Embed Size (px)
Citation preview

POLITECHNIKA WARSZAWSKAWYDZIAŁ ELEKTRONIKI I
TECHNIK INFORMACYJNYCHINSTYTUT INFORMATYKI
Rok akademicki 2004/2005
PRACA DYPLOMOWA MAGISTERSKA
Piotr Kołaczkowski
Zestaw komponentów C++ wspomagających budowę aplikacji internetowych działających po stronie
serwera
Opiekun pracy: dr inż. Ilona Bluemke
Ocena: ..................................................................
..............................................................................Podpis Przewodniczącego Komisji Egzaminu
Dyplomowego

Specjalność: Informatyka
Data urodzenia: 9 stycznia 1982 r.
Data rozpoczęcia studiów: 1 października 2000 r.
Życiorys: Urodziłem się 9 stycznia 1982 r. w Warszawie. W latach 1988-1996 uczęsz-
czałem do Szkoły Podstawowej im. Sandora Petőfiego nr 132 w Warszawie. W 1996 r.
zdałem do XXXIII Liceum Ogólnokształcącego im. Mikołaja Kopernika w Warszawie
do klasy dwujęzycznej z rozszerzonym językiem angielskim. W I klasie zostałem laure-
atem IX miejsca Olimpiady Wiedzy Technicznej, a w IV klasie zdobyłem I miejsce w
Olimpiadzie Wiedzy Technicznej oraz V miejsce w Olimpiadzie Fizycznej. W 2000 r.
zdałem maturę i zostałem przyjęty bez egzaminów wstępnych na studia dzienne na Wy-
dziale Elektroniki i Technik Informacyjnych na Politechnice Warszawskiej. W 2001 r.
zdobyłem III miejsce w Krajowych Eliminacjach Konkursu Prac Młodych Naukowców
Unii Europejskiej oraz otrzymałem stypendium MEN za osiągnięcia w nauce. Studia II
stopnia w Instytucie Informatyki rozpocząłem w 2003 r. W styczniu 2004 r. rozpocząłem
pracę zawodową w one2tribe sp. z o.o. W 2005 r. ponownie otrzymałem stypendium
MEN za osiągnięcia w nauce.
...............................................................podpis studenta
EGZAMIN DYPLOMOWY
Złożył egzamin dyplomowy w dniu ...................................................................... 200 ....r.
z wynikiem ...........................................................................................................................
Ogólny wynik studiów .........................................................................................................
Dodatkowe wnioski i uwagi Komisji ...................................................................................
...............................................................................................................................................
...............................................................................................................................................

Streszczenie
W pracy przedstawiono zestaw komponentów, który pozwala programistom C++ two-
rzyć szybkie i bezpieczne aplikacje internetowe działających po stronie serwera. W ciągu
kilkunastu ostatnich lat obserwuje się wyraźny wzrost popularności takich aplikacji.
Rośnie również popyt na odpowiednie narzędzia. Z zamieszczonego w pracy przeglądu
dostępnych na rynku technologii internetowych wynika jednak, że język C++ bywa rzad-
ko stosowany w aplikacjach internetowych, głównie ze względu na podatność na błędy w
zarządzaniu pamięcią i związane z tym pogorszenie poziomu bezpieczeństwa i nieza-
wodności. Opracowany pakiet zawiera mechanizmy automatycznego zarządzania
pamięcią, które pozwalają uniknąć tych problemów oraz przyczyniają się do uprosz-
czenia procesu implementacji aplikacji. Z użyciem tych mechanizmów zrealizowano
komponenty umożliwiające tworzenie graficznego interfejsu użytkownika dostępnego za
pośrednictwem przeglądarki internetowej.
Słowa kluczowe: aplikacje internetowe, automatyczne zarządzanie pamięcią,
odśmiecacz, serwer WWW, serwlety
The C++ Component Library for Implementation of
Server Side Internet Applications
The paper presents a component library that enables C++ programmers developing ro-
bust and secure server side Internet applications. Popularity of such applications and need
for appropriate tools have rapidly grown in recent years. In the review of popular Internet
technologies was shown that C++ is rarely used as an Internet applications implementa-
tion language, mainly due to difficult and error-prone memory management. The
presented library contains an automatic memory management system (garbage collector)
that helps to avoid these problems and simplifies implementation of complex programs.
The garbage collector has been widely used in the components providing graphical user
interface accessed from a web-browser.
Keywords: Internet applications, automatic memory management, garbage collector,
web server, servlets

Spis treści
Wstęp...................................................................................................................................6Rozdział I – Techniki budowania aplikacji internetowych...............................................11
1. CGI - Common Gateway Interface...........................................................................112. FastCGI....................................................................................................................173. PHP – Hypertext Preprocessor.................................................................................194. ASP – Active Server Pages......................................................................................235. iHTML......................................................................................................................256. ColdFusion...............................................................................................................277. Java Servlets i Java Server Pages.............................................................................298. ASP.NET – Active Server Pages .NET....................................................................32
Rozdział II – Wymagania..................................................................................................361. Wymagania funkcjonalne.........................................................................................36
1.1.Prezentowanie graficznego interfejsu użytkownika..........................................371.2.Reakcja na zdarzenia pochodzące od użytkowników........................................381.3.Obsługa sesji......................................................................................................391.4.Przechowywanie informacji po stronie klienta .................................................401.5.Logowanie zdarzeń............................................................................................401.6.Przechowywanie danych w plikach...................................................................411.7.Współpraca z systemami baz danych................................................................411.8.Komunikacja sieciowa z innymi aplikacjami....................................................41
2. Wymagania niefunkcjonalne....................................................................................422.1.Środowisko pracy i przenośność.......................................................................422.2.Krzywa uczenia się............................................................................................432.3.Niezawodność i bezpieczeństwo.......................................................................432.4.Wydajność.........................................................................................................442.5.Integracja z istniejącym oprogramowaniem......................................................44
Rozdział III – Założenia projektowe.................................................................................451. Metodologia projektowania bibliotek.......................................................................452. Wykorzystanie dostępnych komponentów...............................................................453. Narzędzia wspomagania kompilacji.........................................................................464. Konwencja kodowania.............................................................................................475. Obsługa błędów........................................................................................................506. Testowanie................................................................................................................517. Dokumentacja...........................................................................................................52
Rozdział IV – Projekt i implementacja.............................................................................531. Mechanizmy zarządzania pamięcią..........................................................................55
1.1.Algorytmy..........................................................................................................571.2.Struktury danych................................................................................................611.3.Wyzwalanie procesu odśmiecania.....................................................................65
2. Serwer WWW i serwlety..........................................................................................662.1.Serwlety.............................................................................................................662.2.Odbieranie danych.............................................................................................672.3.Wysyłanie danych..............................................................................................682.4.Pula wątków......................................................................................................692.5.Synchronizacja wątków.....................................................................................69

Spis treści 5
2.6.Obsługa sesji..................................................................................................703. Komponenty pomocnicze.....................................................................................71
3.1.Łańcuchy znaków..........................................................................................713.2.Klasy kontenerowe........................................................................................723.3.Obsługa wątków............................................................................................733.4.Logowanie zdarzeń........................................................................................733.5.Komunikacja sieciowa...................................................................................743.6.Strumienie wejścia/wyjścia............................................................................75
Rozdział V – Testy i zastosowania praktyczne.............................................................771. Wymagania systemowe i sprzętowe.....................................................................772. Kompilacja i instalacja.........................................................................................773. Aplikacja A - „Hello World”................................................................................784. Aplikacja B – serwer DNS...................................................................................805. Automatyczne, modułowe testy funkcjonalne......................................................836. Pomiary wydajności.............................................................................................84
6.1.Wydajność odśmiecacza................................................................................856.2.Wydajność aplikacji testowych......................................................................86
Podsumowanie...............................................................................................................88Spis źródeł.....................................................................................................................91Spis tabel.......................................................................................................................93Spis diagramów.............................................................................................................94Spis rysunków...............................................................................................................95Dodatki na płycie CD
A.Dystrybucja źródłowa komponentów (do instalacji)......................soft/smeil.tar.gzB. Kod źródłowy komponentów..............................................................soft/smeil/srcC. Dokumentacja interfejsu programistycznego komponentów...........soft/smeil/doc/D.Aplikacje wykonane przy użyciu komponentów....................soft/smeil/examples/E. Kod źródłowy serwera DNS.................................................................soft/dns/src/F. Dokumentacja serwera DNS................................................................soft/dns/doc/G.Testy wydajnościowe i stresowe...............................................................soft/perf/H.Dystrybucja źródłowa programu http-load...............................soft/http-load.tar.gzI. Dystrybucja źródłowa programu valgrind...............................soft/valgrind.tar.bz2J. Tekst pracy w wersji elektronicznej..................................................................doc/

Wstęp
W ciągu ostatnich kilkunastu lat obserwuje się lawinowy wzrost popularności
aplikacji internetowych. Internet dotarł bowiem do niemal każdego zakątka świata.
Większość komputerów osobistych jest wyposażona standardowo w aplikacje pozwa-
lające korzystać z jego usług, m.in. przeglądarki internetowe o coraz bardziej rozbudo-
wanych możliwościach. Przeglądarki są nie tylko ogólnodostępne, ale również proste i
wygodne w obsłudze, a przede wszystkim tanie. Dzięki temu aplikacje internetowe za-
częły nawet w pewnych dziedzinach wypierać klasyczne aplikacje. Często tam, gdzie
dotąd konieczne było zainstalowanie tego samego programu na kilkudziesięciu stano-
wiskach komputerowych, można wykorzystać aplikację działającą na centralnym ser-
werze komunikującą się z przeglądarkami zainstalowanymi na poszczególnych sta-
cjach. Takie systemy są na ogół łatwiejsze i tańsze w utrzymaniu, gdyż istnieje tylko
jeden egzemplarz niestandardowej, dopasowanej do konkretnego zastosowania apli-
kacji.
Termin aplikacja internetowa jest niejednoznaczny. Dosłownie oznacza aplikację
działającą w Internecie. Przyjęło się jednak używać go na określenie aplikacji, której
interfejs użytkownika jest realizowany przez przeglądarkę internetową. Przeglądarka
jest odpowiedzialna za pobranie danych od użytkownika oraz prawidłowe
wyświetlenie rezultatów. Podstawowy podział aplikacji internetowych został do-
konany ze względu na położenie kodu odpowiedzialnego za logikę biznesową. Jeśli
kod ten jest wykonywany przez przeglądarkę lub jakiś jej moduł, taką aplikację nazy-
wa się zwyczajowo działającą po stronie przeglądarki. Jeśli kod ten wykonywany jest
gdziekolwiek indziej i komunikuje się z przeglądarką za pomocą protokołu HTTP, to
mówi się, że taka aplikacja działa po stronie serwera. Praca ta dotyczy jedynie tego
drugiego rodzaju aplikacji internetowych i właśnie ten rodzaj aplikacji będzie ro-
zumiany dalej przez termin aplikacja internetowa.
Wymagania stawiane aplikacjom internetowym różnią się od wymagań sta-
wianych typowym graficznym aplikacjom okienkowym lub aplikacjom konsolowym.
Bardzo często aplikacje te muszą obsługiwać jednocześnie wielu użytkowników i
pracować bez przerwy przez wiele miesięcy. Możliwości interfejsu użytkownika są
pod wieloma względami ograniczone, a standardowe biblioteki systemów operacyj-
nych nie dostarczają zbyt wielu użytecznych funkcji do budowy takiego interfejsu, w
przeciwieństwie do rozbudowanych interfejsów programistycznych dla programów
okienkowych. Z powyższych powodów również budowanie aplikacji internetowej

Wstęp 7
różni się znacznie od procesu tworzenia typowego programu użytkowego. Celem
niniejszej pracy jest stworzenie zestawu programów narzędziowych i bibliotek, który
w jak największym stopniu uprości proces budowania aplikacji internetowych.
Istnieje oczywiście wiele dojrzałych technik budowania aplikacji internetowych i
związanych z nimi pakietów oprogramowania. Zdecydowana większość jest oparta o
kod interpretowany lub kompilowany w czasie wykonania. Powszechne w użyciu są
języki interpretowane, takie jak PHP, Perl czy Python oraz zaawansowane platformy
tworzenia aplikacji wykorzystujące interpretery kodu pośredniego, np. Java lub .NET.
Brakuje natomiast rozwiązań opartych o języki kompilowane wysokiego poziomu,
jakim jest C++. Programiści tworzący aplikacje w tym języku są skazani na wykorzy-
stanie prostego, mało wygodnego i ograniczonego mechanizmu CGI lub dostosowy-
wanie swoich aplikacji do specyficznych interfejsów serwerów WWW, co z kolei po-
garsza przenośność tych aplikacji. Skoro istnieje tak niewiele sposobów wykorzystania
C++ w tej dziedzinie, to być może język ten posiada jakieś ograniczenia powodujące,
że mimo jego ogromnej popularności [TIOBE], nie nadaje się zbytnio do pisania apli-
kacji internetowych. Istnieje wiele mitów dotyczących programowania w C++. W opi-
nii niektórych programistów [CPP1], język ten jest bardziej skomplikowany, nie tak
wygodny i mniej przenośny niż języki interpretowane oraz język C. Istotnie, posiada
kilka wad, które mogą stać się istotną przeszkodą w stworzeniu dobrego pakietu
wspomagającego pisanie aplikacji internetowych:
• Zarządzanie pamięcią jest trudne i podatne na błędy. W środowisku sieciowym
rodzi to poważne zagrożenie dla systemu. Błędy mogą być wykorzystane do uzy-
skania niepowołanego dostępu do tajnych danych lub mogą powodować
niestabilną pracę aplikacji. Niektóre aplikacje internetowe muszą działać bez
przerwy przez czas rzędu miesięcy, więc prawdopodobieństwo awarii jest dużo
większe niż dla aplikacji użytkowych, jak np. edytor tekstu.
• Biblioteka standardowa STL również jest podatna na błędy. Funkcje tej biblioteki
ze względu na potrzebę zapewnienia jak największej wydajności prawie w ogóle
nie sprawdzają poprawności danych wejściowych [STRO, STL2]. W bardzo zło-
żonych projektach – nawet zaawansowanym programistom – może sprawiać to
kłopoty.
• Biblioteka standardowa nie zawiera wielu bardzo potrzebnych funkcji do obsługi
sieci, wielowątkowości, logowania, dostępu do baz danych itp. [STL1, STL2]
Całą tę funkcjonalność muszą dostarczyć inne biblioteki, na ogół związane ze spe-

Wstęp 8
cyficznym systemem operacyjnym. Z drugiej strony, istnieją dobrze określone
standardy (np. POSIX), które częściowo rozwiązują ten problem.
Powyższe przeszkody można skutecznie pokonać. Część tej pracy została
poświęcona na zaprojektowanie i zaimplementowanie ogólnych ulepszeń pozwala-
jących lepiej budować aplikacje dowolnego typu, nie tylko internetowe. Warto
poświęcić uwagę na przezwyciężenie trudności, żeby nie przesłoniły wielu oczywi-
stych zalet języka C++:
• Język C++ wspiera różne paradygmaty programowania, m.in. programowanie
strukturalne, obiektowe i uogólnione [STRO]. Powoduje to wprawdzie, że jego
składnia jest złożona, ale poznanie wszystkich jej aspektów nie jest konieczne aby
pisać nawet bardzo rozbudowane programy.
• W języku C++ można tworzyć zespołowo bardzo duże aplikacje dzięki mecha-
nizmowi dzielenia kodu na moduły i możliwości jawnego specyfikowania ich
interfejsów. Silna kontrola typów pozwala wykrywać wiele błędów i niezgodności
na etapie kompilacji, a przestrzenie nazw pozwalają unikać kolizji oznaczeń przy
łączeniu modułów tworzonych przez różne zespoły. Wiele interpretowanych języ-
ków skryptowych nie posiada takich cech i utrzymywanie dużych projektów
napisanych w tych językach jest trudniejsze.
• Kod kompilowany wykonuje się szybciej i potrzebuje zwykle mniej zasobów niż
kod interpretowany. Wydajność aplikacji internetowych może mieć znaczenie w
niektórych zastosowaniach, zwłaszcza tam, gdzie z aplikacji korzysta wielu użyt-
kowników jednocześnie. Większa wydajność oznacza zwykle niższe koszty
infrastruktury, koniecznej by konkretny system spełniał stawiane mu wymagania.
• Aplikacje pisane w języku C++ mają łatwy dostęp do usług systemu operacyjne-
go, na którym pracują. Większość systemów operacyjnych zostało napisanych w
języku C/C++. Dla porównania, na platformach Java i .NET, ze względu na
konieczność zachowania przenośności, taki dostęp jest utrudniony. Stanowi to
istotne ograniczenie dla twórców niektórych aplikacji internetowych. Brak dodat-
kowej warstwy między aplikacją napisaną w C++ a systemem operacyjnym
pozytywnie wpływa też na wydajność.
• Istnieje dużo dobrych kompilatorów języka C++ na różne platformy sprzętowe i
na różne systemy operacyjne. W większości dystrybucji systemu Linux oraz wielu
klonach systemu Unix kompilatory są zainstalowane domyślnie.

Wstęp 9
• W językach C i C++ stworzono wiele programów, które nie posiadają interfejsu
korzystającego z przeglądarki, a interfejs taki byłby wartościowym dodatkiem.
Nic tak dobrze nie integruje się z aplikacjami pisanymi w C i C++ jak zestaw
bibliotek napisanych w C++.
• Aplikacje pisane w języku C++ można przygotować do uruchomienia w ten spo-
sób, że na maszynie docelowej nie będą wymagały instalowania żadnego
dodatkowego oprogramowania. Oznacza to, że instalacja takich aplikacji może
być prostsza i tańsza niż aplikacji wymagających obecności interpretera lub
maszyny wirtualnej.
• Istnieje wielu dobrze wyszkolonych programistów znających język C++. Naucza-
nie tego języka znajduje się w programach wielu uczelni wyższych.
Zestaw narzędzi, który jest przedmiotem tej pracy, oprócz wspomnianych wyżej
ogólnych rozwiązań dotyczących programowania w języku C++, dostarcza podstawo-
we udogodnienia pozwalające szybko budować niewielkie aplikacje internetowe.
Typowe zastosowania mogą obejmować zdalną konfigurację jakiegoś oprogramowania
serwerowego, sklep internetowy lub bramkę internetową do wysyłania i odbierania
poczty elektronicznej. Pakiet nie wymaga instalowania niestandardowych bibliotek i
został przetestowany na wielu różnych systemach operacyjnych z rodziny Linux i
Unix. Całość projektu ma charakter otwarty. Dzięki obiektowej architekturze łatwe po-
winno być rozszerzenie oferowanej funkcjonalności do zastosowań w średnich i
dużych aplikacjach.
W rozdziale pierwszym zostały przedstawione różne powszechnie stosowane me-
tody budowania aplikacji internetowych z uwzględnieniem takich aspektów jak bez-
pieczeństwo, skalowalność, wydajność, przenośność, przydatność w projektach ze-
społowych oraz zakres zastosowań. Przegląd został opracowany głównie na podstawie
dokumentacji technicznej odpowiednich pakietów oprogramowania, podręczników
użytkownika, biuletynów internetowych dotyczących zagadnień bezpieczeństwa oraz
częściowo własnych badań.
Kolejny rozdział zawiera wymagania funkcjonalne i niefunkcjonalne stawiane
budowanemu systemowi. Wymagania te zostały tak sprecyzowane, żeby produkt
końcowy posiadał cechy wyróżniające go od innych systemów tego typu.
Rozdział trzeci opisuje ogólne założenia projektowe wynikające z przyjętych wy-
magań. Dzięki ustaleniu pewnych konwencji przed rozpoczęciem implementacji było

Wstęp 10
możliwe uzyskanie spójnego, czytelnego i łatwego w utrzymaniu kodu. Większość z
nich może być z powodzeniem stosowana w innych projektach opartych o język C++.
W rozdziale czwartym omówione zostały szczegóły projektu oraz wiele aspektów
implementacyjnych najważniejszych komponentów. Rozdział ten będzie przydatną
lekturą nie tylko dla tych, którzy chcieliby rozbudować projekt o dodatkową funkcjo-
nalność, ale również dla bardziej zaawansowanych użytkowników pakietu.
Aspekty praktycznego wykorzystania zestawu bibliotek zostały pokazane w roz-
dziale czwartym na przykładzie zrealizowanej i dokładnie przetestowanej aplikacji.
Omówione zostały również wymagania sprzętowe i systemowe, sposób instalacji oraz
podstawy posługiwania się bibliotekami we własnych programach.
W ostatnim rozdziale zawarto podsumowanie wykonanej pracy, określono stopień
spełnienia postawionych wymagań, ocenę całości pakietu na tle innych rozwiązań oraz
możliwości i kierunki jego dalszego rozwoju.

Rozdział I – Techniki budowania aplikacji internetowych
W chwili obecnej na rynku istnieje wiele różnych pakietów służących tworzenia
aplikacji internetowych. Stworzenie kompletnej i aktualnej ich listy jest trudne (a nie
wiadomo, czy w ogóle możliwe), ponieważ dziedzina ta stale się rozwija, a ilość do-
stępnego oprogramowania stale rośnie. Tabela 1 zawiera najpopularniejsze i naj-
częściej spotykane systemy tworzenia aplikacji internetowych podzielone na 3 grupy
ze względu na sposób uruchamiania aplikacji. Systemy te zostały dokładnie omówione
w pracy [KOL04].
Tabela 1: Najpopularniejsze systemy budowania aplikacji internetowych
Grupa Nazwa systemu Producent / Autorzy
Aplikacje uruchamiane pod bezpośrednią kontrolą sys-temu operacyjnego
CGI – Common Gateway In-terface
NCSA
FastCGI – Fast Common Gateway Interface
Open Market, Inc.
Aplikacje interpretowane, które mogą być zagnieżdżo-ne w dokumentach HTML.
PHP – Hypertext Preproces-sor
Rasmus Lerdorf, PHP Com-munity
ASP – Active Server Pages Microsoft, Inc.
iHTML Inline Internet Systems, Inc.
ColdFusion MX Macromedia
Aplikacje uruchamiane na maszynie wirtualnej
Java Servlets, Java Server Pages
Sun, Inc.
ASP.NET – Active Server Pages .NET
Microsoft, Inc.
1. CGI - Common Gateway Interface
CGI zostało opracowane w 1993 roku przez NCSA. Pierwsza implementacja CGI
powstała dla serwera WWW NCSA działającego w systemie operacyjnym UNIX, jed-
nak bardzo szybko pojawiły się implementacje dla innych serwerów i innych sys-
temów operacyjnych. Obecnie prawie wszystkie serwery WWW potrafią uruchamiać
aplikacje CGI.

Rozdział I – Techniki budowania aplikacji internetowych 12
Zasada działania aplikacji CGI jest bardzo prosta. Kiedy serwer WWW otrzymuje
od klienta żądanie pobrania dokumentu, który jest odpowiednio oznaczonym plikiem
wykonywalnym (np. poprzez rozszerzenie .cgi), to zamiast przesłać ten plik do klienta,
wykonuje go w odpowiednio przygotowanym środowisku. Na środowisko to składają
się odpowiednie zmienne systemowe zawierające m.in. dane wysłane przez klienta
oraz standardowe strumienie: wejścia, wyjścia i błędów. Plik wykonywalny (zwany też
czasem skryptem CGI) przesyła odpowiedź przeglądarce wysyłając wszystkie dane na
standardowe wyjście i kończy swoje działanie. Skrypty CGI można pisać w dowolnym
języku programowania. Najczęściej wykorzystywane są Perl, Python i C/C++. Więcej
szczegółów o projektowaniu i implementacji aplikacji CGI znajduje się w [COLB].
Mechanizm działania CGI ma znaczący wpływ na sposób projektowania złożo-
nych aplikacji. Zwykle aplikacja składa się z wielu samodzielnych, małych plików
wykonywalnych, z których każdy realizuje jeden (czasem więcej) proces przetwarza-
jący dane np. formularz wypełniony przez użytkownika albo zapytanie do relacyjnej
bazy danych. Naturalne więc wydaje się podejście strukturalne. CGI nie daje natomiast
żadnego wsparcia dla obiektowego projektowania aplikacji. Można stworzyć w pełni
obiektowy model całej aplikacji (i zobrazować go np. w języku UML), ale składniki
tego modelu (obiekty, klasy) nie będą się w prosty i bezpośredni sposób przekładały na
składniki działającej aplikacji. Dlatego czasem stosuje się podejście mieszane po-
legające na tym, że poszczególne skrypty projektuje i implementuje się obiektowo (np.
w C++), ale całość opisana jest modelem strukturalnym (np. ERD + DFD).
Realizacja dialogu między aplikacją CGI a użytkownikiem jest dużo trudniejszym
zadaniem niż w przypadku np. zwykłej aplikacji konsolowej. CGI dobrze nadaje się je-
dynie do obsługi konwersacji bezkontekstowych (odpowiedź jest funkcją bieżącego
zapytania – np. tak działają statyczne serwisy WWW). Natomiast, jeśli odpowiedź jest
zależna również od poprzednich zapytań wysłanych przez tego samego użytkownika,
to powstaje szereg problemów. Pierwszy problem polega na identyfikacji klienta.
Dany skrypt CGI może być “odpytywany” przez wielu klientów na raz – jak rozróżnić
poszczególne konwersacje (sesje)? Niestety projektant sam musi poradzić sobie z tym
problemem. Nadmienię, że jednym z częstych błędów jest identyfikowanie użytkow-
nika jedynie po jego numerze IP. Niestety może się zdarzyć, że dwóch klientów z tej
samej podsieci będzie równocześnie korzystać z naszej aplikacji i będą mieli taki sam
nr IP. Metody radzenia sobie z tą sytuacją są omówione szczegółowo dalej. Drugi
problem polega na zapamiętywaniu stanu aplikacji pomiędzy zapytaniami. Niestety, po
wysłaniu odpowiedzi skrypt CGI kończy swoje działanie. Gdy ten sam klient wyśle do

Rozdział I – Techniki budowania aplikacji internetowych 13
tego skryptu nowe zapytanie, to skrypt będzie w tym samym stanie, co przy poprzed-
nim pytaniu. Problem ten projektanci rozwiązują na różne sposoby:
• Zapis stanu sesji na dysku. Jest to sposób dość trudny w implementacji – trzeba
pamiętać o zabezpieczeniu danych przed niepowołanym dostępem oraz ich usu-
waniu po jakimś czasie. Należy też brać pod uwagę możliwość ataku DOS (denial
of service) poprzez całkowite zapełnienie dostępnej przestrzeni na dysku.
• Zapis stanu sesji w bazie danych. Odnoszą się do tego te same uwagi co wyżej.
Jeśli aplikacja korzysta z zewnętrznego systemu baz danych, to na ogół ta opcja
jest stosowana.
• Zapis danych po stronie klienta. Dane można zapisać jako tzw. ciasteczko (ang.
cookie). Mechanizm „ciasteczek” polega na przechowywaniu niewielkich porcji
danych przez przeglądarkę i odsyłaniu ich z każdym zapytaniem do serwera.
Możliwe jest też zapisanie danych w treści wysłanej odpowiedzi. Ponieważ od-
powiedź serwera ma zwykle postać dokumentu HTML, to można ten dokument
tak przygotować, żeby kolejne zapytanie zawierało w sobie stan sesji. Realizuje
się to albo poprzez wykorzystanie parametrów przekazywanych po znaku „?” w
odwołaniu do skryptu (dotyczy zapytań typu GET) albo poprzez zastosowanie
ukrytych pól formularza (dotyczy zapytań typu POST). Sposoby te są dobre, jeśli
zapis stanu sesji jest dość krótki i nie wydłuży znacząco czasu przekazywania
danych między aplikacją a przeglądarką.
Specyfika CGI powoduje, że przechowywanie danych w plikach nastręcza pewne
trudności. W typowych konfiguracjach serwera WWW, wszystkie skrypty CGI są wy-
konywane z uprawnieniami tego samego użytkownika (np. w systemach Unix może
być to “nobody” albo “www”) niezależnie od położenia skryptu. Dlatego wszelkie pli-
ki zapisywane i czytane przez skrypty, muszą mieć ustawione takie uprawnienia, aby
ten użytkownik miał do nich dostęp. Często jednak bywa tak, że istnieje więcej użyt-
kowników niż jeden w danym systemie. Wtedy ich aplikacje CGI mogą uzyskać
wzajemny dostęp do swoich danych.
Żeby rozwiązać ten problem, dla serwerów WWW opracowano szereg ulepszeń,
które pozwalają wykonywać skrypty CGI z uprawnieniami ich właściciela, a nie
wspólnego użytkownika. Jednym z takich ulepszeń jest np. suexec dla serwerów
Apache. Wtedy każdy skrypt ma dostęp jedynie do swoich danych i danych swojego
właściciela. Z drugiej strony mechanizm ten wprowadza ryzyko zdalnego uzyskania
przez niepowołane osoby uprawnień właściciela aplikacji. Uprawnienia te są zwykle

Rozdział I – Techniki budowania aplikacji internetowych 14
dużo szersze niż uprawnienia wspólnego użytkownika, kiedy ten mechanizm nie jest
używany. Dlatego bardzo rzadko mechanizm ten jest stosowany na serwerach ogólno-
dostępnych, gdzie każdy może umieszczać swoje aplikacje CGI.
W przypadku przechowywania danych w bazie danych nie zachodzi problem
ochrony dostępu pojawiający się przy użyciu plików. Każda aplikacja może posiadać
swoją własną, indywidualnie chronioną bazę danych. Zwykle systemy baz danych uży-
wają uwierzytelniania dostępu za pomocą haseł. Hasło może być albo podawane za
każdym razem przez użytkownika aplikacji (klienta), albo zaszyte na stałe w jej
kodzie. Takie przechowywanie hasła jest dosyć bezpieczne, bo zwykle można tak usta-
wić atrybuty plików wykonywalnych zawierających hasło, żeby nie można ich było
czytać, a jedynie można było wykonywać. Niestety z drugiej strony wydajność takiego
rozwiązania może być mniejsza, a poza tym nie zawsze dysponujemy systemem baz
danych.
CGI nie dostarcza żadnych udogodnień w zakresie przetwarzania danych. Twórca
aplikacji jest zdany na udogodnienia oferowane przez język programowania i ewen-
tualnie dodatkowe biblioteki. Z tego powodu być może jednym z popularniejszych
języków pisania aplikacji CGI jest Perl, który jest specjalnie przystosowany do prze-
twarzania zawiłych łańcuchów znaków w różnych formatach za pomocą wyrażeń
regularnych. Ponadto dla wielu języków (głównie C, Perl, Python) powstały pakiety
ułatwiające implementację typowych zadań takich jak np. odbieranie danych przekaza-
nych w formularzu zapisanym w HTML, czy odbieranie ciasteczka.
Wykrywanie błędów w skryptach CGI jest trudne. Nie istnieją narzędzia au-
tomatyzujące ten proces. Standardowe narzędzia jak np. debuggery nie są zbyt przy-
datne, gdyż nie zostały przystosowane do pracy z aplikacjami pracującymi jako skryp-
ty CGI. Nawet te debuggery, które potrafią dołączać się do wcześniej uruchomionego
procesu, na niewiele się zdadzą, bo proces aplikacji CGI uruchamiany jest w nieprze-
widywalnym momencie i istnieje jedynie przez chwilę. Testerzy radzą sobie w inny
sposób – metoda zwana żargonowo “printf debugging” jest łatwa do zastosowania i nie
wymaga żadnych dodatkowych narzędzi. Polega ona na umieszczaniu w kodzie
programu dodatkowych instrukcji informujących testera o przepływie sterowania i
wartościach zmiennych. Informacje te można wysłać do przeglądarki (strumień
wyjściowy), do logów serwera WWW (strumień błędów) lub np. do pliku. Po wykry-
ciu i poprawieniu błędów instrukcje te są dezaktywowane.

