN) model, and then the images inthe cross-modal dataset are further used to fine-tune it. Thiscan be viewed as knowledge transfer from image to image, butnot jointly to multiple modalities in the target domain, whichleads to inadequate transfer and limits the retrieval accuracy.
Our MHTN is proposed for addressing the problem ofjointly transferring knowledge from a single modality tomultiple modalities. It can distill the modal-independentknowledge from the single-modal large-scale dataset and
exploit it to relieve the problem of insufficient cross-modaltraining data, thus improving the accuracy of the cross-modalretrieval.
B. Transfer Learning
Human can effectively exploit the learned knowledge fromknown tasks to promote the learning effectiveness of a newtask. Inspired by this, transfer leaning [10] is a natural wayto relieve the problem of insufficient labeled training data,which transfers knowledge from the source domain to guidethe model training in the target domain. Generally speaking,transfer learning holds the idea that reducing the discrep-ancy of different domains can make the source domain modelwork effectively in the target domain [15]–[17], [27] and hasachieved considerable success in a lot of research areas. Theidea of transfer learning is very important for DNN-basedmethods as [13], whose performance usually heavily relieson the scale of training data. If there is insufficient data for agiven application, transfer learning can be used for relievingthis problem as [11] and [12].
However, most of the existing efforts on transfer learningfocus on single-modal application scenarios, where the sourceand target domains share the same single modality (such asImage→Image). Zhu et al. [28] proposed to adopt a long-shortterm memory network to address the temporal dynamics ofheat flows on 3-D shapes, which also considers the 3-D shapeanalysis problem in the cross-domain structure for multiviewdata. Although there are some studies that involve heteroge-neous domain adaptation [29], [30], they deal with the problemof transferring knowledge between different feature spaces ofonly one same modality.
Beyond these, some studies are proposed to transfer knowl-edge from one modality to another, which is still a one-to-onetransfer paradigm. For example, Tang et al. [31] proposed totransfer the semantic knowledge from texts for image clas-sification. Zhang et al. [32] proposed an adaptation methodto improve action recognition in videos by adapting knowl-edge conveyed from images. Some methods as [33] proposeknowledge transfer between two domains with two modalities,where the modalities of the two domains should be the same.Moreover, Gupta et al. [34] proposed to use a trained modelof the RGB image as a pretrained model for the depth imageby knowledge distillation [35], which assumes that the twokinds of images have pixel correspondences. Cao et al. [36]proposed a transitive hashing network, which learns from anauxiliary cross-modal dataset to bridge two modalities fromsingle-modal datasets.
From the above summarization, we can see that existingstudies pay little attention to knowledge transfer from thesingle-modal source domain to the cross-modal target domain.Because cross-modal data is much more labor-consuming tocollect and label than single-modal data, it is significant toexploit the knowledge in single-modal datasets for relievingthe problem of insufficient cross-modal training data. OurMHTN is proposed to realize this novel transfer paradigm,which can effectively distill modal-independent supplementary

1050 IEEE TRANSACTIONS ON CYBERNETICS, VOL. 50, NO. 3, MARCH 2020
Fig. 2. Overview of our proposed MHTN.
knowledge to promote the model training for cross-modaltasks, such as cross-modal retrieval.
III. MODAL-ADVERSARIAL HYBRID
TRANSFER NETWORK
Fig. 2 shows the overall architecture of our MHTNapproach, which takes an auxiliary image dataset as thesource domain and a cross-modal dataset with five modali-ties (text, image, video, audio, and 3-D model) as the targetdomain. In fact, MHTN can also be easily applied to scenar-ios with the other number of modalities, e.g., image and text.MHTN consists of two subnetworks: 1) modal-sharing trans-fer subnetwork and 2) modal-adversarial semantic learningsubnetwork. These two subnetworks form an end-to-end archi-tecture, jointly trained for generating a cross-modal commonrepresentation.
The single-modal source domain is denoted as Src ={si, ys
i }mi=1 where si is the ith image with label ysi .
The cross-modal target domain is denoted as Tar ={DI, DT , DA, DV , DM}, which means the data of image, text,audio, video, and 3-D model, respectively. DI = {DIl , DIu},where DIl = {dIl
j , yIlj }
NIl
j=1 denotes the labeled images for train-
ing and DIU = {dIuj }N
Iu
j=1 denotes the unlabeled images fortesting, which is similar for DT , DA, DV , and DM . For con-venience, we also use term O = {I, T, A, V, M} to denote allmodalities.
The aim of the proposed MHTN is to transfer knowledgefrom Src to Tar and train a model for generating cross-modal
common representations as R = {RI, RT , RA, RV , RM} for unla-beled data. It is noted that the feature dimensions in R for allmodalities are the same, so the cross-modal similarity can beobtained by directly computing the distance among them.
A. Modal-Sharing Knowledge Transfer Subnetwork
The modal-sharing knowledge transfer subnetwork isproposed to perform knowledge transfer from the single-modalsource domain to the cross-modal target domain, which takesthe modality shared by both two domains as a bridge. Inthe training stage, we arrange the training data in Tar ascross-modal documents. For each image dIl
j , we select oneinstance respectively from each different modality to form
a document set as Dc = {(dIlj , dTl
j , dAlj , dVl
j , dMlj )}NI
lj=1, where
these instances are closely relevant. Instances in each cross-modal document will be input into the network in parallel.If the dataset has predefined co-existence correlation (suchas Wikipedia, NUS-WIDE-10k, and Pascal Sentences), wedirectly select instances according to it. Otherwise, we ran-domly select instances according to the semantic labels as onthe PKU XMedia dataset.
Fig. 3 shows the structure of this subnetwork, where we onlytake three modalities (image, text, and audio) as examples forclarity. For image pathways of both source and target domains,we adopt the widely used CNN to generate feature maps, andthe two pathways are the same in the beginning of training forconsistency. For the other modalities, we use extracted featuresas inputs. All the inputs will be fed into fully connected layers

HUANG et al.: MHTN NETWORK FOR CROSS-MODAL RETRIEVAL 1051
Fig. 3. Structure of the modal-sharing knowledge transfer subnetwork, whereimage, text, and audio are shown as examples.
(specific representation layers) for knowledge transfer, whichis a hybrid transfer structure composed of single-modal andcross-modal transfer parts.
