Embed Size (px)
Citation preview

FACULTAD DE ECONOMIA Y NEGOCIOS
ESCUELA DE INGENIERIA COMERCIAL
VIÑA DEL MAR
MODELO DE PREDICCIÓN:
PRECIO DE LA ACCIÓN DE SONDA
Nombre: Andrés Burgos
Macarena Carrasco
Ángela De La Fuente
Joselyn Garrido
Abdón Ondarza
Ramo: Econometría
Profesor: Carolina Ciervo
Fecha: 18 de Noviembre del 2011

ÍNDICE
Introducción……………………………………………………………….……….. 2
Desarrollo
Descripción de variables…………………………………………………………. 7
Modelo inicial……………………………………………………………………… 7
Interpretaciones del modelo inicial……………………………………………… 10
Prueba de significancia global para el modelo inicial…………………….……. 11
Prueba de significancia individual para el modelo inicial………………………. 11
Replanteo del modelo………………………………….…………………………. 12
Análisis de Multicolinealidad.………………….……….…………………………. 14
Análisis de Autocorrelación….………………..……….…………………………. 15
Análisis de Heterocedasticidad……………….……….…………………………. 16
Conclusión…………………………………………………...…………..……….… 23
Bibliografía…………………………………………………...…………..……….… 24
Anexos…………………………………………………………………………….…. 25

INTRODUCCIÓN
La Econometría, es la rama de la economía, que utiliza métodos y modelos
matemáticos, los cuales son utilizados para analizar, interpretar y predecir diversos
sistemas y variables económicas, sin embargo, el mayor problema con el que se
enfrenta en la investigación es la escasez de datos, los sesgos (Diferencia entre el
valor esperado de un estimador y el verdadero valor del parámetro) que pueden
causar los mismos y la ausencia o insuficiencia de una teoría económica adecuada.
Aun así, la econometría es la única aproximación científica al entendimiento de los
fenómenos económicos.
Es por ello que en este informe se quiere lograr el objetivo, a través de la
econometría, de poder predecir o estimar como distintas variables predictoras, las
cuales en este análisis se utilizaron: tipo de cambio, IPSA, Unidad de Fomento, y el
precio de las acciones de: LAN, CAP, BCI, SOQUIMICH y CUPRUM, influirán en los
precios en que se transan las acciones de la empresa Sonda en la Bolsa de Santiago, la
cual es nuestra variable regresora a estimar. Toda la investigación se basa en datos
diarios tanto de la variable en estudio como sus variables predictoras.
El modelo utilizado en esta investigación es el de “Regresión múltiple”, el cual
considera ciertos supuestos, los cuales corroboraremos por medio de los análisis de:
Multicolinealidad, Heterocedasticidad y autocorrelación, por consiguiente a través de
la observación de estos tres análisis se logrará concluir si las variables consideradas
(tipo de cambio, IPSA, UF, LAN, BCI, SOQUIMICH y CUPRUM) para la predicción son o
no efectivamente correctas.

DESARROLLO
SONDA es la empresa que escogimos para realizar nuestro de predicción, y será el
precio de su acción la variable que queremos predecir.
Esta empresa es la mayor firma latinoamericana de Servicios TI e Integración de
Sistemas. Fundada en Chile en 1974, SONDA es una empresa regional, contando con
una red que abarca los mercados más importantes de América Latina. La Compañía
tiene presencia directa y oficinas comerciales en Argentina, Brasil, Chile, Colombia,
Costa Rica, Ecuador, México, Perú y Uruguay, y cuenta con una dotación de más de
10.000 personas y relaciones comerciales con más de 5.000 clientes en la región.
La oferta de SONDA es integral y abarca Servicios de TI, Aplicaciones y
Plataformas de Hardware y Software. Además, es el proveedor latinoamericano que
dispone de la más completa y amplia cobertura regional, lo que permite que sus
clientes accedan al conocimiento y a la experiencia acumulada en cada uno de sus
territorios.
Para poder realizar la estimación, se consideraron las siguientes variables y por
las razones a continuación mencionadas:
- IPSA: Si estamos analizando los movimientos que experimentan los valores de
las acciones, siempre es adecuado y correcto compararse con la tendencia de
las acciones más transadas de la misma plaza, por ende el índice más
representativo y depurado de la tendencia de ese mercado, en este caso el
IPSA. Además SONDA se encuentra en este grupo selectivo de las 20 acciones
con mayor presencia bursátil.

