Embed Size (px)
Citation preview

Intel P III-S vs. P4
Architecture & Benchmarking
Labor zur Lehrveranstaltung Rechnerstrukturen (RST)Prof. Dr. Thomas Risse
Hochschule BremenUniversity of Applied Sciences
André Ceselski (100520)Raphael Rosendahl (95437)
13. Februar 2007

Zusammenfassung
In dieser Ausarbeitung werden die Intel Prozessorarchitekturen P6und NetBurst betrachtet und ihre Unterschiede vorgestellt. Im Labor-teil dieses Dokuments wurde je ein Prozessor der beiden Architekturenmit verschiedenen Benchmarkprogrammen auf seine Leistung getestet,wobei für die P6-Architektur der Pentium III-S Tualatin 1,133 GHzund für die NetBurst-Architektur der Pentium 4 Northwood 2,0 GHzverwendet wurde. Die Tests wurden auf den Betriebssystemen Win-dows 2003 Standard Server und Ubuntu Linux 6.10 durchgeführt.Der Pentium 4 ist nicht nur aufgrund seiner Taktfrequenz schnel-ler, sondern auch aufgrund der Hyper Pipelined Technology, verbes-serten Branch Prediction und seiner Rapid Execution Unit. Die Be-fehlssatzerweiterung SSE2 läÿt bei den Benchmarks einen deutlichenGeschwindigkeitszuwachs erkennen. Bei den Rendering Benchmarksscha�te der P4 eine Leistungssteigerung von bis zu 47%, jedoch dasdamalige Verkaufsargument "Doppelte Geschwindigkeit durch doppel-ten CPU-Takt"konnte nicht bestätigt werden. Der PIII ist bei kürzerenBerechnungen gelegentlich sogar schneller. Anteil an der Performancedes P4 hat auch der Dual Data Rate-RAM (DDR-RAM). Unterschiedein den Ergebnissen der beiden Betriebssysteme zeigen, dass auch Op-timierungen an Compiler, Software und Betriebssystemen eine Rollespielen.

Inhaltsverzeichnis
1 Ziel 5
2 Architekturen 5
2.1 P6 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 52.2 NetBurst . . . . . . . . . . . . . . . . . . . . . . . . . 102.3 Neuerungen . . . . . . . . . . . . . . . . . . . . . . . . 13
3 Prozessoren 15
3.1 Intel Pentium III-S . . . . . . . . . . . . . . . . . . . . 153.2 Intel Pentium 4 . . . . . . . . . . . . . . . . . . . . . . 15
4 Erwartung 16
5 Testsysteme 16
6 Benchmarks 17
6.1 Super Pi . . . . . . . . . . . . . . . . . . . . . . . . . . 176.2 CineBench 2003 . . . . . . . . . . . . . . . . . . . . . . 196.3 BOINC . . . . . . . . . . . . . . . . . . . . . . . . . . 216.4 Pov-Ray . . . . . . . . . . . . . . . . . . . . . . . . . . 23
6.4.1 Version 3.6 . . . . . . . . . . . . . . . . . . . . 236.4.2 Version 3.7 . . . . . . . . . . . . . . . . . . . . 25
7 Auswertung 26
A Anhang 28
A.1 P4 Leistungszugewinn . . . . . . . . . . . . . . . . . . 28A.2 Benchmarkergebnisse PIII-S . . . . . . . . . . . . . . . 28A.3 Benchmarkergebnisse P4 . . . . . . . . . . . . . . . . . 28
3

Abbildungsverzeichnis
1 Intel P6 Architektur [4] . . . . . . . . . . . . . . . . . 62 Intel P6 Dynamic Execution [8] . . . . . . . . . . . . . 73 Fetch/Decode Unit [8] . . . . . . . . . . . . . . . . . . 84 Dispatch/Execute Unit [8] . . . . . . . . . . . . . . . . 85 Retire Unit [8] . . . . . . . . . . . . . . . . . . . . . . 96 NetBurst Architektur . . . . . . . . . . . . . . . . . . . 107 NetBurst Architektur (detailliert) . . . . . . . . . . . . 118 Pipeline Vergleich . . . . . . . . . . . . . . . . . . . . . 139 Register Allokation . . . . . . . . . . . . . . . . . . . . 1410 ScreenShot SuperPi (Windows Version) . . . . . . . . 1811 Ergebnisse SuperPi 1 . . . . . . . . . . . . . . . . . . . 1812 Ergebnisse SuperPi 2 . . . . . . . . . . . . . . . . . . . 1913 ScreenShot CineBench 2003 . . . . . . . . . . . . . . . 2014 Ergebnisse CineBench 2003 . . . . . . . . . . . . . . . 2015 ScreenShot BOINC (Windows Version) . . . . . . . . . 2216 Ergebnisse BOINC . . . . . . . . . . . . . . . . . . . . 2217 POV-Ray 3.6 Rendering Szene . . . . . . . . . . . . . 2318 Ergebnisse POV-Ray 3.6 . . . . . . . . . . . . . . . . . 2419 POV-Ray 3.7 Rendering Szene . . . . . . . . . . . . . 2520 Ergebnisse POV-Ray 3.7 . . . . . . . . . . . . . . . . . 26
4

Ceselski, Rosendahl Intel P III-S vs. P4
1 Ziel
Aufbau der Intel P6- und NetBurst-Archtitektur sollen in der Ausar-beitung betrachtet und Unterschiede vorgestellt werden.Im Laborteil werden je ein Prozessor der beiden Architekturen mitverschiedenen Benchmarkprogrammen und Betriebssystemen auf ihreCPU-Leistung getestet, wobei PIII-S Tualatin 1,133 GHz (P6) undPentium 4 Northwood 2,0 GHz (NetBurst)verwendet und verglichenwerden.
2 Architekturen
2.1 P6
Die P6 Architektur ist, wie der Name schon sagt, die 6. Generation derPentium Familie. Sie erschien im November 1995 und wird in folgendenProzessoren-Reihen verwendet. Das Blockschaltbild dieser Architektur�nden sie in Abbildung 1.
• Intel Pentium II
• Intel Pentium II XEON
• Intel Pentium Celeron
• Intel Pentium Celeron A
• Intel Pentium III
• Intel Pentium III XEON
Das Hauptaugenmerk der P6 Architektur ist die Dynamic Execu-tion Architecture, die auf den folgenden Seiten erläutert wird. Die P6Architektur arbeitet mit einem 64 bit breiten Daten- sowie einem 36bit breiten Adressbus. Die P6 Architektur besitzt eine superskalareRechnerstruktur. Eine weitere Neuerung gegenüber der Vorgänger Ar-chitektur ist der Dual Independent Bus (DIB). Der DIB ist ein Bus,welcher den L2-Cache mit der CPU direkt verbindet. So muss derDatenstrom nicht mehr über den eventuell ausgelasteten Systembus�ieÿen, sondern kann die Daten schnell an die CPU liefern. [7]
5

Ceselski, Rosendahl Intel P III-S vs. P4
Abbildung 1: Intel P6 Architektur [4]
Dynamic Execution Architektur Die Dynamic Execution Arch-tiketur besitzt unter anderem die Data Flow Analysis. Mit deren Hilfeist es möglich, dass die Daten analysiert werden. So kann durch out-of-order Execution der Instruktionen eine non-blocking Architektur er-möglicht werden, die processor stalls während Cache-, Hauptspeicher-und I/O-Zugri�en vorbeugt. Die ergegnisunabhängigen Instruktionenwerden out-of-order ausgeführt, während die ergebnisabhängigen In-struktionen in Programmreihenfolge ausgeführt werden, sobald ihreOperanden bereit stehen.Ein weiterer Punkt ist die Spekulative Ausführung und die Sprung-vorhersagen. Hier werden Ausführungen spekulativ ausgeführt, sodasssie im evtuell späteren Verlauf schon berechnet vorliegen.Da die P6 Architektur nur acht general purpose Register zur Verfü-gung stellt, werden durch Register Renaming nicht benötigte der 40physikalischen Register umbenannt und genutzt. Das Blockschaltbild,welches die drei Haupteinheiten (Fetch/Decode-, Dispatch/Execute-,Retire Units) zeigt, be�ndet sich in Abbildung 2.
6

