Embed Size (px)
Citation preview

SNR-Dependent Mixture of PLDA for Noise Robust Speaker Verification
Man-Wai Mak
Department of Electronic and Information EngineeringThe Hong Kong Polytechnic University, Hong Kong SAR, China
Interspeech 2014

2
Contents1. Motivation of Work
2. Conventional PLDA
3. Mixture of PLDA for Noise Robust Speaker Verification
4. Experiments on SRE12
5. Conclusions
2

3
Motivation• Conventional i-vector/PLDA systems use a single PLDA
model to handle all SNR conditions.
I-Vector/PLDA Scoring
I-Vector/PLDA Scoring
EnrollmentUtterances
PLDA Score

4
Motivation• We argue that a PLDA model should focus on a small
range of SNR.
PLDA Model 1
PLDA Model 1
PLDA Score
PLDA Model 2
PLDA Model 2
PLDAModel 3
PLDAModel 3
PLDA Score
PLDA Score
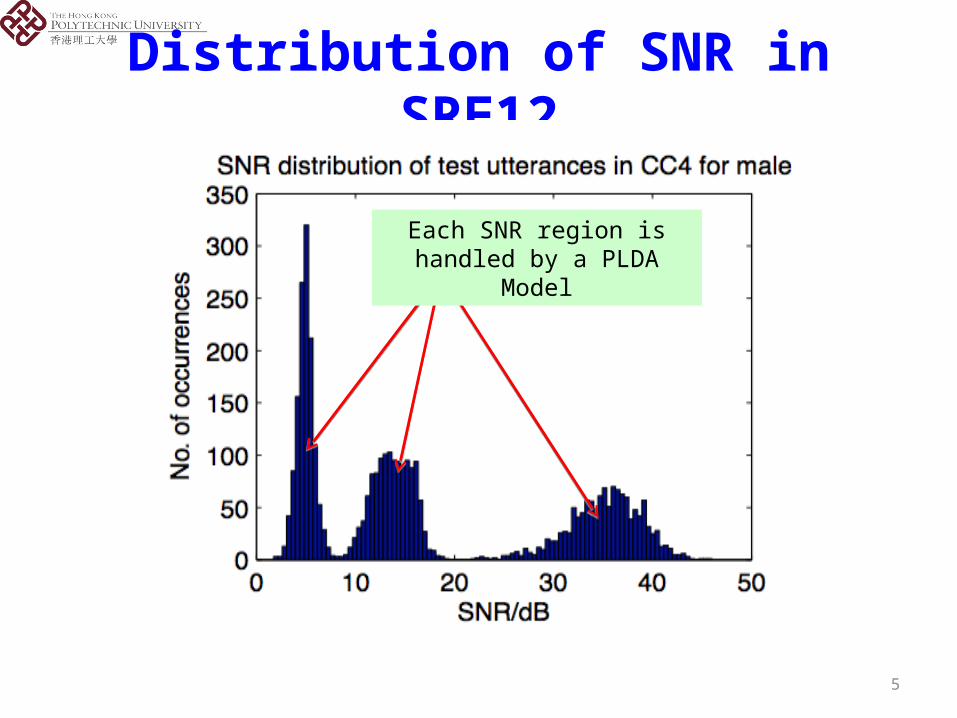
5
Distribution of SNR in SRE12
Each SNR region is handled by a PLDA Model
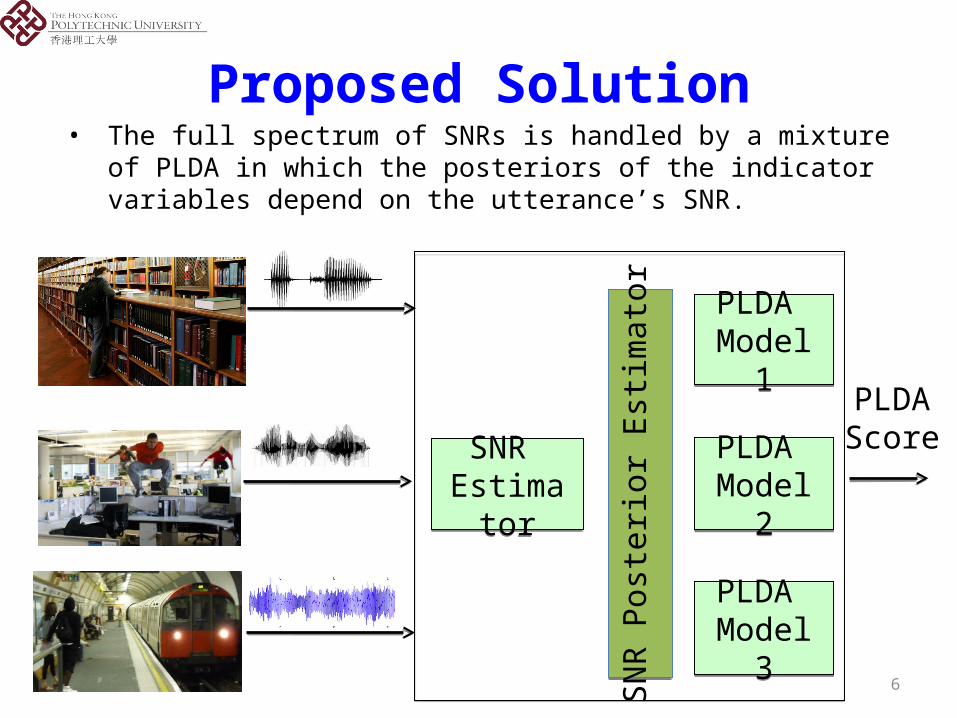
6
Proposed Solution• The full spectrum of SNRs is handled by a mixture of
PLDA in which the posteriors of the indicator variables depend on the utterance’s SNR.
PLDA Model 1
PLDA Model 1
PLDA Score
PLDA Model 2
PLDA Model 2
PLDA Model 3
PLDA Model 3
SNR Estimator
SNR Estimator
SN
R P
oste
rior
Est
imat
or

