Embed Size (px)
Citation preview

Appl. Math. Inf. Sci.9, No. 2L, 439-449 (2015) 439
Applied Mathematics & Information SciencesAn International Journal
http://dx.doi.org/10.12785/amis/092L19
A Personalized News Recommendation using UserLocation and News ContentsHee-Geun Yoon1, Hyun-Je Song1, Seong-Bae Park1,∗ and Kweon Yang Kim2
1 School of Computer Science and Engineering, Kyungpook National University, Daegu 702-701, Korea2 Department of Computer Engineering, Kyungil University, Gyeongsan 712-701, Korea
Received: 18 May 2014, Revised: 19 Jul. 2014, Accepted: 21 Jul. 2014Published online: 1 Apr. 2015
Abstract: Personalized news article recommendation provides interesting articles to a specific user based on the preference of the user.With increasing use of hand-held devices, the interests of users are not influenced only by news contents, but also by their location.Therefore, in this paper, we propose a novel topic model to incorporate user location into a user preference for the location-basedpersonalized news recommendation. The proposed model is Spatial Topical Preference Model (STPM). By representing thepreferenceof a user differently according to the location of the user, the model recommends the user appropriate news articles to the user location.For this purpose, we represent geographical topic patternswith a Gaussian distribution. STPM is trained only with the news articlesthat the user actually reads. As a result, it shows poor performance, when the user reads just a few news articles. This problem ofSTPM is compensated for by LDA-based user profile that is not affected by user location. Therefore, the final proposed model is acombined model of STPM and LDA. In the evaluation of the proposed model, it is shown that STPM reflects user locations into newsarticle recommendation well, and the combined model outperforms both STPM and LDA. These experimental results prove that thelocation-based user preference improves the performance of news article recommendation, and the proposed model incorporates thelocational information of users into news recommendation effectively.
Keywords: Personalized news recommendation, Spatial topical model,Latent Dirichlet Analysis
1 Introduction
These days news reading environment has changedgreatly. Web-based news reading services like GoogleNews and Yahoo! News have become increasinglyprevalent, as the Internet allows fast access to newsarticles. Since news articles are in flood from a number ofnews publishers, news article recommendation has beenstudied to provide interesting news for readers. However,the interests of readers are different one another. Thus,there have been a number of studies on personalized newsarticle recommendation that focuses more on differentinterests of readers in recommending news articles [1].
Most personalized news article recommender systemsfirst build user preferences for their service, and then findnews articles that are fitted well to the preferences. Thesystems based on collaborative filtering obtain userpreferences from a user-news matrix which consists ofnews consumption patterns of news readers [1, 2]. Thepreference of a user is extracted by the patterns of otherusers who have a similar pattern with the target user. On
the other hand, content-based news articlerecommendation systems construct user preferences byanalyzing news contents that they read [3]. In buildinguser preferences, word frequency of news contents hasbeen widely used. However, topics are preferred to wordfrequency recently, since they are good proxies to newsarticles and user preferences. As a result, most recentstudies employ a topic modeling of user preference [4–6].In these systems, the similarity between a news articleand a user preference is computed by calculating thesimilarity between their latent topics.
Personalized news article recommendations aresuccessful and show good performances [1, 4]. The usersof topic-based personalized recommendations have theirown topics that explain their interests. Thus, therecommendation systems can select news articles usingthe topics. However, they neglect the location of a newsreader, even though a location is one of most importantelements that determine user preference. With thepopularization of hand-held devices such as a mobile
∗ Corresponding author e-mail:[email protected]
c© 2015 NSPNatural Sciences Publishing Cor.

440 H. G. Yoon et. al. : A Personalized News Recommendation usingUser...
weather at home
entertainments on the subway
business at the office
Fig. 1: Different news articles at different user locations.
phone or a tablet PC, people read news articles in whichthey are interested at any place that they want. In suchcircumstances, the choice of news articles does notdepend only on usual interests of a reader, but also herlocation. Ordinary people have their own spatial patternsin daily life. For instance, let us consider a person whoworks for a finance company. She gets up at her home andhas brunch at a restaurant near her office; she is workingat her office, and often drinks at her favorite bar; lastly,she comes back home to take a rest. Thus, the type ofnews articles that she reads can be different according toher locations. Figure1 shows example news articles sheread at each location. She often reads entertainments onthe subway, and she reads business articles at her office.This is because business articles are related with herwork, even if she prefers entertainment news to businessnews. In addition, she also reads weather news at herhome to check the weather of tomorrow. Therefore, it isof importance to consider the location of a news reader aswell as the content preference in news articlerecommendation.
This paper proposes a novel method for topicalrepresentation of user preference. The method modelsgeographical patterns of a user jointly with wordco-occurrence patterns of news articles. Topic modelsprovide a good description for document contents ingeneral [7]. Thus, the proposed method exploits topicmodels to build user preference in news recommendation.In addition, the method also employs one other importantelement that affects user preference. Each article read bya user always has a corresponding location at which theuser is positioned. Therefore, topics of a news articleshould be generated from not only content words but alsofrom a location stamp.
People spend most of their time on a few major spots.Therefore, the locations of a news reader are likely to besomewhere around the spots. To reflect this phenomenoninto a topic model, the proposed method parameterizes aGaussian distribution over locations associated with eachtopic. In the existing topic modelings, a topic is generatedby discovering a word co-occurrence pattern overdocuments. Since every article has an observable locationstamp, each word in the article corresponds to the
location stamp of the article. When some words areobserved strongly together around a certain spot and donot appear at other places, the topics for them aregenerated from a Gaussian distribution for the spot. If thespot is a small place, the Gaussian distribution for thespot has a small variance. On the other hand, if the wordsco-occur at most spots, then the topic for them isgenerated from a Gaussian distribution with a broadvariance. By combining location patterns of a user andword co-occurrence patterns of the news articles, thetopics generated by the proposed method become morepersonalized. That is, the trained topic model reflects themore personalized geographical viewpoint of a user.Therefore, the proposed method recommends newsarticles in higher quality according to both contextualpreference and location of a user. The news articles that auser actually reads are collected with a smart phone.Since every smart phone has a GPS module, a GPS tag isattached to each article. This GPS tag records the locationat which the article is read.
