Embed Size (px)
Citation preview

IEEE TRANSACTIONS ON SYSTEMS, MAN, AND CYBERNETICS, VOL. 20, NO. 1, JANUARY/FEBRUARY 1990 149
Estimation of Mixing Probabilities in Multiclass Finite Mixtures
Abstract -The problem of estimating prior probabilities in a mixture of M classes with known class conditional distributions is studied. The observation is a sequence of n independent, identically distributed mixture random variables. The first moments of appropriately formulated functions of observations to facilitate estimation are used. The complexity of these functions may vary from linear functions of the observations (in some cases) to complex functions of class conditional density functions of observations, depending on the desired balance between computational simplicity and theoretical properties. A closed form, recursive, unbiased, and convergent estimator using the density functions is presented; the result is valid for any problem in which prior probabilities are identifiable. Discrete and mixed densities require a minor modification that has been worked out. Three application examples are described. The class condi- tional expectations of density functions, required for the initialization of the estimator algorithm, are analytically evaluated for Gaussian and expo- nential densities. Simulation results on Gaussian mixtures are included. Performance of existing and the proposed estimators are briefly compared. One of the proposed estimators is shown to be mathematically equivalent to an existing method while being computationally efficient to implement.
I. INTRODUCTION
FUNDAMENTAL problem in statistical informa- A tion processing is the design of a procedure to decide the category of an input sample. The Bayesian decision procedure updates a priori class probabilities to a posteri- ori values and decides the class label based on the mini- mum expected cost of classification. The corresponding decision function is a function of 1) the observation, 2) the problem statistics, and 3) the classification costs. The two components of the problem statistics are the class condi- tional distribution functions and the a priori class proba- bilities. In practical implementations, the problem statis- tics are usually estimated using training data which con- sists of sets of labeled samples, each set belonging to one class. Estimation of class conditional distribution func- tions or their parameters is a well addressed problem since it is useful in many application areas of statistics. A straight forward estimate of prior probabilities is the vec- tor of the relative sizes of the sets of different classes in the training data. However training data is usually collected in
Manuscript received November 25, 1988; revised June 7, 1989. This work was partially presented at the 1985 IEEE International Conference on Systems, Man, and Cybernetics, Tucson, AZ, Nov. 1985.
G. R. Dattatreya is with The Department of Computer Science, Uni- versity of Texas at Dallas, P.O. Box 688, Richardson, Texas 75083.
L. N. Kanal is with the Department of Computer Science, University of Maryland, College Park, MD 20742.
IEEE Log Number 8931004.
artificial environments with an intent to collect as many known samples as possible for each class. For example, in images, spatial data in the central part of a region known to belong to a class is selected as training data. Thus the relative sizes of the class sample sets do not necessarily represent a priori probabilities. An important problem, therefore, is the estimation of a priori probabilities using unlabeled samples, with full knowledge of class condi- tional distributions. This paper reports studies on the problem of prior probability estimation (PPE) when suc- cessive samples are statistically independent and identi- cally distributed (i.i.d.). Our general approach uses the mean values of appropriately formulated functions of ob- servations.
A. Problem Statement and Notation
A sequence of samples, X" = { xl; . ., x"}, arrives at the estimator. Each sample is an outcome of i.i.d. vector random variables with the density function
i = l
where
M Pi, i =1;. a , M
is the number of classes, are the unknown prior probabili- ties, are the known class conditional density functions of the N dimen- sional feature vector X .
A vector function of X" is required to be designed to estimate PI, i = 1; . 0 , M . PI(?) denotes an estimate of PI using n pattern samples; P ( n ) is the vector estimate. Random variables are denoted by uppercase letters; their outcomes, by lowercase letters. The previous notation con- forms, by and large, to the standard pattern recognition terminology [7]. Matrices are denoted by upper case let- ters. Bold italic letters indicate vectors. The transpose of a matrix is denoted by the superscript T. The matrix inverse and transpose are commutative; together, they are denoted by the superscript - T. The X " is the sequence of n random vectors corresponding to the sequence of observa- tions x". p, (without the underscore) is the mean vector (or scalar) of class a,. The covariance matrix of the class a, is denoted by 2,. We will frequently use M functions
0018-9472/90/0100-0149$01.00 01990 IEEE

150 IEEE TRANSACTIONS ON SYSTEMS, MAN, AND CYBERNETICS, VOL. 20, NO. 1. JANUARY/FEBRUARY 1990
h I (x) of the observation vector x. The h (x) is the vector of M such functions. The h , , will denote E [ h , ( x ) ( w , ] . The H is the M X M matrix of h,,. The E[p(Xlw,lw,] plays a special role and is denoted by el,. The E is the matrix composed of the elements e,,. The N(a,j?) is used to denote the Gaussian density function with mean a and variance (or covariance matrix) j?. The equation
1 " = - h r ( X k ) (2)
k = l
',s the sample average of the function! of observations. The h ( n ) is the vector with components h , ( n ) . Similarly
1 " i ( n ) = - C xk. (3)
k = l
We also assume that the means and variances of all choices of h , ( X ) we will use are finite. PPE is a shorthand notation for prior probability estimation as well as for prior probability estimate.