1) Single-Modal Knowledge Transfer: This part transfersknowledge from the source domain to target domain, throughthe bridge of shared modality (image). We follow [11] toadopt the feature adaptation method [37] for minimizing themaximum mean discrepancy (MMD) of images between thetwo domains. We denote the distributions of images from thesource domain Src = {s} and target domain DIl = {dIl} as aand b, respectively, and the MMD between them is mk(a, b).We adopt the squared formulation of MMD as follows, whichis in the reproducing kernel Hibert space Hk:
m2k(a, b)
�= ∥∥Ea[φ(s; θS)]− Eb[φ(dIl; θI)]
∥∥
2Hk
(1)
where φ is the representation from a network layer and θS andθI denote the network parameters for Src and DIl , respectively.EX∼af (X) = 〈f (X), μk(a)〉Hk for all f ∈ Hk, where μk(a) isthe mean embedding of a in Hk. The kernel is defined as theconvex combination of PSD kernels [11]. We calculate thevalue of m2
k(Src, DIl) in the corresponding specific represen-tation layers (fc6-S/fc6-I and fc7-S/fc7-I) as the single-modaltransfer loss
LossST =l7∑
l=l6
m2k(Src, DIl). (2)
By minimizing MMD, the model will be guided to matchthe distribution of the target domain so that the knowledge inthe source domain can be effectively transferred to the targetdomain.
Besides, we also fine-tune the source image pathway itselfduring the transfer process as [11] with source domain data,which aims to provide supplementary supervision informationfor the target domain, as well as preserve the semantic con-straints in the source domain to avoid overfitting on the domaindiscrepancy. We define the source domain supervision loss
as follows:
LossSDS = − 1
m
m∑
j=1
fsoftmax(sj, ysj ; θS) (3)
where fsoftmax(x, y; θ) is the softmax loss function
fsoftmax(x, y; θ) =c
∑
q=1
1{y = q} log[
p̂(x, q; θ)]
(4)
where y denotes the label of instance x, θ contains the networkparameters, and c is the number of x’s of all possible classes.If y = q, 1{y = q} equals to 1, and otherwise 0. p̂(x, q; θ)
is the probability distribution over classes of x and can beexpanded as
p̂(x, q; θ) = eφ(x;θq)
∑cl=1 eφ(x;θl)
. (5)
By minimizing LossST and LossSDS, the domain discrepancycan be effectively reduced, and the supplementary semanticinformation from the source domain can be transferred to thetarget domain for guiding the network training.
2) Cross-Modal Knowledge Transfer: The aforementionedpart of single-modal knowledge transfer aims to allow theknowledge to be transferred between images in both thedomains, but the data in source domain also contains rich andvaluable modal-independent semantic knowledge that can bejointly shared across different modalities. We achieve this bycross-modal knowledge transfer, which exploits cross-modalcorrelation to jointly transfer knowledge to all modalities.
Specifically, we consider the pairwise correlation betweeneach image and instances of other modalities as [9] and [19].Intuitively, the network outputs of pairwise data should besimilar to each other, which aims to align their representationsand achieve knowledge sharing. Each cross-modal documentin Dc can be viewed as pairs containing image and anothermodality. Thus each pair can be denoted as (dIl
j , dXlj ), where
X ∈ O∧X = I. To represent the cross-modal pairwise discrep-ancy, we adopt the Euclidean distance between the specificrepresentation layers of the image and every other modal-ity, which leads to a star network structure. The cross-modalpairwise discrepancy of (dIl
j , dXlj ) is denoted as
c2(dIlj , dXl
j ) =∥∥∥φ(dIl
j ; θI)− φ(dXlj ; θX)
∥∥∥
2(6)
where φ is the representation from a network layer, and θI andθX , respectively, denote the network parameters for I and X.Then we get the cross-modal transfer loss as
LossCT =∑
X∈O∧X =I
l7∑
l=l6
NIl∑
j=1
c2(dIlj , dXl
j ). (7)
By optimizing LossCT, the cross-modal pairwise discrepancycan be reduced to achieve cross-modal knowledge transfer.
In the overall structure of modal-sharing knowledge trans-fer subnetworks, the image modality acts as a shared bridgeto link the single-modal and cross-modal transfer parts, whichforms a hybrid transfer structure. By this subnetwork, thesemantic knowledge contained in the source domain can be

1052 IEEE TRANSACTIONS ON CYBERNETICS, VOL. 50, NO. 3, MARCH 2020
Fig. 4. Structure of the modal-adversarial semantic learning subnetwork,where image, text, and audio are shown as examples.
jointly transferred to all modalities in the cross-modal tar-get domain. We denote the output of this subnetwork as
Zc = {(zIlj , zTl
j , zAlj , zVl
j , zMlj )}NI
lj=1, which will be further fed into
the modal-adversarial semantic learning subnetwork.
B. Modal-Adversarial Semantic Learning Subnetwork
This subnetwork is proposed to further adapt the trans-fer process to the cross-modal retrieval task and learn thecross-modal common representation. Although the introducedmodal-sharing knowledge transfer subnetwork has actuallyperformed hybrid knowledge transfer, there still exist twoproblems which limit the retrieval performance.
1) It only exploits pairwise correlation, but the high-levelsemantic consistency is the essential property of thecross-modal target domain, which should be effectivelymodeled.
2) It is actually an image-centric structure, and the pro-cess of each pathway is inconsistent, which cannot fullyextract the modal-independent information to reduce theheterogeneity gap.
For addressing the above problems, we design a modal-adversarial semantic learning subnetwork, inspired by the ideaof adversarial training. Goodfellow et al. [38] indicated thatdeep models can be confused by adding an imperceptiblysmall vector to samples, and training with such adversarialexamples can improve the discriminative ability. Furthermore,Goodfellow et al. [39] proposed the idea of simultaneouslytraining a generative model and a discriminative model andpitting the two adversaries against each other to mutuallyboost, like a game between two players. Such an idea hasinspired a series of works, such as [15] which proposedthe gradient reversal layer (GRL) to distinguish differentdomains, challenging the transfer model to reduce the domaindiscrepancy.
The structure of this subnetwork is shown in Fig. 4. Zc
will be fed into shared fully connected layers (common rep-resentation layers) to generate common representation. Thenthere are two loss branches to drive the network training,
namely, semantic consistency learning and modal-adversarialconsistency learning.
1) Semantic Consistency Learning: In this branch, we letthe cross-modal common representation be semantically dis-criminative. Because all modalities share the same commonrepresentation layers, the cross-modal semantic consistencycan be ensured under the guidance of supervision informationin the target domain.
To achieve this goal, we adopt a fully connected layer as acommon classification layer with a softmax loss function. Thesemantic consistency loss is defined as follows:
LossSC = − 1
NIl
∑
X∈O
NIl∑
j=1
fsoftmax(zXlj , yIl
j ; θC) (8)
where zXlj is the data of X modality in the jth cross-modal
document, yIlj is its semantic label, θC is the network parameter,
and fsoftmax is the softmax loss function as (4). By optimizingLossSC, we can maximize the classification accuracy jointlyfor all modalities, which preserves the semantic consistencycontained in the cross-modal target domain.
