Embed Size (px)
Citation preview

Lexical Analysis
Role, Specification & Recognition
Tool: LEX
Construction:
- RE to NFA to DFA to min-state DFA
- RE to DFA

Conducting Lexical Analysis
Techniques for specifying and implementing lexical analyzers
Hand-written state transition diagram that reveals the structure of the tokens hand-translated driver program
Tools: Pattern Triggered actions pattern-action language: LEX
Other applications: query language, information retrieval AWK shell commands PCB inspection

Lexical Analyzer and Parser
lexicalanalyzer
Parser
symboltable
token &attributes
get nexttoken
sourceprogram
(Aho,Sethi,Ullman, pp.84)
token: smallest logically cohesive sequence of characters of interest in source program

Lexical Analysis
Convert input lexemes to stream of tokens Lexeme: a sequence of characters that comprises a single token
Typical Functions: Removal of white space and comments
instead of writing productions that include spaces and comments keeping line count for associating error message with line number
Digits into Token ID + value/attributes instead of writing productions for integer constants 31+28+59 <num, 31> <+, > <num, 28><+, > <num, 59>
Recognizing Identifiers and Keywords Identifiers: count = count + increment id = id + id Keywords: begin, end, if, elsebegin, end, if, else Operators/punctuations: ‘>’, ‘<=’, ‘<>’

Why Separate Lexical Analysis from Parsing
Simpler Design no production rules and translations for white spaces and
comments Improved Efficiency
lexical analyzer can be optimized separately (e.g., using specialized buffering techniques)
Enhanced Compiler Portability Input alphabet peculiarities and device-specific anomalies
can be restricted to the lexical analyzer

Tokens, Patterns, Lexemes
Token: terminal symbol or lexical unit of a parser, representing a set of strings of particular type e.g., “pi”, “count”, … => id e.g., “3.1416”, “6.02e23”, … => num Typical: keywords, operators, identifiers, constants, literal strings,
punctuation symbols Representation: an integer (e.g., #define ID 258)
with associated attributes Pattern: a specification of the set of strings
a rule describing the set of lexemes that can represent a particular token
e.g., id => “letter followed by letters and digits” Lexeme: a sequence of characters in the source program that is
matched by the pattern for a token Examples: Fig. 3.2

Attributes for Tokens
Attributes: additional information for a particular lexeme when matching multiple patterns parsing decision, translation
Implementation: a pointer to symbol table entry in which the token information is kept
Example: E = M * C ** 2 E (or M, C): <id, ptr to symbol-table entry for E (M, C)> =: <assign_op, > *: <multi_op, > **: <exp_op, > 2: <num, integer value 2>

Lexical Errors
Matched but ambiguous: left to the other phases (e.g., parser) e.g., fi ( a == f(x) ) … : fi => identifier ?? misspelling of “if”
Unmatched: Panic mode recovery: delete successive characters from the
remaining input until a well-formed token is found Repair input (single error):
deleting an extraneous character inserting a missing character replacing with a correct character transposing two adjacent characters
Minimum-distance error correction (multiple errors)

Specification of Tokens
A Formal Specification for Tokens or Patterns
- Strings and Languages
- Regular Expressions & Definitions
- Recognition of Tokens

Strings and Language
alphabet (or character class) (字符集 ): any finite set of symbols
string over some alphabet (字串 ): a finite sequence of symbols drawn from that alphabet
length of string s, |s|: number of symbols in s empty string: a special string of length zero (proper) prefix: abcdef (proper) suffix: abcdef (proper) substring: abcdef subsequence: abcdef

Strings and Language
language: any set of strings over some alphabet empty set: the set containing only empty string, i.e.,
Φ={ε}

Operations on Strings
Concatenation: xy s ε = εs = s x=“Dog” y=“House” => xy = “DogHouse”
Exponentiations: si =si-1 s (s0=ε)

Operations on Languages
Union {s | s is in L or s is in M}
Concatenation {st | s is in L and t is in M}
Kleene closure: zero or more concatenation L*: union of Li (i = 0 … infinity) L0 = {ε}, Li = Li-1 L
Positive closure: one or more concatenation L+: union of Li (i = 1 … infinity)

Examples
L={A, B, …, Z, a, b, …, z}, D={0, 1, …, 9} Union
L U D = {letters and digits of length 1} Concatenation
LD={a letter followed by a digit} (={A0, A1, … B0, …}) L4 = {4-letter strings}(={AAAA, AABC, BBBB, …})
Kleene closure: zero or more concatenation L*: {all strings of letters of length zero (i.e., ε) or more} L(L U D)* = {all strings of letters-and-digits, starting with a
letter} Positive closure: one or more concatenation
D+: {strings of one or more digits}

Regular Expression (R.E.)
A Formal Specification for Tokens

Regular Expression: Syntax for Specifying String Patterns
Regular expression r over alphabet Defines the language L(r) corresponding to r Regular Set: A language denoted by a regular expression
Basic Symbols empty-string: any symbol a in input symbol set
Basic Operators disjunction (OR, union): r | s concatenation (AND): r s (or simply rs) closure (repetition): r* identity (parenthesized): (r)

Regular Expression: Syntax for Specifying String Patterns
Extended operators: ? : optional operator + : positive closure operator . : any character but newline [a-z]: character class [^a-z]: complement (any characters NOT in [a-z]) {m,n}: number of occurrence ^: start of line $: end of line registers: the n-th part of match: \1, \2
sed ‘s/.*<img src=\([^ >]*\).*/\1/g’ escape, meta-symbols: \c (character ‘c’ literally)
[a\-z]: ‘a’, ‘-’or ‘z’ (NOT: ‘a’, ‘b’,…, ‘z’) r/s: r which is followed by s (‘/’: lookahead operator)

Notational ShorthandsNotational Shorthands
One or more instances(r)+ denoting (L(r))+
r* = r+ | r+ = r r*
Zero or one instancer? = r |
Character classes[abc] = a | b | c[a-z] = a | b | ... | z