Ceselski, Rosendahl Intel P III-S vs. P4
Abbildung 2: Intel P6 Dynamic Execution [8]
Fetch/Decode Einheit Die Fetch Decode Einheit fungiert als in-order Pipeline. Im ICache liegen Instruktionen, so dass die CPU beiBedarf schnell darauf zugreifen kann. Die Instruktionen werden von derBus Interface Unit (BIU) angeliefert. Die Next_IP Einheit wird vomBTB gesteuert und zeigt so auf die vorhergesagte Instruktion. Der 512Einträge groÿe Branch Target Bu�er (BTB) benutzt für die Sprung-vorhersage eine Erweiterung des Yeh Algorithmus, um eine Sprung-vorhersagegenauigkeit von über 90% zu gewährleisten. [8]Der ICache lädt die Cachezeile anhand des Next_IP Zeigers, und über-gibt diese an die drei parallel arbeiteten Decoder. Die meisten Instruk-tionen werden direkt in eine µ-op decodiert. Die komplexen Instruk-tionen werden in der Microcode Instruction Sequencer Einheit(MIS)als gespeicherte µ-ops Sequenzen decodiert.Anschliessend werden die µ-ops an die RAT (Register Alias Table)geschickt, wo sie dann in die P6 konformen Register umgewandeltwerden. Verdeutlicht wird dies im Blockschaltbild in der Abbildung3.[8]
7

Ceselski, Rosendahl Intel P III-S vs. P4
Abbildung 3: Fetch/Decode Unit [8]
Dispatch/Execute Einheit Die Dispatch Unit selektiert die µ-ops aus dem Instruktions-Pool entsprechend ihres Status. Wenn für dieµ-op alle Operanden vorhanden sind und die Execution Unit frei ist, sowird die Instruktion an die entsprechende Execution Unit gesendet undabgearbeitet. Das Ergebnis dieser Instruktion wird im Instruction Poolgespeichert. Verdeutlicht wird dies im Blockschaltbild in der Abbildung4.[8]
Abbildung 4: Dispatch/Execute Unit [8]
8

Ceselski, Rosendahl Intel P III-S vs. P4
Retirement Einheit Die Retirement Unit überprüft den Statusder Instuktionen im Instruktions-Pool und sucht die bereits ausge-führten µ-ops. Die Retirement Einheit muss aber auch die richtigeReihenfolge der Befehle wiederherstellen. Die Retirement Unit suchtim Instruction Pool nach der richigen Reihenfolge. Das Ergebnis wirdeinerseits zurück in den Instruction Pool sowie in das Register Reti-rement File (RRF) geschrieben. Die Retirement Einheit kann 3 µ-ops/ clock aussetzen. Veranschaulicht wird dies im Blockschaltbild in derAbbildung 5.[8]
Abbildung 5: Retire Unit [8]
9
Ceselski, Rosendahl Intel P III-S vs. P4
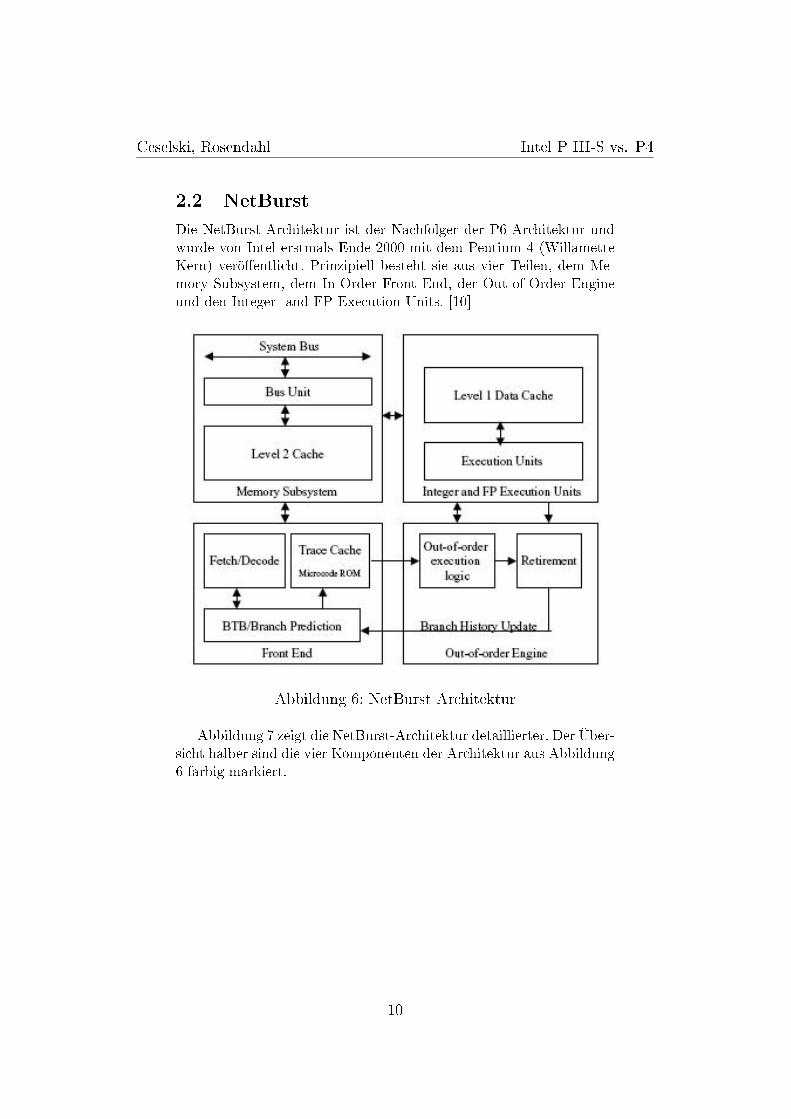
2.2 NetBurst
Die NetBurst-Architektur ist der Nachfolger der P6-Architektur undwurde von Intel erstmals Ende 2000 mit dem Pentium 4 (WillametteKern) verö�entlicht. Prinzipiell besteht sie aus vier Teilen, dem Me-mory Subsystem, dem In-Order Front End, der Out-of-Order Engineund den Integer- and FP Execution Units. [10]
Abbildung 6: NetBurst Architektur
Abbildung 7 zeigt die NetBurst-Architektur detaillierter. Der Über-sicht halber sind die vier Komponenten der Architektur aus Abbildung6 farbig markiert.
10

Ceselski, Rosendahl Intel P III-S vs. P4
Abbildung 7: NetBurst Architektur (detailliert)
Memory Subsystem Farblich nicht markiert ist das Memory Sub-system (rechts in der Abbildung) mit dem Front Side Bus QDR (QuadData Rate). Es beinhaltet den L2 Cache, die Bus Interface Unit (BIU)und den Systembus.Im L2 Cache werden Instruktionen und Daten gespeichert, die nichtmehr im L1 Trace Cache und L1 Daten Cache passen und von der BIUangeliefert werden.Der Systembus wird verwendet, um im Falle eines L2 Cache-Miss aufden Hauptspreicher zuzugreifen und auf die System I/O-Resourcen.[10]
In-Order Front End Das blaue Kästchen zeigt das In-Order FrontEnd. Es holt und decodiert die Befehle, unter Berücksichtigung derSprungvorhersage-Logik, und speichert die µOps im L1 Trace Cache.Die neue Sprungvorhersage-Logik ist zweigeteilt und besteht aus demFront-End BTB (Branch Target Bu�er) und dem Trace Cache BTB.Der Front-End BTB tri�t die Vorhersage für die nächsten IA-32-Instruk-tionen, die vom Prefetcher geholt und vom Instruction Decoder in Mi-croinstruktionen übersetzt werden und anschlieÿend im Trace Cachegespeichert werden.Der Trace Cache BTB tri�t die Vorhersagen für die Microinstruktionenim L1 Trace Cache. Nur wenn eine Microinstruktion nicht im TraceCache vorhanden ist, wird sie vom Prefetcher aus dem L2 Cache ge-laden. Da die bereits decodierten Microinstruktionen im Trace Cache
11

