Embed Size (px)
Citation preview

Data & Knowledge Engineering 60 (2007) 109–125
www.elsevier.com/locate/datak
Category ranking for personalized search
Christos Makris *, Yannis Panagis, Evangelos Sakkopoulos, Athanasios Tsakalidis
Department of Computer Engineering and Informatics, School of Engineering, University of Patras, 26500 Patras, Greece
Research Academic Computer Technology Institute, Internet and Multimedia Technologies Research Unit 5,
N. Kazantzaki Str., 26504 Patras, Greece
Received 31 October 2005; received in revised form 31 October 2005; accepted 30 November 2005Available online 4 January 2006
Abstract
Despite the effectiveness of search engines, the persistently increasing amount of web data continuously obscures thesearch task. Efforts have thus concentrated on personalized search that takes account of user preferences. A new conceptis introduced towards this direction; search based on ranking of local set of categories that comprise a user search profile.New algorithms are presented that utilize web page categories to personalize search results. Series of user-based experi-ments show that the proposed solutions are efficient. Finally, we extend the application of our techniques in the designof topic-focused crawlers, which can be considered an alternative personalized search.� 2005 Elsevier B.V. All rights reserved.
Keywords: Information retrieval—customization and user profiles; Information resource discovery; Inf. services on the web; Web-basedinformation systems
1. Introduction
Contemporary search engines, despite their efficiency in determining correct results, provide the user with abulk of potentially relevant or irrelevant answers. This scenario typically occurs in the case where the user pro-vides generic search terms that trigger polysemy phenomena. ‘‘Polysemy’’ involves the phenomenon of a singleterm to appear in different contexts with different meanings. For example, the term ‘‘spider’’ describes bothweb robots and the insects, while the term ‘‘jaguar’’ can exist both in animal-related and automotive-relatedcontexts.
Search engines partially address this problem by ranking pages returned as results, according to the pop-ularity they have acclaimed in the web graph. Consequently, users usually browse the results to be able toselect the answers of their interest. Still, the majority of users skip long browsing periods. As remarked in[25] the 85% of users concentrate on the first ten results of their queries and they do not revise their query after
0169-023X/$ - see front matter � 2005 Elsevier B.V. All rights reserved.
doi:10.1016/j.datak.2005.11.006
* Corresponding author. Address: Department of Computer Engineering and Informatics, School of Engineering, University of Patras,26500 Patras, Greece.
E-mail addresses: [email protected] (C. Makris), [email protected] (Y. Panagis), [email protected] (E. Sakkopoulos),[email protected] (A. Tsakalidis).

110 C. Makris et al. / Data & Knowledge Engineering 60 (2007) 109–125
the first try for 75% of their queries. A further fact is that users most times have in mind specific categories ofresults that best suit their information need. The latter fact (even subconsciously) plays a critical role for theusers to rule out all the unwanted results.
In view of this fact, search engines such as Google and Yahoo!, tag their search results according to thecategory(ies) they belong to. The maintenance of search categories and tagging of results is a semi-automaticprocedure. It is carried out mainly with human intervention, which results in a partial only coverage of thetagged information, due to the vast volumes of web pages that crop up each day on the web. This manualprocedure is assisted in part by the development of the Open Directory Project (ODP), a publicly availablehierarchy of thematic categories in RDF format. Every URL is usually categorized into a single ODP cate-gory. In our case the Google Web Service was utilized to deliver a transparent ‘‘upgraded’’ Google searchweb site that delivers categories at all cases for the evaluation procedures. (Google’s main web site doesnot always present the category, however, Google Web Service API does return it every time. Moreover, Goo-gle directory section also presents categorization—just like Yahoo! does by default.)
However, the available categorizations that could also assist the user’s task, are chaotic as well and thusdiscourage users from identifying suitable categories before proceeding with the search. This work aims at pro-viding a novel methodology to allow each user have its own personalized subgraph of the ODP categoriesgraph. Notably, this subgraph is implicitly created without demanding any special effort from users. It is pro-duced automatically after a period of recording users browsing older search results, which are assumed toreflect their individual interests. In particular, based on the search results, the user may select a page in anattempt to satisfy some specific information need. Our proposed solution records this browsing history implic-itly by identifying the categories a user selects. This allows for constructing a much smaller subset of categoriesthan the entire ODP and furthermore to implement a novel ranking logic among categories. Ranking of cat-egories is subsequently combined with the search results and thus the ranking of a search engine to producesearch results that adapt more closely to the user’s search profile. Our work is related to other approaches thatexploit manual or automatic classification of pages to categories in order to extract knowledge from the web.However, we exploit this information differently for better quality web searching by explicitly applying linkmetric techniques on the category graph.
Our solution monitors users browsing history and updates their profile whenever their browsing habitschange. When the user submits a query for the next time, the search results adapt based on the new userprofile.
We conducted an extensive experimental study of the proposed techniques, where our methodology dis-played increased precision in the list of returned search results. Finally, we present how our techniques canbe adapted in order to design topic-focused crawlers.
The rest of the paper is organized as follows. In Section 2 a review of the related work is presented. Sub-sequently, in Section 3, an overview of the category personalization technique is presented, taking also intoaccount some practical concerns. Section 4 describes an experimental study that highlights the effectivenessof our approach. Evaluation of the experiments employed is presented in Section 5. In Section 6 we describehow to apply our techniques for building topic-focused crawlers and in Section 7, we conclude with remarksand open issues.
2. Existing work
Our methodology exploits the implicitly created, user’s own category subgraph. This section presents workthat has been conducted in similar contexts, those of personalized web searching and of result post-categorization.
Web searching in general, as has emerged with the booming of the World Wide Web, is a very thoroughlystudied area. Lots of searching techniques have appeared (see [15,23] for brief surveys) with numerous vari-ants. Two of the most empirically and theoretically successful are those in [4,18]. In the area of web searchengines, a category indicator on each returned document is presented by Yahoo!, A9 and Google[29,27,33]. According to [3] this indicator facilitates searches since most users are inclined to follow highlyrated pages even if potentially unrelated to the initial request. Clustering of results into categories is providedby WiseNut [32], Adutopia [28] and Vivisimo [31]. Teoma [30] also clusters its results and provides query

