Embed Size (px)
Citation preview

cnológico
Centro Nacional de Investigación
y Desarrollo Tecnológico
Subdirección Académica
Cuernavaca, Morelos, México. Febrero de 2013.
Departamento de Ciencias Computacionales
TESIS DE MAESTRÍA EN CIENCIAS
Metodología de Preparación de Datos Orientada a Aplicaciones de
Epidemiología Basada en el Modelo CRISP-DM
presentada por
Ing. Gregorio Emmanuel Iturbide Domínguez
como requisito para la obtención del grado de Maestro en Ciencias en Ciencias de la Computación
Director de tesis Dr. Joaquín Pérez Ortega
Codirector de tesis
M. C. Miguel Ángel Hidalgo Reyes



Dedicatoria.
A Dios y la vida… Por permitirme llegar a este momento.
A mi familia… Dulce Ma. Domínguez y Gregorio Iturbide, gracias por su amor y apoyo
incondicional; por creer en mí y ser la fuerza que muchas veces necesito. Gracias
por no soltarme y estar para mí cuando más los he necesitado.
Evita; Wendy, Vivi y Ángeles; Ian, Jazael, Heidi y Elizabeth; siempre están en mi
mente.
Ed., gracias por aparecer en mi vida y hacer mi carga más ligera.
¡Los amo!
A mis amigos…
Bicentenarios y músicos…
A mis amigos de toda la vida… Sé que es un triunfo compartido y lo celebran
conmigo.

Agradecimientos.
Agradezco al Dr. Joaquín Pérez Ortega por todo el apoyo, la paciencia y la
confianza depositada en mí para la realización de este proyecto.
A los miembros del comité revisor de tesis: Dra. Olivia Fragoso, Dr. Moisés
González y Dr. René Santaolaya.
Al MC. Miguel Ángel Hidalgo y la Dra. Adriana Mexicano por su tiempo, ayuda y
consejos. Gracias por todo.
Mi más profundo agradecimiento a la Maestra Lupita Botello (siempre lo diré:
“Gracias por darme alas”) y la Dra. Alicia Martínez Rebollar por su apoyo, sin el
cual habría sido difícil iniciar este viaje.
A la teacher Paty Armas y a mis compañeros de la generación Bicentenario-Fin
del mundo (¡sigo pensando que somos una generación bonita!), especialmente a
Gaby, Pao, Lety, sólo Carlos, Juan C., Chi, Cruz, Rafa y Abel; me llevo mucho de
ustedes.
Al Consejo Nacional de Ciencia y Tecnología (CONACYT).
A CENIDET, al departamento de Ciencias Computacionales y la división de
Ingeniería de Software por permitirme ser parte durante este tiempo.
A mi familia y todos mis amigos, sé que están conmigo y me acompañan siempre.
¡Gracias!

I
Resumen.
En la actualidad, las metodologías de Minería de Datos son de propósito
general y no aportan el nivel de detalle suficiente para su aplicación directa en
proyectos de Minería de Datos. En contraste, en este trabajo se propone una
metodología para la fase de Preparación de Datos, con un nivel de detalle mayor
al propuesto en la metodología CRISP-DM, la cual es factible de ser aplicada
directamente a proyectos de Minería de Datos del dominio epidemiológico.
Para validar la metodología propuesta se desarrolló una aplicación en el área de
epidemiología, con resultados satisfactorios. En particular, la aplicación consistió
en la preparación de los datos de las bases de datos de los censos de los años
2000 y 2010, para las causas de mortalidad por cáncer C16 (cáncer de estómago)
y C32 (cáncer de pulmón) y diabetes E11 (diabetes mellitus no
insulinodependiente) y E14 (diabetes mellitus no especificada), ya que en México,
estas enfermedades, constituyen un problema de salud pública importante. Como
ejemplo, en el año 2005, los tumores malignos fueron la tercera causa de muerte
en el país, registrando 63,128 defunciones.
Las principales aportaciones del trabajo son las siguientes: a) se mostró que es
factible refinar el modelo CRISP-DM a un mayor nivel de detalle en la fase de
Preparación de Datos, b) se muestra que es factible, para el dominio de la
epidemiología, desarrollar metodologías con un mayor nivel de detalle, las cuales
puedan ser usadas en varias aplicaciones de dicho dominio, c) se encontró que la
Preparación de Datos en el dominio epidemiológico se puede dividir en una parte
genérica que concierne a las bases de datos involucradas y otra especifica
asociada con el objetivo de minería de datos en particular.
Finalmente, como resultado de usar un caso de estudio con datos reales, se
obtuvieron hallazgos de posible interés para los organismos encargados de la
administración de los servicios públicos de salud en México, los cuales pueden ser
usados en sus procesos de toma de decisiones, dentro de programas para la
prevención y control de enfermedades como el cáncer y la diabetes.

II
Abstract.
Currently, data mining methodologies are of general purpose and do not
provide the sufficient level of detail for their direct application in data mining
projects. In contrast, in this research we proposed a methodology for the data
preparation phase, with a higher level of detail than the CRISP-DM proposed, this
methodology is feasible to be directly applied in data mining projects to the
epidemiological domain.
In order to validate the proposed methodology an application, in the
epidemiological area, was developed, with satisfactory results. In particular, the
application consisted in the pre-processing of the censuses databases of 2000 and
2010, for the causes of death for cancer C16 (stomach cancer) and C32 (lung
cancer), and diabetes E11 (diabetes mellitus no insulin-dependent) and E14
(unspecified diabetes mellitus), as in Mexico these diseases are a major public
health problem. As an example, in 2005, malignant tumors were the third cause of
death in the country, recording 63,128 deaths.
The main contributions of this research are the following: a) it was shown that is
feasible to refine the CRISP-DM model to a higher level detail in the data
preparation phase; b) it shows that is feasible, for the epidemiological domain, to
develop methodologies with a higher level of detail, which can be used in several
applications in that domain; c) it was found that the data preparation in the
epidemiological domain can be divided into a general part concerning to the
databases involved and other specific part associated with the data mining goal in
particular.
Finally, as a result of using a case of study with real data, we obtained findings of
potential interest for the responsible of managing the public health services in
Mexico, these results can be used in their decision-making processes, within
programs for the prevention and control of diseases such as cancer and diabetes.

III
TABLA DE CONTENIDO
Página V LISTA DE FIGURAS VI LISTA DE TABLAS
Capítulo 1 INTRODUCCIÓN 1 1.1 CONTEXTO DE LA INVESTIGACIÓN. 2 1.2 JUSTIFICACIÓN 4 1.3 DESCRIPCIÓN DEL PROBLEMA DE INVESTIGACIÓN 5 1.4 OBJETIVO GENERAL. 7 1.4.1 Objetivos específicos. 7 1.5 ALCANCES Y LIMITACIONES. 8 1.5.1 Alcances. 8 1.5.2 Limitaciones. 8 1.6 ESTADO DEL ARTE. 9 1.6.1 Trabajos relacionados. 9 1.7 ORGANIZACIÓN DEL DOCUMENTO. 13 2 MARCO TEÓRICO 14 2.1 BASE DE DATOS. 15 2.1.1 Bases de datos poblacionales. 15 2.1.2 Bases de datos espaciales. 16 2.2 ALMACÉN DE DATOS. 17 2.3 MINERÍA DE DATOS. 19 2.3.1 Modelo de referencia CRISP-DM. 20 2.3.1.1 Fase de Preparación de Datos. 22 2.3.1.1.1 Complejidad de la Preparación de Datos. 23 2.3.1.2 Etapas de la Preparación de Datos. 24 2.4 EPIDEMIOLOGÍA. 25 2.4.1 Indicadores en epidemiología. 25 3 METODOLOGÍA PROPUESTA PARA LA PREPARACIÓN DE DATOS. 27 3.1 SISTEMATIZACIÓN DEL PROCESO DE PREPARACIÓN DE DATOS. 28 3.1.1 Definición de los procesos de Preparación de Datos. 29 3.1.2 Modelado de los procesos de Preparación de Datos. 30 3.2 METODOLOGÍA DE PREPARACIÓN DE DATOS. 31 3.2.1 Esquema general de la metodología propuesta. 31 3.2.2 Descripción de la metodología de Preparación de Datos propuesta 32 3.2.2.1 Preparación de Datos General (PDG). 32 3.2.2.1.1 Limpieza de datos. 32 . a) Detección errores 33 b) Corrección de errores. 33 c) Eliminación de registros o atributos con errores. 34 3.2.2.1.2 Selección de datos. 34 a) Selección vertical. 34 b) Selección horizontal. 35 3.2.2.2 Preparación de Datos Específica (PDE). 36 3.2.2.2.1 Formateo de datos. 36 a) Formateo de archivo. 36 b) Formateo de atributos. 36 3.2.2.2.2 Construcción de datos. 37 a) Verificación del conjunto de datos. 38 b) Identificación de atributos para calcular los atributos
faltantes. 38
c) Obtención de los atributos faltantes. 38 3.2.2.2.3 Integración de datos. 39 a) Análisis de las fuentes de datos. 39

IV
b) Detección de conflictos. 40 c) Corrección de conflictos. 41 d) Integración de las fuentes de datos. 42 3.2.3 Niveles de adaptabilidad. 42 3.2.3.1 Cambios en el valor de las variables. 43 3.2.3.2 Cambios en el tipo de dato de los valores. 44 3.3 SEMI-AUTOMATIZACIÓN DEL PROCESO DE PREPARACIÓN DE
DATOS. 45
3.3.1 Arquitectura del sistema de Preparación de Datos. 45 3.3.2 Implementación del prototipo de Preparación de Datos. 47 3.3.2.1 Selección de tareas automatizables. 47 3.3.2.2 Descripción de las tareas de preparación con XML. 48 3.3.2.3 Manipulación y acceso a los datos. 50 4 VALIDACIÓN DE LA METODOLOGÍA PROPUESTA Y RESULTADOS 51 4.1 PLAN DE PRUEBAS. 52 4.1.1 Objetivos. 52 4.1.2 Ambiente de las pruebas. 52 4.1.3 Descripción de los casos de prueba. 53 4.1.3.1 Preparación de los datos de los censos del año 2000 y
2010 de manera manual. 53
4.1.3.1 Preparación de los datos de los censos del año 2000 y 2010 de manera automática.
54
4.2 EXPERIMENTACIÓN. 54 4.2.1 Entendimiento del dominio. 55 4.2.2 Recopilación y entendimiento de los datos. 56 4.2.3 Preparación de Datos manual. 58 4.2.3.1 Preparación de Datos General. 59 4.2.3.1.1 Limpieza de datos. 59 4.2.3.1.2 Selección de datos. 61 4.2.3.2 Preparación de Datos Específica. 63 4.2.3.2.1 Formateo de datos. 64 4.2.3.2.2 Construcción de datos. 65 4.2.3.2.3 Integración de datos. 68 4.2.4 Preparación de Datos automatizada. 71 4.2.4.1 Preparación de Datos Específica. 71 4.2.4.1.1 Construcción de datos. 71 4.2.4.1.2 Integración de datos. 74 4.3 ANÁLISIS DE LOS RESULTADOS. 75 4.3.1 Comparativa de los resultados obtenidos contra los obtenidos en
investigaciones previas. 75
4.3.2 Otras causas analizadas. 79 4.3.3 Comparativa entre los tiempos obtenidos durante la Preparación
de Datos realizada manual y automáticamente. 85
4.3.3.1 Tarea: Cálculo de la incidencia de mortalidad. 85 4.3.3.2 Tarea: Cálculo de la tasa de mortalidad. 86 4.3.4 Niveles de adaptabilidad. 87 4.3.5 Almacén de Datos. 88 5 CONCLUSIONES Y TRABAJOS FUTUROS 90 5.1 CONCLUSIONES. 91 5.2 TRABAJOS FUTUROS. 93 5.3 PUBLICACIONES 93 REFERENCIAS. 94 Anexo A. Definición de procesos y diagramas de actividad 100 Anexo B. Descripción de las tareas de Preparación de Datos con XML 102 Anexo C. Diagramas de clases 105 Anexo D. Descripción del almacén de datos 119 Anexo E. Principales aportaciones al dominio epidemiológico 127

