Embed Size (px)
Citation preview

Arhitectura calculatoarelor 3
ŢIUNI INTRODUCTIVE
1.1. SCHEMA DE BAZĂ A UNUI CALCULATOR
Orice calculator are în componenţă patru mari unităţi fundamentale: -Unitatea centrală (UC). -Unitatea de memorie (UM). -Unitatea de Intrare/Ieşire (U I/E). -Magistrale de interconectare (BUS-uri). Periferic 1 Periferic 2 Periferic n Magistrală (BUS)
ă
UC
UM
U I/E

Sorin Adrian Ciureanu 4
Rolurile acestor componente sunt: -Unitatea centrală (UC) controlează toate componentele, executând
instrucţiunile unui program; efectuează calcule aritmetice şi logice. -Memoria (UM) păstrează programele în curs de execuţie şi datele
asociate lor. -Unitatea de Intrare/Ieşire (U I/E) leagă sistemul cu lumea externă
prin intermediul unităţilor periferice: ecran, tastatură, discuri, benzi magnetice, reţele etc.
-Magistralele sunt de trei feluri: magistrale de adresă, care vehiculează adresa memorie sau a unităţii I/E generată de UC (sau, în unele cazuri de alte unităţi de control); magistrale de date, care vehiculează informaţia (instrucţiuni, date) între UC, memorie şi unităţile I/E; magistrale de control, care vehiculează semnalele utilizate de UC pentru controlul sistemului (adresă, memorie validă, adresă I/E validă, citire/scriere, aşteptare, întrerupere etc.). Principiul de funcţionare a unui calculator este relativ simplu. În
UM există programe, fiecare program având un număr de instrucţiuni. Ciclurile de executare a unei instrucţiuni sunt următoarele:
-Ciclul extragere instrucţiune (instruction fetch). UC face o citire a memoriei la adresa la care se află instrucţiunea. Instrucţiunea are un număr de biţi, în funcţie de arhitectura calculatorului, de obicei multiplu de 8. Instrucţiunea citită este adusă pe magistrală şi depusă într-un registru al UC-ului.
-Ciclul de aflare a operanzilor. Oricare instrucţiune lucrează cu operanzi. Între operanzi se petrece o operaţie dată de un câmp al instrucţiunii, numit codul instrucţiunii. În această fază trebuie depistaţi operanzii, mai precis adresele unde se găsesc operanzii. Aceştia se pot găsi în două tipuri de locaţii:
-în registrele generale ale UC-ului; -la o adresă de memorie. Există mai multe tipuri de adresare pentru determinarea adreselor de
operanzi. La sfârşitul acestui ciclu, în UC trebuie să se existe adresele fizice ale operanzilor participanţi la instrucţiune.
-Ciclul de aducere a operanzilor în UC. În acest ciclu se aduc operanzii participanţi la instrucţiune de la adresele determinate în ciclul anterior. Ei sunt aduşi din registrele generale sau de la adresele de memorie în registrele funcţionale.
-Ciclul de execuţie propriu zisă. În acest ciclu are loc execuţia propriu zisă a instrucţiunii, dată de codul instrucţiunii.

Arhitectura calculatoarelor 5
-Ciclul de depunere a rezultatului. Orice instrucţiune are ca scop final aflarea unui rezultat care poate fi un operand în cazul instrucţiunilor aritmetice(de exemplu suma pentru cod de adunare, produsul pentru cod de înmulţire) sau poziţionarea unor indicatori în cazul instrucţiunilor logice (de exemplu, în cazul unui cod de comparaţie între doi operanzi, poziţionarea indicatorului z=1 pentru identitatea celor doi operanzi).
La sfârşitul acestui ciclu, care înseamnă şi sfârşitul executării instrucţiunii, se calculează adresa instrucţiunii următoare şi adresa de la care va fi adusă instrucţiunea următoare.
Execuţia unui program înseamnă execuţia succesivă a instrucţiunilor din care este alcătuit. Programele care compun sistemul de operare asigură gestiunea resurselor (procesor, memorie, I/E) şi fac legătura cu programele de aplicaţie.
1.2. SCHEMA NIVELELOR CONCEPTUALE A UNUI
CALCULATOR
Un calculator virtual actual are şapte nivele conceptuale.
Interpretare
Microprogram executat direct de hard
Fig.1.2. Nivelurile conceptuale ale maşinii virtuale corespunzătoare calculatoarelor actuale.
Nivelul 7 Nivelul orientat pe aplicaţie
Nivelul 6 Limbaje de nivel înalt
Nivelul 5 Limbaj de asamblare
Nivelul 4 Sistemul de operare
Nivelul 3 Arhitectura setului de instrucţiuni
Nivelul 2 Microarhitectură
Nivelul 1 Nivelul logic digital

Sorin Adrian Ciureanu 6
Maşina virtuală este organizată pe niveluri iar între două niveluri pot exista două operaţii:
-translatarea şi -interpretarea.
Translatare Interpretare
Utilizarea limbajului inferior este greoaie şi de aceea s-a creat un limbaj superior, mult mai aproape de gândirea umană. Se pot scrie programe atât în Lsup cât şi în Linf dar calculatorul va executa totdeauna setul de instrucţiuni din Linf pentru care a fost proiectat fizic.
Translatarea înseamnă transformarea programului din Lsup în întregime într-un program din Linf . Programul din Lsup este abandonat iar noul program din Linf este încărcat în memorie şi executat. Translatarea seamănă cu compilarea.
Interpretarea înseamnă execuţia instrucţiunilor din Lsup , pas cu pas, fiecare instrucţiune fiind executată imediat. Este scrierea unui program în Linf care preia programe din Lsup ca date de intrare şi le execută examinând fiecare instrucţiune pe rând şi executând secvenţa echivalentă de instrucţiuni direct în Linf , dar fără să genereze un nou program în Linf .
Diferenţa fundamentală între cele două tehnici este că în translatare un program mai întâi este transformat în totalitate în alt program şi apoi executat programul translat, în timp ce în interpretare se execută fiecare instrucţiune pas cu pas.
Faţă de interpretare, translatarea are avantajul unei viteze de execuţie mult mai mari.
Nivelurile au următoarele semnificaţii: Nivelul 1 este hard pur. Este format din circuite electrice şi
electronice. Nivelul 2 este nivelul microprogram care interpretează instrucţiunile
nivelului 3 şi le execută în nivelul 1. Fiecare instrucţiune a nivelului 3 este executată de un microprogram.
Nivelul 3 este nivelul setului de instrucţiuni al maşinii, instrucţiuni executate pe nivelul hard.
Nivelul 4 . Sistemul de operare este hibrid deoarece cuprinde atât instrucţiuni interpretate de nivelul patru cât şi instrucţiuni interpretate de nivelul trei.
Limbaj superior(Lsup)
Limbaj inferior (Linf)

Arhitectura calculatoarelor 7
Nivelele 1-4 nu sunt utilizate de programatori, ele conţinând interpretoare şi translatoare construite de către programatorii de sisteme.
Nivelul 5 este nivelul limbajului de asamblare, destinat programatorilor de aplicaţii. Dacă primele niveluri erau interpretate, acesta este translatat de către un program numit asamblor.
Nivelul 6 este nivelul de limbaj înalt. Programele scrise în acest nivel sunt translatate către nivelele cinci şi şase de către programe specializate numite compilatoare.
Nivelul 7 conţine limbaje destinate unor domenii foarte speciale cum ar fi proiectarea asistată, administraţia, grafica etc.
1.3. SCURT ISTORIC AL DEZVOLTĂRII
CALCULATOARELOR
În decursul timpului, de la apariţia primului calculator şi până astăzi, dezvoltarea în acest domeniu s-a datorat celor doi factori principali:
-progresul tehnologic şi -introducerea de noi concepţii în arhitectura calculatoarelor.
1.3.1. Influenţa progresului tehnologic asupra dezvoltării calculatoarelor
De la apariţia primului calculator, tehnologiile au făcut progrese
uriaşe, atât în ceea ce priveşte componentele unui calculator cât şi în tehnologiile de stocare a informaţiei. Din acest punct de vedere, se pot distinge cinci generaţii de calculatoare.
1.3.1.1. Generaţia zero ,calculatoare mecanice,(1642-1945)
Primul care a construit o maşină de calcul funcţionabilă a fost Blaise
Pascal (1623-1662) care, la numai 19 ani, a proiectat o maşină mecanică, folosind roţi dinţate şi fiind acţionată de o manivelă manevrată de om. Maşina putea să facă numai adunări şi scăderi şi a fost creată de tânărul Pascal pentru a-l ajuta pe tatăl său care era colector de taxe pentru guvernul francez.
Gottfried von Leibnitz (1646-1716) a contribuit, teoretic şi practic, la naşterea informaticii. El a perfecţionat maşina lui Pascal, noua maşină reuşind să execute, pe lângă adunări şi scăderi, şi înmulţiri şi împărţiri.

Sorin Adrian Ciureanu 8
Cel care poate fi considerat autorul precursorului calculatorului actual este Charles Babbage (1792-1871). Acesta a creat două maşini: maşina de calcul diferenţială şi maşina analitică.
Maşina de calcul al diferenţelor (diferenţială) era o maşină specializată care, pe baza unui algoritm, calcula tabele de numere utile în navigaţia maritimă prin metoda diferenţelor finite. Cea mai interesantă caracteristică a acestei maşini era înscrierea rezultatelor pe o tablă de aramă gravabilă cu o ştanţă de oţel, previzionând mediile periferice de inscripţionare de azi.
Maşina analitică avea patru componente: -magazia (memoria); -moara (unitatea de calcul); -secţiunea de intrare (cititorul de cartele); -secţiunea de ieşire (ieşire perforată şi imprimată). Magazia consta din 100 de cuvinte a câte 50 cifre zecimale, fiecare
fiind folosite pentru a memora variabile şi rezultate. Moara putea accepta operanzi din magazie, pe care putea aduna , scădea, înmulţi sau împărţi, pentru ca, în final, să întoarcă rezultatul în magazie. Această maşină analitică era programabilă, într-un limbaj simplu de asamblare, care necesita pe cineva care să facă programarea. Acel cineva a fost Ada de Lovelace, fiica lordului Byron, care este cunoscută ca fiind primul programator din istoria calculatoarelor. În cinstea ei limbajul de programare a fost denumit ADA. Din păcate, maşina nu a funcţionat pentru că folosea roţi dinţate care, în sec. IX, erau realizate cu o precizie redusă. Insă această maşină, care a fost realizată practic în 1991 la Muzeul Ştiinţei din Londra, stă la baza calculatoarelor moderne, ideile ei fiind valabile şi astăzi.
Următoarele calculatoare aparţin tehnologiei electromecanice. În 1930, un student german, Konrad Zuse, a construit o serie de
maşini de calcul folosind relee electromagnetice. Din cauza războiului, însă, maşinile lui nu au fost cunoscute şi, mai mult, au fost distruse în bombardamentul Berlinului din 1945.
În SUA, John Atanasoff, de la Colegiul Statului Yowa, a creat, pornind de la ideea lui Babbage, o maşină asemănătoare din punct de vedere logic dar utilizând o altă tehnologie. Memoria era formată din capacităţi care se reîncărcau periodic, idee utilizată astăzi la memoria dinamică RAM cu refresh.
Ca şi maşina Babbage, maşina lui John Atanasoff era tributară tehnologiei şi nu a funcţionat. Se pare, însă, că istoria a reţinut prototipul ABC (Atanasoff-Berry-Computer), Berry fiind un student a lui Atanasoff, realizat în 1939.

Arhitectura calculatoarelor 9
George Stibitz, de la Bell Laboratories, a creat o maşină mai primitivă ca a lui Atanasoff dar care are marele merit că a funcţionat, demonstraţia făcându-se, în 1940, la Colegiul Dartmouth.
În 1944, Howard Aiken a construit o maşină pornind de la maşina Babbage, pe care a studiat-o îndelung, creând o nouă maşină pe bază de relee electromagnetice. Maşina avea 72 cuvinte, fiecare de câte 23 cifre zecimale, şi un timp de instrucţiune de 6 secunde. Intrarea şi ieşirea se făceau pe bază de hârtie perforată.
1.3.1.2. Generaţia întâi, maşini cu tuburi electronice (1945-1955)
Circuitele logice din generaţia întâi erau realizate cu tuburi
electronice şi aveau un consum energetic foarte mare. Principalele caracteristice ale acestor calculatoare au fost:
-memoria realizată cu tambur magnetic; -utilizarea cititorului/perforator de hârtie; -existenţa a 10-20 instrucţiuni simple care constituiau baza unui
limbaj cod maşină. Din punct de vedere logic nu era mare diferenţă faţă de maşina
Babbage dar tehnologic se intra în era electronică. Principalele calculatoare din această generaţie au fost: ENIGMA, maşină realizată de Germania în timpul celui de-al doilea
război mondial pentru transmiterea mesajelor codificate. COLLOSUS, maşini fabricate de Englezi pentru decodificarea
mesajelor ENIGMA. De menţionat că la fabricarea lor a contribuit şi Allan Turing, cunoscut mai târziu drept creator al maşinii TURING.
ENIAC (Electronic Numerical Integrator And Computer), construit de către John Mauchley şi John Eckert (Universitatea din Pensilvania), cu colaborarea lui John von Neumann,. Era destinat rezolvării ecuaţiilor diferenţiale cu derivate parţiale şi a avut aplicaţii în domeniul militar, la calcularea traiectoriilor balistice şi chiar la fabricarea bombei atomice în proiectul Manhatan. Avea următoarele caracteristici:
-19000 tuburi electronice şi 1500 relee; -30 unităţi separate care procesau datele; -20 registre de câte 10 cifre zecimale destinate rezultatelor finale şi parţiale; -efectua 5000 operaţii pe secundă.
EDVAC (Electronic Discrete Variable Automatic Computer), calculator cu numai 4000 tuburi electronice. Este important pentru că în echipa care l-a proiectat s-a aflat şi John von Neumann care în 1947 a

Sorin Adrian Ciureanu 10
publicat principiile calculatorului modern, valabile şi astăzi. Maşina lui von Neumann este un model de maşină universală, nespecializată, cu următoarele elemente:
-o memorie conţinând programe (instrucţiuni) şi date; -o unitate aritmetică şi logică(UAL); -o unitate care permite schimbul de informaţie cu perifericele (U I/E) -o unitate de comandă (UC). Aceste dispozitive realizează funcţiile de bază ale unui calculator:
stocarea de date, tratarea datelor, mişcarea datelor şi controlul lor, funcţii care sunt aceleaşi şi în ziua de astăzi. Calculatoarele moderne se bazează pe schema lui von Neumann.
MANIAC , calculatorul de la Los Alamos Laboratory, utilizat la proiectarea bombei atomice.
UNIAC 1, calculator lansat în 1951 de Eckert şi Mauchley şi utilizat într-o aplicaţie de predicţie a alegerilor din SUA câştigate de Dwight Eisenhower.
IBM 701, calculator cu memorie de 2kcuvinte a 36 biţi şi două instrucţiuni pe cuvânt (primul din seria de calculatoare lansate de celebra firmă IBM, înfiinţată, de altfel, în 1911) .
IBM 704, cu 4kcuvinte de 36 biţi. 1.3.1.3.Generaţia a doua, calculatoare cu tranzistori (1955-1965)
John Bardeen, Walter Brattain şi Wiliam Shockley au inventat în
1948 tranzistorul bipolar cu joncţiune ceea ce le-a adus în 1956 Premiul Nobel pentru Fizică. Tranzitorul are aceleaşi funcţiuni ca tuburile electronice cu vid dar are avantajul de a fi miniaturizabil.
Calculatoarele bazate pe tehnologia cu tranzistori au următoarele caracteristici:
-utilizarea diodelor şi tranzistorilor pe bază de germaniu şi apoi pe bază de siliciu ceea ce a condus la o putere disipată mai mică, gabarit redus şi siguranţă în funcţionare;
-memorii pe inele de ferită, de 1000 de ori mai rapide decât cele din generaţia anterioară, având timpul de acces de 2-12 µs.;
-apariţia cablajului imprimat; -apariţia echipamentelor periferice precum discul, banda magnetică,
imprimanta; -apariţia limbajelor de nivel înalt ca Fortran, Cobol, Algol. Dintre calculatoarele din această generaţie, cele mai cunoscute sunt: TX-0 (Tranzistorised eXperimental computer 0) realizat la MIT.

Arhitectura calculatoarelor 11
PDP-1 (Programmable Data Procesor) realizat de către DEC (Digital Equipement Corporation) , având o memorie internă de 4kcuvinte a 18 biţişi ciclul instrucţiune de 5µs., fiind echipat cu consolă monitor CRT (Cathode Ray Tube) cu posibilitatea de control al fiecărui punct de pe ecran.
PDP-8 , cu o magistrală unică şi cu următoarele module: CPU, memorie, consolă, dispozitive I/E. A fost primul calculator numeric comercial, de mare serie, vânzându-se 5000 bucăţi.
CDC 6600,produs de DEC şi proiectat de Seymour Cray, viitorul proiectant al calculatoarelor Cray 1 şi Cray 2.
IBM 7094, cu memorie de 32kcuvinte de 36 biţi şi ciclu instrucţiune de 2µs.
În această perioadă şi în România au început să se producă primele computere, care în majoritate au fost prototipuri, DACIC, MECIPT, ANCA, CETA, ele fiind realizate la Institutul de Fizică Atomică şi la Institutele Politehnice din Bucureşti şi Timişoara.
1.3.1.4. Generaţia a treia, calculatoare cu circuite integrate (1965-1980)
În 1958 a fost inventat circuitul integrat de către Robert Noyl sau,
după alte surse, de către Jack Kilby de la Texas Instruments. Este vorba despre gruparea pe o pastilă de siliciu a mii şi apoi milioane de componente.. Principalele caracteristici ale calculatoarelor din această generaţie sunt:
-utilizarea circuitelor integrate e scară redusă, cu 100 tranzistori pe chip;
-apariţia memoriilor de semiconductoare, cu timp de acces de 0,5-75µs;
-memorie externă de mare capacitate, discuri de masă şi benzi magnetice.
Sistemele de calcul din această generaţie au fost create de: IBM, cel mai reprezentativ fiind IBM 360; DEC, cu minicalculatoare din seria PDP 11/XX. Minicalculatorul IBM 360 avea următoarele caracteristici: -ciclul instrucţiune 250µs.; -spaţiul de adresare de 216 octeţi (19 Mocteţi); -registre de lucru pe 32 biţi; -apariţia multiprogramării. Minicalculatoarele PDP 11/XX aveau caracteristici asemănătoare cu
ale lui IBM , însă cuvântul era de 16 biţi (şi apoi de 32 biţi la cele din seria VAX); raportul preţ/performanţă era foarte bun, cel mai bun dina anii 80.

