Embed Size (px)
DESCRIPTION
Measurement of Single Top Quark s-channel Cross Section at the ATLAS Experiment. 10 th China HEPS Particle Physics Meeting Jie Yu Nanjing University 2008-04-27. Outlines. Introduction S-channel cut analysis and results Multivariate analysis and results Summary. Introduction. - PowerPoint PPT Presentation
Citation preview
Measurement of Single Top Quark s-channel Cross Section at the
ATLAS Experiment
10th China HEPS Particle Physics Meeting
Jie YuNanjing University
2008-04-27

04/19/23 10th China HEP Particle Physics meeting / Nanjing
2
Outlines Introduction S-channel cut analysis and results Multivariate analysis and results Summary

04/19/23 10th China HEP Particle Physics meeting / Nanjing
3
The reasons of doing single-top analysis:
1. a key particle in the quest for the origin of particle mass.
2. EW interaction of the top quark is sensitive to many types of new physics.
3. the only known way to directly measure CKM matrix element Vtb
4. an important background to many searches for new physics
5. ……
Introduction

04/19/23 10th China HEP Particle Physics meeting / Nanjing
4
Figue1. (a) t-channel (b) W+t channel (c) s-channel
q2 ≤ 0, q2 = M2W, q2 ≥ (mt + mb)2.
Where q is the four momentum of W boson
time
three different single top mechanisms in Standard Model:

04/19/23 10th China HEP Particle Physics meeting / Nanjing
5
The main backgrounds
ttbar events ttbar l+jets mode ttbar2l+jets mode (with one lepton lost)
W/Z + jets di-boson ( like: WWlvjj ) QCD background ( like: ppbbbar)
For the lack of MC data, we are only using ttbar background till now!

04/19/23 10th China HEP Particle Physics meeting / Nanjing
6
process: t-channel s-channel Wt channel ttbarσ(pb): 245 ± 27 10.2 ± 0.7 51 ± 9 835
Decay mode and probability:tWb ~100% Wl v ~2/9 ( l = electron or muon) Wτv ~1/9 (τ decays into muon 17.8%, electron 17.2%) Wjj ~6/9
Process cross section and decay mode (1)

04/19/23 10th China HEP Particle Physics meeting / Nanjing
7
Final state of ttbar events:ttbar: ppttbar W+ b W- b ¯ l v b j j b ¯ l+ v l- v¯bb¯ τ+ τ - v v ¯ b b¯ τv b j j b ¯
a. t-channel: ppWgtb¯qWbb¯ql v b b¯qb. Wt channel: pptW WWb j j l v bc. S-channel: ppW*tb¯Wbb¯ l v b b¯
Final state of the three single top channels :
Process cross section and decay mode (2)
2 or 3 jets, 1 or 2 b jet, 1 lepton, with missing energy
Final state of the signal s-channel :
2 b jets, 1 lepton, with missing energy
Preslection cuts
s-channel selection cuts

04/19/23 10th China HEP Particle Physics meeting / Nanjing
8
Step0: Triggers , Passed e25i or e60 or mu20i Step1: One high Pt lepton at least, with electron pt larger than 25GeV/c muon 20GeV/c Step2: Veto of any 2nd lepton with pt larger than 10GeV/c ΔR>0.4 Step3: at least 2 high pt jets, pt larger than 30GeV/c Step4: Veto on the 5th jet with pT(jet)>15GeV/c Step5: At least 1 btagged high pt jet above 30GeV/c η less than 2.5 Step6: Missing Energy no less than 20GeV
Selection for three single top channelsPreselection cuts:

