Embed Size (px)
Citation preview

Motivation
Many applications require processinghundreds of audio streams in real-time
games/simulators, multi-track mixing, etc.
©Eden Games ©Steinberg

Massive audio processing
Often exceeds available resources
Limited CPU or hardware processing
Bus-traffic
Typically involves
individual processing
mix-down of all signals to outputs
3D audio rendering

Perceptual audio rendering
Perceptually-based processing
Many sources and efficient DSP effects
Level of detail rendering
Independent of reproduction system
Extended sound sources Sound reflections
sound sources

Leveraging limitations of human hearing
A large part of complex sound mixtures is likely to be perceptually irrelevant
e.g., auditory masking
Limitations of spatial hearing
e.g., localization accuracy, ventriloquism
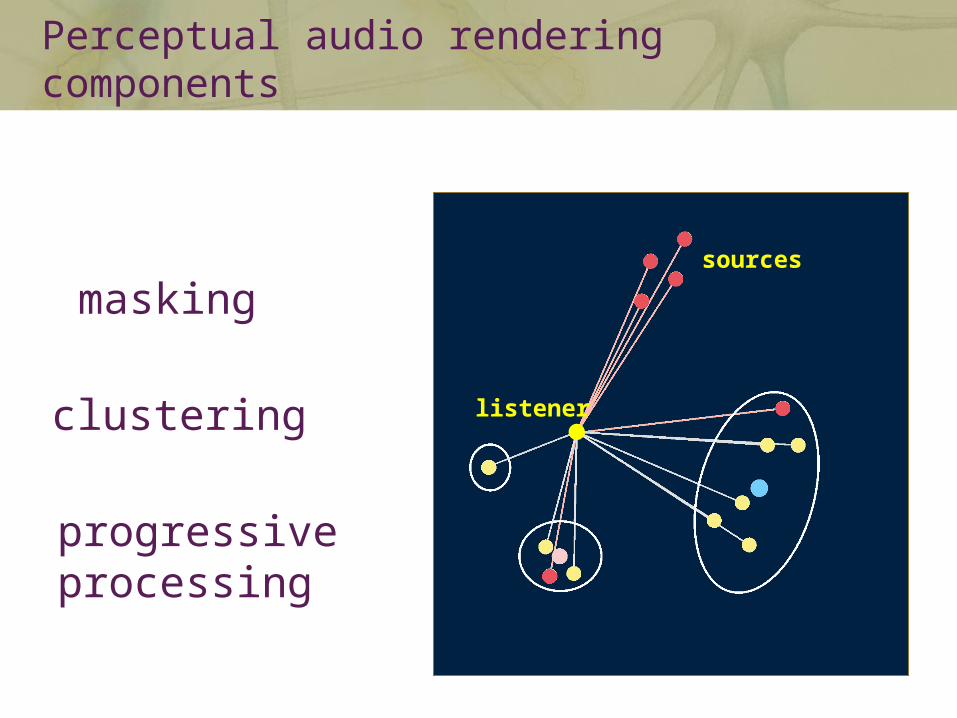
masking
clustering
progressiveprocessing
sources
listener
Perceptual audio rendering components

Masking

Real-time masking evaluation
Remove inaudible sources
Fetch and process only perceptually relevant input
Different from invisible or occluded sound sources
Estimate inter-source masking
Build upon perceptual audio coding work
Computing audibility threshold requires knowledge of signal characteristics
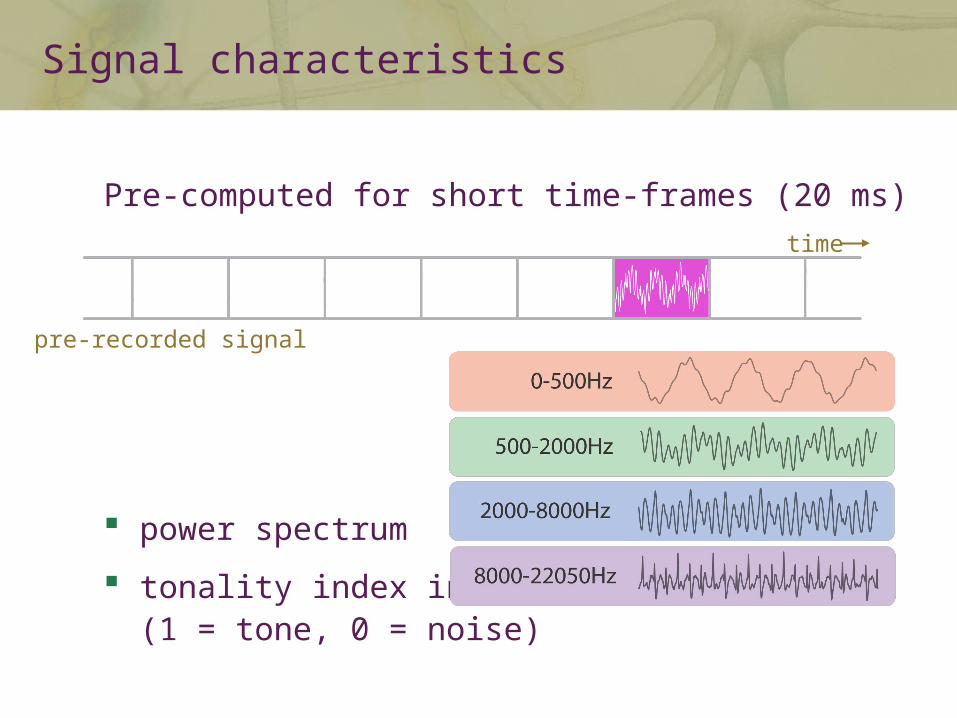
Signal characteristics
Pre-computed for short time-frames (20 ms)
power spectrum
tonality index in [0,1] (1 = tone, 0 = noise)
time
pre-recorded signal