Sorin Adrian Ciureanu 12
Şi în România , în acea perioadă (anii 80), a fost o emulaţie şi o efervescenţă în construcţia de calculatoare, România fiind la un moment dat pe locul 1 din vechiul lagăr socialist în ceea ce privea echipamentele de tehnici de calcul.
În domeniul calculatoarelor numerice, România a produs: FELIX C 512/1024, serie de calculatoare care avea ca patent un
calculator francez produs de firma CII. Din punct de vedere tehnologic, a fost construit pe porţi logice şi bistabile iar urmaşul său, FELIX 5000, a avut în componenţă circuite medii integrate ca registre şi numărătoare. De remarcat că circuitele pentru FELIX C 512/1024 erau de provenienţă românească, produse la IPRS Băneasa Microelectronic. Din punct de vedere al caracteristicilor, FELIX avea cuvâtul de 16 biţi, o memorie de maxim 1 Moctet pe bază de semiconductoare, o unitate de intrare/ieşire numită USM (Unitate de Schimburi Multiple) care emiea 5 instrucţiuni speciale de intrare/ieşire. Ca sistem de operare avea un sistem pe laturi, numit SIRIS V, cu alocare de memorie cu partiţii statice.
CORAL şi INDEPENDENT, minicalculatoare ce emulau instrucţiunile din PDP 11/44. Amândouă calculatoarele româneşti aveau caracteristici tehnice asemănătoare cu PDP 11/44, deosebirea dintre ele fiind aceea că minicalculatorul CORAL avea în componenţă numai cipuri din Europa de Vest şi din America iar INDEPENDENT avea numai cipuri româneşti şi ruseşti. INDEPENDENT a fost proiectat de ITC (Institutul de Tehnică de Calcul) iar Coral de un colectiv de la FCB (Fabrica de Calculatoare Bucureşti) dar toate erau produse de FCB. Sistemul de operare era o prelucrare a SO RSX, numită MIX, creată de cei de la FCB.
RCD (Rom Control Data) fabrica echipamente periferice româneşti. RCD era o societate mixtă, româno-americană, în colaborare cu CD (Control Data). Se fabricau discuri magnetice de masă MD-40, MD-50 (de 50 Mocteţi), benzi magnetice CDC, imprimante liniare BP (Band Printer). Crearea RCD ne-adus un mare avantaj deoarece toate calculatoarele româneşti erau echipate cu periferice Control Data. Datorită acestui fapt am putut exporta calculatoare româneşti FELIX în China, INDEPENDENT în China, Cehoslovacia şi R.D.Germană. CORAL, deşi era cel mai performant şi făcut cu echipament românesc, nu a putut fi exportat deoarece sistemul de operare MIX era o copie a RSX-ului . În vest nu s-a putut exporta pe motiv de drept de autor iar în est cei de la FCB nu au vrut să-l exporte fiind prea bun.
Oricum, în anii 70 eram cei mai buni producători de echipamente de calcul din est. În anii 80, însă, am pierdut supremaţia în favoarea Bulgariei care a învestit mai mult ca noi, în special în echipamente periferice şi soft.

Arhitectura calculatoarelor 13
1.3.1.5. Generaţia a patra . V.L.S.I. (1980-2005) Apariţia acestei generaţii a fost posibilă datorită perfecţionării
tehnologiei integratelor. Circuitele integrate VLSI (Very Large Scale Integration) ajung la 1 miliard de tranzistoare pe cip..
Calculatoarele din această generaţie se caracterizează prin următoarele:
-utilizarea circuitelor VLSI; -apariţia şi dezvoltarea microprocesoarelor; -dezvoltarea de noi tipuri de memorii (MOS, magnetice, holografice)
şi echipamente periferice orientate pe sesizarea primară a datelor; -interconectarea calculatoarelor în reţele, însoţită de întrepătrunderea
industriilor de calculatoare şi telecomunicaţii; -apariţia şi dezvoltarea mediilor de programe complexe cu puternice
facilităţi grafice. În această generaţie au apărut la început calculatoarele personale de
tip Home Computer iar apoi cunoscutele Personal Computer, pe bază de microprocesoare; două dintre firmele cele mai importante care produl microprocesoare sunt INTEL şi MOTOROLA.
1.3.1.6. Generaţia cincia
S-a încercat o definire a generaţiei a cincia, prin formularea
cerinţelor ce stau în faţa calculatoarelor la ora actuală, cerinţe care cuprin următoarele:
-o interfaţă inteligentă care să permită dialogul pe bază de limbaj natural )voce, sunete, imagini, informaţie grafică);
-crearea unei maşini care să realizeze raşionament pentru rezolvarea problemei, fără cunoaşterea prealabilă a algoritmului;
-baze de date imense cu o căutare foarte rapidă. Tabelul 1.1. Tabel sintetic cu principalele evenimente din istoria
calculatoarelor
An Nume Eveniment 1642 Blaise Pascal Prima maşină de calculat mecanică 1834 Charles Babbage Maşina analitică 1904 J.A.Flemming Inventarea diodei 1906 Lee de Forest Inventarea triodei 1936 Konrad Zuse Primul calculator cu relee-Berlin
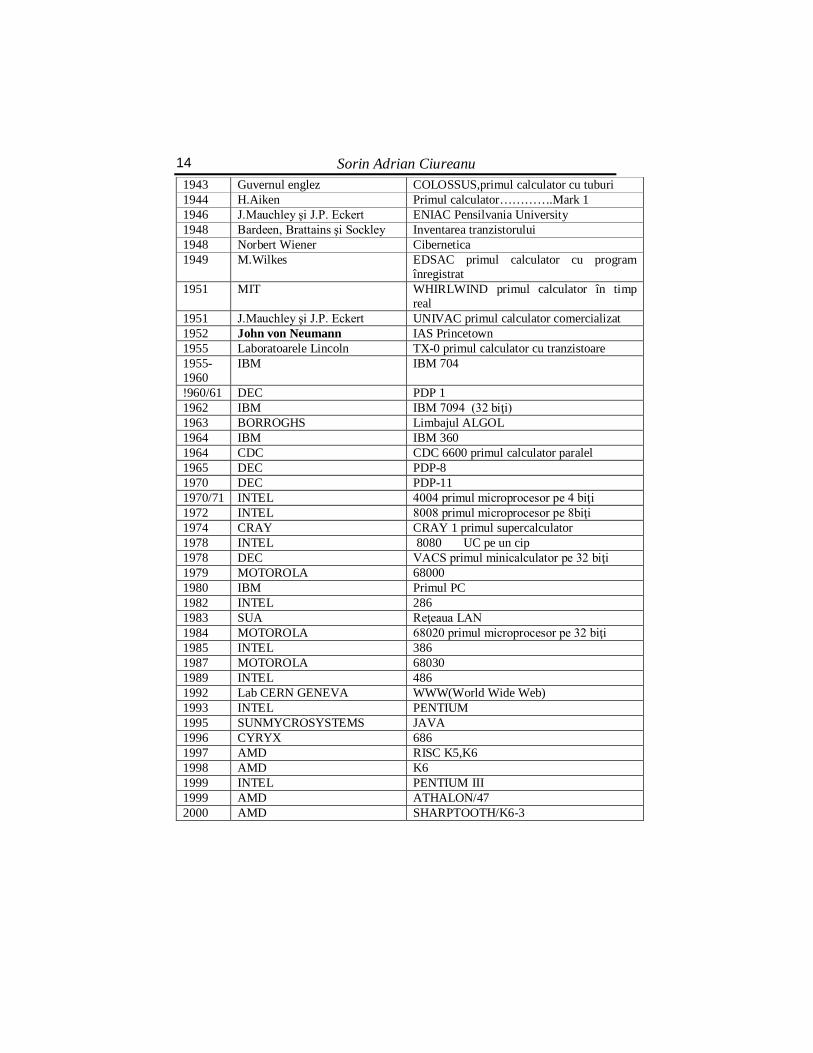
Sorin Adrian Ciureanu 14 1943 Guvernul englez COLOSSUS,primul calculator cu tuburi 1944 H.Aiken Primul calculator………….Mark 1 1946 J.Mauchley şi J.P. Eckert ENIAC Pensilvania University 1948 Bardeen, Brattains şi Sockley Inventarea tranzistorului 1948 Norbert Wiener Cibernetica 1949 M.Wilkes EDSAC primul calculator cu program
înregistrat 1951 MIT WHIRLWIND primul calculator în timp
real 1951 J.Mauchley şi J.P. Eckert UNIVAC primul calculator comercializat 1952 John von Neumann IAS Princetown 1955 Laboratoarele Lincoln TX-0 primul calculator cu tranzistoare 1955-1960
IBM IBM 704
!960/61 DEC PDP 1 1962 IBM IBM 7094 (32 biţi) 1963 BORROGHS Limbajul ALGOL 1964 IBM IBM 360 1964 CDC CDC 6600 primul calculator paralel 1965 DEC PDP-8 1970 DEC PDP-11 1970/71 INTEL 4004 primul microprocesor pe 4 biţi 1972 INTEL 8008 primul microprocesor pe 8biţi 1974 CRAY CRAY 1 primul supercalculator 1978 INTEL 8080 UC pe un cip 1978 DEC VACS primul minicalculator pe 32 biţi 1979 MOTOROLA 68000 1980 IBM Primul PC 1982 INTEL 286 1983 SUA Reţeaua LAN 1984 MOTOROLA 68020 primul microprocesor pe 32 biţi 1985 INTEL 386 1987 MOTOROLA 68030 1989 INTEL 486 1992 Lab CERN GENEVA WWW(World Wide Web) 1993 INTEL PENTIUM 1995 SUNMYCROSYSTEMS JAVA 1996 CYRYX 686 1997 AMD RISC K5,K6 1998 AMD K6 1999 INTEL PENTIUM III 1999 AMD ATHALON/47 2000 AMD SHARPTOOTH/K6-3

Arhitectura calculatoarelor 15
1.3.2. Concepte noi în evoluţia calculatoarelor
În afara progresului tehnologic, concepţiile noi au condus la o
dezvoltare rapidă a sistemelor de calcul.. . Noile idei sunt legate, în primul rând, de arhitectura calculatoarelor. Menţionăm doar cele mai importante dintre ele.
1.3.2.1. Microprogramarea
În 1951, Maurice Wilkes, un cercetător de la Universitatea din
Cambridge, a sugerat construirea unei maşini pe trei niveluri, în loc de două câte erau până atunci. Noul nivel propus de Wilkes avea rolul ca setul de instrucţiuni să fie interpretat de microprogram, în loc să fie realizat direct pe partea electronică. Acest concept, numit microprogramare, a devenit dominant începând cu anii 70.
1.3.2.2. Inventarea sistemului de operare
A fost proiectat şi introdus cu scopul de a automatiza sarcinile
operatorului de calculator. Un sistem de operare este un program care acţionează ca un intermediar între utilizator şi partea fizică a sistemului de calcul şi permite utilizarea eficace a componentelor unui calculator. Primul sistem de operare a fost realizat, în 1955, de către programatorii de la General Motors Research Center care au scris un astfel de program intitulându-l „a monitor program for the IBM 701”
Un pas foarte important în cadrul dezvoltării sistemelor de calcul a fost crearea sistemelor de operare cu timesharing de către MIT la începutul anilor 60. La sfârşitul anilor 60, se remarcă o serie de invenţii precum sistemul de operare UNIX care are deja un sistem de fişiere sofisticat, gestiunea proceselor, interfaţă cu sistemul şi o serie de instrumente specializate în tratarea unor sarcini specifice. Aşa cum arată numele, marca depusă UNIX desemnează începutul sistemelor compatibile.
1.3.2.3. Memoria Cache Memoria cache a fost o idee simplă dar foarte eficientă care a mărit
de zece ori viteza de calcul a unui sistem.

Sorin Adrian Ciureanu 16
1.4. TIPURI DE ARHITECTURI ALE CALCULATOARELOR NUMERICE
1.4.1. Arhitectura von Neumann Într-un articol publicat în 1947, John von Neumann a expus nişte principii care stau la baza calculatoarelor moderne. Acestea sunt: -Existenţa unui mediu de intrare prin intermediul căruia să poată fi introdus un număr practic nelimitat de date şi instrucţiuni.
-Existenţa unei memorii în care să fie depuşi operanzii şi instrucţiunile şi de unde să fie preluate rezultatele în ordinea dorită.
-Existenţa unei secţiuni de calcul care să fie capabilă să execute operaţii aritmetice şi logice asupra datelor din memorie.
-Existenţa unui mediu de ieşire prin intermediul căruia să poată fi comunicat utilizatorului un număr nelimitat de instrucţiuni.
-Existenţa unei unităţi de comandă capabilă să interpreteze instrucţiunile citite în memorie şi, pe baza informaţiilor citite în memorie şi a informaţiilor furnizate de secţiunea de calcul, să fie capabilă să decidă între mai multe variante de desfăşurare a operaţiilor.
-Datele şi instrucţiunile trebuie să fie stocate în memorie sub aceeaşi formă.
Fig. 1.3. Modelul funcţional al maşinii John von Neumann
Unitate de control
Memorie
Dispozitiv de intrare
Dispozitiv de ieşire
Unitate logică
şi aritmetică

Arhitectura calculatoarelor 17
1.4.2. Maşina Turing
În 1936, matematicianul englez Allan Turing a creat un automat
abstract care să opereze cu numere calculabile. Un număr calculabil este un număr a cărei parte zecimală poate fi determinată cu un număr finit de iteraţii.
Automatul a fost sintetizat pe baza următoarelor ipoteze: a)Automatul are un număr n finit de stări. b)Automatul se află în orice moment într-o stare i, 1≤i≥n, urmând ca în momentul imediat următor să se afle în starea j, 1≤j≥n. c)Fiecare din cele n stări se caracterizează prin: -valoarea caracteristică ei, care este o valoare curentă a numărului ce se calculează;
-funcţia fj care aplicată stării ei permite obţinerea următoarei stări ej .
-deplasamentul dij care va trebui aplicat numărului pentru a se realiza din starea i în starea j , adică j=i+dij
Modelul funcţional al maşinii construite pe baza acestor ipoteze este dat în figura 1.4.
C S
SR
Fig. 1.4. Modelul funcţional al maşinii Turing; SR-sistem reprezentativ; C/P-cip citire/scriere.
Procesor

Sorin Adrian Ciureanu 18
-Sistemul reprezentativ (SR) sau memoria maşinii este construit dintr-o bandă magnetică de lungime practic infinită, împărţită în segmente de lungime egală, fiecare segment putând stoca un număr finit de semne.
-Procesorul (P) este un circuit secvenţial cu un număr finit de stări, care poate executa următoarele instrucţiuni, (setul de instrucţiuni al maşinii):
-schimbă segmentul de pe bandă de la poziţia curentă; -poziţionează capul de citire (C ) cu o poziţie la dreapta; -poziţionează capul de citire cu o poziţie la stânga; -opreşte sistemul.
Pentru a realiza un calcul cu această maşină, se înscriu datele într-un mod convenabil şi se descompune algoritmul de calcul, în funcţie de modul de reprezentare a datelor, într-o secvenţă de instrucţiuni ale maşinii. Ultima instrucţiune este cea de oprire a maşinii.
1.5. CLASIFICAREA CALCULATOARELOR
Este destul de dificil să se clasifice tipurile de calculatoare din cauza
multitudinii lor. Totuşi, anumite taxonomii s-au impus. Vom prezenta trei clasificări după arhitectură şi una strict comercială.
1.5.1. Taxonomia Flynn
A fost publicată în 1966 de către Flynn care avea în vedere existenţa
într-un sistem de calcul a două fluxuri: -fluxul de instrucţiuni, care reprezintă programul; -fluxul de date, care reprezintă datele de intrare sau rezultatele
parţiale. Clasificarea lui Flynn ia în consideraţie gradul de multiplicitate ale
celor două fluxuri şi identifică patru tipuri de arhitecturi: SISD (Single Instruction Single Data) SIMD (Single Instruction Multiple Data) MISD (Multiple Instructions Single Data) MIMD (Multiple Instructions Multiple Data) SISD realizează o execuţie sequenţială a instrucţiunilor (figura 1.5.).
Principalul neajuns al acestei arhitecturi este viteza de execuţie care , la un moment dat, este plafonată, situaţie denumită „gâtul sticlei lui Neumann”