One thing to note in personalized news articlerecommendation is that topics are biased by news articlesthat a user read. The proposed topic model is trainedonlyfor each location with the news articles read by the user atthe location. Thus, if the user reads just a few newsarticles at a location, the articles do not provideinformation enough to discriminate the topics of newlyincoming news articles at the location. In order tocompensate for this location-based topic model, weemploy Latent Dirichlet Allocation (LDA) [8] as anothertopic representation. LDA is trained using all availablenews articles. Since a great volume of news articles areavailable online, it can extract diverse topics from them.That is, the topics from LDA can reflect newly comingarticles well. These two topic models of thelocation-based topic model and LDA recommend newarticles by combining their recommendation scores.When a news article is given, each topic model assigns arecommendation score to the article using its own userpreference. Then, the final recommendation score of thearticle is determined by weighted sum of the scores.
A series of experiments were conducted to verify therecommendation performance of the proposed method. Inthe experiments, we compare the proposed method withits base models. That is, LDA and the location-basedtopic model are compared with the proposed combinedmodel respectively. A Korean news corpus mined fromWorld Wide Web is used as recommendation candidates.According to our experimental results, the location-basedtopic model outperforms LDA in topic quality. Inaddition, it is also shown that the combined methodoutperforms both LDA and the location-based topicmodel in recommendation performance. These resultsprove (i) that the reading preference of a user isinfluenced by her location and our method reflects thisfact effectively, and (ii) that the combination of the twomodels provides high quality recommendation of newsarticles.
c© 2015 NSPNatural Sciences Publishing Cor.

Appl. Math. Inf. Sci.9, No. 2L, 439-449 (2015) /www.naturalspublishing.com/Journals.asp 441
The rest of this paper is organized as follows. Section2 reviews the related studies on personalized news articlerecommendation. Section 3 introduces the problem oflocation-based personalized news articlerecommendation. Section 4 and Section 5 explain SpatialTopical Preference Model and Latent Dirichlet Allocationfor personalized news are given in Section 6. Finally,Section 7 draws some conclusions.
2 Related Work
Personalized news recommendation has been of interestfor a long time. Several adaptive news recommendationservices such as Google News and Yahoo! Newsrecommend personalized news articles under thecollaborative filtering [1]. Such a success of thecollaborative filtering encouraged many studies topropose various enhanced collaborative filteringapproaches. Many of them augmented the collaborativefiltering in the use of user profiles and news contentproperties. Liu et al. analyzed user click behaviors andbuilt a user profile on her news interests based on both herpast click behavior and the contents that she read [9].Then, they combined both user click behavior and userprofile simultaneously under a Bayesian framework.Their method has been applied to Google News, and theimprovement of the recommendation quality was shownover the existing collaborative filtering. Chu et al. tried toanalyze dynamic contents at the front page of Yahoo!News according to the passage of time [2]. For this, theyconstructed the general profile of users usingdemographic information, activities on relevant sites, andso on. In order to handle the associations between thedynamic contents and the general profile, they proposed amachine learning approach, so-called a feature-basedbilinear regression model, and showed that their methodoutperforms significantly six existing competitiveapproaches.
Apart from the commercial news recommendationservices, a variety of personalized news recommendationshave been developed also in academiccommunities [4, 10]. Li et al. modeled the personalizedrecommendation of news articles as a contextual-banditproblem [10]. They selected articles sequentially to serveusers based on the contextual information, click behaviorof users, and click through rates of articles. They verifiedtheir method by showing that their method providespersonalized web service effectively on traffic of the frontpage of Yahoo! News. On the other hand, Li et al.proposed two-stage personalized news recommendationsystems [4]. In order to deal with large volume of newlypublished news collections, they employed minhashingand locally sensitive hashing to reduce the number ofcomparisons in the first stage. In addition, they used ahierarchical clustering for further speeding up of newsarticle selection. In the second stage, they recommendednewly published articles by considering not only the
contents of news articles but also the entity preferencessuch as people and events.
Recently many recommendation services try toincorporate a user context into choosing interestingarticles. Lin et al. recommended news articles byincorporating three factors into a probabilistic matrixfactorization [11]. The three factors considered are newscontent information, collaborative filtering, andinformation diffusion in virtual social network. In thiswork, the information from social networks is regarded as“word of mouth” that can be used to help making adecision for unexperienced users. Li and Li also tried toreflect the user behavior and news content simultaneouslyfor news recommendation [12]. In this study, theyemployed a unified graph-based approach to modelmulti-type objects such as event types, topics, andimplicit relations in news reading community. Theyproved through an experiment on a data set collected fromvarious news websites that their method handles thecold-start problem effectively.
Many previous studies have considered not justcontent preference but also some other factors such asuser click behavior, entity preferences, and socialrelationship of users. These studies have proven theeffectiveness of those factors for personalized newsrecommendation. However, none of them consider thespatial context of users even though users’ interestschange according to their location. That is, different userpreferences should be discovered with respect to userlocations. Therefore, it is important to regard the spatialcontext as one of contexts for news recommendation.Then, the news recommendation can reflect the routinelife of users, and derive high quality of news articlerecommendation.
3 Personalized News ArticleRecommendation with User’s SpatialInformation
Figure2 describes the overall process of measuring howwell a news articlea is fitted to the user preference with herlocationl. The news articles that a user has already read areassumed to be given in advance, and all the articles are tobe geo-tagged. Here, the tag of an article comes from userlocation at which the user read the article. When the geo-tagged news articles are given, two kinds of topic modelspredict the relevance score of a new news articlea at thecurrent user positionl respectively. One is Spatial TopicPreference Model (STPM) that predicts the score with theconsideration of the current user location, and the other isLatent Dirichlet Allocation (LDA) that predicts it withoutlocation information. The final score of the articlea is thendetermined by weighted sum of their scores.
In STPM, the user preference should be known first.The topical representation of user preference is denotedasPS in this figure.PS is expressed as a topic vector.
c© 2015 NSPNatural Sciences Publishing Cor.

442 H. G. Yoon et. al. : A Personalized News Recommendation usingUser...
Geo-TaggedNews Articles
Fig. 2: Overall process of the location-based personalized news articles recommendation
This user preference changes whenever the user moves herlocations, so thatPS should be changed according to userlocation. That is, when a current user locationl is given,the topical representation of user preference at a locationl, PS
l , is estimated fromPS using locational information.The locational information at the locationl is representedas topics of the news articles read atl. Therefore,PS
l , theuser preference atl, is also a topic vector.
