Embed Size (px)
Citation preview

Of search quality and relevance
Andrew Aksyonoff, http://sphinxsearch.com/

PARENTAL WARNING:ADULT CONTENT

[0/4] Why this talk?

Why should you care• Performance grows => …unimportant• In production, as opposed to synth behchmarks
• Website visitors are spoiled by Google!• Out-of-the box search is not always great• Out-of-the-box search imho (imho!) can not
be great, requires problem-domain tuning• And, well, it’s a generally interesting topic

[1/4] What isrelevance

Relevance is…• A special word from around search and IR• A big misconception in most people’s minds• A big myth, really• Which I would like to try to dismantle• And mantle some others!
• So “relevance” enters the stage the very moment…
…when someone does a search…

…and, unfortunately*, gets results
(*) the empty query is the quickest!

And now, we have to pull rank.

A random query?
LINCOLN

Lincoln the president?

Lincoln the limo?

Lincoln university, New Zealand?

Suddenly, a shocking truth!!!

There is no spoon!!!

…and there’s no ideal Relevance either.

“The beauty’s in the eyes of the beholder.”

But we still gotta pull rank!

The currentstate of research

Text factors begin with a document"The time has come," the Walrus said,"To talk of many things:Of shoes, and ships, and sealing-wax,Of cabbages, and kings,And why the sea is boiling hot-And whether pigs have wings."

And map query onto it"The time has come," the Walrus said,"To talk of many things:Of shoes, and ships, and sealing-wax,Of cabbages, and kings,And why the sea is boiling hot-And whether pigs have wings."

Example: one text factor, BM25

There are more text factors• BM25 is well-known and important, but• Only takes statistics (not positions) into account• Can’t be used as the only one, really
• There are (much) more factors than that• Other variations on BM25 theme• Factors that account for proximity• Adjustments for morphology (what form
matched)• etc etc etc

And many more non-text factors
PageRank DomainAge DocLength
IsSpam IsPorn HITSAuthority
NumIncomingLinks NumOutgoingLinks
WhateverOtherFactor1 WhateverOtherFactor2

(btw, factor == signal)

Factors overall• Some text factors• Computed from keyword stats, positions, etc
• Some non-text factors• Pagerank, domain age, and gazillions more• Some user-related factors (think location) too
• Up to thousands used by the Web engines• Less than that used for most matches (pruning)• But really thousands for say top-10K matches

What exactly and why exactly we compute?

Target function• Input – a bunch of numbers, aka factors• Output – a single value (relevance), for sorting• Rel = Rel(f1, f2, …, f200, …): RNumFactors R
• S.T.: specific relevance values do not matter• S.T.: what matters a lot is the generated
document order

Relevance judgements• Everything bases on the judgements• Human judgements!
• It’s always a query+doc pair that gets judged• Binary (yes or no), on a scale from 1 to 5, etc• We’ll use binary for simplicity
• We only need judgements to be able to compare different result sets

Example 11. Sphinx | Open Source Search Server2. Sphinx - Wikipedia, the free encyclopedia3. Great Sphinx of Giza - Wikipedia, the free
encyclopedia4. Overview - Sphinx 1.1.2 documentation

Example 21. Great Sphinx of Giza - Wikipedia, the free
encyclopedia 2. Sphinx - Wikipedia, the free encyclopedia3. Sphinx | Open Source Search Server4. Overview - Sphinx 1.1.2 documentation

Example 31. Sphinx - Wikipedia, the free encyclopedia2. Sphinx | Open Source Search Server3. Overview - Sphinx 1.1.2 documentation4. Great Sphinx of Giza - Wikipedia, the free
encyclopedia

Quality metrics• Simple order independent • Precision = result_relevant / result_total• Recall = result_relevant / total_relevant

Example 1, 21. Sphinx | Open Source Search Server
2. Sphinx - Wikipedia, the free encyclopedia
3. Great Sphinx of Giza - Wikipedia, the free encyclopedia
4. Overview - Sphinx 1.1.2 documentation
Precision = 0.5
1. Great Sphinx of Giza - Wikipedia, the free encyclopedia
2. Sphinx - Wikipedia, the free encyclopedia
3. Sphinx | Open Source Search Server
4. Overview - Sphinx 1.1.2 documentation
Precision = 0.5

Quality metrics• Better order dependent • AP, Average Precision, AP• DCG, Discounted Cumulated Gain• BPREF• ERR• pFound, etc
• Very basically (to the point of being incorrect), just kind of weighted sums of relevant pos’s

Example 1, 21. Sphinx | Open Source Search Server
2. Sphinx - Wikipedia, the free encyclopedia P@2 = 0.5
3. Great Sphinx of Giza - Wikipedia, the free encyclopedia P@3 = 0.667
4. Overview - Sphinx 1.1.2 documentation
AveragePrecision = 0.583
1. Great Sphinx of Giza - Wikipedia, the free encyclopedia P@1 = 1
2. Sphinx - Wikipedia, the free encyclopedia P@2 = 1
3. Sphinx | Open Source Search Server
4. Overview - Sphinx 1.1.2 documentation
AveragePrecision = 1.0