Arhitectura calculatoarelor 19
(Neumann Bottleneck). Spargerea acestei limitări este realizată prin arhitectura paralelă.
Fig. 1.5. Arhitectura SISD; UC-secţiunea de comandă a Unităţii centrale; UP-secţiunea de prelucrare a Unităţii centrale; MM-modul de
memorie; FD-flux de date; FI-flux de instrucţiuni.
Arhitectura SIMD se caracterizează prin n unităţi de procesare (UP) care operează sub controlul unui flux unic de instrucţiuni (FI) lansat de o singură unitate de comandă (UC).
FD1 FD2 FI FDn
Fig. 1.6. Arhitectura SIMD; UC-secţiunea de comandă a Unităţii centrale; UP-secţiuni de prelucrare a Unităţii centrale; MM-moduri de
memorie; FD-flux de date; FI-flux de instrucţiuni. Cele mai cunoscute maşini SIMD sunt calculatoarele vectoriale.
Acestea transformă instrucţiuni care se execută în n paşi într-o maşină SIMD, în instrucţiuni care se execută într-un singur pas. De exemplu, suma a doi vectori: c[i]=a[i]+b[i] pentru i=1…n se face într-un pas, fiecare Unitate de Prelucrare calculând o componentă a vectorului sumă.
MISD nu are nici un sens şi de aceea nu este utilizată. MIMD cuprinde două feluri de maşini: -multiprocesoare şi -multicalculatoare. Multiprocesoarele se caracterizează prin existenţa memoriei comune
la care au acces n procesoare. Schimbul de informaţie dintre procesoare se
UC UP MM
UC
UP2
UP1
UPn
MM!
MM2
MMn

Sorin Adrian Ciureanu 20
face prin variabilele partajate din memoria comună la care au acces toate procesoarele, însă accesul trebuie făcut prin excludere mutuală pentru a realiza ceea ce se numeşte consistenţa memoriei.
Multicalculartoarele se caracterizeză prin existenţa unui număr foarte mare de calculatoare ( de la ordinul sutelor în sus) care sunt legate printr-o reţea topologică. Fiecare procesor are memoria lui locală, văzută doar de el, iar comunicarea între procesoare se face prin mesaje.
1.5.2. Taxonomia lui Wang Această clasificare presupune o organizare matricială a datelor. O
matrice de dimensiunea m x n are m cuvinte, fiecare cuvânt are o lungime de n biţi. Criteriul de clasificare este gradul de paralelism în procesarea datelor organizate matricial. Conform acestui criteriu există patru tipuri de arhitecturi şi anume:
-WSBS (Word Serial-Bit Serial) în care se lucrează pe un singur cuvânt, fiecare cuvânt fiind prelucrat serial bit cu bit, ns1, ms1….
-WSBP (Word Serial-Bit Paralel) în care se lucrează pe un singur cuvânt , biţii fiecărui cuvânt fiind prelucraţi simultan, n>1, ms1.
WPBS (Word Paralel-Bit Serial) în care se lucrează pe un singur bit la toate cuvintele simultan, ns1, m>1.
-WPBP (Word Paralel-Bit Paralel) în care se lucrează simultan pe toate cuvintele şi pe toţi biţii, n>1, m>1.
WSBS nu are elemente de paralelism. WSPB şi WPBS sunt parţial paralele, fiind orientate pe prelucrarea
vectorilor. WPBP este complet paralel. 1.5.3. Taxonomia lui Shore Spre deosebire de Flynn, Shore şi-a bazat clasificarea pe modul în
care este organizat calculatorul din părţile sale componente. Din acest punct de vedere, au fost identificate şase tipuri de maşini, fiecăreia atribuindu-se o cifră romană.
Maşina I are o arhitectură convenţională von Neumann, cu următoarea structură:
-unitate de comandă (CU) -unitate de procesare (PU) -memorie pentru instrucţiuni (IM)

Arhitectura calculatoarelor 21
-memorie pentru date (DM)
(orizontal)
Fig. 1.7. Maşina I Shore.
O citire a DM produce toţi biţii unui cuvânt, care sunt prelucraţi în paralel de PU, PU putând conţine mai multe unităţi funcţionale.
Această clasă include calculatoare vectoriale, de exemplu CRAY 1. Maşina II este similară maşinii I, cu deosebirea că, în timp ce
maşina I citeşte slice-uri orizontale, maşina II citeşte un slice vertical. (vertical)
Fig. 1.8. Maşina II Shore Exemple de calculatoare de tip maşina II Shore : ICL, DAP,
STARAN etc. Maşina III este o combinaţie a maşinilor I şi II. Un exemplu de
astfel de maşină este calculatorul ortogonal Shooman(1970)
IM CU
PU
DM
IM
CU
PU
DM

Sorin Adrian Ciureanu 22
(orizontal)
(vertical)
Fig. 1.9. Maşina III Shore Masina IV se obţine prin multiplicarea unităţilor PU şi DM din
maşina I şi prin trimiterea acestui ansamblu de la o singură unitate de control UC. Exemplu: PEPE.
Fig. 1.10. Maşina IV Shore
Maşina Veste exact maşina IV cu facultatea suplimentară că unităţile PU sunt aşezate pe o linie şi se asigură conexiuni între vecinii cei mai apropiaţi; fiecare PU poate adresa informaţii din memoria sa dar şi din cea a vecinilor săi imediaţi. Este un masiv conectat. Exemplu: ILIA CIV.
Maşina VI este denumită maşina cu logica în memorie. Este o abordare alternativă a distribuirii comenzii în memorie.
Fig. 1.11. Maşina VI Shore Exemplu: calculatoare cu memorii asociative.
IM
CU
PU
PU
DM
CU
PU PU PU
DM DM DM
CU
PU + DM

Arhitectura calculatoarelor 23
1.5.4. Clasificare comercială
Dacă primele trei clasificări erau strict legate de arhitectură,
clasificarea următoare are ca punct de vedere piaţa de calculatoare. Sistemele de calcul pot fi:
-calculatoare personale; -servere; -sisteme dedicate. Calculatoarele personale sunt cele mai populare. Au cel mai mic
cost şi în ultimii ani s-au produs 150-200 milioane pe an. Preţul lor nu depăşeşte suma de 10000 dolari.
Serverele sunt destinate să ofere servicii tot mai sofisticate de reţea. Costul lor este de 10.000 – 10.000.000 dolari. În ultimii ani s-au produs aproximativ 4 milioane servere pe an.
Sistemele dedicate sunt construite pentru anumite aplicaţii speciale. Costul lor este de 10.000-100.000 dolari.
1.7. TRENDUL ÎN ARHITECTURA
CALCULATOARELOR
Din punct de vedere tehnologic cele mai importante tendinţe sunt: -gradul de integrare al tranzistorilor pe cip creşte cu cca. 55% pe an;
tehnologia de integrare a microprocesoarelor a evoluat de la 10 microni (1971) la 0,18 microni 2001.
-frecvenţa ceasului creşte şi ea cu 50% pe an; -pentru memoriile DRAM, densitatea de integrare creşte cu cca 40-
50% pe an, iar timpul de acces aferent scade cu 3 % pe an. -tehnologia şi performanţele reţelelor se îmbunătăţesc semnificativ. Se poate spune că aceste tendinţe respectă legea lui Gordon Moore,
cofondator împreună cu Obert Noyce a societăţii INTEL. Acesta, în 1965, enunţă celebra sa lege: „numărul de tranzistori din circuitele integrate se va dubla la fiecare doi ani” . Aceasta înseamnă că, la fiecare 10 ani se schimbă prefixul de măsurare, adică totul creşte de 1000 de ori. Într-adevăr, dacă hard discurile din anii 90 aveau 100 MB, în 2000 ele au 100 GB. Frecvenţa ceasului era în 1990 de 8 MHz iar în 2000 era de 1 GHz etc.
Ceea ce s-a întâmplat într-adevăr cu procesoarele INTEL în ultimele trei decenii se poate constata din tabelul de date reale dat în continuare, date care verifică destul de bine legea lui Gordon.

Sorin Adrian Ciureanu 24
Tabelul 1.2. Evoluţia procesoarelor Intel între 1972 şi 2000 anul numele Frecvenţa
Tranzistor (nr./cip)
1972 8008 200KHz 3500 1974 8080 2MHz 6000 1976 8085 5MHz 6500 1978 8086 10MHz 29000 1982 286 12MHz 134.000 1985 386 16MHz 275.000 1989 486 25MHz 1,2.106 1993 P 60MHz 3,1.106
1997 PII 300MHz 3,3.106
1999 PIII 600MHz 9,5.106
2000 PIV 1,5GHz 42.10.6
Între cele mai evidente tendinţe de evoluţie în arhitectură amintim: -exploatarea paralelismului la nivelul instrucţiunilor şi firelor de
execuţie, atât prin tehnici statice (soft) cât şi dinamice(hard); există şi tehnici hibride cum ar fi cazul procesorului Intel Ithamium IA-64;
-structuri tot mai performante de ierarhizare a sistemului de memorie prin utilizarea arhitecturilor evoluate de memorie cache;
-reducerea latenţei ………critice de program, prin tehnici de predicţie;
-utilizarea microprocesoarelor Shered memory în special în cadrul arhitecturii serverelor şi staţiilor grafice.

Arhitectura calculatoarelor 25
Capitolul 2
UNITATEA CENTRALĂ
Unitatea centrală (UC), în engleză CPU=Central Processing Unit,
este partea din calculator care are rolul de a interpreta şi executa instrucţiunile unui program, de a citi sau salva în memorie rezultatele şi de a comunica cu unităţile de schimb. Toate aceste activităţi sunt cadenţate de un ceas la frecvenţă constantă care împarte timpul în fracţiuni de aceeaşi durată numite cicluri.
2.1. STRUCTURA UNITĂŢII CENTRALE
Unitatea Centrală are în componenţă: -Unitatea Aritmetică şi Logică (UAL); -Unitatea de comandă (UCd); -Registrele generale (RG). a) Unitatea Aritmetică şi Logică (UAL) UAL execută operaţii aritmetice (adunare, scădere, înmulţire
împărţire, complement faţă de 1, complement faţă de 2 etc.) , operaţii logice (negare, şi, sau, suma modulo 2), decalaje şi rotaţii. Are două intrări de date, pe n biţi, o ieşire corespunzătoare operaţiei efectuate, pe n biţi, eventual o ieşire corespunzătoare flagurilor poziţionate de operaţie şi o intrare de comandă care selecţionează operaţia de efectuat.
Toată Unitatea Aritmetică şi Logică este grupată în jurul unui sumator paralel care poate aduna conţinutul a două registre multiplexate la cele două intrări ale sumatorului. Operaţiile de înmulţire şi împărţire se realizează, cu ajutorul diferiţilor algoritmi, prin adunări şi deplasări stânga/dreapta succesive. Scăderea se realizează ca o adunare cu complementul scăzătorului.

Sorin Adrian Ciureanu 26
Schema unei UAL este dată în figura 2.1.
Fig 2.1. Schema bloc UAL
b) Unitatea de Comandă (UCd) Unitatea de comandă este formată din: -Generatorul de Faze (GF); -Generatorul de Tact (GT); -Blocul Circuitelor de Comandă (BCC). Blocul circuitelor de comandă (BCC) dirijează toate operaţiile
executate în cadrul unei instrucţiuni. Există microoperaţii, care sunt operaţiile elementare executate într-o instrucţiune, şi microcomenzi, care sunt semnalele generate de BCC pentru execuţia microoperaţiilor. Microcomenzile sunt trimise elementelor de execuţie din structura calculatorului: registre, UAL, memorie, porturi etc. O instrucţiune este, de fapt, o succesiune de microoperaţii.
Toate microoperaţiile care se execută în acelaşi timp definesc o stare în execuţia unei instrucţiuni, stare numită fază.
Generatorul de faze (GF) construieşte succesiunea fazelor necesară pentru execuţia instrucţiunii.
Generatorul de tact (GT) dă cadenţa schimbărilor de stare pentru toate circuitele secvenţiale.
Set de
registre
Registru tampon
Registru acumulator
Σ Sumator

Arhitectura calculatoarelor 27
c) Registrele generale (RG) Registrele generale (RG) sunt considerate o memorie foarte rapidă şi
de foarte mică capacitate. Structural fac parte din UC şi, în marea majoritate a arhitecturilor, ele sunt adresabile pe magistrală.
Există două moduri de conexiune a registrelor generale: -RG conectate direct între ele: -RG conectate la magistrale.
2.2. CARACTERISTICILE UNITĂŢII CENTRALE
Performanţele în funcţionarea unei Unităţi Centrale sunt redate prin următoarele caracteristici:
-Lungimea cuvântului; -Frecvenţa ceasului; -Numărul de instrucţiuni executate în unitatea de timp; -Gradul de paralelism. 2.2.1. Lungimea cuvântului Calculatoarele lucrează cu ajutorul cuvintelor de cod a căror cantitate
de informaţie este măsurată în biţi. Numărul de biţi reprezintă lungimea unui cuvânt şi este multiplu de doi. Un cuvânt poate reprezenta:
-o instrucţiune; -un segment de date. Într-un calculator, lungimea cuvântului se identifică cu numărul de
biţi ai instrucţiunii. Cele mai noi calculatoare au instrucţiuni pe 64 biţi. Aceasta este o caracteristică principală a UC .
Nu este obligatoriu ca lungimea cuvântului să fie aceeaşi cu dimensiunea magistralei de memorie pe care se aduc instrucţiunile din UM în UC. Un calculator poate avea, de exemplu, lungimea instrucţiunii de 64 biţi şi lărgimea magistralei de 32 biţi; pentru aducerea unei instrucţiuni din memorie sunt necesare, în acest caz, două apeluri la memorie.
2.2.2. Frecvenţa ceasului Orice calculator are un generator de impulsuri, numit ceasul unităţii
centrale.. Acesta este realizat cu un cuarţ care emite impulsuri cu frecvenţă fixă. Ceasul iniţial suferă două tipuri de operaţii:

Sorin Adrian Ciureanu 28
-operaţia de divizare a ceasului, ceea ce înseamnă că ceasul iniţial, cu cuarţ, suferă modificarea frecvenţei sale;
-operaţia de amplificare a semnalului de ceas. Pe acest ceas, care este inima calculatorului, au loc toate
evenimentele hard din UC. 2.2.3. Numărul de instrucţiuni executate în unitatea de timp Dacă facem următoarele notaţii: f = frecvenţa ceasului, în Hz N = numărul mediu de ceasuri în care se execută o instrucţiune n = numărul de instrucţiuni executate într-o secundă atunci
Nfn
De exemplu, pentru un calculator care are frecvenţa ceasului de 2 GHz şi care execută două instrucţiuni pe ceas, numărul de instrucţiuni executate în unitatea de timp este:
410.4
21
2 9 GHz
Nfn miliarde instrucţiuni pe secundă
Pentru calculatoarele moderne se adoptă o unitate de măsură numită MIPS (milioane de instrucţiuni executate într-o secundă). În exemplul precedent, parametrul n va fi de 4000 MIPS.
Trebuie precizat că acest parametru (n) este mai aproape de adevăr decât frecvenţa ceasului (f). Există calculatoare cu frecvenţă mai mică dar care sunt inferioare calculatoarelor cu frecvenţa ceasului mai mare, tocmai datorită mărimii N. De exemplu Intel 586 cu frecvenţa 100 MHz şi Pentium I cu frecvenţa 66 MHz. Ar fi mai bine să fie afişat parametrul n în locul parametrului f, dar partea dificilă este calcularea practică a lui N. Este dificilă, deoarece, în setul de instrucţiuni, fiecare are N diferit şi chiar aceeaşi instrucţiune are N diferit în funcţie de contextul rulării.
2.2.4. Gradul de paralelism Există două feluri de paralelism: -paralelism la nivel de instrucţiuni (pipeline)

Arhitectura calculatoarelor 29
-paralelism la nivel de procesor. 2.2.4.1. Paralelism la nivel de instrucţiuni (pipeline) a)Principiul pipeline-ului este acela al liniei de montaj (de
asamblare): -împărţirea unei sarcini în mai multe subsarcini de durate egale,
numite etaje; -executarea simultană a diferitelor subsarcini din mai multe sarcini. În felul acesta se măreşte debitul de sarcini al sistemului. Sistemul va
fi caracterizat prin doi parametri: durata individuală a unui etaj (T) şi numărul de etaje (l)din pipeline. Latenţa L este durata totală de execuţie a unei sarcini: L= lT
Debitul, d, al pipeline-ului depinde de numărul n de sarcini de executat. Timpul necesar pentru execuţia în pipeline a n sarcini este timpul de execuţie a primei sarcini, L= lT, plus timpul necesar pentru a le termina pe celelalte n-1 următoare:
TnLnd
)1(
sau, la limită: 1lim
Td
n
Apare rezultatul esenţial: pentru un mare număr de sarcini, debitul nu depinde de latenţă ci de durata individuală a fiecărui etaj. Deci, debitul optimal va fi atins fracţionând cât mai fin posibil sarcina în subsarcini. Evident, fracţionarea are limite tehnice.
b)Clasicul pipeline pentru execuţia instrucţiunilor În calculatoare, pipeline-ul constă în fracţionarea execuţiei unei
instrucţiuni în mai multe module, fiecare modul executând hard o parte de instrucţiune. Conceptul de pipeline înseamnă de fapt o bandă de asamblare cu segmente, fiecare segment executând o parte de instrucţiune.
De exemplu, o bandă de asamblare cu 5 segmente. Aceste 5 segmente sunt:
S1 – unitate de extragere a instrucţiunii S2 – unitate de decodificare a instrucţiunii S3 – unitate de calcul şi extragere a operanzilor S4 – unitate de execuţie propriu zisă a operaţiei instrucţiunii S5 – unitate de scriere a rezultatelor

