Embed Size (px)
Citation preview

The Pentium 4CPSC 321
Andreas Klappenecker

Today’s Menu
Advanced PipeliningBrief overview of the Pentium 4

Instruction Level Parallelism
Pipelining exploits the potential parallelism among instructions. There are two main methods to increase the potential amount of parallelism: • Increase the depth of the pipeline to overlap more instructions• Replicate the internal components of the computer so that it can launch multiple instructions in every pipeline stage

Washer-Dryer Example
Suppose that the washer cycle is longer than the other cycles. We can divide our washer into three machines that perform the wash, rinse, and spin steps of a traditional washer. (Move from a four to six pipeline stages)
A multiple issue laundry would replace our household washer and dryer with, say, three washers and three dryers.

Multiple-Issue Processors
We have two different approaches to multiple-issue processors:• The approach to decide at compile time which instructions should be issued is called static multiple issue• The approach to decide at execution time which instructions should be issued is called dynamic multiple issue

Multiple Issues with Multiple-Issue
1. Package instructions into issue slots: How does the processor determine how many instructions and which instructions can be issued in a given clock cycle?
2. Dealing with data and control hazards: In static issue processors, some or all consequences of these hazards are handled statically by the compiler. Dynamic issue processors attempt to alleviate at least some classes of hazards using hardware techniques

Speculation
The most important method to exploit more ILP is speculation. The compiler or the processor guess about the properties of an instruction, to enable execution of instructions that depend on the current instruction. For example, a compiler can use speculation to reorder instructions and move instructions beyond a branch.

Recovery from wrong Speculations
• Speculation in software: the compiler inserts additional instructions to that check the accuracy of a speculation and provide a fix-up routine when the speculation was incorrect.
• Speculation in hardware: The processor usually buffers the results until it knows that they are no longer speculative. If the speculation was correct, then the instructions are completed by allowing the contents to be written to registers or memory; otherwise the buffers are flushed and the correct instruction sequence is re-executed.

Register Renaming
A compiler can get more performance from loops by so-called loop unrolling; this is a technique where multiple copies of the loop are made => more ILP by overlapping instructions from different iterationsIn the loop unrolling, the compiler will usually introduce additional registers to eliminate dependencies that are not true data dependencies (just name dependence). The process is called register renaming.

Pentium 4

Intel’s Intel’s HistoryHistory
IntelFounded
First DRAM
8086Microprocesso
r
Intel286™Processo
r
Intel386™Processo
r
Intel486™Processor
IntelPentium®Processor
Intel Pentium®Processor with
MMX™ technology
IntelPentium® II Processor
First EPROM
Intel Pentium®Pro Processor
DRAMExit
FlashMemory
Intro
Intel Inside®Launch
ProShare® Introduced
100 MbitE-Net Card
First Intel Inside®Brand TV Ad
1968
1970
1971
1978
1982
1985
1986
1989
1991
1992
1993
1995
1994
1997
First Microprocessor4004
First IntelMotherboard
1998
IntelCeleron™ Processor
IntelPentium®
II Xeon™
Processor
1999
1 GbitE-Net Card
IntelPentium® IIIAnd Xeon™ Processors
InternetExchange
Architecture
2000
2001
Pentium® 4 Processor
2002
1st Pb-FreeDevices
Slide courtesy of Intel