- Tipo de cambio: Ingresamos esta variable a nuestro modelo, fundamentados
en la historia que presenta SONDA, en donde podemos ver importantes
negocios en diferentes mercados o países, por tanto, una parte importante de
los ingresos y costos de la empresa están denominados en otras monedas y se
toma al dólar como eje del mercado cambiario. Por otra parte los hardware
están valorizados en esa moneda así como los royalties por uso de software.
- Unidad de Fomento: Una parte de los ingresos de este tipo de prestadores
de servicios se transa en U.F. (pesos indexados a la inflación doméstica con un mes de
desfase) por tanto es válido pensar en que podría existir relación entre la inflación y
los resultados de la empresa y los resultados de esta. En definitiva, deberían ser el
sustento que mueve el precio de esta acción en las bolsas. Por otra parte, al estar los
estados financieros indexados a la inflación vía la corrección monetaria, mayor
relación puede existir.
- LAN; CAP; BCI; SOQUIMICH y CUPRUM: Encontramos razonable considerar
empresas de diferentes sectores de la economía que además tuvieran relación con
nuestra empresa.
Entre ellas, una empresa de servicios (LAN), una industrial (CAP), una bancaria
(BCI), una minera indexada a la producción de alimentos (SOQUIMICH) y una de
inversiones (CUPRUM) para analizar varios sectores de la economía nacional. A todas
ellas, SONDA les suministra sus sistemas informáticos, tanto para la producción –
operación, así como para los sistemas administrativos, así también como de equipos
de cómputo y respaldos vía leasing operativo o arriendo, por lo que se espera que
ocurra con estas compañías es que afecten el valor de la acción de SONDA, puesto
que afectan a los ingresos y potenciales costos de la compañía.

Descripción de las variables
- Variable regresada:
Y: Precio acción de SONDA (pesos)
- Variables predictoras:
X1: IPSA (ptos.)
X2: Tipo de cambio (pesos)
X3: Unidad de Fomento (pesos)
X4: Precio acción LAN Airlines (pesos)
X5: Precio acción CAP (pesos)
X6: Precio acción BCI (pesos)
X7: Precio acción SOQUIMICH B (pesos)
X8: Precio acción CUPRUM (pesos)
Modelo inicial
A continuación se presentan los datos obtenidos al realizar una regresión
múltiple con las variables consideradas en el punto anterior, según el modelo
propuesto a continuación:
Y = β₀ + β₁IPSA + β₂Tipo de cambio + β₃UF + β₄LAN + β₅CAP + β₆BCI + β₇SoquimichB +
β₈CUPRUM + μ
Nuestra tesis es que al aumentar el precio de las acciones utilizadas en el modelo,
el precio de la acción estudiada, también lo haga.

Se considera además que el análisis se realizará bajos los supuestos de regresión
múltiple:
1) Valor medio de μ es igual a cero
2) No correlación lineal
3) Homocedasticidad
4) Covarianza entre μi y cada
variable X igual a cero
5) No hay sesgo de especificación: El
modelo está correctamente
especificado
6) No hay colinealidad exacta entre las
variables X, es decir, no hay relación
lineal exacta entre X2 y X3
Con el fin de realizar una estimación adecuada y representativa del precio de la
acción en estudio, utilizaremos como herramienta de trabajo el software Minitab en
conjunto con Excel, y las funciones que estos poseen.
Mediante este método, se busca la relación existente entre las diferentes
variables explicativas y la variable regresada, proponiendo una ecuación que permita
explicar el comportamiento de esta última en función del mejor subconjunto de
variables independientes, es decir, encontrar el mejor modelo explicativo.
Ingresando todos los datos al software estadístico, los resultados obtenidos son
los siguientes:

Estadísticas de la regresión Coeficiente de correlación
múltiple 0,918231 Coeficiente de determinación
R^2 0,84314816
R^2 ajustado 0,83798431
Error típico 33,8749641
Observaciones 252
ANÁLISIS DE VARIANZA
Grados de
libertad Suma de
cuadrados Promedio de
los cuadrados F
Valor crítico de F
Regresión 8 1498919,28 187364,91 163,27909 3,37677E-93
Residuos 243 278845,706 1147,51319
Total 251 1777764,98
Coeficientes Error típico Estadístico t Probabilidad Inferior 95% Superior
95%
Intercepción -7809,24313 758,699827 -10,2929286 7,4103E-21 -9303,710619 -6314,77563
IPSA 0,16434705 0,02165739 7,58849676 6,8932E-13 0,12168687 0,20700722
Tipo de Cambio 0,56559206 0,25090547 2,25420376 0,02507477 0,071364884 1,05981924
UNIDAD DE FOMENTO 0,33889041 0,03325905 10,1894195 1,5646E-20 0,273377586 0,40440323
LAN AIRLINES 0,01758728 0,00465839 3,77539609 0,00020087 0,008411294 0,02676326
CAP -0,01487858 0,0038816 -3,83310966 0,00016121 -0,022524454 -0,00723272
BCI -0,00023909 0,00102707 -0,23278638 0,81612324 -0,002262195 0,00178402
SOQUIMICH B 0,00705265 0,00248491 2,83818561 0,00492053 0,002157927 0,01194737
CUPRUM 0,02040818 0,00190512 10,7122768 3,4893E-22 0,01665552 0,02416084
El modelo estimado será:
Y = -7809,24313 + 0.16434705xIPSA + 0,56559206xTipo de cambio +
0,33889041xUF + 0,01758728xLAN - 0,01487858xCAP - 0,00023909xBCI +
0,00705265xSoquimichB + 0,02040818xCUPRUM

Interpretaciones del modelo inicial
- β₀: El valor de este parámetro nos indica que el valor piso del precio de la
acción de SONDA será de $-7.809 app. Siendo el resto de los parámetros igual a
cero. Sin embargo, sabemos que el precio de una acción no puede tomar
valores negativos, por lo que el valor piso de esta acción será de $0.
- β₁: Ante el aumento de un punto del valor del IPSA, el precio de SONDA
aumentará en $0.164 app. Siendo el resto de las variables constantes.
- β₂: Ante el aumento de un punto del valor del Tipo de cambio, el precio de
SONDA aumentará en $0.56559 app. Siendo el resto de las variables
constantes.
- β₃: Ante el aumento de un punto del valor de la UF, el precio de SONDA
aumentará en $0.33889 app. Siendo el resto de las variables constantes.
- β₄: Ante el aumento de un punto del valor de LAN, el precio de SONDA
aumentará en $0.017587 app. Siendo el resto de las variables constantes.
- β₅: Ante el aumento de un punto del valor de CAP, el precio de SONDA
disminuirá en $0,01487858 app. Siendo el resto de las variables constantes.
- β₆: Ante el aumento de un punto del valor de BCI, el precio de SONDA
disminuirá en $0,00023909 app. Siendo el resto de las variables constantes.
- β₇: Ante el aumento de un punto del valor de SoquimichB, el precio de SONDA
aumentará en $0,00705265 app. Siendo el resto de las variables constantes.
- β₈: Ante el aumento de un punto del valor de CUPRUM, el precio de SONDA
aumentará en $0,02040818 app. Siendo el resto de las variables constantes.
- R² ajustado: Nos indica que el ajuste del modelo es de aproximadamente un
83,8%, considerando que el mínimo planteado para este análisis es de un 60%,
podemos decir que en primera instancia, nuestro modelo está bien ajustado.

