Embed Size (px)
Citation preview

1. La statistica nella ricerca scientifica
Pubblicazione dei risultati → Presentazione dei dati e la loro elaborazione devono seguire criteri universalmente validi
Impossibile verifica dei risultati da parte di altri studiosi → raccolta dati non corretta, loro presentazione inadeguata ed analisi statistica non appropriata
La metodologia statistica rappresenta uno strumento indispensabile per lo studio, l’interpretazione e la divulgazione delle informazioni contenute nei dati
sperimentali
La metodologia statistica fornisce un criterio oggettivo alla spiegazione del fenomeno

La ricerca sperimentale procede secondo le seguenti fasi:
Osservazione del fenomeno
Formulazione dell’ipotesi
Sperimentazione
Raccolta dati
Discussione
Accettazione o rifiuto dell’ipotesi
Disegno sperimentalePermette che le osservazioni in natura e le
ripetizioni in laboratorio siano scelte e programmate in funzione della ricerca e delle ipotesi esplicative e non casuali
CampionamentoPermette di raccogliere i
dati in funzione dello scopo della ricerca
DescrizioneInsieme delle tecniche utilizzate per la sintesi dei dati grezzi in
parametri statistici (media, deviazione standard, ecc.)
Utilizzazione del test statisticoProcesso logico-matematico che, mediante il calcolo di probabilità specifiche, porta alla conclusione di non o
poter respingere l’ipotesi della casualità
1.1 Come è organizzata la metodologia statistica?

2. Principi e definizioni
Popolazione: totalità degli individui aventi in comune almeno un
carattere
Variabile: caratteristica di una popolazione che può essere misurata
2A. Variabile Discreta: assume solo valori isolati2B. Variabile Continua: tutti i valori di un intervallo
1. Variabile qualitativa: generate da risposte categoriali (es. con un test sulla tossicità, le cavie muoiono o sopravvivono; con un farmaco, i pazienti guariscono o
rimangono ammalati; ecc.);2. Variabile quantitativa: risultato di risposte numeriche ( es., per un’analisi del
dimorfismo animale, le dimensioni dell’organo o il peso dei maschi e delle femmine)
Parametro: stima delle caratteristiche della popolazioneEs. la lunghezza del fusto è di 10 cm
Lunghezza → variabile10 cm → parametro

Campione: parte della popolazione
Fattore: elemento, antropico o naturale, esterno alla popolazione che modifica in maniera più o meno evidente i parametri della popolazione.
Es., l’irrigazione, la concimazione, la tessitura del suolo, ecc.
Livelli: i livelli ai quali i fattori sono testatiEs., dose di fertilizzante, diversi gradi di tessitura, ecc.
Trattamenti: il livello o la combinazione di più livelli di uno o più fattori applicato ad un’unità sperimentale.
Es. 0, 10 e 20 Kg/ha di azoto:Azoto → Fattore
Dose fertilizzante → Livello0, 10 e 20 Kg/ha → Trattamenti

Unità sperimentale: è un’unità di materiale sperimentale alla quale è stato applicato un trattamento.
Es., individuo, una pianta o un’intera parcella
Replica: è un’unità sperimentale ripetuta
0 Kg/ha Azoto
10 Kg/ha azoto
20 Kg/ha azoto
Unità sperimentale
Unità sperimentale
Unità sperimentale
0 Kg/ha Azoto
10 Kg/ha azoto
20 Kg/ha azoto
0 Kg/ha Azoto
10 Kg/ha azoto
20 Kg/ha azoto
1 replica 2 replica 3 replica

Parametro statistico: indice che riassume sinteticamente una o più varianti del campione.
Es. media, moda, deviazione standard, ecc.
Inferenza: estensione dei risultati del campione alla totalità della popolazione
Statistica descrittiva: Insieme delle tecniche utilizzate per la sintesi dei dati grezzi
in pochi indici informativi (Es. metodologia per il calcolo della media, della
deviazione standard, ecc.)
Statistica inferenziale: insieme dei metodi con cui si possono elaborare i dati dei
campioni per dedurne omogeneità o differenze nelle caratteristiche analizzate, al
fine di estendere le conclusioni alla popolazione

3. Studio di un insieme di dati
La sperimentazione porta all’ottenimento di una serie di dati non organizzati
Nessun giudizio sulle ipotesi formulate
“E’ necessario organizzare i dati in modo sintetico e condensato”
1° criterio di organizzazione dei dati: distribuzione per classi di frequenza
Esempio: consideriamo 50 osservazioni di altezza di sorgo da fibra

Raggruppamento per frequenza
Raggruppamento per classi di frequenza e frequenza
relativa (numero di individui della classe/numero totale
d’individui)
Formula per calcolo numero di classi
K = 1 + 3.322 log n
K: numero di classi
n: numero osservazioni

Rappresentazione grafica
VantaggiPresenta la totalità delle
informazioni
SvantaggiA) l’insieme non è chiaro → presentare sotto forma più breve e più chiara
B) l’insieme non si presta a calcoli né a rigorosi confronti → occorre trasformarlo
“Non è efficace”
Un parametro statistico è più efficace:1) quanto meglio riassume il contenuto informativo dei dati iniziali con la minor
perdita di informazioni (sintetico)2) quanto meglio si presta ai calcoli ed ai test ulteriori (numerico e
trasformabile)

2° criterio di organizzazione dei dati: la media
La media aritmetica (m) è ottenuta dividendo la somma dei valori per il numero dei casi
Es. consideriamo le seguenti tre serie di misure:A: 99, 100, 101 (media = m = 100)B: 90, 100, 110 (media = m = 100)C: 1, 100 ,199 (media = m = 100)
Risultato: la media da sola non è in grado di fornire una sufficiente informazione sul campione da cui è estratta.
E’ necessario considerare la dispersione di valori attorno alla media cioè la variabilità del set di dati
La variabilità può essere espressa in diversi modi:1. Intervallo di variazione: differenza tra il valore massimo e minimo;
2. Devianza o scarto quadratico medio: somma delle singole distanze dalla media elevate al quadrato
3. Varianza (s2): rapporto tra la devianza ed il numero delle osservazioni meno 1 (gdL)
4. Deviazione standard (s): radice quadrata della varianza;5. Coefficiente di variazione (CV): rapporto tra la deviazione standard e la media il
tutto per 100

valori ScartiQuadrati degli
scarti18,2 18,2 - 20,3 = -2,1 4,4122,2 22,2 - 20,3 = 1,90 3,6118,7 18,7 - 20,3 = -1,60 2,5622,6 22,6 - 20,3 = 2,3 5,2919,8 19,8 - 20,3 = -0,5 0,25
101,5 0 16,12
Esempio: calcolare la media, la varianza e la deviazione standard delle produzioni parcellari di frumento (Kg)
Totali
1. Media (m) = 101,5 Kg
2. Varianza (s2) : somma quadrati degli scarti/ Gradi libertà16,12 / 4 = 4,03
3. Deviazione standard (s): √Varianza√4,03 = 2,0074
Gradi di libertà: numero osservazioni meno uno
(n-1) = 5-1=4
Numero osservazioni (n) = 5
Soluzione
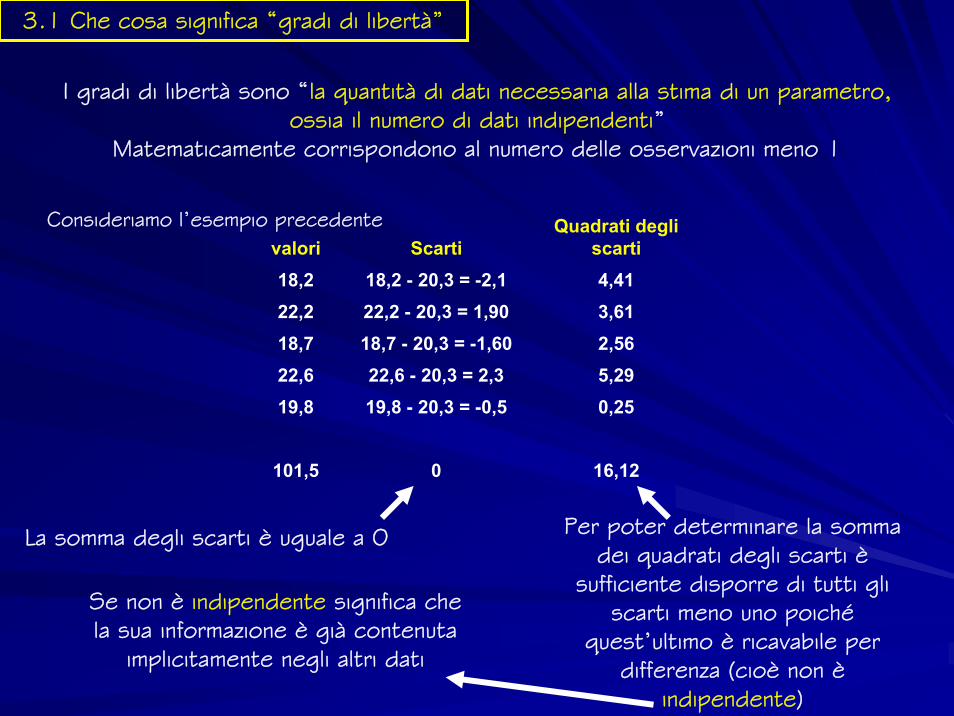
3.1 Che cosa significa “gradi di libertà”
I gradi di libertà sono “la quantità di dati necessaria alla stima di un parametro, ossia il numero di dati indipendenti”
Matematicamente corrispondono al numero delle osservazioni meno 1
valori ScartiQuadrati degli
scarti18,2 18,2 - 20,3 = -2,1 4,4122,2 22,2 - 20,3 = 1,90 3,6118,7 18,7 - 20,3 = -1,60 2,5622,6 22,6 - 20,3 = 2,3 5,2919,8 19,8 - 20,3 = -0,5 0,25
101,5 0 16,12
Consideriamo l’esempio precedente
La somma degli scarti è uguale a 0 Per poter determinare la somma dei quadrati degli scarti è
sufficiente disporre di tutti gli scarti meno uno poiché
quest’ultimo è ricavabile per differenza (cioè non è
indipendente)
Se non è indipendente significa che la sua informazione è già contenuta
implicitamente negli altri dati

