Embed Size (px)
DESCRIPTION
Ronald Mayer, Forensic Logic, Inc [email protected], 2011-05-26 Police car photo by davidsonscott15 (Scott Davidson) on Flickr under (CC BY 2.0) license • Ranking law enforcement documents has interesting challenges. • Many factors affect relevance for a law-enforcement user • A mix of structured, unstructured, semi-structured data • Improving edismax sub-phrase boosting Conclusion 3 interesting challenges: • Solr's flexibility & community are both great. 2
Citation preview

Highly Relevant Search Result Ranking for Law Enforcement
Ronald Mayer, Forensic Logic, [email protected], 2011-05-26
Police car photo by davidsonscott15 (Scott Davidson) on Flickr under (CC BY 2.0) license

What I Will Cover
Highly Relevant Search Result Ranking for Large Law Enforcement Information Sharing Systems
Who I am – Ron Mayer, CTO at Forensic Logic.
The challenge / problem• Ranking law enforcement documents has interesting
challenges.
3 interesting challenges:• Many factors affect relevance for a law-enforcement user
• A mix of structured, unstructured, semi-structured data
• Improving edismax sub-phrase boosting
Conclusion• Solr's flexibility & community are both great.
2

My Background
Ron Mayer
CTO of Forensic Logic, Inc• We power crime analysis and cross-agency search tools for the
LEAP (law enforcement analysis portal) project.
• About 150 State, Local, and Federal law enforcement agencies use our SAAS software to analyze and share data
My background• 8 years of delivering software technologies to law enforcement as
SAAS solutions.
• Use some F/OSS, quite a bit of proprietary.
• Play well with F/OSS projects (contributed back code to PostgreSQL, PostGIS, a memcached client, and earlier
contributions from school that found their way into various projects)
3

The Challenge
Problem I set out to solve• We had a good but complex database-based crime analysis package
for investigators with good computer skills.
• Needed an easy “google-like” interface that any officer could use.
Considerations• Most officers don't want to sit around on desks filling out search
forms.
• Want something like Google – type a guess, and get the most relevant documents on the first page.
Key hurdles or obstacles to success you had to overcome.• What factors even define “the most relevant” document.
• Extremely Disparate data (some almost totally structured; some totally unstructured; most a mix)
• How do we implement ranking.
4

