Embed Size (px)
Citation preview

18
BAB IV
HASIL DAN PEMBAHASAN
4.1. Hasil
4.1.1. Analisis Permasalahan
Plagiarisme adalah tindakan yang dianggap sebagai pencurian ide milik orang
lain oleh seseorang dengan tujuan untuk mendapatkan keuntungan sendiri dari ide
tersebut. Untuk melihat dokumen yang melakukan plagiarisme bisa dilakukan
dengan cara melihat langsung atau menggunakan sebuah sistem yang dapat
melihat persentase kesamaan dokumen-dokumen tersebut. Penelitian ini akan
menjelaskan pembuatan sebuah sistem pendeteksi kesamaan dokumen dengan
menggunakan algoritma Smith-Waterman.
Sistem yang dibutuhkan dalam pendeteksian kesamaan dokumen tentunya
harus bisa menerima masukkan dokumen dengan beberapa tipe diantaranya adalah
yang bertipe Text Files dengan ekstensi (.txt), Word Documents yang berekstensi
(.doc), dan Portable Document Format dengan ekstensi (.pdf), dan juga sistem
mampu membandingkan sampai ratusan dokumen tanpa membatasi kemampuan
sistem untuk menerima inputan dokumen.

19
4.1.2. Analisis Kebutuhan Sistem
1. Sistem mampu menerima file yang memiliki ekstensi (.txt), (.doc), dan
(.pdf)
2. Sistem dapat menerima masukan file lebih dari 1.
3. Sistem dapat menerima masukan file dari lokasi mana saja yang ada di
komputer.
4. Sistem dapat menampilkan hasil perbandingan dokumen.
5. Sistem dapat digunakan pada komputer dengan sistem operasi Microsoft
Windows.
4.1.3. Flowchart Deteksi Kesamaan Dokumen
Mulai
Selesai
Dokumen
Tokenisasi
Perhitungan kesamaan dengan
Algoritma Smith-Waterman
Persentase Kesamaan
Dokumen dan Local
Similarities
Gambar 4.1. Flowchart Untuk Proses Pembobotan Algoritma
Smith-Waterman
Stop Word Removal

20
Dalam proses pembobotan dengan algoritma Smith-Waterman, kalimat akan
melalui proses tokenisasi. Dalam proses tokenisasi ini, kalimat dipecah menjadi
unit-unit kecil yang disebut token atau suatu kata. Dari tiap token tersebut
dilakukan perhitungan dalam bentuk matriks dengan menggunakan algoritma
Smith-Waterman. Setelah perhitungan dilakukan, maka bisa dilakukan traceback
melalui algoritma Smith-Waterman. Traceback dilakukan guna mendapatkan
local similarities. Dari local similarities ini, bisa dilihat seberapa besar kesamaan
dari dokumen.
4.1.4. Perhitungan Bobot
Dalam mendapatkan local similarities dan bobot kesamaan kata dari dua
dokumen, maka diperlukan beberapa tahap. Adapun tahap-tahapnya adalah
sebagai berikut :
1. Input Dokumen
Dokumen yang bisa diinput ke dalam sistem adalah 3 ekstensi file. Dokumen
dengan ekstensi Plain Text (.txt) merupakan file yang dapat dibuat dengan
aplikasi pengolah kata manapun. Dokumen dengan ekstensi ini menyimpan teks
yang tidak terdapat format tertentu. Ekstensi dokumen berikutnya adalah Word
Documents (.doc). Dokumen-dokumen ini menyimpan teks yang bisa memiliki
format tertentu, gambar, dan tabel. Dokumen-dokumen ini dibuat dengan
menggunakan Microsoft Word. Dokumen PDF adalah dokumen yang hampir
sama dengan ekstensi Word Documents, hanya saja dokumen pdf ini tidak bisa
dilakukan pengeditan lagi kecuali dengan menggunakan software tertentu.

