Embed Size (px)
Citation preview

RWTH-‐Aachen, March 2011 HPC&A – UJI 1
Enrique S. Quintana-Ortí
Modern Linear Algebra Libraries for Graphics Processors

RWTH-‐Aachen, March 2011 HPC&A – UJI 2
Index
(Tentative) 1. Multi-threaded architectures 40m 2. Dense linear algebra for multi-core 40m 3. Programming in CUDA 40m 4. Dense linear algebra for GPUs 1,5h 5. Summary

RWTH-‐Aachen, March 2011 HPC&A – UJI 3
Index
1. Multi-threaded architectures 1. Evolution in processor performance 2. Multi-core processors 3. Multi-core processors vs. many-core GPUs 4. Present and future heterogeneity
2. Dense linear algebra for multi-core 3. Programming in CUDA 4. Dense linear algebra for GPUs 5. Summary

RWTH-‐Aachen, March 2011 HPC&A – UJI 4
Multi-threaded Architectures Evolution in Processor Performance
“Computer Architecture: A QuanMtaMve Approach” J. Hennessy, D. PaSerson, 2008

RWTH-‐Aachen, March 2011 HPC&A – UJI 5
Multi-threaded Architectures Evolution in Processor Performance
RISC Architectures: “The attack of the killer micros” (E. Brooks, 1989) or “Cray on a chip” (Intel i860) CMOS technology Pipelined and superscalar processors High frequency Large, multi-level cache memories SIMD FP units

RWTH-‐Aachen, March 2011 HPC&A – UJI 6
Multi-threaded Architectures Evolution in Processor Performance
“Computer Architecture: A QuanMtaMve Approach” J. Hennessy, D. PaSerson, 2008

RWTH-‐Aachen, March 2011 HPC&A – UJI 7
Multi-threaded Architectures Evolution in Processor Performance
“The free lunch is over” (H. Sutter, 2005)
Frequency wall Instruction-level parallelism (ILP) wall Memory wall

RWTH-‐Aachen, March 2011 HPC&A – UJI 8
Multi-threaded Architectures Evolution in Processor Performance
Frequency wall (end of the GHz race):
Energy consumption proportional to f2 Electricity is expensive and produces heat

RWTH-‐Aachen, March 2011 HPC&A – UJI 9
Multi-threaded Architectures Evolution in Processor Performance
ILP wall:
On average, 1 branch every 5 instructions Control hazards block the pipeline Branch prediction is costly
IF ID EX WB
IF ID EX WB
IF ID EX WB
IF ID EX WB
RWTH-‐Aachen, March 2011 HPC&A – UJI 10
Multi-threaded Architectures Evolution in Processor Performance
Memory wall: Memory access
latency has not changed: 1 memory access ≈ 240 cycles (2008)
By design, large caches are slow

RWTH-‐Aachen, March 2011 HPC&A – UJI 11
Multi-threaded Architectures Evolution in Processor Performance
…but Moore’s Law still holds
≡ The number of transistors that can be integrated in a chip (with a constant cost) is doubled every
1.5-2 years
"Cramming more components onto integrated circuits", G. E. Moore, 1965: The complexity for minimum component costs has increased at a rate of roughly a factor of two per year ... Certainly over the short term this rate can be expected to conEnue, if not to increase. Over the longer term, the rate of increase is a bit more uncertain, although there is no reason to believe it will not remain nearly constant for at least 10 years. That means by 1975, the number of components per integrated circuit for minimum cost will be 65,000. I believe that such a large circuit can be built on a single wafer.

RWTH-‐Aachen, March 2011 HPC&A – UJI 12
Multi-threaded Architectures Evolution in Processor Performance
What can we do with these transistors? Smaller chips to increase frequency? More complex architectures to further exploit ILP? Larger caches to hide memory latency?
NO!

RWTH-‐Aachen, March 2011 HPC&A – UJI 13
Multi-threaded Architectures Multi-core Processors
Performance
1980 2005 2015? 2025?? 2035???
Single thread performance More acMve transistors Higher frequency
P. Hofstee, IBM AusMn
MulM-‐core processors More acMve transistors Higher frequency
Exploit ILP: Minimize response Mme
Exploit TLP: While a thread Is blocked waiMng for memory, execute an alternaMve ready thread Maximize throughput

RWTH-‐Aachen, March 2011 HPC&A – UJI 14
Multi-threaded Architectures Multi-core Processors
The race for the multi-core:
DELL PowerEdge C6145: Two four-sockets servers in a 2U chassis with Opteron 12-core processors =
96 cores!
Processor #cores f (GHz) L3 (MB) Power (W)
Intel Xeon X7560 8 2,66 24 130 AMD Opteron 12 2,5 12 105

RWTH-‐Aachen, March 2011 HPC&A – UJI 15
Multi-threaded Architectures Multi-core Processors vs. Many-core GPUs
Performane
1980 2005 2015? 2025?? 2035???
Single thread performance More acMve transistors Higher frequency
Heterogeneous processors More acMve transistors Higher frequency
Specialized processors More acMve transistors Higher frequency
P. Hofstee, IBM AusMn
MulM-‐core processors More acMve transistors Higher frequency

RWTH-‐Aachen, March 2011 HPC&A – UJI 16
Multi-threaded Architectures Multi-core Processors vs. Many-core GPUs
The race for the many-core:
Tesla S2050: four Tesla C2070 in a 1U chassis = 1,792 cores!
Processor #cores f (GHz) Memory (GB)
Power (W)
Tesla C2070 (Fermi) 448 1,15 6 238 AMD Firestream 9270
800 ? 2 <220

RWTH-‐Aachen, March 2011 HPC&A – UJI 17
Multi-threaded Architectures Multi-core Processors vs. Many-core GPUs
Intel Nehalem

RWTH-‐Aachen, March 2011 HPC&A – UJI 18
Multi-threaded Architectures Multi-core Processors vs. Many-core GPUs
NVIDIA GT200 Building block: SM 8 scalar processors 1 DP FP unit 16 Kbytes of shared-memory Register bank (16,384.64 Bytes)
ALU
Shared-‐memory
ALU
ALU ALU
ALU ALU
ALU ALU

RWTH-‐Aachen, March 2011 HPC&A – UJI 19
Multi-threaded Architectures Multi-core Processors vs. Many-core GPUs
NVIDIA GT200 30 SM 240 SP “cores”

RWTH-‐Aachen, March 2011 HPC&A – UJI 20
Multi-threaded Architectures Multi-core Processors vs. Many-core GPUs
CPU
Large caches Few processing elements Tuned for spatial/temporal locality Sophisticated control
GPU
Small caches High number of processing elements Tuned for sequential access to data
(streaming)
Control ALU
Cache
DRAM
ALU
ALU
ALU
DRAM
ALUs

RWTH-‐Aachen, March 2011 HPC&A – UJI 21
Multi-threaded Architectures Present and Future Heterogeneity
Heterogeneous platforms
CPU
RAM
GPU
GPU RAM PCI-‐E: 1-‐8GB/s
20-‐160 GB/s 6-‐30 GB/s
ALUs Cache 40 GB/s

RWTH-‐Aachen, March 2011 HPC&A – UJI 22
Multi-threaded Architectures Present and Future Heterogeneity
NVIDIA Denver (2011/05/01):
CPU with ARM instruction set integrated into the same chip as GPU
AMD Fusion APU: x86 compatible CPU with programmable vector processing engines on a single chip

RWTH-‐Aachen, March 2011 HPC&A – UJI 23
Index
1. Multi-threaded architectures 40m? 2. Dense linear algebra for multi-core
1. Operations 2. BLAS 3. LAPACK 4. High performance
3. Programming in CUDA 4. Dense linear algebra for GPUs 5. Summary

