Embed Size (px)
Citation preview

SSLA, 18,403-432. Printed in the United States of America.
THE EFFECTS OFL1 ORTHOGRAPHY ON
L2 WORD RECOGNITION
A Study of American and ChineseLearners of Japanese
Nobuko ChikamatsuDePaul University
This paper examines the effects of a first language (L1) orthographicsystem on second language (L2) word recognition strategies. Lexicaljudgment tests using Japanese kana (a syllabic script consisting ofhiragana and katakana) were given to native English and native Chi-nese learners of Japanese. The visual familiarity and length in testwords were controlled to examine the involvement of phonological orvisual coding in word recognition strategies. The responses of the En-glish and Chinese subjects were compared on the basis of observedreaction time. The results indicated that (a) Chinese subjects reliedmore on the visual information in L2 Japanese kana words than didEnglish subjects and (b) English subjects utilized the phonological in-formation in Japanese kana words more than did Chinese subjects.Accordingly, these findings demonstrate that native speakers of En-glish and Chinese utilize different word recognition strategies due to L1orthographic characteristics, and such L1 word recognition strategiesare transferred into L2 Japanese kana word recognition.
This study is based on my doctoral dissertation submitted to the University of Illinois at Urbana-Champaign.I would like to express gratitude for the support and advice of Molly Mack, Jerome Packard, and Chin-ChuanCheng. Address correspondence to Nobuko Chikamatsu, Department of Modern Languages, DePaul Univer-sity, 802 West Belden Avenue, Chicago, IL 60614-3214; e-mail: [email protected].
e 1996 Cambridge University Press 0272-2631/96 $7.50 + .10 403

404 Nobuko Chikamatsu
In the psycholinguistic and neurolinguistic literature on first language (LI) wordrecognition and memory, the effects of orthography have been considered a seriousissue. Numerous studies have been conducted to determine whether different ortho-graphies involve different types of word recognition strategies. Although the conclu-sions of these studies may not always seem consistent or compatible, many indicatethat differences exist in word recognition strategies according to the orthography ofthe language at issue (i.e., alphabet, syllabary, or logograph) (Biederman & Tsao,1979; Briggs & Goryo, 1988; H. C. Chen & Tsoi, 1990; M. J. Chen, Yung, & Ng, 1988;Frost, 1994; Frost, Katz, & Bentin, 1987; Morikawa, 1985; Rusted, 1988; Perfetti &Zhang, 1991; Shimamura, 1987; Tabossi & Laghi, 1992; Toma & Toshima, 1989;Wang, 1988). The majority of the previous research in this area has utilized cross-linguistic comparisons or "between-subject" designs (e.g., comparing the languageperformance of English subjects in English to Chinese subjects in Chinese). Onedrawback to this approach, however, is the complexity of result interpretation. Forexample, the results of such comparisons may be unreliable or biased due to (a) alack of uniformity in the test subjects' educational background or language-learningcontext or (b) the inability to control characteristics of the linguistic stimuli (e.g.,word frequency and familiarity) across language groups. Some previous researchershave attempted to study orthographic effects on word recognition or memory in thetwo languages of the bilinguals using a "within-subject" design (e.g., comparingthe language performance of English and Chinese among Chinese-English bilingualsubjects) (H. C. Chen & Tsoi, 1990; Fang, Tzeng, & Alva, 1981; Hsieh, 1994; Liu, Zhu,& Wu, 1992; Tzeng & Wang, 1983). However, because no subject is truly a perfectlybalanced bilingual, inaccuracies may be introduced into the data of such studies. Inother words, a lack of balance in a bilingual subject's proficiency in the two lan-guages, rather than orthographic effects, may cause differences in performance tobe observed in the two languages.
Thus, the first issue in the present study is to examine LI orthographic effects onword recognition using a second language (Japanese) that is equally new or familiarto, and is being learned in the same L2 context by, two subject LI language groups(English and Chinese). The second issue involves the effects of the LI on SLA. LItransfer has been discussed in the literature in terms of syntax, phonology, andpragmatics. However, the transfer of a cognitively based language skill, such as theeffect of LI orthography on L2 word recognition or memory, has not been thesubject of much SLA literature (see the review in Koda, 1994). Orthography may beanother important factor affecting SLA because each orthographic type appears toimplicate different aspects of cognitive language processing. Therefore, if a differ-ence is observed in L2 word recognition among language groups, and if such adifference reflects the LI orthographies of the subjects, it can then be said thatthe strategies involved in LI word recognition might be transferred into L2 wordrecognition.
Writing Systems and Word-Recognition Models
In terms of orthography, languages of the world are classified into three groups:alphabet, syllabary, and logograph. The alphabet is a sound-based script, and usually

Effects of L1 Orthography 405
each letter represents a phoneme (e.g., k for /k/, o for /ko/ in English). For exam-ple, English, French, and other Indo-European languages, as well as Arabic, arealphabetic, even though these languages do not have an equally straightforwardsound-symbol correspondence. A syllabary is another sound-based script in whicheach letter represents a syllable. For example, the Japanese kana (e.g., ^3 for /o/ ,C for /ko/) is a syllabic script. In Japanese kana, a newly encountered word canbe pronounced correctly with grapheme-phoneme correspondence (GPC) rules, aseach letter represents a sound unit. A logograph is a meaning-based, rather than asound-based script in which each character represents a meaning or morpheme. Forexample, Chinese characters and Japanese kanji characters are logographic scripts,which do not have a systematic sound representation or a one-to-one relationshipbetween sound and symbol. Therefore, pronunciation is essentially memorized foreach character (e.g., ^ /nu/, "woman"; M /ma/, "horse"). Even though about39% of Chinese characters are said to contain a phonemic component as a soundcue (Zhou, 1978), this component does not play the same role as alphabetic orsyllabic characters do in GPC rules (Koda, 1994'; Mann, 1985; Perfetti & Zhang,1995). In short, although Chinese characters represent sounds, they are not composi-tional, as are alphabetic or syllabic symbols. Another characteristic of logographicscripts is that many homophones share the same pronunciation (e.g., both i andj] are pronounced /li/ but have the meanings "to stand" and "power, strength,"respectively). Thus, the visual form of the logographic script is crucial to the identityof a character.
The distinctions among the preceding orthographies are important becausewords may be cognitively processed differently according to the type of orthographyinvolved. When one recognizes a printed word, a visual representation of that wordis processed for meaning. This process is referred to as word recognition. Over thelast two decades, it has been claimed that two routes or strategies are involved invisual word recognition processes: (a) the phonological route and (b) the visualroute (Brown, Lupker, & Colombo, 1994; Henderson, 1982; Hoosain, 1991; Meyer,Schvaneveldt, & Ruddy, 1974; Paradis, Higiwara, & Hildebrandt, 1985; Seidenberg,1985; Taylor & Taylor, 1983). In the phonological route, phonological coding isfirst involved in the process of converting a printed word into a phonetic internalrepresentation prior to semantic recoding. GPC rules are used to convert each visualsound constituent of a word, such as a letter of an alphabet or a syllabary, letter byletter into a sound and then into a complete phonetic internal representation. Thus,the visual symbols (i.e., letters) are assembled together to produce a phonologicalrepresentation; this process is called assembled phonology (Besner & Hildebrandt,1987; Brown et al., 1994; Hung, Tzeng, & Tzeng, 1992; Monsell, Patterson, Graham,Hughes, & Milroy, 1992). It has also been termed prelexical phonology, as phonologi-cal coding takes place prior to lexical access (Frost, 1994; Perfetti & Zhang, 1991). Onthe other hand, in the visual route word meaning may be directly retrieved from thevisual representation of a word without phonological mediation. That is, phonologicalcoding takes place simultaneously with or even after semantic coding (i.e., lexicalaccess). This direct retrieval process is called addressed phonology or postlexical pho-nology (Besner & Hildebrandt, 1987; Frost, 1994; Perfetti & Zhang, 1991).

406 Nobuko Chikamatsu
The two preceding routes may be most appropriate to represent the strategies ofdifferent types of language speakers when such speakers encounter a new word. Forexample, a newly encountered English word can generally be read with GPC rules.Similarly, even though a new Chinese word has almost no sound cue for its pronunci-ation, its meaning may be understood without a sound cue.2 Although these strate-gies may explain some observed phenomena, when one tries to explain the wholepicture of word recognition, including both familiar and unfamiliar or phoneticallyregular and irregular words, the analysis becomes more complicated.
The effects of orthography in word recognition has been discussed extensively,but study results have not always been consistent since the "dual code processing"model was introduced in the 1970s (Baron, 1973; Coltheart, 1978; Meyer et al.,1974). This model proposes that phonetic coding and visual coding are both acti-vated in word recognition, whereas the timing and the relative use of the twoprocesses are determined by factors such as word frequency or familiarity, subjectreading ability, and orthography. For example, Seidenberg (1985) and others (Bes-ner & Hidebrandt 1987; Jared & Seidenberg, 1991) controlled word frequency toexamine its effects in word recognition strategies and concluded that the visual routeis a regular, default path in word recognition and that word phonology is activatedafter lexical access (i.e., postlexical or addressed phonology). However, they alsofound that phonological coding gains priority in cases of low-frequency word recog-nition (i.e., prelexical or assembled phonology) regardless of the orthographies in-volved.
To examine orthographic effects on word recognition, many cross-linguistic stud-ies, including the studies between English and Chinese, were conducted in the 1970sand 1980s. These studies demonstrated the influence of orthographic differences onthe involvement of phonological or visual coding. Whereas English word recognitionwas found to have extensive involvement of phonological coding, Chinese wordrecognition was found to rely on visual coding (Biederman & Tsao, 1979; Turnage &McGinnies, 1973). Accordingly, the traditional point of view among researchers wasthat one model described one language and the other model described the otherlanguage. However, a series of studies have discredited this point of view by reveal-ing certain inconsistencies. For example, highly or relatively systematic sound-spelling correspondent orthographic languages, such as Japanese syllabic kana orEnglish alphabetic words, could be processed by way of the direct route withoutsound mediation when the words are quite familiar (Besner & Hildebrandt, 1987;Besner & Smith, 1992; Hirose, 1992; Seindenberg, 1985; Yamada, Imai, & Ikebe,1990). Conversely, logographic words, such as Chinese words, might involve soundmediation at least to some extent (Cheng, 1992; Cheng & Shih, 1988; Wydell, Patter-son, & Humphreys, 1993). For instance, such sound mediation may be involvedwhen the words are very familiar and the association between the visual representa-tion and the sound is strong (i.e., on a character-as-a-whole-to-sound-as-a-wholebasis) with automatic phonological information (Hoosain, 1991; Perfetti & Zhang,1991).
More recent views on orthographic effects focus on the relative timing and de-gree of involvement of phonological coding or the interaction between phonological

