Embed Size (px)
Citation preview

1
Hiding Collaborative Recommendation
Association Rules
Shyue-Liang Wang*, Dipen Patel, Ayat Jafari
Department of Computer Science
New York Institute of Technology
1855 Broadway
New York, New York 10023 USA
+1-212-261-1640 (O)
+1-212-261-1748(Fax)
Tzung-Pei Hong
Department of Electrical Engineering
National University of Kaohsiung
Kaohsiung, Taiwan
ROC
* Corresponding author

2
ABSTRACT
The concept of Privacy-Preserving has recently been proposed in response to the
concerns of preserving personal or sensible information derived from data mining
algorithms. For example, through data mining, sensible information such as private
information or patterns may be inferred from non-sensible information or unclassified
data. There have been two types of privacy concerning data mining. Output privacy
tries to hide the mining results by minimally altering the data. Input privacy tries to
manipulate the data so that the mining result is not affected or minimally affected.
For output privacy in hiding association rules, current approaches require hidden rules or
patterns been given in advance [9, 17-19, 22, 25]. This selection of rules would require
data mining process to be executed first. Based on the discovered rules and privacy
requirements, hidden rules or patterns are then selected manually. However, for some
applications, we are interested in hiding certain constrained classes of association rules
such as collaborative recommendation association rules [14,20]. To hide such rules, the
pre-process of finding these hidden rules can be integrated into the hiding process as long
as the recommended items are given. In this work, we propose two algorithms, DCIS

3
(Decrease Confidence by Increase Support) and DCDS (Decrease Confidence by
Decrease Support), to automatically hiding collaborative recommendation association
rules without pre-mining and selection of hidden rules. Examples illustrating the
proposed algorithms are given. Numerical experiments are performed to show the
various effects of the algorithms. Recommendations of appropriate usage of the
proposed algorithms based on the characteristics of databases are reported.
Keywords: privacy preserving data mining, collaborative recommendation, association
rule
1 Introduction
In recent years, data mining or knowledge discovery in databases has developed into an
important technology of identifying patterns and trends from large quantities of data.
Successful applications of data mining have been demonstrated in marketing, business,
medical analysis, product control, engineering design, bioinformatics and scientific
exploration, among others. While all of these applications of data mining can benefit
commercial, social and human activities, there is also a negative side to this technology:

4
the threat to data privacy. For example, through data mining, one is able to infer
sensitive information, including personal information, or even patterns from
non-sensitive information or unclassified data.
The concept of privacy preserving data mining has recently been proposed in response to
the concerns of preserving privacy information from data mining algorithms
[3,4,5,15,16,24]. There have been two types of privacy concerning data mining. The
first type of privacy, called output privacy, is that the data is minimally altered so that the
mining result will preserve certain privacy. Many techniques have been proposed for
this type of output privacy [1,6,7,8,9,18,19,22,25]. For example, perturbation, blocking,
aggregation or merging, swapping, and sampling are some alternation methods that have
recently been proposed. The second type of privacy, input privacy, is that the data is
manipulated so that the mining result is not affected or minimally affected
[10,11,12,13,23]. For example, the reconstruction-based technique tries to randomize
the data so that the original distribution or patterns of the data can be reconstructed. The
cryptography-based techniques like secure multiparty computation allow users access to
only a subset of data while global data mining results can still be discovered.

5
In output privacy, given specific rules or patterns to be hidden, many data altering
techniques for hiding association, classification and clustering rules have been proposed.
For association rules hiding, two basic approaches have been proposed. The first
approach [9, 22, 25] hides one rule at a time. It first selects transactions that contain the
items in a give rule. It then tries to modify transaction by transaction until the
confidence or support of the rule fall below minimum confidence or minimum support.
The modification is done by either removing items from the transaction or inserting new
items to the transactions. The second approach [17-19] deals with groups of restricted
patterns or association rules at a time. It first selects the transactions that contain the
intersecting patterns of a group of restricted patterns. Depending on the disclosure
threshold given by users, it sanitizes a percentage of the selected transactions in order to
hide the restricted patterns.
However, both approaches require hidden rules or patterns been given in advance. This
selection of rules would require data mining process to be executed first. Based on the
discovered rules and privacy requirements, hidden rules or patterns are then selected
manually. But, for some applications, we are only interested in hiding certain
constrained classes of association rules such as collaborative recommendation association

6
rules, which can be used for recommendation using less number of association rules. To
hide such rules, the pre-process of finding these hidden rules can be integrated into the
hiding process as long as the recommended items are given.
In this work, we assume that recommended items are given and propose two algorithms,
DCIS (Decrease Confidence by Increase Support) and DCDS (Decrease Confidence by
Decrease Support), to automatically hiding collaborative recommendation association
rules without pre-mining and selection of hidden rules. Examples illustrating the
proposed algorithms are given. Numerical experiments are performed to show the
various effects of the algorithms. Recommendations of appropriate usage of the
proposed algorithms based on the characteristics of databases are reported.
The rest of the paper is organized as follows. Section 2 presents the statement of the
problem and the notation used in the paper. Section 3 presents the proposed algorithms
for hiding collaborative recommendation association rules that contain the specified
recommended items. Section 4 shows some examples of the proposed algorithms.
Section 5 shows the experimental results of the performance and various side effects of
the proposed algorithms. Section 6 analyses the characteristics of proposed algorithms