An article can be represented as a topic vector. Thatis, a new articlea is also represented as a topic vectorT S
a . The topics ofa are affected by the user locationl. Asa result, we modify it toT S
a,l by incorporating the location
into T Sa . The appropriateness ofT S
a,l to PSl is determined
by a score function f (PSl ,T
Sa,l). Since both user
preference and the representation of a news article arerepresented as topic vectors, a simple vector similarity isused as the score function. That is, the score functionf (PS
l ,TS
a,l) is computed by
f (PSl ,T
Sa,l) =
PSl ·T
Sa,l
‖ PSl ‖ · ‖ T S
a,l ‖. (1)
Obviously high-scored articles are more likely to berecommended to the user. In LDA, the general preferenceof the user is identified. The topical representation of thispreference is denoted asPL in this figure. UnlikePS
l ,PL is not affected by user location. Thus, the topics ofLDA are estimated using all the news articles available inWorld Wide Web, and the articles need not be geo-tagged.
Then, PL, the personalized preference, is generatedusing the LDA topics and the articles that the user read.However, it is personalized into As in STPM, a newarticle a is represented as a topic vectorT L
a . After that,the appropriateness ofT L
a to PL is determined by thescore functionf (PL,T L
a ) given in Equation (1).The final score of the news articlea is computed by
combining the scores of STPM and LDA. This score iscalculated by their weighted sum. That is,score(a), thefinal score ofa is calculated by
score(a) = γ · f (PSl ,T
Sa,l)+ (1− γ) · f (PL,T L
a ) (2)
where 0≤ γ ≤ 1 is an importance ratio between STPM andLDA. Note that both score functions of STPM and LDAare bounded between 0 and 1 by Equation (1). Thus, theweighted sum is concave and the article with a high finalscore is more likely to be recommended to the user.
If the words generated by the topics of STPM aresimilar to those in an article, STPM is believed to expressthe article well. That is, the larger the number of wordsthat appear both in the topics of STPM and the article is,the more trustworthy STPM is. Therefore,γ can beinduced from the overlapped words between STPM andthe article a, since it is a parameter to control theimportance between STPM and LDA. That is,γ is definedas
γ =|wm ∩wa|
|wa|,
c© 2015 NSPNatural Sciences Publishing Cor.

Appl. Math. Inf. Sci.9, No. 2L, 439-449 (2015) /www.naturalspublishing.com/Journals.asp 443
Fig. 3: The graphical model of STPM.
Table 1: Description of the notations used in the graphicalrepresentation of STPM.
Symbol DescriptionT the number of topicsD the number of documentsV the number of unique wordsNd the number of words in documentdθd multinomial distribution of topics specific to the documentdΦz multinomial distribution of words specific to topicz
µz, Σz Gaussian distribution for a location specific to topiczzdi topic associated with thei-th word indwdi the i-th word indldi location associated with thei-th word ind
wherewm is a set of words generated from STPM topics,andwa is a set of unique words appearing ata.
4 Spatial Topical Preference Model forPersonalized News Article Recommendation
Most existing content-based news recommender systemsconsider only words of articles. Thus, they employ a topicmodel to find hidden meanings among words. Thediscovered topics are used to represent a user preference.This is because the topics are generated from wordco-occurrence patterns over news articles that were readby the target user. However, topic discovery is notaffected only by word co-occurrences. Some previousstudies dealt with other factors for topic discovery [13]. Incase of constructing the user preference, the user’s spatialpatterns of reading articles also affect user preference.Thus, STPM reflects the geographical patterns into newsrecommendation.
Figure 3 shows the graphical model of STPM. Thesymbols used in this figure are explained in Table1.Every word is assumed to have its own location stamp.Then, all words are located in a geographical space.However, the number of locations in which a user ismoving is not large. Normally a user is active on a fewmajor spots. Therefore, the locations of words appearingin the articles read by the user are somewhere around theseveral spots. As a result, the topics discovered from thewords have geographical patterns. Then, STPM can
cluster words through the geographical patterns. That is,the words are clustered by their co-occurrences on theirgeographical locations as well as the co-occurrences inthe articles.
We assume that these geographical patterns of topicsare ruled by a Gaussian distribution. The distributionallows the topics of STPM to be flexible, since it iscontinuous. Note that the location stamps for trainingSTPM are sparse compared to potential locations of auser. By adapting a Gaussian distribution, STPM canavoid the sparsity problem of the locational information.In addition, since each word corresponds to severallocation stamps, the Gibbs sampling can be used to inferthe posterior distribution of the topics.
Let Φz be a probability vector of words in a topicz,andΦ1:T be a probability matrix ofT topics and all words.Under STPM, the words and the locations of a documentdarise from the following generative process with Dirichletparametersα andβ .
1.For each topicz, drawT word distributions byΦz | β ∼ Dirichlet(β ).
2.Draw topic proportionθd | α ∼ Dirichlet(α).3.For each wordwdi and its locationldi of the document
d,(a)Draw a topic byzdi | θd ∼ Multinomial(θd).(b)Draw a word by
wdi | zdi,Φ1:T ∼ Multinomial(Φzdi).(c)Draw a location by
ldi | zdi,µ1:T ,Σ1:T ∼ Normal(µzdi ,Σzdi).
The posterior distributionP(θ ,Φ,z|w, l) should beinferred to train the model, wherew is all words in thearticles andl represents all possible locations. That is,since only words and location stamps are observed in thedata set, all other latent variables should be estimatedfrom them. However, the inference cannot be doneexactly, sinceθ , Φ, and{µ ,Σ} are coupled together inthe summation over latent topics. Thus, the Gibbssampling is used as an alternative method. We samplefirst the assignments of words and locations to topics, andthen θ and Φ are integrated after topics are sampled.Therefore, the conditional posterior distribution forzdi isgiven by
P(zdi|w,z−di, l)∝ P(wdi|w−di,z−di)P(ldi|l−di,z−di)P(z−di)
∝nzdiwdi +βwdi −1
∑Vv=1(nzdiv +βv)−1
(mdzdi +αzdi −1)
×1
2π√
|Σzdi |exp
(
−(ldi − µzdi)T Σ−1
zdi(ldi − µzdi)
2
)
, (3)
wherez−di is the assignment of all words exceptwdi. Inaddition, nzv represents the number that a wordv isassigned to a topicz, andmdz is the number that the wordsin an articled are assigned to a topicz. The Gaussianparameters for each topic are obtained by a maximumlikelihood method [14].
c© 2015 NSPNatural Sciences Publishing Cor.