Effects ofU Orthography 407
and visual coding, rather than an all-or-nothing distinction. Furthermore, in place ofa clear-cut distinction among three types of orthographies, relative distinctions basedon symbol-sound correspondence characteristics have become more widely ac-cepted in this area. These views have emerged as the orthographic depth hypothesis(ODH) (Frost, 1994; Frost et al., 1987; Katz & Feldman, 1983; Tabossi & Laghi, 1992).The ODH proposes that the degree of involvement of phonological coding in readingstrategies depends on "orthographic depth," which refers to the complexity of alanguage's letter-to-sound correspondence characteristics. "Shallow" orthographies,such as Serbo-Croatian, Italian, Spanish or possibly English, show highly or relativelyconsistent sound-spelling correspondence. "Deep" orthographies, such as Chineseor Hebrew, possess sound-spelling correspondence characteristics that are not con-sistent and are more opaque. In these languages, the same symbol may representdifferent phonemes in different contexts and different symbols may share the samepronunciation. The ODH predicts that (a) the more shallow orthographies are, themore phonological (i.e., prelexical) coding is involved, and (b) the deeper ortho-graphies are, the more likely a direct route is activated primarily and word phonol-ogy is retrieved through lexical (i.e., postlexical) access. For instance, Frost et al.(1987) conducted a cross-linguistic word-naming study of three different languagegroups, Serbo-Croatian, English, and Hebrew. Serbo-Croatian was defined as themost shallow, Hebrew as the deepest, and English as between the two other lan-guages in terms of orthographic depth. Their results indicate that phonological cod-ing involvement was observed most in Serbo-Croatian and least in Hebrew, withEnglish in between. Thus, it was concluded that the more shallow orthographies are,the more phonological coding is involved. Moreover, other cross-linguistic studiesbetween relatively shallow and deep orthographies, such as English versus Chinese(Perfetti & Zhang, 1991), Italian versus English (Tabossi & Laghi, 1992), or voweledversus unvoweled Hebrew (Frost, 1994),3 have provided additional evidence oforthographic effects in word recognition across languages or orthographies.
Recently, however, another model of word recognition, the universal phonologi-cal principle (UPP), has been gaining attention. The growing prominence of the UPPis due, in part, to data observed from a number of studies (Lesch & Pollatsek, 1993;Van Orden, 1987). The UPP predicts primary automatic activation of phonologicalinformation in words in all languages, that is, prelexical phonological coding, evenin deep orthographies such as Chinese (Perfetti & Zhang, 1991,1995; Perfetti, Zhang,& Berent, 1992; Tan, Hoosain, & Peng, 1995). For instance, Perfetti and Zhang(1995) examined Chinese subjects' performance in Chinese single-character recogni-tion tasks with synonyms and homophones. In a phonological judgment task, thesubjects were asked to decide whether two characters had the same pronunciation.When the two test item characters were synonyms, Perfetti and Zhang observedsemantic interference. In a semantic judgment task, the subjects were asked todecide whether two characters had a similar meaning. When the two test itemcharacters were homophones, they observed phonological interference. Thus, theseresults support the inevitable automatic involvement of phonological coding in Chi-nese word recognition. Furthermore, even when the exposure duration of the firstcharacter (SOA) was shortened to prevent phonological activation in the semantic

408 Nobuko Chikamatsu
judgment task, phonological interference was observed with homophones. In otherwords, if semantic judgments could be based solely on direct coding, phonologicalinterference should not be observed in the shortened SOA. Therefore, Perfetti andZhang concluded that sound information is primarily activated in Chinese wordrecognition, ruling out the primary role of direct coding.
Thus, according to the UPP, even Chinese words are not necessarily processedthrough the visual route but involve prelexical phonology as a default path. How-ever, although the UPP may initially appear to support an orthographic-independentprinciple of reading in conflict with the ODH, the two principles may be compatible.The UPP focuses on the existence of universal inevitable automatic phonologicalactivation in the process of word recognition prior to or at lexical access, but it doesnot account for the differences in the degree of the phonological coding involvementacross languages. Whereas Tan et al. (1995) presented evidence of prelexical phonol-ogy in Chinese word recognition for the UPP, they claimed that, unlike in alphabeticor syllabic words, the phonological information in Chinese words cannot be obtainedwith GPC rules but must be obtained on a character-as-a-whole-to-sound-as-a-wholebasis. Perfetti and Zhang (1991) also studied the difference in phonological codingbetween English and Chinese word recognition, claiming that automatic phonologyis prelexical for English but at-lexical for Chinese (i.e., neither pre- nor postlexical,but simultaneous with lexical or semantic access). In the summary of the recentdiscussion of the ODH and the UPP, Perfetti et al. (1992) concluded that the theoriescould be compatible. In short, they claimed that although universal automatic phono-logical coding is involved in all languages, orthographic variation in the degreeof involvement of phonological coding is observed across languages. Indeed, theproponent of the ODH, Frost (1994, 1995), also supports the inevitable phonologicalprocessing in all types of word recognition while claiming the involvement of ortho-graphic variation.
Thus, based on previous LI word recognition research, orthography can be onesignificant factor in determining word recognition strategies. Moreover, the involve-ment of phonological coding may vary as a function of the depth of the orthography.
L1 Effects on L2 Word Recognition
Due to differences in writing systems and word recognition models among differentlanguages, the strategies used by learners of a second or foreign language may varyaccording to the orthography of each learner's native language. Although few stud-ies have been conducted that focus on the effect of LI orthography on secondlanguage acquisition, some bilingual studies of word recognition or memory provideevidence of such effects (H. C. Chen & Tsoi, 1990; Hsieh, 1994; Liu et al., 1992;Tzeng&Wang, 1983).
Tzeng and Wang (1983) gave size incongruity tests to Chinese-English bilingualsubjects.4 Prior to their work, Besner and Coltheart (1979) had reported that, amongEnglish monolingual subjects, interference was observed with arabic numerals (e.g.,/) but disappeared when English number words (e.g., one) were used. Thus, the priorliterature concluded that the visual representation of ideographs (arabic numerals)

Effects ofL1 Orthography 409
interfered with performance to a greater degree than did alphabetic words (Englishnumber words). Interestingly, Tzeng and Wang found that among Chinese-Englishbilinguals, these size incongruity effects were observed in English number words inaddition to arabic numerals and Chinese number words (e.g., — , "one") eventhough English number words are not logographic. In contrast, such interferencewas not observed in either English or Spanish number words in Spanish-Englishbilinguals. These results suggested no strong dependence on visual coding in L2English word recognition because the bilinguals' LI (Spanish) possessed a highlysystematic sound-spelling correspondence (i.e., a shallow orthography). Thus, thesize incongruity interference observed in English words only among Chinese-Englishbilinguals could be considered support for the transfer of a word-processing strategyfrom the LI (Chinese) to the L2 (English).
Chen and Tsoi (1990) compared similar types of interference with calculationsymbols (i.e., +, - , x, and -s-) and corresponding words in English (e.g., plus,minus) and/or in Chinese (e.g., J}R, #£ ) between English monolinguals and Chinese-English bilinguals.5 In symbol-naming tasks in English, the two groups showed simi-larly significant interference with symbol and English word distractors. However, inEnglish word-naming tasks, English subjects showed no interference with any ofthe distractors (including English words), while Chinese-English bilinguals indicatedsignificant interference with Chinese word distractors in Chinese word-naming tasks.Furthermore, the bilingual subjects seemed to show some interference effects withEnglish word distractors as well as Chinese word distractors in English word-namingtasks (although Chen and Tsoi did not mention whether such particular interferenceeffects were significant or not). It appears that Chinese bilingual subjects might havetransferred their LI (Chinese) reading strategies into L2 word recognition (English).
Hsieh (1994) focused on the effects of a writing system on word-decoding pro-cesses, comparing subjects' performance in short-term memory (STM) word recogni-tion tests between English monolinguals and Chinese learners of English. In thesetests, a set of English words was briefly presented to the subjects. Shortly after thewords were removed, the subjects were instructed to select the words just presentedfrom among another set of words that also contained phonological, graphic, andsemantic distractors. The results showed that Chinese subjects produced moregraphic errors than did English subjects, although both groups produced phonologi-cal errors most often. Hsieh concluded that both Chinese and English subjects ap-plied phonological strategies the most in reading English words, but that Chineselearners of English depended more on graphic strategies than did English monolin-guals in L2 English word recognition. This observation could be explained by theeffects of LI Chinese orthography on L2 English although the proficiency in Englishmay have varied between the two language groups.
Although the literature on the effects of LI orthography on SLA is limited, theresearch of Koda (1987, 1988, 1989) is the most recognized effort in this area.Dealing with LI cognitive transfer, Koda examined the effects of LI orthography inJapanese, Spanish, and Arabic on L2 English word or sentence processing, claimingthat LI cognitive processing strategies are transferred in L2 English reading due tothe orthographic characteristics of the LI. In her first study of LI cognitive transfer,