3.2 Distribuzione normale: relazioni campione - popolazione
I parametri statistici, media, varianza e deviazione standard, fin qui discussi sono relativi ad un campione, poiché teoricamente è impossibile determinare tali
parametri per un’intera popolazione
Fino a quale punto i dati raccolti su un campione permettono di stimare le caratteristiche della popolazione di origine?
Per dare una risposta a tale domanda facciamo il percorso inverso: partiamo dalle caratteristiche della popolazione per arrivare a quelle del
campione
L’esperienza ha dimostrato che le variabili biologiche quantitative di una
popolazione sono “distribuite normalmente”

Distribuzione del peso di 175 topi Distribuzione del peso di un numero elevatissimo di topi
Che significa “distribuite normalmente”?
In una popolazione normalmente distribuita si ha un addensamento dei valori
attorno ad una frequenza massima ed una dispersione simmetrica che declina man
mano che ci si allontana dai valori centrali.
Tipica curva a campana o di Gauss

Caratteristiche della curva di Gauss
1. è simmetrica rispetto ad un asse2. l’asse di simmetria coincide con la
media3. le distanze misurate a partire dalla
media sono le deviazioni standard
Media
La media della popolazione (μ) è diversa di quella del campione
La deviazione standard della popolazione (σ) è diversa di quella del campione

Quanto si scosta la media di un campione da una media della popolazione?
Studi matematici hanno calcolato la
probabilità che un campione preso a caso
dalla popolazione presenta un valore medio
(m) compreso entro certi limiti
La probabilità di estrarre un campione che abbia
1) una media uguale a quella della popolazione ± 1σ è del 68%
m = μ ±1σ → 68%;
2) una media uguale a quella della popolazione ± 2σ è del 95,44%
m = μ ± 2σ → 95,44%;
3) una media uguale a quella della popolazione ± 3σ è del 99,73%
m = μ ±3σ → 99,73%;
Conclusioni:
1. a partire da un campione estratto da
una popolazione, è impossibile calcolare
esattamente i parametri μ e σ;
2. è invece possibile stimare i loro valori
più probabili che sono la media del
campione (m) e la deviazione standard (s)

Teorema del limite centrale“Se una popolazione è distribuita normalmente con una media μ ed una deviazione standard σ, le medie (m1, m2, …., mn) di un numero infinito di campioni, ciascuno
composto da n individui estratti a caso dalla popolazione si distribuiscono secondo la curva di distribuzione normale la cui media è uguale a m e la deviazione
standard è uguale a s/√n”
Il valore s/√n viene definito deviazione standard della media o errore standard (sm, SE)
Dai dati di un campione è possibile inferire sulla popolazione :
1. m ± 1sm ha il 67% delle probabilità di contenere la media della popolazione
2. m ± 2sm ha il 95% delle probabilità di contenere la media della popolazione
3. m ± 3sm ha il 99% delle probabilità di contenere la media della popolazione

Conclusioni pratiche
1. Una serie di misurazioni devono essere considerati come n individui di un
campione la cui media (m) e deviazione standard (s) rappresentano la migliore
stima della media (μ) e deviazione standard (σ) della popolazione da cui il
campione è estratto;
2. L’estrazione del campione deve essere casuale;
3. Una serie di campioni ognuno aventi n individui ed estratti da una
popolazione, hanno una media m ed una deviazione standard pari a s/√n che
è l’errore standard

4 Statistica inferenziale: il confronto fra campioni
1
2
In precedenzaConfronto fra un
singolo campione e una popolazione
Confronto fra due campioni:1. Fanno parte della stessa
popolazione?2. Fanno parte di
popolazioni diverse?
PraticamenteScelto un arbitrario livello di
probabilità, si stabilisce se due campioni trattati in maniera diversa
siano significativamente differenti tra loro

4.1 Risultati significativi e non-significativi
Conoscere con chiarezza 1) le convenzioni abitualmente usate nell’applicazione dei test statistici e 2) alcune nozioni teoriche fondamentali nell’inferenza.
Test statistico: procedure che, sulla base di dati campionari e con un certo grado di probabilità, consente di decidere se è ragionevole respingere l’ipotesi
nulla H0 oppure non esistono elementi sufficienti per respingerla.
Ipotesi nulla o H0: gli effetti osservati nei campioni sono dovuti a fluttuazioni casuali
1. Se l’HO è accettata → i campioni non sono significativamente differenti: appartengono alla stessa popolazione;
2. Se l’HO non è accettata → i campioni sono significativamente differenti: appartengono a popolazioni differenti;
La scelta delle ipotesi (H0) è fondata sulla probabilità di ottenere per caso il risultato osservato nel campione nella condizione che l’ipotesi nulla sia vera. Quanto più tale
probabilità è piccola, tanto più è improbabile che H0 sia vera.

La probabilità dipende dal valore stimato con il test o indice statistico (P)
L’insieme di valori ottenibili con il test formano la distribuzione campionaria
dell’indice statistico (P) e può essere diviso in due zone:
1. la zona di rifiuto dell’ipotesi nulla (regione critica), che corrisponde ai valori
collocati agli estremi della distribuzione; quelli che hanno una probabilità piccola di
verificarsi per caso;
2. la zona di accettazione dell’ipotesi nulla, che comprende i restanti valori
Se il valore dell’indice statistico cade nella zona di rifiuto, si respinge l’ipotesi nulla
Per convenzione, i livelli di soglia delle probabilità sono tre:0.05 (5%), 0.01 (1%) e 0.001 (0.1%)

4.2 Confronto tra due medie con il test di t Student
Assunzioni:A. I campioni provengono da popolazioni distribuite normalmente
B. le rispettive varianze siano omogenee (omoscedasticità)
Quando si utilizza?1. per il confronto della media di un campione (media osservata) con una generica media attesa

20 21 22 23 24 25 26VAR1
0
1
2
3
Cou
nt
One-sample t test of VAR1 with 7 cases; Ho: Mean = 25.00000
Mean = 23.00000 SD = 1.73205 95.00% CI = 21.39812 to 24.60188t = -3.05505df = 6 Prob = 0.02237
Con probabilità inferiore a 0.05 (di commettere un errore) si rifiuta l’ipotesi nulla, cioè le differenze
non sono dovute al caso
Praticamente:Le sostanze tossiche disperse
inibiscono la crescita delle piante della specie A in modo significativo
Soluzione:


1.1 1.2 1.3 1.4VAR1
0
5
10
15
Cou
nt
One-sample t test of VAR1 with 13 cases; Ho: Mean =1.25000
Mean = 1.23538 99.00% CI=1.18579 to 1.28498SD= 0.05854 t = -0.90018df = 12 Prob = 0.38573
Con probabilità inferiore a 0.01 (di commettere un errore) si accetta l’ipotesi nulla, cioè le differenze sono dovute al caso
Praticamente:La dimensione media dei 13 individui della specie Hetrocypris incongruens
pescati nel fiume, non è significativamente diversa da quella
degli individui della stessa specie che vivono nei laghi della regione.

2. Confronto tra le medie di due campioni indipendenti
2A. Confronto tra un campione di individui sottoposti a trattamento ed un altro campione di individui che servono come controllo (non trattato)
Test unilaterale o ad una coda: il test dirà se una media è superiore ad un’altra
escludendo a priori che essa possa essere minore. O viceversa, ma solamente
l’una o l’altra.
2B. Confronto tra le medie di due trattamenti diversi
Test bilaterale o a due code: hanno significato tutte le teoriche possibili risposte.
Questo test stabilisce se le due medie sono differenti
Entrambi i test si possono attuare sia con campioni indipendenti o appaiati sia su campioni dipendenti o non appaiati

Sono campioni dipendenti o appaiati quando un’osservazione di un campione si accoppia ad una sola osservazione dell’altro campione
Esempio 3
Osservare che i dati sono appaiati
La sostanza può essere la causa di variazioni significative di peso?

Paired samples t test on PRIMA vs DOPO with 10 cases
Mean PRIMA = 168.20000
Mean DOPO = 177.40000
Mean Difference = -9.20000
99.00%
CI = -18.13032 to -0.26968
SD Difference = 8.68971
t = -3.34798
df = 9
Prob = 0.00855
Prob = 0.00855 < 0.05
Si rifiuta l’ipotesi nulla in quanto la probabilità che la differenza riscontrata sia dovuta al caso è minore di 0.05
Praticamente: la nuova dieta determina nelle cavie una differenza ponderale significativa

Sono campioni indipendenti o dati non appaiati campioni formati da individui differenti. Quindi sono due gruppi di osservazioni ottenute in modo indipendente.
Vantaggi: possono avere un numero differente di osservazioni e sono espressione della variabilità casuale
Esempio 4
Gli animali cresciuti nella soluzione con concentrazione algale maggiore (gruppo X1) hanno raggiunto dimensioni significativamente superiori a quelli cresciuti nella soluzione con concentrazione
algale minore (gruppo X2) ?
In questo caso i dati sono indipendenti

X2X1
CONC
2
3
4
5
VAR
IAB
L
05101520Count
0 5 10 15 20Count
Two-sample t test on VARIABL grouped by CONC$Group N Mean SDX1 20 4.04430 0.12596X2 20 3.05135 0.08995
Separate Variancet = 28.68940
df = 34.4 Prob = 0.00000
Difference in Means = 0.99295 95.00%
CI = 0.92264 to 1.06326
Pooled Variancet = 28.68940
df = 38 Prob = 0.00000
Difference in Means = 0.99295 95.00%
CI = 0.92289 to 1.06301
Prob = 0.00000 << 0.05Si rifiuta l’ipotesi nulla in quanto la probabilità
che la differenza riscontrata sia dovuta al caso è minore di 0.05
PraticamenteLa maggior concentrazione algale
influisce in modo altamente significativo sulla maggior crescita
delle Daphnie
Varianza raggruppata o pooled (si calcola quando le varianze tra i due
campioni non sono differenti)