7
and recommends appropriate usage of the proposed algorithms. Concluding remarks
and future works are described in section 7.
2 Problem Statement
2.1 Collaborative Recommendation Association Rules
The problem of mining association rules was introduced in [2]. Let } ,, , { 21 miiiI
be a set of literals, called items. Given a set of transactions D, where each transaction
T in D is a set of items such that ,IT an association rule is an expression YX
where ,IX ,IY and .YX The X and Y are called respectively the
body (left hand side) and head (right hand side) of the rule. An example of such a rule
is that 90% of customers buy hamburgers also buy Coke. The 90% here is called the
confidence of the rule, which means that 90% of transaction that contains X
(hamburgers) also contains Y (Coke). The confidence is calculated as |||| XYX ,
where |X| is the number of transactions containing X and |XY| is the number of
transactions containing both X and Y. The support of the rule is the percentage of
transactions that contain both X and Y, which is calculated as NYX || , where N is

8
the number of transactions in D. In other words, the confidence of a rule measures the
degree of the correlation between itemsets, while the support of a rule measures the
significance of the itemsets. The problem of mining association rules is to find all rules
that are greater than the user-specified minimum support and minimum confidence.
As an example, for a given database in Table 1, a minimum support of 33% and a
minimum confidence of 70%, nine association rules can be found as follows: B=>A (66%,
100%), C=>A (66%, 100%), B=>C (50%, 75%), C=>B (50%, 75%), AB=>C (50%, 75%),
AC=>B (50%, 75%), BC=>A(50%, 100%), C=>AB(50%, 75%), B=>AC(50%, 75%),
where the percentages inside the parentheses are supports and confidences respectively.
Table 1: Database D
TID Items
T1 ABC
T2 ABC
T3 ABC
T4 AB
T5 A
T6 AC
However, mining association rules usually generates a large number of rules, most of
which are unnecessary for the purpose of collaborative recommendation. For example,

9
to recommend a target item {C} to a customer, the collaborative recommendation
association rule set that contains only two rules, B=>C (50%, 60%) and AB=>C (50%,
60%), will generate the same recommendations as the entire nine association rules found
from Table 1. This means that if the new customer has shown interests in purchasing
item {B} or items {AB}, then the collaborative recommender will recommend the new
customer to purchase target item {C}. Therefore, a collaborative recommendation
association rule set can be informally defined as the smallest association rule set that
makes the same recommendation as the entire association rule set by confidence priority.
Formally, given an association rule set R and a target itemset P, we say that the
collaborative recommendation for P from R is a sequence of items Q. Using the rules in
R in descending order of confidence generates the sequence of Q. For each rule r that
matches P (i.e., for each rule whose conclusion is a subset of P), each antecedent of r is
added to Q. After adding a consequence to Q, all rules whose antecedent are in Q are
removed from R.
The following is the definition of collaborative recommendation association rule set:

10
Definition Let RA be an association rule set and RA1 the set of single-target rules in RA.
A set Rc is a collaborative recommender over RA if (1) Rc RA1, (2) r Rc, there does
not exist r’ Rc such that r’ r and conf(r’)> conf(r), and (3) r’’ RA1 –
Rc, r Rc
such that r’’ r and conf(r’’) conf(r).
From this definition, the collaborative recommendation association rules are basically
single target rules such that there is no subset rule with higher confidence and for any
non-collaborative recommendation single-target rule, there is a collaborative
recommendation association rule with higher confidence.
2.2 Problem Description
The objective of data mining is to extract hidden or potentially unknown but interesting
rules or patterns from databases. However, the objective of privacy preserving data
mining is to hide certain sensitive information so that they cannot be discovered through
data mining techniques [1,4-12,16]. In this work, we assume that only recommended
(also called target or hidden) items are given and propose two algorithms to modify data
in database so that collaborative recommendation association rule sets cannot be inferred

11
through association rule mining. More specifically, given a transaction database D, a
minimum support, a minimum confidence and a set of recommended items Y, the
objective is to minimally modify the database D such that no collaborative
recommendation association rules containing Y on the right hand side of the rule will be
discovered.
As an example, for a given database in Table 1, a minimum support of 33%, a minimum
confidence of 70%, and a hidden item Y = {C}, if transaction T5 is modified from A to
AB, then the following rule that contains item C on the right hand side will be hidden:
B=>C (50%, 60%). However, rules AB=>C (50%, 60%), B=>AC (50%, 60%) will be
lost and a new rule A=>B (83%, 83%) will be generated as side effects.
The following notation will be used in the paper. Each database transaction has three
elements: T=<TID, list_of_elements, size>. The TID is the unique identifier of the
transaction T and list_of_elements is a list of all items in the database. However, each
element has value 1 if the corresponding item is supported by the transaction and 0
otherwise. Size means the number of elements in the list_of_elements having value 1.
For example, if I = {A,B,C}, a transaction that has the items {A, C} will be represented as

