Embed Size (px)
Citation preview

MULTIMEDIA BIG DATA COMPUTING FOR TREND DETECTION
MULTIMEDIA BIG DATA COMPUTING FOR TREND DETECTIONDirector:
Codirector:
MASTER THESIS
Phd. Ruben Tous LiesaPhd. Jordi Torres VIñals
Presented byOmar Iván Sulca Correa
FACULTAT D’INFORMÀTICA DE BARCELONA

MULTIMEDIA BIG DATA COMPUTING FOR TREND DETECTION
Agenda1. Introduction2. Background3. Multimedia Big Data Computing for Trend Detection4. Results and Conclusions

MULTIMEDIA BIG DATA COMPUTING FOR TREND DETECTION
Introduction• The relevance of social media data has had an explosive growing in the last few years, because the user’s interactions and communications in social networks provide key information (government and non-government organizations).• Social media data is vast, noisy, distributed, unstructured, and dynamic in nature; thus traditional analysis methods prove to be inefficient and expensive with it. It’s necessary looking new alternatives• Exist a lot potentiality in the photo-sharing social networks as Instagram, especially in digital marketing.
1
This work is a proof of concept on Streaming and Machine Learning functionalities of the new Big Data platform: Apache Spark. Using Spark subprojects MLlib and Spark Streaming. It seeks to implement an application which allows find the Trending Topics (using the model LDA) on data collected from the social network Instagram

MULTIMEDIA BIG DATA COMPUTING FOR TREND DETECTION
II. Background
MULTIMEDIA BIG DATA COMPUTING FOR TREND DETECTION
Older msgs Newer msgs
Kafka topic ProducerConsumer
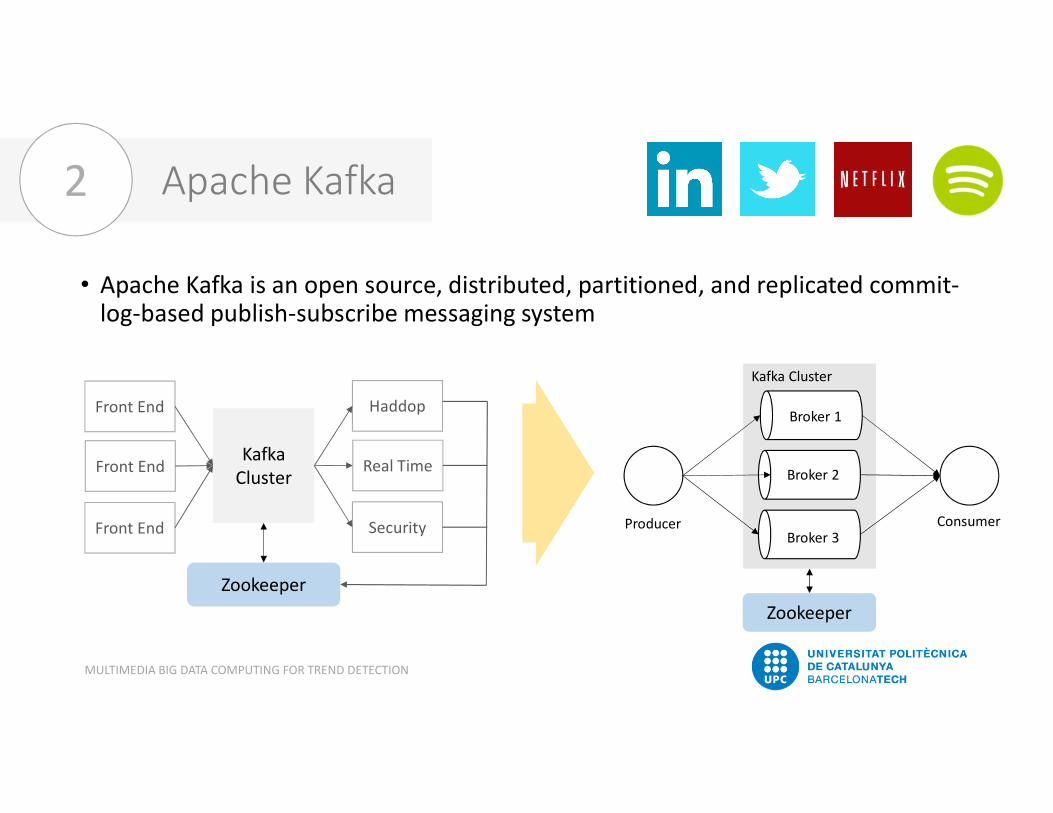
Apache Kafka• Apache Kafka is an open source, distributed, partitioned, and replicated commit-log-based publish-subscribe messaging system
2
• Streams• Batch
Kafka ClusterBroker 1
Broker 2
Broker 3
Zookeeper
Producer Consumer
Front End
Front End
Front End
Haddop
Real Time
Security
Kafka Cluster
Zookeeper