Quality metrics• How to compare a vector of 100+ APs?• What if we fix one query, break ten others?
• Average AP/DCG/BPREF… over many queries!• Get a single magic value (MAP, AvgDCG, …)
• Alright, this is our Ultimate Goal now!• Assume it bumps Average User Happiness

Mysterious ways of relevance• There’s an uber-function Rel()• There’s a document collection• There’s a query log• There’s a bunch of (assessor) judgements• Compute Rel() based on specific factors
=> generate results (sort by Rel() value)=> compute per-query AP (DCG, …)=> average over all queries & finally compare!
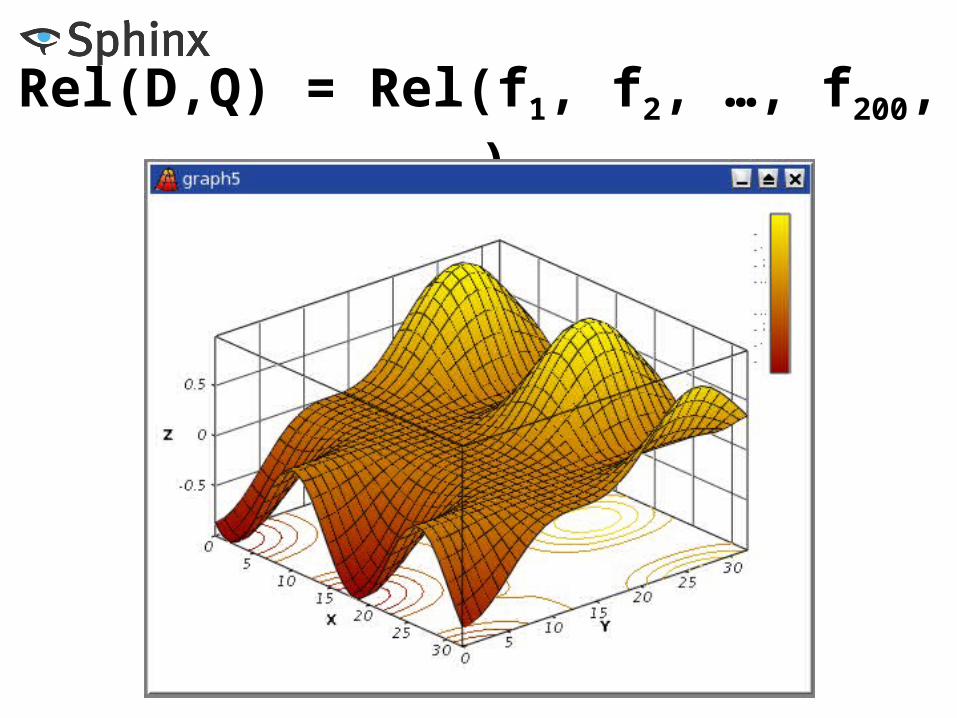
Rel(D,Q) = Rel(f1, f2, …, f200, …)

S.T.: there’s no ideal analytic formula

Machine learning FTW!
Regression analysis on steroids

Same problem, really• We optimize a value of (say) MAP• We know the source factors, aka variables• We need both the type (!) and coefficients
• Rel = a1f1 + a2f2 + … ?
• Rel = a1exp(f1) + 1/(a2-f2) + … ?
• …• No good analytic solution (can’t know type)
Ideal function type is unknown

S.T. So the function type we use….

…is simply piece-wise linear!!! (*)

Summary• Everything begins with judgments• All judgments are subjective
• Input is a huge factors by judgments matrix• Output is some kind of a relevance function• Which indirectly maximizes Happiness Metric
• At web scale, feeble attempts at manual analysis lost to machine learning• Which is, basically, huge scale regression analysis

[2/4] Built-in Sphinx rankers

Aka…• How complicated everything is on web scale• How simple everything is in less elaborate
open-source engines

That’s how it compares

Mind the gap
Everyone (?) else Web search
1-10… factors 100-1000+ factors
0 judgments? 1-10M+ judgments
Simple ad-hoc functions
Sophisticated machine learned functions

