Embed Size (px)
Citation preview

2.3.3 BLEU2.3.4 METEOR2.3.5 RIBES2.3.6 Meta Evaluation2.4 Statistical Testing
MT study / May 14 , 2015Seitaro Shinagawa , AHC-lab1
機械翻訳 Chapter2

2.3.3 BLEU
|}{}{|),(
||)(
rgegerm
egec
nnn
nn
Evaluate matching rate of n-gram between r(ref) and e(translated).☆N-gram position is ignored.
The number of n-gram of e The number of match betweenreference and translated text
Calculate a geometric mean from 1-gram to 4-gram.
4
1
4/1
)(
1
)()(1
)(
)9.2(),()(
)},,...,({
),(n
i
n
i
iM
ii
n
ERBPec
errm
ERBLEU
brevity penalty
|}{}{|)},,...,({1
1 M
j
jnnMn rgegerrm
If you have M references per e,choose max ),( erm jn
)),(,),,(),,(max()},,...,({ 211 ermermermerrm MnnnMn 2

11 7 4 2
9 4 1 0
4
1
4/1
)(
1
)()(1
)(
)9.2(),()(
)},,...,({
),(n
i
n
i
iM
ii
n
ERBPec
errm
ERBLEU
2.3.3 BLEU example
r1 : I’d like to stay there for five nights , from June sixth . r2 : I want to stay for five nights , from June sixth .
e : Well , I’d like to stay five nights beginning June sixth.
),( 1 er
),( 2 er
1m 2m 4m3m n : n-gram
13 12 11 10
1c 2c 4c3c
e
𝑖 = 1
accepted( )|𝑟2| < |𝑟1| < |𝑒|
𝐵𝐿𝐸𝑈 𝑟1, 𝑟2 , 𝑒 = 𝐵𝐿𝐸𝑈 𝑟1, 𝑒 =11
13⋅7
12⋅4
11⋅2
10
14
⋅ 𝐵𝑃 𝑟1, 𝑒 ≅ 0.4353 ⋅ 𝐵𝑃 𝑟1, 𝑒3

※ : Choose one whose length is close to e. (and short)
2.3.3 brevity penalty
N
i
i
N
i
i
e
r
ERBP
1
)(
1
)(
||
|~|
1exp,1min),( (2.10)
N
i
ie1
)( ||
N
i
ir1
)( |~|
N
i
ie1
)( ||
N
i
ir1
)( |~|
N
i
ie1
)( ||
N
i
ir1
)( |~|
<<
>
≅
0),( ERBP
1),( ERBP
1),( ERBP
BP penalizes translated text is too short against reference.
)(~ ir
4

2.3.4 METEOR
Lack of recall
Indirectly measure fluency and grammaticality
Using geometric averaging
There are problems to use BLEU naively. (※ref->134)
Brevity Penalty does not adequately compensate for the lack of recall. [Lavie 2004]
Explicit word-matching is required.
Geometric averaging results in score of zero whenever one of the component n-gram scores is zero.
Metric for Evaluation of Translation with Explicit Ordering assess them.
5

2.3.4 METEOR
r : I ‘d like to stay there for five nights , from June sixth .
e : Well , I ‘d like to stay five nights beginning June sixth .
To Explicit word-matching, taking alignment between r and e.
Ex)
(2.11)
F-measureThe number of words aligned.The number of words in e.
The number of words aligned.The number of words in r.
14 words
13 words
11alignments
6
(if 𝛼 = 0.5)

Harmonic mean is desirable for METEOR
(2.11)
Both high precision and high recall rate are essential.
7

2.3.4 METEOR
: fragmentation penalty
(2.11)
: The number of groups of sequential words
r : I ‘d like to stay there for five nights , from June sixth .
e : Well , I ‘d like to stay five nights beginning June sixth .
Ex)
(1) (2) (3) (4)
Summary of METEOR・High precision and high recall are desirable.・FP intends to divide a text to long sentences. ・Necessary to tune hyper parameter 𝛼, 𝛽, 𝛾8

For scoring Japanese-to-English translation,
(※ref -> 111)There are problems to use BLEU naively.
2.3.5 RIBES
Rank-based Intuitive Bilingual Evaluation Score assess this problem.9
http://www.researchgate.net/profile/Katsuhito_Sudoh/publication/221012636_Automatic_Evaluation_of_Translation_Quality_for_Distant_Language_Pairs/links/00b4952d8d9f8ab140000000.pdf