Sorin Adrian Ciureanu 30
(a)
S1 1 2 3 4 5 6 7 8 9 10 11 S2 1 2 3 4 5 6 7 8 9 10 S3 1 2 3 4 5 6 7 8 9 S4 1 2 3 4 5 6 7 8 S5 1 2 3 4 5 6 7
Timpi de execuţie a
segmentelor
t1 t2 t3 t4 t5 t6 t7 t8 t9 t10 t11
(b) Fig.2.2. Schema unei benzi de asamblare cu 5 segmente; (a) schema de
funcţionare; (b)diagrama temporară a execuţiei segmentelor.
Din figura 2.2. se observă cum funcţionează paralelismul într-o bandă de asamblare, la un moment de timp fiecare segment executând unul din cele 5 segmente de instrucţiune diferite. Dacă timpul de execuţie a unui segment este de 1 secundă, (t1=t2=…….=t10=t11=1s) atunci timpul de execuţie a 7 instrucţiuni este, aşa cum se vede în figură, de 11 secunde. Pe o maşină normală, fără pipeline, timpul de execuţie a 7 instrucţiuni, fiecare necesitând 5 secunde, ar fi de 35 sec. Efectul se vede în creşterea debitului în executarea instrucţiunilor.
Există şi sisteme cu două benzi de asamblare, ca în figura 2.3.
Fig.2.3. Pipeline cu două benzi de asamblare.
Un astfel de sistem are o singură unitate de extragere a instrucţiunii (S1) care extrage perechi de instrucţiuni şi le plasează pe cele două benzi. Condiţia de a lucra în paralel este ca cele două instrucţiuni să nu îşi dispute aceeaşi resursă şi să nu depindă una de rezultatul celeilalte. Această condiţie este garantată fie de compilator , fie de un hard suplimentar dotat cu un sistem de predicţie.
Calculatoarele Pentium I erau dotate cu două benzi de asamblare:
S1 S2 S3 S4 S5
S1
S2 S3 S4 S5
S2 S3 S4 S5

Arhitectura calculatoarelor 31
-bandă de asamblare U (U pipeline), bandă principală, care putea executa orice instrucţiune;
-bandă de asamblare V (V pipeline), care putea executa doar instrucţiunile simple în numere întregi şi o singură instrucţiune simplă în virgulă mobilă.
Existau reguli destul de complicate pentru împerecherea instrucţiunilor. Erau extrase câte două instrucţiuni şi dacă erau compatibile erau executate, dacă nu, se executa doar prima pe banda U, a doua fiind păstrată şi împerecheată cu cea care urma. În acest mod, s-a constatat că Pentium I era de două ori mai rapid decât un 586 la aceeaşi frecvenţă.
c) Arhitecturi suprascalare Pornind de la ideea benzilor de asamblare , s-a ajuns la concluzia că
este mai benefic de a avea o singură bandă de asamblare dar cu mai multe unităţi funcţionale. O astfel de arhitectură se numeşte superscalară, termen introdus de Agerwals şi Cocke în 1987. În figura 2.4. este dată o astfel de arhitectură.
S4
Fig. 2.4. Procesor superscalat cu 5 unităţi funcţionale.
Ideea arhitecturii superscalare este că segmentul S3 poate lansa instrucţiuni mult mai rapid decât le poate executa S4, deci, la o bandă simplă există o gâtuire de timp între S3 şi S4. La arhitectura superscalară, se împarte unitatea de execuţie S4 în unităţi funcţionale pe tipuri de instrucţiuni (de încărcare,LOAD, de memorie, STORE, de virgilă mobilă)
S1 S2 S3 S5 lLOAD
STORE
VIRGULĂ FLOTANTĂ
UAL
UAL

Sorin Adrian Ciureanu 32
2.2.4.2. Paralelism la nivel de procesor Banda de asamblare sau arhitectura superscalară nu cresc
performanţele în mod simţitor. Mult mai eficientă este mărirea numărului de procesoare. Acest lucru se întâmplă în :
-maşinile SIMD, calculatoare vectoriale; -maşinile MIMD, multiprocesoare; -maşinile MIMD, multicalculatoare.
2.3. MODURI DE ADRESARE
După posibilitatea găsirii operanzilor, există mai multe moduri de adresare:
-adresare imediată; -adresare directă; -adresare indirectă; -adresare indexată. a) Adresare imediată Operandul se află chiar în câmpul instrucţiunii. Instrucţiune Câmp operand MOV R 20000 Se transferă valoarea 20000 în registrul R.
b) Adresare directă Operandul se găseşte la o adresă care există în instrucţiune
Câmp adresă
OPERAND MOV R 100 100 20000 În câmpul de adresă al instrucţiunii se află o adresă (100) la care
există operandul.
OPERAND
ADRESĂ

Arhitectura calculatoarelor 33
c) Adresare indirectă În câmpul de adresă al instrucţiunii se află o adresă. La acea adresă
se află operandul. Numărul de indirectări depinde de fiecare calculator în parte.
Câmp adresă
ADRESĂ OPERAND
MOV R 100 100 200 200 20000 La adresa 100 din câmpul instrucţiunii se află altă adresă, 200, iar la
această adresă se află operandul. c) Adresare indexată La adresarea indexată participă un registru numit registru INDEX.
Adresa operandului este: Adresa operand = valoareCÂMP ADRESĂ + valoareREGISTRU INDEX MOV R 100 RINDEX 600 100 700 Adresa calculată: 600 + 700 = D00 D00 20000
2.4. UNITATE CENTRALĂ CABLATĂ
Într-o UNITATE CENTRALĂ CABLATĂ toate transferurile se fac
în mod hard, de către o unitate de comandă. Părţile componente ale unei astfel de UC, aleasă ca exemplu (figura 2.5.), sunt:
-registrul A, numit registru acumulator (32 biţi); -registrul T, numit registrul tampon, cu rol de a păstra rezultatele
parţiale, (32 biţi);
ADRESĂ
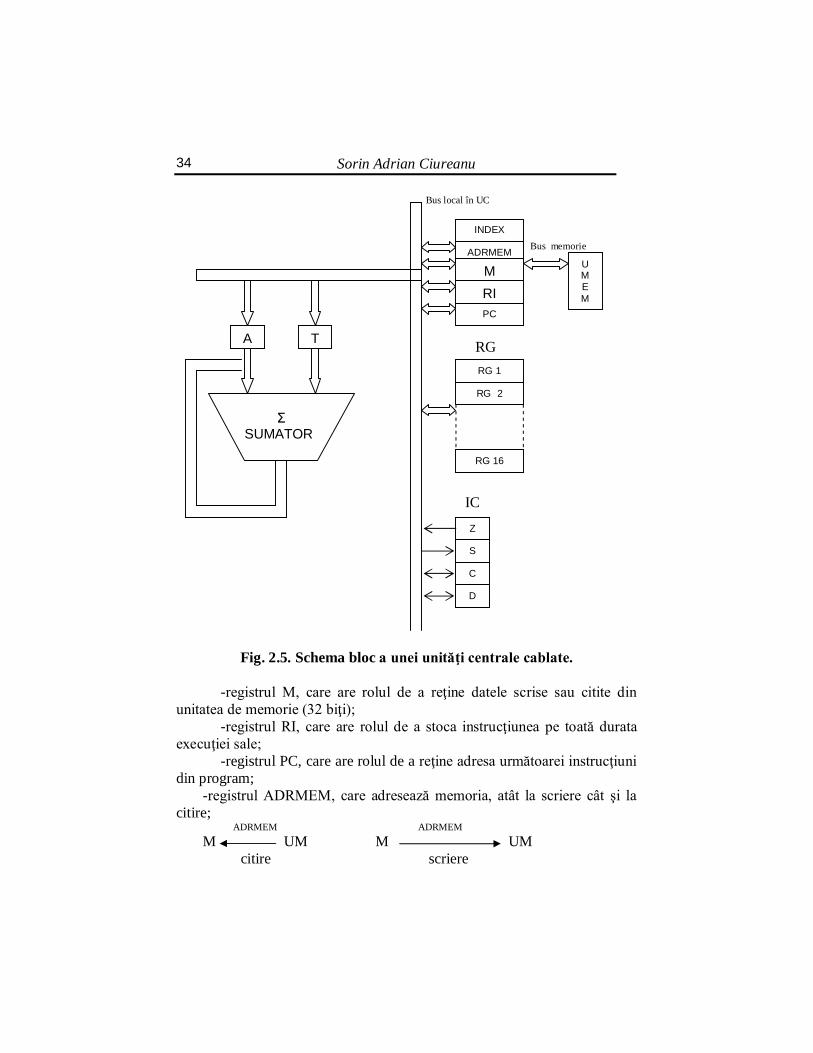
Sorin Adrian Ciureanu 34
Bus local în UC
Bus memorie
RG
IC
Fig. 2.5. Schema bloc a unei unităţi centrale cablate.
-registrul M, care are rolul de a reţine datele scrise sau citite din unitatea de memorie (32 biţi);
-registrul RI, care are rolul de a stoca instrucţiunea pe toată durata execuţiei sale;
-registrul PC, care are rolul de a reţine adresa următoarei instrucţiuni din program;
-registrul ADRMEM, care adresează memoria, atât la scriere cât şi la citire;
ADRMEM ADRMEM M UM M UM citire scriere
A T
Σ SUMATOR
INDEX ADRMEM
M RI PC
RG 1
RG 2
RG 16
Z
S
C
D
U M E M

Arhitectura calculatoarelor 35
de asemenea, prin ADRMEM se adresează şi cele 16 registre generale (RG), dar pe bus-ul local nu pe cel al memoriei; adresele de registre generale sunt primele 16 adrese de memorie, adrese rezervate exclusiv pentru RG, neputând fi utilizate ca adrese de memorie;
-!6 registre generale (RG) adresate pe bus-ul local al UC-ului; -registrul INDEX , care participă la calculul adresei în mod indexat; -4 indicatori de condiţie (ZC) cu următoarele semnificaţii: Z arată două situaţii Compararea între registrele A şi T Z=1 → A=T
Z=0 → A≠T Conţinutul acumulatorului este zero (Z=1) S S=1 rezultat negativ (în A) D D=1 depăşire C C=1 transport -BUS-ul local, un bus foarte rapid în interiorul UC-ului; -BUS-ul de memurie, un bus mai lent care face legătura UC↔UM; Convenţional, o adresă este o adresă de octet. Un cuvânt este pe 32 biţi, deci pe 4 octeţi.
Adresele din PC vor evolua cu 4, următoarea adresă de instrucţiune fiind PC+4.
Adresele celor 16 registre generale sunt: RG 1 0 RG 5 10 RG 9 20 RG 13 30 RG 2 4 RG 6 14 RG 10 24 RG 14 34 RG 3 8 RG 7 18 RG 11 28 RG 15 38 RG 4 C RG 8 1C RG 12 2C RG 16 3C
O instrucţiune are 32 biţi şi are următoarea structură:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 COD MS SURSA MD DESTINAŢIE
COD – 4 biţi – codul instrucţiunii (calculatorul are 16 instrucţiuni) MS - modul operandului sursă – 2 biţi 00 – mod imediat 01 – mod direct 10 – mod indirect 11 – mod indexat SURSA – câmpul operandului SURSA – 12 biţi

Sorin Adrian Ciureanu 36
MD – modul destinaţie 00 – mod imediat 01 – mod direct 10 – mod indirect 11 – mod indexat DESTINAŢIE – câmpul operandului DESTINAŢIE – 12 biţi Setul de instrucţiuni executate de acest calculator este de numai 16
instrucţiuni. Tabelul 2.1. Lista de instrucţiuni a calculatorului
COD MNEMONIC ACŢIUNE 0000 ADD SURSĂ+DESTINAŢIE→DESTINAŢIE 0001 MOV SURSA→DESTINAŢIE 0010 CMP SURSA compară cu DESTINAŢIE→poziţionează Z 0011 C1 SURSA→complement……………DESTINAŢIE 0100 DDn SURSA deplasare dreapta cu n poziţii →DESTINAŢIE : n 0101 DSn SURSA deplasare stânga cu n poziţii → DESTINAŢIE : n 0110 SM2 SURSA suma modulo 2 DESTINAŢIE → DESTINAŢIE 0111 SAU SURSA sau DESTINAŢIE → DESTINAŢIE 1000 SI SURSA şi DESTINAŢIE → DESTINAŢIE 1001 INC SURSA + 1 → DESTINAŢIE 1010 DEC SURSA – 1 → DESTINAŢIE 1011 SWAP SURSA1-16 →DESTINAŢIE17-32 SURSA17-32 → DESTINAŢIE1-16 1100 SALTNEC SALT LA ADRESA DATĂ DE SURSĂ 1101 SALTCOND DACĂ Z=1 SALT LA ADRESA DIN SURSĂ, Z=0 PROGR
CONTINUĂ ÎN SECVENŢĂ 1110 DDCn SURSA deplasare circulară dreapta cu n poziţii→DESTINAŢIE n 1111 DSC n SURSA deplasare circulară stânga cu n poziţii→DESTINAŢIE n
Fiecare instrucţiune, pentru a fi executată, are o serie de comenzi
care, la UC cablată, sunt efectuate de către partea hardware a unităţii centrale.
Orice instrucţiune are o parte comună care se numeşte ifetch (instructionfetch) şi care este partea de aducere a instrucţiunii din memorie în UC. Ea are următoarele comenzi:
PC → ADRMEM ADRMEM
M ← UMEM CITIRE
M → RI PC → PC + 4
În continuare, să vedem care sunt comenzile pentru diferite
instrucţiuni care lucrează în diferite tipuri de adrese.

Arhitectura calculatoarelor 37
1) COD 0001 MNEMONIC ADD MS 00 - imediat SURSA 02A MD 00 - imediat DESTINAŢIA - 05B Adresa instrucţiunii 100 Instrucţiunea este 000A805B
Comenzi: ifetch: PC → ADRMEM 100
ADRMEM
M ← UMEM 000A805B CITIRE
M → RI 000A805B PC → PC + 4 104
RI7-18 → A 0000 002A RI21-32 → T 0000 005B A + T → A 0000 0085 A → RI 0000 0085 2) COD 0001 MNEMONIC MOV R5 ABCDEF01 MS 01 - direct SURSA RG5 10 MD 01 - direct DESTINAŢIA - RG16 3C Adresa instrucţiunii 200 Instrucţiunea este 0404103C Comenzi: ifetch: PC → ADRMEM 200 ADRMEM
M ← UMEM 0404103C M → RI 0404103C
PC → PC + 4 204 RI7-18 → ADRMEM 10

Sorin Adrian Ciureanu 38 ADRMEM
M ← RG5 ABCDEF01 RI21-32 → ADRMEM 3C
ADRMEM M ← RG16 ABCDEF01
3) COD 0010 MNEMONIC CMP MS 10 - indirect SURSA 800 800 F00 MD 10 - indirect 900 E00 DESTINAŢIA - 900 F00 ABCDEF01 Adresa instrucţiunii 200 E00 ABCDEF01 Instrucţiunea este 1A002900 Comenzi: ifetch: PC → ADRMEM 200 ADRMEM
M ← UMEM 1A002900 M → RI 1A002900
PC → PC + 4 204
RI7-18 → ADRMEM 800 ADRMEM
M ← 800 F00 M → ADRMEM F00
ADRMEM
M ← F00 ABCDEF01 M → A ABCDEF01 RI21-32 → ADRMEM 900
ADRMEM
M ← 900 E00 M → ADRMEM E00
ADRMEM M ← E00 ABCDEF01
M → T ABCDEF01 A compara cu T → pozit lui Z=1 prm Σ