MULTIMEDIA BIG DATA COMPUTING FOR TREND DETECTION
SparkSQL SparkStreaming MLlib GraphX
Apache Spark
Apache Spark (I)• Apache Spark is an open source cluster-computing platform designed to be fast and general-purpose. • Allows combine different types of computations in one single plataform• Spark support in-memory processing, allowing a performance up to 100x
2 Interactivequeries
streamingBatchapplications
Iterativealgorithms
DataFrame DStream Vector & Matrix Vertex & Edge
RDDs Actions and Transformations
A RDD (Resilient Distributed Datasets) represent a collection of elements that can be manipulated
SparkStreaming
MULTIMEDIA BIG DATA COMPUTING FOR TREND DETECTION
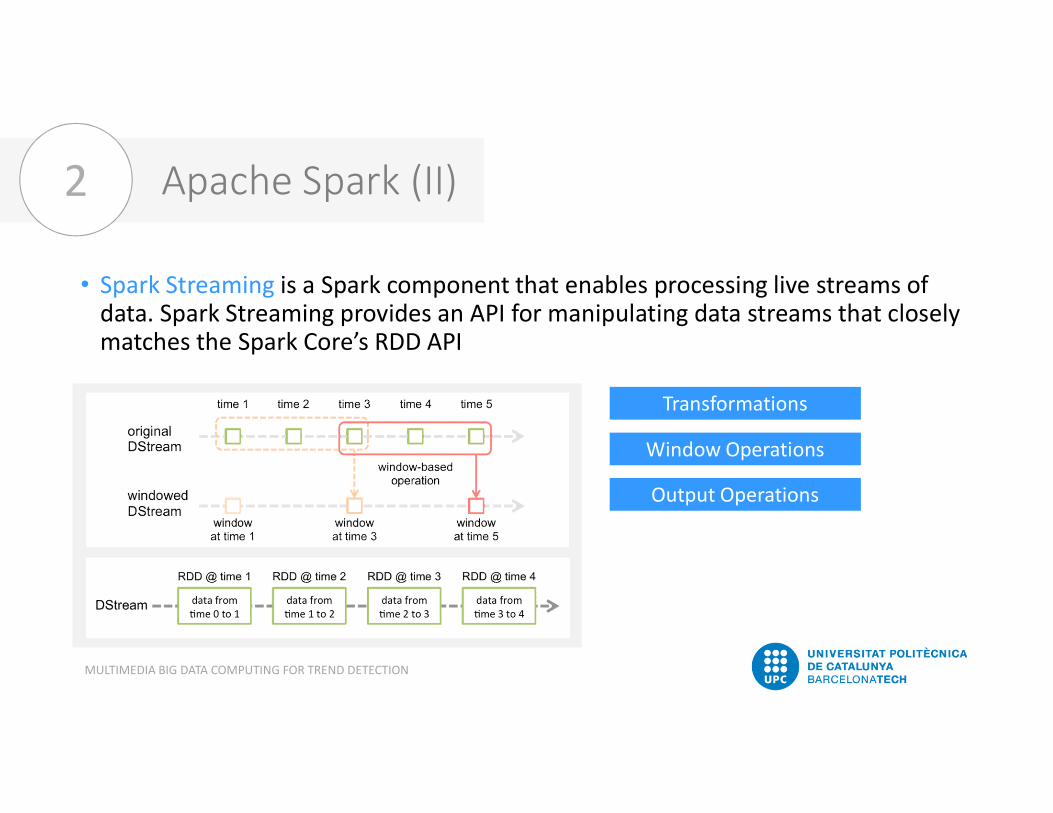
Apache Spark (II)• Spark Streaming is a Spark component that enables processing live streams of data. Spark Streaming provides an API for manipulating data streams that closely matches the Spark Core’s RDD API
2
• Spark Streaming provides a high-level abstraction calledDiscretized Stream or Dstream• A DStream is a sequence (a series of RDDs) of data arrivingover time
SocketsFile Stream
Actors (Akka)Quenue RDDs
TransformationsWindow OperationsOutput Operations

