Embed Size (px)
Citation preview

Econometría Aplicada
Econometría Aplicada
Introducción y repaso
Víctor Medina
Econometría AplicadaAntecedentes Generales
Antecedentes Generales

Econometría AplicadaAntecedentes Generales
I Profesor: Víctor Medina ([email protected])I Cátedras: Lunes y jueves 13:30 a 15:00I Ayudantías: Viernes 15:10 a 16:40
Evaluaciones
I 3 Tareas grupales (30%). Los grupos serán escogidos al azar en laprimera ayudantía. Por cada tarea se entregan, en general, 2 archivos:un informe en pdf y un .do con el código en Stata. Las fechas de entregaserán informadas junto con el contenidod de cada tarea.
I Solemne (35%). La fecha exacta es definida por la escuela y loscontenidos son hasta la semana anterior.
I Examen (35%). La fecha exacta es definida por la escuela y loscontenidos son todos hasta la semana anterior al periodo de exámenes.

Econometría AplicadaAntecedentes Generales
Programa
1. Introducción y repaso de probabilidades y estadísticasI Variables aleatorias discretas y continuasI Propiedades de las v.a.I Teorema de BayesI EstimaciónI Intervalos de confianzaI TCLI Test de hipótesis
2. Modelo de regresión lineal simpleI Regresión lineal simpleI Estimadores y sus propiedadesI Estimadores de Mínimos Cuadrados Ordinarios (MCO)I Supuestos y propiedades de los estimadores MCOI Transformaciones de variables
3. Modelo de regresión lineal múltipleI Representación matricialI Matriz de varianza-covarianzaI Distribución de los estimadores MC

Econometría AplicadaAntecedentes Generales
Programa (continuación)4. Bondad de ajuste e inferencia estadística
I Intervalos de confianzaI Pruebas de hipótesis de un parámetro: test tI Bondad de ajuste: R2 y R2I Descomposición de varianzaI Pruebas de hipótesis de un conjunto de parámetros: test FI Predicción media y puntual
5. EspecificacionesI Regresión particionadaI Variables relevantes omitidasI Inclusión de variables irrelevantesI Criterios de selección de modelos: R2, BIC y AICI Test RESET: variables omitidas y formas funcionales inadecuadasI Colinealidad
6. Modelos de regresión con variables cualitativasI Variables dummysI Modelo de probabilidad linealI Regresión Logit y ProbitI Estimador de Máxima VerosimilitudI Inferencia: test LR, Wald y LM

Econometría AplicadaAntecedentes Generales
Programa (continuación ii)
7. Series de tiempoI MotivaciónI EstacionariedadI Transformando a procesos estacionariosI Modelo autorregresivoI Caminata aleatoriaI Regresiones espúreasI Test de estacionariedad: DFI Orden de integración y cointegraciónI Modelo autorregresivo y de medias móviles (ARMA)I ACF y PACFI Modelo autorregresivo integrado de promedios móviles (ARIMA)I Pronóstico con enfoque Box-Jenkins
8. Series de tiempo III Modelo de descomposición clásicaI EstacionalidadI Descomposición de la tendenciaI FiltrosI PronósticoI Vectores autorregresivosI VEC

Econometría AplicadaIntroducción a la econometría
Introducción a la econometría

Econometría AplicadaIntroducción a la econometría
IntroducciónIn God we trust, all others bring data (W. Deming)
I ¿Qué entendemos por econometría?
La econometría, como disciplina, surge en 1930 en el 1er encuentro de laEconometric Society, Ohio (USA), como una iniciativa de economistas,matemáticos y estadísticos muy relevantes: Fisher, Schumpeter, Wiener,Frisch, entre otros.
De este encuentro surgió la publicación de la revista Econometrica (1933),una de las más prestigiosas en investigación económica. En su primeraedición definió que la econometría era:
I . . . estudios que aspiran a la unificación de las cantidades teóricas juntoa las empíricas de los problemas económicos basados en pensamientosrigurosos similares a los utilizados a las ciencias naturales. . .
Sin embargo, también se especifica que:
I . . . econometristas no son estadísticos de la economía o economístasteóricos o un matemático aplicado en la economía, sino que es launificación de los tres. . .