Ceselski, Rosendahl Intel P III-S vs. P4
vorliegen, ist es meist nicht erforderlich die Instruktionen erneut vomInstruction Decoder decodieren zu lassen (z.B. in Schleifen). Durchdiesen Bypass des Decoders wird die Performance gesteigert.Das Microcode ROM wird gebraucht bei Fehler- und Interrupt hand-ling, sowie komplexen IA-32 Instruktionen (> 4µOps), beispielsweisestring move-Befehl. [10]
Out-of-Order Engine Darunter, in gelb gerahmt, ist die Out-of-Order Engine. Sie bereitet die Instruktionen zur Ausführung in der20-stu�gen Pipeline vor. Dies beinhaltet das Weiterreichen von Ergeb-nisunabhängigen Instruktionen an die Execution Units, sowie das Wie-derherstellen der Reihenfolge der Instruktionen aus dem Programm.Sie sorgt für eine möglichst hohe Auslastung der Execution Units undgibt Rückmeldung an die Sprungvorhersage-Logik in Form von einemSprungvorhersage History Update.Die Execution Units werden mit einem möglichst hohen Strom vonInstruktionen (126 µOps zur Zeit) versorgt. Dabei gibt die executionlogic Instruktionen out-of-order weiter oder sortiert die Microinstruk-tionen in ihrer ursprünglichen Programmreihenfolge und gibt diese zurVerarbeitung weiter, sobald ihre Operanden bereit stehen.Beim Register Renaming werden die acht IA-32 Register auf die 128physikalischen Register der CPU übertragen. So können mehrere In-stanzen eines Registers (z.B. EAX) existieren, wobei jedes Registerund welches den aktuellen Wert enthält in der Register Alias Table(RAT) gespeichert ist.Mehrere Scheduler bestimmen, ob eine Microinstruktion bereit zurAusführung ist, indem die Scheduler die Eingabeoperanden verfolgen.Sind die Operanden bereit, werden die Instruktionen wieder in dieProgrammreihenfolge gebracht, Operanden unabhängige Instruktionenwerden sofort an die Execution Units weitergeleitet.Ein Branch History Update wird von der Retirement-Unit, die auchfür das re-ordering zuständig ist, an das Front End gemeldet, um dieAnzahl der Sprungfehlvorhersagen zu reduzieren. [10]
Integer and FP Execution Units Hier werden die Instruktionausgeführt. Register Files, die Integer und Floating-Point Operandenzur Ausführung speichern, L1 Daten Cache, Adress Generation Units(AGUs), sowie Integer- (ALUs) und Floating-Point Execution Units(FPUs) sind hier untergebracht. ALUs für die Ausführung einfacherInterger-Operationen arbeiten mit doppeltem CPU-Takt. [10]
12

Ceselski, Rosendahl Intel P III-S vs. P4
2.3 Neuerungen
Hyper Pipelined Technology Die Misprediction-Pipeline wur-de von Intel für den Pentium 4 auf 20 Stufen aufgestockt [10] (inspäteren P4 nochmals erweitert). Die Pipelines der Architekturen sindin Abbildung 8 gezeigt.
Abbildung 8: Pipeline Vergleich
Durch verkürzte Pipelinestufen und weniger Arbeit während derStufen kann die Taktrate viel höher verglichen zur P6-Architektur sein(fewer gates of logic). Allerings ergeben sich bei einer längeren Pipe-line gröÿere Strafzeiten bei einer falschen Sprungvorhersage, was eineVerbesserung der Misprediction erforderte. [10]
Branch Prediction Um die Strafzeiten bei Fehlvorhersagen ge-ring zu halten, hat Intel bei der NetBurst-Architektur einen neuenAlgorithmus eingesetzt, der die Sprungvorhersagegenauigkeit im Ver-gleich zur P6-Architektur um 1
3 verbessert. Er wird von beiden Teilender Branch Prediction genutzt: zum Einen von dem Front End BTB,der die Vorhersage für die IA-32 Instruktionen tri�t, zum Anderen vomTrace Cache BTB für die Vorhersage der nächsten µOps im L1 TracheCache. [10]
L1 Trache Cache Im L1 Trace Cache werden 12KµOps gehal-ten, also bereits decodierte Instruktionen, die von der Out-of-OrderEngine an die Execution Units weitergegeben werden. Dies bringt ei-ne Performanceerhöhung, da Instruktionen nur geholt und decodiertwerden müssen, wenn die benötigte Microinstruktion nicht im TraceCache vorrätig ist. [10]
Front Side Bus Quad Data Rate Der quadpumped 100 MHzBus erreicht eine Rate von 3,2 GB/s (4 * 108 1
s * 8 Byte), da er in derLage ist, je Takt vierfach 8 Byte zu übertragen. [10]
13

Ceselski, Rosendahl Intel P III-S vs. P4
Rapid Execution Unit Intel nannte die Simple Instruction ALUs,die Operationen in einem halben CPU-Takt ausführen können, Ra-pid Execution Unit. Dies steigert die Performance, verdoppelt sie abernicht, da nicht alle Operationen mit doppeltem CPU-Takt bearbeitetwerden können. [10]
SSE2 Streaming SIMD Extension 2 ist eine Befehlssatzerweiterungund fügt 144 neue 128-bit Single Instruction Multiple Data (SIMD)Befehle hinzu, die die Performance u.a. bei Multi-media Anwendungenbeschleunigt. [10][1]
Register allocation Bei der P6-Architektur wurden noch Ergeb-nisdaten und Status zusammen als langer Eintrag, bestehend aus Daten-und Statusfeld, im Re-order Bu�er(ROB) gespeichert. Wurden dieDaten für eine gewisse Zeit nicht gebraucht, wurden sie physikalischins Retirement Register File (RRF) kopiert. Der Register Alias Table(RAT) zeigt immer auf den aktuellsten Wert eines Registers, der ent-weder im ROB oder im RRF sein kann.NetBurst speichert Daten und Status getrennt. Es �ndet kein physi-kalisches Kopieren mehr während des Retirements statt, sondern derZeiger vom RAT wird vom Retirement RAT übernommen.[10]Die beiden Verfahrensweisen sind in der Abbildung 9 illustriert.
Abbildung 9: Register Allokation
14

Ceselski, Rosendahl Intel P III-S vs. P4
3 Prozessoren
3.1 Intel Pentium III-S
• Codename Tualatin
• Erscheinungsdatum: Juni 2001
• Taktfrequenz 1,133 GHz
• L1-Cache: 16 KB + 16 KB (Daten + Instruktionen)
• L2-Cache: 512 KB mit Prozessortakt
• MMX, SSE
• 133 MHz Front Side Bus
• Betriebsspannung (VCore): 1,45 V
• Fertigungstechnik: 130 nm
• Die-Gröÿe: 80 mm2 bei 44 Millionen Transistoren
• Imax = 20.1 A, Pmax = 29.1 W, Tmax = 69.0 oC [2][9]
3.2 Intel Pentium 4
Der Intel P4, für den die NetBurst-Architektur entworfen wurde, istder Nachfolger des PIII.Eigesetzt wurde hier der Pentium 4 Northwood 2,0 GHz, der ebenfalls,wie der Pentium III-S Tualatin 1,133 GHz, in der 130nm Fertigungs-technik hergestellt.
• Codename Northwood
• Erscheinungsdatum: Januar 2002
• Taktfrequenz 2,0 GHz
• L1-Cache: 8 KB (Daten) + 12.000 µOps
• L2-Cache: 512 KB mit Prozessortakt
• MMX, SSE, SSE2
• 100 MHz Front Side Bus QDR (Quad Data Rate, FSB 400)
• Betriebsspannung (VCore): 1,5 V
• Fertigungstechnik: 130 nm
• Die-Gröÿe: 146 mm2 bei 55 Millionen Transistoren
• Imax = 44.3 A, Pmax = 52.4 W, Tmax = 68.0 oC [3][1]
15

