Embed Size (px)
Citation preview

1
Creando el próximo Data Warehouse:
Integración y Calidad de Datos
Sesión 1: Fundamentos del DWHAlberto Collado

2
Agenda
Sesión 1: Fundamentos del DWH
Sesión 2: Fundamentos de la Calidad de Datos
Sesión 3: Caso práctico: Un DWH con Calidad

3
Agenda Sesión 1
Presentación PowerData
Presentación asistentes: Conocimientos y Expectativas
Fundamentos DWH Introducción al DWH Arquitectura de un DWH Modelado de Datos y Metadatos Esquemas en Estrella Procesos y Estrategias de carga del DWH Herramientas de Integración de Datos Herramientas de Reporting y Análisis

44
Presentación PowerData

5
Presentación PowerData
Empresa lider especializada en Data Management
Colaboradores de Informatica Corporation en España (Elite Partner), Chile, Argentina, Perú y Uruguay (Distributor) www.powerdata.es www.informatica.com
Informatica Nacida en 1993, en California +1.400 colaboradores
Powerdata Nacida en 1999, en Barcelona 90 empleados

6
Servicios de datos
Proyectos de
integración de datos
Iniciativas de TI
Necesidades
empresariales
La solución: los servicios de datos
Almacenamiento de datos
Consolidación de datos
Migración de datos
Sincronización de datos
Gestión de datos maestros
Eliminación de sistemas heredados
BPOSaaS
Hubs de productos, proveedores
y clientes
Consolidación de
aplicaciones
Inteligencia empresarial
Subcontratar
funciones secundaria
s
Aumentar la rentabilidad del negocio
Fusiones y adquisicione
s
Modernizar el negocio y reducir los
costes de TI
Mejorar decisiones y cumplir con la normativa
InformaticaPowerExchange
InformaticaData Explorer
InformaticaPowerCenter
InformaticaData Quality
Plataforma de productos de Informatica
Servicios de datos

7
Data Explorer Data Quality
Auditoría, control y creación de informesGarantizar la coherencia de los datos, realizar análisis de impacto y
supervisar constantemente la calidad de la información
PowerCenter PowerExchan
ge
AccesoA cualquier sistema, por lotes o en tiempo real
EntregaIntegraciónEntregar los datos adecuados en el momento y formato adecuados
Transformar y conciliar datos de todo tipo
LimpiezaDetecciónValidar, corregir y estandarizar datos de todo tipo
Buscar y perfilar cualquier tipo de datos de cualquier fuente
La plataforma de productos de InformaticaAutomatización de todo el ciclo de vida de la integración de datos
Desarrollo y gestiónDesarrollar y colaborar con un repositorio común y metadatos
compartidos

88
Presentación Asistentes:
Conocimientos y Expectativas

9
Fundamentos del DWH

10
Fundamentos del DWH
Introducción al DWH: ¿Qué es?
Arquitectura de un DWH
Modelado de Datos y Metadatos
Esquemas en Estrella
Procesos y Estrategias de carga del DWH
Herramientas de Integración de Datos
Herramientas de Reporting y Análisis

11
Fundamentos del DWH
Introducción al DWH: ¿Qué es?

12
¿Qué es un Data Warehouse?
Orientado a un Tema Colección de información relacionada organizada
alrededor de un tema central
Integrado Datos de múltiples orígenes; consistencia de datos
Variable en el tiempo ‘Fotos’ en el tiempo Basado en fechas/periodos
No-volátil Sólo lectura para usuarios finales
Menos frecuencia de cambios/actualizaciones Usado para el Soporte a Decisiones y Análisis de
Negocio
13
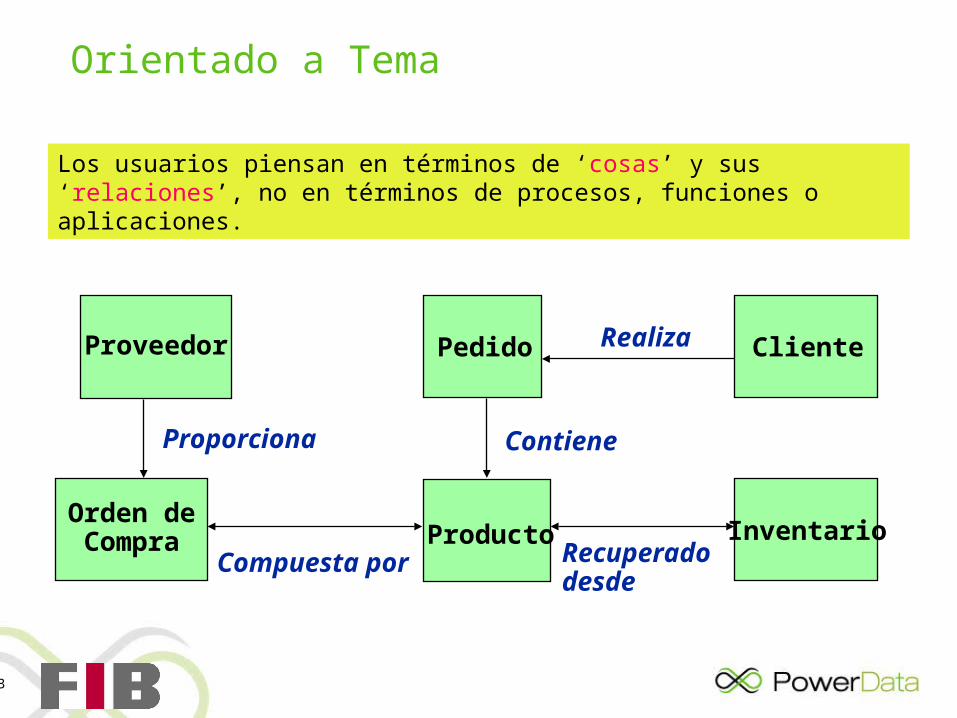
Orientado a Tema
Los usuarios piensan en términos de ‘cosas’ y sus ‘relaciones’, no en términos de procesos, funciones o aplicaciones.
Proveedor
Orden deCompra
Pedido Cliente
Producto Inventario
Proporciona
Compuesta por Recuperado desde
Contiene
Realiza
14
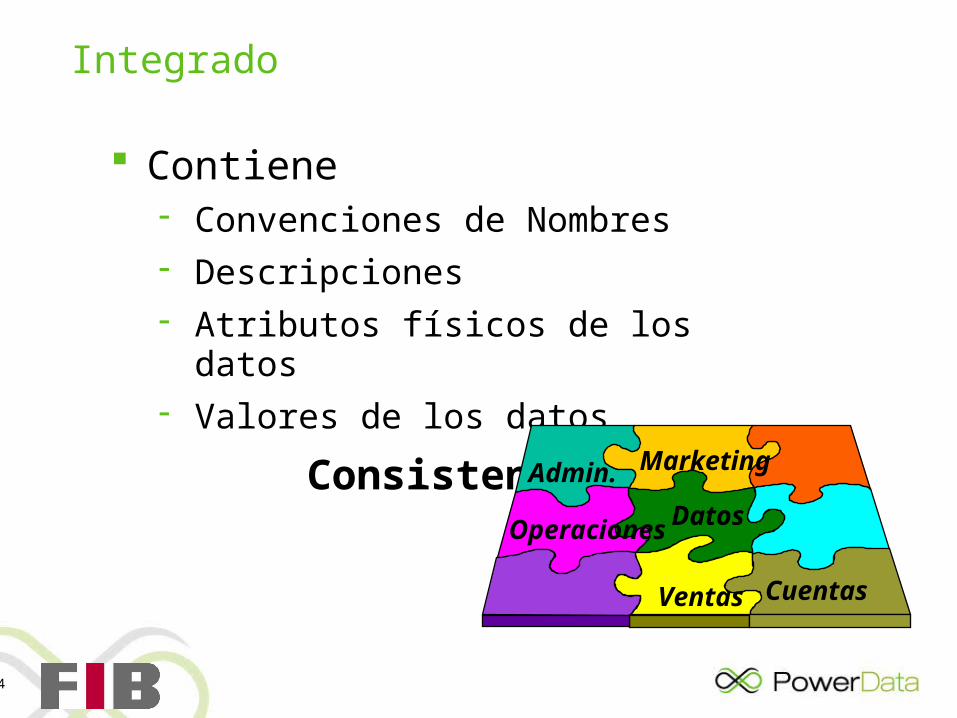
Integrado
Contiene Convenciones de Nombres Descripciones Atributos físicos de los datos Valores de los datos
Consistentes
Datos
Ventas
MarketingAdmin.
Cuentas
Operaciones