Prueba de significancia global para el modelo inicial
Este análisis lo realizaremos bajo las pruebas F se significancia global,
considerando un nivel de significancia (α) de un 5%, y mediante las siguientes
hipótesis:
H₀: β₁= β₂=β₃=β₄=β₅=β₆=β₇=β₈=0
H₁: β₁= β₂=β₃=β₄=β₅=β₆=β₇=β₈≠0
En los datos obtenidos por medio de los software nos indican que el valor crítico
de F=3,37677E-93 es mucho menor al α=0,05, por lo que se rechaza H₀, lo que implica
que las variables son significativas en forma conjunta.
Prueba de significancia individual para el modelo inicial
Ahora se realizará un análisis de significancia individual para cada uno de los
parámetros, para así observar si estos son significativos para el modelo. Para esto se
considerarán los valores de las probabilidades de cada parámetro, obtenidas por
medio del software, y se compararán con el valor de significancia de un 5%, de ser
menor que nuestro α, podemos rechazar la hipótesis nula y decir que nuestro
parámetro es significativo para el modelo.
H₀: β₀=0
H₁: β₀≠0
H₀: β₁= 0
H₁: β₁≠0
H₀: β₂=0
H₁: β₂≠0
H₀: β₃=0
H₁: β₃≠0
H₀: β₄=0
H₁: β₄≠0
H₀: β₅=0
H₁: β₅≠0
H₀: β₆=0
H₁: β₆≠0
H₀: β₇=0
H₁: β₇₁≠0

H₀: β₈=0 H₁: β₈≠0
El programa nos entrega los siguientes valores de probabilidad para cada
parámetro:
Parámetros Probabilidad
β₀ 7,41032E-21
β₁ 6,89316E-13
β₂ 0,025074771
β₃ 1,56459E-20
β₄ 0,000200873
β₅ 0,000161214
β₆ 0,81612324
β₇ 0,004920528
β₈ 3,48927E-22
Finalmente nos encontramos que para el parámetro β₆, el valor de la probabilidad
es mayor al valor de significancia, por ende, podemos decir que existe evidencia muestral
suficiente para no se rechazar H₀ para este parámetro. Por lo tanto el intercepto y las
variables: IPSA, Tipo de cambio, UF, LAN, CAP, SoquimichB y CUPRUM son significativas de
forma individual en el modelo.
Replanteo del modelo
Luego de depurar por significancia debemos replantear nuestro modelo, que
luego de eliminar la variable BCI nos queda:
Y = -7809,24313 + 0.16434705xIPSA + 0,56559206xTipo de cambio +
0,33889041xUF + 0,01758728xLAN - 0,01487858xCAP + 0,00705265xSoquimichB +
0,02040818xCUPRUM