Don’t panic• You are not Google• You are, say, an auto parts website• A bit less data than Google• Slightly less queries than Google• Insignificantly less results found than Google• Got specific problem, can tune
• Even ad-hoc might work mighty well
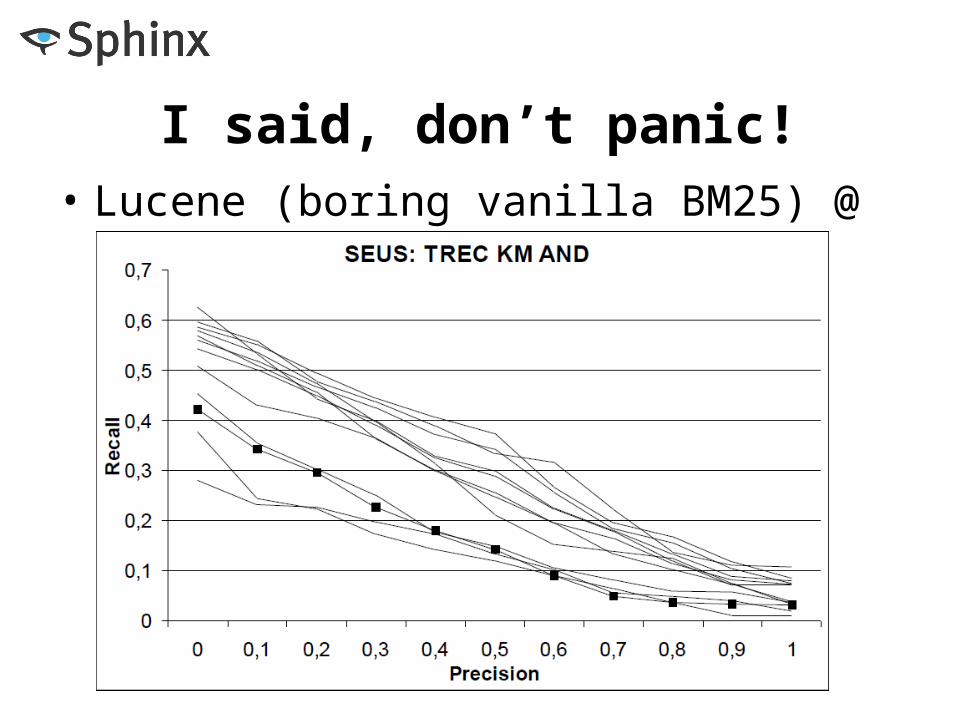
I said, don’t panic!• Lucene (boring vanilla BM25) @ ROMIP

Sphinx “ranker” notion• Ranker is simply a relevance function• Built-in Sphinx upfront by us• Choose it on the fly• $client->SetRankingMode(SPH_RANK_BM25)• SELECT … OPTION ranker=bm25
• Watch your step• Only available in extended mode via API• $client->SetMatchMode(SPH_MATCH_EXTENDED)

What ranker do I use?• BM25 – most basic, de-facto standard• PROXIMITY_BM25 – boosts (sub)phrases• Guarantees max rank for a full phrase match• Does not differentiate freq/rare keyword pairs
• SPH04 – additionally boosts field start match, and exact field match
• No other quality-related rankers yet• Or, perhaps, already

[3/4] Killer feature, formulas on-the-fly

Expression ranker, 2.0.2-beta
SELECT *, WEIGHT() FROM myindexWHERE MATCH('hello world')OPTION ranker=expr('sum(lcs*user_weight) *
1000+bm25')

Yes, THAT simple• That was literally how you use it• SphinxAPI works too, $client->SetRankingMode()
• The default proximity_bm25 is, literally, this• sum(lcs*user_weight) * 1000 + bm25• self-reference, Whole Two Factors

What’s new?• Quite a bunch of new factors• Document Level:• bm25, max_lcs, query_word_count,
doc_word_count
• Field Level:• lcs, user_weight, hit_count, word_count, tf_idf,
min_hit_pos, min_best_span_pos, exact_hit
• More are planned and easy to add

Usage quirks?• Field level factors must be aggregated• SUM() for now, call us for other aggr functions
• Can use any document attributes• Can use any built-in (math) function• Can probably use UDF (did not check)
• Suspiciously performant

Our most complicated ranker• SPH_RANK_SPH04 =
sum((4*lcs+2*(min_hit_pos==1)+exact_hit)*user_weight)*1000+bm25
• I am positive you can outdo this :)• Especially now that you know everything you
have to know :)

[4/4] Other low hanging fruits

[4/4] …or, what else can be done

Quality != relevance ranking• Think typo corrections• Think (excessive) search strictness• Think morphology• Think synonyms, query expansion• Think part/model numbers, other verticals• Think query analysis, attribute mappings

S.T: you CAN do that already

Easier changes• Typos? sphinx/misc/suggest/• Strictness? Quorum operator• Query analysis? regexps, SHOW KEYWORDS

Harder changes• Morphology, synonyms? wordforms• Occasionally inconvenient• Might require significant fiddling time
• Part numbers? Either preprocessing, and/or blend_chars, stopword_step, etc• Occasionally inconvenient• Might require significant fiddling time
• Natural language = manual rules = prepare to put in some work

Summary

What did we learn today?• How relevance in general works• What’s built into Sphinx already• How you can now improve relevance• What are the other search quality issues• How to approach them
• Why is your search not yet top-notch?!

Questions?Preferably, the relevant ones!





