C. Makris et al. / Data & Knowledge Engineering 60 (2007) 109–125 111
refinements. Metasearch environments implement strategies that map user queries to collections [21,17]. In asimilar context, user profiles are constructed either implicitly or explicitly in searching environments such asLetizia [19] and CiteSeer [2]. These profiles assist the user task by providing search suggestions according towhat each user currently browses. Both systems differ from our approach since they are information filteringand not information searching systems. In Letizia the system tracks user behaviour and attempts to anticipateitems of interest by doing concurrent, autonomous exploration of links from the user’s current position. Thesystem uses a simple set of heuristics to model what the user’s browsing behaviour might be and its contentmodel of a document is simply a list of keywords. CiteSeer relies on a number of different representations ofthe user’s notion of an interesting paper. A new paper is deemed relevant if it satisfies the requirements of anyof the representations. CiteSeer attempts to capture a user’s notion of relatedness between papers by (i) iden-tifying the document features that correspond to useful semantic information, and (ii) creating metric func-tions with these features. Citeseer handles these tasks by using the vector space model, TF–IDF (TermFrequency–Inverse Document Frequency) assignment of weights and various citation metrics.
Focused crawling is another technique to filter unrelated documents. Focused crawlers [10,5,9,16,6,7] dis-card significant parts of the web graph and concentrate only to documents that are deemed as relevant to aprespecified category hierarchy. Relevance is achieved by using text categorization strategies. From theseworks special attention should be given to [5,10,6], since some of their ideas are used in our techniques forbuilding topic-focused crawlers. In [5] a focused crawler is presented that can selectively seek out pages thatare relevant to a predefined set of topics; these topics are specified not by using keywords, but by using exem-plary documents that are embedded in a topic taxonomy. The crawler is guided by two software components:a classifier that learns to identify relevance of documents with respect to the topics, by exploiting the providedexamples and a distiller that determines web pages that can be great access points to many relevant pageswithin a few links. Human input is provided either as specific topic nodes in a canonical taxonomy (suchas Yahoo!, and the Open Directory Project), or as a set of example URLs that serve as starting points forthe crawl. The proposed construction is extended in [6] where the basic idea is to use two (instead of one) clas-sifiers: a regular baseline classifier and a new learner termed the apprentice which estimates the relevance of apage to a set of topics by using DOM features on pages that link to it. Experiments have depicted the supe-riority of the proposed technique. In [10] the idea of exploiting the context within which the topical material isusually found is explored. The proposed crawler, exploiting the capability of search engines to return pageslinking to a specified document constructs a representation of pages that occur within a certain link distanceof the target documents. This representation is then used to guide a set of classifiers, to detect and assign doc-uments to different categories based on the expected link distance from the document to the target document;during the crawling stage these classifiers predict how close to a target document the current retrieved docu-ment is likely to be.
Our work is quite closely related to research in customized and personalized web searching. An importantstep forward in this area was the paper of Haveliwala [13] introducing the Topic-sensitive PageRank. Topic-sensitive PageRank is essentially a method to bias PageRank towards specific topics. The authors calculate thetopic-sensitive PageRank by precomputing multiple importance factors biased according to a set of represen-tative topics that are produced by selecting the top categories from the Open Directory Project. The key ideain creating these topic-sensitive PageRanks is that the computation can be biased to favour certain categoriesof pages, by employing nonuniform personalization vectors. At query time, these importance scores are com-bined together based on the topics of the query to form a composite PageRank score for those pages matchingthe query. These representative topics are computed either by using the topic of the query keywords or (forsearches done in context) by using the topic of the context where the query appears; moreover, the classifica-tion of the query and the query context are provided by using a unigram language model.
In [8] algorithms are proposed for creating ‘‘personally customized authority documents’’ to correspondmore closely to the user’s internal model, following the conventions of Kleinberg’s HITS algorithm [18].The proposed techniques are similar to relevance feedback, but instead of manipulating the query to learnthe relevance of the retrieved documents, the weighting of the link matrix is manipulated; the authors usean elegant approach that instead of relying on spreading activation to directly confer authority performs gra-dient ascent on the elements of the link weight to more closely align the principal eigenvector with the docu-ments in question. Moreover, a set of extensive experiments are presented showing that using only a small

112 C. Makris et al. / Data & Knowledge Engineering 60 (2007) 109–125
amount of user feedback, the proposed procedure can significantly improve link ranking being in a betteragreement with both non-link based machine classification and human subject’s preferences. Liu et al. [20] alsopropose a technique to map user queries to categories, in order to assist the search procedure. In particulartechniques are provided to model and gather the user’s search history and then construct a user profile basedon the gathered search history and a general profile that exploits the Open Directory Project category hierar-chy; based on these techniques appropriate categories for each user query are deduced. Speaking in technicalterms a user profile is expressed as a set of categories with each category containing a set of terms (keywords)with weights. Each category represents a user interest in that category while the weight of a term in a categoryreflects the significance of the term in representing the user’s interest in that category. Their technique obtainsinformation about user search history by constructing a Rocchio-based userprofile. They also produce generalODP-based profile and combine both generated profiles to enhance search results. Finally, another relatedtechnique that utilizes the implicit user input of general browsing experience to adapt search results is pre-sented in [26]. In that paper, the proposed system monitors the user’s browsing history and updates his/herprofile whenever his/her browsing page changes. The user profile is conducted by consulting either the purebrowsing history of the user or a modified version of the collaborative filtering technique. The pure browsinghistory is used to construct the user profile by assuming that the preferences of each user consist of the fol-lowing two aspects: (1) persistent (or long term) preferences, and (2) ephemeral (or short term) preferences.Henceforth two profile preference vectors are constructed by using term frequency assignment of weights.On the other hand, in the collaborative filtering technique a subset of users is chosen based on their similarityto the active user (which can be measured as the Pearson coefficient between two rating vectors) and then aweighted combination of their ratings is used to provide descriptions for the active user. The authors presenttwo collaborative filtering methods: (i) user profile construction based on the static number of users, and (ii)user profile construction based on dynamic number of users, and it was depicted that the user profile construc-tion based on modified collaborative filtering achieved the better performance.
3. Personalization in categories
Our personalization technique makes use of a subset of the ODP category structure that is associated withindividual information needs. This subset is processed locally at each user, aiming at enhancing generic resultsoffered by search engines. Processing entails introducing importance weights to those parts of the ODP struc-ture that correspond to user-specific preferences. The results of local processing are subsequently combinedwith global knowledge to derive an aggregate personalized ranking of web results. In the following subsectionwe describe in more detail the theoretical model used and the algorithmic steps deployed.
3.1. Background
The general proposed framework is the following. Consider an arbitrary search engine that uses a directedacyclic graph (DAG) G(V,E) of categories, in order to categorize web pages. Graph G consists of nodes v 2 V
that denote categories and every edge (vi,vj) 2 E denotes that vj is a subcategory of vi and is assigned a weightd(vi,vj) 2 [0,1]. The latter expresses the semantic correlation between categories vi, vj. It is further assumed thatevery web page is tagged with a specific category.
Overall, the proposed approach introduces the idea of incrementally creating, in the client side, a super-graph G 0 of a suitably selected subgraph Gsub of G. This subgraph can be constructed by registering user pref-erences implicitly or explicitly (i.e. by letting the user declare his preferences). In the extreme case Gsub � G.Every category v of G 0 will be assigned a relevance-importance weight b(v) > 0. These weights are used in orderto categorize pages returned to the end user, when posing a query. In particular, the position (rank) of a page p
in the result-set of an arbitrary user query will be given by a function of the form: /(b(c(p)),r(p)).In the above function, c(p) is the category that a page p belongs to, r(p) is the relevance-importance accord-
ing to the ranking algorithm of the engine, and function /( ) indicates how the final ranking will be biasedtowards machine ranking or category importance defined (for example, /(a,b) = (a + b)/2). In general, wehave introduced the function /( ) that combines search engine ranking and our proposed personalized rankingin order to provide better scalability of our solution’s operational configuration.

