Embed Size (px)
Citation preview

Maestría en Ciencias de la Computación
Avance de tesis:
Algoritmos heurísticos aplicados al despacho económico considerando funciones de costo no convexas y zonas muertas de ciclos combinados
Presenta: Ing. Benjamín Carpio Flores Matricula: 203280041
Asesor: Dr. Javier Ramírez Rodríguez
Trimestre 06 -O Noviembre-2006

INDICE
Pág. Lista de tablas y figuras……………………………………………………………….i
Nomenclatura…………………………………………………………………………..iii
Resumen………………………………………………………………………………..iv
Introducción……………………………………………………………………………v
Antecedentes…………………………………………………........................................ix
Justificación…………………………………………………………………………….xiii
Objetivos…………………………………………………………..…….......................xiv
Contenido de la tesis…………………………………………………………………..xiv
CAPÍTULO 1. MÉTODOS HEURÍSTICOS.
1.1 Introducción………………………………………………………………..1
1.2 Algoritmos Genéticos………………………………………………...........2
1.3 Búsqueda en vecindades.………………………………………….............3
1.4 Algoritmo de Recocido Simulado………….……………………………..4
1.5 GRASP.……………….……………………………................................... 5
1.6 Satisfacción de Restricciones.…………………………………………… 8
1.7 Algoritmos Híbridos………………...……………………………..............9
1.8 Evaluación de Métodos Heurísticos………………………………………10
CAPÍTULO 2. DESPACHO ECONÓMICO.
2.1 Introducción……………………………….………………………...........11
2.2 Despacho Económico Sin Pérdidas………….……………………..........11
2.3 Otros problemas de Despacho Económico….…………………..............13
2.4 Técnicas de solución………………………………………………………14
2.5 Casos de Estudio………………………………………………………….15
CAPÍTULO 3. IMPLEMENTACIÓN DEL ALGORITMO GENÉTICO
3.1 Introducción…………………...................................................................18

3.2 Población inicial y codificación..................................................................18
3.3 Evaluación…………………………………………………………………20
3.4 Selección……………………………………………………………………20
3.5 Nuevas Generaciones. Mutación y Cruce………………………………..21
3.6 Resultados………………………………………………………………….22
CAPÍTULO 4. IMPLEMENTACIÓN DEL ALGORITMO DE RECOCIDO SIMULADO 4.1 Introducción…………………...................................................................27
4.2 Solución inicial………………...................................................................27
4.3 Vecindades……………………………………………………………….28
4.4 Algoritmo General………………………………………………………29
4.5 Resultados
CAPÍTULO 5. IMPLEMENTACIÓN DEL ALGORITMO GRASP
5.1 Introducción…………………...................................................................35
5.2 Fase Constructora………….....................................................................35
5.3 Fase de Búsqueda Local…………………………………………………41
5.4 Resultados………………………………………………………………..41
CAPÍTULO 6. IMPLEMENTACIÓN DEL ALGORITMO GENÉTICO HÍBRIDO
6.1 Introducción………………………………………...……………............45
6.2 Población inicial por Satisfacción de Restricciones……………............45
6.3 Ciclo Completo del Algoritmo Genético Hibrido………………………48
6.4 Resultados………………………………………………………………..49
CONCLUSIONES……………………..………… …............................................. 52
AVANCE Y ACTIVIDADES PENDIENTES………………………………….. 53
APENDICE I. Solución al Problema Planteado Mediante un Método Matemático
Clásico.........................................................................................................................54
REFERENCIAS..........................................................................................................58
1

Lista de tablas y figuras Tablas Tabla a. Comparación de los resultados de F. Li et al, AG convencional vs AG Híbrido. Tabla b. Comparación de resultados de Cheng et al, Híbrido AG- RS vs Programación Dinámica,
Relajación Lagrangeana. Tabla 1.1 Algoritmo Genético simple. Tabla 1.2 Algoritmo de Recocido Simulado. Tabla 1.3 Algoritmo GRASP simple. Tabla 1.4 Algoritmo de fase de construcción del GRASP basado en valor. Tabla 1.5 Algoritmo de fase de construcción del GRASP basado en cardinalidad. Tabla 1.6 Algoritmo de búsqueda local del GRASP. Tabla 2.1 Limites de potencia y coeficientes abc de las unidades del caso de estudio1. Tabla 2.2 Centrales del Sistema Baja California. Tabla 2.3 Límites de potencia y coeficientes abc de la unidades del caso de estudio. Tabla 3.1 Resultados del AG para distintos valores del FP Tabla 4.1. Comparativo de soluciones del AG y RS para caso de estudio 1 Tabla 4.2 Resultados del RS al caso de estudio 2. Número de aceptaciones en cada etapa de
enfriamiento, k0 = 40 Tabla 4.3 Resultados del RS al caso de estudio 2. Número de aceptaciones en cada etapa de
enfriamiento, k0 = 100 Tabla 5.1 Algoritmo general GRASP para el DE Tabla 5.2 Algoritmo GRASP (fase constructora) para el DE. Tabla 5.3 Resultados del GRASP para caso estudio 2, sin zona muerta de unidad 7 y ajustes
pequeños de N_itr Tabla 5.4 Resultados del GRASP, caso de estudio 2, fase constructora aleatoria-miope α=0.5 Tabla 5.5 Resultados del GRASP, caso de estudio 2, fase constructora aleatoria α=1 Tabla 5.6 Resultados del GRASP, caso de estudio 2, fase constructora miope α=0 Tabla 5.7 Solución analítica al caso de estudio 2 Tabla 6.1 Algoritmo generador de solución inicial factible por SR Tabla 6.2 Resultados del Algoritmo Genético Hibrido con K0 = 20, DP = 10. Tabla 6.3 Resultados del Algoritmo Genético Hibrido con K0 = 40, DP = 10. Tabla 6.4 Resultados del Algoritmo Genético Hibrido con error en DP = 5. Tabla 6.5 Solución analítica vs mejor solución del AGH. Tabla 6.6 Resultados del Algoritmo de Recocido Simulado. Figuras Figura a) Semana típica del Sistema Interconectado Nacional en México, en verano. Figura b) Curva de entrada-salida de U3 Mérida tg. Figura c) Planta de ciclo combinado. Figura d) Consumo especifico de Ciclo Combinado. Figura e) Entrada/Salida del Ciclo Combinado. Figura 2.1 Consumo específico de CC Mexicali (U7). Figura 2.2 Curvas de entrada-salida del ciclo combinado U7. Figura 3.1 Individuo o cromosoma. Figura 3.2 Subcadena con bits no utilizados. Figura 3.3 Cruza de individuos, con punto de cruza = 14.
i

Figura 3.4 Desempeño del AG con población inicial de soluciones factibles y no factibles
Figura 3.5 Desbalance de potencia de cada generación (población inicial de soluciones factibles y no factibles)
Figura 3.6 Aptitudes de los mejores individuos de cada generación, para poblaciones de 40 y 100 individuos
Figura 3.7 Aptitudes de promedio de cada generación, para poblaciones de 40 y 100 individuos Figura 3.8 Comparación de la convergencia del AG con y sin elitismo. 1) Usando población inicial
con soluciones factibles. 2) Usando población inicial con soluciones no factibles Figura 4.1 Convergencia del algoritmo RS para el caso de estudio 2, k0 = 40 Figura 4.2 Convergencia del algoritmo RS para el caso de estudio 2, k0 = 100 Figura 5.1 Costo de las soluciones mejoradas de cada iteración, fase de construcción con α=0.5 Figura 5.2 Costo de las soluciones mejoradas de cada iteración, fase de construcción con α=1 Figura 5.3 Costo de las soluciones mejoradas de cada iteración, fase de construcción con α=0
ii

Nomenclatura AG Algoritmo Genético A-G Híbrido Genético-Recocido Simulado (annealing-genetics) CC Ciclo Combinado CENACE Centro Nacional de Control de Energía DE Despacho Económico DEA DE con consideraciones Ambientales DED DE Dinámico DEE DE Estático DEFO DE con Flujos Óptimos DEPV DE con Punto de Válvula DESP DE sin pérdidas de transmisión F Función de costo PIE Productor Independiente de Energía RS Algortimo de Recocido Simulado SR Satisfacción de Restricciones V Unidad de vapor tg Unidad turbogás CC Unidad tipo Ciclo Combinado
iii

Resumen En México, el Centro Nacional de Control de Energía (CENACE) tiene como una de sus actividades principales, la realización diaria del Despacho Económico de generación (DE) y es de gran importancia contar con herramientas alternativas que permitan evaluar restricciones que los métodos clásicos de solución no pueden tratar, como son algunas inherentes a la operación de unidades con tecnología de tipo ciclo combinado. El problema de DE consiste en asignar el nivel de potencia que cada unidad generadora debe suministrar para cubrir la demanda de un Sistema Eléctrico de Potencia al menor costo posible. Las restricciones al problema son muy variadas y dan lugar a problemas específicos de despacho económico, como son los que consideran: límites de transmisión, pérdidas eléctricas en líneas de transmisión, puntos de válvula, emisiones de contaminantes al medio ambiente, etc. Así también, es común hacer consideraciones para poder solucionar el problema. Una de las técnicas más utilizadas para solucionar el problema, trata al DE como un problema de programación lineal. Como se sabe, esta técnica de solución requiere que tanto la función objetivo como las funciones de desigualdad, que representan las restricciones, sean lineales. Sin embargo, con esta técnica no es posible evaluar las funciones de costo no convexas de unidades de tipo ciclo combinado (tecnologías muy utilizadas recientemente por su alta eficiencia), ni la consideración de “zonas muertas”, declaradas así por el alto costo y dificultades técnicas que implica operarlas en estas zonas. Los métodos heurísticos son utilizados como herramientas de optimización que, a diferencia de los métodos matemáticos estrictos, no imponen restricciones en el modelado de los elementos implícitos en el problema, ya que tienen la habilidad de adaptarse a las no-linealidades y discontinuidades comúnmente encontradas en los sistemas físicos. En este trabajo se muestran los resultados de la implementación de métodos heurísticos para la solución del despacho económico considerando, como únicas restricciones, las funciones de costo no convexas y las “zonas muertas” de ciclos combinados, que son tratadas de dos formas: en la codificación del problema y mediante la penalización de la función objetivo cuando la unidad es asignada dentro de la zona prohibida. Los métodos heurísticos que se implementaron son GRASP (Greedy Randomized Adaptive Search Procedure), Recocido Simulado, Algoritmo Genético y Algoritmo Genético Híbrido.
iv

Introducción
El patrón de demanda de energía eléctrica de los consumidores es completamente irregular, con tendencias de mayor demanda por las tardes y noches que por las madrugadas, y patrones diferentes para los días de descanso y festivos. En la figura a) se muestra una semana típica del Sistema Interconectado Nacional de México.
0.5
0.6
0.7
0.8
0.9
1.0
1 5 9 13 17 21horas
Dem
anda
en
pu
Sábado Domingo Lun-Vie
Figura a) Semana típica del Sistema Interconectado Nacional en México, en verano. Con estos comportamientos irregulares de las demandas, algunas unidades de generación deben entrar y salir del sistema, mientras que otras sólo necesitan cambiar su aportación en potencia siguiendo el perfil de la demanda. Al problema de decidir qué unidades deben participar para cubrir la demanda se llama Asignación de Unidades y al problema de asignar el nivel de potencia de cada generador en cada hora, se le conoce como Despacho de Generación. El Despacho Económico de Generación (DE) consiste en determinar el nivel de potencia eléctrica que debe suministrar cada generador térmico para cubrir la demanda de energía pronosticada del siguiente día, al menor costo posible. Para ello se consideran principalmente, los costos de generación termoeléctrica que son variables debido a que las unidades generadoras convierten combustible en energía eléctrica con eficiencias que pueden ser muy distintas. Cada generador térmico tiene una curva de entrada-salida que representa la cantidad de combustible o el costo de combustible que la unidad consume por hora, para la potencia generada. Esta curva se determina durante el periodo de pruebas de un generador nuevo o después de un mantenimiento mayor, y se refieren a tres puntos de operación, que son el 50, 75 y 100% de la potencia máxima. Esta curva de entrada-salida es utilizada como función de costo para el problema de Despacho Económico y, por lo general y para simplificar el problema, a estos puntos se les ajusta una curva de segundo grado convexa y continua. La figura b) muestra una curva de entrada-salida de una turbina de gas.
v

30,000
40,000
50,000
60,000
70,000
80,000
90,000
100,000
5 10 15 20 25 30 35 40
MW$
/ h
Figura b) Curva de entrada-salida de U3 Mérida tg En los años sesenta se desarrollaron plantas de ciclo combinado que por su rápida incorporación al sistema presentan ventajas en su operación. Generalmente este tipo de centrales están formadas por varias unidades turbogás y un recuperador de calor con su turbogenerador, figura c). Las curvas de entrada-salida y consumo específico de la unidad de ciclo combinado se obtienen para cada combinación de turbinas de gas y la unidad de vapor.
Figura c) Planta de ciclo combinado
vi

Figura d) Consumo específico de un Ciclo Combinado
Figura e) Entrada/Salida de un Ciclo Combinado Las curvas de consumo específico dan muestra de la eficiencia de una unidad generadora, figura d). La máxima eficiencia se alcanza cuando la unidad se opera cerca de su potencia máxima. En el caso de los ciclos combinados, una misma eficiencia se puede alcanzar para diferentes niveles de potencia y diferentes configuraciones. En realidad, las funciones de costo de las unidades térmicas son discontinuas, debido a que presentan brincos en ciertos puntos debido al cierre y apertura de válvulas para el control de la salida de potencia del generador [13]. Adicionalmente, los ciclos combinados, presentan discontinuidades al cambiar de configuración en el número de unidades turbogás, figura e). Las restricciones al problema de DE son muy variadas y dan lugar a problemas específicos de despacho económico, como son la consideración de límites de transmisión, pérdidas en líneas de transmisión, puntos de válvula, límites de voltaje, con restricciones ambientales, etc. También es común hacer consideraciones para
vii

simplificar el problema, como es el caso de una de las metodologías más utilizadas conocida como técnica del Lagrangiano, que trata al problema como uno de programación lineal, donde las restricciones son incorporadas a la función objetivo a través de de multiplicadores de Lagrange, uno por cada restricción, y luego se aplica la técnica del gradiente o el método SIMPLEX para minimizar la función objetivo. Sin embargo esta técnica requiere de estricta convexidad de la función objetivo, y no se puede aplicar para evaluar funciones de costo no convexas, ni discontinuidades en las funciones de costo. Por lo tanto, se deben buscar otras metodologías que permitan considerar situaciones operativas especiales, como discontinuidades y funciones de costo no convexas, y así poder evaluar el impacto de las simplificaciones que se realizan. Los métodos heurísticos son herramientas eficientes de búsqueda de soluciones a problemas complejos, definidos así porque no existe un algoritmo que lo resuelva, o porque los dominios son tan grandes que no existe un algoritmo eficiente de solución. Las reglas y operaciones matemáticas que definen su funcionamiento son fáciles de entender e implementar. Entre los métodos heurísticos más populares utilizados para problemas de optimización, se encuentran los Algoritmos Genéticos (AG) y el de Recocido Simulado (RS). El AG toma los conceptos de la teoría de la evolución de Darwin, para evolucionar individuos (soluciones) a través de operadores de cruza y mutación, que van sobreviviendo de generación en generación por su mejor aptitud. La base teórica de estos algoritmos fue introducida por su creador John Holland en 1975, y es conocida como la teoría de los esquemas [4]. El RS imita un proceso de templado en metalurgia, una técnica que incluye calentar y luego enfriar controladamente un material para aumentar el tamaño de sus cristales y reducir sus defectos. El calor causa que los átomos se salgan de sus posiciones iniciales (un mínimo local de energía) y se muevan de forma aleatoria. El enfriamiento lento les da mayores probabilidades de encontrar configuraciones con menor energía que la inicial. En la analogía con el método de optimización, las soluciones corresponden a estados del sistema físico. El costo de la solución corresponde a la energía del estado. Se introduce un parámetro de control que corresponde a la temperatura. Si se baja la temperatura suficientemente lento se puede alcanzar el equilibrio térmico en cada temperatura. Esto se hace mediante la generación de varias transiciones en cada temperatura.
viii