Project background
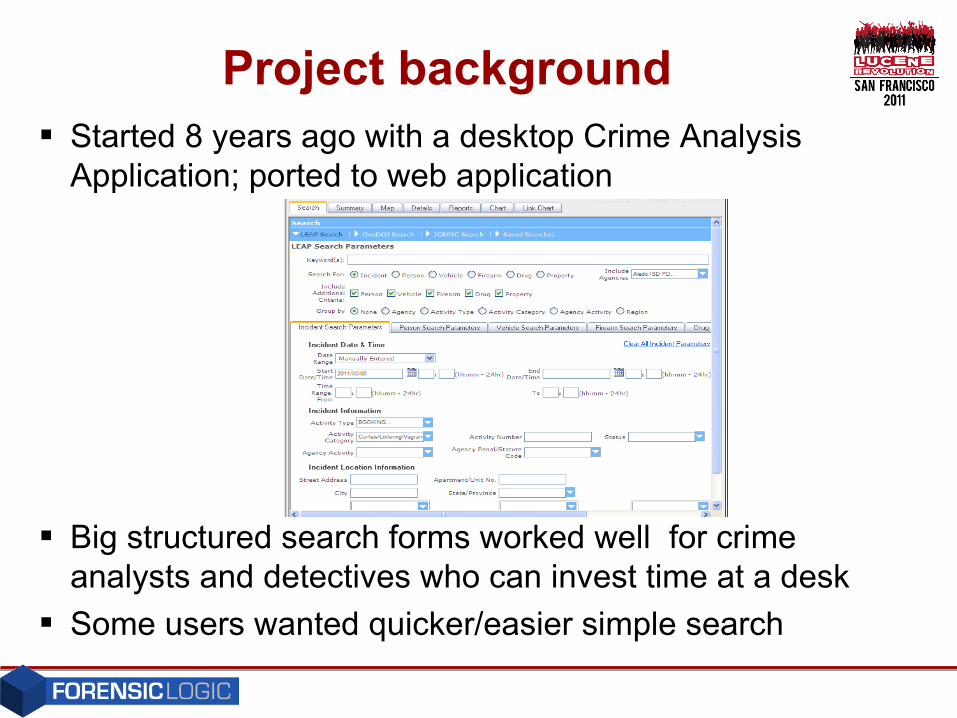
Project background Started 8 years ago with a desktop Crime Analysis
Application; ported to web application
Big structured search forms worked well for crime analysts and detectives who can invest time at a desk
Some users wanted quicker/easier simple search
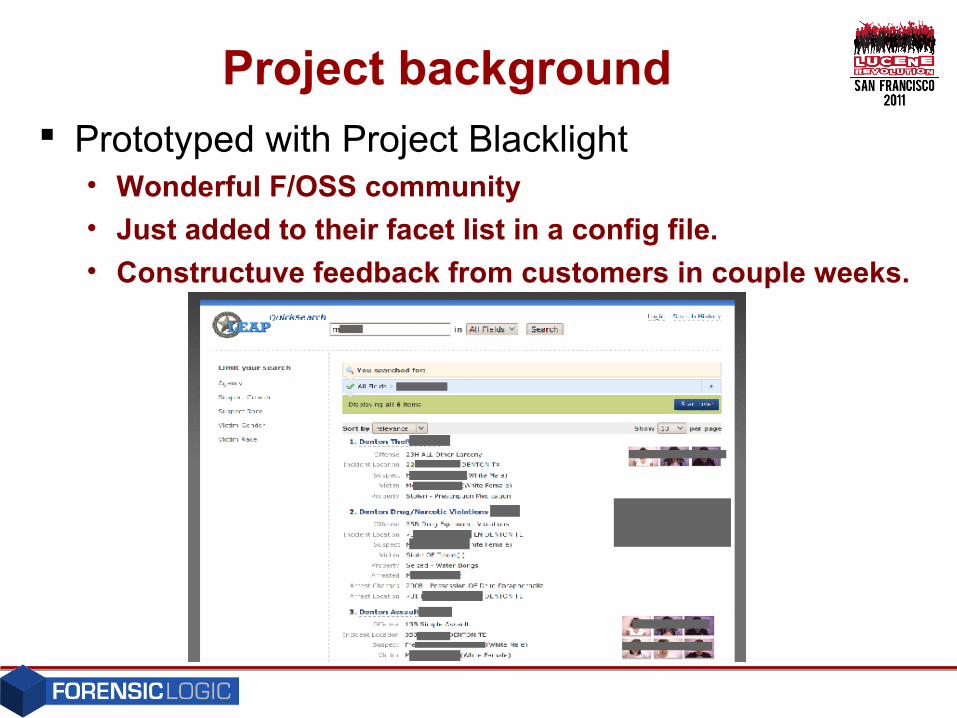
Project background Prototyped with Project Blacklight
• Wonderful F/OSS community
• Just added to their facet list in a config file.
• Constructuve feedback from customers in couple weeks.
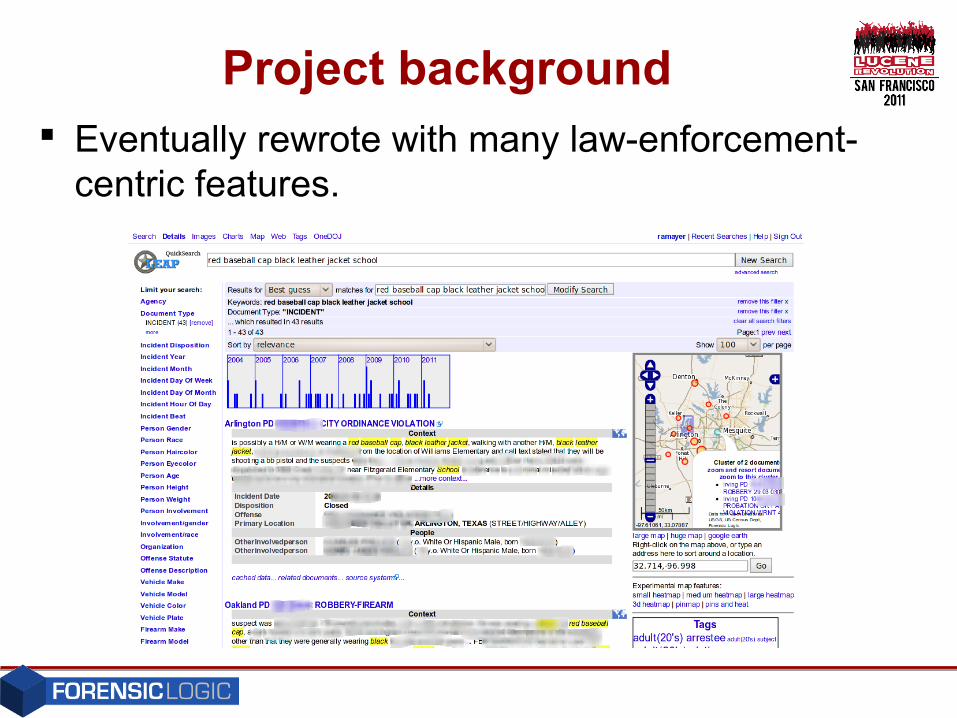
Project background Eventually rewrote with many law-enforcement-
centric features.