V
LISTA DE FIGURAS Página Figura 1. Problema de preparación de datos 6 Figura 2. Representación de un cubo de datos. 18 Figura 3. Niveles de abstracción CRISP-DM. 20 Figura 4. Ciclo de vida de un proyecto de Minería de Datos. 21 Figura 5. Enfoque general de la metodología de Preparación de Datos propuesta. 31 Figura 6. Paquete de Preparación de Datos General. 46 Figura 7. Paquete de Preparación de Datos Específica. 46 Figura 8. Cambios en los valores de entrada. 48 Figura 9. Esquema de descripción de tareas de Preparación de Datos. 49 Figura 10. Formato de los valores de una clave de mortalidad. 64 Figura 11. Normalización de los atributos. 67 Figura 12. Esquema del Almacén de Datos implementado. 69 Figura 13. Representación de la integración de los datos. 70 Figura 14. Operaciones realizadas por el prototipo de Preparación de Datos. 72 Figura 15. Ventana principal del prototipo de preparación de datos. 72 Figura 16. Resultado de la ejecución del prototipo de preparación de datos. 73 Figura 17. Interacción entre prototipo de Preparación de Datos y el de visualización cartográfica.
75
Figura 18. Grupos de municipios para la causa de mortalidad C34. 79 Figura 19. Grupos de municipios para la causa de mortalidad E11, año 2000. 81 Figura 20. Grupos de municipios para la causa de mortalidad E11, año 2010. 82 Figura 21. Grupos de municipios y grupos de interés para la causa de mortalidad E14, año 2000.
83
Figura 22. Grupos de municipios y grupos de interés para la causa de mortalidad E14, año 2010.
84
Figura 23. Representación del cubo de datos. 89 Figura A.1 Diagrama de actividades “Construcción de datos” 101 Figura B.1 Extracción de información desde el archivo XML 104 Figura C.1 Diagrama de clases “Paquetes de Preparación de Datos General y Específica”
105
Figura C.2 Diagrama de clases del paquete de “Preparación de Datos General (PDG)” 106 Figura C.3 Diagrama de clases del paquete de “Limpieza de datos” 107 Figura C.4 Diagrama de clases del paquete de “Selección de datos” 109 Figura C.5 Diagrama de clases del paquete de “Preparación de Datos Específica (PDE)”
111
Figura C.6 Diagrama de clases del paquete de “Formateo de datos” 112 Figura C.7 Diagrama de clases del paquete de “Construcción de datos” 114 Figura C.8 Diagrama de clases del paquete de “Integración de datos” 117 Figura D.1 Esquema del almacén de datos 119

VI
LISTA DE TABLAS
Página Tabla 1. Variables como factor de cambio. 43 Tabla 2. Tipo de dato como factor de cambio. 44 Tabla 3. Características de las bases de datos utilizadas. 57 Tabla 4. Descripción de los atributos proporcionada por INEGI. 58 Tabla 5. Número de registros y atributos después de la preparación de los datos. 68 Tabla 6. Atributos del conjunto de datos final. 74 Tabla 7. Valores de incidencia y tasa de mortalidad para el primer grupo de interés para la causa C16.
76
Tabla 8. Valores de incidencia y tasa de mortalidad para el segundo grupo de interés para la causa C16.
76
Tabla 9. Valores de incidencia y tasa de mortalidad para el segundo grupo de interés para la causa C34.
77
Tabla 10. Valores de incidencia y tasa de mortalidad para el segundo grupo de interés para la causa C34.
78
Tabla 11. Mayores tasas de mortalidad para la causa E11, año 2000. 80 Tabla 12. Mayores tasas de mortalidad para la causa E11, año 2010. 81 Tabla 13. Comparativa de tiempo manual y automático para el cálculo de la incidencia de mortalidad con datos del año 2000.
85
Tabla 14. Comparativa de tiempo manual y automático para el cálculo de la incidencia de mortalidad con datos del año 2010.
86
Tabla 15. Comparativa de tiempo manual y automático para el cálculo de la tasa de mortalidad con datos del año 2000.
86
Tabla 16. Comparativa de tiempo manual y automático para el cálculo de la tasa de mortalidad con datos del año 2010.
87
Tabla A.1 Definición del proceso de “Construcción de datos” 100 Tabla C.1 Descripción de paquetes “PDG y PDE” 105 Tabla C.2 Descripción de paquetes “Preparación de Datos General” 106 Tabla C.3 Descripción de clase “Identificación” 107 Tabla C.4 Descripción de clase “IdentificaciónValoresPerdidos” 107 Tabla C.5 Descripción de clase “detecciónValoresFueraRango” 108 Tabla C.6 Descripción de clase “Corrección” 108 Tabla C.7 Descripción de clase “CorrecciónValoresPerdidos” 108 Tabla C.8 Descripción de clase “CorrecciónValoresFueraRango” 108 Tabla C.9 Descripción de clase “selecciónHorizontal” 109 Tabla C.10 Descripción de clase “selecciónVertical” 110 Tabla C.11 Descripción de paquetes “Preparación de Datos Específica” 111 Tabla C.12 Descripción de clases “formatoArchivo” 112 Tabla C.13 Descripción de clase “formatoAtributos” 112 Tabla C.14 Descripción de clase “otrasModificaciones” 113 Tabla C.15 Descripción de clases “cambiarTipoDato” 113 Tabla C.16 Descripción de clase “Incidencia” 114 Tabla C.17 Descripción de clase “tasaMortalidad” 115 Tabla C.18 Descripción de clase “conversiónDecimal” 115 Tabla C.19 Descripción de clase “Normalización” 116 Tabla C.20 Descripción de clase “minMaxNormalización” 116 Tabla C.21 Descripción de clase “detecciónConflictos” 117 Tabla C.22 Descripción de clase “correcciónConflictos” 118 Tabla C.23 Descripción de clases “Integración” 118 Tabla D.1 Descripción de la tabla “Geográfica” 120 Tabla D.2 Descripción de la tabla “Poblacional” 120 Tabla D.3 Descripción de la tabla “Catálogo” 121 Tabla D.4 Descripción de la tabla “Mortalidad” 121 Tabla D.5 Descripción de la tabla “Hechos” 122 Tabla E.1 Decremento registrado en las tasas de mortalidad. 127 Tabla E.2 Incremento registrado en las tasas de mortalidad. 127

1
Capítulo 1 INTRODUCCIÓN.
Este capítulo presenta el panorama general de la tesis. Se presentan los motivos
que impulsaron esta investigación y se continúa con la definición del problema de
investigación. A su vez se describen los objetivos y se hace una breve
introducción al problema de la fase de Preparación de Datos dentro del proceso de
Minería de Datos. En la última sección se presenta una descripción del contenido
de cada capítulo de la tesis.

Capítulo 1 INTRODUCCIÓN
2
1.1 CONTEXTO DE LA INVESTIGACIÓN.
En la actualidad, la Minería de Datos es aplicada en muchas áreas del
conocimiento como apoyo para la solución de problemas específicos, por ejemplo,
en el dominio de la salud se han realizado varios estudios para observar el
comportamiento de ciertas enfermedades, como la diabetes, el cáncer, etc.
En México, la mortalidad por cáncer constituye un problema de salud
pública importante [1], en especial para ciertos tipos de esta enfermedad, por
ejemplo el cáncer de pulmón [2] y [3]. En el 2005, los tumores malignos fueron la
tercera causa de muerte en el país, ya que 63128 personas fallecieron a causa
éstos, lo que representa un 12.7% del total de las defunciones registradas para
ese año.
Esta investigación forma parte de un proyecto mayor en el área de Minería
de Datos el cual se desarrolla en el Centro Nacional de Investigación y Desarrollo
Tecnológico (cenidet) cuya utilidad se centra en el dominio de la salud. En este
proyecto se han realizado investigaciones encaminadas a desarrollar
metodologías y herramientas, además se han aplicado técnicas de Minería de
Datos sobre bases de datos de mortalidad con el objetivo de identificar patrones
en el comportamiento de las defunciones ocurridas por ciertas enfermedades,
directamente relacionadas al cáncer.
Como una herramienta para la identificación de estos patrones, la Minería
de Datos ha cumplido con su función dentro de las investigaciones realizadas. A
su vez, estas investigaciones han permitido identificar problemas importantes
durante el proceso de minado, particularmente en la etapa de Preparación de
Datos.
Como se menciona en [4], “a través de los años ha habido avances
significativos en las técnicas de Minería de Datos, sin embargo, este avance no ha
ido a la par con el progreso en la preparación de los datos”.

Capítulo 1 INTRODUCCIÓN
3
Y es que, la Preparación de Datos es la etapa que representa un reto mayor
para los expertos mineros, en esta etapa consume la mayor parte del esfuerzo
requerido para un proyecto de minería. Como se menciona en [5], hasta el 90%
del tiempo total requerido para un proyecto de Minería de Datos es invertido en la
etapa de Preparación de Datos.
La Preparación de Datos es una etapa importante del proceso de minería
ya que la calidad de los resultados obtenidos depende, en gran medida, de una
correcta preparación de los datos. Los sistemas de alto desempeño de Minería de
Datos requieren datos de calidad, para generar patrones de calidad.
En [4] se señala que “la diversidad de los datos y las tareas de Minería de
Datos ofrecen diversos temas de investigación para la etapa de Preparación de
Datos”, algunos de esos temas están encaminados a constituir el marco teórico de
la etapa de Preparación de Datos o bien, desarrollar sistemas y algoritmos,
eficaces y eficientes, de Preparación de Datos para fuentes de datos simples y
múltiples considerando datos internos y externos. Esto se traduce en el desarrollo
de metodologías y herramientas que faciliten el trabajo de los expertos mineros
durante esta etapa del proceso de Minería de Datos.

Capítulo 1 INTRODUCCIÓN
4
1.2 JUSTIFICACIÓN.
La Minería de Datos consiste en la extracción, no trivial, de conocimiento que
reside de manera implícita en los datos, la cual es previamente desconocida y que
puede resultar útil para la comprensión de algún fenómeno organizacional [6]. Los
retos actuales que existen en la Minería de Datos incluyen, por ejemplo, mejorar
los procesos y herramientas de Minería de Datos a través de la construcción de
metodologías que beneficien el proceso de minería y la automatización de las
tareas realizadas durante dicho proceso.
La aplicación de la Minería de Datos a problemas reales plantea la
necesidad de sistematizar y automatizar las tareas desarrolladas durante un
proyecto de Minería de Datos. En [5] se mencionan algunos de los retos actuales
que la Minería de Datos enfrenta, entre estos retos se menciona la necesidad de
unificar la teoría de Minería de Datos ya que se considera que muchas de las
técnicas están diseñadas para problemas individuales o muy “ad-hoc”. También se
destacan los problemas relacionados a los procesos, muchos investigadores
sugieren que es necesario mejorar los procesos y herramientas de Minería de
Datos a través de la automatización.
Particularmente, la Preparación de Datos es una etapa fundamental en el
proceso de Minería de Datos. Es en esta etapa donde los datos son procesados
para ser utilizados por las técnicas de minería, además, la calidad de los
resultados obtenidos por el proceso de minado depende, en gran medida, de una
correcta preparación de los datos. Adicionalmente, la Preparación de Datos
representa un problema para los expertos en minería, ya que es en esta etapa
donde se consume la mayor cantidad del tiempo requerido para un proyecto de
Minería de Datos, hasta el 90% como se menciona en [5].
La sistematización y automatización de las tareas de la fase de Preparación
de Datos, aportan un valioso beneficio en la reducción del tiempo que un experto
debe emplear en esta etapa. A su vez, esta disminución en el tiempo impacta

Capítulo 1 INTRODUCCIÓN
5
directamente en los costos del proyecto. En [5] se cita “reducir el costo de la
Preparación de Datos reducirá aún más el costo de construir el modelo y encontrar
los patrones de Minería de Datos”.
Es importante desarrollar metodologías de Preparación de Datos que sirvan
como una guía para los expertos mineros durante esta fase. Para este caso de
estudio, la aplicación de la metodología de Preparación de Datos en el dominio
epidemiológico permitió generar datos con la calidad suficiente para obtener
modelos de Minería de Datos eficaces que permitan, a quienes toman las
decisiones del área de salud, obtener una mejor perspectiva respecto a un
problema de salud y enriquecer el conocimiento que se tiene en relación a dicho
problema, p. ejemplo, el cáncer, y así generar estrategias de prevención y control.
A su vez, la automatización de las tareas de la etapa de Preparación de
Datos permite reducir los tiempos requeridos para desarrollar dichas tareas y,
como algunos autores han señalado, la automatización del proceso de Minería de
Datos es importante ya que “si automatizamos las diferentes operaciones del
proceso de Minería de Datos, se reduciría la labor humana en la medida de lo
posible”, como se señala en [5].
1.3 DESCRIPCIÓN DEL PROBLEMA DE INVESTIGACIÓN.
La Minería de Datos se ha convertido en una actividad de gran interés para
muchas organizaciones, ya que permite la exploración de grandes volúmenes de
datos con la finalidad de obtener conocimiento que soporte y mejore los procesos
de toma de decisiones.
Muchos de los proyectos actuales de Minería de Datos se desarrollan en
base a metodologías como CRISP-DM [7], en colaboración con expertos en
Minería de Datos y expertos del dominio. Sin embargo, los proyectos suelen
enfrentarse con varios problemas, como el hecho de que las metodologías
actuales abordan el proceso de minado con un nivel de detalle muy general, esto

Capítulo 1 INTRODUCCIÓN
6
hace necesario desarrollar una secuencia de pasos para resolver los aspectos
más detallados del proyecto, lo cual repercute en el tiempo requerido para su
realización.
Particularmente, en la fase de Preparación de Datos es donde se consume
la mayor parte del tiempo total requerido para un proyecto de minería. Algunos
autores opinan que el esfuerzo requerido para la Preparación de Datos oscila
entre el 50% y el 70% como se menciona en [7], pero también hay quienes opinan
que la Preparación de Datos llega a consumir el 80% o hasta el 90% del tiempo
requerido como se menciona en [4] y [5], respectivamente.
De manera específica, el problema que se aborda es el siguiente:
Para la fase de preparación de datos, el modelo de referencia CRISP-DM
aporta una metodología de cinco sub-fases, cuyo nivel de detalle es insuficiente
para guiar a los desarrolladores de proyectos de minería durante el proceso de
preparar los datos. Esto implica que los desarrolladores tengan que definir su
propia secuencia de pasos y, de este modo, dotar de un nivel de detalle más fino
cada sub-fase que CRISP-DM propone para su aplicación en un dominio
particular.
Figura 1. Problema de preparación de datos.