Regular Expression
Examples: = {a, b} r = a|b {a, b} r = (a|b)(a|b) {aa, ab, ba, bb}
= aa|ab|ba|bb (another equivalent regular expression) r = a* {, a, aa, aaa, aaaa, …} r = (a|b)* {all strings of a’s and b’s}
= (a*b*)*

Equivalence A language may be represented by two or more
equivalent regular expressions. Equivalence:
L(r) = L(s) r = s Algebraic properties of Regular Expression
Commutative: r|s = s|r Associative:
r|(s|t) = (r|s)|t (rs)t = r(st)
Distribution: r(s|t) = rs|rt & (s|t)r = sr | tr Identity element (): r = r and r=r
Application of properties: Proof of Equivalence r* = (r| )* r** = r*

Regular Definition:A CFG-like Notation of Regular Expression
Regular Definition Similar to CFG Define regular expressions in terms of named regular
expressions d1 r1
d2 r2
… dn rn

Regular Definition
Example of Regular Definition: letter A | B | C | … | z digit 0 | 1 | … | 9 id letter (letter | digit ) *
Another Example: Unsigned numbers (ex. 3.5) // Unsigned numbers (512, 3.14, 6.33 E 4, 1.89 E -5) digit 0 | 1 | … | 9 digits digit digit* optional_fraction . digits |ε optional_exponent ( E (+| - |ε) digits ) |ε num digits optional_fraction optional_exponent

Nonregular Set
Some languages cannot be described by any regular expression
Examples: Balanced and nested constructs
BUT, Can be specified by CFG Repeating strings
{wcw| w is a string of a’s and b’s} ={aca, bcb, abcab, …} Cannot be expressed in CFG either
Context dependent strings nHa1a2…an

Regular Expression: Syntax for Specifying String Patterns
Chomsky Hierarchy: regular set (R.E.) context-free context-sensitive recursively enumerable (Tuning Machine)

Regular Expression: Syntax for Specifying String Patterns
Applications: Matching wildcard characters (shell commands, filename
expansion) string pattern matching (grep, awk) search engine (keyword matching, fuzzy match) string pattern editing/processing (sed, vi, tr)

Recognition of Tokens

Example Task
Grammar: stmt → if expr then stmt | if expr then stmt else stmt | expr → term relop term | term term → id | num

Example Task
Terminal Symbols: if → if then → then else → else relop → < | <= | = | <> | > | >= id → letter (letter | digit)* num → digit+ ( . digit+ )? ( E(+|-)? digit+)?
White Space Delimited: delim → blank | tab | newline ws → delim+

Example Task
Goal: construct a lexical analyzer that isolates lexeme for the next token
Produce token and associated attribute-values
Methods: By hands: constructing FAs & a simulator for the FAs
Simulator (scanner) depends on FAs By tools: writing regular definition for scanner generators
to build FAs for a scanner Scanner: a driver program that is independent of the forms
of the FAs
FA / FSA: Finite (State) Automata

FA and Transition Diagrams
a b c
a state
a transition
the start state
a final state
a
r = (abc)+

FA/FSA and Transition Tables
inputs states
a b c
q0 q1
q1 q2
q2 q3
q3 q1
NextState = Move( CurrentState, Input )

Recognition state = 0; while ( (c = next_char() ) != EOF ) {
switch (state) { case 0: if ( c == ‘a’ ) state = 1;
• break; case 1: if ( c == ‘b’ ) state = 2;
• break; case 2: if ( c == ‘c’ ) state = 3;
• break; case 3: if ( c == ‘a’ ) state = 1;
• else { ungetchar(); return (TRUE); }• break;
default:• error();
} } if ( state == 3 ) return (TRUE) else return (FALSE);
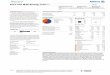
ID
1 20 - 9 0 - 9
NUM
0 - 9
1 2 3
4 5
0 - 9
0 - 9 0 - 9
0 - 9
REAL
1 2 43
5
a- z\n- -
blank, etc.blank, etc.
White space(and comment starting with ‘- -’)
21any but \n
error
IF
1 2a- z a- z
0 - 9
Finite Automata for the Lexical Tokens
1 2i f
3
.
.
(Appel, pp. 21)

if {return IF;}
[a - z] [a - z0 - 9 ] * {return ID;}
[0 - 9] + {return NUM;}
([0 - 9] + “.” [0 - 9] *) | (“.” [0 - 9] +) {return REAL;}
(“--” [a - z]* “\n”) | (“ ” | “ \n ” | “ \t ”) + {/* do nothing*/}
. {error ();}
(Appel, pp. 20)
Regular expressions for tokens

Recognition of the Lexical Tokens Given the FA’s (Naïve Pattern Matching)
Traversal of the transition diagrams in sequence to match any of the above state transition diagrams until match Give different unique state numbers to different initial
states (and other states) in individual diagram before writing a program to simulate the traversal process
Match the longest expression first if two state transition diagrams have super-/sub-string relationship
E.g., match REAL before INTEGER On failure, next_state = init_state of next FA
Example program: [Aho 86]

Finite State Automata

How to Construct a FA Systematically?
You can construct a single complicated state transition diagram directly to recognize all token types if you are smart enough, or E.g., (next page)
You can do it systematically by constructing simpler transition diagrams and composing them into larger networks Preferred for automatic construction Easy to verify its correctness

A DFA for Recognizing Common Token Types
5,6,7,8,15
2,5,6,8,15
10,11,12,13,15
3,6,7,8
11,12,13
6,7,8
15
1,4,9,14
a-e, g-z, 0-9
a-z,0-9
a-z,0-9
0-9
0-9
f
i
a-hj-z
0-9
other
ID
ID
NUM NUM
IF(or ID)
error
ID
a-z,0-9
(Appel, pp. 29)
1st pattern or reserved word in LEX spec.
Longest match

Finite (State) Automata
A set of states: S A set of input symbols: (the input symbol
alphabet) A transition (move) function: (s,a) = s’ Initial (start) state: s0 A set of final (accepting) states: F

