Embed Size (px)
DESCRIPTION
seminarski rad
Citation preview

VISOKA POSLOVNA ŠKOLA STRUKOVNIH STUDIJA BLACE
Tema: Primena genetskih algoritama
Profesor: Branislav Jevtović Student: Mladen Janković 24/10r

GENETSKI ALGORITMI
UVOD:
Genetski algoritmi su osmišljeni tako da oponašaju procese u prirodi vezane za evoluciju, genetiku i prirodnu selekciju. Da li će neka jedinka preživeti i ostaviti potomstvo u velikoj meri zavisi od toga koliko dobro može da iskoristi svoje osobine u datom okruzenju. Osobine svake jedinke su određene su hromozomima.
Prirodna selekcija omogućuju da se uspešni hromozomi reprodukuju mnogo više nego oni koji to nisu. Pod uspešnošću se mogu podrazumevati različite osobine zavisno od konteksta i okruženja. Prilikom procesa reprodukcije postoje dva dodatna mehanizma koja sam proces prirodne selekcije čini vrlo složenim i nepredvidivim. Jedan je mutacija na osnovu koje potomak može biti mnogo drugačiji od svojih bioloških roditelja, a drugi je proces rekombinacije po kome se različitost potomka u odnosnu na roditelje obezbeđuje kombinovanjem genetskog sadržaja oba roditelja.
Slično kao u prirodi, genetski algoritmi pokušavaju da nađu najbolji hromozom manipulišući sa hromozomskim materijalom, i ne udubljujući se preterano u optimizacioni problem koji se rešava. Kod genetskih algoritama pod hromozomom se smatra binarni zapis neke od analiziranih veličina. Jedino o čemu genetski algoritmi vode računa jeste nivo kvaliteta koji pokazuju proizvedeni hromozomi. Ovakvi postupci, manipulisanja nad binarnim zapisima (hromozomima), mogu da reše izuzetno složene probleme a da pri tome nemaju uvid u kompleksnost i prirodu problema koji se rešava.
Osnovni element kojim se GA bavi jeste string, pri čemu svaki string predstavlja binarni kod parametra u prostoru koji se pretražuje. Dakle, svaki string predstavlja tačku u prostorupretrage. Tokom primena različitih operatora genetskog algoritma, ukupni broj hromozoma ne menja, ali se menja njihov sastav.
OSNOVNI OPERATORI GA:
Osnovni operatori genetskog algoritma su:
• reprodukcija (reproduction), • ukrštanje (crossover) • mutacija (mutation).
Reprodukcija je proces u kome se pojedini hromozomi (binarni stringovi) kopiraju u sledećoj generaciji u skladu sa njihovim kriterijumskim funkcijama. Kriterijumska funkcija se pridružuje svakoj jedinki u populaciji, pri čemu visoka vrednost ove funkcije označava visok kvalitet. Ova funkcija može biti bilo koja linearna, nelinearna, diferencijabilna ili nediferencijabilna funkcija sa ili bez prekida, pozitivna funkcija (jer algoritam gleda samo njenu vrednost i ni jednu drugu osobinu). Tehnika reprodukcije se realizuje kroz takozvani postupak ruleta (točka sreće). Okretanjem ruleta određuje se roditelj koji će sereprodukovati. Ova tehnika se može formalizovati na sledeći način:

1. Saberu se kriterijumske funkcije svih članova populacije. Ovaj zbir se naziva totalna performansa.
2. Generiše se slučajno broj n iz intervala od nule do totalne performanse.
3. Izabere se prvi član populacije čija je kriterijumska vrednost sabrana sa kriterijumskim vrednostima svih prethodnih članova veća ili jednaka broju n.
Primer: Posmatrajmo niz od šest hromozoma (stringova) čije su fitnes funkcije date u sledećoj tabeli:
Redni broj Hromozom Vrednost fitnes f-je Kumulativnavrednost
1 01110 8 82 11000 15 233 00100 2 254 10010 5 305 01100 12 426 00011 8 50
Pošto je totalna performansa ovog skupa hromozoma jednaka 50, u cilju izbora roditelja koji će
se reprodukovati treba na slučajan način, generisati brojeve iz intervala [0,50]. U sledećoj tabeli je prikazano kako slučajni izbor 7 ovakvih brojeva vrši izbor roditelja iz populacije.