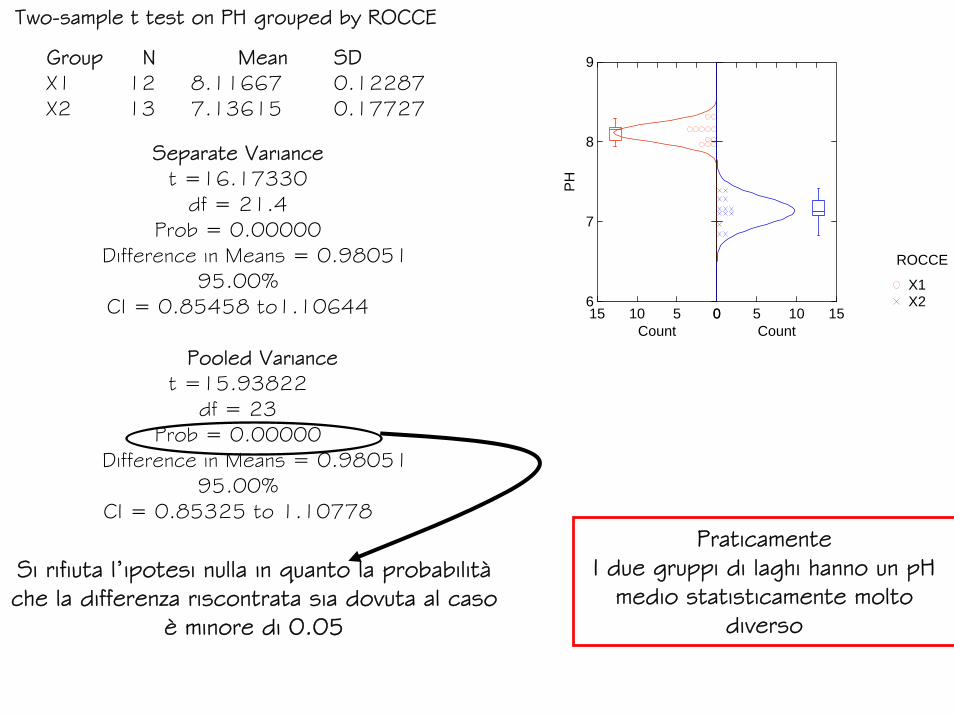
Esempio 5
Dati indipendenti e mancanza di un dato
X2X1
ROCCE
6
7
8
9
PH
051015Count
0 5 10 15Count
Two-sample t test on PH grouped by ROCCE
Group N Mean SDX1 12 8.11667 0.12287X2 13 7.13615 0.17727
Separate Variancet =16.17330
df = 21.4 Prob = 0.00000
Difference in Means = 0.98051 95.00%
CI = 0.85458 to1.10644
Pooled Variancet =15.93822
df = 23 Prob = 0.00000
Difference in Means = 0.98051 95.00%
CI = 0.85325 to 1.10778
Si rifiuta l’ipotesi nulla in quanto la probabilità che la differenza riscontrata sia dovuta al caso
è minore di 0.05
PraticamenteI due gruppi di laghi hanno un pH
medio statisticamente molto diverso

4.3 Errore di I e II tipo
In ogni confronto è possibile, per effetto del caso:1. che venga considerato diverso (rifiuto dell’ipotesi nulla) ciò che in realtà non lo è
(errore di tipo I o α)2. che venga considerato simile (accettazione dell’ipotesi nulla) ciò che in realtà è
differente (errore di tipo II o β)
Non è possibile evitare tali errori, ma è possibile stabilire un limite massimo in cui il caso possa condurre a commettere errori
All’inizio di ogni test si stabiliscono i valori di α o β
Lo scarto di α dall’unità rappresenta il livello di protezione del testEsempio: con α=0.05, il livello di protezione è pari a 0.95 cioè al 95% delle probabilità
Lo scarto di β dall’unità, rappresenta il livello di potenza del test cioè la capacità di evidenziare differenze

Esempio nell’utilizzare diversi livelli di protezione e potenza del test
Se si effettua una prova di pre-screening per individuare specie di probabile
interesse per la produzione di biomassa, potrebbe essere utile abbassare il
livello di protezione (α=0.1) a vantaggio di una maggiore potenza del test.
Quindi, è meglio correre il rischio di includere specie che potrebbero essere
inferiori, piuttosto che eliminare specie che potrebbero rivelarsi di estremo
interesse
La potenza del test
1. diminuisce all’aumentare di α
2. Aumenta se l’effetto del trattamento è maggiore
3. Aumenta se la varianza diminuisce (incremento del numero delle osservazioni)

5. Analisi della varianza (ANOVA)
Nella ricerca sperimentale, il confronto avviene spesso simultaneamente tra più di due gruppi di individui
“Non è corretto ricorrere al test t Student per ripetere l’analisi tante volte quanti sono i possibili confronti a coppie tra i singoli gruppi”
Perché ?
Con il t test
1. si utilizza solo una parte dei dati
2. la probabilità α prescelta per l’accettazione dell’ipotesi nulla è valida solamente per
ogni singolo confronto
L’analisi della varianza consente di effettuare il confronto simultaneo tra più medie
mantenendo invariata la probabilità α prefissata

Novità introdotta dall’ANOVA:Permette di scomporre e di misurare l’incidenza delle diverse fonti di variazione sui
valori osservati di due o più gruppi
Permette la ripartizione della varianza totale della variabile dipendente nella varie componenti attribuibili a fonti di variabilità nota (variabili indipendenti) e non nota
(errore)
Esempio Con il t testPer confrontare l’effetto di due tossici su un gruppo di cavie questi dovevano essere raggruppati il più omogeneo possibile. Cioè gli animali dovevano essere raggruppati per sesso, età, dimensione, ecc. Quindi, le conclusioni sono limitate al gruppo di animali con le caratteristiche prescelte, senza
la possibilità di estensione ad altri caratteri. Per comprendere l’incidenza degli altri caratteri si doveva ripetere l’esperimento variando un carattere alla volta.
Con l’ANOVAConoscendo le cause ed i diversi fattori, è possibile attribuire ad ognuna di essi la parte di
effetto determinata e contemporaneamente ridurre la variabilità d’errore.Quindi, posso testare contemporaneamente l’effetto dei diversi fattori e le loro interazioni:
1) sesso2) età
3) dimensioni

Il giudizio di significatività viene dedotto dal rapporto tra varianza apportata dal trattamento (oggetto d’indagine) e quella dovuta ai fattori non controllabili (errore o
varianza dovuta al caso).Tale rapporto (Foss) viene poi confrontato con la distribuzione di F (statistica di Fisher)
(Ftab)
Se Foss≥ a Ftab, alla probabilità prefissata (α=0.05 o α=0.01)
L’ipotesi nulla può essere rifiutata → almeno una delle medie è diversa dalle altre
SS: scarti quadratici dei fattori; gdl: gradi di libertà; MS: varianza; F: rapporto fra varianze dei fattori e dell’errore; P: livello di significatività

5.1 Assunzioni
1. l’errore e le osservazioni devono essere distribuite normalmente ed
indipendentemente
2. le varianze dei campioni devono essere omogenee (omoscedasticità)
3. le varianze dei campioni non sono correlate alle rispettive medie
4. gli effetti principali devono essere additivi

1A. Distribuzione normale ed indipendente dell’errore
Procedura
1. Costruire la tabella degli
errori: ad ogni dato si sottrae
la media generale, quella del
trattamento e quella del blocco
(se è un disegno a blocchi
randomizzati)
2. Osservare l’andamento
dell’errore: es. errori differenti
tra i trattamenti indicano non
indipendenza
L’errore è simile nei blocchi 1 e 4, e 2 e 3, per cui non è distribuito in modo randomizzato
Soluzione: trasformazione dei dati

1B. Le osservazioni devono essere distribuite normalmente
Test di Kolmogorv-Smirnov
2. Le varianze dei campioni devono essere omogenee (omoscedasticità)
Test negativo: trasformazione dei dati
Test HartleyTest CochranTest BartlettTest Levene
Test Bartlett si utilizza quando ci sono dati mancanti
Test Levene è preferibile in quanto è il più robusto
Comunque per osservare che le varianze siano omogenee è bene controllare graficamente la distribuzione dell’errore sia prima del test sia dopo aver
trasformato i dati
Test negativi: trasformazione dei
dati

4. gli effetti principali devono essere additivi Test di Tukey
Trasformazione dei dati
La trasformazione dei dati stabilizza le varianze, normalizza le distribuzioni e linearizza i rapporti fra le variabili
Esistono diversi tipi di trasformazione: logaritmica, esponenziale, ecc.
Considerazioni per la scelta del tipo di trasformazione:
1. La logaritmica → effetto moltiplicativo dell’errore o quando la varianza è
correlata alla media
2. radice quadrata → rende le varianze omogenee
3. reciproci → efficace quando la varianza aumenta in modo molto pronunciato
rispetto alla media
4. trasformazioni angolari → dati in proporzioni o percentuali

Esempio 5bis
I dati di produzione di queste specie allevate a differenti concentrazioni di azoto
1) sono distribuiti normalmente?
2) le varianze tra i gruppi sono omogenee?

Data source: Data 1 in esempio 5bis
Normality Test: Failed (P < 0,050)
Equal Variance Test: Failed (P < 0,050)
Group Name N Missing Mean Std Dev SEMRN0 4 0 0,300 0,107 0,0535RN1 4 0 0,400 0,0589 0,0294AN0 4 0 2,400 0,589 0,294AN1 4 0 2,900 0,462 0,231QN0 4 0 137,000 23,367 11,683QN1 4 0 151,000 20,116 10,058
Source of Variation DF SS MS F P Between Groups 5 108713,680 21742,736 137,143 <0,001Residual 18 2853,725 158,540Total 23 111567,405
The differences in the mean values among the treatment groups are greater than wouldbe expected by chance; there is a statistically significant difference (P = <0,001).
Power of performed test with alpha = 0,050: 1,000
…i test indicano che i dati non sono distribuiti normalmente ed i gruppi non mostrano varianze omogenee

Data source: Data 1 in esempio 5bis
Normality Test: Passed (P = 0,339)
Equal Variance Test: Passed (P = 0,441)
Group Name N Missing Mean Std Dev SEMln(col(1)) 4 0 -1,253 0,366 0,183ln(col(2)) 4 0 -0,925 0,154 0,0771ln(col(3)) 4 0 0,852 0,250 0,125ln(col(4)) 4 0 1,055 0,160 0,0801ln(col(5)) 4 0 4,909 0,174 0,0872ln(col(6)) 4 0 5,011 0,134 0,0670
Source of Variation DF SS MS F P Between Groups 5 151,806 30,36 618,380 <0,001Residual 18 0,884 0,0491Total 23 152,689
….Dopo la trasformazione dei dati ( in Ln), si è ricorso nuovamente ai tests
…..i test indicano che ora i dati mostrano una distribuzione normale ed i gruppi hanno una varianza omogenea

5.2 Analisi della varianza a un criterio di classificazione (ANOVA I)
Caratteristiche
1 fattore a più livelli
Esempio 6

Source Sum-of-Squares df Mean-Square F-ratio P
FATTORE$ 0.50294 2 0.25147 2.53815 0.12043
Error 1.18890 12 0.09908
P > 0.05 per cui si accetta l’ipotesi nulla, cioè le differenze sono dovuta al caso
PraticamenteLe tre zone non mostrano differenze significative nella quantità in ferro