12
t = <T1,101,2>. In addition, a transaction t supports an itemset I when the elements of
t.list_of_elements corresponding to items of I are all set to 1. A transaction t partially
supports an itemset I when the elements are not all set to 1. For example, if I = {A,B,C}
= [111], p = <T1,[111],3>, and q = <T2,[001],1>, then we would say that p supports I
and q partially supports I.
3 Proposed Algorithms
In order to hide an association rule, X=>Y, we can either decrease its supports,
( NX || or NYX || ), to be smaller than pre-specified minimum support or its
confidence ( |||| XYX ) to be smaller than pre-specified minimum confidence. To
decrease the confidence of a rule, two strategies can be considered. The first strategy is
to increase the support count of X, i.e., the left hand side of the rule, but not support count
of X Y. The second strategy is to decrease the support count of the itemset X Y.
For the second strategy, there are in fact two options. One option is to lower he support
count of the itemset X Y so that it is smaller than pre-defined minimum support count.
The other option is to lower the support count of the itemset X Y so that |||| XYX

13
is smaller than pre-defined minimum confidence. In addition, in the transactions
containing both X and Y, if we decrease the support of Y only, the right hand side of the
rule, it would reduce the confidence faster than reducing the support of X. In fact, we
can pre-calculate the number of transactions required to hide the rule. If there are not
enough transactions exist, then the rule cannot be hidden. To decrease support count of
an item, we will remove one item at a time in a selected transaction by changing from 1
to 0. To increase the support count of an item, we will add one item by changing from 0
to 1.
In order to hide collaborative recommendation association rules, we will consider hiding
association rules with 2 items, x=>z, where z is a recommended item and x is a single
large one item. In theory, collaborative recommendation association rules may have
more specific rules that contain more items, e.g., xY => z, where Y is a large itemset.
However, for such rule to exist, its confidence must be greater than the confidence of
x=>z, i.e., conf(xY=>z) > conf(x=>z) or |xYz| > conf(x=>z) * |xY|. For higher
confidence rules, such as conf(x=>z) = 1, there will be no more specific rules. In
addition, once the more general rule is hidden, the more specific rule might be hidden as
well.

14
Based on the two strategies mentioned above, we propose two data-mining algorithms
for hiding collaborative recommendation association rules, namely DCIS (Decrease
Confidence by Increase Support) and DCDS (Decrease Confidence by Decrease
Support). The first algorithm tries to increase the support of left hand side of the rule.
The second algorithm tries to decrease the support of the right hand side of the rule.
The details of the two algorithms are described as follow.
Algorithm DCIS
Input: (1) a source database D,
(2) a min_support,
(3) a min_confidence,
(4) a set of recommended items Y
Output: a transformed database D’, where rules containing Y on RHS will be hidden
1. Find large 1-item sets from D;
2. For each hidden item y Y
3. If y is not a large 1-itemset, then Y := Y -{y} ;

15
4. If Y is empty, then EXIT;// no AR contains Y in RHS
5. Find large 2-itemsets from D;
6. For each y Y {
7. For each large 2-itemset containing y {
8. Compute confidence of rule U, where U is a rule like x y ;
9. If confidence(U) >= min_conf, then {
//# of transactions required to increase the support of |x|
10. Calculate iterNum = |D|*(supp(xy)/min_conf – supp(x));
11. Calculate | TL | = |D| - |xy|; // |TL|: # of transactions in TL
12. if iterNum > |TL|
13. Can not hide U;
14. else {
15. Find TLk , first k = iterNum transactions that do not contain xy;
16. Sort TLk in ascending order by the number of items;
17. for i = 1 to iterNum do {
18. Choose the first transaction t from TLk;
19. Modify t to support x, the LHS(U);
20. |x| = |x| + 1; // update support count of x

16
21. confidence(U)= |xy| / |x|; // update confidence
22. Remove and save the first transaction t from TLk;
23. }; // end if iterNum
24. }; // end if confidence(U)
25. } //end of for each large 2-itemset containing y
26. Remove y from Y;
27. } // end of for each y
28. Output updated D, as the transformed D’;
Algorithm DCDS
Input: (1) a source database D,
(2) a min_support,
(3) a min_confidence,
(4) a set of recommended items Y
Output: a transformed database D’, where rules containing Y on RHS will be hidden
1. Find large 1-item sets from D;
2. For each hidden item y Y

17
3. If y is not a large 1-itemset, then Y := Y -{y} ;
4. If Y is empty, then EXIT;// no AR contains Y in RHS
5. Find large 2-itemsets from D;
6. For each y Y {
7. For each large 2-itemset containing y {
8. Compute confidence of rule U, where U is a rule like x y;
9. If confidence(U) >= min_conf, then {
//Calculate # of transactions required to lower the confidence of U
10. Calculate iterNumConf = |D|*(supp(xy) - min_conf * supp(x));
//Calculate # of transactions required to lower the support of U
11. Calcualte iterNumSupp = |D|*(supp(xy) - min_supp);
12. Calculate k = minimum (iterNumConf, iterNumSupp);
13. Calculate | TR | = |xy|; // |TR|: # of transactions in TR
14. if k > | TR |
15. Can not hide U;
16. else {
17. Find TRk = first k transactions that contain xy;
18. Sort TRk in ascending order by the number of items;

18
19. for i = 1 to iterNum do {
20. Choose the first transaction t from TRk;
21. Modify t so that y is not supported, the RHS(U);
22. |xy| = |xy| - 1; // update support count of xy
23. confidence(U)= |xy| / |x|; // update confidence
24. Remove and save the first transaction t from TRk;
25. }; // end for iterNum
26. }; // end if confidence(U)
27. }; // end of each large 2-itemset
28. Remove y from Y;
29. } // end of for each y
30. Output updated D, as the transformed D’;
4 Examples
This section shows four examples to demonstrate the two proposed algorithms in hiding
collaborative recommendation association rules.

