Embed Size (px)
Citation preview

ARTICLE IN PRESS
Pattern Recognition 43 (2010) 2330–2339
Contents lists available at ScienceDirect
Pattern Recognition
0031-32
doi:10.1
$This� Corr
E-m
Bernard
(T. Mur
journal homepage: www.elsevier.com/locate/pr
Learning state machine-based string edit kernels$
Aurelien Bellet a,b,c, Marc Bernard a,b,c,�, Thierry Murgue a,b,c, Marc Sebban a,b,c
a Universite de Lyon, F-42023 Saint-Etienne, Franceb CNRS, UMR 5516, Laboratoire Hubert Curien, F-42000 Saint-Etienne, Francec Universite de Saint-Etienne, Jean-Monnet, F-42000 Saint-Etienne, France
a r t i c l e i n f o
Article history:
Received 22 May 2009
Received in revised form
5 November 2009
Accepted 7 December 2009
Keywords:
String kernel
Marginalized kernel
Learned edit distance
03/$ - see front matter & 2009 Elsevier Ltd. A
016/j.patcog.2009.12.008
work is part of the ongoing ARA Marmota r
esponding author at: Universite de Lyon, F-4
ail addresses: [email protected]
@univ-st-etienne.fr (M. Bernard), Thierry.Mu
gue), [email protected] (M. Seb
a b s t r a c t
During the past few years, several works have been done to derive string kernels from probability
distributions. For instance, the Fisher kernel uses a generative model M (e.g. a hidden Markov model)
and compares two strings according to how they are generated by M. On the other hand, the
marginalized kernels allow the computation of the joint similarity between two instances by summing
conditional probabilities. In this paper, we adapt this approach to edit distance-based conditional
distributions and we present a way to learn a new string edit kernel. We show that the practical
computation of such a kernel between two strings x and x0 built from an alphabet S requires (i) to learn
edit probabilities in the form of the parameters of a stochastic state machine and (ii) to calculate an
infinite sum over S� by resorting to the intersection of probabilistic automata as done for rational
kernels. We show on a handwritten character recognition task that our new kernel outperforms not only
the state of the art string kernels and string edit kernels but also the standard edit distance used by a
neighborhood-based classifier.
& 2009 Elsevier Ltd. All rights reserved.
1. Introduction
With the success of kernel-based learning methods [1], anumber of structural kernels have been proposed in the literatureto handle structured data such as strings. A first natural way todesign string kernels consists in representing each sequence by afixed-length numerical vector. In this context, the spectrum kernel
proposed in [2] was one of the first string kernels. It relies on theprinciple that two strings should be considered as similar if theyshare a large number of contiguous subsequences. In the specificcase of a p-spectrum, a string is represented by a histogram offrequencies of all contiguous subsequences of length p. Then, adot product can be performed between two feature vectors tocompute the kernel. To overcome the inconveniences of such anexact matching, the mismatch kernel [3] generalizes the spectrumone by comparing the frequencies of subsequences which are notexactly the same, i.e. allowing a given number of mismatches.Another extension of the spectrum kernel, called subsequence
kernel [4], considers features made of possibly non-contiguoussubsequences. Finally, in the specific context of protein remotehomology detection, the distant segments kernel [5] extends thespectrum kernel to include positional information of polypeptide
ll rights reserved.
esearch project.
2023 Saint-Etienne, France.
tienne.fr (A. Bellet), Marc.
ban).
segments. Each component of the feature vector denotes thenumber of times a segment x is located at a given distancefollowing a segment x0.
Another way to build string kernels while admitting error-tolerant matching consists of deriving kernels from similarity
measures. For instance, Saigo et al. [6] designed a local alignment
kernel to detect remote homologies in protein sequences. Thiskernel assesses the similarity between two sequences by sum-ming up scores computed from local alignments allowing gaps.Other kernels have been derived from the edit distance [7], whichcorresponds to the minimal number of operations (in terms ofinsertion, deletion or substitution of symbols) to transform astring into another one. The edit distance is a metric and tightlyrelated to the optimal alignment between two sequences. Theresulting kernels based on the edit distance are usually calledstring edit kernels. Using this kind of kernels in classification tasksis interesting for a double reason: first, it enables us to bettermeasure the dissimilarity between two strings by consideringmore possible structural distortions than the previously men-tioned string kernels (i.e. spectrum, mismatch, subsequencekernels); second, it allows us to take advantage of powerfullearning algorithms such as the support vector machines (SVM) toleave the constrained context of nearest-neighbor classifiers thatare usually used with the edit distance [8]. For these reasons,string edit kernels have seen an increasing amount of interest inrecent years [8–10]. It is important to note that these kernelfunctions usually assume that the edit distance is negativedefinite. Indeed, to guarantee the convergence of the learning

ARTICLE IN PRESS
A. Bellet et al. / Pattern Recognition 43 (2010) 2330–2339 2331
algorithm (e.g. SVM), this condition is required to ensure that theresulting kernel functions are valid kernels. However, in [9], theauthors proved that the edit distance over a non-trivial alphabet Sis not negative definite. This constitutes a theoretical drawback ofthe state of the art string edit kernels. Moreover, from a practicalpoint of view, they usually use a standard version of the editdistance, i.e. the costs of the edit operations are a priori fixed(often to the same value). This is actually the case when nobackground knowledge is available. Parallel to this work on editkernels, a recent line of research has investigated the ways toautomatically learn the edit parameters from a learning sample inthe form of state machines [11–15]. These edit parameters canthen be used in neighborhood-based classifiers. Given a pair ofstrings ðx; x0Þ, the output of these models is not an edit costanymore, but rather an edit probability to change x into x0 by editoperations. It is important to note that these edit parameters nomore allow us to obtain a true distance (the symmetry andreflexivity properties are often violated) that prevents us fromusing them in standard edit kernels such as those presented in [8–10]. To overcome this problem, we show in this paper how onecan derive a new positive definite string edit kernel from theselearned edit probabilities. Indeed, a third possibility to designstring kernels is to exploit probability distributions issued from
stochastic models as done in the Fisher kernel or its variants [16].For instance, as shown by Haussler [17], the joint probabilitypðx; x0Þ of emitting two strings x and x0 under a pair-hiddenMarkov model (pair-HMM) is a valid kernel that can be used toobtain by convolution new valid string kernels. In this paper, weshow how to exploit edit probabilities that have been learned inthe form of conditional state machines to create a new performingstring edit kernel. We show that the computation of our newkernel requires to perform the intersection of two probabilisticautomata, that is a special case of composition of stochastictransducers, as shown in [9] for designing rational kernels.
The rest of this article is organized as follows: Section 2 isdevoted to the presentation of the state of the art string editkernels. After having introduced in Section 3 our new string editkernel, we briefly recall in Section 4 the main availableapproaches dealing with the learning of the edit parameters.Section 5 is devoted to the computation of our kernel based on aspecific case of composition of stochastic transducers. Finally, wepresent a large experimental study in Section 6, comparing ournew learned edit kernel with the state of the art string kernels.We show that our approach provides significant improvements ona pattern recognition task.
2. Related work on string edit kernels
A common method used to define a string edit kernel from thestandard edit distance ed is the following [9,10]:
kðx; x0Þ ¼ e�t�edðx;x0 Þ; 8x; x0AS�; ð1Þ
where t is a positive real value. However, as mentioned in [9],there exists t40 for which this kernel is not positive definite, thatdoes not guarantee the convergence of training for learningalgorithms such as SVM. In [10], the authors show that t can beexperimentally tuned according to the training data, but thisremains a difficult task. Moreover, note that a slight modificationof t can result in large differences of performance (see Section 6).