Ceselski, Rosendahl Intel P III-S vs. P4
Die au�älligsten Merkmale in den Details liegen in der Befehls-satzerweiterung SSE2 für Multimediaanwendungen, dem quadpumpedFront Side Bus, dem L1 Trace Cache für Micro-Instruktionen, der Die-Gröÿe von 146 mm und einem mehr als doppelt hohen Maximalstromvon 44.3 Ampere.
4 Erwartung
Es ist zu erwarten, dass der P4 sich im Benchmark behaupten wirdund den PIII-S schlägt. Auch wenn der P4 annähernd einen doppeltenCPU-Takt hat, wird eine Bestätigung des Verkaufsargument �Doppel-te Taktfrequenz - Doppelte Leistung� nicht erwartet. Um dieses Argu-ment zu bestätigen, müsste der P4 in einem Benchmark ohne SSE2-Optimierung über 100% Leitungsgewinn erzielen, da auch zu berück-sichtigen ist, dass der P4 einen DDR-RAM (Dual Data Rate) nutzt.Dies würde einen Beschleunigungsfaktor β = βPIII→P4 von gröÿer 2erfordern. Als einen weiteren Faktor der Performancesteigerung solltesich die SSE2-Befehlssatzerweiterung zeigen.
5 Testsysteme
Die Prozessoren wurden auf Mainboards getestet, die einen Intel Chip-satz verwenden und wurden mit 512 MB Arbeitsspeicher betrieben.Zum Einsatz kamen als Betriebssystem zum Einen Ubuntu Linux 6.10,sowie Windows 2003 Standard Server. Tabelle 1 zeigt die Testsystemein der Gegenüberstellung.Für den Benchmark wurden die Rechner entsprechend vorbereitet, d.hes wurde ein neues Windows 2003 Standard Server Betriebssystem in-stalliert und die Gröÿe des Arbeitsspeichers wurde angepasst. Die Gra-�kkarten sind zwar unterschiedlich leistungsfähig, aber bei den Bench-marks spielt die Gra�kkartenleistung eine untergeordnete Rolle, da dergröÿte Teil des Workloads im Cache und Hauptspeicher statt �ndet.
16