Rozdział I – Techniki budowania aplikacji internetowych 15
Szybkość działania aplikacji CGI ustępuje zwykle aplikacjom tworzonym w in-
nych systemach. Obsługa każdego zapytania wiąże się z uruchomieniem i za-
kończeniem nowego procesu, a to może stanowić spory narzut czasowy. W tabeli 2
przedstawione są wyniki pomiaru czasu wykonania bardzo prostego programu w
różnych systemach operacyjnych na tym samym komputerze (Pentium II XEON 450
MHz, 128 MB RAM). Są to czasy minimalne. Jeśli aplikacja będzie wymagała
dynamicznego łączenia z licznymi bibliotekami, to wartości te mogą się znacznie
zwiększyć.
Tabela 2: Porównanie czasów uruchamiania się procesu na różnych systemach operacyjnych
Linux – Slackware (kernel 2.4.19) (7,2 ± 0,2) ms
Unix – FreeBSD 4.6.2 (2,3 ± 0,2) ms
Windows 2000 Professional SP 3 (34 ± 3) ms
Żeby zlikwidować narzuty czasowe na uruchamianie procesu, niektóre serwery
WWW zostały wyposażone we wbudowane interpretery niektórych popularnych języ-
ków, w których pisane są skrypty CGI (np. mod_perl dla serwera Apache). Wtedy
obsługa zapytania nie powoduje uruchomienia nowego procesu, a jest wykonywana w
kontekście działającego wcześniej procesu serwera WWW. Taki sposób uruchamiania
programu narzuca wymaganie, aby plik wykonywalny był dodatkowo “do odczytu”
dla serwera WWW, co z kolei może wiązać się z obniżeniem poziomu bezpieczeństwa
skryptu. Niestety to rozwiązanie można stosować jedynie do języków interpretowa-
nych lub “kompilowanych w locie1”. Zwykle programy pisane w tych językach
ustępują efektywnością programom normalnie kompilowanym (np. Pascal, C/C++),
choć na ogół nie stanowi to poważnej przeszkody, bo skrypty CGI na ogół nie wy-
konują bardzo złożonego i czasochłonnego przetwarzania danych.
Zużycie pamięci skryptów CGI jest ściśle zależne od tego, jak aplikacja została
napisana i do czego służy. Krótkotrwałość istnienia skryptu powoduje, że stworzenie
aplikacji, która bezpowrotnie gubi pamięć (tzw. przecieki pamięci), jest trudne.
1 Kompilacja w locie polega na tym, że skrypt jest kompilowany do pamięci przy pierw-szym uruchomieniu, a przy każdym następnym jest wykonywany zapamiętany wcześniej kod. Ważna jest przy tym szybkość kompilacji, dlatego jakość optymalizacji jest gorsza, a i gramatyka języka nie może być zanadto złożona.

Rozdział I – Techniki budowania aplikacji internetowych 16
Przenośność CGI jest bardzo dobra. Interfejs CGI był projektowany z myślą o
wykorzystaniu go w wielu serwerach WWW i przez wielu różnych programistów
znających różne języki programowania. W tej chwili ciężko jest znaleźć serwer, który
nie posiadałby możliwości wykonywania skryptów CGI, tak samo jak ciężko jest
znaleźć język programowania, który nie dawałby możliwości korzystania ze zmien-
nych systemowych i standardowych strumieni we/wy. Z tego wynika również olbrzy-
mia uniwersalność tej technologii. Dodatkowo możliwość użycia różnych bibliotek
specyficznych dla użytego języka programowania powoduje, że technologia ta znala-
zła bardzo wiele zastosowań (mimo niskiej wydajności).
Standard CGI nie jest zależny również od systemu operacyjnego, dlatego na ogół
przeniesienie aplikacji z jednego systemu na drugi zależy głównie od tego, czy apli-
kacja nie korzysta poza CGI z jakichś niestandardowych bibliotek, rozszerzeń, poleceń
systemowych itd. Prawdopodobnie aplikację napisaną w języku Perl i korzystającą je-
dynie z poleceń tego języka będzie łatwo przenieść na inny system, gdzie jest dostępny
interpreter języka Perl. Natomiast aplikację napisaną w języku C i korzystającą z
niskopoziomowego API systemu Unix bardzo ciężko będzie dostosować do pracy w
systemie MacOS, mimo dostępności kompilatora języka C dla tego systemu. CGI
określa jedynie sposób komunikacji pomiędzy aplikacją a klientem. Wszelkie pozosta-
łe aspekty pozostawia projektantom aplikacji i to od nich zależy, czy stworzą przeno-
śne aplikacje, czy nie.
Bezpieczeństwo aplikacji CGI jest zależne od wielu czynników takich jak np.
użyty język programowania lub środowisko uruchamiania aplikacji. Wiadomo, że nie-
które języki programowania wysokiego poziomu szczególnie ułatwiają popełnianie
błędów krytycznych dla bezpieczeństwa aplikacji (a nawet całego systemu), a inne je-
dynie w mniejszym stopniu. Przykładowo pisząc skrypt CGI w języku C i używając
niskopoziomowych funkcji operujących na łańcuchach znaków takich jak scanf,
strcpy, strcat, gets itp. bardzo łatwo można popełnić błąd typu „buffer over-
flow” lub „off by one”. Błędy tego typu co jakiś czas znajdywane są nie tylko w skryp-
tach CGI pisanych w C, ale nawet w funkcjach jąder popularnych systemów operacyj-
nych, gdzie w końcu bezpieczeństwo i ochrona danych są dosyć ważne. Konsekwencje
ich przeoczenia mogą być bardzo poważne i na ogół skutkują tym, że niepowołana
osoba z zewnątrz może przejąć kontrolę nad aplikacją. Różne rodzaje błędów w skryp-
tach CGI oraz metody ich unikania omówiono w [FORR]. Podobnie środowisko, w
którym aplikacja jest uruchamiana ma kluczowe znaczenie. Wykorzystanie mecha-
nizmów zmieniających poziom uprzywilejowania skryptu (np. suexec) może podnieść

Rozdział I – Techniki budowania aplikacji internetowych 17
poziom bezpieczeństwa (np. poprzez lepszą ochronę plików z danymi), ale z drugiej
strony ich nieumiejętne stosowanie wraz z błędami wewnątrz aplikacji może przynieść
katastrofalne skutki.
2. FastCGI
FastCGI jest technologią wprowadzoną przez firmę OpenMarket Inc. w 1996
roku, aby umożliwić tworzenie bardzo szybkich i wydajnych aplikacji internetowych.
FastCGI zastępuje standardowy interfejs CGI i od strony użytkownika jest do CGI bar-
dzo zbliżone, dzięki czemu konwersja aplikacji CGI do FastCGI prawie nie wymaga
modyfikacji kodu źródłowego. Podobnie jak w klasycznej technologii CGI, zapytania
są przekazywane do aplikacji za pośrednictwem strumienia standardowego wejścia i
zmiennych systemowych, a wyniki zwracane za pośrednictwem strumienia standardo-
wego wyjścia.
W rzeczywistości dane pomiędzy serwerem WWW, a aplikacją są przekazywane
za pośrednictwem specjalnego protokołu, ale mechanizm ten jest dla programisty ukry-
ty. Poza tym FastCGI w nieco inny sposób zarządza uruchamianiem procesów. Za-
miast dla każdego zapytania uruchamiać nowy proces systemowy, serwer WWW uru-
chamia go raz, na samym początku. Proces przetwarza zapytania w pętli i po każdora-
zowym wysłaniu odpowiedzi do przeglądarki, pozostaje w pamięci. Dla zwiększenia
wydajności możliwe jest uruchomienie na początku od razu całej puli procesów, dzięki
czemu uzyskuje się lepszą współbieżność – jeśli jedno zapytanie będzie wymagało
więcej czasu, to nie wstrzyma wykonywania pozostałych. Szczegółowe informacje o
możliwościach konfiguracji FastCGI oraz zasadach tworzenia aplikacji znajdują się na
stronie WWW producenta [FCGI].
Ponieważ narzut na uruchamianie procesu jest pomijalny, zwykle dobrze jest za-
projektować całą aplikację jako pojedynczy skrypt, który przetwarza wszystkie rodzaje
zapytań. Skrypt musi zawierać specjalną pętlę obsługi zapytań, której postać jest okre-
ślona w dokumentacji. Czynności inicjalizacyjne, takie jak np. otwieranie połączeń do
systemu baz danych, dobrze jest umieścić poza tą pętlą (dla zwiększenia wydajności).
Dzięki temu, że skrypt „żyje” dłużej niż czas jednego zapytania, możliwe jest za-
stosowanie obiektowej metodologii projektowania aplikacji. Skrypt nie musi być tylko
izolowanym procesem, który przetwarza dane wprowadzane na jego wejście, ale może
zachowywać się jak obiekt lub zestaw obiektów (w sensie projektowania

Rozdział I – Techniki budowania aplikacji internetowych 18
obiektowego). Pozwala to zaprojektować całą aplikację przy użyciu metod obiek-
towych.
FastCGI oferuje dodatkowe wsparcie dla realizacji dialogu między aplikacją a
użytkownikiem. Stosowany może być bardzo prosty mechanizm sesji, w którym użyt-
kownicy identyfikowani są za pomocą wybranych zmiennych ustawianych przez ser-
wer WWW. Może być to np. numer IP klienta lub nazwa użytkownika. Jeśli aplikacja
działa jako pula procesów, FastCGI dba o to, aby zapytania od jednego klienta trafiały
do dokładnie jednego, zawsze tego samego procesu.
Należy zwrócić uwagę na fakt, że ten mechanizm, choć bardzo wygodny, nie jest
wystarczający, aby zapewnić bezpieczeństwo sesji. Problemem jest tu identyfikacja
użytkowników. W przypadku, gdy aplikacja nie wykorzystuje mechanizmów uwierzy-
telniania takich jak HTACCESS, rozróżnianie użytkowników za pomocą numeru IP
może prowadzić do niebezpiecznych anomalii. Przy powszechnym użyciu NAT2,
korzystanie z jednego numeru IP przez wielu użytkowników na raz nie jest rzadkością.
Dlatego projektant aplikacji musi wprowadzić dodatkowe mechanizmy wsparcia dla
sesji (oparte zwykle o dłuższe lub krótsze numery identyfikacyjne).
FastCGI nie oferuje żadnego specjalnego wsparcia dla mechanizmów dostępu do
danych. Pomaga jednak nieco ten dostęp zoptymalizować. FastCGI eliminuje bowiem
konieczność przeprowadzania czasochłonnych czynności inicjalizacyjnych takich jak
np. otwarcie pliku lub nawiązanie połączenia z systemem baz danych przy obsłudze
każdego zapytania. Zwykle takie czynności wykonuje się jedynie przy uruchamianiu
aplikacji, lub ewentualnie przy rozpoczynaniu nowej sesji. Poza tą drobną różnicą,
sposoby realizacji dostępu do danych w skryptach FastCGI są takie same jak w CGI.
Do śledzenia aplikacji FastCGI można użyć narzędzi do śledzenia zwykłych
programów. Ponieważ proces aplikacji jest obecny w pamięci przez cały czas aktyw-
ności aplikacji, nic nie stoi na przeszkodzie, żeby podłączyć do niego debugger. Usta-
wiając punkt przerwania na początek ciała pętli obsługi zapytań, można prześledzić od
początku do końca, w jaki sposób zachowuje się program przy realizacji zapytania.
Oczywiście plik wykonywalny musi zawierać odpowiednie informacje dla debuggera,
co uzyskuje się poprzez użycie odpowiedniego kompilatora z odpowiednim zestawem
opcji. Możliwości wykorzystania debuggera są uzależnione od języka programowania,
w którym została napisana aplikacja oraz możliwości systemu operacyjnego.
2 NAT – Network Address Translation – technika umożliwiająca wielu użytkownikom w jednej podsieci dzielić jeden publiczny nr IP dla komunikacji z siecią zewnętrzną.

Rozdział I – Techniki budowania aplikacji internetowych 19
FastCGI powinno być stosowane tam, gdzie bardzo ważna jest wydajność pracy
aplikacji. Wprowadzane narzuty czasowe są tak niewielkie, że czas realizacji zapytania
przez aplikację WWW może być zbliżony do czasu realizacji zapytania przez serwer
obsługujący statyczne strony WWW.
Za wydajność niestety trzeba zapłacić brakiem ochrony przed „przeciekami
pamięci”. Można się przed nimi zabezpieczyć poprzez automatyczne ponowne urucha-
mianie procesu co pewien czas (lub co pewną liczbę zapytań).
Ciekawą właściwością technologii FastCGI jest jej wsparcie dla aplikacji roz-
proszonych. Pliki wykonywalne nie muszą znajdować się na tej samej maszynie, co
serwer WWW. Serwer WWW może komunikować się z aplikacjami na innych
maszynach za pomocą protokołu TCP/IP. Dzięki temu całkowite obciążenie aplikacji
można rozdzielić pomiędzy wiele maszyn zmniejszając tym samym ich jednostkowe
obciążenie. Sam serwer WWW, choć obsługuje wszystkie zapytania, nie wykonuje
żadnego czasochłonnego przetwarzania. Często tego typu zrównoleglenie wykonuje
się poprzez postawienie oddzielnych serwerów i dzieleniu ruchu za pomocą odpowied-
nio skonfigurowanego serwera DNS. Jednak taka metoda wymaga posiadania większej
liczby publicznych numerów IP, a zrównoleglenie przy pomocy FastCGI – tylko jed-
nego.
FastCGI jest dostępne dla wielu różnych serwerów WWW, zarówno komercyj-
nych jak i darmowych (m.in. Apache, aXesW3, Microsoft IIS, SunOne, WebStar). Po-
zwala tworzyć aplikacje w wielu różnych językach (m.in. C, C++, Java, Perl, Python,
Lisp, Smalltalk), choć liczba wspieranych języków jest ograniczona przez dostępność
zestawu odpowiednich bibliotek. Biblioteki te nie są na razie dostępne dla języków
Pascal i Basic. Dlatego pod tym względem FastCGI wypada nieco gorzej. Podobnie
jak w CGI, przenośność jest silnie zależna od języka programowania oraz sposobu
programowania. W ogólnym ujęciu FastCGI nie jest ograniczone przez jakiś konkretny
rodzaj architektury ani system operacyjny.
Podobnie jak dla CGI, dla FastCGI istnieją mechanizmy pozwalające kontrolować
uprawnienia aplikacji. Jednym z nich jest FastCGI suexec.
3. PHP – Hypertext Preprocessor
PHP jest językiem skryptowym ogólnego zastosowania dostosowanym szczegól-
nie do potrzeb aplikacji internetowych. Interpreter PHP jest dostępny w sieci bezpłat-
nie, a cały projekt jest rozwijany na zasadach Open Source. W sieci Internet można

Rozdział I – Techniki budowania aplikacji internetowych 20
znaleźć bardzo dużo artykułów i poradników na temat tworzenia aplikacji w PHP. Na
stronie internetowej [PHP] są dostępne: interpreter PHP, pełna dokumentacja technicz-
na oraz bardzo dużo specjalistycznych artykułów dotyczących programowania w PHP.
Jest to prawdopodobnie obecnie najpopularniejsza technika wykorzystywana głównie
w prostych zastosowaniach takich jak strony domowe, niewielkie portale i sklepy in-
ternetowe.
Zasada działania PHP jest odmienna od CGI. Instrukcje PHP mogą być za-
gnieżdżone w kodzie HTML. Kiedy z sieci nadejdzie żądanie pobrania odpowiednio
oznaczonego dokumentu (zwykle jest to plik z rozszerzeniem .php), serwer WWW
przepuszcza dokument przez interpreter PHP działający jako filtr. Interpreter pozosta-
wia kod HTML prawie bez zmian, natomiast wstawki kodu PHP umieszczone po-
między odpowiednimi znacznikami są interpretowane i wykonywane. PHP potrafi
podstawiać w kodzie HTML wartości zmiennych, które są oznaczane znakiem „$”.
Kod HTML, w którym takie zmienne nie występują, nie jest modyfikowany. Dlatego
interpreter PHP może być wykorzystany do udostępniania zarówno aplikacji PHP jak i
statycznych stron WWW. Interpreter PHP może być albo niezależnym programem,
albo może być wbudowany w serwer WWW.
PHP jest językiem, który dobrze sprawdza się w realizacji prostych aplikacji za-
projektowanych strukturalnie. Brak wyraźnego podziału między interfejsem użytkow-
nika (najwyższa warstwa – zwykle statyczny kod HTML) a logiką aplikacji (wstawki
kodu) powoduje, że PHP niezbyt dobrze nadaje się do tworzenia rozbudowanych apli-
kacji. Tę właściwość ma dużo języków skryptowych. Przy większej złożoności zacho-
dzi potrzeba stosowania dodatkowych bibliotek służących do uporządkowania projektu
np. poprzez wprowadzenie systemu szablonów. Przy takim podejściu dane (np. pliki
HTML) są oddzielone od kodu umieszczonego w osobnych plikach. Ułatwia to znacz-
nie późniejszą pielęgnację aplikacji oraz modyfikowanie jej interfejsu użytkownika.
Takie podejście ułatwia też zespołową pracę nad projektem.
PHP posiada wsparcie dla programowania obiektowego. Wykorzystanie obiek-
towości w PHP wiąże się jednak ze znacznie większymi narzutami czasowymi niż w
przypadku języka C++. W PHP nie jest możliwe tworzenie obiektów o długim czasie
życia (przechowywanych w obiektowej bazie danych, pliku, „ciasteczku” itd...). Nie
można przez to stworzyć interfejsu użytkownika sterowanego zdarzeniami. Ponadto
standardowa instalacja PHP dostarcza jedynie zestaw pojedynczych funkcji, nie za-
wiera natomiast definicji ani jednej klasy. W Internecie można oczywiście znaleźć

Rozdział I – Techniki budowania aplikacji internetowych 21
mnóstwo różnych definicji klas dla PHP. Istnieją również całe biblioteki klas ogólnego
przeznaczenia. Jedną z najbardziej rozbudowanych jest PEAR [PEAR].
PHP posiada wbudowany mechanizm sesji realizowany za pośrednictwem
„ciasteczek” oraz przepisywania adresów wywołań. Żeby skorzystać z tego mecha-
nizmu, należy w skrypcie wywołać odpowiednią funkcję, która przydzieli identyfikator
sesji oraz umożliwi przechowywanie danych sesji w zewnętrznej pamięci (zwykle na
dysku). Identyfikator sesji jest odsyłany do przeglądarki w postaci „ciasteczka” lub, je-
śli przeglądarka nie obsługuje „ciasteczek”, zostaje dopisany jako parametr do
wszystkich hiperłączy względnych odwołujących się do skryptów PHP. W ten sposób
kolejne zapytanie HTTP niesie w sobie informację o sesji.
PHP posiada dużo udogodnień służących do obsługi relacyjnych baz danych.
Liczba obsługiwanych systemów baz danych jest bardzo duża i stale rośnie. Dla nie-
komercyjnych systemów baz danych MySQL i PostgreSQL PHP posiada wbudowane
wsparcie i nie zachodzi konieczność instalowania osobnych modułów. Niestety
wielość niekompatybilnych ze sobą interfejsów bazodanowych przyczynia się do tego,
że nie zawsze jest możliwa szybka migracja z jednego systemu baz danych do innego.
PHP obsługuje również uniwersalny interfejs ODBC, jednak jest on rzadko wybierany
przez programistów, ponieważ nie może zapewnić takiej funkcjonalności jak interfejsy
specjalizowane. Dużą zaletą PHP jest możliwość tworzenia połączeń stałych z sys-
temem baz danych. Oznacza to, że przy każdym uruchamianiu skryptu nie zachodzi
konieczność ponownego, czasochłonnego nawiązywania połączenia. Rozwiązania bar-
dziej zaawansowane takie jak wykorzystanie puli połączeń nie są jeszcze dostępne.
Warto wspomnieć, że w PHP bardzo prosto realizuje się operacje pobierania
danych z innych źródeł niż bazy danych, np. z sieci, za pośrednictwem protokołów
FTP, HTTP, POP3 czy IMAP. Można też przechowywać dane na komputerze klienta,
za pośrednictwem ciasteczek.
Wbudowane mechanizmy przetwarzania danych są kolejną mocną stroną PHP.
Sam język programowania jest niemal tak elastyczny jak C (posiada podobną składnię,
choć charakteryzuje się słabszą typizacją), a poza tym programista ma do dyspozycji
bogatą bibliotekę funkcji. Twórcy PHP starali się dostosować zestaw funkcji tak, żeby
odpowiadał niemal każdemu, stąd często te same zadania można wykonać na wiele
sposobów. Przykładowo do obsługi wyrażeń regularnych zaimplementowano zestawy
funkcji znanych z języka Perl oraz określonych standardem POSIX. Zestaw funkcji

Rozdział I – Techniki budowania aplikacji internetowych 22
został opracowany tak, żeby typowe zadania takie jak np. wysłanie poczty, czy wyge-
nerowanie obrazu dało się bardzo łatwo realizować.
Niestety nic nie jest idealne – zdarza się, że wraz z uaktualnieniem PHP do naj-
nowszej wersji, niektóre funkcje nie są do końca „kompatybilne wstecz”. Podobnie
model obiektów został istotnie zmieniony wraz z pojawieniem się nowej wersji PHP 5.
Napisano wiele debuggerów dla PHP. Istnieją zarówno projekty komercyjne jak i
rozprowadzane na bazie licencji GPL. PHP 4 nie posiada wbudowanych narzędzi do
wykrywania błędów. Począwszy od wersji 5 PHP posiada obsługę wyjątków bardzo
podobną do tej znanej z języka Java. Niestety standardowe funkcje nie używają tego
mechanizmu do sygnalizacji błędów. Programista jest zdany pod tym względem na
klasyczną metodę zwracania z funkcji ustalonej wartości w przypadku niepowodzenia
(typowo „-1” lub „0”). Z drugiej strony, jak w większości języków skryptowych, w
PHP trudniej popełniać błędy – nie ma wskaźników ani niskopoziomowych funkcji
dynamicznego przydziału pamięci i innych funkcji, które w języku C sprawiają zwykle
kłopoty. W PHP przyjęto strategię, że skrypt musi się wykonać do końca, nawet jeśli w
trakcie wykonania wystąpią błędy. Zarówno błędy wykonania, jak i błędy składniowe
są sygnalizowane w trakcie wykonywania skryptu poprzez wyświetlenie komunikatu
w oknie przeglądarki (faza kompilacji nie istnieje).
Aplikacje tworzone w PHP działają o wiele szybciej, jeśli interpreter PHP jest
zintegrowany z serwerem WWW. W przeciwnym wypadku, każdorazowe urucha-
mianie interpretera wprowadza narzut większy niż w standardowych aplikacjach CGI.
Natomiast wykonanie kodu PHP przebiega niemal tak szybko, jak gdyby aplikacja
była skompilowana do kodu maszynowego. Dzieje się tak dlatego, że wszystkie funk-
cje biblioteczne są częścią interpretera, który został napisany w C/C++ i skompilowa-
ny do kodu maszynowego. Proces interpretacji też jest dobrze zoptymalizowany. Za-
dbano o to, żeby każda instrukcja była interpretowana dokładnie raz, nawet jeśli wy-
konywana jest więcej razy. Kod źródłowy jest bowiem przy pierwszym wykonaniu
przekształcany do postaci pośredniej, której wykonanie jest prostsze. Kolejne wy-
konania tego samego fragmentu programu trwają krócej niż za pierwszym razem.
Ponadto jest możliwe zastosowanie „akceleratorów”, które zapisują w pamięci wyniki
wykonania skryptu oraz kod pośredni, dzięki czemu unika się niepotrzebnej interpreta-
cji kodu źródłowego, a czasem nawet wykonywanie skryptu nie jest w ogóle potrzebne
(np. jeśli skrypt tylko formatuje dane odczytane z bazy danych, a zawartość bazy nie
była zmieniana od ostatniego wywołania skryptu).

