Embed Size (px)
Citation preview

Intel Many Integrated Core ArchitectureMulti-Core Architectures and Programming
B. Osterwald, J. Doerntlein
Hardware/Software Co-Design, University of Erlangen-Nuremberg
May 15, 2014

Outline
Motivation
Product Overview
Hardware SpecificationInternal StructureCommunication
Programming Paradigms
Comparison to GPU
Summary

Motivation

Motivation
Figure 1: Insatiable need for computing1
1Source: http://download.intel.com/pressroom/archive/reference/ISC_2010_Skaugen_keynote.pdf,p.9
May 15, 2014 | B. Osterwald, J. Doerntlein | Hardware/Software Co-Design | Intel MIC 1

Motivation
Performance increase
• In the past:• Higher density of transistors
• Moore’s Law: number of transistors on a chip will double every two years...
Figure 2: Intel manufacturing progress 2
2Source: http://download.intel.com/pressroom/archive/reference/ISC_2010_Skaugen_keynote.pdf,p.8
May 15, 2014 | B. Osterwald, J. Doerntlein | Hardware/Software Co-Design | Intel MIC 2

Motivation
Performance increase
• In the past:• Higher density of transistors
• Moore’s Law still valid• Intelligent architectures with Pollack’s Rule:
Increase of complexity∼√
increase of computing performanceDoubling of transistors in processor→ 40% more performance
May 15, 2014 | B. Osterwald, J. Doerntlein | Hardware/Software Co-Design | Intel MIC 3

Motivation
Performance increase
• In the past:• Higher density of transistors
• Moore’s Law still valid• Intelligent architectures (Pollack’s Rule)
• Higher frequency• Today:
• Multi, many core• E.g. clustered computing, GPUs...
May 15, 2014 | B. Osterwald, J. Doerntlein | Hardware/Software Co-Design | Intel MIC 4

Motivation
Desired changes and improvements
• Energy efficiency• Single programming architecture (counter example: CPU vs. GPU)• Strengthen their position in HPC
May 15, 2014 | B. Osterwald, J. Doerntlein | Hardware/Software Co-Design | Intel MIC 5

Product Overview

Product Overview
Intel Many Integrated Core (MIC) Architecture
• Goal: highly parallel general-purpose computing with IA compiler• No need for special programming architecture but still all advantages from GPUs
Figure 3: Intel Xeon Phi3
3Source: http://assets.vr-zone.net/16871/INTC_Xeon_Phi_PCIe_Card_57C_6GB.jpg
May 15, 2014 | B. Osterwald, J. Doerntlein | Hardware/Software Co-Design | Intel MIC 6
Product Overview
Larrabee - Intel MIC - Xeon Phi
• 2010: Knights Ferry• 2012: Knights Corner• 2013 announced: Knights Landing• future: Knights Hill
May 15, 2014 | B. Osterwald, J. Doerntlein | Hardware/Software Co-Design | Intel MIC 7

Hardware Specification

Internal Structure
Knight Ferry:• 32 cores @ 1.2 GHz• 4x simultaneous multi-threading per core• Scalar Unit and 512-bit Vector Unit• Short in-order pipeline• L1 cache 32 KByte instruction and data• partitioned L2 cache provides 256 KByte per core• no L3 cache• coherent L1 and L2 cache• 2 GByte GDDR5 Memory
May 15, 2014 | B. Osterwald, J. Doerntlein | Hardware/Software Co-Design | Intel MIC 8
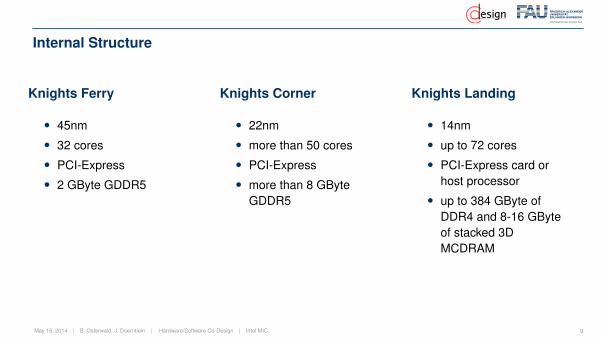
Internal Structure
Knights Ferry
• 45nm• 32 cores• PCI-Express• 2 GByte GDDR5
Knights Corner
• 22nm• more than 50 cores• PCI-Express• more than 8 GByte
GDDR5
Knights Landing
• 14nm• up to 72 cores• PCI-Express card or
host processor• up to 384 GByte of
DDR4 and 8-16 GByteof stacked 3DMCDRAM
May 15, 2014 | B. Osterwald, J. Doerntlein | Hardware/Software Co-Design | Intel MIC 9