Search Relevance for Law Enforcement Users

Search Relevance for Law Enforcement Users
Searches often contain multiple clauses• 'red baseball cap black leather jacket tall male
suspect short asian victim'• These search clauses are often noun clauses with a
few adjectives preceding a noun; but are often independent from each other.
Fuzzy searches are common• Victims give incomplete descriptions
• Suspects lie• Close counts.

Search Relevance for Law Enforcement Users
Geospatial factors• Officers are often interested in things near their own city or beat
Solr does this one well for 1 location of interest in a document:– bf=... recip(dist(2,primary_latlon,vector(#{lat},#{lon})),1,1,1)^0.5
I haven't yet found a great solution for documents with many locations of interest (say, a document regarding a gang importing drugs from Ciudad Juárez Mexico to Denver, which should be highly relevant to every city touching the southern half of I25.
• Often law enforcement officers want to search for documents near a certain type of landmark “near any elementary school in the school district”
“near a particular school”
“in a predominantly Hispanic neighborhood”
“near a freeway”
• Sometimes more convenient to interact with a map and use Solr's geospatial features. Sometimes more convenient to tag the documents with the relevant phrases.

Search Relevance for Law Enforcement Users
Advanced geospatial searches• Not having a lot of luck with Solr/Lucene here yet
• Often intersectingpolygons. Just off a I5
Walking distancefrom a Jr High School
• We do it in amore complexapp w/ Postgis. Would love to be
able to click a schoolor road on a map,and use that to filteror sort Solr results

Search Relevance for Law Enforcement
Temporal factors• Absolute time: Recent documents are often more interesting than
very old documents. Solr handles this well with
– Dismax's bf=”recip(ms(NOW,primary_date),3.16e-11,1,1)^2 ...”
– Edismax's boost=recip(ms(NOW,primary_date),3.16e-11,1,1)&boost=
– (unless you have expressions that can hit 0, edismax's multiplicative boost seem easier to balance against other boosting factors)
• Relative time: Gang retaliations often happen near each other in time. Can replace “NOW” in the above with some other date of interest.
• Time of day: Certain robbers and burglars like to work at certain times of the day (payday after work; dusk; at Raider's games). Can handle as a range facet, and/or by tagging documents with phrases for text
search

Search Relevance for Law Enforcement
Some parts of a document are more important than other parts
• A search for “John Doe” should rank documents where he's the Arrestee (or subject, etc) over those where he's an innocent bystander (or witness or victim, etc).
• Handled nicely by Solr's Dismax and edismax“qf=important_text^2 less_important_text”feature
Important parts of a document can depend a lot on the content of a document itself.
• For a sexual assault, characteristics of a victim like the victim's age and gender can be very "important", while the make/model of her car will be unimportant. For a vehicle theft, the age and gender of the victim will be more unimportant while make/model of the car will be more important.
• Handled reasonably by having logic in the indexer to place some data into different text fields; and by having the app server tweak the boosts in the qf= expression as needed

Search Relevance for Law Enforcement
Some documents are more important than others.• An active warrant on a person is more important
than an inactive one.• An unsolved homicide is more important than a
complaint about noise that was decided to be unfounded.
• A document with complete descriptions is more important (well, or at least more actionable) than a very incomplete form that was abandoned
Handled with the dismax: bf=sqrt(importance) parameter and similar edismax boost= paramters

Search Relevance for Law Enforcement
Exact matches with text from the source document is weighted more than speculative guesses from our algorithms.• We tag documents with additional terms that weren't necessarily in
the source document. Some of this is done by Solr
– Stemming
– Synonyms
Some approximations and guesses are done by our indexers– 6'4” -> 'tall'
– “lat = 37.799, lon = -122.161” -> “Near Skyline High School”
– 8:00pm → 'dusk'( at certain times of the year); 'night' (at others)
• But these additional tags carry less weight in ranking than the source document.
Handled well by solr's• “qf=source_document^10 stemmed_text^1 speculative_guesses^0.1”

Search Relevance for Law Enforcement
Keyword density matters• The Lucene SweetSpotSimilarity feature seems to
be give nicer results than the old default.• We're experimenting with our own that may work
better with our mixed-structured-unstructured content.