5.3 Confronti multipli o a posteriori
Quando il confronto statistico avviene fra più di due campioni e l’ANOVA mostra differenze significative,
per conoscere quali gruppi sono significativamente differenti e quali no
confrontano le medie
I confronti possono avvenire fra singole medie o fra gruppi di medie
Cultivar XCultivar Y
20 Kg/ha azoto80 Kg/ha azoto
X20X80Y20Y80
XY
2040
Confronto1 2 3
Confronto sempliceConfronto complesso

5.3.1 Tipi di test post-hoc Esistono diverse tipologie di test posteriori
Bonferroni, LSD, Tukey,SNK, Sheffé, Dunnet, Duncan.
Considerazioni sulla scelta del tipo di test
Quando si fanno confronti multipli, si possono commettere due tipi di errori:
1. αc : errore riferito al confronto (comparison wise) che indica la probabilità di
dichiarare almeno un confronto significativo quando in realtà non lo è
2. αe : errore riferito a tutto l’esperimento (experiment wise) determinato
dall’incremento del numero di confronti e quindi del comparison wise,
Man mano che aumentano il numero di confronti, α tende a crescere (cioè aumenta l’errore di tipo I)
Può accadere che confronti tra medie possano risultare significativi mentre il test ANOVA aveva evidenziato una significatività (cioè almeno una media differiva dalle altre)
Oppure, ANOVA non rileva differenze significative mentre i test post-hoc le mettano in luce.
causa
Soluzione: effettuare il test solo se i dati ANOVA hanno rilevato differenze significative tra i trattamenti

Test di Bonferroni Caratteristiche Semplice
Esperimenti sbilanciati (numero delle osservazioni sono differenti tra i gruppi)Esperimenti con basso numero di confronti (al massimo 6 o 7 gruppi)
Esempio 5bis
Esistono differenze significative tra i gruppi ?

Data source: Data 1 in esempio 5bis
Normality Test: Failed (P < 0,050)
Equal Variance Test: Failed (P < 0,050)
Group Name N Missing Mean Std Dev SEMRN0 4 0 0,300 0,107 0,0535RN1 4 0 0,400 0,0589 0,0294AN0 4 0 2,400 0,589 0,294AN1 4 0 2,900 0,462 0,231QN0 4 0 137,000 23,367 11,683QN1 4 0 151,000 20,116 10,058
…i test indicano che i dati non sono distribuiti normalmente ed i gruppi non mostrano varianze omogenee
1° step: verificare le assunzioni

Data source: Data 1 in esempio 5bis
Normality Test: Passed (P = 0,339)
Equal Variance Test: Passed (P = 0,441)
Group Name N Missing Mean Std Dev SEMln(col(1)) 4 0 -1,253 0,366 0,183ln(col(2)) 4 0 -0,925 0,154 0,0771ln(col(3)) 4 0 0,852 0,250 0,125ln(col(4)) 4 0 1,055 0,160 0,0801ln(col(5)) 4 0 4,909 0,174 0,0872ln(col(6)) 4 0 5,011 0,134 0,0670
….Dopo la trasformazione dei dati ( in Ln), si è ricorso nuovamente ai tests
…..i test indicano che ora i dati mostrano una distribuzione normale ed i gruppi hanno una varianza omogenea

Data source: Data 1 in esempio 5bis
Normality Test: Passed (P = 0,339)
Equal Variance Test: Passed (P = 0,441)
Group Name N Missing Mean Std Dev SEMRN0 0 -1,253 0,366 0,183RN1 0 -0,925 0,154 0,0771AN0 0 0,852 0,250 0,125AN1 0 1,055 0,160 0,0801QN0 0 4,909 0,174 0,0872QN1 0 5,011 0,134 0,0670
Source of Variation DF SS MS F P Between Groups 5 151,806 30,36 618,380 <0,001Residual 18 0,884 0,0491Total 23 152,689The differences in the mean values among the treatment groups are greater than would beexpected by chance; there is a statistically significant difference (P = <0,001).
L’analisi evidenzia che esiste almeno una media che è differentesignificativamente dalle altre
2 step: Analisi della varianza ad un solo criterio

All Pairwise Multiple Comparison Procedures (Bonferroni t-test):
Comparisons for factor:
Comparison Diff of Means t P P<0,050ln(QN1) vs. ln(RN0) 6,264 39,978 <0,001 Yesln(QN1) vs. ln(RN1) 5,936 37,883 <0,001 Yesln(QN1) vs. ln(AN0) 4,158 26,540 <0,001 Yesln(QN1) vs. ln(AN1) 3,955 25,245 <0,001 Yesln(QN1) vs. ln(QN0) 0,102 0,650 1,000 Noln(QN0) vs. ln(RN0) 6,162 39,328 <0,001 Yesln(QN0) vs. ln(RN1) 5,834 37,233 <0,001 Yesln(QN0) vs. ln(AN0) 4,056 25,890 <0,001 Yesln(QN0) vs. ln(AN1) 3,854 24,595 <0,001 Yesln(AN1) vs. ln(RN0) 2,308 14,732 <0,001 Yesln(AN1) vs. ln(RN1) 1,980 12,637 <0,001 Yesln(AN1) vs. ln(AN0) 0,203 1,294 1,000 Noln(AN0) vs. ln(RN0) 2,105 13,438 <0,001 Yesln(AN0) vs. ln(RN1) 1,777 11,343 <0,001 Yesln(RN1) vs. ln(RN0) 0,328 2,095 0,759 No
3 step: test di Bonferroni
Alcune confronti hanno fornito significatività nelle differenze tra i gruppi (Yes) mentre altri hanno fornito non significatività (No).

Test LSD di Fisher LSD: Least Significant Difference
Caratteristiche:Poco conservativo (più facile nel commettere errori di tipo I)
ed allo stesso tempo più potente (maggiore capacità nell’individuare delle differenze)
Produce elevati e non trascurabili errori quando si testano un numero elevato di confronti
Test di Tukey
CaratteristicheMolto conservativo
Novità: nuova variabile denominata Q (intervallo di variazione studentizzato) che ha lo scopo di aumentare il
livello di protezione
Test SNK
CaratteristicheÈ un’estensione del Tukey, dal quale si differenzia per il Q che è dinamico

Test di Sheffé
CaratteristicheTest molto versatile: permette il confronto tra medie semplici e
complesse (determinate da due o più gruppi)Meno potente
Test di Dunnett
CaratteristichePermette il confronto delle medie dei singoli esperimenti con un
testimone (controllo)Molto potente (perché effettua un numero minore di confronti)
Test di Duncan

5.4 Analisi della varianza a due criteri di classificazione (ANOVA II)
ANOVA ad un criterio: schema semplice e impostazione troppo semplice (la variabilità presente nei gruppi è determinata dai differenti livelli o dalle varie modalità del solo fattore in osservazione)
Due fattori di variabilità
1. Analizzare separatamente quale sia il contributo del fattore principale e quale quello del secondo fattore;
2. Eliminare l’effetto del secondo fattore sulla varianza d’errore, quando l’interesse fosse indirizzato solo verso il primo ed il secondo fosse considerato esclusivamente come un
elemento di forte perturbazione (ridurre sensibilmente la varianza d’errore);
Trattamenti: diverse modalità del primo fattore (il più importante)Blocchi: diverse modalità del secondo fattore
Es: Livelli di Inquinamento in aree diverse (primo fattore) ed ore differenti (secondo fattore)
Analisi a blocchi randomizzati: gli individui dapprima si suddividono in gruppi omogenei (blocchi) per
il secondo fattore; poi, gli individui di ogni blocco devono essere attribuiti in modo casuale ai trattamenti.

Tabella a doppia entrata
Il caso più semplice è quello di una sola
osservazione ad ogniintersezione tra riga (blocco) e colonna
(trattamento).
L'analisi della varianza a due criteri di classificazione con una sola osservazione per casella
permette di verificare, in modo simultaneo ed indipendente, la significatività delle differenze tra le medie dei trattamenti (fattore A) e tra le medie dei blocchi
(fattore B).

ESEMPIO 7. Si vuole verificare se esiste una differenza significativa nella quantità di piombo in
sospensione nell'aria di 5 zone di una città (A, B, C, D, E). Poiché si suppone che esista una forte variabilità determinata dall’ora di campionamento,
è stata fatta una rilevazione simultanea in ogni zona, con ripetizioni a distanza di 6 ore (alle ore 6, 12, 18 e 24), per un totale di 4 campioni per zona.
Esiste una differenza significativa nella presenza media di polveri di piombo in sospensione nell’aria delle 5 zone?
Le differenze tra le ore sono significative?

Data source: Data in esempio 7
Normality Test: Passed (P = 0,409)
Equal Variance Test: Passed (P = 1,000)
Source of Variation DF SS MS F P
Zone (Trattamenti) 4 128,500 32,125 13,432 <0,001
Ore (blocchi) 3 525,800 175,267 73,282 <0,001
Errore 12 28,700 2,392
Total 19 683,000 35,947
Risposta
Con probabilità α inferiore a 0.01 si rifiuta l’ipotesi nulla, sia per le medie delle zone
che per le medie delle ore.
La differenza tra ore risulta statisticamente più significativa di quella tra zone.

5.5 Analisi della varianza a tre o più criteri di classificazione (ANOVA III)
I concetti, le finalità ed i metodi dell’analisi della varianza a due criteri possono
essere facilmente estesi a tre o più criteri di classificazione
ESEMPIO 8. Si intende verificare se
- da parte di 4 essenze (medica, plantago, trifoglio, tarassaco),- cresciute in 2 località ad alto inquinamento (T1 e T2) più un controllo a livelli
normali ( C ),- esistono differenze nell’assorbimento di 4 metalli (cadmio, nichel, piombo e
zinco),- considerando anche i 5 sfalci che vengono praticati durante un anno.
Esperimento di genetica ambientale applicata a un problema d’inquinamento, in cui si
testano contemporaneamente 4 fattori o criteri.

Esistono differenze significative tra le medie di ognuno dei 4 fattori considerati?
240 misure campionarie(4 x 3 x 4 x 5)

Dalla verifica delle assunzione si osserva che la distribuzione non è normale ed esistono grandissime differenze tra le varianze. Ad esempio, risulta del tutto evidente non rispetta le condizioni di validità dell’ANOVA la variabilità presente tra metalli (lo
zinco ha valori nettamente superiore agli altri metalli).
Trasformazione di ogni dato (x) nel suo logaritmo naturale o Ln(x).
Tra i 4 fattori considerati:
-due risultano altamente significativi (metalli ed essenze) con probabilità P < 0.001,
-uno (sfalci) risulta significativo con probabilità P leggermente inferiore al 2% (P = 0.016),
-il quarto (località) non significativo, avendo una probabilità prossima al 20% (P = 0.196).