C. Makris et al. / Data & Knowledge Engineering 60 (2007) 109–125 113
In the next section, two methods for constructing G 0 are proposed. Both approaches have a similar process-ing rationale. The first of them, the offline, is devised in order to allow user profile creation after a period ofobservation concerning user search habits. Graph G 0 is constructed after this period of observation andremains unchanged for some time, during which it is estimated that no particular changes have occurred insearch preferences, before G 0 becomes obsolete. This approach can be applied repeatedly to create and updatethe user profile about the user preferences either in predefined periods (e.g. every month, after every browsingsession, every day—in any case it is system-configurable (similar to [26])) or after user request (e.g. user explicitinvocation of the method). The second approach, the online, updates G 0, and thus profile, after each query. Aswill be exposed in the following sections, the online approach is perhaps impractical in some cases, in partic-ular when considering the size of the graph that requires processing.
The intuition behind G 0 is to create a novel personalized category graph from a general category hierarchy.G 0 expected to be a smaller part of the overall hierarchy that includes categories best reflecting personalizedsearch preferences based on implicit monitoring of users’ browsing history in the result lists of search engines.Our methodology is based in the following observation-concept: at every search attempt, regardless of theactual query, users choose to visit only some of the returned results, which do not necessarily belong to thesame category. This denotes that there is an implicit association of the categories for the specific user prefer-ences. These categories may not be directly connected in the initial category graph G, however, the user wouldlike to have them associated in order to get personalized ranking list of his/her search results in future queries.
Furthermore, users may choose to correlate a category v, which has been of their perennial preference andthus having had obtained a b(v) value, with a category w which has just gained their attention. Consider forexample a user that always searches about soccer results and at a certain point decides to search for films relatedto soccer; in the last case he may find relevant results both under soccer-related and film-related categories. Theabove discussion illustrates two needs: the need to correlate uncorrelated categories and the need to circulateimportance among them. These needs have led to the notion of virtual category nodes, presented in Sections 3.4.
3.2. Off-line methodology roadmap
We assume the execution of k subexperiments, which are user browsing ‘‘sessions’’ that entailed posing aquery and browsing the retrieved results. During these subexperiments the user browsing history is monitoredimplicitly without any special effort from users. In particular, the pages’ categories selected during the subex-periments are recorded. Initially we have G 0 = Gsub.
Consider the ith subexperiment, i 6 k. It is described by the following piece of pseudocode. On completionof the k experiments, b(v) is taken as the mean of the intermediate values obtained by the subexperiments.
EXPERIMENT_iLet Si be the set of the result pages and ai(p) be the importance value ‘‘assigned’’ to the page p by the user
(ai (p) 2 [0,1]). (Note that the importance ‘‘assignment’’ is performed implicitly without any special users’effort overall to the bi(v) values as described in Section 3.5.2 below.)
Step 1. Submit a query, collect Si and allow user(s) to define ai (p).Step 2. For each category v of G 0, set biðvÞ ¼ 1
n
Pnj¼1aiðpjÞ, where pj 2 Si, pj belongs to the category v, n is the
number of pages of Si with category v. (Note that pj belongs to the category v and not to itssubcategories.)
Step 3. Suppose that v1,v2, . . . ,vl are all the categories whose weight has been computed to be greater than apredefined threshold thres1. Create a virtual node v that will be the common father of v1,v2, . . . ,vl andwill have initial weight b(v) = 0.
Exception handling: In the special case where a regular ODP node already exists as common father ofv1,v2, . . . ,vl no virtual node has to be created and the step is overridden.
The threshold thres1 ensures that only the topmost preferred categories are interconnected with a commonfather—virtual node. This threshold is usually defined implicitly by setting a maximum number of correlated

114 C. Makris et al. / Data & Knowledge Engineering 60 (2007) 109–125
categories under a single virtual node. The intuition behind this threshold is that only the most frequently vis-ited categories are significantly correlated and thus crucial for the personalization effect. In the conductedexperiments a virtual node was limited to accept maximum five (5) categories (thres1 value).
Subsequently, we update each category v 2 G 0, as follows:
bðvÞ ¼ bðvÞ þXout degreeðvÞ
i¼1
dðv; viÞbðviÞ þXin degreeðvÞ
i¼1
dðvi; vÞbðviÞ ð1Þ
This sum needs to be computed iteratively a number of times until the ‘correct’ weights have been propa-gated to the entire graph.
The complete algorithm is presented as OFFLINE_CATEGORIES (Gsub).
Algorithm OFFLINE_CATEGORIES (Gsub)Let k be a predefined small constant, and G 0 be the graph incrementally replacing Gsub.
1. G 0 = Gsub;2. for i = 1 to k do3. EXPERIMENT_i;4. for each v 2 G 0
5. bðvÞ ¼ 1k
Pki¼1biðvÞ;
6. UPDATE_WEIGHTS(G 0);7. return G 0.
UPDATE_WEIGHTS(G)
1. for i = 1 to c do (� refer to Section 3.4 for values of c �)2. for each v 2 G
3. update b(v) according to Eq. (1) (pre-updated values of b(vi�1) are only used)4. return G.
The predefined small constant k is essentially the number of queries—browsing periods—before consider-ing the end of a ‘‘browsing session’’. As mentioned in the introduction the offline approach ‘‘can be appliedrepeatedly to create and update the user profile about user preferences either in predefined periods (e.g. everymonth, after every browsing session, every day—in any case it is system configurable (similar to [26])) or afteruser request (e.g. user explicit invocation of the method)’’.
3.3. On-line algorithm
The online algorithm entails performing the computations described above, however, the procedureEXPERIMENT_i is not executed for a fixed number of times before updating the structure and the weightsof graph G 0; it is executed for each user query. Thus, the modified code for the online algorithm is shown inONLINE_CATEGORIES (Gsub).
Algorithm ONLINE_CATEGORIES (Gsub)Let G 0 be the graph incrementally replacing Gsub. It is postulated that this algorithm is transparently exe-
cuted at each user query.
1. G 0 = Gsub;2. EXPERIMENT_i;3. UPDATE_WEIGHTS(G 0);4. return G 0.