2) Modal-Adversarial Consistency Learning: Intuitively,ideal cross-modal common representation will simultaneouslyhave two properties, both of which are very important forcross-modal retrieval.
1) It is discriminative of semantics, so the semantic consis-tency of different modalities can be effectively enhanced.
2) It is indiscriminative of modalities, so the heterogeneitygap is effectively reduced. The aforementioned branchsemantic consistency learning aims to maximize thesemantic discriminative ability, while modal-adversarialconsistency learning is proposed to minimize the cross-modal representation difference.
This branch can be regarded as a modality discriminatornetwork, while the other introduced parts of MHTN beforefc10 in Fig. 4 form a common representation generatornetwork. The modality discriminator aims to distinguish dif-ferent modalities, while the common representation generatorreduces the cross-modal representation difference to confusethe modality discriminator, as an adversarial training style.
The modality discriminator network consists of a GRL [15]and fully connected layers, the last of which is the modalityclassification layer. The GRL is an identity transform duringthe forward propagation, but it multiplies the gradients fromthe following layers by −λ during the backpropagation, whereλ is a positive value. In training stage, each instance is assignedwith a one-hot encoding vector to indicate which modality itbelongs to, and the modal-adversarial consistency loss is
LossMC = − 1
NIl
∑
X∈O
NIl∑
j=1
fsigmoid(zXlj , p(zXl
j ); θM) (9)
where p(·) denotes the label indicator, θM denotes the networkparameters, and fsigmoid(x, p; θ) is the sigmoid cross entropyloss function following [15]:
fsigmoid(x, p; θ) = p(x) log p̂(x; θ)
+ [1− p(x)] log [1− p̂(x)] (10)

HUANG et al.: MHTN NETWORK FOR CROSS-MODAL RETRIEVAL 1053
where the p̂(x; θ) is given as
p̂(x; θ) = 1
1+ e−φ(x;θ). (11)
Due to the existence of GRL, the gradient of this part will bereversed during the training stage. By maximizing LossMC, wecan explicitly reduce the heterogeneity gap among modalitiesand enhance the consistency of the common representation.
Our MHTN is an end-to-end architecture with the modal-sharing knowledge transfer subnetwork and modal-adversarialsemantic learning subnetwork. So the two subnetworks aretrained jointly and boost each other. In the testing stage, eachtesting instance in Tar can be converted into a predicted classprobability vector as the final common representation R forretrieval as [4] and [23]. It is noted that the testing data canbe input separately, which is unnecessary to be input in theform of a cross-modal document.
C. Optimization
As for the network optimization, we first denote the param-eters of different parts for clarity. In modal-sharing knowledgetransfer subnetwork, we denote the parameters of the sourcedomain pathway as θS and the parameters of the target domainpathway for the image as θI , and for all the other modalitiesas θO′ = {θT , θA, θV , θM}. In the modal-adversarial semanticlearning subnetwork, the parameters of the modal-adversarialconsistency learning part are denoted as θM and the others aredenoted as θC.
With the above notations, we can assign the parameters toeach loss function and formally consider the loss function
E(θS, θI, θO′ , θC, θM)
= LossST(θS, θI)+ LossSDS(θS)+ LossCT(θI, θO′)
+ LossSC(θI, θO′ , θC)− λLossMC(θI, θO′ , θC, θM) (12)
where λ is a positive tradeoff parameter between the positiveand negative loss functions in the training stage. Our goal isto find the parameters θS, θI , θO′ , θC, and θM for getting thesaddle point of (12)
(θ̂S, θ̂I, θ̂O′ , θ̂C) = arg minθS,θI ,θO′ ,θC
E(θS, θI, θO′ , θC, θ̂M) (13)
θ̂M = arg maxθM
E(θ̂S, θ̂I, θ̂O′ , θ̂C, θM). (14)
At the saddle point, the parameters θS, θI , θO′ , and θC of theprevious networks minimize (12), while the parameters θM
maximize (12), which is an adversarial training style. Basedon (13) and (14), we can update the parameters as follows:
θS ← θS − μ
(∂LossST
∂θS+ ∂LossSDS
∂θS
)
(15)
θI ← θI − μ
(∂LossST
∂θI+ ∂LossCT
∂θI
+ ∂LossSC
∂θI− λ
∂LossMC
∂θI
)
(16)
θO′ ← θO′ − μ
(∂LossCT
∂θO′+ ∂LossSC
∂θO′− λ
∂LossMC
∂θO′
)
(17)
θC ← θC − μ
(∂LossSC
∂θC− λ
∂LossMC
∂θC
)
(18)
θM ← θM − μ∂LossMC
∂θM(19)
where μ denotes the learning rate. The parameter updates of(15)–(19) can be realized by the stochastic gradient descent(SGD) algorithm. The SGD algorithm can be implemented bythe Caffe framework easily [40], which can compute the gra-dients and update the parameters. In this way, we can optimizethese loss functions and perform knowledge transfer fromthe single-modal source domain to cross-modal target domainin the training stage, so as to get an effective cross-modalcommon representation R.
IV. EXPERIMENTS
A. Details of the Deep Architecture
The implementation of MHTN is based on Caffe,1 a widelyused deep learning framework. It is noted that the presentedarchitecture is for five modalities, which can be easily appliedto the other number of modalities by adjusting the pathwaynumber.
1) Modal-Sharing Knowledge Transfer Subnetworks: In thesource image pathway and target image pathway, we adoptconvolutional layers (conv1–conv5) of AlexNet [13] pretrainedon ImageNet from Caffe Model Zoo.2 The input images arefirst resized as 256 × 256 and then used to generate convo-lutional feature maps (pool5). These convolution layers arefrozen in the training stage because they are regarded as gen-eral layers. All the six pathways have two fully connectedlayers (specific representation layers), and all of them have4096 units. The learning rates of all the fully connected layersare fixed to be 0.01.
The single-modal transfer loss is implemented by MMDloss layers [11] between the source image pathway and targetimage pathway, while the cross-modal transfer loss is imple-mented by the contrastive loss layer from Caffe. After thefc8-S layer and a softmax loss layer of the source imagepathway, we can calculate LossSDS for images of the sourcedomain in the training stage. Moreover, because the magnitudeof LossCT is much larger than those of LossST and LossSDS(about 1000 times), we set its weight as 0.001, and those ofLossST and LossSDS are 1. The weight decay of this subnet-work is set as 0.0005. These parameter settings can be easilyadjusted in the implementation of networks.
