Embed Size (px)
Citation preview

128
BAB IV KESIMPULAN DARI DUA SAMPEL
A. DeskripsiBab ini menjelaskan bagaimana membuat kesimpulan mengenaikarakteristik populasi dengan menggunakan dua sampel.Kesimpulan tersebut dibuat dengan menggunakan prosedur ujihipotesis mengenai parameter dua populasi dan mengkonstruksiselang kepercayaan untuk mengestimasi selisih proporsi dan meandua populasi atau perbandingan simpangan baku dan variansi duapopulasi.
B. RelevansiPada Bab 2 kita telah belajar bagaimana menyusun selangkepercayaan yang digunakan untuk mengestimasi parameter suatupopulasi, sedangkan pada Bab 3 kita berlatih untuk menguji suatuklaim mengenai karakteristik suatu populasi. Dari kedua babtersebut, kita bekerja pada satu sampel. Di bab ini, kita tidak hanyabekerja pada satu sampel, melainkan kita akan menggunakan datadari dua sampel untuk membuat kesimpulan mengenaikarakteristik dua populasi. Dengan menggunakan metode-metodedalam bab ini, misalnya, kita akan bisa menyelidiki keadilan dalamdunia pendidikan dengan membandingkan capaian pembelajaransiswa laki-laki dan perempuan di negara Indonesia.
C. Capaian Pembelajaran· Menggunakan uji hipotesis formal untuk menguji suatu klaim
mengenai proporsi dua populasi.· Mengkonstruksi selang kepercayaan untuk mengestimasi
selisih proporsi dua populasi.· Membedakan sampel-sampel bebas dan sampel-sampel
berpasangan.
Naskah ini masih berupa draf. Beritahu dosen Anda jika Anda menemukan beberapa saltik atau kesalahan lainnya.

129
· Melakukan uji hipotesis formal untuk menguji suatu klaim mengenai mean dua populasi yang bebas.
· Membuat selang kepercayaan untuk mengestimasi selisih mean dua populasi yang bebas.
· Melakukan uji hipotesis formal untuk menguji suatu klaim tentang mean dua populasi yang berpasangan.
· Mengkonstruksi selang kepercayaan untuk mengestimasi selisih mean dua populasi yang berpasangan.
· Menggunakan uji hipotesis formal untuk menguji suatu klaim mengenai simpangan baku atau variansi dua populasi.
· Membuat selang kepercayaan untuk mengestimasi perbandingan simpangan baku atau variansi dua populasi.
· Terampil menggunakan teknologi informasi untuk menyelesaikan permasalahan statistik terkait uji hipotesis dari dua sampel.
· Merefleksikan hasil analisis data, dan berdasarkan hasil analisis tersebut memberikan tindak lanjut untuk kepentingan bersama.
4.1 Kesimpulan Tentang Dua Proporsi Banyak permasalahan sehari-hari yang tujuan akhirnya adalah untuk membandingkan proporsi dari dua populasi. Misalnya, apakah proporsi semua siswa pedesaan yang terkoneksi dengan internet lebih besar, lebih kecil, atau tidak sama dengan tahun lalu? Apakah persentase manula yang melek huruf di perkotaan lebih dari, lebih kecil, atau tidak sama dengan manula di pedesaan? Pertanyaan-pertanyaan semacam ini bisa dijawab dengan membandingkan proporsi dua sampel untuk membuat kesimpulan mengenai proporsi populasi-populasinya.
Asumsi Tidak Ada Perbedaan. Misalkan proporsi sebenarnya dari dua populasi adalah p1 dan p2. Untuk melakukan uji hipotesis
Naskah ini masih berupa draf. Beritahu dosen Anda jika Anda menemukan beberapa saltik atau kesalahan lainnya.

130
untuk membandingkan proporsi dua populasi, biasanya kita akan menggunakan asumsi bahwa proporsi populasi-populasi tersebut sama, yaitu H0: p1 – p2 = 0. Selanjutnya klaim awal akan mempengaruhi bentuk dari hipotesis alternatifnya. Dengan demikian, tiga kemungkinan jenis hipotesis ini adalah sebagai berikut.
Uji Ekor-Kiri Uji Ekor-Kanan Uji Dua-Ekor H0: p1 – p2 = 0 H1: p1 – p2 < 0
H0: p1 – p2 = 0 H0: p1 – p2 > 0
H0: p1 – p2 = 0 H1: p1 – p2 ≠ 0
Proporsi Sampel. Proporsi sampel 1p̂ merupakan estimasi titik
untuk proporsi populasi p1 dan proporsi sampel 2p̂ merupakan
estimasi titik untuk proporsi populasi p2. Proporsi sampel ditentukan dengan rumus berikut.
11
1
ˆ xp
n= dan 2
22
ˆ xp
n=
Notasi x1 dan x2 menyatakan banyaknya sukses dalam masing-masing sampel, sedangkan n1 dan n2 secara berturut-turut menyatakan ukuran sampel pertama dan kedua.
Proporsi Gabungan. Jika hipotesis nol diasumsikan benar, maka tidak ada perbedaan antara p1 dan p2, sehingga sampel-sampel yang dimiliki bisa digabung menjadi satu sampel “besar” untuk mengestimasi proporsi propulasi setelah digabung. Proporsi ini dinotasikan dengan p dan ditentukan dengan rumus berikut.
1 2
1 2
x xp
n n+
=+
(proporsi gabungan)
Statistik Uji. Sekarang misalkan kita akan menguji apakah proporsi sebenarnya populasi p1 kurang dari, lebih dari, atau tidak sama dengan p2. Untuk melakukannya kita bisa menggunakan distribusi normal sebagai pendekatan distribusi binomial, sehingga
Naskah ini masih berupa draf. Beritahu dosen Anda jika Anda menemukan beberapa saltik atau kesalahan lainnya.

131
kita misalkan banyaknya percobaan sukses minimal 10, yaitu np ≥ 10, dan setidaknya juga ada 10 percobaan gagal, n(1 – p) ≥ 10. Dengan demikian, distribusi sampling proporsi pertama merupakan distribusi normal dengan mean p1 dan simpangan baku
1 1 1(1 )p p n- atau variansinya p1(1 – p1)/n1. Hal ini juga berlaku
untuk sampel kedua. Karena distribusi sampling kedua proporsi sampel didekati dengan distribusi normal, maka selisih 1 2
ˆ ˆp p-
juga didekati dengan distribusi normal dengan mean p1 – p2 dan variansi
1 2 1 2
2 2 2 1 1 2 2ˆ ˆ ˆ ˆ( )
1 2
(1 ) (1 )p p p p
p p p pn n
s s s-
- -= + = +
Persamaan di atas didasarkan pada sifat bahwa variansi dari selisih antara dua variabel acak bebas sama dengan jumlah dari variansi kedua variabel tersebut. Selanjutnya jika ganti p1 dan p2 dengan proporsi gabungan p , maka kita peroleh simpangan baku sebagai berikut.
1 2ˆ ˆ( )
1 2
(1 ) (1 )p p
p p p pn n
s -
- -= +
Oleh karena itu, skor z dari distribusi normal yang memiliki mean p1 – p2 dan simpangan baku seperti pada persamaan terakhir dapat ditentukan dengan rumus berikut.
1 2 1 2
1 2
ˆ ˆ( ) ( )(1 ) (1 )
p p p pz
p p p pn n
- - -=
- -+
(statistik uji)
Skor z inilah yang menjadi statistik uji dalam uji hipotesis proporsi dua populasi.
Naskah ini masih berupa draf. Beritahu dosen Anda jika Anda menemukan beberapa saltik atau kesalahan lainnya.

132
Selang Kepercayaan. Ketika kita membuat selang kepercayaan, kita tidak mengasumsikan bahwa dua proporsinya sama, sehingga kita tidak menggunakan simpangan baku dengan proporsi gabungan, tetapi kita mendekati simpangan baku tersebut dengan nilai berikut.
1 1 2 2
1 2
ˆ ˆ ˆ ˆ(1 ) (1 )p p p pn n- -
+
Dengan demikian, kita akan mendapatkan statistik uji
1 2 1 2
1 1 2 2
1 2
ˆ ˆ( ) ( )ˆ ˆ ˆ ˆ(1 ) (1 )p p p p
zp p p p
n n
- - -=
- -+
Dengan menggunakan nilai positif dan negatif dari statistik uji ini (untuk dua-ekor) dan kita selesaikan nilai p1 – p2, maka kita peroleh
1 2 1 2 1 2ˆ ˆ ˆ ˆ( ) ( ) ( )p p E p p p p E- - < - < - + (selang kepercayaan)
dengan E adalah
1 1 2 22
1 2
ˆ ˆ ˆ ˆ(1 ) (1 )p p p pE z
n na
- -= + (batas galat)
Sekarang kita sudah menemukan statistik uji dalam uji hipotesis dan selang kepercayaan untuk mengestimasi selisih proporsi dua populasi. Uji hipotesis dan selang kepercayaan tersebut dapat dirangkum sebagai berikut.
Kesimpulan Tentang Dua Proporsi
Tujuan Menguji suatu klaim mengenai dua proporsi atau membuat selang kepercayaan untuk mengestimasi selisih proporsi dua populasi.
Naskah ini masih berupa draf. Beritahu dosen Anda jika Anda menemukan beberapa saltik atau kesalahan lainnya.

133
Notasi Untuk populasi pertama, kita misalkan
p1 = proporsi populasi n1 = ukuran sampel x1 = banyaknya sukses dalam sampel 1p̂ = proporsi sampel, yaitu x1/n1
Notasi-notasi p2, n2, x2, dan 2p̂ juga berlaku untuk populasi kedua.
Proporsi Sampel Gabungan Proporsi sampel gabungan, dinotasikan dengan p , dapat ditentukan dengan rumus berikut.
1 2
1 2
x xp
n n+
=+
Persyaratan 1. Proporsi-proporsi sampel berasal dari dua sampel acak
sederhana yang bebas atau tidak berpasangan. 2. Untuk masing-masing sampel, banyaknya sukses dan gagal
minimal 10, yaitu np ≥ 10 dan n(1 – p) ≥ 10.
Statistik Uji (dengan H0: p1 – p2 = 0)
1 2 1 2
1 2
ˆ ˆ( ) ( )(1 ) (1 )
p p p pz
p p p pn n
- - -=
- -+
Rumus 4-1
dengan diasumsikan p1 – p2 = 0 (dalam hipotesis nol).
Nilai-P dan Nilai Kritis: Nilai-P (berdasarkan nilai statistik uji) dan nilai-nilai kritis (berdasarkan tingkat signifikansi α) dapat ditentukan dengan menggunakan tabel distribusi normal baku atau teknologi.
Selang Kepercayaan Selang kepercayaan untuk mengestimasi p1 – p2 adalah
Naskah ini masih berupa draf. Beritahu dosen Anda jika Anda menemukan beberapa saltik atau kesalahan lainnya.