21
2. Konversi Huruf
Untuk membuat sistem mampu menyamakan tiap karakter dari dokumen 1
dengan dokumen lainnya, maka semua huruf dalam kalimat atau kata dari tiap
dokumen perlu diubah menjadi huruf kecil. Contoh :
3. Tokenisasi
Proses Tokenisasi yaitu proses untuk membagi kalimat menjadi token-token
atau bagian-bagian terkecil. Karakter spasi dan karakter lain berupa tanda baca
pun dipisahkan. Adapun beberapa tanda baca yang dipisahkan adalah koma (,),
titik (.), titik dua (:), garis miring (/), tanda tanya (?), dan tanda garis/pisah (-).
Tanda baca dipisahkan guna memisahkan kata dari karakter tanda baca. Hasil dari
proses tokenisasi ini disebut sebagai tokens.
Akulturasi akulturasi
Gambar 4.2. Konversi huruf besar/kapital menjadi
huruf kecil
kerajinan ini berkembang
sejak lama dan kini sudah
menjadi sentra kerajinan
khas gorontalo.
kerajinan
ini
berkembang
sejak
lama
dan
kini
sudah
menjadi
sentra
kerajinan
khas
gorontalo
Gambar 4.3. Tokenisasi Kalimat

22
4. Stop Words Removal
Stop Words adalah kata-kata yang disaring sebelum, atau sesudah pengolahan
data teks. Dalam mesin pencarian, kata-kata umum (common words) yang sering
digunakan akan dimasukkan ke dalam daftar Stop Words. Stop Words untuk
bahasa Inggris diantaranya ‘of’, ‘the’, sedangkan untuk bahasa Indonesia
diantaranya ‘yang’,’di’,’ke’. Penghapusan kata-kata Stop Words ini dimaksudkan
untuk lebih mempermudah sistem dalam pembandingan dokumen, terlebih lagi
jika dokumen yang dibandingkan memiliki jumlah kata hingga ribuan kata.
5. Algoritma Smith-Waterman
Algoritma Smith-Waterman ini digunakan dalam ilmu biologi untuk
menemukan keseuaian pasangan DNA. Kesesuaian ini atau dikenal sebagai local
similarities ditemukan dengan membandingkan pasangan-pasangan DNA tersebut
kedalam sebuah matriks. Berikut adalah cara kerja dari algoritma Smith-
Waterman dalam menemukan kesamaan dari dua DNA :
DNA Sequence 1 = AGCAA
DNA Sequence 2 = ATGCA
Nilai Match = +2
Nilai Mismatch = -1
Nilai Gap = -1

23
Langkah awal dari algoritma Smith-Waterman adalah mendefinisikan nilai 0
pada matriks di titik (0,0), (i,0), dan (0,j).
Gambar 4.4. Pendefinisian nilai 0 pada matriks
Kemudian dilakukan perhitungan pada titik (1,1). Apabila DNA i sama
dengan DNA j, maka akan digunakan nilai match. Sebaliknya, apabila DNA dari
kedua sequence berbeda, maka akan digunakan nilai mismatch. Nilai dari tiap titik
pada matriks ditentukan dengan melihat nilai maksimum atau yang paling besar
dari empat nilai yang telah dihitung.
H(1,1) = maks.
H(1,1) = maks.
Gambar 4.5. Penentuan nilai pada titik (1,1)
- A G C A A
- 0 0 0 0 0 0
A 0
T 0
G 0
C 0
A 0
0
H(i-1,j-1) + Nilai Match/Mismatch
H(i-1,j) + Nilai Gap
H(i,j-1) + Nilai Gap
0
0 + 2 = 2
0 + -1 = -1
0 + -1 = -1

24
Dari gambar 4.5, bisa dilihat bahwa DNA dari i dan dari j memiliki
kesamaan, sehingga menggunakan nilai match. Nilai yang paling besar adalah 2,
maka nilai pada titik (1,1) adalah 2. Perhitungan pada titik selanjutnya ditentukan
dengan cara yang sama seperti pada titik (1,1), sehingga menghasilkan matriks
sebagai berikut.
Gambar 4.6. Nilai matriks dari dua pasangan DNA
Setelah dilakukan perhitungan dalam matriks, kemudian dilakukan traceback
dari nilai tertinggi dalam matriks. Nilai tertinggi pada matriks terdapat pada posisi
(5,5). Apabila terdapat kesamaan pada DNA ke-i dengan DNA ke-j, maka
dilakukan jalan mundur ke titik (i-1, j-1) . Jalan mundur dari titik tertinggi yaitu
(5,5), (4,4), (3,4), (2,3), (1,2), (1,1). Traceback yang dilakukan pada matriks
adalah sebagai berikut.
- A G C A G
- 0 0 0 0 0 0
A 0 2 1 0 2 1
T 0 1 1 0 1 1
G 0 0 3 2 1 3
C 0 0 2 5 4 3
G 0 0 2 4 4 6