Effects ofU Orthography 411
ity seriously impaired the reading process for phonographic readers, but not formorphographic readers. Koda claimed that the phonographic group depended onphonological information to a greater extent than did the morphographic group.Therefore, the phonographic group was more impaired in reading a Sanskrit passagebecause of the lack of phonological information.
In summary, these studies by Koda provide important evidence of the effect ofthe LI orthography on L2 English reading. However, several issues remain unre-solved. First, the target language, English, was the LI for one group and the L2 forthe other groups used. In the LI word recognition literature, it has been claimed thatword familiarity is a significant factor in the involvement of phonological coding(i.e., a direct visual route or postlexical coding tends to be used for familiar words)(Besner & Hildebrandt, 1987; Henderson, 1982; Hirose, 1992; Seidenberg, 1985).Because the English words used in the second Koda (1988) study were familiar tothe English subjects (by virtue of the subjects' LI), the visual dependency observedamong them (as well as the Japanese subjects) might be due to word familiarityrather than orthography. Consequently, it is not yet clear whether the visual depend-encies observed in the English and Japanese groups resulted from the existence ofcommon deep orthographies. Furthermore, in her first study, it appears that Koda(1987) assumed that the Japanese subjects knew the rules of English phonology aswell as the LI English subjects did. It is unclear what significance, if any, Englishphonology has to nonnative speakers or whether such speakers distinguish pro-nounceable strings from unpronounceable strings. Therefore, a nonnative speaker'sunfamiliarity with English phonology might have resulted in a lesser involvement ofobservable phonological coding.
A second issue, the use of Japanese subjects in Koda's experiments, also madeinterpretation more difficult because of the complexities of the Japanese writingsystem. The Japanese writing system consists of two types of orthography, logo-graphic kanji and syllabic kana, each possessing different orthographic depths.Therefore, it may be questionable to define the Japanese language as logographic aseven kana are more phonetically transparent or shallow than English script. Thus,although a lesser involvement of phonological coding was observed among Koda'sJapanese subjects, such a result may not accurately reflect LI Japanese orthographiccharacteristics if kana are also considered.
Limitations of Previous Research and Motivationfor the Present Study
The studies described suggest several limitations to forming firm conclusions regard-ing LI orthographic effects in L2 word recognition. Such limitations, as applied tothe present study, include the following.
1. Cross-linguistic methods (between-subject designs) may result in unreliable or biaseddata because control over the subjects (e.g., language-learning contexts, educationalbackground) or linguistic stimuli or materials (e.g., word frequency, familiarity) cannot beuniformly or properly implemented across the different language groups.

412 Nobuko Chikamatsu
2. Bilingual LI and L2 (within-subject designs) may result in unreliable or biased databecause of an imbalance in proficiencies between the two languages among the bilingualsubjects. Such an effect may obscure the influence of orthographic effects and producedifferent results in the two languages.
3. Using Japanese subjects in interpreting LI orthographic effects is complex because theJapanese writing system consists of two types of orthographies, one sound based and theother meaning based.
4. Using native speakers of a second language target language may lead to false assumptionswhen comparing the performance of language groups because word familiarity is asignificant factor in the involvement of phonological coding.
In view of these limitations, subjects in the present study were Chinese andEnglish LI speakers learning Japanese. Unlike Japanese, in which two types oforthographies coexist, Chinese has a logographic orthography and English an alpha-betic script. In terms of orthographic depth, Chinese and English have relativelydeep and shallow orthographies, respectively. In this experiment, Japanese kana (asyllabic script) was used as the L2 target orthography because it was equally new toeach subject group. In addition, the subjects shared the same L2 Japanese educa-tional background, with all subjects learning Japanese in college in the United Statesat the same time. Moreover, the use of a single L2 (of which subjects possessed anidentical L2 learning background) may have minimized the noted limitations ofprevious cross-linguistic studies, even though a between-subject design was usedwithout control over LI educational background. Finally, Japanese kana might beprocessed with or without sound mediation by different language groups, eventhough kana is a sound-based script.
Research Hypotheses
The following hypotheses were formulated for the present study:
1. Word recognition strategies are dependent upon the type of orthography. In other words,reliance on phonological coding or visual coding varies according to the shallow or deeporthographic depth of the script of a language.
2. LI orthographic effects in word recognition are transferred in L2 word recognition. Thus,Chinese speakers (i.e., logographic readers) utilize more visual coding and depend moreupon visual information than do English speakers (i.e., alphabetic readers) in L2 Japaneseword recognition.
Although orthographic effects in word recognition observed in previous studieshave lacked clear consistency, such studies have demonstrated the involvement ofdifferent phonological coding in word recognition among languages having differentorthographic depth, such as English and Chinese. Because Chinese has a meaning-based script that is considered a deep orthography relative to English, less phonologi-cal coding is activated in Chinese word recognition processes; thus, word meaningmight be accessed directly without sound mediation by LI Chinese speakers. Con-versely, because English has a sound-based script that is considered a shallow or-

Effects ofL1 Orthography 413
thography relative to Chinese, English word recognition might occur primarilythrough prelexical phonological coding by LI English speakers. Therefore, due tothe different degree of involvement of phonological coding, dependence upon pho-nological information or visual information in words might differ between the En-glish and Chinese LI groups. In the present study, the use of a second language thatis equally new to the subjects, and learned in the same context, might aid in clarify-ing the effects of an LI writing system on cognitive processing strategies in L2 wordrecognition. Furthermore, if L2 performance reflects the influence of the LI writingsystem, the second hypothesis of the present study, that the LI orthography affectsL2 word recognition strategies, would be supported.
METHOD
Subjects
Forty-five American and 17 Chinese college students participated in the study. Allwere enrolled in Japanese 102, the second semester of a Japanese language courseat a large midwestern university in the United States. The students had no previousformal Japanese learning experience before college and, at the time of the experi-ment, had received 50 minutes of instruction, 5 days per week, for nearly twosemesters. All American subjects were native speakers of English. All Chinese stu-dents were native speakers of Chinese (with native reading and writing abilities)who had came to the United States after the age of 16.
Materials
The Japanese writing system consists of two types of orthographies: a logographicscript, kanji, consisting of Chinese characters, and a syllabic script, kana. Kana isdivided into two systems, hiragana and katakana, which share the same syllabicsound representation and can be transcribed by each other. In each kana system,there are 46 basic symbols and 25 additional symbols with diacritic marks. Hiraganais used primarily for grammatical or function words but is also used for some contentwords. Katakana is used for loan words, mainly from Western languages. Kanji isbasically used for content words, such as nouns, verbs, and adjectives.
In Japanese language class, both hiragana and katakana are introduced at anearly stage (although the timing of the introduction may vary among differentschools). At the school used in the present study, hiragana and katakana wereintroduced during the first week and third month of the first semester (i.e., Japanese101), respectively, and each had been used extensively in writing and reading mate-rials in class. The introduction of kanji was delayed, and consequently, each subject'sknowledge of kanji was limited. Therefore, most of the content words usually writtenin kanji in Japanese published materials, such as newspaper or magazines, werebeing presented to the subjects in hiragana.
For the study, 320 test items consisting of strings of kana letters were preparedfor the Japanese kana lexical judgment test. All the test items were written in

414 Nobuko Chikamatsu
Table 1. Familiarity of visual and sound information of stimuli
Stimulus Familiar Words Unfamiliar Words Nonwords
Visual information Familiar Unfamiliar UnfamiliarSound information Familiar Familiar Unfamiliar
either katakana or hiragana, the two types of Japanese syllabic scripts, and werecategorized according to two factors, visual familiarity and word length.
All 320 items were grouped into three types of stimuli: visually familiar words,visually unfamiliar words, and nonwords. Depending on the functions of each or-thography, usually only one of the three scripts (hiragana, katakana, or kanji) is usedfor a given content word in its conventional representation; such a word is rarelywritten in another script. This property of Japanese enabled visual familiarity to becontrolled using conventional or unconventional scripts for words without changingthe pronunciations. Accordingly, visually familiar words were kana words written ina conventional script (i.e., katakana words that are conventionally written in kata-kana and hiragana words that are conventionally written in hiragana). For exam-ple, y- \s if /terebi/ ("television") is conventionally written in katakana becauseit is a loan word. Therefore, r U t /terebi/is visually familiar. X . V ^ /eiga/("movie") is usually written in hiragana in Japanese class; therefore, the hiraganaform is also visually familiar.
Visually unfamiliar words were kana words written in an unconventional script(i.e., katakana words that are conventionally written in hiragana and hiragana wordsthat are conventionally written in katakana), although the pronunciation of thewords written in a conventional script was maintained. For example, XtltS/terebi/ ("television") in hiragana is a visually unfamiliar form because it is notusually written in hiragana. Also :c--yf iJ /eiga/ ("movie") in katakana is a visuallyunfamiliar form although it sounds familiar due to the identical pronunciation ineither hiragana or katakana.
Nonwords were all pronounceable but were not actual Japanese words in termsof pronunciation and visual form. Only one kana letter differentiated nonwords fromreal words among 2-, 3-, and 4-letter words, and two letters differentiated nonwordsfrom real words in 5-letter words. Thus, unfamiliar word and nonword stimuli weredifferent only in terms of sound familiarity, not visual familiarity. In other words, thesound information in words was familiar in visually familiar words but not in non-words, but the visual information in both conditions was not familiar. The familiarityof the visual and sound information in each type of stimuli is summarized in Table 1.
All of the visually familiar and unfamiliar words used in this study had beenintroduced in Japanese class in a conventional script form (i.e., a visually familiarform) before the study was conducted.
The test items consisted of 80 visually familiar words (40 hiragana and 40 kata-kana), 80 visually unfamiliar words (40 hiragana and 40 katakana), and 160 non-words (80 hiragana and 80 katakana). These items were divided into two blocks, akatakana block and a hiragana block (see Table 2).