Finite (State) Automata
Graphical Representation: State transition diagram
Implementation: State transition table
Deterministic (DFA) Single transition for all states on all input symbols
Non-deterministic (NFA) More than one transitions for at least one state with some
input symbol

NFA: Nondeterministic Finite AutomataNFA: Nondeterministic Finite Automata
An NFA consists of S: A finite set of states : A finite set of input symbols : A transition function that maps (state, symbol) pairs to sets of
states s0: A state distinguished as start state
F: A set of states distinguished as final states

NFA: An ExampleNFA: An Example
RE: (a | b)*abb States: {0, 1, 2, 3} Input symbols: {a, b} Transition function:
(0,a) = {0,1}, (0,b) = {0}(1,b) = {2}, (2,b) = {3}
Start state: 0 Final states: {3}
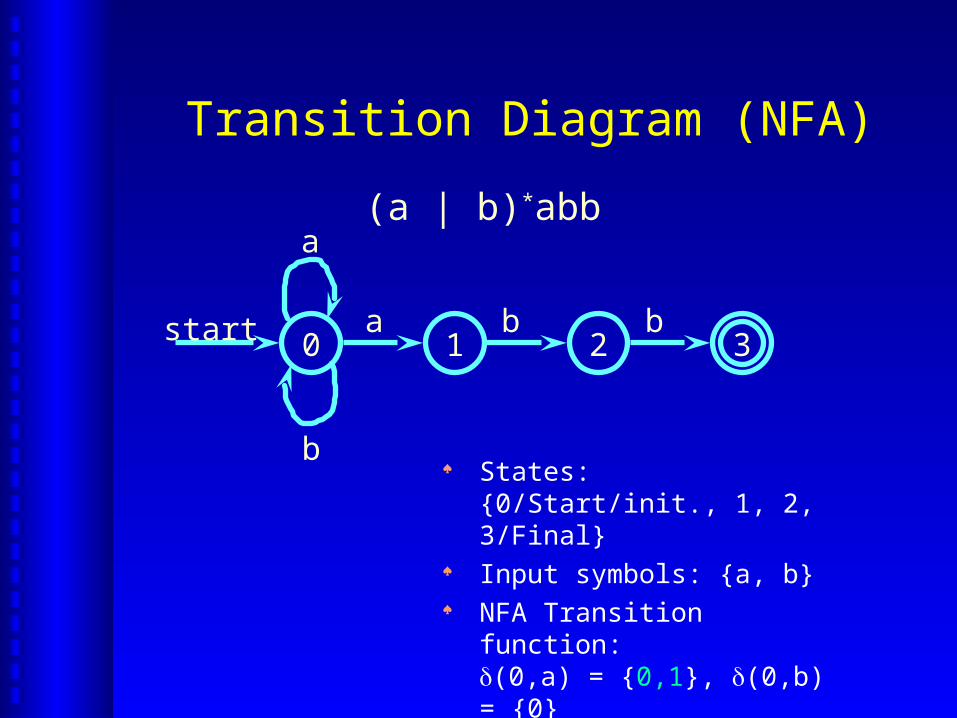
Transition Diagram (NFA)
0 31 2a b b
a
b
start
(a | b)*abb
States: {0/Start/init., 1, 2, 3/Final} Input symbols: {a, b} NFA Transition function:
(0,a) = {0,1}, (0,b) = {0}(1,b) = {2}, (2,b) = {3}

Acceptance of NFAAcceptance of NFA
An NFA accepts an input string s iff there is some path in the transition diagram from the start state to some final state such that the edge labels along this path spell out s
Example: bbababb is accepted by (a|b)*abb bbabab is NOT

NFA: Example with NFA: Example with transition
RE: aa* | bb*
States: {0, 1, 2, 3, 4} Input symbols: {a, b} Transition function:
(0, ) = {1, 3}, (1, a) = {2}, (2, a) = {2}
(3, b) = {4}, (4, b) = {4}
Start state: 0 Final states: {2, 4}

Transition Diagram (NFA)
aa* | bb*
NFA Transition function:(0, ) = {1, 3}, (1, a) = {2}, (2, a) = {2}
(3, b) = {4}, (4, b) = {4}
start0
3
1 2a
b
a
b
4
ε
ε

Deterministic Finite AutomataDeterministic Finite Automata
A DFA is a special case of an NFA in which no state has an -transition for each state s and input symbol a, there is at most one
edge labeled a leaving s

DFA: An ExampleDFA: An Example
RE: (a | b)*abb States: {0, 1, 2, 3} Input symbols: {a, b} Transition function:
(0,a) = {1}, (1,a) = {1}, (2,a) = {1}, (3,a) = {1}(0,b) = {0}, (1,b) = {2}, (2,b) = {3}, (3,b) = {0}
Start state: 0 Final states: {3}

Transition Diagram
A DFA for (a | b)*abb
start 0 31 2ab b
a
ba
b
a

Transition Diagram
a DFA for (a | b)*abb
0 31 2ab b
a
b
start
a
b
a
{0}
{0,1}
{0,3}
{0,2}
0 1 2 3
a
a
b
b bstart

Recognition of Regular Expression Using DFA
Simulating Deterministic Finite Automata (DFA) initialization:
current_state = s0; input_symbol = 1st symbol while (current_state is not fail_state && input_symbol !=
EOF) next_state = (current_state, input_symbol), & Current_state = next_state input_symbol = next_input_symbol
If (current_state in final states) accept() else fail()

Simulating a DFA
Input. An input string ended with eof and a DFA with start state s0 and final states F.Output. The answer “yes” if accepts, “no” otherwise.begin s := s0; c := nextchar; while c <> eof do begin s := move(s, c); // transition function c := nextchar end; if s is in F then return “yes” else return “no”end.

