Embed Size (px)
Citation preview

1
ECE 172Computer Architecture
Chapter 11 Alpha Microprocessor
Herbert G. Mayer, PSUStatus 7/30/2017

2
Syllabus
l Alpha Design Goalsl Unique to Alphal Introductionl Instruction Formatl Data Formatl Register Setl Alpha Instructionsl C Language on Alphal Bibliography
Alpha 21064

3
Alpha Design Goals

4
Design Goalsl True 64-bit architecture: 64-bit registers and integers
designed in from start 1992; also 32-bit data, and all and only 32-bit instructions
l High performance, executing typical business and scientific applications faster than competing, contemporary μP
l Longevity: architecture to be used for multiple decades after launch; goal about ¼ century
l Ubiquity: capable of running multiple OS-es, including Linux, Unix, and VMS for DEC compatibility
l Migration: ease of migrating applications from VAX and MIPS processors
l Simplicity: in line with RISC design goals, arithmetic operations only with register operands, not memory!

5
Unique to Alphal Alpha 21*64 is a four-issue, superscalar 64-bit μPl With out of order (OOO) and speculative executionl With peak instruction execution rate of 6 per cyclel A sustainable rate of 4 instructions per cycle; AKA
four-issue!l Instruction pipeline: 7 deepl At any one moment up to 80 (not a typo: eighty)
different instructions may progress in various stages of completion!
l RISC as opposed to CISC, to allow very fast clockl No branch delay slot, due to four-way issue
architecture!

6
Unique to Alphal Despite regularity of design: custom layout, resulting
in higher optimization than automated tools could possibly provide
l In turn caused renaissance of custom circuit design!l CMOS technologyl Single-cycle instructions; note: also has draw-backs!l Good register pool: 32 integer, and 32 float registers.
Needs log2( 32 ) = 5 bits to ID any int or float registerl Memory access 4-byte aligned; early Alphas had no
single-byte load/storel Traps imprecise; if needed: option to add precision
(TRAPB instruction) is available at expense of cyclesl Multi-processor execution designed in from start

7
Introductionl Original name of Digital μP: Alpha AXPl Earlier aborted DEC architecture was named: PRISM l Internal joke: AXP stands for “Almost eXactly PRISM”l Reality: AXP product name posed no © challengel Further Alpha architecture goals:
l RISC μP product, to succeed DEC’s VAX 32-bit CISCl Speed via: RISC, fast clock, aggressive multi-instruction issuel To have very long product life spanl 64-bit addressing, 64-bit registersl Instruction length 32-bits, byte-orientedl Supporting both VAX FP-formats and IEEE 754 standard
l Life span actually 1992 - 2004 ! due to politics
8
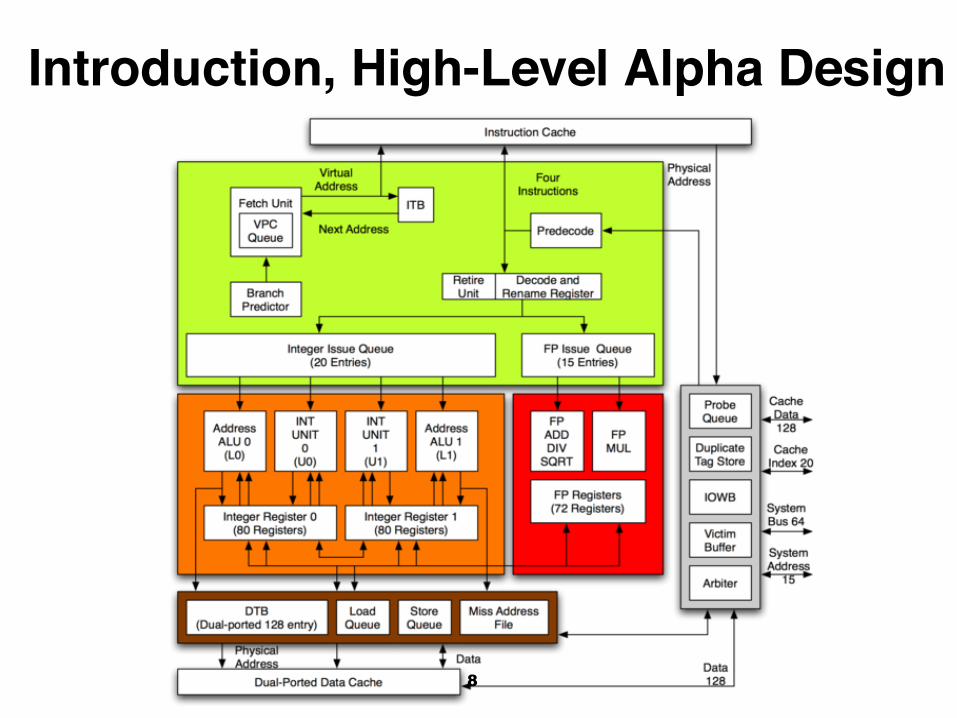
Introduction, High-Level Alpha Design