2) Modal-Adversarial Semantic Learning Subnetworks:This subnetwork has two fully connected layers with 4096units (common representation layers), which are fc8 and fc9in Fig. 4, and the learning rates are fixed to be 0.01. Thenafter a fully connected classification layer (fc10) and a softmaxlayer, we can calculate LossSC for all modalities of the targetdomain in the training stage and get the probability vector asthe final common representation in the testing stage. Besides,for the part of modal-adversarial consistency learning, thereis a GRL [15], three fully connected layers (fc11 and fc12with 1024 units and fc13 with 5 units), and a sigmoid crossentropy loss layer. Note that the unit number of fc13 is thesame with a modality number. The learning rates of fc11–fc13
1http://caffe.berkeleyvision.org2https://github.com/BVLC/caffe/wiki/Model-Zoo

1054 IEEE TRANSACTIONS ON CYBERNETICS, VOL. 50, NO. 3, MARCH 2020
are fixed as 0.001. The weight decay of this subnetwork is alsoset as 0.0005. The weight of LossMC (λ) is set as 0.1 to avoidexcessive influence, while that of LossSC is 1.
B. Datasets
In the experiments, ImageNet [13] serves as the sourcedomain, which is from the ImageNet large-scale visualrecognition challenge (ILSVRC) 2012. The cross-modalretrieval is conducted on four widely used datasets, namely,Wikipedia, NUS-WIDE-10k, Pascal Sentences, and PKUXMedia datasets. These four datasets are briefly introducedas follows.
Wikipedia dataset [3] is constructed from the “featured arti-cles” of Wikipedia, which contains 2866 image/text pairs often classes, where each pair only belongs to one class. Ineach pair, the text is several paragraphs as descriptions ofthe image. The classes are of high-level semantics, such ashistory and warfare. The dataset is split as three parts fol-lowing [5] and [9], where the training set has 2173 pairs, thetesting set has 462 pairs, and the validation set has 231 pairs.
NUS-WIDE-10k dataset [9] is constructed by randomlyselecting 1000 image/tag pairs from each of the ten largestclasses in the NUS-WIDE dataset [41]. Different from theWikipedia dataset, in the NUS-WIDE-10k dataset the textmodality refers to tags, instead of textual descriptions as para-graphs or sentences. The totally 10 000 pairs are randomlysplit into three parts: 1) the training set has 8000 pairs; 2)the testing set has 1000 pairs; and 3) the validation set has1000 pairs. Note that the pairs in the three parts are all evenlyselected from the ten classes.
Pascal Sentences dataset [42] is selected from 2008PASCAL development kit, which contains 1000 images withcorresponding text descriptions as five sentences. Theseimage/text pairs can be evenly classified into 20 classes.A similar split strategy with the NUS-WIDE-10k dataset isadopted for the Pascal Sentences dataset, where the trainingset has 800 pairs, the testing set has 100 pairs, and the vali-dation set has 100 pairs, all of which are evenly from the 20classes.
PKU XMedia dataset3 [1] is the first publicly availablecross-modal dataset with up to five modalities (text, image,video, audio, and 3-D model). There are totally 20 classes inthe PKU XMedia dataset, which are specific objects such asinsect, bird, wind, dog, and elephant. There are 250 texts, 250images, 25 videos, 50 audio clips, and 25 3-D models for eachclass, and the total number of instances is 12 000. Similar toother datasets, we split the PKU XMedia dataset as three parts:1) the training set has 9600 instances; 2) the testing set has1200 instances; and 3) the validation set has 1200 instances.Note that in each set, the instances are evenly from the fivemodalities for ensuring the variety.
In the training phase, taking the PKU XMedia dataset as anexample, the source samples include all images in the trainingset of ILSVRC 2012, with the size of 1 281 167. The tar-get image samples include all training images in the PKUXMedia dataset, with the size of 4000. This setting is the
3http://www.icst.pku.edu.cn/mipl/xmedia
same for Wikipedia, NUS-WIDE-10k, and Pascal Sentencesdatasets. Although all the datasets are split into training, test-ing, and validation sets, only CMDN, Corr-AE, Bimodal AE,and Multimodal DBN actually need the validation set as input.For the other compared methods including our MHTN, thevalidation set is not used in both training and testing stages.
C. Retrieval Tasks and Evaluation Metrics
In the experiments, the bi-modal retrieval is conductedfor evaluation, which means that the retrieval is performedbetween two different modalities. For instance, on theWikipedia dataset, we retrieve the texts by image queries(denoted as Image→Text) and vice versa; and on the PKUXMedia dataset, the retrieval will be performed betweeneach pair of modalities. As for the retrieval process, takingImage→Text as an example, we first obtain the common repre-sentation for all the images and texts in the testing set with allcompared methods and MHTN. Then we select each image inthe testing set as the query, compute the similarity between thequery and every text in the testing set by the cosine distance,and finally get the similarity ranking list.
We evaluate the retrieval results mainly by the mean averageprecision (MAP) score, which is the mean value of averageprecision scores of all queries. All the retrieval results will beconsidered for the computation of MAP scores, instead of top50 results as [9] and [25]. We also adopt the precision–recall(PR) curve for more comprehensive evaluation, which showsthe search precision at all recall levels.
D. Compared Methods and Input Settings
In the experiments, we compare our proposed MHTNapproach with totally 13 existing methods, namely, CCA [2],CFA [19], KCCA (with Gaussian and polynomial kernel) [43],DCCA [24], Bimodal AE [7], Multimodal DBN [8], Corr-AE [9], JRL [4], LGCFL [20], CMDN [5], Deep-SM [23],ACMR [25], and GSPH [26].
For image, the architectures of Deep-SM and our MHTNapproach have CNNs built-in (AlexNet), so they take the orig-inal image pixels as input, while all the other methods takeextracted feature vectors as input. So for all the methods exceptMHTN and Deep-SM, we use the same AlexNet pretrainedon ImageNet which is further fine-tuned with the images ineach dataset to convergence, and extract the output of 4096dimensions from the fc7 layer as the image features.
