Embed Size (px)
Citation preview

An integrated Web System to facilitate personalized web searching algorithms
Christos Makris, Yannis Panagis, Υannis Plegas, Evangelos Sakkopoulos Computer Engineering and Informatics Dpt
University of Patras, GR-26504, Rio Patras, Hellas
{makri, panagis, plegas, sakkopul}@ceid.upatras.gr ABSTRACT Generic web searching often turns out impersonal and frustrating due to lack of adaptivity to user preferences. These problems can be alleviated in the presence of a solution to assist personalization in an effective manner. Such a tool is presented within the context of this paper that enables personalization on the client’s browser and is supported by a Web Service based backend system that implement a number of different personalization approaches as an option. Our aim is to provide a generic platform based on web technologies a) for end-user personalization and b) for assistance in the research & development evaluation of existing or novel personalization techniques. The solution is further underpinned with novel personalization techniques. The latter have emerged as fine-grained and improved alternatives to provably efficient personalization methods previously presented in [10]. The solution altogether has been experimentally evaluated and proved effective.
Keywords H.3.3 Information Search and Retrieval, H.3.4 Systems and Software, H.4.3 Communications Applications
Keywords Web Searching, Personalisation, Categories.
1. INTRODUCTION Web searching comprises a ubiquitous web task over the last decade. However, search engine interface fail to meaningfully express user queries in natural language; search forms only allow for keyword based queries. Therefore, users most of the times find it difficult to fulfill their information need, although popular search engines (see e.g. the landmark papers in [2] and [7]), employ among others intricate spectral graph techniques to provide better result quality.
In the area of web search engines, a category indicator on each returned document is presented by Yahoo!, and Google. According to [3] this indicator facilitates searches since most
users are inclined to follow highly rated pages.Teoma also clusters its results and provides query refinements.
Still, phenomena like polysemy and synonymy, plague web searching. Personalised search engines, seem to partially tackle those phenomena, by means of registering user preferences and reranking search results according to user profiles. User profiles are constructed either implicitly or explicitly in searching environments such as Letizia [8] and CiteSeer [1].
These profiles assist the user task by providing search suggestions according to what each user currently browses. Both systems differ from our approach since they are information filtering and not information searching systems. In Letizia the system tracks user behaviour and attempts to anticipate items of interest by doing concurrent, autonomous exploration of links from the user's current position. The system uses a simple set of heuristics to model what the user's browsing behaviour might be and its content model of a document is simply a list of keywords. CiteSeer relies on a number of different representations of the user’s notion of an interesting paper. A new paper is deemed relevant if it satisfies the requirements of any of the representations. CiteSeer attempts to capture a user’s notion of relatedness between papers by (i) identifying the document features that correspond to useful semantic information, and (ii) creating metric functions with these features. Citeseer handles these tasks by using the vector space model, TF-IDF assignment of weights and various citation metrics.
Our work is quite closely related to research in customized and personalized web searching. An important step forward in this area was the paper of Haveliwala [6] introducing the Topic sensitive Page-Rank. Topic sensitive PageRank is essentially a method to bias PageRank towards specific topics. The authors calculate the topic-sensitive PageRank by precomputing multiple importance factors biased according to a set of representative topics that are produced by selecting the top categories from the Open Directory Project. The key idea in creating these topic-sensitive PageRanks is that the computation can be biased to favour certain categories of pages, by employing nonuniform personalization vectors. At query time, these importance scores are combined together based on the topics of the query to form a composite PageRank score for those pages matching the query. These representative topics are computed either by using the topic of the query keywords or (for searches done in context) by using the topic of the context where the query appears; moreover the classification of the query and the query context are provided by using a unigram language model.
In [3] algorithms are proposed for creating “personally customized authority documents” to correspond more closely to
Permission to make digital or hard copies of all or part of this work for personal or classroom use is granted without fee provided that copies are not made or distributed for profit or commercial advantage, and that copies bear this notice and the full citation on the first page. To copy otherwise, to republish, to post on servers or to redistribute to lists, requires prior specific permission and/or a fee.