444 H. G. Yoon et. al. : A Personalized News Recommendation usingUser...
4.1 User Preference Estimation over UserLocation
Many previous studies defined the preference of a user asa topic proportion of news articles read by the user [4,5].The topic proportion can be represented as a vector whoseelement is a probability of a topic. This probability is thencalculated by summing the conditional posteriordistribution for the topic over the news articles.
Formally, a user preference is represented as the topicproportionP, which is expressed as a vector
P = 〈P(z1), . . . ,P(zi), . . . ,P(zT )〉, (4)
whereT is the number of topics andP(zi) is thei-th topicprobability. When a user reads a set of new articlesD, thetopic probabilityP(zi) is obtained as follows.
P(zi) = ∑d∈D
P(zi|d)P(d)
= ∑d∈D
P(zi|d), (5)
whereP(d) is the probability of an articled ∈ D that issimply assumed to be uniform.P(zi|d) is usually aconditional posterior distribution like Equation (3).
In STPM, the user preference changes whenever theuser moves her locations. Thus, the geographicalinformation should be reflected into user preference.Then,PS
l , the user preference at a locationl is defined as
PSl = 〈E(θz1|l),E(θz2|l), . . . ,E(θzT |l)〉,
whereE(θzk ) is an expectation ofθzk . By the Bayes rule,
E(θzk |l) = P(zk|l)
∝ p(l|zk)P(zk).
Here,p(l|zk) is a conditional probability ofl given a topiczk. Since we assume that geographical information is ruledby a Gaussian distribution,p(l|zk) becomes
p(l|zk) ∝1
2π√
|Σzk |exp(
−(l − µzk)T Σ−1
zk(l − µzk)
2).
Then,PSl is compared with a topic representationT S
a,l of
an article a by Equation (1). Note that ||PSl || is not
always one, while||T Sa,l || = 1. Therefore, to make them
be compared, eachE(θzk |l) of PSl is normalized to a sum
of one. That is,PSl is actually
PSl =
⟨
E(θz1|l)Z
,E(θz2|l)
Z, . . . ,
E(θzT |l)Z
⟩
,
whereZ = ∑Ti=1 E(θzi |l).
4.2 Topic Inference of News Articles with UserLocation
Topic representationT Sa,l of a news articlea with user
location l can be obtained by computing a posterior
(a) Location A
(b) Location B
Fig. 4: Two different topic representations of the samenews article by STPM at two different locations.
distribution θ of {a, l}. Hence, we also conduct asampling procedure for each word in{a, l} by Equation(3). Then, T S
a,l is obtained by marginalizing those
sampled topics. SinceT Sa,l is a topic proportion of{a, l},
it is represented as a vector
TS
a,l = 〈θ {a,l}z1 ,θ {a,l}
z2 , . . . ,θ {a,l}zT 〉.
Then, each topic-document distributionθ {a,l}zk is obtained
by countingzk among sampled topics as follows.
θ {a,l}zk =
mazk + δ∑T
k=1 mazk +Tδ,
whereδ is a smoothing parameter. We useδ = 1 in thispaper.
The current user location is used as a location fornews recommendation. Therefore, even the same article isrepresented as different topic vectors according tolocations. As a result, a news article at different locationsis considered to be different in our model. For instance,Figure 4 shows topic proportions of an article at twodifferent locations. This figure demonstrates the topics ofa user who reads Major League Baseball (MLB)-relatedarticles mostly at the location B and reads general articles
c© 2015 NSPNatural Sciences Publishing Cor.
Appl. Math. Inf. Sci.9, No. 2L, 439-449 (2015) /www.naturalspublishing.com/Journals.asp 445
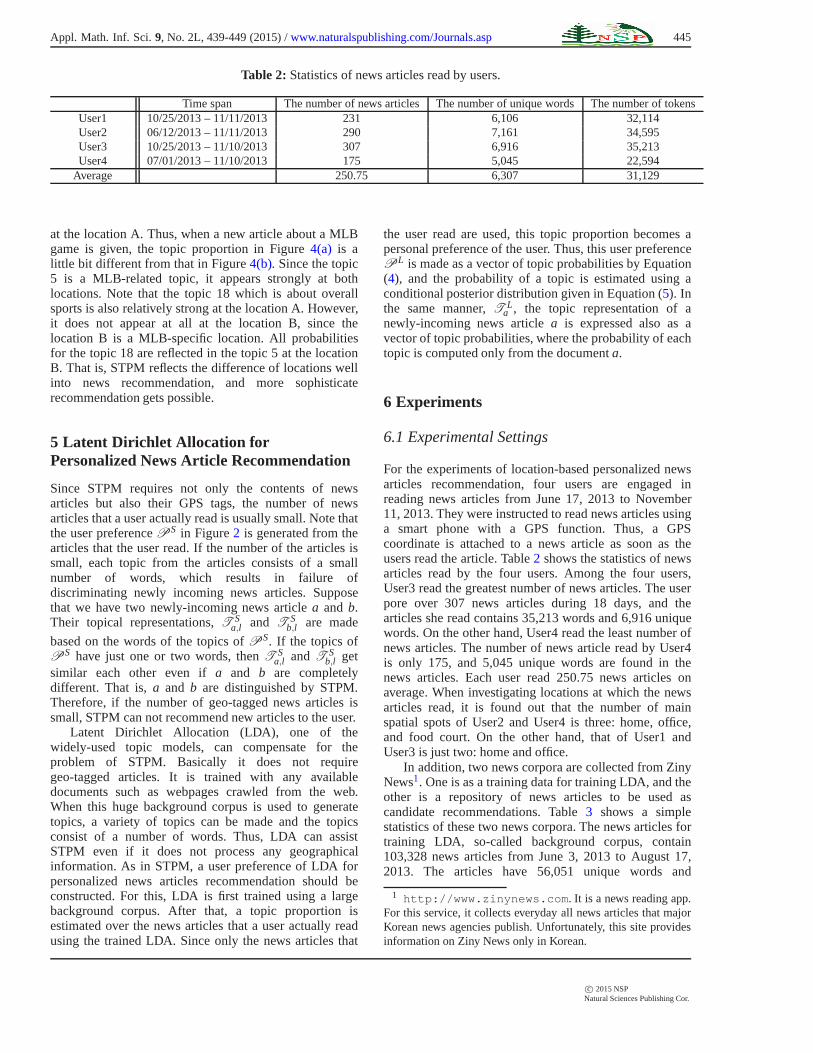
Table 2: Statistics of news articles read by users.
