Embed Size (px)
Citation preview

| 1
› Gertjan van Noord 2014
Search Engines
Lecture 7: relevance feedback & query reformulation

Query expansion
• Global methods: e.g. add (near) synonyms
- Using a thesaurus
- Using automatically constructed resources
• Local methods: based on initial results of query
- Relevance feedback
- Pseude-relevance feedback
- Indirect relevance feedback

Relevance feedback
1. The user formulates a query
1. The system gives a list of results
1. The user marks one or more documents of the result list as relevant
1. The system uses this information to modify the original query
1. The system gives a new (or reordered) list of results

Which document information?
Query and documents both seen as vectors
Positive feedback
Add terms from the document vector to the query / give some original query terms more weight
Negative feedback
Give some query terms less weight

Negative feedback
Not commonly asked from the user
The highest ranked document that is NOT marked relevant can be considered not-relevant by default

Rocchio feedback formula
qmod / q0 modified query / original query
Dr relevant docs
Dnr not-relevant docs
dj document vector
0+1
|D r|∑ j∈D r
j−
1|Dnr|
∑ j∈D nrj

Rocchio feedback formula
α,β,γ: size of effect for the factor
0+β1
|D r|∑ j∈D r
j− γ
1|D nr|
∑ j∈D nrj

alpha = 1, beta = 1, gamma = 0.5
Original query: query retrieval interface
Results:
Document 1: query interface relevant
Document 2: query text relevant
Document 3: gps interface not relevant
0+β1
|D r|∑ j∈D r
j− γ
1|D nr|
∑ j∈D nrj
Exercise

Answer
Terms q0 d1 d2 d3 Value in qmod
gps 0 0 0 1 0 + 0 - 0.5 = -0.5 = 0
interface
1 1 0 1 1 + 0.5 - 0.5 = 1
query 1 1 1 0 1 + 1 – 0 = 2
retrieval
1 0 0 0 1 + 0 – 0 = 1
text 0 0 1 0 0 + 0.5 – 0 = 0.5the new vector qmod is: (interface, query, retrieval, text)
(1, 2, 1, 0.5 )

Changing the query vector

When is RF not sufficient?
• Insufficient relevance judgements (min. 5)• If the first query fails:
• spelling• cross-language• vocabulary mismatch
• If the result includes more than one cluster of relevant documents• subsets with different vocabulary• disjunctive answer set (examples)

Problems of RF
• Users don’t like to go on with a search• Results incomprehensible• High computing costs
• In web search, recall is not very important

Feedback without explicit action from user• Pseudo relevance feedback
• Just assume that top n docs are relevant• Works well, sometimes topic drift
• Indirect relevance feedback• use of clickstream data (general or
individual)

Global methods for query reformulationIndependent of results
• show query processing• let user browse term lists• suggest terms from thesaurus• show related user queries (log mining)
So a user can reformulate his query

Building a thesaurusTo suggest or just include related terms
• Thesaurus with controlled vocabulary in which each concept has a canonical form, like the UMLS (human editors) PubMed
• Manually built thesaurus with synonyms, broader and narrower terms without canonical terms, like WordNet (human editors)

Building it automatically
Automatic derivation of a thesaurus from a set of documents• using simply word cooccurrence• using grammatical analysis or relations
(what is eaten is food)• query log mining
demo Dutch similar words English demo

Word Embedding
Words are represented by a vector of e.g. 200 dimensions• Similar words have similar vectors• Vectors trained on large amounts of text• Popular, free, implementation by Google:
word2vec• Other operations on vectors, e.g. v(Madrid) –
v(Spain) + v(France) yields a vector that is close to v(Paris)

Brief (non-technical) history
• Early keyword-based engines ca. 1995-1997• Altavista, Excite, Infoseek, Inktomi, Lycos
• Paid search ranking: Goto (morphed into Overture.com Yahoo!)• Your search ranking depended on how much
you paid• Auction for keywords: casino was expensive!