15
Id de clientefecha desdefecha hastanombredirección teléfonoratio de crédito
Data Warehouse Datos en ‘fotos’ Horizonte de 5 – 10 años Refleja la perspectiva desde un
momento en el tiempo
Variable en el tiempo
Id de clientenombredirecciónteléfonoratio de crédito
Entorno Operacional Datos con valores actuales Horizonte de 30 - 90 días Exactitud en los accesos

16
No-Volátil
cambioinserción
borrado
cargalectura
Sistema OLTP (dinámico)
Sistema DSS
(más estático)

17
Un Data Warehouse es ...
… un modelo de datos de soporte a decisiones que representa la información que una compañía necesita para tomar BUENAS decisiones estratégicas.
… basado en la estructura de un sistema de gestión de base de datos relacional el cual puede ser usado para INTER-RELACIONAR los datos contenidos en él.
… con el propósito de proporcionar a los usuarios finales un acceso SENCILLO a la información.
… un CONCEPTO, no una COSA

18
¿Para qué construir un Warehouse?
Para tener un mayor conocimiento del negocio
Para tomar mejores decisiones y en un tiempo menor
Para mejorar y ser más efectivos
Para no perder distancia con la competencia
… en definitiva … €€€

19
Visión del Usuario
Usuarios Finales
Base de Datos
Representación de Negocio
Solución integrada de: Consultas, informes y análisis.
Capa semántica que da una representación de los datos desde el punto de vista de negocio.
Los usuarios utilizan términos de negocio, no términos informáticos.
Panel de Consulta

20
Fundamentos del DWH
Arquitectura de un DWH

21
Arquitectura de un DWH
Nomenclatura DWH: Data Warehouse DataMart OLTP: On-Line Transaction Processing OLAP: On-Line Analytic Processing ROLAP: Relational On-Line Analytic Processing MOLAP: Multidimensional On-Line Analytic Processing ODS: Object Data Store DSS: Decision Support System ETL: Extract, Transform and Load ETQL: Extract, Transform, Quality and Load EII: Enterprise Information Integration EAI: Enterprise Application Integration ERP: Enterprise Resource Planning

22
Directo de OLTP a OLAP
LifeInformation System
HealthInformation System
AutoInformation System
Life
Health
Auto
LifeOLAP
HealthQuery
AutoAnalysis

23
Directo de OLTP a OLAP
Es bueno, si los datos lo son.
Horizonte de tiempo limitado
Compite con OLTP por los recursos
Uso frecuente para hojas de cálculo
No tiene metadatos (o sólo implícitos)
Principalmente, para jefes de departamentos, no se considera información “para las masas”
No hay información cruzada entre los diferentes sistemas

24
Data Warehouse Virtual: Directo o Federado
LifeInformation System
HealthInformation System
AutoInformation System
Life
Health
Auto
"Customer"OLAP
EII

25
Data Warehouse “Total”
Extract: CO BO L, SQ L, Etc.Life
Information System
HealthInformation System
AutoInformation System
Life
Health
Auto
LifeOLAP
MDD Tools
HealthR/OLAP
Star Schema
AutoSQL Query
Extract: CO BO L, SQ L, Etc.
Extract: CO BO L, SQ L, Etc.
EnterpriseData
W arehouse

26
Data Marts No Estructurados
Extract: CO BO L, SQ L, Etc.Life
Information System
HealthInformation System
AutoInformation System
Life
Health
Auto
L ifeDataM art
HealthDataM art
AutoDataM art
LifeOLAP
MDD Tools
HealthR/OLAP
Star Schema
AutoSQL Query
Extract: CO BO L, SQ L, Etc.
Extract: CO BO L, SQ L, Etc.

27
Data Marts Estructurados
LifeO LT P
HealthO LT P
AutoO LT P
LifeOLAP
MDD Tools
HealthR/OLAP
Star Schema
AutoSQL Query
EnterpriseData
W arehouse
"Custom er"
EXT RACTSELECT
T RANSFO RMINT EG RAT E
LO AD
Cleanse Datafor:
Nam esForm atsValues
Dom ainsM etadata
L ifeDataM art
HealthDataM art
AutoDataM art

28
OLAP (Online Analytic Processing)
Herramientas orientadas a consulta/análisis
Puede ser ROLAP o MOLAP
'Multi-dimensional', es decir, puede ser visualizada como ’cuadrículas' o 'cubos'
Consulta interactiva de datos, siguiendo un “hilo” a través de múltiples pasos -- 'drill-down'
Visualización como tablas cruzadas, y tablas pivotantes
Actualización de la base de datos
Capacidad de modelización (motor de cálculo)
Pronósticos, tendencias y análisis estadístico.

29
Ejemplo uso de una herramienta de consulta
El interfaz de usuario simple Trabaja contra representación de negocio de los
datos Todos los componentes en una pantalla
Información solicitada
Condiciones
Información disponible

30
Los informes son la capa visible …
• Integración Datos no sólo en entornos analíticos
• Importancia de la Calidad
Extracción
Limpieza de Datos
Servidores
Red
Herramientas de OLAP / Business Intelligence / Cuadro de Mando
Transformación
Carga de Datos
Bases de Datos
Middleware

31
Data Marts Estructurados: Visión Completa
Aplicaciones: ERP,...
BBDD
Tiempo Real, WS, Http
Legacy
Ficheros: FF, XML
Integración + Calidad de
Datos
DWH
DM Compras
DM Financiero
DM Ventas
Diseño MapeosPerfilado de
Datos
ETL, Estandarización, Desduplicación
Almacenamiento:Agregación,
Indexación,...
ReplicaciónDistribución
AnálisisReporting
Cuadros Mando
Metadatos: Análisis Impacto, Linaje de datos, Auditoría, Monitorización, etc

32
Fundamentos del DWH
Modelado de Datos y Metadatos

33
Técnicas de Modelización Estructural
En esta sección veremos técnicas que afectarán a diversos puntos
Consideraciones de Tiempo Técnicas de Optimización

34
Consideraciones de Tiempo
Todo el DW se ve afectado por cambios temporales porque por definición es “Tiempo-dependiente”
Preguntas importantes: ¿Cuan actual deben ser los datos para satisfacer las
necesidades de negocio? ¿Cuánta historia necesitamos en nuestro negocio? ¿Qué niveles de agregación son necesarios para qué
ciclos de negocio?
Data Marts Staging Area
Data Warehouse Relacional Dimensional
Actualidad de Datos
Agrupaciones basadas en tiempo
ES
TR
UC
TU
RA
L
Tie
mp
o
Retención de Histórico
¿Cuál es el impacto del Tiempo en cada Almacén de Datos?