Time span The number of news articles The number of unique words The number of tokensUser1 10/25/2013 – 11/11/2013 231 6,106 32,114User2 06/12/2013 – 11/11/2013 290 7,161 34,595User3 10/25/2013 – 11/10/2013 307 6,916 35,213User4 07/01/2013 – 11/10/2013 175 5,045 22,594
Average 250.75 6,307 31,129
at the location A. Thus, when a new article about a MLBgame is given, the topic proportion in Figure4(a) is alittle bit different from that in Figure4(b). Since the topic5 is a MLB-related topic, it appears strongly at bothlocations. Note that the topic 18 which is about overallsports is also relatively strong at the location A. However,it does not appear at all at the location B, since thelocation B is a MLB-specific location. All probabilitiesfor the topic 18 are reflected in the topic 5 at the locationB. That is, STPM reflects the difference of locations wellinto news recommendation, and more sophisticaterecommendation gets possible.
5 Latent Dirichlet Allocation forPersonalized News Article Recommendation
Since STPM requires not only the contents of newsarticles but also their GPS tags, the number of newsarticles that a user actually read is usually small. Note thatthe user preferencePS in Figure2 is generated from thearticles that the user read. If the number of the articles issmall, each topic from the articles consists of a smallnumber of words, which results in failure ofdiscriminating newly incoming news articles. Supposethat we have two newly-incoming news articlea and b.Their topical representations,T S
a,l and T Sb,l are made
based on the words of the topics ofPS. If the topics ofPS have just one or two words, thenT S
a,l and T Sb,l get
similar each other even ifa and b are completelydifferent. That is,a and b are distinguished by STPM.Therefore, if the number of geo-tagged news articles issmall, STPM can not recommend new articles to the user.
Latent Dirichlet Allocation (LDA), one of thewidely-used topic models, can compensate for theproblem of STPM. Basically it does not requiregeo-tagged articles. It is trained with any availabledocuments such as webpages crawled from the web.When this huge background corpus is used to generatetopics, a variety of topics can be made and the topicsconsist of a number of words. Thus, LDA can assistSTPM even if it does not process any geographicalinformation. As in STPM, a user preference of LDA forpersonalized news articles recommendation should beconstructed. For this, LDA is first trained using a largebackground corpus. After that, a topic proportion isestimated over the news articles that a user actually readusing the trained LDA. Since only the news articles that
the user read are used, this topic proportion becomes apersonal preference of the user. Thus, this user preferencePL is made as a vector of topic probabilities by Equation(4), and the probability of a topic is estimated using aconditional posterior distribution given in Equation (5). Inthe same manner,T L
a , the topic representation of anewly-incoming news articlea is expressed also as avector of topic probabilities, where the probability of eachtopic is computed only from the documenta.
6 Experiments
6.1 Experimental Settings
For the experiments of location-based personalized newsarticles recommendation, four users are engaged inreading news articles from June 17, 2013 to November11, 2013. They were instructed to read news articles usinga smart phone with a GPS function. Thus, a GPScoordinate is attached to a news article as soon as theusers read the article. Table2 shows the statistics of newsarticles read by the four users. Among the four users,User3 read the greatest number of news articles. The userpore over 307 news articles during 18 days, and thearticles she read contains 35,213 words and 6,916 uniquewords. On the other hand, User4 read the least number ofnews articles. The number of news article read by User4is only 175, and 5,045 unique words are found in thenews articles. Each user read 250.75 news articles onaverage. When investigating locations at which the newsarticles read, it is found out that the number of mainspatial spots of User2 and User4 is three: home, office,and food court. On the other hand, that of User1 andUser3 is just two: home and office.
In addition, two news corpora are collected from ZinyNews1. One is as a training data for training LDA, and theother is a repository of news articles to be used ascandidate recommendations. Table3 shows a simplestatistics of these two news corpora. The news articles fortraining LDA, so-called background corpus, contain103,328 news articles from June 3, 2013 to August 17,2013. The articles have 56,051 unique words and
1 http://www.zinynews.com. It is a news reading app.For this service, it collects everyday all news articles that majorKorean news agencies publish. Unfortunately, this site providesinformation on Ziny News only in Korean.
c© 2015 NSPNatural Sciences Publishing Cor.
446 H. G. Yoon et. al. : A Personalized News Recommendation usingUser...
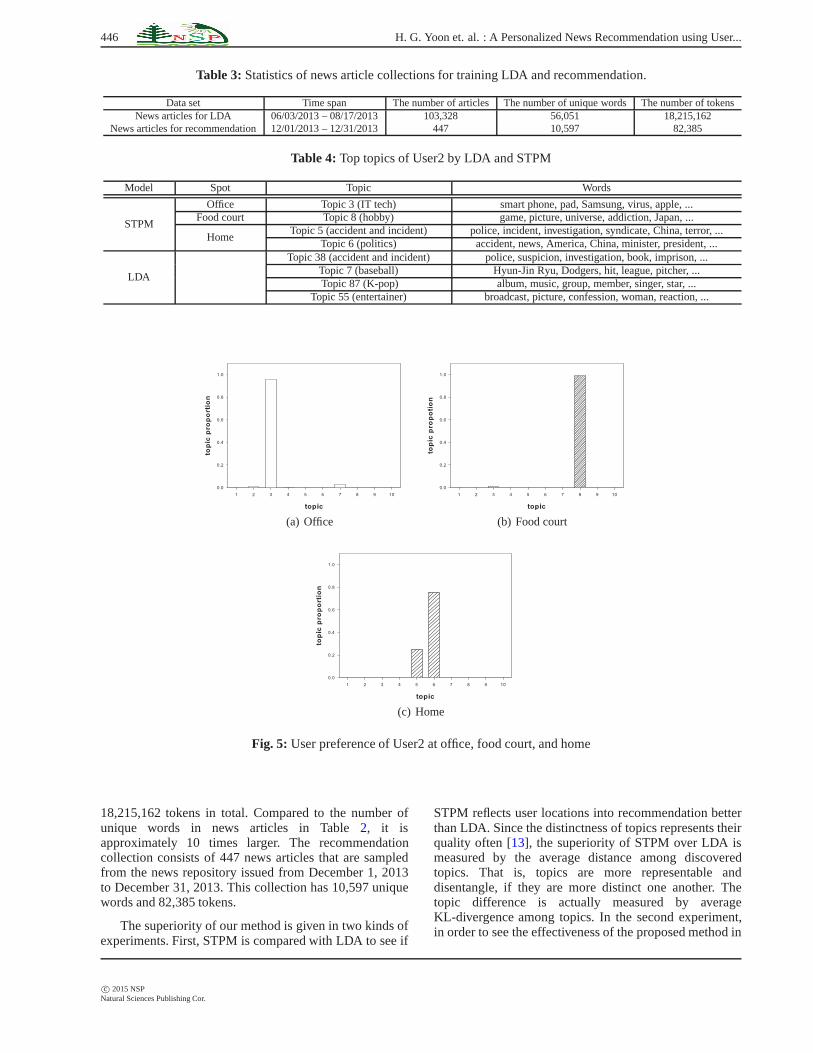
Table 3: Statistics of news article collections for training LDA andrecommendation.