Slučajni broj 26 2 49 15 40 36 9Izabrani hromozom 4 1 6 2 5 5 2
Ovo je potpuno ekvivalentno sa okretanjem točka sreće. Vrednost fitness funkcije direktno utiče na izbor hromozoma u procesu ruleta, kao što je već i napomenuto:

Ukrštanje: Za razliku od reprodukcije koja zaista vodi računa o najboljim jedinkama populacije ali koja ne generiše novi kvalitet u smislu novih hromozoma, ukrštanje se trudi da iz najboljeg stvori još bolje. U prirodi potomstvo ima dva roditelja i nasleđuje gene od oba. Glavni operator koji radi nad genima roditelja jeste ukrštanje i ono se nad izabranim roditeljima vrši se verovatnoćom ukrštanja . Prvo se iz skupa jedinki koje su određene za reprodukciju, na slučajan način biraju dva, a zatim se opet na slučajan način bira mesto prelaska (crossover point) ukoliko se jedinke sa verovatnoćom ukrštanja odrede za ukrštanje. Delovi gena se međusobno razmenjuju na mestu prelaska. Ovim se dobijaju dva hromozoma koji imaju kao roditelje početne hromozome. Reprodukcija i ukrštanje su osnovni mehanizmi kojima genetski algoritami usmeravaju pretragu ka boljim delovima prostora pretrage, a na osnovu postojećeg znanja.
Mutacija: Iako reprodukcija i ukrštanje generalno vode ga boljim rezultatima, oni ne donose nikakav nov kvalitet ili informacije na nivou bita. Kao izvor drugačijih vrednosti bita, koristi se mutacija bita sa malom verovatnoćom , čime se slučajno izabrani bit u hromozomu invertuje. Kao i u prirodi, mutacija može dovesti do degenerativnih jedinki (koje će proces reprodukcije/selekcije verovatno brzo eliminisati) ili do potpuno novog kvaliteta. Stepen mutacije treba pažljivo birati jer je to operator slučajne pretrage.
1100110111 1100100111
PARAMETRI GA:
Parametri koji definisu jedan genetski algoritam su navedeni ispod:
• N – veličina populacije • – verovatnoća ukrštanja (crossover rate) • – verovatnoća mutacije • – generacijski jaz (određuje koliki procenat populacije će činiti nove jedinke u sl. generaciji) • Evaluaciona funkcija (ima istu ulogu kao i okruženje jedinke u prirodnoj evoluciji)

U slučaju jednostavnog genetskog algoritma, potrebno je osim evaluacione (fitnes) funkcije i načina kodovanja, specificirati i N – veličinu populacije, pc – verovatnoću ukrštanja, pm – verovatnoću mutacije iG – generacijski jaz (gap). Operatori reprodukcije, ukrštanja i mutacije se primenjuju na populaciji dok se ne dobije cela populacija potomstva. Ovo potomstvo može biti mutirano nakon ukrštanja, zatim dobijeno ukrštanjem ali bez dodatnih mutacija ili samo odabrano za učestvovanje u narednoj generaciji ali bez ukrštanja ili mutacije. Generacijski razmak predstavlja deo populacije koji će biti zamenjenpotomcima i dat je u kao . U procesu stvaranja potomstva se jedinki zamenjujepotomcima, dok se ostale prepisuju iz prethodne generacije.
Prilikom projektovanja genetskih algoritama potrebno je odlučiti o velikom broju tehničkih pitanja.Neka od njih su: Kako formirati inicijalnu populaciju, kako izabrati terminacioni uslov, šta izabrati za evaluacionu (fitnes) funkciju, kako vršiti reprodukciju (selekciju) jedinki, na koji način vršiti ukrštanje i mutaciju i dosta drugih pitanja. Uspešnost GA kritično zavisi od odgovora na ova pitanja.
FAZE PROJEKTOVANJA GENETSKIH ALGORITAMA:
Vrlo opšta struktura genetskog algoritma koja podrazumeva isključivo poznavanje evaluacione funkcije koja svakom hromozomu pridružuje brojnu vrednost je data sledećim koracima:
1. Inicijalizuje se određena populacija hromozoma
2. Evaluira se svaki hromozom u populaciji
3. Formiraju se novi hromozomi pri čemu se za roditelje uzimaju već postojeći hromozomi, a primenom mehanizama mutacije i rekombinacije.