Econometría AplicadaIntroducción a la econometría
Desde una perspectiva más práctica
La econometría se basa en el estudio de modelos que permitan analizarcaracterísticas o propiedades de una variable económica utilizando comocausas explicativas otras variables económicas.
I ¿Modelos?I Modos de comprimir datos con respecto a algún fenómeno con una
mínima pérdida de información.I ¿Por qué modelar?
I Los modelos se construyen porque, a diferencia de los datos en bruto, sepueden utilizar para inferir, predecir y responder preguntas específicas.
I Además, los datos están afectos a errores (de observación y muestreo), noestán diseñados en condiciones ambientales controladas, entre otra cosas.

Econometría AplicadaIntroducción a la econometría
Objetivos de los modelos econométricos
1. Inferir parámetros que no aparecen en la muestraI Predicción. Ejemplo: riesgo de crédito en préstamos bancarios.I Predicción inversa. Ejemplo: series de inflación en siglos pasados.I Estimación de valores desconocidos de un modelo económico. Ejemplo:
elasticidad de los precios del tabaco (elasticidades de oferta vs. demanda).
2. Simulación de un sistema.I Ejemplo: pruebas de estrés para los bancos bajo escenarios de crisis
económicas.
3. Controlar el comportamiento de un sistema.I Ejemplo: banco central manejando los niveles de inflación para hacer
frente a los posibles escenarios económicos.
4. Extraer señales, como estacionalidad, tendencias o ciclos.
Econometría AplicadaIntroducción a la econometría
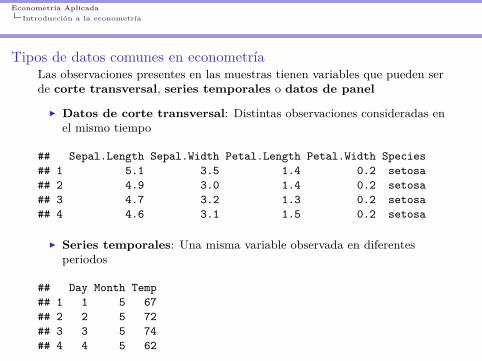
Tipos de datos comunes en econometríaLas observaciones presentes en las muestras tienen variables que pueden serde corte transversal, series temporales o datos de panel
I Datos de corte transversal: Distintas observaciones consideradas enel mismo tiempo
## Sepal.Length Sepal.Width Petal.Length Petal.Width Species## 1 5.1 3.5 1.4 0.2 setosa## 2 4.9 3.0 1.4 0.2 setosa## 3 4.7 3.2 1.3 0.2 setosa## 4 4.6 3.1 1.5 0.2 setosa
I Series temporales: Una misma variable observada en diferentesperiodos
## Day Month Temp## 1 1 5 67## 2 2 5 72## 3 3 5 74## 4 4 5 62
Econometría AplicadaIntroducción a la econometría
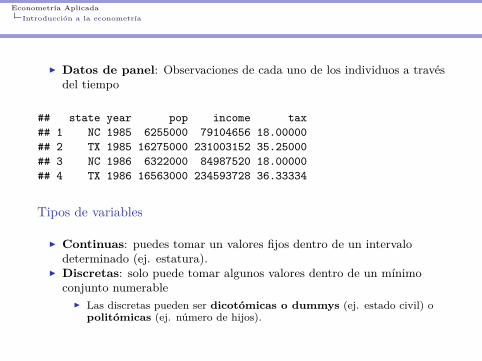
I Datos de panel: Observaciones de cada uno de los individuos a travésdel tiempo
## state year pop income tax## 1 NC 1985 6255000 79104656 18.00000## 2 TX 1985 16275000 231003152 35.25000## 3 NC 1986 6322000 84987520 18.00000## 4 TX 1986 16563000 234593728 36.33334
Tipos de variables
I Continuas: puedes tomar un valores fijos dentro de un intervalodeterminado (ej. estatura).
I Discretas: solo puede tomar algunos valores dentro de un mínimoconjunto numerable
I Las discretas pueden ser dicotómicas o dummys (ej. estado civil) opolitómicas (ej. número de hijos).