Data set Time span The number of articles The number of unique words The number of tokensNews articles for LDA 06/03/2013 – 08/17/2013 103,328 56,051 18,215,162
News articles for recommendation 12/01/2013 – 12/31/2013 447 10,597 82,385
Table 4: Top topics of User2 by LDA and STPM
Model Spot Topic Words
STPM
Office Topic 3 (IT tech) smart phone, pad, Samsung, virus, apple, ...Food court Topic 8 (hobby) game, picture, universe, addiction, Japan, ...
HomeTopic 5 (accident and incident) police, incident, investigation, syndicate, China, terror, ...
Topic 6 (politics) accident, news, America, China, minister, president, ...
LDA
Topic 38 (accident and incident) police, suspicion, investigation, book, imprison, ...Topic 7 (baseball) Hyun-Jin Ryu, Dodgers, hit, league, pitcher, ...Topic 87 (K-pop) album, music, group, member, singer, star, ...
Topic 55 (entertainer) broadcast, picture, confession, woman, reaction, ...
(a) Office (b) Food court
(c) Home
Fig. 5: User preference of User2 at office, food court, and home
18,215,162 tokens in total. Compared to the number ofunique words in news articles in Table2, it isapproximately 10 times larger. The recommendationcollection consists of 447 news articles that are sampledfrom the news repository issued from December 1, 2013to December 31, 2013. This collection has 10,597 uniquewords and 82,385 tokens.
The superiority of our method is given in two kinds ofexperiments. First, STPM is compared with LDA to see if
STPM reflects user locations into recommendation betterthan LDA. Since the distinctness of topics represents theirquality often [13], the superiority of STPM over LDA ismeasured by the average distance among discoveredtopics. That is, topics are more representable anddisentangle, if they are more distinct one another. Thetopic difference is actually measured by averageKL-divergence among topics. In the second experiment,in order to see the effectiveness of the proposed method in
c© 2015 NSPNatural Sciences Publishing Cor.
Appl. Math. Inf. Sci.9, No. 2L, 439-449 (2015) /www.naturalspublishing.com/Journals.asp 447
(a) Office (b) Home
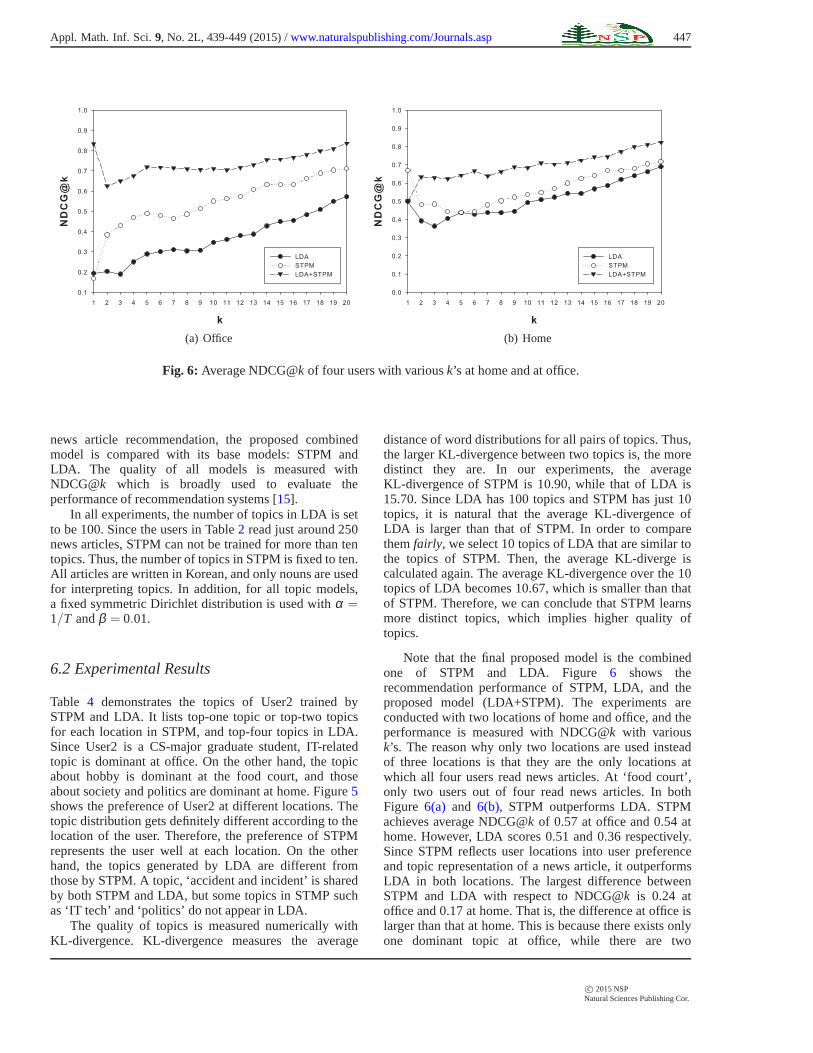
Fig. 6: Average NDCG@k of four users with variousk’s at home and at office.
news article recommendation, the proposed combinedmodel is compared with its base models: STPM andLDA. The quality of all models is measured withNDCG@k which is broadly used to evaluate theperformance of recommendation systems [15].
In all experiments, the number of topics in LDA is setto be 100. Since the users in Table2 read just around 250news articles, STPM can not be trained for more than tentopics. Thus, the number of topics in STPM is fixed to ten.All articles are written in Korean, and only nouns are usedfor interpreting topics. In addition, for all topic models,a fixed symmetric Dirichlet distribution is used withα =1/T andβ = 0.01.