Estadísticas de la regresión
Coeficiente de correlación múltiple
0,91821195
Coeficiente de determinación R^2
0,84311318
R^2 ajustado 0,83861233
Error típico 33,8092461
Observaciones 252
ANÁLISIS DE VARIANZA
Grados de
libertad Suma de
cuadrados
Promedio de los
cuadrados F
Valor crítico de F
Regresión 7 1498857,09 214122,442 187,323048 2,4416E-94
Residuos 244 278907,889 1143,06512
Total 251 1777764,98
Coeficientes Error típico Estadístico t Probabilidad Inferior 95% Superior
95%
Intercepción -7807,16563 757,175547 -10,3109057 6,3154E-21 -9298,60004 -6315,73121
IPSA 0,16387027 0,0215185 7,61531924 5,7663E-13 0,12148455 0,206256
Tipo de Cambio 0,56536403 0,2504168 2,25769204 0,02484935 0,07210954 1,05861852
UNIDAD DE FOMENTO 0,33886998 0,03319441 10,2086456 1,3233E-20 0,27348582 0,40425414
LAN AIRLINES 0,01752984 0,00464283 3,77568086 0,00020047 0,0083847 0,02667498
CAP -0,01494394 0,00386392 -3,86756106 0,00014106 -0,02255483 -0,00733305
SOQUIMICH B 0,00698998 0,0024655 2,83512118 0,00496481 0,00213361 0,01184635
CUPRUM 0,02031272 0,00185686 10,9393044 6,3258E-23 0,01665521 0,02397024
Luego del replanteo, podemos decir que al depurar por significancia, nuestro
ajuste aumenta levemente debido a la eliminación de una variable, quedando en un
83,86%.
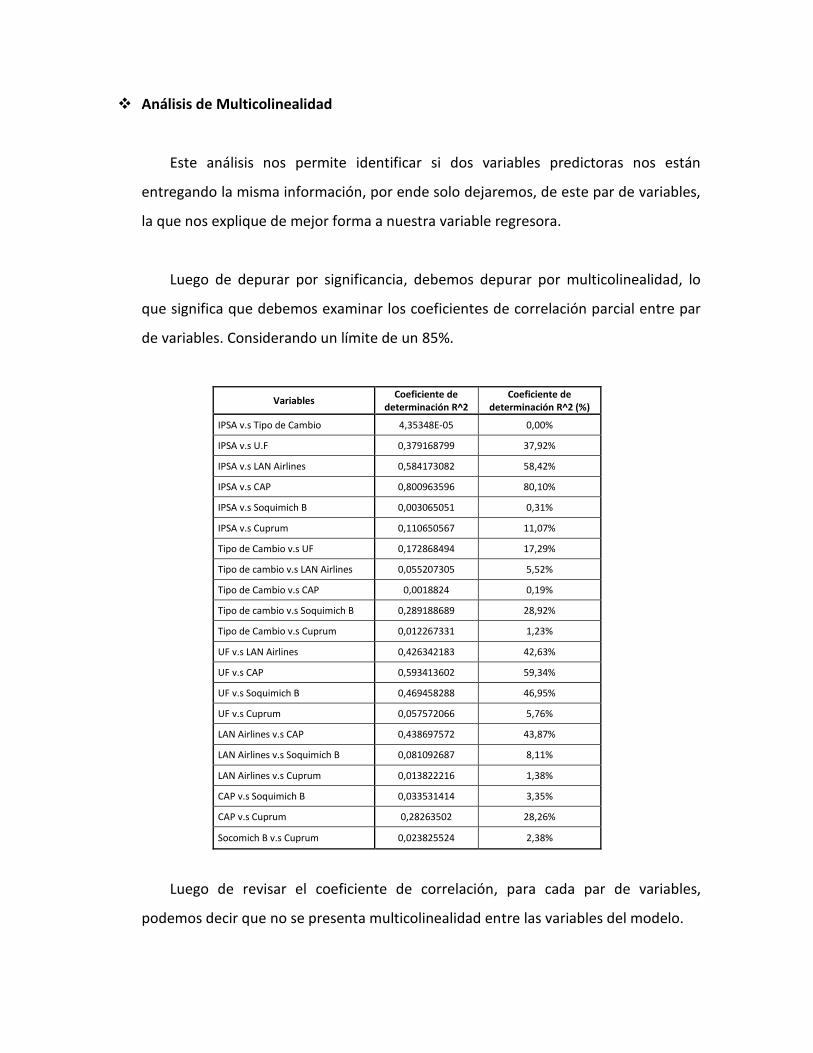
Análisis de Multicolinealidad
Este análisis nos permite identificar si dos variables predictoras nos están
entregando la misma información, por ende solo dejaremos, de este par de variables,
la que nos explique de mejor forma a nuestra variable regresora.
Luego de depurar por significancia, debemos depurar por multicolinealidad, lo
que significa que debemos examinar los coeficientes de correlación parcial entre par
de variables. Considerando un límite de un 85%.
Variables Coeficiente de
determinación R^2 Coeficiente de
determinación R^2 (%)
IPSA v.s Tipo de Cambio 4,35348E-05 0,00%
IPSA v.s U.F 0,379168799 37,92%
IPSA v.s LAN Airlines 0,584173082 58,42%
IPSA v.s CAP 0,800963596 80,10%
IPSA v.s Soquimich B 0,003065051 0,31%
IPSA v.s Cuprum 0,110650567 11,07%
Tipo de Cambio v.s UF 0,172868494 17,29%
Tipo de cambio v.s LAN Airlines 0,055207305 5,52%
Tipo de Cambio v.s CAP 0,0018824 0,19%
Tipo de cambio v.s Soquimich B 0,289188689 28,92%
Tipo de Cambio v.s Cuprum 0,012267331 1,23%
UF v.s LAN Airlines 0,426342183 42,63%
UF v.s CAP 0,593413602 59,34%
UF v.s Soquimich B 0,469458288 46,95%
UF v.s Cuprum 0,057572066 5,76%
LAN Airlines v.s CAP 0,438697572 43,87%
LAN Airlines v.s Soquimich B 0,081092687 8,11%
LAN Airlines v.s Cuprum 0,013822216 1,38%
CAP v.s Soquimich B 0,033531414 3,35%
CAP v.s Cuprum 0,28263502 28,26%
Socomich B v.s Cuprum 0,023825524 2,38%
Luego de revisar el coeficiente de correlación, para cada par de variables,
podemos decir que no se presenta multicolinealidad entre las variables del modelo.