134
1 2 1 2 1 2ˆ ˆ ˆ ˆ( ) ( ) ( )p p E p p p p E- - < - < - +
dengan E adalah batas galat yang dapat ditentukan sebagai berikut.
1 1 2 22
1 2
ˆ ˆ ˆ ˆ(1 ) (1 )p p p pE z
n na
- -= + Rumus 4-2
Pembulatan: bulatkan batas kiri dan kanan selang kepercayaan sampai tiga angka di belakang koma.
Sampel-Sampel Bebas. Persyaratan uji hipotesis dan pembuatan selang kepercayaan di sini mempersyaratkan bahwa sampel-sampel yang dimiliki haruslah merupakan sampel-sampel bebas. Dua sampel dikatakan bebas jika nilai-nilai sampel dari populasi pertama tidak berhubungan atau tidak berpasangan dengan nilai-nilai sampel dari populasi kedua.
Uji hipotesis mengenai proporsi dua populasi dengan asumsi kedua proporsi tersebut sama (H0: p1 – p2 = 0) bisa dilihat pada Contoh 1 berikut.
CONTOH 1—Akses Internet Mahasiswa Pedesaan
Banyak sistem pembelajaran inovatif yang saat ini sudah dilakukan di perguruan tinggi. Salah satu kecenderungan pembelajaran saat ini adalah pembelajaran daring. Untuk melakukan pembelajaran daring ini, tentu saja mahasiswa (khususnya mahasiswa yang tinggal di daerah pedesaan) harus terbiasa dengan koneksi internet. Oleh karena itu, seorang peneliti ingin mengetahui apakah ada peningkatan persentase mahasiswa di pedesaan yang mengakses internet. Setelah dilakukan dua kali survei, yaitu pada tahun 2016 dan 2017, peneliti tersebut mendapatkan dua sampel acak sederhana sebagai berikut.
Naskah ini masih berupa draf. Beritahu dosen Anda jika Anda menemukan beberapa saltik atau kesalahan lainnya.

135
Statistik 2016 2017
Banyak mahasiswa terkoneksi internet selama 3 bulan terakhir
87 123
Banyak mahasiswa yang disurvei 124 160
Pada tingkat signifikansi 0,05, apakah terjadi peningkatan persentase mahasiswa pedesaan yang mengakses internet?
PEMBAHASAN Pertama kita lakukan pemeriksaan persyaratan. (1) Data yang diperoleh merupakan sampel-sampel acak sederhana, dan dua sampel tersebut merupakan sampel-sampel bebas. (2) Pada tahun 2016 ada 87 mahasiswa dan 124 – 87 = 37 mahasiswa yang terkoneksi ataupun tidak terkoneksi internet selama tiga bulan terakhir. Pada tahun 2017 terdapat 123 mahasiswa dan 160 – 123 = 37 mahasiswa yang terkoneksi atau tidak terkoneksi internet selama tiga bulan terakhir. Persyaratan kedua terpenuhi. Dengan demikian, semua persyaratan terpenuhi.
Kita anggap sampel pada tahun 2016 sebagai sampel 1 dan sampel pada tahun 2017 sebagai sampel 2. Untuk melakukan uji hipotesis di sini, kita akan gunakan metode nilai-P.
Langkah 1 Klaim yang menyatakan bahwa terjadi peningkatan persentase mahasiswa pedesaan dalam akses internet dapat dituliskan menjadi p1 – p2 < 0.
Langkah 2 Bentuk alternatif klaim tersebut adalah p1 – p2 ≥ 0.
Langkah 3 Dari dua bentuk sebelumnya, bentuk yang tidak memuat persamaan adalah p1 – p2 < 0. Kita gunakan bentuk ini sebagai hipotesis alternatif. Hipotesis nolnya adalah p1 – p2 = 0. H0: p1 – p2 = 0
Naskah ini masih berupa draf. Beritahu dosen Anda jika Anda menemukan beberapa saltik atau kesalahan lainnya.

136
H1: p1 – p2 < 0
Langkah 4 Tingkat signifikansi yang diminta soal adalah α = 0,05.
Langkah 5 Kita akan gunakan distribusi normal sebagai pendekatan distribusi binomial sebagai distribusi samplingnya. Karena proporsi populasi pertama dan kedua diasumsikan sama, maka kita gunakan proporsi sampel gabungan p untuk mendekati proporsi-proporsi dua populasi tersebut, p1 dan p2.
1 2
1 2
87 123 105124 160 142
x xp
n n+ +
= = =+ +
(Jangan bulatkan nilai p di sini karena nilai ini akan digunakan lagi dalam langkah berikutnya).
Langkah 6 Statistik uji z dapat dihitung dengan menggunakan Rumus 4-1 sebagai berikut.
z 1 2 1 2
1 2
ˆ ˆ( ) ( )(1 ) (1 )
p p p pp p p p
n n
- - -=
- -+
87 123 0124 160
105 105 105 1051 1142 142 142 142
124 160
æ ö- -ç ÷è ø=
æ öæ ö æ öæ ö- -ç ÷ç ÷ ç ÷ç ÷è øè ø è øè ø+
1,28= - Karena uji ini merupakan uji ekor-kiri, maka nilai-P sama dengan luas daerah di sebelah kiri statistik uji z = –1,28. Dengan menggunakan tabel distribusi normal baku kita peroleh nilai-P 0,1003.
Naskah ini masih berupa draf. Beritahu dosen Anda jika Anda menemukan beberapa saltik atau kesalahan lainnya.

137
Uji statistik beserta dengan nilai-P bisa dilihat pada Gambar 4-1.
Gambar 4-1 Metode Nilai-P
Langkah 7 Nilai-P 0,1003 menyatakan bahwa jika memang benar tidak ada perbedaan persentase akses internet mahasiswa pedesaan, maka akan ada sekitar 1 dari 10 sampel yang menunjukkan adanya kenaikan persentase. Nilai peluang ini cukup besar, yaitu lebih dari tingkat signifikansi α = 0,05, sehingga kita kebetulan mendapatkan dua sampel yang proporsinya mengalami kenaikan. Dengan demikian, kita gagal menolak hipotesis nol.
INTERPRETASI Tidak cukup bukti untuk mendukung klaim bahwa terdapat kenaikan persentase mahasiswa pedesaan yang mengakses internet dari tahun 2016 ke tahun 2017.
Statistik-statistik yang digunakan dalam contoh ini merupakan hasil adaptasi dari Statistik Pendidikan Indonesia 2016 dan 2017 dengan ukuran sampel yang disesuaikan. Dengan kata lain, jika ukuran masing-masing sampel tersebut dibuat besar (seperti yang dilakukan BPS), maka kita akan mendapatkan cukup bukti sampel untuk mendukung klaim awal.
Kerjakan latihan 3 n
Naskah ini masih berupa draf. Beritahu dosen Anda jika Anda menemukan beberapa saltik atau kesalahan lainnya.

138
Metode Tradisional. Ketika kita menggunakan metode tradisional untuk menyelesaikan Contoh 1, maka dalam langkah 6 yang kita lakukan adalah menentukan nilai kritis yang membatasi daerah pada ekor-kiri yang luasnya α = 0,05. Dengan menggunakan tabel distribusi normal, kita peroleh nilai kritis ini adalah –1,645. Pada Gambar 4-2 kita bisa melihat bahwa statistik uji z = –1,28 tidak berada di daerah kritis, sehingga kita gagal menolak hipotesis nol dan mendapatkan kesimpulan akhir yang sama dengan kesimpulan akhir pada Contoh 1.
Gambar 4-2 Metode Tradisional
Selang Kepercayaan. Selang kepercayaan untuk mengestimasi selisih proporsi dua populasi bisa dibuat dengan menggunakan rumus yang telah dijelaskan pada awal subbab ini. Lalu bagaimana kita menginterpretasi selang kepercayaan yang sudah dibuat? Jika selang kepercayaan tersebut tidak memuat 0, maka kita memiliki cukup bukti bahwa proporsi populasi pertama dan kedua, p1 dan p2, memiliki nilai yang berbeda. Jika sebaliknya, maka kita tidak cukup bukti sampel untuk mendukung adanya perbedaan antara p1 dan p2.
Perlu diingat bahwa asumsi yang dilakukan ketika kita melakukan uji hipotesis berbeda dengan ketika kita membuat selang kepercayaan. Dalam membuat selang kepercayaan, kita tidak mengasumsikan proporsi kedua populasi sama, sehingga kita gunakan proporsi-proporsi sampel sebagai estimasi dari proporsi-
Naskah ini masih berupa draf. Beritahu dosen Anda jika Anda menemukan beberapa saltik atau kesalahan lainnya.

139
proporsi populasi. Hasilnya, kesimpulan akhir yang dihasilkan dari pembuatan selang kepercayaan mungkin berbeda dengan kesimpulan akhir dari uji hipotesis. Untuk mengetahui bagaimana membuat selang kepercayaan, perhatikan Contoh 2 berikut.
CONTOH 2—Selang Kepercayaan Akses Internet
Gunakan data sampel pada Contoh 1 untuk mengkonstruksi selang kepercayaan 90% dari selisih proporsi dua populasinya. Berdasarkan selang kepercayaan tersebut, apa yang bisa dikatakan mengenai akses internet mahasiswa pedesaan di tahun 2016 dan 2017?
PEMBAHASAN Karena kita menggunakan data sampel yang sama dengan Contoh 1, maka semua persyaratannya telah terpenuhi. Untuk menentukan selang kepercayaan 90%, maka kita memiliki α = 1 – 0,9 = 0,1 dan akibatnya α/2 = 0,05 (hal ini menunjukkan bahwa selang kepercayaan yang akan kita buat bisa dibandingkan dengan uji hipotesis ekor-kiri pada Contoh 1). Dengan demikian, dengan menggunakan tabel distribusi normal baku kita peroleh zα/2 = 1,645. Berikutnya kita tentukan batas galat E dengan menggunakan Rumus 4-2.
E 1 1 2 22
1 2
ˆ ˆ ˆ ˆ(1 ) (1 )p p p pz
n na
- -= +
87 87 123 1231 1
124 124 160 1601,645124 160
æ öæ ö æ öæ ö- -ç ÷ç ÷ ç ÷ç ÷è øè ø è øè ø= +
0,087036= Padahal selisih proporsi sampel pertama dan kedua adalah
1 287 123ˆ ˆ 0,061433
124 160p p- = - = -
Naskah ini masih berupa draf. Beritahu dosen Anda jika Anda menemukan beberapa saltik atau kesalahan lainnya.