Disparate data
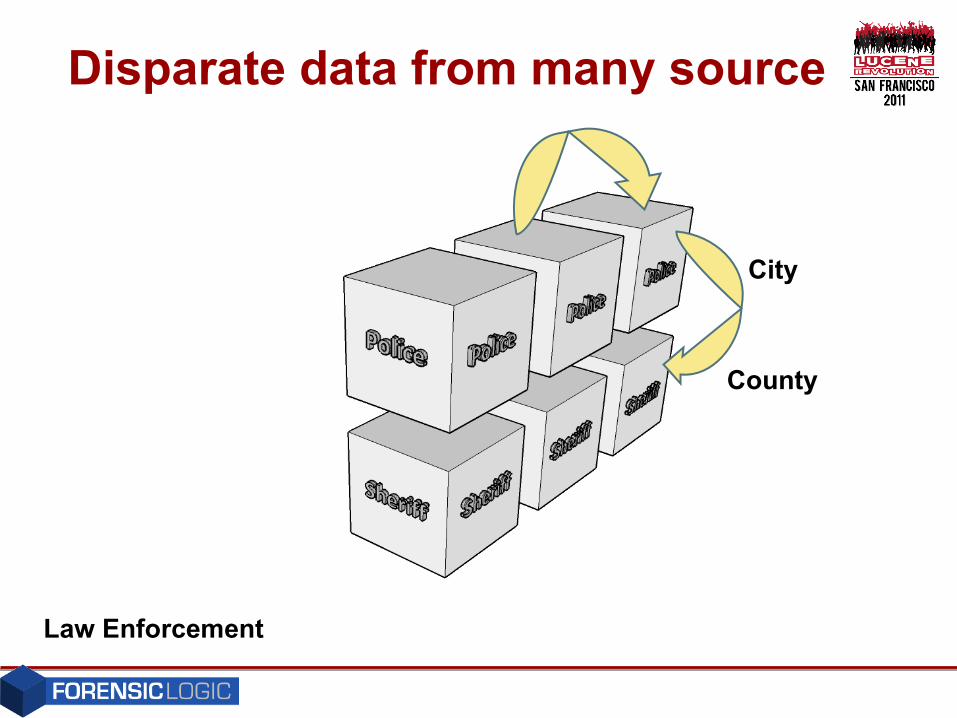
Disparate data from many source
County
City
Law Enforcement
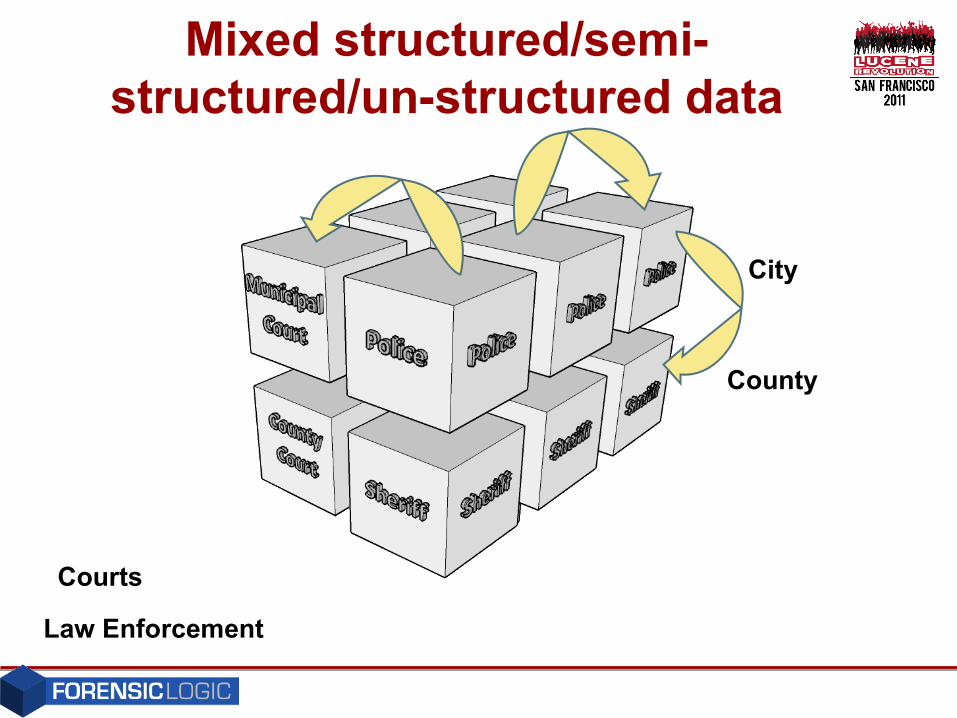
Mixed structured/semi-structured/un-structured data
County
City
Courts
Law Enforcement
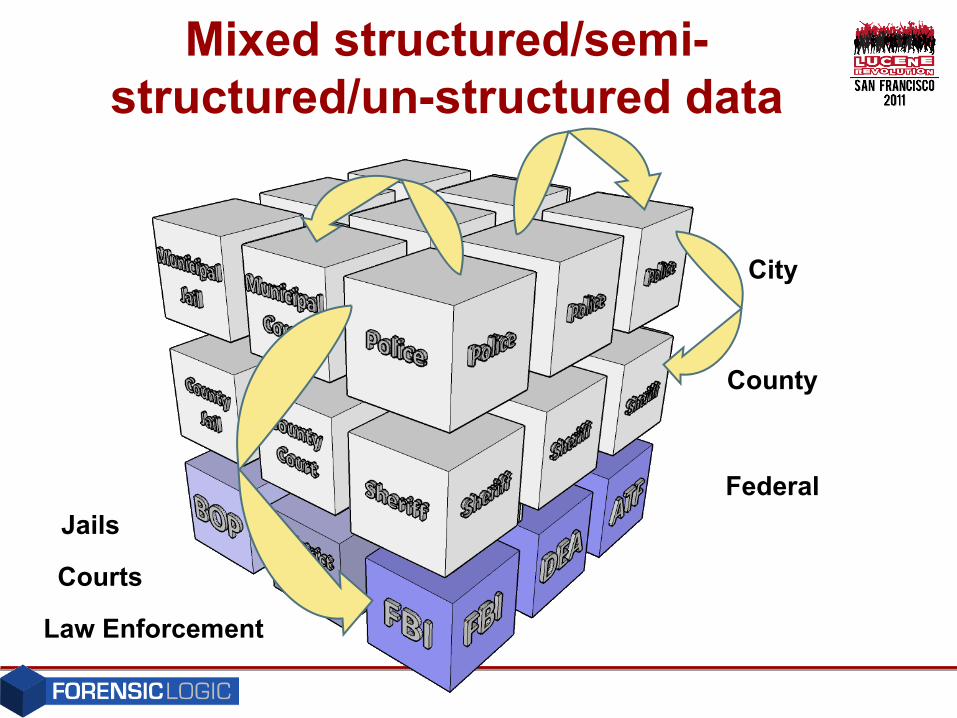
Mixed structured/semi-structured/un-structured data
County
City
Federal
Jails
Courts
Law Enforcement