C. Makris et al. / Data & Knowledge Engineering 60 (2007) 109–125 115
3.4. Achieving correlation using virtual category nodes
Details concerning parts of the previous algorithms are further explained. First of all in Step 3 of EXPER-IMENT_i an extra node (category) is added as a common direct ancestor of some categories that were givengreater importance than others in a specific query. What this choice imposes, is the implicit correlation ofthose categories (v1,v2, . . . ,vl) in the context of a single query. Their correlation results from the fact thatthe user assigns high scores to all of them (larger than thres1). Thus a new virtual category node is createdthat hosts all l of them as subcategories.
This virtual category node is thought of as a channel of distributing ‘importance’ among its descendants,direct and indirect. This is actually achieved with the procedure UPDATE_WEIGHTS. This procedure dis-tributes importance from a node to its neighboring nodes, by updating at each iteration the weight of eachcategory. Updating is performed on the basis that a node u gains from each neighbor v, an amount of impor-tance that equals b(v) · d(u,v) (or b(v) · d(v,u)). The latter quantity is found in each sum of Eq. (1) and isinterpreted as: neighbor’s importance · category correlation.
Fig. 1 depicts in some detail the process taking place locally. Nodes in gray represent interesting subsets ofODP. Square nodes are virtual categories that correlate otherwise potentially unrelated categories and allow aflow of importance weights between them. Node v1 may represent a query of the type ‘‘Film Titles BollywoodSoundtracks’’ whereas v2 a query like ‘‘Movie Titles in London Cinemas’’.
Updating continues until all graph nodes contain their final values. We make the following assumptions:
1. The graph for each user is a balanced binary tree with approx. 650,000 nodes in total.2. The update takes its final form after a small number of steps c, where c is close to the diameter D of the
graph.
According to the first assumption D equals to the tree height, which is logarithmic in the number of nodes.This yields c � dlog2 650,000e = 20. However, we have observed during the evaluation experiments that inpractice a smaller number of repetitions suffices for the weights to take approximately their final values. Inthe experimental evaluation twelve (12) rounds were sufficient enough to update category weights and performsuccessful personalization of search results. We compared the experimental results using only eight (8) updaterounds and the results have also been sufficient returning appropriate personalized ranking lists of searchresults in almost half the processing time (45% improvement). We have observed 99% similarity of the results’list between the two cases, which indicates that our assumption is sound and computationally efficient.
Fig. 1. Nodes in gray indicate parts of the ODP that a user may find interesting. The parts of the paths shown in dashed lines were omittedfor space reasons. Square nodes represent the virtual category nodes that were added.

116 C. Makris et al. / Data & Knowledge Engineering 60 (2007) 109–125
3.5. Engineering the implementation
As already mentioned our proposed methodology exploits the editor-driven taxonomies of the ODP tofacilitate personalized searching. ODP dumps are available through the web1 in RDF format. The volumeof category information maintained in ODP is extremely large reaching up to 650,000 distinct categories. Firstof all, it has to be mentioned that the search algorithm we experimented on, is a hybrid that combines ideasfrom both approaches in Sections 3.2 and 3.3. The implemented algorithm is semi-offline: computation ofimportance weights for the categories of the ODP is performed online at each of subexperiments, e.g. by exe-cuting a fixed number, say k, of online experiments. After that stage, the weights at the categories of the localgraph G 0 are fixed. This approach is generally more practical in terms of execution time than the online oneand it is outlined in algorithm SEMI_OFFLINE_CATEGORIES.
Algorithm SEMI_OFFLINE_CATEGORIES (Gsub)Let k be a predefined small constant, and G 0 be the graph incrementally replacing Gsub.
1. G 0 = Gsub;2. for i = 1 to k do3. EXPERIMENT_i;4. UPDATE_WEIGHTS(G 0);5. return G 0.
3.5.1. Initialization
Regardless of which categorization type is chosen, the subset of ODP where the algorithms operate needs tobe defined at a first step. This process can be described by the following steps:
Step 1. In the case that the preferred user categories are already provided (from previous browsing activityrecording) move to the next step. Otherwise, implicit monitoring of the user’s previous result-brows-ing activity has to be preceded.
Step 2. Isolate the induced subgraph Gsub of categories interesting to the user from all ODP categories.Step 3. For each edge e(u,v), set d(u,v) = 1/(outdegree(u)).
Step 3 computes category semantic correlations in the induced graph. Nevertheless, the computations actu-ally performed in our implementation adopt the assumption that the more general a category is, thus havingmany children, the less correlated will it be with its children. This choice was dictated in the absence of suf-ficient textual category descriptions. If this is not the case, a term-category matrix A can be maintained; we cancompute matrix C = AT Æ A, the element C(i, j) of which keeps the correlation of categories i and j.
3.5.2. Computation of category importance
In the initial description of EXPERIMENT_i the user is required to ‘‘assign’’ a relevance score ai(p) to eachof the returned pages p he/she considers important. The initial score function regardless of its compositiondoes not affect to a great extent the final outcome. Therefore, we chose to assign weights implicitly, by lettingeach ‘vote’ (user’s selection of a result page—browsing visit) for a category vi contribute the same score. Thuswe obtain:
1 Th
bðviÞ ¼# pages of category i in the answer
# pages examined by user
e ODP project RDF dumps: http://rdf.dmoz.org.

C. Makris et al. / Data & Knowledge Engineering 60 (2007) 109–125 117
4. Experiments
We employed the strategies, presented in Section 3, in a series of experimental evaluations to verify theirefficiency and effectiveness. A hundred and one (101) volunteering students of Patras Higher Technological-Educational Institution (ATEI Patras, Greece) participated in the experimental evaluation during the 2004–2005 academic year. Students had an average knowledge of Internet use that allowed them to use the Weband Search engines fluently. To facilitate our experimental exposition, we delivered the experiments in twophases: the initialization phase (implicit recording of user browsing history (queries and results only) andthe query ranking phase (executions of the proposed algorithm). All students participated at both phases.
First, the initialization phase included the following actions: (a) It bootstrapped the personalization by hav-ing students submitting queries and choosing the preferred answers while their choices were logged. (b) In thefollowing, it resulted in a personalized category tree for each user (graph G 0 see Section 3.1 above) suitable forcomputing category weights and inserting virtual nodes according to the proposed algorithms. This phaseimplements the semi-offline methodology of Section 3.5. The mentioned ‘‘k experiments‘‘are the arbitrary que-ries-search sessions of the participating volunteering students in the first phase different for every user(k 2 [5,12]).
After completing initialization, we continued the experiments having students submitting more queries inorder to compare the ranking of the results retrieved from the search engine with the personalized flavourof ranking computed by our algorithms. After the completion of the first-phase actions, no further categoryweight updates were made and a second-different set of queries was submitted to the search engine.
Finally, we compared the precision–recall graphs between the initial ranking returned by the search enginewith no personalization and the ranking after involving the personalization algorithms. Different flavours ofthe proposed algorithms were tested using alternative virtual node creation policies with either single or multi-ple virtual nodes (more details are given in the evaluation section). Details of each experimental step are dis-cussed in the following.
4.1. Setting up the experiment
In contrast to using a document test collection, the web is ‘‘live’’ data that is continuously changing, pre-venting experiments from being exactly reproducible. In addition, it is believed that the set of popular webqueries and the desirable results for those queries change significantly over time and that these changes havea considerable impact on search engine evaluation. Hawking et al. notes ‘‘Search engine performances mayvary considerably over different query sets and over time’’ [14].
Any web search engine could be utilized for the experiments. In our case, results from the Google searchengine2 have been utilized. User experiments took place in student classroom using Pentium III 800 MHz with256 MB of RAM for each user.
The properties of the web graph, as a whole, differ from those of any category index or taxonomy tree.However, it is impossible to get a stable instance of the web graph and to produce the category graph fromit. As a result, categories existing in the widely utilized directory of ODP are only utilized. Other IS-A rela-tionships, ontologies or taxonomies in particular domains can also be utilized without affecting the generalityof the presented algorithms. In particular, as far as the implementation details are concerned, the ODP cate-gory hierarchy information, updated with ODP category move history, has been analyzed and ported in adatabase storage area (Enterprize Edition Microsoft SQL server 2000). In the experiments, results have onlybeen used when they belonged to ODP categories, which includes results mainly coming from the directorysection of search engines (Google was utilized in this case as we have already mentioned). Generality is notlost, though. One may perform text categorization techniques to automatically taxonomize a search engineresult on-the-fly so as to take into consideration unclassified pages in the proposed algorithms (see[5,11,12]). The techniques proposed take advantage of implicit user input—the chosen URLs—in the experi-ments conducted. Additionally, it is also possible to take into account explicit user evaluation of the chosen
2 Google search engine was chosen, mainly because it supports a web service based programmable interface.