In [8], Neuhaus and Bunke present the following string editkernel assuming the symmetry of the edit distance:
kðx; x0Þ ¼ kx0ðx; x0Þ ¼ 1
2ðedðx; x0Þ2þedðx0; x
0Þ2�edðx; x
0Þ2Þ; ð2Þ
where x0 is called a zero string. This kernel describes a measure ofthe squared distance from string x to x0 and from x0 to x0 in
relation to the squared distance from x to x0. Neuhaus and Bunkeshow that two more complex kernels can be obtained by selectinga set I of zero strings and combining the resulting kernels in a so-called sum kernel kþI ðx; x
0Þ and product kernel k�I ðx; x0Þ:
kþI ðx; x0Þ ¼
Xx0 A I
kx0ðx; x0Þ; ð3Þ
k�I ðx; x0Þ ¼
Yx0 A I
kx0ðx; x0Þ: ð4Þ
In these previous two edit kernels, the set I of zero stringsplays an important role. In their experiments, the authors employan iterative greedy selection strategy based on a validation set.Their experimental study shows that this edit kernel outperformsa nearest-neighbor classifier using the standard edit distance.However, it is compared neither to other edit kernels nor to thestate of the art string kernels.
In [6], Saigo et al. present a string alignment kernel specificallydedicated to detect remote homologies in biological sequences.This kernel, computed from a matrix of substitution betweenamino acids, is called LA (local alignment) kernel. It can be derivedfrom Eq. (1), where all the possible local alignments p forchanging x into x0 are taken into account and where an alignmentscore sðx; x0;pÞ is used instead of the edit distance ed:
kLAðx; x0Þ ¼
Xp
et�sðx;x0 ;pÞ; ð5Þ
where t is a parameter and sðx; x0;pÞ is the corresponding score ofp and defined as follows:
sðx; x0;pÞ ¼Xa;b
na;bðx; x0;pÞ � Sða; bÞ�ngd
ðx; x0;pÞ � gd�nge ðx; x0;pÞ � ge;
ð6Þ
where na;bðx; x0;pÞ is the number of times that symbol a is aligned
with letter b, Sða; bÞ is the substitution score between a and b, gd
and ge (and their corresponding number of occurrences ngdðx; x0;pÞ
and nge ðx; x0;pÞ) are two parameters dealing, respectively, with the
opening and extension of gaps.As mentioned in the introduction, another way to use the
kernel described in Eq. (1) is to compute it from edit probabilitydistributions [10]. Indeed, the edit process can be viewed as asequence of probabilistic events. In that way, the edit distancebetween x and x0 can be computed from the summation of thenegative logarithms of the transformation probabilities, asfollows:
edðx; x0Þ ¼ �
Xi
log pðx0ijxiÞ; 8xi; x0iAS [ flg; ð7Þ
where l is the empty symbol, pðx0ijxiÞ is the probability to changethe symbol xi into x0i at the i th operation of the optimal scriptchanging x into x0. Plugging Eq. (7) in Eq. (1), we get the followingedit kernel presented by Li and Jiang [10]:
kðx; x0Þ ¼Y
i
pðx0ijxiÞ
!t
: ð8Þ
As mentioned in [10], this kernel assumes that pðx0ijxiÞ ¼ pðxijx0iÞ
which may not always be true. To guarantee the symmetryproperty, a solution consists of interpreting the edit distance as
edðx; x0Þ ¼ �
1
2
Xi
log pðx0ijxiÞþX
i
log pðxijx0iÞ
!:
Beyond the fact that our previous remark on the parameter t
still holds (how t can be tuned to satisfy the property of positivedefiniteness?), defining a relevant value for pðx0ijxiÞ is a difficultproblem. In specific domains, some background knowledge isavailable allowing the use of such kernels. For instance, in

ARTICLE IN PRESS
A. Bellet et al. / Pattern Recognition 43 (2010) 2330–23392332
molecular biology, some edit matrices have become standards todeal with amino acids (e.g. PAM [18] and BLOSUM [19]). Thesematrices describe similarity scores for amino acids and can betransformed (see [10]) to be used as relevant estimates of pðx0ijxiÞ.However, in many other domains, such an information is notavailable. A solution to overcome this problem is to automaticallylearn those edit probabilities from learning examples. We willpresent some approaches that deal with this problem in Section 4.
3. New edit distance-based kernel
Before that, let us introduce our new string edit kernel, whichis a specific case of the marginalized kernels as described in [20].Let pðx; x0;hÞ be the probability of observing jointly a hiddenvariable hAH and two visible strings x; x0AS�. pðx; x0Þ can beobtained by marginalizing, i.e. summing over all variables hAH,the probability pðx; x0;hÞ, such that
pðx; x0Þ ¼XhAH
pðx; x0;hÞ ¼XhAH
pðx; x0jhÞ � pðhÞ:
A marginalized kernel computes this probability making theassumption that x and x0 are conditionally independent given h:
kðx; x0Þ ¼XhAH
pðxjhÞ � pðx0jhÞ � pðhÞ: ð9Þ
Note that the computation of this kernel is possible since it isassumed that H is a finite set. Let us now suppose that pðhjxÞ isknown instead of pðxjhÞ. Then, as described in [16], we can use thefollowing marginalized kernel:
kðx; x0Þ ¼XhAH
pðhjxÞ � pðhjx0Þ � Kzðz; z0Þ; ð10Þ
where Kzðz; z0Þ is the joint kernel depending on combined variablesz¼ ðx;hÞ and z0 ¼ ðx0;hÞ.
An interesting way to exploit kernel of Eq. (10) as a string edit
kernel is to use the following features:
�
the finite set H of variables h is replaced by the infinite set ofpossible strings yAS�, � as pðyjxÞ, we use peðyjxÞ which is the conditional probability totransform a string x into a string y by using edit operations,
� the Dirac kernel (that returns 1, 8ðz; z0Þ) is used as kernelKzðz; z0Þ.
Therefore, we obtain a new string edit kernel:
kðx; x0Þ ¼X
yAS�peðyjxÞ � peðyjx
0Þ; ð11Þ
which is positive definite as it corresponds to the dot product inthe feature space defined by the following mapping: F :x-fpeðyjxÞgyAS� : However, the practical use of this edit kernelraises two crucial questions:
1.
Is it possible to learn a unique model that provides an estimateof the probability peðyjxÞ for any pair of strings ðx; yÞ?2.
If so, how can we compute from such a model the infinite sumover yAS�?While recent papers have already answered the first question(see the next section for a survey), the reply to the second one isthe matter of the rest of the article.
4. How to learn the edit parameters?
Let us recall that the edit distance between two strings x and y
(built from an alphabet S) is the cost of the best sequence of editoperations that changes x into y. Typical edit operations aresymbol deletion, insertion and substitution, and to each of them isassigned a cost. Since tuning these costs can constitute a difficulttask in many applications, supervised learning has been usedduring the last decade for learning the edit parameters.