Rozdział I – Techniki budowania aplikacji internetowych 23
Zużycie pamięci przez aplikację PHP jest niewielkie. Interpreter zwykle po-
trzebuje kilka megabajtów, ale jest ładowany do pamięci tylko raz.
Aplikacje PHP działają wszędzie, gdzie jest dostępny interpreter tego języka. A
interpreter ten jest dostępny praktycznie dla większości serwerów WWW.
W PHP trudno jest pisać nieprzenośne aplikacje. Wbudowane funkcje bibliotecz-
ne oferują tak dużą funkcjonalność, że bardzo rzadko zachodzi potrzeba wywoływania
funkcji specyficznych dla konkretnego systemu operacyjnego. Jedyne problemy mogą
pojawić się z chwilą uaktualnienia wersji interpretera PHP. Pewne funkcje są wycofy-
wane jako przestarzałe i po pewnym czasie starsze programy mogą nie działać. Jest to
jednak typowe dla szybko rozwijających się technologii.
Bezpieczeństwo każdej aplikacji jest zależne od sposobu jej napisania. Niestety
PHP nie ułatwia pisania bezpiecznych aplikacji. Jest to spowodowane dążeniem do
uniwersalności i wygody użytkowania biblioteki funkcji. Często jedna funkcja może
być użyta w bardzo wielu zastosowaniach. Przykładowo bardzo złą renomę ma funkcja
include służąca do wykonania kodu PHP z innego pliku. Funkcję tę można wy-
korzystać do wstawiania dokumentów HTML, które mają być jakoś zagnieżdżone we-
wnątrz dokumentu generowanego przez skrypt PHP. Niestety funkcja ta potrafi dużo
więcej. Przy pewnych ustawieniach interpretera PHP można za jej pomocą wczytać
kod PHP z innego źródła niż lokalny dysk twardy np. z obcego serwera. Ataki wy-
korzystujące tę technikę nazywane są fachowo „cross site scripting” i ich ofiarą padają
często nawet duże serwisy tworzone przez profesjonalistów. Istnieje również całkiem
poważny problem zabezpieczenia haseł dostępu do baz danych. Są one wstawiane do
kodu, a ten z kolei musi być czytelny dla interpretera. Niepowołanej osobie wystarczy
zdobyć niewielkie uprawnienia, zwykle te przyznane serwerowi WWW, żeby odczytać
hasła.
4. ASP – Active Server Pages
ASP to technologia stworzona przez Microsoft realizująca podobne zadania jak
PHP i sprawdzająca się w podobnych zastosowaniach. Zasada działania aplikacji ASP
jest bardzo podobna do PHP. Interpreter ASP będący częścią serwera WWW (w sys-
temach Windows interpreter jest ładowany jako biblioteka DLL) wczytuje skrypt ASP
i przesyła wynik jego działania przeglądarce internetowej. Postać skryptu jest niemalże
identyczna jak postać skryptu PHP. Jest to plik HTML z wstawkami kodu napisanego
na ogół w języku JScript lub VBScript.

Rozdział I – Techniki budowania aplikacji internetowych 24
ASP posiada podobnie jak PHP posiada wbudowany mechanizm obsługi sesji.
Mechanizm ten wykorzystuje „ciasteczka” do przechowywania identyfikatora sesji, a
stan sesji jest przechowywany w wewnętrznych strukturach danych serwera.
Aplikacje ASP mogą łączyć się z systemami baz danych poprzez interfejs ADO
(ActiveX Data Objects). ASP posiada wbudowane sterowniki do systemów: MS SQL i
MS Access. Może też współpracować z dowolnym systemem baz danych poprzez in-
terfejs ODBC lub za pośrednictwem sterowników dostarczonych przez producenta sys-
temu baz danych. Cechą charakterystyczną interfejsu ADO jest możliwość przetwarza-
nia danych po stronie klienta. Można np. pobrać zawartość części tabeli, a następnie ją
zmodyfikować i odesłać do serwera wykorzystując specjalny mechanizm RDS
(Remote Data Service).
Biblioteka funkcji w ASP nie jest aż tak rozbudowana jak w PHP, ale mimo to
oferuje funkcjonalność wystarczającą w wielu typowych zastosowaniach. Przy two-
rzeniu dużych aplikacji uciążliwy staje się brak typizacji zmiennych. Kod jest przez to
mniej czytelny i łatwiej popełniać błędy. Nie można też tworzyć złożonych struktur
danych takich jak kolejki, drzewa itp. gdyż VBScript i JScript nie udostępniają
wskaźników.
ASP jest zbudowane w oparciu o technologię COM. Powoduje to, że wywołanie
każdej funkcji wbudowanej w ASP wiąże się z dużym narzutem czasowym i
pamięciowym. Dodatkowo skrypty ASP są interpretowane (podobnie jak PHP), a in-
terpreter firmy Microsoft interpretuje kod ASP wolniej, niż interpreter PHP urucho-
miony w tym samym systemie operacyjnym. Interpreter ASP dosyć rozrzutnie traktuje
też przydzielanie pamięci operacyjnej. Wielokrotne włączenie tego samego pliku jako
część składowa aplikacji ASP (za pomocą dyrektywy include) powoduje wielokrot-
ne umieszczenie tego pliku w pamięci. Wady tej nie posiada jedynie interpreter ASP w
wersji 5.0 pracujący pod kontrolą systemu Windows 2000 Server.
ASP nie jest tak przenośne jak PHP - interpreter jest dostępny jedynie dla ser-
werów WWW firmy Microsoft. Istnieją implementacje ASP działające z serwerem
Apache pod kontrolą systemu operacyjnego Linux lub Unix, jednak nie są one
całkowicie zgodne z produktami firmy Microsoft. Mimo że technologia ASP jest roz-
powszechniana bezpłatnie, jej wykorzystanie jest obarczone dodatkowymi kosztami
ukrytymi, związanymi z koniecznością zakupu systemu operacyjnego MS Windows.
Przenośność aplikacji ASP pomiędzy różnymi odmianami systemu MS Windows jest
ograniczona przez przenośność komponentów COM, z których aplikacja korzysta.

Rozdział I – Techniki budowania aplikacji internetowych 25
Komponenty te są bowiem pisane zwykle w języku C++ i korzystają ze specyficznych
usług systemu operacyjnego. Standardowe komponenty wbudowane w ASP są przeno-
śne.
Więcej o szczegółach tworzenia aplikacji ASP można przeczytać w [MITC03].
5. iHTML
iHTML to komercyjny produkt firmy Inline, Inc. Stanowi on rozszerzenie języka
HTML o zestaw znaczników umożliwiających wstawianie do dokumentu treści gene-
rowanych dynamicznie. Zestaw ten jest bardzo szeroki i pozwala na automatyzację
takich czynności jak manipulacja danymi w relacyjnych bazach danych, generowanie
grafiki, czy wykonywanie prostych obliczeń. iHTML posiada też znaczniki od-
powiadające podstawowym instrukcjom kontroli przepływu sterowania takim jak in-
strukcje warunkowe i pętle.
Zasada udostępniania dokumentów iHTML przez WWW jest podobna do PHP,
choć język zastosowany w iHTML bardzo się od PHP różni. Strona jest wczytywana
przez interpreter zainstalowany jako rozszerzenie serwera WWW. Dokumentacja inter-
pretera [INL1] jest dosyć obszerna i zawiera również przykłady gotowych prostych
aplikacji. Można ją uzyskać ze strony producenta [INL2] po uprzednim zarejestrowa-
niu się.
iHTML słabo wspiera metodologię projektowania zarówno strukturalnego jak i
obiektowego. iHTML nie posiada takich możliwości oddzielenia kodu od danych, jak
PHP. Nie jest możliwe tworzenie funkcji, procedur ani złożonych struktur danych w
tym języku. Aplikację najprościej projektuje się poprzez dodawanie do statycznego
serwisu WWW treści generowanych dynamicznie (np. z bazy danych) poprzez uzupe-
łnienie kodu HTML o dodatkowe znaczniki iHTML.
iHTML nie posiada znaczników automatyzujących realizację sesji. Projektant
aplikacji może jednak wykorzystać do tego celu ciasteczka lub przepisywanie adresów.
iHTML został zaprojektowany szczególnie z myślą o wykorzystaniu relacyjnych
baz danych. Potrafi obsługiwać dowolny system, który udostępnia interfejs ODBC.
Znaczniki do konstruowania zapytań i prezentacji danych są bardzo łatwe w użyciu i
można się ich nauczyć w kilka minut. iHTML nie posiada interfejsów dedykowanych
konkretnym systemom baz danych. Dzięki temu możliwe jest przystosowanie
wcześniej napisanej aplikacji do pracy z innym systemem, ale z drugiej strony nie jest

Rozdział I – Techniki budowania aplikacji internetowych 26
możliwe korzystanie z systemu bazy danych, jeśli odpowiedni sterownik ODBC nie
został zainstalowany. iHTML potrafi również przechowywać dane w plikach oraz po-
zyskiwać je za pośrednictwem sieci TCP/IP.
W porównaniu z PHP możliwości przetwarzania danych wyglądają dość skrom-
nie. iHTML pozwala automatyzować wiele typowych, prostych czynności takich jak
wysłanie poczty, złożenie obrazu z kilku plików, przetworzenie uzyskanych danych z
formularza lub zapytania SQL, czy wykonanie prostych obliczeń matematycznych.
Można też korzystać z wyrażeń regularnych.
Brak możliwości programowania strukturalnego powoduje jednak, że iHTML
sprawdza się tylko w typowych sytuacjach. Nietypowe zadania, dla których algorytmu
nie da się zakodować przy pomocy sekwencji kilku prostych instrukcji, implementuje
się bardzo trudno. Brakuje podstawowych struktur danych takich jak wektor lub tabli-
ca asocjacyjna (w innych językach skryptowych takich jak PHP, Perl czy Python jest
to standard). Na szczęście ograniczenie to można pominąć poprzez wprowadzanie wła-
snych znaczników, których znaczenie definiuje się w zewnętrznej bibliotece dołącza-
nej dynamicznie.
iHTML posiada kilka mechanizmów pozwalających usprawnić wykrywanie i usu-
wanie błędów. Za pomocą specjalnego znacznika iERROR można zbudować blok,
który działa jak sekcja wyłapywania wyjątków. Jeśli wystąpi błąd, kod zawarty we-
wnątrz tej sekcji jest wykonywany i program może na tę sytuację zareagować. Drugim
mechanizmem jest logowanie komunikatów o błędach. Można tak skonfigurować
iHTML, żeby wszystkie informacje o błędach (składniowych i wykonania) były
kierowane do określonego pliku tekstowego.
Wymagania sprzętowe iHTML są mniejsze niż PHP. Interpreter jest zintegrowany
z serwerem WWW (działa jako biblioteka dynamicznie dołączana), więc narzuty
czasowe nakładane na realizację pojedynczego zapytania HTTP są pomijalnie małe.
Należy jednak pamiętać, że kod iHTML jest bezpośrednio interpretowany, więc musi
się wykonywać wolniej niż gdyby był skompilowany do postaci natywnej lub kodu
pośredniego. Dlatego przeprowadzanie złożonego przetwarzania w skrypcie iHTML
nie jest wskazane.
iHTML działa na wszystkich serwerach WWW zgodnych ze specyfikacjami
NSAPI, ISAPI i WSAPI. iHTML nie jest teoretycznie zależne od platformy sprzętowej
ani systemu operacyjnego. Niestety firma Inline nie rozprowadza kodu źródłowego,
więc w praktyce instalacja jest jedynie możliwa na tych systemach, dla których dostęp-

Rozdział I – Techniki budowania aplikacji internetowych 27
ne są postaci binarne iHTML tj. na MS Windows, Linux, Solaris, BSDi oraz FreeBSD.
Jeśli aplikacja nie definiuje własnych znaczników, to jej przenośność pomiędzy sys-
temami jest gwarantowana. Na wszystkich platformach wszystkie znaczniki mają
zunifikowane działanie.
6. ColdFusion
ColdFusion to komercyjny pakiet oprogramowania stworzony przez firmę
Macromedia, bardzo podobny do iHTML, ale bardziej rozbudowany i o dużo więk-
szych możliwościach. ColdFusion jest udostępniane w trzech edycjach: „Developer”,
„Standard” i „Enterprise”. Edycja „Developer” jako jedyna jest oferowana bezpłatnie,
jednak umożliwia uruchamianie aplikacji ColdFusion jedynie w ograniczonym,
testowym środowisku (np. możliwe jest podłączenie tylko jednego klienta do
aplikacji). Dokumentacja techniczna do wszystkich edycji jest dostępna pod adresem
[CF].
Zasada działania ColdFusion jest taka sama jak iHTML. Firma Macromedia stwo-
rzyła specjalny język CFML (ColdFusion Markup Language), który jest rozszerzeniem
języka HTML o dodatkowy zestaw znaczników realizujących różne funkcje. Doku-
menty CFML są przetwarzane przez interpreter ColdFusion, który interpretuje
wszystkie znaczniki o nazwach zaczynających się od liter „cf”.
Dostępne są znaczniki pozwalające korzystać z podstawowych protokołów
komunikacyjnych (HTTP, FTP, SMTP, POP3), usług katalogowych (LDAP) oraz z
dostępu do plików. Istnieje również wiele użytecznych funkcji ułatwiających przetwa-
rzanie tekstu (np. biblioteka funkcji pozwalających korzystać z wyrażeniach regular-
nych), sprawdzanie poprawności danych wprowadzanych przez użytkownika oraz
prezentowanie wyników w graficznej postaci. Bardzo ważną cechą jest też uwzględ-
nienie różnych standardów kodowania znaków. ColdFusion posiada również zestaw
komponentów do przetwarzania dokumentów zapisanych w formacie XML. ColdFu-
sion dobrze współpracuje z technologią Macromedia Flash, dzięki czemu prezentacja
danych w przeglądarce nie jest ograniczona jedynie do możliwości języka HTML.
ColdFusion posiada wbudowany mechanizm obsługi sesji, pozwala też używać
mechanizmu sesji J2EE (omówiony w rozdziale poświęconym JSP i Java Servlets).
Standardowy mechanizm sesji udostępnia programiście dwa obiekty „Session” oraz
„Client”. Pierwszy z nich przechowuje dane dotyczące użytkownika, drugi dane
związane z bieżącą sesją. Dane dotyczące użytkownika mogą być zapisywane w

Rozdział I – Techniki budowania aplikacji internetowych 28
„ciasteczku”, bazie danych albo w plikach na twardym dysku serwera i mogą składać
się jedynie ze zmiennych typów prostych. Dane dotyczące sesji są przechowywane w
pamięci serwera i mogą być zmiennymi dowolnego typu, również obiektami. Użyt-
kownicy są identyfikowani za pomocą losowo generowanego numeru. ColdFusion
używa tych samych identyfikatorów do identyfikowania użytkowników i iden-
tyfikowania sesji. Identyfikatory te są generowane losowo przy każdym zapytaniu,
które nie zawiera identyfikatora użytkownika.
ColdFusion potrafi współpracować z dowolnym systemem baz danych dostępnym
przez interfejsy ODBC i JDBC. Ponadto posiada wbudowane sterowniki do systemów:
Oracle, Sybase Adaptive Server, IMB DB2 UDB, Informix Dynamic Server, Microsoft
SQL, Microsoft Access, MySQL, SQLAnywhere i PostgreSQL. Niektóre z tych
sterowników są niestety dostępne tylko w wersji „Enterprise”. ColdFusion udostępnia
jednolity interfejs służący do korzystania z różnych systemów baz danych.
Pakiet ColdFusion zawiera zestaw narzędzi pozwalających monitorować stan apli-
kacji bez ingerencji w jej działanie. Debugger wyświetla informacje dotyczące liczby
zapytań, szybkości odpowiedzi aplikacji, aktywności bazy danych, zawartości zmien-
nych związanych z sesją i wiele innych. Za pomocą specjalnego znacznika można też
w aplikacji ustawiać tzw. punkty kontrolne, o których osiągnięciu debugger będzie in-
formował. Istnieje też możliwość weryfikacji, czy kod CFML nie zawiera błędów skła-
dniowych ani przestarzałych funkcji, które mogłyby spowodować problemy z przeno-
śnością.
Język CFML posiada mechanizm wyjątków działający podobnie do mechanizmu
wyjątków znanego z języka Java czy C++. Umożliwia to eleganckie oddzielenie kodu
obsługi błędów od logiki aplikacji.
Aby wykorzystać w pełni możliwości ColdFusion, należy zaopatrzyć się w sprzęt
o dostatecznie dużej ilości pamięci operacyjnej. Producent zaleca co najmniej 512 MB.
Serwer ColdFusion jest bardzo rozbudowany. Zwykle aplikacje wykorzystują niewiel-
ką część funkcjonalności pakietu, ale nie da się z ColdFusion usunąć niewykorzy-
stywanych komponentów. Producent jedynie oferuje wybór między bardziej rozbudo-
waną wersją „Enterprise” i nieco ograniczoną wersją „Standard”.
Natomiast szybkość działania aplikacji ColdFusion jest porównywalna z szyb-
kością wykonywania skryptów PHP. Dzieje się tak dlatego, że język CFML ma bardzo
prostą składnię, a wszystkie funkcje są częścią interpretera i wykonują się pod kontrolą
systemu operacyjnego, bez pośrednictwa dodatkowych warstw. Stwierdzenie to nie do-

Rozdział I – Techniki budowania aplikacji internetowych 29
tyczy oczywiście wykorzystania komponentów wykonanych w innych technologiach
takich jak J2EE, CORBA, COM, z którymi ColdFusion może współpracować. Cold-
Fusion umożliwia rozproszenie ruchu sieciowego na więcej niż jedną maszynę. Potrafi
też wykorzystać moc obliczeniową maszyn wieloprocesorowych.
Aplikacje ColdFusion mogą pracować na systemach operacyjnych Windows,
Linux, Solaris i HP-UX. W skryptach CFML nie zachodzi na ogół konieczność wywo-
ływania funkcji specyficznych dla systemu operacyjnego (choć istnieje taka możliwo-
ść), więc aplikacje dają się łatwo przenosić pomiędzy różnymi systemami. Jedynym
wymaganiem jest zainstalowanie pakietu ColdFusion na serwerze WWW. ColdFusion
współpracuje z następującymi serwerami WWW: Microsoft IIS, Netscape Enterprise
Server, iPlanet SunONE WebServer, Apache. ColdFusion posiada też własny, wbudo-
wany serwer WWW.
Twórcy ColdFusion poświęcili sporo uwagi zagadnieniom bezpieczeństwa apli-
kacji internetowych. Ich produkt pozwala na ograniczenie aplikacji możliwości użycia
wybranych znaczników. Dzięki temu można zabronić aplikacji korzystać np. z plików.
Takie zabezpieczenie może być utrudnieniem przy przeprowadzaniu ataku typu „cross-
site scripting”. ColdFusion posiada też funkcje pozwalające na sprawdzanie poprawno-
ści danych dostarczanych za pośrednictwem formularzy. Szczególnie zaleca się ich
użycie przy konstruowaniu zapytań SQL.
7. Java Servlets i Java Server Pages
Java Servlets i JSP to technologia umożliwiająca tworzenie aplikacji interne-
towych w języku Java (w edycji „Enterprise” – J2EE) stworzona przez firmę Sun
Microsystems Inc. Język Java powstał dużo wcześniej i sprawdził się w wielu różnych
zastosowaniach (aplikacje okienkowe, „aplety” na stronach internetowych, aplikacje
dla urządzeń przenośnych itp.). Z pewnością jest to jeden z najbardziej uniwersalnych i
najszybciej rozwijających się obiektowych języków programowania dostępnych obec-
nie na rynku.
U podstaw aplikacji internetowych tworzonych w technologii3 Java leżą serwlety.
Serwlet to klasa przystosowana do realizacji żądań HTTP napisana w języku Java.
Obiekt tej klasy jest tworzony przy pierwszym żądaniu. Każde następne żądanie jest
obsługiwane przez wcześniej utworzony obiekt, poprzez wywołanie jego metody do
3 Java to nie tylko język programowania, ale również rozbudowany zestaw bibliotek i na-rzędzi wspomagających projektowanie, implementację i testowanie aplikacji.

Rozdział I – Techniki budowania aplikacji internetowych 30
Get lub doPost. Metody ta przesyłają odpowiedź za pośrednictwem obiektu klasy
Response. Taki sposób komunikowania się aplikacji z użytkownikiem może być
nieco niewygodny, jeśli zachodzi konieczność wysłania dużej ilości statycznych
danych, zwykle określających wygląd interfejsu aplikacji. Wtedy kod „serwletu” może
składać się w większości z wywołań response.write i stać się nieczytelny. Dla
lepszego oddzielenia wyglądu interfejsu od logiki aplikacji, wprowadzono JSP. Apli-
kacje w JSP tworzy się bardzo podobnie jak w ASP lub PHP. Aplikacja składa się z
dokumentów HTML ze wstawkami kodu pisanego w języku Java. Dokumenty te są
przekształcane automatycznie do postaci „serwletów”, kompilowane i uruchamiane.
Pełna dokumentacja techniczna znajduje się na stronach internetowych firmy Sun
[J2EE]. Istnieje też wiele przystępnych podręczników w języku polskim [HOUG02,
GOOD01] opisujących metody tworzenia internetowych aplikacji w języku Java.
Aplikacje internetowe w technologii Java projektuje się zwykle stosując metodo-
logię obiektową, ponieważ język Java jest językiem obiektowym. Zwykle kod od-
powiedzialny za logikę aplikacji realizuje się w postaci zestawu oddzielnych klas języ-
ka Java (na ogół są to komponenty Java Beans), natomiast stronę wizualną interfejsu
tworzy się korzystając z JSP. Cechą charakterystyczną dobrze zaprojektowanych apli-
kacji w języku Java jest ich olbrzymia skalowalność. Java idealnie nadaje się do two-
rzenia dużych aplikacji przez duże zespoły. Szczegóły projektowania dużych aplikacji
w języku Java opisano w [ALUR03].
Java oferuje jednolity i prosty w użyciu interfejs JDBC do łączenia się z różnymi
systemami baz danych. Liczba dostępnych sterowników JDBC do różnych systemów
baz danych jest bardzo duża i bardzo szybko rośnie. W chwili pisania tej pracy, Sun
Microsystems Inc. dysponował 197 sterownikami. Trudno znaleźć system baz danych,
dla którego nie istniałby sterownik.
Java jest uniwersalnym językiem programowania, więc posiada komponenty słu-
żące do dostępu do plików, strumieni, gniazd, gniazd SSL, protokołów internetowych
(m.in. SMTP, POP3, FTP, HTTP) itp. Biblioteka klas jest bardzo duża. Jej omówienie
znacznie wykracza poza zakres tej publikacji. Java oferuje standardowe mechanizmy
przetwarzania danych spotykane w językach wysokiego poziomu. Rozbudowana
biblioteka oferuje zarówno klasy implementujące podstawowe struktury danych takich
jak drzewa, tablice asocjacyjne, itp. jak i komponenty realizujące złożone przetwarza-
nie danych w formacie XML z użyciem szablonów XSLT. W przeciwieństwie do
bibliotek PHP, ASP i ColdFusion, biblioteka klas Java jest biblioteką uniwersalną,
ukierunkowaną nie tylko na użycie jedynie w aplikacjach internetowych.

Rozdział I – Techniki budowania aplikacji internetowych 31
W JSP i „Serwletach” można korzystać z wielu zaawansowanych metod śledzenia
wykonania aplikacji internetowej. Środowisko J2EE umożliwia zarówno śledzenie lo-
kalne jak i zdalne, za pośrednictwem protokołu TCP/IP. Standardowy debugger jdb
udostępnia bardzo wiele funkcji m.in.: ustawianie punktów przerwań, śledzenie war-
tości zmiennych, praca krokowa, śledzenie aplikacji wielowątkowych itp. Dostępnych
jest też wiele graficznych narzędzi zwiększających wygodę użytkowania jdb. Możliwe
jest używanie standardowych sposobów śledzenia poprzez wypisywanie różnych
komunikatów na konsolę za pomocą polecenia System.out.print. Jak przystało
na obiektowy język programowania, w Java nie brakuje też obsługi wyjątków.
Aplikacje Java są kompilowane do pseudokodu, który następnie jest wykonywany
przez tzw. maszynę wirtualną Java (JVM). Dzięki temu aplikacje łatwo dają się prze-
nosić między różnymi platformami, ale mają znacznie mniejszą wydajność niż gdyby
były skompilowane do kodu maszynowego. Szybkość wykonywania aplikacji jest za-
leżna przede wszystkim od jakości maszyny wirtualnej. Można spotkać różne im-
plementacje JVM. Niektóre jedynie interpretują pseudokod, inne stosują bardziej
zaawansowane techniki, polegające zwykle na kompilacji najczęściej wykonywanych
fragmentów pseudokodu do kodu maszynowego.
Podobnie jak w przypadku ColdFusion, aby uruchamiać aplikacje internetowe na-
pisane w Java należy wyposażyć maszynę (nie wirtualną, a rzeczywistą) w dużą ilość
pamięci operacyjnej. Przeciętnej wielkości aplikacje (np. sklepy internetowe) mogą
potrzebować nawet kilkuset MB pamięci. Zwykle aplikacje Java mają tendencje do za-
pełniania całej wolnej pamięci operacyjnej. W języku Java mechanizm destrukcji
obiektów i zwalniania pamięci jest realizowany automatycznie przez tzw. garbage col-
lector, który na ogół zaczyna intensywnie działać z chwilą, gdy pamięci zaczyna bra-
kować.
Pakiet J2EE jest dostępny bezpłatnie i można go wykorzystywać do tworzenia
aplikacji bez konieczności wykupywania licencji. Aplikacje pisane w Java (nie tylko te
internetowe, ale w ogóle wszystkie aplikacje) dają się uruchamiać na różnych platfor-
mach sprzętowych i systemowych bez konieczności rekompilacji kodu źródłowego.
Jedynym warunkiem jest dostępność na danej platformie odpowiedniej maszyny wir-
tualnej. JVM jest dostępne na bardzo wiele systemów operacyjnych m.in. na: MS
Windows, Sun Solaris, HP-UX, BSD, Linux, MacOS.

Rozdział I – Techniki budowania aplikacji internetowych 32
Dla J2EE powstało kilka specjalizowanych serwerów aplikacji (np. JBoss), ale
J2EE dobrze się też integruje z serwerami Apache, Microsoft IIS, Netscape Enterprise
Server czy SunONE WebServer.
Dzięki istnieniu maszyny wirtualnej, projektant aplikacji internetowych ma możli-
wość selektywnego określenia uprawnień aplikacji do poszczególnych zasobów sys-
temowych. Opis przywilejów jest osobną częścią aplikacji. Ograniczenie uprawnień
pozwala zmniejszyć skutki ewentualnej awarii aplikacji. Java jest językiem specjalnie
zaprojektowanym tak, aby utrudnić popełnianie błędów, które często występowały w
aplikacjach C++. Przede wszystkim wskaźniki zastąpiono „inteligentnymi” referen-
cjami, zrezygnowano z niskopoziomowych łańcuchów zakończonych znakiem „0”,
uproszczono zarządzanie pamięcią, zabezpieczono mechanizm rzutowania typów. Pod-
wyższyło to nie tylko stabilność i bezpieczeństwo aplikacji, ale również uprościło
proces implementacji (a wiadomo – im coś jest prostsze tym zwykle mniej podatne na
usterki).
8. ASP.NET – Active Server Pages .NET
Technologia ASP.NET ma niewiele wspólnego z technologią ASP. Obydwie mają
podobne zastosowania, skrót „ASP” w nazwie oraz zostały stworzone przez tę samą
firmę, na tym jednak podobieństwa się kończą. ASP.NET jest częścią systemu .NET,
który stanowi uniwersalną platformę programistyczną wspierającą różne języki
programowania, różne platformy sprzętowe i różne systemy operacyjne. Z założenia
.NET ma spełniać podobne założenia co Java. Zasada działania wszystkich aplikacji
.NET jest podobna do działania aplikacji Java. Kod źródłowy pisany w jednym z wielu
języków programowania wspieranych przez .NET (zwykle C#, C++, VB, Java) jest
kompilowany do kodu pośredniego, który następnie zostaje wykonany na maszynie
wirtualnej CLR (Common Language Runtime).
Aplikacja ASP.NET to specjalna odmiana aplikacji .NET przystosowana do pracy
jako aplikacja internetowa. Kod źródłowy aplikacji jest podzielony na dwie części:
kompilowaną i interpretowaną. W części kompilowanej umieszcza się funkcje od-
powiedzialne za logikę aplikacji (dostęp do danych, przetwarzanie) oraz obsługę zda-
rzeń pochodzących od interfejsu użytkownika, a w części interpretowanej – kod
definiujący wygląd interfejsu. Tak jak w przypadku „serwletów” Java, aplikacja
ASP.NET zostaje uruchomiona przy pierwszym żądaniu HTTP, a później tylko
oczekuje na zdarzenia generowane przez interfejs użytkownika przesyłane przez prze-

Rozdział I – Techniki budowania aplikacji internetowych 33
glądarkę. Zagadnienia tworzenia aplikacji w ASP.NET zostały szczegółowo
omówione w [WORL03].
ASP.NET jest jedyną technologią z omawianych w tej pracy, która pozwala na
projektowanie graficznego interfejsu użytkownika w metodologii obiektowo-zda-
rzeniowej, tj. tak jak projektuje się aplikacje okienkowe za pomocą współczesnych na-
rzędzi typu RAD takich jak Delphi, Kylix, QTDesigner czy JBuilder. Zadaniem
programisty nie jest implementacja obsługi zapytania HTTP, a obsługa zdarzeń. Infor-
macja o zdarzeniu jest przesyłana poprzez protokół HTTP, ale dekodowanie parame-
trów, ustalenie źródła zdarzenia oraz metody obiektu, która powinien na zdarzenie za-
reagować, jest dla programisty przezroczyste. Zdarzeniami są na ogół kliknięcia mysz-
ką w hiperłącza lub przyciski na stronie WWW.
Kolejną ważną cechą ASP.NET jest zwolnienie twórców interfejsu graficznego z
konieczności kodowania interfejsu w języku HTML i pisania skryptów działających po
stronie klienta. ASP.NET oferuje zestaw kontrolek WebForms, z których buduje się
interfejs. Kontrolki te same generują odpowiedni dla danej przeglądarki kod HTML.
Dzięki temu aplikacja ma szanse prawidłowo działać w większej liczbie różnych prze-
glądarek. Oczywiście użycie gotowych komponentów znacznie skraca czas produkcji
aplikacji.
W ASP.NET mechanizm obsługi sesji jest niewidoczny dla twórcy aplikacji.
Każda sesja jest widoczna jako oddzielna, niezależna instancja aplikacji z własnymi
danymi, które nie są kasowane po zakończeniu obsługi zdarzenia. W rzeczywistości
mechanizm obsługi sesji jest realizowany poprzez umieszczanie w kodzie wygene-
rowanej strony WWW zakodowanej informacji o stanie aplikacji. Informacja ta jest
przesyłana przez przeglądarkę z każdym żądaniem HTTP.
Aplikacje ASP.NET mogą korzystać z relacyjnych systemów baz danych za
pośrednictwem interfejsu ADO.NET. Interfejs ten jest nowszą wersją interfejsu ADO i
pod względem funkcjonalności istotnie się od niego nie wyróżnia. Został dostosowany
do obiektowych realiów programowania (np. wykorzystuje wyjątki do sygnalizacji
błędów), umożliwia też korzystanie z puli połączeń w celu zwiększenia wydajności.
Platforma .NET została zaprojektowana z myślą o tworzeniu w niej aplikacji o
różnych zastosowaniach, dlatego dostępne mechanizmy przetwarzania danych są bar-
dzo rozbudowane. Biblioteka standardowa dostarcza wiele gotowych do wykorzysta-
nia komponentów, co znacznie skraca czas produkcji oprogramowania (podobnie jak
w J2EE).