RWTH-‐Aachen, March 2011 HPC&A – UJI 24
Dense Linear Algebra for Multi-core Operations
Dense linear algebra is at the bottom of the food chain for many scientific/engineering apps.
Molecular dynamics simulations Fast acoustic scattering problems Dielectric polarization of nanostructures Magneto-hydrodynamics Macro-economics

RWTH-‐Aachen, March 2011 HPC&A – UJI 25
Dense Linear Algebra for Multi-core Operations
Radar cross-section problem (via BEM)
Solve A x = b dense A → n x n n = hundreds of thousands of boundary points (or panels)

RWTH-‐Aachen, March 2011 HPC&A – UJI 26
Dense Linear Algebra for Multi-core Operations
Estimation of Earth’s gravity field
www.csr.utexas.edu/grace
Solve y = H x0 + Є, dense H → m x n m = 66.000 observations n = 26.000 parameters for a model of resolution 250km

RWTH-‐Aachen, March 2011 HPC&A – UJI 27
Dense Linear Algebra for Multi-core Operations
Optimal cooling of steel profiles
Solve AT X + X A – X S X
+ Q = 0,
dense A → n x n n = 5.177 for a mesh width of 6.91·10-3

RWTH-‐Aachen, March 2011 HPC&A – UJI 28
Dense Linear Algebra for Multi-core BLAS (Basic Linear Algebra Subprograms)
What is BLAS? Routines that provide standard building blocks for
performing basic vector and matrix operations
Why BLAS? Scientific/engineering apps. often use these kernels.
Standardizing the BLAS interfaces allows: Highly tuned, hardware-specific implementations of BLAS Easy to recognize functions, less errors Portability of scientific codes without sacrificing performance

RWTH-‐Aachen, March 2011 HPC&A – UJI 29
Dense Linear Algebra for Multi-core BLAS (Basic Linear Algebra Subprograms)
Implementations of BLAS? Multi-threaded? IBM ESSL, Intel MKL, AMD ACML, NVIDIA CUBLAS K. Goto’s GotoBLAS2, C. Whaley’s ATLAS
Organization of BLAS BLAS-1. O(n) flops on O(n) data: SCAL, AXPY, DOT,… BLAS-2. O(n2) flops on O(n2) data: GEMV, TRSV,… BLAS-3. O(n3) flops on O(n2) data: GEMM, SYRK, TRSM,…
Functionality of BLAS google: BLAS quick reference guide

RWTH-‐Aachen, March 2011 HPC&A – UJI 30
Dense Linear Algebra for Multi-core BLAS (Basic Linear Algebra Subprograms)
Example of BLAS-1: y := y + α x,
α ∈ ℜ, x,y ∈ ℜn
SUBROUTINE DAXPY(N,DA,DX,INCX,DY,INCY) * .. Scalar Arguments .. DOUBLE PRECISION DA INTEGER INCX,INCY,N * .. * .. Array Arguments .. DOUBLE PRECISION DX(*),DY(*)

RWTH-‐Aachen, March 2011 HPC&A – UJI 31
Dense Linear Algebra for Multi-core BLAS (Basic Linear Algebra Subprograms)
Example of BLAS-2: y := β y + α A x,
α ,β ∈ ℜ, A ∈ ℜmxn, x ∈ ℜn, y ∈ ℜm
SUBROUTINE DGEMV(TRANS,M,N,ALPHA,A,LDA,X,INCX,BETA,Y,INCY) * .. Scalar Arguments .. DOUBLE PRECISION ALPHA,BETA INTEGER INCX,INCY,LDA,M,N CHARACTER TRANS * .. * .. Array Arguments .. DOUBLE PRECISION A(LDA,*),X(*),Y(*)

RWTH-‐Aachen, March 2011 HPC&A – UJI 32
Dense Linear Algebra for Multi-core BLAS (Basic Linear Algebra Subprograms)
Example of BLAS-3: C := β C + α A B, α, β ∈ ℜ, A ∈ ℜmxk, B ∈ ℜkxn, C ∈ ℜmxn
SUBROUTINE DGEMM(TRANSA,TRANSB,M,N,K,ALPHA,A,LDA,B,LDB,BETA,C,LDC) * .. Scalar Arguments .. DOUBLE PRECISION ALPHA,BETA INTEGER K,LDA,LDB,LDC,M,N CHARACTER TRANSA,TRANSB * .. * .. Array Arguments .. DOUBLE PRECISION A(LDA,*),B(LDB,*),C(LDC,*)

RWTH-‐Aachen, March 2011 HPC&A – UJI 33
Dense Linear Algebra for Multi-core BLAS (Basic Linear Algebra Subprograms)
Data types: Real/complex, single/double precision:
SGEMV, DGEMV, CGEMV, ZGEMV,…
Matrix types General, symmetric, triangular, band,…:
SGEMV, SSYMV, STRMV, SBDMV,…

RWTH-‐Aachen, March 2011 HPC&A – UJI 34
Dense Linear Algebra for Multi-core LAPACK (Linear Algebra Package)
Builds upon BLAS to provide more complex functionality Systems of linear equations Linear least-squares problems Eigenvalues and singular values

RWTH-‐Aachen, March 2011 HPC&A – UJI 35
Dense Linear Algebra for Multi-core High Performance
Three main sources of inefficiency in the exploitation of multi-core processors: Memory latency Load imbalance Serial bottlenecks
It also holds for GPUs!

RWTH-‐Aachen, March 2011 HPC&A – UJI 36
Dense Linear Algebra for Multi-core High Performance
Memory latency The fundamental obstacle to high performance (executing useful computations at the rate at which the CPU can process) is the speed of memory: fetching and/or storing a data item from/to the memory requires more time than it takes to perform a flop with it
Small Registers
Cache
RAM Slow Large
Fast

RWTH-‐Aachen, March 2011 HPC&A – UJI 37
Dense Linear Algebra for Multi-core High Performance
Impact of cache misses in performance:
laptop$ cat /proc/cpuinfo processor : 0 ... model name : Intel(R) Core(TM)2 Duo CPU P8400 @ 2.26GHz cpu cores : 2 ... laptop$ cat /proc/cpuinfo MemTotal: 3079028 kB ... google: "Intel Core 2 Duo P8400" -‐-‐> 3 MB L2 cache, 2.26 GHz, 1066 MHz FSB
Peak performance is 2 cores × 2.26 ·109 cycles/sec. × 2 flops/cycle = 9.04 GFLOPS

RWTH-‐Aachen, March 2011 HPC&A – UJI 38
Dense Linear Algebra for Multi-core High Performance
>> time_gemv n 100 Time (secs.) 2.9543e-‐05 GFLOPS 6.7698e-‐01 n 200 Time (secs.) 5.9113e-‐05 GFLOPS 1.3533e+00 n 300 Time (secs.) 1.0537e-‐04 GFLOPS 1.7082e+00
Why only 2 GFLOPS?
Why the “hunch”?