4. Obrišu se neki od postojećih hromozoma kako bi ostavili prostora za potomke.
5. Evaluairaju se potomci i pridruže postojećoj populaciji.
6. Ukoliko je kriterijum za zaustavljanje zadovoljen, algoritam se završava. U protivnom, vraćamo se na korak broj 3.
Jedine veze između ovako opšte strukture genetskog algoritma i konkretnog problema koji se rešava jesu u postupku kodiranja hromozoma (formiranja binarnog stringa) i evaluacione funkcije. Postupak kodiranja može biti različit i pokazano je da je binarno kodiranje optimalno. Suština ovog dokaza leži u činjenici da je bolje imati mnogo bita sa manjim brojem mogućih vrednosti za svaki bit, nego imati mali broj bita sa većim brojem bitskih vrednosti. Evaluaciona funkcija, sa druge strane, uzima bitski zapis (hromozom) kao ulaznu promenljivu, a na svom izlazu generiše kriterijum performanse koji se pridružuje tom hromozomu. Evaluaciona funkcija u genetskim algoritmima zapravo igra istu ulogu koju ima okruženje u prirodnoj evoluciji. Interakcija između individue sa okruženjem pokazuje meru kvaliteta hromozomskog rešenja.

PROJEKTOVANJE EVALUACIONE (FITNES) FUNKCIJE:
Fitnes funkcija treba da zadovolji bar dva uslova: da se može upotrebiti u algoritmu GA i da oslikava vezu sa stvarnim problemom koji želimo da optimizujemo (vezu sa objektivnom funkcijom). Prvi uslov se svodi na to da je fitnes funkcija nenegativna. Drugi uslov je posledica toga što GA koristi samo fitnes funkciju kao vezu sa stvarnim problemom i u krajnjoj liniji GA će optimizovati ono što od njega tražimo, tako da fitnes funkcija treba da dobro reprezentuje objektivnu funkciju bar u delu prostora pretrage u kojima očekujemo rešenja.
PRILAGOĐENJE FITNES FUNKCIJE:
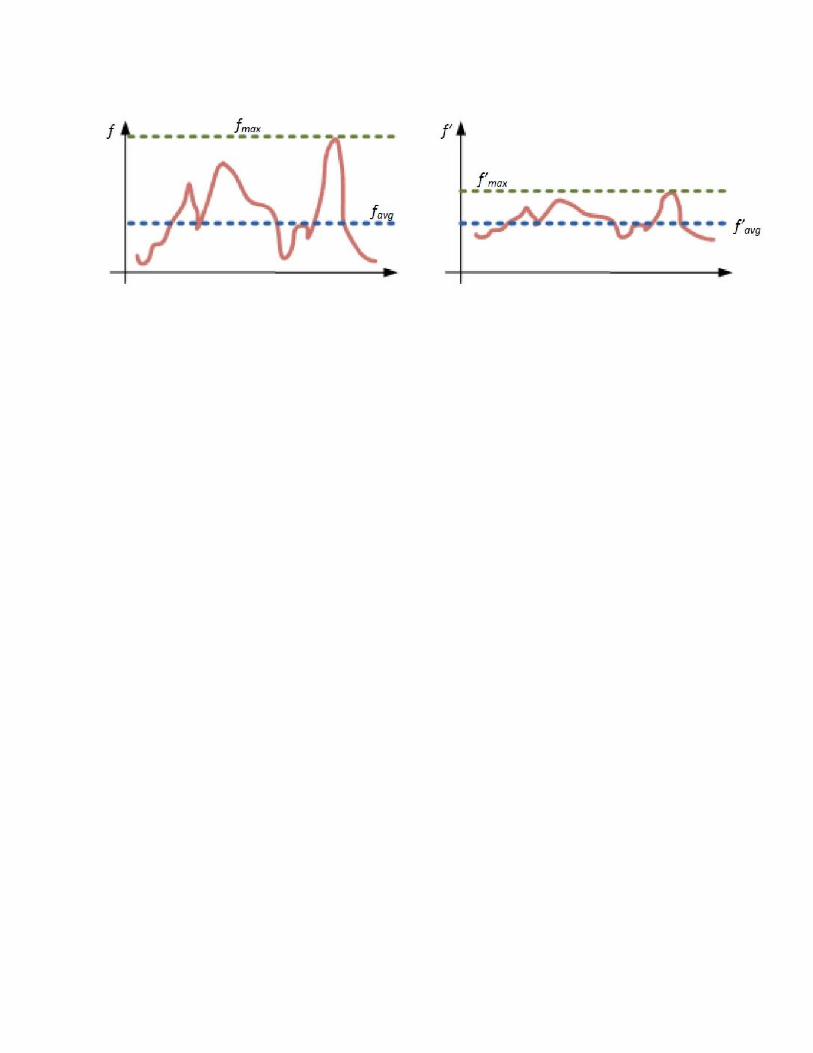
Najjednostavnije prilagođenje objektivne funkcije g je odsecanje. U slučaju da se želi minimizirati funkcije g odabir fitnes funkcije f je prikazan na slici koja sledi:
U slučaju maksimizacije funkcije g, odabir fitnes funkcije f prikazan je na slici ispod:

SKALIRANJE FITNES FUNKCIJE:
U procesu selekcije, verovatnoća odabira jedinke je direktno proporcionalna vrednosti fitnes funkcije date jedinke. Ovim se dobija da bolje jedinke imaju veću prednost u odnosu na one lošije. Ponekad je međutim dinamika fitnes funkcije takva da daje isuviše veliku prednost boljim jedinkama. Drugačije ponašanje GA se dobija ako su verovatnoće selekcije za neke dve jedinke 0.7 i 0.2 nego ako su 0.98 i 0.03. U drugom slučaju se ne daje gotovo nikakva šansa lošijoj jedinki. Ovako velika dinamika fitnes funkcije može dovesti do efekta „super“ jedinki, što je naročito loše u početnim fazama GA. Ukoliko postoji jedinka čija je fitnes funkcija značajno veća u odnosu na ostale jedinke, ova jedinka će dominirati i praktično će uništiti mogućnost za otkrivanje potencijalno dobrih drugih delova prostora pretrage. Bitno je dopustiti i lošijim jedinkama da opstanu u životu kako bi one možda evoluirale u značajno bolje jedinke u drugim delovima prostora pretrage i time otkrile bolji lokalni maksimum. Jedan od osnovnih kompromisa GA je između brzine konvergencije i dela prostora obuhvaćenog pretragom.
Super jedinke u ranoj fazi GA dovode do preuranjene konvergencije ali mogućeg mimoilaženja globalnog ekstrema, što je posledica smanjenja raznolikosti usled dominacije super jedinke. Kao rešenje ovog problema pogodno je skalirati fitnes funkciju f tako da se dobije pogodnija fitnes funkcija
Koeficijenti a i b se biraju tako da je srednja vrednost funkcija i ista:
i da je:
gde je Cmax odabrana konstanta. Konstantom Cmax se može kontrolisati očekivani broj najboljih jedinki koji se odabira za učešće u narednoj generaciji. Npr. ukoliko je Cmax=1.2 očekivani broj najboljih jedinki koji se odabira za sledeću generaciju je 1.2. Nakon skaliranja moguće je da se dobiju negativne vrednosti fitnes funkcije, koje je potrebno zatim postaviti na vrednost 0.

FITNES FUNKCIJA I NEDOZVOLJENA STANJA:
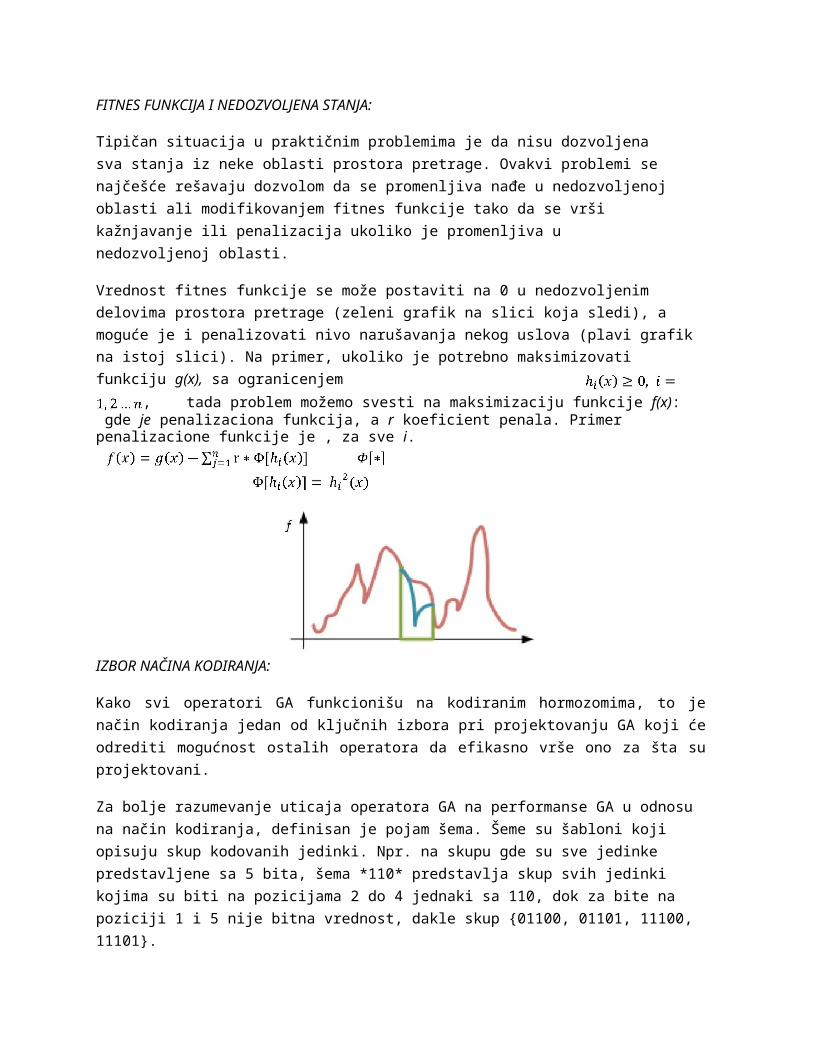
Tipičan situacija u praktičnim problemima je da nisu dozvoljena sva stanja iz neke oblasti prostora pretrage. Ovakvi problemi se najčešće rešavaju dozvolom da se promenljiva nađe u nedozvoljenoj oblasti ali modifikovanjem fitnes funkcije tako da se vrši kažnjavanje ili penalizacija ukoliko je promenljiva u nedozvoljenoj oblasti.