In the context of the alignment of biological sequences, Saigoet al. [21] optimized from a learning set the BLOSUM substitutionmatrix by classical gradient descent. In order to control theoptimization procedure, they designed an objective function thatmeasures how well the local alignment kernel discriminateshomologs from non-homologs. The learned substitution matrixSða; bÞ can then be incorporated in the LA kernel already presented inEq. (5). In order to avoid to call on positive and negative examples,another solution to learn the edit parameters is to use a probabilisticframework and control the optimization process by resorting tostatistical constraints. In this context, that will be used in the rest ofthis paper, a widespread approach uses the maximum likelihood
paradigm to learn probabilistic state machines (e.g. probabilisticautomata, stochastic transducers, pair-hidden Markov models) thatcan be used to model edit probability distributions. When there is noreason that the cost of a given edit operation changes according tothe context where the operation occurs, memoryless machines (i.e.that contain only one state) are sufficient and very efficient from anaccuracy and algorithmic point of view. In this case, training boilsdown to learning a single matrix of jS [ flgj2 parameters, i.e. aprobability for each possible edit operation. A pioneer work thataimed to learn a memoryless transducer for modeling the editprobabilities has been presented by Ristadt and Yianilos in [12]. Thisgenerative model takes the form of a one state machine whoseparameters (i.e. the edit probabilities) are learned by using anexpectation maximization (EM)-based algorithm [22]. Using aforward procedure, it is then possible to deduce the joint editprobability peðx; yÞ from the probabilities of the successive editoperations for changing x into y. However, to perform a classificationtask, one often requires peðyjxÞ rather than peðx; yÞ. A solutionconsists in computing peðyjxÞ ¼ peðx; yÞ=pðxÞ, but it is commonknowledge that this can induce a statistical bias. To overcome thisdrawback, a relevant strategy consists in directly learning aconditional model (that allows an unbiased computation of peðyjxÞ
[23]) by adapting the maximization step of the EM algorithm, asdone in [14]. In this context, the learned parameters are conditional
edit probabilities. The authors of [14] show on ahandwritten digitrecognition task that such a discriminative model outperforms thegenerative one of Ristad and Yianilos.
Note that many applications can be treated by such memory-less models, such as the correction of typing errors made with acomputer keyboard, the recognition of images represented withFreeman codes, or in recognition of musical pieces [24].
However, learning a single matrix of edit costs can be viewed asinsufficient in some applications, particularly when the operationplays a part more or less important in the string transformationaccording to its location. This is the case in molecular biology,where the edit operation on a symbol can depend on its presence ina transcription factor binding site. To deal with such situations,non-memoryless approaches have been proposed in the literature inthe form of probabilistic state machines that are able to take intoaccount the string context. They are mainly based on pair-HMM[11,25], probabilistic deterministic automata (PDFA) [15], orstochastic transducers [26]. The string context is taken into accountin each state by a specific statistical distribution over the editoperations. However, these models are generative and so do notallow the integration of constraints on the input string x. To

ARTICLE IN PRESS
0
a|a
λ|a
b|a
a|λ b|λ
λ|b
a|b
b|b
Fig. 1. Memoryless cPFT. To each transition is assigned an edit probability (not
shown here for the sake of legibility) which can be used to compute the edit
conditional probability of any pair of strings.
A. Bellet et al. / Pattern Recognition 43 (2010) 2330–2339 2333
overcome this limitation, two recent approaches have beenpresented to learn discriminative non-memoryless edit models.In [13], McCallum et al. adapted the conditional random fields tothe finite-state string edit distance. Note that this model, unlike theothers, requires the use of positive and negative examples ofmatches of strings. More recently, in [27], the authors presentedconstrained state machines dedicated to the learning of edit distancesatisfying domain constraints. The main difficulty of this approachis to have such background knowledge that can be expressed in theform of constraints.
Whatever the learning method we use, we have shown in thissection that it is possible to learn a state machine T which modelsa distribution over the edit operations. As we noted before,memoryless transducers are suitable machines to deal withpattern recognition problems for whose the location of the editoperation does not play an important role. This is the case for therecognition of digits represented with Freeman codes as shown in[14]. Since we will use in this paper the same experimentalframework to assess the relevance of our new edit kernel, we willconsider in the rest of this paper that a memoryless transducer T
is learned with the learning algorithm proposed in [14]. To ensurethe self-consistency of our paper, Appendix A presents the mainfeatures of this learning algorithm that returns the machine T.
Such a machine can then be used to compute the joint orconditional edit probability between two strings. In the nextsection, we show how we can use T to compute the infinite sum ofour string edit kernel. Rather than computing each peðyjxÞ;8yAS�,we show that one can deduce from T two probabilistic automatamodeling, respectively, the conditional distribution peðyjxÞ andpeðyjx0Þ, given x and x0. Then, drawing our inspiration from therational kernels [9], we show that the infinite sum of Eq. (11) canbe efficiently calculated by calling on a composition of these twoprobabilistic automata.
5. How to compute the edit kernel over R�?
While the original marginalized kernel of Eq. (9) assumes thatH is a finite set of variables [16], our string edit kernel computesan infinite sum over S�, such that kðx; x0Þ ¼
PyAS� peðyjxÞ � peðyjx0Þ.
We show in the following that (i) given two strings x and x0, peðyjxÞ
and peðyjx0Þ can be represented in the form of two probabilisticautomata, (ii) the product peðyjxÞ � peðyjx0Þ can be performed byintersecting the languages represented by those automata and(iii) the infinite sum over S� can be computed by resorting toalgebraic methods.
5.1. Definitions and notations
Definition 1. A weighted finite-state transducer (WFT) is an 8-tuple T ¼ ðS;D;Q ; S; F;w; t;rÞ where S is the input alphabet, D theoutput alphabet, Q a finite set of states, SDQ the set of initialstates, FDQ the set of final states, w : Q � Q � ðS [ flgÞ � ðD [flgÞ-Rþ the transition weight function, t : S-Rþ the initialweight function, and r : F-Rþ the final weight function. Forconvenience, we denote wðq1; q2; xi; yjÞ by wq1-q2
ðxi; yjÞ.
Definition 2. A joint probabilistic finite-state transducer (jPFT) isa WFT J¼ ðS;D;Q ; S; F;w; t;rÞ which defines a joint probabilitydistribution over the pairs of strings fðx; yÞAS� �D�g. A jPFTsatisfies the following three constraints:
(i)
PiA S tðiÞ ¼ 1;P
(ii) f A F rðf Þ ¼ 1;P1 This specific notation is required to deal with non-memoryless cPFT.
(iii) 8q1AQ : q2 AQ ;xi AS[flg;yj AD[flgwq1-q2ðxi; yjÞ ¼ 1:Definition 3. A conditional probabilistic finite-state transducer(cPFT) is a WFT C ¼ ðS;D;Q ; S; F;w; t;rÞ which defines a condi-
tional probability distribution over the output strings yAD� givenan input string x. We denote the transition wq1-q2ðxi; yjÞ in theconditional form wq1-q2
ðyjjxiÞ. A cPFT satisfies the same first twoconstraints as those of a jPFT and the following third constraint(see [14] for a proof):
8q1AQ ; 8xiAS :X
q2 AQ ;yj AD[flg
ðwq1-q2ðyjjxiÞþwq1-q2
ðyjjlÞÞ ¼ 1:
In the following, since our string edit kernel is based onconditional edit probabilities, we will assume that a cPFT hasalready been learned by one of the previously mentioned methods(see Appendix A for the details of a specific EM-based algorithm).Note that this transducer cPFT is learned only one time and then isused to compute our edit kernel for any pair of strings. Forinstance, a memoryless cPFT is described in Fig. 1, whereS¼D¼ fa; bg and Q ; S and F are composed of only one state oflabel 0. Note that if a generative learning model would have beenused to learn the edit parameters, the resulting jPFT could be aposteriori renormalized into a cPFT.