2.3.5 RIBES
r : I ‘d like to stay there for five nights , from June sixth .
e : Well , I ‘d like to stay five nights beginning June sixth .
Ex)
(1)(2) (3) (4) (5) (6) (7) (8) (9) (10)(11) (12) (13) (14)
(10)(1)(2) (3) (8) (9) (12) (13) (14)(4) (5)
Positionnumber
Aligned by r
Rank vector 𝒉 = 8 , 1 , 2 , 3 , 4 , 5 , 6 , 7 , 9 , 10 , 11
Scoring by using a rank correlation coefficient.To evaluate bilingual translations required to sort extremely.
Rank vector 𝒉
Rank correlation coefficients
Spearman’s 𝝆Kendall’s 𝝉
Considering coefficients as score.
10

Spearman’s 𝝆
Kendall’s 𝝉
If rank vector 𝒉 = 8 , 1 , 2 , 3 , 4 , 5 , 6 , 7 , 9 , 10 , 11 is given …
𝒉𝒌\𝒉𝒌′ 8 1 2 3 4
8 × × × ×
1 ○ ○ ○
2 ○ ○
3 ○
4
𝒉 ∶ length of 𝒉
⋯
⋮
If ℎ𝑘 < ℎ𝑘′ then return 1
(2.13)
(2.14)
𝒉 = ℎ1 , ℎ2 , ⋯ , ℎ|𝒉|ℎ𝑘 ∈ 𝒉 , (𝑘 = 1,2,⋯ , 𝒉 )
Calculate distance between 𝒉 and 𝒌 = (1,2,⋯ , |𝒉|)
11
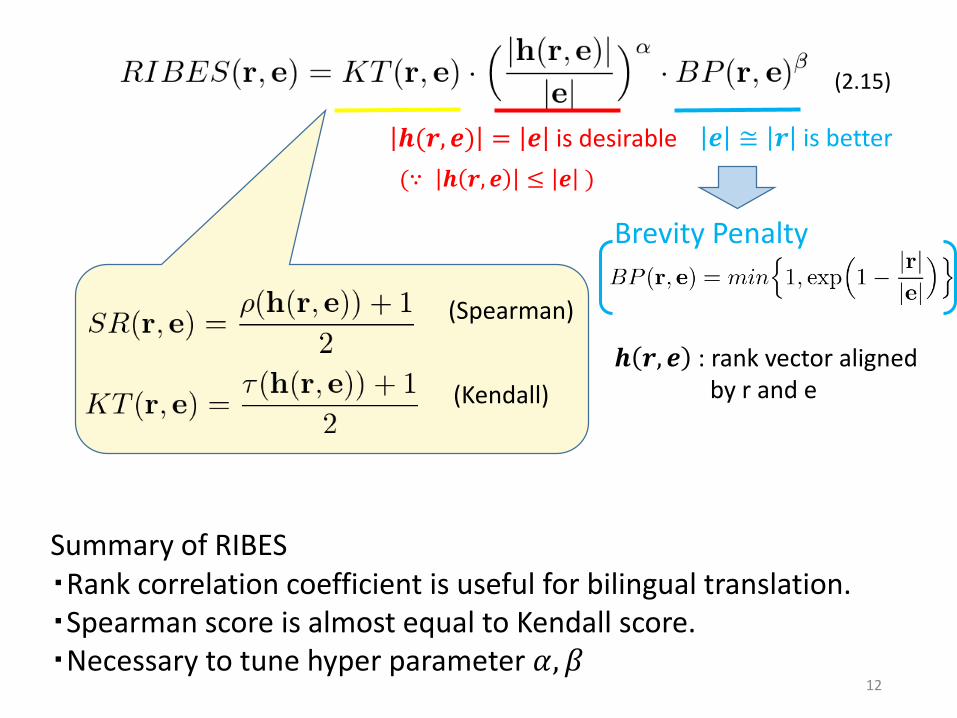
(Spearman)
(Kendall)
𝒉 𝒓, 𝒆 : rank vector aligned by r and e
Brevity Penalty
𝒆 ≅ 𝒓 is better𝒉(𝒓, 𝒆) = 𝒆 is desirable
(∵ 𝒉 𝒓, 𝒆 ≤ 𝒆 )
Summary of RIBES・Rank correlation coefficient is useful for bilingual translation.・Spearman score is almost equal to Kendall score. ・Necessary to tune hyper parameter 𝛼, 𝛽
(2.15)
12

2.3.6 Meta Evaluation of Automatic Evaluation
Good Automatic Evaluation correlates with Human Evaluation.
Human Evaluation 𝑥1 𝑥2 𝑥3 𝑥4 ⋯ 𝑥𝑆−1 𝑥𝑆
Automatic Evaluation 𝑦1 𝑦2 𝑦3 𝑦4 ⋯ 𝑦𝑆−1 𝑦𝑆
Assuming that score sample xs, ys 𝑠 = (1,2,⋯𝑆) are given,
Calculate Pearson product-moment correlation coefficient
(2.19)
13