Econometría AplicadaRepaso Probabilidad y Estadística
Repaso Probabilidad y Estadística

Econometría AplicadaRepaso Probabilidad y Estadística
Variables aleatorias discretasI Una variable aleatoria, X, se dice discreta si distribuye la masa unitaria
de probabilidad entre un conjunto discreto de valores, χ.I Es decir, se puede definir como un conjunto de números reales, x ∈ χ,
cada uno de los cuales tiene asignada una determinada probabilidadp(X = x) = p(x).
I A p() se le denomina función de probabilidad. Esta satisface lassiguientes propiedades
I 0 ≤ p(x) ≤ 1I∑
x∈χ p(x) = 1
Propiedades fundamentales
I Unión: p(A ∨B) = p(A) + p(B)− p(A ∧B)I Probabilidad conjunta (o regla del producto):p(A,B) = p(A ∧B) = p(A|B)p(B)
I Distribución marginal (o regla de las probabilidades totales):p(A) =
∑bp(A,B) =
∑bp(A|B = b)p(B = b)
I Probabilidad condicional: p(A|B) = p(A,B)p(B)

Econometría AplicadaRepaso Probabilidad y Estadística
Ejemplo 1: variable aleatoria discreta
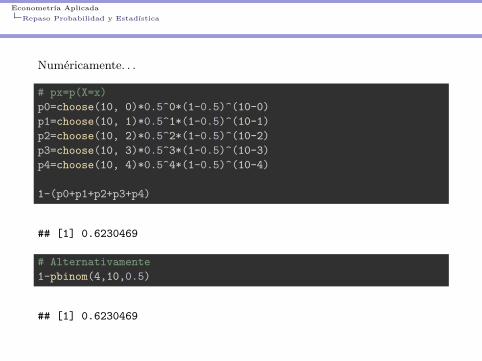
I Si Ud. tiene que dar un exámen de 10 preguntas de Verdadero o Falso yno ha estudiado nada (asumir que la probabilidad de acertar es 50% porpregunta) ¿Cuál es la probabilidad de que tenga al menos 5 preguntascorrectas?
Econometría AplicadaRepaso Probabilidad y Estadística
Numéricamente. . .
# px=p(X=x)p0=choose(10, 0)*0.5^0*(1-0.5)^(10-0)p1=choose(10, 1)*0.5^1*(1-0.5)^(10-1)p2=choose(10, 2)*0.5^2*(1-0.5)^(10-2)p3=choose(10, 3)*0.5^3*(1-0.5)^(10-3)p4=choose(10, 4)*0.5^4*(1-0.5)^(10-4)
1-(p0+p1+p2+p3+p4)
## [1] 0.6230469
# Alternativamente1-pbinom(4,10,0.5)
## [1] 0.6230469

Econometría AplicadaRepaso Probabilidad y Estadística
Variable aleatoria continuaAsumiendo que X puede tomar valores continuos, se pueden definir loseventos A = (X ≤ a), B = (X ≤ b) y W = (a < X ≤ b). Entoces, tenemosque B = A ∨W , con A y W mútuamente excluyentes. Luego, por la regla dela unión se obtiene
p(B) = p(A) + p(W )⇒ p(W ) = p(B)− p(A)
I Se define la función de distribución acumulada comoF (q) ≡ p(X ≤ q) y cumple con
I F (−∞) = 0, F (∞) = 1I Es no decreciente
Usando esta notación, tenemos p(a < X ≤ b) = F (b)− F (a)
I Por otra parte y asumiendo que F es derivable, podemos definir lafunción de densidad de probabilidad (fdp) como f(x) ≡ d
dxF (x)
I Por teorema fundamental del cálculo, se tiene que dada una fdp, se tiene
p(a < X ≤ b) =∫ b
a
f(x)dx

Econometría AplicadaRepaso Probabilidad y Estadística
Esperanza y varianza
La propiedad más familiar de una distribución es su valor esperado,denotado usualmente como µ, y se define
I E(X) =∑
x∈χ xp(x) (variable discreta) y E(X) =∫x∈χ xf(x)dx
(variable continua)
La varianza es una medida de la dispersión de la distribución, denotadacomo σ2 y se define
I var(X) = E[(X − µ)2] = E(X2)− µ2

