Embed Size (px)
Citation preview

EXAMENSARBETE Maskiningenjör med inriktning mot produktionsteknik och logistik Institutionen för ingenjörsvetenskap
Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier Angelica Bengtsson och Arlena Kuć

EXAMENSARBETE
i
Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier. Sammanfattning I detta arbete har studerats hur flödet i en flerstegs- bearbetningsprocess påverkas av stokastiska fluktuationer och störningar i de enskilda processtegen. Mera bestämt har analys utförts av hur de stokastiska variationerna i operationstiderna kan och bör modelleras vid simuleringsstudier. Även hur påverkan av valet av sådana stokastiska modeller kan tänkas ha på processen i sin helhet, till exempel avseende total genomloppstid.
Examensarbetet syftar till att undersöka hur val av fördelning på parametern operationstid, påverkar resultatfaktorn genomloppstid vid flödessimuleringar. För att finna svar på denna påverkan har en fallstudie utförts, med utgångspunkt av indata från en produkt som tillverkas på Volvo Aero. Denna produkt genomgår en tillverkningssekvens innehållande 18 stycken bearbetningsoperationer innefattande tre olika processtyper (automatisk, halvautomatisk och manuell). Dessa tre processtyper är i olika grad beroende av operatörers insats. De 18 bearbetningsoperationernas processtid har analyserats numeriskt och grafiskt. Programvaran Stat:fit har använts som hjälpmedel för att erhålla svar på lämplig fördelning per tillverkningsoperation samt vilka teoretiska fördelningar som är lämpliga att använda för de tre olika processtyperna. De rekommenderade fördelningsteorierna per tillverkningsoperation har genomgått fördelningstest (Chi2
Fallstudien har visat att resultatpåverkan från operationstidernas fördelningstyp är relativt liten vid simulering av komplexa system där faktorer som nivå av tillverkningsvolym och tillgänglighet har större påverkan på resultatfaktorn genomloppstid. Vid enklare modeller utan begränsning i form av reducerad tillgänglighet synliggörs skillnad i simuleringsresultat av olika val av fördelning på parametern operationstid. Fördelningen av dessa simuleringsresultat styrks av den centrala gränsvärdessatsen, det vill säga att om antalet observerade värden är tillräckligt stort, uppträder resultatet som normalfördelat.
, Kolmogorov-Smirnov och Anderson-Darling) och använts som grund vid skapande av försöksplan till simuleringsstudien. Simuleringsstudien har utförts enligt försöksplan i programvaran Simul8. Samtliga körningar från simuleringsmodellen är statistiskt säkerställda med 95 % konfidensintervall.
Datum: 2011-03-15 Författare: Angelica Bengtsson, Arlena Kuć Examinator: Jonas Hansson, Högskolan Väst Handledare: Joakim Svantesson, Volvo Aero och Henrik Johansson, Högskolan Väst Program: Maskiningenjör med inriktning mot produktionsteknik och logistik Huvudområde: Maskinteknik Utbildningsnivå: grund nivå Poäng: 15 högskolepoäng Nyckelord: Fördelningsteori, Diskret händelsestyrd simulering, Fördelningstest, Empirisk
fördelning. Utgivare: Högskolan Väst, Institutionen för ingenjörsvetenskap,
461 86 Trollhättan Tel: 0520-22 30 00 Fax: 0520-22 32 99 Web: www.hv.se

BACHELOR’S THESIS
ii
How different distributions of the parameter operation time impact the result of simulation studies
Summary
.
Discrete event simulation is used to imitate and analyze how systems change over time. The actual behavior of the variation in the system is interpreted by using discrete and continuous probability distributions. In the software program Simul8, simulation models are created based on the information collected from the production. Shifts, operation time and efficiency are examples of information required for the modeling process.
The aim with this bachelor´s thesis was to investigate how different choice of probability distributions on the parameter operation time affects the result of a discrete event simulation.
The thesis is a result of a case study performed at Volvo Aero Corporation, Sweden. The case study involves investigation of probability distribution for 18 manufacturing operations for a product. The manufacturing sequence consists of three different types of processes (automatic, semiautomatic and manual). These three types of processes need different level of instrumentality. The commercial statistical computer software, Stat:fit has been used to find proper probability distribution for each of the manufacturing operations. The results from Stat:fit have been used to analyze if there are any connections between the process type and the probability distributions.
The recommended probability distributions have been tested with Goodness-of-fit tests (Chi2
The result of this study indicates that the variation of process time has limited effect for complex simulation models containing low level of efficiency and high load factors, concerning the result of throughput time. For simple models, excluded from restricted efficiency, the effect on the throughput time is featured.
, Kolmogorov-Smirnov and Anderson-Darling) using Stat:fit and used in the simulation modeling. The simulation model has been validated and verified by a simulation advisor at Volvo Aero. Five different simulation models have been evaluated in Simul8, with five different types of distributions. All simulation runs have been statistical proved, in Simul8 with 95% confidence interval.
Date: 2011-03-15 Author: Angelica Bengtsson, Arlena Kuć Examiner: Jonas Hansson, University West Advisor: Joakim Svantesson, Volvo Aero and Henrik Johansson, University West Programme: Mechanical Engineering, Production and Logistics Main field of study: Mechanical Engineering Education level: basic level Credits: 15 HE credits Keywords: Distribution theory, discrete event system simulation, Goodness-of-Fit Tests,
Empirical distribution. Publisher: University West, Department of Engineering Science S-461 86 Trollhättan, SWEDEN
Phone: + 46 520 22 30 00 Fax: + 46 520 22 32 99 Web: www.hv.se

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
iii
Förord Under hösten 2010 har en förstudie utförts på Volvo Aero inför kommande examensarbete. Förstudiens syfte var att beskriva analysmetoder som är lämpliga att använda vid olika logistiska frågeställningar. Flödessimulering var en av de beskrivna analysmetoderna och fördjupas i detta examensarbete.
Detta examensarbete har utförts vid institutionen för ingenjörsvetenskap, produktionsteknik med inriktning mot logistik vid Högskolan Väst. Examensarbetet utfördes på Logistikutvecklingsavdelningen på Volvo Aero Corporation i Trollhättan. Arbetsfördelningen har varit lika fördelad och samtliga avsnitt i rapporten har utförts i samråd av båda skribenterna.
Vi vill tacka alla som har hjälpt oss under arbetets gång. Framförallt vill vi tacka Joakim Svantesson och Torgny Almgren, våra handledare på Volvo Aero som bidragit med kloka synpunkter och värdefulla diskussioner.
Vi vill även tacka följande personer vid Högskolan Väst:
Handledare Henrik Johansson, examinator Jonas Hansson, professor inom matematik Kenneth Eriksson och universitetslektor i industriell logistik Oskar Jellbo för värdefull konsultation och rådgivning.
Trollhättan, mars 2011
Angelica Bengtsson Arlena Kuć

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
iv
Innehåll Sammanfattning ................................................................................................................................. iSummary ............................................................................................................................................. iiFörord ................................................................................................................................................ iiiNomenklatur ..................................................................................................................................... vi1 Inledning ...................................................................................................................................... 1
1.1 Bakgrund/problembeskrivning ...................................................................................... 11.2 Syfte .................................................................................................................................... 21.3 Mål ...................................................................................................................................... 21.4 Avgränsningar ................................................................................................................... 2
2 Metod/tillvägagångssätt ............................................................................................................ 32.1 Flödessimulering .............................................................................................................. 32.2 Sannolikhetsfördelningar ................................................................................................ 4
3 Teoretiska fördelningar ............................................................................................................. 63.1 Fixed .................................................................................................................................. 63.2 Likformig fördelning, U(a,b) .......................................................................................... 73.3 Triangulärfördelning, triang(a, m, b) ............................................................................. 83.4 Normalfördelning, N(µ,σ2 ) ............................................................................................. 93.5 Lognormalfördelning, LN(µ,σ) .................................................................................... 103.6 Exponentialfördelning, expo(β) ................................................................................... 113.7 Poissonfördelning, Po(µ) .............................................................................................. 123.8 Betafördelning, beta (α1,α2 ) ........................................................................................... 133.9 Weibullfördelning (α,β) ................................................................................................. 14
4 Fördelningstest ......................................................................................................................... 154.1 Chi2 -test ........................................................................................................................... 15
4.1.1 Exempel på ett chi2 -test ................................................................................... 164.2 Kolmogorov- Smirnov test ........................................................................................... 17
4.2.1 Exempel Kolmogorov-Smirnov test ............................................................. 194.3 Jämförelse mellan Kolmogorov-Smirnov test och Chi2 -test ................................... 204.4 Andersson- Darling test ................................................................................................ 214.5 Vid motsägelsefulla testresultat .................................................................................... 21
5 Empirisk fördelning ................................................................................................................. 225.1 Exempel diskret empirisk fördelning .......................................................................... 225.2 Exempel kontinuerlig empirisk fördelning ................................................................. 24
6 Fallstudie .................................................................................................................................... 256.1 Analysmetodik ................................................................................................................ 256.2 Simuleringsstudie ........................................................................................................... 33
7 Resultat från simuleringsstudie ............................................................................................... 358 Slutsats och diskussion ............................................................................................................ 379 Fortsatt arbete ........................................................................................................................... 39

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
v
Bilagor A. Flödessimulering
A2. Fastställande av simuleringstid
B. Resultat från granskning av indata i Excel och Stat:fit C. Villkor vid analys av resultat från Stat:fit tre olika fördelningstest per operation
D. Parameterinställning för körning ett till fem i Simul8
E. Grunddata för simuleringsstudie

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
vi
Nomenklatur Täthetsfunktion Anger sannolikheten om hur olika resultat är i förhållande till
varandra.
Halvautomatisk process En process som periodvis kräver insats från operatör.
Automatisk process En process som kräver ställtid, men ingen insats från operatör under processens gång.
Manuell process En process som utförs av enbart operatör.
Genomloppstid beskriver tiden det tar för en produkt eller en tjänst att passera ett flödesavsnitt

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
1
1 Inledning Detta första kapitel ger en inblick i projektarbetes bakgrund/problembeskrivning, syfte och mål. Även utförda avgränsningar i projektarbetet redovisas här.
1.1 Bakgrund/problembeskrivning Volvo Aero ingår i Volvokoncernen och samarbetar med världens ledande flygmotortillverkare Pratt & Whitney, General Electrics (GE) och Rolls-Royce (RR), genom utveckling, tillverkning och underhåll av komponenter till militära och civila flygmotorer samt även gasturbiner för industriellt och marint bruk.
Volvo Aero har likt andra företag återkommande behov av logistiska analyser för beslutsstöd. Ett verktyg som används på företaget vid logistiska analyser är flödessimulering. Flödessimulering används för att studera arbetsflödens dynamik. Till grund för en sådan flödessimulering ligger en modell som även inkluderar stokastiska variationer i de olika bearbetningsstegen och i övergångarna mellan de olika bearbetningsstegen. För att efterlikna tillverkningssekvensens utfall i simuleringsmodeller används sannolikhetsfördelningar för att beskriva hur stor sannolikheten är för att tillverkningssekvensen skall bete sig på ett visst sätt. Förarbete vid simuleringsstudier är tidskrävande och tidvis komplext, därför är det viktigt att kunna prioritera vilken indata som skall insamlas och analyseras samt hur denna skall behandlas.
Figur 1- Simuleringsmodell i Simul8 innehållande 18 stycken bearbetningsoperationer med vardera parametern
för operationstid inställd Figur 1 illustrerar simuleringsmodellen som används i examensarbetet. Simuleringsmodellen består av en sekvens med 18 stycken bearbetningsoperationer, där operationstiderna är beskrivna med olika sannolikhetsfördelningar. Vid skapande av en simuleringsmodell behövs information för att ställa in

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
2
olika parametrar per tillverkningsoperation, exempel på parametrar är skift, ställtid, resurstillgänglighet och operationstid. Andra faktorer som taktid och prioriteringsregler är även nödvändiga. I detta arbete skall analyseras hur stor påverkan val av teoretisk fördelning för parametern operationstid har på simuleringsresultatets totala genomloppstid.
1.2 Syfte Vid simuleringsstudier skall flertalet parametrar ställas in för att efterlikna en tillverkningssekvens utfall. Exempel på parametrar är operationstid, ställtid och ankomsttid. Syftet med detta examensarbete är att undersöka hur vald fördelning för parametern operationstid påverkar simuleringsresultatets totala genomloppstid, det vill säga tiden för en produkt eller tjänst att passera ett flödesavsnitt.
1.3 Mål Målet med arbetet är att redovisa hur vald fördelning för parametern operationstid påverkar simuleringsresultatets totala genomloppstid. Analysen och redovisningen skall vara tillräckligt genomarbetad för att kunna ligga till grund för beslut av modellering vid framtida simuleringsstudier vid Volvo Aero.
1.4 Avgränsningar För att modellera en simuleringsmodell finns i praktiken ett tjugotal fördelningar [1] att tillgå, för att efterlikna verklighetens utfall. I detta examensarbete har avgränsning utförts i samråd med handledare på Volvo Aero, att endast beskriva fördelningar som normalt används för att representera processtid. Även normalfördelning omnämns. Examensarbetet har inriktats till att avgöra hur vald fördelning för parametern operationstid påverkar simuleringsresultatets genomloppstid. En fallstudie har utförts på en produkt där information varit lättillgänglig och representativ. Dessa indata har tillhandahållits av handledaren. Simuleringsmodellens reliabilitet har testats och säkerställts av handledare på Volvo Aero.

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
3
2 Metod/tillvägagångssätt Arbetet inleds med en litteraturstudie om vilka fördelningar som används vid simulering samt grundläggande fördelningsteori gällande fördelningar som beskriver processtid. För att avgöra om en antagen fördelning är statistiskt säkerställd behövs kunskap om olika fördelningstest. Dessa fördelningstest utförs och analyseras i den statistiska programvaran Stat:fit.
En fallstudie för en vald produkts tillverkningssekvens innehållande 18 stycken tillverkningsoperationer kommer att utföras. Operationstiden för varje tillverkningssteg kommer att analyseras i programvarorna Excel och Stat:fit. Då information från Stat:fit erhållits om vilka fördelningar som är representativa för de olika bearbetningsoperationerna, skall en simuleringsmodell byggas. Denna modellering sker i programvaran Simul8, som är ett flödessimuleringsprogram. För att erhålla en bild av verklig variation sammanställs data från tre olika typer av processer (automatiska, halvautomatiska, manuella).
Utifrån erhållen information upprättas en försöksplan innehållande simuleringar med fem olika val av fördelningstyper inlagda med avseende på parametern operationstid. Slutligen i arbetet analyseras medelvärde och standardavvikelse för genomloppstid i simuleringsstudiens resultat.
Sammanställning av rapport och redovisningsmaterial sker parallellt under arbetets gång.
2.1 Flödessimulering Flödessimulering är en analysmetod som används för att studera hur system förändras under fastställd tidsperiod och givna förutsättningar. Genom observationer av historik omvandlas dessa uppgifter till teoretiska fördelningar, för att efterlikna verklighetens utfall. Detta arbete genomförs vanligen genom antaganden som uttrycks med hjälp av matematiska, logistiska eller symboliska relationer mellan de olika objekten i det system som önskas simuleras [2].
Då behovet av indata i simuleringsmodeller ofta ändras och/eller växer med ökad modellkomplexitet, bör datainsamlingsarbetet alltid ske parallellt och integrerat med modellformuleringen [2]. Eftersom modellen valideras gentemot den insamlade informationen, bör stor vikt läggas på att insamlad data är korrekt. Data som samlas in är både deterministiska och stokastiska, det vill säga förutsägbar respektive slumpmässig.
Användning av data kan ske på två sätt. Antingen används verklig data direkt i modellen, utan att någon statistisk fördelning blivit anpassad (empirisk fördelning), eller så anpassas en statistisk fördelning till de observerade värdena. Nackdelen med att anpassa en statistisk fördelning till de observerade värdena är att denna anpassning ibland kan vara svår att utföra pågrund av otillräcklig och/eller bristfällig indata [3]. Fördelen är dock att extrema utfall tillåts, vilket också efterliknar verkligheten.