140
Dengan demikian kita mendapatkan selang kepercayaan sebagai berikut.
( )1 2ˆ ˆp p E- - < ( )1 2p p- ( )1 2
ˆ ˆp p E< - -
0,061433 0,087036- - < ( )1 2p p- 0,061433 0,087036< - +
0,148469- < ( )1 2p p- 0,025603<
0,148- < ( )1 2p p- 0,026< INTERPRETASI Berdasarkan selang kepercayaan tersebut, kita 90% yakin bahwa selisih proporsi yang sebenarnya dari dua populasi tersebut berada pada nilai di antara –14,8% dan 2,6%. Karena selang kepercayaan ini memuat 0, maka tidak cukup bukti untuk mendukung adanya perbedaan antara proporsi mahasiswa pedesaan yang mengakses internet pada tahun 2016 dan 2017. Kesimpulan ini sama dengan yang kita dapatkan pada Contoh 1.
Kerjakan latihan 4 n
Asumsi Selisih Tidak Nol. Pada uji hipotesis di bagian awal, kita mengasumsikan bahwa tidak ada perbedaan proporsi kedua populasi, sehingga kita menggunakan hipotesis nol H0: p1 – p2 = 0. Uji hipotesis tersebut merupakan kasus kusus dari uji hipotesis dengan selisih sama dengan nilai tertentu d0 di antara dua proporsi. Hipotesis nol dan hipotesis alternatif untuk uji hipotesis seperti ini adalah sebagai berikut.
Uji Ekor-Kiri Uji Ekor-Kanan Uji Dua-Ekor H0: p1 – p2 = d0 H1: p1 – p2 < d0
H0: p1 – p2 = d0 H0: p1 – p2 > d0
H0: p1 – p2 = d0 H1: p1 – p2 ≠ d0
Untuk kasus d0 = 0 sudah dibahas sebelumnya. Untuk kasus d0 ≠ 0, kita tidak menggunakan proporsi sampel gabungan, melainkan yang kita gunakan adalah proporsi masing-masing sampel sebagai estimasi proporsi populasinya. Dengan demikian, statistik ujinya seperti ditunjukkan pada Rumus 4-3 berikut.
Naskah ini masih berupa draf. Beritahu dosen Anda jika Anda menemukan beberapa saltik atau kesalahan lainnya.

141
1 2 1 2
1 1 2 2
1 2
ˆ ˆ( ) ( )ˆ ˆ ˆ ˆ(1 ) (1 )p p p p
zp p p p
n n
- - -=
- -+
Rumus 4-3
Untuk lebih memahami uji hipotesis mengenai dua proporsi berikut, perhatikan Contoh 3.
CONTOH 3—Jaminan Kesehatan
Terdapat kalimat yang cukup provokatif dalam situs web Kementerian Kesehatan Republik Indonesia, yaitu “Jangan mau menjadi sadikin: sakit sedikit, langsung miskin.” Kalimat bernada himbauan ini menunjukkan betapa pentingnya jaminan kesehatan. Akan tetapi, masih banyak penduduk, khususnya di daerah pedesaan, yang tidak memiliki jaminan kesehatan. Untuk itu, sekelompok mahasiswa melakukan proyek dengan mensurvei penduduk Bali secara acak dengan menggunakan telepon, baik yang tinggal di daerah pedesaan ataupun perkotaan, untuk ditanya apakah mereka memiliki jaminan kesehatan. Hasil dari survei tersebut disajikan sebagai berikut.
Statistik Perkotaan Pedesaaan
Banyak penduduk tanpa jaminan kesehatan
163 201
Banyak penduduk yang disurvei
300 480
Dari data sampel ini, sekelompok mahasiswa tersebut mengklaim bahwa selisih antara proporsi penduduk Bali di perkotaan dan pedesaan yang memiliki jaminan kesehatan lebih dari 5%. Dengan tingkat signifikansi 0,05, ujilah klaim tersebut.
PEMBAHASAN (1) Sampel yang dihimpun oleh sekelompok mahasiswa tersebut merupakan sampel acak sederhana. (2) Dari
Naskah ini masih berupa draf. Beritahu dosen Anda jika Anda menemukan beberapa saltik atau kesalahan lainnya.

142
data yang diberikan, jelas bahwa np ≥ 10 dan n(1 – p) ≥ 10 untuk masing-masing sampel. Semua persyaratan terpenuhi.
Kita misalkan sampel penduduk Bali yang tinggal di perkotaan sebagai sampel 1 dan sampel penduduk Bali yang tinggal di pedesaan sebagai sampel 2. Kita akan lakukan uji hipotesis dengan menggunakan metode nilai-P.
Langkah 1 Klaim awal yang menyatakan bahwa proporsi penduduk Bali di perkotaan yang memiliki jaminan kesehatan 5% lebih dari proporsi penduduk Bali di pedesaan bisa dituliskan menjadi p1 – p2 > 0,05.
Langkah 2 Jika klaim awal salah, maka p1 – p2 ≤ 0,05 haruslah benar.
Langkah 3 Dari dua bentuk dalam langkah 1 dan 2, bentuk yang tidak memuat persamaan adalah p1 – p2 > 0,05, sehingga bentuk ini menjadi hipotesis alternatif. Hipotesis nolnya adalah p1 – p2 = 0,05.
H0: p1 – p2 = 0,05 H1: p1 – p2 > 0,05
Langkah 4 Seperti pada soal, tingkat signifikansinya adalah α = 0,05.
Langkah 5 Pada uji ini kita gunakan distribusi normal sebagai distribusi sampling selisih proporsi-proporsinya. Karena kita mengasumsikan selisih proprosi dua populasinya tidak nol, maka kita gunakan proporsi-proporsi sampel sebagai estimasi proporsi populasinya.
Naskah ini masih berupa draf. Beritahu dosen Anda jika Anda menemukan beberapa saltik atau kesalahan lainnya.

143
Langkah 6 Statistik uji z dapat ditentukan dengan menggunakan Rumus 4-3.
z 1 2 1 2
1 1 2 2
1 2
ˆ ˆ( ) ( )ˆ ˆ ˆ ˆ(1 ) (1 )p p p p
p p p pn n
- - -=
- -+
163 201 0,05300 480
163 163 201 2011 1300 300 480 480
300 480
æ ö- -ç ÷è ø=
æ öæ ö æ öæ ö- -ç ÷ç ÷ ç ÷ç ÷è øè ø è øè ø+
2,04= Dengan menggunakan tabel, kita peroleh luas daerah di sebelah kanan statistik uji z = 2,04 adalah 0,0207, perhatikan Gambar 4-3. Nilai inilah yang menjadi nilai-P.
Gambar 4-3 Metode Nilai-P
Langkah 7 Karena nilai-P yang sama dengan 0,0207 kurang dari tingkat signifikansi α = 0,05, maka kita tolak hipotesis nol.
INTERPRETASI Terdapat cukup bukti untuk mendukung klaim yang menyatakan bahwa selisih antara proporsi penduduk Bali di perkotaan dan pedesaan yang memiliki jaminan kesehatan adalah lebih dari 5%.
Naskah ini masih berupa draf. Beritahu dosen Anda jika Anda menemukan beberapa saltik atau kesalahan lainnya.

144
Kerjakan latihan 5 n
4.2 Kesimpulan Tentang Dua Mean Pada subbab ini kita akan segera mengetahui bagaimana melakukan uji hipotesis mengenai mean dua populasi dan membuat selang kepercayaan untuk mengestimasi selisih mean dua populasi dengan menggunakan sampel-sampel yang bebas dan berpasangan (atau tidak bebas) dari populasi-populasi tersebut. Pengertian sampel-sampel bebas sudah kita pelajari pada Subbab 2.1, tetapi kita belum mengenal apa yang dimaksud sampel-sampel berpasangan. Untuk itu, sekarang perhatikan definisi berikut.
DEFINISI
Dua sampel dikatakan bebas jika nilai-nilai sampel dari satu populasi tidak berpasangan secara alamiah dengan nilai-nilai sampel dari populasi lain.
Dua sampel dikatakan berpasangan jika nilai-nilai sampel dari satu populasi berpasangan dengan nilai-nilai sampel dari populasi lain. Pemasangan ini bisa karena nilai-nilai tersebut diukur pada kasus yang sama (misalnya data sebelum/sesudah) atau karena hubungan yang inheren (seperti data suami/istri).
4.2.1 Sampel-Sampel Bebas Di bagian ini kita akan membahas bagaimana melakukan uji hipotesis mengenai mean dua populasi ketika kita memiliki sampel-sampel yang bebas. Di awal bagian ini kita akan membahas kasus yang paling sering terjadi dalam keadaan sebenarnya, yaitu ketika simpangan baku dari dua populasi tidak diketahui dan tidak diasumsikan sama. Kemudian kita juga akan membahas keadaan ketika simpangan baku dua populasi diketahui dan keadaan ketika simpangan baku populasi tidak diketahui, tetapi diasumsikan sama.
Naskah ini masih berupa draf. Beritahu dosen Anda jika Anda menemukan beberapa saltik atau kesalahan lainnya.

145
Misalkan kita memiliki dua sampel acak sederhana bebas yang masing-masing sampel berasal dari populasi yang berdistribusi normal atau ukuran masing-masing sampel tersebut paling tidak 30. Selain itu, misalkan kita tidak mengetahui simpangan baku populasi pertama dan kedua. Dari kondisi-kondisi tersebut, kita bisa menyimpulkan bahwa distribusi sampling dari 1x dan 2x
secara berturut-turut merupakan distribusi t-Student dengan mean μ1 dan μ2 serta variansi 2
1 1s n dan 22 2s n . Dengan demikian,
distribusi sampling dari 1 2x x- juga merupakan distribusi t-
Student, tetapi dengan mean dan simpangan baku
1 2( ) 1 2x xm m m- = - dan
1 2
2 21 2
( )1 2
x xs sn n
s - = +
Persamaan terakhir tersebut diperoleh dari sifat bahwa variansi selisih antara dua variabel acak yang bebas sama dengan variansi variabel pertama ditambah variansi variabel kedua. Dari distribusi sampling selisih dua mean tersebut, kita bisa membangun prosedur uji hipotesis mengenai dua mean populasi yang dapat diringkas sebagai berikut.
Kesimpulan Tentang Dua Mean: Sampel-Sampel Bebas
Tujuan Menguji suatu klaim mengenai mean dua populasi yang saling bebas dan mengestimasi selisih mean dua populasi yang bebas dengan menggunakan selang kepercayaan.
Notasi Untuk populasi pertama, misalkan
μ1 = mean populasi 1 σ1 = simpangan baku populasi 1 n1 = ukuran sampel 1 1x = mean sampel 1
Naskah ini masih berupa draf. Beritahu dosen Anda jika Anda menemukan beberapa saltik atau kesalahan lainnya.