Econometría AplicadaRepaso Probabilidad y Estadística
Ejemplo 2: Media y varianza de V.A. continua
Definiendo la siguiente función de densidad de probabilidad
f(x;λ) ={λe−λx x ≥ 0,0 x < 0.
Y la función de probabilidad acumulada
F (x) = P (X ≤ x) ={
1− e−λx x ≥ 0,0 x < 0.
Con λ > 0
I ¿Qué distribución es?I Calcule la mediaI Calcule la varianza
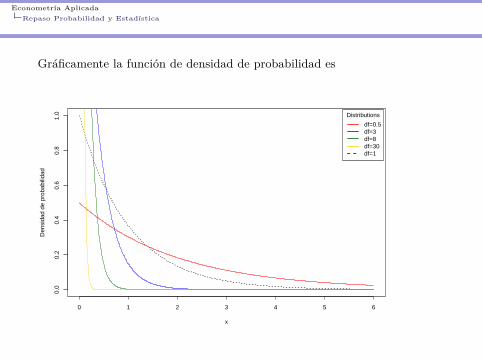
Econometría AplicadaRepaso Probabilidad y Estadística
Gráficamente la función de densidad de probabilidad es
0 1 2 3 4 5 6
0.0
0.2
0.4
0.6
0.8
1.0
x
Den
sida
d de
pro
babi
lidad
Distributions
df=0.5df=3df=8df=30df=1
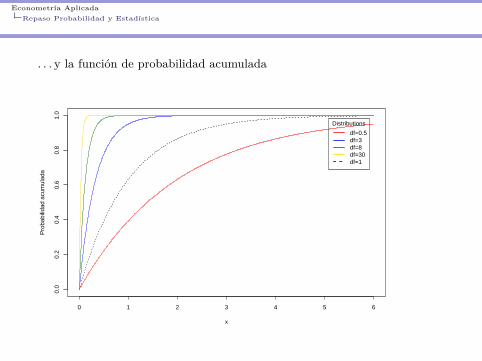
Econometría AplicadaRepaso Probabilidad y Estadística
. . . y la función de probabilidad acumulada
0 1 2 3 4 5 6
0.0
0.2
0.4
0.6
0.8
1.0
x
Pro
babi
lidad
acu
mul
ada
Distributions
df=0.5df=3df=8df=30df=1

Econometría AplicadaRepaso Probabilidad y Estadística
Independencia incondicional y condicional
I Se dice que X e Y son incondicionalmente independientes (omarginalmente independientes), denotado por X ⊥ Y , si podemosrepresentar la probabilidad conjunta como el producto de lasprobabilidades marginales, es decir
X ⊥ Y ⇐⇒ p(X,Y ) = p(X)p(Y )

Econometría AplicadaRepaso Probabilidad y Estadística
En la realidad, la independencia incondicional es poco común, porque lasvariables se influencias unas a las otras. Sin embargo, usualmente estainfluencia es controlada a través de otras variables.
I Se dice que X e Y son condicionalmente independientes dado Z siy sólo si la probabilidad condicional conjunta puede ser representadacomo el producto de las probabilidades condicionales marginales, es decir
X ⊥ Y |Z ⇐⇒ p(X,Y |Z) = p(X|Z)p(Y |Z)
Intuitivamente esto es porque Z causa tanto el evento X como el Y , entoncessi conocemos Z, no necesitamos conocer Y si es que queremos predecir X, oal revés.
I Ejemplo, la probabilidad de que llueva mañana (evento X) esindependiente de que el piso esté mojado hoy (evento Y ) dado que estálloviendo hoy (evento Z)

Econometría AplicadaRepaso Probabilidad y Estadística
Teorema de Bayes
p(X = x|Y = y) = p(X = x)p(Y = y|X = x)∑x
p(X = x)p(Y = y|X = x)
Ejemplo 3: Suponga que una mujer se hace una mamografía y le dapositivo. ¿Cuál es la probabilidad de que tenga cáncer?
Se sabe que:
I Si una persona tiene cancer y se hace una mamografía, con 98% deprobabilidad el test dará positivo (sensibilidad).
I La probabilidad de que una persona, con características similares a estamujer, tenga cancer es 0.4%.
I Un 0.2% de las personas que no tienen cáncer, el test arroja positivo(falsos positivo o 1-especificidad).

