Embed Size (px)
Citation preview

CS 1501 Fall 2006Midterm Exam 1
Name____________________________________
The test is long. Plan accordingly.No calculators allowed !!
Answers in bold italics.

1) a) (5 points) According to your instructor, what is the most important reason that it is customary
to ignore multiplicative constants when computing running times of algorithms and programs?
Because the multiplicative constant is implementation dependent, it depends on the compiler, the
computer architecture, etc.
b) (5 points) What is the main advantage of using a random pivot/splitter in Quicksort over picking
the pivot/splitter to be the first element of the subarray? Both algorithms have expected running
time Θ(n log n). But what is better about the expectation guarantee for randomized Quicksort?
On every input, the expected the running time of randomized quicksort is Θ(n log n). While with the
deterministic version, all you can say is that you expect the running time to be Θ(n log n) on most
inputs (in some sense), which of course is not a very useful statement if the real inputs you get don’t
happen to be the inputs on which deterministic quicksort runs quickly.
2

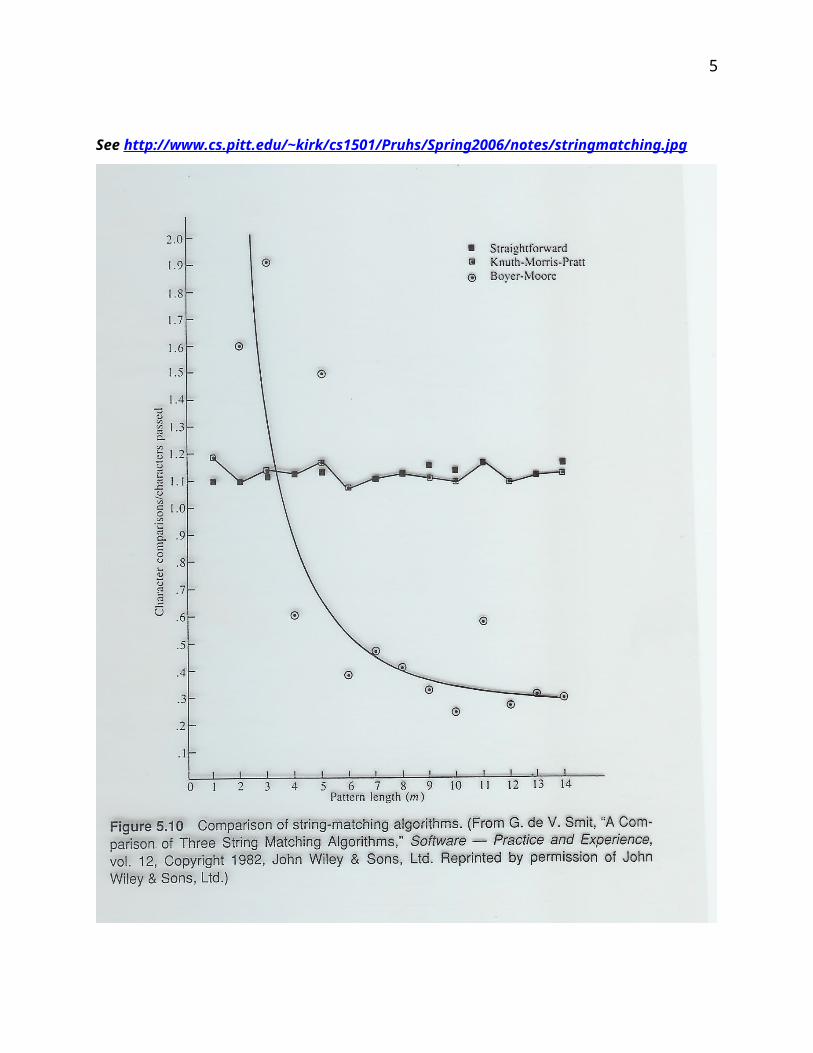
c) (5 points) Consider an average search for an m letter English word in normal English text of n
characters using with the three algorithms:
The brute-force naïve algorithm
Knuth-Morris-Pratt
Boyer-Moore with the mismatched character heuristic
Show the plot of the expected number of character comparisons divided by n, as a function of m,
on the following graph for each of these three algorithms. Make sure to clearly label which plot is
for which algorithm. Obviously your plots will not be exact. In particular, we will be looking for
whether the slopes of you plots is approximately correct, and whether your plots have the correct
relationship with the horizontal line of 1.0 comparisons per text character.
3