Arhitectura calculatoarelor 39
2.5. UNITATE CENTRALĂ CU MICROPROCESOR
Microprocesorul este o unitate centrală de prelucrare a datelor
(UCP), realizată într-un singur circuit integrat. Vom exemplifica o arhitectură de microprocesor pe INTEL 8086, primul microprocesor pe 16 biţi.
2.5.1. Schema generală a unui microprocesor 8086 Microprocesorul 8086 are două componente: -Unitatea de execuţie (UE); -Unitatea de interfaţă cu bus-urile(UI) Structura acestui microprocesor este de tip pipeline, adică este o
structură în bandă de asamblare cu două segmente: UE şi UI. UE decodifică instrucţiunile numerice, elaborează comenzi interne
pentru efectuarea calculelor şi comenzi externe către cea de-a doua unitate. UE conţine 8 locaţii de memorie internă numite registre de uz general.
UI calculează adresele de memorie şi de intrare/ieşire, transferă datele între UE şi memorie, între UE şi I/O şi transferă către UE codurile numerice ale instrucţiunilor citite în memorie.
Cele două segmente efectuează autonom secvenţe de operaţii proprii, transferându-şi în acelaşi timp informaţii. Secvenţele de operaţii efectuate de cele două unităţi ale microprocesorului pentru a executa instrucţiunile se numesc cicluri de instrucţiune, pentru UE şi cicluri maşină de bus, pentru UI.
a)Structura UE UE are componentele: -Unitatea aritmetică-logică (UAL), în engleză Arithmetic-Logic
Unity (ALU), care execută operaţii aritmetice şi logice, deplasări şi rotaţii. -Registrele temporare (RT), care preiau operanzii de pe bus-ul intern
şi îi oferă unităţii UAL. Împreună cu UAL formează un automat. -Registrul de flaguri, F, care conţine indicatorii de stare ALU ai
ultimei operaţii; registrul este actualizat de către ALU. -Blocul de comandă, care decodifică codul instrucţiunii curente,
preluată din coada de aşteptare Q, execută operaţia şi elaborează comenzi externe pentru UI.
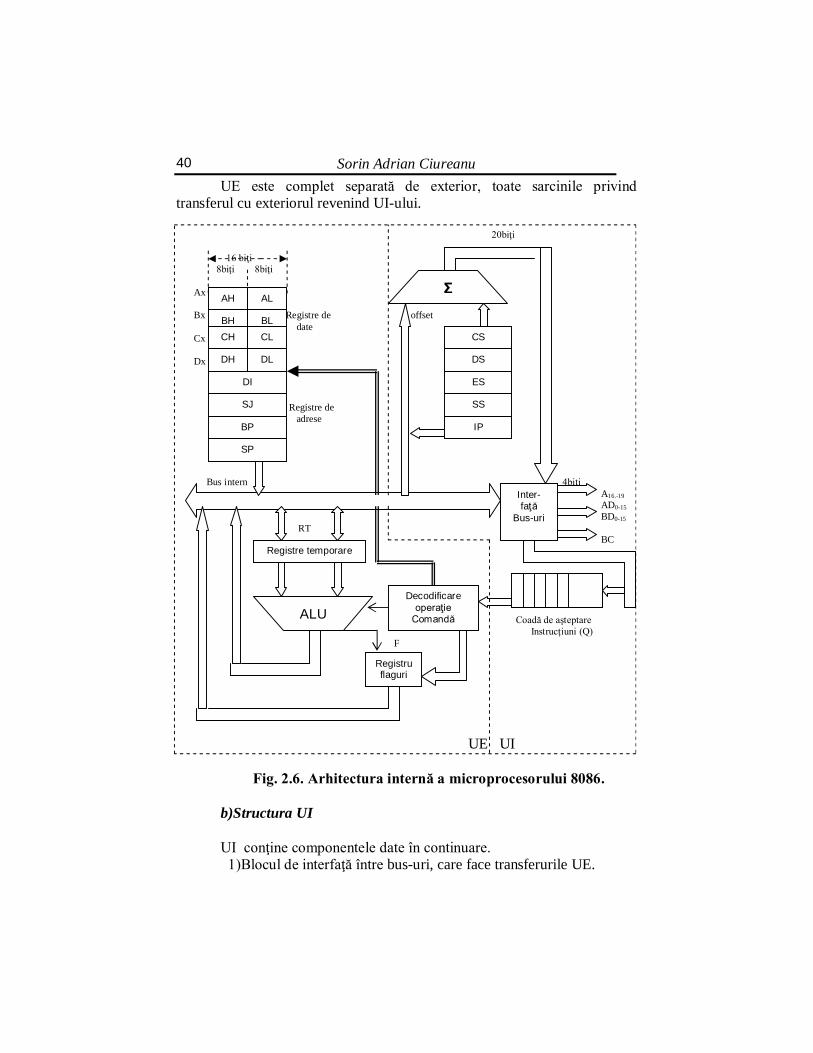
Sorin Adrian Ciureanu 40
UE este complet separată de exterior, toate sarcinile privind transferul cu exteriorul revenind UI-ului.
20biţi 16 biţi 8biţi 8biţi Ax Bx Registre de offset date Cx Dx
Registre de adrese
Bus intern 4biţi A16.-19 AD0-15 BD0-15 RT BC Coadă de aşteptare Instrucţiuni (Q)
F UE UI
Fig. 2.6. Arhitectura internă a microprocesorului 8086. b)Structura UI UI conţine componentele date în continuare. 1)Blocul de interfaţă între bus-uri, care face transferurile UE.
AH AL
BH BL CH CL
DH DL
DI
SJ
BP
SP
Registre temporare
ALU
Registru flaguri
Decodificare operaţie
Comandă
Inter- faţă
Bus-uri
Σ
CS
DS
ES
SS
IP

Arhitectura calculatoarelor 41
Are următoarele cicluri: -cicluri de scriere memorie sau I/E (UC→MEM , I/E) -cicluri de citire memorie sau I/E (UC←MEM , I/E) 2)Coada de aşteptare a codurilor de instrucţiuni (Q), care: -este încărcată de către UI cu coduri de instrucţiune, numai în momentele de timp când UE nu are transferuri de date; -este inactivă dacă este plină sau se cer transferuri pe bus; -este ştearsă complet dacă instrucţiunea este de salt.
3)Blocul de calcul al adreselor fizice, care include: -registrele de segment ce conţin componenta segment a adresei
locaţiei de memorie accesată; -registrul indicator al instrucţiunii curente (IP) cu componenta offset
a adresei instrucţiunii curente; -unitate de deplasare-adunare pentru calculul adresei fizice din
componentele segment şi offset .
2.5.2. Registrele microprocesorului Registrele microprocesorului 8086 au o capacitate de 16 biţi şi pot fi
clasificate în patru grupe, în funcţie de rolul pe care îl au în execuţia instrucţiunilor.
-Registre generale. -Registre segment. -Registru indicator al adresei instrucţiunii curente IP. -Registru de flaguri,F, şi registrul IP. 2.5.2.1. Registre generale Registrele generale se impart în două seturi de registre: -Registre de date: Ax,Bx,Cx,Dx. -Registre de adresare: SP, BP, SI, DI. a)Registre de date Există patru registre de date de 16 biţi: Ax-acumulator; Bx-baza în adresarea datelor; Cx-contor; Dx-date.

Sorin Adrian Ciureanu 42
Fiecare din aceste registre pot fi împărţite în două registre de 8 biţi: 16 biţi 8 biţi 8 biţi Ax AH AL Bx BH BL Cx CH CL Dx DH DL
Registrele de date sunt utilizate în majoritatea instrucţiunilor aritmetice şi logice. Majoritatea instrucţiunilor aritmetice utilizează în acelaşi mod toate registrele. Există şi instrucţiuni aritmetice pentru care anumite registre generale au întrebuinţări speciale. De exemplu:
Ax - operaţii de intrare/ieşire pe 16 biţi, înmulţiri şi împărţiri pe 16 biţi;
AL - operaţii de intrare/ieşire pe 8 biţi, translaţii, aritmetice BCD, înmulţiri şi împărţiri pe 8 biţi;
AH – înmulţiri şi împărţiri pe 8 biţi; Bx – operaţii cu memoria, adresare indirectă, translaţii; Cx – operaţii cu şiruri, bucle program; CL – operaţii de deplasare sau rotaţie cu mai mult de o poziţie; Dx – operaţii de intrare/ieşire, adresare indirectă, înmulţiri şi
împărţiri pe 16 biţi. b)Registre de adresare Sunt de două tipuri: 1)Registre indicatoare de adresă în stivă (pointer): -SP (Stack Pointer), care conţine adresa curentă a vârfului stivei; -BP (Base Pointer), care conţine adresa bază pentru adresarea indirectă a stivei.
2)Registre indicatoare de adrese pentru şiruri (index): -DI (Destination Index)–conţine adresa curentă pentru şirul
destinaţie; -SI (Source Index)–conţine adresa curentă pentru şirul sursei. Registrele de adresare pot fi utilizate şi pentru anumite instrucţiuni
aritmetico-logice. Registrele pointer conţin componente offset ale adreselor de stivă
(adresele relative în segmentul de stivă curent) . Registrul BP poate fi utilizat şi pentru adresarea în cadrul altor
segmente. Registrele index conţin componente offset ale adreselor variabilelor
(adrese relative în segmentul de date curent). Ele sunt utilizate ca registre de

Arhitectura calculatoarelor 43
adresare şi instrucţiunile de transfer sau prelucrări de şiruri de caractere. În acest ultim caz registrul SI conţine adresa relativă curentă a şirului destinaţie în cadrul segmentului de date curent (DS), iar DI conţine adresa relativă curentă a şirului sursă în cadrul segmentului de date suplimentar (ES).
2.5.2.2. Registrele segment Spaţiul de memorie pe care poate să-l adreseze un microprocesor
8086 este împărţit în segmente logice de lungime 64KO. Există patru registre segment:
-CS (Cod Segment), care conţine componenta segment a adreselor codului (instrucţiunile programului);
-DS (Data Segment), care conţine componenta segment a adreselor variabilelor (segment date curent);
-ES (Extra Segment), care conţine componenta segment a adreselor variabilelor (segment suplimentar);
-SS (Stack Segment), care conţine componenta segment a adreselor datelor din segmentul stivă.
Instrucţiunea care urmează să fie executată se găseşte în segmentul a cărui adresă se află în registrul CS, la adresa relativă conţinută în IP.
Conţinutul registrului DS defineşte segmentul de date curent. Toate referirile la datele din memorie, cu excepţia celor prin registrele BP şiSP sau registrul DI în instrucţiunile pentru şiruri, utilizează în mod implicit segmentul referit de DS.
Conţinutul registrul ES defineşte segmentul de date suplimentar. Referirile la date în instrucţiunile pentru şiruri utilizează în mod implicit segmentul referit de ES.
Conţinutul registrului SS defineşte segmentul curent al stivei. Toate referirile la datele din memorie prin registrele BP şi SP utilizează în mod implicit segmentul referit de registrul SS.
2.5.2.3. Registrele IP şi F Registrul indicator al adresei curente , IP (Instrucţion pointer), este
un registru de 16 biţi care conţine componenta ofset a adresei instrucţiunii în segmentul de cod curent.
Programele nu au acces direct la IP, dar există instrucţiuni care îl modifică şi îl încarcă sau îl descarcă prin stivă.
Registrul de flaguri F cuprinde biţii indicatori de stare şi control, numiţi şi flaguri. Aceste flaguri sunt utilizate pentru a memora informaţii

Sorin Adrian Ciureanu 44
referitoare la rezultatul unor operaţii aritmetice şi logice (OF, SF, ZF, AF, PF, CF) şi pentru memorarea unor informaţii de control al microprocesorului (TF, DF, IF). Semnificaţiile acestor flaguri sunt date în continuare.
-CF (Carry Flag) reflectă transportul în exterior al bitului cel mai semnificativ al rezultatului operaţiilor aritmetice. CF=1 înseamnă un transport la operaţia de adunare. CF mai este modificat la operaţiile de rotaţie şi deplasare.
-PF (Parity Plag) este indicator de paritate, el fiind 1 dacă rezultatul are paritate pară; de asemenea acest indicator este utilizat şi de instrucţiunile de aritmetică zecimală.
-AF (Auxiliary Cary Flag) este indicator de transport auxiliar şi este 1 dacă a fost transport de la jumătatea de octet inferioară la jumătatea de octet superioară; este utilizat la instrucţiunile de aritmetică zecimală;. -ZF (Zero Flag) este indicatorul de zero, având valoarea 1 dacă rezultatul operaţiei a fost zero;
-SF (Sign Flag), indicatorul de semn, este 1 dacă cel mai semnificativ bit al rezultatului este 1, adică, în reprezentarea numerelor în complement faţă de 2, rezultatul este negativ.
-OF (Overflow Flag), indicatorul de depăşire aritmetică, a gamei de valori posibil de reprezentat, este 1 dacă dimensiunea rezultatului depăşeşte capacitatea locaţiei memoriei.
-IF (Interrupt Flag), indicatorul de validare a întreruperilor, este 1 dacă se pot valida întreruperile externe mascabile şi 0 dacă întreruperile externe sunt invalidate. De remarcat că acest flag nu afectează întreruperile interne sau pe cele externe nemascabile.
DF (Direction Flag) este utilizat de instrucţiunile pe şiruri de caractere şi specifică direcţia de parcurgere a lor:
0 – de la adrese mici spre adrese mari; 1 – de la adrese mari spre adrese mici. -TF (Trace Flag) este utilizat pentru controlul execuţiei
instrucţiunilor în regim pas cu pas în scopul depănării programelor. Dacă este 1, după execuţia fiecărei instrucţiuni se va genera un semnal de întreruperi intern.
2.5.3. Adresarea memoriei. Segmentarea memoriei.
Intel 8086 poate adresa un spaţiu de memorie din memoria
principală (MP) de 1 Moctet. Conform convenţiei INTEL, datele formate din mai mulţi octeţi sunt memorate cu octetul cel mai semnificativ la locaţia

Arhitectura calculatoarelor 45
de adresă cea mai mare, adică octetul cel mai puţin semnificativ este memorat la adresa cea mai mică.
Intel 8086 vede memoria principală organizată ca un grup de segmente. Un segment este un bloc de memorie de dimensiune 64 Kocteţi. Fiecare segment poate fi accesat, în scriere sau în citire, în mod independent.
Procesoarele pot lucra în două moduri: modul real şi modul protejat. În modul real procesoarele adresează memoria principală printr-o
adresă fizică directă. În modul protejat, procesoarele adresează memoria principală ca pe
o memorie virtuală. O adresă virtuală este, de fapt, un nume pentru o locaţie de memorie pe care procesorul o translatează într-o adresă fizică corespunzătoare. O adresă virtuală are două componente: o adresă de bază (segment) şi un deplasament (ofset). Notaţia consacrată pentru adresa logică este:
Segment : offset Trecerea de la adresa logică la adresa fizică se face astfel: Adresa logică → adresă fizică Adresă fizică = segment x 10(+) + offset Înmulţirea cu zece a unui număr în …. înseamnă deplasarea spre
stânga cu o poziţie. Exemple: 1) adresa logică ABC4 : EFB8
adresa fizică = ABC40 + EFB8 = BACF8 2) adresa logică AB00 : CD00
adresa fizică = AB000 + CD00 = B7D00 Această adresă fizică este calculată în UI în funcţie de modul de
adresare. Structura pe segmente a memoriei face posibilă scrierea unor
programe care sunt independente de poziţia lor în memorie, adică sunt relocabile dinamic. Pentru ca un program să fie relocabil trebuie să fie scris astfel încât să nu altereze registrele sale segment şi să nu facă transferuri directe de la o locaţie în afara segmentului de cod. Aceasta permite programului să fie mutat oriunde în memoria disponibilă, atâta timp cât registrele segment sunt actualizate cu noua adresă de bază.
2.5.4. Formatul instrucţiunii
Instrucţiunile, codificate în binar, pot ocupa în memorie de la 1 la 6
octeţi. Codul instrucţiunii este format din: -codul operaţiei care ocupă 1 sau 2 octeţi şi care specifică:
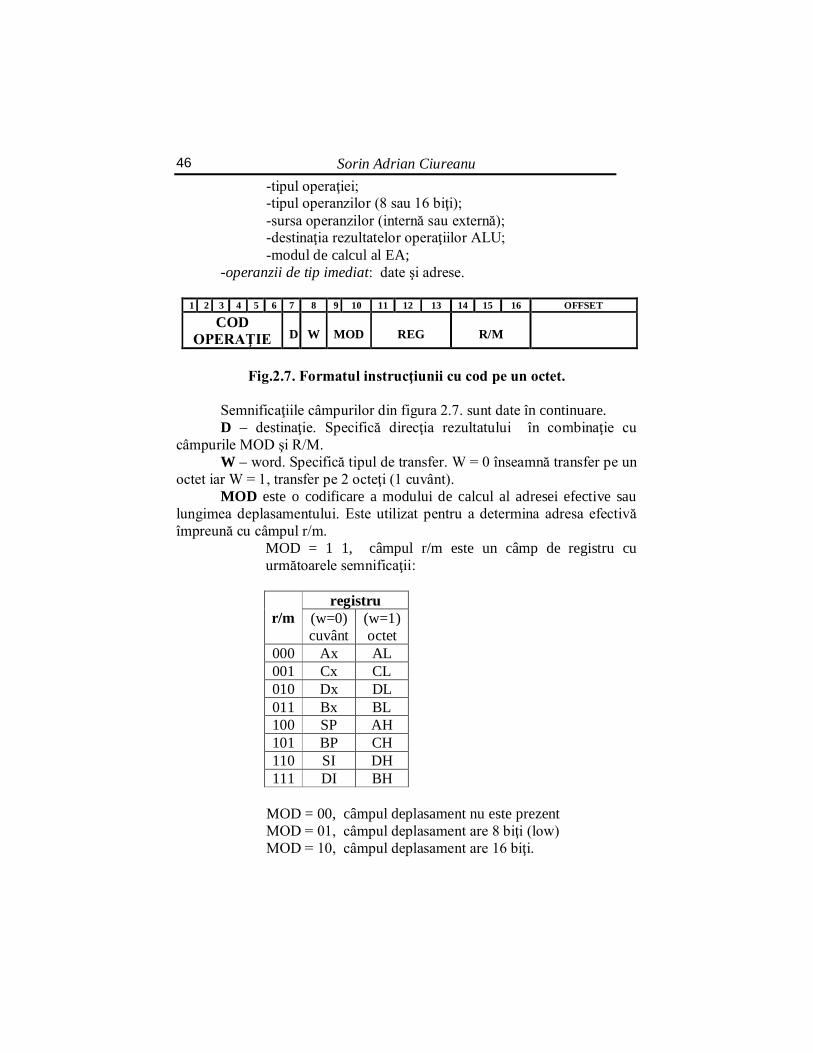
Sorin Adrian Ciureanu 46
-tipul operaţiei; -tipul operanzilor (8 sau 16 biţi); -sursa operanzilor (internă sau externă); -destinaţia rezultatelor operaţiilor ALU; -modul de calcul al EA; -operanzii de tip imediat: date şi adrese.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 OFFSET
COD OPERAŢIE
D
W
MOD
REG
R/M
Fig.2.7. Formatul instrucţiunii cu cod pe un octet.
Semnificaţiile câmpurilor din figura 2.7. sunt date în continuare. D – destinaţie. Specifică direcţia rezultatului în combinaţie cu
câmpurile MOD şi R/M. W – word. Specifică tipul de transfer. W = 0 înseamnă transfer pe un
octet iar W = 1, transfer pe 2 octeţi (1 cuvânt). MOD este o codificare a modului de calcul al adresei efective sau
lungimea deplasamentului. Este utilizat pentru a determina adresa efectivă împreună cu câmpul r/m.
MOD = 1 1, câmpul r/m este un câmp de registru cu următoarele semnificaţii: r/m
registru (w=0) cuvânt
(w=1) octet
000 Ax AL 001 Cx CL 010 Dx DL 011 Bx BL 100 SP AH 101 BP CH 110 SI DH 111 DI BH
MOD = 00, câmpul deplasament nu este prezent MOD = 01, câmpul deplasament are 8 biţi (low) MOD = 10, câmpul deplasament are 16 biţi.