19
For a given database in Table 2, a minimum support of 33% and a minimum confidence
of 70%, the first two examples hide the collaborative recommendation association rules
using the DCIS algorithm. The difference of the two examples is that the order of
hiding item is different. The first example hides item C and then item B. The second
example hides item B and then item C. The result is given in section 4.1. The third
and fourth examples hide the collaborative recommendation association rules using
DCDS algorithm. The difference is also the order of items to be hidden. The result is
given in section 4.2.
Table 2: Database D using the specified notation
TID Items Size
T1 111 3
T2 111 3
T3 111 3
T4 110 2
T5 100 1
T6 101 2
4.1 Examples Running DCIS Algorithm
Example 1 Assuming that the min_supp = 33% and min_conf = 70%, the result of hiding

20
item C and then item B using DCIS algorithm is as follows. To hide item C, the rule
B=>C (50%, 75%) will be hidden if transaction T5 is modified from 100 to 110 using
DCIS. The new database D1 is shown in Table 3. The rule B=>C will have support =
50% and confidence = 60%. In addition, rules AB=>C, B=>AC will be lost and a new
rule A=>B is generated as side effects. However, rules A=>B, C=>B cannot be hidden
by DCIS algorithm when we try to hide item B.
Table 3 Databases before and after hiding item C and item B using DCIS and DCDS
TID D D1 D2 D3 D4
T1 111 111 111 110 101
T2 111 111 111 111 111
T3 111 111 111 111 111
T4 110 110 110 110 110
T5 100 110 101 100 100
T6 101 101 101 101 101
Example 2 As in example 1, reversing the order of hiding items, the result of hiding item
B and then item C using DCIS algorithm is as follows. To hide item B, the rule C=>B
(50%, 75%) will be hidden if transaction T5 is modified from 100 to 101 using DCIS.

21
The new database D2 is shown in Table 3. The rule C=>B will have support = 50% and
confidence = 60%. However, rules A=>C, B=>C cannot be hidden by DCIS algorithm.
One observation we can make is that different sequences of hiding items will result in
different transformed databases, i.e., D1 and D2 for DCIS algorithm.
4.2 Examples Running DCDS Algorithm
Example 3 Assuming that the min_supp=33% and min_conf=70%, the result of hiding
item C and then item B using DCDS algorithm is as follows. To hide item C, the rule
B=>C (50%, 75%) will be hidden if transaction T1 is modified from 111 to 110. The
rule B=>C will have support = 33% and confidence = 50%. The rule C=>B (33%, 67%)
will be lost due to side effect. The new database D3 is shown in Table 3.
Example 4 As in example 3, reversing the order of hiding items, the result of hiding item
B and then item C using DCDS algorithm is as follows. To hide item B, the rule C=>B
(50%, 75%) will be hidden if transaction T1 is modified from 111 to 101 using DCDS.
The rule C=>B will have support = 33% and confidence = 50%. The rule B=>C (33%,

22
67%) will be lost due to side effect. The new database D4 is shown in Table 3.
One observation is that different sequences of hiding items will result in different
transformed databases, i.e., D3 and D4 for DCDS algorithm.
5 Numerical Experiments
In order to better understand the characteristics of the proposed algorithms numerically,
we perform a series of experiments to measure various effects. The following effects
are considered: time effects, database effects, side effects, and item ordering effects. For
time effects, we measure the running time required to hide one and two recommended
items, i.e., one and two collaborative recommendation association rule sets respectively.
The database effects measure the percentage of altered transactions in the database. For
side effects, we measure the hiding failures, new rules generated and lost rules. The
hiding failure side effect measures the number of informative association rules that
cannot be hidden. The new rule side effect measures the number of new rules appeared
in the transformed database but is not in the original database. The lost rule side effect
measures the number of rules that are in the original database but not in the transformed