SAC’08, March 16-20, 2008, Fortaleza, Ceará, Brazil.
Copyright 2008 ACM 978-1-59593-753-7/08/0003…$5.00.
2397
Σ28
1/6

the user’s internal model, following the conventions of Kleinberg’s HITS algorithm [7]. The proposed techniques are similar to relevance feedback, but instead of manipulating the query to learn the relevance of the retrieved documents, the weighting of the link matrix is manipulated; the authors use an elegant approach that instead of relying on spreading activation to directly confer authority performs gradient ascent on the elements of the link weight to more closely align the principal eigenvector with the documents in question. Moreover a set of extensive experiments are presented showing that using only a small amount of user feedback, the proposed procedure can significantly improve link ranking being in a better agreement with both non-link based machine classification and human subject’s preferences.
Liu et al. [9] also propose a technique to map user queries to categories, in order to assist the search procedure. In particular techniques are provided to model and gather the user's search history and then construct a user profile based on the gathered search history and a general profile that exploits the Open Directory Project category hierarchy; based on these techniques appropriate categories for each user query are deduced. Speaking in technical terms a user profile is expressed as a set of categories with each category containing a set of terms (keywords) with weights. Each category represents a user interest in that category while the weight of a term in a category reflects the significance of the term in representing the user's interest in that category. Their technique obtains information about user search history by constructing a Rocchio-based user profile. They also produce general ODP-based profile and combine both generated profiles to enhance search results. Finally, another related technique that utilizes the implicit user input of general browsing experience to adapt search results is presented in [11]. The proposed system monitors the user’s browsing history and updates his/her profile whenever his/her browsing page changes. The user profile is conducted by consulting either the pure browsing history of the user or a modified version of the collaborative filtering technique. The pure browsing history is used to construct the user profile by assuming that the preferences of each user consist of the following two aspects: (1) persistent (or long term) preferences and (2) ephemeral (or short term) preferences. Henceforth two profile preference vectors are constructed by using term frequency assignment of weights. On the other hand, in the collaborative filtering technique a subset of users is chosen based on their similarity to the active user (which can be measured as the Pearson coefficient between two rating vectors) and then a weighted combination of their ratings is used to provide descriptions for the active user. The authors present two collaborative filtering methods: (i) user profile construction based on the static number of users, and (ii) user profile construction based on dynamic number of users, and it was depicted that the user profile construction based on modified collaborative filtering achieved the better performance.
A recent trend to personalizing web searching is introduced in [10], [4], [5]. Those papers introduce a novel approach to construct user profiles; they construct profiles with the aid of a category hierarchy (an ontology can also be used), which contains the categories chosen by users to best reflect their individual preferences. Categories themselves are also assigned a score, denoting the degree of relevance to user preferences. This score is
combined with search engine ranking to yield the final result ranking.
This paper presents two new heuristics for web searching results personalization enhancing the methods presented in [10]. The first heuristic, creates multiple levels of virtual nodes to better represent node interests, while the second heuristic adds edges to the category graph to correlate categories that manifest their common presence in the results returned to users. We have included the above two heuristics in a search tool, also presented here, that can be included as a search toolbar with a web browser. The rest of the paper is structured as follows. Section 2, presents the different heuristics, after some background material. Section 3 presents the architectural outline and functional specifications of the implemented solution that aims to ease end-user personalization and personalization research experimental evaluation. Section 4 presents an experimental paradigm of our web system. Finally, Section 5 concludes the paper.
2. NOVEL PERSONALIZATION 2.1 Multiple levels of virtual nodes Consider an arbitrary search engine that uses a directed acyclic graph (DAG) G(V,E) of categories, in order to categorize web pages. Graph G consists of nodes v∈V that denote categories and every edge (vi, vj)∈E denotes that vj is a subcategory of vi and is assigned a weight d(vi,vj) ∈ [0,1]. The latter expresses the semantic correlation between categories vi, vj.. It is further assumed that every web page is tagged with a specific category. Overall, the proposed approach introduces the idea of incrementally creating, in the client side, a supergraph G’ of a suitably selected subgraph Gsub of G. This subgraph can be constructed by registering user preferences implicitly or explicitly (i.e. by letting the user declare his preferences). In the extreme case Gsub≡G. Every category v of G’ will be assigned a relevance-importance weight β(v)>0. These weights are used in order to categorize pages returned to the end user, when posing a query. In particular, the position (rank) of a page p in the result-set of an arbitrary user query will be given by a function of the form:
))()),((( pp σγβφ .