Ceselski, Rosendahl Intel P III-S vs. P4
Tabelle 1: Testsysteme
6 Benchmarks
6.1 Super Pi
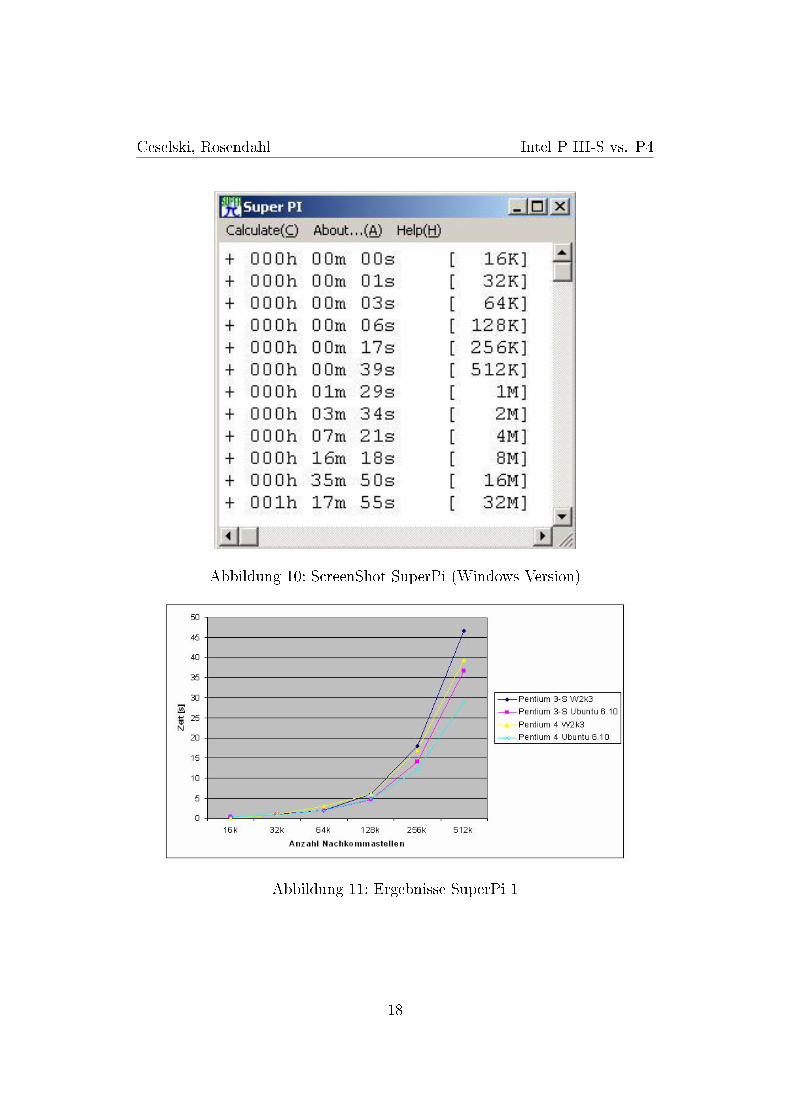
Das Benchmark Programm Super-Pi berechnet Pi auf mehrere Mil-lonen Stellen nach dem Komma. Die Anzahl der Stellen kann hierbeiangegeben werden. Bei der Windows Version stehen 214 (16384 = 16K)bis 225 (33554432 = 32M) Nachkommastellen zur Auswahl und könnenüber ein GUI ausgewählt werden. Für das Betriebssystem Linux wurdeeine andere Version des Programms benutzt. Diese funktioniert ohneGUI nur auf der Konsole. Als Parameter muss jeweils der Exponentzur Basis 2 angegeben werden, um die entsprechende Anzahl an Nach-kommastellen zu berechnen. Für Windows wurde Version 1.1e und fürLinux Version 2 benutzt. Das Programm ist schon etwas betagt unddeswegen fehlt hier die SSE2 Unterstützung. In Abbildung 10 siehtman das Ergenisfenster der Windows Version, in dem links die Be-rechnungszeit und rechts daneben die Anzahl der Nachkommastellendes jeweiligen Tests zu sehen ist.
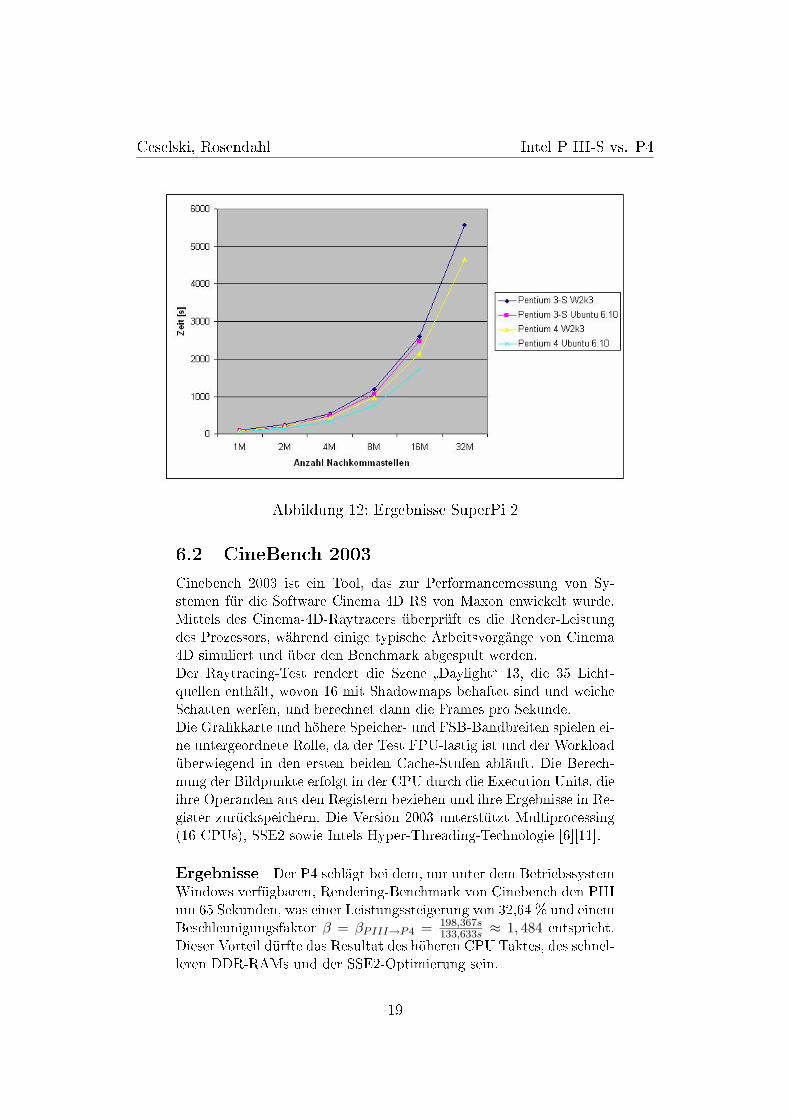
Ergebnisse Bei diesem Benchmark fällt auf, dass der Intel Pen-tium III-S und der Intel Pentium 4 dicht zusammenliegen. Erst beiden längeren Berechnungnen kann der Intel Pentium 4 seine Stärkenaufgrund der höheren Taktfrequenz ausspielen. Ein Beschleunigungs-faktor β = βPIII→P4 < 2 ergibt sich aus der Tatsache, dass der P4nicht die doppelte Taktfrequenz des P3 besitzt ( 2GHz
1,133GHz ≈ 1, 765) undbei der �oating point Berechnung auf die SSE2-Befehlssatzerweiterungoptimiert ist. (siehe Abbildung 11 und 12).
17
Ceselski, Rosendahl Intel P III-S vs. P4
Abbildung 10: ScreenShot SuperPi (Windows Version)
Abbildung 11: Ergebnisse SuperPi 1
18
Ceselski, Rosendahl Intel P III-S vs. P4
Abbildung 12: Ergebnisse SuperPi 2
6.2 CineBench 2003
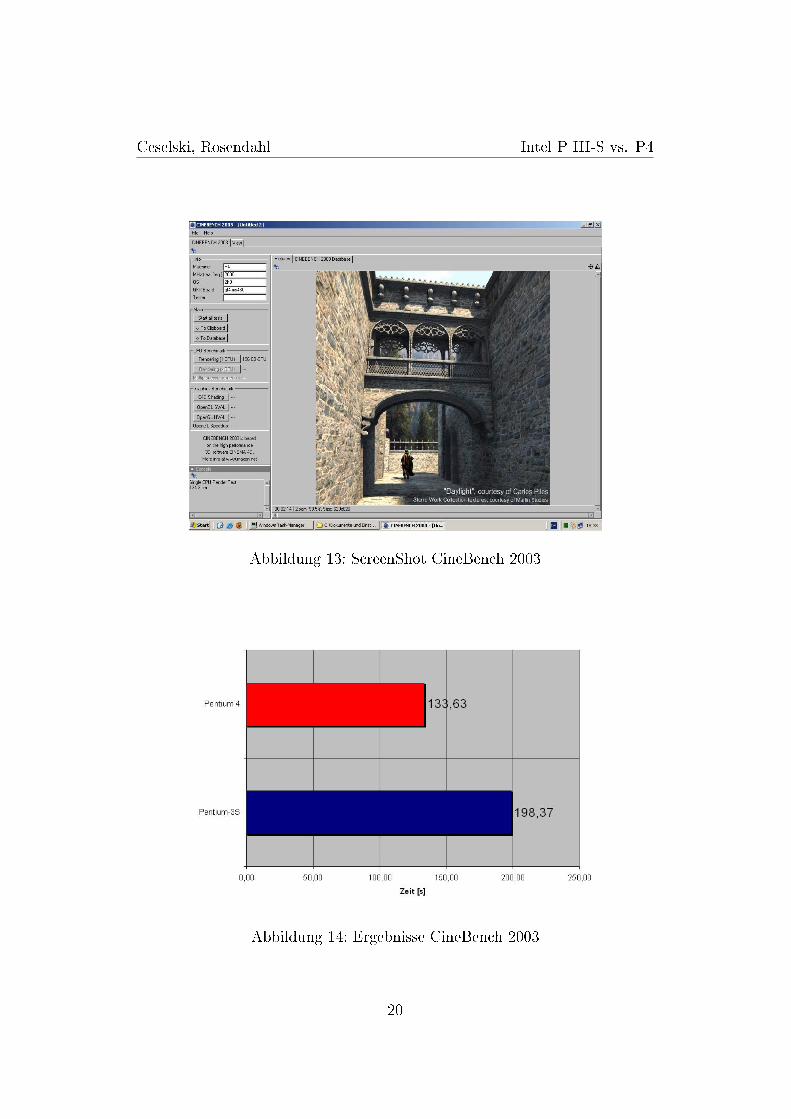
Cinebench 2003 ist ein Tool, das zur Performancemessung von Sy-stemen für die Software Cinema 4D R8 von Maxon enwickelt wurde.Mittels des Cinema-4D-Raytracers überprüft es die Render-Leistungdes Prozessors, während einige typische Arbeitsvorgänge von Cinema4D simuliert und über den Benchmark abgespult werden.Der Raytracing-Test rendert die Szene �Daylight� 13, die 35 Licht-quellen enthält, wovon 16 mit Shadowmaps behaftet sind und weicheSchatten werfen, und berechnet dann die Frames pro Sekunde.Die Gra�kkarte und höhere Speicher- und FSB-Bandbreiten spielen ei-ne untergeordnete Rolle, da der Test FPU-lastig ist und der Workloadüberwiegend in den ersten beiden Cache-Stufen abläuft. Die Berech-nung der Bildpunkte erfolgt in der CPU durch die Execution Units, dieihre Operanden aus den Registern beziehen und ihre Ergebnisse in Re-gister zurückspeichern. Die Version 2003 unterstützt Multiprocessing(16 CPUs), SSE2 sowie Intels Hyper-Threading-Technologie [6][11].
Ergebnisse Der P4 schlägt bei dem, nur unter dem BetriebssystemWindows verfügbaren, Rendering-Benchmark von Cinebench den PIIIum 65 Sekunden, was einer Leistungssteigerung von 32,64 % und einemBeschleunigungsfaktor β = βPIII→P4 = 198,367s
133,633s ≈ 1, 484 entspricht.Dieser Vorteil dürfte das Resultat des höheren CPU Taktes, des schnel-leren DDR-RAMs und der SSE2-Optimierung sein.
19
Ceselski, Rosendahl Intel P III-S vs. P4
Abbildung 13: ScreenShot CineBench 2003
Abbildung 14: Ergebnisse CineBench 2003
20