Vrednost fitnes funkcije se može postaviti na 0 u nedozvoljenim delovima prostora pretrage (zeleni grafik na slici koja sledi), a moguće je i penalizovati nivo narušavanja nekog uslova (plavi grafik na istoj slici). Na primer, ukoliko je potrebno maksimizovati funkciju g(x), sa ogranicenjem
, tada problem možemo svesti na maksimizaciju funkcije f(x): gde je penalizaciona funkcija, a r koeficient penala. Primer penalizacione funkcije je , za sve i.
IZBOR NAČINA KODIRANJA:
Kako svi operatori GA funkcionišu na kodiranim hormozomima, to je način kodiranja jedan od ključnih izbora pri projektovanju GA koji će odrediti mogućnost ostalih operatora da efikasno vrše ono za šta su projektovani.
Za bolje razumevanje uticaja operatora GA na performanse GA u odnosu na način kodiranja, definisan je pojam šema. Šeme su šabloni koji opisuju skup kodovanih jedinki. Npr. na skupu gde su sve jedinke predstavljene sa 5 bita, šema *110* predstavlja skup svih jedinki kojima su biti na pozicijama 2 do 4 jednaki sa 110, dok za bite na poziciji 1 i 5 nije bitna vrednost, dakle skup {01100, 01101, 11100, 11101}.
Dužina šeme se definiše kao rastojanje između prvog i poslednjeg fiksiranog bita, npr.,
Red šeme se definiše kao broj fiksiranih bita u šemi, npr. ,
Primetimo da šeme velike dužine imaju velike šanse da budu uništene rekombinacijom, a da šeme velikog reda imaju velike šanse da budu uništene mutacijom. Zbog toga se definešu šeme malog reda i male dužine, koje imaju natprosečne vrednosti fitnes funkcije - gradivni blokovi (building blocks). Oni imaju najviše šanse da prežive. Ovo je dokazano u vidu Šema teoreme ili Fundamentalne teoreme GA.

Fundamentalna Teoremom GA:Broj jedinki gradivnih blokova se eksponencijalno povećava u narednim generacijama.
Hipoteza gradivnih blokova tvrdi da se optimalno rešenje može rastaviti na gradivne blokove i da se gradivni blokovi kombinuju tako da konvergiraju optimalnom rešenju.