7
Key Features of Proposed Solution• Verification scores depend not only on the same-
speaker and different-speaker likelihoods but also on the posterior probabilities of SNR.

8
Contents1. Motivation of Work
2. Conventional PLDA
3. Mixture of PLDA for Noise Robust Speaker Verification
4. Experiments on SRE12
5. Conclusions

Probabilistic LDA (PLDA)
• In PLDA, the i-vectors x are modeled by a factor analyzer of the form:
9
i-vector extracted from the j-th session of the i-th speaker
Global mean of all i-vectors Speaker factor
loading matrix
Speaker factor
Residual noise with covariance Σ
• Density of x is

Probabilistic LDA (PLDA)
• The PLDA parameters ω={m, V, Σ} are estimated by maximizing
10

11
Contents1. Motivation of Work
2. Conventional PLDA
3. Mixture of PLDA for Noise Robust Speaker Verification
4. Experiments on SRE12
5. Conclusions

12
Mixture of PLDA
2
For modeling SNR of utts.
For modeling SNR-dependent
i-vectors
• Model Parameters of mPLDA:

13
Generative Model for mPLDA
where the posterior prob of SNR is
Po
ste
rior
of
SN
R
: SNR in dB

14
PLDA vs mPLDAGenerative Model

15
Likelihood-Ratio Scores of mPLDA• Same-speaker likelihood:
i-vectors of target and test speakers
SNR of target and test utterances

16
Likelihood-Ratio Scores of mPLDA• Different-speaker likelihood:
• Verification Score = Same-speaker likelihood
Different-speaker likelihood
16

17
PLDA vs mPLDAAuxiliary Function
PLDA:
Mixture of PLDA:
Latent indicator variables:
SNR of training utterances:
Speaker indexes
Session indexes
No. of mixtures
Latent speaker factors:

18
PLDA vs mPLDAE-Step

19
PLDA versus mPLDAM-Step

20
Contents1. Motivation of Work
2. Conventional PLDA
3. Mixture of PLDA for Noise Robust Speaker Verification
4. Experiments on SRE12
5. Conclusions

21
Experiments
• Evaluation dataset: Common evaluation condition 2 of NIST SRE 2012 core set.
• Parameterization: 19 MFCCs together with energy plus their 1st and 2nd derivatives 60-Dim
• UBM: gender-dependent, 1024 mixtures • Total Variability Matrix: gender-dependent, 500 total factors• I-Vector Preprocessing:
Whitening by WCCN then length normalization Followed by LDA (500-dim 200-dim) and WCCN
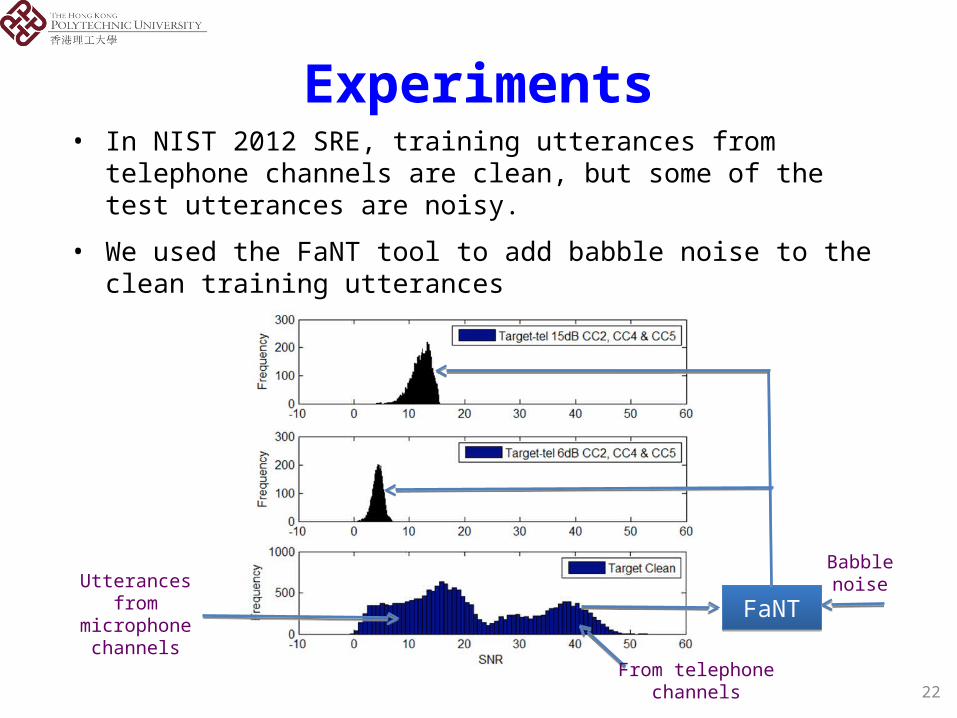
Experiments• In NIST 2012 SRE, training utterances from telephone channels are clean,
but some of the test utterances are noisy.
• We used the FaNT tool to add babble noise to the clean training utterances
Utterances from microphone
channelsFaNTFaNT
Babble noise
From telephone channels 22