Communication
• between several accelerators:PCI peer-to-peer or network card
• on chip:512-bit ringbus in both directions separated into three different rings:data-block, address and acknowledgement
May 15, 2014 | B. Osterwald, J. Doerntlein | Hardware/Software Co-Design | Intel MIC 10
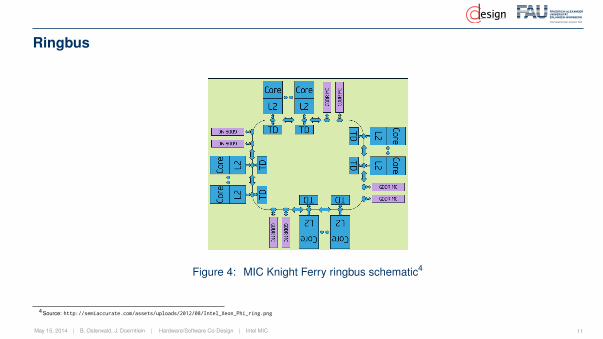
Ringbus
Figure 4: MIC Knight Ferry ringbus schematic4
4Source: http://semiaccurate.com/assets/uploads/2012/08/Intel_Xeon_Phi_ring.png
May 15, 2014 | B. Osterwald, J. Doerntlein | Hardware/Software Co-Design | Intel MIC 11
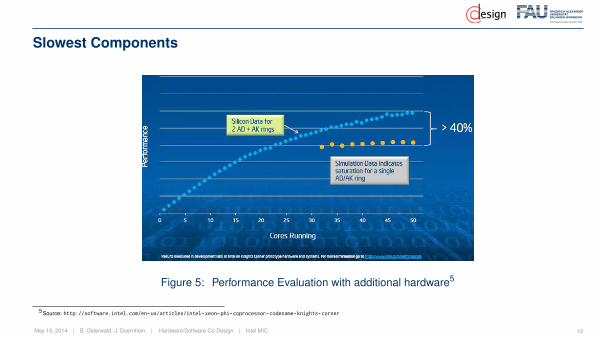
Slowest Components
Figure 5: Performance Evaluation with additional hardware5
5Source: http://software.intel.com/en-us/articles/intel-xeon-phi-coprocessor-codename-knights-corner
May 15, 2014 | B. Osterwald, J. Doerntlein | Hardware/Software Co-Design | Intel MIC 12

Communication
• between several accelerators:PCI peer-to-peer or network card
• on chip:512-bit ringbus in both directions separated into three different rings:data-block, address and acknowledgement• coherent L1 and L2 cache• Cache access is favoured• Memory controller symmetrically interleaved around the ring• Address- and acknowledgementring decelerate
May 15, 2014 | B. Osterwald, J. Doerntlein | Hardware/Software Co-Design | Intel MIC 13

Programming Paradigms

Programming Paradigms
• High-Level:• Supports all traditional IA programming models• Intel Compiler (flag -mmic):
Fortran, C/C++OpenMP, MPI, OpenCL, Intel TBB - Threading Building Blocks, Intel Cilk Plus, Intel Math LibraryAutomatically and manually use of VPU
• Low-Level:• More than 100 new IA-Instructions
Mostly for VPU
May 15, 2014 | B. Osterwald, J. Doerntlein | Hardware/Software Co-Design | Intel MIC 14

Programming Paradigms
Advantages
• GPUs are narrowed down to data parallel programming paradigms→ CUDA, OpenCL• MIC: offers much more flexibility and a simplified handling→ no explicit need for porting programs
Sounds good in theory – what about practice?
May 15, 2014 | B. Osterwald, J. Doerntlein | Hardware/Software Co-Design | Intel MIC 15

Comparison to GPU

Comparison to GPU
Intel Knights Ferry
• Intel Architecture32 general purpose cores @1.2GHz fullycoherent
• 4 hardware threads per core, round-robinscheduling
• GDDR5 memory @125GByteps• 32 KByte L1-Cache, 256 KByte L2-Cache
(32 cores: 8 MB in total)• Vector programming (VPU): supports
C/C++, Fortran, OpenMP, TBB
Nvidia Tesla C2050 (Fermi architecture)
• 14 multiprocessors with 32 processingelements each @1.15GHz
• Memory @144GByteps• 64 KByte L1-Cache, 768 KByte L2-Cache
(in total, shared)• Single instruction multiple threads (SIMT)• Programmed with CUDA or OpenCL
May 15, 2014 | B. Osterwald, J. Doerntlein | Hardware/Software Co-Design | Intel MIC 16

Example benchmark #1 - OpenCL vs IA
Figure 6: Performance comparison of a data-mining application 6
6From GPGPU to Many-Core: Nvidia Fermi and Intel Many Integrated Core Architecture, p. 4
May 15, 2014 | B. Osterwald, J. Doerntlein | Hardware/Software Co-Design | Intel MIC 17