E’interessante verificare tra quali medie dei metalli, delle essenze e degli sfalci
la differenza sia significativa: occorre effettuare confronti singoli, per i quali è
appropriato il test di Tukey.

5.6 Quadrati latini
Nel disegno sperimentale a blocchi randomizzati ogni livello di un fattore deve incrociare tutti i livelli degli altri fattori
2 fattori di variazione a p livelli richiede p2 osservazioni3 fattori di variazione a p livelli richiede p3 osservazioni
All’aumentare dei fattori, si ha un rapido incremento delle misure che occorre raccogliere;
poiché ognuna ha un costo e richiede tempo, sono stati sviluppati metodi che permettono di
analizzare contemporaneamente più fattori con un numero minore di dati.
Conclusione
Il disegno sperimentale a quadrati latini permette di analizzare contemporaneamente 3 fattori a p livelli con sole p2 osservazioni: con 3 fattori a 5 livelli sono sufficienti 25 dati e non 125 dati.
Vantaggirisparmio di materiale, di denaro e di tempo
Svantaggiomaggiore rigidità dell’esperimento stesso: tutti e tre i fattori
devono avere lo stesso numero di livelli.

Per riportare in tabella i risultati di un esperimento a quadrati latini, due fattori vengono
rappresentati nelle righe e nelle colonne, mentre il terzo fattore (fattore principale), è
rappresentato nelle celle formate dall’incrocio tra riga e colonna.
Il terzo fattore è distribuito in modo casuale ma ordinato: deve comparire una volta sola sia in
ogni riga che in ogni colonna.

ESEMPIO 9. Si intende confrontare la produttività di 5 varietà (A, B, C, D, E) di sementi in rapporto al tipo di concime (1, 2, 3, 4, 5) e ad un diverso trattamento del terreno (I, II, III, IV, V). A questo scopo, si è diviso un appezzamento quadrato di terreno in 5 strisce di dimensioni uguali, nelle quali è stata fatta un'aratura di profondità differente; perpendicolarmente a
queste, sono state tracciate altre 5 strisce, che sono state concimate in modo diverso.
Dati
Esistono differenze significative tra le medie delle 5 modalità, per ognuno dei 3 fattori considerati?

In conclusione:1) risulta molto significativa la differenza tra sementi, il cui valore di F è superiore al valore
critico della probabilità 0.01;2) è significativa la differenza tra arature, con un valore di F compreso tra il valore critico
della probabilità 0.01 e quello della probabilità 0.05;3) non è assolutamente significativa, è anzi totalmente trascurabile, la differenza tra concimi
con F minore di 1.

Il disegno sperimentale a quadrati latini ha limiti che dipendono dalle sue dimensioni. Il numero di dati non può essere troppo piccolo, né troppo grande.
Il limite inferiore o minimo è imposto dai gradi di libertà della varianza d'errore.
Un quadrato latino 2 x 2 avrebbe 3 gdl per la devianza totale, che sarebbero scomposti in
- 1 per il fattore principale,
- 1 per le colonne
- 1 per le righe.
Non resterebbero gdl per la varianza d'errore.
In un quadrato latino 3 x 3 (con 8 gdl per la devianza totale e 2 gdl per la devianza di
ognuno dei 3 fattori), la varianza d'errore ha solamente 2 gdl; è possibile condurre l’analisi,
ma i gdl sono pochi per rendere significative differenze tra le medie.
Il limite minimo utile di un quadrato latino è 4x4.
Il limite massimo o superiore è determinato dalla complessità dell'esperimento; viene quindi abitualmente fissato per un quadrato latino che varia tra
10 x 10 e 12 x 12.

Quadrati greco-latini
4 fattori

5.7 Analisi fattoriale ed interazione
Interazioni tra i fattori: se, come e quanto ogni livello o modalità di un fattore interagisce con quelli degli
altri fattori, esaminati in tutte le combinazioni.
1. quando si somministra un farmaco a persone di di età e di sesso diverso, può essere
di grande importanza sapere se esso ha effetti differenti, potenziati o inibiti, nei
giovani rispetto agli adulti o agli anziani, nei maschi rispetto alle femmine.
Se non esiste interazione, il farmaco mediamente migliore sarà il più adatto per tutte le
persone e potrà essere somministrato a tutti indifferentemente, in qualunque
condizione; ma se esiste una sua interazione con l’età e/o con il sesso, occorre
procedere ad una scelta appropriata mediante lo studio delle interazioni.
Ad esempio,

2. Nella ricerca ambientale, quando si confrontano i livelli d’inquinamento in varie zone di una città
tenendo in considerazione anche l’ora, è probabile che le aree ad inquinamento maggiore non siano
sempre le stesse, ma che presentino variazioni in rapporto alla fase del giorno.
Il traffico e l’attività delle fabbriche, che non hanno la stessa intensità a tutte le ore del giorno e sono
distribuiti sul territorio in modo non omogeneo, possono determinare graduatorie d’inquinamento che
si modificano nel corso della giornata. Di conseguenza, anche le politiche d’intervento potranno essere
diverse, se l’interazione tra zone ed ore è significativa quando si analizzano i livelli d’inquinamento.
Ad esempio,
L’analisi della varianza ad uno o più criteri permette di evidenziare gli effetti
principali di ogni fattore, ai suoi diversi livelli; ma esistono anche effetti più
complessi, determinati dalla loro azione congiunta che è l’interazione.

Se si analizzano due fattori (α e β), si parla di interazione di primo ordine o di
interazione a due fattori (αβ).
Se si analizzano 3 fattori si hanno
- gli effetti principali dei 3 fattori (α, β, γ),- 3 interazioni di primo ordine (αβ, αγ, βγ) causate dall’effetto dei fattori due a
due;
- una interazione di secondo ordine (αβγ), determinata dall’effetto congiunto
dei tre fattori.
Si parla di interazione nulla quando non esiste interazione e quindi il risultato
complessivo è determinato esclusivamente dalla somma dei singoli effetti principali.

5.7.1 Interazione tra due fattori a piu’ livelli
Con due fattori è possibile analizzare l’interazione solo quando si dispone di più osservazioni in ognuna delle celle poste all'incrocio tra righe e colonne.
Modello ANOVA a due fattori con replicazioni

ESEMPIO 10. Si vogliono verificare gli effetti di 3 mangimi industriali, contenenti ormoni sintetici, sulla
crescita di animali: un aspetto fondamentale della ricerca è dimostrare se nei due sessi hanno un effetto di segno opposto.
A questo scopo, i 3 tipi di mangime (a1 , a2 , a3 ) sono stati somministrati- a tre gruppi di femmine (b1 ), formati ognuno da 5 individui scelti per estrazione casuale da
un grande gruppo di femmine;- a tre gruppi di maschi (b2 ), formati ognuno da 5 individui scelti per estrazione casuale da
un grande gruppo di soli maschi.
Dopo un mese di dieta, è stato misurato l’accrescimento di ogni cavia.
Esiste interazione tra farmacie sesso?

Conclusioni1 - i tre mangimi danno medie di accrescimento significativamente differenti;
2 - i due sessi hanno accrescimenti significativamente differenti;3 - l'interazione tra i due fattori (mangime e sesso) è significativo, presumibilmente per la
presenza di ormoni sintetici.

Fisher dimostrò il vantaggio del disegno sperimentale di tipo fattoriale:
se si seguono contemporaneamente più fattori, si riesce ad evidenziare le
loro interazioni e si ha una visione più corretta della complessità delle
risposte.
Si ottengono anche i vantaggi di poter utilizzare un numero minore di
osservazioni e di ridurre sensibilmente la varianza d'errore.

5.7.2 Interazione tra tre fattori a piu’ livelli
Esempio 11ANOVA a tre fattori e repliche, di cui
- il primo (A) con 3 livelli,- il secondo (B) con 4 livelli,
- il terzo (Sesso) con 2 livelli o modalitàInoltre, tre repliche per ognuno dei 24 (3 x 4 x 2) gruppi e quindi 72 dati.


Test t di Student e con l'ANOVA a un criterio si sono confrontate le
differenze tra le medie di due o più campioni.
L’analisi della varianza a due o a più criteri di classificazione sono state prese in considerazione
contemporaneamente più fattori casuali, come i trattamenti e i blocchi, eventualmente con le loro
interazioni.
Ma la verifica dell’ipotesi è sempre stata limitata alla medesima ed unica variabile rilevata: una singola
variabile quantitativa
6. Regressione lineare
Due o più variabili quantitative, oltre alle precedenti analisi sulla media e sulla varianza per
ognuna di esse, è possibile esaminare anche il tipo e l'intensità delle relazioni che sussistono
tra loro.

Per esempio, quando per ogni individuo si misurano contemporaneamente il peso e l'altezza, è possibile
verificare
1. quale relazione matematica (con segno ed intensità) esista tra peso ed altezza nel
campione analizzato;
2. se la tendenza calcolata sia significativa (presente anche nella popolazione) oppure debba
essere ritenuta solo apparente (effetto probabile di variazioni casuali del campione);
3. predire il valore di una variabile quando l’altra è nota (ad esempio, come determinare in un
gruppo d’individui il peso di ognuno sulla base della sua altezza).
Analisi della regressioneAnalisi della correlazione

Si ricorre all'analisi della regressione quando dai dati campionari si vuole ricavare
un modello statistico che predica i valori di una variabile (Y) detta dipendente o più
raramente predetta, individuata come effetto, a partire dai valori dell'altra variabile
(X), detta indipendente o esplicativa, individuata come causa.
Si ricorre all'analisi della correlazione quando si vuole misurare l'intensità
dell'associazione tra due variabili quantitative (X1 e X2) che variano
congiuntamente, senza che tra esse esista una relazione diretta di causa-effetto.