04/19/23 10th China HEP Particle Physics meeting / Nanjing
9
Strategy(1): s-channel selection cuts
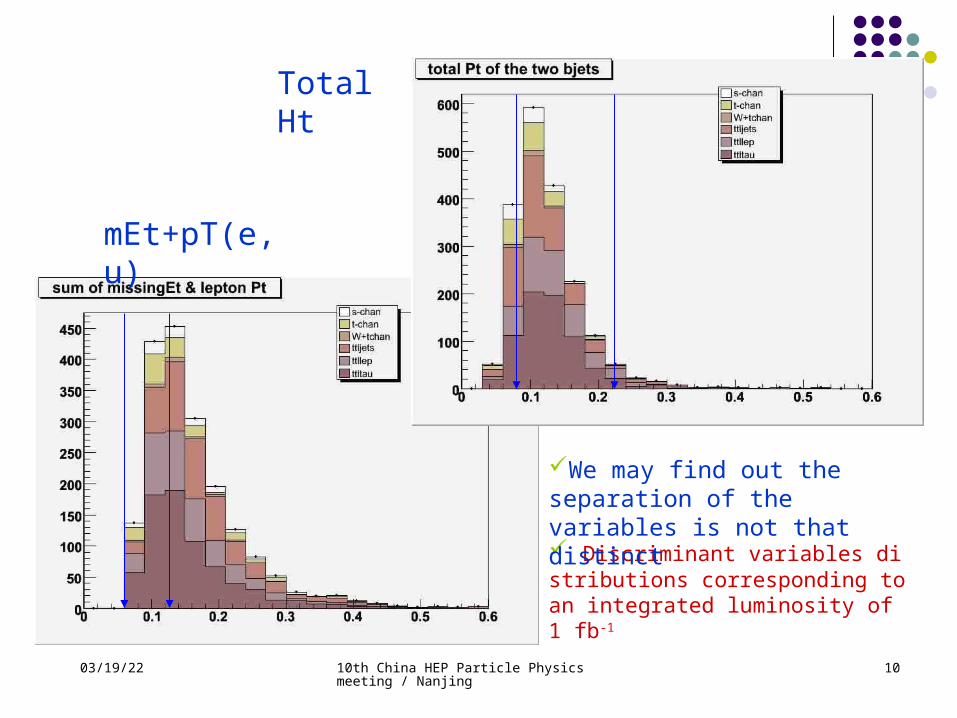
Step1: two b-tagged jets with pT>30GeV/c Step2: Veto on any 3rd Jet with pT>15GeV/c Step3: Total Ht (pT combined jets only): 80<Ht<220 GeV/c Step4: Seperation between 2 btagged jets:
0.5 <ΔR(b1,b2) < 4.0 ; Step5: Sum of missing Et and pT of leptons:
60 <mEt+pT(e,u) < 130 GeV/c;
04/19/23 10th China HEP Particle Physics meeting / Nanjing
10
Total Ht
mEt+pT(e,u)
Discriminant variables distributions corresponding to an integrated luminosity of 1 fb-1
We may find out the separation of the variables is not that distinct

04/19/23 10th China HEP Particle Physics meeting / Nanjing
11
The s-ch cut analysis results Processes muon channel electron channel nEvt to L= 1 fb -1
s-channel 2.47±0.12% 1.49±0.10% 46 s-ch (τ)l 0.71±0.16% 0.64±0.15%
t-channel 0.22±0.04% 0.14±0.03% 84 t-chan (τ)l 0.04±0.04% 0.00±0.00%
W+t channel 0.10±0.03% 0.08±0.03% 11 W+t chan (τ)l 0.00±0.00% 0.00±0.00%
ttl+jets 0.09±0.01% 0.08±0.01% 223 tt(τ)l+j 0.04±0.01% 0.02±0.01% tte + e 0.34±0.05% ttμ+μ 0.48±0.06% 150 ttμ+ e 0.33±0.04% ttμ+τ 0.69±0.05% tt e +τ 0.54±0.05% 273 ttτ+τ 0.24±0.04%
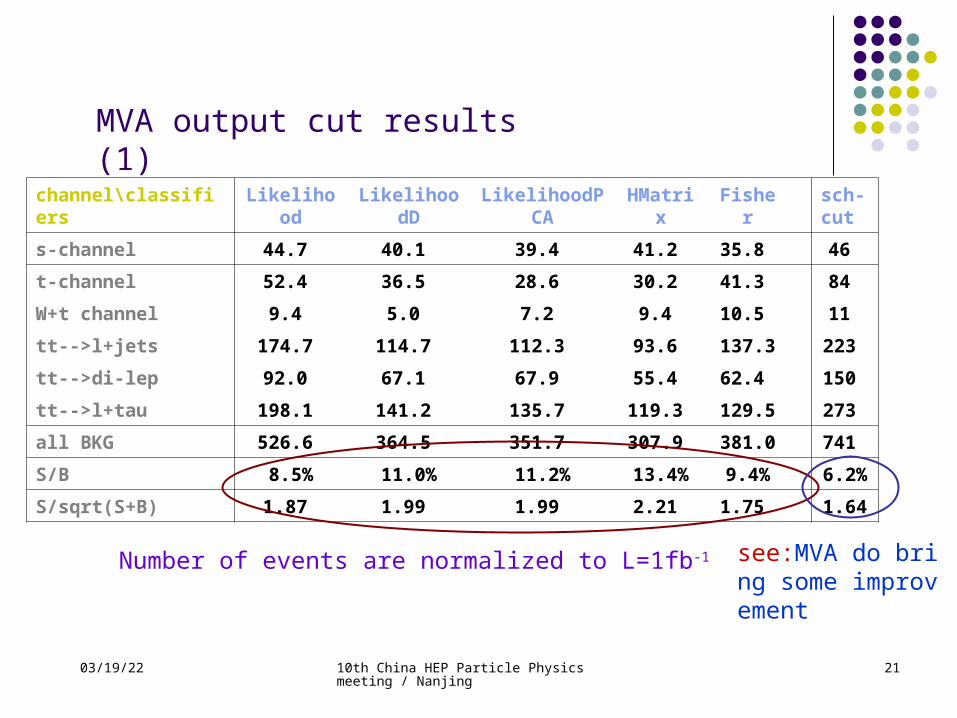
S/B = 46/741 = 6.2%, S/ √ S+B = 1.64 Not good enough
Search for improvement