35
Técnicas de Modelización Temporal
Unidades de tiempo Calendarios de negocio
Técnicas Foto (Snapshot) Trazado de Auditoría
Metadatos temporales Fechas Efectivas de Inicio y Fin Fecha de cambio en Fuentes (evento) Fecha de cambio en Destinos (carga)

36
Foto (Snapshot)
Dos técnicas diferentes Múltiples Tablas Tabla Única
Uso de Fecha Efectiva Inicio en un ejemplo. Metadatos a nivel de registro
F oto (SNAPSHOT)
Nov 2001 CLIENTE
Num C lien teNombre
Ape llido1Ape llido2G én e ro
F echa C arga
Oct 2001 CLIENTE
Num C lien teNombre
Ape llido1Ape llido2G én e ro
F echa C arga
CLIENTE
Num C lien teF echa Efe ctiva In ic io
NombreApe llido1Ape llido2G én e ro
F echa C arga
O b ie n

37
Foto (Snapshot) Múltiple Una tabla para cada período
Se guardan TODOS los datos (cambien o no)
Nombre de la tabla refleja el período
Buen enfoque de (extracción/carga/modelado) para Data Marts. Cada mes, en el ejemplo, representa los datos tal y como estaban
Mal enfoque para Staging, ya que hay mucha replicación de datos F oto (SNAPSHO T)
Nov 2001 CLIENTE
N u m C lie n teN o m b re
Ap e llid o 1Ap e llid o 2Gé n e ro
Fe ch a C a rg a
Oct 2001 CLIENTE
N u m C lie n teN o m b re
Ap e llid o 1Ap e llid o 2Gé n e ro
Fe ch a C a rg a
CLIENTE
Num C lien teF echa Efe ctiva In ic io
NombreApe llido1Ape llido2G én e ro
F echa C arga
O b ie n

38
Foto (Snapshot) Única Se guardan TODOS los datos (cambien o no)
Buen enfoque para Data Marts y puede ser útil en el Warehouse.
Mal enfoque para Staging, ya que hay mucha replicación de datos
Time Stamps imprescindibles
F oto (SNAPSHO T)
Nov 2001 CLIENTE
Num C lien teNombre
Ape llido1Ape llido2G én e ro
F echa C arga
O ct 2001 CLIENTE
Num C lien teNombre
Ape llido1Ape llido2G én e ro
F echa C arga
CLIENTE
Num C lien teF e ch a Efe ctiv a In icio
NombreApe llido1Ape llido2G én e ro
F echa C arga
O b ie n
F e ch a Efe ctiv ad e Ne g ocio

39
Foto (Snapshot) Única
Fechas (Time Stamps) necesarias para identificar la validez de los datos: Fecha efectiva de Inicio Fecha efectiva de Fin (no está en el ejemplo) Fecha de Carga
Num Cliente Fecha Efectiva Inicio Nombre Género Fecha Carga 2304 31/10/2001 Juan Reyes Hombre 01/11/2001 5590 31/10/2001 Julia Astur Mujer 01/11/2001 6720 31/10/2001 Carlos Márquez Hombre 01/11/2001 7841 31/10/2001 Luis Tesquilo 01/11/2001 2304 30/11/2001 Juan Reyes Hombre 01/12/2001 5590 30/11/2001 Julia Picado Mujer 01/12/2001 6720 30/11/2001 Carlos Márquez Hombre 01/12/2001 7841 30/11/2001 Luis Tesquilo 01/12/2001 Vemos la duplicidad de los datos

40
Trazado de Auditoría
Guarda los cambios de los datos de interés
Información: Fecha del cambio Razón del cambio Cómo se ha detectado ...
Sólo se extraen/cargan valores modificados
CLIENTE
ID _ clie n ten o mb re
a p e llid o 1a p e llid o 2g é n e ro
fe ch a _ a n ive rsa r io
AUDITO RIA CLIENTE
ID _ clie n tefe ch a_in icio _e fe ctiv a
n o mb rea p e llid o 1a p e llid o 2g é n e ro
fe ch a_an iv e rsar iofe ch a _ ca rg a
F e ch a d e Ne g o cio(n o Me ta d a to )
Me ta d a to a n ive lre g is tro

41
Trazado de Auditoría
Sólo cambios en la tabla
Usado en Staging Area y Data Warehouse
Posible en Data Marts, pero no es habitual ya que no es claro para un usuario final
Num Cliente
Fecha Efectiva Inicio
Nombre Género Fecha aniversario
Fecha Carga
2304 31/10/2001 Juan Reyes Hombre 01/01/1964 01/11/2001 5590 31/10/2001 Julia Astur Mujer 06/03/1948 01/11/2001 6720 31/10/2001 Carlos
Márquez Hombre 19/09/1960 01/11/2001
7841 31/10/2001 Luis Tesquilo 25/07/1952 01/11/2001 5590 30/11/2001 Julia Picado Mujer 06/03/1948 01/12/2001

42
Técnicas de Optimización Estructural y Física
Data Marts Staging Area
Data Warehouse Relacional Dimensional
Actualidad de Datos Agrupaciones basadas en tiempo
Tie
mpo
Retención de Histórico Seguridad
EST
RU
CT
UR
AL
Posi
ción
Distribución
Acceso Navegación
Uso
Herramientas Rendimiento
Tamaño
Disponibilidad
Recuperación
FÍS
ICO
Impl
emen
taci
ón
DBMS
¿Cómo debe optimizarse cada almacén de datos en la
Implementación?
43
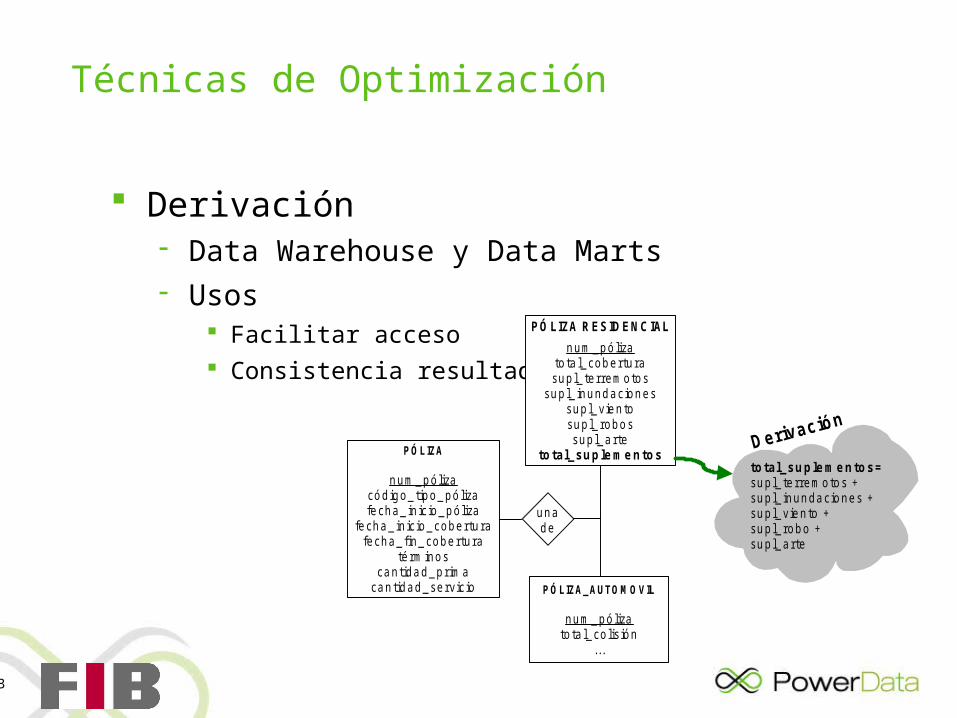
Técnicas de Optimización
Derivación Data Warehouse y Data Marts Usos
Facilitar acceso Consistencia resultados
PÓLIZA_AUTOMOVIL
n um_ p ó lizato ta l_ co lis ión
...
PÓLIZA
n um_ p ó lizacód ig o _ tipo _ p ó lizafe cha _ in ic io _ p ó liza
fe cha _ in ic io _ cob e rtu rafe cha _ fin _ cob e rtu ra
té rmino scan tida d _ p r ima
can tida d _ se rv ic io
PÓLIZA RESIDENCIAL
n um_ p ó lizato ta l_ cob e rtu rasup l_ te rre mo tos
sup l_ in u nd acion essup l_ v ie n tosup l_ ro bo ssup l_ a rte
to tal_sup le me n tos
u nad e
to tal_sup le me n tos=sup l_ te rre mo tos +sup l_ in u nd acion es +sup l_ v ie n to +sup l_ ro bo +sup l_ a rte
Derivación