Capítulo 1 INTRODUCCIÓN
7
1.4 OBJETIVO GENERAL.
Contribuir a la sistematización del proceso de Minería de Datos en el dominio de la
salud, particularmente en la etapa de Preparación de Datos, mediante una
metodología definida a un nivel de detalle mayor respecto al de la metodología
CRISP-DM.
1.4.1 Objetivos específicos.
A continuación se listan los objetivos particulares:
a) Definir la etapa de Preparación de Datos a un nivel de detalle más
fino que el presentado en la metodología CRISP-DM (a nivel de tarea
genérica e instancia de proceso).
b) Identificar las tareas de Preparación de Datos factibles de ser
automatizadas.
c) Utilizar un caso de estudio con datos reales del dominio
epidemiológico para validar la propuesta de solución.

Capítulo 1 INTRODUCCIÓN
8
1.5 ALCANCES Y LIMITACIONES.
A continuación se muestran los alcances y limitaciones de esta investigación:
1.5.1 Alcances.
a) Se analizó la fase de Preparación de Datos tomando como referencia la
metodología CRISP-DM.
b) La metodología sólo se enfocó a aplicaciones de Minería de Datos en el área
de epidemiología, específicamente a bases de datos poblacionales de
mortalidad.
c) Se automatizaron cuatro de las tareas de Preparación de Datos del nivel
específico.
d) El aspecto de adaptabilidad se manejó en términos meramente exploratorios
en las variables CAUSA y AÑO.
1.5.2 Limitaciones.
a) Las bases de datos reales utilizadas para propósitos de prueba
correspondieron a información de mortalidad de los censos de los años 2000
y 2010 de México.
b) La metodología se validó con una aplicación de Minería de Datos relacionada
a defunciones producidas por dos enfermedades cáncer y diabetes.

Capítulo 1 INTRODUCCIÓN
9
1.6 ESTADO DEL ARTE.
En la siguiente sección se describe de manera breve el estado del arte y trabajos
relacionados a esta investigación. Los trabajos serán presentados de manera
cronológica, describiendo de manera breve su aportación y las principales
diferencias con este trabajo de investigación.
1.6.1 Trabajos relacionados.
Desde sus orígenes, la noción de Minería de Datos ha sido vista como el proceso
de “minar” los datos y ha surgido en muchos ámbitos, desde el campo académico
hasta actividades de negocios o médicas [8]. No obstante, este proceso de minado
ha tenido que lidiar con los problemas propios de los datos que en ocasiones se
encuentran con ruido e impurezas, y que deben ser corregidos con el fin de
obtener de ellos conocimiento veraz que sirva como soporte para la toma de
decisiones.
En el año 2000, surge la metodología CRISP-DM [7] (la cual es tomada
como base para esta investigación) que aporta una metodología flexible y sencilla
para las fases del proceso de minado y que actualmente es la más utilizada
debido a estas ventajas.
En particular, para la fase de Preparación de Datos, CRISP-DM describe
cinco sub-fases limpieza, selección, formateo, construcción e integración de los
datos, sin embargo, el nivel de granularidad que CRISP-DM tiene únicamente da
una pista de lo que se puede hacer en cada sub-fase, es decir, no describe con
detalle las acciones a seguir dentro de cada sub-fase.
A lo largo del tiempo, varias investigaciones han abordado la etapa de
Preparación de Datos con el objetivo de resolver los problemas presentes en dicha
etapa. Muchas de estas investigaciones comparten características como el

Capítulo 1 INTRODUCCIÓN
10
dominio de aplicación, en este caso el dominio de la salud, y analizan datos de
diferentes enfermedades como el cáncer o la diabetes.
Para el año 2003; investigaciones como [9], la cual forma parte del proyecto
Europeo llamado Diabcare, proponen desarrollar herramientas de Minería de
Datos para datos clínicos de diabetes, analizar la fase de Preparación de Datos y
proveer herramientas para manejo de inconsistencias y valores perdidos. En este
trabajo se propone un método de Preparación de Datos de tres fases: limpieza,
análisis de los datos faltantes y selección de la técnica de manejo de los datos
faltantes. Este trabajo está enfocado únicamente a la limpieza de los datos y
propone la automatización de dicho proceso.
Otros trabajos, como el propuesto en [10], están enfocados al manejo de los
valores perdidos, en este caso se hace uso de las técnicas de agrupamiento y
regresión para conseguir el objetivo de limpiar los datos. El método reporta
precisión en la predicción de los valores y muestra mayor exactitud al recuperar
los valores perdidos, no obstante, está enfocado sólo a la limpieza de los datos y
manejo de valores perdidos.
En el año 2005, otros trabajos de investigación son reportados, en [11] se
describe el proceso de Preparación de Datos realizado durante un caso de estudio
sobre datos de cáncer en Egipto. Durante la Preparación de Datos se ejecutaron
tareas de limpieza, selección, integración y transformación o construcción de
datos, sin embargo, este proceso de Preparación de Datos no está siendo
reportado como una metodología y proporciona poca información sobre las tareas
ejecutadas durante la preparación de los datos.
En [12] se propone un método que consiste en el reemplazo de valores
perdidos y selección de atributos consultando con expertos en el dominio. Los
datos utilizados pertenecen a registros de cáncer de mama de casos ocurridos en
Suecia. En los resultados se observó un crecimiento en la eficiencia de la

Capítulo 1 INTRODUCCIÓN
11
predicción de los valores perdidos, a pesar de la precisión, el método está
centrado únicamente en el problema de la limpieza y selección de atributos.
Los trabajos descritos en [13] y [14] están enfocados a la Preparación de
Datos espaciales. En estos trabajos se propone una metodología de tres pasos
(selección, materialización y transformación de datos) y un framework para
Preparación de Datos espaciales específicamente. Los registros utilizados en
ambos trabajos están relacionados a enfermos con padecimientos de cáncer y la
ubicación de municipios, fábricas y antenas de telefonía celular.
En [14], se utilizan bases de datos espaciales (ver sección 2.1.2) con el fin
de observar relaciones entre pacientes con padecimientos de cáncer y fábricas o
antenas de telefonía celular, de acuerdo a su ubicación geográfica. Aunque existe
mucha similitud entre estos trabajos y la presente investigación: 1) los datos que
se están manejando, espaciales y poblacionales, pertenecen a pacientes con
padecimientos de cáncer, 2) la propuesta de una metodología y 3) un software de
Preparación de Datos. El objetivo de Minería de Datos en ambas investigaciones
difiere mucho uno del otro. Adicionalmente, los enfoques de las metodologías
propuestas difieren en el nivel de detalle que aportan y el número de sub-fases
que se proponen. La metodología propuesta en [14] está estrechamente
relacionada a las operaciones requeridas en el proyecto, mientras que nuestra
propuesta conserva la flexibilidad de la metodología CRISP-DM, lo cual permite su
uso en otras aplicaciones de minería.
En 2009, el trabajo descrito en [15] propone una metodología para la
sustitución de valores perdidos y selección de atributos, los datos utilizados para
esta investigación están relacionados al dominio epidemiológico, específicamente,
cáncer de próstata. El enfoque es innovador, ya que propone manejar la limpieza y
selección de atributos, como dos fases en la misma actividad, no obstante, no
aborda otras fases del proceso de Preparación de Datos. Es una metodología
simple y genérica, que puede ser utilizada para varios dominios de aplicación.
También, resalta la necesidad de semi-automatizar los procesos de preparación.

Capítulo 1 INTRODUCCIÓN
12
Por último, dos trabajos relacionados y que son antecedentes de esta
investigación, son los propuestos en [16] y [17]; desarrollados en el año 2010.
Estos trabajos siguen el enfoque de Preparación de Datos y objetivo de Minería de
Datos de esta investigación.
En ellos se reporta un sistema para la generación de patrones geográficos y
un Almacén de Datos para diversas causas de mortalidad por cáncer, sin
embargo, el proceso de Preparación de Datos que se realizó, está descrito de
manera muy general y la aportación no supone una metodología de Preparación
de Datos, sino una aplicación de minería de datos; y los objetivos particulares
distan mucho de los planteados en esta investigación.
Adicionalmente, en estas investigaciones se ha trabajado únicamente con
datos de defunciones ocurridas por causas de mortalidad las relacionadas al
cáncer y el presente trabajo amplía la gama de enfermedades que se pueden
explorar.

Capítulo 1 INTRODUCCIÓN
13
1.7 ORGANIZACIÓN DEL DOCUMENTO.
La tesis está organizada de la siguiente manera:
El Capítulo 2 presenta el marco teórico, en éste se presentan los conceptos
básicos relacionados a Minería de Datos y la Preparación de Datos, y algunos
otros conceptos relacionados al dominio de aplicación.
El Capítulo 3 muestra la metodología de Preparación de Datos desarrollada
para su aplicación a un proyecto real de Minería de Datos dentro del dominio
epidemiológico.
El Capítulo 4 muestra la experimentación realizada para validar la
metodología de Preparación de Datos propuesta. Adicionalmente, se analizan los
resultados obtenidos.
El Capítulo 5 presenta las conclusiones y aportaciones más importantes de
esta investigación y las líneas de investigación que se identificaron en el proceso.
Se destacan también las publicaciones conseguidas como resultado de esta
investigación.


14
Capítulo 2 MARCO TEÓRICO.
Este capítulo describe el marco teórico en el que se fundamenta este trabajo de
tesis. Se presentan los conceptos básicos sobre Minería de Datos y Preparación
de Datos, así como algunos otros conceptos del dominio epidemiológico al cual
pertenece este trabajo. Por último, se incluye una sección que contiene una
descripción de los trabajos relacionados al problema de la Preparación de Datos.

Capítulo 2 MARCO TEÓRICO
15
2.1 BASE DE DATOS.
Una base de datos es una colección de datos que contiene información relevante
de una empresa, como se define en [18]. Las bases de datos son ampliamente
usadas, algunas de sus aplicaciones más representativas son la banca, las
telecomunicaciones, las finanzas, en producción, salud, etcétera.
Muchas son las organizaciones interesadas en mantener las grandes
cantidades de datos que se generan día a día sobre las operaciones que realizan,
estos datos son conocidos como datos persistentes. En [19], se define una base
de datos como un conjunto de datos persistentes que es utilizado por los sistemas
de información de alguna empresa. Dichos datos pueden contener información
sobre la producción, la contabilidad, los pacientes, la planeación, etcétera. En esta
definición, se utiliza el término “empresa”, para identificar a cualquier organización
independiente de tipo comercial, técnico, científico u otro
Como ejemplo, en la actualidad los gobiernos de muchos países, en
conjunto con sus organismos de salud, colectan información sobre diferentes
aspectos de las poblaciones de un país, la cual puede estar relacionada a
aspectos geográficos, sociales, culturales, etcétera. Dicha información es
recolectada con la finalidad de conocer estadísticamente a una población, con ella
es posible preparar informes estadísticos, cuadros y gráficas que muestren las
características y el comportamiento de las poblaciones.
Con el almacenamiento de estos datos se da origen a diferentes bases de
datos que pueden ser clasificadas de acuerdo a la información que proporcionan
los datos contenidos en ellas.
2.1.1 Bases de datos poblacionales.
Las bases de datos de tipo poblacional, la mayoría de las veces, cuentan con
información de tipo censal y pueden contener información sobre:

Capítulo 2 MARCO TEÓRICO
16
Volumen de la población total
Distribución geográfica de la población.
Población con discapacidad, tipo y número de discapacidades.
Enfermedades en una población.
Mortalidad poblacional.
Entre otros.
Los datos recolectados se analizan y organizan por temas para obtener
información estadística y sociodemográfica de éstos [20]. Muchos de los estudios
poblacionales están basados en la información contenida en estas bases de datos.
2.1.2 Bases de datos espaciales.
Una base de datos espacial contiene datos pertenecientes a un espacio
determinado, un concepto clave en las bases de datos espaciales es,
precisamente, la dimensión espacio.
Una base de datos espacial permite describir los objetos espaciales que la
forman a través de tres características básicas: atributos, localización y topología
[21]. Los atributos representan características de los objetos que nos permiten
saber lo que son. La localización, representada por la geometría del objeto y su
ubicación espacial de acuerdo a un sistema de referencia, permiten saber dónde
está el objeto y qué espacio ocupa. Finalmente, la topología definida por medio de
las relaciones conceptuales y espaciales entre objetos, permite mejorar la
interpretación semántica del contexto y establecer ciertas jerarquías de elementos
a través de sus relaciones.
En [13] se definen las características localización (direction/order) y
topografía, más una característica adicional, la distancia. Esta característica está
basada en la distancia Euclidiana (o distancia ordinaria) entre dos objetos
ubicados en un espacio.