Aren't there standards to deal with that?
XML, etc?

Aren't there standards to deal with that?
Or course! And the best part is there are many to choose from :)
Many federal efforts• GJXDM (“Global Justice XML Data Model”) 1.0, 2.0, 3.0.3 (2005)
• NIEM (outgrowth of GJXDM + DHS(FBI) + ODNI) NIEM 1.0 (2006) NIEM2.0 (2007) 2.1 (2009)
• LEXS – extends subsets of NIEM
• EDXL (DHS, EIC) “Emergency Data Exchange Language” Not really designed for law enforcement, but with data relevant
to police, and less US-centric in person names and addresses.
And many States define their own XML standards. (which are often Extensions to NIEM Subsets like the Texas Path to NIEM)

Aren't there standards to deal with that?
But many of our datasources aren't thatready to adopt federalstandards.
Small cities who's record management system is a folder of word documents.
Old mainframe computers where every developer has retired
Even when agencies using standardized XML, the most interesting content's not in the structured part.
“The first suspect is described as a tall, heavyset, light skinned black male, possibly half Italian, with 2 inch knots or dreads in his hair with a light brown mustache. He was in possession of a small caliber handgun.”

Aren't there standards to deal with that?
But many of our datasources aren't thatready to adopt federalstandards.
And some never will.