5.2. Modeling peðyjxÞ and peðyjx0Þ by probabilistic automata
Since our kernel kðx; x0Þ depends on two observable strings x
and x0, it is possible to represent in the form of probabilistic statemachines the distributions peðyjxÞ and peðyjx0Þ, where only y is ahidden variable.
Given a cPFT C modeling the edit probabilities and a string x,we can define a new cPFT denoted by Cjx that models peðyjxÞwhilebeing driven by the specific observable string x.
Definition 4. Let C ¼ ðS;D;Q ; S; F;w; t;rÞ be a cPFT that modelspeðyjxÞ, 8yAD�; 8xAS�. We define Cjx as a cPFT that modelspeðyjxÞ; 8yAD� but for a specific observable xAS�.Cjx¼ ðS;D;Q 0; S0; F 0;w0; t0;r0Þ with:
�
Q 0 ¼ f½x�ig � Q where ½x�i is the prefix of length i of x (note that½x�0 ¼ l); in other words, Q 0 is a finite set of states labeled bythe current prefix of x and its corresponding state during itsparsing in of C1; � S0 ¼ fðl; qÞg where qAS; � 8qAS; t0ððl; qÞÞ ¼ tðqÞ; � F 0 ¼ fðx; qÞg where qAF; � 8qAF;r0ððx; qÞÞ ¼ rðqÞ;
ARTICLE IN PRESS
A. Bellet et al. / Pattern Recognition 43 (2010) 2330–23392334
�
Figan i
stat
give
the following two rules are applied to define the transitionweight function:3 8aAD; 8q1; q2AQ ;w0ð½x�i ;q1Þ-ð½x�iþ 1 ;q2Þ
ðajxiþ1Þ ¼wq1-q2ðajxiþ1Þ;
3 8aAD; 8q1; q2AQ ;w0ð½x� ;q Þ-ð½x� ;q ÞðajlÞ ¼wq1-q2ðajlÞ.
. 2.npu
e 1
n x
Fig.
i 1 i 2
As an example, given two strings x¼ a and x0 ¼ ab, Figs. 2(a) and(b) show the cPFT Cja and Cjab constructed from the memorylesstransducer C of Fig. 1. Roughly speaking, Cja and Cjab model theoutput languages that can be, respectively, generated from x andx0. Therefore, from these state machines, we can generate outputstrings and compute the conditional edit probabilities peðyjxÞ andpeðyjx0Þ for any string yAD�. Note that since we are in an edit-based framework, the cycles outgoing from each state model thedifferent possible insertions before and after the reading of aninput symbol.
Since the construction of Cjx and Cjx0 are driven by the parsingof x and x0 in the transducer C, we can omit the input alphabet S.Therefore, a transducer Cjx¼ ðS;D;Q ; S; F;w; t;rÞ can be reducedto a finite-state automaton Ajx¼ ðD;Q ; S; F;w0; t;rÞ. The transi-tions of Ajx are derived from w in the following way:w0q1-q2
ðaÞ ¼wq1-q2ðajbÞ; 8bAS [ flg; 8aAD [ flg; 8q1; q2AQ . For
example, Figs. 3(a) and (b) are the resulting automata deducedfrom the cPFT Cja and Cjab of Figs. 2(a) and (b).
5.3. Computing the product peðyjxÞ � peðyjx0Þ
The next step for computing our kernel kðx; x0Þ requires thecalculation of the product peðyjxÞ � peðyjx0Þ. This can be performedby modeling the language that describes the intersection of theautomata modeling peðyjxÞ and peðyjx0Þ. This intersection can beobtained by performing a composition of transducers as describedby Cortes et al. in [9]. As mentioned by the authors, composition isa fundamental operation on weighted transducers that can beused to create complex weighted transducers from simpler ones.In this context, we can note that the intersection of twoprobabilistic automata (such as those of Figs. 3(a) and (b)) is aspecial case of composition where the input and output labels of
0 1
a|λ
b|λ
λ|a
a|a
b|a
a|λ
b|λ
0 1 2
a|λ
b|λ
λ|a
a|a
b|a
a|λ
b|λ
λ|b
a|b
b|b
a|λ
b|λ
On the left: a cPFT Cja that models the output distribution conditionally to
t string x¼ a; note that for the sake of legibility, state 0 stands for ðl;0Þ, and
for ða;0Þ. On the right: a cPFT Cjab that models the output distribution0 ¼ ab, here again, 0 stands for ðl;0Þ, 1 for ða;0Þ, and 2 for ðab;0Þ.
0 1
a
b
λa
b
a
b
0 1 2
a
b
λa
b
a
b
λa
b
a
b
3. The transducers Cja and Cjab represented in the form of automata.
transitions are identical. This intersection takes the form of aprobabilistic automaton as defined below.
Definition 5. Let C be a cPFT modeling conditional edit prob-abilities. Let x and x0 be two strings of S�. LetAjx¼ ðD;Q ; S; F;w; t;rÞ and Ajx0 ¼ ðD;Q 0; S0; F 0;w0; t0;r0Þ be the auto-mata deduced from C given the observable strings x and x0. Wedefine the intersection of Ajx and Ajx0 as the automatonAx;x0 ¼ ðD;QA; SA; FA;wA; tA;rAÞ such that:
�
a
FigFigs
QA ¼ Q � Q 0;
� SA ¼ fðq;q0Þg with qAS and q0AS0; � FA ¼ fðq;q0Þg with qAF and q0AF 0; � wAðq1 ;q01Þ-ðq2 ;q
02ÞðaÞ ¼wq1-q2
ðaÞ �w0q01-q0
2ðaÞ;
A 0 0
� t ððq; q ÞÞ ¼ tðqÞ � tðq Þ; � rAððq;q0ÞÞ ¼ rðqÞ � rðq0Þ.Fig. 4 describes the intersection automaton of automata ofFigs. 3(a) and (b).
Let us now describe how this resulting automaton can be usedto compute the infinite sum of our kernel over S�.
5.4. Computing the sum over S�
To simplify the notations, let pðzÞ ¼ peðyjxÞ � peðyjx0Þ be thedistribution modeled by an intersection automatonA¼ fS;Q ; S; F;w; t;rg. Let S¼ fa1; . . . ; ajSjg be the alphabet.
Let Makbe the square matrix defined over Q � Q and providing
the probabilities Makðqi; qjÞ ¼wqi-qj
ðakÞ; 8akAS. In other words,Makðqi; qjÞ is the probability that the symbol akAS is emitted by
the transition going from state qiAQ to state qjAQ in A. In thiscontext, given a string z¼ z1 . . . zt , pðzÞ can be rewritten as follows:
pðzÞ ¼ pðz1 . . . ztÞ ¼ sT Mz1. . .Mzt q¼ sT Mzq; ð12Þ
where s and q are two vectors of dimension jQ j whosecomponents are the values returned by the weight function t(8qAS) and r (8qAF), and 0 otherwise, and whereMz ¼Mz1
. . .Mzt .From (12), we can deduce thatX
zAS�pðzÞ ¼
XzAS�
sT Mzq: ð13Þ
To take into account all the possible strings zAS�, Eq. (13) canbe rewritten according to the size of the string z:
XzAS�
pðzÞ ¼X1i ¼ 0
sT ðMa1þMa2
þ � � � þMajSj Þiq¼ sT
X1i ¼ 0
Miq; ð14Þ
0,0 0,1 0,2
1,0 1,1 1,2
a b
ab
ab ab
λ
a b
ab
ab ab
λ
a b
a b
b
a
b
a b
a
b
a
b
. 4. Resulting automaton modeling the intersection of the automata of
. 3(a) and (b).