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
4
För att säkerställa att antagen fördelning är korrekt används olika fördelningstest. Dessa test är viktiga att utföra innan programmering av simuleringsmodellens parametrar, för att säkerställa reliabiliteten i det resultat som erhålls från simuleringsmodellen.
2.2 Sannolikhetsfördelningar För att en simuleringsmodell skall kunna efterlikna verklighetens slumpmässiga utfall, måste kunskap erhållas om hur stor sannolikheten är för att verkligheten skall bete sig på ett visst sätt. Denna information genererar olika sannolikhetsfördelningar.
Information samlas från vald tillverkningssekvens för att omvandlas till en simuleringsmodell. Om denna insamling inte är möjlig på grund av att data inte är tillgänglig, bör expertutlåtande och kunskap om processen användas för att utföra kvalificerade antaganden. Vid avsaknad av historisk data är likformig- och triangulärfördelning användbara, då dessa enkelt kan representera hypoteser för ett utfall. En triangulärfördelning kan representera både ett historiskt och framtida tillstånd [2]. Vid likformig fördelning är alla utfall lika sannolika (inom ett givet intervall). Vid en triangulärfördelning beskrivs min-, max- och ett typvärde. Typvärdet representerar det värde med högst sannolikhet och min- och maxvärde representerar extremfallen.
Utifrån insamlad data identifieras en sannolikhetsfördelning som representerar verklighetens utfall. Då information finns tillgänglig initieras detta steg med skapande av en frekvensfördelning eller skapande av ett histogram av data. Genom att analysera frekvensstaplarnas form, bedöms vilken fördelning datamaterialet illustrerar.
En ytterligare metod för att avgöra vilken fördelning ett datamaterial uppvisar är genom att plotta data i ett såkallat fördelningspapper. Utifrån fördelningspapper eller frekvensfördelning fås kännedom om observationerna för att kunna bestämma en fördelningstyp. Normal-, exponential-, likformig- och weibullfördelningspapper är exempel på fördelningspapper att tillgå [2].
Fördelningspapper är en grafisk metod och ger en subjektiv bedömning av hur nära plottade punkter i normalfördelningspapperet skall förhålla sig till en såkallad normalfördelningslinje. Denna personliga bedömning avgör om en fördelning skall antas eller förkastas. Därför är det viktigt att kombinera fördelningstestet med en objektiv metod som exempelvis Kolmogorov-Smirnov testet [4].
Då en fördelningstyp är fastställd, med hjälp av fördelningspapper eller automatiskt med den statistiska programvaran Stat:fit, utförs ett val av parametrar/parameter som representerar denna fördelning. De utvalda fördelningarna och tillhörande parametrar analyseras för hur väl data modellerats med hjälp av fördelningarna. Denna utvärdering kan ske med någon av standardtesten Chi2, Kolmogorov-Smirnov eller Anderson-Darling test. Om något av dessa standardtest redovisar att vald fördelning inte är en giltig approximation av data, bör ny fördelningstyp väljas och proceduren återupprepas. Om inte en anpassning av data kan ske med en teoretisk fördelning, används en såkallad empirisk fördelning, det vill säga av rådata. Önskvärt vid fördelningsstudier är att en teoretisk fördelning beskriver datamaterialet. En teoretisk fördelning inkluderar ”svansen” i

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
5
datamaterialet och kan testas för att se om den är statistiskt säkerställd, vilket gynnar reliabiliteten i resultatet. Då endast grafisk tolkning, det vill säga subjektiv bedömning av frekvensstaplarnas form utförs, kan inte reliabiliteten i resultatet säkerställas, vilket är viktigt att ha i åtanke vid beslut av åtgärder. Vid empirisk fördelning anges endast utfallen i ett intervall, vilket medför risk att extremfall inte inkluderas i analysen och är därför ett sista alternativ vid fördelningsval [2].

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
6
3 Teoretiska fördelningar Vid simuleringsstudier används teoretiska fördelningar för att beskriva variationen hos olika parametrar som exempelvis processtid, ankomsttid och ställtid [1]. En teoretisk fördelning framställer värden utanför insamlat intervall, det vill säga ”jämnar ut” insamlade värden och genererar uppgifter för den övergripande fördelningen [5]. Utifrån parametern processtid har nedan beskrivna fördelningar valts att studeras, detta eftersom dessa fördelningar kan användas för att efterlikna processtider. Normalfördelning är en fördelning som inte är lämplig att använda för att beskriva processtid, eftersom den alltid omfattar negativa utfall.
3.1 Fixed Då ett fast värde på parametern operationstid används i simuleringsmodeller saknar detta värde spridning. I detta fall är det svårt att återskapa en rättvis bild av verkligheten, då spridning är en naturlig företeelse.

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
7
3.2 Likformig fördelning, U(a,b) Likformig fördelning ger information om att sannolikheten för att varje värde inom ett min- och maxintervall har lika sannolikhet att inträffa. Sannolikheten för att ett värde skall hamna inom ett snävare intervall inom min- och maxgränserna är proportionerlig med basen på intervallet [6].
Parametrar: a och b är reella tal där a <b; a är en lägesparameter, b-a är en skalparameter.
Variationsbredd: [a, b]
Medelvärde:
Varians:
Figur 2- Täthetsfunktion för likformig fördelning [5]
Figur 2 illustrerar täthetsfunktionen för likformig fördelning. En täthetsfunktion [5] anger sannolikheten för olika intervallutfall i jämförelse med total intervallbredd. Exempel på användningsområde för likformig fördelning är avrundningsfel till heltal. Intervallet för avrundning till heltal är (a=-0,5;b=0,5).

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
8
3.3 Triangulärfördelning, triang(a, m, b) Triangulärfördelning beskrivs med tre parametrar; min-, typ- och maxvärde [5]. Min- och maxvärdet beskriver extremfallen för slumpvariabeln, medan typvärdet är det mest frekventa värdet för slumpvariabeln. Denna fördelning är användbar då information om utfall är bristfällig.
Parametrar: a, b, och m är reella tal med a<m<b. a är lägesparameter, b-a är skalparameter, m är formparametern.
Variationsbredd: [a, b]
Medelvärde:
Varians: Anmärkning:
Då m b och ma kallas höger triangulär respektive vänster triangulär fördelning.
Figur 3- Täthetsfunktion för triangulärfördelning [5]
Figur 3 visar täthetsfunktionen för en triangulärfördelning. Denna fördelning används exempelvis vid produkttest då en sannolikhet om minsta processtid och maximalprocesstid är känd. Det som är viktigt att observera vid användning av triangulärfördelning är att fördelningen är asymmetrisk, vilket ger att beräknat medelvärde och typvärde, m är annorlunda då de innehar olika frekvens[2].

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
9
3.4 Normalfördelning, N(µ,σ2
Bland de kontinuerliga fördelningarna är normalfördelning den vanligaste fördelningen. Det som kännetecknar en normalfördelning är att spridningen är symmetrisk kring väntevärdet. Enligt den centrala gränsvärdessatsen, blir summan av n stycken slumpvariabler normalfördelade när n blir stort vid 10≤n≤25 [4].
)
Parametrar: Lägesparameter µ tillhör (-∞,∞), skalparameter σ > 0
Variationsbredd: (-∞,∞) Medelvärde: Varians:
Anmärkning:
Då X är en normalfördelad variabel med medelvärde 0 och spridning 1 det vill säga N(0,1) kallas detta för en standardiserad normalfördelning. Slumpvariabeln X standardiseras med hjälp av följande
formel;
När denna standardisering är beräknad kan sannolikheten erhållas från F-tabell. [7]
Figur 4- Täthetsfunktion för en normalfördelning [5]
Figur 4 gestaltar täthetsfunktionen för en normalfördelning då N(0,3). Normalfördelning används inte för att beskriva exempelvis servicetid på grund av att fördelningen representerar positiv och negativ oändlighet. Normalfördelning utnyttjas istället exempelvis för att beskriva andelen fel enheter i en population [5].

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
10
3.5 Lognormalfördelning, LN(µ,σ) Lognormalfördelning är en positivt sned asymmetrisk fördelning. Om informationen X1,X2…Xn förmodas vara lognormalfördelade, styrks denna hypotes genom att logaritmera samtliga datapunkter ln(X1), ln(X2)… ln(Xn
) och analysera om dessa uppträder symmetriskt kring sitt medelvärde, det vill säga visar på normalfördelning [8].
Parametrar: Formparameter σ>0, skalparameter e µ
>0
Variationsbredd: 0≤x<∞
Medelvärde: Varians:
Figur 5- Täthetsfunktion för lognormalfördelning [5]
Figur 5 illustrerar en täthetsfunktion för en lognormalfördelning. Lognormalfördelning används för att gestalta tiden som går åt för att utföra en uppgift.
Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
11
3.6 Exponentialfördelning, expo(β) En exponentialfördelning modellerar tiden mellan oberoende händelser, eller en processtid som är minneslös. Att den är minneslös innebär att om information finns om hur lång tid en process pågått, ger detta ingen information om hur lång tid som återstår tills processen är klar. Tid mellan händelser exempelvis kötid är exponentialfördelad [2].
Parameter: skalparameter µ>0, medelvärdet.
Variationsbredd: 0≤x<+∞ Medelvärde: µ Varians: µ
2
Anmärkning:
Exponentialfördelning är den enda kontinuerliga fördelning som är minneslös.
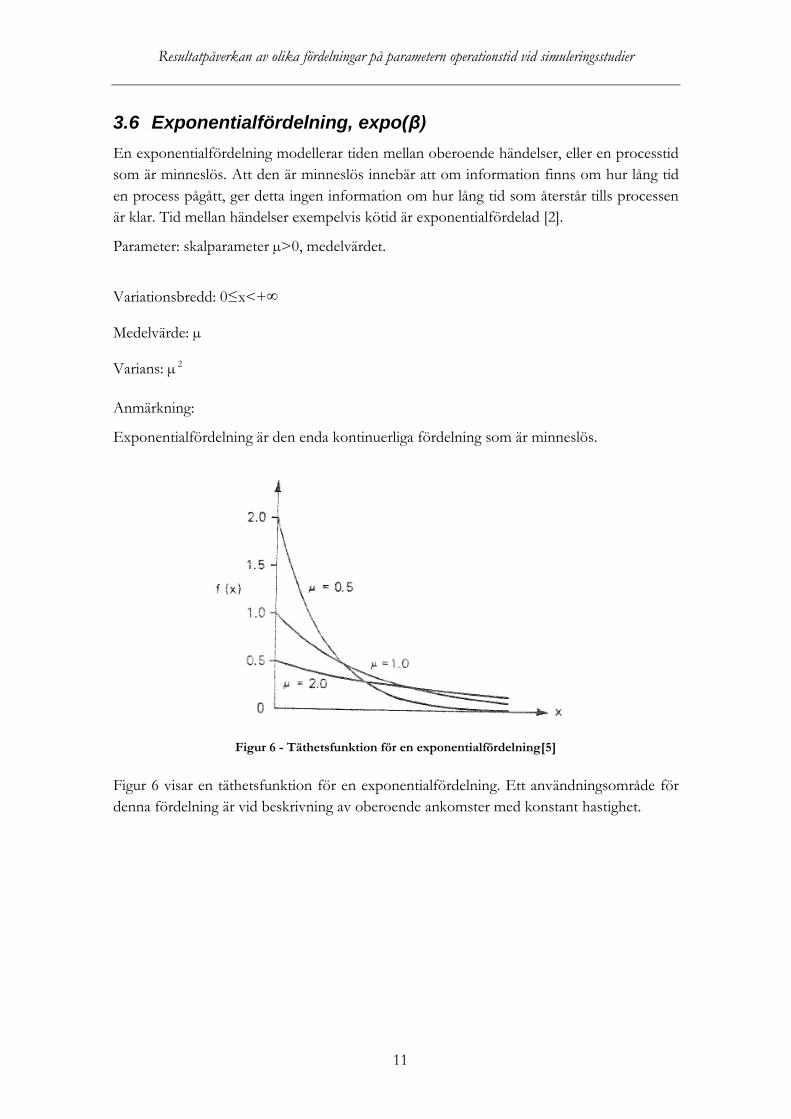
Figur 6 - Täthetsfunktion för en exponentialfördelning[5]
Figur 6 visar en täthetsfunktion för en exponentialfördelning. Ett användningsområde för denna fördelning är vid beskrivning av oberoende ankomster med konstant hastighet.

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
12
3.7 Poissonfördelning, Po(µ) Poissionfördelning är en sannolikhetsmodell för att beskriva antalet gånger en händelse förväntas inträffa under en angiven tidsperiod. Varje försök innehar en liten sannolikhet, p till att händelsen skall inträffa. Antalet händelser, n under ett tidsintervall anges av parametern λ.
Parameter: λ>0, medelvärdet.
Variationsbredd: 0≤x<∞ Medelvärde: Variation: Anmärkning:
Medelvärdet och variansen är lika och kan uppskattas genom att observera egenskaper hos täthetsfunktionen [8].
För stora värden på medelvärdet, närmar sig poissonfördelning normalfördelningen. [5]
Om tid mellan utfall är exponentialfördelad och utfallen förekommer en i taget, kan antalet som förekommer i ett fast tidsintervall visas vara poissonfördelad [5].
Figur 7 - Täthetsfunktion för en poissonfördelnig [5]
Figur 7 illustrerar en grupp täthetsfunktioner för en poissonfördelning. Slutsatsen från dessa figurer är att poissonfördelning närmar sig normalfördelning för stora medelvärden. Poissonfördelning används för att studera händelser som inträffar slumpmässigt och oberoende av varandra i tiden.

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
13
3.8 Betafördelning, beta (α1,α2
Betafördelning är en användbar modell vid brist på information och används för att illustrera en slumpmässig delprocess, exempelvis andel defekta enheter [9]. Betafördelning användas även för att beskriva tidsperioden för att fullborda ett uppdrag som ingår i exempelvis ett PERT-nätverk, det vill säga en tidplan för att utföra en sekvens arbetssteg för att uppnå ett mål [5]. Betafördelning används för att modellera avgränsningar med en fast övre gräns och nedre gräns för slumpmässiga variabler. [2]
)
Parameter: formparameter α1>0 och α2Variationsbredd: [0,1]
>0
Medelvärde:
Varians:
Anmärkning:
U(0,1) och Beta(1,1) fördelning är samma.
Figur 8- Täthetsfunktion för en betafördelning [5]
Figur 8 illustrerar täthetsfunktionen för en betafördelning och hur parametrarna α 1 och α2 påverkar fördelningens form. [5] Exempelvis för α 1> α2
blir betafördelningens form högerfördelad.

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
14
3.9 Weibullfördelning (α,β) Weibullfördelning modellerar tiden tills ett fel uppstår. Exempelvis tid till fel i en utrustning kan beskrivas med en weibullfördelning. Denna två parameters fördelning kan representera minskande, konstant eller ökande felfrekvens [8].
Parametrar: formparameter α>0, skalparameter β >0
Variationsbredd: 0≤x<+∞
Medelvärde:
Varians:
Anmärkning:
expo(β) och weibull(1, β) fördelningar är samma. [5]
Figur 9 - Täthetsfunktion för en weibullfördelning.[5]
Figur 9 exemplifierar en täthetsfunktion för en weibullfördelning med olika värden på formparameter α och skalparameter β.
Weibullfördelningen används som en grov modell vid brist på data. Denna fördelning gestaltar tiden som går åt för att slutföra en uppgift exempelvis tid till fel i en utrustning. [5]

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
15
4 Fördelningstest För att avgöra om insamlad data kan komma från en antagen teoretisk fördelning finns olika statistiska test, såkallade Goodness-of-fit test. Tillvägagångssätt för samtliga metoder grundar sig i hypotesprövning, det vill säga ett test där två påståenden, en nollhypotes och en mothypotes prövas. Med nollhypotes, H0 menas att påståendet stämmer, medan mothypotesen, H1
Exempel på typiska hypoteser är;
beskriver motsatsen till nollhypotesen [6].
H0: Insamlad data är normalfördelad med fördelningsfunktion N(u,σ2
H
)
1: H0
Syftet med fördelningstest är främst att undersöka hur väl observerade resultat följer en teoretisk fördelning, det vill säga med vilken osäkerhet verklighetens utfall har modellerats med antagen fördelning [2]. Risken att förkasta en nollhypotes som är sann kallas för signifikansnivå. Ett vanligt värde på signifikansnivå, α är 0,05 och innebär att risken är 5 % att förkasta en sann nollhypotes.
är osann.
Vid observation av det illustrerade exemplet ovan med hypotesprövning, iakttas att mothypotesen endast ger information om att nollhypotesen är falsk. Mothypotesen ger därmed ingen information om ny lämplig fördelning. En sådan kan erhållas genom att studera data i grafisk form [6]. En vanlig grafisk metod är fördelningspapper, exempelvis likformig-, exponential-, och normalfördelningspapper [4].
Nedan följer beskrivning av fördelningstesterna Chi2, Kolmogorov-Smirnov och Anderson-Darling. Chi2
4.1 Chi
och Kolmogorov-Smirnov redovisas med ett beskrivande exempel av hur testet tillämpats. Då beräkningsgången för Anderson- Darling är numeriskt invecklad, utförs detta test med hjälp av statistiska programvaror. Av detta skäl saknas ett beskrivande exempel för Anderson- Darling i rapporten. För samtliga tre test redovisas villkor som skall vara uppfyllda för att statistiskt säkerställa resultatet.
2
Chi
-test 2-test undersöker om observationsutfallen avviker från förväntat utfall. Förväntat utfall
erhålls från vald teoretisk fördelning. Detta test utförs genom att dela in mätvärdena i intervall, beräkna förväntad frekvens (sannolikhet) för de olika intervallen, hämta information om frekvens per intervall, kvadrera skillnaden mellan observerad och förväntad frekvens per intervall och därefter dividera detta tal med förväntad frekvens [2].
[4]
där:
Oi= Observerad frekvens per intervall

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
16
Ei
Om beräknat Chi
= Förväntad frekvens per intervall 2-värde överstiger ett visst kritiskt värde, förkastas H0
Kritiska Chi
, det vill säga testad fördelning.
2
Antal frihetsgrader= antal klassintervall-1.
-värden finns tabellerade och baseras på antalet frihetsgrader [10] och efterfrågad signifikansnivå. Antalet frihetsgrader erhålls genom formeln:
4.1.1 Exempel på ett chi2
Vid en process vill man undersöka om utfallet är likformigt fördelat mellan
-test
-0.5 och 0.4. Ett stickprov på processen tas ut för n= 100 stycken individer.
Hypotesprövning: H0: Samtliga individer X1, X2,…Xn
H följer en likformig fördelning, U(-0.5;0.4)
1: H0
Tabell 1 - Processutfall, hypotes om likformigfördelning
är osann.
Tabell 1 visar ett fiktivt processutfall för 100 stycken observationer som används som underlag för att testa om utfallet är likformigt fördelat. Beräknat chi2
Antal frihetsgrader= antal klassintervall-1= 10-1=9
-värde är enligt tabell 1 4,6.
Signifikansnivå= 0.05.
Det kritiska värdet 16.919 för chi2
Villkor [9]:
-fördelning erhålls i tabell 4 [10].
Om beräknat chi2-värde < 16.919 [10, tabell 4] innebär detta att H0
Om beräknat chi
är sann. 2-värde > 16.919 [10, tabell 4] innebär detta att H0 är falsk.