For text, video, audio, and 3-D model, exactly the samefeatures are used for all compared methods and our MHTN.For text, following [5], [9], the 3000-D BoW features areadopted for the Wikipedia dataset, and the 1000-D BoW fea-tures are adopted for NUS-WIDE-10k and Pascal Sentencesdatasets. On the PKU XMedia dataset, we take 3000-D BoWtext features, which are the same with the Wikipedia dataset.For video, we use the C3D model [44] pretrained on Sports-1M [45] to extract the output of 4096 dimensions from thefc7 layer as the video features. For audio, audio clips arerepresented by the 78-D features, which are extracted by
HUANG et al.: MHTN NETWORK FOR CROSS-MODAL RETRIEVAL 1055
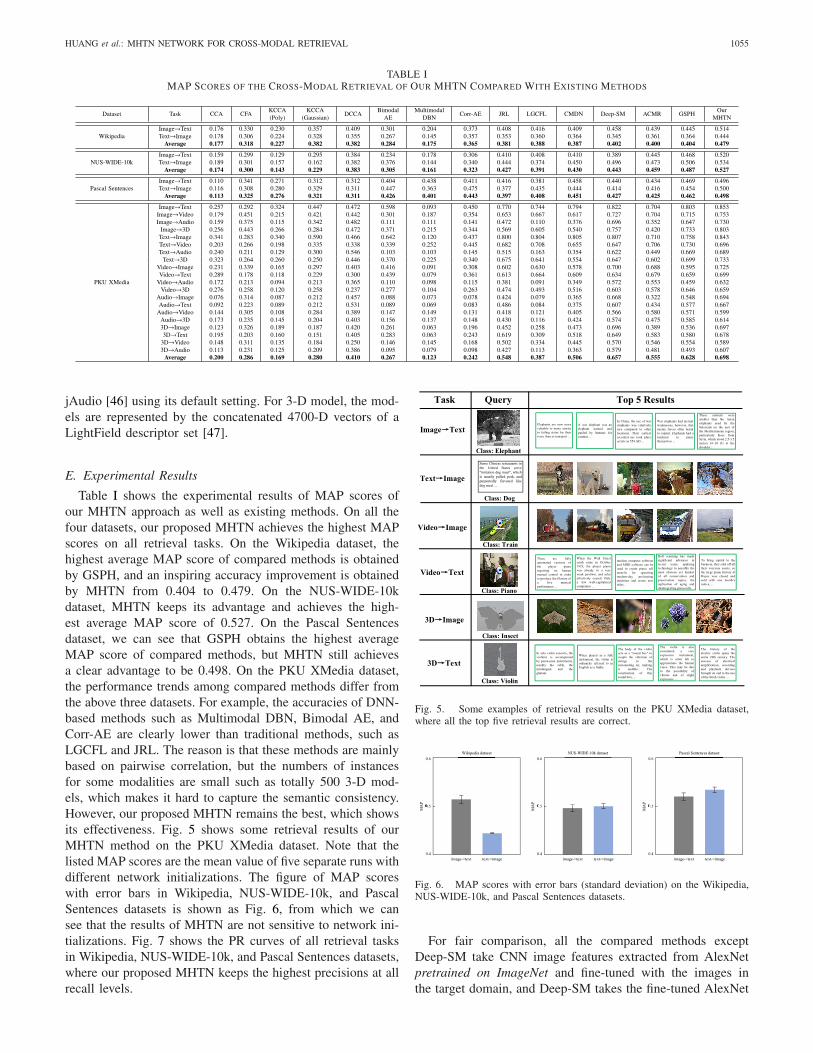
TABLE IMAP SCORES OF THE CROSS-MODAL RETRIEVAL OF OUR MHTN COMPARED WITH EXISTING METHODS
jAudio [46] using its default setting. For 3-D model, the mod-els are represented by the concatenated 4700-D vectors of aLightField descriptor set [47].
E. Experimental Results
Table I shows the experimental results of MAP scores ofour MHTN approach as well as existing methods. On all thefour datasets, our proposed MHTN achieves the highest MAPscores on all retrieval tasks. On the Wikipedia dataset, thehighest average MAP score of compared methods is obtainedby GSPH, and an inspiring accuracy improvement is obtainedby MHTN from 0.404 to 0.479. On the NUS-WIDE-10kdataset, MHTN keeps its advantage and achieves the high-est average MAP score of 0.527. On the Pascal Sentencesdataset, we can see that GSPH obtains the highest averageMAP score of compared methods, but MHTN still achievesa clear advantage to be 0.498. On the PKU XMedia dataset,the performance trends among compared methods differ fromthe above three datasets. For example, the accuracies of DNN-based methods such as Multimodal DBN, Bimodal AE, andCorr-AE are clearly lower than traditional methods, such asLGCFL and JRL. The reason is that these methods are mainlybased on pairwise correlation, but the numbers of instancesfor some modalities are small such as totally 500 3-D mod-els, which makes it hard to capture the semantic consistency.However, our proposed MHTN remains the best, which showsits effectiveness. Fig. 5 shows some retrieval results of ourMHTN method on the PKU XMedia dataset. Note that thelisted MAP scores are the mean value of five separate runs withdifferent network initializations. The figure of MAP scoreswith error bars in Wikipedia, NUS-WIDE-10k, and PascalSentences datasets is shown as Fig. 6, from which we cansee that the results of MHTN are not sensitive to network ini-tializations. Fig. 7 shows the PR curves of all retrieval tasksin Wikipedia, NUS-WIDE-10k, and Pascal Sentences datasets,where our proposed MHTN keeps the highest precisions at allrecall levels.
Fig. 5. Some examples of retrieval results on the PKU XMedia dataset,where all the top five retrieval results are correct.
Fig. 6. MAP scores with error bars (standard deviation) on the Wikipedia,NUS-WIDE-10k, and Pascal Sentences datasets.
For fair comparison, all the compared methods exceptDeep-SM take CNN image features extracted from AlexNetpretrained on ImageNet and fine-tuned with the images inthe target domain, and Deep-SM takes the fine-tuned AlexNet

1056 IEEE TRANSACTIONS ON CYBERNETICS, VOL. 50, NO. 3, MARCH 2020
(a)
(b)
(c)
Fig. 7. PR curves on the Wikipedia, NUS-WIDE-10k, and Pascal Sentencesdatasets. (a) PR curves on the Wikipedia dataset. (b) PR curves on the NUS-WIDE-10k dataset. (c) PR curves on the Pascal Sentences dataset.
as its component for the image. In fact, this can be seen asstraight-forward single-modal knowledge transfer from imagesin the source domain only to images in the cross-modal targetdomain. However, in this way, the knowledge transfer acrossdifferent modalities is not jointly involved, which results ininadequate transfer and limited accuracy. Our proposed MHTNachieves a clear advantage on all four datasets with differentlabel spaces, which is consistent for cross-modal retrieval offive modalities on the PKU XMedia dataset. On the one hand,it can jointly transfer knowledge from a single modality in thesource domain to multiple modalities in the cross-modal targetdomain, which can distill the modal-independent knowledgeto enrich training information and avoid overfitting. On theother hand, the modal-adversarial training strategy can ensurethe cross-modal semantic consistency in the hybrid transferprocess and further improve the accuracy of retrieval.