Antecedentes En general, en el problema de optimización de DE, las restricciones impuestas por los métodos matemáticos clásicos en las curvas de costo de las unidades generadoras ocasionan que se obtenga sólo una aproximación en la minimización. Si se considera el costo total de generación de un sistema de potencia real, resulta evidente que evitar cualquier restricción en el modelado de las funciones de costo se traducirá en un ahorro significativo. Los métodos heurísticos son utilizados como herramientas de optimización que, a diferencia de los métodos matemáticos estrictos, no imponen restricciones en el modelado de los elementos implícitos en el problema, ya que tienen la habilidad de adaptarse a las no-linealidades y discontinuidades comúnmente encontradas en los sistemas físicos, además muestran buenas características de funcionamiento en problemas con espacio de solución multimodal. La utilización del algoritmo genético ha mostrado buenos resultados para problemas de despacho económico donde los métodos clásicos de solución no tienen aplicación. Un problema típico es el despacho económico con punto de válvula, en donde se utiliza una mejor aproximación de las curvas de entrada-salida de las unidades térmicas al considerar curvas de tipo exponencial y senoidal. Los resultados del los métodos heurísticos son siempre comparados con alguna metodología de solución tradicional para los casos donde estos últimos pueden ser aplicados, y se muestra la proximidad de la solución. F. Li [6], por ejemplo, prueba la robustez de los AGs en diferentes problemas de Despacho Económico: sin pérdidas, con pérdidas de transmisión, con punto de válvula sin pérdidas y con pérdidas. Hace un comparativo con las técnicas habituales de solución, y muestra que las ventajas de los AGs son superiores en los casos de mayor complejidad, donde algunas técnicas clásicas ni siquiera se pueden aplicar. El algoritmo genético también ha sido utilizado para problemas de despacho con restricciones de tipo no lineal, por ejemplo, restricciones ambientales [12]. Las emisiones de dióxido de azufre y óxidos de nitrógeno son representadas por funciones de segundo grado en función de la potencia de salida de cada generador. Estas restricciones son incorporadas a la función objetivo mediante un factor de penalización. Se reportan trabajos de algoritmos genéticos modificados o refinados, con operadores especiales de cruza [2] y probabilidades de cruza y mutación que se van adaptando al nivel de progreso en la solución. El algoritmo genético tiene muchos parámetros de control que deben ser ajustados, uno de ellos, por ejemplo, es el tamaño de la población. David Goldberg un estudiante de John Holland que primeramente aplicó los algoritmos genéticos,
ix

determinó que el tamaño óptimo para una codificación binaria de longitud n estaba en función exponencial de n, aunque, posteriormente sugirió que un valor adecuado era de 100 individuos. Otros resultados empíricos sugieren poblaciones de 30 individuos [10]. Olachea A. [6] analiza la aplicación de AGs a problemas de DE de diferente complejidad (sin pérdidas, con punto de válvula, con restricción de flujo máximo en líneas) para un modelo de tres máquinas y para un sistema de gran escala (17 unidades). Reporta una gran variedad de pruebas para diferentes parámetros del algoritmo genético y de sus operadores, coincidiendo sus ajustes con algunos ya ampliamente recomendados en la literatura de AG’s:
- utilizar poblaciones iniciales lo más grande posible para obtener rápida convergencia debido a que se explota con mayor eficacia el recurso de búsqueda en paralelo. Obtiene sus mejores resultados con poblaciones de 100 individuos.
- menores desviaciones de potencia utilizando puntos de cruza uniforme,
respecto al punto de cruza en un solo punto.
- probabilidades de cruza alta (0.8) y de mutación bajas (0.1). En general, se recomiendan probabilidades de mutación más bajas, de 0.01.
- uso de elitismo, conservar al mejor individuo de cada generación.
- las funciones de evaluación estructuradas en forma de sumatorias facilitan el
proceso de sintonización del algoritmo.
- conveniencia del uso de factores de prioridad y penalización en la función de evaluación cuando se incluyen restricciones adicionales.
- utilizar una función de evaluación más compleja, de tipo exponencial, para el
caso del DE con punto de válvula.
También compara los resultados codificando por una parte, las potencias de los generadores y por otra, valores de λ (costo incremental), siguiendo el criterio de que el óptimo se logra cuando todas las unidades operan a un mismo valor de λ. En ambos casos logra convergencia con un número similar de iteraciones, y desviaciones de costo del mismo orden. El desempeño de las heurísticas también ha sido mejorado mediante la hibridación para tratar de compensar algunas deficiencias. Por ejemplo, se sabe que los AG son imperfectos en cuanto a la exactitud de la solución encontrada, y las mejoras siguen en general dos líneas:
- La primera es mejorar los procedimientos genéticos: la representación o codificación de los individuos, el tamaño y calidad de la población inicial,
x

diferentes funciones de evaluación, operadores genéticos avanzados y auto-adaptables, y mediante la selección óptima de los parámetros del algoritmo. - La segunda línea va en el sentido de usar AGH’s, combinando el AG con técnicas de búsqueda local para acelerar el proceso y mejorar la calidad de la solución.
Por ejemplo, F. Li et al [7] proponen un algoritmo híbrido de AG con la técnica del gradiente para el problema de DE, que superan a los AG convencionales (AGC) en calidad y tiempo de solución a la vez. Los AGC son capaces de balancear la exploración y explotación del espacio de búsqueda, lo que significa que un incremento en la exactitud de la solución sólo se logra sacrificando la rapidez de convergencia, y viceversa. No es posible que ambas cosas se mejoren al mismo tiempo. Sin embargo, con el AG híbrido (AGH) que proponen, encuentran soluciones óptimas con mayor rapidez y exactitud. El AGH consta de un AG encargado de dirigir la búsqueda hacia regiones prometedoras, y uno de búsqueda local (técnica del gradiente de primer orden) para hacer el “trabajo fino”. La efectividad de su algoritmo fue probada en un sistema real de 25 unidades generadoras.
Comparación del desempeño de un AGH y un AGC
Generación CostoTiempo de Cómputo
Tiempo adicional (mismo costo)
Costo adicional (mismo tiempo)
AGC 25 1,695,303.25 17 min, 3 s 4 min, 54 s ---AGH 20 1,695,303.25 11 min, 9 s --- ---AGC 10 1,706,070.25 4 min, 1.8 s --- 6130.13AGH 10 1,699,940.12 4 min, 1.8 s --- ---
Tabla a) Comparación de los resultados de F. Li et al, AG convencional vs AG Híbrido
En los resultados de la tabla anterior, se observa que el AGH proporciona mejores resultados de costo para un mismo tiempo de ejecución. El AGC puede dar resultados de costo similares al AGH en un tiempo adicional considerable. Cheng et al., [3] aplican un algoritmo híbrido A-G (annealing-genetics) al problema de asignación de unidades. Señalan que el algoritmo de recocido simulado consume mucho tiempo de cómputo para llegar a la cercanía de un óptimo global. El algoritmo genético, por el contrario, es más rápido, pero logra una solución de menor calidad. El algoritmo genera una población inicial de manera aleatoria, entonces se mejora cada una de las soluciones en una etapa de enfriamiento del recocido simulado para obtener una quasi-población. Luego, actúan los operadores de cruza y mutación para obtener la siguiente generación que ya tiene un costo promedio inferior al de la población anterior. El criterio de paro está determinado por el nivel de energía mínimo que establece el algoritmo de recocido simulado. Sus resultados muestran un mejor desempeño de su AG comparado con las metodologías de programación dinámica y la relajación lagrangeana, para sistemas de 10, 20 y 40 unidades. También muestran que el A-G encontró mejores costos
xi

que un algoritmo genético convencional y menores tiempos de uso de CPU que el algoritmo de recocido simulado.
Comparación de desempeño entre A-G, DP y LRCosto ($) DP Costo ($) LR Costo ($) A-G
10 unidades 565,825 565,825 564,00520 unidades - 1,130,660 1,124,65140 unidades - 2,258,503 2,249,072
DP: Programación dinámicaLR: Relajación LagrangeanaA-G: Hibrido Recocido Simulado-Genético
Comparación del desempeño para diferentes factores de servicioFactor de servicio Costo ($) SA Costo ($) GA Costo ($) A-G tiempo CPU (s) SA tiempo CPU (s) GA tiempo CPU (s) A-G
94% 2,735,427 2,775,344 2,734,402 2,402 2,099 1,80187% 2,377,755 2,408,643 2,376,098 3,092 1,961 2,37180% 2,112,288 2,118,544 2,111,830 3,954 1,882 2,56672% 1,857,257 1,872,381 1,856,584 3,313 1,952 3,270
SA: Recocido SimuladoGA: Algorimo GenéticoA-G: Hibrido Recocido Simulado-Genético
Tabla b) Comparación de resultados de Cheng et al, Híbrido AG- RS vs Programación Dinámica, Relajación Lagrangeana
Ongsakul W. [5] utilizó métodos basados en tablas de mérito para el despacho de unidades tipo ciclo combinado, para resolver una limitación del programa de despacho económico en tiempo real de la compañía Electriciy Generating Authority of Thailand. Esta aplicación sólo consideraba funciones de costo incremental monótonas crecientes y los modelos que se querían utilizar eran funciones lineales decrecientes y de tipo escalón (correspondientes a curvas de entrada-salida de segundo y primer orden, respectivamente). El autor utilizó los costos incrementales de las unidades generando a su máxima potencia como criterio para despachar los ciclos combinados y obtuvo mejores resultados que los obtenidos con el método de Newton, y desviaciones promedio del 0.43 % respecto de la solución óptima. El caso de estudio referido estaba formado por 4 ciclos combinados con curvas de costos incrementales lineales decrecientes y 1 ciclo combinado con curva de costo incremental de tipo escalera decreciente. Sin embargo, el autor no comenta nada acerca de las variaciones derivadas de utilizar modelos aproximados (curvas de costo incremental lineales y de escalera decrecientes).
xii

Justificación Con la reciente modificación a la Ley de Servicio Público de Energía de México, se ha permitido la generación de energía eléctrica por particulares. A dicha modalidad se le ha denominado Producción Independiente de Energía. Actualmente existen 20 productores independientes que operan en distintas áreas del país y utilizan la tecnología de ciclo combinado. Los productores independientes proporcionan al CENACE los consumos específicos en kcal/kWh de tres puntos de operación para la realización del despacho de generación. En algunos casos, los puntos de operación corresponden a curvas no convexas en los primeros rangos de operación (fig. 8) y, adicionalmente, se declaran “zonas muertas” por las dificultades técnicas que se presentan en las transiciones de las diferentes configuraciones del ciclo combinado (1V + 1tg, 1V + 2tg, etc). Por otra parte, las funciones de costo de las plantas térmicas de CFE, incluyendo ciclos combinados, han sido representadas con curvas convexas de segundo grado, como lo exige la aplicación que se utiliza para ejecutar el Despacho de Económico de Generación. Entonces, para poder integrar los modelos antes descritos de los PIE´s, se ajustan los tres puntos de consumo específico a una curva convexa de segundo orden, y cuando los resultados del despacho indican una operación del PIE en una zona muerta, éstos trasladan su punto de operación al límite más cercano de la zona muerta.
1,780
1,800
1,820
1,840
1,860
1,880
50 75 100
% Capacidad
kcal
/ kW
h
“zona muerta”
Fig. 1.2 Curva de consumo específico basada en tres puntos, del PIE CC Mexicali
Se ha comentado en las secciones anteriores que los AGs han mostrado buenos resultados en problemas complejos, como los de Despacho Económico, y son capaces de trabajar con cualquier tipo de función objetivo. Aún cuando se menciona que los AGs son imperfectos en cuanto a la exactitud de la solución encontrada, éstos pueden ser mejorados siguiendo dos líneas. La primera es mejorar los procedimientos genéticos y la segunda va en el sentido de usar AGH’s,
xiii

combinando los AGs con técnicas de búsqueda local para mejorar la calidad de la solución. En este trabajo de tesis, se muestra la aplicación de heurísticas aplicadas a la solución del problema de DE sin pérdidas, considerando las funciones de costo no convexas y las zonas muertas de los ciclos combinados. Se muestra la comparación del desempeño de un Algoritmo Genético Híbrido, con otras heurísticas, GRASP y Recocido Simulado, y luego, para un caso sencillo, la comparación con un método exacto de solución. Se analiza el caso más sencillo de DE, con la única finalidad de que se puedan compara los resultados de las heurísticas empleadas con la solución de un método exacto.
Objetivos
Objetivo General: Aplicar métodos heurísticos al problema de despacho económico sin pérdidas, considerando las funciones de costo no convexas y zonas muertas de los ciclos combinados
Objetivos particulares: - Implementar los métodos heurísticos GRASP, Recocido Simulado, Algoritmo
Genético y Algoritmo Genético Híbrido para el problema de Despacho Económico sin pérdidas.
- Determinar los mejores ajustes de los parámetros de los métodos heurísticos. - Evaluar el efecto en los costos de operación del Despacho Económico, al
considerar las zonas muertas y las curvas no convexas de los ciclos combinados.
Contenido de la tesis
xiv

Capítulo 1. Métodos Heurísticos
1.1 Introducción El término heurística proviene del griego heuriskein que significa encontrar o descubrir. De acuerdo con ANSI/IEEE Std 100-1984 (Standard Dictionary of Electrical and Electronics Terms), la heurística trata de aquellos métodos o algoritmos exploratorios para la resolución de problemas en los que las soluciones se descubren por la evaluación del progreso logrado en la búsqueda de un resultado final. Se trata de métodos en los que, aunque la exploración se realiza de manera algorítmica, el progreso se logra por la evaluación puramente empírica del resultado. Se gana eficacia, sobre todo en términos de eficiencia computacional, a costa de la precisión. Las técnicas heurísticas son usadas en problemas en los que la complejidad de la solución algorítmica disponible es función exponencial de algún parámetro; cuando el valor de éste crece, el problema se vuelve rápidamente inabordable. Una alternativa heurística será practicable si la complejidad de cómputo depende, por ejemplo, polinómicamente del mismo parámetro. Las técnicas heurísticas no aseguran soluciones óptimas sino solamente soluciones válidas, aproximadas; y frecuentemente no es posible justificar en términos estrictamente lógicos la validez del resultado. En este capítulo se hace una breve descripción de los métodos heurísticos que se implementaron para el problema de DE: Algoritmo Genético, Recocido Simulado, GRASP, y de métodos heurísticos que sirvieron de soporte para la implementación del AGH, como son la búsqueda en vecindades y algoritmos de satisfacción de restricciones. También se revisan métodos de evaluación del desempeño de los
1

métodos heurísticos, lo cual permite darnos una idea de la calidad de la solución que generan los métodos heurísticos.
1.2 Algoritmos Genéticos Un algoritmo genético puede considerarse un algoritmo de búsqueda probabilística "inteligente" que puede aplicarse a varios problemas de optimización combinatoria. Las bases teóricas de los algoritmos genéticos fueron desarrolladas por John Holland en los años setenta; la idea está basada en el proceso evolutivo de los organismos biológicos en la naturaleza. Durante el curso de la evolución las poblaciones naturales evolucionan de acuerdo a los principios de la selección natural en que sobreviven y se reproducen los más aptos. Lo que significa que los genes de los individuos mejor adaptados se transmitirán a los individuos de generaciones posteriores. La combinación de buenas características de ancestros altamente adaptados puede producir descendientes aún mejor adaptados. De esta manera, las especies evolucionan y están cada vez mejor adaptadas a su medio ambiente. Los algoritmos genéticos intentan imitar matemáticamente algunos procesos adaptativos del fenómeno biológico, considerando una población inicial de individuos y aplicando operadores genéticos en cada reproducción, con dichos operadores se define un mecanismo de búsqueda sin necesidad de imponer restricciones matemáticas adicionales. En términos de optimización, cada individuo de una población es codificado en una cadena o cromosoma que representa una posible solución de un problema dado. El ajuste de un individuo es evaluado con respecto a una función objetivo propuesta. A los individuos mejor adaptados o mejores soluciones, se les permite reproducirse intercambiando algunos elementos de su información genética en un proceso de cruce con otros individuos también muy aptos. Esto produce nuevas soluciones, que comparten algunas características tomadas de sus padres. Frecuentemente se aplica la mutación después del cruce alterando algunos genes en las cadenas, con el fin de mejorar el ajuste de un conjunto de soluciones iniciales o soluciones de la población inicial. Los descendientes pueden reemplazar a la población total, enfoque generacional, o reemplazar a los individuos menos aptos, enfoque de estado uniforme. Este ciclo de evaluación-selección-reproducción se repite hasta encontrar una solución satisfactoria.
2

Un algoritmo genético estándar se puede resumir en la siguiente tabla: inicio Representar adecuadamente las soluciones del Problema Generar población inicial con individuos o soluciones del Problema Definir una función de aptitud de los individuos de la población do while (NO se haya satisfecho el criterio de parada) Elegir pares de individuos como padres Cruzar los padres elegidos para obtener dos hijos Reemplazar los padres elegidos, por sus hijos Mutar algunas características de los individuos de la generación Evaluar la aptitud de los individuos de la población Seleccionar individuos que sobreviven en la siguiente generación enddo fin Tabla 1.1 Algoritmo Genético simple. Los algoritmos genéticos manejan simultáneamente un conjunto de soluciones (individuos) en cada etapa (la generación). Las características de cada solución deben ser codificadas adecuadamente (el cromosoma) de forma que al combinar dos soluciones para producir una nueva solución, parte de estas características (los genes) se transmitan a ésta.
1.3 Búsqueda en vecindades
3

1.4 Algoritmo de Recocido Simulado El concepto de recocido simulado en optimización combinatoria fue introducido por Kirkpatrick, Gellat y Vecchi en 1983 y en forma independiente por C
( erný en 1985. Usando una analogía entre estos problemas y el recocido de sólidos que es un proceso físico en el cual un sólido se funde y después se enfría lentamente con el fin de obtener estructuras de cristal perfectas las cuales pueden modelarse como un estado de mínima energía. La idea es resolver problemas de optimización combinatoria por un proceso análogo. Sea s la solución actual y N(s) una vecindad de s que contiene soluciones alternativas. Se selecciona de forma aleatoria s’ ∈ N(s) y se calcula la diferencia D = f(s’) – f(s), donde f(s) es el valor de la función objetivo en s. Si D < 0, entonces s’ se selecciona como la nueva solución, lo que quiere decir que soluciones mejores se aceptan siempre. Si D > 0 y e-D/cT > r, donde r es un número aleatorio generado de una distribución uniforme, entonces s’ se acepta como nueva solución, lo que significa que también pueden aceptarse soluciones peores que la actual. T es un parámetro de control llamado temperatura y c es la constante de Boltzman (1.38054x10-3). Como ya se dijo, la temperatura se hace descender lentamente, mediante una constante de enfriamiento α, durante el proceso de búsqueda de tal manera que la probabilidad de aceptar peores soluciones decrece constantemente. En cada temperatura el proceso continúa hasta que se cumple el criterio de parada. inicio inicializa (sini, T, K0) k 0 s sini do while (t< temperatura mínima (criterio de paro) for k=1 to K0 do genera s’ ∈ N(s)) if f(s’) < f(s) then s s’ else genera_aleatorio n en [0,1] if (exp((f(s) – f(s’))/ c T) > n) then s s’ end if end for T α T , α∈ (0,1) end do fin Tabla 1.2 Algoritmo de Recocido Simulado
4