B. Literature Survey
The problem of prior probability estimation has been studied by mathematicians as well as engineers for over two decades. Teicher [20] states and proves a necessary and sufficient condition for the identifiability or estimabil- ity of the a priori probabilities in finite mixtures. Let F( a )
denote the cumulative distribution function. The necessary and sufficient condition for identifiability is that there exist xl; . 0 , x M points in the feature space such that the determinant of the M X M matrix formed by elements F(x;lw,) is nonzero. This condition is equivalent to the M class conditional densities being linearly independent func- tions. Robbins [18] proposes a procedure for PPE. He splits each class conditional density into two additive parts p l (xIwi ) and p 2 ( x I w j ) such that the first part is expressible as a linear combination of the density functions of the rest of the classes; the second part is orthogonal to all other M - 1 density functions. The auxiliary functions
are used to compute 1 n
' I k = l
Estimates I ' , (n) are computed by normalizing # i ( n ) as
j = l
These estimates lie between zero and one, their sum is one, and they converge to the true values with probability one. Boes [2] studies necessary and sufficient conditions for PPEs to attain the Cramer-Rao minimum variance bound [23]. Even in the two class case, these conditions restrict the form of the mixture density function (and thereby the component class conditional density functions). Since we
do not have the ability to control class conditional distri- butions in practice, it is not possible, in general, to design efficient estimators; an efficient estimate is one that at- tains the Cramer-Rao minimum variance bound (MVB).
Young and Calvert [26] demonstrate the use of moment estimators to learn the parameters of a mixture density. As described in the review paper by Redner Walker [17], this method of moments consists generally of equating some set of sample moments to their expected values and thereby obtaining a system of equations for the parameters in the mixture density. If the parameters are prior probabilities, the estimation equations are linear with respect to the parameters. We note that the key to the success of this method is the determination of an adequate number of appropriate moments for a unique solution to the resulting set of equations. Section I1 below addresses this problem.
Davisson and Schwartz [6] analyze a decision-directed scheme for estimating prior probabilities during the pro- cess of detection of signals in Gaussian noise. Estimates are based on the assumption that the decided classes are true classes. They conclude that there exists an inherent possibility of runaway such that the estimate of the proba- bility of one class may converge to one and those of the remaining classes, to zero. Katopis and Schwartz [lo] mod- ify the scheme of [6] to estimate, with zero probability of runaway, the prior probabilities in the two class detection of signals in Gaussian noise. They also extend the tech- niques to estimate any parameter of the mixture density. Kazakos and Davisson [12] report further results on deci- sion-directed learning schemes. By using a set of nonlinear transformations of the data and applying results from stochastic approximation theory, they obtain accelerated convergence and eliminate the asymptotic bias present in the scheme of [lo]. Their results are applicable for multiple classes with arbitrary but known class conditional densi- ties.
Kazakos [ l l ] reports studies on maximum likelihood and recursive estimation techniques for PPE. The maxi- mum likelihood scheme turns out to be nonrecursive and requires solving a set of nonlinear equations by numerical techniques. His recursive scheme is gwen by
F1(n + 1 ) = P l ( n ) - L ( F 1 ( n ) ) G ( x ( n +l), i l ( n ) ) , (7)
in our notation, for the two class problem. In (7)
G ( x ( n + l ) , 4 ( n ) )
- p ( 4 n + W J , ) - p ( x ( n + W 2 ) - M n ) p ( x ( n +l)l@l)+ (1- k ( n ) ) p ( x ( n + 1 ) 1 0 2 )
(8) and L ( p l ( n ) ) is a gain sequence. The estimate (7) turns out to be efficient if
the inverse of the 1 X 1 Fisher's information matrix [23].

DATTATREYA er al. : ESTIMATION OF MIXING PROBABILITIES IN MULTICLASS FINITE MIXTURES 151
Since the optimal gain sequence turns out to be a function of the unknown parameter P, being estimated, Kazakos suggests the use of
iteration step uses density values of all the data samples available for estimation of priors.
The book by Titterington et al. [21] discusses PPE aspects as special cases of mixture density estimation. In particular some of the previously cited literature is com- paratively discussed. Other references on the topic of prior probability estimation include Abend [ 11, Jalalinasab and Bucklew [9], Ode11 [161, and Yakowitz [25].
1 . L ( P , ( n ) ) =
[ P ( X l 4 - P ( X I W * ) I 2 dx
(10)
The k l ( n ) is clipped to lie within (0,l) by using small valued barriers around 0 and 1. The resulting estimator is shown to be asymptotically efficient. For the case of more than two classes, Kazakos extends the above ideas to determine a vector PPE that is nearly asymptotically effi- cient. The vector estimate is similar to (7) with a vector G and a scalar L. He conjectures that asymptotic efficiency could be restored by using an optimally adjusted matrix for L instead of the scalar. Makov [14] stresses the impor- tance of the above gain sequence through numerical com- parisons, and proposes a minor modification to (8), in a two class study.
Makov and Smith [15] and Smith and Makov [19] de- velop PPEs for two and multiple classes respectively and term their approach quasi-Bayes. Their estimation algo- rithm is equivalent to the following, in our terminology, as
a. = al(0) + - . . + aM(0) , al(0), . . . , aM (0) positive
(11 )
a i ( n - 1 ) ~ ( X n I w i ) a l ( n ) = a l ( n - l ) + >
C a j ( n - 1 ) P ( x n I a j )
i = l , . . . , M ; n = l , . . . (12)
j = l
This recursive scheme converges to the true priors; any intermediate estimate is also a valid prior probability vec- tor. The main computation involved (per sample) is the evaluation of density functions of observations and a few multiplications.
In their review article on mixture densities, Redner and Walker [17] prove that the special case of the EM algo- rithm, for estimating the priors, converges to the maximum likelihood estimate within the simplex of valid prior proba- bility vectors. The algorithm is given by
C. Summay and Organization of the Paper
We begin, in Section 11, by studying estimators with linear sufficient statistics. Results are illustrated using the detection of bipolar signals in Gaussian noise as an exam- ple. Simulation results presented compare favorably with those in other publications. Linear estimation is not possi- ble with certain sets of class conditional density functions. Higher degree polynomial estimators are therefore exam- ined. In Section 111, we study an interesting choice for the functions of the data to facilitate PPE. The M class condi- tional density functions of observations are shown to be sufficient for any identifiable problem and an explicit closed form estimator is derived. Three application exam- ples are described. The matrix of expectations required by the estimator are analytically determined for the M class Gaussian mixture with arbitrary mean vectors and covari- ance matrices, and for the hyperexponential density. Simu- lation results are presented for a three class Gaussian problem. Section IV discusses the following issues: 1) discrete and mixed density functions, 2) performance of various PPE schemes, and 3) connections between the scheme proposed in Section I11 and one of the earliest procedures, proposed by Robbins [18]. Section V presents concluding remarks.