DFA: An ExampleDFA: An Example
(a | b)*abb
start0 31 2a
b ba
ba
b
a

An ExampleAn Example
bbababb bbabab
s = 0 s = 0s = move(0, b) = 0 s = move(0, b) = 0s = move(0, b) = 0 s = move(0, b) = 0s = move(0, a) = 1 s = move(0, a) = 1s = move(1, b) = 2 s = move(1, b) = 2s = move(2, a) = 1 s = move(2, a) = 1s = move(1, b) = 2 s = move(1, b) = 2s = move(2, b) = 3 s is not in {3}s is in {3}

Recognition of Regular Expression Using NFA
Simulating Non-Deterministic Finite Automata (NFA) Backtrack/Backup: (Sequential Traversal)
remember next alternative configuration (current input & next alternative state) when alternative choices are possible
Parallelism: (Parallel Traversal) trace every possible alternatives in parallel
Look-ahead: look at more input symbols to make it deterministic

Simulating an NFASimulating an NFA
Input. An input string ended with eof and an NFA with start state s0 and final states F.Output. The answer “yes” if accepts, “no” otherwise.begin S := -closure({s0}); // s0 = => S c := nextchar; while c <> eof do begin S := -closure(move(S, c)); // S =c=> M = => S’ c := nextchar end; if S F <> then return “yes” else return “no”end.

Operations on NFA statesOperations on NFA states
-closure: set of states reachable without consuming any input symbol
-closure(s): set of NFA states reachable from NFA state s on -transitions alone
-closure(S): set of NFA states reachable from some NFA state s in S on -transitions alone
move(S, c): set of NFA states to which there is a transition on input symbol c from some NFA state s in S

Computation of Computation of -closure-closure
Input. An NFA and a set of NFA states S.Output. T = -closure(S).begin push all states in S onto stack; & initialize T := S; while stack is not empty do begin pop t, the top element, off of stack; for each state u with an edge from t to u labeled do if u is not in T [i.e., current -closure(S)] do begin add u to T; push u onto stack end end; return Tend.

An ExampleAn Example
6
4
2
(a | b)*abb
start 0
a
b
a b 101
3
7 8 9
5
b
T=-closure(0):
01: S={0}, T={0}
02: S={}; t=0; T={0}
03: S={1,7}; T={0,1,7}
04: S={1}; t=7; T={0,1,7}
05: S={1}; T={0,1,7}
06: S={}; t=1; T={0,1,7}
07: S={2,4}; T={0,1,2,4,7}
08: S={2}; t=4; T={0,1,2,4,7}
09: S={2}; T={0,1,2,4,7}
10: S={}; t=2; T={0,1,2,4,7}
**: S={}; T={0,1,2,4,7}
ε
ε
ε εε
ε
ε
ε

An ExampleAn Example
6
4
2
(a | b)*abb
start 0
a
b
a b 101
3
7 8 9
5
b
A = -closure ({0})= {0,1,2,4,7}
ε
ε
ε εε
ε
ε
ε

An ExampleAn Example
6
4
2
(a | b)*abb
start 0
a
b
a b 101
3
7 8 9
5
b
move(A,b)= {5}
ε
ε
ε εε
ε
ε
ε
move(A,a)= {3,8}

An ExampleAn Example
6
4
2
(a | b)*abb
start 0
a
b
a b 101
3
7 8 9
5
b
C = -closure (move(A,b))
= {1,2,4,5,6,7}
ε
ε
ε εε
ε
ε
ε
move(A,b)= {5}

An ExampleAn Example
6
4
2
(a | b)*abb
start 0
a
b
a b 101
3
7 8 9
5
b
move(C,b)= {5}
ε
ε
ε εε
ε
ε
ε

An ExampleAn Example
6
4
2
(a | b)*abb
start 0
a
b
a b 101
3
7 8 9
5
b
C = -closure (move(C,b))
= {1,2,4,5,6,7}
ε
ε
ε εε
ε
ε
ε
move(C,b)= {5}

An ExampleAn Example
bbabbS = -closure({0}) = {0,1,2,4,7} = AS = -closure(move({0,1,2,4,7}, b)) = -closure({5}) = {1,2,4,5,6,7} = CS = -closure(move({1,2,4,5,6,7}, b)) = -closure({5}) = {1,2,4,5,6,7} = CS = -closure(move({1,2,4,5,6,7}, a)) = -closure({3,8}) = {1,2,3,4,6,7,8}S = -closure(move({1,2,3,4,6,7,8}, b)) = -closure({5,9}) = {1,2,4,5,6,7,9}S = -closure(move({1,2,4,5,6,7,9}, b)) = -closure({5,10}) = {1,2,4,5,6,7,10}S {10} <>

Recognition of Regular Expression
Simulating NFA is harder than simulating DFA Constructing NFA is easier than constructing DFA
Construct NFA => Construct Equivalent DFA
By pre-defining states in NFA that can be reached in parallel as a state for the DFA
& pre-computing all possible transitions Instead of simulating the parallel transitions in run-time
=> (optional) State Minimization => Simulate DFA

Constructing Automata from R.E.
(1) R.E. NFA (Thompson’s construction) DFA (Subset Construction) State Minimization R.E. decomposition into basic alphabets & operators construct FA for basic alphabets merging FA’s by operator

Constructing Automata from R.E.
(2) R.E. DFA: state_transition position_transition in pattern State Minimization annotate RE symbols with position labels get syntax tree of the annotated pattern compute {nullable, fistpos, lastpos} of subexpressions compute follow(i) s0 = firstpos(root) construct transition function according to follow(i)

Regular Expression to NFA
R.E. NFA (Thompson’s construction)

Constructing NFA
It is very simple. Remember that a regular expression is formed by the use of alternation, concatenation and repetition.
How to define an NFA that accepts a regular expression?
Thus all we need to do is to know how to build the NFAfor a single symbol, and how to compose NFAs.