1.5 GRASP (greedy randomized adaptive search procedures) GRASP es un método iterativo multi-arranque diseñado para resolver problemas difíciles de optimización combinatoria. Una característica importante de GRASP es la facilidad para implementarse, en su forma más simple sólo hay que determinar el número de iteraciones y el tamaño de la lista de candidatos. Cada iteración consiste de 2 fases: una de construcción, en la cuál se produce una solución factible buena, y una de mejora, que es una búsqueda local en la que se examinan vecindades de la solución producida en la fase anterior. La mejor solución encontrada en cada fase se va almacenando hasta concluir el proceso con un criterio de terminación. Se muestra a continuación el seudo código de un GRASP básico, procedure GRASP (f(.), g(.), imax) Require: imáx
f* ← ∞ for i ≤ imáx do construct(g(.), α,x) x ← GreedyRandomized() x ← local_search(x) if f(x) < f* then f* ← f(x) x* ← x end if end for return x* Tabla 1.3 Algoritmo GRASP simple Fase de construcción En esta fase se construye en forma iterativa una solución factible, se incorpora un elemento a la vez. En cada iteración, la elección del siguiente elemento se determina ordenando a todos los candidatos de una lista C con respecto a una función glotona (miope) g:C ⇒ R. Esta función mide el beneficio local de seleccionar cada elemento. La heurística es adaptativa porque los beneficios asociados con cada elemento son actualizados en cada iteración de la fase de construcción para reflejar los cambios resultantes por la selección del elemento previo. El componente probabilístico del GRASP es caracterizado por elegir de forma aleatoria uno de los mejores candidatos en la lista, y no necesariamente al mejor de ellos. La lista de los mejores candidatos es llamada lista restringida de candidatos (RCL, restricted candidate list). Esta técnica de selección permite obtener diferentes soluciones en cada iteración del GRASP. La tabla 1.4 muestra un algoritmo para la fase de construcción.
5

procedure construct(g(.), α, x) x = 0; Inicializar lista de candidatos C; while C ≠ 0 do s = mín{ g(t) | t ∈ C }; s- = máx{ g(t) | t ∈ C }; RCL = { s ∈ C | g(s) ≤ s + α( s- – s) }; Selección aleatoria de s de la RCL; x = x ∪ {s}; actualizar la lista de candidatos C; end while end construct; Tabla 1.4 Algoritmo de fase de construcción del GRASP basado en valor. El parámetro alfa controla el grado de miopía y aleatoriedad en el algoritmo. Un valor de α = 0 corresponde a un procedimiento de construcción puramente miope, mientras que con α = 1, uno aleatorio. Aunque los algoritmos miopes pueden producir buenas soluciones razonables, su principal desventaja como generador de soluciones iniciales para búsquedas locales es su falta de diversidad. Aplicando repetidamente un algoritmo miope, una sola o muy pocas soluciones pueden generarse. Un algoritmo totalmente aleatorio produce una gran cantidad de soluciones diversas, pero la calidad de éstas es generalmente muy pobre, y al usarlas como soluciones iniciales para búsquedas locales, generalmente conducen a una convergencia muy lenta. Así entonces, para beneficiarse de la convergencia rápida del algoritmo miope y la gran diversidad de soluciones del algoritmo aleatorio, se recomienda usar valores de α estrictamente contenido dentro del rango [0,1] El algoritmo de construcción de la tabla 1.4 utiliza una RCL basada en el valor, donde los elementos que la forman cumplen con un valor de la función miope dentro de un rango dado. En la tabla 1.5 se muestra un algoritmo de construcción con RCL basada en cardinalidad, donde la lista está formada por un número fijo de elementos con las mejores evaluaciones de la función miope. Procedure Construcción-C Require: k, E, c(.)
x ← 0 C ← E Calcular costo miope c(e), ∀ e ∈ C while C ≠ 0 do RCL ← { k elementos e ∈ C con el menor c(e) } Seleccionar un elemento s de RCL al azar x ← x ∪ {s}
6

Actualizar el conjunto candidato C Calcular el costo miope c(e), ∀ e ∈ C end while return x
Tabla 1.5 Algoritmo de fase de construcción del GRASP basado en cardinalidad
Existen diferentes variantes del algoritmo de construcción (construcción aleatoria después miope, construcción con perturbaciones, RCL basada en valores con sesgo) que pueden ser revisadas en [11]. Búsqueda Local Como es el caso de muchos métodos deterministas, las soluciones generadas en la fase de construcción del GRASP no son garantizadas de ser localmente óptimas respecto a definiciones simples de vecindades. Por lo cuál es casi siempre benéfico aplicar una búsqueda local para intentar mejorar cada solución construida. Un algoritmo de búsqueda local explora repetidamente la vecindad de una solución en busca de una mejor solución. Cuando no se encuentra una solución que mejora la actual, se dice que la solución es localmente óptima. La clave de éxito de los algoritmos de búsqueda local depende de una apropiada elección de la estructura de vecindades, de técnicas eficientes de búsqueda en vecindades y de la solución inicial. En la tabla 1.6 se muestra un algoritmo sencillo de búsqueda local. Procedure BúsquedaLocal Require : x0, N(.), f(.) x ← x0
while x no es localmente óptimo con respecto a N(x) do Sea y ∈ N(x) | f(y) < f(x) x ← y end while return x Tabla 1.6 Algoritmo de búsqueda local del GRASP La búsqueda local juega un papel muy importante en GRASP ya que sirve para buscar soluciones locales óptimas en regiones prometedoras del espacio de soluciones.
7

1.6 Satisfacción de Restricciones La programación de restricciones puede dividirse en dos ramas claramente diferenciadas: la satisfacción de restricciones y la resolución de restricciones. Ambas comparten la misma terminología pero sus orígenes y técnicas de resolución son diferentes. Un problema de satisfacción de restricciones (PSR) está definido por un conjunto de variables X1, X2,…, Xn, y un conjunto de restricciones r1, r2,…,rm, la aridad de una restricción es el número de variables que tiene. Cada variable Xi tiene un dominio Di de posibles valores. Cada restricción ri comprende algún subconjunto de variables y especifica las combinaciones de valores permisibles para cada subconjunto. Dependiendo si los dominios de las variables son discretos o continuos, finitos o infinitos, se pueden distinguir distintos tipos de PSRs, se tratarán problemas con dominios discretos y finitos. Un estado del problema está definido por una asignación de valores a algunas o a todas las variables, {Xi=vi, Xj = vj,…}. Una asignación que no viola ninguna restricción se llama consistente o asignación válida. Una asignación completa es una en la que cada variable es mencionada, una solución a un PSR es una asignación completa que satisface a todas las restricciones. La resolución de un PSR consta de dos fases:
i. Modelar el problema como uno de satisfacción de restricciones. La modelación expresa el problema mediante un conjunto de variables, dominios y restricciones del PSR. ii. Procesar el problema de satisfacción de restricciones resultante, para lo que hay dos formas.
1. Técnicas de consistencia. Son técnicas de resolución de PSR basadas en la eliminación de valores inconsistentes de los dominios de las variables.
2. Algoritmos de búsqueda. Se basan en la exploración sistemática del espacio de soluciones hasta encontrar una solución o probar que no existe alguna.
Las técnicas de consistencia o inferenciales permite deducir información del problema, niveles de consistencia, valores posibles de variables, dominios mínimos, etc., aunque en general se combinan con las técnicas de búsqueda, ya que reducen el espacio de soluciones y los algoritmos de búsqueda exploran dicho espacio resultante, en este trabajo se utilizan éstas técnicas. Una forma de hacer mejor uso de las restricciones durante la búsqueda se llama inspección hacia delante. Siempre que una variable X es asignada, el proceso de inspección hacia delante mira a cada variable Y no asignada que está conectada a X por una restricción y borra del dominio de Y cualquier valor que es inconsistente para el valor escogido para X.
8

El conjunto formado por todas las posibles asignaciones de un PSR, también conocido como espacio de estados, se representa mediante un árbol de búsqueda. En cada nivel se asigna un valor a una variable, y los sucesores de un nodo son todos los valores de la variable asociada a este nivel. Cada camino del nodo raíz a un nodo terminal representa una asignación completa. Los algoritmos se diferencian en cómo recorren el árbol de búsqueda a la hora de encontrar soluciones: búsqueda hacia atrás, salta hacia atrás, salta hacia atrás directo a conflicto, etc.
1.6 Algoritmos Híbridos En algunos casos, la efectividad de un algoritmo puede ser mejorada al combinarlo con otro algoritmo, a lo que se le conoce como hibridación, y se puede aplicar de diferentes maneras. Por ejemplo para el algoritmo genético, se puede aplicar una heurística específica para crear la población inicial de tal manera que cada individuo sea una solución factible. El algoritmo genético se puede combinar con algoritmos de búsqueda local para mejorar la calidad de la solución. Reeves [10] comenta que aún cuando el principal beneficio del algoritmo genético es el poco conocimiento que requiere del problema, ya que se basa principalmente en una adecuada codificación, considera que es una pequeña violación que vale la pena porque se logra encontrar mejores soluciones para un problema en particular. Los algoritmos híbridos consisten en la combinación de algoritmos, ya sea que formen parte de otro algoritmo o que sirvan para mejorar la entrada o salida de un algoritmo principal. Esto con el fin de mejorar el desempeño del algoritmo y la calidad de la solución. Sin embargo, esto requiere de un conocimiento más específico del problema. A veces estas modificaciones rompen con los paradigmas de cada algoritmo. Por ejemplo, Reeves comenta que el incorporar heurísticas específicas al algoritmo genético, rompe con una de sus principales ventajas, que es la de encontrar soluciones para cualquier tipo de problema, sin tener un conocimiento detallado de éste y su funcionamiento depende de una adecuada codificación del problema. Sin embargo, concluye que esto es preferible si se desea una buena solución para un problema en específico, más que la evaluación del desempeño del algoritmo genético para diferentes problemas. En el caso de recocido simulado, las combinaciones son en el sentido de mejorar la solución a la entrada o a la salida del algoritmo. Cuando se proporciona una buena solución al algoritmo de recocido simulado en lugar de una solución generada de forma aleatoria, se recomienda empezar el algoritmo a temperaturas bajas, para no correr el riesgo de destruir la solución en las primeras etapas. El problema pudiera ser que la solución encontrada sea un mínimo local.
9

1.7 Evaluación de métodos Heurísticos Una pregunta interesante acerca de las heurísticas es qué tan bueno es su desempeño, no sólo en forma general, sino para una instancia en particular. El determinar cuál es el desempeño de una heurística es de gran interés para determinar la calidad de una solución o simplemente para determinar el criterio de paro de heurísticas iterativas como el recocido simulado o algoritmo genético. Dado que no hay garantía de optimalidad, es importante tener un estimado de qué tan buena o mala es una solución heurística. El desempeño de un método heurístico ha sido evaluado por métodos analíticos para el peor caso y el desempeño promedio. También se han evaluado mediante pruebas empíricas o por inferencia estadística. En otros casos, es suficiente con poner límites a las soluciones encontradas. Para algunas heurísticas ha sido posible analizar su operación para establecer límites ya sea para el peor caso o para el desempeño promedio. Por ejemplo, la heurística del algoritmo glotón aplicado al problema de la mochila, consistente en llenar ordenadamente la mochila de acuerdo con los mejores precios unitarios, un análisis para el peor de los casos, determina que la solución es de la mitad del valor de la solución óptima. El análisis del desempeño promedio es aún más fragmentado, ya que esto implicaría la suposición de una distribución de probabilidad de todas las instancias del problema. Se ha demostrado que métodos basados en búsqueda local (recocido simulado y búsqueda tabú) no tienen garantía de desempeño para el problema TSP, aún en tiempo exponencial de búsqueda. Sin embargo, se ha demostrado la convergencia asintótica del algoritmo de recocido simulado bajo condiciones sencillas de satisfacer ciertos parámetros [5]. Aún cuando se puedan establecer límites de desempeño tal información es de poca ayuda para establecer la efectividad de una solución para un problema en particular.
10

Capítulo 2. Despacho Económico
2.1 Introducción El problema de DE se puede hacer tan sencillo o complicado como se quiera. Pero en general, el problema tiene que ser dividido para el análisis de restricciones que dan origen a diferentes problemas de despacho económico. Las diferentes soluciones son iteradas hasta que no se viola ninguna restricción. En este capítulo se describe el problema de despacho económico sin pérdidas, que es ampliamente utilizado para mostrar la naturaleza y un buen entendimiento del problema. Este problema es relativamente fácil de resolver, cuando se hacen consideraciones adicionales como utilizar funciones de costo convexas de segundo orden, que lo convierte en un problema de programación lineal. La única dificultad mayor, viéndolo de esta forma, sería con el número de unidades del sistema a tratar, pero aún así, con los recursos de cómputo y programas de software actuales, no representan más dificultades que el de tener que esperar unos minutos para su solución. En el capítulo se describen brevemente algunos otros problemas de Despacho Económico con el único fin de mostrar las restricciones más estudiadas y al final se presentan los sistemas utilizados como casos de estudio.
2.2 Despacho Económico sin pérdidas El problema más sencillo de despacho es el Despacho Económico Estático (DEE), se plantea para un sólo intervalo de tiempo donde la demanda es constante y generalmente se asume que las curvas de entrada-salida son suaves y convexas, las cuales pueden ser representadas por funciones lineales o cuadráticas. Un caso simple es el DE sin pérdidas de transmisión (DESP), en donde las únicas restricciones son el balance de potencia y los límites de potencia de cada generador. La formulación es la siguiente:
minimizar : (P∑=
n
iiF
1i)
sujeto a:
∑=
=n
ii demandaP
1
Pmini ≤ Pi ≤ PmaxiDonde: n: número de unidades generadoras
11

Fi : Función de costo del generador i Pi : Potencia del generador i Pmini : Potencia mínima que puede suministrar el generador i Pmaxi : Potencia máxima que puede suministrar el generador i Se utilizan multiplicadores de Lagrange para incorporar a la función objetivo las restricciones de igualdad (balance generación-demanda). Función lagrangeana:
⎟⎠
⎞⎜⎝
⎛ −+= ∑∑==
n
ii
n
iii demandaPPFPL
11)(),( λλ
Luego, la condición necesaria para el mínimo es cuando el gradiente de la función lagrangeana es cero: Condiciones de optimalidad
nidPdF
PL
i
i
i
,...,1;0 ==+=∂∂ λ
;01
=−=∂∂ ∑
=
demandaPL n
iiλ
Al término λ = -i
i
dPdF , se le conoce como costo incremental del generador i, y
representa el incremento de costo debido a un incremento en la potencia generada. Se observa de las condiciones de optimalidad, que para lograr el óptimo, todas las unidades deben operar a un mismo costo incremental λ. El problema consiste en la solución de un sistema de ecuaciones simultáneas, el cual se puede resolver por el método SIMPLEX o con el Método de Newton [1], según sea el grado de las funciones de costo de los generadores. Para considerar los límites de generación se agregan nuevos multiplicadores de Lagrange a la función objetivo, dos por cada unidad. La función Lagrangeana es ahora:
∑ ∑∑∑= ===
−+−+⎟⎠
⎞⎜⎝
⎛ −+=n
i
n
iiiii
n
ii
n
iii PPiPPidemandaPPFPL
1 1
minminmaxmax
11)()()(),( µµλλ
Condiciones de optimalidad:
12

nidPdF
PL
iii
i
i
,...,1;0minmax ==+++=∂∂ µµλ
;01
=−=∂∂ ∑
=
demandaPL n
iiλ
Como se observa, la cantidad de términos es considerable al incorporar los límites operativos de las unidades, lo cuál requiere de más recursos de cómputo. El DEE tiene las siguientes desventajas
- No toma en cuenta restricciones de seguridad y confiabilidad que proporcionan continuidad y seguridad al sistema.
- No considera la no linealidad y discontinuidades en las funciones de costo, lo cuál podría traducirse en un menor ahorro
- La asignaciones de potencias del periodo actual no toman en cuenta futuros despachos, y no puede anticiparse a variaciones importantes en la demanda, respecto de los pronósticos
2.3 Otros problemas de Despacho Económico Respecto a la exactitud deseada y relevancia del problema considerado, se han derivado otros problemas de DE [6] los que se describen a continuación: 1.- DE con punto de válvula (DEPV).- el cual considera la no linealidad de las funciones de costo, con el fin de tener mayores ahorros en el costo. En unidades térmicas grandes, los niveles de potencia se van escalando a través de la apertura de válvulas, en forma escalonada, lo cual origina que la función de costo pueda ser no convexa y con discontinuidades. 2.- DE Dinámico (DED).- su objetivo es satisfacer la demanda de energía entre las unidades asignadas, pero tomando en cuenta la demanda actual y futura pronosticada, minimizando costos dentro de un periodo corto de tiempo, y tomando en consideración restricciones como rampas de carga y reserva rodante. 3.- DE con consideraciones Ambientales (DEA).- su objetivo es satisfacer la demanda de energía entre las unidades asignadas minimizando costos por uso de combustibles y las emisiones de contaminantes que generan las unidades de generación.
13

4.- Flujos óptimos (DEFO).- el objetivo es minimizar el costo sujeto a restricciones de seguridad, y las potencias activa y reactiva de cada generador se sujetan a los niveles seguros de voltaje y ángulos de fase en los buses del sistema.
14