In the above function, )( pγ is the category that a page p belongs to, )( pσ is the relevance-importance according to the ranking algorithm of the engine, and function ( )φ indicates how the final ranking will be biased towards machine ranking or category importance defined (e.g. 2)(),( βαβαφ += ). In general, we have introduced the function ( )φ that combines search engine ranking and our proposed personalized ranking to provide better scalability of our solution’s operational configuration. The authors in [10] propose different methods for constructing G’. The approaches in this paper have a similar processing rationale. The first of them, the offline, is devised in order to allow user profile creation after a period of observation concerning user search habits. Graph G’ is constructed after this period of observation and remains unchanged for some time, during which it is estimated that no particular changes have occurred in search preferences, before G’ becomes obsolete. The second approach, the online, updates G’, and thus profile, after each query. Another
2398
Σ28
2/6

more practical approach is the semi-offline, where category weights are only updated at the end of each experiment. Category weights are updated according to the following relation:
)(),()(),()()()(deg
1
)(deg
1i
vreein
ii
vreeout
iii vvvdvvvdvv ββββ ∑∑
==++= (1)
where d(u,v) = 1/outdegree(u), outdegree is the number of offspring categories, and indegree is the number of antesedents of v, respectively.
2.2 Adding multiple layers of virtual nodes The basic idea is to enhance the heuristic that creates virtual nodes that are common ancestors of a set of categories that are simultaneously accessed by creating, instead of a forest of trees of height 1, a multilayer tree structure where layer 0 consists of real categories and the nodes at layer i have children nodes at layer i-1. To describe the algorithm we define the following notions: Let Si={v1,v2,…,vk} be a collection of virtual nodes at layer i and let S0 be a collection of nodes in layer 0. Each virtual node vi defines a set of nodes n(vi) at layer 0; this set of nodes is produced by visiting recursively the subtree with root vi and are the leaves of its subtree.
Let )()( ii vnSn ∪= and ||/|)(|)cov( ooii SSSnS ∩= . Then the
proposed algorithm can be described as follows:
Algorithm Adding Multilayer Virtual Nodes 1. Descend the layers from the maximum to the minimum layer 2. For each layer i do:
3. if n(Si) ⊇ S0, or n(Si) ⊂ S0 then decide whether to add or not a virtual node at level i
according to user’s intent or a prespecified system behaviour. In the case where n(Si) ⊇ S0, the creation of virtual nodes brings as extra benefit the interconnection of categories that have not been accessed simultaneously by the user; in the complementary case we do not permit this to happen and in a sense we correct accidental simultaneous traversal of categories by the user
4. Else there is no containment relationship between n(Si) and S0 5. Compute the set of nodes Si with the maximum
coverage (with respect to the set S0 of categories that were accessed in the session)
6. If the computed maximum coverage is greater than a specified threshold, then create a virtual node at layer i+1 with children the nodes at layer i in Si and terminate the whole process.
2.3 Adding edges to the personalization graph We consider the execution of k experiments, which are the navigation periods of the user. The latter contains query submission and navigation to the retrieved results. During those experiments, user navigation history is refreshed automatically without any effort from users: all the pages chosen during the experiments are being recorded. Initially, G’ = Gsub.
Consider the i-th experiment, i ≤ k. It is described by the following piece of pseudocode. At the end of the k experiments,
βi(pi) can be computed from the graph, using Eqn. (1). We postulate that Si is the set of result pages and let αj(pi) be the importance value being “assigned” from each user to page pi, in query qi. αj(pi) will be the preference ranking for page pi in query qj. In other words if p1 is chosen first then αj(p1) = 1, if it is chosen second then αj(p1) = 2, etc. The expression in Eqn. (2) (step 2 of experiment_i algorithm) is called relevance coefficient because it defines the relevance of the category to the user.