Performance on SRE12• Train on tel+mic speech and test on noisy tel speech (CC4)
• Train on tel+mic speech and test on tel speech recorded in noisy environments (CC5)
• Use FaNT and a VAD to determine the SNR of test utts.
See our ISCSLP14
paper
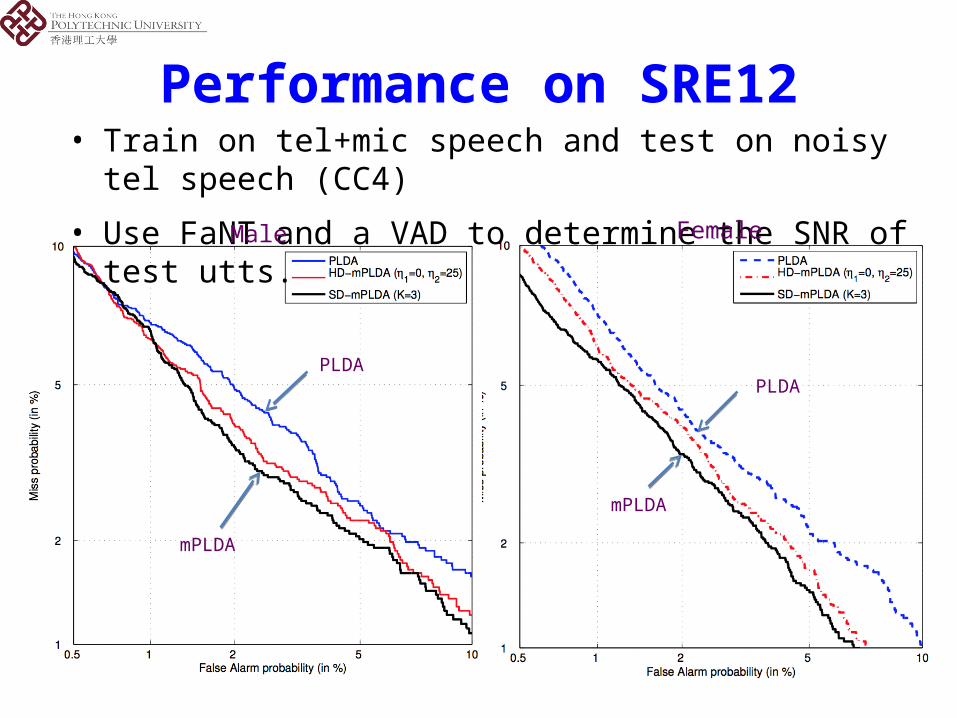
Performance on SRE12• Train on tel+mic speech and test on noisy tel speech (CC4)
• Use FaNT and a VAD to determine the SNR of test utts.Male Female
PLDA
mPLDA
PLDA
mPLDA

Conclusions• Mixture of SNR-dependent PLDA is a flexible model
that can handle noisy speech with a wide range of SNR
• The contribution of the mixtures are probabilistically combined based on the SNR of the test utterances and the target-speaker’s utterances
• Results show that the mixture PLDA performs better than conventional PLDA whenever the SNR of test utterances varies widely.

Hard-Decision Mixture of PLDA

27
Training of mPLDA• Auxiliary function:
where
Latent indicator variables:
SNR of training utterances:
Speaker indexes
Session indexes
No. of mixtures
Latent speaker factors:

PLDA Scoring
28
xs and xt share the same z

Probabilistic LDA (PLDA)
• PLDA example: 2-D data in 1-D subspace
29
Source: S. Prince, “Computer vision: models, learning and inference”, 2012
Take a sample according to p(z)
z





