Composing NFAs with Alternation
The NFA for a symbol a (or ε) is: ai fstart
Given two NFA N(s) and N(t), the NFA N(s|t) is:
start
N(s)
N(t)
i f
(Aho,Sethi,Ullman, pp. 122)

Composing NFAs with Concatenation
start
Given two NFA N(s) and N(t), the NFA N(st) is:
N(s) N(t)i f
(Aho,Sethi,Ullman, pp. 123)

Composing NFAs with Repetition
The NFA for N(s*) is
N(s)
fi
(Aho,Sethi,Ullman, pp. 123)

Properties of the NFAvia. Thompson’s Construction
Following the construction rules, we obtain an NFA N(r) that: has at most twice as many states as the number of
symbols and operators in r has exactly one starting and one accepting state each state has at most one outgoing transition on a
symbol of the alphabet or at most two outgoing -transitions
All “nondeterministic” transitions are introduced by -transitions that connect to/from new/old init./final states.

An ExampleAn Example
(a | b)*abb
start0
3
1
2a
b
a b
4
b7 8 9 10
5
6ε
ε
ε εε
ε
ε
ε

Comparison: NFA (by Heuristics)
0 31 2a b b
a
b
start
(a | b)*abb
States: {0/Start/init., 1, 2, 3/Final} Input symbols: {a, b} NFA Transition function:
(0,a) = {0,1}, (0,b) = {0}(1,b) = {2}, (2,b) = {3}
NOT constructed using Thompson’s
Construction

NFA to DFA
NFA DFA (Subset Construction)

Translating NFA into DFA
Each state of DFA (D) corresponds to a set of states of NFA (N) transforming N to D is done by subset construction
D will be in state {x,y,z} after reading a given input string if and only if N could be in any of the states x, y, or z, depending on the transitions it chooses. D keeps track of all the possible routes N might take and
runs them in parallel.

Simulating an NFA (recall that …)Simulating an NFA (recall that …)
Input. An input string ended with eof and an NFA with start state s0 and final states F.Output. The answer “yes” if accepts, “no” otherwise.begin S := -closure({s0}); // s0 = => S c := nextchar; while c <> eof do begin S := -closure(move(S, c)); // S =c=> M = => S’ c := nextchar end; if S F <> then return “yes” else return “no”end.

Simulating an NFA (recall that …)Simulating an NFA (recall that …)
Input. An input string ended with eof and an NFA with start state s0 and final states F.Output. The answer “yes” if accepts, “no” otherwise.begin S := -closure({s0}); // s0 = => S c := nextchar; while c <> eof do begin S := -closure(move(S, c)); // S =c=> M = => S’ c := nextchar end; if S F <> then return “yes” else return “no”end.
NFA to DFA—S: all states generated during NFA parallel traversal over all possible input prefixes (NOT a particular input): all transitions during traversal
Initial state
Previous state: TNext state: Ucc: extends to
all symbolsin alphabet(not inputSymbolsin some files)

From an NFA to a DFAFrom an NFA to a DFASubset construction Algorithm.Input. An NFA N.Output. A DFA D with states Dstates and transition table Dtran.begin add -closure(s0) as an unmarked state to Dstates; while there is an unmarked state T in Dstates do begin mark T; for each input symbol a do begin U := -closure(move(T, a)); if U is not in Dstates then add U as an unmarked state to Dstates;
mark as final if U contains the original final state; Dtran[T, a] := U endend.

An ExampleAn Example
(a | b)*abb
start
a
b
a b b0
3
1
2
4
7 8 9 10
5
6ε
ε
ε εε
ε
ε
ε

An Example: -closure(s) & move(s,x)
s -closure(s) move(s,a)
move(s,b) important state?
0 {0,1,2,4,7}
1 {1,2,4}
2 2 3 Yes
3 {1,2,3,4,6,7}
4 4 5 Yes
5 {1,2,4,5,6,7}
6 {1,2,4,6,7}
7 7 8 Yes
8 8 9 Yes
9 9 10 Yes
10 10 ((Fin)) ((Fin)) ((?))

An ExampleAn Example-closure({0}) = {0,1,2,4,7} = AA: -closure(move({0,1,2,4,7}, a)) = -closure({3,8}) = {1,2,3,4,6,7,8} = BA: -closure(move({0,1,2,4,7}, b)) = -closure({5}) = {1,2,4,5,6,7} = CB: -closure(move({1,2,3,4,6,7,8}, a)) = -closure({3,8}) = BB: -closure(move({1,2,3,4,6,7,8}, b)) = -closure({5,9}) = {1,2,4,5,6,7,9} = DC: -closure(move({1,2,4,5,6,7}, a)) = -closure({3,8}) = BC: -closure(move({1,2,4,5,6,7}, b)) = -closure({5}) = CD: -closure(move({1,2,4,5,6,7,9}, a)) = -closure({3,8}) = BD: -closure(move({1,2,4,5,6,7,9}, b)) = -closure({5,10}) = {1,2,4,5,6,7,10} = EE: -closure(move({1,2,4,5,6,7,10}, a)) = -closure({3,8}) = BE: -closure(move({1,2,4,5,6,7,10}, b)) = -closure({5}) = C
•Ignore -transitions (0, 1,…)•a-transitions: (2,a)3, (7,a)8•b-transitions: (4,b)5, 89, 910•Good to label states sequentially: such that (s,x)s+1

An ExampleAn Example
StateInput Symbol
a b
A = {0}* ={0,1,2,4,7}
B = {3,8}* ={1,2,3,4,6,7,8}
C = {5}* ={1,2,4,5,6,7}
D = {5,9}* ={1,2,4,5,6,7,9}
E = {5,10}* ={1,2,4,5,6,7,10}
B
B
B
B
B C
E
C
D
C
•Ignore -transitions (0, 1,…)•a-transitions: (2,a)3, (7,a)8•b-transitions: (4,b)5,89,910•Good to label states sequentially: such that (s,x)s+1

An ExampleAn Example
StateInput Symbol
a b
A = {0,1,2,4,7}
B = {1,2,3,4,6,7,8}
C = {1,2,4,5,6,7}
D = {1,2,4,5,6,7,9}
E = {1,2,4,5,6,7,10}
B
B
B
B
B C
E
C
D
C