Rozdział I – Techniki budowania aplikacji internetowych 34
Z pakietem Visual Studio .NET firmy Microsoft jest dostarczany graficzny
debugger, który pozwala śledzić dowolną aplikację ASP.NET, zarówno uruchomioną
lokalnie, jak i na zdalnym serwerze. Możliwości debuggera są zbliżone do możliwości
debuggerów dostępnych dla J2EE.
Ponieważ w .NET można programować w wielu językach programowania, są do-
stępne różne konstrukcje językowe pozwalające tworzyć kod obsługi błędów. W języ-
kach C++ C# i Java jest obsługa wyjątków, w VB podobna trochę, ale niehierarchiczna
konstrukcja ON ERROR.
Wyniki testów producenta dostępnych na stronie [NET] wskazują, że aplikacje
ASP.NET są ponad dwukrotnie szybsze od aplikacji stworzonych w J2EE. W testach
nie podano jednak, które serwery aplikacyjne J2EE były testowane. .NET wykorzy-
stuje technikę zwaną JIT (Just In Time), polegającą na zapamiętywaniu kodu
maszynowego, na który zostały przełożone instrukcje kodu pośredniego w chwili ich
pierwszego wykonania. W ten sposób każde następne ich wykonanie trwa krócej,
ponieważ nie potrzeba wykonywać czasochłonnej interpretacji. Technika JIT nie po-
zwala osiągnąć takiej wydajności, jak aplikacje kompilowane od razu do kodu
maszynowego.
Zapotrzebowanie na pamięć operacyjną przez aplikacje ASP.NET oraz środowi-
sko CLR jest na ogół większe niż J2EE. Maszyna wirtualna, nie dość, że musi mieć
załadowany do pamięci kod wszystkich komponentów wykorzystanych przez apli-
kacje, to na dodatek w trakcie wykonywania kodu pośredniego musi zapamiętywać od-
powiadający mu kod maszynowy.
.NET jest platformą zamkniętą. Microsoft nie udostępnia kodów źródłowych
bibliotek ani narzędzi. Platforma .NET jest przeznaczona do pracy w różnych od-
mianach systemu operacyjnego Microsoft Windows. Istnieją wprawdzie śmiałe projek-
ty przeniesienia jej na inne systemy (np. projekt MONO) na podstawie udostępnionej
specyfikacji, jednak oprogramowanie zapewne długo jeszcze nie będzie w pełni zgod-
ne z oficjalną dystrybucją .NET. Dlatego aplikacje ASP.NET mogą być przenośne je-
dynie pomiędzy różnymi wersjami systemu Windows.
Zupełną nowością, która odróżnia platformę .NET od np. J2EE jest możliwość
tworzenia aplikacji w różnych językach programowania. Nawet jedna aplikacja może
składać się z wielu fragmentów napisanych każdy w innym języku. Dzięki temu
można lepiej dopasować język programowania do konkretnego problemu oraz łatwiej
znaleźć pracowników o odpowiednich kwalifikacjach. Niestety dowolność ta dotyczy

Rozdział I – Techniki budowania aplikacji internetowych 35
jedynie składni języka programowania a nie dostępnych bibliotek. Zestaw bibliotek
musiał zostać ujednolicony.
Nad bezpieczeństwem i stabilną pracą aplikacji .NET czuwa całe środowisko uru-
chamiania tych aplikacji tj. CLR wraz z zestawem odpowiednich komponentów. W
.NET są dostępne komponenty, za pomocą których w bardzo prosty i wygodny sposób
można zbudować moduł autoryzacji użytkowników. Można też grupować użytkow-
ników systemu przydzielając im odpowiednie role i uprawnienia. Rzeczywisty stopień
bezpieczeństwa aplikacji zbudowanej z takich komponentów jest zależny od ich
jakości. Ponieważ firma Microsoft nie dostarcza kodu źródłowego komponentów, nie
ma teoretycznie możliwości sprawdzenia, jaka jest ta jakość. Można jedynie polegać
na opiniach innych użytkowników oraz publikowanych w sieci Internet informacjach o
znalezionych błędach.

Rozdział II – Wymagania
Z zestawienia technik budowania aplikacji internetowych przedstawionego w po-
przednim rozdziale wynika, że programista C++ ma do wyboru dosyć niewielką liczbę
narzędzi. Właściwie tworzenie aplikacji internetowych w C++ jest możliwe jedynie
poprzez użycie interfejsu CGI. Jest to jednak metoda prosta, niewygodna i mało wy-
dajna. Istnieje oczywiście jeszcze możliwość użycia języka C++ na platformie .NET,
lecz niestety środowisko to jest jeszcze niedostatecznie rozwinięte na systemach opera-
cyjnych klasy Unix i Linux, które stanowią obecnie sporą część wszystkich systemów
obsługujących aplikacje internetowe. Obecnie autorowi nie jest znana żadna im-
plementacja kompilatora C++.NET dla systemu Linux.
Stworzenie systemu dorównującemu funkcjonalnością pakietom oprogramowania
opisanym w poprzednim rozdziale oczywiście znacznie wykracza poza zakres tej
pracy. Każdy z tych pakietów jest rozwijany przez wiele lat przez liczne grupy spe-
cjalistów. Dlatego wymagania postawione zestawowi bibliotek tworzonych w ramach
tej pracy zostały postawione w ten sposób, żeby umożliwiał on budowanie niewiel-
kich, prostych aplikacji internetowych, a zarazem dało się go w przyszłości łatwo roz-
szerzyć o moduły niezbędne do budowania większych aplikacji.
1. Wymagania funkcjonalne
Dobry zestaw narzędzi pozwala projektantom i programistom w jak największym
stopniu skupić się na rozwiązywaniu zadań specyficznych dla danego projektu. Nie
powinni oni poświęcać zbyt wiele cennego czasu na szczegóły techniczne tj. projek-
towanie i implementowanie tego, co już zostało wykonane i sprawdzone wcześniej,
być może nawet w innym zastosowaniu, dziedzinie itd. Aplikacje realizujące różne za-
dania składają się na ogół z podobnych elementów. W typowych aplikacjach interne-
towych spotyka się zwykle następujące elementy:
1. Prezentowanie użytkownikowi graficznego interfejsu użytkownika jako strona
WWW.
2. Reakcja na zdarzenia pochodzące od użytkowników oraz dekodowanie informacji
przesłanych za pomoc formularzy.
3. Identyfikacja różnych użytkowników korzystających z aplikacji w tym samym
czasie i prowadzenie z każdym z nich osobnej sesji.

Rozdział II – Wymagania 37
4. Zapisywanie niewielkich ilości informacji po stronie klienta.
5. Logowanie zdarzeń w celu wykrywania nieprawidłowości.
6. Przechowywanie danych w plikach.
7. Współpraca z systemami relacyjnych baz danych.
8. Komunikacja sieciowa z innymi aplikacjami.
Pierwsze cztery punkty opisują zadania specyficzne dla aplikacji internetowych i dlate-
go został im przypisany najwyższy priorytet. W tym zakresie zresztą brakuje bibliotek
dla języka C++. Pozostałe zadania, choć również bardzo często spotykane w apli-
kacjach internetowych, mogą być z powodzeniem realizowane za pomocą istniejących
bibliotek.
1.1. Prezentowanie graficznego interfejsu użytkownika
W tym zakresie pakiet powinien umożliwiać przesłanie do przeglądarki dowol-
nych danych jako odpowiedź na żądanie HTTP dowolnego typu (głównie POST lub
GET, ale czasem są też wykorzystywane inne rodzaje żądań [RFC2616]). Wymagana
jest co najmniej obecność funkcji:
• Wysyłanie danych tekstowych do przeglądarki.
• Wysyłanie danych binarnych (np. obrazek w formacie GIF).
• Określenie rodzaju wysyłanych danych i sposobu ich kodowania.
• Zlecenie przeglądarce odwiedzenia innej strony (przekierowanie).
• Powiadomienie przeglądarki o błędzie w sposób zrozumiały zarówno dla prze-
glądarki jak i użytkownika (czyli poprzez kod statusu HTTP oraz komunikat
tekstowy).
• Ustawianie pozostałych parametrów odpowiedzi HTTP poprzez wysłanie od-
powiednich nagłówków [RFC2616]. Umożliwia to implementację m.in.
Mechanizmu ciasteczek.
Te dosyć niskopoziomowe funkcje dają programiście całkowitą kontrolę nad wy-
glądem interfejsu użytkownika. Mogą one stanowić podstawę do budowy bardziej
zaawansowanego systemu budowy interfejsu użytkownika opartego o szablony. Taki
system zawierałby zestaw najczęściej wykorzystywanych elementów graficznych, wy-
stępujących na dynamicznych stronach WWW – pola do wprowadzania tekstu,

Rozdział II – Wymagania 38
przyciski, obrazki itp. Wszystkie elementy tego typu daje się definiować za pomocą
języka HTML lub XHTML w połączeniu z odpowiednimi plikami binarnymi. Budo-
wanie takiego systemu, samo w sobie jest bardzo złożonym zagadnieniem i wykracza
poza zakres tej pracy.
1.2. Reakcja na zdarzenia pochodzące od użytkowników
Użytkownik zwykle generuje zdarzenia dla aplikacji internetowej poprzez klik-
nięcie w hiperłącze lub przycisk. Kliknięcie to przekłada się na wysłanie do serwera
żądania HTTP. Oczywiście źródłem zdarzeń może być nie tylko aktywność użytkow-
nika, ale również aktywność różnych skryptów działających po stronie klienta napisa-
nych typowo w języku JavaScript, VBscript, apletów Java lub Flash. Programy te na
ogół komunikują się z serwerem również za pośrednictwem protokołu HTTP. Apli-
kacja internetowa musi umieć odczytać informacje o zdarzeniu wysłane przez klienta
zawarte w żądaniu HTTP. Informacje te mogą zawierać następujące składowe:
• Rodzaj żądania (na ogół GET lub POST). Rodzaj żądania decyduje o sposobie
przesłania niektórych danych od klienta do serwera oraz o treści odpowiedzi ode-
słanej przez serwer.
• Identyfikator zasobu, którego dotyczy zdarzenie. Decyduje on o tym, która apli-
kacja lub część aplikacji ma przetworzyć żądanie. Identyfikator ten ma postać
listy łańcuchów znaków oddzielonych znakiem “/” (tak jak w przypadku statycz-
nych stron WWW).
• Dane o systemie operacyjnym oraz przeglądarce, która wysłała żądanie. Dane te
mogą posłużyć do wygenerowania strony WWW wyświetlającej się prawidłowo
w różnych przeglądarkach.
• Dane wprowadzone przez użytkownika w formularzu.
• Metadane informujące o sposobie kodowania i rodzaju przesłanych informacji.
Bardzo często odczytywaną informacją jest wartość nagłówka content-type, która
pozwala np. rozróżnić, czy ciało zapytania HTTP (ang. message body) zawiera
dane formularza, czy plik binarny zawierający obraz.
• Informację o tym, co spowodowało zdarzenie – np. który przycisk lub które hiper-
łącze zostało uaktywnione.
• Dane wcześniej zapisane i obecnie odsyłane przez przeglądarkę (mechanizm
ciasteczek).

Rozdział II – Wymagania 39
• Dane zapisane w ciele zapytania (nie dotyczy niektórych rodzajów żądań np.
GET).
• Inne użyteczne informacje zapisane w nagłówkach HTTP.
Programista musi mieć do dyspozycji funkcje służące do odczytu i interpretacji
tych informacji. Informacje te powinny być dostępne w taki sposób i w takim czasie,
aby na ich podstawie możliwa była zmiana stanu aplikacji oraz odesłanie przeglądarce
odpowiedniej odpowiedzi reprezentującej nowy stan.
1.3. Obsługa sesji
Ponieważ jedna aplikacja może obsługiwać wielu użytkowników jednocześnie,
konieczne jest wprowadzenie mechanizmów kontroli sesji. Dzięki tym mechanizmom
aplikacja może zachowywać się tak, jakby znajdowała się w wielu stanach jedno-
cześnie – dla każdego przyłączonego użytkownika w oddzielnym. Również projektant
aplikacji projektuje ją prawie tak jakby miała docelowo współpracować z jednym użyt-
kownikiem. Moduł obsługi sesji musi posiadać następującą funkcjonalność:
• Umożliwienie projektantowi podziału obiektów na obiekty sesyjne i bezsesyjne.
Obiekty sesyjne to takie, których dane mogą różnić się dla każdej sesji. Dane
obiektów bezsesyjnych są wspólne dla wszystkich sesji. Wykorzystanie obiektów
bezsesyjnych pozwala zmniejszyć zapotrzebowanie na pamięć operacyjną.
• Automatyczne rozpoznawanie nowych użytkowników i inicjowanie struktur
danych potrzebnych do rozpoczęcia nowej sesji.
• Wykonywanie określonych przez programistę zadań w chwili otwarcia nowej
sesji.
• Programowe zakończenie sesji przez aplikację.
• Zakończenie sesji po określonym przez programistę czasie. Przed zamknięciem
sesji aplikacja jest powiadamiana o tym fakcie poprzez wywołanie odpowied-
niego kodu.
Projektant aplikacji musi mieć możliwość zrezygnowania z wbudowanych mecha-
nizmów kontroli sesji. Nie zawsze bowiem gotowy komponent jest w stanie zaspokoić
potrzeby każdego.

Rozdział II – Wymagania 40
1.4. Przechowywanie informacji po stronie klienta
Mechanizm zapisywania informacji po stronie klienta jest wykorzystywany z
wielu względów. Przede wszystkim pamiętanie na serwerze danych indywidualnych
dla każdego klienta w niektórych sytuacjach byłoby niepraktyczne, ponieważ dane zaj-
mowałyby zbyt wiele miejsca. Poza tym związanie danych z klientem powoduje, że je-
śli zrezygnuje on z korzystania z aplikacji, nie są potrzebne mechanizmy usuwania
tych danych z serwera. Projektant aplikacji oczywiście musi sam zadecydować, gdzie
chce przechowywać dane użytkowników. Czasem może być pożądany zapis części
danych po stronie serwera, a części po stronie klienta.
Zapisywanie danych po stronie klienta wykorzystuje mechanizm ciasteczek.
Ciasteczko to pewna nazwana porcja danych wysłana w nagłówkach odpowiedzi
HTTP. Dane te zostają zapisane przez przeglądarkę na dysku użytkownika. W każdym
kolejnym żądaniu HTTP kopia tych danych jest wysyłana z powrotem do serwera.
System budowy aplikacji internetowych powinien zawierać komponent pozwala-
jący na zarządzanie zbiorem informacji zapisanych po stronie klienta o następujących
funkcjach:
• Dodawanie nowych informacji zbioru (wysłanie ciasteczka).
• Odczytywanie informacji ze zbioru (odebranie ciasteczka).
• Modyfikowanie informacji w zbiorze.
• Usuwanie informacji ze zbioru.
• Określenie czasu, po którym konkretna porcja danych (identyfikowana nazwą)
zostanie usunięta z dysku klienta.
1.5. Logowanie zdarzeń
Jedną z możliwych strategii wykrywania błędów oprócz mechanizmu obsługi
sytuacji wyjątkowych wbudowanego w język programowania jest zapis informacji o
zdarzeniach do odpowiedniego dziennika. Dzienniki zdarzeń są bardzo istotnym na-
rzędziem w wykrywaniu prób naruszeń bezpieczeństwa aplikacji sieciowej oraz przy
analizie powłamaniowej [FORR, HACK]. W większości zastosowań wystarczające
jest logowanie czasu, źródła, treści zdarzenia oraz jego rodzaju. Powinno być dostępne
co najmniej 5 rodzajów komunikatów: zwykły komunikat, ostrzeżenie, błąd tymcza-
sowy, błąd krytyczny oraz komunikat serwisowy wykorzystywany w procesie uzdat-

Rozdział II – Wymagania 41
niania kodu. Przydział odpowiednich rodzajów komunikatów do konkretnych zdarzeń
jest pozostawiony projektantom aplikacji, podobnie jak określenie źródeł zdarzeń i ich
opisów. Format zapisu dziennika powinien być tak zdefiniowany, żeby łatwo można
było automatycznie filtrować komunikaty np. na podstawie źródła, rodzaju czy czasu
wystąpienia bez konieczności pisania złożonych parserów. W projekcie należy też
uwzględnić, że w aplikacji może zachodzić konieczność rejestrowania komunikatów
przychodzących z różnych modułów w tym samym czasie.
1.6. Przechowywanie danych w plikach
Każdy system operacyjny dostarcza w tym zakresie wystarczająco dużo funkcji,
które są zwykle znane nawet początkującym programistom. Dlatego tworzenie własne-
go API w tym zakresie nie należy do wymagań funkcjonalnych, choć może być
pożądane z innych względów (np. przenośności lub spójności z resztą systemu). Pliki
są wykorzystywane w aplikacjach internetowych na ogół do przechowywania danych
konfiguracyjnych oraz dokumentów udostępnianych w całości użytkownikowi. Do
przechowywania bardziej złożonych i częściej zmieniających się danych stosuje się
relacyjne bazy danych.
1.7. Współpraca z systemami baz danych
Na rynku istnieje wiele systemów relacyjnych baz danych. Zdecydowana więk-
szość tych systemów posiada interfejsy dostępne z poziomu C lub C++ za pośrednic-
twem bibliotek dostarczonych przez producentów. Istnieje również ujednolicony inter-
fejs ODBC. Z tego powodu interfejs dostępu do baz danych nie musi wchodzić w
skład zestawu bibliotek do budowy aplikacji internetowych.
1.8. Komunikacja sieciowa z innymi aplikacjami
API systemu operacyjnego dostarcza zwykle podstawowe funkcje pozwalające
przesyłać dane między aplikacjami (na poziomie 4 warstwy modelu OSI). Praktycznie
większość systemów klasy Unix dostarcza interfejs gniazd BSD zdefiniowany przez
standard POSIX. Na bazie tego interfejsu mogą być implementowane protokoły
wyższych warstw (5, 6 i 7). Liczba wykorzystywanych protokołów jest duża, ale rów-
nież istnieją już bardzo dobre biblioteki dla języka C++ wspomagające budowanie
aplikacji rozproszonych (RPC, XML-RPC, Apache Axis – SOAP, CORBA itd.). Jest
to jednak odrębne zagadnienie wykraczające poza ramy tej pracy.

Rozdział II – Wymagania 42
2. Wymagania niefunkcjonalne
Istotne jest, aby budowany zestaw komponentów wyróżniał się na tle innych do-
stępnych rozwiązań. Tylko wtedy znajdą się chętni do jego używania. Zdefiniowane
wymagania funkcjonalne nie określają funkcji niedostępnych w innych pakietach oraz
nie przewidują również wielu funkcji oferowanych przez te pakiety (patrz: rozdział
pierwszy tej pracy). Z tego powodu zestaw wymagań niefunkcjonalnych w stosunku
do tworzonych bibliotek musi być tak zdefiniowany, żeby produkt końcowy posiadał
cechy odmienne od produktów dostępnych obecnie na rynku.
2.1. Środowisko pracy i przenośność
Biblioteki muszą być dostępne przynajmniej na następujących systemach opera-
cyjnych:
• Linux kernel 2.4.x, 2.6.x
• OpenBSD 3.4, 3.5
• FreeBSD 4.11, 5.3
Wymienione tu systemy operacyjne są obecnie dosyć popularnymi darmowymi sys-
temami, na których uruchamiane są aplikacje serwerowe. Jeśli biblioteki będą działać
na tych systemach, jest bardzo prawdopodobne, że będą działać również na komercyj-
nych systemach klasy Unix. Kod powinien być napisany w taki sposób, by
przystosowanie go do pracy w innym systemie operacyjnym było zadaniem możliwie
jak najprostszym.
Oprogramowanie jest przeznaczone dla programistów piszących w języku
C++. Kod źródłowy bibliotek powinien dać się kompilować za pomocą kompilatora
GCC w wersjach: 2.95.3, 3.2.x, 3.3.x oraz 3.4.x.
Ważne jest, żeby nie zachodziła konieczność instalacji dodatkowego
oprogramowania takiego jak np. serwer WWW w celu uruchomienia aplikacji przy-
gotowanej przy użyciu komponentów wykonanych w ramach tej pracy. Uprości to
ogólnie proces jej instalacji oraz otworzy nowe zastosowania dla pakietu. Spełnienie
tego warunku będzie możliwe dzięki wyborowi języka C++ na język implementacji i
użycia łączenia statycznego. Takiej możliwości nie mają pakiety oparte o maszynę
wirtualną lub interpretery.

Rozdział II – Wymagania 43
2.2. Krzywa uczenia się
Użytkownicy chętnie używają oprogramowania, z którym można zacząć praco-
wać od razu, bez czytania najpierw 500-stronicowego podręcznika. Doskonale widać
to w stale rosnącej popularności PHP [TIOBE]. Instalacja pakietu powinna odbywać
się w typowy sposób, znany użytkownikom systemów klasy Unix:
$ ./configure [opcje]$ make$ make install
Napisanie najprostszej aplikacji powinno wymagać utworzenia jednego pliku za-
wierającego maksimum 20 linii kodu źródłowego licząc łącznie ze wszystkimi
koniecznymi deklaracjami (ale bez pustych linii i komentarzy). Skompilowanie oraz
uruchomienie takiej aplikacji ma być realizowane w jak najbardziej typowy sposób w
systemach klasy Unix np. tak:
$ g++ program.cpp lbiblioteka o program$ ./program
Do oprogramowania musi być dołączona szczegółowa dokumentacja w postaci
elektronicznej opisująca wszystkie funkcje.
2.3. Niezawodność i bezpieczeństwo
Zagadnienia niezawodności i bezpieczeństwa są szczególnie istotne w dziedzinie
aplikacji sieciowych. Język C++, choć zawiera znacznie więcej mechanizmów uła-
twiających pisanie niezawodnych programów, nie utrudnia programiście popełniania
błędów tak jak język Java, który od początku był projektowany z myślą o bez-
pieczeństwie. Dlatego interfejs programistyczny bibliotek (API) powinien być tak za-
projektowany, żeby programista nie miał potrzeby zbyt często używać potencjalnie
niebezpiecznych konstrukcji języka C++: arytmetyki wskaźnikowej, łańcuchów
znaków zakończonych znakiem '\0', ręcznego zarządzanie pamięcią przez instrukcje
new i delete czy rzutowania w stylu C. Wszelkie funkcje udostępniane przez kom-
ponenty muszą sprawdzać poprawność danych wejściowych. Same komponenty rów-
nież powinny być wolne od błędów, choć jak praktyka wykazuje, w przypadku nawet
niewielkich projektów takich jak ten, nie jest to całkowicie możliwe. Dlatego duży na-
cisk należy położyć na testowanie oraz przejrzystą strukturę kodu.

Rozdział II – Wymagania 44
2.4. Wydajność
Dzięki użyciu języka kompilowanego jako języka implementacji bibliotek
osiągnięcie większej wydajności niż w dostępnych pakietach powinno być dosyć ła-
twe. Nie ma bowiem narzutów związanych z interpretacją kodu. Poza tym istniejące
kompilatory C++ pozwalają generować bardzo wydajny kod.
Wydajność konkretnej aplikacji jest oczywiście zależna od tego jakie funkcje ta
aplikacja spełnia. Ponieważ celem tej pracy jest zbudowanie systemu służącego do
budowy różnych aplikacji, to należy arbitralnie przyjąć jakąś aplikację jako punkt od-
niesienia pomiaru wydajności. Zestaw bibliotek ingeruje głównie w proces
komunikacji między aplikacją a użytkownikiem. Dlatego wymagane jest, aby średnia
liczba możliwych realizacji zapytania w ciągu sekundy do aplikacji dostarczającej 5
kB gotowych danych tekstowych wynosiła nie mniej niż 50 na typowym komputerze
klasy PC wyposażonym w procesor Pentium 4 i częstotliwości zegara 2,4 GHz. Zapy-
tanie musi zawierać formularz o co najmniej 5 parametrach. Za stan maksymalnego
obciążenia systemu przyjęto takie obciążenie dla którego maksymalny czas realizacji
żądania jest krótszy niż 5 s. Większe opóźnienie utrudnia korzystanie z aplikacji. Spe-
łnienie tych wymagań oznaczałoby możliwość obsługi aplikacji przez kilka tysięcy
użytkowników jednocześnie.
2.5. Integracja z istniejącym oprogramowaniem
Musi istnieć prosty sposób wyposażenia istniejącej aplikacji pisanej w języku
C++ w interfejs użytkownika wykorzystujący przeglądarkę. Przez “prosty sposób” jest
rozumiana konieczność wprowadzenia zmian jedynie w kilku miejscach kodu źródło-
wego aplikacji (a najlepiej dokładnie w jednym) oraz dopisanie kodu logiki interfejsu
użytkownika jako osobny moduł. To wymaganie jest bardzo istotne, zwłaszcza że au-
torowi nie jest znane oprogramowanie do budowy aplikacji internetowych, które po-
siadałoby taką możliwość.