118 C. Makris et al. / Data & Knowledge Engineering 60 (2007) 109–125
URLs, however such evaluation increases performed user-clicks and is generally avoided. While the use ofclickthrough data has been advocated for automatic assessment, there is a documented presentation biasinherent in this data, because users are more likely to click on highly ranked documents regardless of theirquality [25].
Furthermore, as stated in Section 3.1, when vj is a subcategory of vi then it is assigned a weightd(vi,vj) 2 [0,1] that expresses the semantic correlation between categories vi, vj. Here, the assumption is that:
dðvi; vjÞ ¼ 1=joffspring categories of vij
As a way to improve the overall execution performance of the algorithm, pre-processing of the ODP graphhas been performed to compute each category’s children a-priori. In partial manner only, the same pre-pro-cessing should be performed every time ODP updates the category hierarchy information in order to take intoconsideration new categories.
Users have overall issued 58 distinct web queries during the initialization phase, which hereafter we denoteas query set Q1. For the second phase, called query phase, users have overall issued 96 distinct web queries.Hereafter, the second query set is denoted as query set Q2. Each user had to perform at least five (5) queriesduring the first phase and at least ten (10) in the second one. On average, each user performed 5.94 queriesduring the query phase and 16.93 queries in the second experimental phase. The users were free to issuequeries according to their own personal choice and interests in both cases. In order to log user activity, havingthe users’ consent during the experiment, a transparent to the user web application recorded users’ queries andsearch result choices into a database system. The queries issued were relatively short as web queries are in gen-eral being approximately 2.3 words long. This is consistent with the aspects of web searching that have beenmeasured from large query logs where the average web query is 2.21 terms in length [25]. Students submitteddifferent queries in the two phases. Monitoring has also shown that there was overlapping in the queries sub-mitted among students, which is normal as students may have similar interests/queries in mind. The latter doesnot affect the experimentation on the algorithms as seperate personalized category graphs are created perstudent.
4.1.1. Initialization phase
The concept is to depict users’ historical choices as weighted score on preference categories. In short, this isachieved while performing a series of queries and recording user ‘‘browsing’’ activity (his/her specific resultchoices) implicitly. Taking into consideration user choices, our algorithm initializes and creates each user’spersonalized category tree. Our approach follows the assumption that in the user-chosen query result list (Rel-ative Set), certain pages have been visited that belong in categories and therefore categories appear with a spe-cific frequency, which is the implicit score that the user assigns to the category.
In the initialization phase different queries (of set Q1) were posed by student and we recorded:
(a) The set R of relative pages for each query (Relative Set, i.e. the pages visited by users).(b) The PageRank of each page returned as result (transformed in the range [0, 1]).
At this point we will clarify what may happen between two successive executions of EXPERIMENT_i (thatis at a query submission). The following situation may occur: At the jth execution of EXPERIMENT_i, aweight bj(v) for category v was computed. Note that previous weights bi (v) may also exist for v for some ofthe values i = 1, . . . , j � 1. In this case the final importance weight �bjðvÞ this category is computed as follows:
�bjðvÞ ¼bjðvÞ j ¼ 1
bjðvÞ þPj�1
i¼1�biðvÞ
k þ 1; j > 1
8><>:
where k denotes the number of times, results from category v were chosen in the experiments 1, . . . , j � 1 (k canbe j � 1). In plain terms we averaged over all the available values of b(v) at the time of the jth iteration.
One further aspect deals with adding new virtual nodes over consecutive executions of EXPERIMENT_i.All the possible configurations are shown in Fig. 2. Suppose that in step 3 we had selected three pages with