Capítulo 2 MARCO TEÓRICO
17
La datos contenidos en una base de datos espacial resultan de importancia
cuando se requiere representar información de manera gráfica, estos datos nos
permiten visualizar formas, puntos y establecer una relación entre éstos.
2.2 ALMACÉN DE DATOS.
Según [22] un Almacén de Datos (data warehouse) es una base de datos que
integra datos procedentes de uno o varios sistemas de información de una
organización, generalmente orientado a la toma de decisiones.
En [23] se define un Almacén de Datos como un conjunto de datos
históricos, internos o externos, y descriptivos de un contexto o área de estudio;
integrados y organizados de tal forma que permite resumir, describir y analizar los
datos con el fin de ayudar en la toma de decisiones estratégicas.
Los almacenes de datos están basados principalmente en información
histórica, por lo cual, los “hechos” son su aspecto central. Los “hechos” son
variables de negocio como el tiempo, las ventas, muertes, costos, etcétera.
Los datos se organizan en torno a los “hechos”, que tienen atributos o
medidas que pueden verse en mayor o menor detalle según ciertas “dimensiones”.
El modelo conceptual de datos más extendido para los almacenes de datos,
es el modelo multidimensional. En [23] se menciona que “cuando el número de
dimensiones no excede de tres se puede representar cada combinación de niveles
de agregación como un cubo”. Cada hecho corresponde por lo tanto, a una casilla
del cubo.

Capítulo 2 MARCO TEÓRICO
18
Figura 2. Representación de un cubo de datos.
La Figura 2 muestra la representación de un cubo de datos con las
dimensiones, espacio y tiempo, relacionadas a un hecho.
Según [23], los almacenes de datos pueden implementarse utilizando dos
tipos de sistemas físicos:
ROLAP (Relational OLAP).- físicamente, el Almacén de Datos se construye
sobre una base de datos relacional. Su principal ventaja es que pueden
utilizar directamente sistemas de gestión de bases de datos genéricos y
herramientas asociadas. Generalmente su costo de implementación es
menor.
MOLAP (Multidimensional OLAP).- físicamente, el Almacén de Datos se
construye sobre estructuras basadas en matrices multidimensionales. Sus
principales ventajas son: su especialización, la correspondencia entre el
nivel lógico y el nivel físico, y lo que lo hace, generalmente, más eficiente
que un ROLAP.
En estas estructuras se construyen tres tipos de tablas:
Espacio

Capítulo 2 MARCO TEÓRICO
19
Tablas copo de nieve (snowflake tables).- Para cada nivel de agregación de
una dimensión se crea una tabla. Cada tabla tiene una clave primaria y
tantas claves ajenas como sea necesario para poder conectar con los
niveles superiores.
Tablas de hechos (fact tables).- Se crea una única tabla de hechos y se
incluye un atributo por cada dimensión.
Tablas estrella (star tables).- Se crea una tabla, para cada dimensión, que
tenga un atributo para cada nivel de agregación diferente en la dimensión.
2.3 MINERÍA DE DATOS.
La Minería de Datos es el proceso de analizar datos desde diferentes perspectivas
y resumirlos en información útil, su meta principal es convertir los datos en
conocimiento [24]. El término Minería de Datos se refiere a extraer o “minar”
conocimiento desde grandes cantidades de datos. Como una analogía a la
extracción de material precioso de las minas, el conocimiento representa “el oro”
que los datos tienen escondido.
Según [25], la Minería de Datos es el proceso de descubrir patrones de
interés y conocimiento desde grandes cantidades de datos, permite analizar datos
de diversas fuentes; estas fuentes incluyen bases de datos, almacenes de datos,
datos tomados desde la web, entre otros repositorios.
En la actualidad, la Minería de Datos se hace necesaria en importantes
áreas, tales como la economía, el cuidado de la salud, la investigación científica,
etcétera. En estas áreas existe una gran cantidad de datos que sólo han sido
analizados parcialmente, y que contienen una gran cantidad de información que
aún no ha sido explorada [8].
En [26] se mencionan dos retos que la Minería de Datos enfrenta: 1)
trabajar con grandes cantidades de datos, procedentes de sistemas de
información, con los problemas que esto representa (ruido, ausencia de datos,

Capítulo 2 MARCO TEÓRICO
20
volatilidad de los datos, etcétera), 2) la utilización de técnicas adecuadas para
analizar los datos y extraer conocimiento novedoso y útil.
2.3.1 Modelo de referencia CRISP-DM.
El modelo de referencia CRISP-DM propone una metodología de Minería de Datos
estandarizada, que es la más utilizada según [27], por su flexibilidad y capacidad
de personalizarse para su aplicación en diferentes dominios fácilmente.
Esta metodología está descrita en términos de un modelo de procesos
jerárquico, consiste de un conjunto de tareas descritas en cuatro niveles de
abstracción: fase, tarea genérica, tarea especializada e instancia de proceso [7].
Figura 3. Niveles de abstracción CRISP-DM.
La Figura 3 nos muestra los niveles de abstracción identificados por CRISP-
DM. El nivel superior está organizado en un número de fases, a su vez, cada fase
está dividida en varias tareas genéricas, que corresponden al segundo nivel en el
modelo, este nivel intenta ser lo suficientemente general para cubrir todas las
posibles situaciones de Minería de Datos. Los dos primeros niveles conforman la
parte genérica del modelo y tienen un nivel de abstracción mayor respecto a los
niveles inferiores.
Fase
Tarea genérica.
Tarea especializada
Instancia de proceso
Modelo
específico
Modelo
genérico
CRISP-DM
Proyección

Capítulo 2 MARCO TEÓRICO
21
El tercer nivel, es el nivel de las tareas especializadas, describe las
acciones que se deben realizar en situaciones específicas. El cuarto nivel,
instancias de proceso, es un registro de las acciones, decisiones y resultados de
un proyecto de Minería de Datos determinado. Estos niveles conforman la parte
específica del modelo y tienen un nivel de abstracción menor.
CRISP-DM proporciona una descripción mayor de la parte genérica del
modelo, es ahí donde se proporciona una visión general de las acciones que se
ejecutan en los niveles específicos. Resultaría muy complicado definir tareas y
procesos que se ajusten a las diferentes aplicaciones de Minería de Datos en
todos los dominios donde se utiliza.
Figura 4. Ciclo de vida de un proyecto de Minería de Datos.
La Figura 4 provee una visión general del ciclo de vida de un proyecto de
Minería de Datos, en ella se muestran las cinco fases que el modelo de referencia
de CRISP-DM detalla en [7]. Estas fases son:
Entendimiento del negocio
Entendimiento de los datos
Preparación de datos
Modelado
Evaluación
Despliegue
Datos

Capítulo 2 MARCO TEÓRICO
22
Entendimiento del negocio.- Enfocada a entender los objetivos y
requerimientos del proyecto desde la perspectiva del negocio.
Entendimiento de los datos.- Comienza con la recolección de datos. En ella,
se realizan actividades con el propósito de familiarizarse con los datos.
Preparación de Datos.- Cubre todas las actividades necesarias para
construir el subconjunto de datos final (dataset) desde los datos originales
(sin procesar).
Modelado.- Enfocada a la selección y aplicación de la técnica de minería
que servirá para obtener un modelo para representar el conocimiento.
Evaluación del modelo.- Hay que revisar los pasos ejecutados en la
construcción del modelo para asegurarse que éste alcanza los objetivos del
negocio para la toma de decisiones.
Despliegue del modelo.- La implementación de esta fase puede ser tan
simple como generar un reporte o tan compleja como implementar un
proceso de Minería de Datos repetible a través de la empresa.
En la sección siguiente se describe ampliamente la fase de Preparación de
Datos, ya que es en esta etapa donde se centra esta investigación.
2.3.1.1 Fase de Preparación de Datos.
La Preparación de Datos es la fase que cubre todas las tareas para construir el
conjunto de datos final (dataset que será utilizado por las herramientas de
modelado) a partir de los datos iniciales en bruto (sin procesar). Comúnmente las
tareas de Preparación de Datos son ejecutadas varias veces y no tienen un orden
prescrito [7].
La Preparación de Datos es una etapa fundamental en la Minería de Datos
ya que, en gran medida, la calidad de los modelos generados por el proceso de
Minería de Datos depende de la calidad de los datos utilizados.

Capítulo 2 MARCO TEÓRICO
23
Actualmente muchas organizaciones están interesadas en cómo
transformar sus datos a formas limpias, las cuales puedan ser usadas para
propósitos de alto rendimiento y como apoyo para la toma de decisiones [4].
2.3.1.1.1 Complejidad de la Preparación de Datos.
A través de los años, la Minería de Datos ha tenido avances significativos pero, a
pesar de su importancia dentro del proceso de minado, en la fase de Preparación
de Datos no ha habido un progreso similar.
La Preparación de Datos es la etapa que más tiempo consume del total
requerido para un proyecto de Minería de Datos. En [7] se menciona que el
esfuerzo requerido para la Preparación de Datos oscila entre el 50% y el 70%,
pero también hay quienes opinan que la Preparación de Datos llega a consumir
hasta el 80% [4] o el 90% [2] del tiempo total de un proyecto de Minería de Datos.
Uno de los principales problemas a los que se enfrenta esta fase, es el
volumen de datos que en ocasiones es necesario manejar, además de que las
fuentes de datos pueden ser muy diferentes, desde simples archivos hasta
grandes y complejas bases de datos. La Preparación de Datos resulta ser una
tarea compleja y laboriosa cuando nos enfrentamos a grandes volúmenes de
datos.
Adicionalmente, como se menciona en [4], la etapa de Preparación de
Datos tiene una fuerte necesidad de nuevas técnicas y herramientas
automatizadas diseñadas para que puedan asistir a los expertos en Minería de
Datos durante esta laboriosa fase, con el objetivo de reducir los costos y el
esfuerzo requerido para su desarrollo.
Y es que, aunque resulta imposible diseñar una metodología que sirva para
todos y cada uno de los dominios en los que la Minería de Datos ha encontrado

Capítulo 2 MARCO TEÓRICO
24
aplicación, es posible diseñar metodologías flexibles o adaptables a dominios que
compartan características.
Así mismo, es necesario desarrollar herramientas que automaticen las
tareas de Preparación de Datos para, de este modo, reducir la labor y el costo que
se requiere invertir durante esta fase.
La Preparación de Datos es una fase importante dentro del proceso de
Minería de Datos, ya que la calidad de los resultados del proceso de minado
depende directamente de la calidad de los datos utilizados. En [4] se señala “los
datos de calidad generan patrones de calidad”.
2.3.1.2 Etapas de la Preparación de Datos.
El modelo de referencia de CRISP-DM describe el segundo nivel de abstracción
para cada una de las fases que propone. Para la Preparación de Datos, el modelo
de referencia CRISP-DM [7] describe cinco tareas genéricas, las cuales son:
Selección de datos.- En esta tarea se eligen los datos que se utilizarán para
el análisis y, generalmente, incluye la selección de filas (registros) y
columnas (atributos). Los datos elegidos deben ser relevantes para los
objetivos del proceso de minado.
Limpieza de datos.- El objetivo de esta tarea es elevar la calidad de los
datos al nivel requerido por la técnica de análisis de datos que se haya
seleccionado. Esto puede incluir acciones como seleccionar subconjuntos
de datos limpios, insertar valores default adecuados o técnicas más
ambiciosas como la estimación de valores faltantes en un atributo.
Construcción de datos.- Incluye operaciones constructivas de Preparación
de Datos tales como la generación de atributos derivados y transformación
de valores para atributos existentes.
Integración de datos.- Son métodos a través de los cuales la información se
combina desde múltiples fuentes de datos para crear nuevos valores,
registros o incluso bases de datos completas o almacenes de datos.