An Example: Result of Subset Construction
start{0,1,2,4,7} {1,2,3,4,
6,7,8}
{1,2,4, 5,6,7}
{1,2,4,5, 6,7,9}
{1,2,4,5, 6,7,10}a
ab
b
b
aa
b
a b
A
B
C
D
E

Every DFA has a unique smallest equivalent DFA.
Given a DFA M, we use splitting to construct the equivalent minimal DFA.
• Normally, we actually merge individual states to larger set of states, instead of splitting wildly
Minimizing Number of States

DFA to Minimum State DFADFA to Minimum State DFAInput. A DFA M=(S,s0,F).Output. An equivalent DFA M’=(S’,’,s0’,F’) with fewer states.begin initialize a partition of two groups of states:
{F(final states), S-F(non-final states)} for each group G of do begin /* until new unchanged */
partition G into subgroups such that any two states s and tof G are in the same subgroup iff for allinput symbol a, states s and t have transitions on ato states in the same group of ;/* at worst, a state will be in a subgroup by itself */
update new by replacing G by the set of all subgroups formed end s0’ = r(s0), representative of s0; S’= {representatives of subgroups}; F’ = {representatives of states in F}; (s,a)=t => ’(r(s),a) = r(t)end.
a a’ a’’ …
s q q’ q’’ …
t q q’ q’’ …

Algorithm:• Initially, there are two sets, one consisting of all accepting states of M, the other containing the remaining states. repeat { Choose a set A = { s1, s2,, sn } Split A into A1, A2,, Am so that for all Ai & all symbols a
if sj, skAi and, on input a
sjtj and sktk // source target
then tj and tk are in the same set.
} until no more change.
Splitting into Equivalent States

An ExampleAn Example
StateInput Symbol
a b
A = {0,1,2,4,7}
B = {1,2,3,4,6,7,8}
C = {1,2,4,5,6,7}
D = {1,2,4,5,6,7,9}
E = {1,2,4,5,6,7,10}
B
B
B
B
B C
E
C
D
C

An ExampleAn Example
StateInput Symbol
a b
A = {0,1,2,4,7}
B = {1,2,3,4,6,7,8}
C = {1,2,4,5,6,7}
D = {1,2,4,5,6,7,9}
E = {1,2,4,5,6,7,10}
B
B
B
B
B C
E
C
D
C
+Fin
-Fin

An ExampleAn Example
StateInput Symbol
a b
A = {0,1,2,4,7}
B = {1,2,3,4,6,7,8}
C = {1,2,4,5,6,7}
D = {1,2,4,5,6,7,9}
E = {1,2,4,5,6,7,10}
B
B
B
B
B C
E
C
D
C

An ExampleAn Example
StateInput Symbol
a b
A = {0,1,2,4,7}
B = {1,2,3,4,6,7,8}
A = {1,2,4,5,6,7}
D = {1,2,4,5,6,7,9}
E = {1,2,4,5,6,7,10}
B
B
B
B
B A
E
A
D
A

Transition Diagram(after State Reduction)
We said… a DFA for (a | b)*abb
0 31 2ab b
a
b
start
a
b
a
{0}
{0,1}
{0,3}
{0,2}

Transition Diagram(after State Reduction)
It really is … a DFA for (a | b)*abb
0 31 2ab b
a
b
start
a
b
a
A
B E
D

RE to DFA
Construct DFA from RE directly without intermediate NFA

Review of Thompson’s Transition Review of Thompson’s Transition Diagram: An ExampleDiagram: An Example
6
4
2
(a | b)*abb
start 0
a
b
a b 101
3
7 8 9
5
b
A = -closure ({0})= {0,1,2,4,7}
ε
ε
ε εε
ε
ε
ε

Review of Thompson’s Transition Review of Thompson’s Transition Diagram: An ExampleDiagram: An Example
6
4
2
(a | b)*abb
start 0
a
b
a b 101
3
7 8 9
5
b
move(A,b)= {5}
ε
ε
ε εε
ε
ε
ε

6
4
2
(a | b)*abb
start 0
a
b
a b 101
3
7 8 9
5
b
C = -closure (move(A,b))
= {1,2,4,5,6,7}
Review of Thompson’s Transition Review of Thompson’s Transition Diagram: An ExampleDiagram: An Example
01247
124567
b2
ε
ε
ε εε
ε
ε
ε

Constructing DFA from R.E. “Important states”: -transitions have no effect on
determining next state since they will not really make a transition on visible input symbol -transitions determine equivalent states in a loose sense Important states are related to a non-null symbol at
particular position in RE e.g., b at position 2 of (a|b)abb#
Re-definition of “States”: Thompson’s Transition diagram: nodes as states (the
status before & after matching a symbol) Alternative method: arcs as states (the position (in RE) of
match) #: simulate the last node for checking final state Only states that consumes symbols matter

DFA directly from R.E.: underlying NFADFA directly from R.E.: underlying NFA
start
(a1|b2)*a3b4b5#6
A
C
B
1a
b
a
2
3
D
Eb
4b
5
F
#
6
Important states ({1…6}): with
non-null transitions
ε
ε
ε εε
ε
ε
ε

DFA directly from R.E.: underlying NFADFA directly from R.E.: underlying NFA
(a1|b2)*a3b4b5#6
startA
C
B
1a
b
a
2
3
D
Eb
4b
5
F
#
6
Followpos(1)={1,2,3}
ε
ε
ε εε
ε
ε
ε

Constructing Automata from R.E.
Example: RE = (a|b)*abb# (a1|b2)*a3b4b5#6
Syntax tree for RE: (Fig. 3.41) Directed graph for followpos():
Node Followpos
1 on a {1,2,3}
2 on b {1,2,3}
3 on a {4}
4 on b {5}
5 on b {6}
6 -
3 4 #6
a
a
b
5b b 1
2
b a
a
b
Ready to match ‘b’ at ‘2’
Ready to match ‘a’ at ‘3’
(a1|b2)* a3b4b5#6 ~((a1|b2) … (a1|b2)) a3b4b5#6
followpos(1):