By computing every γj(pi) we find a coefficient for each query result, we sort results according to those new coefficients and display results according to the new rank.
Figure 1: Snapshot of the personalized graph G’ OnUpdate
with new nodes and edges. a) Grey nodes are last user chosen categories (∈G’), b) rectangle nodes are immediately related
to the result categories c) dark bold lines are edges which pre-exist in the graph (utilized for i) the computation of vother(out-degree of G’) and ii) the computation of vgraph(inner edges of
G’)), d) discontinued edges are those which are added (if they don’t exist) or updated after the query, and e) white round
nodes are the rest not chosen categories not included in personalization computations (∈ G)
Algorithm Experiment_i
Step 1. Submit query, collect Si and let users “define” the values for αi(pi). Step 2. For each pi in the results we compute, based on its category, γj(pi) for this page. More specifically
1) )(pα - (results*) )(p v )(pv21 (1 )(pγ ijigraphiotherij ++∗+= (2)
‘results’ is the number of results in each question and αj(pi) is the rank pi in Google’s result for query qi. We sort the results according to the new scores. Step 3. Let v1, v2, …, vl(G’) denote all the categories in the query results. We join every two nodes in the above set with an edge and assign those edges a weight w(vi, vj). This weight denotes how important those categories to each other are.
The vother(pi) factor results from user-chosen categories in previous queries which are directly related (through edges) to the categories returned by search results, i.e. the categories
2399
Σ28
3/6

connecting G’ to the rest of the graph. The practical importance of vother(pi) lies on the fact that it provides us with a measure as to how relevant are the categories to other categories chosen by the same very user. The factor vgraph(pi) denotes the relevance of results’ categories before the query. Both factors use the category graph shown in Figure 1. vother(pi) is computed as a normalized sum of edge weights connecting vertex i to edges e(i,v), where v∈{G-G’} is a category that co-occurs with i in the results of the same query, while vgraph(pi) is the normalized sum of edge weights connecting vertex i to edges e(i,v), where v∈G’, where connecting vertex i to edges e(i,v), where v∈G’.
The factor 1) )(pα - (results ij + takes into account Google ranking. E.g. for results = 10 the 1st result gets score 10, the 2nd 9 etc. The new categories (nodes) being added to G’ are the categories of the query in progress which are not already included, and the new edges to be added are those between the question categories that are also not already included. (Figure 1)
2.3.1 Edge weight computation Edge weights on the graph are variables measuring how many times have the two categories been correlated and how large their correlation is, i.e. how many times have the same two categories appeared in the same results how relevant they were. The acceptable values range from 1 to n (0 is not acceptable since this indicates absence of an edge). Each time two edges have to be correlated either an edge is been created (if categories have been correlated) or the weight w of an edge e(u,v) is being increased (to take into account the number of times it has been correlated) according to equation 3:
( ) 1( ( , )) ( )[ ( ) - ( )]j k j l j k
k l
w e u v p p pα α α−
=∑∑ (3)
Sums indicate that more than one results may exist in one category, therefore, this category is highly relevant to the query and, consequently, to other categories. In other words, the larger the weight between two categories, the more relevant are those to the user. The above fraction takes values in the range (0,n]. After presenting our novel personalization techniques, we describe in the following section the functional specifications of a solution that implements them and furthermore serves as a generic client-based and server-assisted hosting platform for more personalization algorithms.
3. FUNCTIONAL SPECIFICATIONS 3.1 Architectural Overview Our aim is to provide a generic solution designed and implemented using web technologies a) for end-user client based consumption and b) for assistance in the research & development evaluation of existing or novel personalization techniques.
We present all the functionality using top-down description and following the architectural outline presented in Figure 2.