11. MOMENT ESTIMATORS
Consider h ( X ) , a vector of M functions of the mixture random variable X :
Given h , ( X ) , h, , are known since we assume that p(xlco,), j = 1; . . , M are known. Thus the unknowns PJ are con- netted to E [ h , ( X ) ] through known hlJ . E [ h , ( X ) ] can be estimated by averaging h , ( x k ) , k =1; -, n. The resulting estimator is
p , ’ J + l ) = l 5 p,’J’P ( x k l o i ) M 7
C pr?’~ ( x/cI urn) k = l
rn =1
i =I,. . . , M ; j = l ; . - . (15 ) i ( n ) = H - % ( n ) . (17) This is an iterative numerical optimization scheme; the
iteration is carried out for j = 1 , * - , till convergence. Each This can also be expressed as the following recursive

152 IEEE TRANSACTIONS ON SYSTEMS, MAN, AND CYBERNETICS, VOL. 20, NO. 1, JANUARY/FEBRUARY 1990
estimator
The design of a PPE then boils down to finding M functions h ;( X ) such that the matrix H is invertible. Such functions exist if and only if Pi are identifiable.
A . Linear Estimation
The vector function h ( X ) may be constructed by linear and/or nonlinear combinations of the components of X. Linear functions are attractive, being easy to implement. Consider an M X N matrix A . The equation
h ( X ) = A X (18)
(19)
is a good choice only if the product matrix
A E [ X l w ] is invertible. E [ X l w ] is the matrix of mean vectors with each column corresponding to a class. It should be noted that even if N > M , condition (19) will not be met by any A if the dimensionality of the vector space spanned by the mean vectors of the M classes is less than M . Under (19)
P ( n ) = { A E [ X ( w ] } - ' A i ( n ) . (20) The estimate (20) requires the computation of
C = { A E [ X l w ] } - ' A
once before the observation process begins. Successive estimates require a recursive computation of the sample average of observations and a multiplication of the matrix C by the sample average. The vector estimate in (20) is unbiased and it converges to the true vector with probabil- ity one and in the mean square sense. Convergence follows from the i.i.d. nature of the sequence, the finite variance of x k , and the strong law of large numbers.
Since the M priors sum to 1, it is sufficient to estimate the first M - 1 parameters and substitute
M - 1 *
F M ( n ) = l - P i ( . ) . (22) ;=l
The Mth equation in (16) will then be superfluous. The resulting estimate is not strictly linear but involves the addition of a constant vector; the estimator possesses a linear sufficient statistic. A necessary and sufficient condi- tion for such an estimate to exist is that the rank of the N x M matrix formed by column mean vectors of the class conditional densities is at least M-1 and that a mean vector can not be expressed as a weighted average of the rest. Weighted average is a linear combination with posi- tive or negative coefficients and in which the coefficients sum to one.
B. Bipolar Signals in Gaussian Noise
In a two class problem, the above condition implies that P, can be estimated by a linear function of the data (plus a constant) if the mean vectors are distinct. Let p(xIwl ) =
I
--- I
I 58 lea
(b) Fig. 1. Linear estimate of PI as function of number of samples,
(a) p = 0.5, (b) p = 1.0.
N ( p , a2) and p(xIw2) = N ( - p , U*). Then 1 n 1
is an unbiased estimate of Pl . The variance of the estimate can be verified to be
u2 P , - P ? ~ a r [ F,( n )] = - + ~ . (24) 4p2n n
Fig. 1 shows results of simulation experiments for P, = 0.25, U = 1.0, and for two different cases of means, p = 1.0 and 0.5. They compare very well with the simulation results in [15] and [14] that are based on estimators not as simple as the one discussed previously.
C. Higher Degree Polynomial Estimators
Linear estimation is not feasible for many PPE prob- lems. We can attempt to construct the functions required for estimation by higher degree polynomial transforma- tions of the observation such as
N
h , ( X ) = n x:/ ; = l
where X, are scalar components of the feature vector X and Zy'lk, > 0. Each such function introduces a row vector in the matrix H and a corresponding equation in

DAmATREYA el U / . : ESTlMATlON OF MIXING PROBABILITIES 1N MULTICLASS FlNlTE MIXTURES 153
(16). An ordered sequence of such functions (with increas- ing C,N_lk, imposing a partial order) can be examined to determine M linearly independent equations in (16) for a unique vector estimate. Estimating only M - 1 parameters and using (17) may reduce the number of functions searched. The resulting estimate is unbiased and converges with probability one and in the mean-square sense.
111. USE OF DENSITY FUNCTIONS
A. The Estimator
Intuitively h , ( x ) in (16) should be such that if an observation x is from U , , the probability of h , ( x ) being high should be hgh and the probability of h , ( x ) j # i being high should be low. This leads to the choice
We now show that (26) leads to the realizable estimate h l ( X ) = P ( X l U , ) . (26)
1 n
where E is as defined earlier.
Theorem: If prior probabilities are estimable, then the
Proof: Teicher's condition for estimability, stated in Section I, implies the linear independence of the M class conditional density functions p(x lw , ) . Let I: be the space of functions spanned by linear combinations of the M densities. Let f , ( x ) E F. Note that the product of any two functions in F is integrable; i.e., F is an L2 space with the associated properties [24]. Define an inner product
matrix E is invertible.