Rozdział III – Założenia projektowe
Każdy projekt informatyczny może być realizowany na wiele różnych sposobów.
Przed przystąpieniem do szczegółowego projektowania i implementacji poszczegól-
nych komponentów konieczne jest przyjęcie pewnych ogólnych założeń dotyczących
procesu wytwarzania oprogramowania. Założenia te dotyczą przyjętej metodologii
projektowania, zestawu użytych narzędzi, stosowanych konwencji implementacyjnych
i metod testowania. Konsekwentne ich przestrzeganie ma ułatwiać utrzymanie spójno-
ści i rozumienie całego projektu, szczególnie jeśli w przyszłości miałby być rozwijany
przez większą liczbę osób.
1. Metodologia projektowania bibliotek
Ze względu na konieczność ciągłej rozbudowy pakietu oraz zapewnienia od-
powiedniej niezawodności biblioteki zostały zaprojektowane obiektowo. Oznacza to,
że cała funkcjonalność systemu została podzielona pomiędzy różne klasy o dobrze
zdefiniowanych interfejsach oraz jak najmniejszej liczbie wzajemnych powiązań.
Dzięki temu jest możliwe wykorzystanie części funkcjonalności bez łączenia aplikacji
ze wszystkimi modułami. Takie podejście przyspiesza też znacznie uzdatnianie
pakietu. Wprowadzanie poprawek w jednym module (klasie) pociąga za sobą rekompi-
lację jedynie nielicznych innych modułów, a w idealnym przypadku tylko modułu
zmodyfikowanego. Użycie klas abstrakcyjnych ułatwia utrzymanie wzajemnej nieza-
leżności komponentów oraz dodawanie nowych.
Ważnym aspektem obiektowej metodologii projektowania jest też możliwość wy-
korzystania istniejących, dobrze sprawdzonych wzorców projektowych. Korzystanie z
wzorców pozwala zmniejszyć prawdopodobieństwo popełnienia błędu projektowego
oraz ułatwia zrozumienie architektury projektu osobom, które będą chciały go w przy-
szłości rozwijać.
2. Wykorzystanie dostępnych komponentów
Pewne elementy systemu mogą być zaimplementowane przy użyciu istniejących
bibliotek C lub C++. Przede wszystkim nie można się obejść bez używania API sys-
temu operacyjnego. Jednak wykorzystanie tych funkcji musi być ograniczone jedynie
do funkcji dobrze zdefiniowanych przez szeroko przyjęte standardy, takie jak POSIX,
ANSI/ISO C, 4.4BSD. Używanie innych funkcji ograniczyłoby przenośność pakietu

Rozdział III – Założenia projektowe 46
do jednej platformy systemowej. Pakiet korzysta z następujących standardowych
bibliotek funkcji:
• POSIX Threads – interfejs języka C pozwalający tworzyć aplikacje wielowąt-
kowe. Wielowątkowość jest potrzebna do obsługi wielu użytkowników
jednocześnie w celu zwiększenia wydajności oraz skrócenia czasu oczekiwania na
odpowiedź systemu.
• Gniazda BSD – interfejs gniazd jest używany do obsługi połączeń sieciowych.
• Standardowy interfejs dostępu do plików dla systemu UNIX zdefiniowane w na-
główku unistd.h.
• Standardowe funkcje obsługi czasu zdefiniowane w nagłówkach time.h oraz
sys/time.h.
Użycie standardowej biblioteki C++ STL zostało ograniczone ze względu na nie-
spełnianie przez nią wymagań odnośnie bezpieczeństwa. STL był projektowany głów-
nie z myślą o wysokiej wydajności i wiele istotnych, często używanych funkcji nie
sprawdza poprawności danych wejściowych (np. metody klasy string). Z tego
względu obiekty STL nie mogą być używane w API oprogramowania wspomagające-
go budowę aplikacji internetowych.
Nie ma natomiast żadnych ograniczeń odnośnie stosowanych konstrukcji języka
C++. Obecne kompilatory potrafią kompilować programy zawierające nawet bardzo
zaawansowane konstrukcje wykorzystujące wzorce. Warto zwrócić uwagę, że jeszcze
10 lat temu twórcy bibliotek celowo rezygnowali z używania wzorców, przestrzeni
nazw i mechanizmu wyjątków dla zwiększenia przenośności kodu źródłowego. Tak
zrobili m.in. twórcy znanej biblioteki do budowy aplikacji okienkowych wxWidgets
[WXWI].
3. Narzędzia wspomagania kompilacji
Kompilacja oprogramowania składającego się z wielu powiązanych ze sobą
modułów nie jest prostym zadaniem. Narzędzia oferowane przez różne, nawet podob-
ne do siebie systemy operacyjne nie zawsze są ze sobą kompatybilne. Odnosi się to nie
tylko do postaci opcji konfiguracyjnych kompilatorów, ale również narzędzi pomoc-
niczych takich jak make. Ponadto ręczne definiowanie skryptów kompilacyjnych dla
programu make jest kłopotliwe i podatne na błędy. Trzeba bowiem opisać wszystkie
zależności pomiędzy modułami, a te bywają liczne i mogą się zmieniać. Z powyższych

Rozdział III – Założenia projektowe 47
powodów do wspomagania procesu kompilacji i konsolidacji oprogramowania zostały
użyte narzędzia GNU autoconf oraz GNU automake. Narzędzia te są powszechnie
stosowane w wielu projektach OpenSource i stanowią niepisany standard w świecie
systemu operacyjnego Linux.
Program autoconf pozwala na automatyczną detekcję obecnych w systemie na-
rzędzi i bibliotek. Potrafi stworzyć skrypt configure testujący obecność plików na-
główkowych, a nawet obecność pojedynczych funkcji. Na podstawie zebranych o sys-
temie informacji przekazuje on użytkownikowi instalującemu pakiet, czy instalacja
jest możliwa i jeśli nie, to o jakie brakujące elementy trzeba system wzbogacić. Dodat-
kowo generuje plik nagłówkowy z makrodefinicjami określającymi, które nagłówki i
funkcje są dostępne. Plik ten można włączyć do kodu źródłowego pakietu i dzięki
temu łatwiej go dostosować do kompilacji na różnych platformach.
Z kolei program automake generuje automatycznie dodatkowe dane wejściowe
configure, które pozwalają wygenerować zestaw odpowiednich skryptów dla programu
make (skrypty te mają zwyczajowo nazwę Makefile). W skryptach tych znajduje się
przede wszystkim kod pozwalający z pomocą kompilatora automatycznie analizować
powiązania pomiędzy modułami. Dzięki temu projektant bibliotek określa jedynie, z
których plików źródłowych powstanie ostateczna wersja binarna pakietu. Nie musi też
podawać w jaki sposób ten kod binarny ma być stworzony, bo sposób ten jest ustalany
automatycznie. Istotną cechą tego automatycznego systemu budowania pakietu jest to,
że zmiana jednego z plików źródłowych po dokonaniu kompilacji pociągnie za sobą
rekompilację tylko tych plików, które jej wymagają, a nie wszystkich. Unika się w ten
sposób możliwości popełnienia błędu nie uwzględnienia jakiejś zależności i w efekcie
nie przekompilowania jakiegoś modułu. Takie błędy czasem mogą się objawiać do-
piero w trakcie uruchamiania aplikacji.
4. Konwencja kodowania
Istnieje wiele różnych konwencji kodowania programów w C++. Wybranie kon-
kretnej jest raczej kwestią gustu niż merytorycznej analizy. Ważne jest, aby jakąś kon-
wencję przyjąć i jej systematycznie przestrzegać, w ten sposób zwiększając czytelność
kodu. Ułatwia to jego późniejszą pielęgnację.

Rozdział III – Założenia projektowe 48
Nazewnictwo
Wszystkie nazwy są pisane w języku angielskim ze względu na przyszłe plany
udostępnienia kodu źródłowego szerszej społeczności.
Wszystkie nazwy typów, funkcji oraz zmiennych zaczynają się od wielkiej litery i
są pisane małymi literami. Jeśli nazwa jest wieloczłonowa, każdy człon zaczyna się z
wielkiej litery. Poszczególne człony nie są rozdzielane żadnym znakiem. Zalecane jest
stosowanie nazw możliwie krótkich. Należy jednak unikać skracania poszczególnych
członów. Czytelniejsze, mimo że dłuższe, jest używanie pełnych wyrazów.
Nazwy typów i klas konkretnych posiadają przedrostek T. Nazwy interfejsów i
klas abstrakcyjnych mają przedrostek I. Nazwy typów wskaźnikowych mają przed-
rostek P. Stosowanie przedrostków jest uzasadnione ze względu na częste występowa-
nie tego samego pojęcia w różnych aspektach. Można mieć np. w tym samym miejscu
kodu zadeklarowany typ konkretny TList realizujący listę oraz wskaźnik PList do
niej. Inteligentne typy wskaźnikowe stworzone na potrzeby mechanizmów au-
tomatycznego zarządzania pamięcią są definiowane poprzez wzorce. Pełna nazwa typu
wygenerowanego z wzorca byłaby długa i nieczytelna: TSmartPtr<TList>. Roz-
różnianie poprzez przedrostek nazw typów od pozostałych nazw pomaga szybko od-
różniać w kodzie konstruktory od wywołań funkcji lub metod.
Nazwy stałych są zapisywane wielkimi literami, a poszczególne człony w na-
zwach wieloczłonowych oddziela się znakiem “_”.
Komentarze
Są używane dwa rodzaje komentarzy: wprowadzane znakami “//” oraz “/**”. Te
pierwsze służą do komentowania kodu wewnątrz funkcji i metod, te drugie do opi-
sywania deklaracji klas oraz metod, które są automatycznie dokumentowane. Komen-
tarz wprowadzany przez “/*” jest używany na potrzeby wyłączania/włączania frag-
mentów kodu źródłowego w trakcie jego uzdatniania.
Wcięcia oraz nawiasy klamrowe
Wcięcia uwypuklają strukturę kodu. Przyjęta została szerokość pojedynczego
wcięcia równa 4 spacjom. W plikach zapisywane są wyłącznie spacje, nie znaki
tabulacji. Znaki tabulacji uzależniają szerokość wcięć od edytora, w którym jest
wyświetlany kod źródłowy. Kod, w którym gdzieniegdzie użyto tabulatorów,

Rozdział III – Założenia projektowe 49
gdzieniegdzie spacji mógłby zostać wyświetlony niepoprawnie. Nieprawidłowe
wcięcia utrudniają analizę kodu.
Jako konwencję nawiasów klamrowych przyjęto konwencję stosowaną w książce
[STRO]. Konwencja ta pozwala zmieścić na ekranie więcej linii niż konwencja zakła-
dająca umieszczanie każdego nawiasu klamrowego w osobnej linii, ale zachowuje po-
dobną czytelność.
Konwencja zarządzania pamięcią
Zgodnie z postawionymi wymaganiami dotyczącymi bezpieczeństwa używanie
mechanizmów ręcznego zarządzania pamięcią powinno być ograniczone. Niestety
pisanie programów bez używania alokacji obiektów na stercie za pomocą operatora
new lub funkcji malloc jest prawie niemożliwe do zrealizowania. Posługiwanie się
wskaźnikami do tak stworzonych obiektów jest powszechne. Zagrożenia ze strony
używania wbudowanych w C++ wskaźników to:
• Użycie niezainicjowanego wskaźnika. Konsekwencją może być zapis do przypad-
kowego obszaru pamięci i zniszczenie danych.
• Użycie wskaźnika do obiektu po wcześniejszym zwolnieniu pamięci przydzielo-
nej obiektowi. Sytuacja się komplikuje, jeśli używanych jest wiele wskaźników
do jednego obiektu. Zwolnienie pamięci powinno być dokonane dopiero, gdy ża-
den obiekt nie przechowuje wskaźnika do tej pamięci.
• Niezwolnienie pamięci zajmowanej przez obiekt i zgubienie wszystkich
wskaźników do tego obiektu. Rezultatem jest zwykle tzw. przeciek pamięci ob-
jawiający się tym, że długo pracująca aplikacja potrzebuje coraz więcej pamięci i
po pewnym czasie konieczne jest jej ponowne uruchomienie. Zjawisko to jest
szczególnie niebezpieczne dla wszelkich aplikacji serwerowych.
Z tego powodu jest konieczne opracowanie takich mechanizmów, dzięki którym
będzie możliwe pogodzenie wygody posługiwania się wbudowanymi wskaźnikami z
wymogami bezpieczeństwa. Mechanizmy te wprowadzają nowy rodzaj wskaźników
tzw. inteligentne wskaźniki i zostały szerzej opisane w trzecim rozdziale tej pracy. Ich
użycie nie wszędzie jest konieczne, dlatego należy zdefiniować, które mechanizmy, w
jakich sytuacjach mają być używane.
Do przechowywania obiektów lokalnych i tymczasowych wewnątrz funkcji naj-
bardziej nadaje się stos. Przydział i zwalnianie pamięci dla tych obiektów jest realizo-

Rozdział III – Założenia projektowe 50
wane przez kompilator i cechuje się niezawodnością oraz przede wszystkim wysoką
wydajnością.
Dla udostępnienia obiektów funkcjom i metodom, które nie potrzebują dostępu do
tych obiektów po zakończeniu wykonywania, można zastosować przekazanie przez
wartość, referencję (w stylu C++) lub wbudowany wskaźnik. W tej sytuacji nie zacho-
dzi możliwość popełnienia opisanych wyżej błędów.
Jednak jeśli wskaźnik do obiektu musi być z jakichś powodów zapamiętany na
dłużej, należy przekazać specjalny a nie wbudowany wskaźnik. Gwarantuje on, że
wskazywany obiekt nie będzie usunięty przed usunięciem wskaźnika. To powoduje
również, że obiekty, do których wskazania będą przechowywane w innych obiektach,
muszą być tworzone w specjalny sposób.
Podsumowując konwencja ta polega na zarządzaniu obiektami o niewielkim za-
sięgu (np. lokalnym w ramach funkcji lub jednej klasy) za pomocą mechanizmów
wbudowanych w C++. Natomiast obiekty o szerszym zasięgu (np. obiekty
współdzielone pomiędzy wiele modułów) powinny być zarządzane za pomocą specjal-
nych, bezpieczniejszych mechanizmów będących częścią tworzonych w ramach tej
pracy bibliotek.
5. Obsługa błędów
Do obsługi błędów zastosowany został mechanizm wyjątków wbudowany w C++.
Zostało zdefiniowane osobna hierarchia klas wyjątków, której korzeniem jest klasa
TException. Każdy zgłoszony wyjątek zawiera informacje pozwalające ziden-
tyfikować jego rodzaj oraz odczytać związany z nim komunikat. Dzięki temu w chwili
wyłapania niespodziewanego wyjątku można wyświetlić stosowną informację użyt-
kownikowi. Specyficzne klasy wyjątków mogą przechowywać dodatkowe, rozszerzo-
ne informacje o błędach. Nie zawsze jest przecież celowe przydzielanie do każdego
rodzaju błędu osobnej klasy. Przykładowo wyjątek dotyczący błędu wejścia-wyjścia w
strumieniu plikowym będzie zawierał informację o przyczynie błędu w postaci od-
powiedniego kodu. Wszystkie funkcje i metody, które mogą zgłaszać wyjątki, mają za-
deklarowaną odpowiednią sekcję throws, dzięki której programista wie, jakie rodza-
je wyjątków powinien wyłapać. Sekcje te są też odczytywane przez narzędzia au-
tomatycznie dokumentujące kod.
Dzięki zastosowaniu wyjątków do sygnalizacji błędów wiele funkcji, których ce-
lem jest zwracanie jakiejś użytecznej wartości, może zwrócić tę wartość w sposób

Rozdział III – Założenia projektowe 51
typowy dla funkcji tj. za pomocą return. W programach pisanych bez użycia me-
chanizmu wyjątków do obsługi błędu często stosuje się zwracanie kodu błędu poprzez
return, a wartości użytecznej poprzez referencję przekazaną jako argument funkcji.
Takie rozwiązanie jest mniej czytelne, bo trudno wyróżnić w kodzie, co jest obsługą
błędu, a co wynika z logiki biznesowej aplikacji.
6. Testowanie
Testowanie jest bardzo ważnym czynnikiem mającym wpływ na jakość produktu
ostatecznego. W pracy tej zastosowano kilka rodzajów testów:
• Ręczne testy funkcjonalne. Po dodaniu nowej funkcjonalności, zmieniony kod był
testowany za pomocą przykładowych programów.
• Automatyczne testy funkcjonalne poszczególnych komponentów (czasem zwane
żargonowo “unit-testami”). Wiele komponentów można testować automatycznie.
W tym celu powinna zostać stworzona klasa, która potrafi realizować różne sce-
nariusze testowe. Pojedynczy scenariusz to lista akcji wykonywanych z użyciem
testowanego komponentu oraz zestaw warunków (asercji) definiujących pośrednie
i końcowe wyniki tych działań. W przypadku naruszenia któregoś warunku cały
scenariusz jest przerywany, a na ekranie wypisuje się odpowiedni komunikat. Dla
każdej akcji są obsługiwane 3 sytuacje: wynik poprawny, wynik błędny, akcja
została przerwana poprzez zgłoszenie nieprzewidzianego wyjątku. Mogą istnieć
jeszcze dwa marginalne przypadki takie jak zapętlenie się programu lub jego
przerwanie w wyniku błędu krytycznego (np. segmentation fault). Żeby było
możliwe diagnozowanie również i takich przypadków, rozpoczęcie każdej akcji
jest sygnalizowane stosownym komunikatem. Dzięki temu można sprawnie zlo-
kalizować, która akcja spowodowała usterkę.
• Testowanie funkcjonalne komponentów w praktyce, czyli w większej aplikacji
tworzonej zespołowo. Takie testowanie pozwala wykryć błędy we współpracy
różnych modułów ze sobą oraz ewentualne braki w funkcjonalności.
• Testy wydajnościowe. Specjalny program kliencki symulujący przeglądarkę wy-
syła do przykładowej aplikacji internetowej bardzo dużo żądań w krótkim czasie.
Mierzone są minimalne, średnie i maksymalne czasy odpowiedzi oraz liczba ob-
służonych zapytań HTTP w ciągu sekundy.

Rozdział III – Założenia projektowe 52
7. Dokumentacja
Dokumentacja dla użytkownika końcowego bibliotek musi się składać z następu-
jących części:
• Opis wymagań sprzętowych i systemowych pakietu.
• Opis sposobu instalacji.
• Przykładowe programy pozwalające szybko rozpocząć pracę z bibliotekami.
• Dokumentacja API w formacie HTML wygenerowana automatycznie na podsta-
wie komentarzy zawartych w kodzie źródłowym za pomocą programu DoxyS
[DOXYS]. Takie podejście pozwala utrzymać spójność pomiędzy dokumentacją a
opisywanym przez nią API. Program DoxyS generuje czytelną i przyjemną dla
oka dokumentację wraz z różnorodnymi indeksami w celu ułatwienia wyszukiwa-
nia potrzebnych informacji. Bierze pod uwagę nie tylko informacje zaczerpnięte z
kodu źródłowego, ale również strukturę katalogów projektu. Potrafi również
ilustrować zależności pomiędzy klasami za pomocą diagramów.

Rozdział IV – Projekt i implementacja
Wiele aplikacji internetowych jest budowanych w oparciu o gotowy serwer
WWW i/lub serwer aplikacyjny. Aplikacje te nie są samodzielne – wymagają specjal-
nego środowiska, w którym będą pracować. Środowisko to musi być uprzednio prawi-
dłowo skonfigurowane. Choć zwykle nie jest to zadanie bardzo trudne, to w pewnych
zastosowaniach mogłoby być kłopotliwe, zwłaszcza w przypadku prostych i małych
aplikacji. Przykładowo dostarczanie klientowi aplikacji wielkości 250 kB, która wy-
maga zainstalowania i skonfigurowania konkretnej wersji niestandardowego środowi-
ska roboczego o objętości kilkudziesięciu MB prawdopodobnie nie byłoby przez klien-
ta mile widziane. Zdecydowanie większe problemy jednak mogą się pojawić, jeśli
klient korzysta z wielu aplikacji internetowych, a każda z nich wymaga innej wersji
środowiska wykonawczego. Z powyższego powodu architektura systemu budowanego
w ramach tej pracy jest nieco inna. To nie aplikacja świadczy usługi na rzecz serwera
aplikacyjnego, a odpowiednie komponenty serwerowe świadczą usługi aplikacji. Z po-
zoru różnica jest niewielka, jednak ma dosyć istotne konsekwencje:
• Aplikacja może być całkowicie samodzielną jednostką wymagającą do pracy je-
dynie systemu operacyjnego. Dzięki temu może działać w większej liczbie
konfiguracji niż aplikacja dedykowana dla konkretnego serwera aplikacyjnego.
• Poważna usterka w jednej z aplikacji nie zakłóca pracy pozostałych. W przypadku
uruchomienia dwóch aplikacji na jednym serwerze aplikacyjnym może się zda-
rzyć, że cały serwer zostanie zablokowany w wyniku błędów w jednej aplikacji.
Oczywiście w przypadku pracy wielu aplikacji pod bezpośrednią kontrolą sys-
temu operacyjnego taka możliwość też zachodzi, jednak jądra systemów
operacyjnych klasy Unix są rozwijane od dłuższego czasu niż serwery dla apli-
kacji internetowych. Można przypuszczać, że jądra te są stabilniejsze i
bezpieczniejsze. Ponadto obecność dodatkowej wspólnej warstwy zawsze zwięk-
sza ryzyko negatywnego oddziaływania aplikacji na siebie.
• Aplikacja nadal może współpracować z istniejącym serwerem WWW lub ser-
werem aplikacyjnym za pomocą odpowiednich wtyczek. Np. można napisać
skrypt CGI albo PHP, który pozwoli przekierować zapytania HTTP odebrane
przez serwer Apache do aplikacji napisanej z użyciem bibliotek opisanych w tej
pracy.

Rozdział IV – Projekt i implementacja 54
• Z pozoru pojawia się trudność z instalacją wielu aplikacji nasłuchujących na jed-
nym porcie, tak jak to jest możliwe w przypadku pojedynczego serwera i wielu
zagnieżdżonych aplikacji. Problem ten można rozwiązać poprzez użycie proxy
HTTP.
• Użycie łączenia dynamicznego oszczędza zasoby systemowe. System operacyjny
może załadować do pamięci tylko te biblioteki, z których korzysta aplikacja. Uru-
chomienie aplikacji może być dzięki temu również szybsze. W przypadku
uruchamiania aplikacji na serwerze aplikacyjnym konieczne jest najpierw urucho-
mienie całego serwera.
• Użycie łączenia statycznego zmniejsza rozmiar oraz czas instalacji aplikacji w
stosunku do rozmiaru i czasu instalacji aplikacji wraz z pełnym zestawem
bibliotek dołączanych dynamicznie (lub aplikacji wraz z całym serwerem apli-
kacyjnym).
Tabela 3: Położenie komponentów w strukturze katalogów projektu
Katalog Opis
base Podstawowe klasy abstrakcyjne i interfejsy często używane we wszystkich innych komponentach. Zawiera klasę bazową dla wyjątków.
coll Klasy kontenerowe. Wektory, słowniki, listy, kolejki, stosy itp.
io Strumienie wejścia-wyjścia oraz komponenty umożliwiające czytanie i zapisywanie danych różnych typów.
logging Obsługa dzienników zdarzeń.
mem Automatyczne zarządzanie pamięcią oraz inteligentne wskaźniki.
net Niskopoziomowy, ale obiektowy interfejs dostępu do sieci opakowujący interfejs gniazd BSD.
net/http Wielowątkowy serwer WWW wraz z mechanizmem serwletów umożli-wiającym komunikację z użytkownikiem. Komponenty obsługi sesji.
text Bezpieczne łańcuchy znaków i funkcje do ich przekształcania. Obsługa regionalnych systemów kodowania znaków.
thread Obiektowe opakowanie biblioteki POSIX Threads. Mechanizm sygnali-zacji upłynięcia zadanego czasu. Mechanizmy synchronizacji wątków.
util Proste klasy i funkcje pomocnicze ogólnego zastosowania, których nie można przydzielić do żadnej z pozostałych grup funkcjonalnych. M.in. klasy wspomagające testowanie oraz reprezentacja daty i czasu.

Rozdział IV – Projekt i implementacja 55
Projekt składa się z kilku komponentów, z których mogą korzystać aplikacje.
Komponenty te są pogrupowane funkcjonalnie i umieszczone w osobnych katalogach
jak przedstawiono w tabeli 3.
Każdy z komponentów posiada własne pliki nagłówkowe, których większość jest
udostępniana programiście. Struktura katalogów, w których się znajdują, po zainstalo-
waniu pakietu pozostaje taka sama jak struktura katalogów kodu źródłowego bibliotek.
Wszystkie komponenty są zawarte we wspólnej przestrzeni nazw smeil, żeby nazwy
nie kolidowały z innymi bibliotekami. Szczegółowa dokumentacja programistyczna w
formacie HTML znajduje się na dołączonej do pracy płycie CD-ROM.
1. Mechanizmy zarządzania pamięcią
Brak wbudowanych mechanizmów automatycznego zarządzania obiektami prze-
chowywanymi na stercie utrudnia pisanie niezawodnych programów w języku C++.
Język ten został jednak tak zaprojektowany, że możliwe jest stworzenie takich mecha-
nizmów samodzielnie. Ich celem jest wyręczenie programisty od konieczności zwal-
niania pamięci alokowanej dynamicznie na stercie. Taki system sam wyszukuje niedo-
stępne obiekty i odzyskuje pamięć. Dlatego będzie dalej nazywany odśmiecaczem.
W sieci Internet można znaleźć kilka odśmiecaczy dla języka C++ o różnych cha-
rakterystykach. Różne rodzaje odśmiecaczy stosowanych w C++ zostały zaprezen-
towane w tabeli 4. Ciekawy przegląd różnych technik, które mogą być stosowane w
C++, zawiera praca [ATTAR94]. Autorzy zbudowali uniwersalny system zarządzania
pamięcią w C++, pozwalający wybrać jedną z wielu dostępnych technik odśmiecania.
Tabela 4: Zestawienie odśmiecaczy stosowanych w C++
Rodzaj odśmiecaczy
Zalety Wady Przykłady im-plementacji
Zliczające refe-rencje
Łatwe w implementacji.
Zwalniają pamięć w momencie gdy tylko prze-stanie być używana.
Zwykle nie wymagają dłu-gotrwałego zatrzymywania wykonywania aplikacji na czas odśmiecania.
Niska wydajność zwłasz-cza w aplikacjach wielowątkowych.
Nie zwalniają referencji cyklicznych.
Mogą nadmiernie wydłu-żyć maksymalny czas od-powiedzi aplikacji.
C++ Boost Li-brary [BOOST].