First, the web browser module is provided as a browser enhancement for the clients that choose to apply personalized re-ranking of their search results. The web browser module implements implicit user preferences logging as soon as the user
starts the module. User preferences are kept once the user has acknowledged positively a warning explaining that his/her queries and visited web page results will be store locally in his/her computer. Client Side Modules: The web browser module enables the client based reranking in order to present the personalized version of query results online whenever the user chooses to do so. Using the appropriate rerank button the user may choose to rerank the results using one specific algorithm or to choose a new available one from the server-side back-end system.. Furthermore, the user personalization preferences module stores locally in the client the appropriate ly transformed user’s data that enable the personalization re-ranking of his/her choice online. User preferred pages and categories per query are implicitly logged using the appropriate module to provide with updated information the user personalization preferences module. This module is possible to connect to the back-end system and transmit the data into the multiple-users preferred choices subsystem through web services technologies.
External Interfaces Module (Web Services)
User Preferred Pages/Categories Implicit Logging
Multiple Re-ranking & Personalization
Algorithms
Multiple-Users Preferred Choices
Re-ranking of Search Results at Web Browser Module
Client Based Re-ranking
User Personalization Preferences
Statistics & Evaluation Analysis
Clie
nt-S
ide
Mod
ules
Re-Ranking & Personalization Algorithms Application Server
Server-Side User Preferences
Profiles DB
Web Searching (browser agent)
Bac
k-En
d W
eb S
ervi
ces
Figure 2: My_Bar Personalization Solution Architecture
Back-end Web Services: Interfaces to Servers: The multiple-users preferred choices web service implements interfaces that a) allow data input streams from client side modules and b) allow external applications of researchers to access the preferred choices of users participating in experimental evaluation of their algorithms. It is a layer of abstraction above the server-side user preferences profiles Database sub-system. A separate modular part is included in the solution to host re-ranking and personalization algorithms. This module is a set of interfaces that maybe implemented for a novel or existing personalization approach. It allows the researcher to make his/her algorithms available to the web browser module and therefore acts as an enabler of new personalization approaches for the user. In this module the implementation of our proposed web page category based algorithms is done. This module is proposed to be hosted in a separate reranking and personalization algorithms application server to avoid performance issues.
2400
Σ28
4/6

Statistics and evaluation analysis module is designed to ease experimental evaluation for the researchers. It provides separate interfaces to retrieve statistics for evaluation analysis of the experimental results. All the back end modules have been designed and implemented using web services technologies in order to support cross platform interoperability. In the following section, the web browser module is presented as an enhancement of the user agent providing details about its functionality.
3.2 Functional Specifications At the end-user, client-side the My_Bar personalization toolbar is in fact a web browser enhancement. (Figure 3). The toolbar contains five main functions:
• Start : To initiate the user click implicit logging. • ReRank (two cases):
i. Server Based: The My_Bar toolbar checks for updated rerank of available personalization methods on the server side. If there are available methods the user may choose one of them in order to rank the results of his/her queries including the current one. The user may choose to have one of the new algorithms stored in his/her own My_Bar locally.
ii. Client Side: The user chooses to have the results reranked based on the approach chosen in his personal profile locally. No connection is opened to the backend.
• Connect: My_Bar receives updates on available personalization solution from the server and the user may choose a new one to work with as the default one.
• Send: It is intended to ease the researchers evaluation procedures using user-based experimental setups to get feedback for existing and novel techniques. This function posts (ssl connection optional) the user preferences to the back end server using Web Services.
• End: Terminates server based connection and returns to client side operation for standalone usage.
Figure 3: My_Bar personalization web browser enhancement.
4. EXPERIMENTAL PARADIGM AND EVALUATION My_Bar search adaptation solution was implemented in .NET 2.0 and 3.0 using C#, Web Services by Visual Studio 2005 Technologies. Our tool takes the form of an Internet Explorer toolbar. Note that the current implementation has the option of either recording user profile, locally, with cookies or submitting user information to a database for the sake of conducting an experiment. The client side browser enhancement is already implemented for IE5.5 or greater and Firefox based versions are under development with the same functionality. In this way we mean to cover the vast majority of potential clients’ web agents. We present a real-life runtime paradigm below, where the user submits four queries to Google. Subsequently, the tool reranks them to reflect user preferences and computations are performed to update category scores. The examples are presented following the methodology outlined in section 2.3.