44
Técnicas de Optimización Agregación
No cambio de granularidad
Objetivo: Facilitar el acceso a los datos
PÓLIZA_AUTOM OVIL
nu m_ pó lizato ta l_ co lis ió n
de scuen to _ clien teind ic_ p rec io _e spe cia l
fech a _ ca rg a
PÓLIZA
nu m_ pó lizacó d igo _ tip o _ pó lizafech a _ in ic io _ pó liza
fech a _ in ic io _ co be rtu rafech a _ fin_ co be rtu ra
té rmin osca n tidad _p rima
ca n tidad _ se rv ic iofech a _ ca rg a
PÓLIZA RESIDENCIAL
nu m_ pó lizato ta l_ co be rtu rasu p l_ te rre mo tos
su p l_ inun dacione ssu p l_ vie n tosu p l_ robo ssu p l_ a rte
to ta l_ su p leme n tosfech a _ ca rg a
un ade
PÓLIZA_AUTOM OVIL
nu m_ pó lizato ta l_ co lis ió n
de scuen to _ clien teind ic_ p rec io _e spe cia lcó d igo _tip o _pó lizafe cha_in icio _pó liza
fe cha_in icio _co be rtu rafe cha_fin_co be rtu ra
término scan tidad _p rima
cantidad _se rv iciofech a _ ca rg a
PÓLIZA RESIDENCIAL
nu m_ pó lizacó d igo _tip o _pó lizafe cha_in icio _pó liza
fe cha_in icio _co be rtu rafe cha_fin_co be rtu ra
término scan tidad _p rima
cantidad _se rv icioto ta l_ co be rtu rasu p l_ te rre mo tos
su p l_ inun dacione ssu p l_ vie n tosu p l_ robo ssu p l_ a rte
to ta l_ su p leme n tosfech a _ ca rg a
AGREGACIÓN
AGREGACIÓN
Data Warehouse
Data Marts

45
Técnicas de Optimización
Sumarización Histórica Agrupada
RESUM EN ANUALCLIENTES
id_ c lie n tea ño _ re su me n
va lo r_ in ic io _ a ñova lo r_ fina l_ a ño
to ta l_ cu en ta _ in ic io _ a ñoto ta l_ cu en ta _ fina l_ a ño
to ta l_ a ño s_ co mo _clie n te
CLIENTE
id_ c lie n tefe ch a _ a lta _ clie n tefe ch a _b a ja _ clie n te
n ombrea pe llido 1a pe llido 2
g ru po _ e da dg én e ro
e sta do _ civ ilind ic_ clie n te _ p e rd id o
fe ch a _ ca rg a
AÑO
n u m_ a ñ o
TRIM ESTRE
n u m_ tr ime stre
M ES
n u m_ me s
BASE CLIENTELA
id _ zo n aid _ p ro d u ctocó d ig o _ tip on u m_me s
cu e n ta _ clie n te
BASE CLIENTELAANUAL
id _ zo n aid _ p ro d u ctocó d ig o _ tip on u m_añ o
cu e n ta _ clie n te

46
Técnicas de Optimización
Particionamiento Horizontal Particiones por filas Todos los campos
repetidos en las nuevas tablas
Uso Aislar datos sensibles Reducción tamaño tablas
RESUM EN ANUALCLIENTES - SUR
id _ c lie n tea ñ o _ re su me n
va lo r_ in ic io _ a ñ ova lo r_ fin a l_ a ñ o
to ta l_ cu e n ta _ in ic io _ a ñ oto ta l_ cu e n ta _ fin a l_ a ñ o
to ta l_ a ñ o s_ co mo _ clie n te
RESUM EN ANUALCLIENTES - NO RTE
id _ c lie n tea ñ o _ re su me n
va lo r_ in ic io _ a ñ ova lo r_ fin a l_ a ñ o
to ta l_ cu e n ta _ in ic io _ a ñ oto ta l_ cu e n ta _ fin a l_ a ñ o
to ta l_ a ñ o s_ co mo _ clie n te
RESUM EN ANUALCLIENTES
id _ c lie n tea ñ o _ re su me n
có d ig o _re g ió nva lo r_ in ic io _ a ñ ova lo r_ fin a l_ a ñ o
to ta l_ cu e n ta _ in ic io _ a ñ oto ta l_ cu e n ta _ fin a l_ a ñ o
to ta l_ a ñ o s_ co mo _ clie n te