Besides, examples of failure cases on the Wikipedia datasetare shown as Fig. 8. We can observe that the errors come fromtwo challenging situations. First, when the classes in sourceand target domains differ greatly, the knowledge transfer maycontribute little to accuracy improvement. For example, in the
Fig. 8. Some failure cases of MHTN on the Wikipedia dataset. The resultsin green boxes are correct, while the results in red boxes are wrong.
first example, the class is “history,” while in the source domainthe classes are specific objects. It is very hard to define historyby specific objects, so there is little relevant information tohelp. Second, the semantics of text and image have significantdifference, so it is challenging even for humans to distinguishthe correlation between them. However, MHTN still achievesan inspiring overall accuracy improvement.
F. Impacts of Components in Our MHTN
Because MHTN consists of multiple components, we fur-ther conduct experiments on the impacts of them as Table II.MHTN (Full) means the complete MHTN approach, and theothers denote the baselines.
The source image pathway (the top pathway in Fig. 2)plays a key role as the knowledge source. MHTN (NoSource)means that we remove this pathway, and the other compo-nents remain the same. By comparing MHTN (NoSource)with MHTN (Full), we can see that the source image path-way consistently improves the retrieval accuracy, which showsthat the single-modal source domain can provide considerablemodal-independent knowledge for cross-modal retrieval.
The modal-adversarial semantic learning subnetworkmakes the knowledge transfer process further adapt to thecross-modal retrieval task. MHTN (NoSLnet) means that weremove this subnetwork and directly train a classifier (as fc10and softmax layers in Fig. 4) for the specific representation ofeach modality, to generate probability vectors as the commonrepresentation. By comparing MHTN (NoSLnet) and MHTN(Full), we can see that the accuracies of MHTN (NoSLnet)are clearly lower than MHTN (full).
We also conduct experiments to show the impacts of dif-ferent loss functions. Among the totally five loss functions(i.e., LossSDS, LossST, LossCT, LossSC, and LossMC), LossSCis necessary because MHTN needs supervision information ofthe target domain. The impacts of the other four loss functionsare shown as follows.
1) LossSDS: MHTN (NoSDS) means that we removeLossSDS. The difference between MHTN (NoSDS) andMHTN (NoSource) is that MHTN (NoSDS) keepsLossST, while MHTN (NoSource) equals to remov-ing both LossST and LossSDS. By comparing MHTN

HUANG et al.: MHTN NETWORK FOR CROSS-MODAL RETRIEVAL 1057
TABLE IIMAP SCORES OF EXPERIMENTS TO SHOW THE IMPACTS OF MHTN’S COMPONENTS
(NoSDS) with MHTN (Full), it can be observed that thesupervision information in the source domain improvesthe retrieval accuracy of the cross-modal target domain.
2) LossST: Note that we cannot solely remove LossSTbecause the removal of LossST equals to removing theinfluence of the whole source image pathway. However,the impact of LossST can be verified by comparingMHTN (NoSource) and MHTN (NoSDS), where we cansee that LossST can bring accuracy improvement.
3) LossCT: MHTN (NoCT) means that we remove LossCT.By comparing MHTN (NoCT) with MHTN (Full), it canbe observed that LossCT is helpful for accuracy improve-ment, which shows the effectiveness of cross-modalknowledge transfer.
4) LossMC: MHTN (NoMC) means that we removeLossMC. By comparing MHTN (NoMC) with MHTN(Full), we can see that LossMC effectively addressesthe problem of imbalanced information from the asym-metric transfer paradigm and enhances the cross-modalsemantic consistency accuracy improvement.
We also show the plots of all five loss functions, alongwith the total loss value on training and validation setsof the Wikipedia dataset, as Fig. 9. We can observe thatLossSDS is generally stable with some fluctuations, whichis reasonable because it is a pretrained source model, andthe fluctuations can reflect the influence of LossST on thesource image pathway. LossSC and LossMC both convergebefore about 1000 iterations, while LossST and LossCT con-verge slower. In our experiment, we observe that the retrievalaccuracy on the validation set will be the highest at about2500 iterations, where the plots of total loss become gen-erally stable, and a larger iteration may lead to the risk ofoverfitting.
(a) (b)
(c) (d)
(e) (f)
Fig. 9. Plots of the training and validation losses on the Wikipedia dataset,including all five loss functions and total loss. (a) Plots of LossSDS. (b) Plotsof LossST. (c) Plots of LossCT. (d) Plots of LossSC. (e) Plots of LossMC.(f) Plots of total loss.
To verify the impact of different CNN structures, we replacethe AlexNex networks in source and target image pathwayswith VGG19 [48]. It can be seen that MHTN (VGG19) can

1058 IEEE TRANSACTIONS ON CYBERNETICS, VOL. 50, NO. 3, MARCH 2020
improve the overall retrieval accuracy on four datasets. Notethat although we only modify the image pathways on the PKUXMedia dataset, most retrieval tasks (such as Text→Videoand 3-D→Text) can also benefit a lot, which shows theeffectiveness of cross-modal knowledge sharing.
V. CONCLUSION
This paper has proposed an MHTN, which aims to transferknowledge from the single-modal source domain to cross-modal target domain for promoting cross-modal retrieval. Itis an end-to-end architecture with two subnetworks.
1) Modal-sharing knowledge transfer subnetwork isproposed to jointly transfer knowledge from a singlemodality in the source domain to all modalities in thetarget domain with a star network structure, whichdistills modal-independent supplementary knowledgefor promoting cross-modal common representationlearning.
2) Modal-adversarial semantic learning subnetwork isproposed to construct an adversarial training mecha-nism between the common representation generator andmodality discriminator, making the common representa-tion discriminative for semantics but indiscriminative formodalities to enhance cross-modal semantic consistencyduring the transfer process.
Comprehensive experiments on four datasets show the effec-tiveness of MHTN, including a challenging PKU XMediadataset with five modalities (text, image, video, audio, and3-D model).
In the future, we intend to improve the work in the fol-lowing two aspects. First, we will apply the architecture ofMHTN to other applications involving cross-modal data suchas the image caption. Second, we will attempt to addressthe problem of hybrid knowledge transfer under unsupervisedsetting, which aims to bring stronger flexibility to MHTN.