6.1 Descrizione di una distribuzione bivariata
Quando per ciascuna unità di un campione o di una popolazione si rilevano due caratteri o variabili, si ha una distribuzione che è detta doppia o bivariata.
Rappresentazione distribuzione bivariata:
forma tabellare;
forma grafica.
Se il numero di dati è piccolo, la distribuzione doppia può essere rappresentata in una tabella che riporta in modo dettagliato tutti i valori delle due variabili, indicate
con- X e Y nel caso della regressione,
- X1 e X2 nel caso della correlazione,

Se il numero di osservazioni è grande, Una distribuzione doppia di quantità può essere rappresentata graficamente in vari modi.
-gli istogrammi, quando si riportano le frequenze dei raggruppamenti in classi;
- il diagramma di dispersione (chiamato anche scatter plot) quando le singole coppie di misure osservate sono rappresentate come punti in un piano cartesiano. Si ottiene una nuvola
di punti, che descrive in modo visivo la relazione tra le due variabili.
Esempio 12Con le misure di peso (in Kg.) e di altezza (in cm.) di 7 giovani, è possibile costruire il diagramma, detto
diagramma di dispersione.
Esso evidenzia la relazione esistente tra le due variabili, 1) sia nella sua tendenza generale,
indicata da una retta (al crescere di una variabile aumenta linearmente anche l’altra) e 2)
sia nella individuazione dei dati che se ne distaccano (come l’individuo 6 di altezza 175
cm. e 59 Kg. di peso).
La retta che viene in essa rappresentata ha lo scopo dia) descrivere la relazione complessiva tra X e Y, b) controllare i valori
anomali, che diventano più facilmente individuabili, c) predire la variabile Y, corrispondente a un valore Xi specifico.

6.2 Modelli di regressione
Il diagramma di dispersione fornisce una descrizione visiva, completa e dettagliata della relazione esistente tra due variabili. Tuttavia, la sua interpretazione resterebbe soggettiva.
La funzione matematica che può esprimere in modo oggettivo la relazione di causa-
effetto tra due variabili è chiamata equazione di regressione o funzione di
regressione della variabile Y sulla variabile X.
La forma più generale di una equazione di regressione è
dove il secondo membro è un polinomio intero di X.
Paradosso
L'approssimazione della curva teorica ai dati sperimentali è tanto migliore quanto più elevato è il
numero di termini del polinomio;
L'interpretazione dell’equazione di regressione è tanto più attendibile e generale quanto più la
curva è semplice, come quelle di primo o di secondo grado.

Regressioni di ordine superiore al primo e secondo grado sono quasi sempre legate alle variazioni casuali; sono effetti delle situazioni specifiche del campione raccolto e molto raramente esprimono
relazioni reali e permanenti.
Di conseguenza, tutti coloro che ricorrono alla statistica applicata nell’ambito della
loro disciplina utilizzano quasi esclusivamente regressioni lineari (di primo ordine) o le
regressioni curvilinee (di secondo ordine).
La regressione lineare può essere positiva o negativa:- nel primo caso, all’aumento dei valori di una variabile corrisponde un aumento anche
nell’altra;- nel secondo, all’aumento dell’una corrisponde una diminuzione dell’altra.
E’ la relazione più semplice e frequente tra due variabili quantitative.

Le regressioni curvilinee possono essere quadratiche o seguire vari altri modelli, come l’iperbole, l’esponenziale e la logaritmica.
Le relazioni cubiche (di terzo ordine) e quelle di ordine superiore rappresentano rapporti tra
due variabili che sono eccessivamente complessi per un fenomeno naturale o comunque
biologico.

6.3 La regressione lineare semplice
La relazione matematica più semplice tra due variabili è La regressione lineare semplice che è data dalla seguente equazione:
Yi = a + bXi
Yi è il valore stimato o predetto per il valore X dell'osservazione i,
Xi è il valore empirico di X della stessa osservazione i
a è l'intercetta della retta di regressione,
b è il coefficiente angolare della retta di regressione (quantità unitaria di cui varia Y al variare di una unità di X)
L’intercetta è il valore di Y, quando X è uguale a 0.
Due rette che differiscano solo per il valore di a , quindi con b uguale, sono tra
loro parallele.

Ogni punto sperimentale ha una componente di errore ei, che rappresenta lo scarto verticale
del valore osservato dalla retta (quindi tra la Y osservata e quella proiettata
perpendicolarmente sulla retta).
Poiché la retta di regressione serve per predire Y sulla base di X, l’errore commesso è
quanto la Y predetta (Y’i) si avvicina alla Y osservata (Yi).
Scarto verticale

Metodo dei minimi quadrati. La retta scelta è quella che riduce alminimo la somma dei quadrati degli scarti di ogni punto dalla sua
proiezione verticale
Come è costruita la retta che descrive la distribuzione dei punti?
ESEMPIO 13.Per sette giovani donne, indicate con un numero progressivo, è stato misurato il peso
in Kg e l'altezza in cm.
Calcolare la retta di regressione che evidenzi la relazione tra peso ed altezza.

1. Dalle 7 coppie di dati si devono calcolare le quantità
Risoluzione
2. stima del coefficiente angolare b
3. stima dell’intercetta a
4. Si ricava la retta di regressione

Per tracciare la retta è sufficiente calcolare un solo altro punto oltre quello dell’intercetta
Nel sua interpretazione biologica, il valore calcolato di b indica che in media gli individui che formano il campione aumentano di 0,796 Kg. al crescere di 1 cm in
altezza.
Il valore di a molto spesso non è importante. Serve solamente per calcolare i valori sulla retta; ha uno scopo strumentale e nessun significato biologico.

6.4 Significatività dei parametri b ed a della retta di regressione
Il semplice calcolo della retta non è sufficiente in quanto essa potrebbe indicare
-una relazione reale tra le due variabili, se la dispersione dei punti intorno alla retta è ridotta;
- una relazione casuale o non significativa, quando la dispersione dei punti intorno alla retta è approssimativamente uguale a quella intorno alla media.
Retta che esprime la relazione tra le due variabili: i punti hanno
distanze dalla retta di regressione sensibilmente minori
di quelle dalla media (Y ). Conoscendo X, il valore stimato
di Y può avvicinarsi molto a quello reale, rappresentato dal
punto.

Situazione di maggiore incertezza sulla significatività della retta
calcolata; la semplice rappresentazione grafica risulta insufficiente per decidere se all’aumento di X i valori di Y
tendano realmente a crescere.
Situazione in cui la retta calcolata non è un
miglioramento
effettivo della distribuzione dei punti rispetto alla
media. In questo caso, la retta calcolata può
essere interpretata come una variazione casuale
della media: con questi dati, la retta ha una
pendenza positiva; ma con un altro campione
estratto dalla stessa popolazione o con l’aggiunta
di un solo dato
della stessa popolazione si potrebbe stimare un
coefficiente angolare (b) negativo.

La verifica della significatività della retta calcolata è eseguita con il Test F.
Per rispondere alle domande poste, occorre valutare la significatività della retta, cioè se il coefficiente angolare b si discosta da zero in modo
significativo.
ESEMPIO 14.Con le misure di peso ed altezza rilevati su 7 giovani donne
Nell’esempio precedente abbiamo calcolato l’equazione della retta

Risultati del test F
Con probabilità P<0.01 si può sostenere che nella popolazione dalla quale è stato
estratto il campione di 7 giovani donne, esiste un relazione lineare tra le variazioni in
altezza e quelle in peso.

6.5 Intervalli di confidenza dei parametri b ed a
L’uso della retta di regressione a fini predittivi richiede che possa essere stimato l’errore di previsione A) del coefficiente angolare b e B) dell’intercetta a.
Tramite i limiti di confidenza del parametro b è possibile effettuare confronti di diverse rette di regressione.
Ad esempio, un qualsiasi valore campionario b0, se non è compreso entro i limiti di confidenza di un altro coefficiente angolare b1, è significativamente differente da
esso.
L’intervallo di confidenza o di fiducia è quell’intervallo di valori plausibili di un parametro stimato.

6.6 Intervalli di confidenza della retta
Nella ricerca si rilevano utili tre diversi casi di stima dell’intervallo di confidenza:
1. del coefficiente angolare, come nel paragrafo precedente;
2. del valore medio di Y stimato ( k Yˆ ), corrispondente ad un dato valore k di X; è
chiamato anche intervallo di confidenza della retta, essendo infatti la stima di ogni
punto sulla retta
Esempio 15. Calcolare il valore medio Y’k previsto per Xk = 180, con i dati sull’altezza delle 7 ragazze.

Intervalli di confidenza per valori medi di Y’i al 5% (linee a punti) e all'1% (linee tratteggiate)

6.7 Il coefficiente di determinazione R2
Il coefficiente di determinazione (coefficient of determination) R2 (R square indicato in alcuni testi e in molti programmi informatici anche con R2 oppure r2) è la proporzione di variazione totale che è spiegata dalla variabile dipendente.
r2: coefficiente di determinazione semplice
R2: coefficiente di determinazione multiplo.
In altre parole, il coefficiente di determinazione è il rapporto della devianza dovuta alla regressione sulla devianza totale

Espresso a volte in percentuale, più spesso con un indice che varia da 0 a 1
PraticamenteR2 serve per misurare quanto della variabile dipendente Y sia predetto dalla variabile indipendente X e quindi per valutare l’utilità dell’equazione di regressione ai fini della
previsione dei valori della Y.
Il valore del coefficiente di determinazione è tanto più elevato quanto più la retta passa vicino ai punti, fino a raggiungere 1 quando tutti i punti sperimentali sono
collocati esattamente sulla retta.
Esempio 16Consideriamo le 7 osservazioni su peso ed altezza
Il coefficiente di determinazione è pari a
Questo risultato indica che, noto il valore dell'altezza, il valore del peso è stimato mediante la retta di regressione con una approssimazione di circa l'80 per cento (79,7%).
Il restante 0,2 (oppure 20% ) è determinato dalla variabilità dei valori sperimentali rispetto alla retta.

In questi casi, R2 è una misura che ha scopi descrittivi del campione raccolto; non è legata ad inferenze statistiche, ma a scopi pratici, specifici dell'uso della regressione
come metodo per prevedere Yi conoscendo Xi.
Il valore di R2, in varie situazioni, viene utilizzato per indicare l’errore che si commette nello
stimare Yi sulla base di generici valori Xi; quindi, viene attribuito anche un significato
inferenziale.
A questo scopo, è stato proposto un R2 corretto, chiamato R2 aggiustato (R2 adjusted)
R2 aggiustato è sempre minore di R2 sperimentale, come appunto necessario in caso di inferenza.