47
Técnicas de Optimización
Particionamiento Vertical División por columnas Posibilidad de columnas
redundantes Uso
Seguridad Distribución
Puede ser que tengamos Horizontal y Vertical a la vez
CLIENTE
id_ c lie n tefe ch a _ a lta _ clie n tefe ch a _ b a ja _ clie n te
n ombrea pe llid o1a pe llid o2
g ru p o _ e da dg én e ro
e sta do _ civ ilind ic_clie n te _ p e rd id o
fe ch a _ ca rga
CLIENTE_SEG URO
id_ c lie n tefe ch a _ a lta _ clie n tefe ch a _ b a ja _ clie n te
n ombrea pe llid o1a pe llid o2
n um_cu en ta _ d eb iton ombre _ b an co _ d eb ito
n um_ a u to r iza c ión _ d éb itoran g o _ cré d ito
fe ch a _ u ltimo _ che ck_ cre d ito
CLIENTE
id_ c lie n tefe ch a _a lta _clie n tefe ch a _b a ja _clie n te
n ombrea pe llid o1a pe llid o2
g ru p o _ e da dg én e ro
e sta do _ civ ilind ic_ clie n te _ p e rd id on um_ cu en ta _d eb ito
n ombre _b an co _ d eb iton um_ a u to r iza c ión _ d éb ito
ran g o _ cré d itofe ch a _ u ltimo _ che ck_ cre d ito
fe ch a _ ca rga
Camp o s co nDato s Se n sib le s
Camp o s co nDato s n o Se n sib le s
48
PÓ LIZA RESIDENCIAL
n u m_ p ó lizafe ch a _ in ic io _ p ó liza
fe ch a _ in ic io _ co be rtu rafe ch a _ fin_ co be rtu ra
té rmin o sca n tid a d _ p r ima
ca n tid a d _ se rv ic ioto ta l_ co be rtu rasu p l_ te rre mo tos
su p l_ v ie n tosu p l_ in un d a ción
su p l_ p ie le ssu p l_ a rte
su p l_ jo ya ssu p l_ o tro s
fe ch a _ ca rg a
PÓ LIZA RESIDENCIAL
n u m_ p ó lizafe ch a _ in ic io _ p ó liza
fe ch a _ in ic io _ co be rtu rafe ch a _ fin_ co be rtu ra
té rmin o sca n tid a d _ p r ima
ca n tid a d _ se rv ic ioto ta l_ co be rtu rasu p l_ te rre mo tos
su p l_ v ie n tosu p l_ in un d a ción
fe ch a _ ca rg a
PÓ LIZA RESIDENCIAL
n u m_ p ó lizafe ch a _ in ic io _ p ó liza
su p l_ p ie le ssu p l_ a rte
su p l_ jo ya ssu p l_ o tro s
fe ch a _ ca rg a
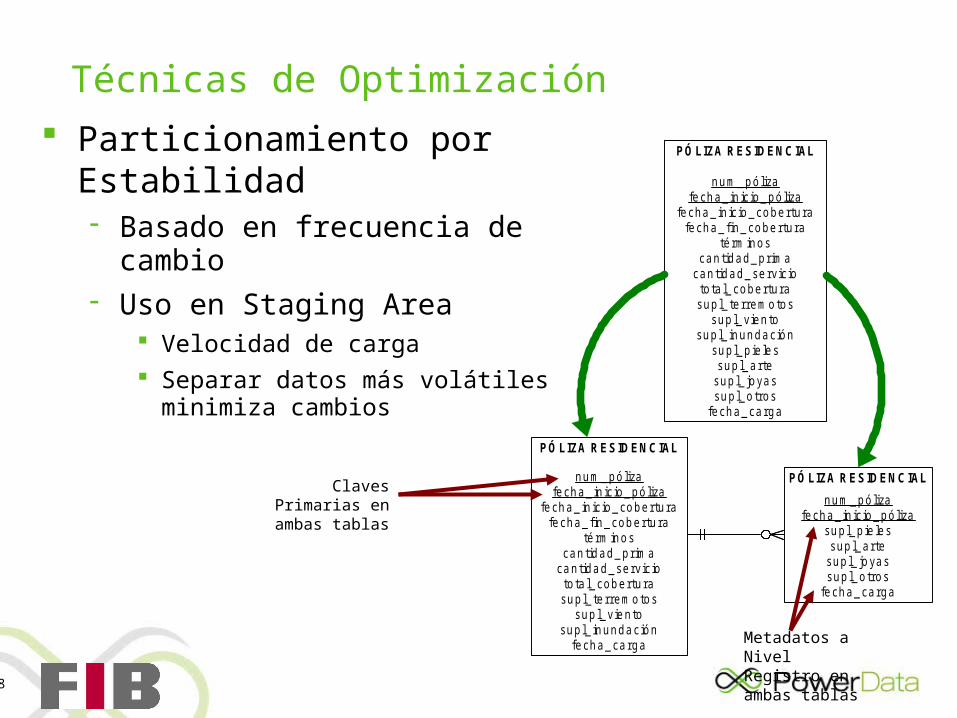
Técnicas de Optimización Particionamiento por
Estabilidad Basado en frecuencia de cambio Uso en Staging Area
Velocidad de carga Separar datos más volátiles minimiza
cambios
Claves Primarias en ambas tablas
Metadatos a Nivel Registro en ambas tablas
49
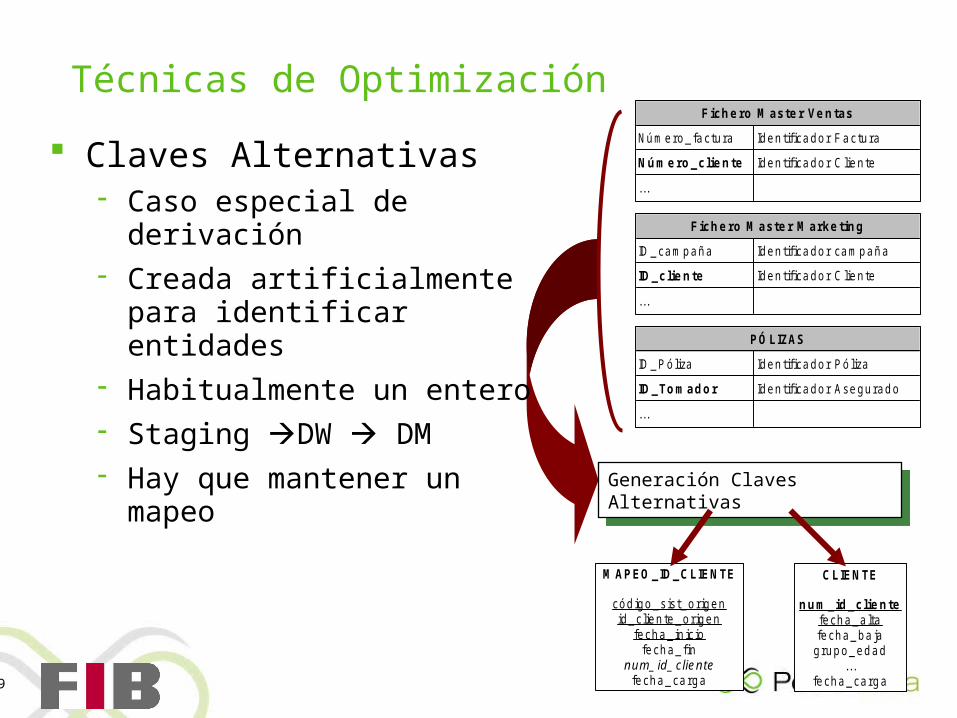
Técnicas de Optimización
Claves Alternativas Caso especial de derivación Creada artificialmente para
identificar entidades Habitualmente un entero Staging DW DM Hay que mantener un
mapeo
F ich e ro M aste r Ve n tas
Número _ factu ra Iden tificado r F actu ra
Nú me ro _clie n te Iden tificado r C lien te
...
F ich e ro M aste r M arke tin g
ID _ campaña Iden tificado r campaña
ID_clie n te Iden tificado r C lien te
...
PÓLIZAS
ID _ Pó liza Iden tificado r Pó liza
ID_To mad o r Iden tificado r Asegu rado
...
CLIENTE
n um_id_clie n tefe ch a _ a ltafe ch a _ b a ja
g rup o _ e da d...
fe ch a _ ca rg a
M APEO _ID_CLIENTE
có d igo _ sis t_ o r ig enid _ clien te _ o r ig en
fe ch a _ in ic iofe ch a _ fin
n um_ id_ clien tefe ch a _ ca rg a
Generación Claves AlternativasGeneración Claves Alternativas

50
Técnicas de Optimización
Pre-Joins Caso especial de Agregación Data Warehouse y Data Marts Existe redundancia de
Información Incrementeo uso espacio
Acceso mucho más rápido En el DW
Mantendremos también las tablas separadas para cuando no necesitemos la Join
PÓLIZA_AUTOMOVIL
n um_ p ó lizafe ch a _ in ic io _ p ó liza
fe ch a _ in ic io _ co be rtu rafe ch a _ fin_ co be rtu ra
té rmin osto ta l_co lis ió nd escu e n to _ clien te
ind ic_p recio _ esp e cia lcó d ig o _ tip o _p ó liza
...fe ch a _ca rga
VEHÍCULO
n um_ b astid o rfe ch a _ in ic io _ve h ícu lo
n um_ p ó lizama rca
mo d e lo...
ind _ ABSind _ a irba g
ind _ ESPfe ch a _ ca rga
PÓ LIZA_Y _VEHÍCULO
n um_ b astid o rfe ch a _ in ic io _ve h ícu lo
n u m_pó lizafe ch a_in icio _co b e rtu ra
fe ch a_fin _co b e rtu ratérmin o sto tal_co lis ió n
d e scu e n to _clie n tein d ic_p re cio _e sp e cial
có d ig o _tip o _p ó lizama rca
mo d e lo...
ind _ ABSind _ a irba g
ind _ ESPfe ch a _ ca rga