Effects of L1 Orthography 415
Table 2. Examples of visual familiarity
Katakana block (160 words)katakana familiar words (40)katakana unfamiliar words (40)katakana nonwords (80)
Hiragana block (160 words)hiragana familiar words (40)hiragana unfamiliar words (40)hiragana nonwords (80)
Table 3. Examples
2 Letters vvfRT
3 Letters /^*x.
4 Letters xA,t>°o
5 Letters &;6>*>£A,
TUX
**;¥
XtiU
[terebi] "television"[eiga] "movie"[kauda]
[eiga] "movie"[terebi] "television"[eibo]
of word length
[isu][doa][namae][rajio][enpitsu][amerika][okaasan][iyaringu]
"chair""door""name""radio""pencil""America""mother""earring"
The katakana block consisted of katakana familiar words, katakana unfamiliarwords, and katakana nonwords; the hiragana block consisted of hiragana familiarwords, hiragana unfamiliar words, and hiragana nonwords. Katakana familiar wordsand hiragana unfamiliar words or hiragana familiar words and katakana unfamiliarwords share the same pronunciation. Therefore, the test item presented first (e.g., akatakana familiar word, f l ^ t f /terebi/, "television") might produce a phonologi-cal or even semantic priming effect on the other word presented later (e.g., ahiragana unfamiliar word, XtlZf /terebi/, "television") regardless of visual famil-iarity. The blocks were devised to reduced the likelihood that such an effect mightbias data in the present study and to maintain sufficient distance between the visu-ally familiar and unfamiliar words having the same pronunciation. Another reasonfor this design is that subjects use one script throughout the block. All items wererandomized in each block for each subject. Furthermore, the order of the blocks wascounterbalanced. In short, although all subjects were presented with both blocks,half of the subjects in each LI group viewed the katakana block first and then thehiragana block, and the other half viewed the hiragana block first then the katakanablock.
Word length (the number of kana letters) varied from 2 to 5 letters among thetest items, as shown in the examples in Table 3.
Procedure
It was assumed that the subjects would be familiar with visually familiar words,which were selected from words that had been introduced and used often in Japa-nese class. To ensure the validity of this assumption of familiarity, the subjects

416 Nobuko Chikamatsu
reviewed and were pretrained on the visually familiar words in Japanese class usingflashcards during the 2 weeks prior to the experiment.
It was important that the subjects' proficiency in Japanese, knowledge of Japa-nese vocabulary, and familiarity with kana be essentially uniform among two subjectgroups. Therefore, the subjects were given a pretest to gauge Japanese languageskills prior to the lexical-judgment test. This pretest consisted of a kana test and avocabulary test. In the kana test, subjects were asked to fill in a katakana chart with46 symbols.7 In the vocabulary test, subjects were asked to state in English themeaning of Japanese hiragana and katakana words. There was no time restrictionon either test. The correct answers were counted, and subjects who had error ratesequal to or greater than 2 standard deviations above the group mean were excludedfrom the study.
All subjects were tested in one session at a college computer laboratory. Partici-pating in a lexical-judgment test containing Japanese kana words, subjects wereasked to decide whether or not they recognized as a Japanese word the visuallypresented test item (a string of kana letters). Items were presented on the screen ofa Macintosh computer and subjects were required to respond by pressing the appro-priate key (i.e., 1 for "yes" and 2 for "no") as quickly as possible. The test program wasimplemented in HyperCard with a supplemental program to improve the measurementresolution of reaction times to an accuracy rate of within 1 millisecond.
A target item was presented and remained visible until a keyboard response wasentered by the subject. A 1-second interval was included after the subject entered akeyboard response to the presented item and before the next item appeared on thescreen. The test program recorded reaction times (RTs) and the subjects' keyboardresponses. The RTs were recorded from the time a test item appeared on the screento the time the subject entered a keyboard response. Although visually unfamiliarwords were written in an unconventional script, the correct response for such testitems was "yes" if the subject knew them as Japanese words because their pronunci-ation was identical to visually familiar words that had been learned and used in class.The correct response for nonword test items was "no" as it was believed that thesubjects could not have learned such test items as a word. This answering procedurewas clearly explained with examples during a test instruction sequence. Then, thesubjects were presented with five practice items prior to the actual test to ensurethat they understood the procedure. Test instructions were written in English be-cause Chinese subjects in the present study were undergraduate or graduate studentsin the United States and were fluent in English. No feedback was given for thesubjects' responses.
Predictions
Based upon the results of the studies previously cited, the following predictions weremade for the present study.
Visual Familiarity.
1. The increase in RT from the visually familiar condition to the unfamiliar condition will begreater among Chinese subjects than among English subjects. In other words, Chinese

Effects ofL1 Orthography 417
2
familiar unfamiliar nonword
Familiarity
Figure 1. Predicted results for visual familiarity.
subjects will slow down more in the visually unfamiliar word conditions compared to thefamiliar word condition.
2. The increase in RT from the visually unfamiliar condition to the nonword condition willbe greater among English subjects than among Chinese subjects. In other words, Englishsubjects will slow down more than will Chinese subjects in the nonword condition com-pared to the unfamiliar word condition.
These predictions are presented in Figure 1.Based upon LI orthographic characteristics, it was predicted that the Chinese
subjects would rely more on visual word information than would the English sub-jects. Therefore, the measured RTs for Chinese subjects were predicted to increaseconsiderably under the visually unfamiliar condition relative to the visually familiarcondition. Likewise, because of their greater reliance on the sound information inwords, it was predicted that the increase in RT for English subjects under the visuallyunfamiliar condition relative to the visually familiar condition would be smaller thanthe increase for Chinese subjects. This prediction is based on the fact that regardlessof the script used (hiragana or katakana), the sound information of visually familiarand unfamiliar words is the same. Therefore, in contrast to the Chinese subjects, agreater dependence on sound information would prevent the English subjects fromslowing down under the visually unfamiliar condition. In other words, looking at thedifference between visually familiar and unfamiliar word conditions in both lan-guage groups, the difference in RTs among the Chinese subjects should be greaterthan that among the English subjects.
Furthermore, it was predicted that the increase in RTs from visually unfamiliar tononword conditions should be greater among the English subjects than among theChinese subjects. Under either visually unfamiliar or nonword conditions, the visualinformation in words is not familiar or available. The sound information in words isphonetically familiar even in visually unfamiliar words because such words have thesame pronunciation as visually familiar words. In contrast, the sound informationin nonwords is truly unfamiliar because such nonwords are not Japanese words.Accordingly, it was predicted that the RTs for English subjects should increase

418 Nobuko Chikamatsu
English
Chinese
2 3 4 5
Word Length (No. of Kana Letters)
Figure 2. Predicted results for word length.
relative to the Chinese subjects from nonword to visually unfamiliar word conditionsbecause of the English subjects' greater reliance upon phonological information.
Word Length. An additional prediction concerns word length, as follows:
3. Subject dependence on the phonological information in words should result in increasedRT as word length increases. Therefore, English subjects should slow down more thanChinese subjects as word length increases.
As indicated in the hypothetical graph (Figure 2), if English subjects convert kanawords into sound units, the time required for word recognition by English subjectsshould increase with word length. That is, if subjects use GPC rules and dependheavily on phonological information, the longer the words are, the longer the sub-jects will take to process such words (Yamada et al., 1990). Alternatively, if Chinesesubjects rely on less phonological coding and recognize a word as a visual represen-tation (without converting each kana letter to a sound unit), the whole word isperceived as a single visual unit. Therefore, the length of words should not affect themeasured RTs among the Chinese as much as among the English subjects.
RESULTS
Mean RTs of correct responses of subjects were subjected to logarithmic transforma-tion8 and submitted to a four-way (Language x Familiarity x Length x Script) 2 x3 x 4 x 2 partially repeated measures ANOVA with unbalanced group size usingthe SAS GLM program (Table 4). To determine whether there were significant maineffects or interactions, planned multiple comparisons were conducted, using themodified Bonferroni test (Keppel, 1982).9 One type of multiple comparison testexamined two comparisons in familiarity: (a) between visually familiar word andvisually unfamiliar word conditions and (b) between visually unfamiliar word andnonword conditions.
The other type of multiple-comparison test produced three comparisons in wordlength: (a) between 2- and 3-kana letter words, (b) between 2- and 4-kana letterwords, and (c) between 2- and 5-kana letter words. Any reference to a planned

Effects ofL1 Orthography 419
Table 4. Analysis of variance for reaction time
Variables
LanguageFamiliarityFamiliarity x LanguageLengthLength x LanguageScriptScript x LanguageFamiliarity x ScriptFamiliarity x Script x LanguageFamiliarity x LengthFamiliarity x Length x LanguageScript x LengthScript x Length x LanguageFamiliarity x Script x LengthFamiliarity x Script x Length x Language
df
122331122663366
Error
561121121681685656
112112336336168168336336
F Value
3.48524.17
5.44344.62
4.9873.21
1.359.155.269.593.343.551.533.972.54
P
.0672 n.s.
.0001*
.0055*
.0001*
.0024*
.0001*
.2502 n
.0002*
.0065*
.0001*
K *
: *
.s.
.0067**
.0159*
.2097 n.s.
.0007***
.0205*
a = .05. *p < .05. "p < .01. *•*/> < .001. n.s. = not significant.
multiple comparison test, therefore, refers to the modified Bonferroni test. Becausethe major focus here is LI effects on L2 word recognition, language effects (i.e.,English compared to Chinese) will be discussed in the following sections. Accuracyrates were 90.61% and 90.10% for English and Chinese subjects, respectively, andno significant difference was observed between the two groups (i.e., overall, Englishand Chinese subjects performed with equal accuracy on the tests). Subjects havingerror rates equal to or greater than two standard deviations above the group meanon the pretest or on the lexical judgment test were excluded from the presentstudy.10
Overall Trends: Main Effects of ANOVA for RTs
Language. As seen in Table 4, there was no significant main effect for Language.In general, English and Chinese subjects responded at similar speeds. The mean RTwas 4.909 and 4.450 seconds, respectively.
Familiarity. There was a significant main effect for Familiarity, F(2, 112) =524.17, p < .0001; overall, visually familiar words were recognized faster (mean RT= 2.703 seconds) than visually unfamiliar words (mean RT = 3.823 seconds), andvisually unfamiliar words were recognized faster than nonwords (mean RT = 6.388seconds). A planned multiple comparison test revealed a significant difference be-tween familiar and unfamiliar conditions, F(l, 56) = 433.04, p < .0001, and be-tween unfamiliar and nonword conditions, F(l, 56) = 335.67,/? < .0001.
Length. There was a significant main effect for Word Length, F(3, 168) =344.62, p < .0001; overall, shorter words were recognized faster than longer words.