( f , ( x ) f , ( - + = / f , ( x ) f , ( x ) dx. (28)
e,, = ( P ( x l U , ) P ( x l q ) ) . (29)
Then
With respect to the inner product (28), there exists an ortho-normal basis of M functions spanning F. Let these be b , ( x ) , i =1;. ., M . Then
where D is a particular M X M invertible matrix. Then
E = ( D b ( x)[ Db( x)] ") (31) where the inner product is taken element by element within the matrix. Simplifying (31)
E = ( D b ( x ) b " ( x ) D " ) = D ( b ( x ) b " ( x ) ) D " =DID" = D D ~ (32)
that is invertible and this proves the theorem.
Thus if the a priori class probabilities are known to be estimable (27) is an explicit estimate; it is unbiased and convergent with probability one and in the mean-square sense. The main computation involved in (27) is the evalu- ation of M 2 expectations and inverting the resulting ma- trix of numbers.
B. Application Examples
Three examples from different application areas are described next. These demonstrate the usefulness and the wide applicability of the approach developed here.
Example 1: An important problem in the analysis of remotely sensed multispectral data is the estimation of acreage of different types of crops. The probability densi- ties of individual crop types are usually accurately avail- able; these are estimated with the help of ground truth information. In most cases, Gaussian functions represent the density functions very well. The problem of acreage estimation then boils down to estimation of mixing proba- bilities from unsupervised Gaussian mixtures. The assump- tion of statistical independence of class labels of samples in a neighborhood may be unrealistic for this problem. However an initial estimate assuming independence is required for iterative refinement through probabilistic re- laxation algorithms. Use of such relaxation algorithms is one current approach for what is known as "context classification" in the analysis of remotely sensed data. Zenzo er al. [27] discuss the problem caused by the lack of knowledge of the initial estimates for prior probabilities. The estimator (27) successfully solves this problem and is ideally suited for obtaining these initial estimates. The expectations required for the computation of the estimates, i.e., the elements of E can be analytically determined for Gaussian problems with arbitrary mean vectors and co- variance matrices. If
(33)
then by a cumbersome sequence of manipulations, the expectations can be shown to be
Thus the estimation scheme of (27) is easily implemented for Gaussian problems. The matrix formed by elements in (34) needs to be computed and inverted only once. The following three class Gaussian problem is used to simulate
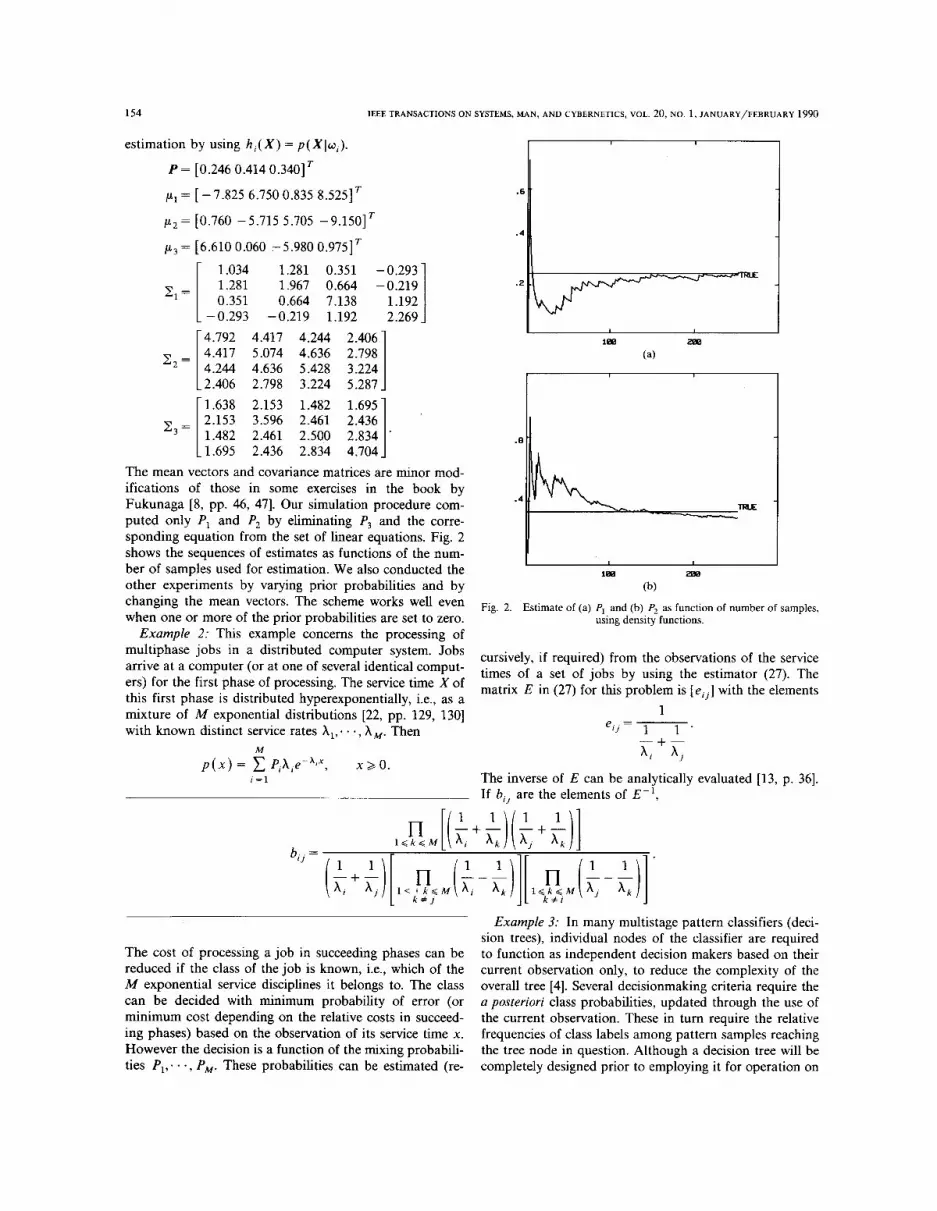
154 IEEE TRANSACTIONS ON SYSTEMS, MAN, AND CYBERNETICS, VOL. 20, NO. 1, JANUARY/FEBRUARY 1990
estimation by using h , ( X ) = p ( X l o , ) .