ARTICLE IN PRESS
86
88
90
92
94
96
98
100
0 1000 2000 3000 4000 5000 6000 7000 8000
Learned string edit kernel
1-NN with de
1-NN with dl
Number of learning samples
Acc
urac
y on
200
0 te
st s
trin
gs
Fig. 6. Comparison of our edit kernel with edit distances on a handwritten digit
recognition task.
A. Bellet et al. / Pattern Recognition 43 (2010) 2330–2339 2335
where M¼Ma1þMa2
þ � � � þMajSj . Let us replaceP1
i ¼ 0 Mi by B.Therefore,
B¼ IþMþM2þM3þ � � � ; ð15Þ
where I is the identity matrix. Multiplying B by M we get
MB¼MþM2þM3þ � � � : ð16Þ
Subtracting Eq. (15) from Eq. (16), we get
B�MB¼ I 3 B¼ ðI�MÞ�1: ð17Þ
Plugging Eq. (17) in Eq. (14), we get our kernel:
kðx; x0Þ ¼X
yAS�peðyjxÞ � peðyjx
0Þ ¼ sTX1i ¼ 0
Miq¼ sT ðI�MÞ�1q: ð18Þ
5.5. Tractability
Given two strings x and x0, we deal here with the complexity ofcomputing kðx; x0Þ. As we just wrote, this involves the computationof an infinite sum computed by solving a matrix inversion.
Let us denote C the cPFT that models the edit probabilities, andlet be t the number of states of C. We denote by n the length of thestring x and by m the length of the string x0.
First, recall that in the case of the classical edit distance withnon-learned costs, the complexity is n �m for the calculation ofdeðx; x0Þ.
The weighted automaton Cjx describing peðyjxÞ has ðnþ1Þ � tstates, and Cjx0 describing peðyjx0Þ has ðmþ1Þ � t states (e.g. seeFig. 3). Thus the matrix ðI�MÞ is of dimension ðnþ1Þ � ðmþ1Þ � t2.The computation cost of each element of this matrix linearlydepends on the alphabet size jSj. Therefore, the computation costof the entire matrix is n2 �m2 � t4 � jSj. Since M is triangular, thematrix inversion ðI�MÞ�1 can be performed by back substitution,avoiding the complications of general Gaussian elimination. Thecost of the inversion is of order of the square of the matrixdimension, that is n2 �m2 � t4. This leads to a cost of
n2 �m2 � t4 � jSj:
Note the factor t4 stands for the size of C that models editprobabilities. In the case of memoryless models (that will be usedin the experimental study of Section 6), we have t¼ 1 and thus acost reduced to
n2 �m2 � jSj:
Starting point
2222344
Fig. 5. A digit and its st
Therefore, in the case of a conditional memoryless transducer, andfor small alphabet sizes, the computation cost of our edit kernel is‘‘only’’ the square of that of the standard edit distance.
Despite the advantage of triangular matrices, the algorithmiccomplexity remains a problem in the case of learning processeswith long strings and/or large alphabet sizes. To overcome thisproblem, we can efficiently approximate our kernel kðx; x0Þ bycomputing a finite sum only considering the strings y that belongto the learning sample. Therefore, we get
kðx; x0Þ ¼XyAS
peðyjxÞ � peðyjx0Þ;
where S is the learning sample. Since the computation of eachprobability peðyjxÞ requires a cost of nþjyj, the average cost ofeach kernel computation is
ðnþmþjyjÞ � jSj;
where jyj is the average length of the learning strings.In conclusion, even if our kernel is a priori rather costly from a
complexity point of view, it has the advantage to be usable fromany transducer modeling edit probabilities, and its calculationremains reasonable. Moreover, the analysis of this kernel mustalso take into account the gain in accuracy it implies in a patternrecognition task. This is the aim of the next section.
0
1
2
3
4
5
6
7
Freeman Codes
45533445666660222217760021107666501
coding string
ring representation.
ARTICLE IN PRESS
Table 1Statistical comparison between our edit kernel (EK) and a (learned or standard) edit distance (ED).
Learning set size 1000 2000 3000 4000 5000 6000 7000 8000
EK vs learned ED 1E�02 6E�02 2E�02 2E�02 2E�02 9E�02 3E�02 3E�01EK vs standard ED 6E�06 4E�04 1E�03 3E�03 2E�03 8E�03 2E�03 3E�02
Using a risk of 5%, a p-value of less than 5E-02 means that the difference is significant in favor of our kernel.
86
88
90
92
94
96
98
100
0 1000 2000 3000 4000 5000 6000 7000 8000A
ccur
acy
on 2
000
test
stri
ngs
Number of learning samples
Learned string edit kernelSpectrum kernel
Subsequence kernelLi and Jiang kernel
Neuhaus and Bunke kernel
Fig. 7. Comparison of our edit kernel with the state of the art edit kernels on a
handwritten digit recognition task.
A. Bellet et al. / Pattern Recognition 43 (2010) 2330–23392336
6. Experiments
6.1. Database and experimental setup
To assess the relevance of using learned edit distances in thedesign of a new string edit kernel, we carried out someexperiments. We studied the behavior of our approach on thewell known NIST Special Database 3 of the National Institute ofStandards and Technology, describing a set of handwrittencharacters.
We focus on handwritten digits consisting of 128� 128bitmaps images. We use a learning set of about 8000 digits anda test sample of 2000 instances. Each instance is represented by astring. To code a given digit, the algorithm scans the bitmap left toright and starting from the top until encountering the first point.Then, the algorithm builds the string following the border of thecharacter until it returns to the starting pixel. The string isconstructed considering the succession of Freeman codes asdescribed in Fig. 5.
To compare our approach with other string kernels, we usedSVM-Light 6.02 [28]. In order to deal with our multi-class task, welearn 10 binary SVM models Mi. The model Mi, 8iAf0; . . . ;9g, islearned from a positive class composed by all the handwrittencharacters labeled i and a negative class grouping all the otherdigits. Then, the class of an unknown example x is determined asfollows: we compute for each model Mi the margin gMi
ðxÞ and theclass of x is given by argmaxigMi
ðxÞ. Obviously, a high positive valueof margin gMi
ðxÞ represents a high probability for x to be of class i.
6.2. Edit kernels vs edit distance
As done by Neuhaus and Bunke [8], our first objective was toshow the interest of our edit kernel in comparison with the editdistance used in a nearest-neighbor algorithm. To achieve thistask, we first used a standard edit distance dl with costs of all editoperations (deletion, insertion and substitution) set to 1. On theother hand, we used the SEDiL platform [29] to learn a matrix ofedit probabilities from which one can deduce conditional editprobabilities peðyjxÞ and compute a so-called stochastic editdistance
deðx; yÞ ¼ �log peðyjxÞ:
We assessed the performance of a 1-nearest neighbor algorithmusing both edit distances dl and de, and compared them with ournew string edit kernel (using SVM-Light 6.02) on a test setcomposed of 2000 instances. Note that the conditional probabil-ities peðyjxÞ required in our edit kernel are the same as those usedin deðx; yÞ. Results are presented in Fig. 6 according to anincreasing number of learning examples (from 100 to 8000).