Arhitectura calculatoarelor 47
R/M conţine: -adresa unui registru (pentru MOD=11) -o codificare utilizată pentru calculul adresei efective.
R/M Adresa efectivă 000 BX + SI + deplasament 001 BX + DI + deplasament 010 BP + SI + deplasament 011 BP + DI + deplasament 100 SI + deplasament 101 DI + deplasament 110 BP + deplasament 111 BP + deplasament
Unitatea de execuţie (UE) are acces la operanziiimediaţi şi de registre; când este nevoie de un operand de memorie, se transmite la UI deplasamentul acestuia şi registrul de segment IC determină adresa fizică a operandului în funcţie de modul de adresare.
2.5.5. Moduri de adresare
Există, în principal, cinci moduri de adresare. 2.5.5.1. Adresare directă Adresa efectivă (AE) a operandului este reprezentată de
deplasamentul conţinut în instrucţiune.
Fig. 2.8 Adresare directă. AE, adresă efectivă. AS, adresă
segment. AF, adresă fizică.
deplasament
AE
AS
AF OPERAND +
MEMORIE

Sorin Adrian Ciureanu 48
2.5.5.2. Adresare indirectă prin registre
În câmpul calculat nu se află operandul, ca la adresarea directă, ci o
altă adresă de operand. Memorie
Fig. 2.8. Adresare indirectă prin registre. Sintaxa instrucţiunilor în limbajul de asamblare utilizează pentru
adresarea indirectă operatorul [ ]. De exemplu: mov ax, [bx], se deplasează la adresa conţinută de bx.
2.5.5.3. Adresare indexată La calculul adresei participă şi un registru index (SI sau DI în cazul
procesoarelor 8086).
Memorie
Fig. 2.9. Adresare indexată
Cod operaţie Deplasament
BX
BP
SI
DI
AE
AS
AF + OPERAND
AE
AS
AF
+
OPERAND
SI
DI
COD OP MOD R/M DEPLASAMENT
+
7 07 015

Arhitectura calculatoarelor 49
Adresa se obţine din suma registrului index şi deplasamentul din instrucţiune.
Acest mod de indexare este utilizat, în cele mai multe cazuri, pentru referirea elementelor unui vector. Deplasamentul marchează începutul vectorului iar registrul index selectează elementul prin poziţia sa relativă în cadrul vectorului. Deoarece toate elementele vectorului sunt de aceeaşi lungime, prin operaţii aritmetice elementare asupra registrului index se va selecta orice element. De aceea se poate specifica un factor de scală (1,2,3,4) pentru index, pentru a referi vectori cu componente de lungime fixă de 1,2,3,4 octeţi.
Fig. 2.10. Referirea vectorilor de lungime fixă în adresarea
indexată.
2.5.5.4. Adresare imediată
În acest caz operandul se află chiar în instrucţiune.
Fig. 2.11. Adresare imediată.
Adresare efectivă
Deplasament
Registru index
+ V[2 ]
V[1 ]
V[0 ]
V[3 ]
V[4 ]
V[5 ]
V[6 ]
Memorie
OPERAND
AE

Sorin Adrian Ciureanu 50
2.5.5.5. Adresarea porturilor de intrare/ieşire Porturile de intrare/ieşire se adresează unde aceeaşi adresă se găseşte
în instrucţiune, pe 8 biţi, cu 256 de adrese.
Fig. 2 11. Adresarea porturilor intrare/ieşire
2.5.6. Procesoare 286
Faţă de procesoarele 8086, procesoarele 286 au o serie de modificări
importante. a)Se introduc două moduri de lucru: -modul KERNEL; -modul USER. În modul KERNEL, care este un mod protejat, se pot executa toate
instrucţiunile procesorului, inclusiv cele privilegiate. Este un mod specific sistemului de operare.
În modul USER nu toate instrucţiunile se pot executa. Este un mod specific aplicaţiilor utilizator.
b) Spectrul de adrese creşte la 16MB , acest lucru realizându-se prin adăugarea a patru linii de adrese. În acest fel numărul de linii de adrese este 14.
16 MB = 24.210 B = 214 B nr. linii de adrese = log 2 214 = 14 c) Se îmbunătăţeşte tehnica pipeline. În varianta 286, procesorul are
patru unităţi funcţionale: -unitatea de interfaţă cu magistrala; -unitatea de instrucţiuni; -unitatea de execuţie; -unitatea de adresare. Unitatea de interfaţă cu magistrala realizează toate operaţiile de
transfer pe magistrală, adică extragerea instrucţiunilor şi citirea/scrierea operanzilor. Instrucţiunile sunt citite în avans şi sunt transferate către unitatea de instrucţiuni.
COD OP SI AE sursă
DI AE destinaţie

Arhitectura calculatoarelor 51
Unitatea de instrucţiuni decodifică instrucţiunile şi le plasează într-o coadă de instrucţiuni decodificate.
Unitatea de execuţie preia aceste instrucţiuni şi le execută, în funcţie de codul fiecărei instrucţiuni.
Unitatea de adresare calculează adresele de memorie în funcţie de diferitele moduri de adresare. Adresele de memorie sunt transmise către unitatea de interfaţă cu magistrala pentru efectuarea transferurilor.
2.5.7. Procesoare 386
La aceste procesoare s-au introdus unele îmbunătăţiri. a) Arhitectura de bază este extinsă la 32 biţi. Atât magistrala cât şi
registrele interne sunt de 32 biţi. b) Se poate adresa o memorie de 46 B, utilizându-se în acest scop 32
linii de adresă. 46 B = 22.230 B = 232 B nr linii de adresă = log 2 232 =32 c) S-a introdus mecanismul de paginare în microprocesor. Cipul
MMU (Memory Management Unity), care la 8086 şi 286 era separat de procesor, a fost plasat în interiorul microprocesorului.
d) Tehnica pipeline este îmbunătăţită cu două module: unitate de paginare şi unitatea de preîncărcare a instrucţiunilor.
Fig. 2.12. Schema pipeline pentru procesorul 386.
2.5.8. Procesoare 486
La procesoarele 486 s-au adus următoarele îmbunătăţiri: a) S-a înglobat în procesor aşa numitul coprocesor matematic,
pentru calcului în virgulă mobilă.
Unitatea de segmentare Unitatea de paginare
Unitate de execuţie Unitate de interfaţă
Unitate de decodificare
Unitate de preîncărcare a instrucţiunilor

Sorin Adrian Ciureanu 52
b) S-a înglobat memorie cache de level 1 de 8kB şi, de asemenea, o unitate de management a memoriei Cache.
c) Structura pipeline a fost extinsă prin divizarea unităţii de extragere şi execuţie a instrucţiunilor în cinci nivele. Fiecare nivel poate să prelucreze o altă instrucţiune, traversarea unui nivel făcându-se într-o perioadă de ceas.
d) Pentru raţionalizarea consumului de energie s-a introdus un mecanism de management ce permite comutarea procesorului în regim de consum redus.
Fig. 2.13. Schema bloc a procesorului 486.
2.5.9. Procesoare PENTIUM Familia de procesoare PENTIUM se bazează pe o arhitectură
pipeline superscalară, ceea ce înseamnă că utilizează mai multe linii de prelucrare pipeline autonome ce lucrează în paralel. La varianta de bază există două linii de asamblare (liniile U şi V). Versiunile mai noi au trei linii de asamblare.
Controlorul de întreruperi APIC (Advanced Programable Interrupt Controller) a fost inclus în structura microprocesorului.
În ceea ce priveşte lungimea cuvântului şi a magistralelor , intern procesorul a rămas pe 32 biţi şi magistrala principală externă are 64 biţi. Anumite magistrale interne, însă, au 128 sau chiar 256 biţi.
S-a introdus un mecanism de protecţie a salturilor care se bazează pe memorarea ultimelor salturi efectuate în cadrul secvenţei de program. Citirea în avans a instrucţiunilor şi introducerea lor în linia de prelucrare se face pe baza probabilităţii de realizare a unor salturi.
Unitate de segmentare Unitate de programare
Procesor virgulă fixă
Procesor virgulă mobilă
Unitate cache
Decodificare instrucţiuni Preîncărcare instrucţiuni
Unitate de
interfaţă cu
magistrala

Arhitectura calculatoarelor 53
2.5.9.1. Microarhitectura familiei de procesoare PENTIUM Fig. 2.14. Schema de principiu a arhitecturii PENTIUM.
Microarhitectura specifică procesoarelor de tip PENTIUM PRO,
PENTIUM II şi PENTIUM III conţine trei unităţi de tip pipeline care comunică prin intermediul unui REZERVOR DE INSTRUCŢIUNI :
-unitatea de extragere şi decodificare a instrucţiunii care se ocupă de extragerea în avans a instrucţiunilor şi transformarea lor în secvenţe de microoperaţii;
-unitatea de dispecerizare şi execuţie care selectează microoperaţiile ce pot fi executate şi le distribuie pentru execuţie;
-unitate de retragere care asamblează rezultatele parţiale în ordinea prestabilită de program.
Această arhitectură se bazează pe execuţia instrucţiunilor într-o ordine dictată de disponibilităţile datelor şi a unităţilor de execuţie. În acest sens unitatea de extragere şi decodificare ca şi unitatea de retragere sunt unităţi „in order”, adică unităţi care respectă ordinea de prelucrare a instrucţiunilor prestabilită în program. Unitatea de dispecerizare şi execuţie este o unitate „aut of order” care nu respectă această ordine. Datorită unită-ii de retragere, care reordonează rezultatele parţiale pe baza ordinii iniţiale, se elimină multe din situaţiile de blocare temporară a liniei de prelucrare pipeline cauzate de aşteptările provocate de transferurile externe de date.
La procesoarele PENTIUM, odată cu apariţia lui PENTIUM PRO, se introduce conceptul de execuţie dinamică. Aceasta este o combinaţie de trei tehnici:
-predicţia salturilor;
UNITATE DE EXTRAGERE ŞI DECODIFICARE
INSTRCŢIUNI
UNITATE DE DISPECERIZARE
ŞI EXECUŢIE
UNITATE DE
RETRAGERE
REZERVOR DE
INSTRUCŢIUNI

Sorin Adrian Ciureanu 54
-execuţie speculativă; -analiza fluxului de date. Cele trei tehnici soluţionează majoritatea situaţiilor de blocare a
liniilor de prelucrare şi procesorul poate să lucreze la capacitatea maximă de 3 instrucţiuni într-o perioadă de tact. La aceasta mai contribuie şi existenţa mai multor unităţi de execuţie care lucrează în paralel.
Această arhitectură elimină în mare parte neajunsurile unei arhitecturi pipeline clasice prin evitarea situaţiilor de întârziere a liniei pipeline. Întârzierea poate să survină din diverse cauze:
-linia este golită în urma unei instrucţiuni de salt; -operanzii solicitaţi nu sunt disponibili; -nu există o unitate de execuţie. Prezenţa rezervorului de instrucţiuni oferă unităţii de dispecerizare şi
execuţie o anumită perspectivă ce permite optimizarea ordinii de execuţie a instrucţiunilor astfel încât să se reducă timpii de aşteptare.
2.5.9.2. Unitatea de extragere şi decodificare a instrucţiunilor Dela BIU (Basic Interface Unit) Spre rezervorul de microinstrucţiuni
Fig. 2.15. Unitatea de extragere şi decodificare a instrucţiunilor.
L1 I CACHE NEXT IP
DECODIFICARE
DE
INSTRUCŢIUNI
Bloc de memorie a adresei de salt
Secvenţîator de microinstrucţiuni
Alocator de registre alias

Arhitectura calculatoarelor 55
Instrucţiunile se extrag din Cache-ul de instrucţiuni la nivelul 1(L1). Adresarea instrucţiunilor se face cu ajutorul modului Next IP care foloseşte în acest scop informaţiile conţinute în blocul de memorare a ultimelor adrese de salt. Astfel vor fi extrase secvenţele de instrucţiuni care au probabilitatea cea mai mare de a fi executate în vectorul apropiat.
Pe fiecare perioadă de tact se extrage câte o linie de memorare cache de 32 biţi. Se marchează începutul fiecărei instrucţiuni, după care extras este transmis către cele trei modul de decodificare independente. Există două module de decodificare simple şi unul pentru instrucţiunile complexe.
În urma procesului de decodificare, o instrucţiune este transformată într-o secvenţă de microoperaţii triadice. O operaţie triadică este o operaţie elementară care are maximum trei operanzi: doi operanzi sursă şi unul rezultat.
Instrucţiunile simple se decodifică în unu până la patru microoperaţii. Instrucţiunile complexe sunt decodificate în secvenţe predefinite de microoperaţii păstrate în modulul de secvenţiere a microoperaţiilor. Decodificatorul poate genera până la 6 microoperaţii pe o perioadă de tact.
Deoarece sunt utilizate un număr restrâns de registre interne, pot să apară dependenţe false între variabilele care utilizează temporar acelaşi registru intern. Aceste dependenţe conduc la întârzieri în linia de prelucrare pipeline. Pentru a evita astfel de situaţii, unitatea de decodificre alocă microoperaţiilor un registru alias dintr-un set de registre invizibile pentru programator. Registrele alias pot fi utilizate în operaţii aritmetice şi logice. Fiecărei microoperaţii îi sunt ataşaţi biţi de stare, necesari în procesul de execuţie.
Microoperaţiile sunt plasate în rezervorul de instrucţiuni, rezervor care face legătura între cele trei unităţi independente de prelucrare din această arhitectură superscalară.
2.5.9.3. Unitate de dispecerizare şi execuţie În Unitatea de dispecerizare şi execuţie există diferite module: UEI - unitate de execuţie pentru numere întregi; UEF – unitate de execuţie pentru numere în virgula flotantă; UE-MMX – unitate de execuţie a operaţiilor MMX; UES – unitate de execuţie a salturilor; UGA – unitate de generare a adreselor pentru citirea operanzilor şi scrierea rezultatelor. Staţie de rezervare

Sorin Adrian Ciureanu 56
i i
Fig.2.16. Unitate de dispecerizare şi execuţie.
Staţia de rezervare extrage din rezervorul de instrucţiuni microoperaţii ale căror condiţii de execuţie sunt îndeplinite şi le alocă în funcţie de specificul operaţiei. O microoperaţie este executabilă dacă operanzii cu care lucrează sunt disponibili şi dacă unitatea de execuţie pe care o solicită este liberă. Pentru a determina disponibilitatea operanzilor se foloseşte o metodă de analiză a fluxului de date, în urma căreia se generează un graf al dependenţelor de ordine existente între mai multe operaţii care utilizează aceleaşi variabile. Dacă mai multe microoperaţii sunt simultan disponibile, atunci se foloseşte un algoritm de planificare de tip FIFO care favorizează execuţia în secvenţă a microoperaţiilor.
Staţia de rezervare dispune de 5 porturi prin care poate să comunice cu unităţile de execuţie. Pot fi executate simultan maximum 5 microoperaţii. Sunt disponibile mai multe unităţi de execuţie care pot să lucreze în paralel:
-două unităţi pentru numere întregi: - o unitate pentru numere în virgulă mobilă; -o unitate de execuţie a salturilor; -două unităţi pentru MMX; -două unităţi pentru scrierea şi citirea operanzilor. Microoperaţiile executate, împreună cu rezultatele obţinute, sunt
plasate din nou în rezervorul de instrucţiuni.
Staţie de rezervare
Port 0
Port 1
Port 2
Port 3, 4
UEI UEF UE- MMX
UEI UES UE- MMX
UGA
UGA
Citire operanzi
Scriere operanzi
Rezervor de
instrucţiuni

Arhitectura calculatoarelor 57
Pentru instrucţiunile de salt, se verifică dacă previziunea cu privire la adresa de salt a fost corectă. În caz contrar, unităţile de execuţie a salturilor invalidează toate operaţiile care urmează după instrucţiunea de salt, spre a fi eliminate din rezervor.
2.5.9.4. Unitatea de retragere
Fig. 2.17. Unitate de retragere.
Unitatea de retragere are rolul de a restabili ordinea iniţială (aceea a programului iniţial) între rezultatele parţiale generate în urma executării microoperaţiilor. În acest scop se extrag din rezervorul de instrucţiuni microoperaţiile a căror execuţie este terminată şi care urmează în ordinea secvenţială de execuţie. Rezultatele păstrate în registrele alias sunt transferate în registrele interne sau în memorie. Unitatea de retragere poate extrage trei microoperaţii într-o perioadă de tact.
2.6. UNITATE CENTRALĂ DE TIP RISC
2.6.1. CISC versus RISC
Din punct de vedere al complexităţii instrucţiunilor, procesoarele pot fi de două tipuri:
-CISC (Complex Intruction Set Computer); -RISC (Reduced Instruction Set Computer).
D Cache
UIM (unitate de interfaţă cu memoria)
FER (Fişierul de registre de retragere)
Rezervor de instrucţiuni
Staţie de rezervare