23
database. The item order effects examine the previous effects when the order of
recommended item is changed.
The experiments are performed on a PC with Pentium four 3G Hz processor and 256 MB
RAM running on Windows XP operating system. The data sets used are generated from
IBM synthetic data generator. The sizes of the data sets range from 5K to 15K
transactions with average transaction length, |ATL| = 5, and total number of items, |I| =
50.
For each data set, various sets of association rules are generated under various minimum
supports and minimum confidences. The minimum support range tested is from 0.5% to
10%. The minimum confidence range tested is from 20% to 40%. Total number of
association rules is from 6 to 404. The number of hidden rules ranges from 0 to 73,
which in percentage over total association rules is from 0% to 66%. The number of
recommended items considered here are one and two items. The characteristics of data
sets are shown in the following three figures. Figure 1 shows the total number of
association rules in 5k-data set tested under various minimum supports and minimum
confidences. Figure 2 shows the hidden rule percentages for two recommended items in
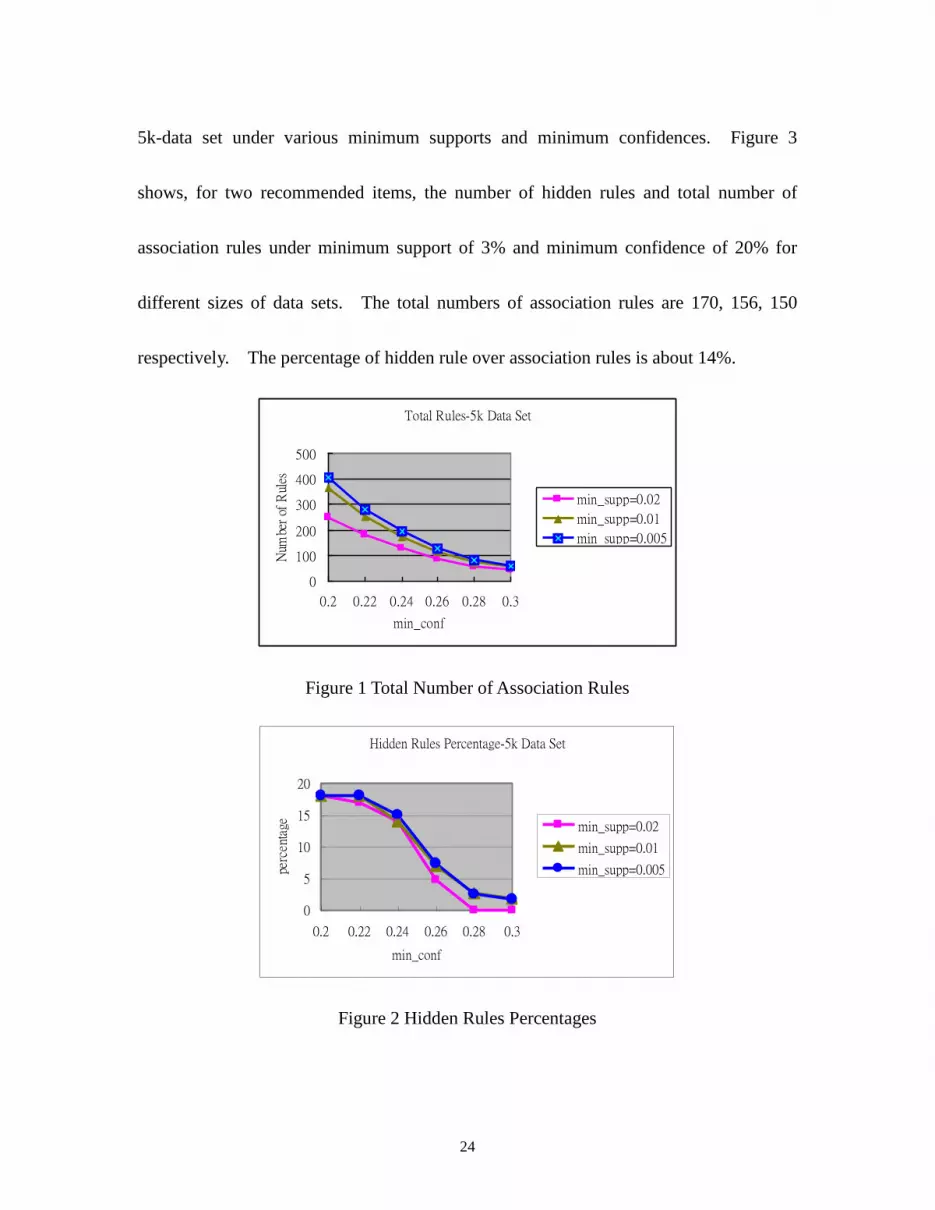
24
5k-data set under various minimum supports and minimum confidences. Figure 3
shows, for two recommended items, the number of hidden rules and total number of
association rules under minimum support of 3% and minimum confidence of 20% for
different sizes of data sets. The total numbers of association rules are 170, 156, 150
respectively. The percentage of hidden rule over association rules is about 14%.
Total Rules-5k Data Set
0
100
200
300
400
500
0.2 0.22 0.24 0.26 0.28 0.3
min_conf
Num
ber
of R
ules
min_supp=0.02
min_supp=0.01
min_supp=0.005
Figure 1 Total Number of Association Rules
Hidden Rules Percentage-5k Data Set
0
5
10
15
20
0.2 0.22 0.24 0.26 0.28 0.3
min_conf
perc
enta
ge min_supp=0.02
min_supp=0.01
min_supp=0.005
Figure 2 Hidden Rules Percentages