RWTH-‐Aachen, March 2011 HPC&A – UJI 39
Dense Linear Algebra for Multi-core High Performance
Matrix-matrix product has the potential of hiding memory latency!
Opera&on flops memops flops/memops
Vector-‐vector
AXPY y := y + α x 2n 3n 2/3
Matrix-‐vector
GEMV y := β y + α A x 2n2 n2 2/1
Matrix-‐matrix
GEMM C := β C + α A B 2n3 4n2 n/2

RWTH-‐Aachen, March 2011 HPC&A – UJI 40
Dense Linear Algebra for Multi-core High Performance
Naïve implementation: sequence of matrix-vector products
+=
C A B
… …
for (j=0; j<n; j++) for (i=0; i<n; i++) for (k=0; k<n; k++) C[i][j] += A[i][k] * B[k][j];

RWTH-‐Aachen, March 2011 HPC&A – UJI 41
Dense Linear Algebra for Multi-core High Performance
>> time_gemm n 100 Time (secs.) 2.9543e-‐05 GFLOPS 6.7698e-‐01 n 200 Time (secs.) 5.9113e-‐05 GFLOPS 1.3533e+00 n 300 Time (secs.) 1.0537e-‐04 GFLOPS 1.7082e+00
Mimics the performance of matrix-vector product!

RWTH-‐Aachen, March 2011 HPC&A – UJI 42
Dense Linear Algebra for Multi-core High Performance
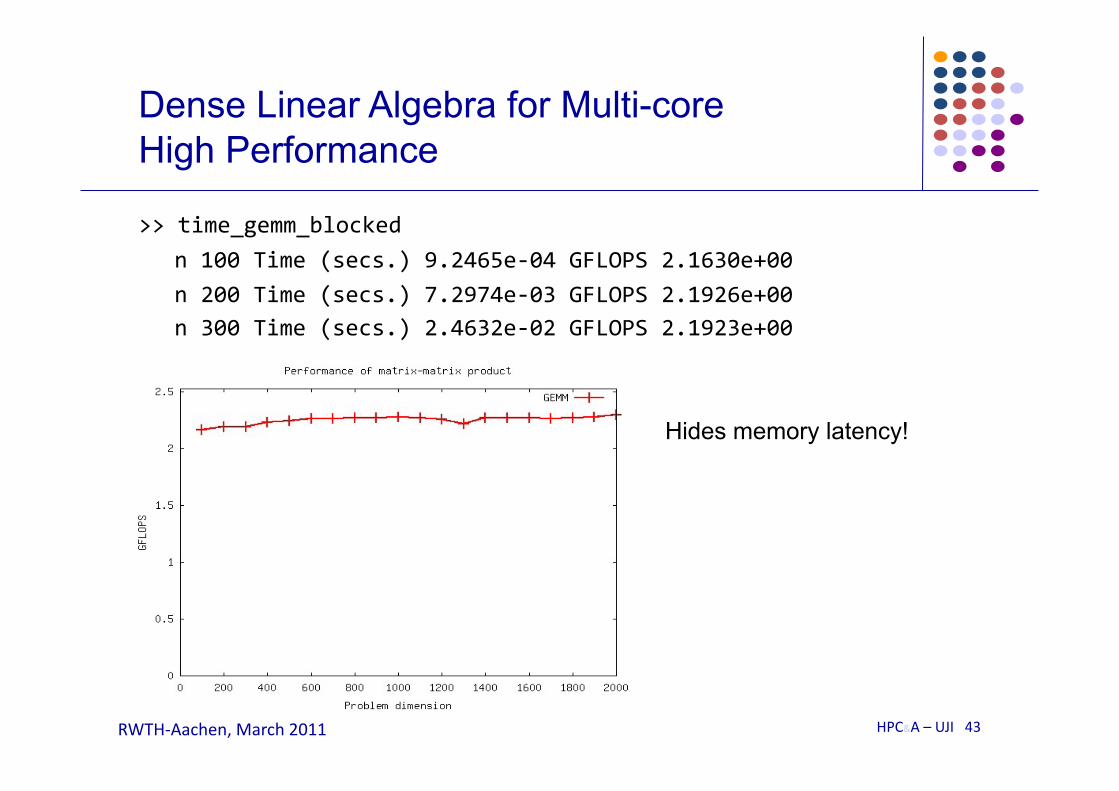
Blocked implementation:
Keep in cache during the whole sequence of updates!
RWTH-‐Aachen, March 2011 HPC&A – UJI 43
Dense Linear Algebra for Multi-core High Performance
>> time_gemm_blocked n 100 Time (secs.) 9.2465e-‐04 GFLOPS 2.1630e+00 n 200 Time (secs.) 7.2974e-‐03 GFLOPS 2.1926e+00 n 300 Time (secs.) 2.4632e-‐02 GFLOPS 2.1923e+00
Hides memory latency!

RWTH-‐Aachen, March 2011 HPC&A – UJI 44
Dense Linear Algebra for Multi-core High Performance
Load imbalance and serial bottlenecks Distribute the computational load evenly among the cores and push forward the execution of the work in the critical path

RWTH-‐Aachen, March 2011 HPC&A – UJI 45
Dense Linear Algebra for Multi-core High Performance
Cholesky factorization (LAPACK)
Key in the solution of s.p.d. linear systems A x = b ≡ (LLT)x = b L y = b ⇒ y LT x = y ⇒ x
A = * L LT
RWTH-‐Aachen, March 2011 HPC&A – UJI 46
Dense Linear Algebra for Multi-core High Performance
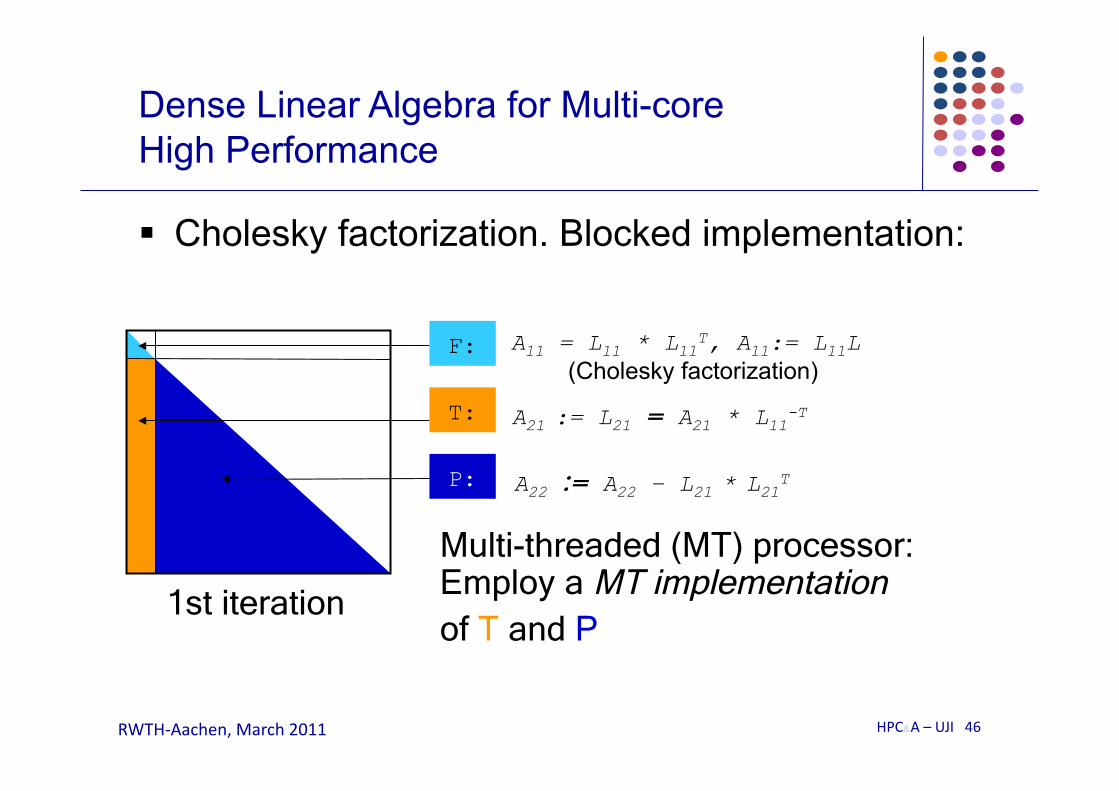
Cholesky factorization. Blocked implementation:
A11 = L11 * L11T, A11:= L11L (Cholesky factorization)
F:
A21 := L21 = A21 * L11-T T:
A22 := A22 – L21 * L21T P:
Multi-threaded (MT) processor: Employ a MT implementation of T and P
1st iteration