04/19/23 10th China HEP Particle Physics meeting / Nanjing
12
Step1: two b-tagged jets with pT>30GeV/c Step2: Veto on any 3rd Jet with pT>15GeV/c --------------------------------------------------------------------------- Using MVA
Events selected by steps above the line will be used as MVA input
Strategy (2): MultiVariate Analysis
MVA uses multi-variables as input and get an output which in the most of the cases obtain better separation

04/19/23 10th China HEP Particle Physics meeting / Nanjing
13
MultiVariate data Analysis
Methods in MVA Rectangular cut optimisation Likelihood estimator (PDE approach) Multidimensional likelihood estimator (PDE Range Search
approach) Fisher discriminant HMatrix approach (2 estimator) Multilayer Perceptron Artificial Neural Network (three
different implementations) Boosted Decision Trees RuleFit …
04/19/23 10th China HEP Particle Physics meeting / Nanjing
14
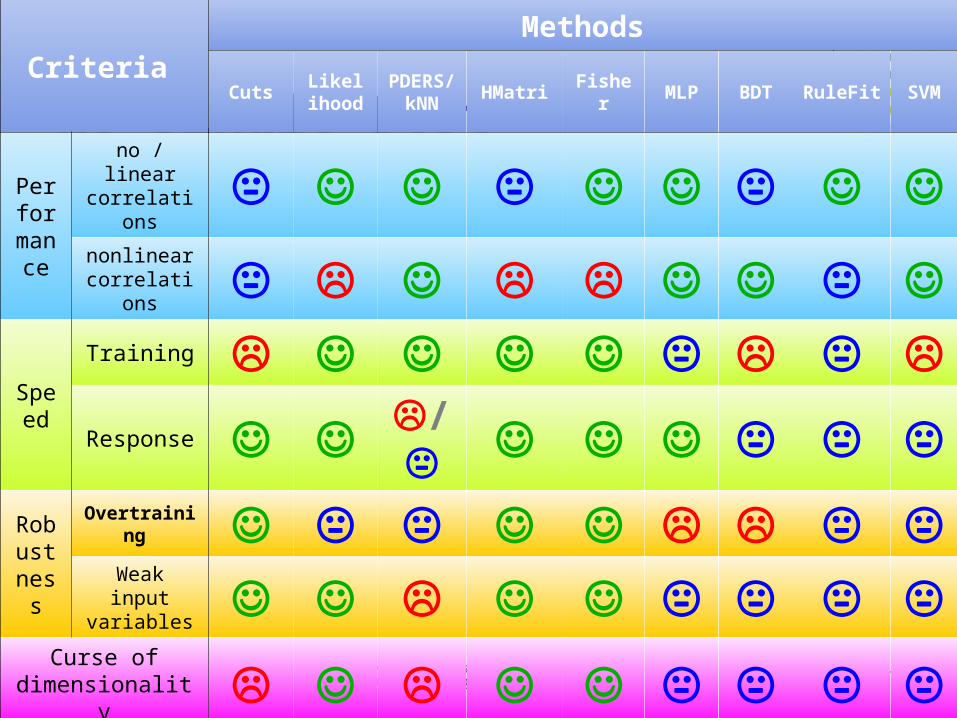
No Single BestCriteria
Methods
CutsLikelih
oodPDERS/
kNNHMatri Fisher MLP BDT RuleFit SVM
Performance
no / linear correlations nonlinear
correlations
Speed
Training
Response /
Robustness
Overtraining Weak input variables
Curse of dimensionality
Clarity

04/19/23 10th China HEP Particle Physics meeting / Nanjing
15
Combine probability density distributions to likelihood estimator
Projected Likelihood Estimator (PDE Approach)
Assumes uncorrelated input variables
variables
,//Lh )()(,)()(
)()(
vvvBSBS
BS
S ixpiLiLiL
iLiy
Reference PDF’s
)(Lh iy is an output of Likelihood for every single event,
1 (signal like) , 0 ( background like)
Output is a likelihood ratio