Sort sources by decreasing loudness
Loudness relates to the sensation of sound intensity
Efficient run-time loudness evaluation
Retrieve pre-computed power spectrum for each source
Modulate by propagation effects
Convert to loudness using look-up tables [Moore92]
Greedy culling algorithm

power[dB]
listener
1Candidatesources
Currentmix
Currentmasking
threshold
STOP !
2
3
4
Currentmasking
threshold
Currentmasking
threshold
Currentmasking
threshold
Masking evaluation

Clustering

Dynamic spatial clustering
Amortize (costly) 3D-audio processing over groups of sources
Leverage limited resolution of spatial hearing
Group neighboring sources together
Compute an “impostor” for the group
Perceptually equivalent but cheaper to render
Unique point source with a complex response (mixture of all source signals in cluster)

Dynamic spatial clustering
Limited spatial perception of human hearing [Blauert, Middlebrooks]
Static sound source clustering [Herder99]
non-uniform subdivision of direction space
use Cartesian centroid as representative

Group neighboring sources together
Uniform direction constraint
Log(1/distance) constraint
Weight by loudness
Hochbaum-Schmoy heuristic [Hochbaum85]
Fast hierarchical implementation
Dynamic spatial clustering
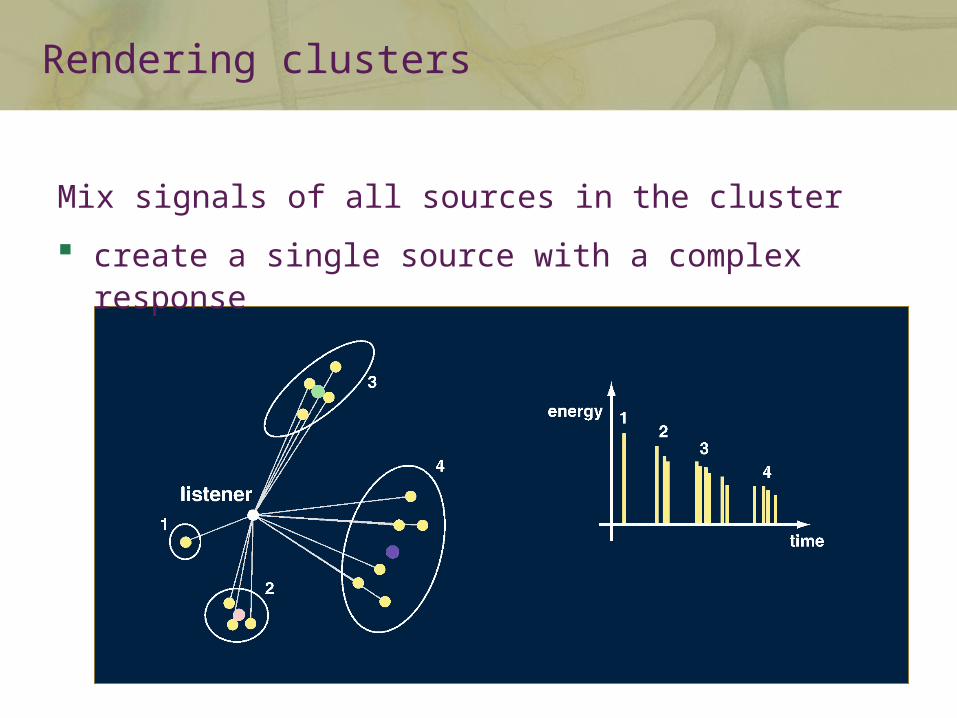
Mix signals of all sources in the cluster
create a single source with a complex response
Rendering clusters
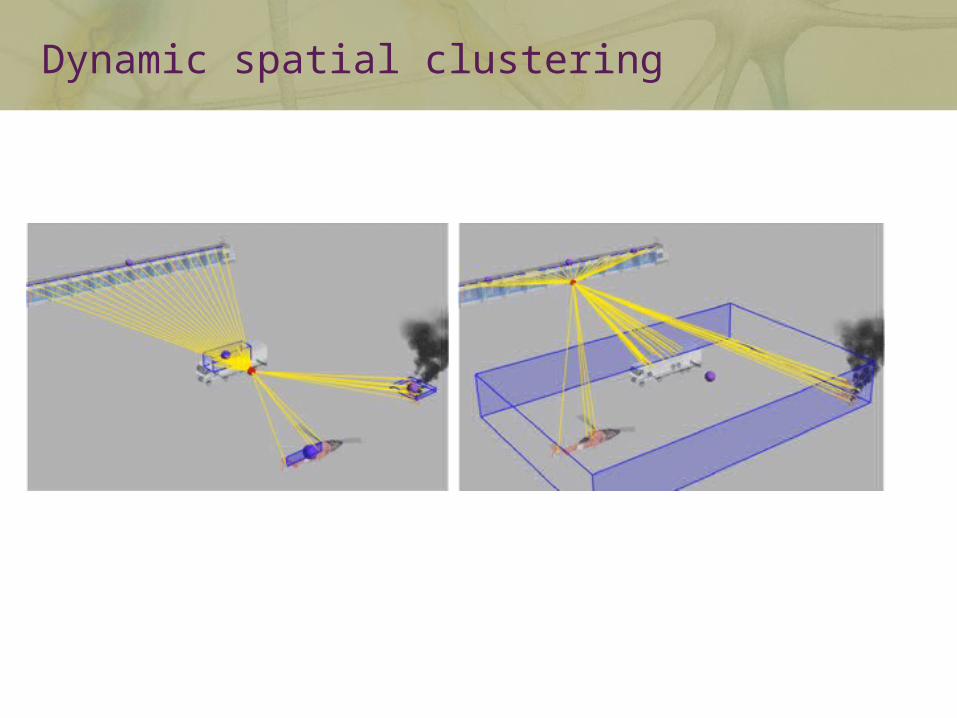
Dynamic spatial clustering

Culling and masking are transparent
rated 4.4/5 avg. (5 = indistinguishable from reference)
Clustering preserves localization cues
74% success avg. (90% within 1 meter of true location)
no significant correlation with number of clusters
Pilot validation study

Progressive processing

Progressive signal processing
A scalable pipeline for filtering and mixing many audio streams
fetch & process only perceptually relevant input
continuously adapt quality vs. speed
remain perceptually transparent
use a “standard” representation of the inputs