P = [0.246 0.414 0.3401
p, = [ - 7.825 6.750 0.835 8.5251
p 2 = [0.760 -5.715 5.705 -9.15OlT
p 3 = [6.610 0.060 75.980 O.975IT
1 1.034 1.281 0.351 -0.293 1.281 1.967 0.664 -0.219
x,= [ 0.351 0.664 7.138 1.192
4.792 4.417 4.244 2.406 4.417 5.074 4.636 2.798
x,= [ 4.244 4.636 5.428 3.224 2.406 2.798 3.224 5.287
1.482 2.461 2.500 2.834 '
1.638 2.153 1.482 1.695 2.153 3.596 2.461 2.436
1.695 2.436 2.834 4.704 The mean vectors and covariance matrices are minor mod- ifications of those in some exercises in the book by Fukunaga [8, pp. 46, 471. Our simulation procedure com- puted only P, and P2 by eliminating P3 and the corre- sponding equation from the set of linear equations. Fig. 2 shows the sequences of estimates as functions of the num- ber of samples used for estimation. We also conducted the other experiments by varying prior probabilities and by changing the mean vectors. The scheme works well even when one or more of the prior probabilities are set to zero.
Example 2: This example concerns the processing of multiphase jobs in a distributed computer system. Jobs arrive at a computer (or at one of several identical comput- ers) for the first phase of processing. The service time X of this first phase is distributed hyperexponentially, i.e., as a mixture of M exponential distributions [22, pp. 129, 1301 with known distinct service rates A,; e , A,. Then
-0.293 -0.219 1.192 2.269
1 1 x 3 = [
M
p ( x ) = P1X,e-'IX, x > 0. I =1
I I iea 288
(b)
using density functions. Fig. 2. Estimate of (a) PI and (b) P2 as function of number of samples,
cursively, if required) from the observations of the service times of a set of jobs by using the estimator (27). The matrix E in (27) for t h s problem is [e , , ] with the elements
1
-+ - ' I ' J
The inverse of E can be analytically evaluated [13, p. 361. If b,, are the elements of E-',
The cost of processing a job in succeeding phases can be reduced if the class of the job is known, i.e., which of the M exponential service disciplines it belongs to. The class can be decided with minimum probability of error (or minimum cost depending on the relative costs in succeed- ing phases) based on the observation of its service time x . However the decision is a function of the mixing probabili- ties P,; . -, P,. These probabilities can be estimated (re-
Example 3: In many multistage pattern classifiers (deci- sion trees), individual nodes of the classifier are required to function as independent decision makers based on their current observation only, to reduce the complexity of the overall tree [4]. Several decisionmaking criteria require the a posteriori class probabilities, updated through the use of the current observation. These in turn require the relative frequencies of class labels among pattern samples reaching the tree node in question. Although a decision tree will be completely designed prior to employing it for operation on

DATTATREYA et al. : ESTIMATION OF MIXING PROBABILITIES I N MULTICLASS FINITE MIXTURES 155
TABLE I COMPARJSON OF PERFORMANCE OF PPEs
Two Class Mu1 ticlass Estimator, Makov, Linear Kazakos, Smith, EM Question Kazakos Smith Technique; Kazakos Davisson Makov Algorithm Technique:
or property U11 ~ 5 1 Section I1 [ll] [121 u91 ~ 7 1 Section 111
Density
Recursive Yes Yes Yes Yes Yes Yes no Yes Sufficient no no Yes no no no no Yes
Statistic
on simplex
1
Estimate Yes Yes no Yes Yes Yes Yes no
Unbiased no no Yes no no no no Yes
Variance a- no no Yes no no no no Yes
Initial nil nil class nil nil nil nil M 2
Computation expectation density minimal expectations expectations density not density
I1 Asymptotically yes no no no no no Yes no
efficient
computation means expectations
per sample evaluations evaluations applicable evaluations
unlabeled pattern samples, the design of optimal trees is an exceedingly complex task and hence there may be room for improvement in the performance of a designed tree. The performance of an intermediate node can be fine tuned by estimating the prior probabilities of samples (appearing at that node) as the tree operates on unsuper- vised data. The estimator proposed in this section is di- rectly applicable for this task.
IV. DISCUSSION
A. Discrete and Mixed Density Functions
When class conditional densities possess impulse func- tion components, (27) can not be used to estimate P since we can not evaluate density functions at many observation points. Let
K
P ( X l 4 = A b ) + c 6 ( x - u , ) a , , (35) k =1
be the class conditional density function of U,. 6 ( - ) is the Dirac delta function. The f , ( x ) are devoid of Dirac delta functions and hence may be evaluated at all x. Consider the following M functions as candidates for PPE:
h,(Uk) = f , ( U k ) + a r k , k = l , - . . , K (36) h , ( x ) =f , (x ) , X Z U ~ , k = l ; . - , K
can be evaluated at all x. The equation
J q W ) l w , ] = j m - , ( 4 dx
K
+ c [ aka,, + M U , > a,k + f / k ( U k ) a,,]
= E [ P ( X l 4 l U , ] (37)
k = I
shows that h( x) yields an invertible H. If f,( x) = 0, I =
1; * , M , this problem reduces to one of discrete class conditional distributions in which case the computations involved are very simple.