Capítulo 2 MARCO TEÓRICO
25
Formateo de datos.- Se refiere a modificaciones sintácticas que no cambian
el significado de los datos, pero pueden ser requeridas por las herramientas
de modelado.
2.4 EPIDEMIOLOGÍA.
Según [28], la epidemiología es el estudio de cómo se distribuyen las
enfermedades en las poblaciones y los factores que influyen o determinan esta
distribución.
En [29], se define a la epidemiología como el estudio de la distribución y los
determinantes de los estados de salud o los eventos relacionados con la salud en
poblaciones específicas y la aplicación de este estudio al control de los problemas
de salud. Según [30], la epidemiología puede ser clasificada como:
Epidemiología analítica.- Evalúa hipótesis relacionadas con asociaciones
entre posibles exposiciones a ciertos factores de riesgo y los desenlaces de
procesos relacionados con la salud.
Epidemiología descriptiva.- Hace uso de los datos disponibles para
examinar cómo las tasas (por ejemplo de mortalidad), varían de acuerdo a
variables demográficas, como las obtenidas en los censos.
2.4.1 Indicadores en epidemiología.
En términos generales, los indicadores representan medidas que capturan
información relevante sobre distintos atributos y dimensiones del estado y del
desempeño del sistema de salud que, vistos en conjunto, intentan reflejar la
situación sanitaria de una población y sirven para vigilarla [31].
Para este estudio, son dos los indicadores que nos interesan: primero, la
incidencia de mortalidad y, segundo, la tasa de mortalidad.

Capítulo 2 MARCO TEÓRICO
26
El término “incidencia” ha sido tradicionalmente empleado para aludir a una
proporción de casos nuevos (incidentes) de una enfermedad. En rigor, el término
abarca la frecuencia de cualquier nuevo acontecimiento relacionado con la salud o
la enfermedad y, por tanto, también incluye la muerte, recaída en la enfermedad,
la curación, etcétera [30].
La estructura básica de cualquier indicador de incidencia es la siguiente: el
número de sucesos que ocurren en una población definida a lo largo de un lapso
(periodo) de tiempo determinado.
La mortalidad es claramente un índice de la gravedad de la enfermedad
desde el punto de vista clínico y de salud pública, pero también puede usarse
como un índice de riesgo de enfermedad [28].
Las tasas son valores relativos que se utilizan como indicadores de la salud
de la población, expresan la probabilidad de sufrir un riesgo como padecer cierta
enfermedad o morir por determinada causa, etcétera.
En [32], se define la tasa de mortalidad general como el volumen de
muertes ocurridas por todas las causas de enfermedad, en todos los grupos de
edad y para ambos sexos. Se dice que la tasa de mortalidad es cruda cuando
expresa la relación que existe entre el volumen de muertes ocurridas en un
periodo dado y el tamaño de la población en la que éstas se presentaron. Para
este estudio, es requerido este indicador.
(1)
La tasa cruda de mortalidad se calcula de acuerdo a la Expresión 1, donde
TM es la tasa de mortalidad, la incidencia es el número de muertes ocurridas en
un periodo, población total es el número de habitantes promedio en la población
para el mismo periodo y modificador es un valor comúnmente potencia de 10
(10n).


27
Capítulo 3 METODOLOGÍA PROPUESTA PARA LA PREPARACIÓN
DE DATOS.
Este Capítulo está conformado por tres secciones: 3.1 Sistematización del proceso
de preparación de datos, 3.2 Metodología de preparación de datos y 3.3 Semi-
automatización del proceso de preparación de datos.
La sección 3.1 describe cómo se definieron y modelaron los procesos
identificados en la fase de preparación de datos.
La sección 3.2 describe la metodología de preparación de datos propuesta,
presenta el esquema general de la metodología propuesta (3.2.1) y la descripción
de la metodología (3.2.2).
Por último, la Sección 3.3 describe la arquitectura de un sistema de
preparación de datos (3.3.1) y cómo se implementaron algunas tareas (3.3.2).

Capítulo 3 METODOLOGÍA PROPUESTA PARA LA PREPARACIÓN DE DATOS
28
3.1 SISTEMATIZACIÓN DEL PROCESO DE PREPARACIÓN DE DATOS.
La sistematización está muy ligada al ámbito de la investigación científica y la
computación, sistematizar un proceso permite comprender mejor el mismo.
Nos referimos a la sistematización como una interpretación crítica de una o
varias experiencias que, a partir de su ordenamiento y reconstrucción, descubre o
explica la lógica de un proceso vivido, los factores que han intervenido en dicho
proceso, cómo se han relacionado entre sí y porqué lo han hecho de ese modo
[33].
En este documento, la sistematización se refiere a: establecer un
procedimiento repetible, ordenado y jerarquizado, basado en experiencias previas,
que sirva de apoyo al experto en Minería de Datos para llevar a cabo la laboriosa
tarea de preparar los datos.
Retomando lo anterior, se analizó la experiencia contenida en los trabajos
previos [34], [35], [36] y [37]; con el objetivo de identificar cuáles son las tareas y
procesos que se ejecutan durante la fase de Preparación de Datos.
Estas investigaciones están centradas al análisis de datos epidemiológicos
para diversas causas de mortalidad por cáncer, sin embargo, cada una de ellas
tienen el mismo objetivo de Minería de Datos: identificar grupos de municipios en
México con altas tasas de mortalidad para las diferentes causas de mortalidad por
cáncer.
Se identificaron las tareas y procesos de Preparación de Datos que se
realizaron en cada uno de los trabajos previos y se procedió a definirlos,
modelarlos y unificarlos para poder generar un proceso único de Preparación de
Datos.

Capítulo 3 METODOLOGÍA PROPUESTA PARA LA PREPARACIÓN DE DATOS
29
3.1.1 Definición de los procesos de Preparación de Datos.
El objetivo de definir los procesos de la etapa de Preparación de Datos es,
conseguir el mayor nivel de detalle posible en cada una de las tareas realizadas
durante dicho proceso.
Para describir dichas tareas se tomaron en cuenta algunos de los
elementos sugeridos por el patrón de procesos definido en [38]. A continuación se
listan los elementos tomados en cuenta para definir las tareas de Preparación de
Datos:
1) Nombre del proceso,
2) responsable,
3) descripción,
4) objetivo,
5) entrada,
6) salida,
7) actividades,
8) subprocesos relacionados.
El Anexo A, contiene un ejemplo de las tablas de definición de procesos
que fueron creadas utilizando los elementos que se listaron anteriormente. Las
tareas descritas en estas tablas corresponden a las tareas de la sub-fase de
construcción de datos.
Se describen a detalle las tareas de cálculo de la incidencia de mortalidad y
cálculo de la tasa de mortalidad por ser de especial interés para los fines de esta
investigación. Después de describir del proceso realizado para ambas tareas, se
procedió al modelado de éste.

Capítulo 3 METODOLOGÍA PROPUESTA PARA LA PREPARACIÓN DE DATOS
30
3.1.2 Modelado de los procesos de Preparación de Datos.
La definición de los procesos de Preparación de Datos muestra una visión más
clara del orden en el que éstos se ejecutan durante la fase de preparación, el
modelado nos presenta una visión más simplificada de dichos procesos.
En [39], se dice que los modelos de un sistema de software capturan
requisitos sobre el dominio de aplicación, la interacción con los usuarios, los
módulos que lo constituyen, entre otras cosas; para el modelado de los procesos
de la fase de Preparación de Datos se utilizaron diagramas de actividad (Anexo
A).
Los diagramas de actividad nos permitieron representar dos tipos de tareas:
compuestas (actividades) y simples (acciones). Las tareas compuestas están
conformadas por la ejecución de varias tareas simples. Por otro lado, una tarea
simple nos indica acciones concretas, es decir, un paso determinado que se
realiza dentro de un proceso. Las tareas compuestas pueden mapearse a tareas
genéricas o especializadas, mientras que las tareas simples pueden ser vistas
como instancias del proceso, según lo propuesto en la metodología CRISP-DM.
Uno de los propósitos en esta investigación es la implementación de
algunos de los procesos de Preparación de Datos, por ello, es necesario modelar
dichos procesos apoyándose de herramientas como UML.
En la sección siguiente se describe la metodología de Preparación de Datos
que se obtuvo como resultado del análisis y definición de los procesos de la fase
de Preparación de Datos.

Capítulo 3 METODOLOGÍA PROPUESTA PARA LA PREPARACIÓN DE DATOS
31
3.2 METODOLOGÍA DE PREPARACIÓN DE DATOS.
En esta sección del documento se presenta la metodología de Preparación de
Datos que resultó del análisis realizado a trabajos de investigación previos
desarrollados en CENIDET.
3.2.1 Esquema general de la metodología propuesta.
El principal objetivo de esta investigación fue desarrollar una metodología de
Preparación de Datos, para su aplicación en el dominio epidemiológico, definida
con un nivel de detalle mayor al propuesto por CRISP-DM.
Figura 5. Esquema general de la metodología de Preparación de Datos propuesta.
La Figura 5 muestra el esquema general de la aportación de esta
investigación. En color verde, se observa la metodología de Preparación de Datos
propuesta por CRISP-DM, la cual está compuesta de cinco sub-fases: limpieza,
selección, formateo, construcción e integración de datos; estas sub-fases fueron

Capítulo 3 METODOLOGÍA PROPUESTA PARA LA PREPARACIÓN DE DATOS
32
clasificadas dentro de los dos niveles de Preparación de Datos que se proponen
en esta investigación (PDG y PDE). En color azul, se muestra la metodología
particularizada al dominio epidemiológico, la cual define con mayor detalle cada
una de las sub-fases de Preparación de Datos que CRISP-DM propone.
Por último, en color rojo, observamos dos niveles de Preparación de Datos,
que constituyen un nuevo enfoque propuesto por esta investigación, a los cuales
hemos denominado: Preparación de Datos General (PDG) y Preparación de Datos
Específica (PDE).
3.2.2 Descripción de la metodología de Preparación de Datos propuesta.
En los párrafos siguientes se describe la metodología que se propone para la fase
de Preparación de Datos, la cual enfocada al dominio epidemiológico, según el
esquema presentado en la sección 3.2.1.
3.2.2.1 Preparación de Datos General (PDG).
La Preparación de Datos General, se refiere a un conjunto de tareas
“independientes” del objetivo de Minería de Datos que se desea alcanzar. En este
nivel se intenta homogeneizar y seleccionar desde diferentes fuentes, los datos
que serán utilizados.
La Preparación de Datos General agrupa tareas que presentan mayor
flexibilidad, una característica que las hace generales, es decir, pueden ser
aplicadas en otros dominios con mayor facilidad. En este nivel hemos incluido
aquellas tareas que tienen que ver con la limpieza y la selección de los datos.
3.2.2.1.1 Limpieza de datos.
En esta tarea se intenta elevar la calidad de los datos al nivel requerido por la
técnica de análisis seleccionada. Esto puede incluir la selección de subconjuntos

Capítulo 3 METODOLOGÍA PROPUESTA PARA LA PREPARACIÓN DE DATOS
33
de datos limpios, inserción de valores default adecuados o la aplicación de
técnicas de limpieza más ambiciosas como la estimación de valores faltantes [7].
a) Detección errores.
Se debe realizar una revisión exhaustiva de los datos con el fin de identificar
posibles errores en los valores de los datos (valores vacíos, valores fuera del
rango permitido por el atributo, etc), por ejemplo, para la detección de valores
erróneos en atributos numéricos, se suele buscar outliers (valores anómalos,
atípicos o extremos), también llamados datos aislados.
Se debe destacar que no detectar un valor anómalo puede ser un problema
importante si el atributo se normaliza posteriormente, ya que la mayoría de los
datos estarán en un rango muy pequeño y puede haber poca precisión o
sensibilidad [23].
Otro tipo de error comúnmente presente en los datos son los valores
faltantes, perdidos o ausentes (missing values). La detección de valores faltantes
puede parecer sencilla, si los datos proceden de una base de datos, basta con
mirar la tabla de resumen de atributos y ver la cantidad de valores nulos que tiene
cada atributo [23].
b) Corrección de errores.
Se corrigen los errores identificados en los registros o atributos. Las técnicas de
tratamiento de errores en los datos pueden variar dependiendo del error
identificado, una alternativa puede ser, por ejemplo, el reemplazo del valor. Se
puede intentar reemplazar el valor (o corregirlo) de manera manual, si no son
muchos los errores identificados, o de manera automática utilizando un valor que
preserve la media o la varianza, posiblemente, hacer una sustitución por un valor
que represente la moda. También es posible sustituir por un valor máximo o
mínimo o, incluso, predecir el valor a partir de otros datos. En [23] se describen

Capítulo 3 METODOLOGÍA PROPUESTA PARA LA PREPARACIÓN DE DATOS
34
algunas técnicas de tratamiento de errores en los datos para outliers y missing
values.
c) Eliminación de registros o atributos con errores.
Si no fue posible corregir el error identificado aplicando alguna técnica de
corrección de errores, se eliminan los registros o atributos que aún contengan
errores. En este caso, la solución se considera extrema y se debe ser muy
cuidadoso al realizar la eliminación, ya que esto puede sesgar los datos.
3.2.2.1.2 Selección de datos.
En esta tarea se eligen los datos que se utilizarán para el análisis, generalmente
incluye la selección de filas (registros) y columnas (atributos) [7]. Los criterios de
selección incluyen: la calidad de los datos, qué tan importante es el atributo o
registro para los objetivos del proceso de minería (los datos seleccionados deben
ser relevantes para dicho proceso), también aparecen restricciones como el
volumen de los datos.
Dada la definición anterior, podemos decir que es posible dividir la selección
de datos en:
a) Selección vertical.
Es la selección de aquellos atributos que representan información de interés para
los objetivos del proyecto de Minería de Datos que se esté desarrollando.
Podemos listar una serie de tareas que se ejecutan durante la selección vertical:
I. Eliminación de atributos vacíos.- Se eliminan aquellos atributos cuya
proporción de valores nulos es tan alta que no se puede arreglar la
columna.