Mix of structured/semi-structured/un-structured data
Typical data we get Typical searches from our users• 'tall red haired blue eyed
teen male with dragon tattoo'
• '”Johnnie Doe” dallas'• 'Burglar broke rear
bedroom window, stole jewelry'
<?xml version="1.0" encoding="UTF-8"?><SomeXMLContainer> [... hundreds more lines...] <Incident> <nc:ActivityDate> <nc:DateTime>2007-01-01T10:00:00</nc:DateTime> </nc:ActivityDate> </Incident> [... hundreds more lines...] <tx:SubjectPerson s:id="Subject_id"> <nc:PersonBirthDate> <nc:Date>1970-01-01</nc:Date> </nc:PersonBirthDate> <nc:PersonEthnicityCode>N</nc:PersonEthnicityCode> <nc:PersonEyeColorCode>BLU</nc:PersonEyeColorCode> <nc:PersonHeightMeasure> <nc:MeasurePointValue>604</nc:MeasurePointValue> </nc:PersonHeightMeasure> <nc:PersonName> <nc:PersonGivenName>Jonathan</nc:PersonGivenName> <nc:PersonMiddleName>William</nc:PersonMiddleName> <nc:PersonSurName>Doe</nc:PersonSurName> <nc:PersonNameSuffixText>III</nc:PersonNameSuffixText> </nc:PersonName> <nc:PersonPhysicalFeature> <nc:PhysicalFeatureDescriptionText>Green Dragon Tattoo</nc:PhysicalFeatureDescriptionText> <nc:PhysicalFeatureLocationText>Arm</nc:PhysicalFeatureLocationText> </nc:PersonPhysicalFeature> <nc:PersonRaceCode>W</nc:PersonRaceCode> <nc:PersonSexCode>M</nc:PersonSexCode> <nc:PersonSkinToneCode>RUD</nc:PersonSkinToneCode> <nc:PersonHairColorCode>RED</nc:PersonHairColorCode> <nc:PersonWeightMeasure> <nc:MeasurePointValue>150</nc:MeasurePointValue> </nc:PersonWeightMeasure> [... dozens more lines of xml about the person ...] </tx:SubjectPerson> [... hundreds more lines of xml...] <tx:Location s:id="Subjects_Home_id"> <nc:LocationAddress> <nc:AddressFullText>1 Main St</nc:AddressFullText> <nc:StructuredAddress> <nc:LocationCityName>Dallas</nc:LocationCityName> <nc:LocationStateName>Texas</nc:LocationStateName> <nc:LocationCountryName>USA</nc:LocationCountryName> <nc:LocationPostalCode>54321</nc:LocationPostalCode>
<...

De-structuring structured data
Typical data we get Typical searches done by users• 'tall blue eyed teen male with
dragon tattoo'
• '”Johnnie Doe” “red hair” dallas'
One nice trick for solr: • Convert XML to English.
Jonathan Doe, a tall (6'4”) red haired blue eyed teen (17 year old) white male of Dallas TX was arrested at 1 Main St on Jan 1. Possible nicknames, johnny, william, bill, billy ...”
<?xml version="1.0" encoding="UTF-8"?><SomeXMLContainer> [... hundreds more lines...] <Incident> <nc:ActivityDate> <nc:DateTime>2007-01-01T10:00:00</nc:DateTime> </nc:ActivityDate> </Incident> [... hundreds more lines...] <tx:SubjectPerson s:id="Subject_id"> <nc:PersonBirthDate> <nc:Date>1990-01-01</nc:Date> </nc:PersonBirthDate> <nc:PersonEthnicityCode>N</nc:PersonEthnicityCode> <nc:PersonEyeColorCode>BLU</nc:PersonEyeColorCode> <nc:PersonHeightMeasure> <nc:MeasurePointValue>604</nc:MeasurePointValue> </nc:PersonHeightMeasure> <nc:PersonName> <nc:PersonGivenName>Jonathan</nc:PersonGivenName> <nc:PersonMiddleName>William</nc:PersonMiddleName> <nc:PersonSurName>Doe</nc:PersonSurName> <nc:PersonNameSuffixText>III</nc:PersonNameSuffixText> </nc:PersonName> <nc:PersonPhysicalFeature> <nc:PhysicalFeatureDescriptionText>Green Dragon Tattoo</nc:PhysicalFeatureDescriptionText> <nc:PhysicalFeatureLocationText>Arm</nc:PhysicalFeatureLocationText> </nc:PersonPhysicalFeature> <nc:PersonRaceCode>W</nc:PersonRaceCode> <nc:PersonSexCode>M</nc:PersonSexCode> <nc:PersonSkinToneCode>RUD</nc:PersonSkinToneCode> <nc:PersonHairColorCode>RED</nc:PersonHairColorCode> <nc:PersonWeightMeasure> <nc:MeasurePointValue>150</nc:MeasurePointValue> </nc:PersonWeightMeasure> [... dozens more lines of xml about the person ...] </tx:SubjectPerson> [... hundreds more lines of xml...] <tx:Location s:id="Subjects_Home_id"> <nc:LocationAddress> <nc:AddressFullText>1 Main St</nc:AddressFullText> <nc:StructuredAddress> <nc:LocationCityName>Dallas</nc:LocationCityName> <nc:LocationStateName>Texas</nc:LocationStateName> <nc:LocationCountryName>USA</nc:LocationCountryName> <nc:LocationPostalCode>54321</nc:LocationPostalCode> </nc:StructuredAddress> </nc:LocationAddress>
...