25
0
50
100
150
200
5k 10k 15k
Total Rules
Hidden Rules
%*100
Figure 3 Numbers of Total and Hidden Rules
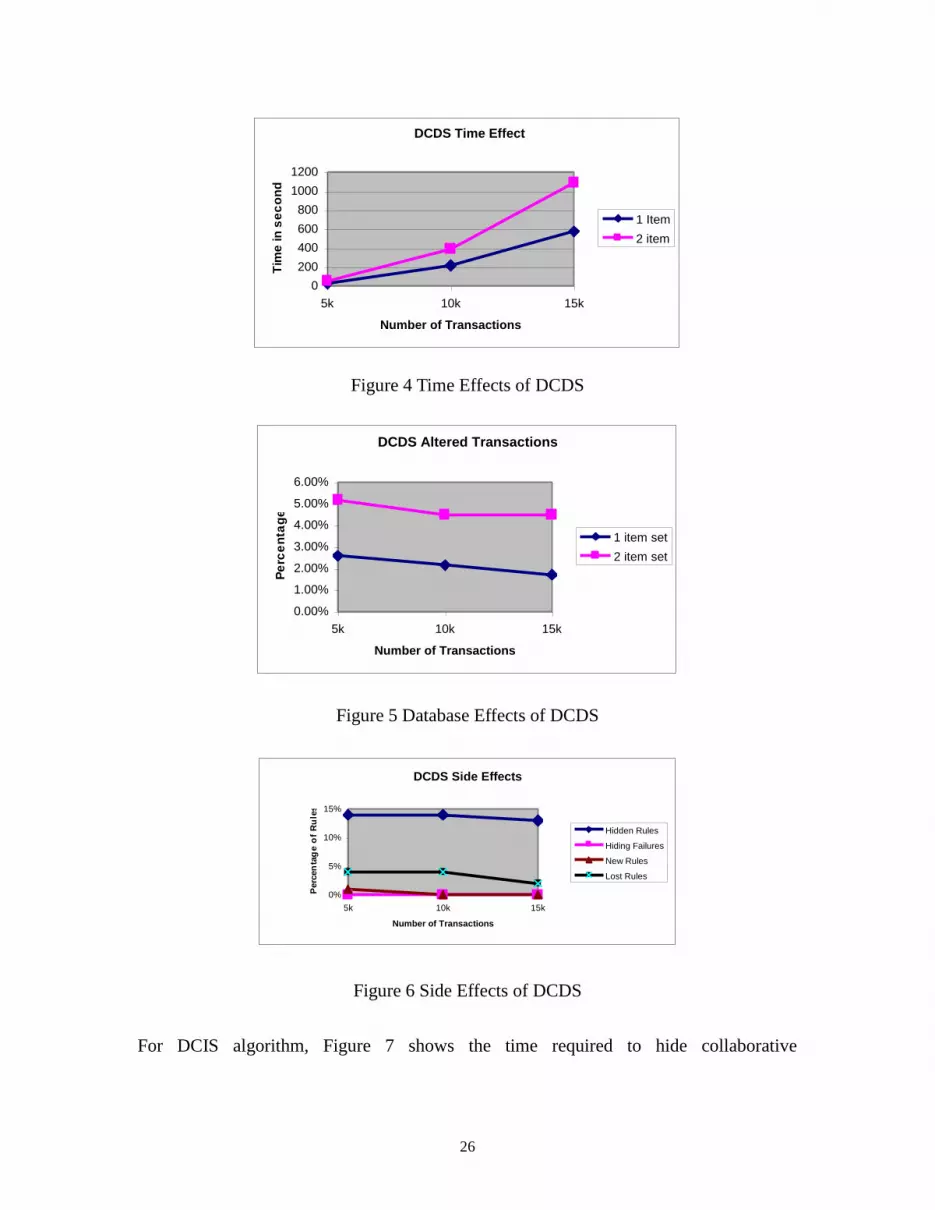
Figure 4 shows the time required for DCDS algorithm to hide collaborative
recommendation association rule sets for one and two recommended items. The
processing times increase in proportion to the sizes of the data sets and the number of
recommended items. Figure 5 shows the percentage of transactions altered using DCDS
algorithm. Even for different database sizes, the percentages of altered transactions
remain constant, about 2% and 5% for one and two items respectively. Figure 6 shows
the various side effects of DCDS algorithm hiding two recommended items. The
percentages of hidden rules for three data sets are 14%, 14% and 13%. There is no
hiding failure using DCDS algorithm, meaning every rule can be hidden. There are
about 1% of new rules generated and about 4% of association rules are lost on the
average.
26
DCDS Time Effect
0
200
400
600
800
1000
1200
5k 10k 15k
Number of Transactions
Tim
e in
se
co
nd
1 Item
2 item
Figure 4 Time Effects of DCDS
DCDS Altered Transactions
0.00%
1.00%
2.00%
3.00%
4.00%
5.00%
6.00%
5k 10k 15k
Number of Transactions
Pe
rce
nta
ge
1 item set
2 item set
Figure 5 Database Effects of DCDS
DCDS Side Effects
0%
5%
10%
15%
5k 10k 15k
Number of Transactions
Perc
en
tag
e o
f R
ule
s
Hidden Rules
Hiding Failures
New Rules
Lost Rules
Figure 6 Side Effects of DCDS
For DCIS algorithm, Figure 7 shows the time required to hide collaborative