We can make the following remarks:
2
�We did not use the LA kernel which is too specific (it searches for remote
homologies between biological sequences by achieving local alignments) to be
easily compared in this series of experiments with the state of the art string
kernels.
First, learning a stochastic edit distance de on this classificationtask leads to better results than using the standard editdistance dl. Indeed, whatever the size of the learning set weuse, the accuracy computed from de is always higher.
�
Second, our string edit kernel outperforms not only thestandard edit distance dl, but also the stochastic edit distancede. This clearly shows the usefulness of our string edit kernel totake advantage of powerful classifiers such as SVMs. Toestimate the statistical significance of these results, compar-isons between the three approaches were performed using aStudent paired-t test. Table 1 presents the so-called p-valuesobtained while comparing our kernel with de and dl. Using arisk of 5%, a p-value of less than 0.05 means that the differenceis significant in favor of our kernel (in bold font in the table).We can note that this is always the case except for the twolearning samples of size 2000 and 6000.However, these previous remarks are not sufficient to prove therelevance of our edit kernel. Indeed, as presented in Section 2,other string kernels have been proposed in the literature that canalso take advantage of SVMs. How does our edit kernel behave incomparison with those state of the art string kernels? This is thematter of the next section.
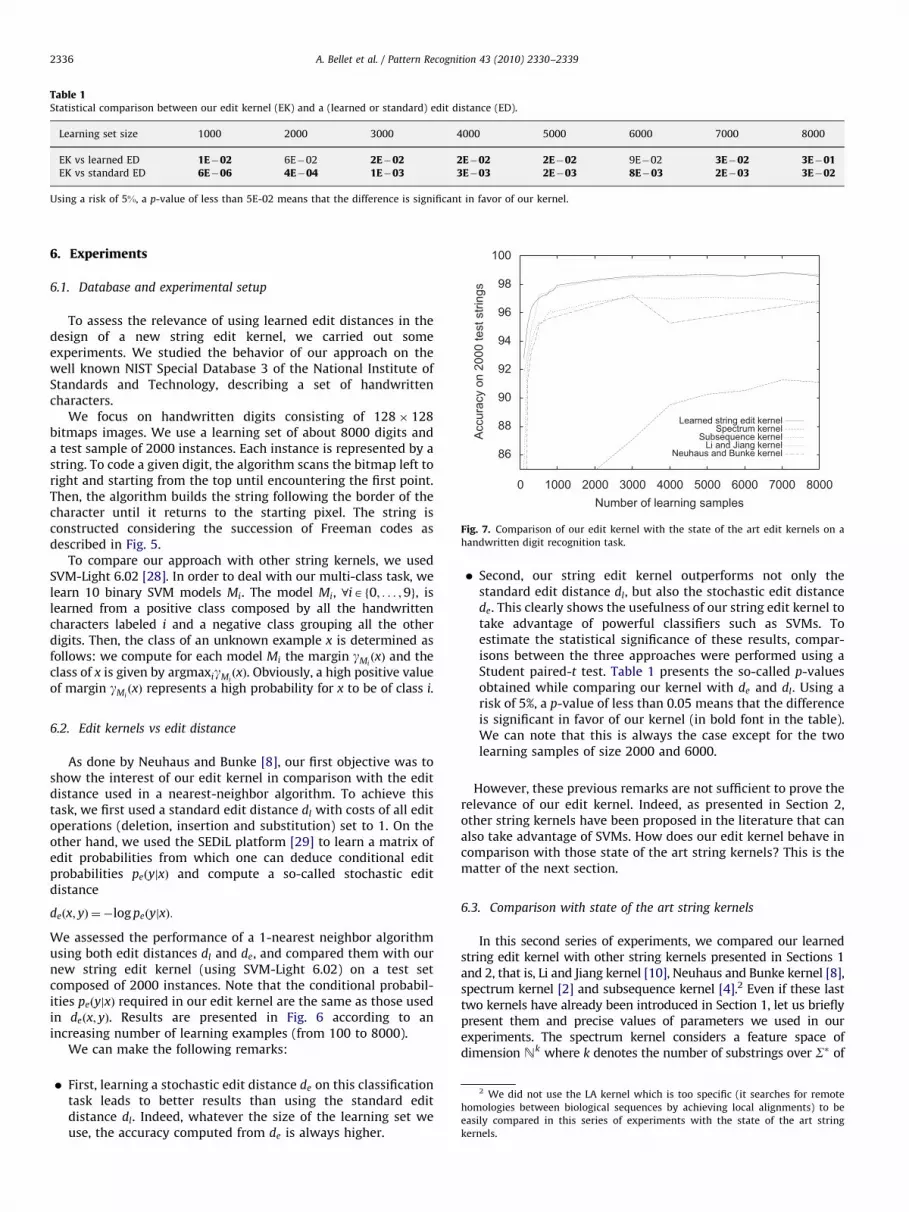
6.3. Comparison with state of the art string kernels
In this second series of experiments, we compared our learnedstring edit kernel with other string kernels presented in Sections 1and 2, that is, Li and Jiang kernel [10], Neuhaus and Bunke kernel [8],spectrum kernel [2] and subsequence kernel [4].2 Even if these lasttwo kernels have already been introduced in Section 1, let us brieflypresent them and precise values of parameters we used in ourexperiments. The spectrum kernel considers a feature space ofdimension Nk where k denotes the number of substrings over S� of

ARTICLE IN PRESS
Table 2Statistical comparison between our edit kernel (EK) and the state of art string kernels.
Learning set size 1000 2000 3000 4000 5000 6000 7000 8000
EK vs spectrum 0 0 0 0 0 0 0 0EK vs subsequence 4E�04 8E�04 5E�04 2E�04 2E�04 4E�04 2E�05 4E�05EK vs Li and Jiang 3E�01 4E�01 3E�01 3E�01 3E�01 4E�01 4E�01 7E�01
EK vs Neuhaus and B. 6E�06 6E�06 1E�03 2E�10 6E�09 4E�08 4E�07 1E�04
Using a risk of 5%, a p-value of less than 5E-02 means that the difference is significant in favor of our kernel.
86
88
90
92
94
96
98
100
0 0.02 0.04 0.06 0.08 0.1 0.12 0.14 0.16 0.18 0.2
Acc
urac
y on
200
0 te
st s
tring
s
LiJiang Kernel
t
Fig. 8. Tuning of the parameter t in Li and Jiang kernel.
A. Bellet et al. / Pattern Recognition 43 (2010) 2330–2339 2337
length smaller than a parameter p. In this space, each example x isrepresented by the vector of the number of occurrences ofsubstrings. Thus, the spectrum kernel of x and y is trivially computedusing the inner product between the two string representations. Inour experiments, the parameter p has been fixed to 2.
The subsequences gap weighted kernel extends the spectrumkernel considering subsequences instead of substrings. Thus, thiskernel is able to take into account long term dependenciesinformation using sets of letters with gaps. The same parameter p
is used to limit the size of subsequences. Moreover, a weight l isdefined in order to give less importance to subsequences withlarge gaps. In our experiments, l has been set to 2 which leads inour case to the best results with this kernel.