The Pentium4 Architecture
Graphic courtesy of Tom’s hardware guide
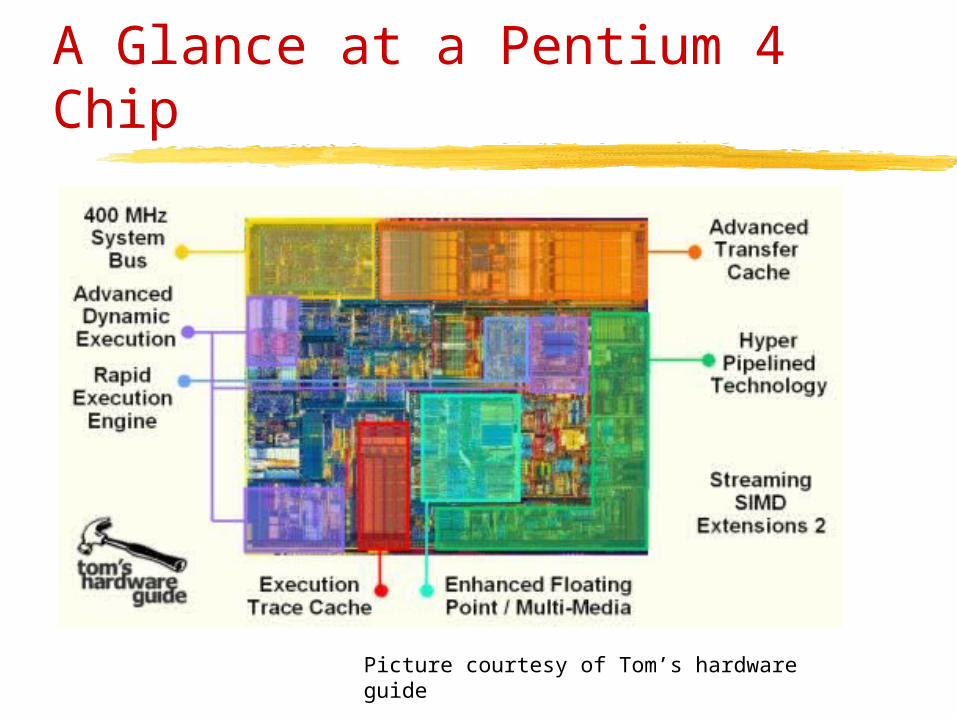
A Glance at a Pentium 4 Chip
Picture courtesy of Tom’s hardware guide

Pentium4
• The Pentium 4 was first released in 2000. Some of its features are: • fast system bus• advanced transfer cache• advanced dynamic execution (execution trace
cache and enhanced branch prediction)• “hyper” pipeline technology• rapid execution engine• enhanced floating point and multimedia (SSE2)

Some Features
• The processor uses micro-operations/operands• simple instructions of unified length• easier sequencing than variable length x86
instr.• understood by the execution units• the length is not exactly small

System Bus
• The system bus is clocked at 100 MHz, 64 bits wide, “quad-pumped”, meaning that is can transfer
8 bytes * 100 million/s*4= 3,200 MB/s
(this is about 3 times the speed of the system bus of the Pentium 3)
• Intel introduced the 850 chipset to sustain high data exchange rates between processor and system

Data Caches
• Data passes a level 2 cache (256 KB), (8-way associative, 128 byte cache lines that are
divided into 64 byte blocks that are read in one burst, read latency is 7 clock cycles; we come back later to such issues)
• Data passes a small level 1 cache (8 KB)
• Hardware pre-fetch unit (allows the processor to guess and fetch some that
that is presumably used next; good for streaming video applications).

Execution Pipeline: The Trace Cache
• The Pentium 4 does not use an L1 instruction cache, but rather an “execution trace cache”.
• Note that the decoding of x86 instructions is much more complex than on MIPS
• The execution trace cache is basically an instruction cache after the decoding unit (which generates the micro-operations), so that decoding does not have to be repeated.
• Supplies next pipeline stage with 6 micro-operations every 2 clock cycles.

The Trace Cache
Actual program instructions
Trace cache can contain instructions of both branches

The Pipeline
The branch prediction aids the execution trace cache; it has a fairly large branch target buffer
• The 20 stage hyper pipeline
• The pipeline can keep up to 126 instructions