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
17
I detta exempel är 4.6<16.919 och därmed är nollhypotesen sann, det vill säga observationerna följer likformig fördelning.
Exemplet ovan illustrerar en fördelning med samtliga kända parametrar. Det vanligaste fallet i praktiken är dock fördelningar med okända parametrar och tillvägagångssättet för att utföra ett fördelningstest är då annorlunda. Lösningen till dessa problem är att skatta ett medelvärde och att därefter, med hjälp av ett skattat medelvärde, beräkna en skattad standardavvikelse. Frihetsgrad, skattat medelvärde och skattad standardavvikelse erhålls från följande formler;
Frihetsgrad= (antal klasser)-(antal skattade parametrar)-1.
Skattat medelvärde=
Standardavvikelse, s= [11]
Observera att om förväntad frekvens per klass/processvärde är noll eller om mer än 20 procent av alla klasser/processvärden<5 är Chi2–test inte en lämplig metod [10] som fördelningstest och användaren tvingas omfördela klassintervallen i Chi2- testet. En hypotes kan accepteras om datamaterialet är indelat i vissa intervall, men kan också förkastas om klassindelningen skulle vara annorlunda, det vill säga hypotesprövningen blir indelningsberoende. Detta är anledningen till varför Chi2
4.2 Kolmogorov- Smirnov test
-test är ett känsligt test [10]. Urvalet skall bestå av ett stort antal observationer för att minimera risk för omarbete.
Kolmogorov- Smirnov (KS) test går ut på att finna det beloppsmässigt största avståndet mellan teoretisk fördelning, F(x) och empirisk fördelning, SN
Avstånd, D= max │F(x)- S
(x) [2].
N
(x)│
Figur 10 - illustration av påvisat maximalt avstånd vid Kolmogorov-Smirnov test [12]

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
18
I figur 10 visas ett identifierat maximalt avstånd mellan teoretisk fördelning och verkligt utfall. Bland maxavstånden från de olika teoretiska fördelningarna, väljs den med minst maxavstånd till empirisk fördelning.
Kolmogorov-Smirnov test är applicerbart på kontinuerliga fördelningar med kända parametrar. För att testa om exempelvis en likformig fördelning representerar ett datamaterial, följer följande arbetssteg [2]:
1. Datapunkterna rangordnas i stigande ordning. Låt x(i) representera det minsta värdet och x(n) det största värdet av samtliga observationer.
2. Därefter beräknas största - och minsta avståndet, D+ respektive D-
för respektive rangordningstal och observerat värde.
D+= max { }, för 1≤i≤N
D-= min { }, för 1≤i≤N
där,
N är antalet observationer och
i är rangordningstal
3. Beräkna sedan, D = max (D+, D-
).
4. Fastställ det kritiska värdet. Kritiskt värde, Dα erhålls från tabell A.8, Kolmogorov- Smirnov kritiska värden [2]. Dα
För tillexempel:
väljs med hänsyn till vald signifikansnivå, α och given stickprovsstorlek, N.
N>35 och α=0.05 är Dα =
5. Om D-värde överstiger Dα
Om D-värde understiger D, förkastas nollhypotesen. α
kan slutsats dras att antagen teoretisk fördelning är korrekt.
Nedan följer ett exempel då Kolmogorov-Smirnov test använts för att avgöra om en likformig fördelning är representativ för ett insamlat datamaterial.

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
19
4.2.1 Exempel Kolmogorov-Smirnov test Anta att fem datapunkter är insamlade: 0.44, 0.81, 0.14, 0.05, 0.93 och att intresse finns att studera om dessa värden följer en likformig fördelning. Detta testas med hjälp av ett Kolmogorov-Smirnov test.
Hypotesprövning: H0
H: Insamlad data följer en likformig fördelning
1: H0
är falsk
Tabell 2- Sammanställda beräkningar för Kolmogorov-Smirnov test [2]
Tabell 2 innehåller sortering av datapunkter på den övre raden, samt beräkning för fortsatt Kolmogorov-Smirnov test.
Från tabell 2 erhålls värdena: D+=0.26 och D-
D= max (0.26, 0.21)=0.26.
=0.21. Denna information ger
Det kritiska värdet, Dα
N=5 och α=0.05 ger därmed D
erhålls i tabell A.8, Kolmogorov-Smirnov kritiska värden.
α= 0.565.[2]
D-värde max=0.26
Slutsats:
Dα
Då D-värde max <D
= 0.565
α
förkastas inte nollhypotesen [2], och slutsats dras att antagen teoretisk fördelning är korrekt.
Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
20
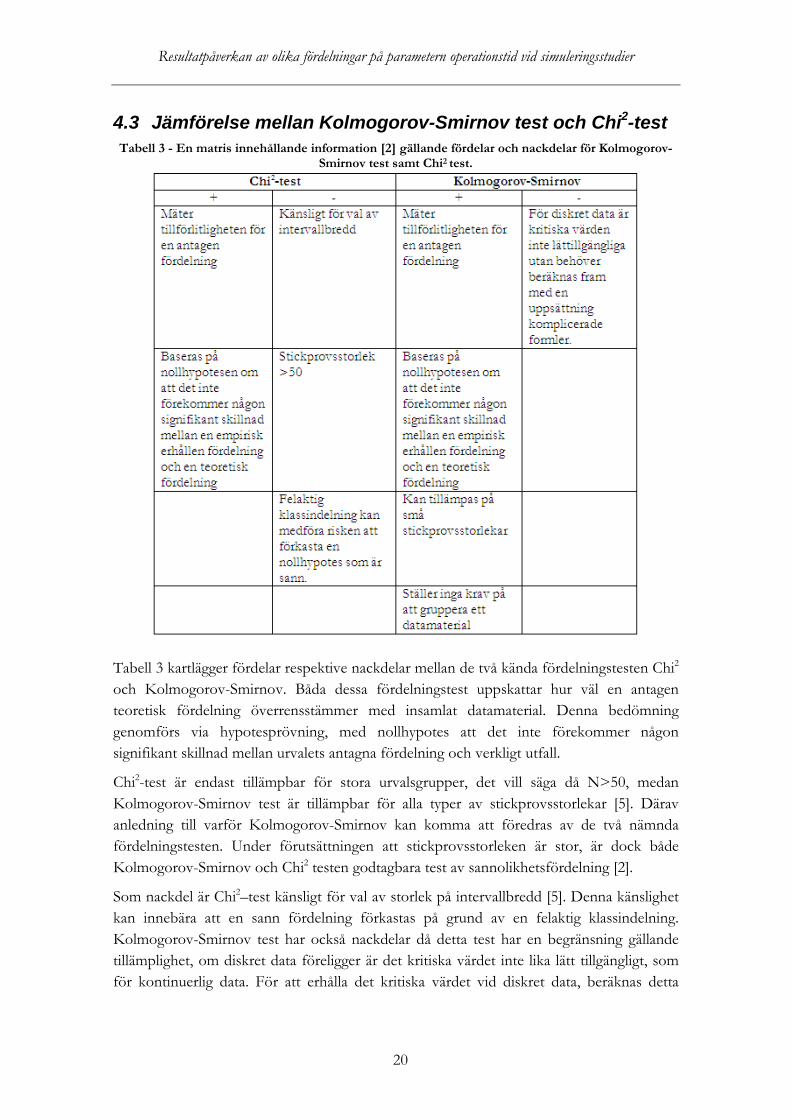
4.3 Jämförelse mellan Kolmogorov-Smirnov test och Chi2Tabell 3 - En matris innehållande information [2] gällande fördelar och nackdelar för Kolmogorov-
Smirnov test samt Chi
-test
2 test.
Tabell 3 kartlägger fördelar respektive nackdelar mellan de två kända fördelningstesten Chi2
Chi
och Kolmogorov-Smirnov. Båda dessa fördelningstest uppskattar hur väl en antagen teoretisk fördelning överrensstämmer med insamlat datamaterial. Denna bedömning genomförs via hypotesprövning, med nollhypotes att det inte förekommer någon signifikant skillnad mellan urvalets antagna fördelning och verkligt utfall.
2-test är endast tillämpbar för stora urvalsgrupper, det vill säga då N>50, medan Kolmogorov-Smirnov test är tillämpbar för alla typer av stickprovsstorlekar [5]. Därav anledning till varför Kolmogorov-Smirnov kan komma att föredras av de två nämnda fördelningstesten. Under förutsättningen att stickprovsstorleken är stor, är dock både Kolmogorov-Smirnov och Chi2
Som nackdel är Chi
testen godtagbara test av sannolikhetsfördelning [2]. 2–test känsligt för val av storlek på intervallbredd [5]. Denna känslighet
kan innebära att en sann fördelning förkastas på grund av en felaktig klassindelning. Kolmogorov-Smirnov test har också nackdelar då detta test har en begränsning gällande tillämplighet, om diskret data föreligger är det kritiska värdet inte lika lätt tillgängligt, som för kontinuerlig data. För att erhålla det kritiska värdet vid diskret data, beräknas detta

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
21
kritiska värde genom en uppsättning formler [5]. För kontinuerlig data erhålls kritiska värden från tabell A.8, Kolmogorov-Smirnov kritiska värden [2].
4.4 Andersson- Darling test Anderson-Darling (AD) test är ytterligare ett test för att beräkna avståndet mellan antagen- och teoretisk fördelning. Arbetsgången för detta avståndstest liknar beräkningen för Kolmogorov-Smirnov. Som för Kolmogorov-Smirnov lämpar sig detta test för små-, men även för större stickprov. Anderson- Darling använder teoretisk fördelning som utgångspunkt vid beräkning av kritiska värden, vilket gör att detta test är känsligare än Kolmogorov-Smirnov test. Det är känsligare i bemärkelsen att det är mer omfattande vid mätning av avstånd i fördelningens svansar än ett Kolmogorov-Smirnov test [2]. Då beräkningsgången för Anderson-Darling test är numeriskt invecklat, krävs kommersiella statistiska programvaror som exempelvis Minitab, Stat:fit och SPSS för att utföra beräkningarna. Anderson- Darling test används vanligen för att testa om normal-, lognormal-, weibull- och exponentialfördelning föreligger. För att avgöra om en fördelning rekommenderad av ett Anderson- Darling test är statistiskt säkerställd, skall följande villkor vara uppfyllda:
Om AD- värde < AD kritiskt tabell värde, följer data teoretisk fördelning och antagen fördelning är korrekt [13].
4.5 Vid motsägelsefulla testresultat För att avgöra valet mellan exempelvis två rekommenderade fördelningar i Chi2
Om de tre testen rekommenderar olika fördelning till en tillverkningsoperation och ingen av dessa är statistiskt säkerställd, bör en empirisk fördelning användas. Skulle fallet vara att två av tre test, helst KS och AD rekommenderar lika fördelning till ett datamaterial som inte är statistiskt säkerställda, och att ett grafiskt antagande även visar denna fördelning, kan slutsats dras att denna rekommendation är användbar. Detta kan användas som vägledning till vilka fördelningar som är passande till processtyperna halvautomatisk, manuell och automatisk.
testet analyseras p-värdet för de rekommenderade fördelningarna, där fördelning med högst p-värde [2] avgör valet. Om p-värde överstiger signifikansnivå, α betyder detta att antagen fördelning följer teoretisk fördelning och att nollhypotesen är korrekt [2].
.
Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
22
5 Empirisk fördelning Om en anpassning av data inte kan fastställas med hjälp av något fördelningstest, skall istället en så kallad empirisk fördelningsfunktion användas. En empirisk fördelning bygger direkt på gruppering av erhållen rådata. Fördelningen saknar den information som erhålls från ”svansarna”. Detta är negativt då många förbättringsområden i en simuleringsstudie upptäcks enbart om även extremfallen inkluderas. Fördelen med att använda en teoretisk fördelning vid simuleringsstudier är att parametrar enkelt kan ändras för att genomföra känslighetstest. En empirisk fördelning kan tas fram från material innehållande diskreta eller kontinuerliga värden [2].
Nedan följer exempel på hur en empirisk fördelning tagits fram från ett datamaterial.
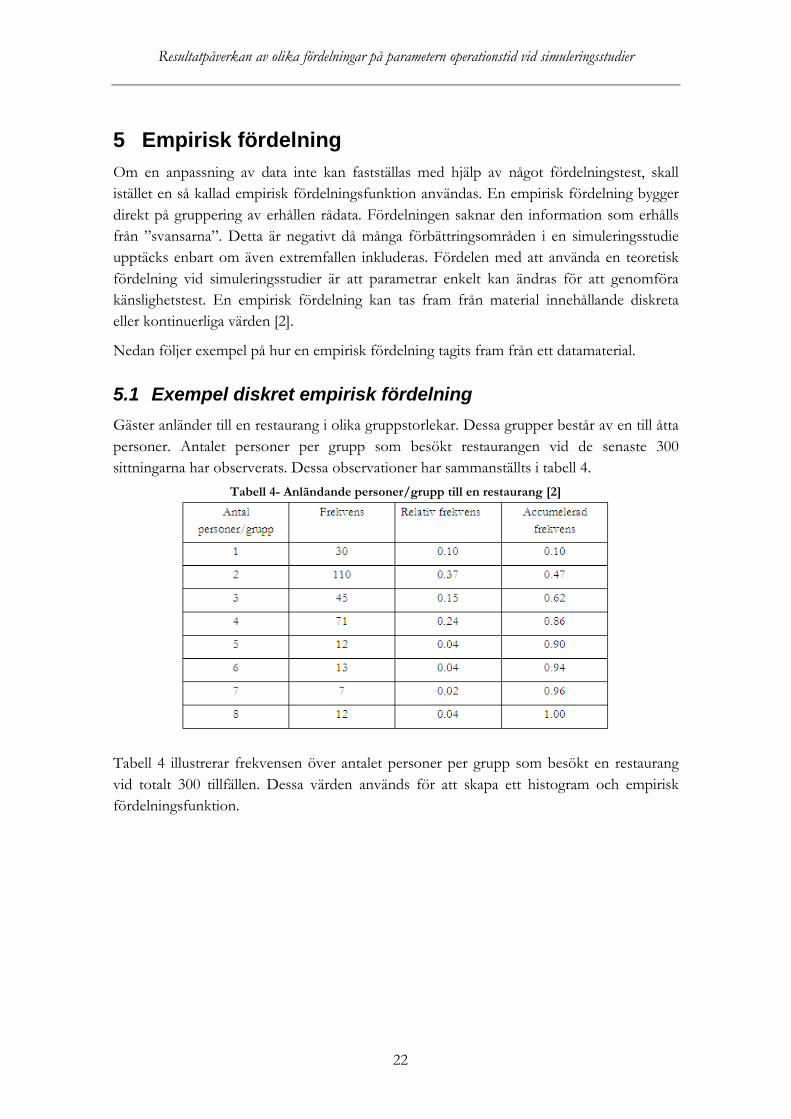
5.1 Exempel diskret empirisk fördelning Gäster anländer till en restaurang i olika gruppstorlekar. Dessa grupper består av en till åtta personer. Antalet personer per grupp som besökt restaurangen vid de senaste 300 sittningarna har observerats. Dessa observationer har sammanställts i tabell 4.
Tabell 4- Anländande personer/grupp till en restaurang [2]
Tabell 4 illustrerar frekvensen över antalet personer per grupp som besökt en restaurang vid totalt 300 tillfällen. Dessa värden används för att skapa ett histogram och empirisk fördelningsfunktion.

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
23
Figur 11 - Histogram för gruppstorlek vid restaurangbesök [2]
Figur 11 visar relativ frekvens för antalet personer i grupp som varit på restaurangen. Från detta histogram ses att oftast besöks restaurangen av en grupp bestående av två personer.
Nästkommande figur illustrerar hur denna frekvens kan illustreras i en empirisk fördelningsfunktion.
Figur 12 - Empirisk fördelningsfunktion för gruppstorlek [2]
Figur 12 gestaltar en empirisk fördelningsfunktion. En kurva skapas bitvis genom att varje frekvenspunkt sammankopplas med en rak linje.

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
24
5.2 Exempel kontinuerlig empirisk fördelning Tiden för de 100 senaste reparationerna av ett transportörsystem har samlats in. Dessa varierar mellan några minuter upp till tre timmar beroende orsak till fel.
Tabell 5- Reparationstid av ett transportörsystem [2]
Tabell 5 visar reparationstiden indelat i klassintervall. Från denna tabell kan utläsas att oftast tar det 1.0 till 1.5 timmar att underhålla tranportören.
Figur 13- Empirisk fördelningsfunktion för reparationstid av en tranportör.[2]
Figur 13 visar en empirisk fördelningsfunktion för olika klassintervall. Denna kurva bildas genom att förbinda varje punkt [x, F(x)]. Den kurva med högst lutning är det tidintervall som är mest frekvent av de övriga intervallen. I figur 13 utläses skarpast lutning mellan 1.0 och 1.5, vilket ger samma slutsats som från tabell 5. [2]

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
25
6 Fallstudie Denna fallstudie syftar till att erhålla ökad förståelse om resultatpåverkan från operationstidernas fördelning i analyser. Tillvägagångssätt för fallstudien är att studera indata från en produkt som tillverkas på Volvo Aero. Denna produkt genomgår en tillverkningssekvens innehållande 18 stycken bearbetningsoperationer innefattande tre olika processtyper (halvautomatisk, automatisk och manuell).
Studien syftar till att undersöka hur operationer inom dessa processtyper kan representeras med teoretiska fördelningar, om det finns något samband med en viss processtyp och en specifik fördelning samt att undersöka hur olika fördelningar av operationstid påverkar resultatet från en simuleringsstudie.
6.1 Analysmetodik Arbetet initieras med granskning av produktens operationstid för de 18 bearbetningsoperationer, i den kommersiella programvaran Excel. I Excel skapas linjediagram för varje operation, för att granska om eventuella extremvärden förekommer och om dessa skall inkluderas eller exkluderas i analysen. Exempel på extremvärden som skall exkluderas i analysen är rapporteringsfel. Då extremvärden efterliknar verklighetens utfall är det riskabelt att filtrera dessa utan samråd med uppdragsgivare eller tekniker. Tidsberoende tendenser studeras även för de olika operationerna med syfte att avgöra om flera fördelningar förekommer i olika intervall i datamaterialet.
Figur 14- illustration av rådata innehållande extremvärden samt intervall med tidsberoende utfall.
Vikten av att granska indata exemplifieras av figur 14. Om uppdelning av data inte utförs och extremvärden inte exkluderas, kan detta resultera i att programvaran Stat:fit inte finner någon lämplig fördelning och missvisande resultat kan då erhållas.
För att studera datamaterialets fördelning, skapas histogram utan extremvärden och tidsberoende utfall. Dessa diagram analyseras grafiskt för att kunna utföra ett antagande om vilken fördelning som bäst återger indata.