25
Gambar 4.7. Traceback pada matriks
Dari traceback tersebut bisa ditentukan local similarities. Local Similarities
dari kedua DNA tersebut adalah :
Gambar 4.8. Local Similarities dari dua sequence DNA
6. Perhitungan Bobot
Dari gambar 4.5, kita bisa menghitung bobot kesamaan. Dari satu alignment
tersebut terdapat 4 karakter yang sama dari total karakter masing-masing
dokumen adalah 5 karakter, maka hasilnya adalah (((4/5) + (4/5)) x 100) / 2 = 80.
Jadi, dapat disimpulkan dari kedua sequence DNA tersebut terdapat kecocokan
80%.
- A G C A G
- 0 0 0 0 0 0
A 0 2 1 0 2 1
T 0 1 1 0 1 1
G 0 0 3 2 1 3
C 0 0 2 5 4 3
G 0 0 2 4 4 6
Sequence 1 = A- GCAG
Sequence 2 = ATGC - G
26
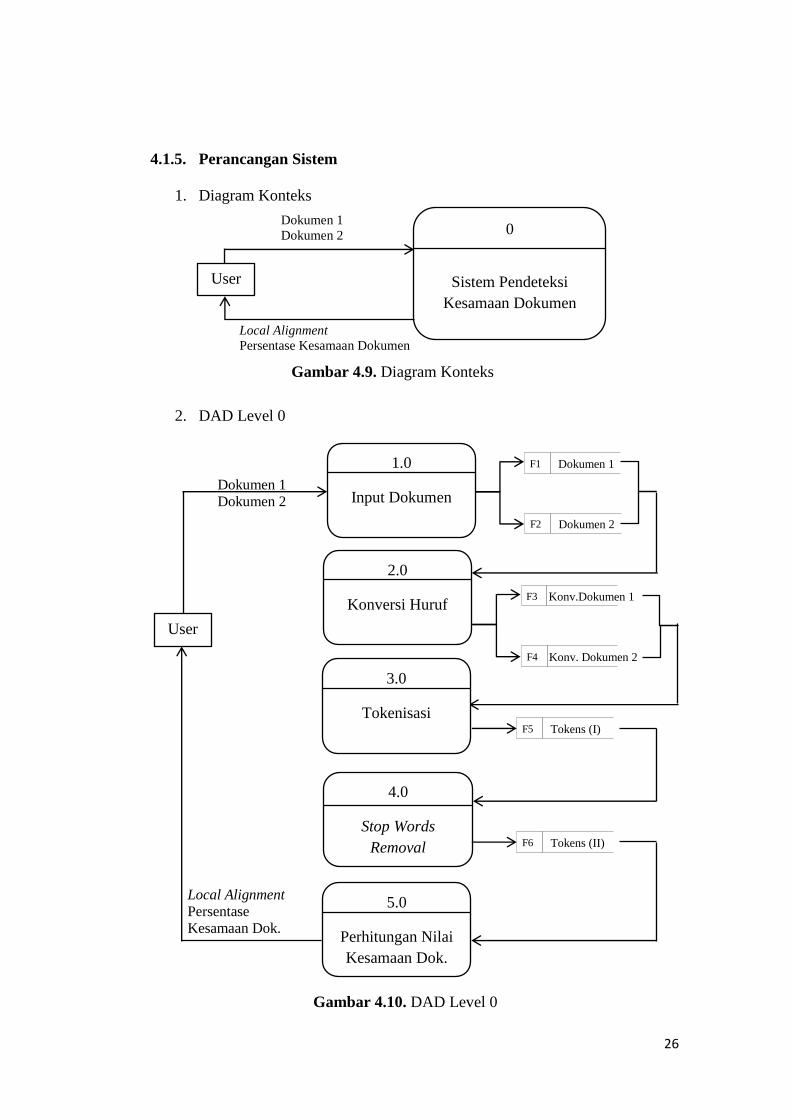
4.1.5. Perancangan Sistem
1. Diagram Konteks
2. DAD Level 0
User
0
Sistem Pendeteksi
Kesamaan Dokumen
Dokumen 1
Dokumen 2
Local Alignment
Persentase Kesamaan Dokumen
User
Dokumen 1 F1
Dokumen 2 F2
Tokens (I) F5
1.0
Input Dokumen
2.0
Konversi Huruf
3.0
Tokenisasi
4.0
Stop Words
Removal
5.0
Perhitungan Nilai
Kesamaan Dok.
Dokumen 1
Dokumen 2
Local Alignment
Persentase
Kesamaan Dok.
Gambar 4.9. Diagram Konteks
Gambar 4.10. DAD Level 0
Konv.Dokumen 1 F3
Konv. Dokumen 2 F4
Tokens (II) F6