146
s1 = simpangan baku sampel 1
Untuk populasi kedua, notasi-notasi yang bersesuaian adalah μ2, σ2, n2, 2x , dan s2.
Persyaratan 1. Simpangan baku dua populasi, yaitu σ1 dan σ2, tidak
diketahui dan tidak diasumsikan sama. 2. Dua sampel merupakan sampel-sampel bebas. 3. Dua sampel merupakan sampel-sampel acak sederhana. 4. Paling tidak satu dari dua kondisi berikut terpenuhi: Kedua
sampel berasal dari populasi yang berdistribusi normal atau kedua sampel berukuran cukup besar, yaitu n1 ≥ 30 dan n2 ≥ 30.
Statistik Uji
1 2 1 2
2 21 2
1 2
( ) ( )x xt
s sn n
m m- - -=
+
Rumus 4-4
Nilai dari μ1 – μ2 tergantung dari klaim yang disebutkan.
Derajat bebas: Derajat bebas bisa ditentukan dengan cara sebagai berikut.
1. Versi sederhana: df = nilai yang lebih kecil dari n1 – 1 dan n2 – 1.
2. Versi yang lebih akurat: Misalkan 21
1
sA
n= dan
22
2
sB
n= ,
maka
2
2 2
1 2
( )df
1 1
A BA B
n n
+=
+- -
Rumus 4-5
Selang Kepercayaan Selang kepercayaan untuk mengestimasi μ1 – μ2 adalah
Naskah ini masih berupa draf. Beritahu dosen Anda jika Anda menemukan beberapa saltik atau kesalahan lainnya.

147
1 2 1 2 1 2( ) ( ) ( )x x E x x Em m- - < - < - +
dengan E adalah batas galat yang ditentukan dengan rumus berikut.
2 21 2
21 2
s sE t
n na= + Rumus 4-6
Derajat bebas ditentukan dengan cara yang sama ketika menentukan derajat bebas pada uji hipotesis.
Derajat Bebas. Dalam buku ini kita akan menggunakan derajat bebas seperti yang dinyatakan dalam Rumus 4-5. Meskipun rumus tersebut terlihat tidak sederhana, tetapi dengan derajat bebas ini kita akan mendapatkan hasil yang lebih akurat. Selain itu, derajat bebas ini juga digunakan dalam perangkat-perangkat lunak statistik, seperti Minitab dan SPSS.
CONTOH 4—Pendidikan Berkeadilan
Meskipun capaian pembelajaran bidang matematika siswa-siswa Indonesia tergolong rendah dibandingkan dengan negara-negara lain yang mengikuti TIMSS 2015, tetapi tidak ditemukan perbedaan antara capaian pembelajaran siswa laki-laki dan perempuan di Indonesia. Hal ini menunjukkan bahwa baik siswa laki-laki ataupun perempuan memiliki kesempatan yang sama untuk mengikuti pembelajaran matematika. Gunakan Data 1 (tersedia daring) dengan tingkat signifikansi 0,05 untuk menanggapi klaim yang menyatakan bahwa mean capaian pembelajaran di bidang matematika siswa laki-laki sama dengan mean capaian pembelajaran siswa perempuan.
PEMBAHASAN Untuk menanggapi klaim yang diberikan, pertama kita lihat capaian pembelajaran antara siswa laki-laki dan
Naskah ini masih berupa draf. Beritahu dosen Anda jika Anda menemukan beberapa saltik atau kesalahan lainnya.

148
perempuan di bidang matematika. Data capaian pembelajaran tersebut bisa dilihat pada Gambar 4-4.
Gambar 4-4 Capaian siswa laki-laki dan perempuan
Dari Gambar 4-4 mungkin kita menduga bahwa memang tidak ada perbedaan antara capaian pembelajaran siswa laki-laki dan perempuan di bidang matematika. Selanjutnya, kita lakukan uji hipotesis secara formal.
Berdasarkan Data 1, (1) simpangan baku dari kedua populasi tidak diketahui dan kita tidak mengasumsikan bahwa kedua nilai tersebut sama, (2) dua sampel yang diberikan adalah sampel-sampel bebas, (3) sampel-sampel tersebut bisa dikatakan sebagai sampel-sampel yang acak sederhana, (4) kedua sampel berukuran besar, sehingga kita tidak perlu menunjukkan bahwa kedua sampel tersebut berasal dari populasi-populasi yang berdistribusi normal. Semua persyaratan terpenuhi.
Selanjutnya kita akan melakukan uji hipotesis dengan memisalkan capaian pembelajaran siswa laki-laki sebagai sampel 1 dan capaian pembelajaran siswa perempuan sebagai sampel 2.
Langkah 1 Klaim yang menyatakan bahwa tidak ada perbedaan antara capaian pembelajaran matematika siswa laki-laki dan perempuan bisa disimbolkan ke dalam bentuk μ1 – μ2 = 0.
Naskah ini masih berupa draf. Beritahu dosen Anda jika Anda menemukan beberapa saltik atau kesalahan lainnya.

149
Langkah 2 Pernyataan yang harus benar ketika klaim awal salah adalah μ1 – μ2 ≠ 0.
Langkah 3 Dari dua langkah sebelumnya, bentuk yang tidak memuat persamaan adalah μ1 – μ2 ≠ 0, sehingga bentuk ini menjadi hipotesis altenatif. Hipotesis nolnya adalah μ1 – μ2 = 0.
H0: μ1 – μ2 = 0
H1: μ1 – μ2 ≠ 0
Langkah 4 Tingkat signifikansi yang akan kita gunakan α = 0,05.
Langkah 5 Di sini kita memiliki dua sampel bebas dan akan menguji klaim terkait mean dua populasi, maka kita akan menggunakan distribusi t-Student sebagai distribusi dari selisih mean dua sampel.
Langkah 6 Berdasarkan Data 1, kita mempunyai statistik-statistik berikut.
1x = 399,0, s1 = 89,0, n1 = 301, dan
2x = 397,9, s2 = 81,7, n2 = 275
Dengan menggunakan statistik-statistik tersebut, selanjutnya statistik uji t dapat ditentukan sebagai berikut.
t 1 2 1 2
2 21 2
1 2
( ) ( )x x
s sn n
m m- - -=
+
2 2
(399,0 397,9) 0
89,0 81,7301 275
- -=
+
Naskah ini masih berupa draf. Beritahu dosen Anda jika Anda menemukan beberapa saltik atau kesalahan lainnya.

150
0,155=
Untuk menentukan nilai-P, pertama kita tentukan derajat bebas dengan menggunakan Rumus 4-5.
df
2
2 2
1 2
( )
1 1
A BA B
n n
+=
+- -
22 2
2 22 2
89,0 81,7301 275
89,0 81,7301 275
301 1 275 1
æ ö+ç ÷
è ø=æ ö æ öç ÷ ç ÷è ø è ø+
- -
574,0= Karena uji ini merupakan uji dua-ekor dan statistik uji t = 0,155 terletak di kanan 0, maka nilai-P sama dengan dua kali luas daerah di kanan statistik uji tersebut, perhatikan Gambar 4-5. Dengan df = 574,0, kita peroleh nilai-P = 0,88.
Gambar 4-5 Metode nilai-P
Langkah 7 Karena nilai-P = 0,88 lebih besar dari tingkat signifikansi α = 0,05, maka kita gagal menolak hipotesis nol.
INTERPRETASI Tidak cukup bukti untuk menolak klaim yang menyatakan bahwa capaian pembelajaran matematika siswa laki-
Naskah ini masih berupa draf. Beritahu dosen Anda jika Anda menemukan beberapa saltik atau kesalahan lainnya.

151
laki sama dengan siswa perempuan. Tampak bahwa perbedaan antara capaian pembelajaran matematika siswa laki-laki dan perempuan di Indonesia secara statistik tidak signifikan.
Kerjakan latihan 7 n
Selang Kepercayaan. Misalkan kita akan membuat selang kepercayaan yang ekuivalen dengan uji hipotesis pada Contoh 4. Selang kepercayaan tersebut memiliki tingkat kepercayaan 95%. Dengan menggunakan derajat bebas yang telah dihitung pada Contoh 4, yaitu df = 574,0, maka kita peroleh nilai kritis tα/2 = 1,96. Dengan demikian, batas galatnya adalah
2 289,0 81,71,96 13,9
301 275E = + =
Karena 1 2 1,1x x- = , maka kita 95% yakin bahwa nilai-nilai pada
1,1 ± 13,9 akan memuat selisih sebenarnya dari mean dua populasi. Karena selang yang kita peroleh memuat 0, maka tampak bahwa mean kedua populasi mungkin akan sama.
Simpangan Baku Populasi Diketahui. Metode yang telah kita bahas sebelumnya digunakan ketika kita tidak mengetahui simpangan baku populasi. Jika simpangan baku tersebut diketahui, maka kita akan gunakan distribusi normal baku sebagai distribusi samplingnya dan statistik ujinya dapat ditentukan dengan Rumus 4-7 berikut.
1 2 1 2
2 21 2
1 2
( ) ( )x xz
n n
m m
s s
- - -=
+
Rumus 4-7
Simpangan Baku Populasi Diasumsikan Sama. Terdapat metode lagi yang bisa digunakan untuk menguji klaim mengenai mean dua
Naskah ini masih berupa draf. Beritahu dosen Anda jika Anda menemukan beberapa saltik atau kesalahan lainnya.

152
populasi. Metode ini digunakan untuk kasus ketika kita tidak mengetahui simpangan baku dua populasi tersebut, tetapi kita asumsikan kedua simpangan baku ini sama. Ketika simpangan baku dua populasi sama, maka kita gunakan variansi gabungan sp
2 sebagai estimasi dari variansi populasi σ2. Variansi gabungan tersebut bisa dihitung dengan rumus berikut.
2 2
2 1 1 2 2
1 2
( 1) ( 1)( 1) ( 1)p
n s n ss
n n- + -
=- + -
Setelah diperoleh variansi gabungan dua sampel diperoleh, statistik uji metode ini bisa ditentukan dengan Rumus 4-8 berikut.
1 2 1 2
2 2
1 2
( ) ( )
p p
x xt
s sn n
m m- - -=
+
Rumus 4-8
Nilai-P dan nilai kritis dalam uji ini ditentukan dengan menggunakan distribusi t-Student dengan menggunakan derajat bebas df = n1 + n2 – 1. Dibandingan dengan metode pertama (ketika simpangan baku dua populasi tidak diasumsikan sama), metode ini akan menghasilkan derajat bebas yang sedikit lebih besar. Akibatnya, uji hipotesis dalam metode ini akan lebih kuat (lebih sering menolak hipotesis nol) dan selang kepercayaan yang dibuat akan sedikit lebih sempit.
Metode Mana yang Dipilih? Meskipun metode terakhir memiliki beberapa kelebihan, tetapi metode ini juga memiliki kekurangan, yaitu kita harus mengasumsikan bahwa variansi dua populasi yang diberikan sama. Asumsi ini sangatlah kuat (akan dibahas pada Subbab 4.3), dan seringkali tidak benar. Oleh karena itu, kita sebaiknya menggunakan metode pertama, yaitu dengan tidak mengasumsikan bahwa simpangan baku kedua populasi sama.
Naskah ini masih berupa draf. Beritahu dosen Anda jika Anda menemukan beberapa saltik atau kesalahan lainnya.