Brief (non-technical) history
• 1998+: Link-based ranking pioneered by Google• Blew away all early engines save Inktomi
• Great user experience in search of a business model
• But: Goto/Overture’s annual revenues were nearing $1 billion
• Result: Google added paid search “ads” to the side, independent of search results• Yahoo followed suit, acquiring Overture (for paid
placement) and Inktomi (for search)
• 2005+: Google gains search share, dominating in Europe and very strong in North America

Algorithmic results.
PaidSearch Ads
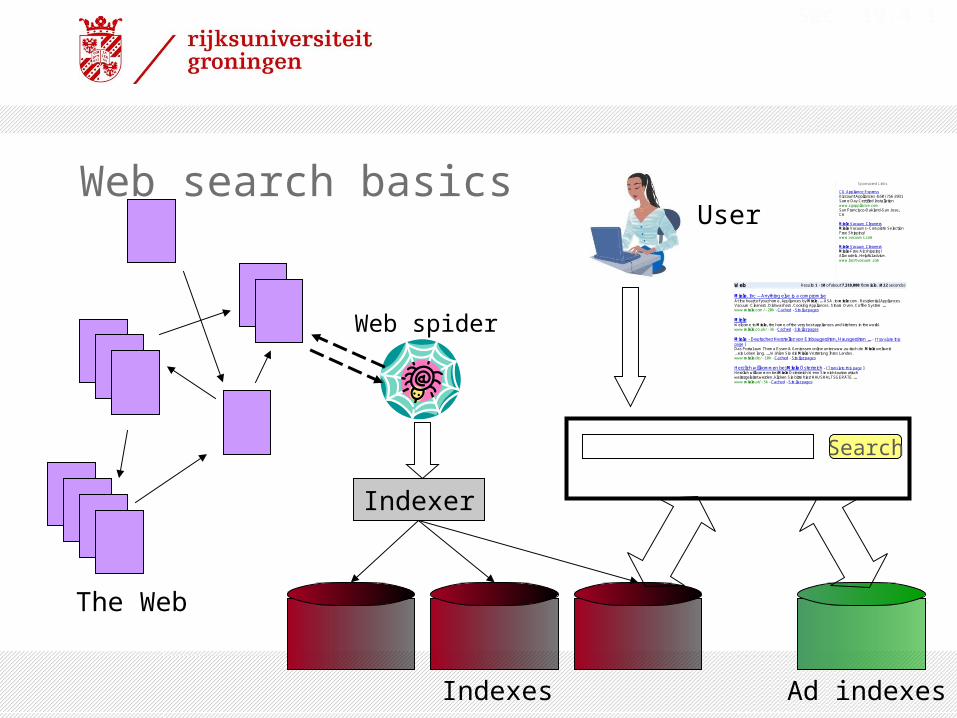
Web search basics
The Web
Ad indexes
Web Results 1 - 10 of about 7,310,000 for miele. (0.12 seconds)
Miele, Inc -- Anything else is a compromise At the heart of your home, Appliances by Miele. ... USA. to miele.com. Residential Appliances. Vacuum Cleaners. Dishwashers. Cooking Appliances. Steam Oven. Coffee System ... www.miele.com/ - 20k - Cached - Similar pages
Miele Welcome to Miele, the home of the very best appliances and kitchens in the world. www.miele.co.uk/ - 3k - Cached - Similar pages
Miele - Deutscher Hersteller von Einbaugeräten, Hausgeräten ... - [ Translate this page ] Das Portal zum Thema Essen & Geniessen online unter www.zu-tisch.de. Miele weltweit ...ein Leben lang. ... Wählen Sie die Miele Vertretung Ihres Landes. www.miele.de/ - 10k - Cached - Similar pages
Herzlich willkommen bei Miele Österreich - [ Translate this page ] Herzlich willkommen bei Miele Österreich Wenn Sie nicht automatisch weitergeleitet werden, klicken Sie bitte hier! HAUSHALTSGERÄTE ... www.miele.at/ - 3k - Cached - Similar pages
Sponsored Links
CG Appliance Express Discount Appliances (650) 756-3931 Same Day Certified Installation www.cgappliance.com San Francisco-Oakland-San Jose, CA Miele Vacuum Cleaners Miele Vacuums- Complete Selection Free Shipping! www.vacuums.com Miele Vacuum Cleaners Miele-Free Air shipping! All models. Helpful advice. www.best-vacuum.com
Web spider
Indexer
Indexes
Search
User
Sec. 19.4.1

The Web document collection
•No design/co-ordination•Distributed content creation, linking, democratization of publishing•Content includes truth, lies, obsolete information, contradictions … •Unstructured (text, html, …), semi-structured (XML, annotated photos), structured (Databases)…•Scale much larger than previous text collections … but corporate records are catching up•Growth – slowed down from initial “volume doubling every few months” but still expanding•Content can be dynamically generated
The Web
Sec. 19.2

Indexing anchor textWhen indexing a document D, include (with
some weight) anchor text from links pointing to D.
www.ibm.com
Ar-basIBM anno
Sun HPIBM
Big Blue today announcedrecord profits for the quarter

26
Indexing anchor text
• Thus: anchor text is often a better description of a page’s content than the page itself.
• Anchor text can be weighted more highly than document text.