REFERENCES
[1] Y. Peng, X. Huang, and Y. Zhao, “An overview of cross-media retrieval:Concepts, methodologies, benchmarks, and challenges,” IEEE Trans.Circuits Syst. Video Technol., vol. 28, no. 9, pp. 2372–2385, Sep. 2018.
[2] H. Hotelling, “Relations between two sets of variates,” Biometrika,vol. 28, nos. 3–4, pp. 321–377, 1936.
[3] N. Rasiwasia et al., “A new approach to cross-modal multimediaretrieval,” in Proc. ACM Int. Conf. Multimedia (ACM MM), 2010,pp. 251–260.
[4] X. Zhai, Y. Peng, and J. Xiao, “Learning cross-media joint representationwith sparse and semisupervised regularization,” IEEE Trans. CircuitsSyst. Video Technol., vol. 24, no. 6, pp. 965–978, Jun. 2014.
[5] Y. Peng, X. Huang, and J. Qi, “Cross-media shared representation byhierarchical learning with multiple deep networks,” in Proc. Int. JointConf. Artif. Intell. (IJCAI), 2016, pp. 3846–3853.
[6] V. Ranjan, N. Rasiwasia, and C. V. Jawahar, “Multi-label cross-modal retrieval,” in Proc. IEEE Int. Conf. Comput. Vis. (ICCV), 2015,pp. 4094–4102.
[7] J. Ngiam et al., “Multimodal deep learning,” in Proc. Int. Conf. Mach.Learn. (ICML), 2011, pp. 689–696.
[8] N. Srivastava and R. Salakhutdinov, “Learning representations formultimodal data with deep belief nets,” in Proc. Int. Conf. Mach. Learn.Workshop (ICML), 2012, pp. 1–8.
[9] F. Feng, X. Wang, and R. Li, “Cross-modal retrieval with correspondenceautoencoder,” in Proc. ACM Int. Conf. Multimedia (ACM MM), 2014,pp. 7–16.
[10] S. J. Pan and Q. Yang, “A survey on transfer learning,” IEEE Trans.Knowl. Data Eng., vol. 22, no. 10, pp. 1345–1359, Oct. 2010.
[11] M. Long, Y. Cao, J. Wang, and M. I. Jordan, “Learning transferablefeatures with deep adaptation networks,” in Proc. Int. Conf. Mach. Learn.(ICML), 2015, pp. 97–105.
[12] M. Long, H. Zhu, J. Wang, and M. I. Jordan, “Unsupervised domainadaptation with residual transfer networks,” in Proc. Adv. Neural Inf.Process. Syst. (NIPS), 2016, pp. 136–144.
[13] H. G. Krizhevsky, I. Sutskever, and G. E. Hinton, “ImageNet classifi-cation with deep convolutional neural networks,” in Proc. Adv. NeuralInf. Process. Syst. (NIPS), 2012, pp. 1106–1114.
[14] T. Mikolov, K. Chen, G. Corrado, and J. Dean, “Efficient estimation ofword representations in vector space,” arXiv preprint arXiv: 1301.3781,2013.
[15] Y. Ganin et al., “Domain-adversarial training of neural networks,” J.Mach. Learn. Res., vol. 17, no. 59, pp. 1–35, 2016.
[16] Z. Cui et al., “Flowing on Riemannian manifold: Domain adapta-tion by shifting covariance,” IEEE Trans. Cybern., vol. 44, no. 12,pp. 2264–2273, Dec. 2014.
[17] M. Jiang, W. Huang, Z. Huang, and G. G. Yen, “Integration of globaland local metrics for domain adaptation learning via dimensionalityreduction,” IEEE Trans. Cybern., vol. 47, no. 1, pp. 38–51, Jan. 2017.
[18] X. Huang, Y. Peng, and M. Yuan, “Cross-modal common representationlearning by hybrid transfer network,” in Proc. Int. Joint Conf. Artif.Intell. (IJCAI), 2017, pp. 1893–1900.
[19] D. Li, N. Dimitrova, M. Li, and I. K. Sethi, “Multimedia contentprocessing through cross-modal association,” in Proc. ACM Int. Conf.Multimedia (ACM MM), 2003, pp. 604–611.
[20] C. Kang, S. Xiang, S. Liao, C. Xu, and C. Pan, “Learning consistent fea-ture representation for cross-modal multimedia retrieval,” IEEE Trans.Multimedia, vol. 17, no. 3, pp. 370–381, Mar. 2015.
[21] Y. Hua, S. Wang, S. Liu, A. Cai, and Q. Huang, “Cross-modal correlationlearning by adaptive hierarchical semantic aggregation,” IEEE Trans.Multimedia, vol. 18, no. 6, pp. 1201–1216, Jun. 2016.
[22] H. Qiao, Y. Li, F. Li, X. Xi, and W. Wu, “Biologically inspired modelfor visual cognition achieving unsupervised episodic and semantic fea-ture learning,” IEEE Trans. Cybern., vol. 46, no. 10, pp. 2335–2347,Oct. 2016.
[23] Y. Wei et al., “Cross-modal retrieval with CNN visual features: A newbaseline,” IEEE Trans. Cybern., vol. 47, no. 2, pp. 449–460, Feb. 2017.
[24] G. Andrew, R. Arora, J. Bilmes, and K. Livescu, “Deep canonicalcorrelation analysis,” in Proc. Int. Conf. Mach. Learn. (ICML), 2010,pp. 3408–3415.
[25] B. Wang, Y. Yang, X. Xu, A. Hanjalic, and H. T. Shen, “Adversarialcross-modal retrieval,” in Proc. ACM Int. Conf. Multimedia (ACM MM),2017, pp. 154–162.
[26] D. Mandal, K. N. Chaudhury, and S. Biswas, “Generalized semanticpreserving hashing for N-label cross-modal retrieval,” in Proc. IEEEConf. Comput. Vis. Pattern Recognit. (CVPR), 2017, pp. 2633–2641.
[27] X. Huang and Y. Peng, “Deep cross-media knowledge transfer,” inProc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), 2018,pp. 8837–8846.
[28] F. Zhu, J. Xie, and Y. Fang, “Heat diffusion long-short term memorylearning for 3D shape analysis,” in Proc. Eur. Conf. Comput. Vis.(ECCV), 2016, pp. 305–321.
[29] W. Li, L. Duan, D. Xu, and I. W. Tsang, “Learning with augmentedfeatures for supervised and semi-supervised heterogeneous domainadaptation,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 36, no. 6,pp. 1134–1148, Jun. 2014.
[30] Y.-H. H. Tsai, Y.-R. Yeh, and Y.-C. F. Wang, “Learning cross-domainlandmarks for heterogeneous domain adaptation,” in Proc. IEEE Conf.Comput. Vis. Pattern Recognit. (CVPR), 2016, pp. 5081–5090.