9
Introduction, Photo Alpha 21064 μP

10
Introductionl Product designation: Alpha 21*64l 21 alluding to 21st century, 64 to 64-bit addressing,
and * to specific product designation 0, 1, 2, 3, 4:l 21064: CMOS μP with fast clock; like main framesl 21164: first μP with large L2 cache on chipl 21264: first μP with ooo execution!l 21364: first μP with on-chip memory controllerl 21464: support of SMT (symmetric multi-threading)l Bankrupt DEC was purchased in 1998 by Compaql Compaq sold Alpha to Intel 2001; yet Intel developed
competing 64-bit Itanium architecture; froze Alphal Bankrupt Compaq was purchased in 2001 by HP;
supported Alpha production a few years

11
Introductionl Alpha developed at Digital Corp. by:
Richard Sites, Richard T. Witekl Sites was Herb’s prof at UCSDl High-performance μP techniques:
l Fast clock, enabled by RISCl Absence of complex opcodes –e.g. no divide– thus one
achieves very fast clock; replaced divide by other meansl Conditional move, replaces branches, avoids I-cache missl Initially 7-stage pipeline for int, 9-stage for float opsl Out of order (OOO) executionl Aligned memory addresses
l Privileged Architecture Library (PAL) to support multiple OS options
Dr. Richard Sites
12
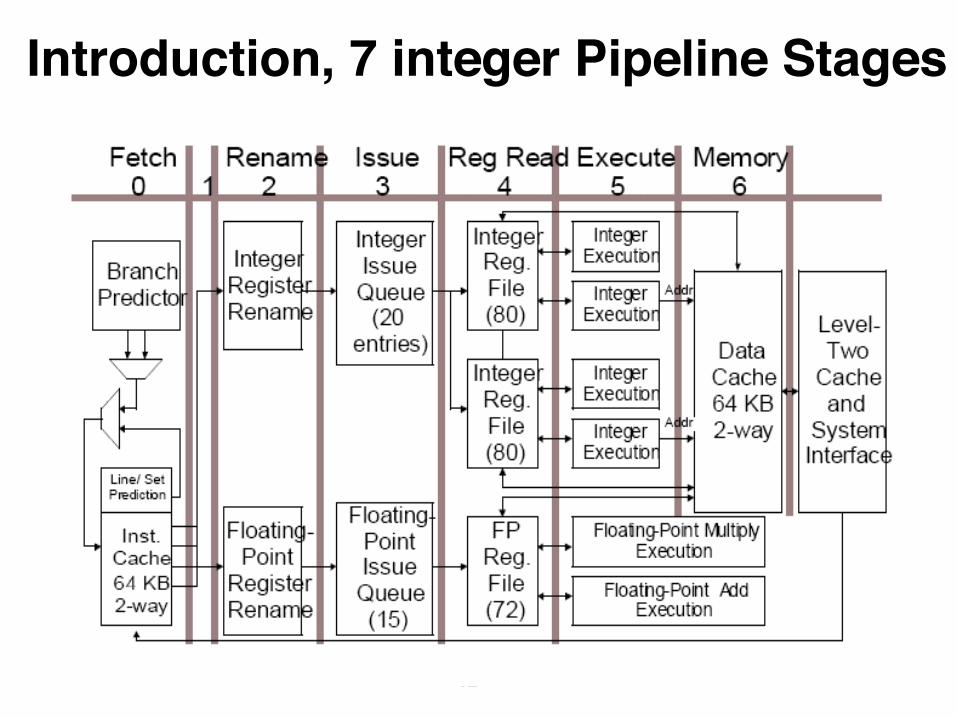
Introduction, 7 integer Pipeline Stages

13
Introductionl How to handle exceptions (AKA traps), when
multiple instructions are in various stages of completion?
l Hard problem on pipelined architecture, if precision needed, i.e. if it is necessary to know the exact instruction causing that exception!
l Alpha handles traps imprecisely: recovery action may not be at address of exact opcode causing the exception
l If precision needed, insert trap barrier instructionsl Trap barrier slows down execution; luckily for
performance this is rare, yet guarantees needed precision when required
l Overall performance goal achieved on Alpha!