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
26
0
5
10
15
20
25
30
35
40
45
50
5 5,5 5,7 6 6,2 6,4 6,5 6,7 6,9 7 7,2 7,3 7,5 8 8,1 8,2 8,3 8,5 8,6 8,8 9
op.200
Total
Figur 15 - Ett histogram som illustrerar utfallet av operationstid för en tillverkningsoperation.
Från figur 15 kan ett antagande om fördelning utföras. Ett subjektivt antagande om fördelning till denna figur är lognormalfördelning.
För att kunna göra antaganden och uppskattningar per operation, krävs kunskap och erfarenhet. Därför har bedömningar och eventuella förenklingar diskuterats med ansvarig huvudplanerare/tekniker. Denna information är grundläggande för att kunna sortera vilka operationer som är användbara att studera i fallstudien och att utföra fördelningstest på med hjälp av programvaran Stat:fit.
Programvaran Stat:fit framställer även grafiskt, likt Excel olika teoretiska fördelningar för att kunna jämföra vilken fördelning som är representativ för ett datamaterial.
Figur 16- Jämförelse mellan olika teoretiska fördelningar till ett datamaterial i programvaran Stat:Fit. Figur 16 som skapats i Stat:fit illustrerar olika tänkbara fördelningar till datamaterialet. Denna figur styrker att lognormalfördelning är ett rimligt antagande.
Stat:fit genererar resultat från tre fördelningstest Chi2, Kolmogorov-Smirnov och Anderson-Darling. Dessa test ger information om vilka fördelningar som kan representera
Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
27
datamaterialet samt hur väl de företräder datamaterialet. Information erhålls även från fördelningstesten för att kunna avgöra om rekommenderade fördelningar är statistiskt säkerställda. Denna information jämförs mot tabell för kritiska värden för respektive fördelningstest. För att undersöka om erhållna fördelningar är statistiskt säkerställda kontrolleras följande villkor enligt bilaga C för respektive fördelningstest. Dessa villkor ligger till grund för Stat:fit gällande resultat ”Reject” eller ”Do not reject” för samtliga fördelningstyper per tillverkningsoperation, se bilaga B.
För att finna samband mellan de tre processtyperna (automatiska, halvautomatiska och manuella) och för att avgöra lämplig fördelning per tillverkningsoperation har resultat från Stat:fits erhållit nedanstående resultatmatriser (figur 17,18, 19 och 20). Simuleringsmodellens parameterinställningar är erhållna från Stat:fit och illustreras i nedanstående figurer samt är sammanställda i bilaga D.
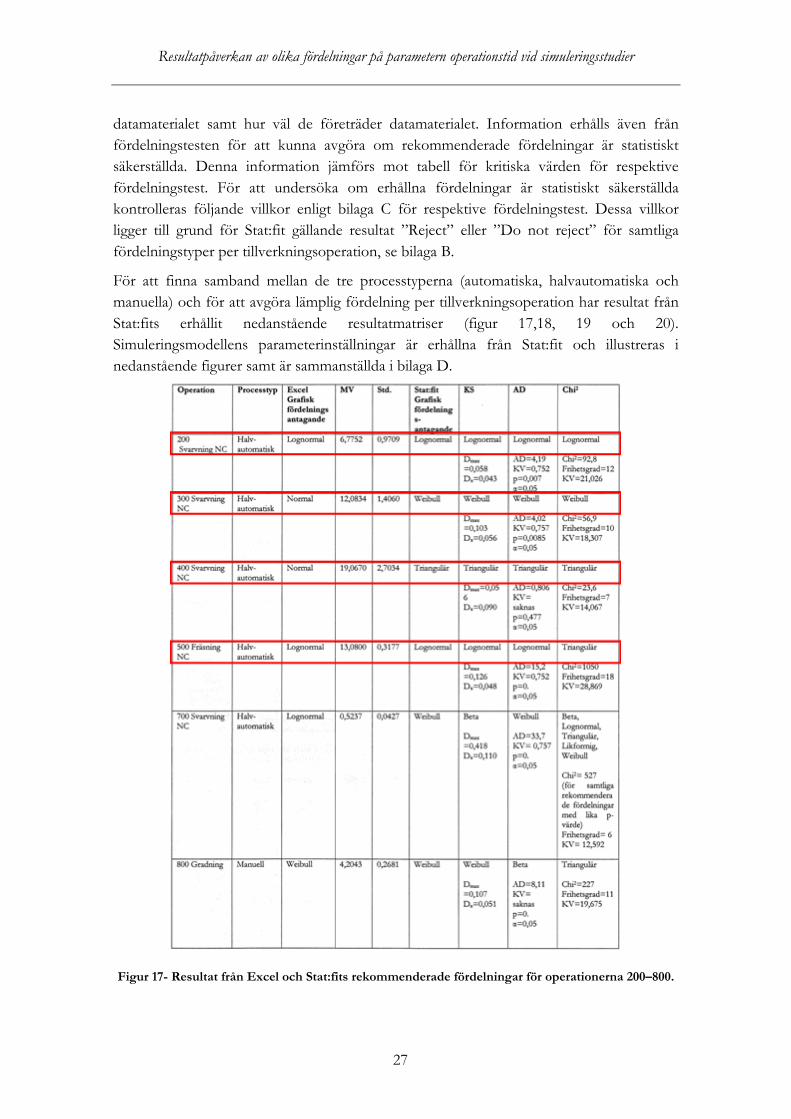
Figur 17- Resultat från Excel och Stat:fits rekommenderade fördelningar för operationerna 200–800.
Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
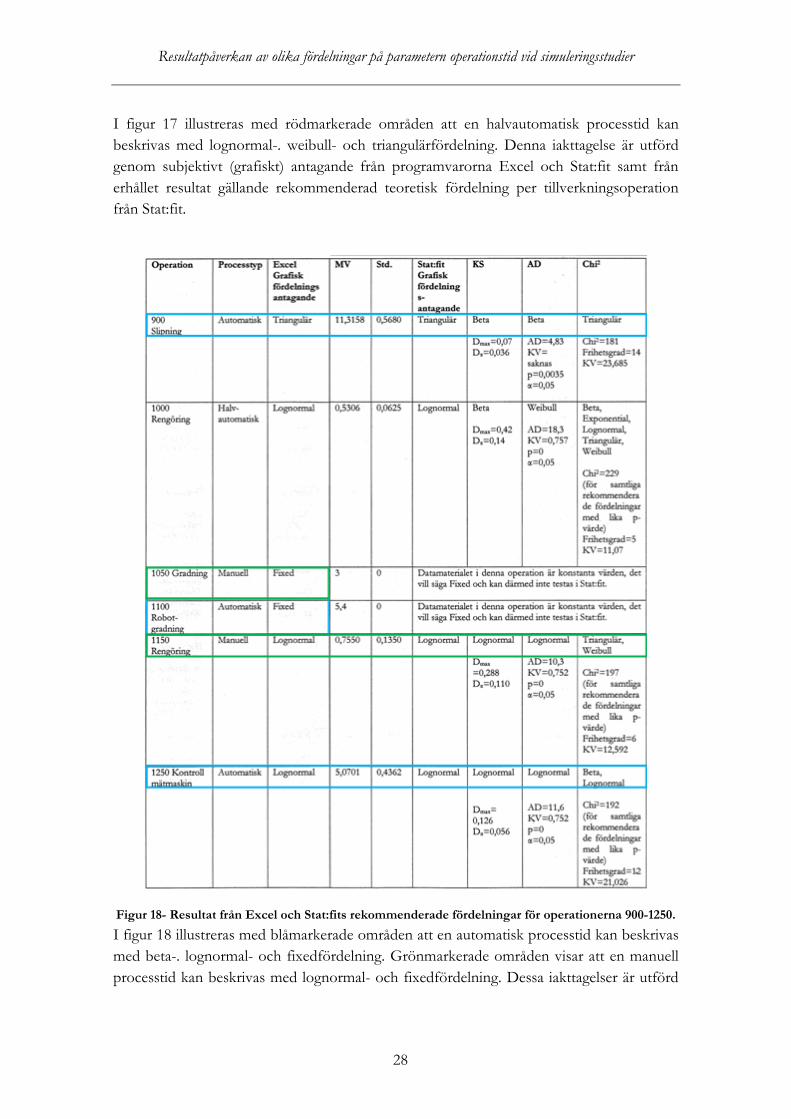
28
I figur 17 illustreras med rödmarkerade områden att en halvautomatisk processtid kan beskrivas med lognormal-. weibull- och triangulärfördelning. Denna iakttagelse är utförd genom subjektivt (grafiskt) antagande från programvarorna Excel och Stat:fit samt från erhållet resultat gällande rekommenderad teoretisk fördelning per tillverkningsoperation från Stat:fit.
Figur 18- Resultat från Excel och Stat:fits rekommenderade fördelningar för operationerna 900-1250. I figur 18 illustreras med blåmarkerade områden att en automatisk processtid kan beskrivas med beta-. lognormal- och fixedfördelning. Grönmarkerade områden visar att en manuell processtid kan beskrivas med lognormal- och fixedfördelning. Dessa iakttagelser är utförd

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
29
genom subjektivt (grafiskt) antagande från programvarorna Excel och Stat:fit samt från erhållet resultat gällande rekommenderad teoretisk fördelning per tillverkningsoperation från Stat:fit.
Figur 19 - Resultat från Excel och Stat:fits rekommenderade fördelningar för operationerna 1350-
1700. Genom grafiskt antagande från programvarorna Excel och Stat:fit samt från erhållet resultat från Stat:fit illustreras i figur 19 tillägg av fördelningar som är användbara för att representera en manuell processtid. Grönmarkerat område gäller tillägg för manuell processtid och är weibull- och betafördelning. En summering av iakttagelser från figur 17,

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
30
18 och 19 gällande lämpliga fördelningar för de tre olika processtyperna följer efter figur 20.
Figur 20- Resultat från Excel och Stat:fits rekommenderade fördelningar för operation 1800
Automatisk process= Beta-, lognormal- eller fixedfördelning Manuellprocess= Weibull-, lognormal-, fixed- eller betafördelning Halvautomatisk= Lognormal- weibull eller triangulärfördelning Från matris i figur 17, 18, 19 och 20 erhålls information om vilka fördelningar som kan användas för att beskriva de olika processtyperna halvautomatisk, automatisk och manuell. För halvautomatisk process används lognormal-, weibull-, eller triangulärfördelning. Beta-, lognormal- eller fixedfördelning är användbara för att beskriva en automatisk processtid. För att illustrera processtid i en manuell operation är weibull-, lognormal-, fixed- eller betafördelning brukbara. Dessa funna samband för processtyperna är dock grundade på ett fåtal analyser av varje processtyp.
Nedanstående sammanfattning för de 18 bearbetningsoperationerna har erhållits från figur 17-20 och bilaga B. Dessa har resulterat i den körplan som presenteras i bilaga D.
Operation 200 Samtliga nollhypoteser förkastas i Stat:fit för operation 200, det vill säga ingen teoretisk fördelning är statistiskt säkerställd för att kunna anpassas till datamaterialet. Dock dras slutsats, från grafisk tolkning samt av rekommendationsresultat från KS, AD och Chi2
Operation 300
att lognormalfördelning bäst beskriver datamaterialets fördelning med parametrarna lognormal (µ; σ)= (6,7752; 0,9709).
Samtliga nollhypoteser förkastas i Stat:fit för operation 300, det vill säga ingen teoretisk fördelning är statistiskt säkerställd för att kunna anpassas till datamaterialet. Dock dras slutsats av grafiskt antagande och av rekommendationsresultat från KS, AD och Chi2
att weibullfördelning bäst beskriver datamaterialets fördelning med parametrarna weibull (α; β; min)= (3,1505; 4,5408;8)

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
31
Operation 400 Enligt KS och AD i Stat:fit test, är triangulärfördelning statistiskt säkerställd för att representera operation 400. Även Chi2 rekommenderar triangulärfördelning för operation 400, dock är detta inte statistiskt säkerställt från Chi2
Operation 500
och kan bero på vald intervallbredd. Även grafiska antaganden styrker denna hypotes om triangulärfördelning. Parametrarna som kommer att användas är triangulär(min, max, mode)=(12; 22,0938; 17,6751).
Samtliga nollhypoteser förkastas i Stat:fit för operation 500, det vill säga ingen teoretisk fördelning är statistiskt säkerställd för att kunna anpassas till datamaterialet. Dock dras slutsats av rekommendationsresultat från KS och AD att lognormalfördelning bäst beskriver datamaterialets fördelning med parametrarna lognormal(u, σ)=(13,0800; 0,3177).
Operation 700 Fördelningstesten i Stat:fit rekommenderar olika fördelningar till operation 700. Samtliga nollhypoteser förkastas i Stat:fit, det vill säga ingen teoretisk fördelning är statistiskt säkerställd för att kunna anpassas till datamaterialet. Då samtliga fördelningstest visar olika fördelningar både grafiskt och numeriskt, kan slutsats om lämplig fördelning inte fastställas. Därmed skall empirisk fördelning användas för att beskriva datamaterialet. Därmed tas beslut om att operation 700 skall illustreras med en empirisk fördelning i simuleringsstudien.
Operation 800 Fördelningstesten i Stat:fit rekommenderar olika fördelningar till operation 800. Samtliga nollhypoteser förkastas i Stat:fit, det vill säga ingen teoretisk fördelning är statistiskt säkerställd för att kunna anpassas till datamaterialet. Då samtliga fördelningstest visar olika fördelningar både grafiskt och numeriskt, kan slutsats om lämplig fördelning inte fastställas. Därmed skall empirisk fördelning användas för att beskriva datamaterialet. Beslut tas att operation 800 skall illustreras med en empirisk fördelning i simuleringsstudien.
Operation 900 Fördelningstesten i Stat:fit rekommenderar olika fördelningar till operation 900. Samtliga nollhypoteser förkastas då dessa inte är statistiskt säkerställda för att kunna anpassas till datamaterialet. Dock dras slutsats, från rekommendationsresultat från KS och AD att betafördelning kommer att användas för att beskriva datamaterialets fördelning för operation 900. Parametrarna som kommer att användas är beta(min; max, a1, a2)= (10; 12.4; 2.55955; 1.9707).
Operation 1000 Fördelningstesten i Stat:fit rekommenderar olika fördelningar till operation 1000. Samtliga nollhypoteser förkastas i Stat:fit, det vill säga ingen teoretisk fördelning är statistiskt säkerställd för att kunna anpassas till datamaterialet. Då samtliga fördelningstest visar olika fördelningar både grafiskt och numeriskt, kan slutsats om lämplig fördelning inte fastställas. Därmed skall empirisk fördelning användas för att beskriva datamaterialet. Beslut tas att operation 1000 skall illustreras med en empirisk fördelning i simuleringsstudien.

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
32
Operation 1050 och 1100 Datamaterialet för dessa operationer är ett konstant värde på processtid, det vill säga fixed och kan därmed inte testas i Stat:fit. Detta är skälet till att dessa saknas i bilaga B och C.
Operation 1150 Samtliga nollhypoteser förkastas i Stat:fit för operation 1150, det vill säga ingen teoretisk fördelning är statistiskt säkerställd för att kunna anpassas till datamaterialet. Dock dras slutsats av grafiskt antagande och av rekommendationsresultat från KS och AD att lognormalfördelning bäst beskriver datamaterialets fördelning med parametrarna lognormal (µ; σ)= (0,7550; 0,1350).
Operation 1250 Samtliga nollhypoteser förkastas i Stat:fit för operation 1250, det vill säga ingen teoretisk fördelning är statistiskt säkerställd för att kunna anpassas till datamaterialet. Dock dras slutsats, från grafisk tolkning samt av rekommendationsresultat från KS, AD och Chi2
Operation 1350
att lognormalfördelning bäst beskriver datamaterialets fördelning med parametrarna lognormal (µ; σ)= (5,0701; 0,4362).
Enligt KS, AD och Chi2
Operation 1450
i Stat:fit test, är weibullfördelning statistiskt säkerställd för att representera operation 1350. Parametrarna som kommer att användas är weibull (α; β: min)= (2,39; 1,2409; 3).
Samtliga nollhypoteser förkastas i Stat:fit för operation 1450, det vill säga ingen teoretisk fördelning är statistiskt säkerställd för att kunna anpassas till datamaterialet. Dock dras slutsats, från rekommendationsresultat från KS, AD och Chi2
Operation 1550
att lognormalfördelning bäst beskriver datamaterialets fördelning med parametrarna lognormal (µ; σ)= (0,7150;0,0750).
Datamaterialet för denna operation är ett konstant värde på processtid, det vill säga fixed och kan därmed inte testas i Stat:fit. Detta är skälet till att denna saknas i bilaga B och C.
Operation 1600 Samtliga nollhypoteser förkastas i Stat:fit för operation 1600, det vill säga ingen teoretisk fördelning är statistiskt säkerställd för att kunna anpassas till datamaterialet. Dock dras slutsats, från grafisk tolkning samt av rekommendationsresultat från KS, AD och Chi2
Operation 1700
att betafördelning beskriver datamaterialets fördelning med parametrarna beta(min; max; a1; a2;)= (1; 3,9; 2,5817; 1,9122).
Samtliga nollhypoteser förkastas i Stat:fit för operation 1700, det vill säga ingen teoretisk fördelning är statistiskt säkerställd för att kunna anpassas till datamaterialet. Dock dras slutsats av rekommendationsresultat från KS, AD och Chi2 att lognormalfördelning bäst beskriver datamaterialets fördelning med parametrarna lognormal (µ; σ)= (0,7248;0,0737).