Fig. 2. Inserting virtual nodes.
C. Makris et al. / Data & Knowledge Engineering 60 (2007) 109–125 119
b(v) > thres1, and a virtual node is created (‘Virtual1’ in Fig. 2a). If the same pages appear again at some laterstep, no virtual node is created. If a subset (resp. superset) of them appears then a new node is created, exam-ples appear in Fig. 2b and c, respectively. According to the exception handling rule in the algorithm of section ,virtual nodes are only created when no existing ODP category or pre-existing virtual node does not intercon-nect the categories at hand. In this exceptional case VU creation is simply ignored.
4.1.2. Query phaseIn this phase, the experiment moved on to the stage where no category updates or creation of virtual nodes
were performed in the personalized user category graphs (user profiles). The only operations performed werenew query submission and presentation of resulting answers in the personalized manner of the proposed algo-rithm. A new and distinct query set Q2 was submitted to the search engine. Having in mind the description inSection 3.1, recall that our retrieval system uses a ranking function /(b(c(p)),r(p)), a combination of rankingfunction r(p) of the generic search engine and the importance b(c(p)) of the category page where p belongs.For the purposes of our experiment we set the following alternative ranking score that utilizes the effects ofour personalized category graph:
/ðbðcðpÞÞ;rðpÞÞ ¼ ðbðcðpÞÞ þ rðpÞÞ=2;
where r(p) was the PageRank of p (2[0, 1]), p belongs to category v and v 2 G 0.After each query the results were ranked according to /( ). In order to evaluate the results and to compute
the precision at predefined levels of recall we applied the relevance feedback method [24], where the userswhere asked to mark which retrieved answers were most relevant after examining them. The list of relativeresults for each query was selected using as guidance the user behaviour as was implicitly recorded duringthe initialization phase. Overall, the key aim of this phase is to monitor user relevance feedback that wouldassist us in the evaluation of the system performance.
5. Evaluation of results
5.1. Precision–recall graphs
Experimental results are depicted using the precision and recall approach [1]. Consider a query request Qi
and its resulting set R of relevant documents (i.e. the query answers chosen by the students). Then jRj denotesthe number of URLs—documents in this set. Assuming that a given strategy returns a document answer set A,then jAj is the number of these URLs-documents (i.e. the results of the Google search engine). Recall and pre-cision measures are defined as
120 C. Makris et al. / Data & Knowledge Engineering 60 (2007) 109–125
Recall ¼ jR \ AjjRj ; Precision ¼ jR \ Aj
jAj
During the experiments, answers–results were at most one hundred (100) for each query. In fact, there is ageneral sense that the majority of users would only search the web for a small number of highly relevant pagesand that would limit themselves to look only a part of the results. Proper evaluation requires plotting precisionand recall curve progressively. In the experiments, we examined the precision with a 10% recall step in order toget precision and recall graphs.
Additionally, to evaluate the performance of the algorithm over all posed queries, we averaged the preci-sion figures at each recall level as follows:
P ðrÞ ¼XNq
i¼1
P iðrÞNq
where P ðrÞ is the average precision at the recall level r, Nq is the number of queries used, and Pi(r) is the pre-cision at recall level r for the ith query.
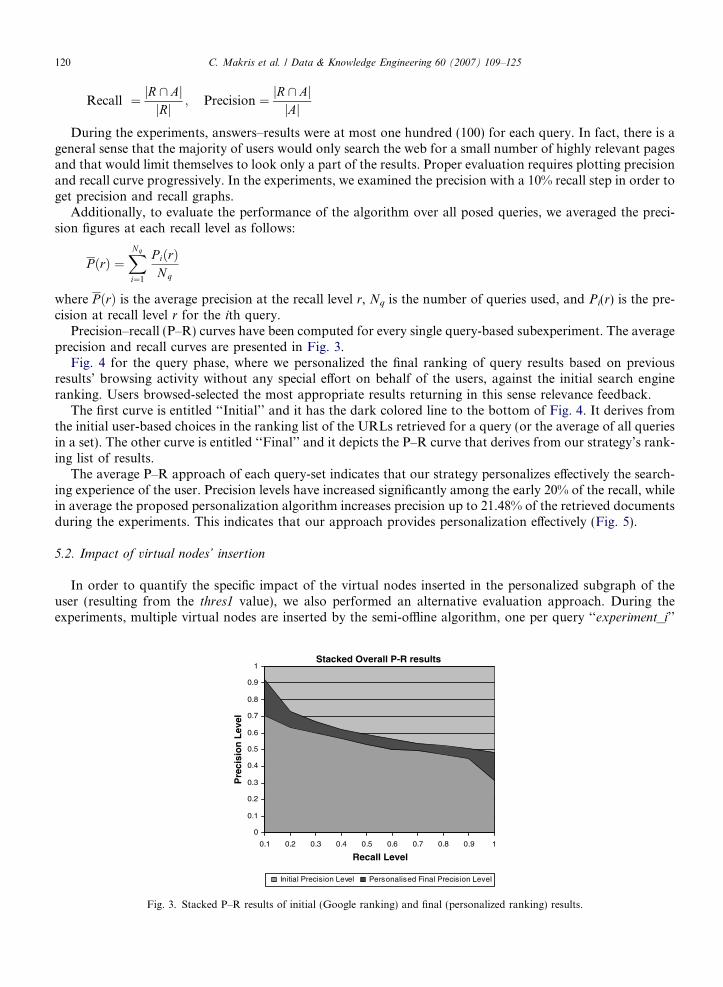
Precision–recall (P–R) curves have been computed for every single query-based subexperiment. The averageprecision and recall curves are presented in Fig. 3.
Fig. 4 for the query phase, where we personalized the final ranking of query results based on previousresults’ browsing activity without any special effort on behalf of the users, against the initial search engineranking. Users browsed-selected the most appropriate results returning in this sense relevance feedback.
The first curve is entitled ‘‘Initial’’ and it has the dark colored line to the bottom of Fig. 4. It derives fromthe initial user-based choices in the ranking list of the URLs retrieved for a query (or the average of all queriesin a set). The other curve is entitled ‘‘Final’’ and it depicts the P–R curve that derives from our strategy’s rank-ing list of results.
The average P–R approach of each query-set indicates that our strategy personalizes effectively the search-ing experience of the user. Precision levels have increased significantly among the early 20% of the recall, whilein average the proposed personalization algorithm increases precision up to 21.48% of the retrieved documentsduring the experiments. This indicates that our approach provides personalization effectively (Fig. 5).
5.2. Impact of virtual nodes’ insertion
In order to quantify the specific impact of the virtual nodes inserted in the personalized subgraph of theuser (resulting from the thres1 value), we also performed an alternative evaluation approach. During theexperiments, multiple virtual nodes are inserted by the semi-offline algorithm, one per query ‘‘experiment_i’’
Stacked Overall P-R results
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
Recall Level
Pre
cisi
on
Lev
el
Initial Precision Level Personalised Final Precision Level
Fig. 3. Stacked P–R results of initial (Google ranking) and final (personalized ranking) results.

Overall Users' P-R graph
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
Recall Level
Pre
cisi
on
Lev
el
Initial Final
Fig. 4. P–R results of initial (Google ranking) and final (personalized ranking) results.
Average Precision Increase
0
0.05
0.1
0.15
0.2
0.25
0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
Recall Level
Ave
rag
e In
crea
se o
f P
reci
sio
n L
evel
Fig. 5. Increase of the precision level is especially raised in the 20% of the recall.
C. Makris et al. / Data & Knowledge Engineering 60 (2007) 109–125 121
session for every user. To estimate the impact of the virtual nodes on the algorithm, we computed precision–recall according to an alternative of the semi-offline algorithm where only a single virtual node is created at theend for all query ‘‘experiment_i’’ sessions, minimizing in this way the number of appearing virtual nodes.Results indicate that the proposed semi-offline algorithm behaves better than the alternative where a singlevirtual node only instantiates all historical user preferences. Analytic gain in personalization effect is depictedin Fig. 6.
It is widely believed, that web search engines are optimized to retrieve highly relevant documents with highprecision at low levels of recall, features desirable for supporting known-item search. In such cases, the differ-ence in the precision levels can be expected to be lower; still the virtual nodes inserted, facilitate improved reor-dering of results by using the neighboring related categories, as they automate category graph personalization.
6. An extension: focused crawling
Our technique can also be applied in order to implement focused crawlers. Focused crawlers are proposedas a solution to our inability to perform efficiently exhaustive crawling due to the increasing size and contentof the web; focused crawlers search only the subset of the web related to specific topics and offer a potentialsolution to the scaling problem.