51
Técnicas de Optimización
Cadenas de Datos Caso especial de
Agregación Eficiente para Reporting NUNCA en operacionales o
Staging, pero muy útil en DW y DM

52
Técnicas de Optimización
Balancear diferentes Factores
Base s d e Datos d e lData W are h o se
Re n d imie n to
Se g urid ad
Re cup e racióne rro re s
Estab ilid ad
Platafo rma
Acce so &Nav e g ació n
Histó r ico
Tamañ o &Cre cimie n to
Distr ib u ció n

53
Fundamentos del DWH
Esquemas en Estrella

54
Puntos Fuertes de la Modelización Dimensional
Coincide con las percepciones de los usuarios
Estructura predecible, estándar
Facilita el desarrollo de consultas y análisis
Las herramientas OLAP pueden hacer suposiciones
Cada dimensión es equivalente para todos los datos
Puede ser modificada fácilmente
Usa perspectivas de modelización comunes
Simplifica la agregación

55
Modelización Dimensional - Regla de Oro
Los Esquemas en Estrella deberían ser utilizados para
cualquier dato accedido directamente por los usuarios
finales.

56
El Esquema en Estrella
Hechos
Dimensiones
De-normalizado (generalmente)
Tiene caminos de unión bien diseñados
Paraleliza la visión de los datos por el usuario
Son fácilmente modificables
Simplifica la comprensión y navegación por los metadatos
Amplia la elección de herramientas de usuario final

57
Modelización Dimensional
Tablas de Hechos: contienen datos cuantitativos sobre el negocio La clave primaria es una concatenación de claves de
dimensión, incluyendo el tiempo Cada elemento de la clave primaria compuesta es una
clave de integridad referencial hacia una tabla de dimensión.
Contienen menos atributos, pero muchos más registros
Tablas de Dimensión: gestionan datos descriptivos que reflejan las diversas dimensiones del negocio Contienen muchos atributos pero menos (pocos)
registros La clave primaria ‘ayuda’ a componer las claves
primarias de las tablas de hechos

58
Esquema en Estrella (conceptual)

59
Diseño de una Tabla de Hechos
Elija el PROCESO del Data Mart Comience el contenido del data mart a partir de datos
de un solo origen
Defina la GRANULARIDAD de la tabla de hechos Elija el nivel granular más bajo posible Transacciones individuales o fotos
Elija las DIMENSIONES Reflejan el contenido de la tabla de hechos y la
granularidad
Elija los HECHOS Los hechos individuales y el ámbito de estos hechos
deben ser específicos a la granularidad de la tabla de hechos

60
Identifique el Proceso Departamental
¿Cuál es el proceso o función subyacente para el DM?
¿Cuál es el ámbito aproximado del DM?
¿Quién usará el DM? ¿A qué preguntas les gustaría a
los usuarios que contestaran los datos del DM?

61
Determine los Hechos
¿Qué hechos están disponibles? ¿Cuáles son los datos cuantitativos fundamentales que
hay por debajo? Los hechos más útiles son los numéricos y aditivos
¿Qué nivel de detalle (granularidad) necesita mantener? Serán datos ‘atómicos’ (todo el detalle) o datos
agregados (sumarizados)? Si son agregados, cómo (usando qué algoritmo)? ¿Para qué propósito de negocio?
¿Cuál es la frecuencia de carga de datos requerida? ¿Cada transacción? ¿Cada hora? ¿Día? ¿Semana? ¿Mes?

62
Tablas de Hechos ‘Sin Hechos’ - EVENTOS
Eventos: Algo que ‘ha ocurrido’ Ejemplo: Asistencia de estudiantes a una clase,
asientos de pasajeros de línea aérea o habitaciones de hotel ocupadas
Enlace el evento a: Tiempo / estudiante / profesor / curso / facilidades
Típico para crear un ‘hecho vacío’ Asistencia = 1
La granularidad es el evento individual de ‘asistencia a clase’
FUENTE: Kimball, 1998

63
Las Agregaciones Pueden:
Asegurar la consistencia entre data marts
Ser hechas reutilizables para mantenerlas de manera centralizada
Mejorar el rendimiento del usuario
Reducir los recursos necesarios para preparar las consultas (CPU, disco, memoria)
Ser utilizadas en base a: Frecuencia de acceso Efecto del número de registros

64
Determine las Dimensiones
¿Qué dimensiones pueden necesitar los usuarios? ¿Cuáles son los conceptos fundamentales
(entidades o temas) con los que los usuarios trabajarán?
Siempre existirán al menos dos dimensiones; quizá hasta una decena.
El tiempo será una dimensión prácticamente siempre
¿Cuál es el identificador (clave primaria) de cada una de las dimensiones? No_Cliente, ID_Cuenta, NoFactura
Los atributos de la dimensión se convierten en las cabeceras de los registros SQL

65
Para Cada Tabla de Dimensión
Establezca la clave primaria para cada registro dimensional
Use la clave primaria como una parte de la clave compuesta de la tabla de hechos
Identifique los atributos de interés para los usuarios ¿Qué atributos deben ser de-normalizados? ¿Qué otros atributos podrían tener valores
significativos? ¿Hay alguna oportunidad de incluir datos ‘de fuera’?
¿Cuáles? Ayúdese de los valores reales contenidos en los
atributos

66
La Dimensión de Tiempo
Debe ser día a día durante 5-10 años
Separe los campos de semana, mes, día, año, día de la semana, vacaciones, estaciones, etc.
Trimestres naturales y fiscales
Créela como una sola tabla en el DWH
Cargue el contenido en los DM a medida que se necesiten

67
Establezca Relaciones
Dibuje la relación visualmente
Identifique la cardinalidad (1-N)
Entre la tabla de hechos . . . y cada tabla de dimensión
“Una Imagen vale más . . .”

68
Métodos para Identificar Dimensiones y Hechos
Informes de Concepto
Reuniones y Entrevistas
Requerimientos Especiales del Proyecto
Documentos sobre Ámbito del Proyecto
Peticiones de Información
‘Cartas a los Reyes Magos’
Modelos y Bases de Datos Existentes
Informes Actuales (y Deseados)

69
Ejemplo:Intereses de la División Financiera
La división financiera ha preparado la siguiente lista de funcionalidades deseables en el data mart.
Muchos de estos datos son información de cliente / demográfica.
Nos permitirá evaluar el impacto de costes en nuestros clientes, ubicación y uso por nuestros clientes, costes incurridos por ubicación para servir a nuestros clientes y otros tipos de evaluaciones financieras relativas a costes, uso, etc.
Este tipo de información será muy valiosa para dirigir los aspectos financieros y políticos de las planificaciones y soluciones futuras a los problemas actuales.
Esta información nos permitirá contestar mejor a las importantes preguntas que aparecerán durante ese proceso.

70
Ejemplo:Frase de Ejemplo de Misión
Capture datos de nuestro sistema para realizar evaluaciones por zonas de nuestros clientes, intereses y beneficios y para asesorar el impacto de costes sobre nuestra base de clientes.

71
Ejemplo:Preguntas a la División Financiera
1. Datos demográficos de nuestros clientes - el tipo de datos que aparece en un censo (tipo de vivienda, valor de la vivienda, ocupación, sexo, educación, ingresos, etc.) Puede ser usado para enviar mensajes oficiales, evaluación de intereses de penalización, y mercado objetivo.
2. Clientes por clase de interés – definición por clientes residenciales, comerciales, industriales, gobierno y multifamiliares.
3. Beneficio demográfico por cliente y consumo – como valor de la vivienda, ingresos o educación.