We present together with each query a list of the first ten results returned by Google, the corresponding link, the associated category and user preference ranking. Only the last path of the category path is shown, whereas some category names remain in Greek to preserve results’ integrity. Pages not chosen by the user are indicated with ‘-‘.
Googlerank
Link Category Preference rank
1 www.upatras.gr/ University of Patras - 2 www.ceid.upatras.gr/ Πανεπιστήμιο_Πατρών 1 3 www.ee.upatras.gr/ Academic Departments - 4 www.ee.upatras.gr/en/index.php Greece - 5 www.hpclab.ceid.upatras.gr/ Research_Institutes 2 6 www.math.upatras.gr/ Greece - 7 www.wcl.ee.upatras.gr/ai/ Education - 8 www.med.upatras.gr/ Medical Schools - 9 www.lar.ee.upatras.gr/csit2002/index.htm 2002 - 10 www.geology.upatras.gr/ Πανεπιστήμιο_Πατρών 3
Google rank
Link Category Preference rank
1 www.ceid.upatras.gr/ Πανεπιστήμιο_Πατρών 2 2 www.ceid.upatras.gr/en/ Greece - 3 www.hpclab.ceid.upatras.gr/ Research_Institutes 1 4 www.public-health.uiowa.edu/CEID/ Research Centres - 5 arcadia.ceid.upatras.gr/arkadia/ Guides and Directories - 6 arcadia.ceid.upatras.gr/thomtrip/ Greece 3 7 www.uvic.cat/ceid/ca/inici.html Universitat de Vic - 8 www.cti.gr/sirocco2002/ Past Conferences - 9 www.cle.unicamp.br/wcp3/interlingua.htm Scientia -
10 www.balthisar.com/site/index.php? ceid=11
Tools -
Google rank
Link Category Preference rank
1 www.lib.teipat.gr/ Ακαδημαϊκές 2 2 www.upatras.gr/ University of Patras - 3 openarchives.gr/ Ψηφιακές - 4 www.superb.gr/ Τηλεόραση - 5 www.philosophy.upatras.gr/ Φιλοσοφία - 6 www.metanastis.com/ Γερμανία - 7 www.ceid.upatras.gr/ Πανεπιστήμιο_Πατρών 1 8 www.microchip.gr/ Υπολογιστές, Μηχανογράφηση - 9 www.kallia.gr/ Εικαστικές τέχνες -
10 athens.indymedia.org/ Περιοδικά On Line - Google rank
Link Category Preference rank
1 www.eap.gr/ Πανεπιστήμια - 2 www.eap.gr/lib/index.htm Ακαδημαϊκές 4 3 www.lib.uoi.gr/ Ακαδημαϊκές 3 4 www.cso.auth.gr/ Εργασία - 5 openarchives.gr/ Ψηφιακές - 6 library.aua.gr/ Ακαδημαϊκές 1 7 www.xhmikos.gr/ Δευτεροβάθμια - 8 www.doukas.gr/ib/ib.htm Greece 2 9 library.panteion.gr/ Ακαδημαϊκές - 10 www.ucy.ac.cy/~classics/ Cyprus -
Query 1: upatras Query 2: ceid Query 3: Patra libraries (in Greek) Query 4: Greek Universi-ties