2.4 Técnicas de solución Convencionalmente, se aplican diferentes técnicas para atacar los diferentes tipos de problemas del despacho. Sin embargo, cualquier cambio en la formulación del problema, puede requerir una alteración parcial o el reemplazo total de la técnica utilizada. El tiempo y esfuerzo que se requiere para adecuar la técnica son inadecuados para muchas aplicaciones prácticas. Algunas de las técnicas utilizadas para solucionar los problemas de DE son el método de gradiente, el método de la lambda iterativa, el método del gradiente y la programación dinámica. Todas ellas utilizan reglas deterministas transitorias para obtener estrategias de solución. 1.- Tabla de mérito. La idea es que la unidad más eficiente opere a su máxima capacidad, luego la segunda más eficiente, y así sucesivamente hasta satisfacer la demanda de energía. Este método es muy simple y eficiente, pero no permite considerar un gran número de restricciones y da resultados costosos. 2.- Método de la lambda iterativa. Está basado en el principio de costos incrementales iguales. Se empieza por un valor de λ inicial y se termina hasta que las potencias de las unidades se ajustan a la demanda. Este método requiere estricta convexidad y continuidad de las funciones objetivo. 3.- Programación Dinámica. Es una técnica matemática útil en la toma de una serie de decisiones interrelacionadas. Proporciona un procedimiento sistemático para determinar la combinación óptima de decisiones. Sin embargo, en la práctica el espacio de búsqueda es tan grande que simplemente no es posible completarla. 4.- Técnica del gradiente. Es un método iterativo muy eficiente cuando se parte de una buena solución inicial, ya que busca óptimos locales. En contraste a las técnicas convencionales, los Algoritmos Genéticos han exhibido robustez en la habilidad para encontrar óptimos globales en la solución de los problemas de despacho económico de diferente complejidad. Los AGs están inspirados en la teoría de evolución natural (supervivencia de los más aptos). La mayor atracción de estos algoritmos es que son computacionalmente simples, pero bastante poderosos en la búsqueda de óptimos globales. Estos algoritmos no están limitados por las restricciones de continuidad y la existencia de información del gradiente, por el contrario, permiten no linealidades y discontinuidades en el espacio de búsqueda. En el caso del problema de despacho económico, estos algoritmos permiten utilizar de igual manera funciones de costo lineal o no lineales, de ahí que sean una buena opción para resolver el DEPV.
15

2.5 Casos de Estudio Caso 1. Sistema de 3 unidades Demanda = 400 MW
coeficientes abc de la función de
costo de segundo orden U1 U2 U3 a b c
Pmax 210 325 315 P1 0.03546 38.31 1243.53 Pmin 35 130 125 P2 0.02111 36.33 1658.57 P3 0.01799 38.27 1356.66Tabla 2.1 Limites de potencia y coeficientes abc de las unidades del caso de estudio1 Caso 2. El sistema de prueba es un sistema aislado del Sistema Eléctrico Nacional en México, Sistema Baja California (SBC). EL SBC es un sistema aislado que cubre el estado de Baja California. Este sistema cuenta con el siguiente parque de unidades generadoras:
Nombre central Tipo Unidades MW
Presidente Juárez vapor convencional 2 320.0
Ciprés Turbogás 1 27.4
Mexicali Turbogás 3 62.0
Tijuana Turbogás 3 210.0
Presidente Juárez Ciclo combinado 2 496.0
CC Mexicali Ciclo combinado 3 489.0
Cerro Prieto cuatro Geotérmica 4 100.0
Cerro Prieto dos Geotérmica 2 220.0
Cerro Prieto tres Geotérmica 2 220.0
Cerro Prieto uno Geotérmica 5 180.0
Total 31 2,324.4
Tabla 2.2 Centrales del Sistema Baja California El SBC tuvo en el año 2005 una demanda mínima de 623, máxima de 1,909 y promedio de 1,195 MW. La generación de tipo geotérmico es un tipo de generación base, es decir, que mantienen su generación prácticamente constante durante su operación. Debido a esto, no son tomadas en cuenta en el DE. Estas unidades cubren una demanda de 700 MW en promedio.
16

Así entonces el SBC queda reducido a un despacho económico de 7 unidades1. Se muestran los datos del caso de estudio: Demanda: 804 MW coeficientes
Pmin Pmax a b c
central tipo [MW] [MW] [$/MWh2] [$/MWh] [$]
Presidente Juárez U1 vapor convencional 40 160 1.2800 368.0 22770
Presidente Juárez U2 ciclo combinado 62 248 0.5635 158.5 33830
Presidente Juárez U3 ciclo combinado 62 248 0.5635 158.5 33830
Ciprés U4 turbogás 7 27 24.9200 1154.0 13330
Mexicali U5 turbogás 7 26 19.4500 1204.0 16680
Tijuana U6 turbogás 8 30 21.1600 1190.0 16660
CC Mexicali 1) U7 ciclo combinado 122 489 0.0291 467.7 6957
Total 308 1,228 1) Coeficientes abc de la curva ajustada a los tres puntos de la curva de régimen térmico Tabla 2.3 Límites de potencia y coeficientes abc de la unidades del caso de estudio 2
MW [$/MWh]
122 494.5
245 500.1
489 480.9
Curva de regimen termico (Heat Rate)CC Mexicali
475
480
485
490
495
500
505
50 75 100
% Capacidad
$ / M
Wh
Figura 2.1 Consumo específico de CC Mexicali (U7).
1 Las centrales de ciclo combinado pueden tener varios “paquetes” integrados por una unidad de vapor y unidades turbogás. Un paquete puede ser modelado como una sola unidad. Existen paquetes uniflecha en donde las turbinas de vapor y turbogás están acopladas en un mismo eje, junto con un generador eléctrico. En otros casos, las turbinas de vapor y turbogás tienen su propio generador eléctrico. El número de unidades se refiere al número de generadores eléctricos y no al número de turbinas.
17
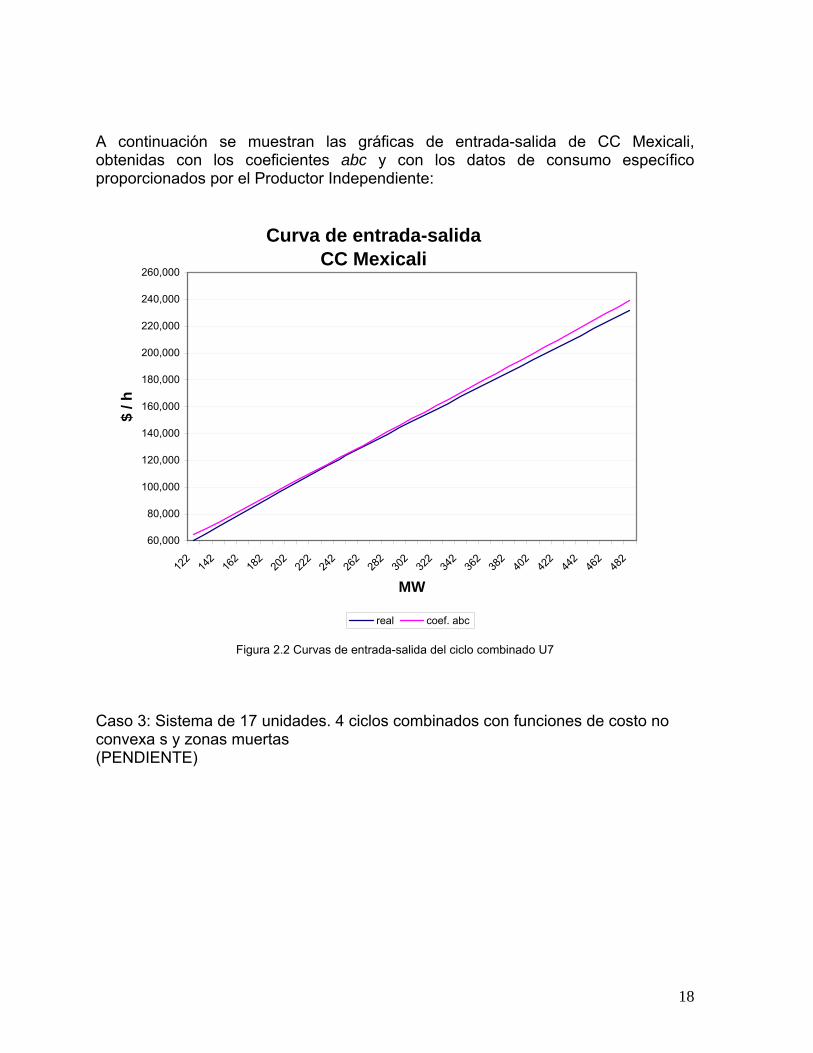
A continuación se muestran las gráficas de entrada-salida de CC Mexicali, obtenidas con los coeficientes abc y con los datos de consumo específico proporcionados por el Productor Independiente:
Curva de entrada-salidaCC Mexicali
60,000
80,000
100,000
120,000
140,000
160,000
180,000
200,000
220,000
240,000
260,000
122
142
162
182
202
222
242
262
282
302
322
342
362
382
402
422
442
462
482
MW
$ / h
real coef. abc
Figura 2.2 Curvas de entrada-salida del ciclo combinado U7
Caso 3: Sistema de 17 unidades. 4 ciclos combinados con funciones de costo no convexa s y zonas muertas (PENDIENTE)
18

Capítulo 3. IMPLEMENTACIÓN DEL ALGORTIMO GENÉTICO
3.1 Introducción El algoritmo genético es quizá el método heurístico más utilizado para problemas de DE e incluso de asignación de unidades, debido a su fácil representación en código binario. Para el problema de DE, tiene una ligera desventaja ya que requiere de un algoritmo que repare las soluciones que se generan después de cada generación. Aún cuando la población inicial este conformado por soluciones factibles, los operadores de cruza y mutación se encargan de descomponer la solución factible, ya que las nuevas combinaciones de potencias resultantes no cumplen con el balance de potencia. Si se quiere ver de otra forma, el algoritmo genético tiene la ventaja de que no requiere más que de una apropiada codificación y del establecimiento de la función objetivo; no requiere conocer más del problema en cuestión. Basta con generar números aleatorios para conformar los individuos de la población inicial y poner en marcha el AG para encontrar una solución. De la calidad de la solución, se sabe que no es muy buena, pero existe la ventaja de que se tienen varios parámetros de control para mejorarla. En el desarrollo del capítulo se muestra la implementación de un algoritmo genético simple al problema de DE. Se utiliza una codificación binaria para representar el nivel de potencia de cada generador. Un cromosoma está formado por las potencias codificadas de las unidades. El algoritmo propuesto tiene 4 módulos: - Pob_ini. Crea la población inicial de forma aleatoria. - Evaluación: Evalúa la función objetivo. - Selección, Selecciona por "torneo" a los mejores individuos de acuerdo a su evaluación - Hijos. Implementa los operadores de cruza y mutación y que aplicados a los individuos seleccionados por el módulo de selección, dan paso a una nueva población.
3.2 Población inicial y codificación La población inicial se crea con un generador de números enteros aleatorios dentro del rango 0 a 2ti-1, con n números enteros por individuo. Módulo Pob_ini. Crea la población inicial de forma aleatoria.
19

Entrada: límites de potencia de generadores: Pimin, PimaxSalida: Archivo con p individuos generados aleatoriamente. Individuos. Los individuos o cromosomas se representaron por una cadena binaria. Cada cadena binaria está formada por n enteros (de 2 bytes), dónde n es el número de unidades. El problema del despacho económico no requiere mucha precisión en el nivel de generación asignado, normalmente se utilizan cifras enteras tanto para las potencias como para la demanda pronosticada. Sin embargo, si se quisiera usar una precisión de 1 decimal, con 2 bytes se podría disponer de un rango de 216/10 = 6553.6, suficiente para representar la potencia de una unidad generadora (en México las unidades de la CN Laguna Verde son las de mayor potencia: 682.4 MW) 7 6 5 4 3 2 1 0 7 6 5 4 3 2 1 0
U1 7 6 5 4 3 2 1 0 7 6 5 4 3 2 1 0
U2 . . s u b c a d e n a . 2 b y t e s 7 6 5 4 3 2 1 0 7 6 5 4 3 2 1 0
Un Figura 3.1 Individuo o cromosoma Representación de los límites de potencia del generador. Está en función del rango de valores y la precisión que se desea utilizar. Por ejemplo, si el rango de operación de la unidad es de 35 a 210 MW, y se desea una precisión de un decimal, entonces se necesitan (210-35)*10 = 1750 rangos de igual tamaño, que se cubren con 11 bits: 210 < 1750 < 211
211=2048 210=1024 Para esta unidad sólo se utilizarían 11 de los 16 bits, tamaño subcadena t =11: entero de 2 bytes 7 6 5 4 3 2 1 0 7 6 5 4 3 2 1 0
Figura 3.2 Subcadena con bits no utilizados
20

Decodificación. Para convertir una subcadena binaria (bt -1,..., b3, b2, b1, b0) al valor entero correspondiente, se utiliza la siguiente ecuación:
1,...,0;10)...(10
1
02011 −==⎟
⎠
⎞⎜⎝
⎛ ⋅= ∑−
=− tkenterovalorbbbb
t
k
kkt
El valor entero representa un valor de potencia entre los límites de generación especificados, que se puede decodificar con la siguiente ecuación:
12min)max(min
−−+= ti
PiPienteroxvalorPiPi
3.3 Evaluación Modulo Evaluación: Evalúa la función objetivo. Entrada: Archivo con 20 individuos (cada uno con las potencias asignadas), coeficientes de la curva de costos Salida: Archivo con 20 evaluaciones de la función objetivo (números reales). Para evaluar la función es necesario decodificar cada uno de los valores enteros de cada individuo. La función de evaluación es originalmente: F = F1 + F2 +...+ Fn (funciones de costo) y se agrega un factor de penalización (FP) debida al desbalance de potencias, para hacer que se cumpla en lo posible P1 + P2 +... + Pn = demanda. Entonces la función objetivo es: Ftotal = F1 (P1) + F2 (P2) +...+ Fn(Pn) + |FP*(P1 + P2 + ... + Pn - demanda)|
3.4 Selección Módulo Selección: Selecciona por "torneo" a los mejores individuos de acuerdo a su evaluación. Entrada: Archivo con 20 evaluaciones de la función objetivo (números reales). Salida: Archivo con 20 individuos seleccionados de manera proporcional (mediante torneo) a su evaluación.
21

Se implementaron 2 algoritmos de selección: por jerarquías y por torneo.
Selección por jerarquías Los individuos se ordenan de mejor a peor (con base a su aptitud o evaluación) y es jerarquizado en orden decreciente de aptitud, de 1 al número de individuos. El valor esperado de cada individuo i en la población en la generación t es :
1
1),()(),(−
−−+=N
tijerarquíaMinMaxMintiExpVal
Después, usando estos valores esperados, se calcula la proporción de aptitud de cada individuo respecto al total, y se aplica la selección proporcional conocida como la ruleta. Esta forma de selección es muy útil cuando no se desea utilizar las aptitudes reales. En el problema de despacho económico se trata de minimizar la función objetivo, y no se puede aplicar ésta directamente como evaluación de aptitud porque los más aptos son los que tienen un menor valor en la función objetivo. Entonces era necesario utilizar otra forma de evaluar la aptitud. La desventaja es que se pierde información sobre que tanto es mejor un individuo sobre otro.
Selección por torneo Se escogen a los ganadores de una competencia entre dos individuos seleccionados aleatoriamente. El ganador es el que tenga una evaluación menor (cuando el problema es de maximizar, el ganador es el que tiene una evaluación mayor). El individuo más apto es seleccionado tantas veces como haya sido puesto a competir (aleatoriamente), y el que tiene una evaluación mayor nunca pasa a la siguiente generación. Este tipo de selección es muy fácil de implementar y tiene la ventaja sobre otros métodos porque no necesita ordenar a los individuos.
3.5 Nuevas generaciones. Mutación y cruce Módulo hijos. Implementa los operadores de cruza y mutación y que aplicados a los individuos seleccionados por el módulo de selección, dan paso a una nueva población Entrada: Archivo con 20 individuos que han sido seleccionados para crear la siguiente generación, Pc, Pm. Salida: Archivo con una nueva generación de 20 individuos Este módulo implementa las operaciones de cruza y mutación para generar la siguiente generación de individuos. Se utilizó una probabilidad de cruza Pc= 0.6 y una probabilidad de mutación Pm=0.01 durante todo el proceso evolutivo. Los puntos de cruza se eligen aleatoriamente en la generación de cada uno de los hijos. Un par de padres generan un par de hijos. Los padres se leen de forma secuencial de un archivo y se cruzan con una probabilidad Pc. Después cada bit del cromosoma es revisado con el operador de mutación.
22