6.2 Experimental Results
Table 4 demonstrates the topics of User2 trained bySTPM and LDA. It lists top-one topic or top-two topicsfor each location in STPM, and top-four topics in LDA.Since User2 is a CS-major graduate student, IT-relatedtopic is dominant at office. On the other hand, the topicabout hobby is dominant at the food court, and thoseabout society and politics are dominant at home. Figure5shows the preference of User2 at different locations. Thetopic distribution gets definitely different according to thelocation of the user. Therefore, the preference of STPMrepresents the user well at each location. On the otherhand, the topics generated by LDA are different fromthose by STPM. A topic, ‘accident and incident’ is sharedby both STPM and LDA, but some topics in STMP suchas ‘IT tech’ and ‘politics’ do not appear in LDA.
The quality of topics is measured numerically withKL-divergence. KL-divergence measures the average
distance of word distributions for all pairs of topics. Thus,the larger KL-divergence between two topics is, the moredistinct they are. In our experiments, the averageKL-divergence of STPM is 10.90, while that of LDA is15.70. Since LDA has 100 topics and STPM has just 10topics, it is natural that the average KL-divergence ofLDA is larger than that of STPM. In order to comparethemfairly, we select 10 topics of LDA that are similar tothe topics of STPM. Then, the average KL-diverge iscalculated again. The average KL-divergence over the 10topics of LDA becomes 10.67, which is smaller than thatof STPM. Therefore, we can conclude that STPM learnsmore distinct topics, which implies higher quality oftopics.
Note that the final proposed model is the combinedone of STPM and LDA. Figure 6 shows therecommendation performance of STPM, LDA, and theproposed model (LDA+STPM). The experiments areconducted with two locations of home and office, and theperformance is measured with NDCG@k with variousk’s. The reason why only two locations are used insteadof three locations is that they are the only locations atwhich all four users read news articles. At ‘food court’,only two users out of four read news articles. In bothFigure 6(a) and 6(b), STPM outperforms LDA. STPMachieves average NDCG@k of 0.57 at office and 0.54 athome. However, LDA scores 0.51 and 0.36 respectively.Since STPM reflects user locations into user preferenceand topic representation of a news article, it outperformsLDA in both locations. The largest difference betweenSTPM and LDA with respect to NDCG@k is 0.24 atoffice and 0.17 at home. That is, the difference at office islarger than that at home. This is because there exists onlyone dominant topic at office, while there are two
c© 2015 NSPNatural Sciences Publishing Cor.
448 H. G. Yoon et. al. : A Personalized News Recommendation usingUser...
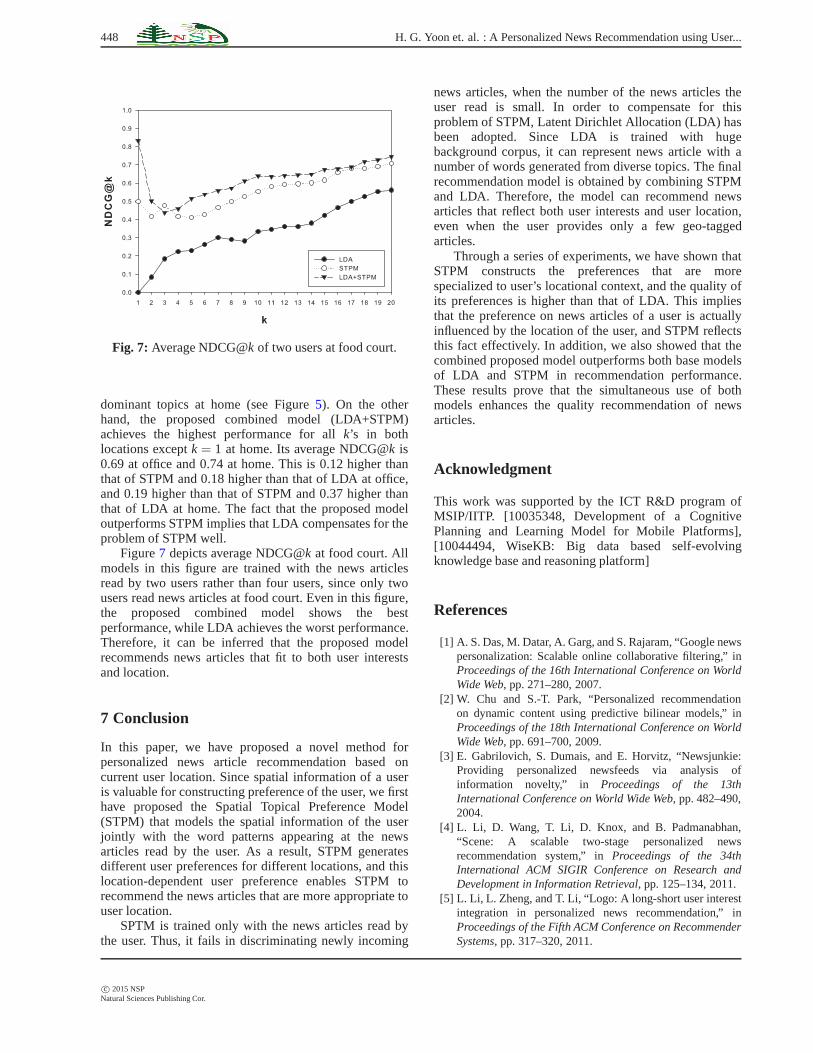
Fig. 7: Average NDCG@k of two users at food court.
dominant topics at home (see Figure5). On the otherhand, the proposed combined model (LDA+STPM)achieves the highest performance for allk’s in bothlocations exceptk = 1 at home. Its average NDCG@k is0.69 at office and 0.74 at home. This is 0.12 higher thanthat of STPM and 0.18 higher than that of LDA at office,and 0.19 higher than that of STPM and 0.37 higher thanthat of LDA at home. The fact that the proposed modeloutperforms STPM implies that LDA compensates for theproblem of STPM well.
Figure7 depicts average NDCG@k at food court. Allmodels in this figure are trained with the news articlesread by two users rather than four users, since only twousers read news articles at food court. Even in this figure,the proposed combined model shows the bestperformance, while LDA achieves the worst performance.Therefore, it can be inferred that the proposed modelrecommends news articles that fit to both user interestsand location.
7 Conclusion
In this paper, we have proposed a novel method forpersonalized news article recommendation based oncurrent user location. Since spatial information of a useris valuable for constructing preference of the user, we firsthave proposed the Spatial Topical Preference Model(STPM) that models the spatial information of the userjointly with the word patterns appearing at the newsarticles read by the user. As a result, STPM generatesdifferent user preferences for different locations, and thislocation-dependent user preference enables STPM torecommend the news articles that are more appropriate touser location.