27
4.1.6. Implementasi
Implementasi dilakukan untuk mengetahui apakah program mampu
melakukan berbagai proses, menangani suatu kondisi tertentu, dan mengetahui
kelebihan serta kekurangan dari program yang telah dibuat. Program yang
digunakan dalam pembuatan aplikasi dari penelitian ini adalah Microsoft Visual
Basic 6.0. Adapun tampilan dari program sistem pendeteksi kesamaan dokumen
yang dibuat adalah sebagai berikut.
1. Tampilan Utama
Gambar 4.11. Tampilan Menu Utama
Karena program ini ditujukan untuk siapa saja yang ingin menggunakannya,
maka saat program dijalankan, pengguna bisa langsung masuk ke menu utama
tanpa perlu melalui menu login atau verifikasi jenis pengguna.

28
2. Tampilan Input Dokumen
Gambar 4.12. Tampilan Input Dokumen (I)
Di bagian kiri program terdapat menu input dokumen. Dokumen Sumber
didefinisikan sebagai dokumen ke-1, dan Dokumen Target sebagai dokumen ke-2.
Pengguna diharuskan memasukkan minimal 1 dokumen untuk tiap menu input
dokumen. Terdapat dua tombol untuk tiap menu input dokumen. Tombol
“Select...” digunakan untuk memilih dokumen, dan tombol “Clear” untuk
menghapus seluruh dokumen dari daftar input dokumen.
Saat pengguna memilih tombol “Select...”, maka program akan menampilkan
menu select files seperti pada Gambar 4.13 di bawah ini. Dari menu ini pengguna
bisa memilih lokasi dari file yang akan dibandingkan. Pengguna bisa memilih
langsung lebih dari 1 file untuk memasukkan file tersebut ke dalam daftar
dokumen yang akan dibandingkan pada program. Sebagai standar dari program,
jenis berkas yang bisa dipilih bisa berupa .txt, .doc, .docx, dan .pdf. Pengguna bisa

29
melakukan filter jenis berkas yang ingin dimasukkan ke dalam program pada
menu drop-down yang terletak di sebelah kanan dari nama berkas.
Gambar 4.13. Tampilan Input Dokumen (II)
3. Tampilan Menu Saat Proses Dokumen
Gambar 4.14. Tampilan Menu Saat Proses Dokumen
Setelah pengguna memasukkan dokumen, bisa melakukan proses
perbandingan dengan memilih tombol “Run”. Dikarenakan program akan
memakan waktu yang agak lama dalam perbandingan, maka judul dari menu

30
utama akan diubah menandakan bahwa program sedang dalam tahap memproses
dokumen. Tetapi apabila pengguna tidak memasukkan dokumen yang ingin
dibandingkan pada menu input dokumen sumber atau target, maka program akan
menampilkan menu dialog seperti Gambar 4.15, yang mengatakan bahwa
pengguna harus memasukkan dokumen.
Gambar 4.15. Tampilan Dialog Informasi
4. Tampilan Hasil Perbandingan
Gambar 4.16. Tampilan Hasil Perbandingan
Setelah proses telah dilakukan, maka pada menu hasil perbandingan akan
dituliskan daftar dokumen yang dibandingkan beserta hasil dari perbandingan.
Untuk membersihkan daftar hasil perbandingan, pengguna bisa memilih tombol
“Clear”. Dan untuk keluar dari program, pengguna bisa memilih tombol “Exit”.