420 Nobuko Chikamatsu
10 iftw •
8 •
7 •
6 •
5 •
4 '
3 •
2 '
1 •
0 '
D ' * "
1 1
— • English— Q - - Chinese
—1 1familiar unfamiliar
Familiarity
Figure 3. Language X Familiarity.
nonword
The mean RTs for all subjects were 3.840, 4.397, 5.083, and 6.225 seconds for the 2-,3-, 4-, and 5-letter words, respectively. A planned multiple-comparison test revealedsignificant differences between 2 and 3 letters, F(l, 56) = 85.18, p < .0001, 2 and 4letters, F(l, 56) = 240.16, p < .0001; and 2 and 5 letters, F(l, 56) = 801.70, p <.0001. Two-letter words were recognized faster than 3-, 4-, and 5-letter words.
Script. There was a significant main effect for Script, F(l, 56) = 73.21, p <.0001; overall, hiragana words were recognized faster than katakana words. Thus,subjects were generally more familiar with hiragana than with katakana. The meanRTs for all subjects were 5.800 and 3.843 seconds for katakana and hiragana, respec-tively.
Language Effects: Interactions Between English andChinese Subjects
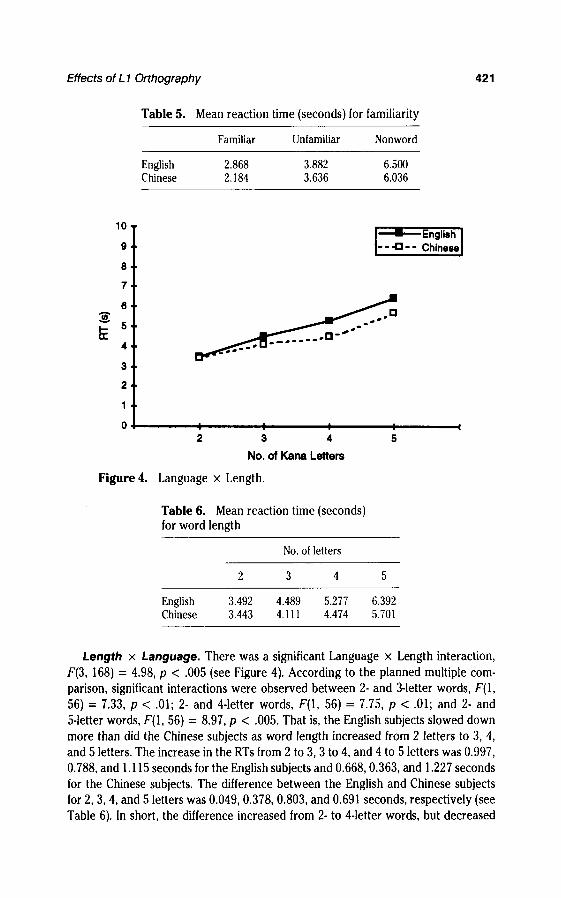
Familiarity x Language. There was a significant interaction between Lan-guage and Familiarity, F(2, 122) = 5.44, p < .01 (see Figure 3). A planned multiple-comparison test revealed a significant language effect between familiar and un-familiar conditions, F(l, 56) = 15.97, p < .001 (i.e., the Chinese subjects sloweddown in the unfamiliar condition more than did the English subjects).9 The differ-ences in the mean RTs between familiar and unfamiliar conditions were 1.104 and1.452 seconds for the English and Chinese subjects, respectively. There was nosignificant interaction between the visually unfamiliar and nonword conditions. Val-ues are cited in Table 5.
Effects ofL1 Orthography
Table 5. Mean reaction time (seconds) for familiarity
421
EnglishChinese
10 j
9 •
8-
7 •
6 •
5 '
4 '
3 •
2<
1 •
Familiar
2.8682.184
2 3
No.
Unfamiliar
3.8823.636
^
-- "°
4
of Kana Letters
Vonword
6.5006.036
— • English- - - Q - - Chinese
*
5
Figure 4. Language x Length.
Table 6. Mean reaction time (seconds)for word length
EnglishChinese
2
3.4923.443
No.
3
4.4894.111
of letters
4
5.2774.474
5
6.3925.701
Length x Language. There was a significant Language x Length interaction,F(3, 168) = 4.98, p < .005 (see Figure 4). According to the planned multiple com-parison, significant interactions were observed between 2- and 3-letter words, F(l,56) = 7.33, p < .01; 2- and 4-letter words, F(\, 56) = 7.75, p < .01; and 2- and5-letter words, F(l, 56) = 8.97, p < .005. That is, the English subjects slowed downmore than did the Chinese subjects as word length increased from 2 letters to 3, 4,and 5 letters. The increase in the RTs from 2 to 3, 3 to 4, and 4 to 5 letters was 0.997,0.788, and 1.115 seconds for the English subjects and 0.668,0.363, and 1.227 secondsfor the Chinese subjects. The difference between the English and Chinese subjectsfor 2, 3, 4, and 5 letters was 0.049, 0.378, 0.803, and 0.691 seconds, respectively (seeTable 6). In short, the difference increased from 2- to 4-letter words, but decreased
422 Nobuko Chikamatsu
10 -r
9 • •
8-
7 • •
6 • •
4 . .
3 • •
2-
1 •
• English- - Q - - Chinese
-D-"
3 4
No. of Kana Letters
Figure 5. Language x Length (hiragana).
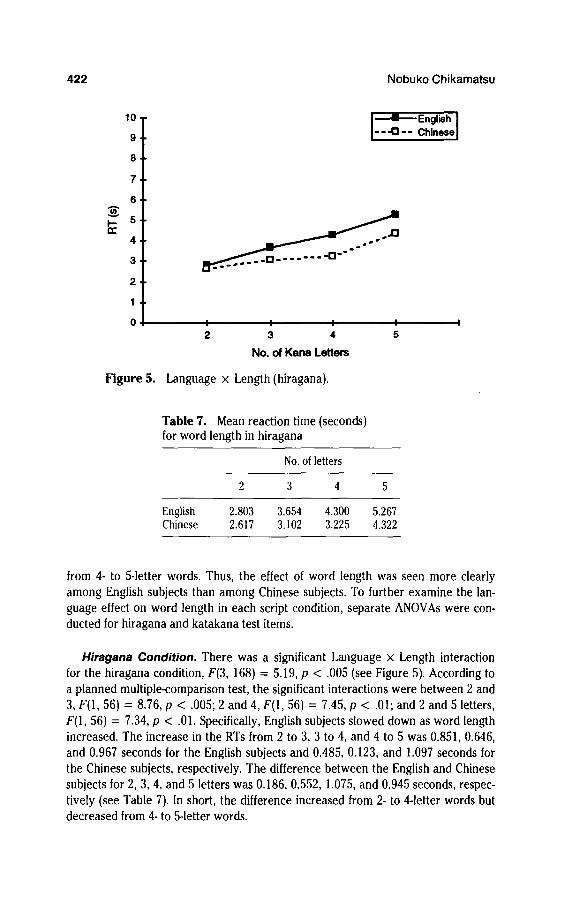
Table 7. Mean reaction time (seconds)for word length in hiragana
EnglishChinese
2
2.8032.617
No.
3
3.6543.102
of letters
4
4.3003.225
5
5.2674.322
from 4- to 5-letter words. Thus, the effect of word length was seen more clearlyamong English subjects than among Chinese subjects. To further examine the lan-guage effect on word length in each script condition, separate ANOVAs were con-ducted for hiragana and katakana test items.
Hiragana Condition. There was a significant Language x Length interactionfor the hiragana condition, F(3, 168) = 5.19, p < .005 (see Figure 5). According toa planned multiple-comparison test, the significant interactions were between 2 and3, F(l, 56) = 8.76, p < .005; 2 and 4, F(l, 56) = 7.45, p < .01; and 2 and 5 letters,F(\, 56) = 7.34, p < .01. Specifically, English subjects slowed down as word lengthincreased. The increase in the RTs from 2 to 3, 3 to 4, and 4 to 5 was 0.851, 0.646,and 0.967 seconds for the English subjects and 0.485, 0.123, and 1.097 seconds forthe Chinese subjects, respectively. The difference between the English and Chinesesubjects for 2, 3, 4, and 5 letters was 0.186, 0.552, 1.075, and 0.945 seconds, respec-tively (see Table 7). In short, the difference increased from 2- to 4-letter words butdecreased from 4- to 5-letter words.
Effects of L1 Orthography 423
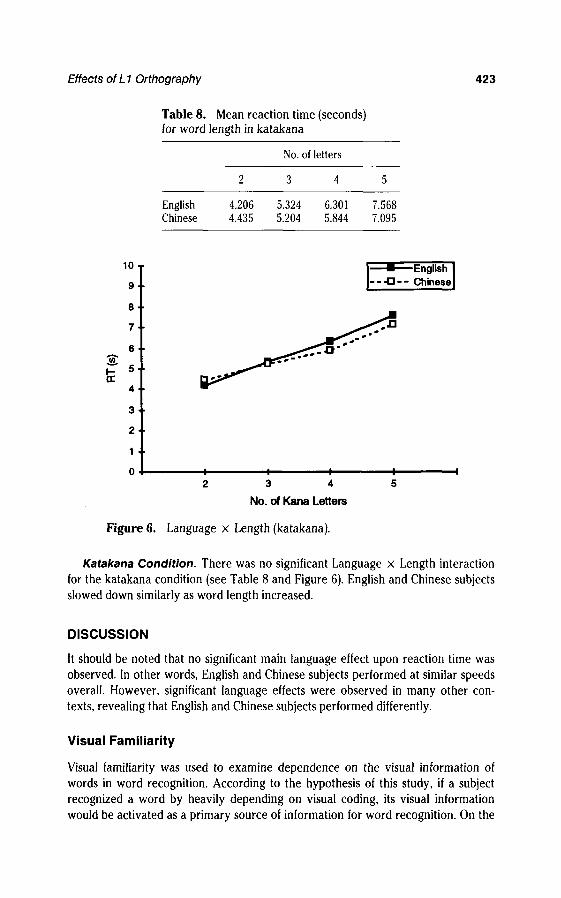
Table 8. Mean reaction time (seconds)for word length in katakana
EnglishChinese
2
4.2064.435
No.
3
5.3245.204
of letters
4
6.3015.844
5
7.5687.095
10
9
B
7 •
6
5 <
4
3
2
1
0
• English• - D - - Chinese
•+•
2 3 4 5
No. of Kana Letters
Figure 6. Language x Length (katakana).
Katakana Condition. There was no significant Language x Length interactionfor the katakana condition (see Table 8 and Figure 6). English and Chinese subjectsslowed down similarly as word length increased.
DISCUSSION
It should be noted that no significant main language effect upon reaction time wasobserved. In other words, English and Chinese subjects performed at similar speedsoverall. However, significant language effects were observed in many other con-texts, revealing that English and Chinese subjects performed differently.
Visual Familiarity
Visual familiarity was used to examine dependence on the visual information ofwords in word recognition. According to the hypothesis of this study, if a subjectrecognized a word by heavily depending on visual coding, its visual informationwould be activated as a primary source of information for word recognition. On the