Rozdział IV – Projekt i implementacja 56
Rodzaj odśmiecaczy
Zalety Wady Przykłady im-plementacji
Zachowawcze trasujące bloku-jące
Wysoka wydajność.
Brak konieczności do-stosowywania istniejącego kodu do współpracy z odśmiecaczem.
Odśmiecanie niedokładne, możliwe niewielkie prze-cieki pamięci.
Konieczność zatrzymywa-nia wszystkich wątków aplikacji na czas odśmiecania.
Implementacja silnie za-leżna od architektury sprzętowej i systemu ope-racyjnego.
Odśmiecacz BDW (Boehm-Demers-Weiser) [BOE04]
Dokładne trasu-jące blokujące
Gwarancja odzyskania całej niedostępnej pamięci.
Niezależność implementa-cji od architektury sprzętowej i systemu ope-racyjnego.
Zwykle wolniejsze niż odśmiecacze zachowaw-cze.
Konieczność zatrzymywa-nia wszystkich wątków aplikacji na czas odśmiecania.
Odśmiecacz Śmieciuch autor-stwa Sebastiana Kaliszewskiego [SMI]
Odśmiecacz uży-ty w bibliotekach MoreFor [MOR4]
Zachowawcze trasujące przy-rostowe
Brak konieczności do-stosowywania istniejącego kodu do współpracy z odśmiecaczem.
Możliwość pracy w sys-temach interakcyjnych i czasu rzeczywistego.
Bardzo trudna implemen-tacja.
Słaba przenośność, konieczność wykorzy-stywania niestandardo-wych mechanizmów sys-temu operacyjnego.
Zwykle wolniejsze niż odśmiecacze blokujące.
Odśmiecacz BDW (Boehm-Demers-Weiser) w trybie przy-rostowym
Dokładne trasu-jące przy-rostowe lub współbieżne lub przy-rostowo-współbieżne
Gwarancja odzyskania całej niedostępnej pamięci.
Niezależność implementa-cji od architektury sprzętowej i systemu ope-racyjnego.
Możliwość pracy w sys-temach interakcyjnych i czasu rzeczywistego.
Zwykle wolniejsze niż odśmiecacze blokujące.
Reverse Trace Garbage Collec-tor autorstwa Stephene'a Fa-vora [RTGC]
Odśmiecacz uży-ty w tej pracy.
Ze względu na postawione wymagania wydajnościowe dotyczące krótkiego i
przewidywalnego czasu odpowiedzi przy dużym obciążeniu aplikacji, najkorzystniej-
szym rozwiązaniem jest zastosowanie odśmiecacza współbieżnego lub przyrostowego
(ang. incremental) Odśmiecacze blokujące są wprawdzie bardzo wydajne, jednak

Rozdział IV – Projekt i implementacja 57
mogą powodować przestoje w pracy aplikacji zajmujących dużo pamięci, szczególnie
jeśli zapotrzebowanie na pamięć przekracza rozmiar pamięci fizycznej komputera i
część danych zostaje przeniesiona z pamięci na dysk twardy. Takie przestoje mogą iry-
tować użytkownika, lub jeśli aplikacja jest częścią większego systemu rozproszonego,
zakłócać pracę tego systemu.
Wykorzystanie odśmiecacza zachowawczego było brane pod uwagę, jednak z na-
tury odśmiecacze zachowawcze są trudne w przenoszeniu pomiędzy różnymi
systemami operacyjnymi i różnymi platformami sprzętowymi. Szczególnie dotyczy to
odśmiecaczy zachowawczych przyrostowych. Dodatkowo odśmiecacze te charaktery-
zują się większą nieprzewidywalnością pracy niż odśmiecacze dokładne, powodowaną
zastosowanymi w nich heurystykami rozpoznawania wskaźników. Pewne niedostępne
obiekty mogą, w wyniku przypadku, nie zostać zwolnione przez bardzo długi czas po-
wodując większe zużycie zasobów. Problem ten został dokładnie omówiony w pracy
[HIRZ00].
Jedyny znany autorowi dokładny, przyrostowo-współbieżny odśmiecacz to RTGC
[RTGC]. Odśmiecacz ten stosuje połączenie techniki zliczania referencji z technikami
przeszukiwania grafu obiektów typowymi dla odśmiecaczy trasujących. Niestety
konieczność zliczania referencji powoduje znaczne obniżenie wydajności względem
odśmiecaczy, które nie stosują tej techniki. Każde bowiem stworzenie wskaźnika do
obiektu, bądź zmiana wartości wskaźnika wiąże się z koniecznością zmiany licznika
referencji wewnątrz sekcji krytycznej.
W ramach tej pracy został stworzony dokładny, współbieżny odśmiecacz, nie-
korzystający z techniki zliczania referencji i niewymagający od systemu operacyjnego
niczego prócz obsługi wątków i podstawowych mechanizmów synchronizacji.
Odśmiecacz ten, ze względu na swoją współbieżność, może być stosowany również w
aplikacjach multimedialnych [KOL05a]. Projekt oraz szczegóły implementacyjne
zostały dokładniej omówione w pracy [KOL05b].
1.1. Algorytmy
Zaprojektowany na potrzeby tej pracy odśmiecacz używa algorytmu opracowane-
go na podstawie algorytmu mark and sweep zaprezentowanego w [WILS92]. Składa
się on z dwóch etapów: etapu zaznaczania i etapu odzyskiwania pamięci. W etapie za-
znaczania odśmiecacz wyszukuje wszystkie dostępne obiekty i tym samym znajduje
również niedostępne obiekty. W drugim etapie niedostępne obiekty są usuwane.

Rozdział IV – Projekt i implementacja 58
Żywy obiekt to taki obiekt, który może być czytany lub zapisywany przez apli-
kację. Martwy obiekt to obiekt, który istnieje na stercie, ale jest niedostępny z punktu
widzenia logiki aplikacji. Odśmiecacz ma oczywiście dostęp zarówno do martwych jak
i żywych obiektów. Obiekt X jest uznawany za dostępny wtedy i tylko wtedy gdy:
• Istnieje wskaźnik do na stosie, w rejestrach procesora lub w pamięci zmiennych
globalnych wskazujący na początek lub do środka obszaru pamięci zajmowanej
przez obiekt X. Taki obiekt nazywany jest bezpośrednio dostępnym, a wskaźnik
wskaźnikiem bezpośrednim.
• Istnieje wskaźnik w innym dostępnym obiekcie wskazujący na początek lub do
środka obszaru pamięci zajmowanej przez obiekt X. Taki obiekt nazywany jest
pośrednio dostępnym, a wskaźnik wskaźnikiem pośrednim. Do takiego obiektu
można się odwoływać tylko za pośrednictwem innego obiektu.
Odśmiecacz musi znać położenia wszystkich wskaźników bezpośrednich. Zbiór
ten nazywany jest dalej zbiorem wskaźników bezpośrednich (w literaturze anglojęzycz-
nej często nazywany: root set). Zbiór ten jest wykorzystywany w pierwszym etapie
odśmiecania.
Etap zaznaczania
Obiekty wraz ze wskaźnikami tworzą pewien graf skierowany. Obiekty to węzły
grafu, a wskaźniki to krawędzie. Etap zaznaczania ma na celu znalezienie obiektów
żywych poprzez przeszukanie tego grafu wszerz poczynając od obiektów bezpośrednio
dostępnych. Każdy obiekt posiada specjalne flagi oznaczające jego „kolor”. Obiekty
mogą być pokolorowane na jeden z trzech umownych kolorów:
• Biały: Tak oznaczane są obiekty, które jeszcze nie były brane pod uwagę przed
odśmiecacz.
• Szary: Obiekty, które nie były brane pod uwagę przez odśmiecacz, ale wiadomo,
że są dostępne. Tylko białe obiekty mogą zostać zaznaczone na szaro. Obiekt
zostaje zaznaczony na szaro w chwili gdy zaczyna na niego wskazywać nowy
wskaźnik.
• Czarny: Obiekty, które zostały uznane przez odśmiecacz za dostępne.
W wyniku działania algorytmu wszystkie dostępne obiekty zostają zaznaczone na
czarno, a wszystkie niedostępne pozostają białe. Użycie pomocniczego koloru szarego
umożliwia współbieżną pracę wątku odśmiecacza z pozostałymi wątkami aplikacji.

Rozdział IV – Projekt i implementacja 59
Inne wątki mogą zmieniać wartości wskaźników, a tym samym zmieniać powiązania
między obiektami. Zmiana wartości wskaźnika po uwzględnieniu go w procesie prze-
szukiwania mogłaby spowodować przypadkowe pominięcie nowo wskazywanego
obiektu. Dlatego tuż przed zmianą wartości każdego wskaźnika, nowo wskazywany
obiekt jest zaznaczany na szaro. Jeśli po przeszukaniu grafu pozostaną jakieś szare
obiekty, oznacza to, że zostały pominięte i należy zacząć przeszukiwać graf jeszcze raz
zaczynając tym razem od tych obiektów, a nie od obiektów bezpośrednio dostępnych.
Proces się powtarza aż na końcu pozostaną tylko same czarne i białe obiekty. Ilustruje
to diagram 1.
Etap odzyskiwania pamięci
W etapie odzyskiwania pamięci wszystkie obiekty, które pozostały zaznaczone na
biało po etapie zaznaczania, zostają usunięte. Proces usuwania składa się z dwóch po-
Diagram 1: Algorytm wyszukiwania żywych i martwych obiektów

Rozdział IV – Projekt i implementacja 60
detapów. Najpierw są wywoływane destruktory wszystkich niedostępnych obiektów,
później pamięć przydzielona obiektom jest zwalniana. Gdyby każdy obiekt był nisz-
czony od razu po wywołaniu destruktora, mogłoby się zdarzyć, że późniejsze wy-
konanie destruktora innego obiektu spowodowałoby błąd naruszenia ochrony pamięci.
Martwe obiekty mogą przecież zawierać wskaźniki zarówno na żywe jak i na martwe
obiekty. Zwalnianie obiektów dopiero po wywołaniu wszystkich destruktorów gwaran-
tuje uniknięcia tego zjawiska, jednak nadal może powodować problemy:
• Metoda danego obiektu może zostać wywołana po wywołaniu jego destruktora.
• Destruktor może „przywrócić obiekt do życia” tj. zapisać wskaźnik do martwego
obiektu w jakimś żywym obiekcie lub zmiennej globalnej.
Przed pierwszym problemem można się obronić poprzez ustawianie specjalnej
flagi w obiekcie w chwili wywołania destruktora. Wartość tej flagi można sprawdzać i
dzięki temu nie dopuścić do wykonania potencjalnie nieprawidłowych operacji.
Przed drugim problemem można się bronić poprzez ponowne wykonanie etapu
zaznaczania przed zniszczeniem obiektów. W ten sposób można sprawdzić, czy po
wywołaniu destruktorów nadal wszystkie obiekty są martwe. Jeśli nie, to można zgło-
sić błąd. Prezentowany tu odśmiecacz nie został wyposażony w taki mechanizm
ochrony, gdyż w praktyce problemu można całkowicie uniknąć stosując się do zasady,
że destruktor nie powinien modyfikować innych obiektów poza obiektem, do którego
należy.
W programach, gdzie jest dostępny odśmiecacz, używanie destruktorów jest mało
powszechne. W programach, gdzie stosuje się ręczne zarządzanie pamięcią, destruk-
tory bardzo często służą właśnie do niszczenia obiektów i odzyskiwania zasobów.
Tutaj jednak proces ten jest zautomatyzowany. Zwalnianie innych zasobów niż pamięć
(np. uchwyty plików) nie powinno być realizowane w destruktorach ze względu na
nieprzewidywalność czasu ich wywołania. Podobnie nie należy umieszczać tam żadne-
go innego „ważnego” kodu – destruktor w końcu może w ogóle nigdy nie być wywoła-
ny. Zagadnienia pisania destruktorów zostały szerzej omówione w pracy [BOE03].

Rozdział IV – Projekt i implementacja 61
1.2. Struktury danych
Odśmiecacz przechowuje informacje o wskaźnikach, obiektach i ich typach w
swoich wewnętrznych strukturach danych. Do części tych struktur dostęp ma jedynie
odśmiecacz, do pozostałych zarówno odśmiecacz jak i kod użytkownika. Z tego powo-
du przy projektowaniu tych struktur uwzględnione zostały aspekty synchronizacji wąt-
ków.
Wskaźniki
Ze względu na brak dostępności szczegółowej informacji typu czasu wykonania
(ang. runtime type information) w języku C++, nie jest możliwe stworzenie dokładne-
go odśmiecacza, który nie wymagałby żadnego wsparcia ze strony programisty.
Programista musi pomóc odśmiecaczowi odnaleźć wskaźniki w pamięci, rozpoznać
poszczególne typy obiektów, odróżnić wskaźniki bezpośrednie od pośrednich. Proces
ten można na szczęście na tyle zautomatyzować, żeby używanie odśmiecacza nie było
trudniejsze niż używanie standardowych mechanizmów języka C++. Zastosowany w
pracy odśmiecacz wykorzystuje tzw. inteligentne wskaźniki [EDEL91]. Za pomocą
wzorców i przeciążania operatorów został stworzony nowy typ wskaźnikowy o bardzo
zbliżonych właściwościach do wbudowanego typu wskaźnikowego. Każdy inteligen-
tny wskaźnik składa się z dwóch pól:
• ObjectPtr – Wskazuje na obiekt. To pole ma tę samą wartość jaką miałby
standardowy wbudowany wskaźnik do obiektu.
• BlockPtr – Wskazuje na początek bloku pamięci przydzielonej na obiekt.
Oprócz samego obiektu ten blok pamięci zawiera pewne dodatkowe dane opisu-
jące ten obiekt wykorzystywane przez odśmiecacz. Dane te są nazywane
deskryptorem obiektu. Deskryptor obiektu zawiera m.in. flagi określające kolor
obiektu używany w etapie zaznaczania.

Rozdział IV – Projekt i implementacja 62
Na architekturach 32-bitowych każde pole zajmuje po 4 bajty, czyli cały wskaźnik
zajmuje 8 bajtów. Jedno pole byłoby niewystarczające ze względu na konieczność
uwzględnienia możliwości wielodziedziczenia klas. Przy rzutowaniu wskaźników
kompilatory C++ czasem dokonują zmiany wartości wskaźnika, w ten sposób że
wskaźnik wskazuje do środka obiektu zamiast na jego początek. Taka sytuacja jest
przedstawiona na diagramie 2. Znajomość wskaźnika do środka obiektu nie wystarcza
aby dostać się do deskryptora obiektu.
Jak już wcześniej wspomniano, istnieją dwa rodzaje wskaźników: pośrednie oraz
bezpośrednie. Położenia wskaźników bezpośrednich są pamiętane w zbiorze zaim-
plementowanym jako tablica mieszająca. O umieszczeniu wskaźnika w zbiorze
wskaźników bezpośrednich decyduje konstruktor wskaźnika, natomiast o usunięciu
jego destruktor. Rozpoznawanie, czy wskaźnik jest pośredni czy nie, jest dokonywane
na podstawie porównania adresu wskaźnika (nie mylić z wartością wskaźnika) z adre-
sem aktualnie tworzonego obiektu. Adres i rozmiar każdego obiektu, dla którego
została przydzielona pamięć, ale którego wszystkie składowe nie zostały jeszcze
zainicjowane, znajduje się na stosie nowych obiektów. Konieczne jest użycie stosu,
ponieważ konstruktor obiektu może tworzyć nowe obiekty, które z kolei mogą powo-
łać do życia kolejne itd. Jeśli adres nowo tworzonego wskaźnika leży wewnątrz
obiektu opisanego przez wierzchołek stosu nowych obiektów, to jest on wskaźnikiem
pośrednim. W przeciwnym przypadku jest wskaźnikiem bezpośrednim i zostaje
umieszczony w zbiorze wskaźników bezpośrednich. Podobne kryterium jest stosowane
przy usuwaniu wskaźnika – z tą różnicą, że usuwanie obiektów jest procesem sekwen-
cyjnym (a nie rekurencyjnym), więc zamiast stosu usuwanych obiektów są jedynie
odpowiednie zmienne globalne dotyczące aktualnie usuwanego obiektu.
Modyfikowanie zbioru wskaźników bezpośrednich musi być dokonywane we-
wnątrz sekcji krytycznej. Sama modyfikacja zawartości tego zbioru jest operacją
Diagram 2: Wskaźnik do obiektu - kod i wynikowe rozmieszczenie obiektów w pamięci

Rozdział IV – Projekt i implementacja 63
bardzo szybką, zajmującą od kilku do kilkunastu taktów procesora. Dlatego żeby nie
wprowadzać zbyt dużych narzutów czasowych związanych z obsługą sekcji krytycz-
nej, z każdym wątkiem są skojarzone dwie kolejki FIFO o pojemności kilkudziesięciu
wskaźników. Do jednej są wpisywane dodawane do zbioru wskaźniki bezpośrednie, do
drugiej są wpisywane wskaźniki usuwane. Po zapełnieniu którejkolwiek kolejki, na-
stępuje aktualizacja zbioru wskaźników bezpośrednich w sekcji krytycznej. W ten
sposób wejście w sekcję krytyczną następuje raz na kilkadziesiąt operacji tworzenia
lub niszczenia wskaźnika. W trakcie aktualizacji zbioru wskaźników bezpośrednich,
do zbioru może być dodany ten sam wskaźnik kilka razy (kolejka dodawanych
wskaźników jest przetwarzana w pierwszej kolejności). Całkowite usunięcie
wskaźnika ze zbioru wymaga wykonania operacji usuwania tyle razy ile razy wskaźnik
był dodany.
Destrukcja inteligentnego wskaźnika może zostać wstrzymana na semaforze przez
wątek odśmiecacza na czas przetwarzania wskaźników bezpośrednich w etapie za-
znaczania. Ponieważ wskaźników tego typu jest zwykle niewiele nawet w dużych
aplikacjach, czas ten jest wystarczająco krótki by nie mógł być zauważony przez użyt-
kownika. Zwykle nie przekracza kilku mikrosekund. Liczba wskaźników
bezpośrednich jest w głównej mierze zależna od liczby obiektów globalnych oraz licz-
by zagnieżdżeń wywołań funkcji. Liczba obiektów globalnych powinna być jak
najmniejsza,
Obiekty
Jak wcześniej zaznaczono, każdy blok pamięci alokowany przez odśmiecacz roz-
poczyna się deskryptorem obiektu. Deskryptor składa się z następujących pól:
• Flaga oznaczająca, że obiekt ma kolor „szary”.
• Flaga oznaczająca, że obiekt ma kolor „czarny”. Jeśli flaga ta jest ustawiona, war-
tość flagi „kolor szary” jest ignorowana.
• Indeks deskryptora typu w tablicy deskryptorów typów. Deskryptor typu zawiera
głównie informacje o położeniach wskaźników względem początku obiektu dane-
go typu.
• Wskaźnik do następnego deskryptora obiektu. Deskryptory obiektów tworzą listę
jednokierunkową.
Obiekty na liście łatwo się przegląda, a operacja dodawania i usuwania elementu
ma stałą złożoność czasową. Możliwe byłoby oddzielenie deskryptorów od obiektów i

Rozdział IV – Projekt i implementacja 64
przechowywanie ich w wektorze, ale rozszerzanie takiego wektora mogłoby wiązać się
z kopiowaniem wszystkich deskryptorów, co wprowadziłoby niepotrzebne opóźnienia.
Deskryptory muszą być dostępne zarówno dla wątków użytkownika, jak i dla wątku
odśmiecacza. Dzięki zastosowaniu listy, deskryptory nie są przemieszczane w pamięci
i jedyna operacja synchronizacji wątków potrzebna jest przy dodawaniu obiektu na
końcu listy (obiekt jest dodawany w kontekście wątku użytkownika).
Informacja typu czasu wykonania
Informacja typu czasu wykonania jest przechowywana w deskryptorach typu. Słu-
ży odśmiecaczowi do określania położeń wskaźników wewnątrz obiektów. Jest
również używana w algorytmie rozpoznawania wskaźników bezpośrednich oraz przy
destrukcji obiektów. Każdy deskryptor typu przechowuje:
• Rozmiar obiektu.
• Listę położeń wskaźników względem początku bloku pamięci, wewnątrz którego
znajduje się obiekt.
• Wskaźnik do kodu destruktora obiektów danego typu.
• Flagę oznaczającą, czy deskryptor typu jest kompletny.
Deskryptory typu są przechowywane w rozszerzalnej tablicy. Każdy deskryptor
jest tworzony wraz z pierwszą instancją obiektu danego typu. Przed wywołaniem kon-
struktorów składowych nowego obiektu (w tym wskaźników) flaga kompletności
ustawiana jest na 0. Konstruktor każdego wskaźnika, który znajduje się wewnątrz no-
wego obiektu, sprawdza tę flagę i jeśli jest ustawiona na 0, dodaje swoje względne
położenie do deskryptora typu. Po zainicjowaniu wszystkich składowych obiektu, fla-
Diagram 3: Obiekty różnego typu w pamięci

Rozdział IV – Projekt i implementacja 65
ga jest ustawiana na 1, aby tworzenie kolejnych obiektów tego samego typu nie zapi-
sywało w deskryptorze typu ponownie tych samych informacji.
1.3. Wyzwalanie procesu odśmiecania
Odśmiecacz musi w odpowiednim momencie podjąć decyzję o rozpoczęciu
odśmiecania. Odśmiecanie jest realizowane w osobnym wątku. Jeśli odśmiecanie
będzie przeprowadzane zbyt często, aplikacja będzie używała mniej pamięci, ale
będzie wykonywała się wolniej. Każde odśmiecanie wymaga sięgnięcia do całej
pamięci przydzielonej procesowi, co obniża skuteczność pamięci podręcznej proce-
sora. Jeśli odśmiecanie będzie przeprowadzane zbyt rzadko, aplikacja będzie używała
więcej pamięci, ale będzie wykonywała się szybciej. Mniej czasu będzie poświęcone-
go na proces odśmiecania oraz pamięć podręczna będzie lepiej wykorzystana.
Niektóre odśmiecacze rozpoczynają proces odśmiecania w chwili, gdy pamięci
zaczyna brakować. Takie podejście maksymalizuje wprawdzie wydajność, ale naraża
aplikację na długie przerwy w pracy, w chwili gdy pamięci brakuje i należy czekać na
jej odzyskanie przez odśmiecacz. Poza tym w obecnych systemach operacyjnych
ciężko jest określić, kiedy pamięci zaczyna brakować, zwłaszcza jeśli jednocześnie
uruchomionych jest wiele aplikacji. Mechanizm pamięci wirtualnej korzystający z dys-
ku twardego pozwala znacznie zwiększyć ilość dostępnej pamięci. Używanie całej
dostępnej pamięci mogłoby powodować znaczną utratę wydajności. Najkorzystniejsza
sytuacja zachodzi wtedy, gdy każda aplikacja używa nie więcej pamięci, niż jest jej w
rzeczywistości potrzebne. Zastosowany w niniejszym odśmiecaczu algorytm realizuje
kompromis pomiędzy zużyciem pamięci a wydajnością. Odśmiecanie jest przeprowa-
dzane, kiedy zostanie spełniony co najmniej jeden z warunków:
• Programista uruchomi odśmiecanie poprzez wywołanie odpowiedniej metody.
• Całkowita ilość przydzielonej pamięci przekroczy zadany przez użytkownika li-
mit.
• Ilość pamięci przydzielonej od chwili ostatniego odśmiecania przekroczy od-
powiedni limit. Limit ten jest wyznaczony jako iloczyn pewnej zdefiniowanej
przez użytkownika stałej k oraz ilości aktualnie przydzielonej pamięci M. W ten
sposób, jeśli aplikacja alokuje pamięć ze stałą szybkością, odstęp w czasie między
kolejnymi cyklami pracy odśmiecacza jest proporcjonalny do ilości przydzielonej
pamięci. Czas procesora potrzebny na jeden cykl pracy odśmiecacza jest też
proporcjonalny do ilości przydzielonej pamięci. W ten sposób wątki użytkownika

Rozdział IV – Projekt i implementacja 66
mają dostępną zawsze stałą moc obliczeniową procesora. Dodatkowo całkowite
zużycie pamięci nie przekracza nigdy (k + 1) Mr, gdzie Mr to pamięć zajmowana
przez wszystkie żywe obiekty.
2. Serwer WWW i serwlety
Serwer WWW jest jednym z najważniejszych komponentów. Jest zrealizowany
przez klasę THttpServer, która komunikuje się z przeglądarką internetową za po-
mocą protokołu HTTP. Programista jedynie musi stworzyć obiekt tej klasy,
opcjonalnie ustawić pewne właściwości serwera oraz wywołać metodę Run. Dzięki
zawarciu serwera w obrębie jednej klasy możliwe jest uruchomienie w jednej aplikacji
kilku serwerów nasłuchujących na różnych portach.
Oprócz klasy serwera, istnieje kilka klas współpracujących, rozszerzających funk-
cjonalność serwera. Ilustruje je diagram 4.
2.1. Serwlety
Serwlet to obiekt przetwarzający żądania HTTP, zarejestrowany w serwerze.
Serwlet jest tworzony przez użytkownika bibliotek. Każdy serwlet musi implemen-
tować interfejs IHttpServlet. Typowy przebieg obsługi żądania przez serwer z
zarejestrowanymi serwletami wygląda tak:
Diagram 4: Diagram klas związanych z serwerem WWW

Rozdział IV – Projekt i implementacja 67
1. Serwer WWW odbiera żądanie i sprawdza jego formalną poprawność. Jeśli żąda-
nie jest niepoprawne, odsyła przeglądarce komunikat o błędzie.
2. Na podstawie identyfikatora zasobu URI przesłanego w żądaniu, serwer iden-
tyfikuje serwlet odpowiedzialny za obsługę żądania. Serwlety są przypisywane do
odpowiednich identyfikatorów podczas rejestracji. Jeśli serwlet nie zostanie od-
naleziony, do przeglądarki odsyłany jest komunikat odpowiadający błędowi o
kodzie HTTP 404.
3. Serwer tworzy obiekt klasy THttpRequest i wypełnia go danymi wysłanymi
przez przeglądarkę. W obiekcie zapamiętywany jest identyfikator zasobu, którego
żąda klient, wszystkie przesłane nagłówki HTTP oraz wskaźnik do otwartego
strumienia wejścia, z którego można odczytać dane wysłane po nagłówkach
(ciało żądania).
4. Serwer tworzy obiekt klasy THttpResponse, który reprezentuje odpowiedź na
żądanie.
5. Obiekty stworzone w punktach 3. i 4. zostają przekazane do serwletu. Serwer po-
wraca do oczekiwania na kolejne żądania.
6. Serwlet odczytuje dane z obiektu klasy THttpRequest i generuje odpowiedź
poprzez zapisanie odpowiednich danych w obiekcie klasy THttpResponse.
Serwlet może wysłać przeglądarce ciasteczko HTTP poprzez stworzenie obiektu
klasy THttpCookie i zapisanie go w obiekcie THttpResponse.
7. Serwer zamyka połączenie. Obecnie połączenia typu keep-alive nie są obsługiwa-
ne, gdyż do ich obsługi konieczna jest dokładna znajomość rozmiaru odpowiedzi
jeszcze przed rozpoczęciem jej wysyłania. Serwlet może wygenerować
odpowiedź o dowolnym, nieznanym z góry rozmiarze.
2.2. Odbieranie danych
Dane wysłane przez przeglądarkę zostają zapisane w obiekcie klasy
THttpRequest, który serwlet otrzymuje w chwili nadejścia żądania HTTP. Klasa ta
posiada metody zwracające następujące dane:
• Metoda żądania HTTP (GET, POST albo inna).
• Identyfikator żądanego zasobu (URI).
• Łańcuch znaków przesłanych po znaku „?” w identyfikatorze żądanego zasobu.

Rozdział IV – Projekt i implementacja 68
• Zdekodowana zawartość parametrów przesłanych po znaku „?” w identyfikatorze
żądanego zasobu dostępna jako tablica asocjacyjna. Wszelkie znaki specjalne w
nazwach i wartościach parametrów takie jak „+” oraz znaki zapisane za pomocą
kodu rozpoczynającego się znakiem „%” zostają zamienione na właściwe od-
powiedniki zgodnie z [RFC1738].
• Zawartość wskazanych nagłówków. Możliwe jest też otrzymanie listy nazw
wszystkich otrzymanych nagłówków.
• Ciasteczka HTTP. Możliwe jest sprawdzenie, czy ciasteczko o danej nazwie
zostało odebrane, odczytanie danych z ciasteczka o danej nazwie oraz odczytanie
listy wszystkich odebranych ciasteczek.
• Typ MIME ciała żądania zapisany w nagłówku content-type.
• Wszelkie dane tekstowe i binarne przesłane w ciele żądania, dostępne jako
buforowany strumień wejściowy. Dane tekstowe można wygodnie wczytać za po-
mocą klasy dekorującej TStringReader.
• Zawartość formularza typu application/x-www-form-urlencoded przesłanego w
ciele żądania HTTP. Dane te są dostępne w taki sam sposób jak dane formularza
przesłanego w URI.
2.3. Wysyłanie danych
Serwlet otrzymuje obiekt klasy THttpResponse, za pomocą którego przysyła
odpowiedź do przeglądarki. Dostępne są następujące metody:
1. Ustawienie kodu oraz komunikatu statusu HTTP.
2. Ustawienie dowolnego nagłówka.
3. Ustawienie, modyfikacja lub usunięcie ciastek HTTP.
4. Ustawienie typu MIME wysyłanego dokumentu: content-type.
5. Otwarcie buforowanego strumienia wyjściowego i wysłanie ciała odpowiedzi.
Klasa TStringWriter umożliwia wygodne wysyłanie danych tekstowych.
Strumień buforowany ma określoną wielkość. Jeśli zostanie wysłanych więcej danych
niż rozmiar bufora, bufor zostaje opróżniony i dane poprzedzone nagłówkami HTTP
zostaną wysłane do klienta. Od tego momentu nie można modyfikować ani dodawać
nagłówków.