Econometría AplicadaRepaso Probabilidad y Estadística
Ejemplo 4: Test de ELISA (VIH) como prueba única
I Sensibilidad: 99%I Especificidad: 98%I Prevalencia: 0.3% (dato Chile para personas entre 15 y 49 años,
UNAIDS)
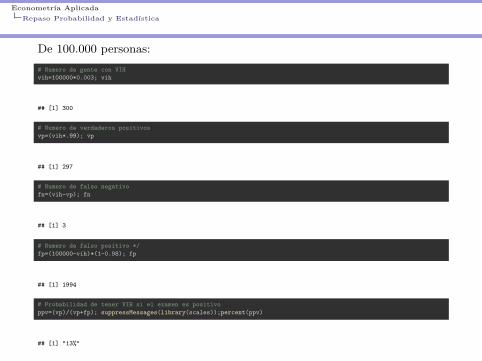
Econometría AplicadaRepaso Probabilidad y Estadística
De 100.000 personas:# Numero de gente con VIHvih=100000*0.003; vih
## [1] 300
# Numero de verdaderos positivosvp=(vih*.99); vp
## [1] 297
# Numero de falso negativofn=(vih-vp); fn
## [1] 3
# Numero de falso positivo */fp=(100000-vih)*(1-0.98); fp
## [1] 1994
# Probabilidad de tener VIH si el examen es positivoppv=(vp)/(vp+fp); suppressMessages(library(scales));percent(ppv)
## [1] "13%"

Econometría AplicadaRepaso Probabilidad y Estadística
Libro entretenido
Econometría AplicadaRepaso estadística
Repaso estadística
Econometría AplicadaRepaso estadística
Repaso estadística
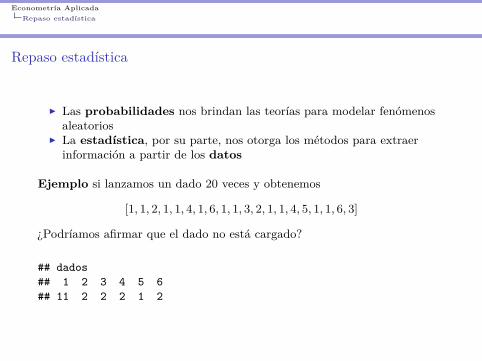
I Las probabilidades nos brindan las teorías para modelar fenómenosaleatorios
I La estadística, por su parte, nos otorga los métodos para extraerinformación a partir de los datos
Ejemplo si lanzamos un dado 20 veces y obtenemos
[1, 1, 2, 1, 1, 4, 1, 6, 1, 1, 3, 2, 1, 1, 4, 5, 1, 1, 6, 3]
¿Podríamos afirmar que el dado no está cargado?
## dados## 1 2 3 4 5 6## 11 2 2 2 1 2

Econometría AplicadaRepaso estadística
I El modelo probabilista: sea X la cantidad de 1’s obtenidas. Suponiendoque son lanzamientos independientes y que p es la probabilidad de quesalga un 1, se tiene que X ∼ Binom(20, p)
I Estadística: suponiendo que el dado está equilibrado (H0 : p = 16 ),
calcular la probabilidad de obtener al menos 11 unos (ya que en lamuestra se obtuvo 11 unos)
Probabilidad de obtener al menos 11 unos
## [1] "0.0105%"
Como “0.01%” es una “probabilidad muy baja” (?), es razonable concluir queel dado no está equilibrado.
I Ejemplo de test de hipótesis
Econometría AplicadaEstimación
Estimación

Econometría AplicadaEstimación
Estimación
Def. Una muestra aleatoria simple (m.a.s.) es una colección de X1, ..., Xnv.a.’s iid (independientes e idénticamente distribuidas). Usualmente, unam.a.s. se obtiene al repetir un experimento n veces de manera independiente.
I Supongamos que la distribución de Xi(∀i ∈ 1, ..., n) depende de uncierto parámetro θ que no conocemos y queremos estimar en base a lamuestra que tenemos (X1, ..., Xn).
Ejemplo si Xi ∼ N(µ, σ2), ∀i: θ = µ es un parámetro.

Econometría AplicadaEstimación
Def. Un estadístico e es una función de la muestra. Por ejemplo,e = µ(X1, ..., Xn) con µ : Rn → R
Def. Un estimador para el parámetro θ es un cierto estadístico θ que tiene elobjetivo de aproximarse a θ.
Ejemplo si θ = E(Xi), un posible estimador para θ es
θ = 1n
n∑i=1
Xi
Otro posible estimador de θ, por ejemplo, podría ser la mediana,θ = mediana(X1, ..., Xn)
Obs. El estimador de un parámetro no es único. Por lo tanto, es necesariodefinir algunos criterios para saber cuando θ es un buen estimador de θ.