IZBOR NAČINA REPRODUKCIJE - SELEKCIJA:
Osnovni zadatak selekcije je da obezbedi da bolje jedinke imaju veću šansu da prežive. Većina strategija su elitističke, što znači da garantuju boljim jedinkama sigurno mesto u narednoj generaciji. Značaj elitističkih strategija selekcije se može videti na primeru sa slike koja sledi. Označena jedinka je među boljima u populaciji i po svemu sudeći bi trebala da vodi do nalaženja globalnog maksimuma. U slučaju rulet selekcije, ova jedinka možda ne bi bila odabrana u narednu generaciju i time bi moguće globalni maksimum ostao dugo neotkriven (do neke značajnije mutacije) jer bi dominirale jedinke oko lokalnog maksimuma. U slučaju elitističke strategije, ova jedinka bi ostala u igri sve dok je među boljima u celoj populaciji (ali bi time smanjila broj mesta za jedinke koje pokušavaju da nađu neke druge pogodnije delove prostora pretrage). Elitističke strategije ubrzavaju konvergenciju na račun globalne perspektive, ali u proseku čini se da poboljšavaju performanse GA.
Elitizam predstavlja način selekcije u kome se neki broj najboljih jedinki direktno kopira u narednu generaciju.
Deterministički odabir se vrši tako što se svakoj jedinki garantuje onoliko kopija koliki je očekivani broj odabira te jedinke u procesu roulet-wheela. Dakle, za jedinku i bira se garantovanih kopija (pri
čemu se vrši odsecanje razlomljenog dela). Preostali broj jedinki se bira po redu od najboljih jedinki ka gorim.
Odabiranje ostataka sa zamenom se razlikuje od prethodne samo po odabiru preostalog broja jedinki. U ovom slučaju se one biraju tako što razlomljeni (decimalni) delovi očekivanog broja kopija učestvuju u ponovnom rulet algoritmu. Npr. ukoliko je očekivani broj 2.73 jedinke, garantovane su 2 kopije jedinke, dok u rulet algoritmu ova jedinka učestvuje sa brojem 0.73.

Odabiranje ostataka bez zamenom se razlikuje od prethodne samo po odabiru preostalog broja jedinki.U ovom slučaju se one biraju tako što razlomljeni (decimalni) delovi očekivanog broja kopija predstavljaju verovatnoću da će jedinka dobiti još jednu kopiju više u odnosu na garantovani broj jedinki. Npr. ukoliko je očekivani broj 2.73 jedinke, garantovane su 2 kopije jedinke, dok je verovatnoća da će ova jedinka imati 3 kopije jednaka 0.73.
Rangiranje predstavlja proces u kome se vrši anuliranje loše dinamike fitnes funkcije, tako što se jedinke biraju samo na osnovu ranga u celoj populaciji. Npr. najbolja jedinka dobija 3 kopije, sledećih 10 najboljih 2 kopije, narednih 20 najboljih 1 kopiju i ostali nijednu.
Turnir je način selekcije u kome se sve jedinke podele u k grupa na slučajan način i iz svake grupe izabere po jedna najbolja jedinka. Zatim se ovaj proces ponavlja dok se ne izaberu sve jedinke. Slično rangiranju, ovim se donekle vrši kompenzacija loše dinamike fitnes funkcije jer verovatnoća izbora jedinke ne zavisi od apsolutne vrednosti fitnes funkcije nego od ranga među ostalim jedinkama.
Dodavanje slučajnih jedinki je jedan od retkih metoda selekcije koji nije elitstički i koji dodavanjem slučajno generisanih jedinki teži da poveća raznovrsnost cele populacije. Često se vrši i kombinacija opisanih metoda selekcije, npr. u početku se vrši selekcija sa blažim elitizmom i dodavanjem slučajnih jedinki kako bi se povećala raznovrsnost, dok se kasnije (kada su već ustanovljeni pogodni delovi prostora pretrage) vrši prelazak na elitističkije metode selekcije kako bi se ubrzala konvergencija.
IZBOR NAČINA UKRŠTANJA – REKOMBINACIJA:
Do sada smo pokazali ukrštanje u kome se vrši razmena hromozoma na samo jednom mestu:
Jedan od nedostataka ukrštanja na jednom mestu je sledeći: pri ukrštajnu dva hromozoma čiji su gradivni blokovi podvučeni, ni na jedan način se ne mogu iskobinovati gradivni blokovi oba hromozoma i dobiti još bolja jedinka. Ovaj problem se može rešiti ukrštanjem na više mesta (multi point crossover), što je ilustrovano na slici koja sledi:
Problem ukrštanja na više mesta je povećava šanse za razgradnju gradivnih blokova.
Jedan od čestih metoda je i uniformno ukrštanje. Kod ovog tipa ukrštanja se razmenjuju samo biti hormozoma koji su određeni slučajno generisanom maskom:
Roditelji Deca
101100100010 100100100110
000111110111 001111110011
001000100100 Maska
IZBOR NAČINA MUTACIJE:
Mutacije je ključni faktor u dobijanju novog kvaliteta. Prevelika mutacija može međutim degradirati performanse GA usled česte mutacije dobrih jedinki.