424 Nobuko Chikamatsu
other hand, when a word was not visually familiar, its visual information was not asaccessible as that of a familiar word. As a result, readers who depended morestrongly on direct coding and who customarily utilized visual information in theprocessing of words (i.e., "Chinese" or "visual readers" as defined by Brown et al.[1994]) should have taken more time to recognize visually unfamiliar words thanvisually familiar words. In addition, if readers did not adopt visual coding and insteaddepended more on prelexical coding with sound mediation, the visual unfamiliarityof words should not have played a major role in word recognition. As a result,readers with a strong dependence on phonological coding (i.e., "phonetic readers"or "Phoenicians" as defined by Brown et al. [1994]) should have shown an increasein RT to the same extent as "visual readers."
Indeed, in the present study the results of the planned comparison test revealed asignificant language effect (a Language x Familiarity interaction) between the visu-ally familiar word condition and the visually unfamiliar word condition. This indi-cates that the increase in the RTs from familiar to unfamiliar conditions amongChinese subjects was significantly greater than among English subjects. In otherwords, the Chinese subjects slowed down more dramatically in the visually unfamil-iar word conditions relative to the familiar conditions than did the English subjects.Although in both conditions the Chinese subjects took less time (means of 2.184 and3.636 seconds for visually familiar and visually unfamiliar words, respectively) thandid the English subjects (means of 2.868 and 3.882 seconds for visually familiar andvisually unfamiliar words, respectively), the relative decrement in RT was muchgreater among the Chinese subjects (1.452 seconds) than among the English subjects(1.014 seconds)." These results indicate a stronger dependence on visual or ortho-graphic information in words among the Chinese subjects than among the Englishsubjects. That is, different word recognition strategies were used, depending on asubject's LI orthography (alphabetic or logographic). Furthermore, these resultssupport the second hypothesis of the study, that LI strategies are transferred into L2Japanese word recognition.
Unlike the significant language effects between visually familiar and unfamiliarconditions, the Language x Familiarity interaction between visually unfamiliar andnonword conditions was not significant. This observation was contrary to an initialprediction of this study that, because visual information was not available in eitherunfamiliar or nonword conditions, Chinese subjects would not slow down as muchas English subjects in nonword relative to visually unfamiliar word conditions. Themean difference in RT between these two conditions (2.618 and 2.400 seconds forthe English and Chinese subjects, respectively) was not statistically significant. Thus,the results indicate that both language groups slowed down at a similar rate in thevisually unfamiliar and the nonword conditions.
These results might be explained by phonological accessibility rather than visualinaccessibility. For all subjects the visual information in both the visually unfamiliarand the nonword conditions was equally unfamiliar. The only strategy readers coulduse to recognize such words might have involved the use of phonological informa-tion in the words by accessing prelexical phonological coding with assembled pho-nology (i.e., letter-by-letter spelling-sound conversion). Therefore, all subjects may

Effects of L1 Orthography 425
have been forced to use a phonological strategy in the visually unfamiliar andnonword conditions due to the absence of visual accessibility. Consequently, nodifference was observed between the English and Chinese groups. This suggests thatthe initial prediction made for RTs between the two conditions was premature.Indeed, some researchers (Brown et al., 1994) have even claimed that "Phoenicians"are faster than "Chinese" in an English nonword naming task because the "phoeni-cians" are more accustomed to utilizing phonological strategies than are the "Chi-nese." l2 Further research should be conducted to examine the nonword condition interms of visual familiarity.
Word Length
Word length was used to examine the involvement of phonological coding and eachsubject's dependence on phonological information in words. This approach has beenused in several recent word recognition studies of sound-based scripts (Brown et al.,1994; Frost, 1994; Goryo, 1987; Yamada et al., 1990). For example, Yamada et al.(1990) adopted word length as a factor in examining how reaction time is affected ina Japanese kana lexical-decision test with native Japanese speakers. They statedthat
[i]f readers are always affected by string length and it takes them longer to readlonger kana strings than shorter ones, given equal familiarity, and so forth, thatfact might be pursued to support the phonological assembly hypothesis. But ifreaders are not affected by word length under certain conditions, and/or if"sight" words are used, then the dual-route hypothesis would be supported, (p.313)
Thus, in the present study it was predicted that kana word recognition RTs wouldincrease as word length increased for subjects who used assembled or prelexicalphonology and depended on phonological information in words. On the other hand,for subjects having no, or a lesser, dependence on phonological coding or informa-tion, word length effects on RTs should not be observed as clearly among visualreaders as among phonological readers.
In this study, the observed language effect on word length (i.e., the Language xLength interaction) was significant. English subjects slowed down more than Chinesesubjects as word length increased. In short, although the RTs for both languagegroups increased as the numbers of letters in the test items increased from 2 to 5,the word length effects were seen more clearly among English subjects than amongChinese subjects. This phenomenon was observed more clearly in the hiraganacondition than in the katakana condition. In the hiragana condition, the Languagex Length interaction was significant, and English subjects took significantly longerto respond than Chinese subjects as word length increased from 2 to 5 letters.On the other hand, in the katakana condition, there was no Language x Lengthinteraction. English and Chinese subjects slowed down at a similar rate as wordlength increased from 2 to 5 letters. This might be explained by the familiarity of thescripts involved. Specifically, hiragana is introduced as a basic script in Japanese

426 Nobuko Chikamatsu
language classes and is usually used extensively at the beginning level (Chikamatsu,1994). Katakana is also introduced at an early stage but is used less frequently thanhiragana in class. Katakana is used in specific types of words, such as loanwords andstudents' names, which makes it less familiar than hiragana to L2 learners of Japa-nese. This study supports this familiarity difference between hiragana and katakana.The main effect for script was significant (on average for all subjects, hiraganawords were recognized 1.957 seconds faster than katakana words). Furthermore,the observed Language x Script interaction was not significant. In other words,both English and Chinese subject groups were more familiar with hiragana than withkatakana words. However, word length effects were observed more clearly amongEnglish subjects than among Chinese subjects in the hiragana condition, but not inthe katakana condition. This implies that for Chinese speakers to utilize their LIstrategies as visual readers in the L2 they must be sufficiently familiar with the words(in this case hiragana words). This interpretation is consistent with previous studiesin LI word recognition. For instance, Yamada et al. (1990) claimed that word lengtheffects were seen in unconventional kana words and nonwords (visually unfamiliaritems), but not in conventional kana words (visually familiar items) in lexical-decision kana tests with Japanese native speakers. Seidenberg (1985) and Besnerand Hildebrandt (1987) also concluded that direct coding without sound mediationcould occur when words were visually familiar even in sound-based scripts. Indeed,in the present study, the Familiarity x Script interaction was significant, with kata-kana words being recognized more slowly than hiragana words as word lengthincreased. Thus, greater word length effects were observed in the katakana condi-tion.
At the same time, a major question arises: Could the word length differenceobserved between Chinese and English subjects be attributed simply to a differencein visual familiarity rather than a difference in word recognition strategies betweenthe two language groups? That is, were the Chinese subjects simply more familiarwith hiragana words than were the English subjects, and did they perform faster andbetter than the English subjects? Both groups could have used prelexical phonologi-cal coding, but Chinese subjects could activate it more quickly and effectively thanEnglish subjects by converting word spelling into sounds letter by letter. In thekatakana condition, however, even the Chinese subjects were not sufficiently famil-iar with the words, so they slowed down in the spelling-sound conversion task asmuch as the English subjects did, revealing similar word length effects.
However, this interpretation does not seem valid if we recall that there was nomain effect for language observed: Chinese and English subjects responded at similarspeeds in general, including both the hiragana and katakana conditions. '3 This indi-cates that, in general, English and Chinese subjects were equally familiar with hira-gana and katakana words. Therefore, it is doubtful that Chinese subjects were morefamiliar with the words and thus used phonological coding more efficiently orquickly than did English subjects. Hence, the different word length effects observedbetween the two language groups were most likely due to the degree of the involve-ment of phonological coding, rather than to the speed or effectiveness of phono-logical coding. Thus, the performance of the English subjects indicated more

Effects of L1 Orthography 427
involvement of phonological coding than did the performance of the Chinese sub-jects.
Furthermore, the observed weaker word length effects, in addition to the ob-served strong visual familiarity effects discussed earlier, are more evidence for theChinese subjects' greater dependence on visual information. Thus, if the observedword length effects had been caused by the English subjects' relative unfamiliarityand the Chinese subjects' relative familiarity with the script involved, visual familiar-ity effects should not have been observed in the Chinese subjects (i.e., the Chinesesubjects would not have slowed down as much as the English subjects).
CONCLUSION
The present study explored the two primary research issues: (a) whether wordrecognition strategies differ depending on LI orthographic type or depth and (b)whether LI orthographic effects in word recognition are transferred in L2 wordrecognition.
To address these issues, word recognition strategies in two language groups,Chinese and English, were examined in a single L2 (Japanese), which was equallynew to both groups. If differences were observed in the common L2 performance ofthe two language groups, such differences suggest that the two language groups usedifferent word recognition strategies. Furthermore, if the differences appear to re-flect the influence of the LI writing system, this supports the second hypothesis ofthe study, that LI orthographies affect L2 word recognition.
According to predictions based on these hypotheses, visual familiarity effectswere observed between visually familiar and unfamiliar word conditions. That is,the Chinese subjects depended more on visual information in words than did theEnglish subjects. Furthermore, observed word length effects indicated that the En-glish subjects depended more on phonological information in words than did theChinese subjects, especially when the words were written in a familiar script, hira-gana. Thus, each language group showed different word recognition strategies in L2Japanese kana word recognition that reflected each group's LI orthography. Theseresults support the orthographic depth hypothesis, or ODH, which claims that "thedegree to which the (prelexical) phonology is active is a function of the depth of theorthography" (Frost, 1994, p. 116). Moreover, it was found that LI word recognitionstrategies are transferred into L2 word recognition. Although the study indicatessignificant implications for psycholinguistic theories involving word recognitionmodels and LI transfer in SLA, several additional issues remain to be investigated.
First, the Chinese subjects in this study were fluent in English and used thislanguage as a communication tool in daily life. Therefore, the Chinese subjects'Japanese kana word recognition strategies might have exhibited interference fromtheir "real L2" (i.e., English, a sound-based script) in addition to their LI (i.e., Chi-nese). However, even if there was possible L2 English sound-based script interfer-ence, the performance of the Chinese subjects demonstrated LI meaning-basedorthographic effects on Japanese kana word recognition. Thus, this potential L2