Sorin Adrian Ciureanu 58
Modelele CISC sunt caracterizate printr-un set foarte mare de instrucţiuni cod maşină, prin formate de instrucţiuni de lungime variabilă, şi prin numeroase moduri de adresare foarte sofisticate. Desigur că această complexitate arhitecturală are repercursiuni negative asupra performanţelor computerului. Arhitecturile CISC au fost concepute începând cu anii 1960, pe baza datelor tehnologice din epocă . Atunci compilatoarele nu puteau utiliza bine registrele, microinstrucţiunile se executau mai rapid decât instrucţiunile (pentru că se situau în memorii cu semiconductori în timp ce instrucţiunile se situau in memorii toroidale), memoria centrală era de dimensiuni limitate etc.
Modelele RISC încearcă să corecteze neajunsurile modelelor CISC şi, de aceea, sunt caracterizate printr-o simplitate şi eficienţă mărite. Ideea de bază este utilizarea unui număr redus de instrucţiuni, cu mult mai mic decât în modelele CISC, instrucţiuni care sunt cele mai frecvent utilizate şi care conferă o mai mare flexibilitate în funcţionare. Primele microprocesoare RISC au fost proiectate la Universităţile de Stanford (coordonator profesorul John Hennessy) şi Berkeley (cooordonator profesorul John Patterson, cel care a şi propus denumirea de RISC), în 1981.
Caracteristicile de bază ale modelului RISC sunt următoarele: -timp de proiectare şi erori de construcţie mai reduse decât la CISC; -unitate de comandă hardware cablată, fără microprogramare, ceea
ce măreşte rata de execuţie a instrucţiunilor; -utilizarea tehnicilor de procesare pipeline; -utilizarea instrucţiunilor LOAD/STORE cu referire la memorie,
ceea ce înseamnă că nu mai există instrucţiuni cu operanzi în memorie ci numai în registrele generale;
-există un format fix al instrucţiunilor, codificate pe un singur cuvânt de 32 biţi sau, mai recent, pe 64 biţi;
-datorită unor particularităţi ale procesării pipeline şi anume datorită, mai ales, hazardurilor pe care aceasta le implică, apare necesitatea unor compilatoare optimizate (schedulere), cu rolul de a reorganiza programul sursă pentru a putea fi procesat optimal din punct de vedere al timpului de execuţie;
-numărul de registre generale este substanţial mai mare decât la arhitectura CISC, deoarece la arhitectura RISC se lucrează cu „ferestre” (register WINDOWS); numărul mare de registre generale este util şi pentru mărimea spaţiului intern de procesare, tratarea optimizată a evenimentelor de excepţie şi modelul ortogonal de programare.
Microprocesoarele RISC scalare reprezintă modele cu adevărat evolutive în istoria tehnicii de calcul. Primul articol despre modelele RISC ,

Arhitectura calculatoarelor 59
semnat de David Petterson şi Carlo Sequin, a apărut în 1981, şi numai peste 6-7 ani toate marile firme producătoare de hardware realizau microprocesoare RISC scalare, în scopuri comerciale sau de cercetare. Performanţa acestor microprocesoare creşte cu 75% în fiecare an.
2.6.2. Setul de instrucţiuni
În proiectarea setului de instrucţiuni aferent unui microprocesor
RISC intervine o multitudine de consideraţii: -compatibilitatea cu seturile de instrucţiuni ale altor tipuri de
procesoare pe care s-au dezvoltat produse soft consacrate; portabilitatea acestor produse pe noile procesoare este condiţionată de această cerinţă care, în general, vine în contradicţie cu cerinţele de performanţă a sistemului;
-setul de instrucţiuni este în strânsă dependenţă de tehnologia folosită care, de obicei, limitează sever performanţele (constrângeri legate de aria de integrare, numărul de ……., cerinţe specifice tehnologiei etc);
-minimizarea complexităţii unităţii de comandă şi a fluxului de informaţie procesor-memorie;
-în cazul multor procesoare RISC setul de instrucţiuni este ales ca suport pentru implementarea unor limbaje de nivel înalt.
Setul de instrucţiuni din procesoarelor RISC este caracterizat prin simplitatea formatului precum şi de un număr limitat de moduri de adresare. De asemenea se urmăreşte ortogonalalizarea setului de instrucţiuni.
În primul procesor RISC 1 BERKELEY exista un set de 31 instrucţiuni grupate în patru categorii:
-aritmetice/logice; -acces la memorie; -salt/apel subrutine -instrucţiuni speciale. Formatul unei astfel de instrucţiuni este dat în figura 2.18. 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31
OP CODE
SCC
DEST SOURCE 1 IMM
SOURCE 2
Fig.2.18. Formatul instrucţiunii Berkley RISC 1.
IMM = 0 cei mai puţini semnificativi 5 biţi ai câmpului SOURCE 2 codifică al doilea registru operand ;

Sorin Adrian Ciureanu 60
IMM =1 SOURCE 2 semnifică o constantă pe 13 biţi cu extensie semn pe 32 biţi; SCC (Store Condition Code) semnifică validare/invalidare a activităţilor de condiţie, corespunzător operaţiilor aritmetice/logice executate. Cu toate că setul său de instrucţiuni este redus, procesorul Berkley
RISC 1 poate sintetiza o multitudine de instrucţiuni „aparent” inexistente. Practic nu se pierd instrucţiuni ci doar „opcode-uri”. Dar prin aceasta se simplifică foarte mult logica de decodificare şi unitatea de comandă.
Iată mai jos câteva exemple de instrucţiuni emulate de RISC 1 în comparaţie cu un calculator CISC, VAX 11/780:
Instrucţiunea VAX11/780 RISC 1
Incrementare INC Ri ADD Ri, ≠ 1, Ri Decrementare DEC Ri SUB Ri , ≠1, Ri Încărcare contor MOVL, #N, Ri ADD R0, #N, Ri
Complement faţă de 1 MCOMPL Ri , Rj XOR Ri , ≠1, Rj
2.6.3. Principiul de procesare pipeline într-un procesor RISC
Procesarea pipeline a instrucţiunilor reprezintă o tehnică prin
intermediul căreia fazele aferente multiplelor instrucţiuni sunt suprapuse în timp. Arhitectura RISC este mai bine adaptată la procesarea pipeline decât cea CISC, datorită lungimii fixe a instrucţiunilor, modurilor de adresare specifice, structurii interne bazate pe registre generale ş.a. În general, există 4-6 niveluri. Iată un exemplu cu 5 niveluri:
1. Nivelul IF (Instruction fetch) Este ciclul de încărcare a instrucţiunii, care constă în calculul adresei
instrucţiunii ce trebuie încărcată din cache sau memorie şi din aducerea efectivă a instrucţiunii din cache sau memorie în procesor.
2. RD (ID) Se decodifică instrucţiunea adusă şi se citesc operanzii din setul de
registre generale. 3. Nivelul ALU Se execută operaţia ALU asupra operanzilor selectaţi, în cazul
instrucţiunilor aritmetice/logice. Se calculează adresa la memoria de date pentru instrucţiunile LOAD/STORE.

Arhitectura calculatoarelor 61
4. Nivelul MEM Este nivelul în care se face acces la memoria principală sau CACHE,
dar numai pentru instrucţiuni LOAD/STORE. În cazul citirii, apar probleme datorate neconcordanţei între rata de
procesare şi timpul de acces la memoria principală. Rezultă, teoretic, că într-un sistem pipeline cu N niveluri, memoria trebuie să fie de N ori mai rapidă decât într-un sistem clasic. Acest lucru se realizează, de obicei, prin implementarea de memorii rapide, în special CACHE.
La scriere, această problemă nu apare, datorită procesorului de ieşire specializat (DWB), ce va fi studiat la memoria CACHE.
5. Nivelul WB (write buffer) Se scrie rezultatul în registrul destinaţie din setul de registre generale
al microprocesorului.
Fig 2.19. Principiul procesării pipeline într-un procesor RISC. Prin procesarea pipeline se urmăreşte o rată ideală de o instrucţiune
pe ciclu maşină, ca în figura 2.19., deşi, după cum se observă, timpul de execuţie pentru o instrucţiune dată nu se reduce.
Se observă necesitatea suprapunerii a două nivele concurenţiale: nivelul IF şi respectiv MEM, ambele cu referire la memorie. Deseori această situaţie se rezolvă prin legături (busuri) separate între procesor şi memoria de date respectiv de instrucţiuni .
O deficienţă importantă a acestor microprocesoare este că nu orice instrucţiune trece prin cele 5 nivele de procesare. De exemplu prin nivelul MEM trec doar instrucţiunile LOAD/STORE . Corectarea acestui neajuns se face, uneori, prin comprimarea a două niveluri.
IF RD ALU MEM WB
IF RD ALU MEM WB
IF RD ALU MEM WB
IF RD ALU MEM WB
IF RD ALU MEM WB
IF RD ALU MEM WB Un ciclu maşi nă
Sensul fluxului de date

Sorin Adrian Ciureanu 62
2.6.4. Structura unui Procesor RISC
Structura hardware a unui procesor RISC, prezentată în continuare, permite procesarea pipeline a instrucţiunilor. Interconectarea nivelurilor (IF/ID , ID/EX, EX/MEM; MEM/WB) sunt implementate sub forma unor registre de încărcare, actualizaţi sincron cu fiecare ciclu de procesare. Memorarea anumitor informaţii de la un nivel la altul este absolut necesară, pentru ca informaţiile conţinute în formatul instrucţiunii curente să nu se piardă prin suprapunerea fazelor de procesare. Adresă de salt
4 IF/ID ID/EX sum EX/MEM MEM/WB / 2 32 sum 5 / 1 / 32 / / 5 32 ALU
. S1+S2 / 19 / S2 32 / 13
5 DEST
CLK Adr. Reg, DEST. Data in reg.
Fig.2,20. Schema de principiu a unui procesor RISC. Câmpul DEST este memorat succesiv din nivel în nivel şi este
rebuclat la intrarea setului de registre generale. Utilitatea acestui câmp devine oportună abia în faza WB, când şi data de înscris în setul de registre generale devine disponibilă (cazul instrucţiunilor aritmetico/logice sau STORE)
PC
Adr MEM
I
S1 S2 SET REG D D IN
mux 2:1
Ext. semn mux 2:1
mux
2:1
adr M E M D D in
mux
2:1

Arhitectura calculatoarelor 63
Multiplexorul de la intrarea ALU are rolul de a genera registrul sursă 2, în cazul instrucţiunilor aritmetice/logice, indexul de calcul adresă (constanta pe 13 biţi cu extensie semn), în cazul instrucţiunilor LOAD/STORE. Sumatorul sum 2 calculează adresa de salt în cazul instrucţiunilor salt (branch) după formula
PCnext=PC+Ext.semn(IR18-=0 Multiplexorul 2:1 de la ieşirea nivelului MEM/WB multiplexează
rezultatul de ALU în cazul unei instrucţiuni aritmetice/logice, respectiv data citită din memoria de date în cazul unei instrucţiuni LOAD. Ieşirea acestui multiplexor se va înscrie în registrul destinaţie codificat de instrucţiune. Evident, întreaga structură este comandată de o unitate de control.
2.6.5. Problema hazardurilor în procesoarele RISC
Hazardurile sunt situaţiile care pot apărea în procesarea pipeline şi
care determină blocarea procesării, având o influenţă negativă asupra ratei de execuţie a instrucţiunilor. Există trei categorii de hazarduri:
-structurale; -de date; -de ramificaţie. 2.6.5.1. Hazarduri structurale Aceste hazarduri sunt determinate de conflictele la resurse comune,
adică atunci când mai multe procese simultane, aferente mai multor instrucţiuni în curs de procesare, accesează o resursă comună.
Pentru a le elimina prin hardware, este nevoie ca numărul de resurse să fie mărit. Prin multiplicarea resurselor hardware s-a creat posibilitatea execuţiei mai multor operaţii, fără a avea conflicte la resurse.
2.6.5.2. Hazarduri de date Aceste hazarduri apar când o instrucţiune depinde de rezultatele
unei instrucţiuni anterioare în banda de asamblare. Există trei categorii de hazarduri de date, funcţie de ordinea acceselor de citire respectiv scriere, în cadrul instrucţiunilor:
-hazardul RAW (Read After Write); -hazardul WAR (Write After Read); -hazardul WAW (Write After Write).

Sorin Adrian Ciureanu 64
a) Hazardul RAW Apare atunci când instrucţiunea 2 încearcă să citească o sursă înainte
ca instrucţiunea 1 să o scrie în sursă. Este foarte frecvent în actualele procesoare pipeline. De exemplu:
Dată disponibilă
I1 LOAD R1 Memorie
I2 LOAD R1+R2→R2 . Dată necesară În acest caz, R1 fiind sursa, data ce urmează a fi încărcată în R1 este
disponibilă abia la sfârşitul ciclului MEM aferent instrucţiunii I1 , prea târziu, deoarece pentru procesarea corectă a lui I2 ar fi nevoie ca data să fie disponibilă cel târziu la începutul nivelului ALU din I2 . Ar fi necesar ca I2 să fie stagnată cu un ciclu maşină. Se cunosc mai multe metode pentru a preîntâmpina hazardul RAW.
-Prin înscrierea unei instrucţiuni NOP (metodă software) se stagnează a doua instrucţiune; timpul nu mai este critic. În exemplul ales, programul devine:
I1 NOP I2 -Prin tehnica scoreboarding (metodă hardware), se stagnează
hardware a doua instrucţiune, stagnare determinată de detecţia hazardului RAW de către unitatea de control. Această tehnică de întârziere a fost propusă de Saymour Cray în 1964. Se impune ca fiecare registru al procesorului să aibă un bit de scor asociat:
bit de scor =0 registru disponibil bit de scor =1 registru ocupat Dacă pe un anumit nivel al procesării este necesar accesul la un
anumit registru având bitul de scor 1, respectivul nivel va fi întârziat, permiţându-i-se accesul numai când bitul respectiv a fost şters de către procesul care l-a setat.
Pentru exemplul anterior, se arată în figura 2.21 cum se testează şi se setează bitul de scor şi în figura 2.22 cum se face resetarea procesării instrucţiunilor.
De remarcat că ambele soluţii bazate pe stagnarea fluxului de instrucţiuni (NOP şi score boarding) scad performanţele.
IF RD ALU MEMMI
WB
IF RD MEM ALU WB
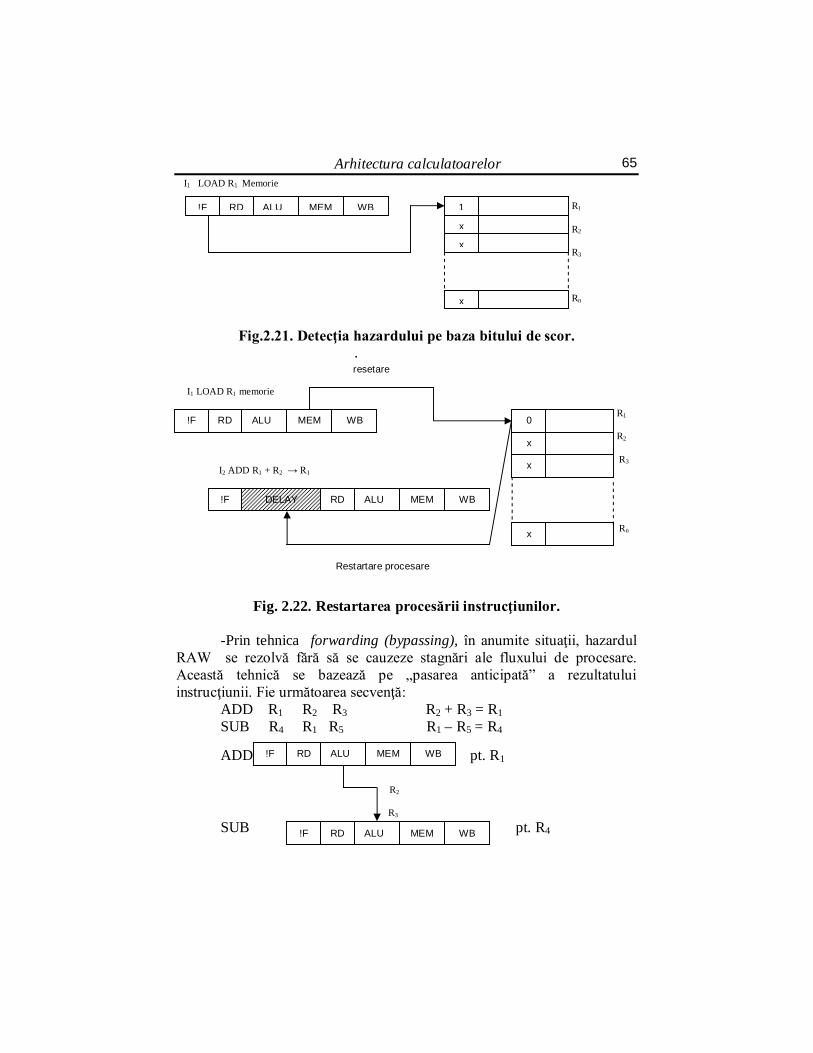
Arhitectura calculatoarelor 65 I1 LOAD R1 Memorie
R1 R2 R3 Rn
Fig.2.21. Detecţia hazardului pe baza bitului de scor. . R1 R2 R3 Rn
Fig. 2.22. Restartarea procesării instrucţiunilor.
-Prin tehnica forwarding (bypassing), în anumite situaţii, hazardul
RAW se rezolvă fără să se cauzeze stagnări ale fluxului de procesare. Această tehnică se bazează pe „pasarea anticipată” a rezultatului instrucţiunii. Fie următoarea secvenţă:
ADD R1 R2 R3 R2 + R3 = R1 SUB R4 R1 R5 R1 – R5 = R4 ADD pt. R1
R2 R3
SUB pt. R4
!F RD ALU MEM WB 1
x
x
x
Restartare procesare
!F RD ALU MEM WB 0
x
x
x
!F RD ALU MEM WB DELAY
resetare
I1 LOAD R1 memorie
I2 ADD R1 + R2 → R1
!F RD ALU MEM WB
!F RD ALU MEM WB
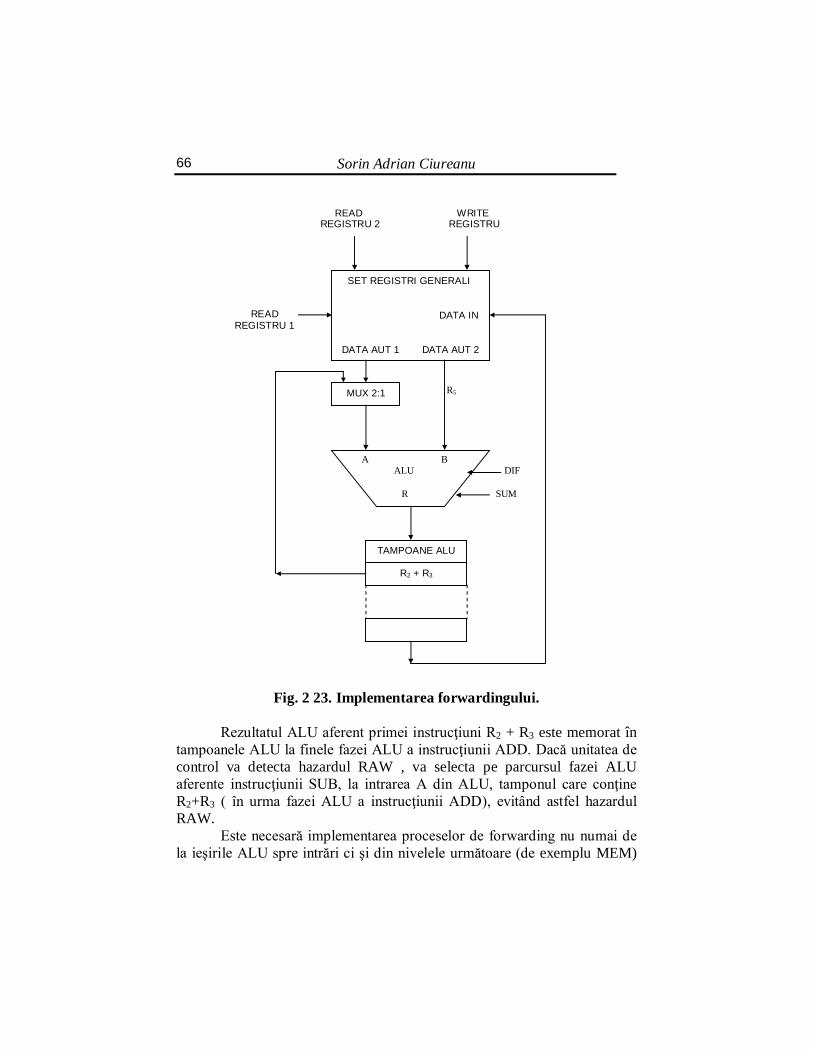
Sorin Adrian Ciureanu 66
R5 A B ALU DIF R SUM
Fig. 2 23. Implementarea forwardingului. Rezultatul ALU aferent primei instrucţiuni R2 + R3 este memorat în
tampoanele ALU la finele fazei ALU a instrucţiunii ADD. Dacă unitatea de control va detecta hazardul RAW , va selecta pe parcursul fazei ALU aferente instrucţiunii SUB, la intrarea A din ALU, tamponul care conţine R2+R3 ( în urma fazei ALU a instrucţiunii ADD), evitând astfel hazardul RAW.
Este necesară implementarea proceselor de forwarding nu numai de la ieşirile ALU spre intrări ci şi din nivelele următoare (de exemplu MEM)
SET REGISTRI GENERALI DATA IN DATA AUT 1 DATA AUT 2
READ REGISTRU 1
READ REGISTRU 2
WRITE REGISTRU
MUX 2:1
TAMPOANE ALU
R2 + R3