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
33
Operation 1800 Fördelningstesten i Stat:fit rekommenderar olika fördelningar till operation 1800. Samtliga nollhypoteser förkastas i Stat:fit, det vill säga ingen teoretisk fördelning är statistiskt säkerställd för att kunna anpassas till datamaterialet. Dock dras slutsats av rekommendationsresultat från AD och Chi2
6.2 Simuleringsstudie
att lognormalfördelning bäst beskriver datamaterialets fördelning med parametrarna lognormal (µ; σ)= (2,0723; 0,2440).
Modellbyggandet för simuleringsstudien har skett i samråd med uppdragsgivare och handledare på Volvo Aero. En simulering innebär att återskapa produktens tillverkningssteg [5] under en fastställd tidsperiod och analysera exempelvis resultatfaktorn genomloppstid. Ett medelvärde och standardavvikelse på genomloppstid beräknas per produkt, avseende på totalt antal produkter under en given tidsperiod. Simuleringstid har fastställts enligt bilaga A2. De olika simuleringskörningarna har utförts på ett strukturerat sätt enligt bilaga D och testats med två olika tillverkningsvolymer, 400 respektive 50 stycken detaljer per år samt med 100 % tillgänglighet respektive reducerad tillgänglighet enligt figur 21. Med tillgänglighet menas resurser som tillexempel maskiner, verktyg och personal. Eftersom de olika körningarna har olika fördelningar kring ett gemensamt medelvärde på operationstid, förväntas denna variation visas i resultat på genomloppstid.
Figur 21-Försöksupplägg med avseende på tillgänglighet och tillverkningsvolym
Figur 21 visar försöksupplägg vid olika scenarion gällande tillgänglighet och tillverkningsvolym för körning ett till fem. Förkortningarna HH, HL, LH, och LL förklarar nivå av tillgänglighet respektive tillverkningsvolym. HL illustrerar ett störningsfritt tillstånd med låg tillverkningsvolym och hög resurstillgänglighet medans LH representerar ett komplext tillstånd med begränsande faktorer som låg resurstillgänglighet och hög tillverkningsvolym. Område LH är ett typiskt tillstånd som efterliknar en tillverkningsprocess. För var och en av de fyra fallen i figur 21 har fem simuleringskörningar utförts.

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
34
Figur 22-Fördelningsinställningar per operation, körning ett till fem
Mer information om parameterinställningar i figur 22, finns att tillgå i bilaga D. Reducerad tillgänglighet för de olika körningarna utläses i bilaga E.
Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
35
7 Resultat från simuleringsstudie Resultat från simuleringsstudie har sammanfattats nedan.
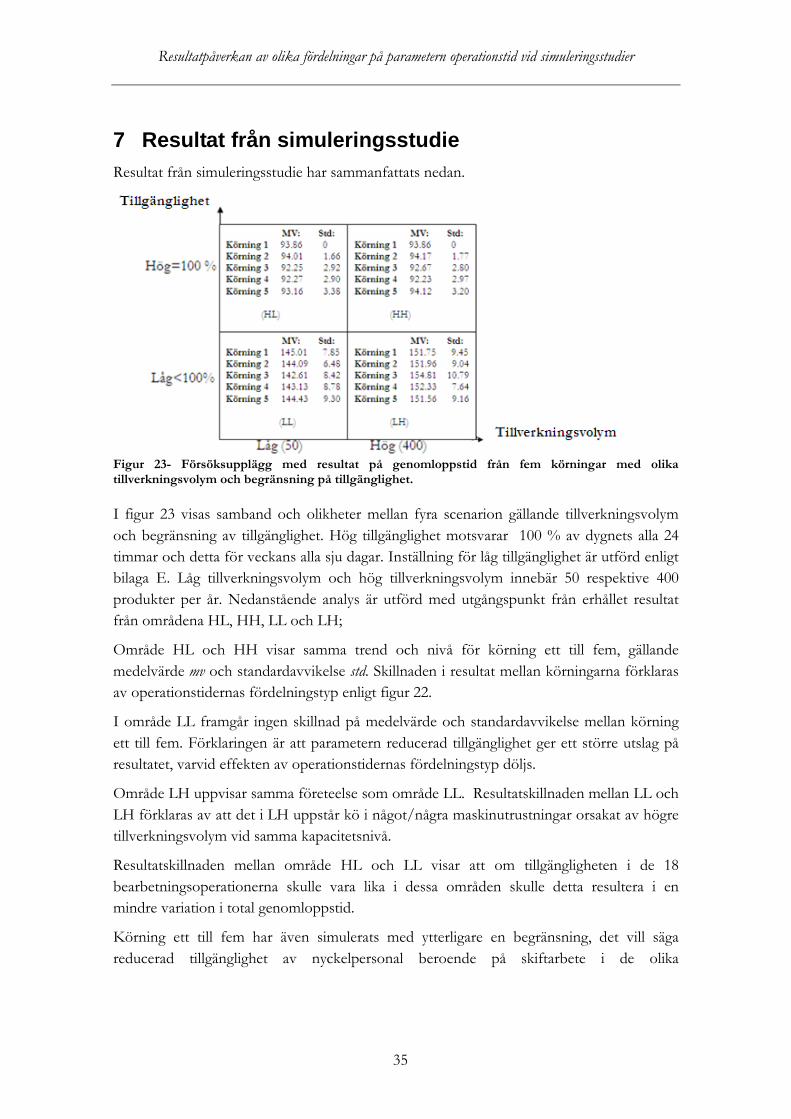
Figur 23- Försöksupplägg med resultat på genomloppstid från fem körningar med olika tillverkningsvolym och begränsning på tillgänglighet. I figur 23 visas samband och olikheter mellan fyra scenarion gällande tillverkningsvolym och begränsning av tillgänglighet. Hög tillgänglighet motsvarar 100 % av dygnets alla 24 timmar och detta för veckans alla sju dagar. Inställning för låg tillgänglighet är utförd enligt bilaga E. Låg tillverkningsvolym och hög tillverkningsvolym innebär 50 respektive 400 produkter per år. Nedanstående analys är utförd med utgångspunkt från erhållet resultat från områdena HL, HH, LL och LH;
Område HL och HH visar samma trend och nivå för körning ett till fem, gällande medelvärde mv och standardavvikelse std. Skillnaden i resultat mellan körningarna förklaras av operationstidernas fördelningstyp enligt figur 22.
I område LL framgår ingen skillnad på medelvärde och standardavvikelse mellan körning ett till fem. Förklaringen är att parametern reducerad tillgänglighet ger ett större utslag på resultatet, varvid effekten av operationstidernas fördelningstyp döljs.
Område LH uppvisar samma företeelse som område LL. Resultatskillnaden mellan LL och LH förklaras av att det i LH uppstår kö i något/några maskinutrustningar orsakat av högre tillverkningsvolym vid samma kapacitetsnivå.
Resultatskillnaden mellan område HL och LL visar att om tillgängligheten i de 18 bearbetningsoperationerna skulle vara lika i dessa områden skulle detta resultera i en mindre variation i total genomloppstid.
Körning ett till fem har även simulerats med ytterligare en begränsning, det vill säga reducerad tillgänglighet av nyckelpersonal beroende på skiftarbete i de olika

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
36
maskinutrustningarna. Denna reducering sker enligt bilaga E. Simuleringsresultaten redovisas i nedanstående tabell och histogram.
Tabell 6- Körning ett till fem med olika nivå på tillverkningsvolym med ytterligare reducering av
tillgänglighet, det vill säga reducerad tillgänglig arbetstid beroende på skiftgång.
Figur 24- Histogram över körning ett till fem med olika nivå av tillverkningsvolym, skiftform och
resurstillgänglighet Från tabell 6 och figur 24 styrks hypotesen om att påverkan av operationstidernas fördelning döljs i simuleringsresultatet vid komplexa flöden. I figur 24 illustreras likheten mellan de olika simuleringskörningarnas medelvärden och standardavvikelser. Skillnaden är liten mellan samtliga test och förklaras av att andra faktorer i simuleringsmodellen har större påverkan på resultatet än operationstidernas fördelning.

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
37
8 Slutsats och diskussion Syftet med examensarbetet var att studera hur valet av fördelningstyp för parametern operationstid påverkar simuleringsresultatets totala genomloppstid. Studien visade en märkvärd skillnad på den totala genomloppstidens medelvärde och standardavvikelse beroende på vald fördelningstyp gällande operationstid. Denna skillnad framgick inte lika tydligt vid komplexa flöden, där andra faktorer hade större påverkan på simuleringsresultatet än operationstidens fördelning. Analysen av hur operationstidernas fördelningar påverkar simuleringsresultatets genomloppstid är invecklad och kräver förståelse inom logistisk och fördelningsteori. Att representera operationstidens variation med en sannolikhetsfördelning kräver kunskap för att avgöra vilken av de rekommenderade fördelningarna från programvaran Stat:fit som bäst beskriver ett datamaterial.
Från detta arbete har insikt erhållits att komplexa flöden, med fler påverkande faktorer som exempelvis nivå av tillgänglighet, köer och tillverkningsvolym, riskerar att överrida operationstidernas variationstyp vid flödessimuleringar. Innan start av en simuleringsstudie är därför granskning av verklighetens komplexitet ett viktigt moment innan skapande av simuleringsmodell.
Vikten av att analysera vilken fördelning som representerar en operationstid framgår i figur 25 och område HL och HH. I dessa områden förekommer stabila flöden utan begränsning och därmed påverkar operationstidernas fördelning simuleringsstudiens genomloppstid.
Figur 25- Område HL, det vill säga hög tillgänglighet och låg tillverkningsvolym
Figur 25 illustrerar vikten av att beslut tas med hänsyn till variation kring medelvärdet. Empirisk fördelning är en fördelning som speglar ett begränsat antal utfall som uppträtt. Medan en teoretisk fördelning predikterar utfall utanför insamlat intervall, det vill säga utjämnar insamlade värden och genererar uppgifter för den övergripande fördelningen. För att minimera risken att fel beslut tas, är det viktigt att granska och analysera det erhållna datamaterialet och använda en teoretisk fördelning som följer dessa data.

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
38
Enligt central gränsvärdessatsen blir summan av ett antal oberoende fördelningar normalfördelad under förutsättning att antalet observationer är tillräckligt stort [2]. För de olika körningarna ett till fem har produkten genomgått 18 stycken oberoende bearbetningsstegs och total genomloppstid analyserats i Stat:fit. Fördelning per genomloppstidsresultat för körning två, tre, fyra och fem uppträder som normalfördelade, vilket styrks av centrala gränsvärdesatsen. Körning ett kan förklaras av att ingen variation på operationstid förekommer.
Det är svårt att finna den nivå av komplexitet där resultatpåverkan av olika fördelningar på parametern operationstid döljs. Därför är det viktigt att alltid vara noggrann med att granska indata och finna en lämplig fördelning att beskriva indata med.

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
39
9 Fortsatt arbete Vid simuleringsstudier rekommenderas att analysera och granska indata väl innan skapande av simuleringsmodell. För att efterlikna verklighetens stokastiska variationer och erhålla hög reliabilitet i simuleringsresultatet, skall dessa indata beskrivas med fördelningsparametrar som erhålls från programvaran Stat:fit.
För att få ökad kunskap om samband mellan faktorerna förelås fortsatt arbete fokuserat på framtagande av en matematisk formel som visar hur genomloppstidens variation påverkas av storlek på faktorerna operationstidsvariation, tillgänglighetsgrad och belastningsgrad. Förslag på tillvägagångssätt är försöksplanering.

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
40
Källförteckning
1. Hauge, J & Paige, K (2004). Learning Simul8. 2.uppl. Washington: PlainVu Publishers.
2. Banks, J (2001). Discrete event system simulation. 3.uppl. New Jersey: Prentice – Hall, Inc.
3. http://kiosk.nada.kth.se/utbildning/grukth/exjobb/rapportlistor/2003/rapporter03/dudas_catarina_03129.pdf [2010-11-29 13:06]
4. Vännman, Kerstin (2002). Matematisk statistik. 2.uppl. Lund: Studentlitteratur.
5. Law, Averill M (2007). Simulation modeling and analysis. 4.uppl. New York: The McGraw-Hill Companies, Inc.
6. Körner, S & Wahlgren, L (2006) Statistisk dataanalys. 4. uppl. Lund: Studentlitteratur.
7. Körner, Svante (2005) Tabeller och formler för statistiska beräkningar. 2uppl: Lund: Studentlitteratur
8. Evans, M & Hastings, N & Peacock, B (2000) Statistical distributions. 3.uppl. New York: John Wiley and Sons, Inc.
9. Råde, L & Rudemo, M (1994) Sannolikhetslära och statistik för teknisk högskola. 2.uppl. Lund: Studentlitteratur.
10. Djurfeldt, G & Larsson, R & Stjärnhagen, O (2003) Statistisk verktygslåda. Lund: Studentlitteratur.
11. Frennelius, Arne.(1999) Sannolikhetslära och statistisk inferens för tekniska utbildningar. 4.uppl. Västerås: Bokservice B Persson AB.
12. http://www.physics.csbsju.edu/stats/KS-test.html [2011-02-21 14:01]
13. http://www.theriac.org/pdfs/startsheets/a_dtest.pdf [2011-02-11 08:52]
14. http://epubl.ltu.se/1402-1617/2009/038/LTU-EX-09038-SE.pdf [2010-11-29 12:13]
15. Medbo, Per (2003) Kompendie: Simuleringsmetodik 030121. Institutionen för logistik och transport. Chalmers Tekniska Högskola, Göteborg
16. Medbo, Per (2004) Kompendie: Datainsamling och indatamodellering 040127. Institutionen för logistik och transport. Chalmers Tekniska Högskola, Göteborg
17. Medbo, Per (2004) Kompendie: Simuleringsprogramvaror, verifiering och validering 040203. Institutionen för logistik och transport. Chalmers Tekniska Högskola, Göteborg
18. Robinson, Stewart (1994) Successful simulation. Berkshire: McGraw-Hill Book Company Europe.
19. http://www.informs-sim.org/wsc07papers/060.pdf [2011-03-06 11:04]

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
Bilaga A:1
A. Flödessimulering Flödessimulering är grundläggande verktyg då det önskas studeras hur system förändras över tid. Ett system är en samling enheter av människor och/eller maskiner som samverkar mot ett mål under ett begränsat tidsintervall. Med observationer av historik, kan slutsatser dras om hur väl modellen efterliknar verkligheten.
Simuleringsmodeller kan delas upp i statiska eller dynamiska, deterministiska eller stokastiska och diskreta eller kontinuerliga modeller. Skillnaden mellan en statisk och dynamisk modell är att en statisk simuleringsmodell representerar systemet vid en bestämd tidpunkt, medan en dynamisk modell representerar förändringen av systemet över tid. [2]
En deterministisk simuleringsmodell är fri från slumpmässig data, detta betyder att om indata är känt är även utdata känt. Skillnaden mellan en deterministisk och stokastisk simuleringsmodell är att den stokastiska innehåller minst en slumpmässig indata. Detta medför att om indata är slumpmässig blir även utdata densamma.
Ett system kan antigen vara diskret eller kontinuerligt. Det som utgör skillnaden mellan dessa två är att i ett diskret system ändras tillståndsvariablerna momentant vid specifika tidpunkter medan tillståndsvariablerna i det kontinuerliga systemet ändras fortlöpande över tiden. [14]
I figur 26 visas ett diskret system, där ett tillstånd momentant förändras över tid. Ett exempel på ett diskret system är att en produkts tillstånd i en fabrik förändras i en tillverkningsprocess.
Figur 26 - illustration av hur en tillståndsvariabel ändras vid specifika tidpunkter.
Figur 27 - illustration av ett typiskt kontinuerligt system som visar hur tillståndsvariablerna ändras fortlöpande över tiden.
Figur 27 demonstrerar ett kontinuerligt system. Ett exempel på ett kontinuerligt system är då gas rör sig i en cylinder. Detta betyder att gasens förändring inte sker på vissa tidpunkter, utan kontinuerligt.