14
Introduction, Quotes by Dr. SitesArchitecture vs. Implementation, according to Sites in Alpha design documents:
“Computer architecture is defined as the attributes and behavior of a computer as seen by a machine-language programmer. This definition includes the
instruction set, instruction formats, operation codes, addressing modes, and all registers and memory locations that may be directly manipulated by a
machine-language programmer.”
“Implementation is defined as the actual hardware structure, logic design, and data-path organization of
a particular embodiment of the architecture”

15
Alpha Instruction Format

16
Instruction Format - Simplifiedl Other Alpha documents use simplified grouping of
instructions into 4 general formats, shown below:1. Using 26 bits to identify some PAL function2. Register operand Ra plus 21-bit displacement Δ3. Two register operands Ra, Rb, plus 16-bit Δ4. Three register operands Ra, Rb, Rc, 11 additional function bits
l We’ll use instead a more detailed form, separating 4th format into 3 refined groups: resulting in 6 groups ttl.

17
Instruction Formatl Using 6 different categories: still:l All instructions 32 bits longl Immediate operands cannot span full address range,
only displacements, AKA offsets! Problem?l Clearly, 64-bit addresses only reside in registers, not
in immediate fields –AKA Displacement; see belowl Six types (groups) summarized below:

18
Instruction Format 1: PAL Calll Always 6 opcode bits: Caveat: only 64 opcodes? ☺l Remaining 26 bits define particular PAL function calll Leftmost 2 of 6 opcode bits are 00 for PALl PAL stands for Privileged Architecture Libraryl And PAL has set of functions, specific to any
particular Alpha operating-systeml Each function provides unique, defined servicel Comparable to (a better ☺) Microsoft BIOSl Calls any PAL function, specified for any OS running
on Alpha

19
Instruction Format 2: Branchl Register Ra specifies, which register will be tested for
condition of conditional branchl And if true, add signed integer 21-bit Displacement to
pc to compute branch targetl Spans 8 MB instruction range max: Way, way less
than logical 64-bit addressing spacel Recall: implied left shift << by 2 bits due to alignment
yielding 23-bits; 1 bit used as sign, thus covers total relative range of +- 4 MB instruction bytes!

20
Instruction Format 3: Memory Accessl Opcode refines specific load or store instruction l For loads, Rb specifies part of double-word-aligned!
source address of data to be loadedl Ra defines destination register
l Note irregular DEC Alpha nomenclature: Double-word is sequence of 4 bytes; like Intel’s quirky vocabulary stemming from tiny 16-bit x86 computers !
l Displacement added to Rb to form virtual address val Overflow ignored for va computationl Bytes at va are loaded into 64-bit register Ra

21
Instruction Format 4: Floating-Point Opl Specifies register-to-register floating-point
operation, with Rc being destinationl Ra and Rb are source operands, 64 bits
wide floating-point operandsl Particular FP function refined via 11 further
Function bitsl Note: this extends notion of 6-bit opcode:
Recall caveat on p. 18 ☺

22
Instruction Format 5: Integer-Literal Opl Specifies register-to-register integer operations with
8-bit literal operandl Register Rc is destinationl Ra is a 64-bit integer source operandl Bits 5 .. 11 in conjunction with the opcode specify
the exact integer ALU functionl Bits 13 .. 20 define an 8-bit literal source operandl Fixed 1 bit at position 12 further extends opcode:
“Opcode uses a literal operand”

23
Instruction Format 6: Integer Opl Specifies register-to-register integer type operations,
with Rc being destinationl Ra and Rb are 64-bit integer source registersl Bits 5 .. 11 in conjunction with the opcode specify the
exact integer ALU integer functionl Bits 13 .. 15 are unused and reservedl The fixed 0 bit in position 12 extends the opcodel This format uses no literal operand

24
Alpha Data Format

25
Data Formats on Alphal Memory is byte-addressablel Default stored in Little-Endian formatl Big-Endian can be set to override the defaultl ALU operations performed on 64-bit registersl Addresses are 64-bits in lengthl Floating point data support old VAX formats,
two different methods:l F-float -- for VAX compatibilityl G-float -- double-precision, also VAX compatibility

26
Data Formats on Alphal Floating point computation also in three IEEE
754 formatsl Single precision 32-bitl Double precision 64-bitl Extended precision 80-bit
l Operands can be of sizes:l Bytel Two byte word – like Intel x86 little-endianl Double-word – 4 bytes, 32-bitsl And Quad word – 8 byte, 64-bits
l ALU operations performed between 64-bit regs
27
Alpha IEEE 754 Precision