Cruza de individuos, con punto de cruza = 14 Padre 1 Padre 2
7 6 5 4 3 2 1 0 7 6 5 4 3 2 1 0 7 6 5 4 3 2 1 0 7 6 5 4 3 2 1 0
1 1 0 0 0 1 0 0 0 1 0 1570 0 1 0 0 0 1 1 0 0 1 0 5621 2 3 4 5 6 7 8 9 10 11 1 2 3 4 5 6 7 8 9 10 11
7 6 5 4 3 2 1 0 7 6 5 4 3 2 1 0 7 6 5 4 3 2 1 0 7 6 5 4 3 2 1 0
1 1 1 0 1 1 0 0 1 1 1 1895 1 1 1 0 0 0 0 0 0 1 0 179412 13 14 15 16 17 18 19 20 21 22 12 13 14 15 16 17 18 19 20 21 22
7 6 5 4 3 2 1 0 7 6 5 4 3 2 1 0 7 6 5 4 3 2 1 0 7 6 5 4 3 2 1 0
0 1 1 0 1 1 0 0 0 0 1 865 0 0 1 0 1 1 0 1 0 0 1 36123 24 25 26 27 28 29 30 31 32 33 23 24 25 26 27 28 29 30 31 32 33
hijo 1 hijo 27 6 5 4 3 2 1 0 7 6 5 4 3 2 1 0 7 6 5 4 3 2 1 0 7 6 5 4 3 2 1 0
1 1 0 0 0 1 0 0 0 1 0 1570 0 1 0 0 0 1 1 0 0 1 0 5621 2 3 4 5 6 7 8 9 10 11 1 2 3 4 5 6 7 8 9 10 11
7 6 5 4 3 2 1 0 7 6 5 4 3 2 1 0 7 6 5 4 3 2 1 0 7 6 5 4 3 2 1 0
1 1 1 0 0 0 0 0 0 1 0 1794 1 1 1 0 1 1 0 0 1 1 1 189512 13 14 15 16 17 18 19 20 21 22 12 13 14 15 16 17 18 19 20 21 22
7 6 5 4 3 2 1 0 7 6 5 4 3 2 1 0 7 6 5 4 3 2 1 0 7 6 5 4 3 2 1 0
0 0 1 0 1 1 0 1 0 0 1 361 0 1 1 0 1 1 0 0 0 0 1 86523 24 25 26 27 28 29 30 31 32 33 23 24 25 26 27 28 29 30 31 32 33
Figura 3.3 Cruza de individuos, con punto de cruza = 14
Cada nueva generación es mejorada mediante los procesos de evaluación, selección y creación de una nueva generación, hasta un número de generaciones dónde la población está formada por copias de un mismo individuo, que ha sobrevivido gracias a su mejor aptitud.
3.6 Resultados A continuación se muestran los resultados de la aplicación del Algoritmo Genético al Caso de estudio 2 (7 unidades). Demanda = 870 MW Zona muerta unidad 7 tipo CC: 260 a 320 MW Funciones de costo: convexas de segundo grado - Dos tipos de población inicial: con soluciones factibles y con soluciones no factibles - Tamaño de la población: 40 y 100 individuos Se usó la misma semilla para generar números aleatorios para generar resultados comparativos de los parámetros del AG.
23

Población inicial factible y población inicial no factible. Un individuo está formado por las potencias codificadas que son asignadas a cada unidad. En su forma más simple de AG, la población inicial puede estar formada por asignaciones de potencia aleatorias, sin importar o no si cumplen con el balance de potencia, es decir, que la suma de las potencias asignadas a cada unidad sea igual a la demanda que se desea cubrir. Se puede optar por mejorar la calidad de la población inicial del AG con individuos que cumplan el balance de potencia (soluciones factibles), en espera de que mejore la calidad de la solución final del AG. En las diferentes pruebas realizadas, sí se observó mejoría en la solución final para la mayoría de los casos, pero hubo ocasiones en que las soluciones fueron de peor calidad, debido a que la factibilidad de las soluciones se pierde de inmediato, al iniciar el proceso generacional, con los operadores de cruza y mutación. Se requiere entonces de un algoritmo de reparación para conservar la factibilidad en las siguientes generaciones. La convergencia del AG es independiente de la calidad de la población inicial, como lo muestra la figura 3.4, donde se comparan las aptitudes de los mejores individuos de cada generación para poblaciones conformadas por soluciones factibles y por soluciones no factibles. Se intuye de esta gráfica la posibilidad de utilizar algoritmos de búsqueda local para mejorar la solución a partir de la generación ochenta, a partir de ahí el AG ya no es tan eficiente.
480,000485,000490,000495,000500,000505,000510,000515,000520,000525,000530,000
0 10 20 30 40 50 60 70 80 90 100
110
120
130
140
150
generaciones (mejor individuo)
aptit
ud
no factibles factibles
24

Figura 3.4 Desempeño del AG con población inicial de soluciones factibles y no factibles
En la figura 3.5 se muestra como se pierde la factibilidad de la solución inicial. Los resultados finales del AG para ambos tipos de población son muy similares. Los resultados de la gráfica corresponden a un factor de penalización por desbalance de potencia (FP=500) inadecuado, ya que la solución final tuvo un error de 42 MW. En la siguiente sección, se comenta la dependencia de las soluciones respecto del ajuste del FP.
0
50
100
150
200
250
300
0 10 20 30 40 50 60 70 80 90 100 110 120 130 140 150
generaciones (mejor individuo)
desb
alan
ce (M
W)
factibles no factibles
Figura 3.5 Desbalance de potencia de cada generación (población inicial de soluciones factibles y no factibles)
Factor de penalización (FP)
25

El factor de penalización es un factor que se agregó a la función objetivo para castigar a aquellas soluciones que no cumplieran el balance de potencia, y por lo tanto empeora su aptitud. Este factor debe ser ajustado adecuadamente para cada instancia del problema. Un valor bajo, causa que la solución final tenga un costo bajo, pero que no sea una solución factible respecto al balance de potencia. Por el contrario, un valor alto causará que la solución final se ajuste al valor de potencia de forma exacta, pero el costo de operación estará lejos del óptimo. En la tabla 3.1 se muestran los resultados de tres valores del FP (bajo, alto, medio). Un valor de FP = 1000 resultó adecuado para este caso de estudio. Se utilizó la misma semilla para generar los números aleatorios para los 3 casos.
Demanda FP P1 P2 P3 P4 P5 P6 P7a) Costo de operación
b) Penalización por DP
Aptitud (a+b)
error costo
829.3 500 51.4 248.0 248.0 7.0 7.0 8.0 259.8 467,341 20,369 487,710 -4.1870.0 10000 125.1 196.2 166.3 10.3 13.6 8.2 350.3 517,923 290 518,213 6.2870.0 1000 72.1 189.8 247.9 7.0 7.0 8.0 338.2 492,594 27 492,621 1.0
870 40.0 240.0 248.0 7.0 7.0 8.0 320.0 487,484
solución AG
solución óptima
Tabla 3.1 Resultados del AG para distintos valores del FP
Tamaño de la población.
26

Al incrementar el tamaño de la población, se evalúan en paralelo un mayor número de individuos el espacio de solución y es más probable encontrar mejores individuos. La convergencia es ligeramente más rápida al incrementar el tamaño de la población en un 150%. La aptitud promedio de cada generación es muy similar, pero la solución final mejora en 0.92 %
485,000
495,000
505,000
515,000
525,000
535,000
545,000
0 10 20 30 40 50 60 70 80 90 100
110
120
130
140
150
aptit
ud
Pob= 40 Pob= 100
495,000
515,000
535,000
555,000
575,000
595,000
0 10 20 30 40 50 60 70 80 90 100
110
120
130
140
150
aptit
ud
Pob= 40 Pob= 100 Figura 3.6 Aptitudes de los mejores individuos de cada generación, para poblaciones de 40 y 100 individuos
Figura 3.7 Aptitudes de promedio de cada generación, para poblaciones de 40 y 100 individuos
Elitismo El elitismo consiste en conservar al mejor individuo de cada generación. Tiene la ventaja de no perder la información de una buena solución, sobre todo si este fue generado en las primeras generaciones. En la figura 3.8 se observa un mejor desempeño del AG con la aplicación del elitismo. Cunado se usa en combinación con una población inicial de soluciones factibles, se observa que la convergencia es más rápida.
27

490000495000500000505000510000515000520000525000530000535000
0 10 20 30 40 50 60 70 80 90 100
110
120
130
140
150
generaciones
aptit
ud
1) elitismo 2) elitismo 1) Sin elitismo
Figura 3.8 Comparación de la convergencia del AG con y sin elitismo. 1) Usando población inicial con soluciones factibles. 2) Usando población inicial con soluciones no factibles
28

Capítulo 4. IMPLEMENTACIÓN DEL ALGORTIMO DE RECOCIDO SIMULADO
4.1 Introducción El recocido simulado es un algoritmo de aproximación a la solución óptima, fundado en una analogía del comportamiento de sistemas termodinámicos simples; y viene siendo utilizado en ciertos problemas de ingeniería. En el método de Recocido Simulado, la aceptación de soluciones esta gobernada por un parámetro denominado ``Temperatura''. Las soluciones que mejoran el costo actual siempre son aceptadas. Aquellas que lo empeoran también pueden ser aceptadas con cierta probabilidad, que será alta al inicio de la ejecución. A medida que la búsqueda progresa, la temperatura disminuye, disminuyendo entonces la probabilidad de aceptación de soluciones peores. Hacia el final de la ejecución, solo las soluciones mejores son aceptadas. La implementación de este algoritmo es muy sencilla, sólo hay que trabajar en el algoritmo que genera la solución inicial, que debe ser una solución factible, es decir, que cumpla con el balance de potencia y que las potencias asignadas a los generadores estén dentro de los sus límites, para el caso de DESP. Para la consideración de zonas muertas, hay que revisar que el algoritmo generador de soluciones factibles y el algoritmo de vecindades, no asigne una potencia dentro de la región prohibida. Las funciones no convexas o discontinuas no tienen ninguna consideración especial, más que la implementación de una función que evalué cada solución generada. Programa Módulos: - Sol_ini: Da una solución inicial S0 = P10 + P20 + P30 = Demanda - Vecindades: Genera soluciones vecinas a una solución dada. - Despacho: Implementa el algoritmo de Recocido Simulado, integrado los módulos
anteriores.
4.2 Solución inicial
Módulo Sol_ini. Entrada: Estado mínima P1min, P2min, P3minSalida: Solución inicial S0 = P10 + P20 + P30 = Demanda
29

El algoritmo de este módulo incrementa la generación de las unidades de acuerdo a la que tenga un menor costo Fc(∆Pi) .
∑=
−=∆N
i
PiDemandaPi1
min
Si la unidad elegida no cubre el incremento de demanda, este será completado por las siguientes unidades más baratas, por lo cual es necesario hacer un ordenamiento de las unidades de acuerdo a costos.
4.3 Vecindades Las vecindades a una solución dada, se determinan al incrementar o disminuir la potencia de una unidad seleccionada aleatoriamente. El movimiento hacia arriba o hacia abajo también es aleatorio:
5.05.0
<≥
rsibajarsisube
r es un número aleatorio entre 0 y 1. La cantidad de MW que se mueve la unidad es aleatorio y está limitado por las potencias máximas y mínimas de las unidades. El movimiento de la unidad seleccionada en forma aleatoria debe ser cubierto por las demás unidades de tal manera que no se modifique el valor de demanda suministrado. El movimiento de todas las unidades es aleatorio a excepción de la última unidad, la cuál tendrá que absorber la diferencia que falte por cubrir. Ejemplo:
Pmin Pmax P1 35 210 P2 130 325 P3 125 315
Demanda = 400 P1= 40 P2= 160 P3=200 Movimiento seleccionado: subir (aleatorio) Unidad seleccionada: 2 (aleatorio) Rangos permisibles de movimiento:
baja max sube max P1 5 170 P2 30 165 P3 75 115
30

MW a mover: 25 (aleatorio) Para P1 se selecciona un número aleatorio entre 0 y 5 (rango permisible hacia abajo), digamos 3, P1= 40-3= 37 demanda por contrarrestar : 25-3=22 El cuál es proporcionado por la unidad 3: P3=200-22= 178 P2=160+25= 185 El movimiento es exitoso porque se cumple con la demanda y con los rangos disponibles de potencia de cada unidad. solución inicial: (40, 160,200) solución vecina: (37,178,185) Cuando un movimiento no es permisible porque rebasa los límites de potencia, entonces es no exitoso y se sigue un proceso aleatorio de movimientos que sean permisibles para encontrar la vecindad.
4.4 Algoritmo general de RS
Despacho. Entrada: solución inicial (P10, P20, P30) Salida: Solución (P1s, P2s,P3s) Es el programa principal y utiliza las funciones anteriores para implementar el algoritmo de recocido simulado. Se utilizaron los siguientes parámetros de control del algoritmo de recocido simulado: T: temperatura, parámetro de control K0: número de aceptaciones criterio de paro: un valor suficientemente bajo de T alfa: factor de disminución de temperatura T se determinó con base a la regla de decisión conocida como criterio Metrópolis que utiliza la distribución de Boltzman:
si r< TjFciFc
e)()(( −
se acepta la vecindad generada por el mecanismo de generación de soluciones vecinas r es un número aleatorio en el intervalo [0,1]
31

Entonces había que buscar una T que hiciera que la distribución de Boltzman tuviera un rango similar al definido para el número aleatorio. Originalmente se buscó una T que a lo más hiciera 1 a la expresión, y esto se logra haciendo T igual a la diferencia de los costos de las potencias máximas y mínimas que se pueden suministrar: Fc(Pmax)= Fc(P1max)+ Fc(P2max) + Fc(P3max) = 41,743 Fc(Pmin)= Fc(P1min)+ Fc(P2min) + Fc(P3min) = 15,787 ⇒ T = 41,743 -15, 787 = 25,956 Pero los resultados fueron mejores al duplicar el valor, es decir con T = 50000. Y es que como se evalúan vecindades, difícilmente se iban a generar soluciones tan extremas, por lo que se buscó un valor más grande (50,000). En las tablas de resultados se observará la diferencia al usar estos dos valores de T. El número de aceptaciones K0 se fijó en 10. El criterio de paro se fijo, como lo sugiere la literatura, en un valor suficientemente bajo, T>10. Igualmente para alfa (factor de reducción geométrico) se utilizó un valor sugerido en la literatura alfa=0.9
32

4.5 Resultados Caso 1: Sistema de 3 unidades. Funciones de costo de segundo orden. Se muestra la tabla de resultados obtenidos con el algoritmo genético y con el algoritmo de recocido simulado:
P1 P2 P3 a b cPmax 210 325 315 P1 0.03546 38.31 1243.53Pmin 35 130 125 P2 0.02111 36.33 1658.57
P3 0.01799 38.27 1356.66
Algoritmo genéticoFP
A B C 500Demanda P1 P2 P3 P1 P2 P3 P1+P2+P3 Fct Fc1(P1) Fc2(P2) Fc3(P3) A+B+C FP(P1+P2+P3-Dem)
400 177 292 729 50.1 157.8 192.7 400.6 20,875 3,253 7,917 9,398 20,568 307400 548 187 490 81.0 147.0 170.0 398.0 21,416 4,579 7,455 8,383 20,416 1,000400 247 184 735 56.1 147.5 193.2 396.9 21,972 3,505 7,477 9,423 20,405 1,567700 1651 1581 1300 176.1 280.6 245.7 702.4 35,659 9,091 13,515 11,844 34,450 1,209700 608 2010 1808 87.0 321.5 292.8 701.3 35,103 4,844 15,519 14,105 34,468 635700 1952 1201 1388 201.9 244.4 253.8 700.1 34,510 10,422 11,798 12,230 34,450 60
Recocido simulado T=50,000 K0=10 alfa= 0.9FP
A B C 500Demanda P1 P2 P3 P1 P2 P3 P1+P2+P3 Fct Fc1(P1) Fc2(P2) Fc3(P3) A+B+C FP(P1+P2+P3-Dem)
400 70 182 148 400 20,483 4,099 8,969 7,415 20,483 0400 NA 77 169 154 400 20,481 4,403 8,401 7,677 20,481 0400 99 147 154 400 20,515 5,383 7,455 7,677 20,515 0700 143 284 273 700 34,270 7,446 13,678 13,145 34,270 0700 NA 132 293 275 700 34,274 6,918 14,115 13,242 34,274 0700 142 279 279 700 34,270 7,398 13,437 13,434 34,270 0
Resultados con T= 25956700 129 290 281 700 34,275 6,775 13,969 13,531 34,275 0700 NA 145 245 310 700 34,319 7,543 11,826 14,949 34,319 0700 110 286 304 700 34,315 5,886 13,775 14,653 34,315 0
Potencia generadaCodificado Decodif icado
coeficientes Función costo, Fc
Codif icado Decodif icadoPotencia generada
Tabla 4.1 Comparativo de soluciones del AG y RS para caso de estudio 1 En general se observan mejores resultados con la aplicación del algoritmo de recocido simulado. En el caso de la demanda de 400, el algoritmo genético parece dar mejores resultado, pero en los casos que así es, la generación total de potencia es inferior a la demanda. El algoritmo de recocido simulado no fue necesario codificar los datos y siempre se prueban soluciones factibles (que cumplan con los rangos de operación de las unidades generadoras, y con el balance de potencia), por lo que no existe costo penalizado por desbalance de potencia.
33