7. La regressione non lineare
La regressione non lineare è un metodo di stima di una curva interpolante un modello della forma
su un insieme di osservazioni (eventualmente multi-dimensionali), concernenti le variabili X ed Y
Approssimazione di un set di osservazioni tramite polinomi di diversi gradi

La determinazione dei valori dei parametri che garantiscono la migliore interpolazione dei
dati viene effettuata mediante classi di algoritmi numerici di ottimizzazione, che a partire
da valori iniziali, scelti a caso o tramite un'analisi preliminare, giungono a punti ritenuti
ottimali.
Diversi software matematici contengono librerie di ottimizzazione: Gauss, GNU Octave, Matlab, Mathematica
Esempi illustrativi con il softwareTable Curve v. 4.0

Esempio 17Valutazione delle risposte dell’accrescimento radicale all’esposizione di diverse dosi di
differenti allelopatici (Nicolò et al., 2005)
Arabidopsis allevata per 12 giorni in presenza di differenti dosi (0, 10, 50, 75, 100, 125, 250, 500 e
1000 μM) di cumarina ed umbelliferone
Valutazione dose-risposta
Concentrazione (μM)
0 200 400 600 800 1000 1200
Lung
hezz
a R
adic
i(c
m)
0
5
10
15
20
25
30
35CUMARINA
Concentrazione (μM)
0 200 400 600 800 1000 1200
Lung
hezz
a R
adic
i(c
m)
0
5
10
15
20
25
30
35
UMBELLIFERONE
L’equazione lineare non garantisce la migliore interpolazione dei dati sperimentali:l’andamento dei dati sperimentali mostra una relazione non-lineare!

La relazione matematica che “ottimamente” descrive l’andamento di un esperimento dose-risposta è una funzione log-logistica a quattro parametri.
)]/ln([ 501 EDxBeCDCy •+
−+=
C: risposta(y) alle maggiori dosi
D: risposta media del controllo
B: velocità di variazione attorno a ED50
ED50: dose che causa il 50% della risposta totale
C: asintoto inferioreD: asintoto superiore
B: pendenzaED50: punto di inflessione
Concentrazione (μM)
0 200 400 600 800 1000 1200
Lung
hezz
a R
adic
i(c
m)
0
5
10
15
20
25
30
ED50B
D
C
C: 1,61 cmD: 22 cm
B: 2,52 cm μM-1
ED50: 63 μMR2: 0,835P:0,020

….ma l’andamento della lunghezza radicale in funzione della cumarina è ottimamente descritto dall’equazione log-logistica?
Concentrazione (μM)
0 200 400 600 800 1000 1200
Lung
hezz
a R
adic
i (c
m)
0
5
10
15
20
25
30
35
A basse dosi esiste uno stimolo, definito effetto ormetico, che non è computato dall’equazione log-logistica.

Un’adeguata descrizione dell’andamento della risposta della lunghezza radicale alle dosi di cumarina è ottenuta incorporando un parametro f>0 nel modello log-logistico
f: velocità di incremento della risposta a basse dosi
)]/ln([50 50)21(1 EDxBeCD
EDfxfCDCy
⋅⋅−⋅⋅
++
⋅+−+=
Concentrazione (μM)
0 200 400 600 800 1000 1200
Lung
hezz
a R
adic
i(c
m)
0
10
20
30
40
C: 0 cmD: 18 cm
B: 2,06 cm μM-1
ED50: 465 μMf: 0,24 cm μM-1
R2: 0,884P:0,037

Esempio 18Descrizione del sistema ad alta affinità dell’assorbimento del nitrato in radici di grano
(Abenavoli et al., 2001)
Tempo (ora)0 5 10 15 20 25 30V
eloc
ità d
i ass
orbi
men
to
del N
itrat
o
( μm
oli c
m-2
ora-1
)
0,00
0,02
0,04
0,06
0,08
La velocità di assorbimento del nitrato, dapprima, aumenta all’incrementare dell’esposizione della radice al nitrato stesso e poi diminuisce secondo un’inibizione a feedback

Tempo (ora)0 5 10 15 20 25 30V
eloc
ità d
i ass
orbi
men
to
del N
itrat
o( μ
mol
i cm
-2or
a-1 )
0,00
0,02
0,04
0,06
Qual è l’equazione che meglio descrive tale andamento?
)()()( ][)( tkconst
tktk
inddec
ind decdecind eIeekk
kAy ⋅−⋅−⋅− ⋅+−⋅−⋅
=
AA = velocità alla massima induzione raggiunta dal sistema
di trasporto inducibile
IconstIconst = velocità del sistema di trasporto costitutivo
KKindind = costante della velocità di induzione
dell’assorbimento netto del nitrato
KKdecdec = costante della velocità di decadimento dell’assorbimento netto
del nitrato

Tempo (ora)Vel
ocit
à d
i ass
orb
imen
to
net
to d
el n
itra
to
)()()( ][)()( tkeBtketkekk
kAtI decdecind
inddec
ind ⋅−⋅−⋅− ⋅+−⋅−⋅
=

8. La correlazione La regressione lineare è finalizzata all'analisi della relazione causa (X) –effetto (Y) che in alcuni casi non ha senso analizzarla
1. la relazione causa-effetto non ha direzione logica o precisa:potrebbe essere
ugualmente applicata nei due sensi, da una variabile all'altra
Ad esempio, coppie di gemelli hanno strutture fisiche simili e quella di uno può essere
stimata sulla base dell'altro
2. La causa può essere individuata in un terzo fattore, che agisce simultaneamente sui primi
due, in modo diretto oppure indiretto, determinando i valori di entrambi e le loro variazioni.
Ad esempio, la quantità di polveri sospese nell’aria e la concentrazione di benzene, entrambi
dipendenti dall’intensità del traffico.
3. l’interesse può essere limitato a misurare come due serie di dati variano congiuntamente,
per poi andare alla ricerca delle eventuali cause, se la risposta fosse statisticamente
significativa.
In tutti questi casi, è corretto utilizzare la correlazione.

Esempio delle differenze tra regressione lineare e correlazione
In un’ampia area rurale, per ogni comune durante il periodo invernale è stato contato il
numero di cicogne e quello dei bambini nati. E’ dimostrato che all’aumentare del primo cresce anche
il secondo.
Ricorrere all'analisi della regressione su queste due variabili, indicando per ogni comune con X il
numero di cicogne e con Y il numero di nati, implica una relazione di causa-effetto tra presenza di
cicogne (X) e nascite di bambini (Y). Anche involontariamente si afferma che i bambini sono portati
dalle cicogne; addirittura, stimando b, si arriva ad indicare quanti bambini sono portati mediamente
da ogni cicogna.
In realtà durante i mesi invernali, nelle case in cui è presente un neonato, la temperatura viene
mantenuta più alta della norma, passando indicativamente dai 16 ai 20 gradi centigradi. Soprattutto
nei periodi più rigidi, le cicogne sono attratte dal maggior calore emesso dai camini e nidificano più
facilmente su di essi o vi si soffermano più a lungo. Con la correlazione si afferma solamente che le
due variabili cambiano in modo congiunto.
L'analisi della correlazione misura solo il grado di associazione spaziale o temporale dei due fenomeni; ma lascia liberi nella scelta della motivazione
logica, nel rapporto logico tra i due fenomeni.

La correlazione viene quantificata con il coefficiente di correlazione prodotto-momento di Pearson, r (Pearson product-moment correlation coefficient) che è una
misura dell’intensità dell’associazione tra le due variabili.
Le due variabili vengono indicate con X1 e X2, non più con X (causa) e Y
(effetto), per rendere evidente l'assenza del concetto di dipendenza funzionale.
L'indice statistico (+r oppure –r) misura il tipo (con il segno + o -) ed il grado (con il valore
assoluto) di interdipendenza tra due variabili.
Il segno indica il tipo di associazione:
- positivo quando le due variabili aumentano o diminuiscono insieme,
- negativo quando all'aumento dell'una corrisponde una diminuzione dell'altra o viceversa.
Il valore assoluto varia da 0 a 1:
- è massimo (1) quando c'è una perfetta corrispondenza lineare tra X1 e X2;
- tende a ridursi al diminuire della corrispondenza ed è zero quando essa è nulla.

Esempio 19In 18 laghi dell'Appennino Tosco-Emiliano sono state misurate la conducibilità e la
concentrazione di anioni + cationi, ottenendo le coppie di valori riportati nella tabella
Calcolare il coefficiente di correlazione tra queste due variabili in modo diretto e mediante i due coefficienti angolari

In modo diretto con la formula che utilizza le singole coppie di valori
Utilizzando i coefficienti angolari delle due regressioni, che dai calcoli risultano

il coefficiente di correlazione è calcolato con questa formula

E' importante ricordare che un valore assoluto basso o nullo di correlazione non deve
essere interpretato come assenza di una qualsiasi forma di relazione tra le due variabili,
ma possiamo dire che:
- è assente solo una relazione di tipo lineare,
- ma tra esse possono esistere relazioni di tipo non lineare, espresse da curve di
ordine superiore, tra le quali la più semplice e frequente è quella di secondo grado.
L'informazione contenuta in r riguarda solamente la quota espressa da una relazione
lineare.

9. Il disegno sperimentale: campionamento, programmazione dell’esperimento e potenza
Il motivo principale del ricorso all’analisi statistica per “fare inferenze” negli esperimenti
deriva dalla variabilità che è misurata mediante misure ripetute.
L'esistenza della variabilità impone l'estensione dell'analisi al numero maggiore possibile di
oggetti, poiché l'errore nella stima dei parametri è inversamente proporzionale al numero di
repliche raccolte.
Come e quanti dati raccogliere è un problema statistico fondamentale, che è risolto
con il disegno sperimentale, il campionamento e la potenza del test

1 - il campionamento, cioè come scegliere le unità dalla popolazione per formare il
campione;
2 - il disegno sperimentale, che consiste nello scegliere
- (a) i fattori sperimentali che si ritengono più importanti, i cosiddetti trattamenti,
la cui analisi rappresenta l’oggetto principale della ricerca,
- (b) i fattori sub-sperimentali che in genere rappresentano le condizioni in cui
avviene
l’esperimento e che possono interagire con quelli sperimentali,
- (c) i fattori casuali, che formeranno la varianza d’errore;
3 - la stima della potenza del test, per valutare
- (a) quanti dati è utile raccogliere,
- (b) quale è la probabilità che, con l’esperimento effettuato, il test prescelto
possa alla fine risultare statisticamente significativo.