28
Alpha Register Set

29
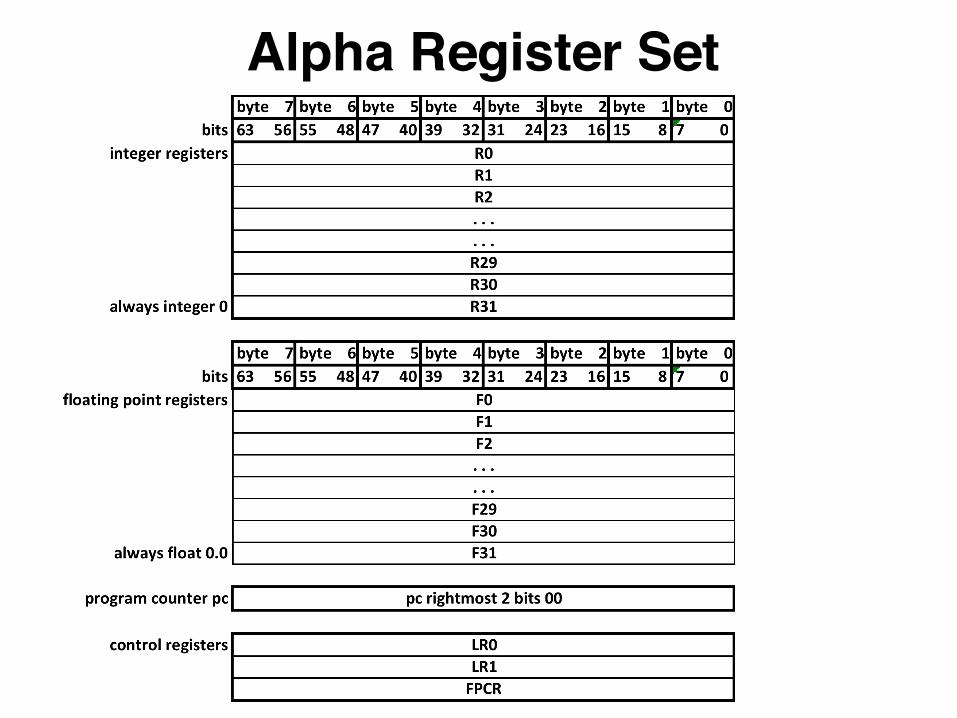
Alpha Register SetSubset of this shown in earlier presentation on Registersl On MP system, each Alpha processor has its own, full
complement of architecture registersl The pc register addresses next instruction in 4-byte
aligned instruction streaml The pc is 64-bits wide, yet the rightmost 2 bits are
implied 0 and not explicitly stored, due to the 4-byte alignment of all instructions
l Alpha has 32 integer registers, each 64 bits wide, conventionally named R0 .. R31
l R31 has special meaning: Always supplies integer 0l Obviously, R31 is not writeable!l Exceptions not raised, when R31 is specified as a
destination for a load! Careful programmers!

30
Alpha Register Set
l Alpha has 32 floating-point registers, conventionally named F0 .. F31
l Each float register is 64 bits widel Register F31 always holds the true 0.0 floating-
point value as a constant, cannot be writtenl Note: An exception is not signaled for a load, when
specifying F31 as destination!l Float instructions computing single-precision data
–only 32-bits wide– still write all 64 bits of their respective floating point destination register, in a sign-extended way

31
Alpha Register Setl Alpha has 2 special registers, named lock-registers,
LR0 and LR1; not further explained herel Process Cycle Counter (PCC) register consists of
two 32-bit fields; usable for performance monitoringl Low order 32 bits (31..0), known as PCC_CNT, uses
as interval timer, unsigned wrapping counter, tracking number of nanoseconds of an event
l High order 32 bits (63..32) are known as PCC_OFF, and are operating-system dependent
l Suggested: use as cycle counter for process, threadl PCC read by special RPCC instruction; for OS
supportl FPCR (64-bit Floating Point Control Register) used in
IEEE 754 format; else FPCR is not visible; among others, selects one of 4 different rounding modes
32
Alpha Register Set