De-structuring structured data
Typical searches done by users• 'tall blue eyed teen male with dragon tattoo'
• '”Johnnie Doe” “red hair” Dallas'
Solution: • Convert XML to English.
“Jonathan Doe, a tall (6'4”) red haired blue eyed teen (17 year old) white male of Dallas TX was arrested at 1 Main St at 0456 Jan 1, 1999 (1999-01-01 04:56.) Possible nicknames, johnny, william, bill, billy ...”
• A little more subtle than that Terms generated by our speculative algorithms (possible nicknames,
'tall', etc) are put in a separate lower-weighted text field that the users can exclude when doing “exact match” searches.

De-structuring structured data
We've developed a pretty nice NIEM(*) to Human-friendly English Text tool that enables users uncomfortable with databases to search their agency's structured data much as they would google something.
Side benefit – easier to fit one text field on a mobile phone than search forms with many dozen fields.
* NIEM is a large government XML standard often used for law enforcement information exchange. Much of our data is sent to us in this format or closely related ones; and for other data sources we map it to NIEM as as early part of our import pipeline.

De-structuring structured data Another example – Vehicle VIN numbers
• Translate “1N19G9J100001”
• To “The VIN number suggests the vehicle a 1979 4-door Chevrolet (Chevy) Caprice”in one of our speculative-content fields.
• (but only if the document didn't already have this information)

De-structuring structured data Another example – GPS coordinates
• Translate “37.799,-122.161”
• To “Near Skyline HighSchool”in one of our speculative-content fields.
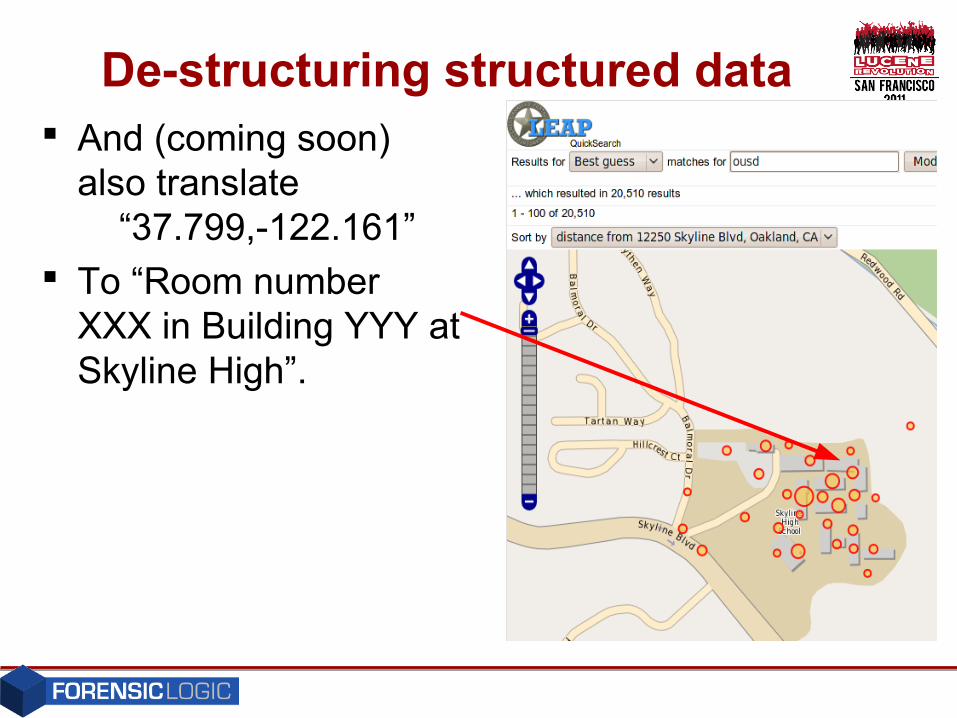
De-structuring structured data And (coming soon)
also translate “37.799,-122.161”
To “Room number XXX in Building YYY at Skyline High”.