Ceselski, Rosendahl Intel P III-S vs. P4
6.3 BOINC
BOINC (Berkeley Open Infrastructure for Network Computing) ImJuni 2004 begann die Ablösung des seit Mai 1999 laufende DistributedComputing Projektes SETI@home Classic. Nach den Vorstellungender Universität von Kalifornien, Berkeley soll mit BOINC (BerkeleyOpen Infrastructure for Network Computing) eine neue Infrastrukturdie positiven Erfahrungen von SETI@home Classic umsetzen und des-sen Nachteile vermeiden.BOINC soll die monolithische Einheit von Projekt und Infrastrukturbeenden, die bei SETI@home bisher nur für einen Zweck - die Suchenach Signalen aus dem Weltraum - genutzt werden kann.Im zweistu�gen Aufbau wird BOINC die Entwicklung der Technik fürVerwaltung und Verteilung von Daten und Programmen, die Teilneh-merverwaltung und die Statistiken usw. übernehmen. Die wissenschaft-lichen Projekte wie SETI@home und Astropulse aus Berkeley, aberauch beliebige andere Projekte, wie z.B. Predictor@home oder Cli-matePrediction.net, brauchen sich dieser Techniken dann nur noch zubedienen.Jedes Projekt muss eine eigene Serverinfrastruktur bereitstellen. Meh-rere redundante Server zur Lastverteilung und Erhöhung der Verfüg-barkeit sind möglich. Der Projektteilnehmer muss sich für jedes Pro-jekt anmelden, erhält jeweils eine Account ID und muss auf seinemheimischen PC das BOINC Clientprogramm installieren.Innerhalb des BOINC Netzwerkes werden die Accountinformationenund Kon�gurationen zwischen den Projekten ausgetauscht, sodass all-gemeine Einstellungen an jedem Server vorgenommen werden könnenbei dem der Teilnehmer eine Account ID hat. Eingestellt werden kön-nen dann z. b. auch Dinge wie die Pu�erung von WU's, die Nutzungvon Festplattenplatz und Netzwerkbandbreite, sowie die Aufteilungder Ressourcen unter den Projekten.Hier ist ein Benchmark eingebunden, der bei jedem Start von BOINCdie Rechenleistung ermittelt und so die Anzahl der zu berechnendenPakete berechnet, damit diese in der vorgegebenen Zeit berechnet wer-den können. Der Benchmark ist in 2 Teile aufgeteilt. Einerseits wer-den Integer Berechnungen in integer-MIPS (million instruktions persecond) und andereseits Gleitkomma Berechnungen in �oatingpoint-MIPS gemessen.[12] (integer-MIPS = Dhrystones; �oatingpoint-MIPS= Whetstones)
21

Ceselski, Rosendahl Intel P III-S vs. P4
Abbildung 15: ScreenShot BOINC (Windows Version)
Abbildung 16: Ergebnisse BOINC
Ergebnisse Das Ergebnis bei diesem Benchmark ist ungewöhnlich,da der Pentium III den P4 in der Floatberechnung schlägt. Dies resul-tiert aus der längeren Pipeline des P4, deren Inhalt vermutlich häu�gerungültig wird. Die dadurch erfoderlichen Neuberechnungen ziehen ho-he Strafzeiten nach sich. Der Pentium 4 ist der klar bessere, wennauch mit einem Manko in der Floatingpoint-Berechnung. Im Integer-benchmark sieht es anders aus, bei dem sich der Vorteil der RapidExecution Unit des Pentium 4 bemerkbar zu machen scheint. Der Be-
22

Ceselski, Rosendahl Intel P III-S vs. P4
schleunigungsfaktor βPIII→P4 fällt erwartungsgemäÿ kleiner 2 aus, dadas CPU-Taktverhältnis kleiner 2 und die NetBurst Architektur undder DDR-RAM dies nicht zu kompensieren vermögen.
6.4 Pov-Ray
Pov-Ray steht für Persistence of Vision Raytracer und ist ein RayTracing Tool, beinhaltet einen Benchmark und ist frei verfügbar. Esrendert während des Benchmarks eine Szene und ermittelt die CPU-Leistung. Pov-Ray ist aktuell in der Version 3.7, jedoch wurde auchunter der Version 3.6 getestet. Die Tests der beiden Versionen sindnicht vergleichbar, da sie unterschiedliche Szenen berechnen. [5].
6.4.1 Version 3.6
In der Version 3.6 fehlt die SSE2-Optimierung und lässt einen Vergleichder Prozessoren zu, ohne die neue Befehlssatzerweiterung des P4 zunutzen.Im Benchmark wird die Szene der Abbildung 17 mit dem Raytracerberechnet und gerendert.
Abbildung 17: POV-Ray 3.6 Rendering Szene
23
Ceselski, Rosendahl Intel P III-S vs. P4
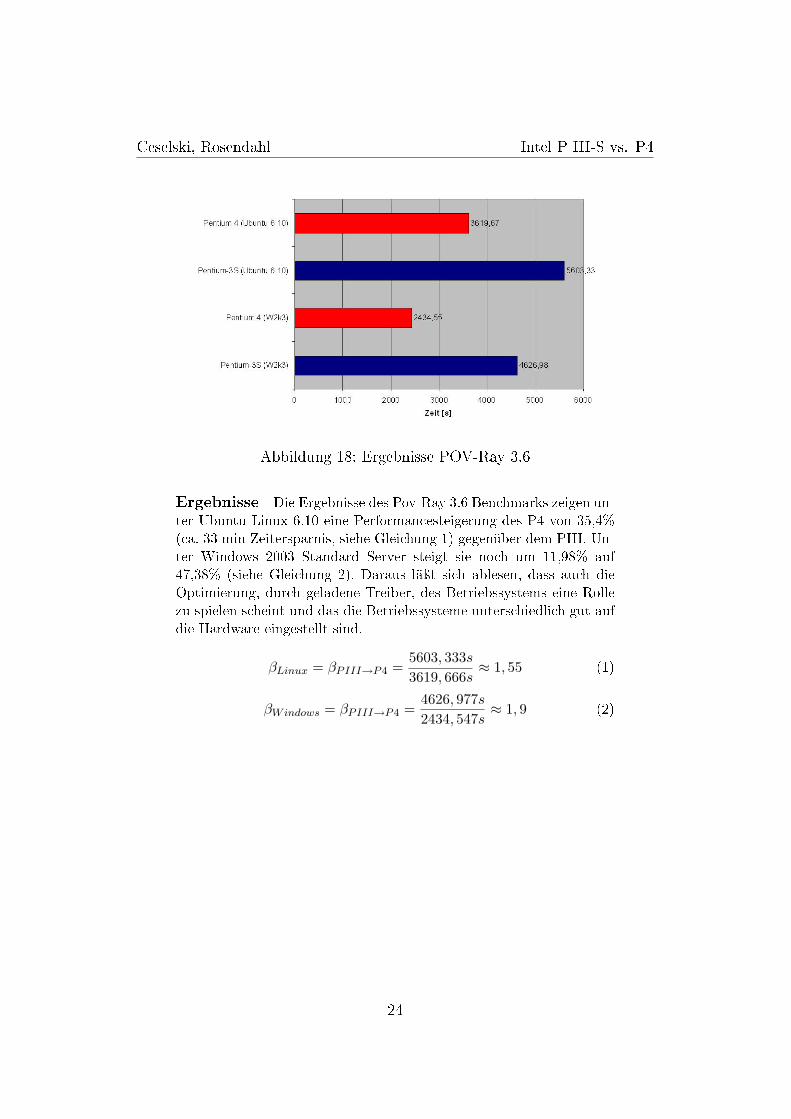
Abbildung 18: Ergebnisse POV-Ray 3.6
Ergebnisse Die Ergebnisse des Pov-Ray 3.6 Benchmarks zeigen un-ter Ubuntu Linux 6.10 eine Performancesteigerung des P4 von 35,4%(ca. 33 min Zeitersparnis, siehe Gleichung 1) gegenüber dem PIII. Un-ter Windows 2003 Standard Server steigt sie noch um 11,98% auf47,38% (siehe Gleichung 2). Daraus läÿt sich ablesen, dass auch dieOptimierung, durch geladene Treiber, des Betriebssystems eine Rollezu spielen scheint und das die Betriebssysteme unterschiedlich gut aufdie Hardware eingestellt sind.
βLinux = βPIII→P4 =5603, 333s
3619, 666s≈ 1, 55 (1)
βWindows = βPIII→P4 =4626, 977s
2434, 547s≈ 1, 9 (2)
24