The Pipeline
Trace cache
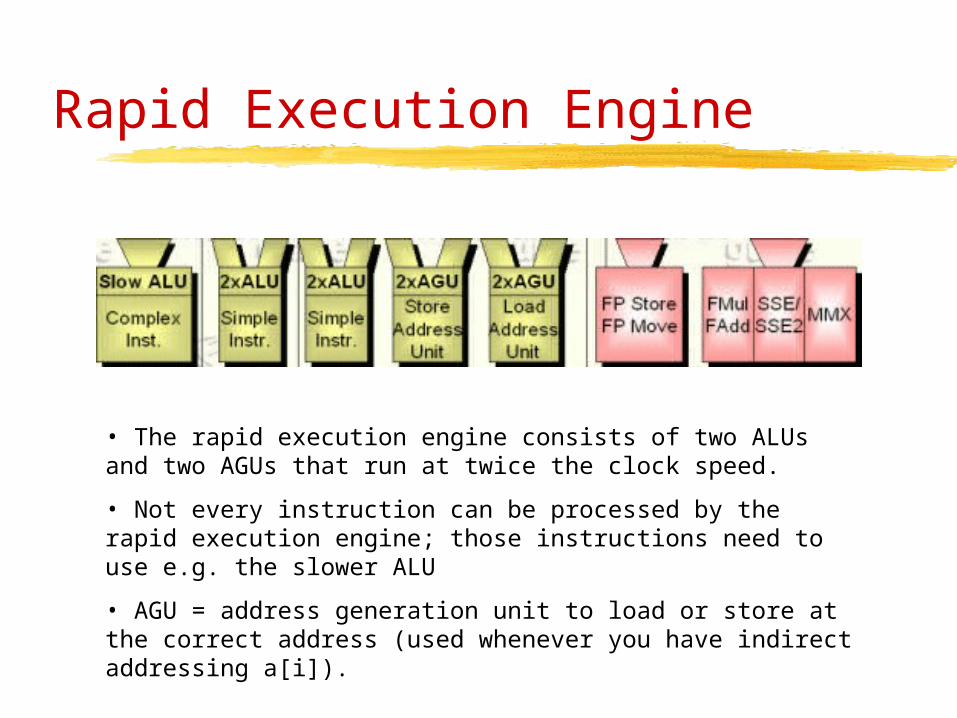
Rapid Execution Engine
• The rapid execution engine consists of two ALUs and two AGUs that run at twice the clock speed.
• Not every instruction can be processed by the rapid execution engine; those instructions need to use e.g. the slower ALU
• AGU = address generation unit to load or store at the correct address (used whenever you have indirect addressing a[i]).

Streaming SIMD Extensions SSE2
The Pentium 4 can operate on 128 bit data as• 4 single precision FP values (SSE)• 2 double precision FP values (SSE2)• 16 byte values (SSE2)• 8 word values (SSE2)• 4 double word values (SSE2)• 2 quad word values• 1 128 bit valuessingle instruction multiple data instructions

Pentium 4 Pipeline
1. Trace cache access, predictor 5 clock cycles• Microoperation queue
2. Reorder buffer allocation, register renaming 4 clock cycles
• functional unit queues
3. Scheduling and dispatch unit 5 clock cycles4. Register file access 2 clock cycles5. Execution 1 clock cycle
• reorder buffer
6. Commit 3 clock cycles (total: 20 clock cycles)

Pentium 4 Generations
• Willamette• Northwood (smaller transistors, later hyper-
threading)• Extreme Edition (added 2MB level 3 cache)• Prescott (90 nm process, new micro architecture)• Irwindale (as Prescott, but with doubled L2 cache)• Dual Core

Hyper-Threading
A typical thread of code of the IA-32 architecture uses about 35% of the microarchitecture execution resources.
Intel added a little bit of hardware to schedule and control two threads.
The operating system sees two logical processors

To Probe Further
• Read Chapter 6• Hennessy and Patterson, Computer
Architecture: A Quantitative Approach
• Intel website• AMD websiter









![Designingenergyefficient’ microprocessor:Howtofight ... Memory ... [MHz] 8086 80286 386DX 486DX 486DX4 Pentium Pentium Pro Pentium II Pentium MMX Pentium III ... Delay buffers are](https://img.dokumen.tips/doc/110x75/5ac1a5637f8b9ac6688d9ef1/designingenergyecient-microprocessorhowtoght-memory-mhz-8086.jpg)
![Pipelining & Parallel Processing - ics.kaist.ac.krics.kaist.ac.kr/ee878_2018f/[EE878]3 Pipelining and Parallel Processing.pdf · Pipelining processing By using pipelining latches](https://img.dokumen.tips/doc/110x75/5d40e26d88c99391748d47fb/pipelining-parallel-processing-icskaistackricskaistackree8782018fee8783.jpg)


















