Embed Size (px)
Citation preview

Wykład 2
Elementy statystyki.
Statystyka opisowa.
1. Słownik podstawowych pojęć:
Populacja generalna-zbiorowość poddawana statystycznemu badaniu (np.
klienci sieci telekomunikacyjnych, telefony określonej marki, rozmowy
telefoniczne)
Cecha-własność elementów populacji generalnej
(np. czas korzystania z sieci na danym obszarze, liczba sprzedanych
telefonów danej marki w różnych miesiącach danego roku, parametry
technologiczne produkowanych urządzeń, liczba usterek itp.)
Cecha ilościowa-wyraża się ją liczbowo (ilość sprzedanych telefonów danej
marki, ilość usterek, długość rozmów, ilość pobrań pliku itp. )
Cecha jakościowa-trudna lub niemożliwa do zmierzenia
(np. wykształcenie klientów, miejsce zamieszkania, kolor obudowy
telefonów, itp.)
Cecha skokowa-wielkość cechy może być wyrażona przez skończoną liczbę
wariantów (np. ilość klientów, liczba wejść na stronę, itp.).
Cecha ciągła-wielkość cechy wyrażona przez elementy pochodzące z
przedziału liczbowego (np. czas dostępu do informacji, masa, natężenie
prądu itp.)
Próba (próbka)-podzbiór populacji generalnej otrzymany drogą losowania
(zależnego, niezależnego).
Losowanie zależne-każdy element może być wylosowany co najwyżej jeden
raz.
Losowanie niezależne-każdy element populacji generalnej może być
wylosowany wielokrotnie.

Oznaczenie próby:
x1, x2, x3,...,xn
n - liczność (liczebność) próby
mała próba (n≤30)
duża próba (n>30)
Wstępne opracowanie danych.
Szeregi statystyczne:
Szereg pozycyjny dla małej próby-
uporządkowujemy dane w ciąg niemalejący.
xxxxx nn )()1()3()2()1(...
Szereg punktowy dla dużej próby-
wyodrębniamy wielokrotnie powtarzające się wielkości.
xj nj
x1
x2
...
xk
n1
n2
...
nk
Przykład:
W dziale kontroli jakości bada się liczbę usterek w wylosowanym wyrobie.
W ciągu 100 dni było:
25 dni –brak usterek
35 dni- 1 usterka,

25 dni-2 usterki,
10 dni-3 usterki,
5 dni-4 usterki
Liczba
usterek
Liczba dni
0 25
1 35
2 25
3 10
4 5
Szereg rozdzielczy dla dużej , zróżnicowanej próby
10 Rozstęp: R=xmax-xmin
20 Liczba klas:
nknk4
3lub
30 Długość klasy:
l=R/k
klasy liczność klasy
xmin÷(xmin+l)
(xmin+l)÷ (xmin+2·l)
...
(xmax-l)÷xmax
n1
n2
...
nk
razem n

Przykład.
Niejaki J. M. Pawlak zebrał informacje na temat czasu, jaki upłynął od
odjazdu ostatniego pociągu metra do momentu wejścia na peron ( w
sekundach):
0,20,20,30,30,30,30,50,60,70,80,80,80,90,100,110,110,110,
120,130,130,130,140,150,150,150,165,170,170,170,190,
200,200,200,200,210,210,210,220,220,220,230,230,230,240,
250,250,250,250,250,260,260,270,270,270,280
n=56
Uporządkować dane w szereg rozdzielczy.
R=280, k=7, l=40
Nr klasy Klasa liczność
1 0-40 7
2 40-80 6
3 80-120 6
4 120-160 7
5 160-200 9
6 200-240 10
7 240-280 11
razem 56
Charakterystyki liczbowe z próby.
Miary pozycyjne:
Średnia z próby:

k
j
jj
k
j
jj
n
i
i
nxn
x
nxn
x
nxn
x
1
1
1
1
1
30,1
Uwaga:
to środek j-tej klasy
Miary rozproszenia:
Wariancja z próby:
k
j
jj
k
j
jj
n
i
i
nxxn
s
nxxn
s
nxxn
s
1
22
1
22
1
22
)(1
)(1
30,)(1
Odchylenie standardowe z próby-
pierwiastek kwadratowy z wariancji z próby ozn. s
Współczynnik zmienności:
%100x
sv