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
Bilaga A:2
Arbetsgången för ett simuleringsprojekt startar med en problemformulering. Det är viktigt att problemet beskrivs i tydligaste grad och att företaget förstår och godkänner denna formulering innan arbetet initierats. Här formuleras även en projektplanering och målet med simuleringsprojektet.
Figur 28 - illustration av arbetsgång för simulering [5]
Figur 28 visar de riktlinjer som finns för hur en modellformulering skall genomföras. Dessa riktlinjer grundar sig i att sammanfatta de egenskaper som utgör problemet för att sedan välja och modifiera enkla antagande som karakteriserar systemet. Det krävs kunskap och erfarenhet för att bygga en modell av ett system, vars komplexitet aldrig överskrider syftet med modellen. Då det är lättare att förbättra en befintlig modell, än att arbeta med en för komplex modell från början, är det viktigt att i ett tidigt stadie göra avgränsningar av systemet. Kvaliteten på den färdiga modellen, samt användarens förståelse ökar genom att involvera slutanvändaren vid modelleringsarbetet. Det är av stor vikt att de personer som ingår i projektet får möjlighet att granska modellen och komma med förbättringsförslag. [2]
Vid sammansättning av en simuleringsmodell, det vill säga, sammansättning av modellformuleringen och indata, kan denna programmering ske på två sätt. Antingen
Problem- formulering och planering av studie
Samla data och definiera modell
Bygga modell
Experimentera och analysera
Dokumentera, rapportera
Modell valid?
Simulering ok?
Konceptuell modell valid

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
Bilaga A:3
genom att programmera modellen med ett simuleringsspråk (datakod), eller genom att bygga modellen med ett specialanpassat simuleringsprogram. Fördelen med simuleringsspråket är vanligtvis att det är mer kraftfullt och flexibelt, nackdelen är dock den programmeringstid som krävs för att utföra detta arbete. Idag är simuleringsprogrammen normalt tillräckligt flexibla för att lösa vanliga problem och fördelaktiga, då programmeringstiden med dessa drastiskt reduceras. [14]
Verifiering Då simuleringsmodell är sammansatt skall denna verifieras och valideras. Med verifiering av modellen menas att bekräfta att modellen har byggts korrekt, det vill säga att den överrensstämmer med den konceptuella modellen. Denna verifiering sker genom att jämföra grundmodellen med programmet. Ju högre grad av komplexitet i modellen, desto längre tid kommer det att ta att korrigera eventuella fel.
Validering Att validera en modell innebär att bekräfta att modellen beskriver verkligheten. I detta steg kontrolleras hur väl simuleringsmodellen representerar det verkliga systemet. Ofta talas det om två typer av validering, subjektiv och objektiv validering. Med subjektiv validering menas att personer med kunskap om hur det verkliga systemet fungerar ger åsikter om modellen och dess utdata. Objektiv validering kräver data från systemets beteende och motsvarande data som producerats av modellen [15].
Då simuleringsmodellen är validerad och godkänd görs en försöksplanering. Denna anger vilka parametrar som skall användas och körningar som skall genomföras. Här måste även beslut om konstanter tas som till exempel tidsintervall, uppvärmningstid och antal upprepningar för respektive körtid.
Efter körning av modellen sker en efterföljande analys för att uppskatta det tänkta systemets prestanda. Därefter beslutas om nya körningar behövs samt vilket syfte de kommer att ha.
Det sista steget i simuleringsprocessen är att utifrån resultatet från simuleringsmodellen göra rekommendationer till det verkliga systemet. Resultatet från simuleringsprojektet sammanställs i en rapport och ligger till grund för beslut gällande det definierade uppdraget. [14]
Diskret händelsestyrd simulering Diskret händelsestyrd simulering handlar om att modellera system, där de ingående valda objektens tillstånd förändras momentant, vid vissa specifika tidpunkter.[2] Dessa händelser kan exempelvis vara av typen ”operatör A anländer”, ”tillverkningsfixtur B ledig” och ”maskin A startas”. Då händelser sker kan dessa skapa nya framtida företeelser vilka automatiskt sorteras i en händelselista.

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
Bilaga A:4
Figur 29- illustration av en händelselista
Figur 29 visar en händelselista bestående av en tidsaxel med en mängd händelsenotiser. Dessa notiser innehåller en tidsreferens som fastställer när händelsen skall inträffa samt en processreferens innehållande vad som skall inträffa [16].
Användningsområden Simuleringsmodeller används för att undersöka och förutspå hur olika faktorers påverkan kan tänkas bli i det verkliga systemet. Även i konceptstadiet, då nya system utvecklas, används simulering för att granska bland annat kapacitet och olika scenarion.
Simulering har ett brett användningsområde med avseende på både system och frågeställning. Exempel på system som kan simuleras är bland annat produktions-, trafik-, materialhanteringssystem samt system inom tjänstesektorn. Simulering är behjälpligt vid utvärdering av en eller flera speciella funktioner i ett system, och vid olika frågeställningar som till exempel hur olika faktorer påverkar en resultatvariabel?, ”Vad händer om” frågor, vid jämförelse av olika system och evaluering av prognostiserade resultat. Simulering är även användbart för att undersöka om ett system är stabilt mot störningar.
Simulering är en lämplig metod att använda vid;
• Framtagning av beslutsunderlag för att utvärdera kommande investeringar och förändringar exempelvis behov av nya maskiner, verktyg och fixturer.
• Komplexa och stokastiska system för att skapa förståelse
• Analys av dynamiska händelseförlopp, exempelvis vid uppstart av ett system efter haveri.
• Beskrivning av befintlig verksamhet för att identifiera behov av förändring och förbättring
• Flaskhalsanalys
• Test av olika alternativ gällande planering och styrning av produktion.
[2]

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
Bilaga A:5
Indata och utdata För att kunna skapa en modell av exempelvis ett produktionsflöde krävs information om bland annat fysisk layout, operations- och ställtider, operationsföljd, tillgänglighet av personal och maskiner samt prioriteringsregler. Syftet med simuleringsstudien avgör detaljeringsnivå och noggrannhet på indata.
Det är viktigt att indata analyseras väl för att ta reda på informationens fördelning, vid ”fel” angiven fördelning i simuleringsmodellen påverkar det resultatet.
Den insamlade informationen översätts efter analys till en lämplig indatamodell som används i simuleringen. Det finns tre huvudtyper av indatamodeller;
1. Insamlade mätvärden används oförändrade. Det finns två negativa aspekter med
detta då simuleringen endast kan återskapa vad som historiskt skett samt att det då sällan finns tillräcklig mängd data för att utföra alla önskvärda simuleringar. Fördelen är att validering av modellen är enklare, då det verkliga historiska händelseförloppet skall jämföras med samma simulerade förlopp.
2. Den vanligaste och i många fall lämpligaste indatamodellen är då informationen beskrivs med en teoretisk fördelningsfunktion. För att kunna omvandla mätvärdena till en teoretisk fördelningsfunktion krävs att indata är oberoende, likformigt fördelad samt modal det vill säga att fördelningen innehåller en ”topp”. Exempel på statistiska fördelningar är normalfördelning, exponentialfördelning, lognormalfördelning samt triangulärfördelning.
3. Den insamlade datamängden översätts till en empirisk fördelningsfunktion,
datamängden delas då in i intervall med avseende på mätvärde och sannolikheten för de olika intervallen beräknas. Empiriska fördelningsfunktioner används när det inte finns en teoretisk fördelningsfunktion som indatamodell. [16]
Resultatet från en simuleringsmodell är som tidigare nämnt en förenklad bild av verkligheten, men resultatet ger en god uppfattning om hur olika faktorer samverkar, vilken faktor som har störst effekt på resultatet samt en insikt om eventuella systemkonsekvenser som vissa beslut ger om de tas eller uteblir [2]. Ofta krävs att resultatet genomgår en känslighetsanalys för att undersöka om systemet som byggts upp är stabilt mot störningar i vissa faktorer. Vid känslighetstestet utreds hur extremvärden eller mindre ändringar i modellens indata påverkar utdata. Testet utförs för att minimera modellens känslighet mot förändringar i kritiska faktorer.

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
Bilaga A:6
Tid- och resursbehov Tiden att bygga en simuleringsmodell beror på vilken noggrannhet och detaljeringsnivå som uppdraget kräver. Storleken på modellen är också en avgörande faktor på hur lång tid som krävs för skapande av modell och framförallt validering och verifiering. Tidsavgörande faktorer är även om de olika programvarorna innehåller fördefinierade funktioner eller enbart fri programmering.
Det finns en mängd olika grafiska interaktiva simulatorer, där användaren utgår från fördefinierade byggstenar som byggs ihop till en modell. Fördelen med dessa programvaror är att de kräver lite programmeringskunskap, innehar animeringsmöjlighet samt att inlärningstiden för dessa program är kort. Exempel på grafiska interaktiva simulatorer är; Taylor, Automod, Quest, Extend, Witness och Simul8 [17]. Nackdelen med dessa programvaror är att de bland annat är dyra att köpa in samt att de kan vara relativt långsamma vid körning av modellen. Stor spridning gällande pris och licenskostnad finns även mellan de nämnda simuleringsprogramvarorna.
Exempel på frågeställningar där flödessimulering använts som verktyg Flödessimulering är ett bra verktyg vid exempelvis följande komplexa frågeställningar;
• Hur mycket minskar genomloppstiden om skiftgraden ökar från 2- till 3-skift?
• Hur mycket mindre PIA kan uppnås om möjligheten finns att ändra ”några” operationstider?
• Hur många fixturer krävs för att kunna producera planerade volymer?
• Hur mycket minskar genomloppstiden vid ökning med en fixtur?
• Hur mycket ökar genomloppstiden på detalj A om volymen på detalj B ökar.

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
Bilaga A2:1
A2. Fastställande av simuleringstid Simuleringstiden i Simul8 består av två delar; en varmkörnings- och en resultatinsamlingsperiod. Uppvärmningstiden i en simuleringsstudie syftar till att fylla modellen till en mättad och konstant nivå av produkter i arbete. Varmkörningstiden bestäms enklast grafiskt genom att rita in antal produkter i arbete ställt mot tid. Denna graf erhålls från simuleringstest där varmkörningstiden är exkluderad.
Figur 30- Metodik för val av varmkörningstid
I figur 30 illustreras tillvägagångssätt för val av varmkörningstid. Brytpunkt avläses från graf där flödet är mättat och detaljnummer väljs med marginal från brytpunkt. Total genomloppstid avläses därefter för valt detaljnummer, vilket blir tid för varmkörning. Det är ingen nackdel med lång uppvärmningstid, då detta ger en tillförlitlig tidsperiod [18].
Efter denna uppvärmningstid startar simuleringsstudiens resultatinsamlingsperiod. För att erhålla ett statistiskt säkerställt resultat från simuleringsmodellen, gäller att antalet granskade observationer är tillräckligt många. Sambandet beskrivs med formeln [19]:
där
dn
t, är t-värde erhålls från tabell t-fördelning för frihetsgrad= n-1 och för signifikansnivå α/2.
, är halva vidden av konfidensintervallet
, är medelvärdet av observationernas medelvärden
Sn n, är antalet körningar
, är observationernas standardavvikelse

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
Bilaga A2:2
En förutsättning för att använda denna formel är att observationerna är normalfördelade. Enligt den centrala gränsvärdessatsen är fördelningen av summan för samtliga observationer normalfördelad, om n är tillräckligt stort. För att kunna fastställa resultatinsamlingstid med hänsyn tagen till konfidensgrad i simuleringsresultat har Simul8 en inbyggd funktion. Denna funktion beräknar löpande uppnådd konfidensgrad och kör tills önskad nivå av konfidensgrad erhållits. Denna funktion har använts under testerna.
Figur 31 – Grafisk beräkning av antal körningar i Simul8 [19]
I figur 31 illustreras hur Simul8 beräknar antal körningar som erfordras för att uppnå önskad konfidensgrad. Erhållet antal körningar i detta exempel visar åtta stycken för konfidensgrad 95%. Simul8 utvärderar detta antal körningar med ytterligare fem körningar för att säkerställa att önskad konfidensgrad är uppnådd.

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
Bilaga B:1
B. Resultat från granskning av indata i Excel och Stat:fit Vid granskning och analys av indata plottas linjediagram. Med hjälp av dessa linjediagram kan beslut fattas om vilka extremvärden och trender som skall inkluderas, exkluderas eller uppdelas i analysmaterialet. Därefter skapas histogram som hjälpmedel för att grafiskt utse lämplig teoretisk fördelning av indata. Vidare analyseras datamaterialet i programvaran Stat:fit för att undersöka vilken fördelning som representerar datamaterialet. I Stat:fit erhålls en grafisk bild av olika lämpliga fördelningar att analysera och de tre fördelningstesten (Chi2
Operation 200
, KS och AD) utförs för att därefter undersöka om det finns någon fördelning som är statistiskt säkerställd.
0,000
2,000
4,000
6,000
8,000
10,000
12,000
1 11 21 31 41 51 61 71 81 91 101
111
121
131
141
151
161
op.t
id, t
im
op.200
Series1
Figur 32- Linjediagram med extremvärden
0,0001,0002,0003,0004,0005,0006,0007,0008,0009,000
10,000
1 11 21 31 41 51 61 71 81 91 101
111
121
131
141
151
161
op.t
id, t
im
op.200
Series1
Figur 33- Linjediagram utan extremvärden

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
Bilaga B:2
0
5
10
15
20
25
30
35
40
45
50
5 5,5 5,7 6 6,2 6,4 6,5 6,7 6,9 7 7,2 7,3 7,5 8 8,1 8,2 8,3 8,5 8,6 8,8 9
op.200
Total
Figur 34- Grafiskt antagande om fördelning i histogram, lognormalfördelning.
Figur 35 - illustration av resultat från Stat:fit för operation 200, grafiskt antagande,
lognormalfördelning.

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
Bilaga B:3
Mätresultat från fördelningstest i Stat:fit för operation 200

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
Bilaga B:4

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
Bilaga B:5

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
Bilaga B:6

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
Bilaga B:7

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
Bilaga B:8
Operation 300
0,000
5,000
10,000
15,000
20,000
25,000
1 11 21 31 41 51 61 71 81 91 101
111
121
131
141
151
161
Op.
tid,
tim
Op.300
Series1
Figur 36 – Linjediagram med extremvärden
Figur 37 - Linjediagram utan extremvärden

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
Bilaga B:9
0
5
10
15
20
25
30
35
40
7,1
8,5
9,2 10
10,5 11
11,4
11,6
11,8 12
12,2
12,4
12,7 13
13,3
13,5
13,8
14,3
14,5
01
15,3
15,7 16
op.300
Total
Figur 38 - Grafiskt antagande av fördelning i histogram, normalfördelning.
Figur 39- illustration av resultat från Stat:fit för operation 300, grafiskt antagande, weibullfördelning.

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
Bilaga B:10
Mätresultat från fördelningstest i Stat:fit för operation 300

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
Bilaga B:11

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
Bilaga B:12

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
Bilaga B:13
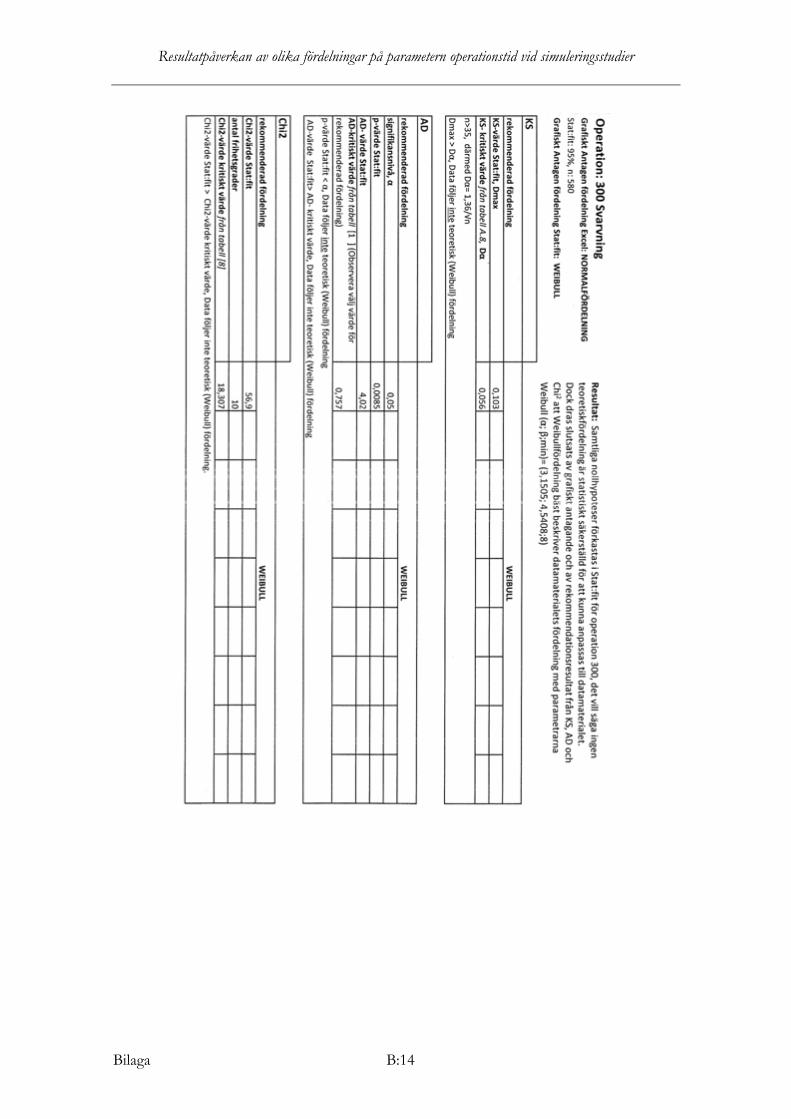
Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
Bilaga B:14

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
Bilaga B:15
Operation 400
0,000
5,000
10,000
15,000
20,000
25,000
30,000
35,000
1 11 21 31 41 51 61 71 81 91 101
111
121
131
141
151
161
op.t
id, t
im
op.400
Series1
Figur 40 – Linjediagram med extremvärden.
0,000
5,000
10,000
15,000
20,000
25,000
30,000
111 21 31 41 51 61 71 81 91 10
111
112
113
114
115
1
Op.
tid,
tim
Op.400
Series1
Figur 41 – Linjediagram utan extremvärden.

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
Bilaga B:16
0
2
4
6
8
10
12
12,5
14,6
15,5
16,4
16,8
17,3
17,6 18
18,3
18,6
18,9
19,2
19,6
19,9
20,4
20,9
21,5
21,9
22,3
23,7
op.400
Total
Figur 42 – Grafiskt antagande av fördelning i histogram, normalfördelning.
Figur 43 - illustration av resultat från Stat:fit för operation 400, grafiskt antagande,
triangulärfördelning.

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
Bilaga B:17
Mätresultat från fördelningstest i Stat:fit för operation 400

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
Bilaga B:18

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
Bilaga B:19

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
Bilaga B:20

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
Bilaga B:21
Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
Bilaga B:22
Operation 500
0,000
5,000
10,000
15,000
20,000
25,000
1 11 21 31 41 51 61 71 81 91 101
111
121
131
141
151
161
op.t
id, t
im
op.500
Series1
Figur 44 - Linjediagram med extremvärden
10,000
15,000
20,000
1 11 21 31 41 51 61 71 81 91 101
111
121
131
141
151
161
op.t
id, t
im
op.500
Series1
Figur 45 - Linjediagram utan extremvärden

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
Bilaga B:23
0
20
40
60
80
100
120
140
160
12 12,5 13 13,2 13,5 14 14,2 15
op.500
Total
Figur 46 - Grafiskt antagande av fördelning i histogram, lognormalfördelning.
Figur 47- illustration av resultat från Stat:fit för operation 500, grafiskt antagande,
lognormalfördelning.