RWTH-‐Aachen, March 2011 HPC&A – UJI 47
Dense Linear Algebra for Multi-core High Performance
Cholesky factorization. n3/3 flops vs. n2 memops
…
1st iteration 2nd iteration 3rd iteration

RWTH-‐Aachen, March 2011 HPC&A – UJI 48
Dense Linear Algebra for Multi-core High Performance
Cholesky factorization. Performance
Intel Xeon Quad-Core @ 2.3 GHz (8 cores)
MKL 10.1
Why? 71% peak
57% peak
80% peak

RWTH-‐Aachen, March 2011 HPC&A – UJI 49
Dense Linear Algebra for Multi-core High Performance
Cholesky factorization. Sequential bottlenecks!
…
1st iteration 2nd iteration 3rd iteration

RWTH-‐Aachen, March 2011 HPC&A – UJI 50
Dense Linear Algebra for Multi-core High Performance
Cholesky factorization. There is more parallelism!
1st iteration
Inside the same iteration
2nd iteration
In different iterations

RWTH-‐Aachen, March 2011 HPC&A – UJI 51
Dense Linear Algebra for Multi-core High Performance
Exploit task-level parallelism dictated by data dep.
Dependencies among tasks define a tree
…
for (k=0; k<nb; k++){
Chol(A[k,k]);
for (i=k+1; i<nb; i++)
Trsm(A[k,k], A[i,k]); …
DAG: Dependency Acyclic Graph

RWTH-‐Aachen, March 2011 HPC&A – UJI 52
Dense Linear Algebra for Multi-core High Performance
Run-time: Identifies/extracts Task-level Parallelism (TLP) Schedules tasks to execution Maps tasks onto specific cores
ISS N0
N1
N2
→ …

RWTH-‐Aachen, March 2011 HPC&A – UJI 53
Dense Linear Algebra for Multi-core High Performance
Cholesky factorization. Performance
AMD Dual-Core @ 2.0 GHz (16 cores)
MKL 10.1

RWTH-‐Aachen, March 2011 HPC&A – UJI 54
Index
1. Multi-threaded architectures 2. Dense linear algebra for multi-core 40m? 3. Programming in CUDA
1. Preliminaries 2. A simple kernel 3. Parallel programming
4. Dense linear algebra for GPUs 5. Summary

RWTH-‐Aachen, March 2011 HPC&A – UJI 55
Programming in CUDA Preliminaries
The origins of CUDA Beginning of 1990s: use of 2D display accelerators 1992: Silicon Graphics opens OpenGL Mid-1990s: Boost of gaming market 2001: GeForce 3 with programmable vertex and pixel
shaders (DirectX) 2006: GeForce 8800 GTX, first GPU with CUDA

RWTH-‐Aachen, March 2011 HPC&A – UJI 56
Programming in CUDA Preliminaries
To use CUDA, you will need… A CUDA-enabled GPU (Nov. 2006 GeForce 8800
GTX or more recent) An NVIDIA device driver (allows user’s programs to
communicate with CUDA hardware) A CUDA development kit (includes a compiler for
GPU code) A standard C compiler (to compile CPU code)

RWTH-‐Aachen, March 2011 HPC&A – UJI 57
Programming in CUDA A Simple Kernel
Scalar addition: c := a + b, a,b,c ∈ ℜ
__global__ void scalar_addition( float a, float b, float *c ) { *c = a + b; }
int main( void ) { float a_h = 5.0, b_h = 3.0, c_h, *c_d;
cudaMalloc( (void**) &c_d, sizeof(float) ) ); scalar_addition<<<1,1>>>( a_h, b_h, c_d ); cudaMemcpy( &c_h, c_d, sizeof(float), cudaMemcpyDeviceToHost ); printf( “%g + %g = %g\n", a_h, b_h, c_h ); cudaFree( c_d );
return 0; }

RWTH-‐Aachen, March 2011 HPC&A – UJI 58
Programming in CUDA A Simple Kernel
Scalar addition: c := a + b, a,b,c ∈ ℜ
__global__ void scalar_addition( float a, float b, float *c ) { *c = a + b; }
int main( void ) { float a_h = 5.0, b_h = 3.0, c_h, *c_d;
cudaMalloc( (void**) &c_d, sizeof(float) ) ); scalar_addition<<<1,1>>>( a_h, b_h, c_d ); cudaMemcpy( &c_h, c_d, sizeof(float), cudaMemcpyDeviceToHost ); printf( “%g + %g = %g\n", a_h, b_h, c_h ); cudaFree( c_d );
return 0; }
Allocate memory for float number in
GPU
IdenMfies CUDA kernel (code to be executed on GPU)
Free memory for float number in
GPU

RWTH-‐Aachen, March 2011 HPC&A – UJI 59
Programming in CUDA A Simple Kernel
Scalar addition: c := a + b, a,b,c ∈ ℜ
__global__ void scalar_addition( float a, float b, float *c ) { *c = a + b; }
int main( void ) { float a_h = 5.0, b_h = 3.0, c_h, *c_d;
cudaMalloc( (void**) &c_d, sizeof(float) ) ); scalar_addition<<<1,1>>>( a_h, b_h, c_d ); cudaMemcpy( &c_h, c_d, sizeof(float), cudaMemcpyDeviceToHost ); printf( “%g + %g = %g\n", a_h, b_h, c_h ); cudaFree( c_d );
return 0; }
Invoke execuMon of kernel in GPU. Parameters transferred
automaMcally to device memory
Retrieve data back to host memory

RWTH-‐Aachen, March 2011 HPC&A – UJI 60
Programming in CUDA A Simple Kernel
scalar_addition.cu Compiler (nvcc, invoking naMve C
compiler)
CPU: scalar_addition.o GPU: scalar_addition.o
Linker
scalar_addition.x

RWTH-‐Aachen, March 2011 HPC&A – UJI 61
Programming in CUDA A Simple Kernel
Interleaved execution: CPU, GPU, CPU,…
int main( void ) { Fragment of CPU code GPU_kernel1<<a,b>>(k1,k2,…); Fragment of CPU code GPU_kernel2<<c,d>>(i1,i2,…); Fragment of CPU code GPU_kernel3<<e,f>>(j1,j2,…); Fragment of CPU code ... }
CPU
GPU

RWTH-‐Aachen, March 2011 HPC&A – UJI 62
Programming in CUDA A Simple Kernel
Summary: CUDA C looks much like standard C (with extensions) The GPU is passive. It does what the CPU (via a
kernel call) instructs it to do The runtime takes care of transferring kernel
parameters to GPU memory Memory must be allocated/deallocated in GPU
memory via appropriate calls Do not dereference pointers to GPU memory in host!

RWTH-‐Aachen, March 2011 HPC&A – UJI 63
Programming in CUDA Parallel programming
Vector addition: vc := va + vb, va,vb,vc ∈ ℜn
#define N 256
int main( void ) { float va_h[N], vb_h[N], vc_h[N], a_d, b_d, c_d; // Initialize va_h, vb_h, vc_h…
// Allocate space for va_d, vb_d, vc_d in device memory cudaMalloc( (void**) &va_d, N*sizeof(float) ) );
// Transfer contents of va_h, vb_h, vc_h from host to device cudaMemcpy( va_d, va_h, N*sizeof(float), cudaMemcpyHostToDevice ); ...