Fig. 7 shows the results we obtained with the differentmentioned kernels. We can first note that the best results areobtained with edit distance based kernels. As we did before, Table 2presents the p-values of the Student paired-t test. Except the kernelof Li and Jiang, our edit kernel significantly outperforms all the otherstring kernels. Second, even if their behaviors are quite similar, wecan note that our kernel almost always outperforms that of Li andJiang (even if the difference is not statistically significant). It is alsoimportant to note in this analysis that the parameter t required inthe Li and Jiang kernel is very difficult to tune. In [10], the authorsindicated that the best results were obtained with a valuet¼ 0:00195. In order to optimally tune this parameter, we testedmany values of t (from t¼ 0 to 0:2). Fig. 8 shows that the bestperformances are obtained on 2000 test strings with a value of 0.02,while using t40:1 leads to a dramatic drop of the accuracy.Therefore, we used t¼ 0:02 throughout our comparison.
7. Conclusion
The common way to use the edit distance in classification tasksconsists in exploiting it in a classical k-nearest-neighbor algo-
rithm. Recently, machine learning techniques have been used toautomatically learn the probabilities of the edit operations tocapture background knowledge and so improve the performanceof the edit distance. On the other hand, in order to take advantageof the widely used framework of support vector machines, recentworks have been done to derive edit kernels from the editdistance. In this article, we suggested to embed the advantages ofboth approaches by designing a learned string edit kernel. Weexperimentally showed that such a strategy allows significantimprovements in terms of classification accuracy.
A first perspective of our work is to improve the algorithmiccomplexity of our kernel. A crucial point in its calculationconcerns the size of the product automaton allowing thecomputation of peðyjxÞ � peðyjx0Þ. To reduce this size, a possiblesolution would consist in simplifying the original conditionaltransducers Cjx and Cjx0 by only considering the most probabletransitions and states. A simplification of Cjx and Cjx0 would havea direct impact on the dimension of the matrix we have to invert.
A second natural perspective of this work relies on theextension of our method to the elaboration of tree edit kernels.Indeed, some recent papers dealing with the learning of tree editdistance in the form of stochastic models [30,31] would allow usto generalize our method to the learning of more complexstructured data-based edit kernels.
Appendix A
This appendix describes the way to learn the parameters of aconditional memoryless transducer as proposed in [14].
Let us suppose that we have a learning set S of pairs of stringsðx; yÞ and for the sake of simplicity that the input and the outputalphabets are the same, noted S. Let S� be the set of all finitestrings over S. Let xAS� be an arbitrary string of length jxj overthe alphabet S. In the following, unless stated otherwise, symbolsare indicated by a; b; . . ., strings by u; v; . . . ; z, and the empty stringby l. Rþ is the set of non-negative reals. Let f ð�Þ be a function,from which ½f ðxÞ�pðx;...Þ is equal to f ðxÞ if the predicate pðx; . . .Þ holdsand 0 otherwise, where x is a (set of) dummy variable(s).
Let c be the conditional probability function that returns forany edit operation ðbjaÞ the probability to output the symbol b
given an input letter a. The aim of this appendix is to show howwe can automatically learn the function c from the learningsample S. The different values cðbjaÞ; 8aAS [ flg; bAS [ flgrepresent the parameters of the memoryless machine T. Theseparameters are trained using an EM-based algorithm that calls ontwo auxiliary functions called forward and backward.
The conditional probability p : S� �S�-½0;1� of the string y
given an input one was an x (noted pðyjxÞ) can be recursivelycomputed by means of an auxiliary function (forward) a : S� �S�-Rþ as
aðyjxÞ ¼ ½1�x ¼ l4y ¼ lþ½cðbjaÞ � aðy0jx0Þ�x ¼ x0a4y ¼ y0b
þ½cðljaÞ � aðyjx0Þ�x ¼ x0aþ½cðbjlÞ � aðy0jxÞ�y ¼ y0b:

ARTICLE IN PRESS
A. Bellet et al. / Pattern Recognition 43 (2010) 2330–23392338
Using aðyjxÞ, we get,
pðyjxÞ ¼ aðyjxÞ � g;
where g is the probability of the termination symbol of a string(note that g and cðljlÞ are synonyms). In a symmetric way, pðyjxÞ
can be recursively computed by means of an auxiliary function(backward) b : S� � S�-Rþ as
bðyjxÞ ¼ ½1�x ¼ l4y ¼ lþ½cðbjaÞ
� bðy0jx0Þ�x ¼ ax04y ¼ by0 þ½cðljaÞ � bðyjx0Þ�x ¼ ax0 þ½cðbjlÞ � bðy
0jxÞ�y ¼ by0 :
And we can deduce that
pðyjxÞ ¼ bðyjxÞ � g:
Both functions can be computed in Oðjxj � jyjÞ time using adynamic programming technique and will be used in thefollowing to learn the current function c. In this model aprobability distribution is assigned conditionally to each inputstring. ThenXyAS�
pðyjxÞAf1;0g; 8xAS�:
The 0 is in the case the input string x is not in the domain of thefunction. It can be shown that the normalization of eachconditional distribution can be achieved if the following condi-tions over the function c and the parameter g are fulfilled,
g40; cðbjaÞ; cðbjlÞ; cðljaÞZ0; 8aAS; bAS; ð19Þ
XbAS
cðbjlÞþXbAS
cðbjaÞþcðljaÞ ¼ 1; 8aAS; ð20Þ
XbAS
cðbjlÞþg¼ 1: ð21Þ
The expectation-maximization algorithm [22] can be used inorder to find the optimal parameters of the function c. Given anauxiliary ðjSjþ1Þ � ðjSjþ1Þ matrix d, the expectation step aims atcomputing the values of d as follows: 8aAS; bAS,
dðbjaÞ ¼X
ðxax0 ;yby0 ÞA S
aðyjxÞ � cðbjaÞ � bðy0jx0Þ � gpðyby0jxax0Þ
;
dðbjlÞ ¼X
ðxx0 ;yby0 ÞAS
aðyjxÞ � cðbjlÞ � bðy0jx0Þ � gpðyby0jxx0Þ
;
dðljaÞ ¼X
ðxax0 ;yy0 ÞA S
aðyjxÞ � cðljaÞ � bðy0jx0Þ � gpðyy0jxax0Þ
;
dðljlÞ ¼Xðx;yÞA S
aðyjxÞ � gpðyjxÞ
¼ jSj:
The maximization step allows us to iteratively deduce thecurrent edit costs:
cðbjlÞ ¼dðbjlÞ
NðinsertionÞ;
g¼ N�NðlÞN
ðtermination symbolÞ;
cðbjaÞ ¼dðbjaÞNðaÞ
�N�NðlÞ
NðsubstitutionÞ;
cðljaÞ ¼dðljaÞNðaÞ
�N�NðlÞ
NðdeletionÞ;
where
N¼X
a AS[flgb AS[flg
dðbjaÞ; NðlÞ ¼XbAS
dðbjlÞ; NðaÞ ¼X
bAS[flg
dðbjaÞ:
References
[1] B. Scholkopf, A.J. Smola, Learning with Kernels: Support Vector Machines,Regularization, Optimization, and Beyond, MIT Press, Cambridge, MA, USA,2001.
[2] C. Leslie, E. Eskin, W.S. Noble, The spectrum kernel: a string kernel for SVMprotein classification, in: Proceedings of the Pacific Symposium on Biocom-puting, , 2002, pp. 564–575.
[3] C. Leslie, E. Eskin, A. Cohen, J. Weston, W.S. Noble, Mismatch string kernels fordiscriminative protein classification, Bioinformatics 20 (4) (2004) 467–476.