Econometría AplicadaEstimación
Def. Un estimador θ se dice insesgado si se cumple que E(θ) = θ. El sesgose define como
E(θ)− θ
Ejercicio 1 Si θ = E(Xi) y definimos el estimador θ = 1n
∑n
i=1 Xi. Calculeel sesgo.
Ejercicio 2 Si θ = σ2 = var(Xi) = E(X2i )− µ2 y definimos el estimador
S2 = 1n
∑n
i=1 X2i − µ2. Calcule el sesgo. Sin embargo, el parámetro µ es, en
general, desconocido y se tiene que estimar. . . ¿Qué hacemos?
I S2n varianza muestral y S2 varianza muestral insesgada.

Econometría AplicadaEstimación
Otro criterio para ver “que tan bueno” es un estimador es con el ErrorCuadrático Medio.
Def. El error cuadrático medio del estimador θ se define comoECM(θ) = E[(θ − θ)2]. ¿Cómo podemos expresar la definición de unamanera más sencilla?
Sin embargo, hay otros dos métodos conocidos para estimar parámetros deuna distribución.
I Método de máxima verosimilitud (se verá más adelante en el curso)I Método de los momentos (no entraremos en detalles)
Econometría AplicadaIntervalos de confianza
Intervalos de confianza

Econometría AplicadaIntervalos de confianza
Intervalos de confianzaIdea: calcular un intervalo [θL, θU ] (ambos dependientes de la muestra),tales que el parámetro θ esté en ese intervalo con una alta probabilidad. Enotras palabras
P (θ ∈ [θL, θU ]) = 1− α
Con α un número chico que se determina a priori (1% o 5%, por ejemplo) yrepresenta el error dispuesto a aceptar.
Def. [θL, θU ] se llama intervalo de confianza para θ al nivel 1− α.
El método para encontrar el intervalo [θL, θU ] consiste en utilizar unestadístico cuya distribución sea conocida y no dependa del parámetro aestimar.
Ejercicio Sea X1, ..., Xn m.a.s. proveniente de una distribución N(µ, σ2),con µ desconocido y σ2 conocido. Encontrar el intervalo de confianza para µal nivel 95%.
I ¿Qué pasa si σ2 es desconocido? (como pasa en la realidad!)

Econometría AplicadaIntervalos de confianza
Prop. Si X1, ..., Xn m.a.s. proveniente de una distribución N(µ, σ2),entonces
T := X − µS/√n∼ tn−1
Con S2 el estimador insesgado de la varianza, es decir,
S2 = 1n− 1
n∑i=1
(Xi −X)2
Ejercicio 3 Sea X1, ..., X21 m.a.s. de una distribución N(µ, σ2) con µ y σ2
desconocidos. Encuentre un intervalo de confianza para µ al nivel 95%.
Econometría AplicadaIntervalos de confianza
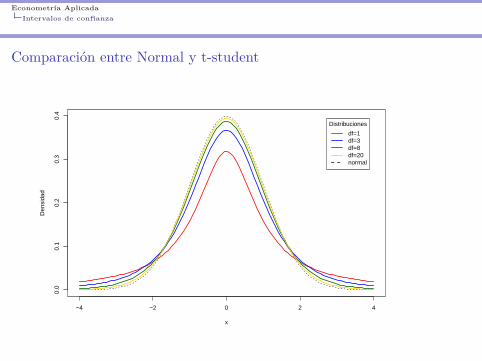
Comparación entre Normal y t-student
−4 −2 0 2 4
0.0
0.1
0.2
0.3
0.4
x
Den
sida
d
Distribuciones
df=1df=3df=8df=20normal
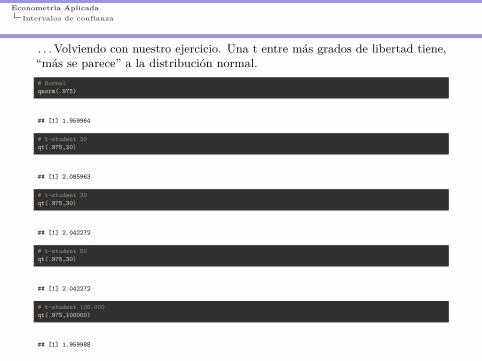
Econometría AplicadaIntervalos de confianza
. . . Volviendo con nuestro ejercicio. Una t entre más grados de libertad tiene,“más se parece” a la distribución normal.# Normalqnorm(.975)
## [1] 1.959964
# t-student 20qt(.975,20)
## [1] 2.085963
# t-student 30qt(.975,30)
## [1] 2.042272
# t-student 50qt(.975,30)
## [1] 2.042272
# t-student 100.000qt(.975,100000)
## [1] 1.959988