27
recommendation association rule sets for one and two recommended items. The
processing times also increase in proportion to the sizes of the data sets and the number
of recommended items. Figure 8 shows the percentage of transactions altered using
DCIS algorithm. Even for different database sizes, the percentages of altered
transactions still remain constant, about 22% and 45% for one and two items respectively.
Figure 9 shows the various side effects of DCIS algorithm hiding two recommended
items. The percentages of hidden rules for three data sets are 14%, 14% and 13%.
There is no lost rule using DCIS algorithm, meaning no association rule is lost. There
are 0% of hiding failure and about 75% of new association rules generated on the
average.
DCIS Time Effect
0
2000
4000
6000
5k 10k 15k
Number of Transactions
Tim
e in
se
co
nd
1 item
2 item
Figure 7 Time Effects of DCIS

28
DCIS Altered Transactions
0
10
20
30
40
50
60
5k 10k 15k
Number of Transactions
Pe
rce
nta
ge
1 item
2 item
Figure 8 Database Effects of DCIS
DCIS Side Effects
0%
20%
40%
60%
80%
100%
5k 10k 15k
Number of Transactions
Pe
rce
nta
ge
of
Ru
les
Hidden Rules
Hiding Failures
New Rules
Lost Rules
Figure 9 Side Effects of DCIS
6 Analysis
This section analyzes some of the characteristics of the proposed algorithms based on our
experimental results. The first characteristic we observe is the time effects. On all the
datasets we tested, DCDS requires less running times than DCIS. This is due to the size
of candidate transactions to be modified, TLk, in DCIS is larger than TR
k in DCDS. The

29
number of transactions required to lower the confidence in DCDS is the minimum of
iterNumConf = |D|*(supp(xy) - min_conf * supp(x)); and iterNumSupp = |D|*(supp(xy)
- min_supp). The number of transactions required to lower the confidence in DCIS is
iterNum = |D|*(supp(xy)/min_conf – supp(x)). However, iterNumConf = min_conf *
iterNum. This implies that DCDS requires less number of transactions to lower the
confidence below the minimum confidence. Another running time issue is that most
computation time of both algorithms is spent on sorting TLk and TR
k. If faster sorting
technique is used, instead of simple sort in current programs, better running time could be
achieved.
The second characteristic we observe is the database effects. The percentages of
transactions altered in each algorithm remain quite stable. In DCDS, for all data sets
tested, 2% and 5% of transaction are altered for one and two predicting items respectively.
In DCIS, 22% and 45% of transactions are altered for one and two recommended items
respectively. One reason that DCIS algorithm alters much more transactions is that
some transactions are modified more that once. When more transactions are modified,
the more processing time is required. This supports the time effect characteristic that
DCIS requires more running time. However, even though the percentages of altered

30
transaction remain stable, the transformed databases are quite different. In section 4, the
four examples show that when the orders of recommended items are different, the
transformed databases are different. In addition, for same recommended item, different
algorithm returns different transformed database.
The third characteristic we observe is the side effects. The two algorithms exhibit
contrasting side effects. DCDS algorithm shows no hiding failure (0%), few new rules
(1%) and some lost rules (4%). DCIS algorithm shows no hiding failure (0%), many
new rules (75%) and no lost rule (0%). Even though the DCIS algorithm shows no
hiding failure in this particular example, it actually could have up to 14% of hiding
failures in other parameter settings. In addition, hiding failures appear in examples one
and two in section 4.1. The new rules generated in DCIS algorithm include some rules
that were previously hidden, but got generated again when trying to hide other rules.
Due to different privacy concerns and requirements, designers can fully take advantage of
these side effect characteristics. Fore example, if no hiding failure is required, the
DCDS approach should be adopted. However, if no lost rule is required, then DCIS
approach is a better choice.

31
The fourth characteristic we observe is the item effects. In DCDS, the support of
recommended item decreased and the supports of non-recommended item remained
constant. In DCIS, the support of non-recommended item increased and supports of
recommended item remained constant. This phenomenon suggests that when
recommended items have high supports, DCDS approach should be considered.
However, when the supports of non-recommended items are low, DCIS approach should
be considered.
7 Conclusions
In this work, we have studied the database privacy problems caused by data mining
technology and proposed two naïve algorithms for hiding collaborative recommendation
association rules. Current approaches for dealing with output privacy of association
rules are all based on the same fundamental techniques of reducing confidences and/or
reducing supports. In [9, 22, 25], Verykios etc’s algorithms deal with hiding
pre-selected rules one rule at a time. In [17–19], Oliveria etc’s algorithms sanitize a set
of restricted patterns and their supersets by reducing their supports, but the confidences of
rules are not considered. The proposed algorithms here can automatically hide

32
collaborative recommendation rule sets without pre-mining and selection of a class of
rules. Examples illustrating the proposed algorithms are given. Numerical
experiments are performed to show the time effects, database effects, and side effects of
the algorithms. Based on the characteristics of databases, recommended items and
non-recommended items, recommendations of appropriate usage of the proposed
algorithms are reported. In the future, we will continue to improve the efficiency of the
algorithms by reducing the number of scanning of the databases. In addition,
maintenance of privacy is another issue to be considered when databases are updated
frequently.
8 References
[1] D. Agrawal and C. C. Aggarwal, “On the design and quantification of privacy
preserving data mining algorithms”, In Proceedings of the 20th Symposium on
Principles of Database Systems, Santa Barbara, California, USA, May 2001.
[2] R. Agrawal, T. Imielinski, and A. Swami, “Mining Association Rules between Sets
of Items in Large Databases”, In Proceedings of ACM SIGMOD International
Conference on Management of Data, Washington DC, May 1993.