See http://www.cs.pitt.edu/~kirk/cs1501/Pruhs/Spring2006/notes/stringmatching.jpg
Number of character comparisons divided by n
2.0
1.0
4
m = number of letters in search string
d) (5 points) Which of the following propositions are logically implied by the proposition, “The
worst case running time of algorithm A is θ(n2).” You need not justify your answer, just mark
5

each statement as “implied” or “not implied”.
i) The worst case running time of A is O(n2). Implied
ii) The worst case running time of A is Ω(n2). Implied
iii) The worst case running time of A is Ω (n3). Not Implied
iv) The worst case running time of A is Ω (n). Implied
v) The worst case running time of A is O (n3). Implied
vi) The worst case running time of A is O(n). Not Implied
2)
a) (6 points) Assume that we have a program that is known to run in time θ (n2). Fill in the following table.
Input Size Machine Speed Time
50,000 109 operations/second 3 Hours
50,000 4 x 109 operations/second ¾ hour
300,000 109 operations/second 108 hours
(1000)1/2 * 50,000 =
150,000
1012 operations/second 3 Hours
b) (6 points) Assume that we have a program that is known to run in time θ(2n). Fill in the following table.
6

Input Size Machine Speed Time
50,000 109 operations/second 3 Hours
50,000 4 x 109 operations/second ¾ hour
300,000 109 operations/second Infinite for all practical purposes
50,000 + lg 1000 =
50,010
1012 operations/second 3 Hours
c) (3 points) Explain the standard argument that the asymptotic run time of a program/algorithm becomes more important as machine speeds increase. You can base your answer on the above two tables if you like.
If the goal is to run the program on the largest input that can be handled in a fixed amount of time, then programs with higher asymptotic run times gain less from increased processor speed. Notice in the above example that the increase in the size of input that the exponential time program can handle is only plus 10 when the speed increases by a factor of a 1000.
7

3) Consider the string matching problem with the text and pattern as shown.
Text: ABABCABABAAAXXXXXXXXXXPattern: ABABABA
For each of the the Knuth-Morris-Pratt algorithm and the Boyer-Moore algorithm (with the mismatched character heuristic) show each of the first four alignments of the pattern with the text that occurs in the execution of the algorithm, and the character comparisons that are performed in this alignment. As an example, we give the sort of answer that we seek for the first four alignments of the naïve brute-force algorithm
Alignment 1:
ABABCABABAAAXXXXXXXXXX ||||| 5 comparisonsAlignment 1: ABABABAAlignment 2: | 1 Comparison
ABABABAAlignment 3: ||| 3 Comparisons
ABABABAAlignment 4: | 1 Comparison
ABABABA
8

a) (5 points) Give the answer for Knuth-Morris-Pratt here.
Text: ABABCABABAAAXXXXXXXXXX
Pattern: ABABABA
ABABCABABAAAXXXXXXXXXX||||| 5 comparisons
ABABABA
ABABCABABAAAXXXXXXXXXX ||| 3 comparisons
ABABABA
ABABCABABAAAXXXXXXXXXX | 1 comparison
ABABABA
9