31
5. Tampilan Menu Show Alignment
Gambar 4.17. Tampilan Menu Show Alignment
Untuk melihat hasil dari perbandingan, pengguna bisa menekan tombol Show
Alignment yang berada di menu utama. Di menu ini, pengguna bisa melihat
alignment yang dibuat oleh program untuk menentukan seberapa besar jumlah
kesamaan dari kedua dokumen yang telah dibandingkan.
6. Tampilan Menu Settings
Di dalam menu ini, pengguna bisa menambah atau menghilangkan kata yang
akan digolongkan ke dalam Stopwords.
Gambar 4.18. Tampilan Menu Settings

32
4.1.7. Pengujian
1. Pengujian Black Box
Pengujian Black Box dilakukan untuk memberikan kepastian bahwa program
telah melakukan proses sesuai dengan desain yang telah dibuat. Pengujian Black
Box dilakukan pada menu utama program.
Tabel 4.1. Hasil Pengujian Black Box
Input/Event Proses Output Hasil
Pengujian
Penekanan
Tombol Select
Menampilkan menu
pemilihan file dokumen
Menu Select Files
ditampilkan
Sesuai
Penekanan
Tombol Clear
List
Menghapus daftar
dokumen yang akan
dibandingkan
Daftar dokumen
dihapus
Sesuai
Penekanan
Tombol Run
Menjalankan proses dan
mengubah judul program
Proses dijalankan dan
judul program
berubah
Sesuai
Penekanan
Tombol Clear
Menghapus daftar hasil
dokumen yang telah
diproses
Daftar hasil dokumen
dihapus
Sesuai
Penekanan
Tombol Show
Alignment
Membuka menu show
alignment
Menu Show Alignment
ditampilkan
Sesuai
Penekanan
Tombol
Settings
Membuka menu settings Menu Settings
ditampilkan
Sesuai
Penekanan
Tombol Exit
Menutup program utama Program utama
ditutup
Sesuai

33
Berdasarkan hasil pengujian diatas, maka dapat disimpulkan bahwa program
telah berjalan sesuai dengan desain yang dibuat.
2. Pengujian Dokumen Contoh
Dalam pengujian ini, program diberi masukan beberapa dokumen contoh
untuk dibandingkan. Isi dari tiap dokumen memiliki beberapa kesamaan dan
perbedaan. Isi dari dokumen contoh disajikan pada tabel 4.2. berikut.
Tabel 4.2. Dokumen Contoh
No. Dokumen Isi Dokumen
1. D 1 Pada zaman dahulu di suatu tempat di tanah U Duluo lo’u
Limo lo Pohite, hiduplah seorang pemuda bernama Lahilote.
Perawakannya tegap, badan tinggi besar dan mempunyai
kegemaran berburu. Dengan pekerjaan mengejar binatang
buruan itu memaksa ia sering moleleyangi (mengembara
masuk hutan keluar hutan).
2. D 2 Pada zaman dahulu, di suatu tempat di tanah U Duluo Lo'u
Limo Lo Pohite, hiduplah seorang pemuda bernama Lahilote.
Perawakan tegap,badan tinggi besar dan suka berburu. Dengan
pekerjaan mengejar binatang buruan, ia sering moleleyangi
(mengembara masuk keluar hutan).
3. D 3 Alkisah, pada jaman dahulu kala di hulu sungai dekat sebuah
mata air sebuah dusun terpencil di Gorontalo tinggallah
seorang pemuda sederhana bernama Lahilote yang sering
mencari rotan di hutan sebagai mata pencahariannya.
4. D 4 Hiduplah seorang pemuda bernama Lahilote. Kegemarannya
berburu di hutan dan moleleyangi (mengembara). Suatu hari,
saat sedang berburu di hutan, dia melihat putri-putri kahyangan
yang sedang mandi di kolam yang ada di hutan tempat Lahilote
berburu, dia berniat memperistri salah satu dari putri-putri
kahyangan tersebut.
5. D 5 Alkisah, di Tanah U Duluo Lo'u Limo Lo Pohite, Gorontalo,
ada seorang pemuda tampan dan gagah bernama Piilu Le
Lahilote, yang akrab dipanggil Lahilote. Ia tinggal di sebuah
rumah kecil di pinggir hutan. Untuk memenuhi kebutuhan
hidupnya, setiap hari ia moleleyangi (mengembara masuk
keluar hutan).