B. Comparison with Other PPES
Important aspects of the performance of a PPE are whether or not it is recursive, the initial computation at the start of the algorithm, computation required per sample during the updating process, bias, variance, etc. These are tabulated for several PPE's in Table I.
All the estimators in Table I are asymptotically unbi- ased. The linear estimator for two classes assumes that the class means are distinct and that the random variable is a scalar. Its variance is
J . (38) 3 (PI - 1 * 2 ) 2
Pa:+(l- P ) u ; - P ( l - P ) +
The covariance matrix of the estimator using the densities is
1 - [ P E [ p ( X l o , ) p ( x l w , ) ] E - ' - P P ' ] (39)
where E [ p ( X l w , ) p ( ( X l o , ) ] is the matrix of expectations of the quantity within the square brackets. The finite sample variances of other estimators are not available and are hard to analyze since the estimates are not sample averages of i.i.d. random variables. The only asymptoti- cally efficient estimators in the table are the two class Kazakos [ll] estimator and the maximum likelihood esti- mator via the EM algorithm. The former requires the evaluation of expectation by integration for every sample. The latter is impractical for sample by sample updating, since it iteratively uses all the samples till the estimate converges. For small sample sets, the maximum likelihood estimate may lie outside the simplex of valid priors in which case the EM algorithm is claimed to converge to a vertex of the simplex.
Among the other estimators in Table I, the quasi-Bayes approach results in a practical scheme; it needs no extra computation to initiate the estimator, in contrast with our estimator using density functions, which needs E , the M X M matrix of expectations and its inverse. Computa-

156 IEEE TRANSACTIONS ON SYSTEMS, MAN, AND CYBERNETICS, VOL. 20, NO. 1, JANUARY/FEBRUARY 1990
TABLE I1 SAMPLE CPU TIMES
Scheme Linear Makov 1 Iteration 10 Iterations Technique Smith, EM Algorithm EM Algorithm Density
CPU time for
CPU time for
CPU time for
1000 samples 0.28 0.80 0.83 1.58 0.75
3000 samples 0.70 2.13 2.50 4.28 2.43
5000 samples 1.33 3.78 4.22 7.38 4.05
tions involved in the sample by sample updating processes in the quasi-Bayes approach as well as our density ap- proach are comparable. However if linear (or linear plus constant) estimation is possible, it is computationally supe- rior to the quasi-Bayes procedure. Statistical performance is harder to compare. Titterington et al. [21] provides the following expression for the asymptotic variance of the two class quasi-Bayes procedure
2 P, (1 - PI) I ( PI) - 1
where I( PI) is the 1 X 1 Fisher's $formation matrix for a single observation, given by L-'( Pl(n)) in (9). The expres- sion (40) is valid only if the denominator is greater than 0 and hence is not applicable for all the problems. For the bipolar signals in Gaussian noise problem, the linear (plus constant) estimator and the estimator of Section I11 pos- sess superior asymptotic variance for all sets of parameters we experimented with. We have not been able to construct any problem for which the quasi-Bayes asymptotic vari- ance is superior to the asymptotic variances of our PPEs although we do not rule out the possibility. Intermediate estimates in the quasi-Bayes scheme are valid prior proba- bility vectors; this is not true of our PPE's. However our PPE's may be normalized by a procedure used by Robbins [18] to meet this requirement. Robbins shows that such a modification does not affect convergence. The only prop- erties affected by such a normalization are the finite sam- ple bias and variance.
For a given problem all the applicable estimators in Table I, except the EM algorithm, require a computational complexity of O ( n ) where n is the number of samples. These also yield estimates based on each subsequence of the n sample sequence. This feature facilitates the examination of whether or not more data samples will substantially change the current estimates. With some rear- rangement of computations, the following provide the re- quirements for sample by sample updating. The linear technique requires M additions and multiplications, and M divisions. The Smith and Makov scheme [19], M den- sity evaluations, 2 M additions, M multiplications, and 2 M divisions. The density technique, M density evalua- tions, M 2 additions and multiplications, and M divisions. The EM algorithm, on the other hand, requires a complex- ity of O(nk) where k is the number of iterations required for convergence. This scheme does not provide estimates for subsequences of the n sample sequence. For n samples
the EM algorithm requires nM density evaluations, knM2 additions, knM multiplications, and knM divisions.
We implemented four estimators due to 1) Smith and Makov [19], 2) the linear technique, 3) the EM algorithm, and 4) the density technique, for a problem involving four-class conditionally independent Gaussian features. The objective of the experiment was to determine the computer time required for the estimation portion of the programs only. Table I1 lists the times obtained in seconds. The estimates resulting from the EM algorithm did not change after one iteration.
C. Relation to Robbins' PPE
In Section I, we reviewed Robbins' [18] procedure to estimate prior probabilities. The technique involves deter- mining components pl(xIwi) and p 2 ( x l o i ) such that
for some a i j , and
The normalized p 2 ( x l y ) , i.e., +;(I) given in (4), was used to compute J l ; (n ) = +;(n) in (5). The Jl,(n) itself is an estimate of Pi, although Robbins suggests normalization through (6). As a consequence of _the following theorem, J l i ( n ) is the same as our estimate P, (n) in (27).