Gain in Precision
0.000.050.100.150.200.250.300.35
0.400.450.500.550.600.650.700.75
0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1Recall Level
Incr
ease
at
Pre
cisi
on
Lev
el
Final One Final Multiple
Fig. 6. Gain in precision for one and multiple virtual node insertion policies in the semi-offline algorithm.
122 C. Makris et al. / Data & Knowledge Engineering 60 (2007) 109–125
Thus, our setting is as follows: we are given a set of exemplary documents that implicitly specify the topicsthat the user is interested in and we are asked to provide a crawling strategy that favours pages thematicallyrelated to the implicitly specified topics. The desired crawling strategy should be composed of two parts: a clas-
sifier that ranks the outgoing links of a web page according to their relevance with the set of topics and a dis-tiller that locates good access points for starting the crawling [5]. Our technique can be adapted for designingthe classifier component as follows.
Let G be the graph used to categorize the web pages and let S be the set of given exemplary documents.The classifier module will initially perform the following pre-processing steps:
1. Apply on the set S, a link metric algorithm (either [4] or [18]) and compute for each page p 2 S its respectiveweight w(p).
2. For each category v of G, compute wðvÞ ¼ 1nðvÞPnðvÞ
j¼1wðpvjÞ, where pv
1; . . . ; pvnðvÞ are the pages of S that belong
to category v and n(v) = jSj.3. UPDATE_WEIGHTS(G).
After the above steps have been performed, each category in G will have been attached a weight designatingthe relevance of the topics represented by the category with the topics given in the exemplary documents. Con-sequently, the crawler can classify an outgoing link of a page by simply using as relevance metric the weight ofthe category of the web page where the link points.
A weakness of the above approach stems from the fact that it is possible for a page not to belong to a cat-egory. In this case we can either use an approach, as that described in [5] to locate the category/ies that bestmatched the topic of the page or we can sift to a different approach in order to estimate the relevance of anoutgoing link. In this approach (see also [22]) we use combinations of taxonomies and thesauri that relateterms contained in the web pages (an example of such an thesaurus is Wordnet) and proceed as follows.
Let O be the taxonomy relating the various terms and let S denote again the set of given exemplary doc-uments. In an initial phase the classifier module will perform the following steps:
1. Compute for each term v and document p in the collection, a weight w(pv) denoting the significance of termv for the description of the content of p (a suitable choice for this could be the tf-idf metric, see [1]).
2. For each term v of O, compute: wðvÞ ¼ 1nðvÞPnðvÞ
j¼1wðpvjÞ,
where pv1; . . . ; pv
nðvÞ are the pages of S that contain term v and n(v) = jSj.3. UPDATE_WEIGHTS(O).

C. Makris et al. / Data & Knowledge Engineering 60 (2007) 109–125 123
After the above steps have been performed, each term in the ontology will have a weight denoting its sim-ilarity with the topics represented by the exemplary documents. Then, for a given outgoing link the relevancemetric will be equal to the weighted sum of the relevance of the terms contained in the anchor text of the link(or to a window around the anchor text as in [5]).
7. Conclusions and future steps
Personalization of web search results can be achieved when adaptation of the web search results to therequirements of the user is performed. We proposed link metric techniques to categorize web search resultsaccording to the personal choices in previous search sessions. To evaluate the algorithms presented, we per-formed a series of experiments based on the popular category lists of Open Directory and the query results ofGoogle. Precision and recall curves of the results indicate that the strategy described is both effective andefficient.
We believe that the major advantage of our proposed techniques is that they permit, via the employment ofa quite simple methodology, the personalization of web search results, without incurring any serious time costimplications. We achieve this goal by applying link processing techniques not to the web graph but to the quitesmaller graphs formed by available semantic ontologies/taxonomies; we have applied our techniques to thewell known ODP category pool, however, they can similarly be applied to other category pools. In particularthe power of the technique is twofold: (a) ranking of categories that affects the ranking of search results and(b) the individual category graph enhanced by the user-based virtual category nodes that interconnect relatedcategories per user session. The category graph derives from categories of the chosen search results. The vir-tual categories are operating as a channel that distributes ‘‘strong’’ correlations among its descendants. Thisprocedure distributes importance from a node to its neighboring nodes, by updating the weight of each cat-egory at each iteration.
One could argue that a possible drawback of our methodology is that it is based solely on user’s priorsearch behaviour in order to learn and predict his future behaviour, which might not be the right thing todo especially in cases where the user tends to change his search behaviour. Nonetheless, it could be claimedthat in these cases the problem appears only in transitional periods (when this change of behaviour takesplace) and then disappears. We can alleviate this situation by giving users the ability, to explicitly modify theirsearch profile, during these time periods.
Moreover, we outlined how to combine taxonomies and thesauri with our proposed algorithms. Thereby,we have extended our approach to design topic-focused crawlers.
Future work includes investigation of possible enhancements for the personalized category structure usingvirtual nodes such as
• Support for multiple levels of virtual nodes to correlate further virtual categories from previous usersessions.
• Use of collaborative user profile knowledge to include ‘‘collaborative virtual nodes’’ in the personalized cate-gory structure.
• Autonomous peer-to-peer based update among users for the individual personalized category graph toavoid single point of failure hazards.
• Further investigation-research can measure how fast the algorithm adapts to deal with radical shifts in thefocus of the users’ search habits. Such a measurement demands longer experimental period and even moreusers involved.
Acknowledgments
We would like to thank all participating students of ATEI Patras for their cooperation. We would also liketo thank Manolis Viennas for his aid in manipulating and porting the initial Open Directory RDF dumps.