33
Alpha Instructions−Small Subset Only−

34
Load StoreAlpha mnemonics below move bits between memory and registers. Store Byte included in newer Alphas!
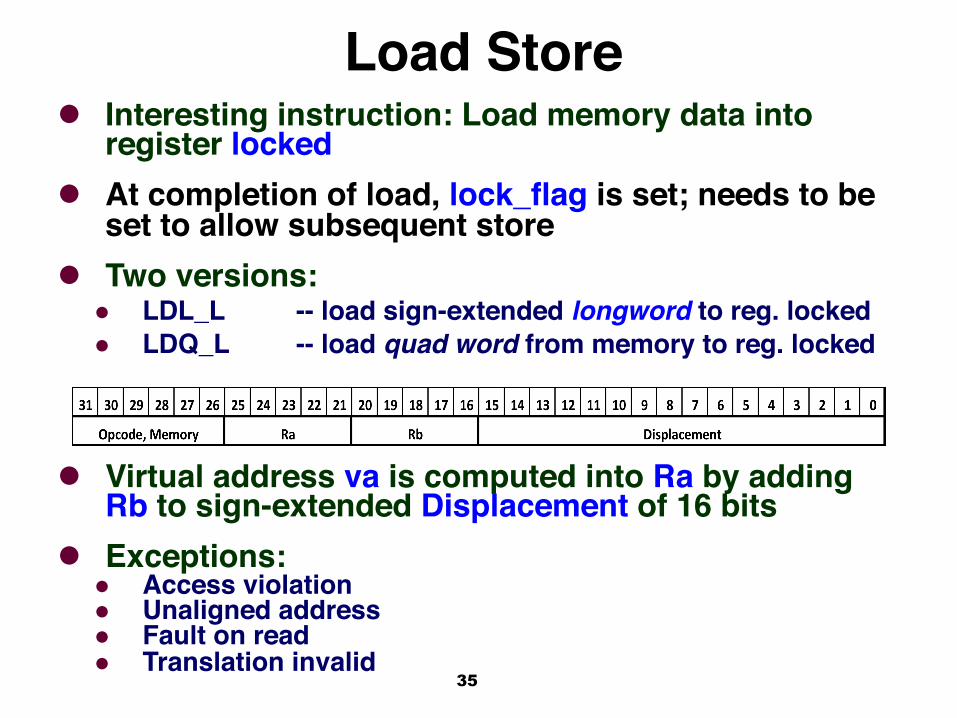
35
Load Storel Interesting instruction: Load memory data into
register lockedl At completion of load, lock_flag is set; needs to be
set to allow subsequent storel Two versions:
l LDL_L -- load sign-extended longword to reg. lockedl LDQ_L -- load quad word from memory to reg. locked
l Virtual address va is computed into Ra by adding Rb to sign-extended Displacement of 16 bits
l Exceptions: l Access violationl Unaligned addressl Fault on readl Translation invalid

36
Load Storel LDx_L is a fairly complex instruction; used for
synchronization:l When LDx_L instruction is executed without
faulting, μP records target address in per-processor locked_physical_address register, then sets per-processor lock_flag
l But only if lock_flag still set when STx_C is executed on same 16-byte naturally aligned memory block as the LDx_L; and only then the store occurs
l Else it does not occur; then the behavior of STx_C is defined to be unpredictable

37
Control Instructionsl Alpha has branch and jump instructionsl Jumps include prediction bits in the opcode,
assembled by compiler or programmer! Think about this, students!!
l Most branches are conditional, with all conditions only checking some register operand vs. 0 value
l Labels used in branches in assembly code are interpreted as relative to pc
l Thus maximum branch distance was strongly restricted to + - 4 MB!
l Jumps encode transfer of control to target address, and have optional prediction hints
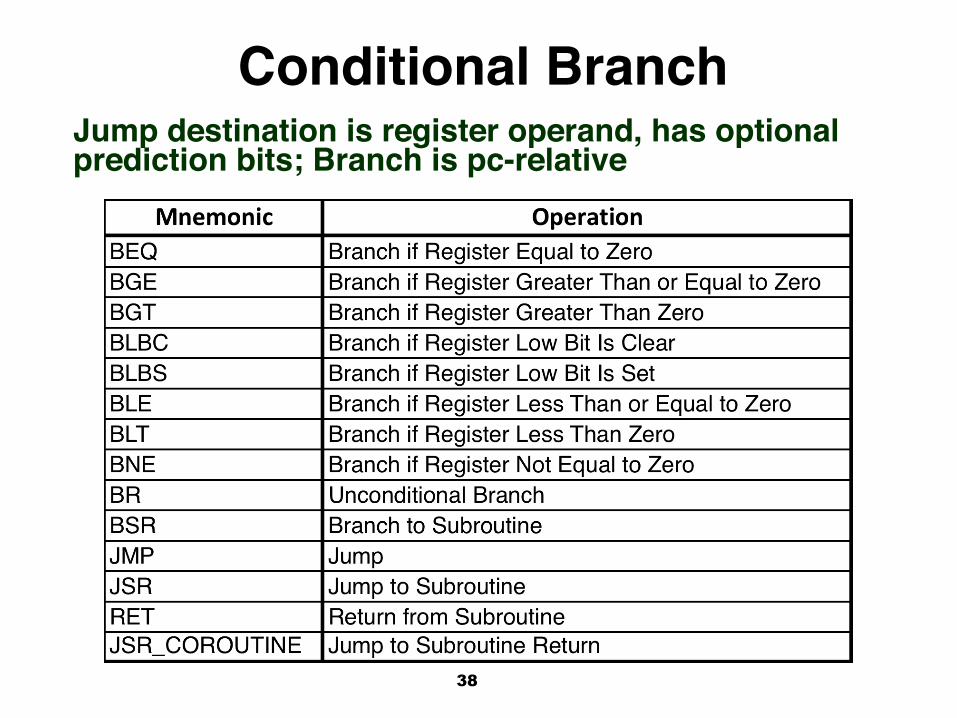
38
Conditional BranchJump destination is register operand, has optional prediction bits; Branch is pc-relative