153
4.2.2 Sampel-Sampel Berpasangan Dalam kehidupan sehari-hari kita sering menjumpai data berpasangan. Misalnya, indeks prestasi mahasiswa pada semester 1 dan 2, gaji suami dan istri, suhu suatu kota ketika diukur pada pukul 10.00 dan 14.00, dan sebagainya. Pada bagian ini kita akan membahas metode uji hipotesis tentang mean dua populasi ketika kita memiliki sampel-sampel berpasangan semacam ini.
Ketika kita akan membuat kesimpulan mengenai mean data berpasangan, kita cari selisih skor masing-masing pasangan dan kemudian kita gunakan selisih-selisih skor tersebut bersama dengan metode yang telah dijelaskan pada Subbab 2.2 untuk membuat selang kepercayaan dan metode pada Subbab 3-3 untuk melakukan uji hipotesis. Dengan kata lain, meskipun kita memiliki dua sampel, tetapi setelah kita tentukan selisih skor masing-masing pasangan maka kita akan mendapatkan satu sampel, sehingga kita bisa menggunakan metode pembuatan kesimpulan dari satu sampel seperti yang telah dibahas pada Bab 2 dan 3.
Kesimpulan Tentang Dua Mean: Sampel-Sampel Berpasangan
Tujuan Menguji klaim mengenai mean dua populasi atau membuat selang kepercayaan untuk mengestimasi selisih mean dua populasi dari sampel-sampel berpasangan.
Notasi d = selisih nilai dalam setiap pasangan μd = mean dari selisih semua pasangan dalam populasi d = mean dari selisih nilai pasangan dalam data sampel sd = simpangan baku dari selisih nilai pasangan dalam data
sampel n = banyaknya pasangan dalam data sampel
Persyaratan
Naskah ini masih berupa draf. Beritahu dosen Anda jika Anda menemukan beberapa saltik atau kesalahan lainnya.

154
1. Data sampel merupakan sampel-sampel berpasangan. 2. Data sampel merupakan sampel-sampel acak sederhana. 3. Paling tidak salah satu kondisi berikut terpenuhi:
Banyaknya pasangan cukup besar (n ≥ 30) atau selisih masing-masing pasangan berasal dari populasi yang berdistribusi normal.
Statistik Uji
d
d
dt
sn
m-=
dengan derajat bebas df = n – 1.
Nilai-P dan Nilai Kritis: Nilai-P dan nilai-nilai kritis ditentukan dengan menggunakan distribusi t-Student.
Selang Kepercayaan dd E d Em- < < +
dengan E adalah batas galat yang dihitung dengan rumus berikut.
2ds
E tna=
Nilai Kritis: Nilai kritis tα/2 ditentukan dengan menggunakan distribusi t-Student dengan derajat bebas df = n – 1.
Asumsi Normalitas. Ketika kita memiliki data sampel-sampel berpasangan, maka terdapat dua kemungkinan, yaitu banyaknya pasangan cukup besar (n ≥ 30) atau tidak. Jika banyaknya pasangan yang kita miliki cukup besar, maka kita tidak perlu melakukan uji normalitas. Jika sebaliknya, maka kita perlu melakukan uji normalitas. Tetapi ingat, uji normalitas tersebut kita lakukan pada data selisih, bukan pada dua sampel awal.
Naskah ini masih berupa draf. Beritahu dosen Anda jika Anda menemukan beberapa saltik atau kesalahan lainnya.

155
CONTOH 5—IP Mahasiswa Naik?
Seorang mahasiswa mendapati bahwa indeks prestasinya naik dari semester 1 ke semester 2. Dari pengalaman pribadinya ini dia bertanya-tanya apakah kondisi ini juga terjadi pada mahasiswa-mahasiswa lainnya. Untuk menguji klaim bahwa mean IP mahasiswa naik dari semester 1 ke semester 2, dia melakukan survei kepada 10 mahasiswa secara acak dan diperoleh data sebagai berikut.
Mahasiswa IP Semester 1 IP Semester 2
1 2,25 2,05
2 2,4 2,95
3 2,6 2,25
4 2,8 3,2
5 2,8 3,2
6 2,9 2,95
7 3,15 3,25
8 2,85 2,75
9 3,1 4
10 3,5 2,96
Gunakan tingkat signifikansi 0,05 untuk menguji klaim mahasiswa tersebut.
PEMBAHASAN Pertama kita periksa semua persyaratannya. (1) Sampel-sampel merupakan data berpasangan. IP semester 1 dan 2 dipasangkan oleh mahasiswa pemilik IP tersebut. (2) Data sampel merupakan sampel-sampel acak sederhana. (3) Karena ukuran masing-masing sampel kecil, yaitu n = 10, maka kita perlu melakukan uji normalitas. Karena klaim menyatakan bahwa terjadi
Naskah ini masih berupa draf. Beritahu dosen Anda jika Anda menemukan beberapa saltik atau kesalahan lainnya.

156
kenaikan IP dari semester 1 ke semester 2, maka kita cari selisih antara IP semester 2 dan 1 untuk masing-masing mahasiswa. Selisih-selisih tersebut adalah sebagai berikut.
–0,2 0,55 –0,35 0,4 0,4 0,05 0,1 –0,1 0,9 -0,54
Setelah itu kita lakukan uji normalitas data selisih tersebut, perhatikan Gambar 4-6.
Gambar 4-6 Uji Normalitas di SPSS
Berdasarkan uji Kolmogorov-Smirnov yang dikoreksi Lilliefors dalam SPSS, kita bisa simpulkan bahwa selisih IP yang kita miliki berasal dari populasi yang berdistribusi normal. Semua persyaratan terpenuhi.
Langkah 1 Terjadi kenaikan IP mahasiswa dari semester 1 ke semester 2 bisa disimbolkan μd > 0.
Langkah 2 Negasi dari pernyataan dalam langkah sebelumnya adalah μd ≤ 0.
Langkah 3 Hipotesis nol dan hipotesis alternatif uji ini adalah sebagai berikut.
H0: μd = 0 H1: μd > 0
Langkah 4 Tingkat signifikansi yang diminta adalah α = 0,05.
Naskah ini masih berupa draf. Beritahu dosen Anda jika Anda menemukan beberapa saltik atau kesalahan lainnya.

157
Langkah 5 Karena di sini kita memiliki sampel-sampel berpasangan dan akan menguji klaim mengenai mean dua populasi dari sampel-sampel tersebut, maka kita gunakan distribusi t-Student.
Langkah 6 Dari data selisih d yang diperoleh, kita dapatkan statistik-statistik berikut.
d = 0,121 dan sd = 0,443
Dengan demikian, statistik uji t dapat dihitung dengan cara berikut.
0,121 0 0,8640, 443
10
t -= =
Karena tingkat signifikansi α = 0,05, maka dengan derajat bebas df = n – 1 = 9, maka kita peroleh nilai kritisnya t = 1,833 (dari tabel distribusi t-Student).
Langkah 7 Karena statistik uji tidak berada di dalam daerah kritis (lihat Gambar 4-7), maka kita gagal menolak hipotesis nol.
Gambar 4-7 Metode Tradisional H0: μd = 0
INTERPRETASI Tidak cukup bukti sampel untuk mendukung klaim yang menyatakan bahwa terjadi kenaikan mean IP mahasiswa dari semester 1 ke semester 2.
Naskah ini masih berupa draf. Beritahu dosen Anda jika Anda menemukan beberapa saltik atau kesalahan lainnya.

158
Kerjakan latihan 11 n
Selang Kepercayaan. Dari Contoh 5, kita bisa membuat selang kepercayaan 90% dan didapatkan selang –0,136 < μd < 0,378. Karena selang tersebut memuat 0, maka secara statistik selisih IP mahasiswa di semester 1 dan 2 tidak signifikan.
Sampel-Sampel Berpasangan dan Bebas. Mungkin Anda bertanya-tanya seperti ini: Mengapa kita tidak menganggap sampel-sampel berpasangan sebagai sampel-sampel bebas? Untuk menjawab pertanyaan ini, misalkan kita memiliki data sampel sebagai berikut dan kita gunakan data sampel tersebut untuk uji ekor-kanan.
Kasus Sampel 1 Sampel 2 Selisih, d
1 55 61 6
2 61 97 36
3 60 58 –2
4 55 69 14
5 69 84 15
6 63 87 24
7 51 31 –20
8 65 65 0
9 62 77 15
10 61 66 5
Mean 1 60,2x = 1 69,5x = 9,3d = Simpangan Baku 1 5,3s = 2 18, 4s = 15,3ds =
Dengan menganggap sampel-sampel tersebut sebagai sampel-sampel yang bebas, maka dengan menggunakan metode pertama
Naskah ini masih berupa draf. Beritahu dosen Anda jika Anda menemukan beberapa saltik atau kesalahan lainnya.

159
dalam bagian 4.2.1, kita peroleh t = 1,536 dan nilai-P 0,078. Akibatkanya kita gagal menolak hipotesis nol. Akan tetapi, jika kita anggap sampel-sampel tersebut sebagai data berpasangan, maka kita peroleh t = 1,917 dan nilai-P 0,044. Pesan moralnya, dengan mengabaikan fakta bahwa sampel-sampel yang kita miliki merupakan data yang berpasangan (dan menganggapnya sebagai sampel-sampel yang bebas), maka kita akan mengorbankan kekuatan uji hipotesis kita. Artinya, kita akan lebih jarang menolak hipotesis nol.
4.3 Kesimpulan Tentang Dua Variansi Beberapa uji statistik mengasumsikan bahwa variansi antara sampel-sampel yang dimiliki sama, misalnya metode terakhir pada bagian 4.2.1. Oleh karena itu penting untuk menguji kesamaan variansi dua sampel atau lebih. Kesamaan variansi antara sampel-sampel tersebut dinamakan homogenitas variansi. Pada bagian ini kita akan mempelajari bagaimana melakukan uji hipotesis mengenai variansi dua populasi dan membuat selang kepercayaan untuk mengestimasi perbandingan variansi dua populasi.
Terdapat banyak metode yang bisa digunakan untuk melakukan uji homogenitas variansi. Metode yang paling mudah dilakukan adalah uji F. Uji F tersebut menggunakan distribusi F yang akan dikenalkan pada subbab ini.
Kesimpulan Tentang Dua Variansi
Tujuan Menguji klaim mengenai variansi dua populasi dan membuat selang kepercayaan untuk mengestimasi perbandingan variansi dua populasi.
Notasi s1
2 = variansi yang lebih besar dari dua sampel n1 = ukuran sampel dengan variansi lebih besar
Naskah ini masih berupa draf. Beritahu dosen Anda jika Anda menemukan beberapa saltik atau kesalahan lainnya.