Rozdział IV – Projekt i implementacja 69
2.4. Pula wątków
Wraz ze startem serwera uruchomiona zostaje odpowiednia liczba wątków, które
początkowo są zawieszone na semaforze, dopóki nie nadejdzie jakieś żądanie HTTP.
Wątek główny serwera nasłuchuje na lokalnym porcie (domyślnie 80) i przekazuje
każde zapytanie do jednego z pozostałych, oczekujących wątków. Jeśli po przejęciu
obsługi żądania przez inny wątek, pula wątków oczekujących jest pusta (tzn. wszystkie
wątki są zajęte), wątek główny przestaje przyjmować nowe zadania. Została za-
stosowana pula wątków, aby uniknąć niepotrzebnej straty czasu spowodowanej
uruchamianiem wątków przez system operacyjny. Z kolei zastosowanie pojedynczego
wątku do obsługi wszystkich żądań miałoby negatywny wpływ na wydajność, gdyż
serwer przez większą część czasu prawdopodobnie czekałby na przesyłanie danych od
i do przeglądarki. Pula wątków nie przyspiesza wprawdzie czasu trwania obsługi poje-
dynczego żądania, ale poprzez zrównoleglenie obsługi żądań, skraca czas
bezczynności serwera, a tym samym zwiększa znacznie liczbę żądań obsłużonych w
danej jednostce czasu.
Liczbę wątków w puli użytkownik może ustawić dowolnie, ponieważ optymalna
wielkość tej puli może zmieniać się w zależności od zastosowania aplikacji. Aplikacja
o niewielkim obciążeniu np. panel administracyjny jakiegoś systemu prawdopodobnie
w ogóle nie będzie potrzebować więcej niż jednego wątku. Uruchamianie nadmiernej
liczby wątków marnuje zasoby systemu (m.in. pamięć), które mogłyby być wykorzy-
stane przez inne aplikacje. Z drugiej strony aplikacja obsługująca np. portal
internetowy może wymagać uruchomienia kilkuset wątków, ponieważ częstotliwość
żądań może być rzędu od kilku do kilkudziesięciu na sekundę. Dlatego każdą sytuację
należy rozpatrywać indywidualnie poprzez wykonanie odpowiednich testów wydajno-
ściowych.
2.5. Synchronizacja wątków
Równoległa obsługa wielu żądań może rodzić problemy związane z ochroną
danych przed jednoczesną modyfikacją przez dwa lub więcej wątków. Ochronę tę
może zapewnić twórca aplikacji, ale możliwe jest również zastosowanie mechanizmu
bardziej ogólnego, wbudowanego w serwer WWW. Duży udział w czasie obsługi
żądania może mieć czas przesłania danych z i do przeglądarki, szczególnie jeśli logika
aplikacji jest prosta, a przesyłanych danych dużo. Użytkownicy, którzy korzystają z
aplikacji internetowej mogą dysponować łączami o niewielkiej wydajności w porów-
naniu z wydajnością łącza, za pośrednictwem którego podłączony jest do Internetu

Rozdział IV – Projekt i implementacja 70
serwer WWW. Dlatego proces odbierania i wysyłania danych może być realizowany
równolegle lub współbieżnie, ale samo przetwarzanie danych przez serwlet może od-
bywać się sekwencyjnie. Na uzyskanie takiego efektu pozwalają buforowane
strumienie wejścia/wyjścia. Rozmiar każdego bufora musi być wtedy dostatecznie
duży, żeby zmieściło się w nim całe zapytanie i cała odpowiedź. Rozmiar bufora
można ustawiać.
W ten sposób można uzyskać wyższą wydajność niż w systemie pracującym
sekwencyjnie bez konieczności uwzględniania wielowątkowego wykonania serwletu.
Z drugiej strony mechanizm ten nie jest prawdopodobnie w stanie zapewnić takiej wy-
dajności, jak system, w którym zarówno przesyłanie, jak i przetwarzanie danych
odbywa się równolegle. Z tego powodu użytkownik może wybrać, w jakim „trybie
równoległości” ma pracować jego serwlet.
2.6. Obsługa sesji
Obsługę sesji realizuje zarządca sesji, czyli klasa THttpSessionBroker. Jest
to serwlet, który odpowiada za rozpoznawanie klientów, przydzielanie im numerów
sesji oraz kierowanie żądań do właściwych serwletów sesyjnych. Serwlet sesyjny to
obiekt klasy implementującej interfejs IHttpSessionServlet. Interfejs ten do-
daje do interfejsu IHttpServlet metody zwrotne wywoływane przez zarządcę
sesji informujące o otwarciu i zamknięciu sesji. Zarządca może otwierać nową sesję
dla każdego nowego klienta lub sesja może być otwierana „ręcznie” – poprzez jawne
wywołanie odpowiedniej metody zarządcy sesji. Zarządca zamyka sesję po określo-
nym czasie nieaktywności. Dla każdej sesji istnieje osobny serwlet sesyjny.
Identyfikator sesji ma długość 128 bitów i jest generowany za pomocą generatora
liczb losowych o ziarnie długości 1024 bity. Generator jest inicjowany czasem sys-
temowym w momencie uruchomienia zarządcy sesji. Czas systemowy jest też brany
pod uwagę przy każdorazowej modyfikacji stanu generatora. Stan generatora jest
modyfikowany przy obsłudze każdego żądania HTTP. Ponieważ nie da się przewi-
dzieć dokładnych czasów nadejścia wszystkich żądań, ani ich liczby, tak zbudowany
generator generuje liczby całkowicie przypadkowe. Identyfikator sesji nie zawiera,
prócz wylosowanej liczby, żadnych innych informacji. Powiązanie identyfikatora z
serwletem sesyjnym jest dokonywane za pomocą tablicy asocjacyjnej.
Identyfikator sesji jest przechowywany domyślnie w ciastku HTTP. Zarządca
sesji potrafi również odczytać identyfikator przekazany jako parametr żądania typu

Rozdział IV – Projekt i implementacja 71
GET lub jako ukryte pole formularza. W tym przypadku identyfikator musi być jawnie
wysłany przez serwlet do przeglądarki np. wewnątrz strony WWW.
Zaletą zastosowania serwletów sesyjnych jest wygoda pisania aplikacji korzysta-
jącej z obsługi sesji. Zwykle z każdą sesją są związane jakieś dane. Dane te można
zapisać jako składowe klasy reprezentującej serwlet sesyjny. Nie jest konieczne
wprowadzanie takich mechanizmów jak serializacja tych danych. Z drugiej strony tak
stworzone sesje nie są trwałe. Przerwanie pracy aplikacji powoduje utratę wszystkich
sesji. W przyszłości problem ten będzie rozwiązany przez wprowadzenie osobnego
rodzaju zarządcy sesji (jako klasy pochodnej do THttpSessionBroker), który
będzie zapisywał identyfikatory sesji na dysku lub w bazie danych. W chwili wzno-
wienia pracy, będzie ponownie tworzył instancje wszystkich serwletów sesyjnych, a
następnie umożliwiał im odzyskanie danych poprzez wywołanie odpowiedniej metody.
Oczywiście zagadnienie zapisu i odtwarzania danych sesji np. poprzez serializację
nadal pozostanie zadaniem dla programisty.
3. Komponenty pomocnicze
Pakiet został wyposażony w wiele pomocniczych klas, które mogą być wykorzy-
stane nie tylko w aplikacjach internetowych. Czasem wprowadzają one dodatkową
funkcjonalność w porównaniu z funkcjami API systemu operacyjnego, czasem pozwa-
lają lepiej zrealizować wymagania dotyczące bezpieczeństwa stawiane pakietowi, a
czasem stanowią jedynie dodatkową warstwę ułatwiającą dostosowanie pozostałych
komponentów do pracy pod kontrolą różnych systemów operacyjnych na różnych plat-
formach sprzętowych.
3.1. Łańcuchy znaków
Łańcuchy znaków są wykorzystywane w większości komponentów pakietu, a
aplikacje internetowe przetwarzają na ogół dane tekstowe. Dlatego ważne jest, żeby
użytkownik miał do swojej dyspozycji wygodną i bezpieczną reprezentację łańcuchów
znaków. Klasa std::string wchodząca w skład biblioteki STL nie została użyta,
ponieważ jest podatna na błędy ochrony pamięci – niektóre metody nie sprawdzają po-
prawności danych wejściowych. Pakiet został wyposażony w klasę TString o
podobnej funkcjonalności, ale znacznie bezpieczniejszą, gdyż nie dopuszcza ona od-
czytu ani zapisu danych poza obszarem pamięci zarezerwowanej na łańcuch znaków.
Takie sprawdzanie wprowadza oczywiście pewien narzut czasu wykonania. Spełnienie
wymagań dotyczących bezpieczeństwa jest jednak ważniejsze niż wymagań do-

Rozdział IV – Projekt i implementacja 72
tyczących wydajności, szczególnie w środowisku sieciowym. Ponadto czasami kompi-
lator potrafi wyeliminować zbędne instrukcje sprawdzające w metodach typu inline.
Taką strategię zastosowali również projektanci języka Java.
Klasa TString dodatkowo przechowuje informacje o regionalnym kodowaniu
znaków. Każdy znak jest reprezentowany jako wchar_t, dzięki czemu możliwe jest
przechowywanie łańcuchów zakodowanych jako Unicode UCS-2. Dostępne są me-
tody przekształcające kodowanie znaków w łańcuchu, a więc można pisać aplikacje
wielojęzyczne.
3.2. Klasy kontenerowe
Wraz z wprowadzeniem mechanizmów automatycznego zarządzania pamięcią
okazało się, że klasy kontenerowe (kolekcje) biblioteki STL niezbyt dobrze nadają się
do przechowywania obiektów kontrolowanych przez odśmiecacz. Zapisanie listy inte-
ligentnych wskaźników w kontenerze STL powoduje jego rejestrację jako wskaźnik
bezpośredni, a więc przyczynia się do nadmiernego rozrastania się zbioru wskaźników
bezpośrednich. Ponadto operacja tworzenia wskaźnika bezpośredniego zajmuje więcej
czasu niż wskaźnika pośredniego. Może to mieć negatywny wpływ na wydajność apli-
kacji.
Zestaw komponentów został wyposażony w dwa wzorce klas: wektor oraz
asocjacyjną tablicę mieszającą. Klasy te nie posiadają wyżej wymienionej wady.
Utworzenie instancji każdej z nich powoduje zarejestrowanie jednego wskaźnika bez-
pośredniego niezależnie od liczby przechowywanych obiektów. Wewnętrzne struktury
danych wykorzystywane przez te klasy znajdują się pod kontrolą odśmiecacza. Ponad-
to wszelkie operacje dostępu do elementów przechowywanych w kontenerach są
kontrolowane i programista nie ma możliwości przypadkowego spowodowania błędów
naruszenia ochrony pamięci.
Oprócz wzorców klas konkretnych, dostępne są wzorce implementowanych przez
nie interfejsów, jak pokazano na diagramie . Interfejs IMap reprezentuje uogólnioną
tablicę asocjacyjną, IList uogólnioną listę jednokierunkową,
IBidirectionalList listę dwukierunkową, a IRandomAccessList listę o
dostępie swobodnym. Obecnie struktura interfejsów wydaje się niepotrzebnie rozbudo-
wana, jednak w przyszłości dodanych zostanie więcej klas implementujących te
interfejsy.

Rozdział IV – Projekt i implementacja 73
Zarówno klasy konkretne, jak i interfejsy, definiują iteratory służące do dostępu
do elementów. Iterator to obiekt wskazujący na dany element kolekcji. Dzięki wy-
korzystaniu inteligentnych wskaźników, możliwe jest zapewnienie, że iterator albo jest
ważny tj. wskazuje na prawidłowo utworzony obiekt, albo jest nieważny. Iterator za-
wsze „wie” czy jest ważny czy nieważny, więc nie istnieje ryzyko spowodowania
błędu ochrony pamięci. W przypadku iteratorów z biblioteki STL możliwa jest
sytuacja, że pozornie ważny iterator wskazuje na nieprzydzieloną pamięć. Wystarczy
bowiem utworzyć iterator do jakiegoś elementu, a następnie zniszczyć kolekcję za-
wierającą ten element. W praktyce takie błędy przy posługiwaniu się iteratorami są
dosyć częste.
3.3. Obsługa wątków
Interfejs obsługi wątków POSIX nie jest dostępny na wszystkich systemach ope-
racyjnych. Aby umożliwić w przyszłości przeniesienie całości pakietu na inny system
nieposiadający tego interfejsu, funkcje służące do zarządzania wątkami zostały
opakowane w klasę TThread. Obiekt tej klasy reprezentuje pojedynczy wątek apli-
kacji. W ten sposób jedynym miejscem w kodzie, w którym są wywoływane funkcje
API systemu operacyjnego związane z obsługą wątków, jest ta klasa oraz odśmiecacz.
Odśmiecacz nie może korzystać z klasy TThread, ponieważ klasa ta korzysta z
odśmiecacza, a procedury inicjalizacyjne odśmiecacza korzystają z wątków jeszcze
zanim odśmiecacz jest gotowy do pracy. Oprócz klasy TThread została stworzona
klasa TMutex pozwalająca synchronizować ze sobą wątki. Klasy te są wykorzystywa-
ne przez serwer WWW, ale mogą być też użyte przez programistę do dowolnego celu.
3.4. Logowanie zdarzeń
Najprostszą metodą logowania zdarzeń jest w wywołanie w odpowiednim miejscu
funkcji zapisującej jakiś komunikat do pliku lub wyświetlającej go na ekranie. Takie
podejście ma oczywiście szereg wad i może być stosowane jedynie w bardzo małych
projektach – liczących nie więcej niż kilkaset linii kodu. Podstawową wadą jest nie-
możność selektywnego włączenia lub wyłączenia komunikatów pochodzącego z
danego źródła lub o danym poziomie ważności. Ponadto zmiana docelowego miejsca
zapisu dziennika zdarzeń lub sposobu jego zapisu (np. zmiana formatu czasu) wymaga
zmiany kodu we wszystkich miejscach, w których zdarzenia były logowane. Klasy
TLogger oraz TLogCollector zapewniają prosty i elastyczny mechanizm lo-
gowania zdarzeń pozbawiony powyższych wad.

Rozdział IV – Projekt i implementacja 74
Obiekty logujące to obiekty klasy TLogger pełniące rolę pośredników po-
między źródłami zdarzeń a globalnym obiektem klasy TLogCollector
zapisującym komunikaty bezpośrednio do dziennika. Obiekty logujące są iden-
tyfikowane za pomocą nazw, które są umieszczane w dzienniku zdarzeń, dzięki czemu
można zidentyfikować źródło zdarzenia. Jeśli np. nazwa obiektu logującego pokrywa
się z nazwą klasy generującej komunikaty, to z dziennika zdarzeń można łatwo wydo-
być komunikaty przez nią wygenerowane. Zastosowanie obiektów logujących pozwala
uniknąć konieczności powtarzania nazwy źródła zdarzenia przy każdym zgłoszeniu
zdarzenia i przez to uniknąć pomyłek w pisaniu tych nazw. Ewentualne błędy w
pisowni nazwy obiektu logującego wyłapane zostaną przez kompilator.
Obiekt klasy TLogCollector odbiera komunikaty i zapisuje je w dzienniku
zdarzeń, uzupełniając je o datę i czas wystąpienia zdarzenia. Na tym etapie następuje
też synchronizacja dostępu różnych wątków do dziennika zdarzeń. Ponieważ jest to
obiekt wspólny dla wszystkich źródeł zdarzeń, zmiana docelowego miejsca zapisu
wszystkich komunikatów aplikacji wymaga edycji kodu źródłowego jedynie w jednym
miejscu. Podobnie łatwo można określić format wszystkich komunikatów – sposób za-
pisu daty, priorytetów komunikatów itp.
3.5. Komunikacja sieciowa
Serwer WWW nie korzysta bezpośrednio z interfejsu gniazd BSD, tylko korzysta
z klas TSocket oraz TServerSocket. Klasy te stanowią opakowanie dla interfej-
su gniazd BSD i udostępniają niezależny od systemu operacyjnego interfejs do
komunikacji sieciowej poprzez protokół TCP/IP.
Klasa TSocket umożliwia nawiązanie połączenia z aplikacją nasłuchującą na
danym porcie zdalnego komputera oraz przesyłanie danych w obu kierunkach. Adres
komputera można podać jako nazwę FQDN lub adres IP. W przypadku podania na-
zwy, do ustalenia adresu IP zostanie użyty systemowy resolver DNS. Przesyłanie
danych odbywa się za pomocą metod zdefiniowanych przez interfejs strumienia
wejścia/wyjścia IInputOutputStream. Możliwe jest blokujące i nieblokujące
przesyłanie danych binarnych w postaci tablic bajtów.
Klasa TServerSocket pozwala nasłuchiwać na danym porcie lokalnego kom-
putera i przyjmować połączenia. Po nawiązaniu połączenia obiekt klasy
TServerSocket tworzy i przekazuje użytkownikowi obiekt klasy TSocket.

Rozdział IV – Projekt i implementacja 75
3.6. Strumienie wejścia/wyjścia
Klasy realizujące strumienie wejścia/wyjścia zostały napisane z powodu niewy-
starczającej funkcjonalności standardowych strumieni z biblioteki STL. Serwer WWW
potrzebował bowiem strumieni buforowanych do komunikacji sieciowej za pośrednic-
twem gniazd. Strumienie z biblioteki STL nie dostarczają buforowania strumieni oraz
nie można ich w prosty sposób, bez definiowania dodatkowej klasy, powiązać z klasa-
mi opakowującymi interfejs gniazd BSD. Z tego powodu pakiet został wyposażony we
własne klasy obsługujące strumienie. Hierarchia tych klas została przedstawiona na
diagramie 5. Jest ona wzorowana na hierarchii klas strumieniowych języka Java.
Klasa abstrakcyjna IStream reprezentuje uogólniony strumień. Każdy stru-
mień może znajdować się w jednym z trzech stanów: zamknięty, otwarty,
nieprawidłowy. Każdy strumień można też zamknąć. Klasa ta dostarcza metody słu-
żące do ustawiania i odczytu stanu strumienia oraz definiuje postać metody
zamykającej strumień, której implementacja jest zależna od konkretnego strumienia.
Klasa ta nie definiuje sposobu otwierania strumienia, gdyż zwykle sposób ten jest za-
leżny od rodzaju strumienia. Czasem jeden rodzaj strumienia można otwierać na kilka
różnych sposobów.
Interfejsy IInputStream oraz IOutputStream deklarują metody słu-
żące do odczytu i zapisu danych. Przyjęto, że metody przesyłające dane są zawsze
nieblokujące. Aby zrealizować blokujące przesyłanie danych należy dodatkowo użyć
osobnych metod czekających. Metody te nie przesyłają danych, a jedynie zatrzymują
Diagram 5: Hierarchia klas związanych ze strumieniami (bez klas wyjątków)

Rozdział IV – Projekt i implementacja 76
wykonywanie wątku na określony czas. Dzięki temu możliwa jest sygnalizacja prze-
rwania oczekiwania poprzez zgłoszenie wyjątku TInterruptedException przez
metody czekające. Zgłaszanie wyjątku w metodzie przesyłającej dane mogłoby wiązać
się utratą całości lub części tych danych. Błędy wejścia/wyjścia są również sygnalizo-
wane za pomocą wyjątków. Interfejs IInputOutputStream to proste połączenie
interfejsów IInputStream oraz IOutputStream.
Klasy TBufferedInputStream oraz TBufferedOutputStream
dodają do dowolnej klasy będącej strumieniem usługę buforowania. Każdy obiekt tej
klasy zawiera bufor cykliczny FIFO o wielkości definiowanej przez użytkownika.
Istnienie bufora poprawia wydajność, gdyż funkcje API systemu operacyjnego służące
do przesyłania danych są wywoływane rzadziej i z większymi porcjami danych. Poza
tym strumienie buforowane dostarczają dodatkową funkcjonalność: możliwość
podejrzenia zawartości bufora oraz anulowanie dokonanego zapisu bądź odczytu.
Możliwe jest też sprawdzenie, czy jakiekolwiek dane z bufora strumienia wyjściowego
zostały wysłane. Ta funkcja jest wykorzystywana przez serwlety w celu określenia,
czy nagłówki HTTP zostały już wysłane, czy jeszcze nie, i czy w związku z tym
można je zmienić.
Klasy TStringReader oraz TStringWriter pozwalają odczytywać i
zapisywać dane w postaci łańcuchów znaków. Mogą współpracować z dowolną klasą
zgodną z interfejsami strumieni buforowanych. Dane są przekazywane od i do
użytkownika w postaci obiektów klasy TString, gdyż właśnie obiekty tej klasy są
zalecane do reprezentacji informacji tekstowych i używane w wielu pozostałych
komponentach. Użycie strumieni buforowanych było konieczne, ponieważ klasa
TStringReader udostępnia metodę do odczytywania całej linii tekstu.
Buforowanie pozwala na odczytywanie tekstu większymi porcjami i, po napotkaniu
znaku końca linii w tekście, zwrócenie pozostałego fragmentu z powrotem do
strumienia. Gdyby nie było takiej możliwości, konieczne byłoby czytanie danych ze
strumienia po jednym znaku, co obniżyłoby znacznie wydajność.

Rozdział V – Testy i zastosowania praktyczne
Duża część pracy została poświęcona dokładnemu przetestowaniu komponentów,
również w praktycznych aplikacjach internetowych. Jakość komponentów użytych do
budowy aplikacji przekłada się mianowicie na łatwość jej tworzenia oraz ostateczną jej
jakość. Dobre komponenty powinny umożliwiać szybkie stworzenie ograniczonej, ale
działającej aplikacji, którą następnie można łatwo rozbudowywać. Komponenty nie
mogą również ograniczać w żaden sposób twórcy aplikacji.
1. Wymagania systemowe i sprzętowe
Wymagany jest komputer wyposażony w 32-bitowy procesor i system operacyjny
klasy Unix. Pakiet był testowany na systemach:
• Linux kernel 2.4.29, 2.6.11 – dystrybucje Slackware 9.1, Mandrake 9.1, RedHat
• OpenBSD 3.3, 3.4, 3.5
• FreeBSD 4.11, 5.3
Konieczne jest zainstalowanie biblioteki POSIX threads. Jest ona dostępna stan-
dardowo w większości systemów operacyjnych klasy Unix.
W celu kompilacji pakietu potrzebne są dodatkowe programy:
• GNU C/C++ Compiler (wersja co najmniej 2.95.3)
• GNU make
Pakiet nie ma szczególnych wymagań odnośnie pamięci operacyjnej i wydajności
procesora – wystarczy tyle, ile jest potrzebne dla prawidłowej pracy systemu operacyj-
nego.
2. Kompilacja i instalacja
Zgodnie z wymaganiami niefunkcjonalnymi odnośnie łatwości uczenia się, insta-
lacja powinna być procesem prostym, standardowym i niewymagającym czytania
obszernych opisów. Tak jest w istocie. Pakiet jest dostarczony w postaci archiwum
standardowych dla systemów operacyjnych klasy Unix programów gzip i tar.
Archiwum to znajduje się w dodatku A. Kompilacja i instalacja bibliotek przebiega na-
stępująco:

Rozdział V – Testy i zastosowania praktyczne 78
1. Należy umieścić archiwum w jakimś katalogu na twardym dysku swojego kompu-
tera i rozpakować je. Powstanie katalog o takiej samej nazwie jak nazwa pakietu.
$ gunzip smeil0.4.2.tar.gz$ tar xf smeil0.4.2.tar$ cd smeil0.4.2
Do rozpakowania można użyć również okienkowego programu mc albo ark.
2. Należy skonfigurować kod źródłowy za pomocą skryptu configure. Skrypt ten
przygotuje kod do kompilacji i sprawdzi, czy w systemie nie brakuje jakichś
bibliotek.
$ ./configure
Opcjonalnie można podać docelowe miejsce instalacji pakietu:
$ ./configure prefix=/usr/lib
3. Kompilacja pakietu następuje poprzez uruchomienie programu make:
$ make
4. Opcjonalnie można wykonać automatyczne testy najważniejszych komponentów:
$ make check
5. Następnie należy zainstalować pakiet wydając polecenie:
$ make install
Na niektórych systemach operacyjnych, w zależności od tego, gdzie zostaną zain-
stalowane biblioteki, czasem może zachodzić konieczność określenia lokalizacji tych
bibliotek w odpowiednich plikach konfiguracyjnych lub zmiennych systemowych.
Aby w pełni wykorzystać możliwości oferowane przez bibliotekę, konieczne jest
sięgnięcie do dokumentacji HTML zawartej w dodatku C.
3. Aplikacja A - „Hello World”
Kod źródłowy bardzo prostej aplikacji przedstawia listing 1. Aplikacja ta jest jed-
ną z aplikacji przykładowych znajdujących się w dodatku D. Aplikacja ta wyświetla
jedynie napis “Hello World!” w przeglądarce internetowej. Aby ją skompilować i uru-
chomić, należy zapisać kod w pliku hello.cpp i wydać polecenia:

Rozdział V – Testy i zastosowania praktyczne 79
$ g++ hello.cpp lsmeil o hello$ ./hello
Po uruchomieniu, wyniki działania będą dostępne pod adresem: http://localhost:8080/.
// Dołączenie bibliotek:
#include <smeil/net/http/servlet.h>#include <smeil/net/http/server.h>#include <smeil/mem/smartptrimpl.h>using namespace smeil;
// Definicja serwletu:
class THelloServlet : public IHttpServlet {public: void OnRequest(THttpRequest& Request, THttpResponse& Response) { Response.WriteLine("<html><head></head><body><p>"); Response.WriteLine("Hello World!"); Response.WriteLine("</p></body></html>"); }};
// Uruchomienie serwera WWW i zarejestrowanie serwletu:
int main() { THttpServer Server; Server.RegisterServlet(TSmartPtr<THelloServlet>::Create(), "/"); Server.SetLocalPort(8080); Server.Run(); return 0;}
Listing 1: Kod źródłowy prostej aplikacji internetowej
Kod składa się z trzech części. Pierwsza część zawiera jednie informacje dla
preprocesora i kompilatora, które komponenty będą wykorzystane. W drugiej części
jest zawarta definicja serwletu. Konieczne jest pokrycie jednej metody: OnRequest,
do której są przekazywane obiekty służące do komunikacji z przeglądarką (Request
i Response). W trzeciej części, w procedurze głównej programu stworzona zostaje
instancja serwera WWW nasłuchująca na porcie 8080 i obiekt serwletu, który następ-
nie jest rejestrowany pod adresem „/”. Wywołanie Server.Run() powoduje
zatrzymanie wykonywania programu i oczekiwanie na kolejne żądania HTTP.

Rozdział V – Testy i zastosowania praktyczne 80
4. Aplikacja B – serwer DNS
Przy użyciu komponentów opisanych w niniejszej pracy, został stworzony serwer
DNS wyposażony w panel administracyjny dostępny za pośrednictwem przeglądarki
internetowej [dodatki E, F]. Serwer posiada następującą funkcjonalność:
• Odpowiadanie na zapytania dotyczące obsługiwanych stref.
• Odpowiadanie na zapytania dotyczące innych stref w dwóch trybach: rekursyw-
nym i iteracyjnym.
• Zwracanie pełnej nazwy domenowej (FQDN) na podstawie numeru IP.
• Zwracanie numeru IP na podstawie FQDN.
• Zwracanie dodatkowych informacji dotyczących hosta takich jak: opis przecho-
wywany w rekordach TXT (na potrzeby systemu anty-spamowego) oraz opis
przechowywany w rekordach NS.
• Udostępnianie administratorowi szczegółowych logów pozwalających stwierdzić
poprawność działania serwera. Logi zawierają informacje o wszelkich ważnych
czynnościach podejmowanych przez serwer i niejednokrotnie przyczyniały się do
wykrycia usterek w jego pracy.
• Możliwość ustalenia z jakich komputerów można dokonywać zapytań dla każdej
ze stref.
• Możliwość ustalenia czy serwer odpowiada na zapytania rekursywne (dla każdej
ze stref).
• Możliwość skonfigurowania numeru nasłuchującego portu oraz numeru portu, na
którym nasłuchują inne serwery DNS (w celach testowania).
• Możliwość ustalenia praw (użytkownika) z jakimi będzie działał serwer.
Serwer może być konfigurowany za pomocą tekstowych plików konfiguracyjnych
o formacie znanym z popularnego serwera BIND lub za pomocą graficznego interfejsu
WWW, który został dodany w końcowym etapie rozwoju projektu. Interfejs ten jest
dostępny na porcie 8888 komputera, na którym jest uruchomiony serwer. Interfejs
WWW udostępnia następujące funkcje:
• Wyświetlanie listy stref.