39
Conditional Movel Conditional Move operations conditionally update a
register; accomplished without branching!l Better performance than conditional branch around
some code: shorter, and generates less I-cache misses, due to straight-line execution
l Compact instruction space reduces I-cache needl Two versions: 1.) all 3 register operands, or 2.) one
literal operand plus 2 register operands, cc being condition code:
cmovcc Ra, Rb, Rccmovcc Ra, Lit, Rc
l Ra register value tested against 0l Rb (or Lit) holds small literal operand to be movedl Rc destination for moved bits, if condition holds

40
Conditional Movel Condition codes cc spelled out here: e.g. eq l Example: if Ra is eq 0, then move bits in register
Rb to destination Rc
41
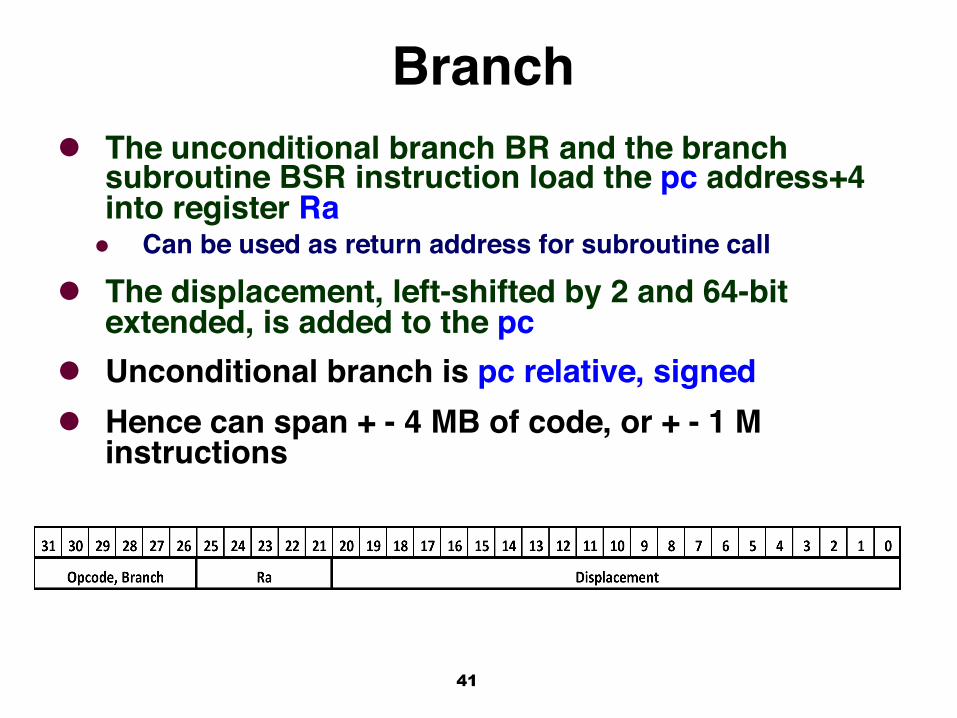
Branchl The unconditional branch BR and the branch
subroutine BSR instruction load the pc address+4 into register Ra
l Can be used as return address for subroutine call
l The displacement, left-shifted by 2 and 64-bit extended, is added to the pc
l Unconditional branch is pc relative, signedl Hence can span + - 4 MB of code, or + - 1 M
instructions

42
Branchl Mnemonics are BR and BSRl BR and BSR are essentially identical, except:l Provide different hints to branch prediction logicl BSR is predicted as a subroutine call, and pushes
the return address (located in Ra) onto the branch prediction stack
l While the unconditional BR is predicted as a general code branch and thus does not affect the branch prediction stack