RWTH-‐Aachen, March 2011 HPC&A – UJI 64
Programming in CUDA Parallel programming
Vector addition: vc := va + vb, va,vb,vc ∈ ℜn
... vector_addition<<<N,1>>>( va_d, vb_d, vc_d );
// Retrieve results back to host memory cudaMemcpy( vc_h, vc_d, N*sizeof(float), cudaMemcpyDeviceToHost );
for (i=0; i<N; i++) printf( “%g + %g = %g\n", va_h[i], vb_h[i], vc_h[i] );
// Free memory in device for va_d, vb_d, vc_d cudaFree( va_d ); ... return 0; }
N copies of the kernel are executed
on the GPU!
Goal: each copy adds two
components of the vectors

RWTH-‐Aachen, March 2011 HPC&A – UJI 65
Programming in CUDA Parallel programming
Vector addition: vc := va + vb, va,vb,vc ∈ ℜn
Data parallelism or SIMD programming model!
__global__ void vector_addition( float *va, float *vb, float *vc ) { int tid = blockIdx.x; if (tid < N)
vc[tid] = va[tid] + vb[tid]; }
Built-‐in variable of CUDA runMme
Index of CUDA thread running this
kernel

RWTH-‐Aachen, March 2011 HPC&A – UJI 66
Programming in CUDA Parallel programming
CPU vs. GPU (CUDA)
void vector_addition( float va[], float vb[], float vc[] ) { int i; for (i=0; i<N; i++) vc[i] = va[i] + vb[i]; }
__global__ void vector_addition( float *va, float *vb, float *vc ) { int tid = blockIdx.x; if (tid < N)
vc[tid] = va[tid] + vb[tid]; }

RWTH-‐Aachen, March 2011 HPC&A – UJI 67
Programming in CUDA Parallel programming
Summary: A CUDA kernel is executed by an array of threads
All threads execute the same code Each thread has a unique identifier (blockIdx.x,…) Creating/destroying threads is extremely cheap
0 1 2 3 4 5 6 7
int tid = blockIdx.x; if (tid < N) vc[tid] = va[tid] + vb[tid];
0 1 2 3 4 5 6 7
KERNEL

RWTH-‐Aachen, March 2011 HPC&A – UJI 68
Programming in CUDA Parallel programming
Threads are organized hierarchically Threads are grouped into blocks: threadIdx, blockDim Blocks are grouped into grids: gridDim, blockIdx
Block (0,0) Block (1,0) Block (2,0)
Block (0,1) Block (1,1) Block (2,1)
Grid 1
Thread (0,0)
Thread (1,0)
Thread (2,0)
Thread (3,0)
Thread (0,1)
Thread (1,2)
Thread (2,1)
Thread (3,1)
Thread (0,2)
Thread (1,2)
Thread (2,2)
Thread (3,2)
Block (2,0)
blockDim.x
gridDim.x
gridDim
.y
blockD
im.y

RWTH-‐Aachen, March 2011 HPC&A – UJI 69
Programming in CUDA Parallel programming
Exercise. Matrix addition: MC := MA + MB, MA,MB,MC ∈ ℜnxn
#define M 256 #define N 16
int main( void ) { … matrix_addition<<<???,???>>>( MA_d, MB_d, MC_d ); }
__global__ void matrix_addition( float *MA, float *MB, float *MC ) { ??? }

RWTH-‐Aachen, March 2011 HPC&A – UJI 70
Programming in CUDA Parallel programming
All kernel invocations are asynchronous Control returns to CPU before the kernel is completed
Explicit blocking cudaThreadSynchronize();
Memory copies are synchronous, though there are also asynchronous versions (overlap computation and communication!)

RWTH-‐Aachen, March 2011 HPC&A – UJI 71
Programming in CUDA Parallel programming
Developing efficient CUDA code is far from trivial! Memory is controlled by user and is key to high
performance Use fast shared memory Coalesced accesses Avoid conflicts
Avoid frequent transfer of small messages through PCI-E Overlap computation and communication Maximize flops/memops ratio Avoid branching in CUDA code Etc.

RWTH-‐Aachen, March 2011 HPC&A – UJI 72
Index
1. Multi-threaded architectures 40m? 2. Dense linear algebra for multi-core 40m? 3. Programming in CUDA 40m?
4. Dense linear algebra for GPUs 1. Preliminaries 2. CUBLAS 3. Building on top of CUBLAS 4. Multi-GPU platforms
5. Summary

RWTH-‐Aachen, March 2011 HPC&A – UJI 73
Dense Linear Algebra for GPUs Preliminaries
Matrices are logically viewed as a 2-D data structure, but in memory they are stored in 1-D, by rows or by columns:
Because Fortran-77 was the standard language to program scientific codes for many decades, numerical libraries assume storage in column major order (Fortran-like). Be careful when using these libraries from C!

RWTH-‐Aachen, March 2011 HPC&A – UJI 74
Dense Linear Algebra for GPUs Preliminaries
All parameters passed by reference:
Invoked from C program:
SUBROUTINE SGEMV(TRANS,M,N,ALPHA,A,LDA,X,INCX,BETA,Y,INCY) * .. Scalar Arguments .. REAL ALPHA,BETA INTEGER INCX,INCY,LDA,M,N CHARACTER TRANS * .. * .. Array Arguments .. REAL A(LDA,*),X(*),Y(*)
int m, n, incx, incy, lda; float alpha, beta, x, y, A;
// Initializations: m, n, alpha, beta, A, lda, x, y, incx, incy sgemv(”No transpose”, &m, &n, &alpha, A, &lda, x, &incx, &beta, y, &incy );

RWTH-‐Aachen, March 2011 HPC&A – UJI 75
Dense Linear Algebra for GPUs Preliminaries
BLAS assumes matrices stored in column major order, but C compilers generate row major order
Fortran indices start at 1, but C at 0 A useful trick: store Fortran-like structures in C vectors:
#define Aref ( a1, a2 ) A[ (a1−1)*Alda + (a2−1) ] #define xref ( a ) x[ (a−1) ] #define yref ( a ) y[ (a−1) ]
float A[MN], x[N], y[M]; int Alda = M; … for (i=1; i<=M; i++){ tmp = yref( i ) ; for (j =1; j<=N; j++) tmp += Aref( i, j ) xref ( j ) ; yref( i ) = tmp ; }

RWTH-‐Aachen, March 2011 HPC&A – UJI 76
Dense Linear Algebra for GPUs CUBLAS
Programming dense linear algebra libraries on heterogeneous CPU+GPU architectures Multiple address spaces without hardware coherence (as difficult
as message-passing) Scheduling on heterogeneous resources (also much harder) Possibly, more than one accelerator per node Take advantage of single precision speed-up: iterative
refinement

RWTH-‐Aachen, March 2011 HPC&A – UJI 77
Dense Linear Algebra for GPUs CUBLAS
Requires initialization/termination: #include "cublas.h"
cublasStatus cublasInit(); enum cublasStatus CUBLAS_STATUS_SUCCESS CUBLAS_STATUS_NOT_INITIALIZED CUBLAS CUBLAS_STATUS_ALLOC_FAILED CUBLAS_STATUS_INVALID_VALUE CUBLAS_STATUS_ARCH_MISMATCH CUBLAS_STATUS_MAPPING_ERROR CUBLAS_STATUS_EXECUTION_FAILED CUBLAS_STATUS_INTERNAL_ERROR
cublasStatus cublasShutdown();