160
σ12 = variansi populasi dari sampel dengan variansi lebih besar
Simbol-simbol s22, n2, dan σ2
2 digunakan untuk sampel atau populasi dengan variansi yang lebih kecil.
Persyaratan 1. Dua populasi merupakan populasi-populasi yang bebas. 2. Dua sampel merupakan sampel-sampel acak sederhana. 3. Masing-masing populasi berdistribusi normal.
Statistik Uji
2122
sF
s=
dengan s12 adalah variansi sampel yang memiliki variansi lebih
besar.
Nilai-P dan Nilai Kritis: Nilai-P dan nilai-nilai kritis ditentukan dari distribusi F dengan derajat bebas pembilang df = n1 – 1 dan derajat bebas penyebut df = n2 – 1.
Selang Kepercayaan
2 2 21 1 12 2 22 2 2
1 1
R L
s sF Fs s
ss
æ ö æ ö× < < ×ç ÷ ç ÷
è ø è ø
dengan FR dan FL secara berturut-turut adalah nilai kritis ekor-kanan dan nilai kritis ekor-kiri.
Asumsi Normalitas. Seperti yang telah dikatakan pada bagian 4.2.1, uji homogenitas variansi ini sulit dilakukan karena uji ini mempersyaratakan secara ketat bahwa dua sampel yang dimiliki harus berasal dari populasi-populasi yang berdistribusi normal (berapapun besarnya ukuran sampel-sampel tersebut). Uji ini sangat sensitif terhadap normalitas sampel-sampel yang dimiliki. Oleh karena itu, ketika kita melakukan uji hipotesis, kita harus mengeksplorasi data yang kita miliki. Kita bisa membuat histogram
Naskah ini masih berupa draf. Beritahu dosen Anda jika Anda menemukan beberapa saltik atau kesalahan lainnya.

161
dan diagram P-P atau Q-Q normal untuk melihat normalitas sampel-sampel yang kita miliki. Kita juga bisa melakukan uji hipotesis formal, seperti uji Kolmogorov-Smirnov atau uji Anderson-Darling, untuk menguji normalitas data yang kita miliki.
Distribusi F Fisher. Jika kita secara berulang-ulang memilih sampel dari dua populasi yang berdistribusi normal dan variansinya sama, σ1
2 = σ22, maka distribusi dari s1
2/s22 merupakan
distribusi F dengan derajat bebas n1 – 1 dalam pembilang dan n2 – 1 dalam penyebutnya. Distribusi F memiliki karakteristik sebagai berikut.
1. Distribusi F tidak simetris. Distribusi ini condong ke kanan. 2. Nilai dari distribusi F tidak pernah negatif. 3. Bentuk distribusi F tergantung pada derajat bebas pembilang
dan penyebutnya, perhatikan Gambar 4-8. Hal ini serupa dengan distribusi t-Student dan chi-square yang tergantung pada derajat bebasnya.
Gambar 4-8 Distribusi F
Nilai Kritis. Nilai-nilai kritis bisa ditentukan dengan menggunakan tabel F. Tabel tersebut disusun berbeda dengan tabel-tabel lainnya. Baris paling atas menunjukkan derajat bebas
Naskah ini masih berupa draf. Beritahu dosen Anda jika Anda menemukan beberapa saltik atau kesalahan lainnya.
162
pembilang, sedangkan kolom paling kiri merupakan derajat bebas penyebut. Tabel F tersebut terdiri dari dua bagian, yaitu untuk α = 0,025 dan α = 0,05, keduanya merupakan luas ekor-kanan. Nilai kritis mana yang dipilih tergantung dari jenis uji hipotesis yang dilakukan.
Uji dua-ekor: Gunakan tabel distribusi F dengan luas ekor kanan 0,025. Nilai 0,025 merupakan hasil dari tingkat signifkansi α = 0,05 dibagi dengan 2.
Uji ekor-kanan: Gunakan tabel distribusi F dengan luas ekor-kanan 0,05, sama dengan tingkat signifikansinya.
Ketika kita membuat selang kepercayaan, kita harus menentukan nilai kritis ekor-kanan FR dan nilai kritis ekor-kiri FL. Nilai kritis ekor-kanan FR bisa langsung ditentukan dengan menggunakan tabel distribusi F. Untuk menentukan FL dengan tabel, pertama tukarlah derajat bebasnya dan kemudian baliklah nilai F yang ditemukan dari tabel tersebut.
CONTOH 6—Menentukan Nilai-Nilai Kritis
Tentukan nilai kritis ekor-kanan FR dan nilai kritis ekor-kiri FL pada distribusi F dengan derajat bebas pembilang 24 dan derajat bebas penyebutnya 20 untuk uji dua-ekor pada tingkat signifikansi α = 0,05.
PEMBAHASAN Gambar 4-9 menunjukkan distribusi F dengan derajat bebas pembilang 24 dan derajat bebas penyebut 20. Luas daerah di kanan FR adalah α/2 = 0,025, sehingga dengan menggunakan tabel F kita peroleh FR = 2,4076. Selanjutnya kita tukar derajat bebas antara pembilang dan penyebutnya, kemudian kita tentukan kebalikan dari nilai kritis yang diperoleh dari tabel untuk menentukan FL. Karena nilai kritis ekor-kanan untuk derajat
Naskah ini masih berupa draf. Beritahu dosen Anda jika Anda menemukan beberapa saltik atau kesalahan lainnya.

163
bebas pembilang 20 dan derajat bebas penyebut 24 adalah 2,3273, maka
1 0, 42972,3273LF = =
Dengan menggunakan Excel kita bisa menggunakan rumus =F.INV(0.975, 24, 20) untuk menentukan FR dan =F.INV(0.025, 24, 20) untuk menghitung FL. (Berbeda dengan tabel F dalam buku ini, Excel menggunakan luas daerah ekor-kiri).
Gambar 4-9 Nilai-nilai kritis uji dua-ekor dengan α = 0,05
Kerjakan latihan 15 n
Interpretasi Statistik Uji F. Misalkan s12 dan s2
2 secara berturut-turut adalah variansi yang lebih besar dan yang lebih kecil di antara dua sampel yang kita miliki. Jika populasi-populasi dari sampel tersebut memang benar memiliki variansi yang sama, maka nilai statistik uji F = s1
2/s22 akan dekat ke 1. Jika nilai statistik uji tersebut
jauh di kanan 1, maka kedua populasi tersebut memiliki variansi yang sangat berbeda.
CONTOH 7—Tekanan Darah
Seorang perawat ingin mengetahui apakah ada perbedaan variabilitas tekanan darah sistolik antara laki-laki dan perempuan. Untuk itu, dia memilih 25 laki-laki dan 21 perempuan secara acak
Naskah ini masih berupa draf. Beritahu dosen Anda jika Anda menemukan beberapa saltik atau kesalahan lainnya.

164
untuk diukur tekanan darahnya. Data yang diperoleh disajikan sebagai berikut.
Laki-Laki Perempuan
107 123 129 117 127 130 129 137 112 128 139 141 124 135 128 131 141 126 132 119 146 102 138 122 116 109 122 125 130 130 146 116 128 143 145 132 114 119 137 121 112 136 148 122 135 126
Gunakan data tersebut dengan tingkat signifikansi 0,05 untuk menguji klaim yang menyatakan bahwa variansi tekanan darah sistolik laki-laki berbeda dengan perempuan.
PEMBAHASAN (1) Jelas bahwa dua populasi yang diberikan merupakan populasi-populasi bebas. (2) Sampel-sampel tersebut merupakan sampel-sampel acak sederhana. (3) Untuk melihat apakah dua sampel tersebut berasal dari populasi-populasi yang berdistribusi normal, kita lakukan uji Anderson-Darling pada Minitab, lihat Gambar 4.10(a) dan (b).
(a) (b)
Gambar 4-10 Diagram peluang tekanan darah sistolik
Dari Gambar 4-10(a) dan (b) kita bisa melihat bahwa baik tekanan darah sistolik laki-laki maupun perempuan berasal dari populasi-populasi yang berdistribusi normal. Semua persyaratan terpenuhi.
Naskah ini masih berupa draf. Beritahu dosen Anda jika Anda menemukan beberapa saltik atau kesalahan lainnya.

165
Langkah 1 Klaim bahwa ada perbedaan antara variansi tekanan darah sistolik laki-laki dan perempuan bisa dinyatakan dengan σ1
2 ≠ σ22.
Langkah 2 Jika klaim awal salah, maka σ12 = σ2
2.
Langkah 3 Karena tidak σ12 ≠ σ2
2 memuat persamaan, maka bentuk ini menjadi hipotesis alternatif. Hipotesis nolnya adalah σ1
2 = σ2.
H0: σ12 = σ2
2. H1: σ1
2 ≠ σ22.
Langkah 4 Seperti yang dinyatakan dalam soal, tingkat signifikansinya adalah α = 0,05.
Langkah 5 Karena klaim dibuat tentang variansi dua populasi, maka statistik yang relevan adalah F = s1
2/s22.
Untuk itu, kita gunakan distribusi F.
Langkah 6 Dari data yang diberikan, kita dapatkan variansi tekanan darah sistolik laki-laki dan perempuan secara berturut-turut adalah
s12 = 166,08 dan s2
2 = 69,66
Dengan demikian, kita peroleh statistik uji F sebagai berikut.
2122
166,08 2,38469,66
sF
s= = =
Dengan tingkat signifikansi 0,05, derajat bebas pembilang df = 24, derajat bebas penyebut df = 20, pada Contoh 6 kita telah menemukan nilai-nilai kritisnya adalah sebagai berikut.
FL = 0,4297 dan FR = 2,4076
Naskah ini masih berupa draf. Beritahu dosen Anda jika Anda menemukan beberapa saltik atau kesalahan lainnya.

166
Langkah 7 Karena statistik uji F = 2,384 tidak berada dalam daerah kritis (lihat Gambar 4-11), maka kita gagal menolak hipotesis nol.
Gambar 4-11 Metode tradisional
INTERPRETASI Tidak cukup bukti untuk mendukung klaim yang menyatakan bahwa terdapat perbadaan variansi antara tekanan darah sistolik laki-laki dan perempuan.
Kerjakan latihan 16 n
Selang Kepercayaan. Kita bisa membuat selang kepercayaan untuk mengestimasi perbandingan antara variansi tekanan darah sistolik semua laki-laki dan perempuan dengan menggunakan informasi dalam Contoh 7. Selang kepercayaan tersebut dapat ditentukan seperti ini.
2122
1
R
sFs
æ ö× <ç ÷
è ø
2122
ss
2122
1
L
sFs
æ ö< ×ç ÷
è ø
166,08 169,66 2, 4076
æ ö× <ç ÷è ø
2122
ss
166,08 169,66 0, 4297
æ ö< ×ç ÷è ø
0,99 < 2122
ss
5,55<
Dari hasil ini, kita bisa melihat bahwa selang kepercayaan tersebut memuat 1. Dengan demikian, perbedaan antara variansi tekanan darah sistolik semua laki-laki dan perempuan secara statistik tidak signifikan.
Naskah ini masih berupa draf. Beritahu dosen Anda jika Anda menemukan beberapa saltik atau kesalahan lainnya.