04/19/23 10th China HEP Particle Physics meeting / Nanjing
16
MVA methods output variables( take Likelihood as an example )
five main background processes
ttbarlepton+jet,
ttbardilepton,
ttbarτ+lepton,
W+jets,
t−channel
Every event has such five MVA output value , and then we shall apply proper cuts on them
define likelihood functions specific to suppress each background:
yttbar/lepton+jets,
yttbar/dilepton,
yttbar/τ+lepton,
yW+jets,
yt−channel

04/19/23 10th China HEP Particle Physics meeting / Nanjing
17
Note: each yLh(i ) use some of the variables as input
Variables yttbar/lepton+jets, yttbar/dilepton, yttbar/τ+lepton,yW+jets, yt−channel

04/19/23 10th China HEP Particle Physics meeting / Nanjing
18
MVA method to suppress the Bkg: tt->l+jets,tt->l+l,tt->l+tau,W+jets,t-ch --- Factory : ----------------------------- --- Factory : Method: Cut value:Cut value:Cut value:Cut value:Cut value: --- Factory : --------------------------------------------------------------------- --- Factory : Likelihood: +0.538 +0.523 +0.525 +0.539 +0.525 --- Factory : LikelihoodD: +0.004 +0.223 +0.214 +0.019 +0.188 --- Factory : LikelihoodPCA: +0.592 +0.525 +0.519 +0.600 +0.576 --- Factory : HMatrix: -0.184 -0.138 -0.153 -0.183 -0.174 --- Factory : Fisher: +0.051 +0.039 +0.056 +0.057 +0.064 --- Factory : MLP: -0.242 -0.135 -0.194 -0.001 -0.179 --- Factory : CFMlpANN: +0.392 +0.379 +0.395 +0.398 +0.380 --- Factory : TMlpANN: +0.203 +0.355 +0.337 +0.214 +0.546 --- Factory : BDT: -0.069 -0.115 -0.131 -0.081 -0.093 --- Factory : BDTD: -0.141 -0.131 -0.072 -0.120 -0.105 --- Factory : RuleFit: -0.197 -0.221 -0.217 -0.187 -0.227 --- Factory : --------------------------------------------------------------------- --- Factory : which correspond to the working point: eff(signal) = 1 - eff(background)
Cut value for each method:
04/19/23 10th China HEP Particle Physics meeting / Nanjing
19
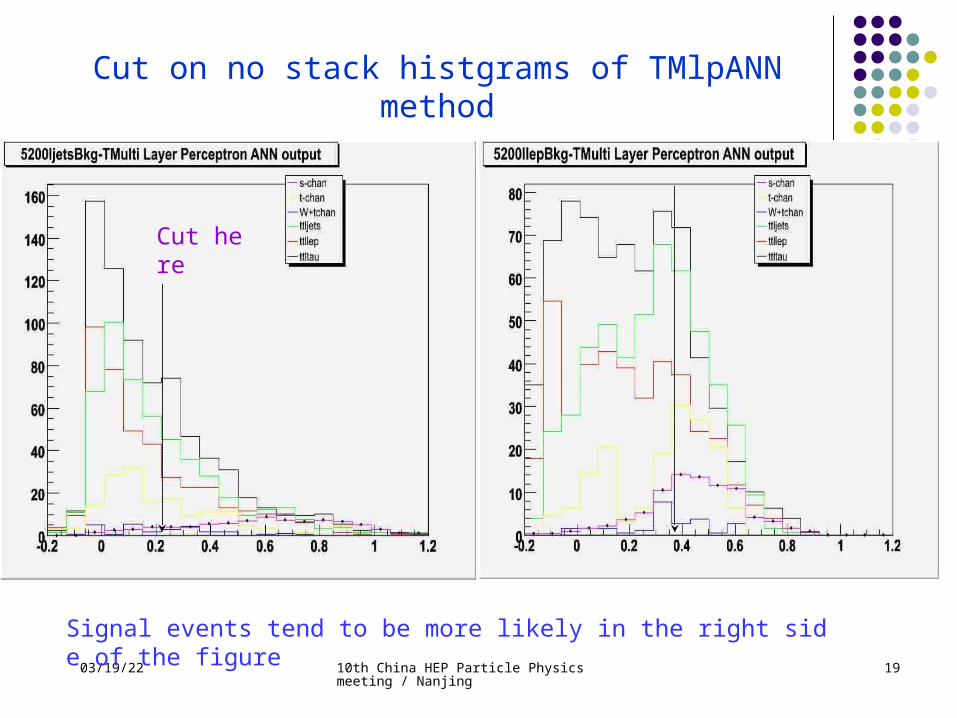
Cut here
Signal events tend to be more likely in the right side of the figure
Cut on no stack histgrams of TMlpANN method
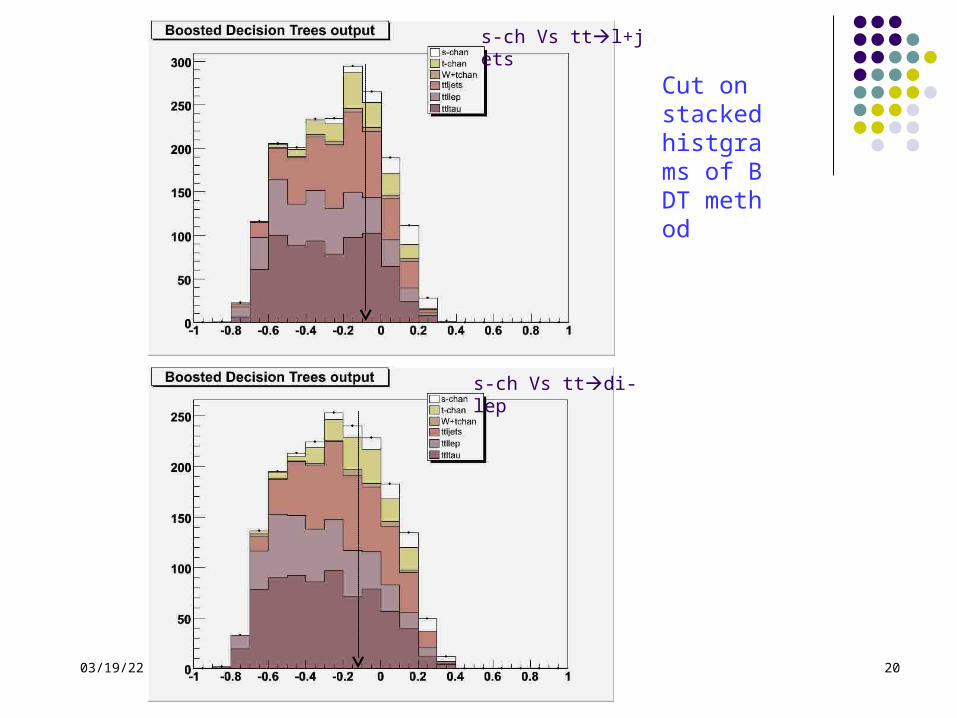
04/19/23 10th China HEP Particle Physics meeting / Nanjing
20
s-ch Vs ttl+jets
s-ch Vs ttdi-lep
Cut on stacked histgrams of BDT method
04/19/23 10th China HEP Particle Physics meeting / Nanjing
21
channel\classifiers Likelihood
LikelihoodD
LikelihoodPCA
HMatrix Fisher sch-c
uts-channel 44.7 40.1 39.4 41.2 35.8 46 t-channel 52.4 36.5 28.6 30.2 41.3 84 W+t channel 9.4 5.0 7.2 9.4 10.5 11 tt-->l+jets 174.7 114.7 112.3 93.6 137.3 223 tt-->di-lep 92.0 67.1 67.9 55.4 62.4 150 tt-->l+tau 198.1 141.2 135.7 119.3 129.5 273 all BKG 526.6 364.5 351.7 307.9 381.0 741 S/B 8.5% 11.0% 11.2% 13.4% 9.4% 6.2%S/sqrt(S+B) 1.87 1.99 1.99 2.21 1.75 1.64
MVA output cut results (1)
Number of events are normalized to L=1fb-1 see:MVA do bring some improvement
04/19/23 10th China HEP Particle Physics meeting / Nanjing
22
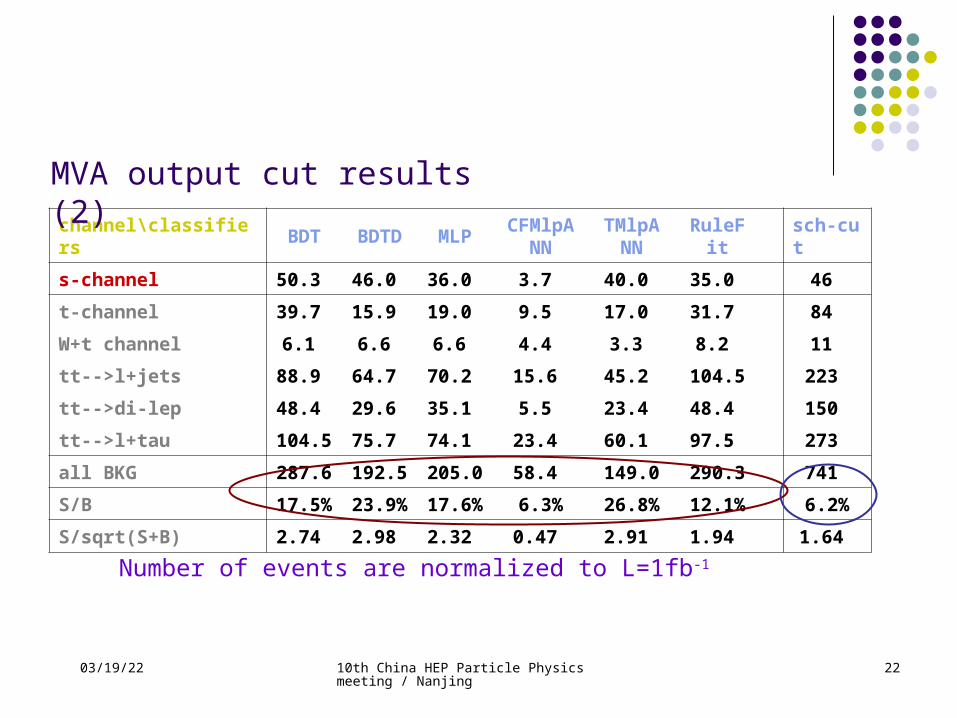
channel\classifiers BDT BDTD MLP CFMlpANN