MULTIMEDIA BIG DATA COMPUTING FOR TREND DETECTION
1:k : Los tópicos : Es una distribución sobre el vocabulario: Las proporciones de tópicos para el th documento
, : Es la proporción de tópicos del tópico en el documento : Las asignaciones de tópicos para el th documento
, : Es la asignación tópicos para la n-sima palabra en el documento : Son las palabras observadas en el documento,
, : Es la nth palabra en el documento , que es un elemento del vocabulario fijo
: , : , : , : = ∏ ∏ (∏ , | ( , | : , , ))
Topic Modeling• It’s a suite of statistical algorithms that aim to discover and annotate large archives of documents with thematic information• topic models do not require any prior annotations or labeling of the documents, the topics emerge from the analysis of the original texts
2 Latent Dirichlet Allocation (LDA)
Documents
Topic proportions andassigments
gene 0.04dna 0.02genetic 0.01….
life 0.02evolve 0.01organism 0.01
brain 0.04neuron 0.02nerve 0.01
data 0.02number 0.02computer 0.01
Topics

MULTIMEDIA BIG DATA COMPUTING FOR TREND DETECTION
III. Multimedia Big Data Computing for Trend Detection

MULTIMEDIA BIG DATA COMPUTING FOR TREND DETECTION
Overview
JSONfiles
Spark Streaming MLlib
Apache SparkSpark SQL
3
Instgram’s API
Kafka
Ingest Read Data Pre-processing & filtering Topic Modeling
Visualization
MULTIMEDIA BIG DATA COMPUTING FOR TREND DETECTION
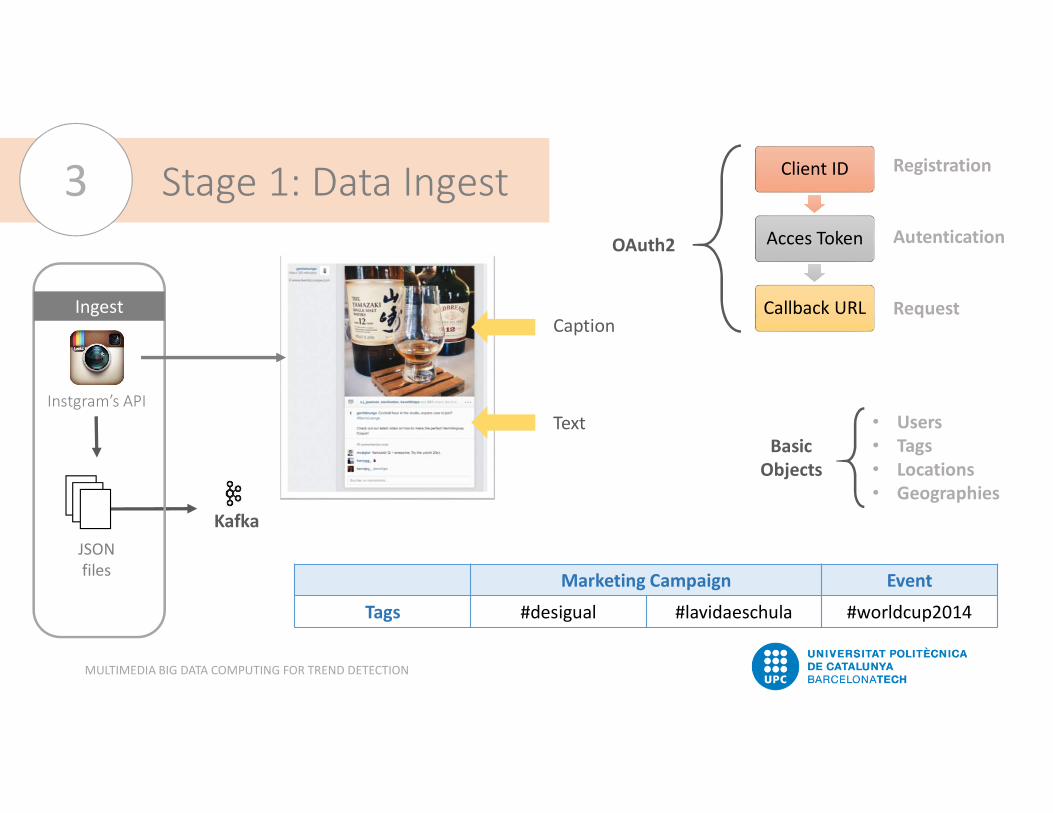
Stage 1: Data Ingest3
JSONfiles
Instgram’s API
Kafka
IngestOAuth2
BasicObjects• Users• Tags• Locations• Geographies
Caption
Text
Client ID
Acces Token
Callback URL
Registration
Autentication
Request
Marketing Campaign EventTags #desigual #lavidaeschula #worldcup2014