DFA directly from R.E.
a DFA for (a | b)*abb (a1|b2)*a3b4b5#6
0 31 2ab b
a
b
start
a
b
a
{1,2,3}
{1,2,3,4}{1,2,3,6}
{1,2,3,5}
Possible matching positions
Next Possible matching positions

Constructing DFA from RE: FirstPos, LastPos, Nullable
Matching RE’s – 3 possible cases x(c1|c2)y x(c1.c2)y x(c*)y
Followpos: Which position(s)/symbol(s) to match after matching lastpos of ‘x’ ? Requires firstpos of c, c1, c2, y Need to know whether c1, c2 can be pass-through
(nullable) (c* is always nullable)

Constructing DFA from R.E.
R.E. DFA: State (set of) position(s) ( respective symbols) in RE
(where an input character is being matched) State_transition allowed position transition for RE
DFA Construction: Augment RE: (r)# [#: end-of-pattern mark] Annotate RE symbols (excluding ) with position labels Get syntax tree T of the annotated pattern Compute {nullable, firstpos, lastpos} of nodes [sub-RE’s] Compute follow(i) [by making DFT over the tree T] Initial state: s0 = firstpos(root) [ complete RE]
Construct transition function according to follow(i) (i,a)=i’]
Set of Positions Set of Important States of NFA (that consumes input symbols)

Constructing DFA from R.E.
DFA Construction: Initial state: s0 = firstpos(root) & S = {s0} While there is an unmarked state Q in S do begin
For each input symbol ‘a’ do begin For each position ‘p’ in Q s.t. symbol(p)=‘a’,
• Let U = followpos(p) // take Union if more than one such p If U is not (empty), and U S, then S += U // new state (Q,a)=U // new transition
End /* a* / End /* while */
Q:{pap} a U ={followpos(p)}
Compare : NFA DFA

Lexical Analyzer GeneratorLexical Analyzer Generator
RE
NFA
DFA
construction
construction
Thompson’s
Subset

Time-Space TradeoffsTime-Space Tradeoffs
RE (r) to NFA, simulate NFA on input x time: O(|r| * |x|), space: O(|r|) [max. 2|r| states]
RE to NFA, NFA to DFA, simulate DFA time: O(|x|), space: O(2|r|)
Lazy transition evaluation transitions are computed as needed at run time; computed
transitions are stored in cache for later use

LEX
A Language for Specifying Lexical Analyzers

LexLex
A language for specifying lexical analyzers(for any language, say, X)
lex compiler lex.yy.clex.l
C compiler a.outlex.yy.c
a.out tokens (for parser)source code in X
(Lex. Analyzer in C)(Lex. Analyzer Spec.)
(Lex. Analyzer Exe.)
next_token = yylex();

Using a Scanner Generator: Lex
Lex is a lexical analyzer generator developed by Lesk and Schmidt of AT&T Bell Lab, written in C, running under UNIX.
Lex produces an entire scanner module that can be compiled and linked with other compiler modules.
Lex associates regular expressions with arbitrary code fragments. When an expression is matched, the code segment is executed.
A typical lex program contains three sections separated by %% delimiters.

Lex ProgramsLex Programs
%{auxiliary declarations%}regular definitions%%translation rules%%auxiliary procedures

First Section of Lex The first section define character classes and auxiliary regular
expression. (Fig. 3.5 on p. 67) [] delimits character classes - denotes ranges: [xyz] = = [x-z] \ denotes the escape character: as in C. ^ complements a character class, (Not):
[^xy] denotes all characters except x and y. |, *, and + (alternation, Kleene closure, and positive closure) are
provided. () can be used to control grouping of subexpressions. (expr)? = = (expr)|, i.e. matches Expr zero times or once. {} signals the macroexpansion of a symbol defined in the first section.

First Section of Lex, cont.
Catenation is specified by the juxtaposition of two expressions; no explicit operator is used. [ab][cd] will match any of ad, ac, bc, and bd.
begin = = “begin” = = [b][e][g][i][n]

Second Section of Lex The second section of lex defines a table of regular
expressions and corresponding commands. When an expression is matched, its associated command is
executed. Auxiliary functions may be defined in the third section.
Input that is matched is stored in the string variable yytext whose length is yyleng.
Lex creates an integer function yylex() that may be called from the parser.
The value returned is usually the token code of the token scanned by Lex.
When yylex() encounters end of file, it calls a user-supplied integer function named yywrap() to wrap up input processing.

Translation RulesTranslation Rules
P1 {action1}P2 {action2}
...Pn {actionn}
where Pi are regular expressions andactioni are program segments to beexecuted on matching Pi

Dealing with Multiple Input Files
yylex() uses three user-defined functions to handle character I/O: input(): retrieve a single character, 0 on EOF output(c): write a single character to the output unput(c): put a single character back on the input to be
re-read

An ExampleAn Example
%{ #define LT 24#define LE 25#define EQ 26 ...%}delim [ \t\n]ws {delim}+letter [A-Za-z]digit [0-9]id {letter}({letter}|{digit})*number {digit}+(\.{digit}+)?(E[+\-]?{digit}+)?%%
// auxiliary declarations (in C)
// regular definitions

An ExampleAn Example
{ws} { /* no action and no return */ }if {return (IF);}then {return (THEN);}else {return (ELSE);}{id} {yylval=install_id(); return (ID);}{number} {yylval=install_num(); return (NUMBER);}“<” {yylval=LT; return (RELOP);}“<=” {yylval=LE; return (RELOP);} ...%%install_id() { … /* yytext to symbol table */ }install_num() { ... /* yytext to symbol table */ }
// translation rules (actions are in C)
// auxiliary procedures (in C)

Functions and VariablesFunctions and Variables
yylex() a function implementing the lexical analyzer and returning the token matched
yytext a global pointer variable pointing to the lexeme matched
yyleng a global variable giving the length of the lexeme matched
yylval an external global variable storing the attribute of the token

NFA from Lex ProgramsNFA from Lex Programs
P1 | P2 | ... | Pn
N(P2)
...
N(P1)
N(Pn)
s0

