Embed Size (px)
Citation preview

0
0.01
0.02
0 1 2 3 4 5
Cum
ulat
ive
reca
ll
t x 100000
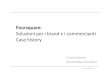
FourSquare New York
0
0.2
0.4
0.6
0 1 2 3 4 5
t Millions
Twitter 200 tweets
0
0.01
0.02
0.03
0.04
0.05
0 2 4 6 8 10
t x 100000
FourSquare Tokyo
0
0.2
0.4
0.6
0.8
0 1 2 3 4 5
t Millions
Twitter 1 month
0
0.2
0.4
0.6
0 1 2 3
t Millions
MovieLens 1M
00.20.40.60.8
1
012345Div
ersi
ty
t
k = 1 k = 10 k = 100 Most popular Random
Neighbor bandit
Bandit Recommender Systems
Use of bandit algorithms to generate recommendations
Usually arms = items
Personalized approaches: contextual bandits
o Stochastic versions of Probabilistic Matrix Factorization (PMF)
o Clusters of users/items
Our approach: user-based kNN with stochastic (bandit-based) neighborhood selection
A Simple Multi-Armed Nearest-Neighbor Bandit for Interactive RecommendationJavier Sanz-Cruzado, Pablo Castells and Esther López
Universidad Autónoma de Madrid{javier.sanz-cruzado,pablo.castells}@uam.es
IRGIR Group @ UAM
Nearest-neighbor bandit
Neighbor bandit Given a user 𝑢, choose the best neighbor 𝑣
Conditional preference: Instead of similarity, 𝑃 𝑢 𝑣 probability that 𝑢 likes an item that 𝑣 likes
Thompson sampling bandit
o Rewards considered as a Bernoulli distribution with mean 𝑃 𝑢 𝑣
o 𝑃 𝑢 𝑣 estimated from data using posterior Beta distributions, 𝑝 𝑢 𝑣 ∼ 𝛣 𝛼 𝑣 𝑢 , 𝛽 𝑣 𝑢
o Hits α 𝒗 𝒖 : Positive common ratings between u and v: 𝛼 𝑣 𝑢 = 𝛼0 + 𝑖∈ℐ 𝑟 𝑢, 𝑖 𝑟 𝑣, 𝑖
o Misses 𝜷 𝒗 𝒖 : 𝑣’s positive ratings not shared by u. 𝛽 𝑣 𝑢 = 𝛽0 + 𝑖∈ℐ 𝑟 𝑣, 𝑖 − 𝛼 𝑣 𝑢
o Select 𝑣 maximizing 𝑝 𝑢 𝑣
Recommend the item 𝑖 that 𝑣 likes most (ties randomly broken)
Update 𝛼 𝑤 𝑢 for all users 𝑤 ∈ 𝒰 who have rated the recommended item 𝑖
Multi-armed bandits
Dataset #Users #Items #Ratings
FourSquare New York 1,083 38,333 227,428
FourSquare Tokyo 2,293 61,858 573,703
Twitter 1 month 9,511 9,511 650,937
Twitter 200 tweets 9,253 9,253 475,608
MovieLens 1M 6,040 3,706 1,000,209
Interacts
User System
Recommends items
𝑣1
𝑣2
𝑣3
𝑣4
𝑖1
𝑖2
𝑖3
𝑖5
𝑖4
𝑟 𝑢, 𝑖2 ≠ ?
3. Neighbor 𝑣 selects item 𝑖to recommend
? 1 ? ? 0
1 0
1 0 1
0 1 1
0 0 1
1. Choose targetuser 𝑢
0
0
1
0
5. Update 𝑢′s conditional preferences with𝑣 ∈ 𝒰𝑖 = 𝑤 ∈ 𝒰 𝑟 𝑤, 𝑖 ≠ ?
Recommendation
4. Obtain 𝑟 𝑢, 𝑖 ∈ 0,1
Update
𝒊
6. Add 𝑟 𝑢, 𝑖 to rating matrix
Current state(Binary rating matrix)
Items
Use
rs
𝒖
𝑣1
𝑣2
𝑣3
𝑣4
𝑖1
𝑖2
𝑖3
𝑖5
𝑖
ℛ:𝒰 × ℐ → 0,1, ? 𝑟 𝑢, 𝑖5 ≠ ?
Evaluation approach Offline evaluation: simulate user feedback using offline data
Extreme cold start: start with no ratings
Random user selection (one at a time)
Metric: cumulative recall – fraction of discovered positive ratings (growth curve)
Algorithms
Bandits
Exploitation-only
Data Implicit feedback datasets
o 2 Twitter follows graphs (1 month, 200 tweets)
o 2 FourSquare venue recommendation datasets (New York, Tokyo)
Explicit ratings dataset: MovieLens 1M
o We take ratings ≥ 4 as positive (𝑟 𝑢, 𝑖 = 1)
Extension: 𝒌 neighbors
Given a target user 𝑢, select the best 𝑘 neighbors
Multiple play Thompson sampling bandit
Pick 𝒩𝑘 𝑢 : the 𝑘 users maximizing 𝑝 𝑢 𝑣
Recommend the item maximizing:
Again, update 𝛼 𝑤 𝑢 for all users 𝑤 ∈ 𝒰 who have rated 𝑖
Penalizes exploration in favor of exploitation
Experiments
Results
Motivation
$
7 7 7 7 7 7
Arms
Reward Reward
Bandit
Which arm maximizes the gain?
Select the best among several actions (arms)
Exploration vs. exploration
o Select arm with highest estimated value (exploit)
o Select arm to gain knowledge (explore)
Algorithms: ε-greedy, UCB1, Thompson Sampling, etc.$
Neighbors 𝑣 ∈ 𝒰
Ratings 𝑟 𝑢, 𝑖
Cond. preference 𝑃(𝑢|𝑣)
Items 𝑖 ∈ ℐ
Target user 𝑢 ∈ 𝒰
Ratings 𝑟 𝑢, 𝑖
Metric (e.g. CTR)
Target user 𝑢 ∈ 𝒰
Arms
Rewards
Estimated arm value
Context
Our approachRecommender bandits Multi-armed bandits
13th ACM Conference on Recommender SystemsCode for this paper is available at https://github.com/ir-uam/kNNBandit
Full text Code
Our approach: nearest-neighbors bandit
Item-oriented: ε-greedy, Thompson sampling
Collaborative filtering: matrix factorization, user-based kNN (cosine)
Sanity-check: most-popular, random
Interactive recommendation
More realistic perspective
Recommendation operates in cycles
o Users react to and interact with recommendations
o The system gains further input from this interaction
o The input is used in the following recommendations
argmax𝑖∈ℐ
𝑣∈𝒩𝑘 𝑢
𝑝 𝑢 𝑣 𝑟𝑣 𝑖
0.0000100,000200,000300,000400,000500,000A
c c.
Re
cal l
Num. Iter. Neighbor bandit Neighbor bandit k = 10 User-based kNN Th. sampling ε-greedy Implicit MF Most popular Random