ABABCABABAAAXXXXXXXXXX |||||| 6 Comparisons
ABABABA
10

b) (5 points) Give the answer for Boyer-Moore here.
Text: ABABCABABAAAXXXXXXXXXXPattern: ABABABA
ABABCABABAAAXXXXXXXXXX | 1 comparison
ABABABA
ABABCABABAAAXXXXXXXXXX |||| 4 comparisons
ABABABA
ABABCABABAAAXXXXXXXXXX || 2 comparisons
ABABABA
ABABCABABAAAXXXXXXXXXX | 1 comparison
11

ABABABA
12

4) In this question we consider the algorithm Insertion Sort for sorting an n element array.a) (8 points) Write pseudo-code for Insertion Sort
Code from book:
void insertion(itemType a[], int N) {
int i, j; itemType v; for (i = 2; i <= N; i++)
{ v = a[i]; j = i;
while (a[j-1] > v) { a[j] = a[j-1]; j--; }
a[j] = v; }
}
b) (1 point) On what sort of input is Insertion Sort the fastest?
Sorted inputs
c) (1 point) What is the best case time for Insertion Sort?
Θ(n)
d) (1 point) On what sort of input is Insertion Sort the slowest?
13

The reverse of sorted order
e) (2 points) What is the worst case time for Insertion Sort?
Θ(n2)
f) (2 points) If each of the n! permutations/orderings is equally likely, what is the average case time for Insertion Sort?
Θ(n2)
5) Consider the execution of the following code for Quick Sort from the Sedgewick’s text:
void Quicksort(itemType A[], int l, int r)
{ int i;
if (r > l) {
i = Partition(A, l, r); Quicksort(A, l, i-1);
Quicksort(A, i+1, r); }
}
14

a) (5 points) Assume that the array A initially is
17 22 15 8 9 14 5 33 3 10
0 1 2 3 4 5 6 7 8 9
After the call to first call to Partition, before any recursive calls are made, the array A looks like
8 5 3 9 17 14 22 33 17 10
0 1 2 3 4 5 6 7 8 9
What was the value of the variable i was returned by the function Partition? Explain your answer.
Note that the code for Partition need not be implemented as described in the book or in class. All you know about the code for Partition is that it provides a partition that gives you the minimal properties that you need in order to ensure the correctness of Quicksort code. You must justify/explain your answer.
i=3 as the elements to the left of position 3 in A are less than A[3] and the elements to the right of A[3] in A are larger than A[3]
b) (5 points) Write a recurrence relation for the best case running time for Quick Sort as a function of n, the initial size of the array to be sorted.
T(n) = 2 T(n/2) + n.This occurs when each splitter is the median of the subarray.
15

c) (5 points) Explain as convincingly as you can why the best case running time for Quick Sort is θ(n log n). To ask the same question in another way, explain as convincingly as you can why the solution to the above recurrence relation is θ(n log n).
The ith level of the recursive call tree consists of 2i nodes where the subarray is of size n/2i. Thus the time for partition on level i nodes is n/2i. Thus the aggregate time for the nodes on level i is the number of nodes on the level times the time per node = 2i * n/2i = n. Since the input size is going down by a factor of 2 at the level increases, the number of levels is lg n. Then the total time is the number of levels times the time per level = n lg n. Pictorially the recursion tree (with node labeled with time) looks like
n
n/2 n/2
n/4 n/4 n/4 n/4
16