RWTH-‐Aachen, March 2011 HPC&A – UJI 78
Dense Linear Algebra for GPUs CUBLAS
Other interesting routines (wrappers in fortran.c): int CUBLAS_SET_MATRIX( const int *rows, const int *cols, const int *elemSize, const void *A, const int *lda, const devptr_t *B, const int *ldb ) int CUBLAS_GET_MATRIX( ... )
int CUBLAS_SET_VECTOR( ... )
int CUBLAS_GET_VECTOR( ... )

RWTH-‐Aachen, March 2011 HPC&A – UJI 79
Dense Linear Algebra for GPUs CUBLAS
Same functionality and interface as standard BLAS
No need to pass parameters by reference!
SUBROUTINE SGEMV(TRANS,M,N,ALPHA,A,LDA,X,INCX,BETA,Y,INCY) * .. Scalar Arguments .. REAL ALPHA,BETA INTEGER INCX,INCY,LDA,M,N CHARACTER TRANS * .. * .. Array Arguments .. REAL A(LDA,*),X(*),Y(*)
void cublasSgemv( char trans, int m, int n, float alpha, const float *A, int lda, const float *x, int incx, float beta, float *y, int incy);

RWTH-‐Aachen, March 2011 HPC&A – UJI 80
Dense Linear Algebra for GPUs CUBLAS
axpy: y := y + α x, α ∈ ℜ, x,y ∈ ℜn
#include “cublas.h” #define N 256
int main( void ) { float x_h[N], y_h[N], x_d[N], y_d[N], alpha;
// Initialize x_h, y_h, alpha and CUBLAS environment cublasInit();
// Allocate space for x_d, y_d in device memory cudaMalloc( (void**) &x_d, N*sizeof(float) ) ); cudaMalloc( (void**) &y_d, N*sizeof(float) ) );
// Transfer contents of x_h, y_h from host to device
cudaMemcpy( x_d, x_h, N*sizeof(float), cudaMemcpyHostToDevice ); cudaMemcpy( y_d, y_h, N*sizeof(float), cudaMemcpyHostToDevice ); ...

RWTH-‐Aachen, March 2011 HPC&A – UJI 81
Dense Linear Algebra for GPUs CUBLAS
axpy: y := y + α x, α ∈ ℜ, x,y ∈ ℜn
... // Invoke CUBLAS kernel cublasSaxpy( n, alpha, x_d, 1, y_d, 1 );
// Retrieve results back to host memory cudaMemcpy( y_h, y_d, N*sizeof(float), cudaMemcpyDeviceToHost );
for (i=0; i<N; i++) printf( “%y(%d) = %g\n", i, y[i] );
// Free memory in device for x_d, y_d; Destroy CUBLAS environment cudaFree( x_d );
cudaFree( y_d ); cublasStatus cublasShutdown();
return 0; }

RWTH-‐Aachen, March 2011 HPC&A – UJI 82
Dense Linear Algebra for GPUs CUBLAS

RWTH-‐Aachen, March 2011 HPC&A – UJI 83
Dense Linear Algebra for GPUs CUBLAS

RWTH-‐Aachen, March 2011 HPC&A – UJI 84
Dense Linear Algebra for GPUs CUBLAS
Insights: Cost of invoking a CUBLAS kernel is not zero! Take
into account for BLAS-1 or small problem dimensions Cost of transferring data/results is not zero! Take into
account for BLAS-1 or small problem dimensions In NVIDIA Fermi generation, GeForce has more cores
than Tesla, but less memory and reliability

RWTH-‐Aachen, March 2011 HPC&A – UJI 85
Dense Linear Algebra for GPUs Building on Top of CUBLAS
Cholesky factorization (LAPACK)
Key in the solution of s.p.d. linear systems A x = b ≡ (LLT)x = b L y = b ⇒ y LT x = y ⇒ x
A = * L LT

RWTH-‐Aachen, March 2011 HPC&A – UJI 86
Dense Linear Algebra for GPUs Building on Top of CUBLAS
Cholesky factorization. Unblocked code:
a11 := l11 = a111/2 (square root) R:
a21 := l21 = a21 / l11 SCAL:
A22 := A22 – l21 * l21T SYR:
1st iteration

RWTH-‐Aachen, March 2011 HPC&A – UJI 87
Dense Linear Algebra for GPUs Building on Top of CUBLAS
Cholesky factorization. Unblocked code:
…
1st iteration 2nd iteration 3rd iteration

RWTH-‐Aachen, March 2011 HPC&A – UJI 88
Dense Linear Algebra for GPUs Building on Top of CUBLAS
Cholesky factorization. CPU unblocked code: SUBROUTINE CPU_SPOTF2( UPLO, N, A, LDA, INFO ) ... DO J = 1, N * AJJ = A( J, J ) A( J, J ) = SQRT( AJJ )
* IF( J.LT.N ) THEN CALL SSCAL( N-‐J, ONE / AJJ, A( J+1, J ), 1 ) CALL SSYR( 'Lower', N-‐J, -‐ONE, A( J+1, J ), 1, $ A( J+1, J+1 ), LDA ) END IF
END DO

RWTH-‐Aachen, March 2011 HPC&A – UJI 89
Dense Linear Algebra for GPUs Building on Top of CUBLAS
Cholesky factorization. GPU unblocked code: #define SIZEOF_REAL 4 #define IDX2F(I,J,LD) ((((J)-‐1)*(LD))+((I)-‐1))*SIZEOF_REAL SUBROUTINE GPU_SPOTF2( UPLO, N, DEVPTRA, LDA, INFO ) ... DO J = 1, N CALL CUBLAS_GET_MATRIX( 1, 1, SIZEOF_REAL,
$ DEVPTRA+IDX2F(J,J,LDA), LDA, AJJ, 1 ) A( J, J ) = SQRT( AJJ ) CALL CUBLAS_SET_MATRIX( 1, 1, SIZEOF_REAL, $ AJJ, 1, DEVPTRA+IDX2F(J,J,LDA), LDA ) IF( J.LT.N ) THEN CALL CUBLAS_SSCAL( N-‐J, ONE / AJJ, DEVPTRA+IDX2F(J+1,J,LDA), 1 )
CALL CUBLAS_SSYR( 'Lower', N-‐J, $ -‐ONE, DEVPTRA+IDX2F(J+1,J,LDA), 1, $ DEVPTRA+IDX2F(J+1,J+1,LDA), LDA ) END IF END DO

RWTH-‐Aachen, March 2011 HPC&A – UJI 90
Dense Linear Algebra for Multi-core Building on Top of CUBLAS
Cholesky factorization. Blocked code:
A11 = L11 * L11T, A11:= L11L (Cholesky factorization)
F:
A21 := L21 = A21 * L11-T T:
A22 := A22 – L21 * L21T P:
1st iteration

RWTH-‐Aachen, March 2011 HPC&A – UJI 91
Dense Linear Algebra for GPUs Building on Top of CUBLAS
Cholesky factorization. Blocked code:
…
1st iteration 2nd iteration 3rd iteration

RWTH-‐Aachen, March 2011 HPC&A – UJI 92
Dense Linear Algebra for GPUs Building on Top of CUBLAS
Cholesky factorization. CPU blocked code: SUBROUTINE CPU_SPOTRF( UPLO, N, A, LDA, INFO ) ... DO J = 1, NB, N * JB = MIN( NB, N-‐J+1 ) CALL CPU_SPOTF2( 'Lower', JB, A(J,J), LDA, INFO )
* IF( J+JB.LT.N ) THEN CALL STRSM( 'Right', 'Lower', 'Transpose', 'Non-‐unit', $ N-‐J-‐JB+1, JB, ONE, A( J, J ), LDA, $ A( J+JB, J ), LDA ) CALL SSYRK( 'Lower', 'No transpose',
$ N-‐J-‐JB+1, JB, -‐ONE, $ A( J+JB, J ), LDA, ONE, $ A( J+JB, J+JB ), LDA ) END IF END DO