Na sledećoj slici su prikazani scenariji bez (dovoljne) i sa mutacijom. Prikazane su vrednosti najboljih jedinki u populaciji u prostoru pretrage. Mutacija je u drugom slučaju dovela do trenutnog pogoršanja situacije ali na račun otkrivanja globalnog maksimuma. U drugim slučajevima mutacija može dovesti do pogoršanja situacije koja neće doneti nikakav novi kvalitet. Mali stepen mutacije dovodi do brže konvergencije lokalnom maksimumu, a veći stepen mutacije vodi ka većem pokrivanju prostora pretrage, dok veliki stepeni mutacije vode ka algoritmima pretraga na slučajan način.
Bit inverzna mutacija je tip mutacije koji je do sada razmatran, gde se slučajno izabrani bit u hromozomu invertuje.
Uniforma i neuniformna mutacija se odnose na mutacije gde se vrednost mutiranog simbola dobija iz neke slučajne raspodele. Npr. ako je očekivano da optimalno rešenje ima male vrednosti simbola, mogu se mutirane vrednosti birati iz raspodele koja ima takav neki oblik.
Mutacija centar i krajevi mutira neku tačku tako da joj menja koordinatu na maksimalnu moguću, minimalnu moguću ili na aritmetičku sredinu ove dve. Cilj ove mutacije je što veće povećanje raznovrsnosti populacije (razbacivanje u granične delove prostora pretrage).
Mutacija je najefikasnija u početnim fazama kada treba ustanoviti plodne delove prostora pretrage raspršivanjem jedinki po što većem delu prostora stanja, dok u kasnijim fazama može može usporiti GA zbog uništavanja dobrih jedinki. Nonuniform decay je princip po kome se nakon nekog trenutka (praga slabljenja) verovatnoće mutacije smanjuje:
gde je:
• - verovatnoca mutacije • - prag slabljenja • - redni broj generacije
POVEĆANJE RAZNOVRSNOSTI POPULACIJE – SHARING:
Jedan od procesa u prirodi koji povećava verovatnoću preživaljanja neke vrste je specijalizacija. Vrste koje su specifičnije i koje se razlikuju od većine imaju bar po nečemu veću šansu da prežive (ako sve životinje u nekom regionu jedu travu, one koje ne jedu su verovatno u prednosti po pitanju nalaženja hrane). Ovo dovodi do povećanja raznovrsnosti (diversity). U prirodi neke od specijalizovanih vrsta jednostavno izumru, dok neke budu uspešne i prevladaju. Jedan od načina modelovanja ovih mehanizama u sklopu GA se ogleda u uvođenju sharing funkcije. Cilj sharing funkcije je da modifikacije

fitnes funkcije dozvoli jedinkama koje su različite od većije jedinki (koje povećavaju diversity, koje su specifične) da opstanu iako nisu među najboljima. Ovo se najčešće realizuje korišćenjem Hamming-ovog rastojanja dve binarne sekvence. To rastojanje predstavlja broj bita na kojima se ove sekvence razlikuju. Hamming-ovo rastojanje hromozoma 10110 i 10011 je d(10110, 10011)=2.
Sharing funkcija s(d( )) se bira tako da opada sa porastom Hamming-ovog rastojanja d( )), jermanja vrednost sharing funkcije znači i manje sličnosti:
Uticaj sharing funkcije na evaluacionu funkciju, čime dobijamo modifikovanu evaluacionu funkciju, dat je sledećim izrazom:
Sledi da jedinke koje se nalaze u istoj okolini smanjuju međusobno vrednost svojih fitnes funkcija. Kao rezultat dobijamo ograničenje nekontrolisanog rasta odrađene vrste unutar populacije.
Rezultati bez i sa upotrebom sharing funkcije su dati na slici koja sledi:

PRAKTIČNI PROBLEMI U PROJEKTOVANJU:
Neki od najčešćih praktičnih problema u projektovanju GA su naznačeni ovde:
• Generisanje mogućih rešenja. Nekada nije trivijalno naći inicijalnu populaciju. Problem može biti u pronalaženju bilo kakvih validnih jedinki ili može biti u nemogućnosti da se izabere inicijalna populacija koja relativno ravnomerno prekriva prostor pretrage.