Graficzne przedstawienie danych-
histogram liczności.
10,0 11,8 13,6 15,4 17,2 19,0
Zmn1
0
2
4
6
8
10
12
14
Lic
zba o
bs.
xj nj
0 25
1 35
2 25
3 10
4 5
klasy liczność
10,0-11,8 13
11,8-13,6 10
13,6-15,4 8
15,4-17,2 7
17,2-19,0 2
1 2 3 4
35
25
10
5

Przykład.
Obliczyć charakterystyki liczbowe dla szeregów statystycznych:
a)3,5,6,6,7,8,8,9,9,9
średnia:
wariancja:
s2=
+
odchylenie standardowe: s≈1,9
współczynnik zmienności:
v=
b)
Liczba
usterek xi
Liczba dni
ni
xini (xi- 2ni
0 25 0 25
1 35 35 0
2 25 50 25
3 10 30 40
4 5 20 45
razem 100 135 135
=1,35
s2=1,35 s
v=
%
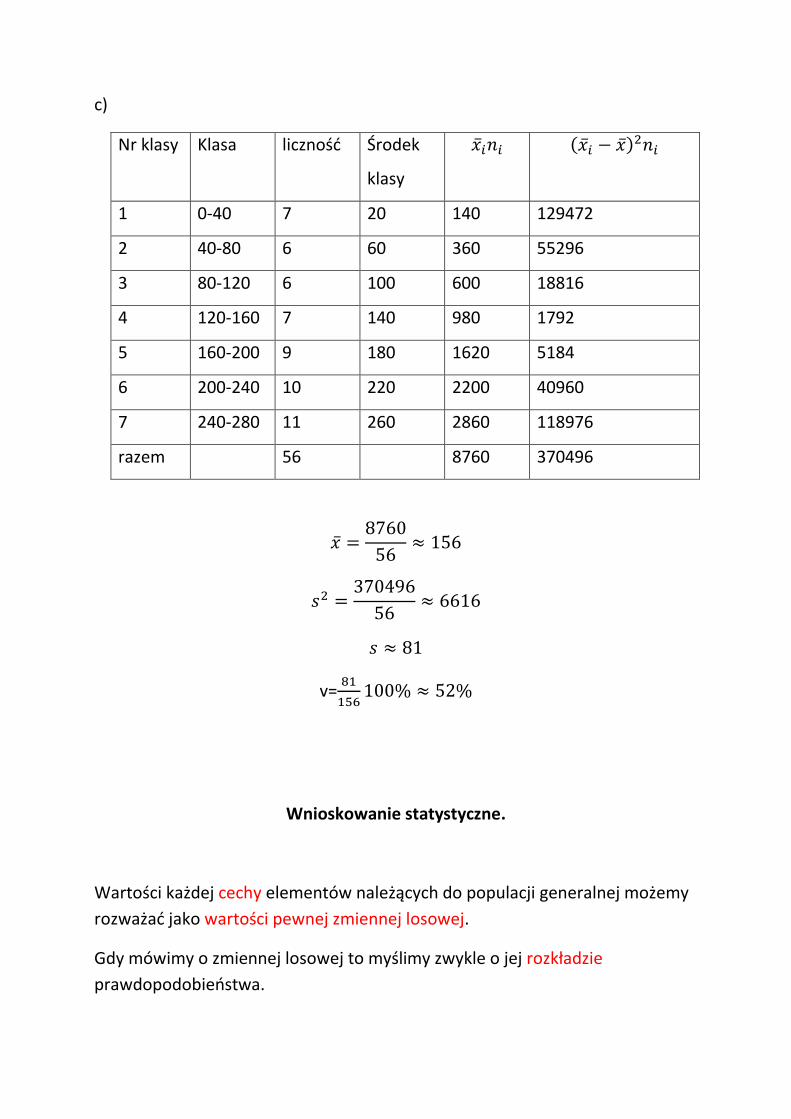
c)
Nr klasy Klasa liczność Środek
klasy
1 0-40 7 20 140 129472
2 40-80 6 60 360 55296
3 80-120 6 100 600 18816
4 120-160 7 140 980 1792
5 160-200 9 180 1620 5184
6 200-240 10 220 2200 40960
7 240-280 11 260 2860 118976
razem 56 8760 370496
v=
Wnioskowanie statystyczne.
Wartości każdej cechy elementów należących do populacji generalnej możemy
rozważać jako wartości pewnej zmiennej losowej.
Gdy mówimy o zmiennej losowej to myślimy zwykle o jej rozkładzie
prawdopodobieństwa.