Caso 2: Sistema de 7 unidades. Funciones de costo convexas de segundo grado. Demada = 870 MW. Zona muerta unidad 7 tipo CC: 260 a 320 MW Las tablas 4.2 y 4.3 muestras los resultados de 10 ejecuciones del programa de RS, para dos niveles de búsqueda determinadas por el parámetro de control k0.
Demanda P1 P2 P3 P4 P5 P6 P7 SVM Cost870.0 óptima 40.0 240.0 248.0 7.0 7.0 8.0 320.0
o
k0=40 búsquedas= 44001 869.6 sol ini 151.7 210.8 217.6 21.9 11.5 27.4 228.8 1134 559,573
869.6 91.6 248.0 248.0 7.0 7.0 8.0 260.0 489,6042 869.8 sol ini 74.9 247.1 214.0 21.8 25.8 26.7 259.4 1169 563,316
869.8 91.9 248.0 248.0 7.0 7.0 8.0 259.9 489,6793 869.7 sol ini 94.6 71.7 199.9 11.0 8.0 29.9 454.6 1087 558,499
869.7 40.0 248.0 239.7 7.0 7.0 8.0 320.0 487,3714 869.8 sol ini 156.7 156.9 212.7 8.5 7.0 8.0 320.0 1023 515,609
869.8 40.0 244.9 242.9 7.0 7.0 8.0 320.0 487,3875 869.6 sol ini 87.7 89.8 214.1 13.6 11.8 21.5 431.0 987 544,452
869.6 40.0 247.0 240.6 7.0 7.0 8.0 320.0 487,3246 869.7 sol ini 61.5 77.8 201.0 11.5 10.1 25.5 482.3 1134 549,098
869.7 40.0 245.6 242.1 7.0 7.0 8.0 320.0 487,3627 869.8 sol ini 89.2 204.8 240.5 26.1 25.8 27.1 256.2 1081 574,522
869.8 91.9 248.0 248.0 7.0 7.0 8.0 259.9 489,6938 869.6 sol ini 159.1 111.9 130.5 18.3 17.0 17.0 415.9 1100 571,430
869.6 40.0 239.9 247.8 7.0 7.0 8.0 320.0 487,3279 869.8 sol ini 89.9 190.8 195.1 10.6 23.5 24.4 335.4 998 546,550
869.8 40.0 247.7 240.0 7.0 7.0 8.0 320.0 487,39510 869.8 sol ini 64.4 238.1 236.3 25.5 15.9 29.7 259.8 1083 559,036
91.9 248.0 247.9 7.0 7.0 8.0 260.0 489,703promedio 488,284desv. est. 34,717
487,484
Tabla 4.2 Resultados del RS al caso de estudio 2. Número de aceptaciones en cada etapa de enfriamiento, k0 = 40
34

k0=100 búsquedas= 110001 869.8 sol ini 45.6 178.6 220.1 18.6 24.4 18.3 364.3 2351 545,952
869.8 40.0 247.6 240.2 7.0 7.0 8.0 320.0 487,4012 869.8 sol ini 133.3 116.3 158.1 11.1 24.4 24.0 402.6 2490 571,494
869.8 40.0 245.5 242.3 7.0 7.0 8.0 320.0 487,3983 869.8 sol ini 85.0 159.3 151.5 12.1 14.2 15.4 432.3 2577 530,719
869.8 40 240.3 247.5 7 7 8.0009 320 487,3874 869.7 sol ini 140.9 156.2 111.4 26.8 10.0 17.2 407.1 2357 569,371
869.7 40.0 247.6 240.1 7.0 7.0 8.0 320.0 487,3445 869.8 sol ini 105.0 188.7 119.1 14.2 19.9 29.5 393.5 2504 568,724
869.8 40.0 241.3 246.5 7.0 7.0 8.0 320.0 487,4036 869.8 sol ini 77.3 200.3 175.9 10.8 22.3 15.9 367.3 2588 531,759
869.8 40.0 245.5 242.3 7.0 7.0 8.0 320.0 487,3937 869.7 sol ini 136.0 66.2 159.0 25.5 25.9 27.8 429.2 2618 615,779
869.7 40.0 240.4 247.3 7.0 7.0 8.0 320.0 487,3418 869.7 sol ini 126.6 128.2 220.2 22.5 16.3 26.9 329.0 2624 570,623
869.7 40.0 246.2 241.5 7.0 7.0 8.0 320.0 487,3689 869.8 sol ini 141.5 214.9 87.7 21.7 11.1 27.5 365.4 2455 576,057
869.8 40 239.9 247.9 7 7 8 320 487,39510 869.8 sol ini 76.5 227.6 230.2 24.8 24.4 28.4 257.8 2814 569,793
91.9 248.0 248.0 7.0 7.0 8.0 259.9 489,697promedio 487,613desv. est. 41,901
Tabla 4.3 Resultados del RS al caso de estudio 2. Número de aceptaciones en cada etapa de enfriamiento, k0 = 100 Las figuras 4.1 y 4.2 muestran como se explora un espacio de solución más amplio en las primeras fases de “enfriamiento” del algoritmo, donde se permiten peores soluciones. En las últimas fases, casi no se permiten soluciones de calidad inferior a la solución en curso.
K0=100
485000
505000
525000
545000
565000
585000
605000
625000
0 1000 2000 3000 4000 5000 6000 7000 8000 9000
soluciones generadas
cost
o
Figura 4.1 Convergencia del algoritmo RS para el caso de estudio 2, k0 = 40
35

K0=40
485000
505000
525000
545000
565000
585000
605000
625000
0 1000 2000 3000 4000
soluciones generadas
cost
o
Figura 4.2 Convergencia del algoritmo RS para el caso de estudio 2, k0 = 100
36

Capítulo 5. IMPLEMENTACIÓN DEL GRASP
5.1 Introducción La implementación del GRASP para el DE queda muy natural, debido a que la fase constructora guía la forma de construir una solución factible, y asegura que ésta pueda tener diversidad en cada ejecución. La fase de búsqueda local fue prácticamente tomada del algoritmo de RS. El método GRASP consta de una fase constructora y una fase de búsqueda local. La fase constructora crea una solución factible, que es mejorada por el algoritmo de búsqueda local y la mejor solución es guardada dentro del proceso iterativo. El algoritmo utilizado es el que se describe en la sección 1.5: f* ← ∞ for i ≤ imáx do fase constructora(g(.), α,x) x ← búsqueda local(x) if f(x) < f* then f* ← f(x) x* ← x end if end for regresar x* donde
imáx es el número máximo de iteraciones. g(.) es la función miope que evalúa la incorporación de cada elemento x es el conjunto solución, que contiene las potencias asignadas a las N unidades f(x) es el costo de la solución x f* es el costo de la mejor solución encontrada x* es la mejor solución encontrada α es un factor [0,1], que establece el grado de aleatoriedad o miopes del algoritmo
Tabla 5.1 Algoritmo general GRASP para el DE
5.2 Fase constructora Entrada: - Salida: Una solución factible x ∈P P representa el espacio de soluciones factibles
37

La solución en la fase constructora se genera bajo el siguiente algoritmo: 0. inicio 1. x = {}; 2. dem_resto ← Demanda 3. Inicializar lista de candidatos C 4. mientras |C| ≠ 1 do 5. calcula Nuevos límites NPmini, NPmaxi | i∈ C 6. pi ← aleatorio(NPmini, NPmaxi) | i ∈ C 7. calcula fmiope(pi) | i ∈ C 8. f ← mín{ fmiope(pi) | i ∈ C } 9. f+ ← máx{ fmiope(pi) | i ∈ C } 10. RCL ← { p ∈ C | fmiope(pi) ≤ f + α( f+ – f) } 11. selección aleatoria de p de RCL 12. x ← x ∪ {p} 13. C ← C – {p} 14. dem_resto ← dem_resto – p 15. end mientras 16. p {C} ← dem_resto 17. fin Donde Demanda: es la demanda que deben cubrir todas las unidades C: lista de candidatos RCL: lista restrictiva de candidatos x: conjunto solución pi: elemento i de la solución factible p {c} : ultimo elemento en la lista de candidatos Tabla 5.2 Algoritmo GRASP (fase constructora) para el DE Descripción del algoritmo. El algoritmo forma una solución factible x = {p1, p2, … pi, …,pn}. Al principio, el conjunto solución x está vacío (1), la variable dem_resto inicia con el valor de demanda que deben cubrir las N unidades y reduce su valor conforme se asignan potencias a cada elemento de la solución. La lista de candidatos inicial C está integrada por todas las unidades C = { U1, U2, …, Ui, …, Un}. Posteriormente, a cada unidad se le asigna una potencia aleatoria (6) dentro de los dominios restringidos, calculados (5) por un algoritmo de satisfacción de restricciones. La aplicación de este algoritmo permite asignar valores a una unidad para que luego, en etapas posteriores, sea posible la asignación de potencias a las unidades restantes. La función miope (7) es la función de costo de generación que evalúa a cada generador de acuerdo con su potencia asignada de forma aleatoria. La lista restrictiva RCL contendrá a las unidades con menor costo que estén dentro del rango determinado en 10. El elemento que se agrega a la solución se escoge, de
38

forma aleatoria, de la lista RCL (11). Luego se actualizan el conjunto solución (12), la lista de candidatos (13) y la demanda por cubrir (14). En cada ciclo se agrega un elemento a la solución hasta que la lista de candidatos contenga un sólo elemento. A esta última unidad se le asigna la demanda restante dem_resto. A continuación un ejemplo de la aplicación de este algoritmo, para el caso de estudio de 7 unidades térmicas. Datos: demanda 804 MW U1 U2 U3 U4 U5 U6 U7Pmax [MW] 160 248 248 27 26 30 489Pmin [MW] 40 62 62 7 7 8 122 coef. A 1.28 0.56 0.56 24.92 19.45 21.16 0.029coef. B 368.0 158.5 158.5 1154 1204 1190 467.7coef. C 22770 33830 33830 13330 16680 16660 6957 Encontrar una solución factible Una solución factible es cualquier asignación de potencias a las N unidades, que cumpla con el balance de potencia y con los límites de generación de cada una de ellas. El costo de generación total no es precisamente el más barato. Aplicación del algoritmo de la fase constructora:
1. x = {} 2. dem_resto = 804 3. se inicializa conjunto C, C = {P1, P2, P3, P4, P5, P6, P7} 4. |C| = 7 5. Nuevos límites
U1 U2 U3 U4 U5 U6 U7 NPmáx 160 248 248 27 26 30 489 NPmín 40 62 62 7 7 8 122
Los nuevos límites NPmin, NPmax, son iguales a los originales, esto quiere decir que cualquier asignación de potencias dentro de los límites originales, hace posible una asignación de potencias de las demás unidades para cubrir la demanda.
6, 7.
P aleat [MW]
fmiope [$/MW]
P1 130 710 P2 95 568 P3 247 435 P4 9 2,859 P5 26 2,351 P6 24 2,392 P7 247 503
fmiope(P) = (coef. a (P)2 + coef. b (P) + coef. c) / P [$/ MW]
8, 9
Rango RCL s-= 435 mín 1,212 s+= 2,859 máx 1,647
39

10. Se observa como el valor de α determina el grado de miopes o aleatoriedad, ya que un valor de α=0, hará al algoritmo totalmente dependiente de la evaluación de la función miope, y se la RCL estará integrada solamente por el elemento con la mejor evaluación. Por otra parte con α=1, se permite que integren a la RCL, todos los elementos de C. RCL = { P1 P2 P3 P7 } 130 95 247 247
11 Se selecciona de forma aleatoria un elemento de RCL, digamos el elemento 2 12, 13, 14. x= {(P2 = 95)}, C = {P1, P3, P4, P5, P6, P7}, dem-resto = 804 – 95 = 709 Siguiente ciclo, |C| = 6 5. Nuevos límites
U1 U2 U3 U4 U5 U6 U7 NPmáx 160 248 27 26 30 489 NPmín 40 62 7 7 8 218
El límite inferior de U7 ha sido modificado. Una asignación de potencia inferior a 218 para U7, no permitiría cubrir la demanda restante de 709, aún asignando a U1, U3, U4, U5, U6 con sus valores máximos
6, 7.
P aleat [MW]
fmiope [$/MW]
P1 104 720 P2 P3 64 723 P4 20 2,319 P5 21 2,407 P6 16 2,570 P7 295 500
8, 9, 10.
Rango RCL s-= 500 mín 1,035 s+= 2,570 máx 1,535 RCL = { P1 P3 P7 } 104 64 295
11 Se selecciona de forma aleatoria un elemento de RCL, digamos el elemento 1 12. x= {(P2 = 95), (P1 = 104)} 13. C = {P3, P4, P5, P6, P7} 14. dem_resto = 709 – 104 = 605 Siguiente ciclo, |C| = 5 5. Nuevos límites
U1 U2 U3 U4 U5 U6 U7 NPmáx 248 27 26 30 489 NPmín 62 7 7 8 274
6, 7.
P aleat [MW]
fmiope [$/MW]
P1
40

P2 P3 99 556 P4 19 2,329 P5 24 2,366 P6 15 2,618 P7 287 500
8, 9, 10.
Rango RCL s-= 500 mín 1,059 s+= 2,618 máx 1,559 RCL = { P3 P7 } 99 287
11 Se selecciona de forma aleatoria un elemento de RCL, digamos el elemento 1 12. x= {(P2 = 95), (P1 = 104), (P3 = 99)} 13. C = {P4, P5, P6, P7} 14. dem_resto = 605 – 99 = 506 Siguiente ciclo, |C| = 4 5. Nuevos límites
U1 U2 U3 U4 U5 U6 U7 NPmáx 27 26 30 484 NPmín 7 7 8 423
6, 7.
P aleat [MW]
fmiope [$/MW]
P1 P2 P3 P4 21 2,312 P5 19 2,451 P6 27 2,378 P7 471 496
8, 9, 10.
Rango RCL s-= 496 mín 978 s+= 2,451 máx 1,474 RCL = { P7 } 471
11 Se selecciona de forma aleatoria un elemento de RCL, no queda más opción que 1 12. x= {(P2 = 95), (P1 = 104), (P3 = 99), (P7 = 471)} 13. C = {P4, P5, P6} 14. dem_resto = 506 – 471 = 35 Siguiente ciclo, |C| = 3 5. Nuevos límites
U1 U2 U3 U4 U5 U6 U7
41

NPmáx 20 20 21 NPmín 7 7 8
6, 7.
P aleat [MW]
fmiope [$/MW]
P1 P2 P3 P4 20 2,319 P5 9 3,232 P6 19 2,469 P7
8, 9, 10.
Rango RCL s-= 2,319 mín 457 s+= 3,232 máx 2,776
RCL = { P4 P6 } 20 19
11 Se selecciona de forma aleatoria un elemento de RCL, sea el elemento 2 12. x= {(P2 = 95), (P1 = 104), (P3 = 99), (P7 = 471), (P6 = 19)} 13. C = {P4, P5} 14. dem_resto = 35 – 19 = 16 Siguiente ciclo, |C| = 2 5. Nuevos límites
U1 U2 U3 U4 U5 U6 U7 NPmáx 9 9 NPmín 7 7
6, 7.
P aleat [MW]
fmiope [$/MW]
P1 P2 P3 P4 8 3,020 P5 9 3,232 P6 P7
8, 9, 10.
Rango RCL s-= 3,020 mín 106 s+= 3,232 máx 3,126
RCL = { P4 }
42

8
11 Se selecciona de forma aleatoria un elemento de RCL, sólo hay una opción, elemento 1 12. x= {(P2 = 95), (P1 = 104), (P3 = 99), (P7 = 471), (P6 = 19), (P4 = 8)} 13. C = {P5} 14. dem_resto = 16 – 8 = 8
Se detiene el ciclo, |C| = 1 16. P5 = 8 FIN x = {104, 95, 99, 8, 8, 19, 471}
costo de la solución:
5.3 Fase búsqueda local Entrada: solución factible x Salida: solución mejorada. El algoritmo utilizado es el mismo que se utilizó en para el algoritmo de recocido simulado, y se describe en la sección 4.3.
5.4 Resultados Caso 2: Sistema de 7 unidades. Funciones de costo convexas de segundo grado. Demada = 870 MW. Zona muerta unidad 7 tipo CC: 260 a 320 MW El algoritmo GRASP es de los algoritmos más sencillos en cuanto a parámetros de control. Una vez definidos los algoritmos de las fases constructora y de búsqueda local, basta con ajustar el número de iteraciones (N_itr) y el grado de aletoriedad-miopía de la fase constructora (α). Como se describió en la anteriormente, un valor de α= 1, permite escoger de forma aleatoria cualquier elemento candidato para formar parte de la solución. Con α= 0, se escoge al mejor elemento evaluado por una función miope, para ser agregado a la solución. Un término medio, con α= 0.5, permite formar una lista restringida de candidatos, integrada por los mejores elementos, de donde se puede elegir, de forma aleatoria, al siguiente elemento que formara parte de la solución. Con N_itr= 1000 y un número de vecinos de 100 que genera la fase de búsqueda local, se tiene que se revisan 100, 000 soluciones (el espacio de solución total para el caso de estudio 2 de 7 unidades es:1.27374 x 1014). Primeramente se probó el desempeño del GRASP con N_itr pequeños, y sin considerar la zona muerta de la unidad 7. La tabla 3.5 muestra las desviaciones en costo, respecto de la solución analítica. Numero de iteraciones solución
43

10 20 50 100 500 analíticacosto mejor solución 455,355 455,306 455,192 455,143 455,129 455,099Desviación 0.06 0.05 0.02 0.01 0.01 desviación promedio* 0.26 0.11 0.11 0.05 0.02
* 10 corridas Tabla 5.3 Resultados del GRASP para caso estudio 2, sin zona muerta de unidad 7 y ajustes pequeños de N_itr Después se probó con un Nitr = 1000. Las tablas 3.6 a 3.8 muestran los resultados para diferentes valores de α, y con la consideración de la zona muerta de la unidad 7.
α = 0.5Demanda P1 P2 P3 P4 P5 P6 P7 Costo
1 870.0 40.0 246.3 241.7 7.0 7.0 8.0 320.0 487,4722 870.0 40.0 247.2 240.7 7.0 7.0 8.0 320.0 487,4793 870.0 40.0 242.4 245.6 7.0 7.0 8.0 320.0 487,4704 870.0 40.0 243.4 244.5 7.0 7.0 8.0 320.1 487,4715 870.0 40.0 244.8 243.2 7.0 7.0 8.0 320.0 487,4686 870.0 40.0 244.0 244.0 7.0 7.0 8.0 320.0 487,4677 870.0 40.0 243.7 244.3 7.0 7.0 8.0 320.0 487,4688 870.0 40.0 245.9 242.1 7.0 7.0 8.0 320.0 487,4719 870.0 40.0 242.4 245.6 7.0 7.0 8.0 320.0 487,470
10 870.0 40.0 245.0 243.0 7.0 7.0 8.0 320.0 487,468promedio 487,471desv. est. 3
Tabla 5.4 Resultados del GRASP, caso de estudio 2, fase constructora aleatoria-miope α=0.5
α = 1.0Demanda P1 P2 P3 P4 P5 P6 P7 Costo
1 870.0 40.0 245.5 242.4 7.0 7.0 8.0 320.1 487,4732 870.0 40.0 240.8 247.1 7.0 7.0 8.0 320.1 487,4843 870.0 40.0 246.0 242.0 7.0 7.0 8.0 320.0 487,4714 870.0 40.0 243.5 244.4 7.0 7.0 8.0 320.1 487,4705 870.0 40.0 245.0 243.0 7.0 7.0 8.0 320.1 487,4706 870.0 40.0 244.6 243.3 7.0 7.0 8.0 320.1 487,4717 870.0 40.0 241.3 246.6 7.0 7.0 8.0 320.0 487,4758 870.0 40.0 244.5 243.5 7.0 7.0 8.0 320.0 487,4679 870.0 40.0 244.9 243.1 7.0 7.0 8.0 320.0 487,468
10 870.0 40.0 243.1 244.8 7.0 7.0 8.0 320.1 487,473promedio 487,471desv. est. 5
Tabla 5.5 Resultados del GRASP, caso de estudio 2, fase constructora aleatoria α=1
44