167
4.4 Rangkuman 1. Banyak penelitian yang
tujuannya adalah untuk membandingkan proporsi dua populasi. Untuk melakukannya, peneliti bisa menggunakan data dari dua sampel dan menggunakan prosedur uji hipotesis untuk menguji klaimnya mengenai proporsi dua populasi asal kedua sampel tersebut.
2. Selang kepercayaan bisa dikonstruksi untuk menarik kesimpulan terkait proporsi dua populasi. Selang kepercayaan tersebut menggunakan data dua sampel untuk memperkirakan nilai selisih proporsi dua populasi asal sampel-sampel tersebut. Dengan demikian, signifikan atau tidaknya perbedaan proporsi dua populasi bisa disimpulkan.
3. Jika terdapat dua sampel, maka kemungkinannya sampel-sampel tersebut saling bebas atau berpasangan. Kedua sampel
tersebut merupakan sampel-sampel berpasangan ketika nilai-nilai sampelnya secara alamiah berpasangan. Jika sebaliknya, maka sampel-sampel tersebut saling bebas.
4. Dengan menggunakan dua sampel bebas, klaim mengenai mean populasi asal sampel-sampel tersebut bisa diuji. Uji tersebut bisa dilakukan ketika simpangan baku populasi tidak diketahui tetapi tidak diasumsikan sama, simpangan baku populasi diketahui dan diasumsikan sama, dan simpangan baku populasi diketahui. Untuk masing-masing kondisi tersebut digunakan metode-metode yang berbeda.
5. Estimasi selisih mean dua populasi yang saling bebas bisa dibuat dengan menggunakan selang kepercayaan. Dengan selang ini bisa dibuat kesimpulan apakah terjadi perbedaan
Naskah ini masih berupa draf. Beritahu dosen Anda jika Anda menemukan beberapa saltik atau kesalahan lainnya.

168
yang signifikan antara mean kedua populasi tersebut.
6. Diberikan dua sampel berpasangan (atau tidak bebas), uji hipotesis yang dilakukan relatif lebih mudah karena pada dasarnya teknik yang digunakan sama dengan uji hipotesis mean satu sampel. Akan tetapi, ketika menggunakan dua sampel berpasangan, data yang digunakan adalah data selisih masing-masing pasangan.
7. Selang kepercayaan mengenai selisih dua populasi berpasangan bisa dkonstruksi dengan menggunakan distribusi selisih masing-masing pasangan. Selang ini memberikan estimasi nilai-nilai yang diyakini menjadi
mean selisih semua pasangan dalam populasi.
8. Homogenitas simpangan baku atau variansi dua populasi sering digunakan sebagai asumsi dari beberapa metode statistik. Untuk menjamin homogenitas tersebut, prosedur uji hipotesis formal simpangan baku atau variansi dua populasi bisa digunakan.
9. Kesimpulan mengenai homogenitas simpangan baku atau variansi dua populasi juga bisa dibuat dengan memanfaatkan selang kepercayaan. Lebih dari itu, selang kepercayaan juga memberikan estimasi nilai-nilai perbandingan simpangan baku atau variansi dua populasi.
Pustaka Badan Pusat Statistik. (2016). Potret Pendidikan Indonesia: Statistik
Pendidikan 2016. Jakarta: Badan Pusat Statistik.
Badan Pusat Statistik. (2016). Statistik Upah Agustus 2016: Berdasarkan Hasil Sakernas. Jakarta: Badan Pusat Statistik
Naskah ini masih berupa draf. Beritahu dosen Anda jika Anda menemukan beberapa saltik atau kesalahan lainnya.

169
Badan Pusat Statistik. (2017). Potret Pendidikan Indonesia: Statistik Pendidikan 2017. Jakarta: Badan Pusat Statistik.
Badan Pusat Statistik. (2017). Statistik Lingkungan Hidup Indonesia 2017. Jakarta: Badan Pusat Statistik
Badan Pusat Statistik. (2017). Statistik Indonesia dalam Infografis 2017. Jakarta: Badan Pusat Statistik.
Badan Pusat Statistik. (2017). Statistik Kesejahteraan Rakyat 2017. Jakarta: Badan Pusat Statistik.
Bluman, A. G. (2017). Elementary Statistics: A Step By Step Approach. New York: McGraw-Hill Education.
Gastwirth, J. L., Gel, Y. R., & Miao, W. (2009). The Impact of Levene’s Test of Equality of Variances on Statistical Theory and Practice. Statistical Science, 24(3), 343-360. doi:10.1214/09-sts301.
International Association for the Evaluation of Educational Achievement (IEA). (2015). [International Database]. Unpublished raw data.
Levene, H. (1960). Robust testes for equality of variances. In I. Olkin (Ed.), Contributions to Probability and Statistics: Essays in Honor of Harold Hotelling (pp. 278-292). Palo Alto, CA: Stanford University Press.
Triola, M. F. (2017). Elementary Statistics. Boston: Pearson.
Undang-Undang Republik Indonesia. (2013). Sistem Pendidikan Nasional.
Weiss, N. A. (2017). Elementary Statistics. Boston: Pearson.
Naskah ini masih berupa draf. Beritahu dosen Anda jika Anda menemukan beberapa saltik atau kesalahan lainnya.

170
Latihan 1. Pemeriksaan Persyaratan. Seseorang melakukan survei
melalui Twitter dan diperoleh bahwa 45% laki-laki dan 43% perempuan menganggap bahwa Statistika itu penting. Mengapa hasil survei ini tidak bisa digunakan untuk menguji klaim yang menyatakan bahwa proporsi laki-laki dan perempuan yang menganggap Statistika itu penting adalah sama.
2. Metode-Metode Ekuivalen. Misalkan Anda akan menguji klaim bahwa proporsi mahasiswa yang menyukai film drama berbeda dengan proporsi mahasiswa yang menyukai film aksi dan petualangan. Untuk menguji klaim tersebut, Anda bisa menggunakan tiga cara, yaitu uji hipotesis metode nilai-P dan tradisional dengan tingkat signifikansi 0,05, serta selang kepercayaan dengan tingkat kepercayaan 95%. Apakah ketiga cara tersebut selalu menghasilkan kesimpulan yang sama? Jelaskan.
3. Akses Internet. Di hampir semua provinsi di Indonesia pada tahun 2016, proporsi penduduk laki-laki yang mengakses internet lebih besar daripada penduduk perempuan. Akan tetapi anomali dijumpai pada Provinsi Gorontalo setelah dilihat dari hasil survei yang dilakukan secara acak kepada penduduk Gorontalo berikut.
Statistik Laki-Laki Perempuan Banyak penduduk yang mengakses internet 3 bulan terakhir
24 29
Banyak penduduk yang disurvei
248 256
Gunakan tingkat signifikansi 0,05 untuk menguji klaim bahwa, tidak seperti provinsi-provinsi lainnya, proporsi penduduk laki-laki di Provinsi Gorontalo yang mengakses
Naskah ini masih berupa draf. Beritahu dosen Anda jika Anda menemukan beberapa saltik atau kesalahan lainnya.

171
internet selama 3 bulan terakhir lebih kecil daripada penduduk perempuannya.
4. Perundungan. Perundungan merupakan masalah yang berlarut-larut di dunia pendidikan. Untuk melihat apakah ada perbedaan antara sekolah negeri dan swasta, 166 dan 128 siswa dipilih secara acak dari sekolah tersebut dan diperoleh banyaknya siswa yang melaporkan pernah dirundung adalah sebagai berikut.
Statistik Negeri Swasta Banyak siswa yang pernah dirundung
14 8
Ukuran sampel 166 128 Dengan tingkat kepercayaan 95%, konstruksilah selang kepercayaan yang mengestimasi selisih proporsi kasus perundungan di sekolah negeri dan swasta. Dari selang kepercayaant tersebut, apakah bisa disimpulkan bahwa perbedaan tersebut signifikan?
5. Akses Pendidikan. Seorang peneliti ingin mengetahui apakah ada perbedaan kemudahan akses pendidikan siswa pedesaan dan perkotaan. Untuk itu, dia mensurvei 544 siswa pedesaan dan 557 siswa perkotaan yang baru saja lulus SMP. Dari hasil survei tersebut diperoleh bahwa 71,9% siswa pedesaan dan 82,6% siswa perkotaan tersebut melanjutkan pendidikan ke jenjang SMA/SMK. Dari hasil ini, gunakan tingkat signifikansi 0,05 untuk menguji klaim yang menyatakan bahwa proporsi siswa SMP di pedesaan yang melanjutkan ke jenjang SMA 5% kurang dari siswa SMP di perkotaan.
6. Derajat Bebas. Dua sampel memiliki mean, simpangan baku, dan ukuran sebagai berikut. 1 94,2x = , s1 = 15,9, n1 = 40, dan
2 103,9x = , s2 = 23,0, n2 = 32.
Naskah ini masih berupa draf. Beritahu dosen Anda jika Anda menemukan beberapa saltik atau kesalahan lainnya.

172
Untuk menguji hipotesis apakah mean populasi pertama kurang dari mean populasi kedua, Anda bisa menggunakan dua kemungkinan derajat bebas. Pertama, df = nilai yang lebih kecil dari n1 – 1 dan n2 – 1, sehingga df = 31 dan pada tingkat signifikansi 0,05 akan diperoleh nilai kritis –1,696. Kedua, Anda bisa menggunakan derajat bebas pada Rumus 4-5 untuk mendapatkan df = 53,069 dan nilai kritis –1,674. Jelaskan mengapa dengan menggunakan derajat bebas df = 31 lebih “konservatif” daripada df = 53,069? (Periksalah definisi istilah “konservatif” dalam KBBI).
7. Wajib Belajar 9 Tahun? Indonesia sudah cukup lama melaksanakan program wajib belajar 9 tahun seperti yang diamanatkan dalam UU No 20 Tahun 2003. Untuk memonitor program tersebut, 640 penduduk laki-laki dan 648 penduduk perempuan berumur 15 tahun ke atas disurvei untuk diketahui lama masa sekolahnya dan diperoleh statistik-statisik berikut.
Laki-Laki Perempuan
1 8,83x = s1 = 6,33
2 8,17x = s2 = 6,4
Dari sampel-sampel tersebut, gunakan tingkat signifikansi 0,05 untuk menguji klaim bahwa mean masa sekolah penduduk laki-laki berumur 15 tahun ke atas lebih besar dari penduduk perempuan.
8. Lama Sakit. Survei dilakukan kepada penduduk yang sakit di DKI Jakarta dan Jawa Barat untuk mengetahui lama sakit penduduk tersebut. Dari survei ini diperoleh statistik-statistik sebagai berikut.
DKI Jakarta Jawa Barat
1 4,20x = hari 5,75x = hari
Naskah ini masih berupa draf. Beritahu dosen Anda jika Anda menemukan beberapa saltik atau kesalahan lainnya.