[31] J. Tang, X. Shu, Z. Li, G.-J. Qi, and J. Wang, “Generalized deep transfernetworks for knowledge propagation in heterogeneous domains,” ACMTrans. Multimedia Comput. Commun. Appl., vol. 12, no. 4s, p. 68, 2016.
[32] J. Zhang, Y. Han, J. Tang, Q. Hu, and J. Jiang, “Semi-supervised image-to-video adaptation for video action recognition,” IEEE Trans. Cybern.,vol. 47, no. 4, pp. 960–973, Apr. 2017.
[33] X. Yang, T. Zhang, and C. Xu, “Cross-domain feature learning inmultimedia,” IEEE Trans. Multimedia, vol. 17, no. 1, pp. 64–78,Jan. 2015.
[34] S. Gupta, J. Hoffman, and J. Malik, “Cross modal distillation for super-vision transfer,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit.,2016, pp. 2827–2836.
[35] G. E. Hinton, O. Vinyals, and J. Dean, “Distilling the knowledge in aneural network,” arXiv preprint arXiv: 1503.02531, 2015.
[36] Z. Cao, M. Long, J. Wang, and Q. Yang, “Transitive hashing network forheterogeneous multimedia retrieval,” in Proc. AAAI Conf. Artif. Intell.(AAAI), 2017, pp. 81–87.

HUANG et al.: MHTN NETWORK FOR CROSS-MODAL RETRIEVAL 1059
[37] A. Gretton, K. M. Borgwardt, M. J. Rasch, B. Schölkopf, and A. Smola,“A kernel two-sample test,” J. Mach. Learn. Res., vol. 13, pp. 723–773,2012.
[38] I. J. Goodfellow, J. Shlens, and C. Szegedy, “Explaining and harnessingadversarial examples,” arXiv preprint arXiv:1412.6572, 2014.
[39] I. J. Goodfellow et al., “Generative adversarial nets,” in Proc. Adv.Neural Inf. Process. Syst. (NIPS), 2014, pp. 2672–2680.
[40] Y. Jia et al., “Caffe: Convolutional architecture for fast feature embed-ding,” in Proc. 22nd ACM Int. Conf. Multimedia, 2014, pp. 675–678.
[41] T. Chua et al., “NUS-WIDE: A real-world Web image database fromNational University of Singapore,” in Proc. ACM Int. Conf. Image VideoRetrieval (CIVR), 2009, p. 48.
[42] C. Rashtchian, P. Young, M. Hodosh, and J. Hockenmaier, “Collectingimage annotations using Amazon’s mechanical turk,” in Proc. NorthAmer. Ch. Assoc. Comput. Linguist., 2010, pp. 139–147.
[43] D. R. Hardoon, S. Szedmák, and J. Shawe-Taylor, “Canonical correlationanalysis: An overview with application to learning methods,” NeuralComput., vol. 16, no. 12, pp. 2639–2664, 2004.
[44] D. Tran, L. Bourdev, R. Fergus, L. Torresani, and M. Paluri, “Learningspatiotemporal features with 3D convolutional networks,” in Proc. IEEEInt. Conf. Comput. Vis. (ICCV), 2015, pp. 4489–4497.
[45] A. Karpathy et al., “Large-scale video classification with convolutionalneural networks,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit.(CVPR), 2014, pp. 1725–1732.
[46] C. McKay, I. Fujinaga, and P. Depalle, “jAudio: An feature extractionlibrary,” in Proc. Int. Conf. Music Inf. Retrieval, 2005, pp. 600–603.
[47] D.-Y. Chen, X.-P. Tian, Y.-T. Shen, and M. Ouhyoung, “On visual simi-larity based 3D model retrieval,” Comput. Graph. Forum, vol. 22, no. 3,2003, pp. 223–232.
[48] K. Simonyan and A. Zisserman, “Very deep convolutional networks forlarge-scale image recognition,” arXiv preprint arXiv: 1409.1556, 2014.
Xin Huang received the B.S. degree in computerscience and technology from Peking University,Beijing, China, in 2014, where he is currently pursu-ing the Ph.D. degree with the Institute of ComputerScience and Technology.
His current research interests include cross-mediareasoning and machine learning.
Yuxin Peng received the Ph.D. degree in computerapplication from Peking University, Beijing, China,in 2003.
After that, he was an Assistant Professor withthe Institute of Computer Science and Technology(ICST), Peking University, where he was promotedto an Associate Professor and a Professor in 2005and 2010, respectively, and currently a Professorwith ICST and the Chief Scientist with the NationalHi-Tech Research and Development Program ofChina (863 Program). In 2006, he was authorized
by the Program for New Star in Science and Technology of Beijing and theProgram for New Century Excellent Talents in University. He has authoredover 130 papers in refereed international journals and conference proceed-ings, including the International Journal of Computer Vision, the IEEETRANSACTIONS ON IMAGE PROCESSING, the IEEE TRANSACTIONS ON
MULTIMEDIA, the IEEE TRANSACTIONS ON CIRCUITS AND SYSTEMS FOR
VIDEO TECHNOLOGY, the IEEE TRANSACTIONS ON CYBERNETICS, ACMMultimedia Conference, IEEE International Conference on Computer Vision,IEEE Conference on Computer Vision and Pattern Recognition, InternationalJoint Conference on Artificial Intelligence, and AAAI Conference on ArtificialIntelligence. He has submitted 38 patent applications and received 21 of them.His current research interests include cross-media analysis and reasoning,image and video analysis and retrieval, and computer vision.
Prof. Peng was a recipient of the First Prize of the Beijing Science andTechnology Award in 2016 (ranking first). He led his team to participate in theTREC Video Retrieval Evaluation (TRECVID) many times. In 2009, his teamreceived four first places on four subtasks of the High-Level Feature Extractiontask and Search task. In 2012, his team received four first places on all foursubtasks of the Instance Search (INS) task and the Known-Item Search task.In 2014, his team received the first place in the Interactive Instance Searchtask. His team also received first places in both the INS task of TRECVIDfrom 2015 to 2018, respectively.
Mingkuan Yuan received the B.S. degree inmicroelectronics from Northwestern PolytechnicalUniversity, Xi’an, China, in 2016. He is cur-rently pursuing the Ph.D. degree with the Instituteof Computer Science and Technology, PekingUniversity, Beijing, China.
His current research interests include text-to-image synthesis and machine learning.





