RWTH-‐Aachen, March 2011 HPC&A – UJI 93
Dense Linear Algebra for GPUs Building on Top of CUBLAS
Cholesky factorization. GPU blocked code (1): SUBROUTINE GPU_SPOTRF_VAR1( UPLO, N, A, LDA, INFO ) ... DO J = 1, NB, N JB = MIN( NB, N-‐J+1 ) CALL GPU_SPOTF2 ( 'Lower', JB, DEVPTRA+IDX2F(J,J,LDA), LDA, INFO ) IF( J+JB.LT.N ) THEN
CALL CUBLAS_STRSM( 'Right', 'Lower', ‘Transpose', 'Non-‐unit', $ N-‐J-‐JB+1, JB, $ ONE, DEVPTRA+IDX2F(J,J,LDA), LDA, $ DEVPTRA+IDX2F(J+JB, J,LDA), LDA ) CALL CUBLAS_SSYRK( 'Lower', 'No transpose', N-‐J-‐JB+1, JB, $ -‐ONE, DEVPTRA+IDX2F(J+JB,J,LDA), LDA,
$ ONE, DEVPTRA+IDX2F(J+JB,J+JB,LDA), LDA ) END IF END DO

RWTH-‐Aachen, March 2011 HPC&A – UJI 94
Dense Linear Algebra for GPUs Building on Top of CUBLAS
Cholesky factorization. GPU blocked code (2): SUBROUTINE GPU_SPOTRF_VAR2( UPLO, N, A, LDA, INFO ) ... FLOAT WORK( NBMAX*NBMAX ) ... DO J = 1, N JB = MIN( NB, N-‐J+1 )
CALL CUBLAS_GET_MATRIX( JB, JB, SIZEOF_REAL, $ DEVPTRA+IDX2F(J,J,LDA), LDA, WORK, JB ) CALL CPU_SPOTRF( ‘Lower’, JB, WORK, JB, INFO ) CALL CUBLAS_SET_MATRIX( JB, JB, SIZEOF_REAL, $ WORK, JB, DEVPTRA+IDX2F(J,J,LDA), LDA ) IF( J+JB.LT.N ) THEN
CALL CUBLAS_STRSM( ... ) CALL CUBLAS_SSYRK( ... ) END IF END DO

RWTH-‐Aachen, March 2011 HPC&A – UJI 95
Dense Linear Algebra for GPUs Building on Top of CUBLAS

RWTH-‐Aachen, March 2011 HPC&A – UJI 96
Dense Linear Algebra for GPUs Multi-GPU Platforms
How do we program these?
View as a… Shared-memory multiprocessor + DSM
CPU(s) PCI-‐e bus
GPU #1
GPU #2
GPU #3
GPU #4

RWTH-‐Aachen, March 2011 HPC&A – UJI 97
Dense Linear Algebra for GPUs Multi-GPU Platforms
Software Distributed-Shared Memory (DSM) Software: flexibility vs. efficiency Underlying distributed memory hidden from the users Reduce memory transfers using write-back, write-
invalidate,… Well-known approach, not too efficient as a
middleware for general apps.
Regularity of dense linear algebra operations makes a difference!
RWTH-‐Aachen, March 2011 HPC&A – UJI 98
Dense Linear Algebra for GPUs Multi-GPU Platforms
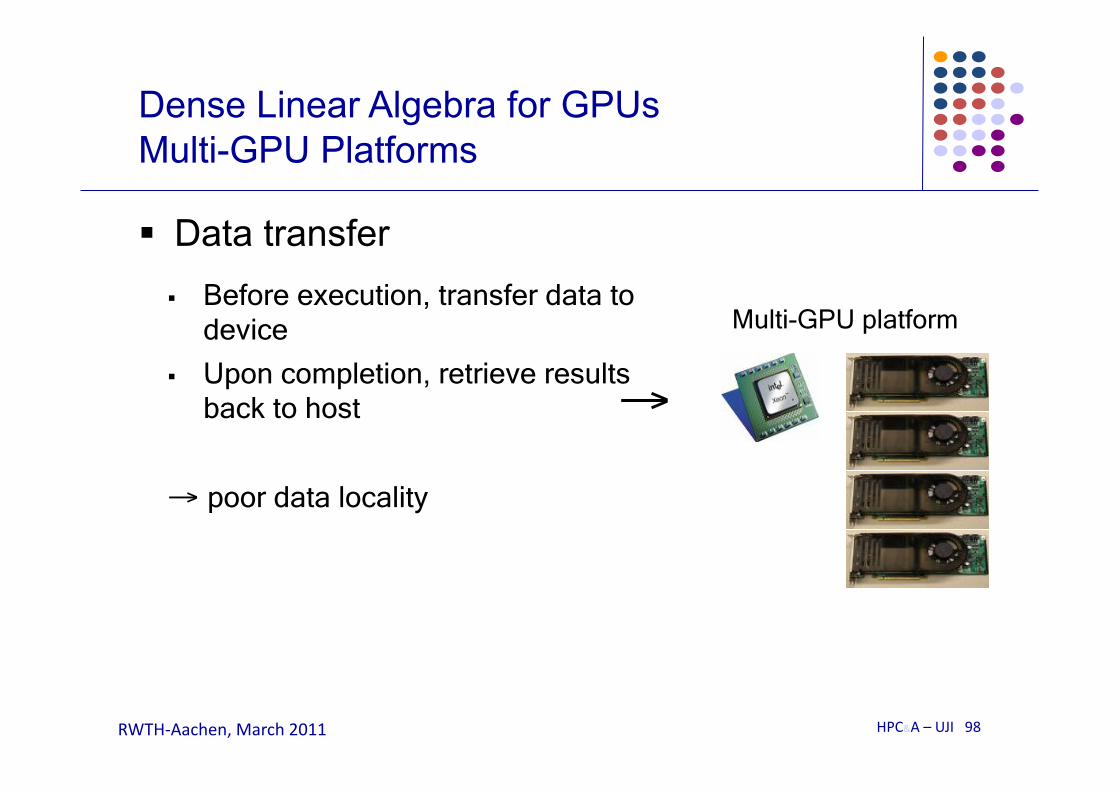
Data transfer Before execution, transfer data to
device
Upon completion, retrieve results back to host
→ poor data locality
Multi-GPU platform
→