Figure 4: Queries, returned results and user preferences The situation after the execution of each of the four queries is depicted in Figure 5 After each query the program recognizes the different result categories, chosen by the user. The categories of the first query are “Πανεπιστήμιο_Πατρών” (University of Patras-UP) and Research_Institutes (RI). Then the algorithm computes the edge weight connecting these two categories and constructs the category graph as shown in Figure 5(a). A further category added in query 2 is “Greece” (GR). The weights computed by the algorithm are 2,5 for edge (UP,RI), 0,5 for (UP,GR) and 0,5 for (RI,GR). The graph construction continues as shown in Figure 5(b). After the third query the categories identified are UP and “Ακαδημαϊκές” (Academics-AC). The weight (UP,AC) is computed to be 1 and graph construction continues as shown in Figure 5(c). Finally, after execution of query 4, the selected categories are AC and Greece (GR). The weight of (GR,AC) is computed to 1.75 and graph construction is continued as in Figure 5(d). In order to confirm the correctness of our technique, we perform a query and then, we rerank results to see whether the theoretical calculations are confirmed. We resubmit the query “upatras” and we compute γj(pi) according to (2) and vother(pi), vgraph(pi) according to the discussion in section 2.3. The computations are applied to categories UP, GR and RI which are the relevant
2401
Σ28
5/6
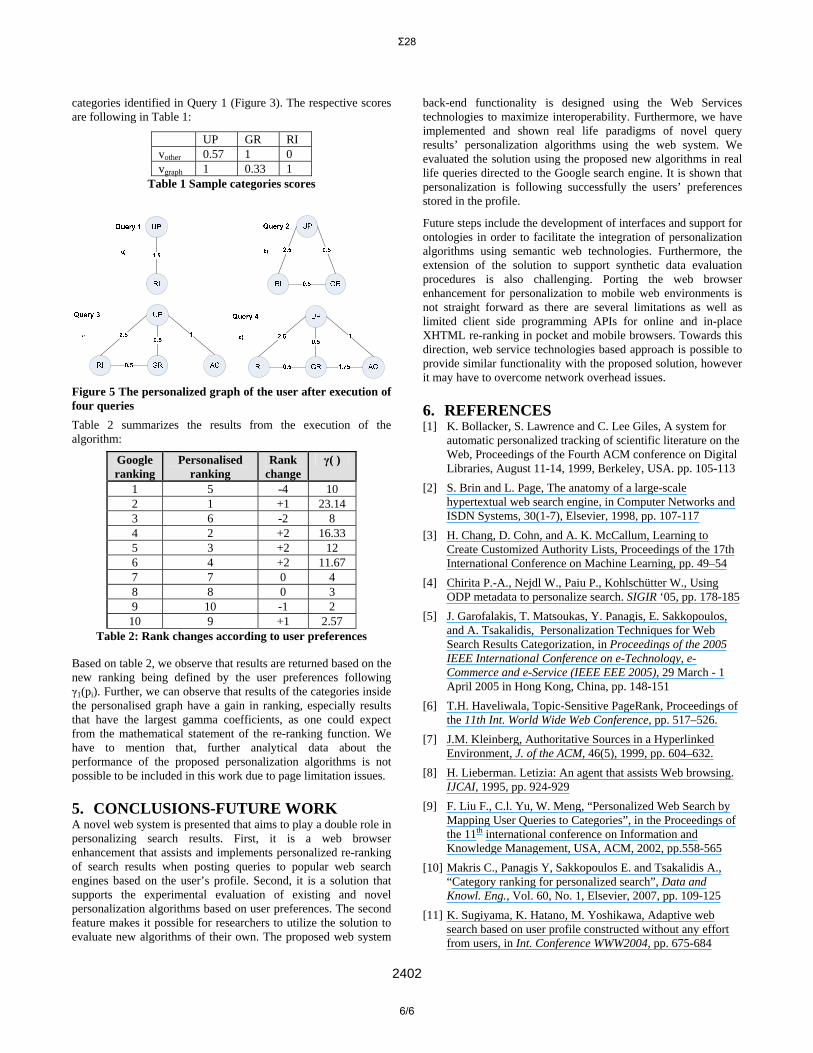
categories identified in Query 1 (Figure 3). The respective scores are following in Table 1:
UP GR RI vother 0.57 1 0 vgraph 1 0.33 1
Table 1 Sample categories scores
Figure 5 The personalized graph of the user after execution of four queries Table 2 summarizes the results from the execution of the algorithm:
Google ranking
Personalised ranking
Rank change
γ( )
1 5 -4 10 2 1 +1 23.14 3 6 -2 8 4 2 +2 16.33 5 3 +2 12 6 4 +2 11.67 7 7 0 4 8 8 0 3 9 10 -1 2 10 9 +1 2.57
Table 2: Rank changes according to user preferences
Based on table 2, we observe that results are returned based on the new ranking being defined by the user preferences following γ1(pi). Further, we can observe that results of the categories inside the personalised graph have a gain in ranking, especially results that have the largest gamma coefficients, as one could expect from the mathematical statement of the re-ranking function. We have to mention that, further analytical data about the performance of the proposed personalization algorithms is not possible to be included in this work due to page limitation issues.