TMlpANN RuleFit sch-cut
s-channel 50.3 46.0 36.0 3.7 40.0 35.0 46 t-channel 39.7 15.9 19.0 9.5 17.0 31.7 84 W+t channel 6.1 6.6 6.6 4.4 3.3 8.2 11 tt-->l+jets 88.9 64.7 70.2 15.6 45.2 104.5 223 tt-->di-lep 48.4 29.6 35.1 5.5 23.4 48.4 150 tt-->l+tau 104.5 75.7 74.1 23.4 60.1 97.5 273 all BKG 287.6 192.5 205.0 58.4 149.0 290.3 741
S/B 17.5%
23.9%
17.6% 6.3% 26.8% 12.1% 6.2%
S/sqrt(S+B) 2.74 2.98 2.32 0.47 2.91 1.94 1.64 Number of events are normalized to L=1fb-1
MVA output cut results (2)
04/19/23 10th China HEP Particle Physics meeting / Nanjing
23
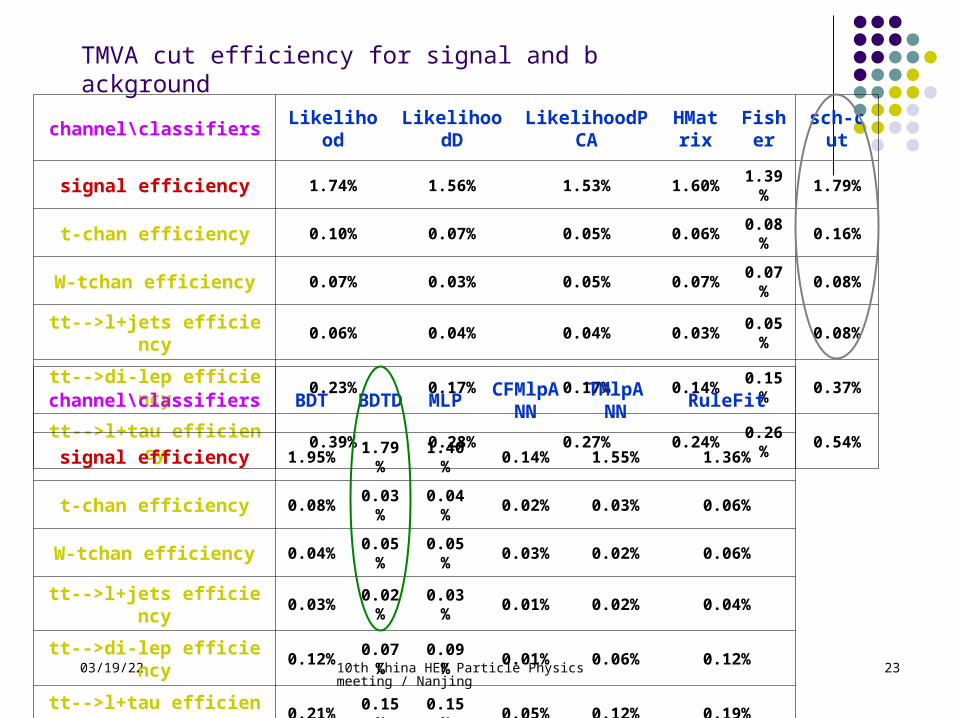
channel\classifiers Likelihood
LikelihoodD
LikelihoodPCA
HMatrix
Fisher
sch-cut
signal efficiency 1.74% 1.56% 1.53% 1.60% 1.39% 1.79%
t-chan efficiency 0.10% 0.07% 0.05% 0.06% 0.08% 0.16%
W-tchan efficiency 0.07% 0.03% 0.05% 0.07% 0.07% 0.08%
tt-->l+jets efficiency 0.06% 0.04% 0.04% 0.03% 0.05% 0.08%
tt-->di-lep efficiency 0.23% 0.17% 0.17% 0.14% 0.15% 0.37%
tt-->l+tau efficiency 0.39% 0.28% 0.27% 0.24% 0.26% 0.54%
channel\classifiers BDT BDTD MLP CFMlpA
NNTMlpA
NN RuleFit
signal efficiency 1.95% 1.79%
1.40% 0.14% 1.55% 1.36%
t-chan efficiency 0.08% 0.03%
0.04% 0.02% 0.03% 0.06%
W-tchan efficiency 0.04% 0.05%
0.05% 0.03% 0.02% 0.06%
tt-->l+jets efficiency 0.03% 0.02%
0.03% 0.01% 0.02% 0.04%
tt-->di-lep efficiency 0.12% 0.07%
0.09% 0.01% 0.06% 0.12%
tt-->l+tau efficiency 0.21% 0.15%
0.15% 0.05% 0.12% 0.19%
TMVA cut efficiency for signal and background