Econometría AplicadaIntervalos de confianza
Teorema central del límite (TCL)
Sea X1, X2,. . . , Xn un conjunto de variables aleatorias, independientes eidénticamente distribuidas de una distribución con media µ y varianzaσ2 6= 0. Entonces, si n es suficientemente grande, la variable aleatoria
X = 1n
n∑i=1
Xi
tiene aproximadamente una distribución normal con µX = µ y σ2X
= σ2
n

Econometría AplicadaIntervalos de confianza
Intervalo de confianza para la varianza
Prop. Si Z1, ..., Zn son N(0, 1) independientes, entonces la variable
U ∼n∑i=1
Z2i
se denomina chi-cuadrado con n grados de libertad U ∼ χ2n
Luego, sea X1, ..., Xn m.a.s. de una distribución N(µ, σ2) con µ y σ2
desconocidos. Se quiere encontrar un intervalo de confianza para σ2 al nivel1− α.
I Por la propiedad, sabemos que el estadístico
W = (n− 1)S2
σ2 =n∑i=1
(Xi − X)2
σ2 ∼ χ2n−1
Esto permite encontrar el intervalo deseado 1−α = P (W ∈ [c, d]) (asumimosuna simetría de probabilidad, es decir, P (W < c) = P (W > d)).
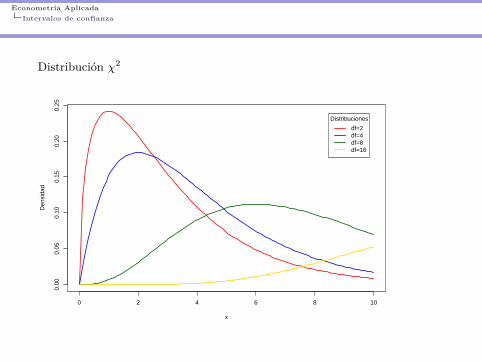
Econometría AplicadaIntervalos de confianza
Distribución χ2
0 2 4 6 8 10
0.00
0.05
0.10
0.15
0.20
0.25
x
Den
sida
d
Distribuciones
df=2df=4df=8df=16
Econometría AplicadaTest de hipótesis
Test de hipótesis

Econometría AplicadaTest de hipótesis
Test de hipótesisIdea responder una cierta afirmación acerca de la distribución de la muestra(o sobre sus parámetros), en base a los valores observados en la muestra.
Elementos de un test de hipótesis
I H0: hipótesis nula. Es una afirmación sobre la distribución de lamuestra, usualmente sobre algún parámetro.
I H1: hipótesis alternativa. Es una afirmación que contrasta H0.I R ⊆ Rn: región de rechazo. H0 se rechaza SSI. (X1, ..., Xn) está en R.
Comúnmente R será de la forma
R = { ~X ∈ Rn|X ≤ cte.}
(o bien X ≥ cte. o |X| ≥ cte.). Dependiendo del caso, también es posibletrabajar con otro estadístico en lugar de X
I α ∈ (0, 1): tolerancia. Para fijar la región de rechazo se impone
P ( ~X ∈ R|H0) = α
Es decir, P (rechazar H0|H0 es cierta). Corresponde entonces al controlde la probabilidad de error (usualmente ≈ 1% o 5%)

Econometría AplicadaTest de hipótesis
Ejercicio 4: el mismo ejemplo del lanzamiento del dado. Es decir, se tieneun dado y una muestra con 20 resultados. Se quiere determinar si el dadoestá balanceado o cargado al uno. Se pide plantear un test de hipótesis conα = 0.01
I H0: p = 1/6 (balanceado)I H1: p > 1/6 (cargado)
Consideramos X =∑20
i=1 Xi (cantidad de unos) y una región de rechazo, noúnica y arbitráriamente, de la forma
R = { ~X ∈ {0, 1}20|20∑i=1
Xi ≥ k}
0.01 = α = P (20∑i=1
Xi ≥ k|p = 1/6)

Econometría AplicadaTest de hipótesis
Numéricamente# k=11-pbinom(0,20,1/6)
## [1] 0.9739159
# k=21-pbinom(1,20,1/6)
## [1] 0.8695797
# k=31-pbinom(3,20,1/6)
## [1] 0.4334544
# k=81-pbinom(8,20,1/6)
## [1] 0.002841616
Es decir, para todos los X ≥ 8 rechazamos que el dado esté balanceado conuna tolerancia del 1%.





