W statystyce mówimy krótko, że rozważana populacja ma rozkład
prawdopodobieństwa.
Z kolei jeśli z populacji pobieramy próbę n - elementową to wartości
x1, x2, …,xn przedstawiają układ pewnych liczb rzeczywistych.
Jeśli próbę będziemy uważać za jedną ze wszystkich możliwych prób to
x1, x2, …,xn możemy uznać za zmienne losowe ( bo przy każdym wyborze próby
przybierają one różne wartości) o jednakowych rozkładach.
Stąd oznaczymy je X1, X2, …, Xn.
Wówczas dowolna funkcję tych zmiennych losowych
nazywamy statystyką.
Jest to więc zmienna losowa będąca funkcją z próby i ma określony rozkład.
Nazywamy go krótko rozkładem z próby. Znajomość rozkładów statystyk
odgrywa bardzo ważna rolę we wnioskowaniu statystycznym.
Rozkłady z próby.
1. Rozkład średniej arytmetycznej
Z populacji o rozkładzie normalnym losujemy n – elementową
próbę i przez X1, X2, …, Xn oznaczamy kolejne wyniki w próbie, będące
zmiennymi losowymi.
Statystyka
tj. średnia arytmetyczna ma rozkład
.
Wniosek:
Średnia arytmetyczna podlega mniejszej zmienności niż pojedyncze
wyniki i zmienność ta maleje wraz ze wzrostem liczebności próby n.
2. Rozkład chi-kwadrat
Z populacji o rozkładzie normalnym losujemy n – elementową
próbę i przez X1, X2, …, Xn oznaczamy kolejne wyniki w próbie, będące
zmiennymi losowymi.
Statystyka
gdzie
ma rozkład zwany rozkładem chi-kwadrat o n-1 stopniach swobody.
Gęstość ma dość skomplikowany wzór.
Wykres przyjmuje różny kształt w zależności od liczby stopni swobody.
W zastosowaniach statystycznych korzystamy z prawdopodobieństw
postaci:
przy danej wielkości i określonej liczbie stopni swobody:
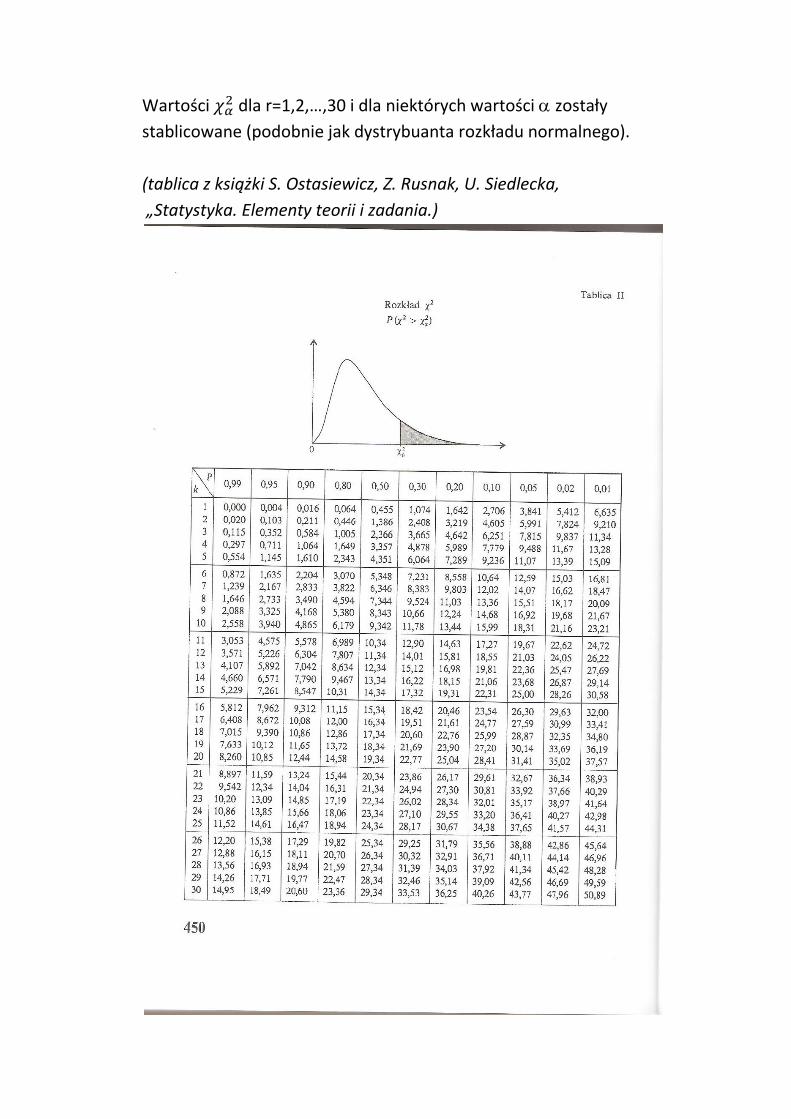
Wartości dla r=1,2,…,30 i dla niektórych wartości zostały
stablicowane (podobnie jak dystrybuanta rozkładu normalnego).
(tablica z książki S. Ostasiewicz, Z. Rusnak, U. Siedlecka,
„Statystyka. Elementy teorii i zadania.)