43
Jumpl Mnemonics and semantics:
l JMP jump instructionl JSR jump to subroutinel RET return from subroutinel JSR_COROUTINE jump to subroutine return
l The pc of instruction after the Jump –i.e. the already updated pc– is written to register Ra
l And pc is loaded with target virtual address l New pc is supplied from register Rb; the 2 low bits
of Rb are ignoredl Ra and Rb may specify the same register; the target
calculation using the old value is computed first, before new value is assigned

44
Jumpl All Jumps perform similar functions; only differ in
hints to branch-prediction logicl Displacement bits of the instruction used to pass
such predictionl Four different ‘‘opcodes’’ set different bit patterns
in disp<15:14>l The hint operand sets disp<13:0>

45
Jumpl Jump design specifies low 16 bits of a likely
longword (4 bytes in Alpha nomenclature) target address
l Suffices to start a useful I-cache access earlyl Allows distinguishing call from return and from the
other two less frequent operationsl Prediction info solely used as hint; correct setting
of these bits can improve performance but is not necessary for correct execution
l Coroutine linkage not explained her

46
Integer Arithmeticl Integer arithmetic instructions perform add, subtract,
multiply, signed and unsigned compare, and bit count operations
l Alpha has no integer divide instruction! Division by a constant done via UMULH; see below
l Integer division by int holds the divisor in register, then executed via subroutine call! Side-effect of RISC decision!!
l All integer instructions are listed on next pagel General integer instruction format:

47
Integer Arithmeticl Mnemonics listed here are generic, e.g. ADDl Specific mnemonics for 32 vs. 64-bit integer
operations are shown on following pages

48
Integer Arithmetic: ADDLl The longword ADDL is the unnatural ☺ version of
integer addition on Alpha: 32-bit operandsl Two versions: 1.) all 3 register operands, or 2.) one
literal operand plus 2 register operands:ADDL Ra, Rb, RcADDL Ra, Lit, Rc
l Ra register holds one 32-bit summandl Rb (or Lit) holds second 32-bit summandl Rc destination for suml Exception: Overflow may occur, HW must checkl High order 32 bits in Ra and Rb are ignored for
ADDL

49
Integer Arithmetic: ADDQl Quadword integer addition of two 64-bit operands,
computing sum into Rc l Two versions: 1.) all 3 register operands, or 2.) one
literal operand plus 2 register operands:ADDQ Ra, Rb, RcADDQ Ra, Lit, Rc
l Ra register holds one 64-bit summandl Rb holds second 64-bit summand, or lit holds the
second, short summand that is to be sign extendedl Rc is destination for sum of Ra + Rb, or Ra + litl Exception: 64-bit integer Overflow may occur, HW
must check, set flag

50
Integer Quadword Multiplyl Quadword integer multiply of two 64-bit integer
operands, computing product into Rc l Two versions: 1.) all 3 register operands, or 2.) one
literal operand plus 2 register operands:MULQ Ra, Rb, RcMULQ Ra, Lit, Rc
l Ra register holds one signed integer 64-bit factorl Rb holds second 64-bit factor, or lit holds the
second, short integer factor to be sign extendedl Rc destination for product of Ra * Rb, or Ra * litl Exception: 64-bit integer Overflow may occur, HW
must check, set flag

51
Unsigned Quadword Multiply Highl Quadword unsigned multiply computes 128-bit
product of two 64-bit unsigned operands, stores only upper 64 bits into Rc; no overflow possible
l Two versions: 1.) all 3 register operands, or 2.) one literal operand plus 2 register operands:
UMULH Ra, Rb, RcUMULH Ra, Lit, Rc
l Ra register holds one unsigned 64-bit factorl Rb holds second 64-bit unsigned factor, or lit holds
a short unsigned factor to be zero-filled to 64 bitsl Rc holds upper 64 bits of Ra * Rb, or Ra * litl No Integer Overflow can occur

52
IEEE Floating Multiplyl The factor (AKA multiplicand operand) in Fb is
multiplied by factor (AKA multiplier operand) Fal Product of either format is written to register Fc:
MULS Fa, Fb, Fc –S_FloatingMULT Fa, Fb, Fc –T_Floating
l Product is rounded to specified precisionl Then the corresponding range is checked for
overflow/underflowl Single-precision operation on canonical single-
precision values produces a canonical single-precision result
l Exceptions: Invalid operation, Floating point overflow, Underflow, and Inexact result