9.1 Il campionamento
Obiettivo: come costruire un campione, in modo che esso fornisca informazioni corrette su tutta la popolazione?
Nella scelta di un campione esistono metodi probabilistici e non probabilistici.
1. Nel campionamento probabilistico, ogni unità dell’universo ha una probabilità prefissata e non nulla di essere inclusa nel campione, anche se non uguale per tutte.
Ricerca ambientale e biologica
1A) Il metodo fondamentale è il campionamento casuale semplice senza ripetizione (simplerandon sampling o random sampling without replacement), in cui ogni individuo della
popolazione ha le stesse probabilità di essere inserito nel campione. Come nel gioco del
lotto, le unità sono estratte una alla volta, mentre quelle rimanenti hanno la stessa probabilità
di essere estratte successivamente. Si utilizzano numeri casuali, che fino ad alcuni anni fa
erano presi da tabelle e ora spesso sono prodotti mediante computer, con un metodo
chiamato Monte Carlo, fondato su estrazioni caratterizzate dall’assenza di una legge di
ordinamento o di successione.

1B) Il campionamento sistematico o scelta sistematica è un altro metodo semplice: da
un elenco numerato degli individui che formano la popolazione, dopo l’estrazione
casuale della prima unità effettuata con un numero random, si selezionano gli individui
successivi a distanza costante.
Per esempio, se da una popolazione di 1000 individui se ne vogliono estrarre 50,
dall’elenco si deve estrarre una unità ogni 20, a distanza costante. Se il primo numero
estratto è stato 6, le unità campionate successive saranno 26, 46, 66, … .
1C) Nel campionamento casuale semplice con ripetizione, le n unità del campione
vengono estratte con ripetizione e con probabilità costante, uguale a 1/N.
1D) Il campionamento casuale stratificato rappresenta un raffinamento di quello
casuale; richiede la conoscenza delle caratteristiche della popolazione, per aumentare
l’efficienza del metodo di estrazione per formare il campione. La differenza
fondamentale da quello totalmente casuale è che la popolazione prima è divisa in
gruppi tra loro omogenei (detti appunto strati) e l’estrazione casuale è esercitata
all’interno di essi, in modo indipendente per ognuno, come se si trattasse di tanti
campioni casuali semplici.

1E) Il campionamento casuale a grappoli è utilizzato quando gli individui sono suddivisi, in
modo naturale oppure artificiale, in gruppi legati da vincoli di contiguità. Caratteristica
distintiva del metodo è che le unità non sono scelte in modo diretto, ma estratte in quanto
appartenenti a un certo gruppo.
Ad esempio, per rispondere alle domande di un questionario sul traffico, si immagini di
interrogare tutti gli abitanti di alcune vie, scelte in modo casuale o ragionato. Le domande
sono rivolte agli individui, ma la scelta è avvenuta sulla base della strada in cui la persona
risiede.
1F) Il campionamento a due stadi, detto anche campionamento a grappoli con sotto-
campionamento, è analogo a quello a grappoli in quanto le aree da campionare sono scelte
come i grappoli. Questo metodo si differenzia dal precedente, in quanto solo una parte delle
unità elementari contenute nei grappoli fanno parte del campione. Al primo stadio, o livello, si
estraggono i grappoli, chiamati unità primarie; al secondo, si estraggono le unità secondarie
o elementari.
1G) Il campionamento con probabilità variabili si differenzia dai precedenti, in quanto le unità sono scelte con probabilità differenti.

2. Nel campionamento non probabilistico, detto campionamento a scelta ragionata, si
prescinde dai criteri di scelta totalmente casuale delle unità campionarie.
Per indagini sulla popolazione, sono campionamenti non probabilistici anche quelli definiti di convenienza, come i campioni volontari, utilizzati soprattutto nelle indagini
sociologiche o a carattere medico ed epidemiologico,

Nei vari tipi di campionamento, seppure a
livelli differenti, compare quasi sempre il
campionamento casuale o random. Il
metodo appare semplice e intuitivo, con
l’uso di tavole dei numeri casuali.
Le tavole di numeri casuali sono costituite da una serie di numeri tra 0 e 9, disposti a caso e caratterizzati
dall’avere una distribuzione rettangolare, cioè uniforme.
I numeri possono essere scelti con un criterio qualsiasi. Ad esempio,
procedendo- dal basso verso l’alto oppure
viceversa,- da sinistra verso destra oppure
nell’altra direzione,- in modo continuo oppure a intervalli
regolari,

Esempio 18
Se da una disponibilità di 80 cavie precedentemente numerate devono esserne scelte 15
per un esperimento, è possibile partire dalla quinta riga e procedere in orizzontale
muovendosi poi verso il basso, leggendo le prime due cifre di ogni serie. Sono scelti i
primi 15 numeri di due cifre, escludendo quelli maggiori di 80 e quelli già sorteggiati.

9.2 Il disegno sperimentale I test di significatività sono sempre fondati sul rapporto tra la varianza dovuta ai fattori sperimentali e la varianza d’errore o
non controllata, cioè quella dovuta a fattori non presi in considerazione.
Per rendere minima la varianza d’errore, è necessario identificare le cause sperimentali che determinano nei dati le variazioni maggiori. A tale scopo è necessario:
1. raffinare la tecnica di misurazione,2. selezionare del materiale qualitativamente adeguato,
3. utilizzare dei campioni sufficientemente numerosi.
4. necessario eliminare l’influenza dei fattori estranei, quelli che aumenterebbero la varianza d’errore se non presi in considerazione.
opportuno disegno sperimentale.I fattori possono essere distinti in
- fattori sperimentali, che rappresentano l’oggetto specifico della ricerca e sono
chiamati trattamenti;
- fattori sub-sperimentali, che generalmente riguardano le condizioni in cui si svolge la
prova; sono chiamati blocchi;
- fattori casuali, che formano la componente accidentale.
Il campionamento ha lo scopo preciso di evitare che questi fattori non controllati esercitino un ruolo non simmetrico sui gruppi a confronto, per i fattori sperimentali.

Con il campionamento casuale o a stratificato, si vuole ottenere che, almeno
approssimativamente, gli individui di queste varie condizioni siano distribuiti in modo quasi
bilanciato in tutti i gruppi. Se invece avviene che un gruppo di pazienti al quale è stato
somministrato un farmaco specifico, a differenza degli altri gruppi sia composto in netta
prevalenza da individui dello stesso sesso, si ha un effetto non simmetrico e ignoto sul
farmaco, che altererà il risultato in modo sconosciuto.
Il risultato dell’esperimento sarà errato in modo irrimediabile. Per uno studio sarà necessario
ripeterlo, evitando l’errore commesso.
Esempio 19Si supponga di voler valutare il differente effetto di alcuni farmaci sulla riduzione del
colesterolo.Il disegno sperimentale molto semplice sarà:
1. i farmaci rappresentano il fattore sperimentale;2. la distinzione dei pazienti per classi d’età può rappresentare il fattore sub-sperimentale,
per eliminare appunto l’effetto ritenuto più importante, quello dell’età sul livello di colesterolo dei pazienti;
3. se sono presenti pazienti di sesso maschile e femminile, individui magri e grassi, cioè condizioni che sono ritenute ininfluenti (eventualmente sbagliando) sul livello di colesterolo ma
che vengono ignorati nell’analisi della varianza, sono i fattori casuali.

Nell’analisi della varianza, i diversi disegni sperimentali possono essere classificati sulla base
del numero di fattori sub-sperimentali che sono tenuti in considerazione.
Quelli più frequentemente utilizzati sono
- il disegno completamente casualizzato, quando non è tenuto in considerazione nessun
fattore subsperimentale, ma si ha solo il fattore sperimentale e i fattori casuali;
- il disegno a blocchi randomizzati, quando si ha un solo fattore subsperimentale;
- il disegno multifattoriale, tra cui anche il quadrato latino e i quadrati greco-latini, con due o
più fattori sub-sperimentali.
Tra questi ultimi rientrano anche i disegni fattoriali, nei quali l’attenzione del ricercatore è
posta soprattutto sull’analisi delle interazioni tra i due o più fattori presi in considerazione,
senza distinzioni tra fattori sperimentali e sub-sperimentali.

9.3 Le dimensioni del campione e la potenza del test
Prima informazione: dichiarare lo scopo per cui il campione di dati è raccolto.
Schematicamente, nei casi più semplici, un campione di dati serve per
1. calcolare una media,
2. confrontare due medie,
3. stimare la varianza, sempre nel caso di misure con scale a intervalli o di rapporti;
4. calcolare una proporzione o percentuale, nel caso di risposte qualitative o categoriali.
“quanti dati servono?”
Seconda informazione: il livello di precisione, con cui si vuole conoscere il parametro
indicato oppure la probabilità α di commettere un errore.
La precisione del parametro può essere espressa
1. con una misura relativa, come la percentuale dell’errore accettato rispetto alla media,
2. in valore assoluto, come la distanza massima tra la media del campione e quella reale o
della popolazione,
3. mediante l’intervallo di confidenza, che permette di derivare con facilità il valore assoluto
dello scarto massimo accettato (lo scarto tra un limite e la media).
Terza informazione: parametri che sono presi in considerati nella formula proposta e la varianza.

A) una prima stima approssimata della dimensione minima ( n ) del campione è ricavabile con la seguente formula
d = errore massimo assoluto dichiarato
s = deviazione standard, misurata su un campione precedente o con uno studio pilota
t = il valore per gdl n-1 e probabilità α (in pratica con α = 0.05 bilaterale, come
richiesto di norma nell’approssimazione di una media campionaria a quella reale, t = 2,
se il campione è di dimensioni superiori alle 20 unità).

Esempio 20.Alcune misure campionarie della concentrazione di principio attivo hanno dato una
media X = 25 e una deviazione standard s = 11 Quanti dati raccogliere, per una media campionaria che non si allontani dal valore reale di una differenza massima d = 3?
Se il fenomeno è nuovo, non è possibile avere una stima della varianza (s2) o della deviazione standard (s), mentre è facile conoscere l’intervallo di variazione, cioè la differenza tra il valore
massimo e il valore minimo. Una legge empirica molto generale permette di calcolare la varianza per mezzo di un fattore
di conversione del campo di variazione in deviazione standard, ritenuto generalmente uguale a 0,25 (1/4).
Esempio 21Solo gli esperti del settore possono conoscere la varianza o la deviazione standard
dell’altezza in ragazzi di 20 anni; ma tutti possono stimare come accettabile, nel loro gruppo di amici, un campo di variazione di 30 cm, tra il più basso (circa 160) e il più alto (circa 190
cm).

…però, il campo di variazione aumenta al crescere della numerosità del campione.
Pertanto, sono stati proposti fattori di conversione (FC) del campo di variazione in
deviazione standard, che considerano la numerosità (N) del campione:
In assenza di esperienze e di dati citati in letteratura, in varie situazioni le informazioni sulla varianza e sul valore della media devono essere ricavate da uno studio
preliminare, chiamato studio pilota.





