5. CONCLUSIONS-FUTURE WORK A novel web system is presented that aims to play a double role in personalizing search results. First, it is a web browser enhancement that assists and implements personalized re-ranking of search results when posting queries to popular web search engines based on the user’s profile. Second, it is a solution that supports the experimental evaluation of existing and novel personalization algorithms based on user preferences. The second feature makes it possible for researchers to utilize the solution to evaluate new algorithms of their own. The proposed web system
back-end functionality is designed using the Web Services technologies to maximize interoperability. Furthermore, we have implemented and shown real life paradigms of novel query results’ personalization algorithms using the web system. We evaluated the solution using the proposed new algorithms in real life queries directed to the Google search engine. It is shown that personalization is following successfully the users’ preferences stored in the profile.
Future steps include the development of interfaces and support for ontologies in order to facilitate the integration of personalization algorithms using semantic web technologies. Furthermore, the extension of the solution to support synthetic data evaluation procedures is also challenging. Porting the web browser enhancement for personalization to mobile web environments is not straight forward as there are several limitations as well as limited client side programming APIs for online and in-place XHTML re-ranking in pocket and mobile browsers. Towards this direction, web service technologies based approach is possible to provide similar functionality with the proposed solution, however it may have to overcome network overhead issues.
6. REFERENCES [1] K. Bollacker, S. Lawrence and C. Lee Giles, A system for
automatic personalized tracking of scientific literature on the Web, Proceedings of the Fourth ACM conference on Digital Libraries, August 11-14, 1999, Berkeley, USA. pp. 105-113
[2] S. Brin and L. Page, The anatomy of a large-scale hypertextual web search engine, in Computer Networks and ISDN Systems, 30(1-7), Elsevier, 1998, pp. 107-117
[3] H. Chang, D. Cohn, and A. K. McCallum, Learning to Create Customized Authority Lists, Proceedings of the 17th International Conference on Machine Learning, pp. 49–54
[4] Chirita P.-A., Nejdl W., Paiu P., Kohlschütter W., Using ODP metadata to personalize search. SIGIR ‘05, pp. 178-185
[5] J. Garofalakis, T. Matsoukas, Y. Panagis, E. Sakkopoulos, and A. Tsakalidis, Personalization Techniques for Web Search Results Categorization, in Proceedings of the 2005 IEEE International Conference on e-Technology, e-Commerce and e-Service (IEEE EEE 2005), 29 March - 1 April 2005 in Hong Kong, China, pp. 148-151
[6] T.H. Haveliwala, Topic-Sensitive PageRank, Proceedings of the 11th Int. World Wide Web Conference, pp. 517–526.
[7] J.M. Kleinberg, Authoritative Sources in a Hyperlinked Environment, J. of the ACM, 46(5), 1999, pp. 604–632.
[8] H. Lieberman. Letizia: An agent that assists Web browsing. IJCAI, 1995, pp. 924-929
[9] F. Liu F., C.l. Yu, W. Meng, “Personalized Web Search by Mapping User Queries to Categories”, in the Proceedings of the 11th international conference on Information and Knowledge Management, USA, ACM, 2002, pp.558-565
[10] Makris C., Panagis Y, Sakkopoulos E. and Tsakalidis A., “Category ranking for personalized search”, Data and Knowl. Eng., Vol. 60, No. 1, Elsevier, 2007, pp. 109-125
[11] K. Sugiyama, K. Hatano, M. Yoshikawa, Adaptive web search based on user profile constructed without any effort from users, in Int. Conference WWW2004, pp. 675-684
2402
Σ28
6/6





