72
Ejemplo:Preguntas a la División Financiera (2)
4. Información sobre el servicio al cliente – incluyendo beneficio por los diferentes tipos de intereses y cobros por zona geográfica, beneficio y consumo.
5. Beneficio total por clase de cliente y categoría de intereses – a lo largo de los últimos cinco años. ¿Qué clases de clientes dan más beneficio?
6. Presupuesto del año en curso por zona – debe mostrar el presupuesto actual y en qué áreas se han ido incurriendo esos costes.
7. Valor de activos por zona – un informe que muestre el valor depreciativo de los activos propios por zona.

73
Ejemplo:El Esquema Financiero en Estrella

74
Fundamentos del DWH
Procesos y Estrategias de Carga del DWH

75
Mapeo de Datos Mapeo LÓGICO -
describe cómo ir desde donde se encuentra hasta donde quiere ir
Mapeo FÍSICO - Indica las rutas, baches, desvíos atajos de la
carretera
TRANSPORTE - Decida si está conduciendo un coche
deportivo o un camión de recogida de chatarra
PLANIFICACIÓN - Indica cuándo saldrá y cuánto espera que le
lleve llegar al destino

76
Soluciones de Extracción, Transformación y Carga de Datos (ETL)
Aproximación de primera generación (o crecimiento ‘casero’)
Mapean origen a destino con capacidades variables de transformación y limpieza
Generan código o directamente deben programarse
Suelen controlar metadatos limitados
FUENTE: Doug Hackney, 1998

77
Plataformas de Integración de Datos
Soluciones integradas
Capacidad de implantación a nivel corporativo
Metadatos completos, abiertos y extensibles
Abanico de transformaciones y reglas de negocio
Análisis, entrega y planificación integradas
Gestión Ad-hoc de agregaciones
Monitorización y Auditoría integradas
Funciones avanzadas de Calidad de Datos
Versionados, despliegues inteligentes

78
Def Origen
2. IMPORTACIÓN DE DEFICIONES DE ORÍGENES
Def Destino3. CREACIÓN DE ESQUEMADESTINO
Mapeo
4. CREACIÓN DE MAPPINGS
Proceso de Diseño
1. CREACIÓN DE REPOSITORIO

79
Transformaciones Más Comunes
Creación de valores por defecto para los nulos
Gestión de fechas
Selección o filtrado de datos origen
Unión de orígenes heterogéneos (SAP+Ficheros+Tablas+…)
Normalización de los ficheros de datos
Generación de esquemas en estrella
Creación de estrategias de actualización
Creación y actualización de agregaciones
Creación de dimensiones ‘slowly-changing’

80
Algunas Transformaciones
Selección de datos del Origen representa la consulta o primer filtrado/ordenación de los datos origen
Normalización convierte registros de orígenes relacionales o VSAM a registros normalizados (cláusulas OCCURS, REDEFINES)
Cálculo de Expresiones/Nuevos Campos realiza cálculos a nivel de campo
Filtro funciona como un filtro condicional de los registros procesados
Agregación realiza cálculos agregados (totales o incrementales)
Rango limita los registros a los primeros o últimos de un rango
Estrategia de Actualización para marcar cada registro como inserción, actualización, borrado, o registro rechazado
Lookup busca valores complementarios y los pasa a otros objetos
Procedimientos Externos/Almacenados llama a programas desarrollados en otros lenguajes o en la base de datos
Generador de Secuencia genera nuevos identificadores únicos

81
Trabajo con Transformaciones
DESTINOESTRATEGIA DE ACTUALIZACIÓNBasado en la coincidencia de Job_IDs,
LOOKUPBusca Job_IDs en el destinoT_JOBS
ORIGENEXTRACCIÓNDEL ORIGEN
Ejemplo: Estrategia de Actualización

82
Diseño de Cargas
Ordene los datos por secuencias específicas de carga
Fuerce a reglas limitadas de integridad de datos
Busque la carga correcta de cada paso
Construya estadísticas de carga y mensajes de error
Cree el plan para cargas fallidas – qué debe ocurrir
Produzca la notificación inmediata y automática en caso de fallos (y/o éxitos) en las cargas
FUENTE: O’Neil, 1997

83
Consejos sobre Planificación de Cargas Orden de carga – cargue primero las tablas independientes
Determine la ventana necesaria de carga – use las horas de inicio y final para determinar el tiempo necesario para las cargas
Ejecute cargas en paralelo Ejecución concurrente Uso de threads, desarrollos multiproceso, paralelización de
base de datos No sobrecargue los sistemas origen o destino
Carque en paralelo un mismo destino Datos de sistemas independientes que van al mismo
destino
Cargue múltiples destinos en paralelo Datos del mismo origen que vayan a diferentes destinos –
ahorre accesos de lectura

84
Plan de Carga de Destinos
Primero, tablas independientes Después, tablas que no contienen claves foráneas
a otras tablas Por último, las tablas que contienen claves
foráneas a otras tablas Tenga cuidado con transacciones de base de
datos e intervalos de commit: los datos pueden estar cargados pero no validados

85
Timing
Ejecución manual
Ejecución periódica cada n minutos/horas/días un máximo de veces/ para siempre
Ejecución concreta En un momento determinado Cada primer martes de mes a las
21:43
Ejecución basada en eventos Disponibilidad del fichero origen Sólo si la carga anterior acabó
bien/mal
Planificación de Cargas
Planificación Planificación propio de la herramienta
Planificador genérico Control^M, Tareas Programadas de Windows
Scripts de carga (.bat, .sh, JCL)

86
El mantenimiento de un data mart es una revisión constante de los procesos para optimizar valores de datos, pasos, tiempos, recursos utilizados, accesos a sistemas origen o destino … debido a los constantes requerimientos nuevos de los usuarios finales y el crecimiento en funcionalidad y volumen de datos que eso conlleva
Monitorización de Cargas

87
La Creación de un Data Warehouse Sostenible y sus Data Marts
Incrementales Requiere la Automatización
de los Procesos de Carga

88
Fundamentos del DWH
Herramientas de Integración de Datos

89
Integración de Datos, más allá del BI
El ETL se ha quedado relegado a entornos analíticos
Aparecen necesidades de Integración de datos para otro tipo de proyectos Externalización Migraciones Integración de Aplicaciones, BBDD Sincronización etc

90
¿Un proceso simple?
ETL

91
EIM, Content Management
Aplicacionesy
Midleware(SAP, Siebel, TIBCO, Biztalk,
…)
BI(BO, SAS, Microstrategy,
Hyperion, Cognos …)
Bases de Datos
(Oracle, Microsoft, IBM, …)
Ensanchando el concepto de Integración de Datos
EAI
RealTime
Scheduling
ChangedData
Capture
Complex Data
Exchange
Mainframe
ETL
Data Grid
High Availabili
ty
Data Profiling
DWL
Auditing
Data
Quality
Team Base
Develop/
Federation
Web Services
(SOA)
Metadatos

92
IBM MQSeriesTIBCO webMethodsSAP NetWeaver XI
SAP NetWeaverSAP IDOCSAP BCISAP DMISAP BW
OracleDB2 UDBDB2/400SQL ServerSybase
ADABASDatacomDB2IDMSIMS
Flat Files, XLS, PPTFTPEncrypted StreamXML, PDF, DOC, …
InformixTeradataODBCFlat FilesWeb Logs …
VSAMC-ISAMComplex FilesTape Formats…
Web ServicesXMLJMSODBC…
PeoplesoftOracle AppsSiebelSAS…
OracleSQL ServerIndustry Formats
Acceso Universal a los DatosEntrega de datos a Sistemas, Procesos y Organizaciones
Etc etc ….
XML, Messaging, and Web Services
Packaged Applications
Relational and Flat Files
Mainframe and Midrange
Systems