Arhitectura calculatoarelor 67
spre intrările ALU. Această situaţie corespunde unor instrucţiuni dependente RAW dar nesuccesive strict în program. Valoarea „pasată” uneia din intrările din ALU, în acest caz, reprezintă rezultatul ALU memorat în nivelul următor (MEM) pentru instrucţiunile aritmetice/logice sau data citită în memoria CACHE de date pentru unele instrucţiuni LOAD.
În implementarea controlului mecanismului de forwarding, pot apărea situaţii conflictuale care trebuie rezolvate pe baze de arbitrare-priorizare.
Se consideră secvenţa de instrucţiuni:
I1 SUB R2 R1 R3 I2 AND R2 R2 R5 I3 ADD R6 R2 R4
În acest exemplu apar necesare două „pasări” anticipate de valori, de
la I1 la I3 (R3) pe intrarea A de la ALU şi respectiv de la I2 la I3 (R2) pe aceeaşi intrare A de la ALU. Trebuie acordată prioritate nivelului pipeline mai apropiat de ALU, informaţiei produsă de ieşirile ALU şi nu celei situate în nivelul următor (aici MEM). Se preia pe intrarea A a unităţii ALU rezultatul produs de I2 şi nu cel produs de I1 . Rezultă deci că şi astfel de potenţiale situaţii conflictuale trebuie implementate în logica de control a mecanismelor forwarding.
b) Hazardul WAR Apare atunci când o instrucţiune scrie o destinaţie înainte ca aceasta
să fie citită pe post de sursă de către o instrucţiune anterioară. Poate avea loc dacă într-o structură pipeline există o fază de citire posterioară unei faze de scriere. De exemplu, modurile de adresare indirectă cu predecrementare pot introduce acest hazard şi de aceea nici nu sunt implementate în calculatoarele RISC.
Aceste hazarduri de tip WAR mai pot apărea şi datorită execuţiei instrucţiunilor în afara ordinii lor normale din program, în aşa numita execuţie Out of Order. Această procesare este impusă de necesitatea creşterii performanţei şi se poate realiza atât prin mijloace hardware cât şi software.
c)Hazardul WAW Apare atunci când o instrucţiune scrie un operand înainte ca acesta să
fie scris de o instrucţiune anterioară, scrierile fiind făcute într-o ordine eronată.
Hazardul WAW poate apărea în structurile care au mai multe niveluri de scriere sau care permit unei instrucţiuni să fie procesată chiar

Sorin Adrian Ciureanu 68
dacă o instrucţiune anterioară este blocată. Modul de adresare indirect cu postincrementare poate introduce acest hazard, fapt pentru care acest mod de adresare nu este implementat în maşina RISC. De asemenea, hazardul WAW poate apărea în cazul execuţiei Aut of Order a instrucţiunilor cu aceeaşi destinaţie.
Hazardurile WAW, ca şi cele WAR de altfel, nu reprezintă hazarduri reale, ci mai degrabă conflicte de nume. Ele pot fi eliminate de către compilator (scheduler) prin redenumirea resurselor utilizate de program. De aceea se mai numesc autodependente, cele WAW, şi dependente de ieşire cele WAR.
Exemple: I1 MULF Ri Rj Rk Rj * Rk → Rj I2 ADD Rj Rp Rm Rp+Rm → Rj În acest caz poate să apară hazard WAR deoarece instrucţiunea I1
fiind o instrucţiune de coprocesor (cu virgulă mobilă) se va încheia în execuţie după I2 care este o instrucţiune de procesor (cu operanzi întregi) Pentru că numărul de niveluri aferent structurii pipeline a coprocesorului este mai mare decât numărul de nivele aferentprocesorului, instrucţiunile I1 şi I2 se termină „Out of Order” (I2 înaintea lui I1). Secvenţa care elimină hazardul WAR, reorganizată prin software este:
MULF Ri Rj Rk ADD Rx Rp Rm MOV Rj Rx
c) Graful dependenelor de date Mai jos este dat un exemplu de reorganizare a unui program în
vederea eliminării hazardurilor de date şi a procesării optimale, folosind graful dependenţelor de date.
I0 ADD R3 R1 R2 I1 LD R9 A(R7) I2 ADD R4 R3 R2 I3 ADD R5 R4 R6 I4 LD R4 A(R6) I5 LD R2 A(R4)

Arhitectura calculatoarelor 69
R3 R4 R4 R4
Fig. 2. 24. Graful dependenţelor de date aferent secvenţei de instrucţiuni din exemplul ales O primă secvenţă de reorganizare a programului ar fi
I0 ADD R3 R1 R2 I1 LD R9 A(R7) I4 LD R4 A(R6) I2 ADD R4 R3 R2 I3 ADD R5 R4 R6
Se observă că în această reorganizare execuţia aut of order a
instrucţiunilor I4 şi I2 determină o procesare eronată a programului prin hazardul de tip WAW prin R4 .De asemenea, între I3 şi I4 exestă hazard WAR prin acelaşi registru. Aşadar detecţia hazardului WAW între instrucţiunile I2 şi I4 determină impunerea unei relaţii de precedenţă intre aceste instrucţiuni, adică procesarea lor trebuie să se realizeze în ordinea din program (order). Exte necesar ca I3 , dependent RAW de I2 , să se execute înaintea instrucţiunii I4 . Aceste restricţii au fost evidenţiate prin linii punctate în graful dependenţelor de date.. În aceste condiţii secvenţa reorganizată corect este:
I0 ADD R3 R1 R2 I1 LD R9 A(R7) I2 ADD R4 R3 R2 I3 ADD R5 R4 R6 I4 LD R4 A(R6)
I0 I1 I4
I2
I3
I5

Sorin Adrian Ciureanu 70
NOP I5 LD R2 A(R4)
Hazardul WAR între I3 şi I4 ar putea fi eliminat prin redenumirea registrului R4 în instrucţiunea I4 . deoarece hazardurile WAR şi WAW nu reprezintă conflicte reale ci doar conflicte de nume. Considerând un procesor cu mai multe registre fizice decât logice, precedenţele impuse de aceste hazarduri pot fi eliminate uşor prin redenumirea registrelor logici cu cei fizici (Register Reaming). Principiul constă în existenţa unei liste a registrelor active, adică folosite momentan, şi o altă listă cu registrele libere. Fiecare schimbare a conţinutului unui registru logic prin program se va face asupra unui registru fizic disponibil în lista registrelor libere registru care va fi trecut în lista registrelor active. In acest caz secvenţa se va rescrie astfel:
I0 ADD R3a R1a R2a I1 LD R9a A(R7a) I2 ADD R4a R3a R2a I3 ADD R5a R4a R6a I4 LD R4b A(R6a) I5 LD R2b A(R4b)
În acest caz în optimizare nu ar mai avea importanţădecât
dependenţele RAW, celelalte fiind eliminate. În baza grafului dependenţelor de date, procesarea optimă ar însemna, în exemplul ales, secvenţa:
I0 I1 I4 I2 I3 I5
2.6.5.3. Hazarduri de ramificaţie Sunt generate de către instrucţiunile de salt (ramificaţie). Cauzează
pierderi de performanţă mult mai importante decât hazardul de date. Diverse statistici arată că instrucţiunile de salt necondiţionat au o
frecvenţă de 2-8% din instrucţiunile unui program, iar cele de salt condiţionat 11-17%. De asemenea salturile condiţionate simple au o probabilitate de apariţie de 50% iar buclele de 90%.
În principiu, efectele defavorabile ale instrucţiunilor de ramificaţie (Branch) pot fi reduse prin:
.metode soft, care reorganizează programul sursă; -metode hard, în care se determină în avans dacă saltul se va face
sau nu şi se calculează în avans noul Program Counter,

Arhitectura calculatoarelor 71
O primă soluţie pentru o procesare corectă ar fi aceea de a dezvolta unitatea de control hardware în vederea detectării prezenţei saltului şi de a întârzia procesarea instrucţiunilor următoare cu un număr de cicluri egal cu latenţa BSD-ului, până când adresa ar fi disponibilă. Soluţia implică, însă, reducerea performanţelor. Acelaşi efect l-ar avea şi „umplerea” BSD-ului de către scheduler cu instrucţiuni NOP
Efectul defavorabil al unei instrucţiuni de salt este sugerat în fig.2.24. pentru o structură pipeline cu 5 nivele în care la finele nivelului RD adresa se salt este disponibilă. Evident că în alte structuri Branch Delay Slot (BDS) poate fi mai mare decât un ciclu.
Fig. 2.25. Hazardul de ramificaţie pe un procesor scalar. În principiu, efectele defavorabile ale instrucţiunilor de ramificaţie
(branch) pot fi reduse prin: -metode soft, care reorganizează programul sursă; -metode hard, în care se determină în avans dacă saltul se va face sau
nu şi calculează în avans noul Program Counter. a) Metode soft. Metoda Gross Hennesy (1982). Se defineşte o instrucţiune de salt situată la adresa b spre o
instrucţiune aflată la adresa a ca un „salt întârziat de ordinul n” dacă, atunci când se face saltul, sunt executate instrucţiunile situate la adresele b, b+1, b+2,………b+n şi a .
O primă soluţie de optimizare ar fi mutarea instrucţiunii de salt cu „n instrucţiuni mai sus”. Acest lucru este posibil doar când nici una dintre precedentele instrucţiuni nu afectează condiţiile de salt. Atunci se poate muta instrucţiunea de salt cu k instrucţiuni mai „în sus”, unde k reprezintă
BRANCH: I1 I2
IF RD ALU MEM WB
IF RD ALU MEM WB
IF RD ALU MEM WB
1 ciclu Branch delay slot (BDS)= 1
Dacă saltul se va face, I1 se va executa în mod nedorit

Sorin Adrian Ciureanu 72
numărul maxim de instrucţiuni anterioare care nu afectează condiţiile de salt. Se duplică primele (n-k) instrucţiuni, plasate începând de la adresa de destinaţie a saltului, imediat după instrucţiunea de salt. Se modifică corespunzător adresa de salt, la acea adresă care urmează imediat după cele (n-k) instrucţiuni originale (figura 2.25)
În cazul în care saltul necondiţionat nu se execută, este necesar ca nici una dintre cele (n-k) instrucţiuni adiţionale să nu afecteze execuţia următoarelor (1+n-k) instrucţiuni.
Fig. 2.25. Soluţionarea unui hazard de ramificaţie prin duplicarea instrucţiunilor.
b)Metode hardware. Predicţii prin hardware Cele mai performante strategii actuale de gestionare a ramificaţiilor
de program sunt predicţiile hardware. Au la bază un proces de predicţie „run-time” a ramurii de salt condiţionat precum şi determinarea în avans a noului Program Counter (PC).
Notând cu BP (Branch Penalty) numărul mediu de cicluri de aşteptare pentru fiecare instrucţiune din program, introduşi de salturile fals predicţionate, se poate scrie relaţia:
BP=C(1-Ap)b IR unde:
C = numărul de cicluri de penalizare introduşi de un salt prost predicţionat Ap = acurateţea predicţiei p= procentele de instrucţiuni de salt instrucţiunile procesate în program IR = rata medie de lansare în execuţie a instrucţiunilor.
BRANCH (cond), ADR BRANCH (cond), ADR M
I instr. (n-k) instr.
k[ ADR ADR 1
k[ ADR 2 ADR M
(n-k) instr. adiţionale I instr. (n-k) instr. „originale” ADR M=ADR+ 1+2(n-k)

Arhitectura calculatoarelor 73
Se observă că BP(Ap=0)=CbIR iar BP(Ap=1)=0, predicţia ideală. Impunând BP=0.1 şi considerând valorile tipice C=5, IR=4, b=22,5 %=0,225 rezultă Ap =0,977=97,7%. Este necesară o predicţie aproape perfectă pentru a nu se simţi efectul defavorabil al ramificaţiilor de program asupra performanţelor procesoarelor.
O metodă consacrată în acest sens este metoda „Branch Prediction Buffer” (BPB). BPB reprezintă o mică memorie adresată cu cei mai puţin semnificativ biţi ai PC-ului aferent unei instrucţiuni de salt condiţionat. Cuvântul BPB este constituit în principiu dintr-un singur bit. Dacă acesta este 1 logic, se prezice că saltul se va face iar dacă este 0 logic, e prezice că saltul nu se va face. Evident că nu se poate şti în avans dacă predicţia este corectă. Oricum structura va considera predicţia corectă şi va declanşa aducerea instrucţiunii următoare pe ramura prezisă. Dacă predicţia se dovedeşte a fi fost falsă, structura pipeline se evacuează şi se iniţiază procesarea celeilalte ramuri de program. Totodată valoarea bitului de predicţie din BPB se inversează.
C N START: C (C-1)
NU DA
Fig. 2.25. O buclă tipică. BPB cu un singur bit are un dezavantaj care se manifestă cu
precădere în cazul buclelor de program ca cea din figura 2.25., în care saltul se va face de (N-1) ori; o dată, la ieşirea din buclă nu se va face. În acest caz, vom avea două predicţii false: una la intrarea în buclă (prima parcurgere) şi alta la ieşirea din buclă (ultima parcurgere a buclei). Acurateţea predicţiei va fi de (N-2).100/N% iar saltul se va face în proporţie
C=0

Sorin Adrian Ciureanu 74
de (N-1).100/N%. Pentru a elimina acest dezavantaj se utilizează 2 biţi de predicţie modificabili conform graficului de tranziţie de mai jos (numărător saturat). În acest caz acurateţea predicţiei unei bucle care se face de (N-1) ori va fi (N-1).100/N%.
Prin urmare, în cazul în care se prezice că branch-ul va avea loc, aducerea noii instrucţiuni se face de îndată ce conţinutul noului PC este cunoscut. În cazul unei predicţii incorecte, se evacuează structura pipeline şi se atacă cealaltă ramură a instrucţiunii de salt. Totodată biţii de predicţie se modifică în conformitate cu graful din figura 2.26.
DA NU
DA DA NU NU NU DA
Fig. 2.26. Automat de predicţie de tip numărător saturat pe 2 biţi.
Prezice DA 01
Prezice DA 00
Prezice NU 11
Prezice NU 10





