RulesRules
Look for the longest lexeme e.g., Number Match until no transition & retract to longest match
Look for the first-listed pattern that matchesthe longest lexeme keywords and identifiers
List frequently occurring patterns first white space

RulesRules
View keywords as exceptions to the rule of identifiers construct a keyword table to distinguish them from id’s
Lookahead operator: r1/r2 - match a string in r1 only if followed by a string in r2
DO 5 I = 1. 25DO 5 I = 1, 25DO/({letter}|{digit})* = ({letter}|{digit})*,

Lexical Error RecoveryLexical Error Recovery
Error: none of the patterns matches a prefix of the remaining input
Panic mode error recovery delete successive characters from the remaining input until the
pattern-matching can continue Error repair:
delete an extraneous character insert a missing character replace an incorrect character transpose two adjacent characters

Appendix: Regular Expression and Pattern Matching
- KMP algorithm- AC algorithm

R.E. and Pattern Matching
Naïve Pattern Matching: Specify the pattern with a regular expression R.E. for each
keyword Construct a FA for each such R.E., and conduct left-to-right
matching: DFA := State_Transition_Table := Construct_DFA(R.E.) while (input_pointer != EOF)
stop_state = recognize(input_pointer, DFA) if fail (stop_state not in final_states) : move input pointer by one
character if not match if success (stop_state in final_states) : output matching status &
skip over matched pattern upon successful match

R.E. and Pattern Matching
Why Is It Slow? match multiple keywords multiple times for each keyword, move input pointer backward to the character
next to the last begin of matching & reset to initial state on failure, even though some repeated pattern might appear in recently matched partial string
probability of failure is significantly larger than probability of success match in most applications (success or match only a few times)
will therefore start the next matching session by setting the input pointer one character behind the starting position of the previous match most of the time

R.E. and Pattern Matching
RE vs. Pattern Matching R.E. <=> FA for recognizing one of a set of
keywords/patterns in input string say “yes” if input string is in Lang(R.E.) (the regular
language for the expression)
Pattern Matching (PM): recognizing all the occurrences of any keyword/pattern, specified in regular expression, within a text document
specify each pattern/keyword with a RE output all occurrences, in addition to saying yes/no

R.E. and Pattern Matching Formal Method for Pattern Matching (PM)
Constructing a FA for (single/multi-keyword) PM is equivalent to constructing a FA that recognizes the regular expression: PM = (.* | RE)* , and outputting a keyword upon visiting a final state of the original FA for recognizing RE
RE = K1 | K2 | K3 | … | Kn (the regular expression for all specified keywords) “.” : any character not starting in the first characters of K1 ~ Kn “.*”: unspecified patterns (or unknown keywords)

R.E. and Pattern Matching Constructing FA1 for recognizing RE = K1 | K2 | … | Kn
equivalent to merging prefixes of the keywords to avoid redundant forward matching => TRIE lexicon tree = a DFA for RE
Constructing FA2 for recognizing PM = (.*|RE)* extending FA1 by (a) including ‘unknown keywords’ and (2) introducing
epsilon-moves from the original final states to original initial states on matching failure, redundant backward matching can be avoided if a sub-
string preceding current input pointer is the prefix of another keyword failure function: the state (in TRIE) to backoff on failure (!= init. state if the
above mentioned sub-string exists and is non-null) epsilon-moves & failure function make FA2 a NFA, whose DFA
counterpart can be simulated by backtracking

R.E. and Fast Methods for Pattern Matching
Fast Single Keyword Matching [KMP - Knuth, Morris & Pratt 1977]
Reference: [Aho et. al 1986, Ex. 3.26-3.27] keyword => state_transition_table reduce repeated matching suggested by keyword pattern failure function: where to backoff on failure

R.E. and Fast Methods for Pattern Matching
Fast Multiple Keyword Matching [AC, Cherry 1982]
Reference: [Aho, Ex. 3.31-32] keywords => TRIE (state_transition_table) reduce repeated matching suggested by TRIE of the
keywords TRIE failure function

R.E. and Fast Methods for Pattern Matching
Boyer & Moore [1977] Harrison [1971]: Hashing Method

KMP: Failure Function
If failed at state 5 on x => Input = “ababax” (input pointer => x) Need to re-try “babax”, “abax”, “bax”, “ax” from state 0 “babax”: fail again; (do not start with prefix “ab…”) “abax”: success until state 3, pointing at x Look back from s5 & see longest match (s3) to prefix
Choose the longest one so we can re-try the least
Do you need to go back and try all these? No. Simply set s :=3 and keep the input pointer to x State 3 is the “failure state” of state 5
start0 1
b32
a4
a5 6
a ab

KMP: Failure Function
start0 1
b32
a4
a5 6
a ab
If failed at state 5 on x => Input = “ababax” (input pointer => x) Need to re-try “babax”, “abax”, “bax”, “ax” from state 0 “babax”: fail again; (do not start with prefix “ab…”) “abax”: success until state 3, pointing at x Look back from s5 & see longest match (s3) to prefix
Choose the longest one so we can re-try the least
Do you need to go back and try all these? No. Simply set s :=3 and keep the input pointer to x State 3 is the “failure state” of state 5
s f(s)
0 0
1 0
2 0
3 1
4 2
5 3
6 1

KMP: Re-Matching on Failure
If failed at state 5 on x => (5,x) = fail (“ababax” does not match prefix) f(5)=3 => (3,x)=??, if fail (“abax” unmatch) f(3)=1 => (1,x)=??, if fail (“ax” unmatch) f(1)=0 => (0,x)=??, try x from initial state (since no
partial match in failed prefixes is observed) If (.,x) is legal transition, just go ahead to (.,x)
start0 1
b32
a4
a5 6
a ab
s f(s)
0 0
1 0
2 0
3 1
4 2
5 3
6 1

KMPKMP
start0 1
b32
a4
a5 6
a ab
Recursively compute f(s) based on f(.) of previous states