Conclusion: MIC is faster!?
• Divergency penalty: GPUs cores are simple ALUs• MIC: higher complexity and efficiency in hardware supports fast branching!• Benchmark #1 annotation: L2-Cache is much bigger on Xeon Phi
→ use MIC for special parallel algorithms with many branches
May 15, 2014 | B. Osterwald, J. Doerntlein | Hardware/Software Co-Design | Intel MIC 18

Conclusion: MIC is faster...
• Divergency penalty: GPUs cores are simple ALUs• MIC: higher complexity and efficiency in hardware supports fast branching!• Benchmark #1 annotation: L2-Cache is much bigger on Xeon Phi
→ use MIC for special parallel algorithms with many branches
Peak performance in theory (single precision)• C2050: 32 processing elements×14 multi processors×1.15 GHz×2 FMA= 1030.4 GFLOPs• MIC: 16 VEC×32 cores×1.2 GHz×2 FMA = 1228.8 GFLOPs
May 15, 2014 | B. Osterwald, J. Doerntlein | Hardware/Software Co-Design | Intel MIC 19

Conclusion: MIC is faster...
Peak performance in theory (single precision)• C2050: 32 processing elements×14 multi processors×1.15 GHz×2 FMA= 1030.4 GFLOPs• MIC: 16 VEC×32 cores×1.2 GHz×2 FMA = 1228.8 GFLOPs
Hiding latency• C2050: 32 threads per processing element• MIC: 4 threads per core• → applications with much more computing operations than memory operations fit perfect on
GPUs (massive simultaneous multi-threading, SMT)!
May 15, 2014 | B. Osterwald, J. Doerntlein | Hardware/Software Co-Design | Intel MIC 20

Example benchmark #2
Monte-Carlo LIBOR Swaption Portfolio Pricer Algorithm 7
• LIBOR: London Interbank Offered Rate – algorithm details are incidental• LIBOR development paths are simulated• Parallel Monte-Carlo algorithms – 3 different code bases (OpenMP, CUDA, Vectorization,
CUBLAS, MKL)• Setup: RedHat 6 with Dual Xeon E5-2670 CPUs, Intel Xeon Phi 5110P, NVIDIA Tesla K20X GPU
Paths Sequential Sandy-Bridge CPU Xeon Phi Tesla GPU128K 13.062ms 694ms 603ms 146ms256K 26.106ms 1.399ms 795ms 280ms512K 52.223ms 2.771ms 1.200ms 543ms
7http://blog.xcelerit.com/intel-xeon-phi-vs-nvidia-tesla-gpu/
May 15, 2014 | B. Osterwald, J. Doerntlein | Hardware/Software Co-Design | Intel MIC 21

Power consumption – important factor
Figure 7: Energy consumption comparison 8
8Source: http://software.intel.com/en-us/articles/intel-xeon-phi-coprocessor-codename-knights-corner
May 15, 2014 | B. Osterwald, J. Doerntlein | Hardware/Software Co-Design | Intel MIC 22

Summary

Summary
• Intel MIC: promising approach for flexible and simplified use• GPUs: practice proven but still in the need of special programming paradigms
• Be aware: who published the paper that clearly favors one side?
• Intel compilers still under heavy development• Most of the time GPUs perform better with well implemented CUDA/OpenCL programs• Porting to GPU still the way to go for fast applications
May 15, 2014 | B. Osterwald, J. Doerntlein | Hardware/Software Co-Design | Intel MIC 23

Thanks for listening.Any questions?

References

References I
[1] Intel. Developer Zone. http://software.intel.com/en-us/articles/intel-xeon-phi-coprocessor-codename-knights-corner. [Accessed 10-May-2014].
[2] J. Lotze. Benchmarks: Intel Xeon Phi vs. NVIDIA Tesla GPU.http://blog.xcelerit.com/intel-xeon-phi-vs-nvidia-tesla-gpu/. [Accessed13-May-2014].
[3] K. Skaugen. Petascale to Exascale - Extending Intel HPC commitment. http://download.intel.com/pressroom/archive/reference/ISC_2010_Skaugen_keynote.pdf.[Accessed 10-May-2014].
[4] H. J. Bungartz A. Heinecke M. Klemm. From GPGPU to Many-Core: Nvidia Fermi and Intel ManyIntegrated Core Architecture. Computing in Science & Engineering (Volume:14 , Issue: 2 ): IEEE,2012.
![Untitled-1 [insurem.com.mx]insurem.com.mx/MercadoLibre/Catalogo HardWare.pdfintel CORE i7 intel CORE i7 intel CORE i7 intel CORE i7 inter CORE inside inter CORE inside inter CORE inside](https://img.dokumen.tips/doc/110x75/5ea5f42d3dcb49308f6ef996/untitled-1-hardwarepdf-intel-core-i7-intel-core-i7-intel-core-i7-intel-core.jpg)