• Merenje kvaliteta jedinki. Vrlo često je izračunavanje fitnes funkcije na nekoj od jedinki iz populacije dugotrajan proces koji umnogome usporava kompletan GA. U praktičnim slučajevima, evaluacija jedinki se vrlo verovatno vrši pokretanjem posebne simulacije koja ima za cilj nalaženjem parametara koji su od važnosti za rešavani problem.
• Podešavanje parametara. Izbor velikog broja parametara GA drastično utiče na performanse: brzinu konvergencije i relevantnost nađenog rešenja.
HIBRIDIZACIJA:
Hibridizacija je spoj GA i specijalizovanih optimizacionih metoda razvijenih za razne specifične oblasti. Ideja je da GA preuzme ulogu globalne pretrage, dok bi nakon nalaženja oblasti gde se nalaze maksimumi optimizaciju preuzeli specijalizovani algoritmi razvijani nezavisno od GA za tu specifičnu oblast. Tipični rezultati sa i bez hibridizacije prikazani su na slici koja sledi:
Hibridizacija GA metodom simuliranog kaljenja (simulated annealing) mogla bi da znači modifikaciju mutacije i rekombinacije tako da se one vrše samo ukoliko su rezultujuće jedinke zadovoljavajućeg kvaliteta.Mutacija ili rekombinacija bi bile dozvoljene ako je novodobijena jedinka bolja od polazne jedinke. U početku izvršavanja ovog algoritma bi bile dozvoljene i novodobijene jedinke koje su gore od polazne jedinke sa većom verovatnoćom da budu prihvaćene, dok bi kasnije ova verovatnoća opala i gore jedinke bi teže bile prihvatane. Ovime se postiže efekat povećanja raznovrsnosti u ranim fazama(globana pretraga GA) i efekat simuliranog kaljenja kasnije (lokalna pretraga).
GENETSKO PROGRAMIRANJE:
Genetsko programirajne je podvrsta GA koja je specijalizovana za traženje rešenja u vidu algebarskih izraza. Dok su opisani GA uglavnom prilagođeni nalaženju optimalne tačke u višedimenzionalnom prostoru stanja, GP ima mogućnost da kao rešenje vrati čitav izraz, npr. . Za definisanje problema GP potrebno je odrediti skup terminala i skup funkcija ili operacija. Terminali predstavljajuobjekte koji se mogu pojavljivati u rešenju problema, npr. … Funkcije ili operacije su funkcijekoje se mogu izvršavati nad terminalima ili drugim funkcijama ili operacijama. Primeri funkcija su
, , , i slično.
Kodovanje kod GP se vrši u vidu drveta u čijim čvorovima su funkcije, a u listovima drveta su terminali.
Primer jednog drveta koje predstavlja funkciju dat je na slici ispod:

Ukrštanje se vrši tako što se razmene dva poddrveta dva izabrana drveta (roditelja), što je prikazano na narednoj slici:
Mutacija se vršti mutiranjem terminala i funkcija, i u nekim slučajevima produbljivanjem ili skraćenjem poddrveta. Kod mutacije treba voditi da se zadovolji uslov n-arnosti funkcije, npr. da IFLTE čvor ima zaista 4 podstabla.

ZAKLJUČAK:
Genetski algoritmi predstavljaju stohastičke optimizacione metode za rešavanje problema. GA se razlikuju od uobičajenih optimizacionih metoda. Prvo, GA manipulišu sa velikim brojem stringova, tražeći veći broj lokalnih maksimuma u paraleli. Primenjujući mehanizme genetskih algoritama, razmenjuju se informacije o ovim lokalnim maksimuma, sa ciljem da se algoritam ne završi u jednom od njih, već da se među njima prepozna onaj koji je istovremeno i globalni maksimum. Druga značajna razlika jeste da ovi algoritmi rade sa kodiranim vrednostima argumenata a ne sa samim argumentima. Treća, vrlo značajna razlika jeste da GA zahtevaju samo poznavanje evaluacionih funkcija, a ne i njenih izvoda. Konačno, poslednja razlika leži u činjenici da je trajektorija pretraživanja stohastička, ne može se predvideti. Primenjujući operacije genetskih algoritama, ovo pretraživanje efikasno ispituje delove prostora u kome leže argumenti funkcija koje se optimiziraju, sa velikom verovatnoćom povećanja kriterijumske funkcije.






