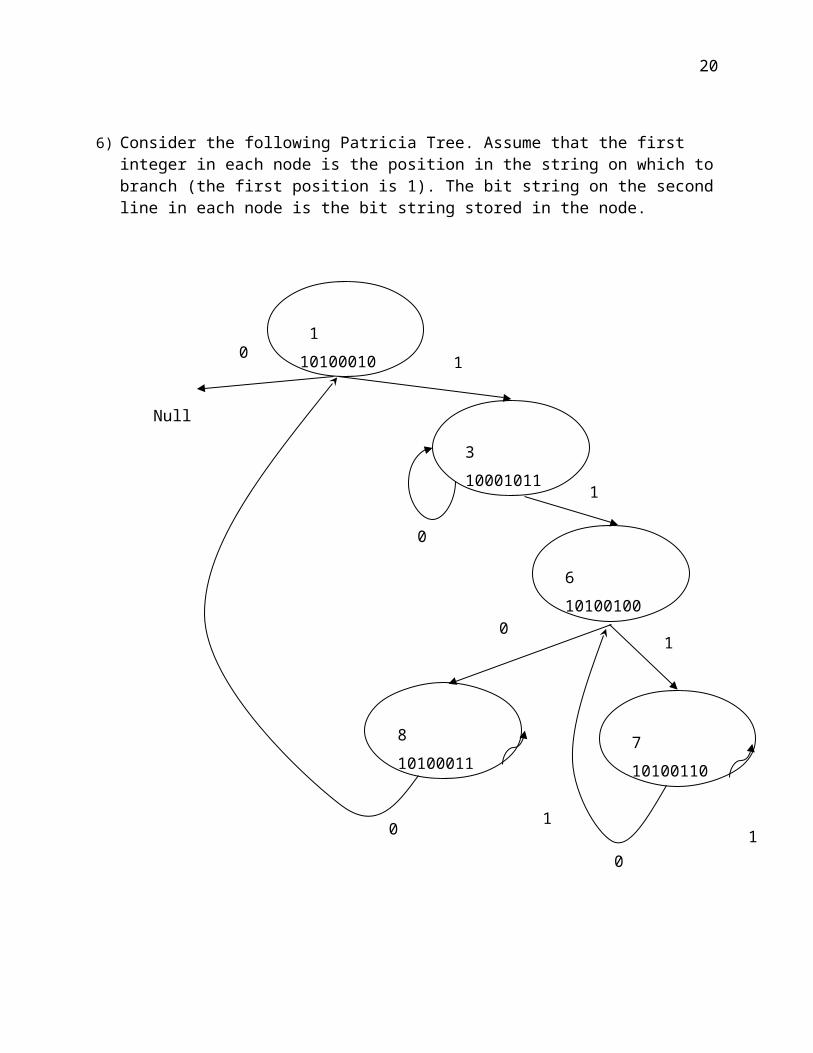
6) Consider the following Patricia Tree. Assume that the first integer in each node is the position in the string on which to branch (the first position is 1). The bit string on the second line in each node is the bit string stored in the node.
110100010
710100110
310001011
610100100
810100011
0
0
1
1
0 1
Null
0
1
01
17

a) (5 Points) Specify the node where a Search for the bit string 10101101 terminates. You may specify the node by giving the position field of the node, since the position field is unique in this instance.
The node that has position equal to 6
b) (10 Points) Show the tree resulting from inserting the bit string 10101101.
110100010
710100110
310001011
610100100
810100011
0
0
1
1
01
Null
0
1
01
510101101
1
1
18

c) (10 points) Write Java-like pseudo-code to determine whether a bitstring Key, of length L, is a prefix of some bitstring in a Patricia tree T. Assume that each node has three fields: Value is a bit string that is stored in the Patricia tree Depth is the depth of the node in the tree Next is a two element array of references/pointers to the children.
You may assume that all the bit strings in the Patricia tree are of the same length, which is longer than L. there is a function Prefix(X, Y) to determine if a bitstring X is a prefix of a bitstring
Y
PrefixSearch(bitstring Key, integer L, node T)If T = Null then return falseElse if T.depth >= L then return Prefix(Key, T.value)Else
Child=T.next[Key[T.depth]]If Child.depth <= T.depth then return Prefix(Key, Child.Value)Else PrefixSearch(Key, L, Child)
19
Students: Do not write on this page.
Total Score: _________________________________
1. a) _________________b)_________________c)_________________d)_________________
2. a) _________________b)_________________c)_________________
3. a) _________________b)_________________
4. a) _________________b)_________________c)_________________d)_________________ e)_________________f)_________________
20

5. a) _________________b)_________________c)_________________
6. a) _________________b)_________________c)_________________
21