124 C. Makris et al. / Data & Knowledge Engineering 60 (2007) 109–125
References
[1] R. Baeza-Yates, R. Ribeiro-Neto, Modern Information Retrieval, ACM Press Series/Addison Wesley, New York, 1999.[2] K. Bollacker, S. Lawrence, C. Lee Giles, A system for automatic personalized tracking of scientific literature on the Web, ACM DL,
1999.[3] J. Boyan, D. Freitag, T. Joachims, A machine learning architecture for optimizing web search engines. In AAAI’96 (August, 1996)
Workshop on Internet Based Information Systems. Available from: <http://www.cs.cornell.edu/People/tj/publications/boyan_etal_96a.pdf>.
[4] S. Brin, L. Page, The anatomy of a large-scale hypertextual web search engine, in: Proc. of the 7th World-Wide Web WWWConference, 1998.
[5] S. Chakrabarti, M. van der Berg, B. Dom, Focused crawling: a new approach to topic-specific web resource discovery, ComputerNetworks 31 (11–16) (1999) 1623–1640.
[6] S. Chakrabarti, B. Dom, P. Indyk, Enhanced hypertext categorization using hyperlinks, in: Proceedings of the ACM InternationalConference on Management of Data SIGMOD98, 1998, pp. 1–12.
[7] S. Chakrabarti, K. Punera, M. Subramanyam, Accelerated focused crawling through online relevance feedback, in: Proceedings of the11th International Conference on World Wide Web, 148–159.
[8] H. Chang, D. Cohn, A.K. McCallum, Learning to create customized authority lists, in: Proceedings of the 17th InternationalConference on Machine Learning (ICML 2000), 2000, pp. 49–54.
[9] P. De Bra, G.J. Houben, Y. Kornatzky, R. Post, Information retrieval in distributed hypertexts, in: Proceedings of RIAO-94Conference, New York, 1994, pp. 481–492.
[10] M. Diligenti, F. Coetze, S. Lawrence, C.L. Giles, M. Gori, Focused crawling using context graphs, in: 26th International Conferenceon Very Large Databases, VLDB 2000, pp. 527–534.
[11] S.T. Dumais, E. Cutrell, H. Chen, Bringing order to the web: Optimizing search by showing results in context, in: Proceedings ofCHI’01, Human Factors in Computing Systems, April 2001, pp. 277–283.
[12] J. Garofalakis, T. Matsoukas, Y. Panagis, E. Sakkopoulos, A. Tsakalidis, Personalization Techniques for Web Search ResultsCategorization, in: Proceedings of the 2005 IEEE International Conference on e-Technology, e-Commerce and e-Service (IEEE EEE2005), 29 March–1 April 2005 in Hong Kong, China, pp. 148–151.
[13] T.H. Haveliwala, Topic-sensitive PageRank, in: Proceedings of the 11th International World Wide Web Conference (WWW2002),2002, pp. 517–526.
[14] D. Hawking, N. Craswell, K. Griffiths, Which search engine is best at finding online services? in: Proceedings of WWW10 (HongKong, May 2001), Posters. Actual poster in http://pigfish.vic.cmis.csiro au/~nickc/pubs/www10actualposter.pdf.
[15] M. Henzinger, Algorithmic challenges in web search engines, Internet Mathematics 1 (1) (2003) 115–126.[16] M. Herscovici, M. Jacovi, Y.S. Maarek, D. Pelleg, M. Shtalhaim, S. Ur, The shark-search algorithm. An application: tailored web site
mapping, in: Proceedings of the WWW7 Conference, 1998, pp. 317–326.[17] A.E. Howe, D. Dreilinger, SavvySearch: A meta-search engine that learns which search engines to query, AI Magazine 18 (2) (1997)
19–25.[18] J.M. Kleinberg, Authoritative sources in a hyperlinked environment, Journal of the ACM 46 (5) (1999) 604–632.[19] H. Lieberman. Letizia: An agent that assists Web browsing. IJCAI, 1995.[20] F. Liu, C. Yu, W. Meng, Personalized web search by mapping user queries to categories, in: Proceeding of the CIKM, 2002, pp. 558–
565.[21] W. Meng, C. Yu, K. Liu, Building efficient and effective metasearch engines, ACM Computing Surveys 34 (1) (2002) 48–89.[22] B. Nguyen, M. Vazirgiannis, I. Varlamis, M. Halkidi, THESUS: Organizing web document collections based on link semantics,
VLDB Journal vol. 12 (4) (2003) 320–332, special issue on Semantic Web.[23] G.A. Ozsoyoglu, Al-Hamdani Web Information Resource Discovery: Past, Present, and Future, ISCIS2003, pp. 9–18, LNCS 2869,
2003.[24] J. Rocchio, Relevance feedback in information retrieval, in: G. Salton (Ed.), The Smart Retrieval System: Experiments in Automatic
Document Processing, Prentice-Hall, Englewood Cliffs, NJ, 1971, pp. 313–323.[25] C. Silverstein, M. Henzinger, H. Marais, M. Moricz, Analysis of a very large web search engine query log, SIGIR Forum 33 (1) (1999)
6–12.[26] K. Sugiyama, K. Hatano, M. Yoshikawa, Adaptive web search based on user profile constructed without any effort from users,
in: Proceedings of the WWW Conference, 2004, pp. 675–684.[27] A9 Search http://www.a9.com.[28] Adutopia http://www.adutopia.com/.[29] Google Search http://www.google.com.[30] Teoma http://www.teoma.com/.[31] Vivisimo http://www.vivisimo.com/.[32] Wisenut http://www.wisenut.com/.[33] Yahoo! http://www.yahoo.com.

C. Makris et al. / Data & Knowledge Engineering 60 (2007) 109–125 125
Christos Makris was born in Greece, in 1971. He graduated from the Department of Computer Engineering andInformatics, School of Engineering, University of Patras, in December 1993. He received his Ph.D. degree fromthe Department of Computer Engineering and Informatics, in 1997. He is now an Assistant Professor in the sameDepartment. His research interests include Data Structures, Web Algorithmics, Computational Geometry, DataBases and Information Retrieval. He has published over 40 papers in various scientific journals and refereedconferences.
Yannis Panagis was born in Greece, in 1978. He is currently a Ph.D. candidate at the Computer Engineering andInformatics Department at the University of Patras and a member of the Research Unit 5 of the Research
Academic Computer Technology Institute (RACTI). Yannis holds an M.Sc. from the same Department, where he has also completed his undergraduate studies. His interests span the areas of Data Structures, String ProcessingAlgorithms and Web Engineering, where he has published papers in international journals and conferences. Hehas also co-authored two book chapters.Evangelos Sakkopoulos was born in Greece, in 1977. He is currently a Ph.D. candidate at the Computer Engi-
neering and Informatics Department, University of Patras, Greece and a member of the Research Unit 5 of theResearch Academic Computer Technology Institute (RACTI). He has received the M.Sc. degree with honors andthe diploma of Computer Engineering and Informatics at the same institution. His research interests include WebSearching, Large Data set Handling, Data Mining, Web Services, Web Engineering, Web Usage Mining, Webbased Education and Intranets. He has more than 20 publications in international journals and conferences atthese areas.Athanasios Tsakalidis, Computer-Scientist, Professor of the University of Patras. Born 27.6.1950 in Katerini,Greece. Studies: Diploma of Mathematics, University of Thessaloniki in 1973. Diploma of Informatics in 1980and Ph.D. in Informatics in 1983, University of Saarland, Germany. Career: 1983–1989, researcher in the Uni-versity of Saarland. He has been student and cooperator (12 years) of Prof. Kurt Mehlhorn (Director of Max-Planck Institute of Informatics in Germany). 1989–1993 Associate Professor and since 1993 Professor in theDepartment of Computer Engineering and Informatics of the University of Patras. 1993–1997 and 2001–today,Chairman of the same Department. 1993–today, member of the Board of Directors of the Research AcademicComputer Technology Institute (RACTI), 1997–today, Coordinator of Research and Development of RACTI,2004–today Vice-Director of RACTI. He is one of the contributors to the writing of the ‘‘Handbook of Theo-retical Computer Science’’ (Elsevier and MIT-Press 1990). He has published many scientific articles, having anespecial contribution to the solution of elementary problems in the area of data structures. Scientific interests:Data Structures, Computational Geometry, Information Retrieval, Computer Graphics, Data Bases, and Bio-Informatics.





