Progressive signal processing
Uses Fourier-domain coefficients for processing
Degrade both signal quality and spatial cues
Combines processing and audio coding
Uses additional signal descriptors for decision making
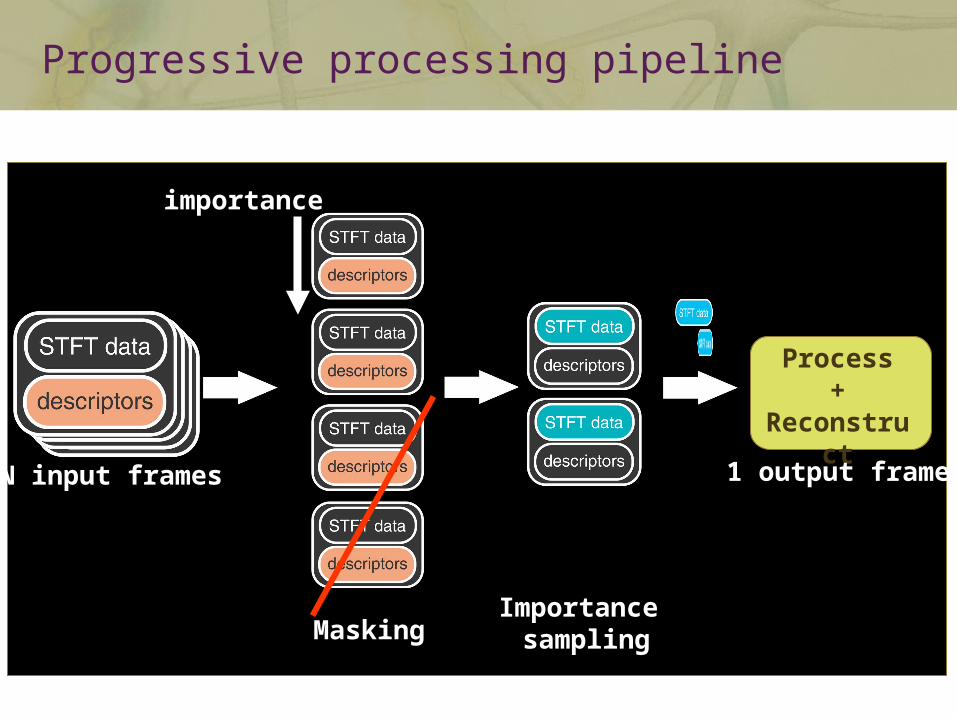
Progressive processing pipeline
N input frames
importance
Process+
Reconstruct
MaskingImportance
sampling
1 output frame
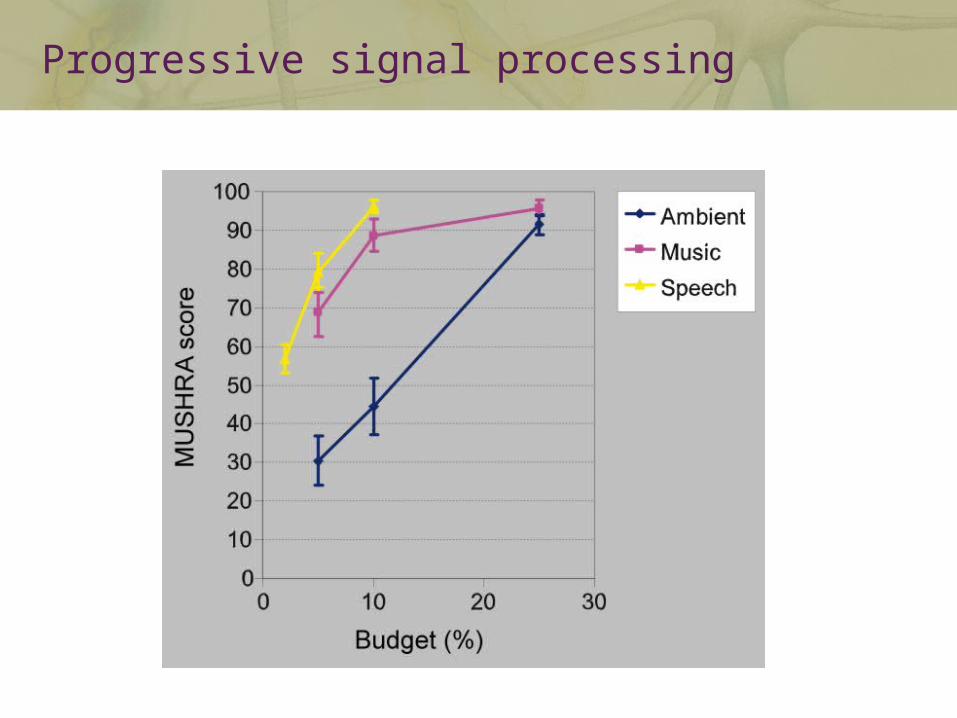
Progressive signal processing

Progressive processing and sound synthesis
Sound synthesis from physics-driven animation
Modal models
Resonant modes can be synthesized in Fourier domain
numer of Fourier coefficients can be allocated on-the-fly
Balance processing costs for recorded and synthesized sounds at the same time

Conclusions
Perceptually motivated techniques for rendering and authoring virtual auditory environments
human listener only process a small amount of information in complex situations
Extend to
more complex auditory processing model
cross-modal perception
Efficient and Practical Audio-Visual Rendering for Games using Crossmodal Perception David Grelaud, Nicolas Bonneel, Michael Wimmer, Manuel Asselot, George Drettakis, Proceedings
of the ACM SIGGRAPH Symposium on Interactive 3D Graphics and Games - 2009
other problems : dynamic range managemente.g., HDR audio approach of EA/Dice studio for Battlefield

Additional references
www-sop.inria.fr/reves
This work was supported by RNTL project OPERA
http://www.inria.fr/reves/OPERA
EU IST Project CREATE EU IST Project CREATE http://www.cs.ucl.ac.uk/create
EU FET OPEN Project CROSSMOD EU FET OPEN Project CROSSMOD http://www-sop.inria.fr/reves/CrossmodPublic/