Ceselski, Rosendahl Intel P III-S vs. P4
6.4.2 Version 3.7
Die Benchmarks der Version 3.7 wurden für den Pentium 4 ohne undmit SSE2-Optimierung durchgeführt. Leider war es nicht möglich, die-se Version unter Ubuntu Linux 6.10 zum Laufen zu bringen. Nach In-stallation der Software konnte diese nicht gestartet werden, aufgrundangeblich fehlender Dateien, die jedoch, in den der Fehlermeldung an-gegebenen Pfaden, vorhanden waren. Deshalb wurde die Szene derAbbildung 19 mit dem Raytracer nur unter Windows berechnet undgerendert.
Abbildung 19: POV-Ray 3.7 Rendering Szene
Ergebnisse Ein erheblicher Leistungsgewinn des P4, bei Verwen-dung der SSE2-Optimierung, ist zu beobachten. Beträgt der Perfor-mancegewinn ohne SSE2 nur 10,8% (ca. 3,5 min. Ersparnis, siehe Glei-chung 3) gegenüber dem PIII, steigt er mit SSE2 auf 41,7% (ca. 14 min.Ersparnis, siehe Gleichung 4). Das bedeutet einen Leistungsgewinn von30% allein durch die Befehlssatzerweiterung SSE2.
βWindows = βPIII→P4−SSE2 =1982, 11s
1767, 97s≈ 1, 12 (3)
βWindows = βPIII→P4+SSE2 =1982, 11s
1155, 52s≈ 1, 72 (4)
25

Ceselski, Rosendahl Intel P III-S vs. P4
Abbildung 20: Ergebnisse POV-Ray 3.7
7 Auswertung
Die Benchmarkergebnisse zeigen, dass der Pentium 4, wie erwartet, diebesseren Ergebnisse erzielt. Er steigert die Performance bei den mei-sten Tests bis zu 30%, welches ein Beschleunigungsfaktor β ≈ 1, 43 ent-spricht. Bei den Rendering Tests erreicht er sogar einen Zuwachs von47%, was einen Beschleunigungsfaktor β ≈ 1, 9 entspricht. Hier zeigtsich der Vorteil des neuen SSE2-Befehlssatzes deutlich. Aber nicht nurSSE2 und der höhere CPU-Takt bringen den Performancegewinn al-lein, sondern auch der schnellere DDR-RAM. In einigen Benchmarksliefert der PIII ähnliche, teilweise bessere Ergebnisse. Die Tests zeigten,dass Optimierungen, beispielsweise an Compilern und Betriebssyste-men, ebenfalls eine wichtige Rolle spielen.Es ist zu erwähnen, dass Benchmarks nicht eine reale Nutzung einesRechners durch einen Benutzer widerspiegeln, sondern immer nur spe-zielle Anwendungen testen.
Die Erwartungen an die Ergebnisse wurden bestätigt und das Ver-kaufsargument widerlegt.
26

Ceselski, Rosendahl Intel P III-S vs. P4
Quellenverzeichnis
[1] Activenetwork cpu architecture. http://www.activewin.com/
reviews/hardware/processors/intel/p42ghz/designsse.
shtml. (accessed 13 February 2007).
[2] Balusc pentium !!! http://balusc.xs4all.nl/srv/
har-cpu-int-p3.php. (accessed 13 February 2007).
[3] Balusc pentium 4. http://balusc.xs4all.nl/srv/
har-cpu-int-p4.php. (accessed 13 February 2007).
[4] New fault into the old bellows. conroe: the grandson of processorpentium iii, the nephew of architecture netburst? http://www.
ixbt.com/cpu/p6-nexgen.shtml. (accessed 13 February 2007).
[5] Persistence of vision raytracer. http://www.povray.org/. (ac-cessed 13 February 2007).
[6] Computer Base. Cinebench. http://www.computerbase.de/
downloads/software/benchmarks/cinebench/. (accessed 13 Fe-bruary 2007).
[7] Intel Corporation. The p6 architecture: Background informationfor developers. http://www.x86.org/ftp/manuals/686/p6arc.
pdf, 1995. (accessed 13 February 2007).
[8] Intel Corporation. Tour of the p6. http://www.x86.org/ftp/
manuals/686/p6tour.pdf, 1995. (accessed 13 February 2007).
[9] Intel Corporation. P6 family of processors - hardwa-re developers manual. http://download.intel.com/design/
PentiumII/manuals/24400101.pdf, 1998. (accessed 13 February2007).
[10] Hinton G. et al. The microarchitecture of the pentium 4 proces-sor. ftp://download.intel.com/technology/itj/q12001/pdf/art_2.pdf, 2001. (accessed 13 February 2007).
[11] IDG Business Media GmbH. Cinebench 2003. http:
//www.tecchannel.de/technologie/prozessoren/434002/
index10.html, 2006. (accessed 13 February 2007).
[12] University of California. Berkeley open infrastructure for networkcomputing. http://boinc.berkeley.edu/, 2007. (accessed 13February 2007).
27

Ceselski, Rosendahl Intel P III-S vs. P4
A Anhang
A.1 P4 Leistungszugewinn
A.2 Benchmarkergebnisse PIII-S
A.3 Benchmarkergebnisse P4
28
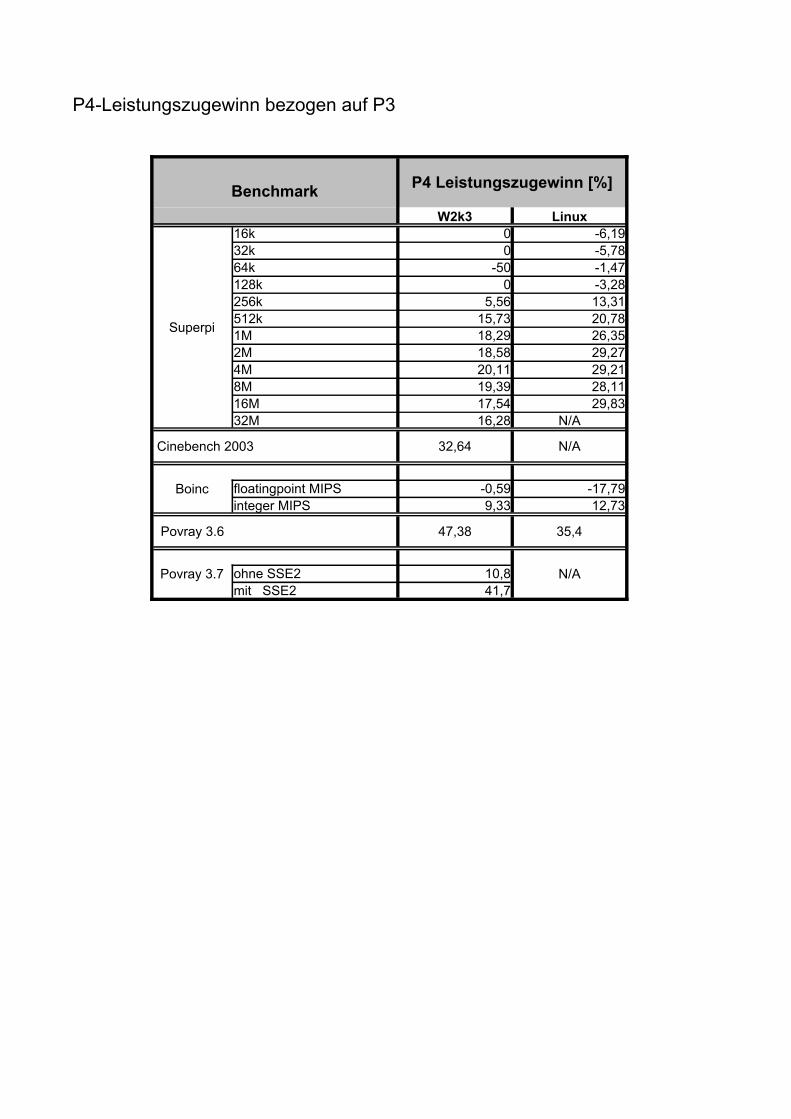
BenchmarkW2k3 Linux
16k 0 -6,1932k 0 -5,7864k -50 -1,47128k 0 -3,28256k 5,56 13,31512k 15,73 20,781M 18,29 26,352M 18,58 29,274M 20,11 29,218M 19,39 28,1116M 17,54 29,8332M 16,28 N/A
32,64 N/A
-0,59 -17,79integer MIPS 9,33 12,73
47,38 35,4
N/Aohne SSE2 10,8mit SSE2 41,7
P4-Leistungszugewinn bezogen auf P3
P4 Leistungszugewinn [%]
Superpi
Cinebench 2003
Boinc floatingpoint MIPS
Povray 3.6
Povray 3.7