53
C Language on Alpha

54
C Language on Alphal Alpha was one of the early natural 64-bit μPl Porting C source programs, originally conceived
to run on 32-bit architectures, brought surprises when running on Alpha
l Surprising observations shown taken from [4]l Recall:
l Alpha addresses are 64 bits longl A C int on Alpha is 32 bits long, 4 bytesl A C long int on Alpha 64 bits long, 8 bytesl A C pointer on Alpha, regardless of type pointed-to,
must always be 64 bits long
l Also recall, that in C the precision of data in bits is not strictly defined, except that for example, a long int is no shorter than an int type object

55
C Language on Alphal Similar fuzziness exists for integer numeric literals,
AKA int constantsl In C, the l or L qualifier at the end of an int literal can
resolve thisl Thus in Alpha C compilers:
int a; // likely 4 bytes, 32 bits
long int b; // likely 8 bytes, 64 bits
. . . = 0x0123456789abcdef; // 01234567 lost bits
. . . = 0x0123456789abcdefL; // full 64-bits 0..f

56
C Language on Alphal Sample taken from [4]l C long int objects b and d are initialized likely as
intended by the programmerl While a and c are full of surprises, i.e. wrong bits!long int a = 0xFFFFFFFF7FFFFFFF; // == 0x000000007FFFFFFFL
long int b = 0xFFFFFFFF7FFFFFFFL; // == 0xFFFFFFFF7FFFFFFFL
long int c = 0x0000000080000000; // == 0xFFFFFFFF80000000L
long int d = 0x0000000080000000L; // == 0x0000000080000000L
l Similar to printing long int objects via printf() in C:The format specifier %d has to be %ld for full 64-bit integral values
l Ditto for hex printing: the format must be %lx

57
Bibliography
1. Wikipedia article 1: https://en.wikipedia.org/wiki/DEC_Alpha
2. Wikipedia article 2: https://www.cs.auckland.ac.nz/courses/compsci210s2c/resources/AlphaArch.pdf
3. Compaq reference manual for Alpha wq264 CPU: http://www.ece.cmu.edu/~ece447/s15/lib/exe/fetch.php?media=21264hrm.pdf
4. Randal E. Bryant: Alpha Assembly Language Guide, CMU, 2/23/1998

58
Definitions

59
DefinitionsAlignmentl Attribute of some memory address A,
stating that A must be evenly divisible by some power of two, e.g. a page size, or line size
l For example, word-aligned on a 4-byte, 32-bit architecture means: address is divisible by 4, or the rightmost 2 address bits are both 0

60
DefinitionsBranch Delay Slotl Highly pipelined μPs execute just one more instruction
before completing the current unconditional branchl That step before is the target instruction, otherwise
located physically at the target of the branchl The reason is to greedily recover some of the lost
time, caused otherwise by the pipeline stalll Place target instruction of the branch physically after
the branch: Placed after the branch, executed before the branch completes, never reached as branch target
l Since it is supposed to be executed anyway, as soon as branch target is reached, time for that instruction is recovered by this code-rearrangement

61
DefinitionsBranch Delay Slotl Note: instruction no longer sits at the branch target!l Example: Intel i860 architecture: When a suitable
candidate cannot be found, a NOP instruction is placed physically after branch, i.e. into the delay slot
l So done on Sun SPARC architecturel There are architecture restrictions: control-transfer
instructions cannot be placed into the delay slotl If that would happen, a phenomenon called code
visiting would occur, with unpredictable side-effects at times; hence the restriction

62
DefinitionsLogical Addressl Address as defined by the architecture; is
the address as seen by the programmer or compiler
l Synonym: virtual address, and on Intel architecture known as linear address
l Antonym: physical address

63
DefinitionsPipeliningl Mode of execution, in which one
instruction is initiated every cycle and ideally one retires every cycle, even though each requires multiple (possibly many) cycles to complete
l Highly pipelined Xeon processors, for example, have around two dozen pipeline stages

64
DefinitionsStatic Branch Predictionl A branch prediction policy that is embedded in the
binary code –ISA visible, so done on Alpha!l Or implemented in HW executing the branches –not
ISA visiblel The policy does not change during execution of the
program, even if known to be wrong almost alwaysl In the latter case, execution would be better off
without branch predictionl No longer used in the 2000s; was Alpha’s major
shortcomingl BTFN heuristic is a static branch prediction policy

65
DefinitionsStatic Branch Prediction, Cont’dl If not ISA visible, requires no opcode bits, e.g. BTFNl HW compares the destination of a branch with the
conditional branch’s own address. Destinations at smaller address lead backwards, assumed taken
l Destination addresses larger than the branch address are assumed not taken –AKA forward branch
l Typical industry benchmarks (SPECint89) achieve almost 65% correct prediction with this simple scheme
l Not adequate for highly pipelined architectures





