428 Nobuko Chikamatsu
English interference could add support to the argument for LI orthographic effectsamong the Chinese subjects.
Second, the task required in the lexical-decision test might have been biased toyield or permit phonological coding. The subjects were instructed to decide whetheror not they knew a presented test item as a Japanese word, regardless of its scriptpresentation. Thus, the responses to the visually unfamiliar words should have been"yes" even though the visual presentation was not appropriate for such words.Furthermore, half of the experimental test items were nonwords, which might haveencouraged the use of a prelexical phonological coding in shallow orthographies(Baluch & Besner, 1991; Besner & Smith, 1992). Although the task might haveencouraged dependence upon phonological information, the Chinese subjectsshowed greater dependence upon visual information.
Third, although English is a sound-based phonemic script and considered a shal-low orthography (relative to Chinese), its symbol-sound correspondence is not al-ways straightforward. In short, one symbol can be pronounced more than one wayand more than one symbol may represent the same phone. Therefore, some previ-ous studies in LI English word recognition have claimed a variation of the depen-dence on each coding even among native English readers (Baron & Strawson, 1976;Brown et al., 1994). Although the variation in LI English word recognition might notbe as great as in L2 novice Japanese word recognition among English native speak-ers, the English subjects in the study could have been more heterogeneous than thelearners of Japanese from language backgrounds with more shallow LI orthograph-ies, such as Serbo-Croatian or Spanish. However, even with this potentially heteroge-neous English L2 group, a difference was observed between the English and Chinesesubjects.
Fourth, previous studies of native speakers of Japanese have shown that theytend to use a direct visual route without phonological mediation in kana wordrecognition if the words are familiar (e.g., Besner & Hildebrandt, 1987; Hirose, 1992;Yamada et al., 1990). In this study, beginning students of Japanese were used assubjects. Therefore, if LI English subjects' Japanese language skills become moreadvanced and they grow increasingly familiar with Japanese words, they might relyless on phonological information and begin to use the direct route for Japanese kanaword recognition to a greater extent. As a result, the difference between the twolanguage groups might disappear at a later stage in their study of Japanese. Thus,the effects of LI orthography or LI transfer might be detected only in the earlystages of learning a foreign language.
The final issue is to what extent LI orthography affects L2 reading beyond theword level. Criticisms are often heard about the empirical validity of unnaturallaboratory experimental tasks using words in isolation from contexts in word recog-nition studies. However, word recognition skills examined in isolation show a strongcorrelation with reading abilities in both LI (A. E. Cunningham, Stanovich, & Wilson,1990; Stanovich, 1982, 1991) and L2 reading studies (Koda, 1992). Thus, the impor-tance of word recognition skills in reading is not in doubt. Now the question is howLI orthography affects L2 reading beyond the word level. For the practical applica-tion of the results of the present study to foreign language teaching, it is difficult to

Effects of L1 Orthography 429
say which word recognition strategy (i.e., visual dependency or sound dependency)is more effective in L2 reading. The Chinese subjects performed neither faster normore accurately than did the English subjects in general. Therefore, it is prematureto conclude that language instructors should develop vocabulary learning methodsin order to encourage learners to become visual readers or in order to encouragelearners to use their LI word recognition strategies in the L2.14 To address this issue,it may be most interesting to examine the possible relationship between visual orsound dependence in word recognition and reading comprehension skills.
(Received 24 July 1995)
NOTES
1. Koda (1994) explains that the phonetic radical cannot provide a sound cue until its phonological codeis retrieved through lexical access because the phonetic radical itself is an independent character.
2. A phonetic component may provide a pronunciation cue for the character, but the majority ofcommonly used Chinese characters do not contain this sound cue (see summary in Tan, Hoosain, & Peng,1995).
3. Hebrew is an alphabetic language, but texts can be written in two different ways, with and withoutdiacritic marks for vowels (i.e., voweled and unvoweled). Therefore, in terms of orthographic depth, voweledscript is considered relatively shallow, whereas unvoweled script is deep.
4. Size incongruity tests are a modified version of Stroop tests that are based on the assumption that afluent reader cannot avoid activating the semantic code of a printed word once he or she sees the word(Stroop, 1935). In size incongruity tests, one number word (e.g., one) or arabic numeral (e.g., /) is printedphysically larger than another, and subjects are asked to indicate which item appears to be physically larger.Reaction times are slower when the number word or arabic numeral indicating a smaller value is printedphysically larger than the other (e.g., if 6/A is printed larger than 9/Ji ). In this case, there is an inconsis-tency between the meaning of the character and its physical size, a phenomenon termed interference.
5. In Stroop-like tests, calculation symbols and words were presented simultaneously (one printed overthe other). All of the possible combinations between target and distractor items were tested, such as symboland word (e.g., + and plus), word and symbol (e.g., plus and +) , symbol and symbol (e.g., + and - ) , andword and word (e.g., plus and minus), in between-language and within-language conditions. The target wasprinted physically larger than the distractor and subjects were instructed to name the targets as quickly aspossible.
6. Koda (1989) termed logographic readers morphogmphic readers because the representational unit inkanji or Chinese characters is a morpheme and semantically oriented.
7. Although all of the hiragana were used in class for writing and reading and the students were veryfamiliar with them, students might not have been familiar with some of the katakana that do not appear asoften as high-frequency katakana. Therefore, to determine how well students remembered katakana, theywere asked to fill in a katakana chart but not a hiragana chart.
8. Logarithmic transformation is used to ensure that the underlying assumptions of ANOVA are moreclosely adhered to when the dependent variable is reaction time and the data are positively skewed (Kirk,1982).
9. In the modified Bonferroni test, the following formulas are adopted to set up "a planned a" to avoid aType I error as cited by Keppel (1982, pp. 148-149):
This can be accomplished easily by calculating the a^n associated with a — 1 orthogonalcomparisons and then dividing this probability by the actual number of planned comparisonsincluded in the analysis plan. The resulting probability is a new PC rate to be used inassessing these comparisons that maintains <*FW a t this presumably acceptable standard. Insymbols, we use Eq. (8-3) to calculate the maximum FW error for planned comparisons,
«FwP,,mai = (dfAX«) (8-3)
and divide this value by the number of comparisons actually planned (c):
"planned = aFWplanne<l/c (8-4)

430 Nobuko Chikamatsu
This method of adjusting the PC rate is related to a procedure known as the Bonferroni test.In the Bonferroni test, the numerator in Eq. (8-4) is the overall FW rate adopted by aresearcher for the experiment—not the aFWpianned-1 have suggested as a method for controllingFW error with planned comparisons. I will refer to the present technique as the modifiedBonferroni test.
10. One English subject and one Chinese subject were excluded from the analysis due to the results ofthe pretest. Two Chinese subjects were excluded due to the results of the lexical judgment test. These subjectsappeared to have misunderstood the test procedure.
11. These last two values indicate the difference in seconds between visually familiar and unfamiliarconditions (i.e., RTs for the unfamiliar word condition minus RTs for the familiar word condition).
12. Brown, Lupker, and Colombo (1994) grouped English subjects into two groups: "Phoenicians" whoshowed strong dependence on phonological coding and "Chinese" who showed strong dependence on visualcoding. Grouping was conducted based on the results of a "pseudo homophone detection task" designed byBaron and Strawson (1976).
13. The main effect for language was not significant in the hiragana condition or in the katakanacondition in either ANOVA.
14. Smith (1985) claimed that skillful English readers (i.e., native speakers of English) recognize Englishwords in the same way that fluent Chinese readers recognize Chinese. In short, visual readers are consideredmore efficient readers.
REFERENCES
Baluch, B., & Besner, D. (1991). Visual word recognition: Evidence for the strategic control of lexicaland nonlexical routines in oral reading. Journal of Experimental Psychology: Learning, Memory, andCognition, 17, 644-652.
Baron, J. (1973). Phonemic stage not necessary for reading. Quarterly Journal of Experimental Psychology,25, 241-246.
Baron, J., & Strawson, C. (1976). Orthographic and word-specific mechanisms in children's reading of words.Child Development, 50, 60-72.
Besner, D., & Coltheart, M. (1979). Ideographic and alphabetic processing in skilled reading of English.Neuropsychologia, 17, 467-472.
Besner, D., & Hildebrandt, N. (1987). Orthographic and phonological codes in the oral reading of Japanesekana. Journal of Experimental Psychology: Learning, Memory, and Cognition, 13, 335-343.
Besner, D., & Smith, M. C. (1992). Basic processes in reading: Is the orthographic depth hypothesis sinking? InR. Frost & L. Katz (Eds.), Orthography, phonology, morphology, and meaning (pp. 45-66). Amsterdam:Elsevier.
Biederman, I., & Tsao, I. C. (1979). On processing Chinese ideographs and English words: Some implicationsfrom Stroop-test results. Cognitive Psychology, 2, 125-132.
Briggs, P., & Goryo, K. (1988). Biscriptal interference: A study of English and Japanese. The Quarterly Journalof Experimental Psychology, 40A, 515-531.
Brown, P., Lupker, S., & Colombo, L. (1994). Interacting sources of information in word naming: A study ofindividual differences. Journal of Experimental Psychology: Learning, Memory, and Cognition, 20, 537-554.
Chen, H. C, & Tsoi, K. C. (1990). Symbol-word interference in Chinese and English. Ada Psychologica, 75,123-138.
Chen, M. J., Yung, Y. F., & Ng, T. W. (1988). The effect of context on perception of Chinese characters. InI. M. Liu, H. C. Chen, & M. J. Chen (Eds.), Cognitive aspects of the Chinese language (pp. 27-39). HongKong: Asian Research Service.
Cheng, C. M. (1992). Lexical access in Chinese: Evidence from automatic activation of phonological informa-tion. In H. C. Chen & 0 . J. L. Tzeng (Eds.), Language processing in Chinese (pp. 67-92). Amsterdam:North-Holland.
Cheng, C. M., & Shih, S. (1988). The nature of lexical access in Chinese: Evidence from experiments on visualand phonological priming in lexical judgment. In I. M. Liu, H. C. Chen, & M. J. Chen (Eds.), Cognitiveaspects of the Chinese language (pp. 1-14). Hong Kong: Asian Research Service.
Chikamatsu, N. (1994, October). The gap between high schools and colleges in Japanese language instruction{2\- Survey results. Paper presented at the Illinois Council of Teaching of Foreign Languages Conference,Rockford.
Coltheart, M. (1978). Lexical access in simple reading tasks. In G. Underwood (Ed.), Strategies of informationprocessing (pp. 151-216). San Diego: Academic Press.