Rozdział V – Testy i zastosowania praktyczne 81
• Wyświetlenie opisu strefy: adresu e-mail administratora, adresu komputera
udzielającego autorytatywnych odpowiedzi dotyczących strefy.
• Wyświetlenie listy rekordów danej strefy. Przedstawiany jest typ rekordu, klucz
oraz wartość.
• Dodawanie i usuwanie stref.
• Zmiana opisu strefy.
• Dodawanie i usuwanie rekordów w strefie.
Na na rysunku 1 przedstawiono widok główny z listą stref, a na rysunku 2 inter-
fejs edycji ustawień danej strefy.
Rysunek 1: Konfiguracja serwera DNS - widok główny

Rozdział V – Testy i zastosowania praktyczne 82
Ponieważ moduł obsługujący przeglądarkowy interfejs użytkownika został doda-
ny w końcowej fazie rozwoju projektu, pozostałe moduły nie korzystają z udogodnień
opracowanych przez autora pracy. W trakcie uzdatniania wersji końcowej programu
właśnie w tych modułach najczęściej ujawniały się błędy ochrony pamięci oraz prze-
cieki pamięci. Błędy te powodowały nagłe przerwanie pracy aplikacji z komunikatem
“segmentation fault”. Stosowanie automatycznych mechanizmów obsługi pamięci oraz
funkcji, które dokładnie sprawdzają poprawność danych wejściowych, przynosi wy-
mierne rezultaty w postaci skrócenia czasu wytwarzania oprogramowania oraz
Rysunek 2: Konfiguracja serwera DNS - ustawienia strefy

Rozdział V – Testy i zastosowania praktyczne 83
podniesienia jego jakości. W samym module interfejsu użytkownika nie został wykry-
ty ani jeden błąd ochrony pamięci, natomiast napisanie tego modułu przyczyniło się do
znalezienia kilku nieprawidłowości w kodzie odśmiecacza oraz klasach związanych z
przetwarzaniem tekstu. Nieprawidłowości te były spowodowane pomyłkami im-
plementacyjnymi i udało się je szybko usunąć. Nie zachodziła konieczność zmiany
projektu komponentów.
5. Automatyczne, modułowe testy funkcjonalne
Część funkcjonalności komponentów jest testowana automatycznie. Test te znaj-
dują się w plikach o nazwie test.cpp w drzewie kodu źródłowego projektu
[dodatek B] i mogą być uruchamiane za pomocą programu make. Stosowanie testów
automatycznych utrudnia wprowadzanie nowych błędów do starych komponentów.
Scenariusze testów zostały stworzone dla najważniejszych i najbardziej skomplikowa-
nych komponentów:
• odśmiecacza,
• buforowanych strumieni wejścia/wyjścia,
• klas reprezentujących łańcuchy znaków,
• klas kontenerowych.
Testy odśmiecacza polegają na tworzeniu nowych obiektów, ustalaniu pomiędzy
nimi odpowiednich powiązań, a następnie ręcznym wywołaniu głównej procedury
odśmiecacza (TGarbageCollector::Collect) i sprawdzeniu, czy wszystkie
niedostępne obiekty zostały usunięte na podstawie informacji o wewnętrznym stanie
odśmiecacza. Zostały również przeprowadzone testy, w których odśmiecacz nie jest
uruchamiany ręcznie, a uruchamia się automatycznie i pracuje współbieżnie z wątkiem
wykonującym różne operacje na obiektach: masowe tworzenie nowych obiektów, two-
rzenie i niszczenie wskaźników oraz zmiana wartości wskaźników. Zwykle dla
każdego testu tego typu operacje powtarzane są przynajmniej kilkadziesiąt tysięcy ra-
zy. Po wykonaniu każdego testu, liczba pozostałych obiektów jest weryfikowana.
Testy strumieni buforowanych polegają na zapisywaniu dużej ilości danych do
pliku, a następnie odczytaniu całej zawartości pliku i weryfikacji odczytanych danych.
Z kolei testy klas łańcuchów znaków oraz klas kontenerowych testują poprawność
każdej metody osobno. Sprawdzane są wszystkie podstawowe operacje takie jak: two-

Rozdział V – Testy i zastosowania praktyczne 84
rzenie łańcucha typu TString z łańcucha w stylu C, konkatenacja łańcuchów, usu-
wanie fragmentu łańcucha, odczyt pojedynczego znaku lub całego fragmentu łańcucha,
konwersja łańcucha do liczby i odwrotnie, wyszukiwanie i zastępowanie podła-
ńcuchów. Dla kontenerów sprawdzane jest wstawianie, usuwanie i wyszukiwanie
elementów.
Wielokrotnie testy automatyczne przyczyniały się do znalezienia istotnych
błędów w implementacji komponentów. Dodatkową pomocą w znajdowaniu błędów w
implementacji odśmiecacza był program valgrind [VALGR, dodatek I]. Program ten
potrafi wykrywać wszelkie nieprawidłowości w zarządzaniu pamięcią. Skutecznie
znajduje też wycieki pamięci. Za pomocą tego programu zostało ostatecznie potwier-
dzone, że odśmiecacz działa. Wyniki testów aplikacji A przedstawia listing 2. Widać,
że aplikacja nie straciła dostępu do żadnego zaalokowanego bloku pamięci. Niewielka
ilość zaalokowanej pamięci pozostałej po zakończeniu procesu jest wynikiem alo-
kowania pamięci przez odśmiecacz na swoje wewnętrzne struktury danych. Rozmiar
tej pamięci nie rośnie w trakcie pracy aplikacji.
==24611== ERROR SUMMARY: 0 errors from 0 contexts (suppressed: 39 from 8) ==24611== malloc/free: in use at exit: 29948 bytes in 213 blocks. ==24611== malloc/free: 509781 allocs, 509568 frees, 21179752 bytes allocated. ==24611== For counts of detected errors, rerun with: v ==24611== searching for pointers to 213 notfreed blocks. ==24611== checked 13239548 bytes. ==24611== ==24611== LEAK SUMMARY: ==24611== definitely lost: 0 bytes in 0 blocks. ==24611== possibly lost: 0 bytes in 0 blocks. ==24611== still reachable: 29948 bytes in 213 blocks. ==24611== suppressed: 0 bytes in 0 blocks.
Listing 2: Wyniki testów aplikacji A programem valgrind
6. Pomiary wydajności
W niektórych zastosowaniach wydajność aplikacji może mieć znaczenie. Prezen-
towany w niniejszej pracy zestaw komponentów wykorzystuje automatyczne
mechanizmy zarządzania pamięcią, które mimo posiadania wielu zalet, mogą negatyw-
nie wpływać na wydajność. Odśmiecacz potrzebuje czasu na znalezienie
niedostępnych obiektów oraz na zarządzanie swoimi wewnętrznymi strukturami
danych. Zostały wykonane zarówno pomiary wydajności samego odśmiecacza jak i

Rozdział V – Testy i zastosowania praktyczne 85
prostej aplikacji internetowej wykorzystującej większość prezentowanych w pracy
komponentów.
6.1. Wydajność odśmiecacza
Jak każdy odśmiecacz, również odśmiecacz prezentowany w niniejszej pracy
wprowadza pewne narzuty czasowe względem ręcznego zarządzania pamięcią:
• Każda zmiana wartości wskaźnika wymaga zaznaczenia nowo-wskazywanego
obiektu na szaro.
• Każda operacja kopiowania wskaźnika wymaga kopiowania dwukrotnej ilości
pamięci w porównaniu z kopiowaniem wskaźnika wbudowanego w C++.
• Każda operacja utworzenia i zniszczenia wskaźnika wymaga sprawdzania, czy
wskaźnik jest pośredni czy bezpośredni oraz ewentualnego umieszczenia
wskaźnika w tablicy mieszającej.
• Każda operacja tworzenia i niszczenia obiektu wymaga zmian informacji w we-
wnętrznych strukturach odśmiecacza.
• Główny wątek odśmiecacza potrzebuje czasu na znalezienie wszystkich niedo-
stępnych obiektów. Czas ten jest proporcjonalny do liczby wszystkich obiektów
zarządzanych przez odśmiecacz.
W tabeli 5 przedstawiono wyniki testów wykonanych na komputerze wyposażo-
nym w procesor Intel Celeron 2.4 GHz, 128 kB L2 cache i pamięć operacyjną 256 MB
RAM pracującym pod kontrolą systemu operacyjnego Linux z jądrem w wersji 2.4.25.
Ze względu na niewielką rozdzielczość zegara systemowego wynoszącą 55 ms, w
testach powtarzano daną operację tak długo, aby łączny czas wykonywania każdej
operacji był nie mniejszy niż 10 s. Narzut związany z wykonywaniem pętli nie był bra-
ny pod uwagę, więc rzeczywiste wyniki mogą być nieznacznie mniejsze. Należy
pamiętać, że obecne mikroprocesory mają bardzo złożoną architekturę i czas wykony-
wania danej operacji jest silnie zależny od operacji wykonywanych wcześniej i
później.Oznacza to, że prezentowane tu wyniki nie dotyczą każdej aplikacji i każdego
przypadku, i mają charakter poglądowy. Wynika z nich przede wszystkim, że dosyć
częste wykonywanie operacji tworzenia i usuwania wskaźnika może spowodować
duży narzut. Dlatego zalecane jest przekazywanie inteligentnych wskaźników możli-
wie jak najczęściej przez referencję, a nie przez wartość, oraz w przypadku używania
wskaźników w pętli – deklarowanie ich przed pętlą, a nie wewnątrz. Zmierzony czas

Rozdział V – Testy i zastosowania praktyczne 86
tworzenia i usuwanie obiektów zawiera w sobie również czas konieczny na wyszu-
kiwanie obiektów nadających się do usunięcia. Ponieważ wyszukiwanie może
odbywać się w chwili bezczynności aplikacji (np. oczekiwania na zdarzenie), rzeczy-
wisty narzut może być mniejszy.
Tabela 5: Czas wykonywania podstawowych operacji związanych z zarządzaniem pamięcią
Czas wykonania [ns]
Ręczne zarządza-nie pamięcią
Automatyczne zarządzanie
pamięcią
Dostęp do obiektu za pośrednictwem wskaźnika 1,0 ± 0,1 1,0 ± 0,1
Zmiana wartości wskaźnika 1,0 ± 0,1 2,2 ± 0,2
Utworzenie i usunięcie wskaźnika 0,0 ≤ 56 ± 6
Utworzenie i usunięcie obiektu o wielkości 24 B 360 ± 40 ≤ 1100 ± 150
6.2. Wydajność aplikacji testowych
Do testów został użyty bezpłatny program http_load [HTLOAD, dodatek H] opra-
cowany w ACME [ACME], w których również został stworzony jeden z najszybszych
serwerów internetowych thttpd [THTTPD]. Na stronach internetowych ACME zostało
także zamieszczone porównanie wydajności popularnych serwerów internetowych.
Testowane były dwie proste aplikacje [dodatek G]:
• hello – aplikacja wyświetlająca stronę z bardzo krótkim napisem. Celem tego
testu był pomiar narzutu czasowego na kompletne obsłużenie żądania HTTP.
• polynomial – aplikacja obliczająca wartości wielomianu 5 stopnia przekazanego
za pośrednictwem formularza i prezentująca wyniki w postaci tabelki o objętości
większej niż 5 kB. Celem testu było sprawdzenie wydajności mechanizmów prze-
syłania danych od i do przeglądarki.
Program testujący symulował 100 użytkowników pobierających strony równo-
cześnie. W praktyce oznaczałoby to kilka tysięcy użytkowników korzystających na raz
z aplikacji, ponieważ użytkownicy nie wysyłają zapytań do aplikacji w sposób ciągły,
a jedynie co kilkanaście sekund do kilku minut. Dla każdego przypadku zostało prze-
prowadzonych po 5 pomiarów po 1000 pobrań każdy. Uśrednione wyniki prezentuje
tabela 6.
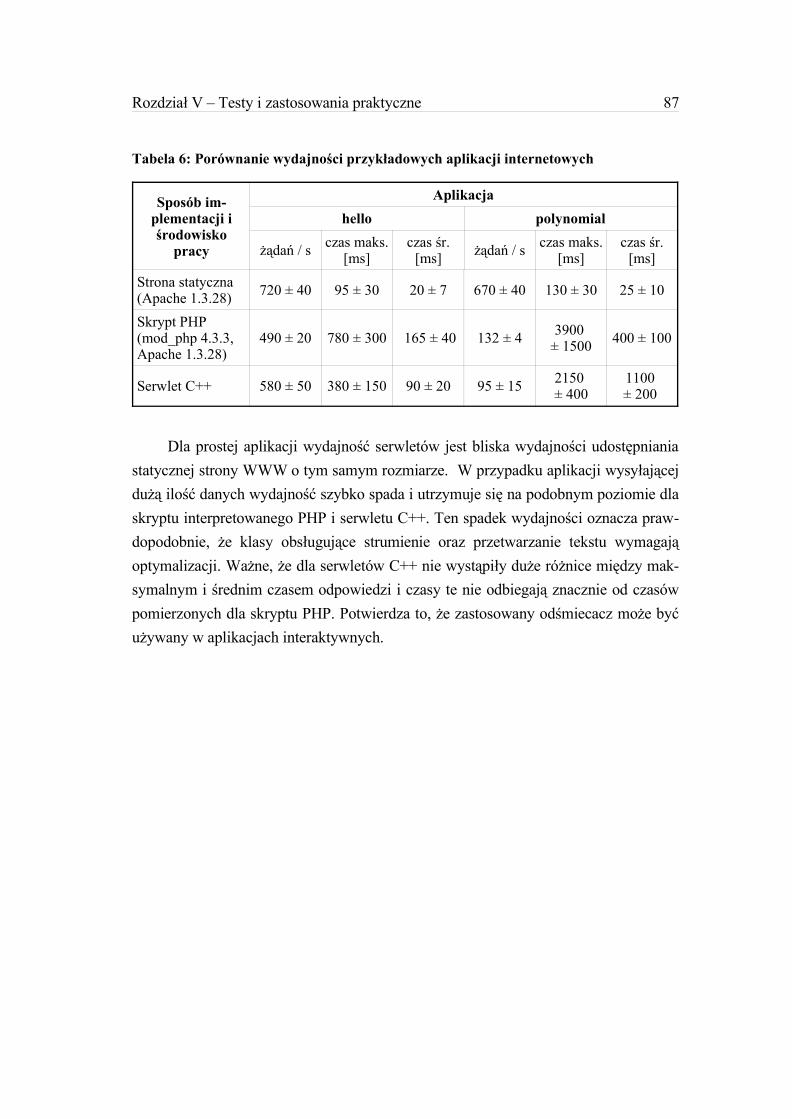
Rozdział V – Testy i zastosowania praktyczne 87
Tabela 6: Porównanie wydajności przykładowych aplikacji internetowych
Sposób im-plementacji i środowisko
pracy
Aplikacja
hello polynomial
żądań / sczas maks.
[ms]czas śr.
[ms]żądań / s
czas maks. [ms]
czas śr. [ms]
Strona statyczna (Apache 1.3.28)
720 ± 40 95 ± 30 20 ± 7 670 ± 40 130 ± 30 25 ± 10
Skrypt PHP (mod_php 4.3.3, Apache 1.3.28)
490 ± 20 780 ± 300 165 ± 40 132 ± 43900
± 1500400 ± 100
Serwlet C++ 580 ± 50 380 ± 150 90 ± 20 95 ± 152150 ± 400
1100 ± 200
Dla prostej aplikacji wydajność serwletów jest bliska wydajności udostępniania
statycznej strony WWW o tym samym rozmiarze. W przypadku aplikacji wysyłającej
dużą ilość danych wydajność szybko spada i utrzymuje się na podobnym poziomie dla
skryptu interpretowanego PHP i serwletu C++. Ten spadek wydajności oznacza praw-
dopodobnie, że klasy obsługujące strumienie oraz przetwarzanie tekstu wymagają
optymalizacji. Ważne, że dla serwletów C++ nie wystąpiły duże różnice między mak-
symalnym i średnim czasem odpowiedzi i czasy te nie odbiegają znacznie od czasów
pomierzonych dla skryptu PHP. Potwierdza to, że zastosowany odśmiecacz może być
używany w aplikacjach interaktywnych.

Podsumowanie
W ramach pracy został zrealizowany pakiet komponentów ułatwiających two-
rzenie aplikacji internetowych w C++. Wykorzystano go do budowy praktycznej
aplikacji internetowej i m.in. na podstawie jej działania można stwierdzić, że spełnia
on postawione mu wymagania, a oczekiwania dotyczące przydatności odśmiecacza w
programach C++ potwierdziły się.
Najważniejsze cechy, wyróżniające pakiet od innych rozwiązań w dziedzinie apli-
kacji internetowych to:
• Wykorzystanie popularnego, sprawdzonego i bardzo elastycznego języka
programowania jakim jest C++. Wynika z tego nie tylko duża wydajność two-
rzenia nowych aplikacji internetowych, ale również łatwość korzystania z
różnorodnych bibliotek napisanych w językach C lub C++.
• Dogodny dostęp do API systemu operacyjnego. Tej cechy nie mają systemy opar-
te o wszelkie interpretery bądź maszyny wirtualne. Systemy operacyjne są pisane
zwykle w języku C lub C++.
• Duża wydajność pracy aplikacji przy niskim zużyciu zasobów. W porównaniu ze
skryptami CGI nie występuje narzut czasowy związany z koniecznością urucha-
miania nowego procesu, a w porównaniu z systemami opartymi o języki
interpretowane nie występuje narzut związany z interpretacją kodu. Z wyników
testów wydajnościowych opisanych w rozdziale V wynika, że wymagania sta-
wiane odnośnie wydajności zostały spełnione, choć dalsze ulepszenia w tym
zakresie są możliwe i pożądane.
• Podwyższony poziom bezpieczeństwa i stabilność pracy dzięki zastosowaniu me-
chanizmów automatycznego zarządzania pamięcią oraz odpowiednio
skonstruowanego interfejsu programistycznego. Wprawdzie mechanizmy te nie
gwarantują poprawności programów pisanych przy użyciu opisanego tu pakietu,
to utrudniają popełnianie wielu potencjalnie niebezpiecznych pomyłek oraz
zwiększają produktywność programistów. W trakcie pisania przykładowej apli-
kacji (serwer DNS), błędy ochrony pamięci nie wystąpiły w modułach
korzystających z komponentów przedstawionych w niniejszej pracy, gdy tymcza-
sem w pozostałych modułach ujawniały się wielokrotnie.

Podsumowanie 89
• Łatwy proces instalacji i konfiguracji pakietu. Własność tę uzyskano głównie
dzięki zastosowaniu standardowych narzędzi GNU wspomagających kompilację i
instalację programów pisanych w C/C++.
• Łatwe napisanie pierwszej aplikacji internetowej. W mniej niż 20 liniach kodu
C++ można zawrzeć bardzo prostą, ale działającą aplikację internetową. Za-
stosowanie znanego wzorca projektowego jakim są serwlety powinno ułatwić
początkującym naukę korzystania z prezentowanych w niniejszej pracy kom-
ponentów.
• Niezależność tworzonych aplikacji internetowych od jakiegokolwiek
oprogramowania poza systemem operacyjnym. Bez tej własności wykorzystanie
komponentów w przykładowym serwerze DNS znacznie skomplikowałoby jego
procedurę instalacyjną.
Należy pamiętać, że prezentowane w niniejszej pracy oprogramowanie wymaga
dalszych uzupełnień i udoskonaleń:
• Oddzielenie warstwy prezentacji od warstwy logiki biznesowej. Kod HTML opi-
sujący to, co widzi użytkownik, jest umieszczony w kodzie serwletu. Zmiana
wyglądu interfejsu użytkownika pociąga za sobą rekompilację projektu, a poza
tym niesie ryzyko wprowadzenia błędów do logiki aplikacji. Konieczne jest stwo-
rzenie komponentów umożliwiających umieszczenie opisu wyglądu interfejsu w
osobnych szablonach. Taki szablon mogłaby edytować osoba nie znająca języka
C++. Dane do szablonu generowane byłyby przez serwlet.
• Napisanie obsługi odbierania plików od przeglądarki. Użytkownik może sobie
oczywiście taką obsługę stworzyć wykorzystując istniejące komponenty, jednak
jest to zadanie tak typowe, że powinny być do tego gotowe funkcje.
• Rozszerzenie zestawu klas kontenerowych korzystających z odśmiecacza o inne
klasy kontenerowe spotykane w językach obiektowych. Prawdopodobnie można
tego dokonać modyfikując istniejące biblioteki.
• Aplikacje internetowe korzystają bardzo często z baz danych, a systemy baz
danych mają zwykle niekompatybilne ze sobą interfejsy dostępu. Uniwersalny,
ujednolicony interfejs (tak jak JDBC w języku Java) mógłby być bardzo dużym
udogodnieniem dla twórców aplikacji.

Podsumowanie 90
• Dodanie mechanizmów wspomagające zapis stanu sesji użytkownika w bazie
danych. Dzięki temu można byłoby łatwiej uzyskać odpowiedni poziom nieza-
wodności aplikacji.
• Optymalizacja niektórych „wąskich gardeł” - testy wydajnościowe wykazały do-
syć niską wydajność strumieni.
• Uruchomienie wersji działającej na systemach klasy Windows.
• Dzięki obiektowej architekturze, uzupełnienie pakietu o powyższe elementy nie
powinno wiązać się z przeróbkami większych fragmentów istniejącego kodu.
Przedstawione w niniejszej pracy oprogramowanie zostało przetestowane w prak-
tyce jedynie w dosyć prostych aplikacjach internetowych. Aby umożliwić dalsze testy
w różnych zastosowaniach oraz szerszy rozwój projektu, jak również uzyskać opinie
użytkowników, kod źródłowy wraz z dokumentacją zostanie udostępniony w sieci In-
ternet na bazie licencji GNU General Public License [GPL].

Spis źródeł
[ACME] ACME Laboratories Homepage, http://www.acme.com/[ALUR03] Alur D., Crupi J., Malks D., Wzorce projektowe, Helion, Warszawa,
2003[ATTAR94] Attardi G., Flagella T., A customizable memory management framework.,
Proceedings of the USENIX C++ Conference, , Cambridge, Massachussetts, 1994
[BOE03] Boehm H. J., Destructors, Finalizers, and Synchronization, Proceedings of the 30th ACM SIGPLAN-SIGACT Symposium on Programming Languages, ACM Press, New York, NY, USA, 2003
[BOE04] Boehm H. J., Space Efficient Conservative Garbage Collection, ACM SIGPLAN Notices, ACM Press, New York, USA, 2004
[BOOST] C++ Boost Smart Pointers, http://www.boost.org/libs/smart_ptr/smart_ptr.htm
[CF] Cold Fusion 7 Documentation, http://www.macromedia.com/support/documentation/en/coldfusion/
[COLB] Colburn R., CGI - Sams Teach Yourself CGI Programming in a Week, Sams Publishing, Indianapolis, Indiana, USA, 1998
[CPP1] One Reason C++ Sucks Compared To C, http://nothings.org/computer/cpp.html
[DOXYS] DoxyS - C++ Documentation, http://www.doxys.dk/doxys_homepage/index.html
[EDEL91] Edelson D. R., Pohl I., They're Smart, but They're Not Pointers, Proceedings of the 1991 Usenix C++ Conference, University of California at Santa Cruz, Santa Cruz, CA, USA, 1992
[FCGI] FastCGI homepage, http://www.fastcgi.com/ [FORR] Forristal J., Traxler J., Hack Proofing Your Web Applications, edycja
polska, Helion, Gliwice, 2003[GOOD01] Goodwill J., Java Server Pages. Podręcznik z przykładami, Helion,
Warszawa, 2001[GPL] GNU General Public License, http://www.gnu.org/copyleft/gpl.html[HACK] Hacking PL, http://hacking.pl/[HIRZ00] Hirzel M., Diwan A., On the Type Accuracy of Garbage Collection,
Proceedings of the 2nd international symposium on Memory management, ACM Press, Minneapolis, USA, 2000
[HOUG02] Hougland D., Tavistock A., JSP – tworzenie stron WWW, RM, Warszawa, 2002
[HTLOAD] http_load - Multiprocessing HTTP test client, http://www.acme.com/software/http_load/
[INL1] Inline Internet Systems, Inc., User’s Guide to iHTML Extensions Version 2.20, 2001
[INL2] Inline - The Internet Applications Company, http://www.ihtml.com/

Spis źródeł 92
[J2EE] Java 2 Platform, Enterprise Edition, http://java.sun.com/j2ee/[KOL04] Kołaczkowski P., Technologie tworzenia aplikacji internetowych
działających po stronie serwera, Pro Dialog 18, Nakom, Poznań, 2004[KOL05a] Kołaczkowski P., Bluemke I., A soft-real time precise garbage collector
for multimedia applications, materiały konferencyjne Multimedia w Biznesie i Edukacji, Fundacja Współczesne Zarządzanie, Białystok, 2005
[KOL05b] Kołaczkowski P., Bluemke I., A Soft Real-Time Precise Tracing Garbage Collector for C++, praca złożona do publikacji w Pro Dialog , Nakom, Poznań, 2005
[MITC03] Mitchell S., Active Server Pages 3.0 dla każdego, Helion, Gliwice, 2003[MOR4] More for C++, http://www.morefor.org/[NET] Microsoft .NET Developer Center - Technology Overview,
http://msdn.microsoft.com/netframework/technologyinfo/ overview/default.aspx
[PEAR] The PHP extension and Application Repository, http://pear.php.net/[PHP] PHP Homepage, http://www.php.net/[RFC1738] Uniform Resource Locators, http://rfc.net/rfc1738.html[RFC2616] Hypertext Transfer Protocol - HTTP 1.1,
http://www.w3.org/Protocols/rfc2616/rfc2616.html[RTGC] Reverse Trace Garbage Collector, http://sourceforge.net/projects/librtgc/[SMI] Smieciuch Project Home Page, http://smieciuch.sourceforge.net/[STL1] Standard Template Library Programmer's Guide,
http://www.sgi.com/tech/stl/[STL2] HP aC++ Online Programmer's Guide,
http://docs.hp.com/en/6162/libs.htm[STRO] Stroustrup B., Język C++, WNT, Warszawa, 2000[THTTPD] thttpd - Tiny/turbo/throttling HTTP server,
http://www.acme.com/software/thttpd/[TIOBE] TIOBE - Tiobe Programming Community Index,
http://www.tiobe.com/tpci.htm[VALGR] Valgrind Home, http://valgrind.org/[WILS92] Wilson P. R., Uniprocessor Garbage Collection Techniques,
Proceedings of the International Workshop on Memory Management, Springer-Verlag, London, UK, 1992
[WORL03] Worley S., ASP.NET. Vademecum Profesjonalisty, Helion, Warszawa, 2003
[WXWI] wxWidgets - the open source, cross-platform native UI framework with twelve years of evolution behind it , http://www.wxwidgets.org/

Spis tabel
Tabela 1: Najpopularniejsze systemy budowania aplikacji internetowych...................11Tabela 2: Porównanie czasów uruchamiania się procesu na różnych systemach operacyjnych.................................................................................................................15Tabela 3: Położenie komponentów w strukturze katalogów projektu...........................54Tabela 4: Zestawienie odśmiecaczy stosowanych w C++.............................................55Tabela 5: Czas wykonywania podstawowych operacji związanych z zarządzaniem pamięcią.........................................................................................................................86Tabela 6: Porównanie wydajności przykładowych aplikacji internetowych.................87

Spis diagramów
Diagram 1: Algorytm wyszukiwania żywych i martwych obiektów............................59Diagram 2: Wskaźnik do obiektu - kod i wynikowe rozmieszczenie obiektów w pamięci..........................................................................................................................62Diagram 3: Obiekty różnego typu w pamięci................................................................64Diagram 4: Diagram klas związanych z serwerem WWW...........................................66Diagram 5: Hierarchia klas związanych ze strumieniami (bez klas wyjątków)............75

Spis rysunków
Rysunek 1: Konfiguracja serwera DNS - widok główny..............................................81Rysunek 2: Konfiguracja serwera DNS - ustawienia strefy..........................................82





