MULTIMEDIA BIG DATA COMPUTING FOR TREND DETECTION
Stage 2: Read Data3
JSONfiles
Spark SQLInstgram’s API
Kafka
Ingest Read Data
single node – single broker
clúster de Kafka
consumerproducer
{"type": "record","name": "JSON","namespace": "avro","fields": [ {
"name": "text","type": "string","doc": " The content of the user's
message "} ],"doc": "A basic schema for storing
Instagram metadata"}
val batchInterval = Seconds(5)
"testing-input"
Zookeeper

MULTIMEDIA BIG DATA COMPUTING FOR TREND DETECTION
consumer
Stage 3: Filtering & Preprocessing3
Spark Streaming
Spark SQL
Kafka
Read Data Pre-processing & filtering• Unnecessary characters• Stop words
Do not provide any benefit
LDA and the others ML algorithms from MLlib doesn't work on streaming, that why is necessary to store the results in files

MULTIMEDIA BIG DATA COMPUTING FOR TREND DETECTION
the first MLlib algorithm built upon GraphX
Expectation-Maximization (EM)
With Spark 1.3, MLlib now supports Latent Dirichlet Allocation (LDA)
Stage 4: Topic Modeling3
Spark Streaming
Topic ModelingPre-processing & filtering
MLlib
vectors of word counts(Word, frecuency)

MULTIMEDIA BIG DATA COMPUTING FOR TREND DETECTION
Stage 5: Visualization3
MLlib
Topic Modeling
Visualization
val topicIndices = ldaModel.describeTopics(maxTermsPerTopic = 10)topicIndices.foreach { case (terms, termWeights) =>println("TOPIC:")terms.zip(termWeights).foreach { case (term, weight) =>println(s"${vocabArray(term.toInt)}\t$weight")}println()
TOPIC :forza 0.005192139298507153after 0.004892488884851435side 0.004873250064472125first 0.004837548137749428partido 0.004762856710768013netherlands 0.004658646778099761going 0.004562908515970665…