04/19/23 10th China HEP Particle Physics meeting / Nanjing
24
Combine two or more MVA methods --- Factory : Inter-MVA overlap matrix (signal): --- Factory : -------------------------------------------------------------------------------------------------------------------- --- Factory : Likelihood LikelihoodD LikePCA HMatrix Fisher MLP CFMlpANN TMlpANN BDT BDTD RuleFit --- Factory : Likelihood: +1.000 +0.798 +0.801 +0.763 +0.746 +0.740 +0.775 +0.771 +0.754 +0.739 +0.756 --- Factory : LikelihoodD: +0.798 +1.000 +0.862 +0.858 +0.813 +0.791 +0.719 +0.806 +0.755 +0.788 +0.763 --- Factory : LikelihoodPCA:+0.801 +0.862 +1.000 +0.882 +0.836 +0.815 +0.730 +0.817 +0.778 +0.798 +0.778 --- Factory : HMatrix: +0.763 +0.858 +0.882 +1.000 +0.887 +0.854 +0.700 +0.866 +0.820 +0.845 +0.820 --- Factory : Fisher: +0.746 +0.813 +0.836 +0.887 +1.000 +0.867 +0.699 +0.882 +0.829 +0.863 +0.818 --- Factory : MLP: +0.740 +0.791 +0.815 +0.854 +0.867 +1.000 +0.647 +0.899 +0.873 +0.900 +0.853 --- Factory : CFMlpANN: +0.775 +0.719 +0.730 +0.700 +0.699 +0.647 +1.000 +0.680 +0.649 +0.634 +0.643 --- Factory : TMlpANN: +0.771 +0.806 +0.817 +0.866 +0.882 +0.899 +0.680 +1.000 +0.873 +0.882 +0.846 --- Factory : BDT: +0.754 +0.755 +0.778 +0.820 +0.829 +0.873 +0.649 +0.873 +1.000 +0.872 +0.859 --- Factory : BDTD: +0.739 +0.788 +0.798 +0.845 +0.863 +0.900 +0.634 +0.882 +0.872 +1.000 +0.845 --- Factory : RuleFit: +0.756 +0.763 +0.778 +0.820 +0.818 +0.853 +0.643 +0.846 +0.859 +0.845 +1.000
If two classifiers have similar performance, but significant non-overlapping classifications check if they can be combined
The combining job is kind of trivial: do cuts on different classifier output!