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
Bilaga B:24
Mätresultat från fördelningstest i Stat:fit för operation 500

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
Bilaga B:25

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
Bilaga B:26

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
Bilaga B:27

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
Bilaga B:28

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
Bilaga B:29
Operation 700
Figur 48 – Linjediagram med extremvärden.
Figur 49 - Linjediagram utan extremvärden.
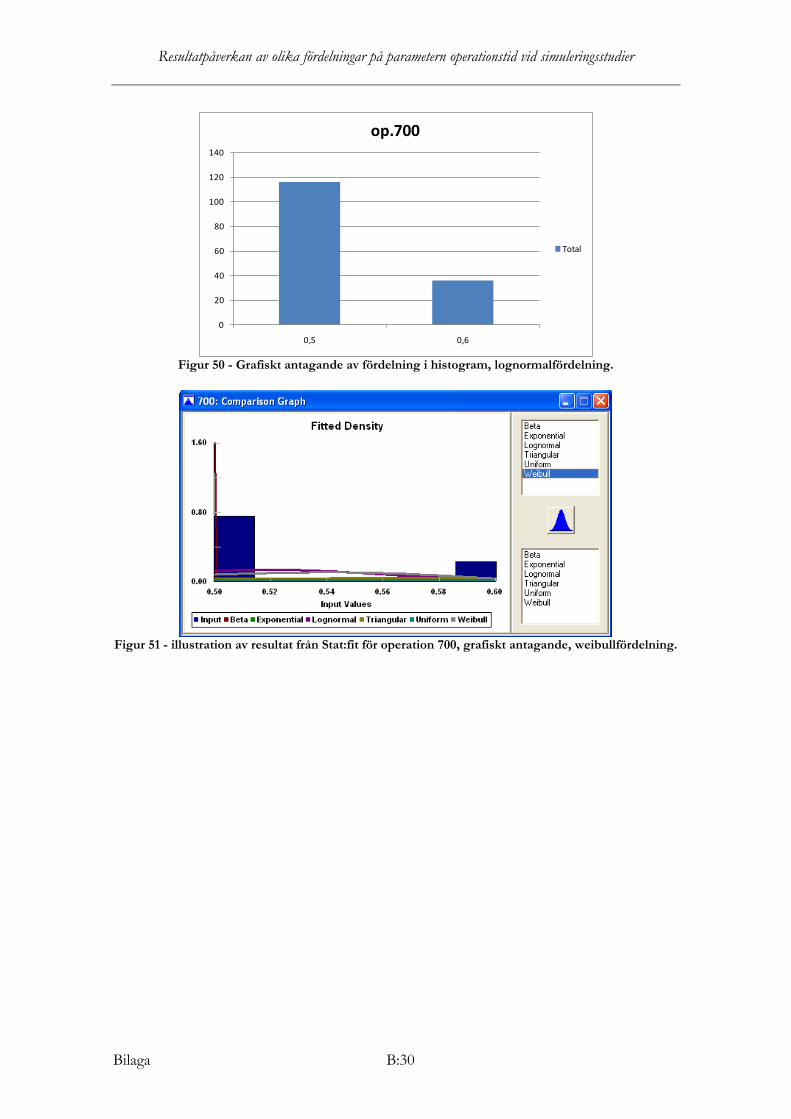
Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
Bilaga B:30
0
20
40
60
80
100
120
140
0,5 0,6
op.700
Total
Figur 50 - Grafiskt antagande av fördelning i histogram, lognormalfördelning.
Figur 51 - illustration av resultat från Stat:fit för operation 700, grafiskt antagande, weibullfördelning.

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
Bilaga B:31
Mätresultat från fördelningstest i Stat:fit för operation 700

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
Bilaga B:32

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
Bilaga B:33

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
Bilaga B:34

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
Bilaga B:35

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
Bilaga B:36
Operation 800
0,000
1,000
2,000
3,000
4,000
5,000
6,000
7,000
1 11 21 31 41 51 61 71 81 91 101
111
121
131
141
151
161
Op.
tid,
tim
op.800
Series1
Figur 52 - Linjediagram med extremvärden.
Figur 53 - Linjediagram utan extremvärden

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
Bilaga B:37
65
70
75
80
85
90
4 4,5
op.800
Total
Figur 54 - Grafiskt antagande av fördelning i histogram, weibullfördelning.
Figur 55 - illustration av resultat från Stat:fit för operation 800, grafiskt antagande, weibullfördelning.

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
Bilaga B:38
Mätresultat från fördelningstest i Stat:fit för operation 800:

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
Bilaga B:39

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
Bilaga B:40

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
Bilaga B:41

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
Bilaga B:42

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
Bilaga B:43
Operation 900
0,000
2,000
4,000
6,000
8,000
10,000
12,000
14,000
16,000
1 11 21 31 41 51 61 71 81 91 101
111
121
131
141
151
Op.
tid,
tim
op.900
Series1
Figur 56 – Linjediagram med extremvärden
10,000
10,500
11,000
11,500
12,000
1 10 19 28 37 46 55 64 73 82 91 100
109
118
127
136
145
Op.
tid,
tim
op.900
Series1
Figur 57 - Linjediagram utan extremvärden
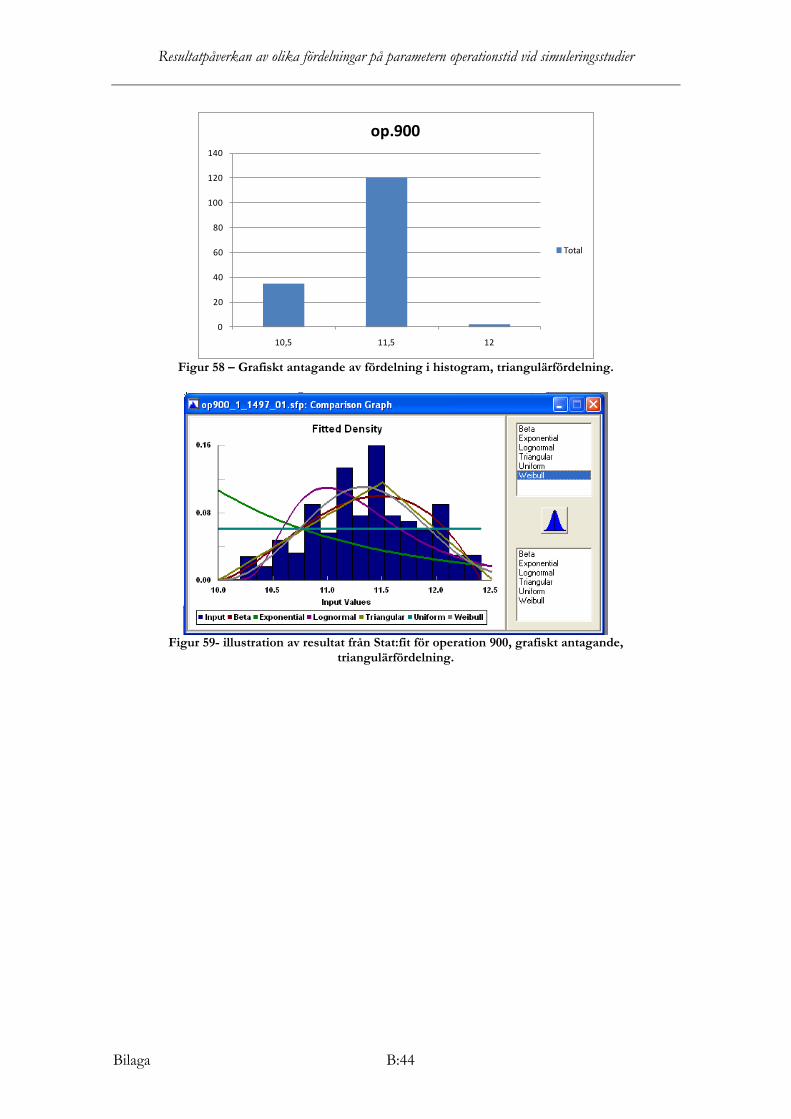
Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
Bilaga B:44
0
20
40
60
80
100
120
140
10,5 11,5 12
op.900
Total
Figur 58 – Grafiskt antagande av fördelning i histogram, triangulärfördelning.
Figur 59- illustration av resultat från Stat:fit för operation 900, grafiskt antagande,
triangulärfördelning.

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
Bilaga B:45
Mätresultat från fördelningstest i Stat:fit för operation 900

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
Bilaga B:46

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
Bilaga B:47

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
Bilaga B:48

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
Bilaga B:49

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
Bilaga B:50
Operation 1000 Mätvärden använda från order 63 till 153. Detta på grund av att extremvärden och tidsberoende trender valts att exkluderas i analysen.
0,000
0,100
0,200
0,300
0,400
0,500
0,600
0,700
0,800
1 11 21 31 41 51 61 71 81 91 101
111
121
131
141
151
Op.
tid,
tim
Op.1000
Series1
Figur 60 - Linjediagram med extremvärden
0,000
0,100
0,200
0,300
0,400
0,500
0,600
0,700
0,800
1 10 19 28 37 46 55 64 73 82 91 100
109
118
127
136
145
Op.
tid,
tim
Op.1000
Series1
Figur 61 - Linjediagram utan extremvärden

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
Bilaga B:51
0,440
0,460
0,480
0,500
0,520
0,540
0,560
0,580
0,600
0,620
1 6 11 16 21 26 31 36 41 46 51 56 61 66 71 76 81 86
Op.
tid,
tim
Op.1000 order 63-153
Series1
Figur 62- Utfall av op.1000 order 63-153
0
10
20
30
40
50
60
70
0,5 0,6
Fördelning order 63-153
Total
Figur 63- Grafiskt antagande av fördelning i histogram, lognormalfördelning.
Figur 64 - illustration av resultat från Stat:fit för operation 1000, grafiskt antagande,
lognormalfördelning.

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
Bilaga B:52
Mätresultat från fördelningstest i Stat:fit för operation 1000

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
Bilaga B:53

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
Bilaga B:54

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
Bilaga B:55

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
Bilaga B:56
Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
Bilaga B:57
Operation 1050
0,000
1,000
2,000
3,000
4,000
5,000
6,000
1 11 21 31 41 51 61 71 81 91 101
111
121
131
141
151
Op.
tid,
tim
Op.1050
Series1
Figur 65 - Linjediagram med extremvärden.
0,000
0,500
1,000
1,500
2,000
2,500
3,000
3,500
1 11 21 31 41 51 61 71 81 91 101
111
121
131
141
151
Op.
tid,
tim
Op.1050
Series1
Figur 66 - Linjediagram utan extremvärden.
0
50
100
150
200
250
300
350
400
450
500
3
op1050
Series1
Figur 67 - Grafiskt antagande av fördelning i histogram, fixedfördelning.
Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
Bilaga B:58
Operation 1100
0,000
1,000
2,000
3,000
4,000
5,000
6,000
7,000
8,000
1 11 21 31 41 51 61 71 81 91 101
111
121
131
141
151
Op.
tid,
tim
Op.1100
Series1
Figur 68 – Linjediagram med extremvärden
0,000
1,000
2,000
3,000
4,000
5,000
6,000
1 11 21 31 41 51 61 71 81 91 101
111
121
131
141
151
Op.
tid,
tim
Op.1100
Series1
Figur 69 – Linjediagram utan extremvärden
0
20
40
60
80
100
120
140
160
180
5,4
op.1100
Total
Figur 70 – Grafiskt antagande av fördelning i histogram, fixedfördelning.

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
Bilaga B:59
Operation 1150
0,000
0,200
0,400
0,600
0,800
1,000
1,200
1,400
1,600
1 11 21 31 41 51 61 71 81 91 101
111
121
131
141
151
Op.
tid,
tim
Op.1150
Series1
Figur 71 - Linjediagram med extremvärden.
0,000
0,200
0,400
0,600
0,800
1,000
1,200
1 9 17 25 33 41 49 57 65 73 81 89 97 105
113
121
129
Op.
tid,
tim
Op.1150
Series1
Figur 72 - Linjediagram utan extremvärden
0
10
20
30
40
50
60
70
80
90
0 0,5 0,6 0,7 0,8 1 1,2 1,3 1,5
op.1150
Total
Figur 73 - Grafiskt antagande av fördelning i histogram, lognormalfördelning.

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
Bilaga B:60
Figur 74 - illustration av resultat från Stat:fit för operation 1150, grafiskt antagande,
lognormalfördelning.

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
Bilaga B:61
Mätresultat från fördelningstest i Stat:fit för operation 1150

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
Bilaga B:62

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
Bilaga B:63

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
Bilaga B:64
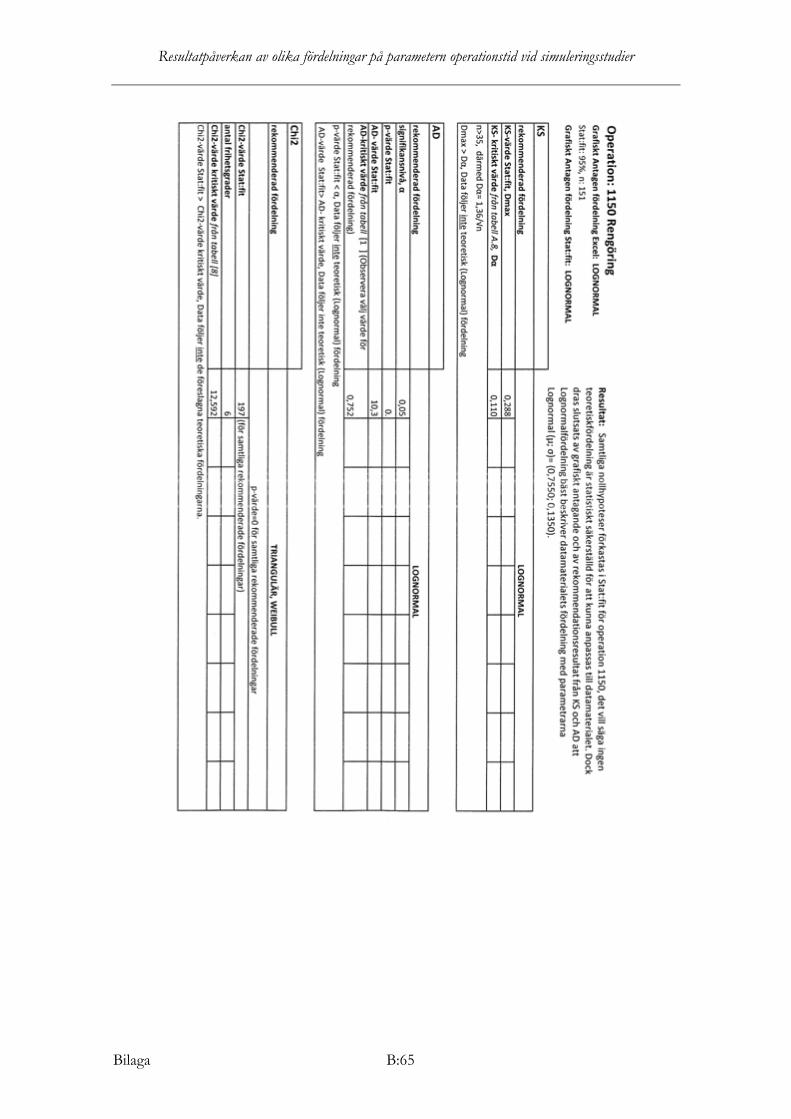
Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
Bilaga B:65

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
Bilaga B:66
Operation 1250
Figur 75 - Linjediagram med extremvärden.
Figur 76 - Linjediagram utan extremvärden.

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
Bilaga B:67
0
10
20
30
40
50
60
70
80
90
04,
54,
84,
9 55,
15,
25,
35,
55,
85,
9 66,
16,
46,
56,
7 77,
27,
5 88,
59,
7 11 1214
,1
op.1250
Total
Figur 77 - Grafiskt antagande av fördelning i histogram, lognormalfördelning.
Figur 78 - illustration av resultat från Stat:fit för operation 1250, grafiskt antagande,
lognormalfördelning.