93
Informatica PowerCenter Puntos de interés como plataforma de integración de datos (1/2)
Permite integrar múltiples fuentes de datos heterogéneas
Desarrollo de alta productividad Herramientas de trabajo visuales. Interfaz gráfico totalmente
intuitivo Asistentes de transformación NO hay generación de código Detección de errores (debugger integrado) Reutilización de componentes
Fácil de mantener: Metadatos corporativos Análisis de Impacto Análisis del Linaje de datos Presentación Web Metadatos y Autodocumentación Metadatos extensibles Despliegues guiados. Rollback Versionado

94
Informatica PowerCenter Puntos de interés como plataforma de integración de datos (2/2)
Plataforma de Alto rendimiento Grid computing Alta Disponibilidad Tolerancia a fallos y recuperación automática Soporte a cargas BULK
Capacidades de Tiempo real Conectores WebServices, ESB, EAI
Adaptabilidad y escalabilidad Plataforma, recursos, volumen y usuarios
Capacidad de expandir las Transformaciones con módulos externos (PL/Sql, C++, …)
Autodocumentación Planificador integrado

95
Informatica PowerCenter “Trabajar como pienso” Del papel …
MAESTRO
DETALLE UNION
TABLA REFERENCIA
TOTALES
DESTINO
DATAWAREHOUSE
SALIDA_XML

96
Informatica PowerCenter … a la práctica

97
Informatica PowerCenter Metadata Reporter Presentación web de los metadatos del repositorio

98
Fundamentos del DWH
Herramientas de Reporting y Análisis

99
Tipos de Herramientas OLAP
Herramientas de Consulta y Generación de Informes
Consultas Ad Hoc
Herramientas EIS
Herramientas de Data Mining
Herramientas basadas en Web

100
On-Line Analytic Processing - (OLAP)
Perspectiva ‘multidimensional’ de los datos pueden ser vistos como ‘cuadrículas’ de datos
Consulta interactiva de datos seguimiento de un flujo de información mediante múltiples
pasos de “drill-down”
Los resultados son mostrados como tablas cruzadas, o tablas pivotantes
Capacidades de modelización (incluyendo un motor de cálculos)
Usado para análisis de previsiones, tendencias y estadísticas
FUENTE: Neil Raden, 1995

101
Características del Procesamiento OLAP
Acceden a volúmenes de datos ENORMES
Analizan las relaciones entre muchas dimensiones
Involucran a datos agregados (ventas, presupuestos, beneficios, etc.)
Comparan datos agregados a lo largo del tiempo
Presentan los datos en diferentes jerarquías
Realizan cálculos complejos
Pueden responder rápidamente a los usuarios

102
Motores Relacionales:
Almacenan los datos como líneas (registros) en tablas
Todos siguen el mismo modelo relacional
Se accede a ellos a través de un lenguaje común - SQL
Tienen aproximadamente el mismo conjunto de funcionalidades

103
OLAP Relacional:
Permite el acercamiento mayor a las percepciones de los usuarios
NO requiere la regeneración de la base de datos si cambian las dimensiones
No requiere más trabajo de front-end
Posiblemente requiere menos re-trabajo a lo largo del tiempo
ESTÁ limitado por un conjunto de funciones disponibles
Permite una granularidad más flexible en los datos

104
OLAP Relacional (total):
Posee un potente generador SQL, capaz de crear consultas multi-pasada
Puede crear rangos no triviales, comparaciones y cálculos de porcentajes respecto al total
Genera SQL optimizado, con extensiones Usa metadatos para modelos / consultas Está siendo promocionado por los
fabricantes de BBDD

105
OLAP Multidimensional
Refleja los pensamientos de los usuarios sobre la actividad del negocio
Hace referencia a cubos de datos
Los cubos de más de tres dimensiones se conocen como hipercubos
El modelo de datos representado por el hipercubo es un modelo multidimensional
Cualquier base de datos que pueda almacenar y representar ese modelo es una BD multidimensional
FUENTE: O’Neil, 1997

106
Bases de Datos Multidimensionales:el ‘HiperCubo’
Time
Customer
Pro
du
ctMÁS:
Región
Territorio
Vendedor
Etc.

107
OLAP Multidimensional
Normalmente almacena los datos como vectores internos
Proporciona un gran rendimiento ante las consultas Porque los datos han sido preparados previamente
dentro de la estructura A veces limitado a un número concreto de celdas del
cubo
Dispone de librerías especiales de funciones
Cambios en la estructura dimensional pueden requerir la regeneración del cubo
Requiere recursos que administren la generación de las estructuras

108
. . . La ‘Zona de Guerra’
MOLAP Propietario (SQL) Vectores/Cubos Respuesta muy rápida Consultas predefinidas Funciones especiales Nuevos perfiles de
desarrollo
ROLAP SQL ‘Estándar’ Tablas/Registros Respuesta más lenta Consultas de SQL flexibles Funciones limitadas Uso de perfiles existentes

109
Argumentos de MOLAP contra ROLAP
Los gestores de bases de datos relacionales no gestionan las relaciones multidimensionales con eficiencia
Inherentemente de dos dimensiones
El SQL no es obvio para los usuarios finales
Las uniones múltiples y el pobre rendimiento son un serio problema
Las tablas denormalizadas absorben el rendimiento y los recursos

110
Argumentos de ROLAP contra MOLAP
Los cubos ofrecen niveles limitados de detalle No están de acuerdo con el modelo dimensional Las MDDs no disponen de un un método de
acceso estándar (como SQL) No se pueden cambiar las dimensiones sin
regenerar completamente el cubo El ámbito de cada producto y su funcionalidad
para el soporte a decisiones pueden variar ampliamente
Cada herramienta es prácticamente de una categoría diferente

111
Data Mining
Análisis del Warehouse Comienza con una hipótesis Busca aquellos datos que soportan esa
hipótesis. Muestra los clientes mayores que (asumimos que)
compran los artículos más caros
Data mining El proceso crea la teoría en base a la
navegación automática por los datos ¿Quién compra realmente los artículos más caros? ¿Cuáles son sus nombres para el mercado indicado?
FUENTE: Computerworld, March 29, 1999

112
Herramientas de Data Mining:
Requieren datos detallados históricos
Requieren una calidad de datos muy alta
Buscan patrones de comportamiento
Necesitan una selección equilibrada de variables
FUENTE: ComputerWorld, Mar 29, 1999

113
Selección de Herramientas Finales:
Debería ocurrir MÁS TARDE en el proceso
La CLAVE de la selección de la herramienta son los usuarios finales: es la única parte que verán de todo el proyecto de DW
Enfóquese hacia los requerimientos que solucionan problemas técnicos y de negocio importantes para diferenciarlas
Involucre a los usuarios finales que usarán las herramientas
Compruebe sus funciones, facilidad de uso, integración, metadatos, cuota de mercado y estabilidad
FUENTE: O’Neil, 1997 (y others)

114
Múltiples Necesidades = Múltiples Herramientas
La realidad del data mart es que necesitará múltiples herramientas para dar soporte a los diferentes usuarios
Use un número manejable de estas herramientas
Estas herramientas deberían ser consideradas en los cambios de tecnología y necesidades de usuarios

115
Sin Datos de Calidad
todo lo que Tenemos
son Opiniones

116





