SPTM is trained only with the news articles read bythe user. Thus, it fails in discriminating newly incoming
news articles, when the number of the news articles theuser read is small. In order to compensate for thisproblem of STPM, Latent Dirichlet Allocation (LDA) hasbeen adopted. Since LDA is trained with hugebackground corpus, it can represent news article with anumber of words generated from diverse topics. The finalrecommendation model is obtained by combining STPMand LDA. Therefore, the model can recommend newsarticles that reflect both user interests and user location,even when the user provides only a few geo-taggedarticles.
Through a series of experiments, we have shown thatSTPM constructs the preferences that are morespecialized to user’s locational context, and the quality ofits preferences is higher than that of LDA. This impliesthat the preference on news articles of a user is actuallyinfluenced by the location of the user, and STPM reflectsthis fact effectively. In addition, we also showed that thecombined proposed model outperforms both base modelsof LDA and STPM in recommendation performance.These results prove that the simultaneous use of bothmodels enhances the quality recommendation of newsarticles.
Acknowledgment
This work was supported by the ICT R&D program ofMSIP/IITP. [10035348, Development of a CognitivePlanning and Learning Model for Mobile Platforms],[10044494, WiseKB: Big data based self-evolvingknowledge base and reasoning platform]
References
[1] A. S. Das, M. Datar, A. Garg, and S. Rajaram, “Google newspersonalization: Scalable online collaborative filtering,” inProceedings of the 16th International Conference on WorldWide Web, pp. 271–280, 2007.
[2] W. Chu and S.-T. Park, “Personalized recommendationon dynamic content using predictive bilinear models,” inProceedings of the 18th International Conference on WorldWide Web, pp. 691–700, 2009.
[3] E. Gabrilovich, S. Dumais, and E. Horvitz, “Newsjunkie:Providing personalized newsfeeds via analysis ofinformation novelty,” in Proceedings of the 13thInternational Conference on World Wide Web, pp. 482–490,2004.
[4] L. Li, D. Wang, T. Li, D. Knox, and B. Padmanabhan,“Scene: A scalable two-stage personalized newsrecommendation system,” inProceedings of the 34thInternational ACM SIGIR Conference on Research andDevelopment in Information Retrieval, pp. 125–134, 2011.
[5] L. Li, L. Zheng, and T. Li, “Logo: A long-short user interestintegration in personalized news recommendation,” inProceedings of the Fifth ACM Conference on RecommenderSystems, pp. 317–320, 2011.
c© 2015 NSPNatural Sciences Publishing Cor.

Appl. Math. Inf. Sci.9, No. 2L, 439-449 (2015) /www.naturalspublishing.com/Journals.asp 449
[6] M. Ovsjanikov and Y. Chen, “Topic modeling forpersonalized recommendation of volatile items,” inProceedings of the 2010 European Conference on MachineLearning and Knowledge Discovery in Databases: Part II,pp. 483–498, 2010.
[7] X. Wei and W. B. Croft, “Lda-based document modelsfor ad-hoc retrieval,” inProceedings of the 29th AnnualInternational ACM SIGIR Conference on Research andDevelopment in Information Retrieval, pp. 178–185, 2006.
[8] D. M. Blei, A. Y. Ng, and M. I. Jordan, “Latent dirichletallocation,”Journal of Machine Learning Research, vol. 3,pp. 993–1022, 2003.
[9] J. Liu, P. Dolan, and E. R. Pedersen, “Personalized newsrecommendation based on click behavior,” inProceedingsof the 15th International Conference on Intelligent UserInterfaces, pp. 31–40, 2010.
[10] L. Li, W. Chu, J. Langford, and R. E. Schapire, “Acontextual-bandit approach to personalized news articlerecommendation,” inProceedings of the 19th InternationalConference on World Wide Web, pp. 661–670, 2010.
[11] C. Lin, R. Xie, L. Li, Z. Huang, and T. Li, “Premise:Personalized news recommendation via implicit socialexperts,” in Proceedings of the 21st ACM InternationalConference on Information and Knowledge Management,pp. 1607–1611, 2012.
[12] L. Li and T. Li, “News recommendation via hypergraphlearning: Encapsulation of user behavior and news content,”in Proceedings of the Sixth ACM International Conferenceon Web Search and Data Mining, pp. 305–314, 2013.
[13] X. Wang and A. McCallum, “Topics over time: A non-markov continuous-time model of topical trends,” inProceedings of the 12th ACM SIGKDD InternationalConference on Knowledge Discovery and Data Mining, pp.424–433, 2006.
[14] A. Rencher,Methods of Multivariate Analysis. Wiley,1995.
[15] K. Jarvelin and J. Kekalainen, “Cumulated gain-basedevaluation of ir techniques,”ACM Transactions onInformation Systems, vol. 20, no. 4, pp. 422–446, 2002.
Hee-Geun Yoonreceived his MS in computerengineering from KyungpookNational University, Daegu,Rep. of Korea, in 2009. Now,he is a PhD candidate at theSchool of Computer Scienceand Engineering, KyungpookNational University. His mainresearch interests include
machine learning and natural language processing.
Hyun-Je Song receivedhis B.S. and MS degreein Computer Engineeringfrom Kyungpook NationalUniversity in 2008 and2010 respectively. Currentlyhe is a PhD candidate inSchool of Computer Scienceand Engineering, KyungpookNational University. His
research interests include machine learning and naturallanguage processing.
Seong-Bae Park receivedhis MS and PhD degrees incomputer science from SeoulNational University, Seoul,Rep. of Korea, in 1996 and2002, respectively. Now, he isan associate professor at theSchool of Computer Scienceand Engineering, KyungpookNational University, Daegu,
Rep. of Korea. He focuses on machine learning, naturallanguage processing, text mining, and bio-informatics.
Kweon Yang Kimreceived his MS andPhD degrees in ComputerEngineering from KyungpookNational University,Daegu, Rep. of Korea, in1990 and 1998, respectively.Now, he is a professor atthe Department of ComputerEngineering, Kyungil
University, Gyeongsan, Rep. of Korea. He focuses onsemantic web and Korean language engineering.
c© 2015 NSPNatural Sciences Publishing Cor.





