34
Hasil pengujian dari dokumen contoh diatas, adalah sebagai berikut :
Tabel 4.3. Hasil Pengujian Dokumen Contoh
Dokumen D 1 D 2 D 3 D 4 D 5
D 1 100 % 87% 12% 12% 20%
D 2 87% 100% 13% 13% 23%
D 3 12% 13% 100% 12% 9%
D 4 12% 13% 12% 100% 5%
D 5 20% 23% 9% 5% 100%
Dari tabel hasil pengujian tersebut bisa dilihat dokumen yang memiliki
tingkat kesamaan dokumen yang tinggi dan juga rendah.
Berdasarkan dari pengujian yang telah dilakukan sebelumnya, maka didapat
beberapa kelebihan dan kekurangan yang bisa didapat dari penggunaan algoritma
Smith-Waterman. Kelebihan dari algoritma ini adalah :
1. Algoritma Smith-Waterman ini bisa digunakan untuk menemukan letak
kesamaan dari kedua dokumen yang dibandingkan.
2. Mampu menemukan letak terjadinya penghapusan atau penyisipan kata pada
dokumen.
Dan juga kelemahan dari algoritma Smith-Waterman yaitu :
1. Algoritma ini tidak mampu membandingkan dokumen dengan data yang lebih
banyak. Dengan data yang lebih banyak, maka waktu yang dibutuhkan pun
akan lebih banyak.

35
2. Perlu digabungkan dengan metode lain guna mendapatkan hasil yang lebih
maksimal dan mampu mengefisienkan waktu.
4.2. Pembahasan
Algoritma Smith-Waterman dalam penerapan di program ini mampu
melakukan pendeteksian kesamaan dari dokumen-dokumen yang memiliki format
berkas yang berbeda. Algoritma ini mampu menemukan letak kesamaan dari
kedua dokumen yang dibandingkan. Adapun algoritma Smith-Waterman yang
digunakan dalam penelitian ini dan program yang dibuat bukanlah sistem yang
mampu melakukan justifikasi bahwa dokumen yang memiliki tingkat persentasi
kesamaan yang tinggi adalah dokumen yang melakukan plagiat.
Dalam proses perbandingan dokumen, algoritma Smith-Waterman ini
memiliki kekurangan dalam hal efisiensi waktu. Jumlah kata yang harus dituliskan
dalam abstrak adalah 150-200 kata. Dalam membandingkan berkas berisi abstrak
yang memiliki jumlah kata berkisar antara 170-an kata, maka program
membutuhkan waktu yang cukup lama, yakni sekitaran 10-12 menit untuk
menghitung matriks yang dibuat dari algoritma dan menemukan letak
kesamaannya. Dari hasil perbandingan dokumen abstrak ini, bisa diperkirakan
apabila digunakan dalam membandingkan dokumen laporan penelitian yang utuh,
maka akan dibutuhkan waktu yang lebih lama lagi. Algoritma Smith-Waterman
ini bisa digunakan dalam membandingkan dokumen, namun alangkah lebih
baiknya algoritma ini tetap dipergunakan dalam bioinformatika yaitu dalam
menemukan kesamaan DNA.




![SULIT 4531/2...SULIT 4531/2 4531/2 ©PPD SIMUNJAN [Lihat Sebelah] 2 SULIT Maklumat berikut mungkin berguna. Setiap simbol mempunyai maksud …](https://img.dokumen.tips/doc/110x75/5eaea70217f099768917320e/sulit-45312-sulit-45312-45312-ppd-simunjan-lihat-sebelah-2-sulit-maklumat.jpg)
