Capítulo 3 METODOLOGÍA PROPUESTA PARA LA PREPARACIÓN DE DATOS
35
II. Eliminación de claves primarias.- Por regla general, se eliminan aquellos
atributos que son claves primarias, clave candidatas o incluso, parte de la
clave candidata total o parcialmente. Por ejemplo, hay que eliminar
números de documentos de identificación, códigos internos, teléfonos,
etcétera [23].
III. Eliminación de atributos dependientes.- se eliminan aquellos atributos que
presentan información redundante o aquellos que tienen dependencia
funcional.
IV. Eliminación de atributos con valores nulos.- Si el atributo posee el mismo
valor para todas sus instancias, se elimina.
V. Eliminación de atributos que no son de interés.- Por último, se eliminan
aquellos atributos que, aunque no hayan clasificado en los puntos
anteriores, no aportan información de interés que contribuya para alcanzar
el objetivo de Minería de Datos planteado.
b) Selección horizontal.
Se refiere a la selección de aquellos registros que representan información de
interés para los objetivos de Minería de Datos que se está desarrollando [34]. Las
acciones que se ejecutan durante la selección horizontal son las siguientes:
I. Eliminación de registros con valores fuera de rango.- Se eliminan los
registros cuyos valores se encuentran fuera del rango (o clasificación) de
elementos que se estudian, por ejemplo, si se estudian los elementos de
una población cuyas edades van de los 30 a los 50 años, los elementos
adicionales que no cumplen con esta condición se eliminan.
II. Eliminar registros que no son de interés.- Se eliminan aquellos registros que
no aportan información de interés que contribuya a alcanzar el objetivo de
Minería de Datos planteado, por ejemplo, si adicionalmente se desea que
los elementos que se estudian sean del género masculino, todos los que no
son de este género deben ser eliminados.

Capítulo 3 METODOLOGÍA PROPUESTA PARA LA PREPARACIÓN DE DATOS
36
3.2.2.2 Preparación de Datos Específica (PDE).
La Preparación de Datos Específica, agrupa un conjunto de tareas que guardan
una estrecha relación con el objetivo de Minería de Datos que se desea alcanzar.
En la Preparación de Datos Específica se desarrollan tareas que están
enfocadas a alcanzar un objetivo de Minería de Datos en particular, estas tareas
varían significativamente de un proyecto de Minería de Datos a otro. En este nivel
hemos incluido las tareas que tienen que ver con el formateo, la construcción y la
integración de los datos.
3.2.2.2.1 Formateo de datos.
Se refiere principalmente a modificaciones sintácticas (hechas a los datos) que no
cambian su significado, pero pueden ser requeridas por las herramientas de
modelado.
a) Formateo de archivo.
Las modificaciones al formato del archivo tienen que ver directamente con la
extensión que éste tiene. Es decir, algunas herramientas requieren que el archivo
de entrada tenga una extensión específica (ej. Weka utiliza la extensión .arff,
Attribute-Relation File Format), por lo cual es necesario pasar los datos de una
base de datos a un archivo de formato específico o viceversa si las herramientas
que utilizamos así lo requieren.
b) Formateo de atributos.
El formateo de atributos implica realizar varias de las modificaciones que se listan
a continuación:

Capítulo 3 METODOLOGÍA PROPUESTA PARA LA PREPARACIÓN DE DATOS
37
I. Modificar el tipo de dato de un atributo.- En ocasiones es necesario realizar
modificaciones al tipo de dato de cada atributo, especialmente si el tipo de
dato no está acorde a los valores que maneja la columna, por ejemplo,
podríamos encontrar una columna cuyos valores son numéricos, pero el
tipo de dato del atributo es cadena de caracteres, si requerimos realizar
operaciones con estos valores, es necesario cambiar el tipo de dato del
atributo.
II. Ordenar los atributos.- Algunas herramientas tienen requerimientos en
relación al orden de los atributos, por ejemplo, que el primer campo sea un
identificador único para cada registro [7].
III. Modificaciones adicionales.- Existen modificaciones puramente sintácticas
hechas para satisfacer los requerimientos de una herramienta de modelado
en específico [7], por ejemplo, remover comas de un campo de texto en un
archivo de datos delimitado por coma, recortar todos los valores a un
máximo de 32 caracteres, etcétera.
3.2.2.2.2 Construcción de datos.
Incluye operaciones constructivas de Preparación de Datos tales como la
generación de atributos derivados y transformación de valores para atributos
existentes [7].
La construcción de datos engloba cualquier proceso que modifique la forma
de los datos. Prácticamente todos los procesos de Preparación de Datos entrañan
algún tipo de transformación de los datos [23].
La construcción de datos se refiere a derivar atributos que no existen en el
conjunto de datos original, desde otros existentes; por ejemplo, el cálculo de la
edad a partir de la fecha de nacimiento. Durante esta tarea se deben realizar las
acciones que se describen a continuación:

Capítulo 3 METODOLOGÍA PROPUESTA PARA LA PREPARACIÓN DE DATOS
38
a) Verificación del conjunto de datos.
Se realiza una revisión del conjunto de datos con la finalidad de detectar la
ausencia de valores o atributos que son necesarios para alcanzar los objetivos del
proyecto de Minería de Datos, pero que no se encuentran entre los atributos del
conjunto original.
b) Identificación de atributos para calcular los atributos faltantes.
Se identifican aquellos atributos con los que es posible calcular los atributos
faltantes. En [23] se menciona que, en algunos casos, es necesario el uso de uno
o más atributos para producir un único atributo derivado.
c) Obtención de los atributos faltantes.
Se realizan las operaciones necesarias con la finalidad de estimar los valores
faltantes, estas operaciones pueden ser de tipo aritmético para los atributos
numéricos u operaciones como la concatenación en el caso de atributos de tipo
cadena o carácter.
En [23] se mencionan algunas de las operaciones que transforman
atributos, algunas de ellas transforman un conjunto de atributos en otros, o bien
derivan nuevos atributos o cambian el tipo (mediante numerización o
discretización) o el rango (mediante escalado).
La creación o agregación de características consiste en crear nuevos
atributos para mejorar la calidad, visualización o comprensibilidad del
conocimiento extraído; la mayoría o todos los atributos originales se preservan. La
importancia de añadir atributos se demuestra cuando existen patrones complejos
en los datos que no pueden ser adquiridos por el método de Minería de Datos
utilizado [23].

Capítulo 3 METODOLOGÍA PROPUESTA PARA LA PREPARACIÓN DE DATOS
39
3.2.2.2.3 Integración de datos.
La integración de datos se refiere a la utilización de métodos a través de los
cuales la información se combina desde múltiples tablas o registros para crear
nuevos registros, tablas o, incluso, bases de datos [7].
Según [23], uno de los objetivos de la integración de datos es entender el
potencial de los datos. Existen proyectos encaminados a entender qué existe en
los datos, qué tan confiables son esos datos y qué datos adicionales son
necesarios para responder preguntas complejas; ejemplo, los proyectos
relacionados con la epidemiología donde se analiza cómo afectan las
enfermedades a ciertos sectores de la población.
En [25] se menciona que una integración de datos cuidadosa puede ayudar
a reducir y evitar redundancias e inconsistencias en el conjunto de datos final.
Esto ayuda a mejorar la velocidad y exactitud de los procesos de Minería de Datos
subsecuentes.
a) Análisis de las fuentes de datos.
Es necesario analizar las diversas fuentes de datos que se desean integrar con el
objetivo de entender sus elementos. Este análisis nos dará un panorama de las
posibles maneras en las que los datos se pueden integrar. Adicionalmente, el
análisis de las fuentes de datos nos dará una perspectiva de los posibles conflictos
que podríamos enfrentar al momento de integrar los datos.
El análisis de la estructura de las fuentes de datos originales tiene el
objetivo de identificar qué atributos nos permitirán establecer una relación entre
éstas. En [25] se menciona “cuando se hacen coincidir atributos de una base de
datos con los de otra durante la integración, es necesario poner atención especial
en la estructura de los datos”.

Capítulo 3 METODOLOGÍA PROPUESTA PARA LA PREPARACIÓN DE DATOS
40
b) Detección de conflictos.
Existen algunos problemas en los datos que pueden verse agravados por el
proceso de integración de distintas fuentes, especialmente si este proceso no es
cuidadoso. En [40], [41] y [42] se mencionan algunos de estos conflictos presentes
al momento de integrar datos, las acciones a seguir son:
I. Detectar diferencias de nombre (o conflictos de nombre).- Se refiere a
términos léxicos distintos denotando los mismos objetos semánticos, por
ejemplo “costo” y “precio”. Otras diferencias se caracterizan por la
disparidad de símbolos utilizados para denotar sinónimos, por ejemplo “NC”
y “NO_Control”. Los conflictos de nombres pueden estar presentes tanto en
tablas, como en atributos.
II. Detectar diferencias estructurales (o conflictos estructurales).- Una de las
razones por las que los esquemas resultan con estructuras diferentes, tiene
que ver con el nivel de detalle requerido por quien diseña el esquema, es
decir, desde dos perspectivas diferentes, un concepto puede ser modelado
como una entidad o simple y sencillamente como un atributo. También,
existen diferencias estructurales que tienen que ver con la buena o mala
normalización de las tablas, atributos que no son atómicos, dos entidades
que han sido resumidas en una misma tabla, etcétera. En [23] se muestra
como ejemplo el proceso de descomposición de claves, el cual se refiere a
claves internas de sistemas mal diseñados que puede entrañar información
no normalizada y es preciso detectar durante el proceso de integración.
III. Detectar diferencias de contenido.- Ocurren cuando los datos
representados en una base de datos no son directamente representados en
otra. Estos datos pueden ser implícitos (son constantes que son asumidas
“por defecto” en un contexto local, pero no global), derivables (atributos que
se pueden obtener por medio de otros atributos) o simplemente perdidos
(cuando no pueden ser asumidas por defecto o derivadas desde otros
atributos).