α = 0.0Demanda P1 P2 P3 P4 P5 P6 P7 Costo
1 870.0 40 243.27 244.7 7 7 8 320.03 487,4682 870.0 40.0 243.9 244.1 7.0 7.0 8.0 320.0 487,4673 870.0 40.0 243.3 244.7 7.0 7.0 8.0 320.0 487,4674 870.0 40.0 242.4 245.6 7.0 7.0 8.0 320.0 487,4695 870.0 40.0 244.6 243.3 7.0 7.0 8.0 320.1 487,4706 870.0 40.0 244.4 243.6 7.0 7.0 8.0 320.0 487,4697 870.0 40.0 244.6 243.3 7.0 7.0 8.0 320.1 487,4718 870.0 40.0 245.0 242.9 7.0 7.0 8.0 320.0 487,4699 870.0 40.0 243.7 244.3 7.0 7.0 8.0 320.0 487,467
10 870.0 40.0 243.6 244.4 7.0 7.0 8.0 320.1 487,470promedio 487,471desv. est. 1
Tabla 5.6 Resultados del GRASP, caso de estudio 2, fase constructora miope α=0 Demanda P1 P2 P3 P4 P5 P6 P7 costo fitness1
870.0 45.9 248.0 248.0 7.0 7.0 8.0 306.1 487,018 487,018 sol. analítica (Unidad 7 en zona muerta)870.0 40.0 240.0 248.0 7.0 7.0 8.0 320.0 487,484 487,484 corregida por "tanteo"
Tabla 5.7 Solución analítica al caso de estudio 2 El desempeño de este algoritmo para el caso de estudio 2 fue excelente. Las soluciones tienen un costo menor al de la solución corregida por tanteo de la solución analítica, que asigna un valor de potencia en zona muerta de la unidad 7. Con los tres valores de alfa probados, se presentó, en promedio, la misma calidad en la solución. En las figuras 3.11 a 3.13 se muestra la convergencia del algoritmo GRASP. Realmente no converge, debido a la filosofía del algoritmo, de buscar la mejor solución de un conjunto de soluciones factibles generadas por un algoritmo miope, y que son mejoradas por el algoritmo de búsqueda local en cada iteración. Se observa que cuando alfa = 0, las variaciones en el costo de las soluciones mejoradas es menor porque no se permite elegir a elementos que aumenten el costo de la solución. α = 0.5
485000
495000
505000
515000
525000
535000
545000
1 78 155
232
309
386
463
540
617
694
771
848
925
mejores soluciones
cost
o
45

Figura 5.1 Costo de las soluciones mejoradas de cada iteración, fase de construcción con α=0.5 α = 1.0
485000
495000
505000
515000
525000
535000
5450001 78 155
232
309
386
463
540
617
694
771
848
925
mejores soluciones
cost
o
Figura 5.2 Costo de las soluciones mejoradas de cada iteración, fase de construcción con α=1 α = 0.0
485000
495000
505000
515000
525000
535000
545000
1 62 123
184
245
306
367
428
489
550
611
672
733
794
855
916
977
mejores soluciones
cost
o
Figura 5.3 Costo de las soluciones mejoradas de cada iteración, fase de construcción con α=0
46

Capítulo 6. IMPLEMENTACIÓN DEL ALGORITMO GENÉTICO HÍBRIDO
6.1 Introducción Dadas las sugerencias que se dan en la literatura de “hibridizar” el AG con otros algoritmos de búsqueda local para mejorar la calidad de la solución y rapidez de convergencia, se decidió aprovechar algunos módulos de otros métodos heurísticos implementados en este trabajo para mejorar la entrada y salida del AG. Para la entrada, en la generación de la población inicial, se utilizó un algoritmo de satisfacción de restricciones para que todos los individuos de la población representaran una solución factible. En los resultados del capítulo 2, se muestra la ventaja de que la población inicial esté conformada por individuos de buena calidad. Luego, dada la naturaleza de la fase constructora del GRASP de generar soluciones factibles, se integra este algoritmo al AG para crear la población inicial (pendiente mostrar resultados). Para mejorar la salida del AG, se integró, además del algoritmo reparador de la solución para que se cumpliera el balance de potencia, se incluyó el algoritmo de búsqueda en vecindades utilizado por el RS. Aunque también está pendiente mejorar la salida del AG con una versión del RS disminuida en el sentido de reducir el proceso de enfriamiento.
6.2 Población inicial a partir de un algoritmo de Satisfacción de Restricciones El algoritmo de satisfacción de restricciones se aplica al elegir los valores aleatorios de las unidades para cubrir una demanda dada. Como valores posibles de potencia para una unidad se consideran, en un principio, sus límites de potencia (dominio). Pero aplicando satisfacción de restricciones (SR) se modifica este dominio inicial, verificando que el valor de potencia elegido en forma aleatoria permita seleccionar valores para las demás unidades. En el problema de despacho, el número de unidades que participan, han sido seleccionadas previamente mediante la solución del problema de “asignación de unidades” de tal forma que estas deben despacharse con algún valor de potencia, por lo menos el mínimo. Así entonces, en el caso de estudio se tiene que: demanda = 400, límites de potencia:
47

U1 35 ≤ P1 ≤ 210 U2 130 ≤ P2 ≤ 325 U3 125 ≤ P3 ≤ 315
Por ejemplo, no es posible elegir un valor de potencia de 150 para la primera unidad, ya que la mínima potencia que podrían suministrar las otras 2 unidades sería de 255. El total suministrado sería de 455 y no cumpliría con la demanda a cubrir. El valor máximo que se podría escoger para la unidad U1 sería: NPmax1 = demanda – Pmin2 - Pmin3 = 400 – 130 – 125 = 145 y el valor mínimo se determina como sigue: NPmin1 = demanda – Pmax2 - Pmax3 = 400 – 325 – 315 = - 240 Como el valor es menor que Pmin1 , entonces este límite no se modifica, y tenemos que para la unidad 1: U1 Pmin1 ≤ P1 ≤ NPmax1 o sea, 35 ≤ P1 ≤ 145 De forma similar se modifican los límites de las demás unidades, y la última simplemente absorbe el faltante de demanda por cubrir. A continuación se muestra el algoritmo que se aplicó al módulo que obtiene la población inicial, el cuál, originalmente, sólo asignaba potencias en forma aleatoria a cada unidad, sin importar si satisfacían el valor de demanda, y el algoritmo genético se encargaba de encontrar una buena solución factible, pero con un número mayor de iteraciones. dr ← dem Haz calcular DRi Xi ← aleat(DRi) dr ← dr - Xi i ← i + 1 hasta i=n Xn ← dr dem - demanda n - número de unidades Xi - potencia asignada a la unidad i, 1 < i <= n Di - dominio de la unidad i, determinado por los límites de potencia de generación mínimo y máximo de cada unidad, Di = [Pmini, Pmaxi] SR - Satisfacción de restricciones dr - demanda restante DRi - Dominio mínimo de la unidad i por SR, DRi = [NPmini, NPmaxi] NPmaxi = dr - Suma(Pminj), i<j NPmini = dr - Suma(Pmaxj), i<j
48

⎩⎨⎧ <
=casootroP
PNPsiNPNP
i
iiii max
maxmaxmaxmax
⎩⎨⎧ >
=casootroP
PNPsiNPNP
i
iiii min
minminminmin
Tabla 6.1 Algoritmo generador de solución inicial factible por SR
49

6.3 Ciclo Completo del Algoritmo Genético Hibrido Dado que el AG se encarga de dirigir la búsqueda hacia zonas prometedoras, se utiliza un algoritmo de BL para hacer una búsqueda fina en esta zona. Después de un cierto número de generaciones creadas por el AG, se ordenan los individuos de acuerdo a la función de costos y se busca una solución que tenga un error en el balance de potencia EP inferior al 1% de la demanda a cubrir. En caso de no encontrar un individuo en la población que cumpla el criterio EP, entonces se vuelven a considerar otras n generaciones, y así sucesivamente, hasta lograr el criterio EP. El mejor individuo generado por el AG es la solución inicial del algoritmo de BL, encargado de refinar la calidad de la solución en cuanto a costo. El algoritmo BL busca la mejor solución entre K0 soluciones vecinas generadas de forma aleatoria.
inicio
Pob_ini
Evaluación
Selección
Repara solución∑Pi =demanda
Ordena por fc
Hijos
DP < 1% dem
si
no
Solución inicial
MEJOR SOLUCIÓN
Ciclo de ngeneraciones
Búsqueda en k0 vecindades
inicio
Pob_ini
Evaluación
Selección
Repara solución∑Pi =demanda
Ordena por fc
Hijos
DP < 1% dem
si
no
Solución inicial
MEJOR SOLUCIÓN
Ciclo de ngeneraciones
Búsqueda en k0 vecindades
Figura 6.1 Ciclo completo del AGH
50

6.4 Resultados del Algoritmo Genético Híbrido Resultados para caso de estudio 2. Se muestran los resultados de:
- AGH con 2 valores de k0 (vecindades generadas) - AGH con 2 valores de DP (criterio de balance de potencia) - Recocido Simulado
El algoritmo genético híbrido resuelve el problema de despacho económico con funciones de costo de segundo grado convexas para las primeras 6 unidades, y la función de costo real del ciclo combinado U7. Los resultados que se muestran a continuación muestran el desempeño del AGH con diferentes criterios de paro para el ciclo del AG y cambios en el número máximo de vecindades que se pueden explorar en la búsqueda local.
AGH con diferentes valores de k0 (vecindades generadas) Se hicieron 10 pruebas con K0= 20 y K0 = 40, y con ambas se obtuvo un promedio de 8 mejores soluciones. Al duplicar las posibilidades de búsqueda, no se obtiene la misma relación en cuanto a mejores soluciones encontradas. En promedio sí se obtuvieron mejores soluciones en el segundo caso, pero fueron producto de que los ciclos de AG proporcionaron mejores soluciones, incluso con un menor número de ellos. En sí, lo que se quiere decir, es que el mejor desempeño de la segunda prueba, no fue dependiente del incremento de k0, sino de las mejores soluciones que proporcionó el AG.
Costo (r-R)*100núm. G's V's P1 P2 P3 P4 P5 P6 P7 Σ (P1..P7) Fc(P1) Fc(P2) Fc(P3) Fc(P4) Fc(P5) Fc(P6) Fc(P7) Σ (Fc) Fcr(7) r=Σ (Fcr) R r<R
1 500 6 66.0 248.0 247.9 7.0 7.0 8.0 220.1 804.0 52,636 107,774 107,754 22,629 26,061 27,534 111,326 455,714 109,842 454,230 0.002 100 6 48.7 247.6 248.0 7.0 7.0 8.0 237.6 804.0 43,747 107,634 107,787 22,629 26,061 27,534 119,748 455,140 118,766 454,158 -0.023 300 4 55.6 247.9 247.9 7.0 7.0 8.0 230.5 804.0 47,213 107,757 107,766 22,629 26,061 27,534 116,310 455,270 115,122 454,082 -0.034 300 7 53.0 247.9 247.6 7.0 7.0 8.0 233.5 804.0 45,868 107,755 107,635 22,629 26,061 27,534 117,733 455,215 116,630 454,112 -0.035 1900 6 42.0 208.6 246.3 7.0 7.0 8.0 285.0 804.0 40,493 91,407 107,073 22,633 26,068 27,590 142,617 457,880 141,616 456,878 0.586 300 14 53.2 248.0 248.0 7.4 7.0 8.0 232.3 804.0 45,979 107,796 107,796 23,263 26,068 27,563 117,192 455,657 116,057 454,522 0.067 100 7 109.1 247.6 248.0 7.0 7.0 8.0 177.3 804.0 78,165 107,629 107,795 22,629 26,061 27,534 90,778 460,591 88,105 457,918 0.818 200 8 53.6 248.0 248.0 7.0 7.0 8.1 232.2 804.0 46,175 107,796 107,796 22,636 26,086 27,763 117,136 455,387 115,998 454,249 0.009 200 5 136.1 237.5 234.4 7.0 7.0 8.0 174.0 804.0 96,579 103,258 101,944 22,629 26,061 27,534 89,207 467,213 86,445 464,451 2.2510 1200 13 54.6 248.0 248.0 7.0 7.0 8.0 231.4 804.0 46,691 107,780 107,787 22,629 26,061 27,534 116,755 455,237 115,593 454,076 -0.03
prom: 510 8 promedio 455,867 0.36 4/10
Costo real
Tabla 6.2 Resultados del Algoritmo Genético Hibrido con K0 = 20, DP = 10
51

Costo (r-R)*100núm. G's V's P1 P2 P3 P4 P5 P6 P7 Σ (P1..P7) Fc(P1) Fc(P2) Fc(P3) Fc(P4) Fc(P5) Fc(P6) Fc(P7) Σ (Fc) Fcr(7) r=Σ (Fcr) R r<R
1 300 8 55.0 247.9 248.0 7.0 7.0 8.0 231.1 804.0 46,899 107,751 107,779 22,629 26,061 27,538 116,597 455,255 115,426 454,084 -0.032 100 6 43.1 247.7 248.0 7.0 7.0 8.0 243.3 804.0 40,985 107,655 107,793 22,629 26,061 27,534 122,459 455,116 121,641 454,298 0.013 100 4 48.3 247.6 247.0 7.0 7.0 8.0 239.1 804.0 43,542 107,606 107,359 22,629 26,061 27,534 120,450 455,181 119,511 454,242 0.004 100 9 48.7 248.0 248.0 7.0 7.1 8.2 236.9 804.0 43,744 107,796 107,796 22,662 26,276 27,809 119,397 455,479 118,394 454,476 0.055 300 0 53.2 248.0 248.0 7.0 7.0 8.0 232.8 804.0 45,995 107,796 107,796 22,629 26,061 27,534 117,390 455,200 116,267 454,077 -0.036 100 13 106.1 244.5 248.0 7.1 7.1 8.0 183.2 804.0 76,218 106,249 107,796 22,768 26,269 27,547 93,624 460,469 91,112 457,957 0.827 300 9 47.4 248.0 247.8 7.0 7.0 8.0 238.7 804.0 43,107 107,793 107,724 22,629 26,061 27,534 120,270 455,118 119,319 454,168 -0.018 200 13 74.0 247.5 248.0 7.0 7.3 8.1 212.1 804.0 56,995 107,592 107,796 22,696 26,474 27,649 107,462 456,664 105,750 454,952 0.169 200 8 52.2 247.7 247.8 7.0 7.0 8.0 234.2 804.0 45,489 107,683 107,719 22,629 26,061 27,534 118,081 455,197 116,999 454,115 -0.0310 700 7 52.9 247.9 248.0 7.0 7.0 8.0 233.2 804.0 45,820 107,762 107,790 22,629 26,061 27,534 117,600 455,196 116,490 454,086 -0.03
prom: 240 8 promedio 454,646 0.09 5/10
Costo real
Tabla 6.3 Resultados del Algoritmo Genético Hibrido con K0 = 40, DP = 10
AGH con diferentes valores de DP. En la siguiente prueba se reduce el criterio DP a 5 para obligar a los ciclos de AG a dar una solución más precisa en cuanto a balance de potencia. La tabla 6.3 muestra los resultados de 10 ejecuciones del AGH con DP = 5.
Costo (r-R)*100núm. G's V's P1 P2 P3 P4 P5 P6 P7 Σ (P1..P7) Fc(P1) Fc(P2) Fc(P3) Fc(P4) Fc(P5) Fc(P6) Fc(P7) Σ (Fc) Fcr(7) r=Σ (Fcr) R r<R
1 300 9 53.2 247.6 247.6 7.0 7.0 8.0 233.6 804.0 45,969 107,623 107,617 22,629 26,061 27,606 117,778 455,283 116,678 454,183 -0.012 100 2 52.7 247.9 247.5 7.0 7.0 8.0 233.8 804.0 45,714 107,767 107,589 22,629 26,061 27,534 117,917 455,211 116,825 454,120 -0.023 1500 2 53.8 248.0 247.9 7.0 7.0 8.0 232.3 804.0 46,265 107,782 107,769 22,629 26,061 27,534 117,177 455,217 116,041 454,081 -0.034 1700 11 51.5 248.0 248.0 7.0 7.0 8.0 234.4 804.0 45,142 107,796 107,796 22,676 26,080 27,534 118,187 455,209 117,111 454,134 -0.025 300 11 47.0 245.9 246.7 7.0 7.2 8.9 241.2 804.0 42,910 106,877 107,242 22,683 26,362 28,873 121,472 456,420 120,595 455,542 0.296 1000 10 48.9 247.9 248.0 7.0 7.0 8.0 237.1 804.0 43,833 107,741 107,789 22,672 26,124 27,545 119,506 455,210 118,510 454,214 0.007 800 0 57.5 247.9 248.0 7.0 7.0 8.0 228.6 804.0 48,146 107,756 107,796 22,629 26,061 27,534 115,403 455,325 114,161 454,083 -0.038 400 0 54.9 248.0 248.0 7.0 7.0 8.0 231.1 804.0 46,826 107,796 107,796 22,629 26,061 27,534 116,600 455,242 115,430 454,071 -0.049 400 7 48.3 246.3 247.9 7.0 7.0 8.0 239.4 804.0 43,551 107,071 107,773 22,629 26,061 27,534 120,575 455,195 119,644 454,263 0.0110 1500 7 110.5 248.0 248.0 7.0 7.0 8.0 175.6 804.0 79,052 107,786 107,777 22,629 26,061 27,534 89,973 460,812 87,254 458,094 0.85
prom: 800 6 promedio 454,678 0.10 6/10
Costo real
Tabla 6.4 Resultados del Algoritmo Genético Hibrido con error en DP = 5 Al reducir el criterio de paro del AG no se mostró una mejora en la calidad de la solución. El costo promedio con DP = 5 fue 0.007% mas caro que con DP = 10, y en cambio, el número de ciclos del AG se triplicó. Independientemente de que se deben de hacer ajustes en el AGH para hacerlo más consistente en cuanto a la calidad de la solución, se hace evidente que es posible encontrar un mejor despacho de generación, considerando la curva real de costo de la U7 de ciclo combinado. En la tabla 6.5 se hace la comparación de los dos despachos.
Solución óptima con funciones de costo de segundo orden convexasCosto
P1 P2 P3 P4 P5 P6 P7 Σ (P1..P7) Fc(P1) Fc(P2) Fc(P3) Fc(P4) Fc(P5) Fc(P6) Fc(P7) Σ (Fc) Fcr(7) R=Σ (Fcr)44.4 248.0 248.0 7.0 7.0 8.0 241.6 804.0 41,649 107,796 107,796 22,629 26,061 27,534 121,635 455,099 120,767 454,231
AGH 54.9 248.0 248.0 7.0 7.0 8.0 231.1 804.0 46,826 107,796 107,796 22,629 26,061 27,534 115,430 454,071 -0.04
Costo realFc(P) = aP 2 + bP + c
Tabla 6.5 Solución analítica vs mejor solución del AGH
52