3. Rozkład t-Studenta.
Z populacji o rozkładzie normalnym losujemy n – elementową
próbę i przez X1, X2, …, Xn oznaczamy kolejne wyniki w próbie, będące
zmiennymi losowymi.
Statystyka
gdzie
zwana statystyką Studenta ma rozkład Studenta o n-1 stopniach
swobody.
Kształt funkcji gęstości jest zbliżony do gęstości rozkładu normalnego.
W praktyce korzystamy z prawdopodobieństwa
Wielkości te są stablicowane dla określonej liczby stopni swobody i
niektórych wielkości .
(tablica z książki S. Ostasiewicz, Z. Rusnak, U. Siedlecka,
„Statystyka. Elementy teorii i zadania.)
t -t
1-


Estymacja parametrów.
Jednym z głównych zagadnień wnioskowania statystycznego jest
estymacja (oszacowanie). Estymacja polega na szacowaniu wartości
parametrów bądź postaci rozkładu populacji na podstawie próby.
Estymacja może być:
a) parametryczna, gdy na podstawie próby chcemy oszacować jeden lub
kilka parametrów populacji, której rozkład jest znany;
b) nieparametryczna, gdy nie jest znana postać dystrybuanty rozkładu
populacji.
Jeśli wartość parametru ( nieznaną) możemy oszacować jedną liczbą
odpowiadającą przypuszczalnej wartości parametru to mówimy o
estymacji punktowej.
W estymacji punktowej do oszacowania parametru posługujemy się
odpowiednią statystykę Zn będącą funkcją zmiennych losowych X1, X2, …,
Xn n- elementowej próby.
Statystykę Zn służącą do oszacowania nieznanego parametru nazywamy
estymatorem.
Jej wartość zn odpowiadającą realizacji próby x1, x2, …, xn nazywamy
oceną parametru. Ocenę tę przyjmujemy jako oszacowanie (z wartości)
parametru.
Estymator jest więc zmienną losową, a ocena to konkretna liczba
odpowiadająca danej realizacji próby.
Najstarszą metodą punktowego szacowania nieznanego parametru jest
tzw. metoda momentów.
Polega ona na szacowaniu parametrów przez odpowiednie
charakterystyki z próby. I tak:

Estymatorem wartości oczekiwanej jest średnia z próby:
Estymatorem wariancji jest wariancja z próby
Trzeba zauważyć, że dla każdej próby wartości oszacowań są
różne i nie możemy w sposób bezpośredni powiedzieć jaki błąd
popełniamy przy tej ocenie.
Stąd inny sposób estymacji nazywamy estymacją przedziałową.
Polega ona na określeniu przedziału, który zawiera prawdziwą wartość
parametru.
Przedział liczbowy (losowy), który zawiera prawdziwą wartość parametru
z określonym z góry prawdopodobieństwem 1- nazywamy przedziałem
ufności.
Wartość 1- nazywamy współczynnikiem ufności, a poziomem
istotności ( błąd estymacji). Długość przedziału ufności zwiększa się wraz
ze wzrostem współczynnika ufności.
Interpretacja przedziału ufności:
z prawdopodobieństwem 1- prawdziwa wartość parametru znajduje się
w tym przedziale.
Przy tworzeniu przedziałów ufności korzysta się z rozkładu statystyki,
która jest estymatorem rozpatrywanego parametru lub go zawiera.
W przypadku małych prób korzysta się z rozkładów z próby, a dla dużych
prób z rozkładów granicznych ( najczęściej jest to rozkład normalny).
Przedziały ufności dla średniej.
Model I.
Populacja generalna ma rozkład normalny Wielkości
szacujemy na podstawie małej próby.

Skorzystamy z faktu, że statystyka
ma rozkład Studenta o n-1 stopniach swobody.
Dla tego rozkładu
1ttP
Stąd
111
11
1
n
StX
n
StXP
tnS
XtP
tttP
Ostatecznie przedział ufności ma postać:
n
i
i
n
i
i xxn
sxn
x
n
stx
n
stx
1
2
1
)(1
,1
1,
1
Natomiast t odczytujemy z tablic rozkładu Studenta
dla danego i n-1 stopni swobody.
Model II.
Populacja generalna ma rozkład normalny Wielkości
szacujemy na podstawie dużej próby.

Skorzystamy z faktu, że statystyka
ma dla dużych n rozkład normalny N(0,1).
Dla tego rozkładu
1uuP
Po przekształceniach, analogicznych jak dla modelu I, przedział ufności
ma postać:
n
i
i
n
i
i xxn
sxn
x
n
sux
n
sux
1
2
1
)(1
,1
,
Natomiast u odczytujemy z tablic rozkładu Studenta dla danego i
największej liczby (np. 120) stopni swobody.
Istnieją tablice przygotowane tak, że istnieje wiersz opatrzony liczbą
stopni swobody
Przykład:
W pewnym doświadczeniu chemicznym bada się czas całkowitego
zakończenia pewnej reakcji chemicznej. Czas ma rozkład normalny.
Dokonano 12 doświadczeń i otrzymano 46 [s] i odchylenie
standardowe s=13 [s]. Przyjmując współczynnik ufności 1-=0,99
oszacować metodą przedziałową oczekiwany czas zakończenia rekcji.
Rozwiązanie:
Korzystamy z modelu I.
Ustalamy n-1=11, szukamy t dla rozkładu Studenta przy 11 stopniach
swobody i =0,01.

Otrzymujemy: t=3,106.
Wystarczy teraz dane z przykładu i ustaloną wartość „tablicową” wstawić
do wzoru. Otrzymujemy rozwiązanie:
17,58;83,33
17,1246;17,1246
11
13106,346,
11
13106,346
z prawdopodobieństwem 0,99.
Przykład.
W celach antropometrycznych dokonano na wylosowanych niezależnie
400 studentach z pewnego miasta pomiaru długości stopy. Długość ta ma
rozkład normalny. Otrzymano z tej próby =26,4 [cm] oraz s=1,7 [cm].
Oszacować za pomocą przedziału ufności przy współczynniku ufności 0,9
średnią długość stopy studentów z tego miasta.
Rozwiązanie:
Korzystamy z modelu II.
Ustalamy n=400, szukamy u dla rozkładu Studenta przy największej
liczbie stopni swobody i =0,1.
Otrzymujemy: u=1,658.
Wystarczy teraz dane z przykładu i ustaloną wartość „tablicową” wstawić
do wzoru. Otrzymujemy rozwiązanie:

54,26;26,26
14,04,26;14,04,26
400
7,1658,14,26;
400
7,1658,14,26
z prawdopodobieństwem 0,9.





