Capítulo 3 METODOLOGÍA PROPUESTA PARA LA PREPARACIÓN DE DATOS
41
En [25] se mencionan varios de estos conflictos y se proponen algunas
alternativas para solucionarlos.
c) Corrección de conflictos.
La corrección de los conflictos detectados puede ser muy simple en algunos
casos, pero a la vez, muy compleja o imposible en otros. Las acciones son:
I. Corregir diferencias de nombre (o conflictos de nombre).- La corrección de
las diferencias de nombres se realiza homogeneizando los términos
utilizados para referirnos a las tablas y atributos que manejan datos
equivalentes.
II. Corregir diferencias estructurales (o conflictos estructurales).- Las
diferencias estructurales son un poco más complejas de resolver. En
algunos casos esto significa agregar o eliminar atributos, hasta conseguir
homogeneizar los datos, si el nivel de detalle es diferente. Otras acciones
consisten en atomizar los atributos o descomponer las tablas de forma
vertical u horizontalmente para separar los conceptos que se encuentran
unidos.
III. Corregir diferencias de contenido.- La corrección varía dependiendo del
caso observado, por ejemplo, cuando los valores son constantes asumidas
“por defecto” basta con conocer el valor default del contexto local. Por otro
lado, si los valores pueden ser derivados desde otros atributos, se deben
realizar las operaciones necesarias para obtener estos valores. Por último,
si hablamos de valores perdidos se deben analizar las opciones, de manera
que el objetivo que se persigue no se vea afectado por la ausencia de
valores que son requeridos para alcanzarlo.
En [23] se menciona que “la integración produce disparidad de formatos, nombres,
rangos, etcétera; que podría no existir, o en menor medida, en las fuentes
originales. Esto dificulta en gran medida los procesos de análisis y extracción de

Capítulo 3 METODOLOGÍA PROPUESTA PARA LA PREPARACIÓN DE DATOS
42
conocimiento”. También se propone una serie de consejos para la integración de
los datos de manera que éstos, sean lo más apropiados para la minería.
d) Integración de las fuentes de datos.
La heterogeneidad semántica y de estructura de los datos supone grandes retos
en la integración de los datos [25], teniendo homogeneizadas las fuentes de datos,
la integración de éstas puede resultar simple. Los datos pueden quedar integrados
en una tabla, base de datos o incluso una forma más compleja como un Almacén
de Datos, esto depende de las necesidades del proyecto de Minería de Datos que
se está realizando. La integración de los datos requiere:
I. Diseñar el esquema de integración.- Se debe modelar el esquema en el
cual se integrarán los datos, es necesario plasmar la estructura que
deseamos obtener, definir sus elementos y cómo se relacionan unos con
otros.
II. Implementar el esquema.- Una vez definido el esquema, su
implementación puede requerir de herramientas que, mediante el uso de
sentencias y comandos, nos permita generar la estructura que hemos
definido.
III. Poblado del esquema.- Por último, se deben cargar los datos que han sido
preparados desde las diversas fuentes que se desean integrar.
3.2.3 Niveles de adaptabilidad.
En esta sección se plantean dos casos de adaptabilidad con el fin de analizar, de
manera exploratoria dicha característica y, basados en la metodología descrita en
la sección 3.2.2, ubicar ambos casos dentro del proceso de Preparación de Datos.
En muchos dominios, los problemas cambian constantemente, no son
estacionarios; es ahí donde la computación adaptativa es de utilidad. Es

Capítulo 3 METODOLOGÍA PROPUESTA PARA LA PREPARACIÓN DE DATOS
43
importante que los procesos, en especial si están automatizados, sean flexibles y
tengan la capacidad de soportar variaciones ocurridas en los valores o su tipo.
En un sentido más informático, la adaptabilidad es la habilidad de un
sistema para cambiar su comportamiento en presencia de una perturbación [43].
Los sistemas adaptables dan la posibilidad al usuario de cambiar ciertos
parámetros del sistema con el fin de personalizar y adaptar su comportamiento.
Los beneficios de estas aplicaciones se ven reflejados al conseguir mejoras
en el tiempo de respuesta o rendimiento, reduciendo el trabajo que el usuario debe
realizar, siendo más consistente, flexible en su comportamiento y requiriendo
menos tiempo en el entrenamiento del usuario con el sistema [44]. Desde el
enfoque de esta investigación, la adaptabilidad será vista de manera exploratoria y
estará basada en dos niveles en particular:
a) Cambios en el valor de las variables.
b) Cambios en el tipo de dato de los valores
3.2.3.1 Cambios en el valor de las variables.
En este nivel hay que analizar variaciones en los valores de los datos, dos fueron
las variables de interés que se analizaron: AÑO y CAUSA; sus valores fueron el
factor de cambio considerado.
Tabla 1. Variables como factor de cambio.
AÑO CAUSA
2000 2049 causas de
muerte 2010
En la Tabla 1 se muestran las dos variables que serán utilizadas para
probar la adaptabilidad como factor de cambio en los valores de las variables:

Capítulo 3 METODOLOGÍA PROPUESTA PARA LA PREPARACIÓN DE DATOS
44
Para la variable AÑO.- Probar que el proceso de Preparación de Datos se
adapta para realizar la preparación de los datos de mortalidad de los
censos oficiales del año 2000 y 2010.
Para la variable CAUSA.- Probar que el proceso de Preparación de Datos
se adapta para una familia de neoplasias (causas de cáncer: C16, C34) y,
posteriormente, analizar otras causas de muerte (diabetes: E11 y E14).
3.2.3.2 Cambios en el tipo de dato de los valores.
En este nivel hay que analizar variaciones en el tipo de dato de los atributos. En
ocasiones, el tipo de dato de los atributos contenidos en una base de datos puede
sufrir modificaciones, esto puede producirse por alguna variación sintáctica en los
valores o formato de almacenamiento de alguna variable.
En este sentido, hay que probar que el proceso de Preparación de Datos
puede adaptarse a los cambios ocurridos en el tipo de dato de un atributo.
Tabla 2. Tipo de dato como factor de cambio.
CAUSA
TIPO NUMERICO TIPO CADENA
34 C34
La Tabla 2 se muestra la variación en el tipo de dato del atributo CAUSA.
Para una familia de casos, podemos referenciar una causa de muerte como C34
(cadena de caracteres) o simplemente como 34 (numérico).

Capítulo 3 METODOLOGÍA PROPUESTA PARA LA PREPARACIÓN DE DATOS
45
3.3 SEMI-AUTOMATIZACIÓN DEL PROCESO DE PREPARACIÓN DE DATOS.
La automatización es el proceso de seguir una secuencia predeterminada de
operaciones con muy poca o nula labor humana, usando equipos y dispositivos
especializados [45]. En informática, los programas son los encargados de
automatizar las operaciones que se llevan a cabo.
Podemos decir que la automatización es un buen medio para controlar la
evolución del software, ayuda a aplicar buenas prácticas, a evaluar
sistemáticamente la calidad [46]. Sin embargo, a pesar de los importantes avances
de la ingeniería de software, existen muchas tareas cuya automatización sigue
resultando difícil debido a la naturaleza de éstas.
En este sentido, las tareas de la fase de Preparación de Datos representan
un reto difícil de automatización ya que, en algunas tareas, el número de
decisiones que el experto en minería debe tomar para solucionar un problema en
los datos, resulta una cuestión no trivial. En general, el proceso de Minería de
Datos puede ser automático o (más usual) semi-automático [47].
Retomando la idea anterior, hablamos de un proceso semi-automatizado
cuando no se ha conseguido la automatización del proceso en su totalidad. En la
siguiente sección, se muestra la arquitectura de un sistema de Preparación de
Datos que incluye todas las sub-fases de Preparación de Datos.
3.3.1 Arquitectura del sistema de Preparación de Datos.
La arquitectura está basada principalmente en paquetes que implementan los
diferentes procesos identificados. A continuación se describen, de manera
general, algunos de los diagramas de paquetes pertenecientes a dicha
arquitectura:

Capítulo 3 METODOLOGÍA PROPUESTA PARA LA PREPARACIÓN DE DATOS
46
class generalMod
DLimpieza DSelección
PDG
<<use>>
class specificMod
DConstrucción DIntegración DFormateo
PDE
<<use>>
Dentro de cada paquete se encuentran agrupadas las clases que
corresponden a las tareas realizadas en cada una de las sub-fases de preparación
que CRISP-DM propone.
Figura 6. Paquete de Preparación de Datos General.
La Figura 6 nos muestra la estructura generada para el conjunto de tareas
definido como Preparación de Datos General (PDG), el cual incluye los paquetes
para limpieza y selección de datos.
Figura 7. Paquete de Preparación de Datos Específica.
La Figura 7 nos muestra la estructura generada para el conjunto de tareas
definido como Preparación de Datos Específica (PDE), el cual incluye los
paquetes para formateo, construcción e integración de datos.

Capítulo 3 METODOLOGÍA PROPUESTA PARA LA PREPARACIÓN DE DATOS
47
La descripción de los paquetes y las clases que integran cada paquete se
ha incluido en el Anexo C.
3.3.2 Implementación del prototipo de Preparación de Datos.
La implementación del prototipo combina tres potentes tecnologías: Java, XML y
SQL. Las tareas seleccionadas para automatizarse fueron codificadas utilizando el
lenguaje de programación Java. XML fue utilizado con el propósito de describir las
tareas de Preparación de Datos y, principalmente, el orden en el que éstas se
ejecutan. Por último, se requirió MySQL como herramienta de manipulación y
acceso a los datos.
3.3.2.1 Selección de tareas automatizables.
Las tareas automatizadas corresponden a tareas del conjunto denominado
Preparación de Datos Específica, las tareas seleccionadas son:
Del paquete de Construcción de datos:
1. Cálculo de la incidencia de mortalidad.
2. Cálculo de la tasa de mortalidad.
3. Cálculo de la tasa de mortalidad normalizada.
Del paquete de Integración de datos:
1. Construcción del dataset final.
Éstas son las tareas que representan el mayor esfuerzo dentro del proceso
de Preparación de Datos que se realizó para este dominio en particular, de todo el
proceso, son las tareas que se repiten con mayor frecuencia, lo cual supone
realizar los cálculos para cada CAUSA de mortalidad, por cada AÑO que se desea
analizar.

Capítulo 3 METODOLOGÍA PROPUESTA PARA LA PREPARACIÓN DE DATOS
48
Figura 8. Cambios en los valores de entrada.
La Figura 8 representa que al realizar un cambio en los valores de las
variables CAUSA y AÑO, éste repercute en los resultados de ejecución ya que al
variar estos valores, los resultados de incidencia y tasa de mortalidad son
diferentes, por lo tanto el conjunto de datos generado y el modelo desplegado,
serán diferentes.
3.3.2.2 Descripción de las tareas de preparación con XML.
En [48] se propone el esquema de metadatos, mostrado en la Figura 9, utilizado
para describir cómo proceder con la ejecución de las tareas durante el proceso de
Preparación de Datos.
El esquema permite describir el orden en el que las tareas de preparación
de datos se van ejecutando, esta descripción se realiza con el fin de automatizar la
fase de Preparación de Datos y así, conseguir reducir el tiempo invertido durante
esta fase.
El esquema categoriza la información que se necesita para describir las
tareas de Preparación de Datos con el objetivo de clasificar los requerimientos y, a
su vez, documentar dicha tarea.

Capítulo 3 METODOLOGÍA PROPUESTA PARA LA PREPARACIÓN DE DATOS
49
Figura 9. Esquema de descripción de tareas de Preparación de Datos.
El esquema de metadatos de la Figura 9 permite definir una tarea (o
conjunto de tareas) a través del MetadataSet, y a su vez, por medio del
MetadataItem las acciones relacionadas durante dicha tarea. También, permite
especificar el orden de ejecución utilizando el MetadataFlow.
El Anexo B muestra un ejemplo de la descripción de tareas de preparación
de datos que se puede realizar siguiendo el esquema de metadatos de la Figura 9.
El esquema tiene la capacidad de describir tareas simples como el cálculo
de la incidencia de mortalidad, mostrada en el Anexo C, o tan complejas como la
tarea de integrar los datos desde distintas fuentes en un almacén de datos. Los
nombres de los metadatos son asignados de acuerdo a la acción que describen,
así que el número de éstos dependerá de las acciones que se describirán.

Capítulo 3 METODOLOGÍA PROPUESTA PARA LA PREPARACIÓN DE DATOS
50
3.3.2.3 Manipulación y acceso a los datos.
Por último, se utilizó la herramienta MySQL para la implementación del Almacén
de Datos de modelo multidimensional ROLAP (Relational OLAP). MySQL es un
sistema de administración de bases de datos (Database Management System,
DBMS) para bases de datos relacionales.
MySQL ofrece la capacidad para manejar los almacenes de datos más
comunes [49]:
Data marts.
Almacenes de datos tradicionales.
Grandes almacenes de datos históricos/archivo.
Almacenes de datos de tiempo real.
Con respecto a esto último, MySQL nos ofrece las ventajas necesarias para
la implementación del Almacén de Datos y permite una manipulación sencilla de
los datos, además facilita el acceso a éstos.

51
Capítulo 4 VALIDACIÓN DE LA METODOLOGÍA PROPUESTA Y
RESULTADOS.
Este Capítulo contiene tres secciones: 4.1 Plan de pruebas, 4.2 Experimentación y
4.3 Análisis de los resultados.
La Sección 4.1 describe el plan de pruebas utilizado para validar la
metodología propuesta.
La Sección 4.2 describe la experimentación realizada, describe las acciones
realizadas durante las fases de Entendimiento del dominio (4.2.1), Recopilación y
entendimiento de los datos (4.2.2) y Preparación de datos (4.2.3). Por último, se
describe la Preparación de datos realizada de manera automatizada (4.24).
La Sección 4.3, presenta el análisis de los resultados obtenidos, presenta
una comparativa de los resultados obtenidos en esta investigación, contra los
resultados obtenidos en investigaciones previas (4.3.1). Muestra los resultados del
análisis realizado para otras causas de mortalidad (4.3.2) y finaliza con una
comparativa entre el tiempo requerido para realizar, de manera manual y
automatizada, las tareas de cálculo de la incidencia de mortalidad y cálculo de la
tasa de mortalidad.