04/19/23 10th China HEP Particle Physics meeting / Nanjing
25
Summary
It is no doubt that top quark analysis can lead us to some new physics
MVA methods can positively improve the cut efficiency in our analysis
Now that real data is in the air, we couldn’t be too prepared

04/19/23 10th China HEP Particle Physics meeting / Nanjing
26
Thank you ! !

04/19/23 10th China HEP Particle Physics meeting / Nanjing
27
Backup slides

04/19/23 10th China HEP Particle Physics meeting / Nanjing
28
Fisher Linear Discriminant Analysis (LDA)
Well known, simple and elegant classifier
LDA determines axis in the input variable hyperspace such that a projection of events onto this axis pushes signal and background as far away from each other as possible
Classifier computation couldn’t be simpler:
event evevari
Fabl
i 0e
nts
k kk
i iy F x F
“Fisher coefficients”
Fisher coefficients given by: , where W is sum CS + CB var
1, ,
1
N
k S BkF W x x
Fisher requires distinct sample means between signal and background
Optimal classifier for linearly correlated Gaussian-distributed variables
F0 centers the sample mean yFi of all NS + NB events at zero

04/19/23 10th China HEP Particle Physics meeting / Nanjing
29
Nonlinear Analysis: Artificial Neural Networks
Achieve nonlinear classifier response by “activating” output nodes using nonlinear weights
Call nodes “neurons” and arrange them in series:
1( ) 1 xA x e
1
i
. . .N
1 input layer k hidden layers 1 ouput layer
1
j
M1
. . .
. . . 1
. . .Mk
2 output classes (signal and background)
Nvar discriminating input variables
11w
ijw
1jw. . .. . .
1( ) ( ) ( ) ( 1)
01
kMk k k kj j ij i
i
x w w xA
var
(0)1..i Nx
( 1)1,2kx
(“Activation” function)
with:
Fee
d-fo
rwar
d M
ultil
ayer
Per
cept
ron
Weierstrass theorem: can approximate any continuous functions to arbitrary precision with a single hidden layer and an infinite number of neurons
Adjust weights (=training) using “back-propagation”:
Three different MultiLayer Per-ceptrons available in TMVA
For each training event compare received and desired MLP outputs {0,1}: ε = d – r
Correct weights, depending on ε and a “learning rate” η
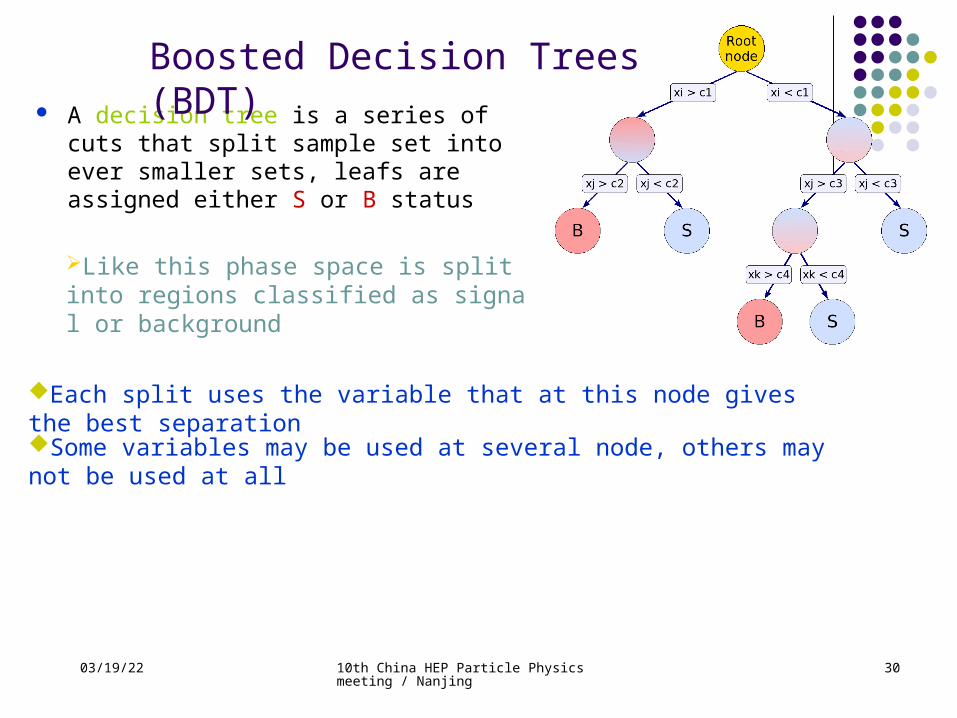
04/19/23 10th China HEP Particle Physics meeting / Nanjing
30
A decision tree is a series of cuts that split sample set into ever smaller sets, leafs are assigned either S or B status
Boosted Decision Trees (BDT)
Like this phase space is split into regions classified as signal or background
Each split uses the variable that at this node gives the best separation
Some variables may be used at several node, others may not be used at all





