BenchmarkPIIIS
W2k3 LinuxI II III Mittelwert I II III Mittelwert
[s] [s] [s] [s] [s] [s] [s] [s]16k 0 0 0 0,000 0,43 0,44 0,44 0,43632k 1 1 1 1,000 0,9 0,9 0,9 0,89964k 2 2 2 2,000 1,98 1,97 1,96 1,972128k 6 6 6 6,000 4,6 4,69 4,62 4,636256k 18 18 18 18,000 14,06 14,02 14,06 14,046512k 46 47 47 46,667 36,66 36,66 36,56 36,6251M 108 110 110 109,333 90,62 90,51 90,61 90,5832M 259 263 264 262,000 207,42 207,43 209,11 207,9864M 544 553 554 550,333 485,87 484,96 484,95 485,2628M 1196 1214 1215 1208,333 1090,84 1052,46 1056,31 1066,53716M 2585 2604 2600 2596,333 2492,82 2488,91 2411,14 2464,28932M 5530 5596 5581 5569,000 NA NA NA NA
[s] [s] [s] [s] [s] [s] [s] [s]199 198 198,1 198,367 NA NA NA NA
[MIPS] [MIPS] [MIPS] [MIPS] [MIPS] [MIPS] [MIPS] [MIPS]1016 1025 1024 1021,667 818 819 819 818,667
integer 1827 1842 1842 1837,000 1206 1208 1208 1207,333[s] [s] [s] [s] [s] [s] [s] [s]4686,19 4580,99 4613,75 4626,977 5601 5609 5600 5603,333[s] [s] [s] [s] [s] [s] [s] [s]
ohne SSE2 1992,43 1979,48 1974,43 1982,110mit SSE2 NA NA NA NA NA NA NA NA
Benchmarkergebnisse Intel Pentium III-S
Superpi
Cinebench
Boincfloatingpoint
Povray 3.6cpu time
Povray 3.7
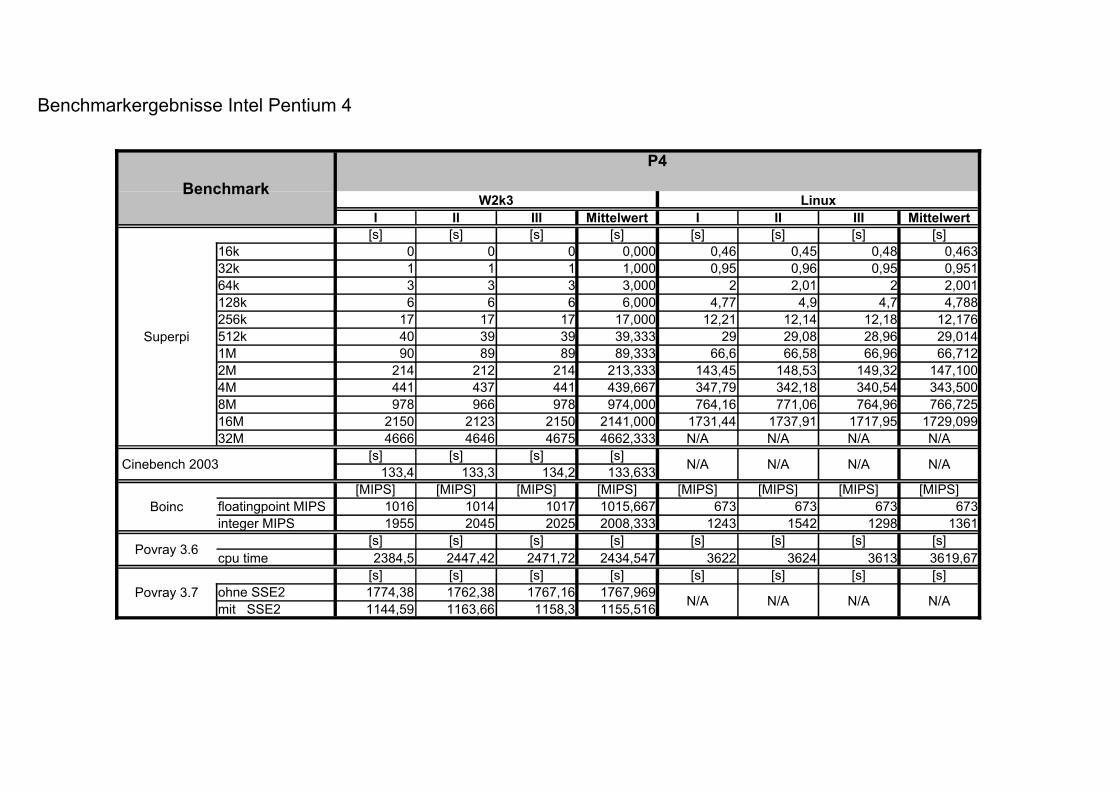
Benchmark
P4
W2k3 LinuxI II III Mittelwert I II III Mittelwert
[s] [s] [s] [s] [s] [s] [s] [s]16k 0 0 0 0,000 0,46 0,45 0,48 0,46332k 1 1 1 1,000 0,95 0,96 0,95 0,95164k 3 3 3 3,000 2 2,01 2 2,001128k 6 6 6 6,000 4,77 4,9 4,7 4,788256k 17 17 17 17,000 12,21 12,14 12,18 12,176512k 40 39 39 39,333 29 29,08 28,96 29,0141M 90 89 89 89,333 66,6 66,58 66,96 66,7122M 214 212 214 213,333 143,45 148,53 149,32 147,1004M 441 437 441 439,667 347,79 342,18 340,54 343,5008M 978 966 978 974,000 764,16 771,06 764,96 766,72516M 2150 2123 2150 2141,000 1731,44 1737,91 1717,95 1729,09932M 4666 4646 4675 4662,333 N/A N/A N/A N/A
[s] [s] [s] [s] N/A N/A N/A N/A133,4 133,3 134,2 133,633[MIPS] [MIPS] [MIPS] [MIPS] [MIPS] [MIPS] [MIPS] [MIPS]
1016 1014 1017 1015,667 673 673 673 673integer MIPS 1955 2045 2025 2008,333 1243 1542 1298 1361
[s] [s] [s] [s] [s] [s] [s] [s]2384,5 2447,42 2471,72 2434,547 3622 3624 3613 3619,67
[s] [s] [s] [s] [s] [s] [s] [s]ohne SSE2 1774,38 1762,38 1767,16 1767,969 N/A N/A N/A N/Amit SSE2 1144,59 1163,66 1158,3 1155,516
Benchmarkergebnisse Intel Pentium 4
Superpi
Cinebench 2003
Boinc floatingpoint MIPS
Povray 3.6 cpu time
Povray 3.7





