2.4 Statistical Testing
How can we judge which evaluation is the best ?
Score may be different by another system or evaluators.
Our test resources (data, human) are limited.
Statistical Testing Problem
Calculating confidence interval“You can get score which is out of confidence interval with probability p.”
14
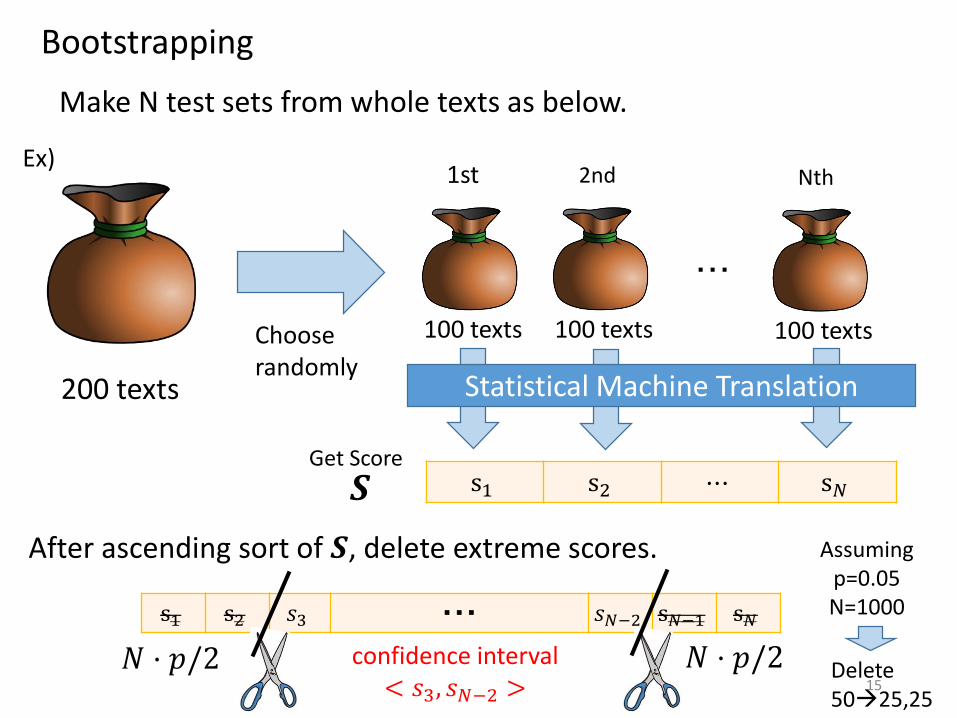
Bootstrapping
200 texts
Make N test sets from whole texts as below.
Choose randomly
100 texts 100 texts 100 texts
・・・
Ex)1st 2nd Nth
Statistical Machine Translation
s1 s2 ⋯ s𝑁Get Score
After ascending sort of 𝑺, delete extreme scores.
𝑺
s1 s2 𝑠3 ・・・ 𝑠𝑁−2 s𝑁−1 s𝑁
𝑁 ⋅ 𝑝/2 𝑁 ⋅ 𝑝/2confidence interval< 𝑠3, 𝑠𝑁−2 >
Assuming p=0.05N=1000
Delete5025,25
15

Comparing SMT system using bootstrapping
200 texts
Choose randomly
100 texts 100 texts 100 texts
・・・
Ex)1st 2nd Nth
Statistical Machine Translation
s1(a)
s2(a) ⋯ s𝑁
(𝑎)
s1(b)
s2(b) ⋯ s𝑁
(b)
Get Score
𝑺
s𝑡𝑒𝑠𝑡𝑠𝑒𝑡(System)
Win rate of system a
If 𝑁𝑎 is over 95% , System a is better than b with p=0.05
16

References
[Lavie 2004] Lavie, Alon, Kenji Sagae, and Shyamsundar Jayaraman. "The significance of recall in automatic metrics for MT evaluation." Machine Translation: From Real Users to Research. Springer Berlin Heidelberg, 2004. 134-143.
111) Isozaki, Hideki, et al. "Automatic evaluation of translation quality for distant language pairs." Proceedings of the 2010 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, 2010.
134) Lavie, Alon, and Michael J. Denkowski. "The METEOR metric for automatic evaluation of machine translation." Machine translation 23.2-3 (2009): 105-115.
17