RWTH-‐Aachen, March 2011 HPC&A – UJI 99
Dense Linear Algebra for GPUs Multi-GPU Platforms
Shared memory system
Multi-core processor:
MP P0+C0
P1+C1
P2+C2
P3+C3
Multi-GPU platform
RWTH-‐Aachen, March 2011 HPC&A – UJI 100
Dense Linear Algebra for GPUs Multi-GPU Platforms
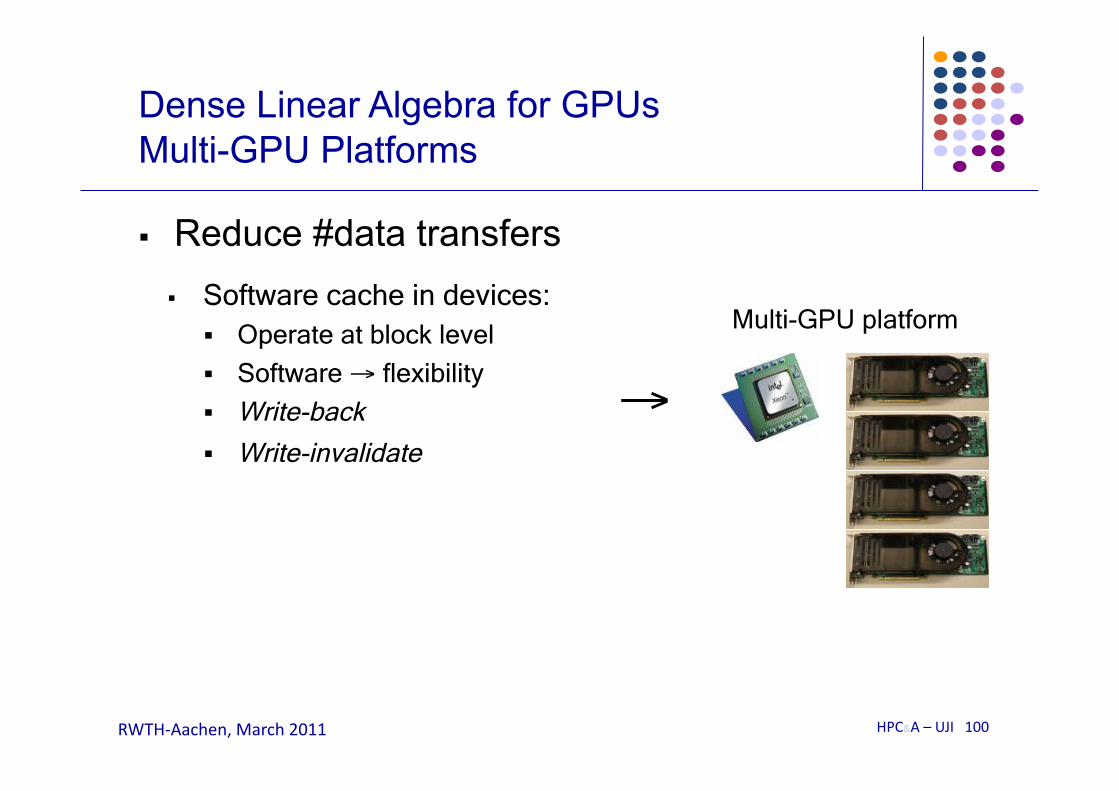
Reduce #data transfers Software cache in devices:
Operate at block level
Software → flexibility
Write-back
Write-invalidate
Multi-GPU platform
→

RWTH-‐Aachen, March 2011 HPC&A – UJI 101
Dense Linear Algebra for GPUs Multi-GPU Platforms

RWTH-‐Aachen, March 2011 HPC&A – UJI 102
Index
1. Multi-threaded architectures 40m? 2. Dense linear algebra for multi-core 40m? 3. Programming in CUDA 40m?
4. Dense linear algebra for GPUs 5. Summary

RWTH-‐Aachen, March 2011 HPC&A – UJI 103
Summary (Wrap up) More FLOPS!
System Rmax (TFLOPS)
1 Tianhe-‐1A -‐ NUDT TH MPP, X5670 2.93Ghz 6C, NVIDIA GPU, FT-‐1000
2,566*
2 Jaguar -‐ Cray XT5-‐HE Opteron 6-‐core 2.6 GHz
1,759
3 Nebulae -‐ Dawning TC3600 Blade, Intel X5650, NVidia Tesla C2050 GPU
1,271 4 TSUBAME 2.0 -‐ HP ProLiant SL390s
G7 Xeon 6C X5670, Nvidia GPU 1,192
5 Hopper -‐ Cray XE6 12-‐core 2.1 GHz 1,054
*1 día Tianhe-‐1A = 95 years of all the people in the world (6.000 millions) with a calculator

RWTH-‐Aachen, March 2011 HPC&A – UJI 104
Summary (Wrap up) More Cores!
PFLOPS (1015 flops/sec.)
2010 JUGENE 109 core level 3.4 GFLOPS
101 node level Quad-Core
105 cluster level 73,728 nodes
EFLOPS (1018 flops/sec.)
109.5 core level
103 node level!
105.5 cluster level
GPUs?
RWTH-‐Aachen, March 2011 HPC&A – UJI 105
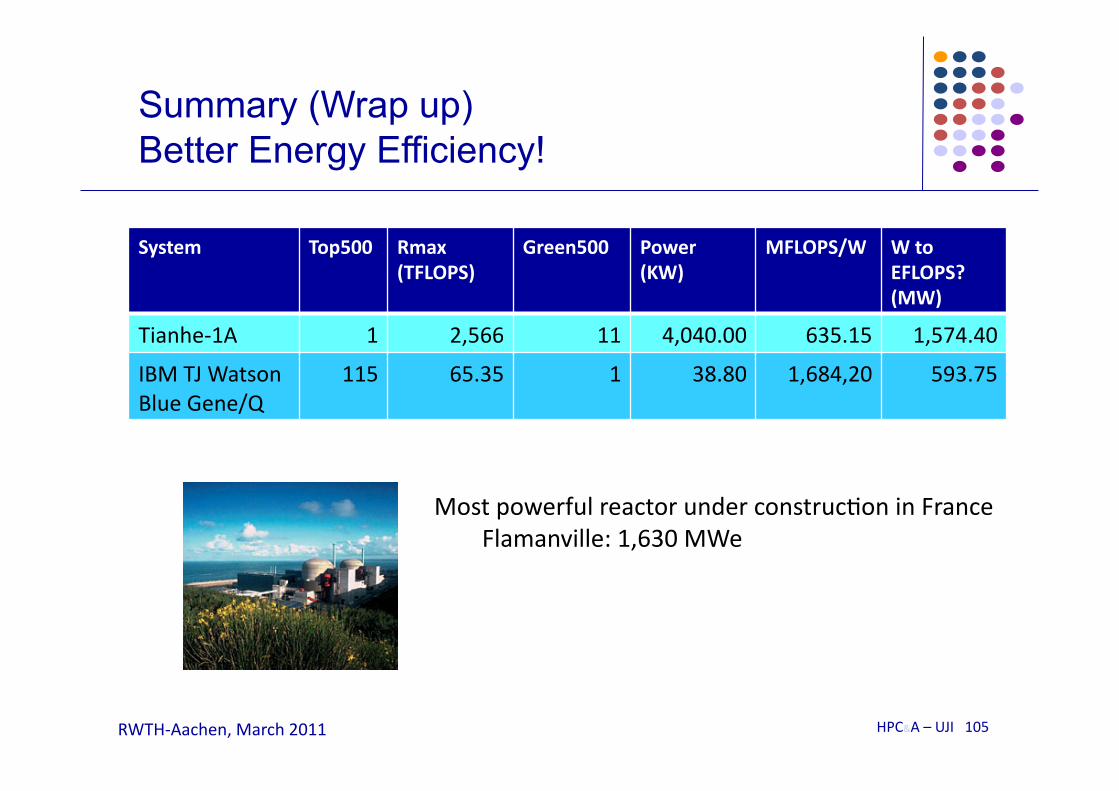
Summary (Wrap up) Better Energy Efficiency!
System Top500 Rmax (TFLOPS)
Green500 Power (KW)
MFLOPS/W W to EFLOPS? (MW)
Tianhe-‐1A 1 2,566 11 4,040.00 635.15 1,574.40
IBM TJ Watson Blue Gene/Q
115 65.35 1 38.80 1,684,20 593.75
Most powerful reactor under construcMon in France Flamanville: 1,630 MWe

RWTH-‐Aachen, March 2011 HPC&A – UJI 106
Thank you!
Questions?





