Al considerar la curva real de costo (no convexa) de la U7, se encuentra que es mejor despachar a la U1 con 55 MW y a la U7 con 231 MW. Con ello se logra un ahorro de 160 pesos en una hora, aproximadamente 115,000 pesos mensuales. Tal vez una cantidad pequeña, pero finalmente un ahorro. Además, hay que considerar que este ahorro se logra con la participación de sólo 2 unidades porque las demás son tan caras o tan baratas que se despachan al mínimo y al máximo, respectivamente. En la tabla 6.4 se muestran los resultados de la aplicación del algoritmo de Recocido Simulado. La calidad de la solución es mejor y más consistente, se encuentran 7 mejores soluciones en 10 pruebas, respecto de la solución analítica evaluada con la función de costo real. Sólo que la búsqueda es más amplia, encontrándose un promedio de 1100 mejores soluciones.
Costo (r-R)*100núm. G's V's P1 P2 P3 P4 P5 P6 P7 Σ (P1..P7) Fc(P1) Fc(P2) Fc(P3) Fc(P4) Fc(P5) Fc(P6) Fc(P7) Σ (Fc) Fcr(7) r=Σ (Fcr) R r<R
1 1032 45.7 248.0 248.0 7.0 7.0 8.0 240.3 804.0 42,257 107,796 107,796 22,629 26,061 27,534 121,028 455,101 120,124 454,196 -0.012 1110 49.6 248.0 248.0 7.0 7.0 8.0 236.4 804.0 44,155 107,796 107,796 22,629 26,061 27,534 119,163 455,133 118,146 454,116 -0.033 1138 40.0 248.0 248.0 7.0 7.0 8.0 246.0 804.0 39,538 107,795 107,796 22,629 26,061 27,534 123,771 455,124 122,987 454,340 0.024 1086 57.4 248.0 248.0 7.0 7.0 8.0 228.6 804.0 48,091 107,796 107,796 22,629 26,061 27,534 115,411 455,318 114,170 454,076 -0.035 1097 64.3 248.0 248.0 7.0 7.0 8.0 221.7 804.0 51,706 107,796 107,796 22,629 26,061 27,534 112,092 455,613 110,653 454,174 -0.016 1093 49.2 248.0 248.0 7.0 7.0 8.0 236.8 804.0 43,979 107,796 107,796 22,629 26,061 27,534 119,334 455,128 118,327 454,122 -0.027 1132 47.3 248.0 248.0 7.0 7.0 8.0 238.7 804.0 43,047 107,796 107,796 22,629 26,061 27,534 120,248 455,110 119,296 454,158 -0.028 1132 50.0 248.0 248.0 7.0 7.0 8.0 236.0 804.0 44,373 107,796 107,796 22,629 26,061 27,534 118,951 455,140 117,921 454,110 -0.039 1108 66.2 248.0 248.0 7.0 7.0 8.0 219.8 804.0 52,744 107,796 107,796 22,629 26,061 27,534 111,160 455,719 109,666 454,225 0.0010 1165 43.7 248.0 248.0 7.0 7.0 8.0 242.3 804.0 41,296 107,796 107,796 22,629 26,061 27,534 121,988 455,099 121,142 454,253 0.00
prom: 1109 promedio 454,177 -0.01 7/10
Costo real
Tabla 6.6 Resultados del Algoritmo de Recocido Simulado
53

CONCLUSIONES
Se han presentado un avance de la aplicación de los siguientes métodos heurísticos al Despacho Económico sin pérdidas, y en los casos de estudio se incluye la evaluación de la curva de costo no convexa y la zona muerta de una unidad de ciclo combinado, estas son condiciones que no puede ser evaluada con métodos de optimización clásicos. Los algoritmos genéticos han sido aplicados utilizando ajustes recomendados en forma general, como son las probabilidades de mutación y cruza. Se ha hecho evidente que el poder evaluar la curva de costo real del ciclo combinado con una metodología heurística, ha resultado en la obtención de un menor costo de generación en el despacho de generación del caso de estudio presentado. El algoritmo genético simple es fácil de implementar, pero tiene problemas en la calidad de la solución, sobre todo cuando se han codificado las potencias. Ya que un asignación aleatoria de potencias no permite soluciones factibles en cuanto al balance de potencia. Y si se mejora la población inicial con soluciones factibles, éstas pierden esta característica en las primeras generaciones por los operadores de cruza y mutación. Por lo que es necesario adicionar algoritmos de reparación y algoritmos de búsqueda local para mejorar la rapidez de convergencia y la calidad de la solución. Hasta ahora, para problemas pequeños, el RS y GRASP han mostrado mejor desempeño en cuanto a tiempo de ejecución. En la comparación de los desempeños de los métodos heurísticos, el GRASP ha presentado los mejores desempeños en cuanto a la calidad de la solución final, para un caso de estudio de 7 unidades. Está pendiente probar el desempeño de los métodos heurísticos AG, AGH, RS y GRASP para un caso de estudio más grande, con varias unidades tipo ciclo combinado con funciones no convexas y zonas muertas.
54

AVANCE Y ACTIVIDADES PENDIENTES CALENDARIZACIÓN
Actividades / semanas 1 2 3 4 5 6 7 8 9 10 11 1 2 3 4 5 6 7 8 9 10 11
Presentación segundo avance
programadorealnuevas actividades
Escribir reporte de tesis
Presentación primer avance
Solución analítica de casos de estudio
Ajuste parámetros y operadores genéticos
Pruebas y análisis de resultados del AG Híbrido
Análisis comparativo de resultados
Implementación Heurísticas Recocido Simulado y GRASP
Consideración de zonas muertas de ciclos combinados
Trimestre I Trimestre II
Revisión Estado del Arte
Incorporación algoritmo de búsqueda local
De acuerdo con los resultados preliminares del primer reporte de avance, se hicieron las siguientes actividades:
1- Mejorar el desempeño del AGH - Incorporación de Elitismo - Aumentar población inicial - Mejorar algoritmo que repara la solución del AG (parcial)
2- Considerar zonas muertas de los ciclos combinados.
Pendientes:
- Utilizar sistema de reemplazo parcial de la población, para tener siempre población con soluciones factibles
- Trabajar con un modelo en donde el ciclo combinado U7 pueda “competir” con más unidades.
55

APENDICE II. Solución analítica mediante un método matemático clásico. La formulación del problema de Despacho Económico sin pérdidas es la siguiente:
minimizar : (P∑=
n
iiF
1i)
sujeto a:
∑=
=n
ii demandaP
1
Pmini ≤ Pi ≤ PmaxiDonde: n: número de unidades generadoras Fi : Función de costo del generador i Pi : Potencia del generador i Pmini : Potencia mínima que puede suministrar el generador i Pmaxi : Potencia máxima que puede suministrar el generador i Se utiliza un multiplicador de Lagrange para incorporar a la función objetivo la restriccion de igualdad (balance generación-demanda). Función lagrangeana:
⎟⎠
⎞⎜⎝
⎛ −+= ∑∑==
n
ii
n
iii demandaPPFPL
11)(),( λλ
El mínimo de la función se obtiene a partir del gradiente, dando lugar a las siguientes condiciones de optimalidad:
nidPdF
PL
i
i
i
,...,1;0 ==+=∂∂ λ
;01
=−=∂∂ ∑
=
demandaPL n
iiλ
Datos del caso de estudio: Demanda: 804 MW coeficientes
56

Pmin Pmax a b c
central tipo [MW] [MW] [$/MWh2] [$/MWh] [$]
Presidente Juárez U1 vapor convencional 40 160 1.2800 368.0 22770
Presidente Juárez U2 ciclo combinado 62 248 0.5635 158.5 33830
Presidente Juárez U3 ciclo combinado 62 248 0.5635 158.5 33830
Ciprés U4 turbogás 7 27 24.9200 1154.0 13330
Mexicali U5 turbogás 7 26 19.4500 1204.0 16680
Tijuana U6 turbogás 8 30 21.1600 1190.0 16660
CC Mexicali 1) U7 ciclo combinado 122 489 0.0291 467.7 6957
Total 308 1,228 1) Coeficientes abc de la curva ajustada a los tres puntos del consumo específico proporcionado por el Productor Independiente
Sustituyendo los coeficientes abc en las ecuaciones de optimalidad:
;0)2277036828.1(
1
12
1 =+++ λdP
PPd
;0)338305.1585635.0(
2
22
2 =+++ λdP
PPd
;0)338305.1585635.0(
3
32
3 =+++ λdP
PPd
;0)13330115492.24(
4
42
4 =+++ λdP
PPd
;0)16680120445.19(
5
52
5 =+++ λdP
PPd
;0)16660119016.21(
6
62
6 =+++ λdP
PPd
;0)69577.4670291.0(
7
72
7 =+++ λdP
PPd
8047654321 =++++++ PPPPPPP
57

Estas derivadas generan el siguiente sistema de ecuaciones lineales: A p = B
Matriz A Matriz p
Matriz B
U1 U2 U3 U4 U5 U6 U7 λ 2.560 0 0 0 0 0 0 1 P1 -368
0 1.127 0 0 0 0 0 1 P2 -158.5 0 0 1.127 0 0 0 0 1 P3 -158.5
0 0 0 49.840 0 0 0 1 P4 = -1154 0 0 0 0 38.900 0 0 1 P5 -1204 0 0 0 0 0 42.320 0 1 P6 -1190 0 0 0 0 0 0 0.058 1 P7 -467.7 1 1 1 1 1 1 1 0 λ 804
p = A -1 B
A -1 B p revisión límites U1 U2 U3 U4 U5 U6 U7 λ min max
0.3828 -0.0178 -0.0178 -0.0004 -0.0005 -0.0005 -0.3457 0.0201 -368 44.3 40 160-0.0178 0.8468 -0.0405 -0.0009 -0.0012 -0.0011 -0.7853 0.0457 -158.5 286.5 Sup 62 248-0.0178 -0.0405 0.8468 -0.0009 -0.0012 -0.0011 -0.7853 0.0457 -158.5 286.5 Sup 62 248
-0.0004 -0.0009 -0.0009 0.0200 0.0000 0.0000 -0.0178 0.0010 -1154 = -13.5 Inf 7 27-0.0005 -0.0012 -0.0012 0.0000 0.0257 0.0000 -0.0228 0.0013 -1204 -18.6 Inf 7 26-0.0005 -0.0011 -0.0011 0.0000 0.0000 0.0236 -0.0209 0.0012 -1190 -16.7 Inf 8 30-0.3457 -0.7853 -0.7853 -0.0178 -0.0228 -0.0209 1.9776 0.8850 -467.7 235.5 122 4890.0201 0.0457 0.0457 0.0010 0.0013 0.0012 0.8850 -0.0515 804 -481.4
El resultado muestra que se han violado los límites de potencia de 5 unidades generadoras. Para encontrar una solución, se pueden sustituir los valores fuera de límite por los límites que violaron, mínimo o máximo, y resolver para las ecuaciones que queden: A p = B
Matriz A Matriz p
Matriz B
U1 U2 U3 U4 U5 U6 U7 λ 2.560 0 0 0 0 0 0 1 P1 -368
0 1 0 0 0 0 0 0 P2 -248 0 0 1 0 0 0 0 0 P3 -248
0 0 0 1 0 0 0 0 P4 = -7 0 0 0 0 1 0 0 0 P5 -7 0 0 0 0 0 1 0 0 P6 -8 0 0 0 0 0 0 0.058 1 P7 -467.7 1 1 1 1 1 1 1 0 λ 804
58

A -1 B p revisión límites U1 U2 U3 U4 U5 U6 U7 λ min max 0.3819 -0.0222 -0.0222 -0.0222 -0.0222 -0.0222 -0.3819 0.0222 -368 44.4 40 1600.0000 1.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 -248 248.0 62 2480.0000 0.0000 1.0000 0.0000 0.0000 0.0000 0.0000 0.0000 -248 248.0 62 248
0.0000 0.0000 0.0000 1.0000 0.0000 0.0000 0.0000 0.0000 -7 = 7.0
7 270.0000 0.0000 0.0000 0.0000 1.0000 0.0000 0.0000 0.0000 -7 7.0 7 260.0000 0.0000 0.0000 0.0000 0.0000 1.0000 0.0000 0.0000 -8 8.0 8 30
-0.3819 -0.9778 -0.9778 -0.9778 -0.9778 -0.9778 0.3819 0.9778 -467.7 241.6 122 4890.0222 0.0569 0.0569 0.0569 0.0569 0.0569 0.9778 -0.0569 804 -481.7
La solución encontrada cumple con todos los límites de potencia y con el balance de potencia. En la Tabla 6.1 se muestra la evaluación del costo de esta solución.
CostoP1 P2 P3 P4 P5 P6 P7 Σ (P1..P7) Fc(P1) Fc(P2) Fc(P3) Fc(P4) Fc(P5) Fc(P6) Fc(P7) Σ (Fc) Fcr(7) R=Σ (Fcr)
44.4 248.0 248.0 7.0 7.0 8.0 241.6 804.0 41,649 107,796 107,796 22,629 26,061 27,534 121,635 455,099 120,767 454,231
Fc(P) = aP 2 + bP + c Costo real
Tabla 6.1 Solución analítica, con funciones de costo cuadráticas; y evaluación con la función de costo real de la U7.
59

REFERENCIAS
[1] Aboytes, F., Guerrero, J.J.: Despacho económico, flujos óptimos y control de generación. Curso de Capacitación en Sistemas de Potencia, CENACE. México, D.F. , 2001.
[2] Cai, X., Lo, K.: Unit Commitment by a genetic algorithm. Nonlinear Analysis, Theory, Methods & Applications, Vol. 30, No. 7, pp. 4289-4299, 1997.
[3] Cheng, C.-P., Liu, C.-W., Liu, C.-C.: Unit commitment by annealing-genetic algorithm. Electrical Power and Energy Systems 24, 149-158, 2002.
[4] Goldberg, D. E., Genetic Algorithms in Search, Optimization, and Machina Learning, The University of Alabama, Adison-Wesley publishing Company, 1989
[5] Gutierrez A. M. A. “La técnica de Recocido Simulado y sus aplicaciones”, Tesis
para obtener el grado de Doctor en Ingeniería. UNAM, México, 1991
[6] Li, F.: A comparison of genetic algorithms with conventional techniques on a spectrum of power economic dispatch problems. Expert Systems with Applications 15, 133-142, 1998.
[7] Li, F., Morgan, R., Williams, D.: Hybrid genetic to ramping rate constrained dynamic economic dispatch. Electric Power Systems Research 43, 97-103, 1997.
[8] Olachea, A.: Aplicación de la técnica de algoritmos genéticos al problema de despacho económico. Tesis para obtener el grado de MC en Ing. Eléctrica. Universidad Autónoma de Nuevo León, 2003.
[9] Ongsakul, W.: Real-time economic dispatch using merit order loading for linear decreasing and staircase incremental cost functions. Electric Power Systems Research 51, 167-173, 1999.
[10] Reeves, R.: Modern Heuristic Techniques for Combinatorial Problems. Edited by Colin R. Reeves, Mc Graw Hill, 1995
[11] Resende, M.: Greedy Randomized adaptive search procedure (GRASP), AT&T Labs Research Technical Report: 98.41.1. December 22, 1998.
60

[12] Sudhakaran, M., Slochanal, S.M.R., Sreeram, R., Chandrasekhar, N.: Application of refined genetic algorithm to combined economic and emission dispatch. IE (I) Journal-EL. Vol. 85, September 2004.
[13] Wood & Wollemberg: Power generation operation and control. Ed. John Wiley and Sons Inc.,1984.
61





