Improving phrase searches
33

Improving phrase searches
Dismax's “pf” (Phrase Fields) and “ps” (Phrase Slop) are very useful.• pf = 'the "pf" param can be used to "boost" the
score of documents in cases where all of the terms in the "q" param appear in close proximity'
• ps = 'Amount of slop on phrase queries built for "pf" fields (affects boosting)'
34

Improving phrase searches
Dismax's “pf” (Phrase Fields) and “ps” (Phrase Slop) are very useful.• A high-boost “pf” with 0 “ps” is great for ensuring
that our very most relevant documents show up on the very top in search results.
• A modest-boost “pf” with a largeish “ps” (paragraph sized) is great for ensuring that quite relevant documents appear in the first page of results.
Examples:• If an exact phrase matches, it's probably the
document he's looking for.
• If a single paragraph contains all the words of a user's search, it's probably relevant too.
35

Improving phrase searches
Edismax's pf2 and pf3 are even more powerful.• A modest “pf2” with a relatively small “ps”
(about noun-clause sized) is excellent for searching for adjective/noun clauses.
Examples:• Document text: “The suspect was a tall thin teen
male wearing a red baseball cap and black leather jacket”
• Quite relevant for searches for “black jacket”, “tall male”, “leather jacket”, etc.
36

SOLR-2058 – best of both
So with some experimentation, for our docs:• We want a high pf with a very small (0) ps• We want a low pf with large ps• We want a moderate pf2 with moderate ps
Solution • SOLR-2058• ...&pf2=text^10~10&pf=text^100&pf=text~100• your constants may change depending how much
you weigh other boosting factors like document age or distance
37

SOLR-2058 – best of both
38
Scary Parsed Query: [... many dozen lines... ]DisjunctionMaxQuery((text_stem:"black leather"~1^50.0)~0.01) DisjunctionMaxQuery((text_stem:"leather jacket"~1^50.0)~0.01)) (DisjunctionMaxQuery((text_stem:"red basebal"~10^10.0)~0.01) DisjunctionMaxQuery((text_stem:"basebal cap"~10^10.0)~0.01) [... many dozens more lines...]
But it's fast enough in the end:
This worked pretty well for us when we first implemented: "pf" => "source_doc~1^500 text_stem~1^100 source_doc~50^50 text_stem~20^50", "pf3" => "text_unstem~1^250", "pf2" => "text_stem^50 text_stem~10^10 text_unstem~10^10", "ps" => 1,
org.apache.solr.handler.component.QueryComponent: time: 658.0

Alternatives that may work even better
39
This whole project started trying to boost adjectives connected to nouns• With document text like “Tall white heavyset male
suspect with eyes that looked blue or gray and red hair wearing a black and yellow jacket a hat that looked purple and a green dragon tattoo on his right arm using a knife with an orange handle”.
• And a search clause like 'white male, orange knife, black jacket' boosting this document appropriately.
Had an interesting conversation with one of this conference's sponsors about looking at the grammar to see which color goes with which noun.

Wrap Up
Law Enforcement has some pretty interesting challenges for finding the most relevant document.
Solr's a very nice tool for companies to get started with text search and tuning it for domain specific needs; thanks to nice projects already using it, and a very helpful community.
Solr's flexibility makes it easy to configure to even quite demanding requirements.
40

Thanks to the Community
Extremely helpful community!
Thanks to many in the Lucene community's help!!!
• Jayendra Patil-2
Who experienced a similar issue and pointed me to exactly where in the code they applied a similar patch.
• Yonik Seeley
Proposed a good syntax for the parameters, and politely critiqued my really ugly first implementation.
• Chris Hostetter
Voicing support for the syntax and gave encouraging comments
• Erik Hatcher
For Blacklight which introduced us to solr and powered our initial prototypes.
• Swapnonil Mukherjee, Nick Hall
Expressing interest in and trying the patches. “Sor-2058 allows for a dramatic increase in search relevance” - Nick
• Andy Jenkins and team at Ejustice
Another Lucene user we're working with who's giving me great advice how to further improve ranking
• Lucid Imagination
Thanks much for your free advice during early sales calls.
Thanks even more for your free support on mailing lists, IRC, etc.
41

Sources
Resource • http://leap.nctcog.org
Links• https://issues.apache.org/jira/browse/SOLR-2058
• https://github.com/ramayer/lucene-solr/tree/solr_2058_edismax_pf2_phrase_slop
White paper
42






