Theorem:
(44)
Proof: As mentioned in Section 111, F the space of all functions formed by linear combinations of the M density

DATTATREYA et al. : ESTIMATION OF MIXING PROBABILITIES IN MULTICLASS FINITE MIXTURES 157
( Bb ( x) [ Db ( I)] ’) = I
or
Thus B = D-’. (49)
from (32) and this proves the theorem. Therefore the PPE due to Robbins [18] and our estima-
tor (27) are theoretically equivalent. In practice they differ in implementation. Robbins does not give an algorithm to determine the components p l ( x l w i ) and p2(x lo i ) ; a straightforward procedure to determine them for all the class conditional densities would require M Gram- Schmidt orthonormalization procedures. Further it is not applicable if the densities p ( xlw,) possess both continuous and Dirac impulse functions. On the other hand our esti- mators are expressed in closed form for any identifiable problem; we have evaluated the expectations required to compute the matrix E for Gaussian and exponential den- sity functions.
V. CONCLUSION
Prior probability estimators are useful in pattern recog- nition, communication engineering, and expert diagnostic systems [3]. In this paper we have studied a class of recursive, convergent estimates of the form
n - 1 ~ 1 & n ) = - P ( n - l )+ - H - ’ h ( x , ) (50)
with a constant H-’. The h ( x ) may be constructed by using linear, higher degree polynomials, or other functions of x. Only those functions resulting in an invertible H are useful. We proposed another explicit h ( x ) , the vector of probability density functions. This is suitable for any iden- tifiable problem. Modification for discrete and mixed probability density functions has been worked out. This choice of density functions for h(w) turns out to be theoretically equivalent to Robbins’ [18] apparently com- plicated proposal. But our scheme yields a closed form solution for any identifiable problem and a ready made estimator for the multidimensional Gaussian problem with arbitrary mean vectors and covariance matrices.
Elsewhere [5] , we discuss a particular choice of h ( x ) that requires the current estimate for computing the up- dated estimate. The resulting estimator belongs to the class of PPE‘s given by (17) and is asymptotically efficient.
The authors have become aware of a paper [28] that describes estimators of the form (17) and (27) with the density and h i ( x ) functions restricted to be bounded. The proof of invertibility of the resulting matrix is not given.
REFERENCES
K. Abend, “Compound decision procedures for unknown distribu- tions and for dependent states of nature,” in L. N. Kanal, Ed., Pattern Recognition. Washington, DC: Thompson Book Co., 1968. D. C. Boes, “On the estimation of mixing distributions,” Ann. Muth. Statist., vol. 37, pp. 177-188, Jan. 1966. P. Cheeseman, “In defense of probability,” Proc. Int. Joint Conf. Artificial Intell., Aug. 1985, Los Angeles, CA, vol. 2, pp. 1002-1009. G. R. Dattatreya and L. N. Kanal, “Decision trees in pattern recognition,” in Progress in Pattern Recognition 2, L. N. Kanal and A. Rosenfeld, Eds., Amsterdam: North Holland, pp. 189-240, 1985. -, “Asymptotically efficient estimation of prior probability in multiclass finite mixtures,” submitted for publication in IEEE Trans. Inform. Theoty. L. D. Davisson and S . C. Schwartz, “Analysis of a decision-directed receiver with unknown priors,” IEEE Trans. Inform. Theoty, vol. IT-16, pp. 270-276, May 1970. R. 0. Duda and P. E. Hart, Puttern Classification and Scene Analysis. K. Fukunaga, Introduction to Statistical Pattern Recognition. NY: Academic Press, 1972. R. Jalalinasab and J. A. Bucklew, “A simple suboptimum estimator of prior probability in mixtures,” IEEE Trans. Inform. Theory, vol.
A. Katopis and S . C. Schwartz, “Decision-directed learning using stochastic approximation,” Proc. Third Ann. Pittsburgh Conf. Mod- eling and Simulation, Pittsburgh, PA, Apr. 1972, pp. 473-481. D. Kazakos, “Recursive estimation of prior probabilities using a mixture,” IEEE Trans. Inform. Theory, vol. IT-23, pp. 203-211, Mar. 1977. D. Kazakos and L. D. Davisson, “An improved decision-directed detector,” IEEE Trans. Inform Theory, vol. IT-26, pp. 113-116, Jan. 1980.
New York: John Wiley, 1973.
IT-29, pp. 619-621, July 1983.

IEEE TRANSACTIONS ON SYSTEMS, MAN, AND CYBERNETICS, VOL. 20, NO. 1, JANUARY/FEBRUARY 1990
D. Knuth, The Art of Computer Programming: Fundamental Algo- rithms, Vol. 1. 2nd ed. U. E. Makov, “On the choice of gain functions in recursive estima- tion of prior probabilities,” IEEE Trans. Inform. Theory, vol. IT-26. DO. 497-498. Julv 1980.
pattern recogmtion, statistical signal processing and applications, estima- tion theory, and performance of distributed computing systems. Reading, MA: Addison-Wesley, 1973.
U. E. ‘Makov and A.’ E. Smith, “A quasi-Bayes unsupervised learning procedure for priors,” IEEE Trans. Inform. Theory, vol.