27
Google bombs
• A Google bomb is a search with “bad” results due to maliciously manipulated anchor text.
• Google introduced a new weighting function in January 2007 that fixed many Google bombs.
• Still some remnants: [gengszterek] (gangsters)
• Coordinated link creation by those who dislike Fidesz, the main ruling political party
• Defused Google bombs: [miserable failure], [dangerous cult]

Indexing anchor text
• Can sometimes have unexpected side effects
• Solution: score anchor text with weight depending on the authority of the anchor page’s website• E.g., if we were to assume that content from
cnn.com or yahoo.com is authoritative, then trust the anchor text from them
Sec. 21.1.1

The trouble with paid search ads …
• It costs money• The alternative? Search Engine
Optimization:• “Tuning” your web page to rank highly in the
algorithmic search results for select keywords
• Alternative to paying for placement
• Thus, intrinsically a marketing function
• Performed by companies, webmasters and consultants for their clients
• Some perfectly legitimate, some very shady
Sec. 19.2.2
29

Simplest forms
Sec. 19.2.2
•First generation engines relied heavily on tf/idf • The top-ranked pages for the ‘query maui resort’
were the ones containing the most ‘maui’s and ‘resort’s
•SEOs responded with dense repetitions of chosen terms
• e.g., “maui resort maui resort maui resort ”• Often, the repetitions would be in the same color as
the background of the web page• Repeated terms got indexed by crawlers• But not visible to humans on browsers
• Variant: repeated/misleading meta tags
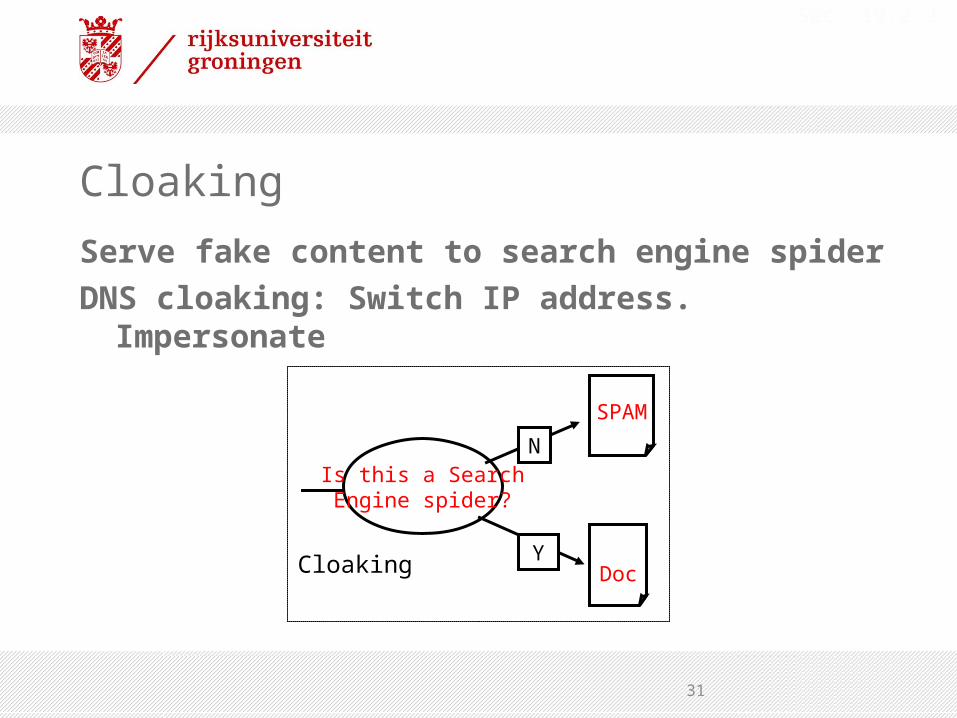
Cloaking
Serve fake content to search engine spiderDNS cloaking: Switch IP address.
Impersonate
Is this a SearchEngine spider?
N
Y
SPAM
RealDocCloaking
Sec. 19.2.2
31

More spam techniques
• Doorway pages (pages optimized for a single keyword that re-direct to the real target page)
• Link spamming • mutual admiration societies, hidden links, awards –
more on these later)• domain flooding (numerous domains that point or re-
direct to a target page)• Robots
• Fake query stream – rank checking programs• Millions of submissions via Add-Url
Sec. 19.2.2





