Análisis de Autocorrelación
Para analizar la autocorrelación de las variables utilizaremos el test de Durbin-
Watson, para esto se realiza la siguiente dócima:
H0: ρ = 0 (independencia de los residuos) v/s
H1: ρ ≠ 0 (dependencia de los residuos)
Del software Minitab se obtiene la siguiente información entregada: Estadístico
D-W = 0,357859 para un nivel de significancia del 5%, n=252, k= 6 se obtiene según
tabla, sin embargo como los datos de la tabla solo llegan hasta un N=200:
dL = 1,707 y dU = 1,831
Por lo tanto como d < dL se rechaza la Hipótesis nula, existe evidencia estadística
para suponer que los residuos presentan autocorrelación positiva.
Por otro lado a partir del estadístico Durbin-Watson, se puede obtener el
coeficiente de autocorrelación simple ρ igual a 0,821071 lo que nos indica que existe
una alta asociación entre los residuos.
A continuación utilizaremos test de Rachas para verificar la información obtenida
anteriormente mediante Durbin- Watson.
H0: La secuencia de datos es aleatoria (no hay correlación en los residuos)
v/s
H1: La secuencia de datos no es aleatoria (hay correlación en los residuos)
R: Número de rachas
N1: Número de residuos positivos
N2: Número de residuos negativos
N: Número de observaciones en análisis

0
N1= 131 N2 = 121 R = 42
E [R] = 126,8 V[R] = 62,55
A partir de estos datos se puede determinar el siguiente intervalo de confianza:
=
Igual a [111,3; 142, 3]
Dado que R no se encuentra dentro del Intervalo, por lo tanto existe evidencia
muestral suficiente para rechaza la Hipótesis Nula y se puede concluir que hay
presencia de autocorrelación de los residuos. Lo que coincide con lo obtenido con la
prueba de Durbin-Watson. (Anexo 1)
Análisis de Heterocedasticidad
Se realiza una primera inspección analizando los gráficos de los residuos
estandarizados versus cada variable explicativa del modelo para tener una idea a
priori de presencia de heterocedasticidad.

Según lo observado en las gráficas anteriores, y considerando lo expuesto en el
libro Gujarati de Econometría, podemos inferir no hay un patrón sistemático entre las
dos variables, lo cual sugiere que posiblemente no hay heterocedasticidad en los

datos. Para verificar lo observado según el método gráfico, se realizará el contraste de
Golfeldt y Quandt.
Para ello se establece la siguiente docima:
H0: Ausencia de Heterocedasticidad v/s H1: Presencia de heterocedasticidad
Luego se ordena cada variable de menor a menor para luego eliminar las n/3
observaciones centrales. Se realiza la regresión para cada uno de los grupos. En este
caso n = 252, el grupo 1 se formara de los 84 primeros datos y el grupo dos por los 84
últimos datos.
El estadígrafo para cada caso corresponde al cuociente entre los SC de las
regresiones de cada grupo, el que es contrastado con la distribución de F, que se
detalla a continuación .
1. IPSA
- Primeras 84 observaciones
- Últimas 84 observaciones
Estadígrafo: E = = = 1,886 F (81; 81 ; 0,95) = 1,448