MULTIMEDIA BIG DATA COMPUTING FOR TREND DETECTION
IV. Results and conclusions

MULTIMEDIA BIG DATA COMPUTING FOR TREND DETECTION
ExperimentsHardwareCore i5-3337U de 1.80 Ghz6GB RAM OS Ubuntu v14.04
4
Software Apache Spark 1.3Scala 2.11 JDK 7Spark Cluster• Standalone mode• 1 master y 5 workers
#desigual #Lavidaeschula #worldcup14Processed posts 3258 12471 501Size in bytes 8.4 MB 33.7 MB 995.1 kbNumber of words 43763 185390 6594
2014August November

MULTIMEDIA BIG DATA COMPUTING FOR TREND DETECTION
Results (I)4
Topic 1 Topic 2 Topic 3 Topic 4 Topic 5Forza 0.0063970partido 0.0063084after 0.0061240going 0.0060892more 0.0056626love 0.0051733netherlands 0.0049420fifa 0.0049102watching 0.0047937your 0.0047628
forza 0.0051921after 0.0048924side 0.0048732first 0.0048375partido 0.0047628netherlands 0.0046586going 0.0045629more 0.0045417viva 0.0043852watching 0.0042613
partido 0.0053369number 0.0052725love 0.0050586fifa 0.0048055after 0.0047837mundial 0.0046185forza 0.0045615italy 0.0044705viva 0.0043077life 0.0042818
your 0.0055476still 0.0048858going 0.0047801good 0.0045066italy 0.0043234first 0.0043203before 0.0042764partido 0.0042220after 0.0041471netherlands 0.0041207
netherlands 0.0061293mexico 0.0049672fifa 0.0047969brazil 0.0046036viva 0.0045627number 0.0045547about 0.0045023going 0.0043588forza 0.0042632mundo 0.0042261
#worldcup2014 datasetIterations : 3, 5, 7 Topics : 5Processing Time : 145 seg
Netherlands vs MexicoItaly

MULTIMEDIA BIG DATA COMPUTING FOR TREND DETECTION
Results (II)
Topic 1 Topic 2 Topic 3 Topic 4 Topic 5ماشاءهللا 0.0044680just 0.0041317like 0.0030537that 0.0027004happy 0.0024657يسعدلي 0.0024515best 0.0023213minha 0.0020576todos 0.0020428هللا 0.0019363
just 0.0038730ماشاءهللا 0.0035151that 0.0031203like 0.0026153
التيا 0.0025304يسعدلي 0.0024014التي 0.0023665الحنين 0.0019909best 0.0019291apenas 0.0019265
ماشاءهللا 0.0030372that 0.0028397just 0.0026653like 0.0024058سعاده 0.0018991todos 0.0018570يسعدلي 0.0018346الحنين 0.0018248هللا 0.0017642from 0.0017207
ماشاءهللا 0.0034158just 0.0028399like 0.0028013that 0.0024385التي 0.0023819يسعدلي 0.0021320best 0.0020799happy 0.0020573سعاده 0.0018726last 0.0018066
ماشاءهللا 0.0035831يسعدلي 0.0027622like 0.0026387just 0.0025732األعزاء 0.0024545that 0.0024106minha 0.0023892متابعيني 0.0021237سعاده 0.0020168from 0.0019959
4#Desigual datasetIterations : 2Topics : 5Processing Time : 53 min
• Bangkok (Thailandia)• Bhaucha Dhakka (India) • Maldives (Mumbai)
#Lavidaeschula dataset ¿?Iterations : 1Topics : 5Processing Time : 129 min

MULTIMEDIA BIG DATA COMPUTING FOR TREND DETECTION
Conclusions• Spark fulfills its purpose efficiently; however Spark Streaming is not yet entirely stable.• The algorithms available in MLlib are basic and do not work in streaming (until Spark 1.3.0)• Factors that influence the performance of the application: the size of the dataset, number of iterations and number of searched topics.• It is necessary that the dataset count on a certain amount of words so that the result is consistent
4

MULTIMEDIA BIG DATA COMPUTING FOR TREND DETECTION
Thanks





