33
[3] R. Agrawal and R. Srikant, ”Privacy preserving data mining”, In ACM SIGMOD
Conference on Management of Data, pages 439–450, Dallas, Texas, May 2000.
[4] Ljiljana Brankovic and Vladimir Estivill-Castro, “Privacy Issues in Knowledge
Discovery and Data Mining”, Australian Institute of Computer Ethics Conference,
July, 1999, Lilydale.
[5] C. Clifton and D. Marks, “Security and Privacy Implications of Data Mining”, in
SIGMOD Workshop on Research Issues on Data Mining and knowledge Discovery,
1996.
[6] C. Clifton, “Protecting Against Data Mining Through Samples”, in Proceedings of
the Thirteenth Annual IFIP WG 11.3 Working Conference on Database Security,
1999.
[7] C. Clifton, “Using Sample Size to Limit Exposure to Data Mining”, Journal of
Computer Security, 8(4), 2000.
[8] Chris Clifton, Murant Kantarcioglu, Xiaodong Lin and Michael Y. Zhu, “ Tools for
Privacy Preserving Distributed Data Mining”, SIGKDD Explorations, 4(2), 1-7,
Dec. 2002.
[9] E. Dasseni, V. Verykios, A. Elmagarmid and E. Bertino, “Hiding Association Rules
by Using Confidence and Support” in Proceedings of 4th
Information Hiding

34
Workshop, 369-383, Pittsburgh, PA, 2001.
[10] A. Evfimievski, R. Srikant, R. Agrawal, and J. Gehrke, “Privacy preserving mining
of association rules”, In Proc. Of the 8th ACM SIGKDD Int’l Conference on
Knowledge Discovery and Data Mining, Edmonton, Canada, July 2002.
[11] Alexandre Evfimievski, “Randomization in Privacy Preserving Data Mining”,
SIGKDD Explorations, 4(2), Issue 2, 43-48, Dec. 2002.
[12] Alexandre Evfimievski, Johannes Gehrke and Ramakrishnan Srikant, “Limiting
Privacy Breaches in Privacy Preserving Data Mining”, PODS 2003, June 9-12,
2003, San Diego, CA.
[13] M. Kantarcioglu and C. Clifton, “Privacy-preserving distributed mining of
association rules on horizontally partitioned data”, In ACM SIGMOD Workshop on
Research Issues on Data Mining and Knowledge Discovery, June 2002.
[14] Weiyang Lin, Sergio Alvarez, and Carolina Ruiz, “Efficient Adaptive-Support
Association Rule Mining for Recommender Systems”, Data Mining and Knowledge
Discovery, Volume 6, 83-105, 2002.
[15] Y. Lindell and B. Pinkas, “Privacy preserving data mining”, In CRYPTO, pages
36–54, 2000.
[16] D. E. O’ Leary, “Knowledge Discovery as a Threat to Database Security”, In G.

35
Piatetsky-Shapiro and W. J. Frawley, editors, Knowledge Discovery in Databases,
507-516, AAAI Press/ MIT Press, Menlo Park, CA, 1991.
[17] S. Oliveira, O. Zaiane, “Privacy Preserving Frequent Itemset Mining”, Proceedings
of IEEE International Conference on Data Mining, November 2002, 43-54.
[18] S. Oliveira, O. Zaiane, “Algorithms for Balancing Priacy and Knowledge Discovery
in Association Rule Mining”, Proceedings of 7th
International Database Engineering
and Applications Symposium (IDEAS03), Hong Kong, July 2003.
[19] S. Oliveira, O. Zaiane, “Protecting Sensitive Knowledge by Data Sanitization”,
Proceedings of IEEE International Conference on Data Mining, November 2003.
[20] Michael O’Mahony, Neil Hurley, Nicholas Kushmerick and Guenole Silvestre,
“Collaborative Recommendation: A Robustness Analysis”, ACM Transactions on
Internet Technology, Volume 4, Issue 4, 344-377, Nov. 2004.
[21] S. J. Rizvi and J. R. Haritsa, “Privacy-preserving association rule mining”, In Proc.
of the 28th Int’l Conference on Very Large Databases, August 2002.
[22] Y. Saygin, V. Verykios, and C. Clifton, “Using Unknowns to Prevent Discovery of
Association Rules”, SIGMOND Record 30(4): 45-54, December 2001.
[23] J. Vaidya and C.W. Clifton. “Privacy preserving association rule mining in
vertically partitioned data”, In Proc. of the 8th
ACM SIGKDD Int’l Conference on

36
Knowledge Discovery and Data Mining, Edmonton, Canada, July 2002.
[24] V. Verykios, E. Bertino, I.G. Fovino, L.P. Provenza, Y. Saygin, and Y. Theodoridis,
“State-of-the-art in Privacy Preserving Data Mining”, SIGMOD Record, Vol. 33,
No. 1, 50-57, March 2004.
[25] V. Verykios, A. Elmagarmid, E. Bertino, Y. Saygin, and E. Dasseni, “Association
Rules Hiding”, IEEE Transactions on Knowledge and Data Engineering, Vol. 16,
No. 4, 434-447, April 2004.





