Luego, como E > F, entonces no se acepta la Hipótesis nula, es decir, existe
evidencia estadística que indica presencia de heterocedasticidad.
2. Tipo de cambio
- Primeras 84 observaciones
- Últimas 84 observaciones
Estadígrafo: E = = = 2,2146 F (81; 81 ; 0,95) = 1,448
Luego, como E > F, entonces no se acepta la Hipótesis nula, es decir, existe
evidencia estadística que indica presencia de heterocedasticidad.
3. Unidad de Fomento
- Primeras 84 observaciones
- Últimas84 observaciones

Estadígrafo: E = = = 2,496 F (81; 81 ; 0,95) = 1,448
Luego, como E > F, entonces no se acepta la Hipótesis nula, es decir, existe
evidencia estadística que indica presencia de heterocedasticidad.
4. LAN
- Primeras 84 observaciones
- Últimas 84 observaciones
Estadígrafo: E = = = 2,4744 F (81; 81 ; 0,95) = 1,448
Luego, como E > F, entonces no se acepta la Hipótesis nula, es decir, existe
evidencia estadística que indica presencia de heterocedasticidad.
5. CAP
- Primeras 84 observaciones

- Últimas 84 observaciones
Estadígrafo: E = = = 2,3187 F (81; 81 ; 0,95) = 1,448
Luego, como E > F, entonces no se acepta la Hipótesis nula, es decir, existe
evidencia estadística que indica presencia de heterocedasticidad.
6. Soquimich B
- Primeras 84 observaciones
- Últimas84 observaciones
Estadígrafo: E = = = 2,3156 F (81; 81 ; 0,95) = 1,448
Luego, como E > F, entonces no se acepta la Hipótesis nula, es decir, existe
evidencia estadística que indica presencia de heterocedasticidad.

7. CUPRUM
- Primeras 84 observaciones
- Últimas84 observaciones
Estadígrafo: E = = = 2,277 F (81; 81 ; 0,95) = 1,448
Luego, como E > F, entonces no se acepta la Hipótesis nula, es decir, existe
evidencia estadística que indica presencia de heterocedasticidad.
La prueba de Golfeldt y Quandt nos indica, a diferencia de lo observado en las
pruebas gráficas, que si nos encontramos en presencia de heterocedasticidad en el
modelo, de hecho en todas las variables, por lo que a pesar de que se podrían realizar
correcciones para este modelo, la recomendación óptima, es de replantear las
variables predictoras y realizar un nuevo modelo y su respectivo análisis.

CONCLUSIÓN
Luego de analizado el proceso, nuestro objetivo principal de encontrar un modelo
que pudiese predecir el precio de la acción de SONDA, se ve truncado, así como la tesis de
que al aumentar el precio de las otras acciones involucradas, el precio de nuestra acción
también aumentaría, esto, posiblemente por las variables consideradas para este análisis.
Los estadísticos de correlación y luego el análisis de significancia global e individual
nos deja un modelo propuesto con variables como el IPSA, el Tipo de cambio y el precio de
otras acciones que son transadas en la bolsa, al igual que SONDA, y que además son
clientes de ésta empresa, nos deja un modelo que a priori podría servirnos para estimar lo
que se busca. Sin embargo, luego de realizar los análisis que nos permiten corroborar los
supuestos en los que se basa la regresión múltiple, nos indican que nuestro modelo viola
estos supuestos, el de heterocedasticidad y de autocorrelación, lo que finalmente nos
señala que el modelo luego de depurado por multicolinealidad y finalmente propuesto no
es eficiente ni significativo.
En conclusión, podemos decir que no basta con contar con los mejores programas
matemáticos, ni saber realizar una regresión y todos sus análisis, para poder estimar
modelos. Como hemos visto en este trabajo, lo más importante es recopilar buenos datos
muéstrales, así como definir variables apropiadas para la estimación, de lo contrario,
todas las herramientas antes mencionadas no lograrán buenos resultados.

BIBLIOGRAFÍA
- Libro de Econometría, Damodar N. Gujarati
- http://webdelprofesor.ula.ve/economia/dramirez/MICRO/FORMATO_PDF/Mat
erialeconometria/Autocorrelacion.pdf
- www.bolsadesantiago.com
- www.bovalpo.cl
- www.bcentral.cl

ANEXOS
1- Anexo 1: Análisis de residuos






