Effects of L1 Orthography 431
Cunningham, A. E., Stanovich, K. E., & Wilson, M. R. (1990). Cognitive variation in adult college studentsdeferring in reading ability. In T. H. Carr & B. A. Levy (Eds.), Reading and its development: Componentskills approaches (pp. 129-160). San Diego: Academic Press.
Cunningham, P. M., & Cunningham, J. W. (1978). Investigating the "print to meaning" hypothesis. In P. D.Pearson & J. Hansen (Eds.), Reading: Disciplined inquiry in process and practice: 27th Yearbook of theNational Reading Conference (pp. 116-120). Clemson, SC: The National Reading Conference.
Fang, S. P., Tzeng, 0 . J. L, & Alva, L. (1981). lntralanguage vs. interlanguage Stroop effects in two types ofwriting systems. Memory and Cognition, 9, 609-617.
Frost, R. (1994). Prelexical and postlexical strategies in reading: Evidence from a deep and a shalloworthography. Journal of Experimental Psychology: Learning, Memory, and Cognition, 29, 116-129.
Frost, R. (1995). Phonological computation and missing vowels: Mapping lexical involvement in reading.Journal of Experimental Psychology: Learning, Memory, and Cognition, 21, 398-401.
Frost, R., Katz, L, & Bentin, S. (1987). Strategies for visual word recognition and orthographical depth: Amultilingual comparison. Journal of Experimental Psychology: Human Perception and Performance, 13,104-115.
Goryo, K. (1987). Yomuto lukoto [Psychology of Reading]. Tokyo: Tokyo University Press.Henderson, L. (1982). Orthography and word recognition in reading. London: Academic Press.Hirose, T. (1992). Recognition of Japanese kana words in printing tasks. Perceptual and Motor Skills, 75, 907-
913.Hoosain R. (1991). Psycholinguistic implications for linguistic relativity: A case study of Chinese. Hillsdale, NJ:
Erlbaum.Hsieh, L. T. (1994, March). The effects of writing system on decoding processes in Chinese (LI) and English
{FL). Paper presented at the American Association of Applied Linguistics Annual Conference, Baltimore,MD.
Hung, D. L., Tzeng, O. J. L., & Tzeng, A. K. Y. (1992). Automatic activation of linguistic information inChinese character recognition. In R. Frost & L. Katz (Eds.), Orthography, phonology, morphology, andmeaning (pp. 119-130). Amsterdam: Elsevier.
Jared, D., & Seidenberg, M. S. (1991). Does word identification proceed from spelling to sound to meaning?Journal of Experimental Psychology: General, 120, 358-394.
Katz, L., & Feldman, L. B. (1983). Relation between pronunciation and recognition of printed words in deepand shallow orthographies. Journal of Experimental Psychology: Learning, Memory, and Cognition, 9,157-166.
Keppel, G. (1982). Design and analysis: A researcher's handbook. Englewood Cliffs, NJ: Prentice-Hall.Kirk, R. E. (1982). Experimental design: Procedures for the behavioral sciences. Pacific Grove, CA: Brooks/
Cole.Koda, K. (1987). Cognitive strategy transfer in second language reading. In Devine, J., Carrell, P. L., & Esky,
D. E. (Eds.), Research in reading in English as a second language (pp. 127-144). Washington, DC:TESOL.
Koda, K. (1988). Cognitive process in second language reading: Transfer of LI reading skills and strategies.Second Language Research, 4,133-156.
Koda, K. (1989). The use of LI reading strategies in L2 reading: Effects of LI orthographic structures of L2phonological recoding strategies. Studies in Second Language Acquisition, 12, 393-410.
Koda, K. (1992). The effects of lower-level processing skills on FL reading performance: Implications forinstruction. The Modern Language Journal, 76, 502-512.
Koda, K. (1994). Second language reading research: Problems and possibilities. Applied Psycholinguistics, 15,1-28.
Lesch, M. F., & Pollatsek, A. (1993). Automatic access of semantic information by phonological codes invisual word recognition. Journal of Experimental Psychology: Learning, Memory, and Cognition, 19,285-294.
Liu, I. M., Zhu, Y., & Wu, J. (1992). The long-term modality effect: In search of differences in processinglogographs and alphabetic words. Cognition, 43, 31-66.
Mann, V. A. (1985). A cross-linguistic perspective on the relation between temporary memory skills and earlyreading ability. Remedial and Special Education, 6, 37-42.
Meyer, D. E., Schvaneveldt, R. W., & Ruddy, M. G. (1974). Functions of graphemic codes in visual wordrecognition. Memory and Cognition, 2, 309-321.
Monsell, S., Patterson, K. E., Graham, A., Hughes, C. H., & Milroy, R. (1992). Lexical and sublexical translationof spelling to sound: Strategic anticipation of lexical status. Journal of Experimental Psychology: Learn-ing, Memory, and Cognition, 18, 452-467.
Morikawa, Y. (1985). Stroop phenomena in the Japanese language (ii): Effects of character-usage frequency

432 NobukoChikamatsu
and number of strokes. In H. S. R. Kao & R. Hoosain (Eds.), Linguistics, psychology, and the Chineselanguage (pp. 73-80). Hong Kong: University of Hong Kong Centre of Asian Studies.
Paradis, M., Higiwara, H., & Hildebrandt, N. (1985). Neurolinguistic aspects of the Japanese writing system.New York: Academic Press.
Perfetti, C. A., & Zhang, S. (1991). Phonological processes in reading Chinese characters. Journal of Experi-mental Psychology: Learning, Memory, and Cognition, 17, 633-643.
Perfetti, C. A., & Zhang, S. (1995). Very early phonological activation in Chinese reading. Journal of Experi-mental Psychology: Learning, Memory, and Cognition, 21, 24-33.
Perfetti, C. A., Zhang, S., & Berent, I. (1992). Reading in English and Chinese: Evidence for a "universal"phonological principle. In R. Frost & L. Katz (Eds.), Orthography, phonology, morphology, and meaning(pp. 227-248). Amsterdam: Elsevier.
Rusted, J. (1988). Orthographic effects of Chinese-English bilinguals in a picture-word interference task.Current Psychology: Research & Reviews, 7, 207-220.
Seidenberg, M. S. (1985). The time course of phonological code activation in two writing systems. Cognition,19, 1-30.
Shimamura, A. (1987). Word comprehension and naming: An analysis of English and Japanese orthographies.American Journal of Psychology, 100, 15-40.
Smith, F. (1985). Reading without nonsense. New York: Teachers College Press.Stanovich, K. E. (1982). Word recognition skill and reading ability. In M. H. Singer (Ed.), Competent reader,
disabled reader: Research and application (pp. 81-102). Hillsdale, NJ: Erlbaum.Stanovich, K. E. (1991). Changing models of reading and reading acquisition. In L. Rieben & C. H. Perfetti
(Eds.), Learning to read: Basic research and its implications (pp. 19-32). Hillsdale, NJ: Erlbaum.Stroop, J. R. (1935). Studies of interference in serial verbal reactions. Journal of Experimental Psychology,
18, 643-661.Tabossi, P., & Laghi, L. (1992). Semantic priming in the pronunciation of words in two writing systems: Italian
and English. Memory and Cognition, 20, 303-313.Tan, L. H., Hoosain, R., & Peng, D. (1995). Role of early presemantic phonological code in Chinese character
identification. Journal of Experimental Psychology: Learning, Memory, and Cognition, 21, 43-54.Taylor, I., & Taylor, M. M. (1983). The psychology of reading. New York: Academic Press.Toma, C, & Toshima, T. (1989). Developmental change in cognitive organization underlying Stroop tasks of
Japanese orthographies. International Journal of Psychology, 24, 547-559.Turnage, T. W., & McGinnies, E. (1973). A cross-cultural comparison of the effects of presentation mode and
meaningfulness on short-term memory. American Journal of Psychology, 86, 369-381.Tzeng, O. J. L, & Wang, W. S. Y. (1983). The first two R's. American Scientist, 71, 238-243.Van Orden, G. C. (1987). A ROWS is a ROSE: Spelling, sound and reading. Memory and Cognition, 15, 181-
198.Wang, J. (1988). Do phonological and semantic processing of kanji finish at the same time? The Japanese
Journal of Psychology, 59, 252-255.Wydell, T. N., Patterson, K. E., & Humphreys, G. W. (1993). Phonologically mediated access to meaning for
kanji: Is a rows still a rose in Japanese kanji? Journal of Experimental Psychology: Human Learning andMemory, 19, 491-514.
Yamada, J., Imai, H., & Ikebe, Y. (1990). The use of the orthographic lexicon in reading kana words. TheJournal of General Psychology, 117, 311-323.
Zhou, Y. G. (1978). To what degree are the "phonetics" of present-day Chinese characters still phonetic?Zhonggou Yuwen, 146, 172-177.





