173
s1 = 2,16 hari n1 = 212
s2 = 3,01 n2 = 309
Dengan tingkat kepercayaan 95%, buatlah selang kepercayaan yang mengestimasi selisih lamanya sakit penduduk DKI Jakarta dan Jawa Barat?
9. Upah Buruh. Soal ini disusun bertepatan dengan hari buruh. Oleh karena itu penulis ingin mengetahui apakah ada perbedaaan rerata upah buruh di Provinsi DI Yogyakarta dan Jawa Tengah pada tahun 2016. Berdasarkan Statistik Upah Agustus 2016, upah (dalam rupiah) sampel-sampel acak sederhana di kedua provinsi tersebut memiliki statistik-statistik sebagai berikut.
DI Yogyakarta Jawa Tengah
1 2.392.246x = s1 = 1.745.180
n1 = 84
2 3.056.295x = s2 = 4.376.320
n2 = 394 Dari sampel-sampel tersebut apakah sudah cukup bukti untuk mendukung klaim bahwa terdapat perbedaan rerata antara upah buruh di Provinsi DI Yogyakarta dan Jawa Tengah? Gunakan tingkat signifikansi 0,05.
10. Metode-Metode Ekuivalen. Misalkan Anda akan membuat kesimpulan mengenai sampel-sampel berpasangan. Apakah uji hipotesis metode nilai-P dan metode tradisional, serta selang kepercayaan akan menghasilkan kesimpulan yang sama?
11. Kebiasan Belajar. Sebagai upaya untuk memperbaiki kebiasan belajar mahasiswa, sepuluh mahasiswa dipilih secara acak untuk menghadiri seminar mengenai pentingnya pendidikan. Data berikut menunjukkan lamanya waktu (dalam jam) yang digunakan oleh mahasiswa-mahasiswa tersebut untuk belajar per minggunya sebelum dan setelah mengikuti seminar.
Naskah ini masih berupa draf. Beritahu dosen Anda jika Anda menemukan beberapa saltik atau kesalahan lainnya.

174
Sebelum Setelah 12,6 10,2 4,3 6,9 4,6 11,7
10,5 16,7 5,9 10,3
10,5 9,7 11,5 9,7 16,4 15,9 9,2 18,7
12,9 24,4 Pada tingkat signifikansi 0,05, apakah seminar tersebut efektif meningkatkan lamanya mahasiswa belajar tiap minggunya?
12. Laporan Tidur. Sebanyak 20 mahasiswa dipilih secara acak untuk melaporkan lamanya waktu tidur mereka di hari-hari kerja dan akhir pekan. Data yang diperoleh adalah sebagai berikut.
Hari Kerja Akhir Pekan Hari Kerja Akhir Pekan 5,6 5,5 6,6 9,8 6,9 8,5 6,9 6,7 7,7 8,3 7,9 4,1 7,6 9,1 6,6 6,8 7,2 5,5 6,9 7,5 7,3 6,9 7,2 11,3 6,1 4,3 7,3 11,3 8,5 9,6 6,6 12,3 6,8 4,9 5,8 10,0 8,3 9,4 6,7 8,8
Apakah sampel tersebut cukup untuk menjadi bukti bahwa terdapat perbedaan lamanya waktu tidur mahasiswa di hari-hari kerja dan akhir pekan?
13. Indeks Kualitas Air. Sebagai peneliti lingkungan hidup, Anda diminta untuk mencari tahu apakah kualitas air di Indonesia
Naskah ini masih berupa draf. Beritahu dosen Anda jika Anda menemukan beberapa saltik atau kesalahan lainnya.

175
semakin menurun dari tahun 2014 ke tahun 2015. Untuk itu, Anda melakukan pengukuran indeks kualitas air ke 10 daerah yang dipilih secara acak dan diperoleh hasil sebagai berikut.
2014 2015 2014 2015 60,67 53,89 58,00 55,33 52,48 52,35 53,71 40,71 53,71 40,71 49,11 50,33 56,29 56,29 48,49 50,67 48,49 50,67 56,67 46,00
Buatlah selang kepercayaan 95% untuk mengestimasi penurunan kualitas air di Indonesia dari tahun 2014 ke tahun 2015.
14. Normalitas Data. Misalkan Anda akan menguji perbedaan variansi dua sampel yang masing-masing berukuran n1 = 125 dan n2 = 134. Ketika Anda akan menggunakan uji F, apakah Anda tidak perlu melakukan uji normalitas kedua sampel tersebut karena sampel-sampel ini berukuran besar, n1 ≥ 30 dan n2 ≥ 30?
15. Nilai-Nilai Kritis. Diberikan hipotesis alternatif dan ukuran dua sampel seperti berikut. Jika Anda akan melakukan uji F, tentukan nilai-nilai kritisnya pada tingkat signifikansi 0,05. (a) H1: σ1
2 ≠ σ22, n1 = 31, dan n2 = 25.
(b) H1: σ12 < σ2
2, n1 = 10, dan n2 = 9. (c) H1: σ1
2 > σ22, n1 = 61, dan n2 = 41.
16. Mesin Kopi. Seorang manajer kedai kopi ingin mengetahui apakah mesin baru yang digunakan untuk menuangkan kopi ke gelas pelanggan memiliki variabilitas yang lebih rendah daripada mesin lama. Manajer tersebut kemudian mengkalibrasi mesin baru dan lama tersebut untuk mengisi gelas kopi 200 mL. Setelah digunakan selama 5 jam, dia
Naskah ini masih berupa draf. Beritahu dosen Anda jika Anda menemukan beberapa saltik atau kesalahan lainnya.
176
memilih 15 gelas secara acak dari masing-masing mesin dan diukur isi sebenarnya. Dia mendapatkan hasil sebagai berikut.
Mesin Lama Mesin Baru 200,13 200,50 199,50 200,25 199,50 200,63 200,00 200,88 198,63 199,38 199,88 200,25 200,50 200,63 198,88 200,00 199,63 200,38 201,25 200,13 200,00 200,75 200,63 199,25 199,00 202,00 199,00 201,00 199,50 199,38
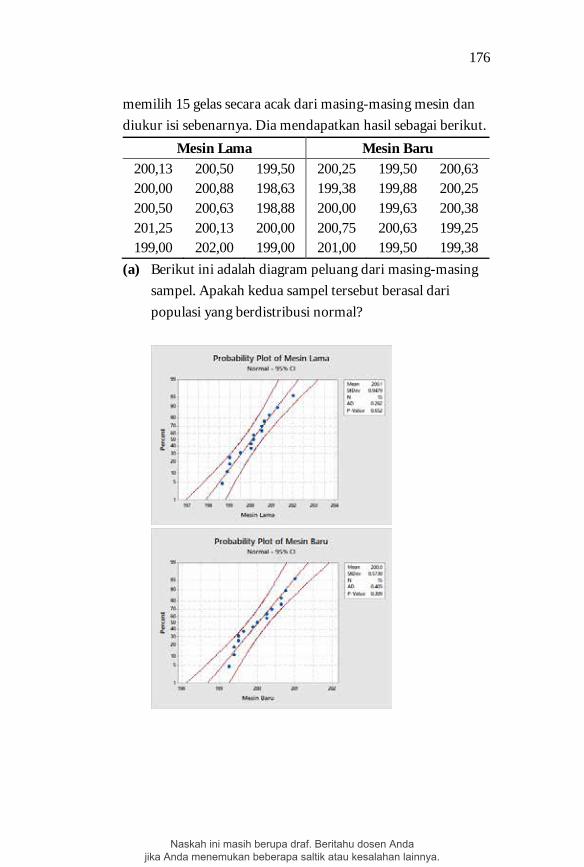
(a) Berikut ini adalah diagram peluang dari masing-masing sampel. Apakah kedua sampel tersebut berasal dari populasi yang berdistribusi normal?
Naskah ini masih berupa draf. Beritahu dosen Anda jika Anda menemukan beberapa saltik atau kesalahan lainnya.

177
(b) Gunakan tingkat signifikansi 0,05 untuk menguji klaim bahwa mesin baru memiliki variabilitas yang lebih rendah daripada mesin lama.
17. Selang Kepercayaan. Gunakan informasi pada soal nomor 15 untuk membuat selang kepercayaan 90% untuk mengestimasi perbandingan varians mesin lama dan mesin baru.
Umpan Balik dan Tindak Lanjut Dalam Bab 4 ini ada dua hal yang kita pelajari. Pertama, kita belajar bagaimana melakukan uji hipotesis untuk menguji klaim mengenai proporsi, mean, simpangan baku, atau variansi dua populasi. Kedua, kita juga telah belajar bagaimana membuat selang kepercayaan untuk mengestimasi selisih proporsi dan mean, serta perbandingan simpangan baku dan variansi dua populasi.
Dari Contoh 1 sampai Contoh 3, kita sudah melihat bagaimana data sampel digunakan untuk membuat kesimpulan mengenai proporsi dua populasi. Contoh 4 dan Contoh 5 memberikan ilustrasi bagaimana klaim mengenai mean dua populasi, baik yang bebas ataupun berpasangan, dapat diuji dengan menggunakan uji hipotesis formal. Selanjutnya, Contoh 6 memberikan penjelasan bagaimana kita bisa menentukan nilai-nilai kritis pada distribusi F. Nilai-nilai kritis ini penting ketika kita akan melakukan uji hipotesis atau membuat selang kepercayaan terkait variasi dari dua populasi. Dalam contoh terakhir, yaitu Contoh 7, kita telah dijelaskan bagaimana melakukan pengujian klaim mengenai variansi dua populasi. Uji klaim mengenai simpangan baku dua populasi bisa dilakukan dengan cara yang serupa.
Inti materi dalam bab ini adalah pembuatan kesimpulan mengenai dua populasi. Pada bab berikutnya, kita akan belajar bagaimana membandingkan lebih dari dua mean secara bersamaan dengan menggunakan analisis variansi atau sering disingkat ANOVA.
Naskah ini masih berupa draf. Beritahu dosen Anda jika Anda menemukan beberapa saltik atau kesalahan lainnya.








![Pengumpulan Uji Kelayakan Kesimpulan Dan Data Awal Kuisionereprints.umm.ac.id/40823/4/BAB III.pdf · terhadap semua sampel atau bagian populasi yang menjadi target sampel [27][28]](https://img.dokumen.tips/doc/110x75/5d1b9dd288c993283c8d74d2/pengumpulan-uji-kelayakan-kesimpulan-dan-data-awal-iiipdf-terhadap-semua-sampel.jpg)




