[4] H. Lodhi, C. Saunders, N. Cristianini, C. Watkins, B. Scholkopf, Textclassification using string kernels, Journal of Machine Learning Research 2(2002) 563–569.
[5] S. Boisvert, M. Marchand, F. Laviolette, J. Corbeil, Hiv-1 coreceptor usageprediction without multiple alignments: an application of string kernels,Retrovirology 5 (1) (2008) 110.
[6] H. Saigo, J.-P. Vert, N. Ueda, T. Akutsu, Protein homology detection usingstring alignment kernels, Bioinformatics 20 (11) (2004) 1682–1689.
[7] R. Wagner, M. Fischer, The string-to-string correction problem, Journal of theACM (JACM) 21 (1974) 168–173.
[8] M. Neuhaus, H. Bunke, Edit distance-based kernel functions for structuralpattern classification, Pattern Recognition 39 (10) (2006) 1852–1863.
[9] C. Cortes, P. Haffner, M. Mohri, Rational kernels: theory and algorithms,Journal of Machine Learning Research 5 (2004) 1035–1062.
[10] H. Li, T. Jiang, A class of edit kernels for SVMs to predict translation initiationsites in eukaryotic mRNAs, in: Proceedings of the Eighth Annual InternationalConference on Research in Computational Molecular Biology (RECOMB’04),ACM, New York, 2004, pp. 262–271.
[11] R. Durbin, S. Eddy, A. krogh, G. Mitchison, Biological Sequence Analysis,Cambridge University Press, Cambridge, 1998.
[12] S. Ristad, P. Yianilos, Learning string-edit distance, IEEE Transactions onPattern Analysis and Machine Intelligence 20 (5) (1998) 522–532.
[13] A. McCallum, K. Bellare, P. Pereira, A conditional random field fordiscriminatively-trained finite-state string edit distance, in: Proceedings ofthe 21th Conference on Uncertainty in Artificial Intelligence (UAI’2005), ,2005, pp. 388–400.
[14] J. Oncina, M. Sebban, Learning stochastic edit distance: application inhandwritten character recognition, Journal of Pattern Recognition 39 (9)(2006) 1575–1587.
[15] M. Bernard, J.-C. Janodet, M. Sebban, A discriminative model of stochastic editdistance in the form of a conditional transducer, in: 8th InternationalColloquium on Grammatical Inference (ICGI’06), Lecture Notes in ComputerScience, vol. 4201, Springer, Berlin, 2006, pp. 240–252.
[16] K. Tsuda, T. Kin, K. Asai, Marginalized kernels for biological sequences,Bioinformatics 18 (90001) (2002) 268–275.
[17] D. Haussler, Convolution kernels on discrete structures, Technical Report,University of California, Santa Cruz, 1999.
[18] M.O. Dayhoff, R.M. Schwartz, B.C. Orcutt, A model of evolutionary change inproteins, in: M.O. Dayhoff, Atlas of Protein Sequence and Structure, vol. 5,National Biomedical Research Foundation, Washington, DC, 1978, pp. 345–358.
[19] S. Henikoff, J.G. Henikoff, Amino acid substitution matrices from proteinblocks, National Academy of Sciences of USA 89 (22) (1992) 10915–10919.
[20] H. Kashima, K. Tsuda, A. Inokuchi, Marginalized kernels between labeledgraphs, in: Proceedings of the Twentieth International Conference onMachine Learning, AAAI Press, 2003, pp. 321–328.
[21] S. Hiroto, V. Jean-Philippe, A. Tatsuya, Optimizing amino acid substitutionmatrices with a local alignment kernel, BMC Bioinformatics 7 (2006) 246.
[22] A.P. Dempster, N.M. Laird, D.B. Rubin, Maximum likelihood from incompletedata via the EM algorithm, Journal of the Royal Statistical Society. Series B(Methodological) 39 (1) (1977) 1–38.
[23] G. Bouchard, B. Triggs, The tradeoff between generative and discriminativeclassifiers, in: IASC International Symposium on Computational Statistics(COMPSTAT), Prague, 2004, pp. 721–728.
[24] A. Habrard, M. Inesta, D. Rizo, M. Sebban, Melody recognition with learnededit distances, in: Structural, Syntactic, and Statistical Pattern Recognition,Joint IAPR International Workshops, SSPR 2008 and SPR 2008, 2008, pp. 86–96.
[25] M. Bilenko, R.J. Mooney, Adaptive duplicate detection using learnable stringsimilarity measures, in: Proceedings of the 9th ACM SIGKDD InternationalConference on Knowledge Discovery and Data Mining (KDD-2003), 2003, pp.39–48.
[26] J. Eisner, Parameter estimation for probabilistic finite-state transducers, in:Proceedings of the 40th Annual Meeting on Association for ComputationalLinguistics (ACL’02), Morristown, NJ, USA, 2001, pp. 1–8. doi: /http://dx.doi.org/http://dx.doi.org/10.3115/1073083.1073085S.
[27] L. Boyer, A. Habrard, F. Muhlenbach, M. Sebban, Learning string editsimilarities using constrained finite state machines, in: Proceedings of the10th French Conference in Machine Learning (CAp-2008), , 2008, pp. 37–52.
[28] T. Joachims, Making large-scale SVM learning practical, in: B. Schlkopf, C.Burges, A. Smola (Eds.), Advances in Kernel Methods—Support VectorLearning, MIT Press, Cambridge, MA, 1999, pp. 169–184.
[29] L. Boyer, Y. Esposito, A. Habrard, J. Oncina, M. Sebban, Sedil: software for editdistance learning, in: Proceedings of the 19th European Conference on

ARTICLE IN PRESS
A. Bellet et al. / Pattern Recognition 43 (2010) 2330–2339 2339
Machine Learning (ECML 2008), Lecture Notes in Computer Science, vol.5212, Springer, Berlin, 2008, pp. 672–677.
[30] M. Bernard, L. Boyer, A. Habrard, M. Sebban, Learning probabilistic models oftree edit distance, Pattern Recognition 41 (8) (2008) 2611–2629.
[31] L. Boyer, A. Habrard, M. Sebban, Learning metrics between treestructured data: application to image recognition, in: Proceedings ofthe 18th European Conference on Machine Learning (ECML 2007), , 2007,pp. 54–66.
About the Author—AURELIEN BELLET was born in Saint-Etienne, France in 1986. He is currently pursuing a Ph.D. in Computer Science at the Hubert Curien Laboratory inthe Machine Learning group.
About the Author—MARC BERNARD was born in France in 1971. He received his Ph.D. in Computer Science from the University of Burgundy in 1998. Since 1999, he hasbeen assistant professor within the Faculty of Science at the University of Saint-Etienne. His current research interests include machine learning and grammatical inference.
About the Author—THIERRY MURGUE was born in France in 1977. He received his Ph.D. in Computer Science from the University of Saint-Etienne in 2006. He is currentlya network and security ingeneer at the University of Saint-Etienne.
About the Author—MARC SEBBAN was born in Lyon, France, in 1969. He received his Ph.D. in Computer Science from the University of Lyon I in 1996. Since 2001, he hasbeen full professor within the Faculty of Science at the University of Saint-Etienne, and since 2006, the vice-director of the Hubert Curien Laboratory (UMR CNRS 5516). Hiscurrent research interests include machine learning, boosting and grammatical inference.





