P. L. Odell, “Statistical theory and methodology for remote sensing data analysis with special emphasis on LACIE,” Ann. Report, Univ. of Texas at Dallas, June 1975. R. A. Redner and H. F. Walker, “Mixture densities, maximum likehhood, and the EM algorithm,” SIAM Review, vol. 26, pp. 195-239, Apr. 1984. H. Robbins, “The empirical Bayes approach to statistical decision problems,” Ann. Math. Statist., vol. 35, pp. 1-20, Mar. 1964. A. F. M. Smith and U. E. Makov, “A quasi-Bayes sequential procedure for mixtures,” J . Roy. Statist. Soc., part B, vol. 40, pp. 106-112, 1978, in Ann. Math. Statist., vol. 35, pp. 1-20, Mar. 1964. H. Teicher. “Identifiability of finite mixtures,” Ann. Math. Statist.,
D. M. Titterington, A. F. M. Smith, and U. E. Makov, Statistical Analysis of Finite Mixture Distributions. New York: John Wiley, 1985. K. S. Trivedi, Probability and Statistics with Reliability, Queuing, and Computer Science Applications. Englewood Cliffs, NJ: Pren- tice Hall, 1982. H. L. Van Trees, Detection, Estimation, and Modulation Theory, Part 1. R. L. Wheeden and A. Zygmund, Measure and Integral. New York: Marcel Dekker, 1977. S. Yakowitz, “A consistent estimator for the identification of finite mixtures,” Ann. Math. Statist., vol. 40, pp. 1728-1735, Aug. 1969. T. Y. Young and T. W. Calvert, Classification, Estimation, and Pattern Recognition. S. Di Zenzo, R. Bernstein, S. D. Degloria, and H. G. Kolsky, “Gaussian maximum likelihood and contextual classification algo- rithms for multicrop classification,” IEEE Trans. Geosci. Remote Sensing. vol. GE-25, pp. 805-814, Nov. 1987. J. C. Tilton, S. B. Vardeman, and P. H. Swain, “Estimation of context for statistical classification of multispectral image data,” IEEE Trans. Geosci. Remote Sensing, vol. GE-20, no. 4, pp. 445-452, Oct. 1982.
IT-23, pp. 761-764, NOV. 1977.
vol. 34, pp. 1265-1269, 1963.
New York: John Wiley, 1968.
New York: American Elsevier, 1974.
Laveen N. Kanal (S’50-A’54-M59-SM64- F’72) was born in Dhond, India, on September 29. 1931 He received the B.S.EE and M S.E.E degrees from the Umversity of Washmgton, Seattle, in 1951 and 1953, respectively, and the Ph.D. degree from the University of Pennsylva- nia, Phladelphia, in 1960.
From 1953-1955 he was a Communications Engineer with the Canadian General Electnc Company, and from 1955-1960 he was on the research and teaching staff of the Moore School
of Electrical Engineering. Umversity of Pennsylvma. From 1959-1960 he was associated with the Department of Psychology, University of Pennsylvania In 1960 he joined General Dynamics/Electronics, Rochester, NY. as Manager of the Machine Intelhgence Laboratory In 1962 he joined the Philco Research Laboratory, Blue Bell, PA, as Re- search Manager for Information Sciences. From 1965-1969 he was Manager, Advanced Engineenng and Research in Phlco-Ford’s Commu- mcations Division During 1963-1970 he was also an Adjunct Professor of Operations Research. Regional Science and Statishcs at the Wharton Graduate School of Business of the Umversity of Pennsylvania and an Adjunct Professor of Electrical Engineering at Lehgh University, Bethle- hem, PA Since 1969 he has been Managing Director of L.N.K. Corpora- tion, a firm doing management consulting, research and development, on problems in computer cartography, data visualization, intelhgent data management, image processing, pattern recognition, expert systems, plan- ning, and technology assessment. In 1970 he was appointed Professor of Computer Science at the University of Maryland, College Park, where he is teaching courses in computer science and directing research in machine intelligence, pattern analysis, and artificial neural systems and their application to problems in search, optimation, vision and reasomng in uncertain domans. From 1968-1971 he was an Associate Editor for Pattern Recognition of the IEEE TRANSACTIONS ON INFORMATION THE- ORY He is an Associate Editor of Robotics and Autonomous System, the Journal of Combinatorics, Information and System Science, Pattern Recog- nition Letters, and InJormation Sciences; and an Advisory Editor for the Journal of Cvbernetics and other journals. He is an editor or coeditor of eleven books on pattern recognition and artificial intelhgence beginning with Pattern Recognition (Thompson), 1968, and including Handbook of Statrstrcs, vol 2 (North Holland 1982), Uncertainty in AI (North Holland, 1986). Search in A I 1Sonneer-Verlae. 1988). and Parallel Alaorithm in ,. ~ ~1 U ,.
G. R. Dattatreya (M84) received the B.Tech. in Machine Intelligence (Springer, 1989). He is coeditor of a book series on electrical engineering from the Indian Institute machine intelligence and pattern recognition (North Holland). He holds of Technology, Madras, India, the M.E. in elec- two U.S. patents on pattern recognition systems. trical communication engineering, and the Ph.D. In 1972 Dr. Kanal was elected a Fellow of the American Association from the School of Automation, Indian Institute for the Advancement of Science. He is a member of the Society of of Science, Bangalore, India in 1975, 1977, and Manufacturing Engineers, the Robotics Institute of America, the Ma- 1981, respectively. chine Vision Association, the Association for Computing Machinery, the
During 1981-82, he was a Scientist at the Pattern Recognition Society for Photogrammetry, Sigma Xi, and several Scientific Analysis Group, Delhi, India, and other societies. He was elected to the Board of Governors of the IEEE worked on some pattern recognition and speech Information Theory Group in 1973 and 1976. He also served two terms processing problems. During 1983-85, he was a on the Administrative Committee of the IEEE Systems, Man, and Cyber-
Visiting Assistant Professor at the Machine Intelligence and Pattern netics Society and was the SMC Society’s Vice President for Conferences Analysis Laboratory, Department of Computer Science, University of and Meetings from 1980-1982. He has served on advisory boards to Maryland where he taught and conducted research in information pro- several scientific agencies, including the U.S. Dept. of Defense, the cessing. Since January 1986, he is an Assistant Professor of Computer National Research Council, and NASA. He is listed in Who’s Who in Science at the University of Texas at Dallas. His research interests are in America (43rd ed.), Who’s Who in Engineering, and other international and national biographical references. and national biographical references.





