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
Bilaga B:68
Mätresultat från fördelningstest i Stat:fit för operation 1250

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
Bilaga B:69

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
Bilaga B:70

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
Bilaga B:71

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
Bilaga B:72

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
Bilaga B:73

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
Bilaga B:74
Operation 1350
0,000
1,000
2,000
3,000
4,000
5,000
6,000
7,000
1 10 19 28 37 46 55 64 73 82 91 100
109
118
127
136
145
Op.
tid,
tim
Op.1350
Series1
Figur 79- Linjediagram med extremvärden
0,000
1,000
2,000
3,000
4,000
5,000
6,000
1 10 19 28 37 46 55 64 73 82 91 100
109
118
127
136
145
Op.
tid,
tim
Op.1350
Series1
Figur 80 – Linjediagram utan extremvärden
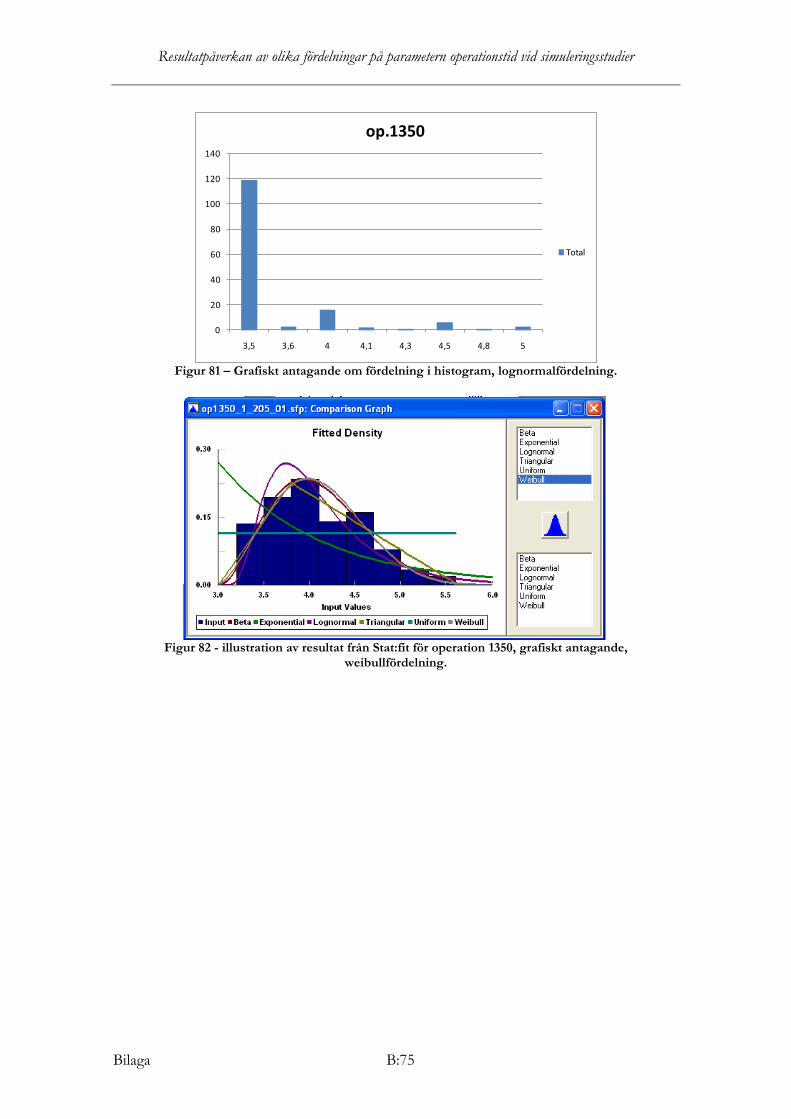
Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
Bilaga B:75
0
20
40
60
80
100
120
140
3,5 3,6 4 4,1 4,3 4,5 4,8 5
op.1350
Total
Figur 81 – Grafiskt antagande om fördelning i histogram, lognormalfördelning.
Figur 82 - illustration av resultat från Stat:fit för operation 1350, grafiskt antagande,
weibullfördelning.

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
Bilaga B:76
Mätresultat från fördelningstest i Stat:fit för operation 1350

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
Bilaga B:77

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
Bilaga B:78

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
Bilaga B:79

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
Bilaga B:80
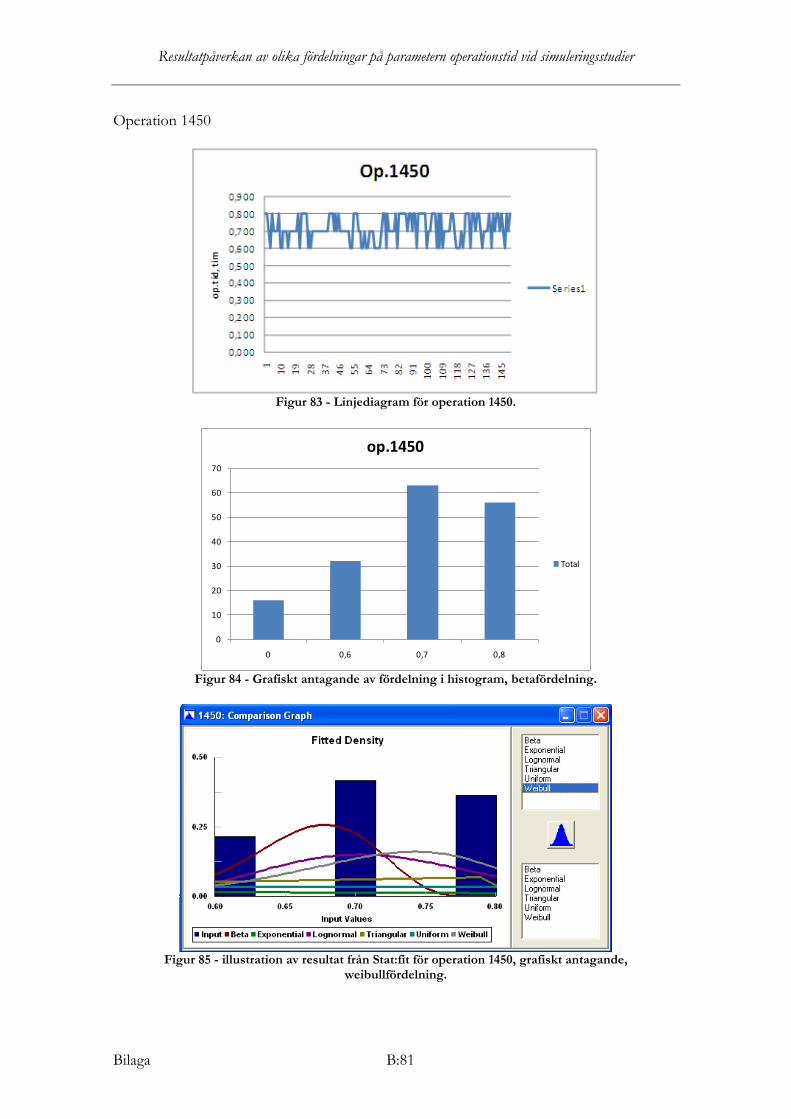
Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
Bilaga B:81
Operation 1450
Figur 83 - Linjediagram för operation 1450.
0
10
20
30
40
50
60
70
0 0,6 0,7 0,8
op.1450
Total
Figur 84 - Grafiskt antagande av fördelning i histogram, betafördelning.
Figur 85 - illustration av resultat från Stat:fit för operation 1450, grafiskt antagande,
weibullfördelning.

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
Bilaga B:82
Mätresultat från fördelningstest i Stat:fit för operation 1450

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
Bilaga B:83

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
Bilaga B:84

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
Bilaga B:85

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
Bilaga B:86

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
Bilaga B:87
Operation 1550
0,000
0,500
1,000
1,500
2,000
2,500
3,000
3,500
4,000
1 10 19 28 37 46 55 64 73 82 91 100
109
118
127
136
145
Op.
tid,
tim
Op.1550
Series1
Figur 86 - Linjediagram med extremvärden.
Figur 87 – Linjediagram utan extremvärden.
0
50
100
150
200
250
300
2
op1550
Series1
Figur 88-Grafiskt antagande av fördelning i histogram, fixedfördelning.
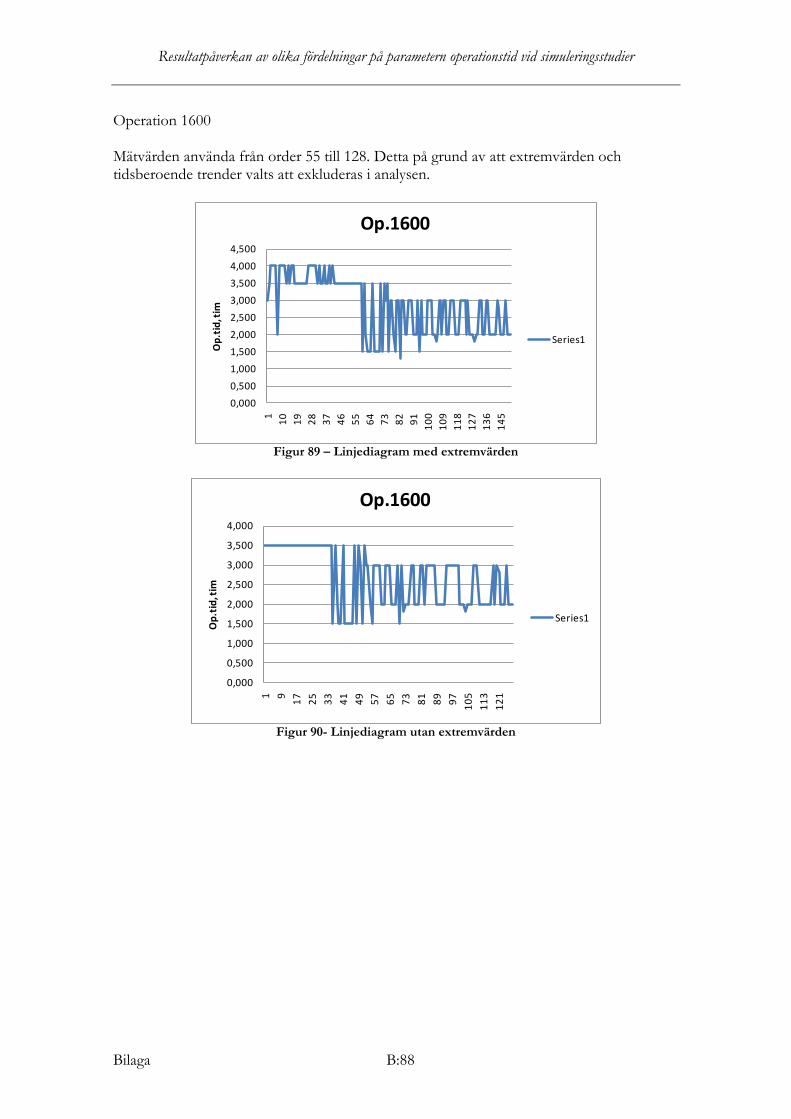
Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
Bilaga B:88
Operation 1600 Mätvärden använda från order 55 till 128. Detta på grund av att extremvärden och tidsberoende trender valts att exkluderas i analysen.
0,000
0,500
1,000
1,500
2,000
2,500
3,000
3,500
4,000
4,500
1 10 19 28 37 46 55 64 73 82 91 100
109
118
127
136
145
Op.
tid,
tim
Op.1600
Series1
Figur 89 – Linjediagram med extremvärden
0,000
0,500
1,000
1,500
2,000
2,500
3,000
3,500
4,000
1 9 17 25 33 41 49 57 65 73 81 89 97 105
113
121
Op.
tid,
tim
Op.1600
Series1
Figur 90- Linjediagram utan extremvärden
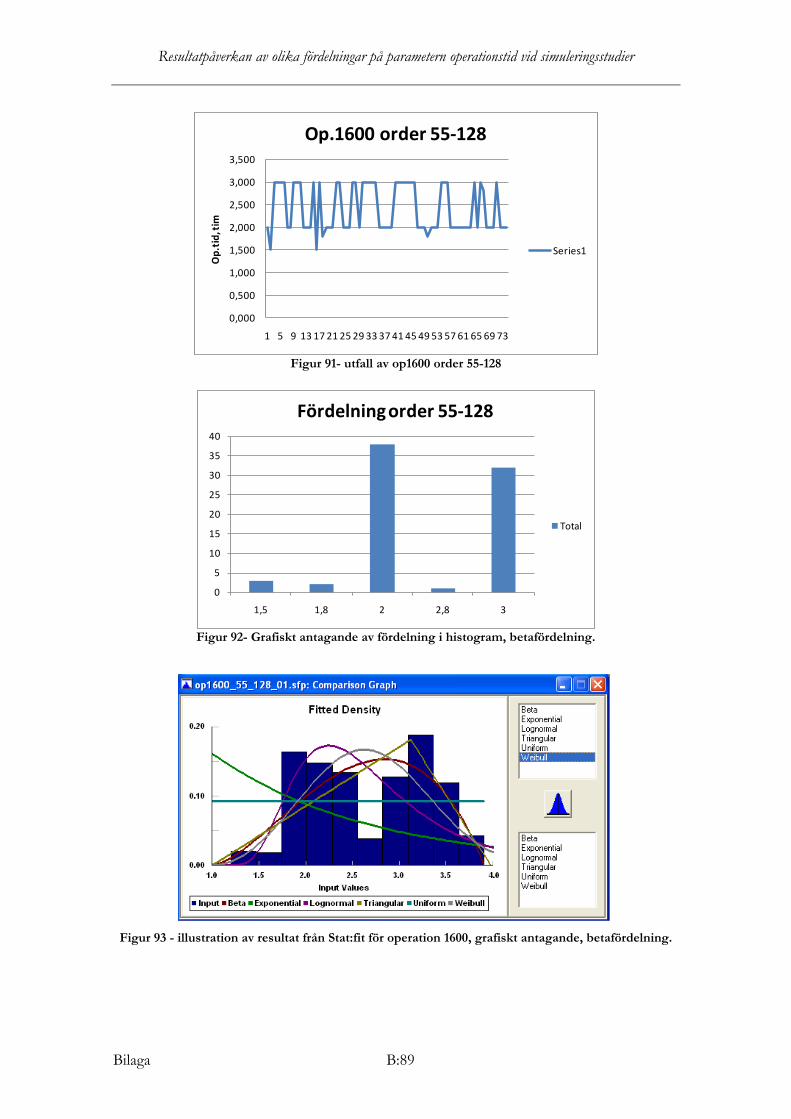
Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
Bilaga B:89
0,000
0,500
1,000
1,500
2,000
2,500
3,000
3,500
1 5 9 13 17 21 25 29 33 37 41 45 49 53 57 61 65 69 73
Op.
tid,
tim
Op.1600 order 55-128
Series1
Figur 91- utfall av op1600 order 55-128
0
5
10
15
20
25
30
35
40
1,5 1,8 2 2,8 3
Fördelning order 55-128
Total
Figur 92- Grafiskt antagande av fördelning i histogram, betafördelning.
Figur 93 - illustration av resultat från Stat:fit för operation 1600, grafiskt antagande, betafördelning.

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
Bilaga B:90
Mätresultat från fördelningstest i Stat:fit för operation 1600

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
Bilaga B:91

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
Bilaga B:92

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
Bilaga B:93

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
Bilaga B:94

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
Bilaga B:95
Operation 1700
0,000
0,100
0,200
0,300
0,400
0,500
0,600
0,700
0,800
0,900
1 10 19 28 37 46 55 64 73 82 91 100
109
118
127
136
145
Op.
tid,
tim
Op.1700
Series1
Figur 94 - Linjediagram för operation 1700.
0
10
20
30
40
50
60
70
0 0,6 0,7 0,8
op.1700
Total
Figur 95 - Grafiskt antagande av fördelning i histogram, betafördelning.
Figur 96 - illustration av resultat från Stat:fit för operation 1700, grafiskt antagande,
weibullfördelning. Mätresultat från fördelningstest i Stat:fit för operation 1700

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
Bilaga B:96

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
Bilaga B:97

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
Bilaga B:98

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
Bilaga B:99

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
Bilaga B:100

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
Bilaga B:101
Operation 1800
0,000
0,500
1,000
1,500
2,000
2,500
3,000
3,500
4,000
1 10 19 28 37 46 55 64 73 82 91 100
109
118
127
136
145
Op.
tid,
tim
Op.1800
Series1
Figur 97 - Linjediagram med extremvärden.
0,000
0,500
1,000
1,500
2,000
2,500
3,000
1 10 19 28 37 46 55 64 73 82 91 100
109
118
127
136
Op.
tid,
tim
Op.1800
Series1
Figur 98 - Linjediagram utan extremvärden.

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
Bilaga B:102
0
20
40
60
80
100
120
140
0 0,6 2 2,1 2,3 2,5 3 3,5
op.1800
Total
Figur 99 - Grafiskt antagande av fördelning i histogram, lognormalfördelning.
Figur 100 - illustration av resultat från Stat:fit för operation 1800, grafiskt antagande,
lognormalfördelning.

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
Bilaga B:103
Mätresultat från fördelningstest i Stat:fit för operation 1800

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
Bilaga B:104

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
Bilaga B:105

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
Bilaga B:106

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
Bilaga B:107

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
Bilaga C:1
C. Villkor vid analys av resultat från Stat:fit tre olika fördelningstest per operation
För att undersöka om de rekommenderade teoretiska fördelningarna per fördelningstest (KS, AD och Chi2
) är statistiskt säkerställda, skall följande villkor undersökas för varje fördelningstests rekommendation för samtliga operationer.
KS[2]:
KS förordar den fördelning som visar lägst Dmax
D
-värde av samtliga fördelningstyper. Detta värde erhålls från Stat:fit och avläses i bilaga B per tillverkningsoperation.
max< Dα
D
, Data följer teoretisk fördelning
max> Dα, Data följer inte
AD[13]:
teoretisk fördelning.
AD rekommenderar den fördelning med lägst AD-värde av samtliga fördelningstyper. Detta värde erhålls från Stat:fit och avläses i bilaga B per tillverkningsoperation.
AD-värde Stat:fit< AD kritiskt tabellvärde (KV), Data följer teoretisk fördelning
p-värde< signifikansnivå, α, Data följer inte
Chi
teoretisk fördelning 2
Chi
[11]: 2 förordar den fördelning med lägst Chi2
Chi
-värde av samtliga fördelningstyper. Detta värde erhålls från Stat:fit och avläses i bilaga B per tillverkningsoperation.
2-värde Stat:fit < Chi2
teoretisk fördelning
kritiskt tabellvärde (KV), Data följer
Chi2-värde> Chi2 kritiskt tabellvärde (KV), Data följer inte
För att avgöra valet mellan exempelvis två rekommenderade fördelningar i Chi
teoretisk fördelning 2
testet analyseras p-värdet för de rekommenderade fördelningarna, där fördelning med högst p-värde [2] avgör valet.
Ho: Rekommenderad teoretisk fördelning är korrekt.
H1: H0 är falsk.

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
Bilaga D:1
D. Parameterinställning för körning ett till fem i Simul8

Resultatpåverkan av olika fördelningar på parametern operationstid vid simuleringsstudier
Bilaga E:1
E. Grunddata för simuleringsstudie
Tabell 7 - Grunddata vid simuleringsstudie
Från tabell 7 utläses skift, reducerad tillgänglighet och tillverkningsvolym som använts vid körning ett till fem i simuleringsstudien.





