Capítulo 4 VALIDACIÓN DE LA METODOLOGÍA PROPUESTA Y RESULTADOS
52
4.1 PLAN DE PRUEBAS.
A continuación se describe el plan de pruebas seguido para la metodología de
Preparación de Datos que se propone.
4.1.1 Objetivos.
1. Aplicar la metodología propuesta para preparar los datos poblacionales y
espaciales del año 2000 y 2010; y así, verificar que la sistematización del
proceso sea adecuada.
2. Comparar el tiempo ocupado al preparar los datos de manera manual
contra el tiempo ocupado para la preparación que se hizo automáticamente.
3. Comprobar la capacidad de adaptabilidad, de la metodología y el prototipo
de Preparación de Datos, a los cambios realizados en las variables AÑO y
CAUSA.
4.1.2 Ambiente de las pruebas.
Las pruebas se realizaron en un equipo portátil con las siguientes características
en el hardware:
Procesador AMD E-450 a 1.65 GHz.
Memoria RAM de 2 GB.
Las características del software:
Sistema operativo Windows 7 Ultimate.
MySQL versión 5.5.
Microsoft Excel 2007.
Prototipo de Preparación de Datos.

Capítulo 4 VALIDACIÓN DE LA METODOLOGÍA PROPUESTA Y RESULTADOS
53
Los datos utilizados son:
Base de datos espaciales: posición geográfica de los municipios de México.
Bases de datos poblacionales: mortalidad por diversas causas, población
total por municipio en México y el catálogo internacional de enfermedades.
4.1.3 Descripción de los casos de prueba.
Para validad la metodología propuesta se utilizaron los datos de los censos
oficiales del año 2000 y 2010, en ambos casos de prueba, la adaptabilidad está
dada en relación al cambio en el valor de las variables CAUSA y AÑO de
mortalidad.
A continuación se describen los dos casos de prueba sobre los cuales se
aplicó la metodología de Preparación de Datos y el prototipo de Preparación de
Datos descritos en las secciones 3.2 y 3.3 respectivamente. Estos son:
Preparación de datos manual (4.1.3.1) y Preparación de datos automatizada
(4.1.3.2):
4.1.3.1 Preparación de los datos de los censos del año 2000 y 2010 de
manera manual.
Este caso de prueba consistió en realizar de manera manual el proceso de
Preparación de Datos, se utilizaron los datos de los años 2000 y 2010. La
Preparación de Datos se realizó con ayuda del paquete Microsoft Excel con el fin
de facilitar la manipulación de los datos y de que el proceso fuese lo más manual
posible.
El proceso de Preparación de Datos se repitió completamente de manera
manual, se generaron los conjuntos de datos (dataset) para diferentes causas de
mortalidad, entre ellas, mortalidad por cáncer de estómago (C16) y cáncer de
pulmón (C34), las cuales habían sido analizadas en los trabajos de [34] y [35]; con

Capítulo 4 VALIDACIÓN DE LA METODOLOGÍA PROPUESTA Y RESULTADOS
54
el objetivo de comparar los resultados actuales, con los obtenidos previamente y
así, obtener la certeza de la fiabilidad de estos resultados.
Adicionalmente, se generaron los conjuntos de datos para analizar las
causas de mortalidad por diabetes mellitus no insulinodependiente (E11) y
diabetes mellitus no especificada (E14).
Para cada tarea realizada, se registró el tiempo que llevó su ejecución con
el propósito de comprobar la reducción del tiempo al utilizar el prototipo de
preparación.
4.1.3.2 Preparación de los datos de los censos del año 2000 y 2010 de
manera automática
Este caso de prueba consistió en repetir el proceso de Preparación de Datos de
manera automática utilizando los datos de los años 2000 y 2010, pero, a diferencia
del proceso manual, únicamente se ejecutaron las tareas automatizadas por el
prototipo descrito en la Sección 3.3. Éstas son:
Cálculo de la incidencia de mortalidad.
Cálculo de la tasa de mortalidad.
Cálculo de la tasa de mortalidad normalizada.
Construcción del conjunto de datos final (dataset).
Este proceso se realizó para las mismas causas de mortalidad que se
utilizaron en el caso de prueba manual, éstas son: C16, C34, E11 y E14;
relacionadas a mortalidad por cáncer y diabetes mellitus.
4.2 EXPERIMENTACIÓN.
Como se ha descrito en las secciones previas, la experimentación consistió
en realizar el proceso de Preparación de Datos para las bases de datos espaciales

Capítulo 4 VALIDACIÓN DE LA METODOLOGÍA PROPUESTA Y RESULTADOS
55
y poblacionales de los años 2000 y 2010; el proceso se realizó de manera manual
y automática para dichos datos. Diversas causas de mortalidad, relacionadas a
mortalidad por cáncer y diabetes mellitus, sirvieron como casos de prueba
específicos.
Aun cuando la investigación está enfocada a analizar el proceso de la fase
de Preparación de Datos, fue necesario recurrir a otras fases del proceso de
minería, esto se debe a la dependencia que la fase de preparación tiene con las
fases previas y la necesidad (posterior) de conseguir el objetivo de desplegar y
visualizar modelos que sirvan como apoyo para la toma de decisiones.
En las secciones siguientes se describe de manera breve el proceso de
minería, las acciones realizadas durante otras fases y, con mayor amplitud, el
proceso realizado durante la fase de Preparación de Datos.
4.2.1 Entendimiento del dominio.
Es la primera fase del proceso de Minería de Datos, está enfocada a familiarizarse
con el dominio al que pertenece la aplicación de Minería de Datos que se
desarrollará.
Se revisaron algunas fuentes con el fin de recabar información relacionada
a los problemas de salud en el dominio epidemiológico, por ejemplo:
1) el INSP (Instituto Nacional de Salud Pública, [50]),
2) el INCan (Instituto Nacional de Cancerología, [51])
3) y la SS (Secretaría de Salud, [52]), por mencionar algunos.
Las actividades se realizaron con la finalidad de conocer los problemas
existentes en el dominio y cuáles se encuentran directamente relacionados con los
datos e información que está disponible. Se realizó una búsqueda y recopilación

Capítulo 4 VALIDACIÓN DE LA METODOLOGÍA PROPUESTA Y RESULTADOS
56
de información (artículos, libros, revistas, etcétera) relacionada al dominio que
sirvió como apoyo para entender de manera clara los datos con los que se cuenta.
En esta fase, también, se planteó el objetivo que se pretenden alcanzar con
el proyecto de Minería de Datos, se evaluaron las condiciones del proyecto y las
metas o criterios de éxito del proyecto.
En este caso, el objetivo de Minería de Datos es “identificar regiones o
grupos de municipios con alta incidencia de mortalidad por diversas causas de
mortalidad en México”.
4.2.2 Recopilación y entendimiento de los datos.
La recopilación de los datos se hizo desde diversas fuentes, en este caso, los
datos fueron obtenidos desde distintas fuentes oficiales. A continuación se listan
las bases de datos con una breve descripción y el nombre de la fuente de donde
fueron descargadas:
Base de datos de mortalidad: registros de las defunciones por diferentes
causas de muerte ocurridas en los años 2000 y 2010. Fuente: SINAIS
(Sistema Nacional de Información en Salud), disponible en [53].
Base de datos geográfica: registros de la ubicación de los municipios de
México. Fuente: SIMBAD (Sistema Municipal de Base de Datos), disponible
en [54].
Base de datos poblacional: registros de la población total por municipio en
México para los años 2000 y 2010. Fuente: INEGI (Instituto Nacional de
Estadística y Geografía), disponible en [55].
Catálogo Internacional de Enfermedades (CIE-10): clasificación de las
enfermedades, causas externas de daños y circunstancias sociales de
mortalidad; incluye 2049 causas de muerte diferentes. Fuente: CEMECE
(Centro Colaborador para la Familia de Clasificadores Internacionales de la
OMS en México), disponible en [56].

Capítulo 4 VALIDACIÓN DE LA METODOLOGÍA PROPUESTA Y RESULTADOS
57
Tabla 3. Características de las bases de datos utilizadas.
Base de datos Número de
atributos
Número de
registros
Formato de
archivo
Geográfica 11 2475 XLS
Mortalidad 2000 38 437,667
DBF 2010 40 592,018
Poblacional 2000
3 2475 XLS 2010
Catálogo de
enfermedades 24 14,259 XLS
La Tabla 3 nos muestra las características más importantes de las bases de
datos, éstas tienen que ver con el tamaño y volumen de datos que se manejan, así
como el formato de archivo que hay que manipular para cada una de las bases de
datos.
Posterior al acopio de los datos, éstos fueron analizados con el fin de
entender su estructura, significado, tipos de datos, valores, rangos, etcétera. En
[34] se menciona que el entendimiento de los datos está guiado por el interés y las
necesidades establecidas en el entendimiento del dominio, esto, con el fin de
saber qué datos son de interés y qué tareas son útiles para su preparación.
Los datos extraídos desde las fuentes anteriormente mencionadas,
contienen un archivo de descripción. Este archivo describe cada uno de los
atributos presentes, así como los valores y rangos relacionados a cada atributo.
Por ejemplo:

Capítulo 4 VALIDACIÓN DE LA METODOLOGÍA PROPUESTA Y RESULTADOS
58
Tabla 4. Descripción de los atributos proporcionada por INEGI.
Atributo Tipo Etiqueta Valores
MPORES Numérico Municipio de
residencia
1 … 570
(según la entidad)
La Tabla 4 muestra un ejemplo de la descripción de los atributos
proporcionada para la base de datos de mortalidad. Los archivos de descripción
contienen una definición similar para cada atributo contenido en las bases de
datos utilizadas.
Por último, cabe resaltar que el entendimiento de los datos es importante ya
que nos permite identificar cuáles son los datos que nos servirán para alcanzar el
objetivo de Minería de Datos que se haya planteado.
4.2.3 Preparación de Datos manual.
El proceso de Preparación de Datos se realizó de manera manual, utilizando el
paquete Excel, para abrir y manipular los archivos de datos espaciales y
poblacionales, de los años 2000 y 2010, siguiendo la metodología que se
desarrolló en esta investigación.
Para los datos de población y el CIE-10, el proceso de preparar los datos
requirió de la ejecución de un menor número de tareas, para generar las
condiciones que se requerían en los datos.
La preparación de los datos de mortalidad y los datos de población se
realizó dos veces: 1) para los datos del año 2000 y 2) para los datos del año 2010,
esto se debe a que los datos, para cada año, se encontraban en archivos
separados, con la información respectiva para cada año. El número de
defunciones y el número de habitantes por municipio en el año 2000 varía
respecto a los del año 2010. Por último, los datos geográficos se prepararon una

Capítulo 4 VALIDACIÓN DE LA METODOLOGÍA PROPUESTA Y RESULTADOS
59
única vez para ambos años, ya que la posición y el número de municipios no
cambiaron.
A continuación se describen las tareas de Preparación de Datos ejecutadas
durante el proceso manual:
4.2.3.1 Preparación de Datos General.
En este nivel de Preparación de Datos se realizaron las tareas de limpieza y
selección de datos. Después de haber analizado los datos, estas tareas resultan
más sencillas, ya que el reconocimiento de los datos nos permite identificar
posibles errores en los datos y, a su vez, identificar cuáles de ellos representan
información de interés para el objetivo de minería que se haya planteado.
4.2.3.1.1 Limpieza de datos.
En esta primera etapa, la limpieza de los datos consistió en detectar, corregir o
eliminar aquellos registros o atributos con valores anómalos. Según [23], las
anomalías en los registros se refieren a registros con valores fuera de contexto, o
que no concuerdan con los valores de los demás registros.
Durante esta fase, es importante resaltar tres acciones:
a) Detectar los errores en los datos (registros o atributos).
b) Corregir los errores identificados en los datos.
c) Eliminar aquellos (registros o atributos) que no se hayan podido corregir.
Al revisar los archivos de datos, fue posible detectar los siguientes errores:
En el caso de la base de datos de mortalidad del año 2000, se registraron
381 registros con errores en los atributos CVE_JUR, FECH_REG, GÉNERO,

Capítulo 4 VALIDACIÓN DE LA METODOLOGÍA PROPUESTA Y RESULTADOS
60
E_LETRA, E_NUM, CAUSA, E_CIVIL, FECH_DE, LUG_DEF, PRES, TRABAJA_
EDAD, VIOLENCIA. El error se produjo por la ausencia de valores en la columna
CVE_JUR, lo cual propició que el resto de los valores de los atributos se
recorrieran y ocuparan los espacios de los valores ausentes. Para corregir este
error, fue necesario desplazar los valores de cada uno de los 381 registros, hacia
a la derecha, y posicionarlos en su columna original. Se corrigieron los 381
registros con errores que habían sido identificados, no fue necesario eliminar
registros después de realizar las acciones de corrección.
En los datos de mortalidad del año 2010, se identificaron 322 registros con
valores no especificados (cero) en el atributo SEXO, pero esto no representa un
obstáculo en el objetivo de minería, ya que las defunciones se contabilizarán
indistintamente del sexo, por lo tanto, no fue necesario eliminar los registros.
Los archivos de datos de población, para ambos años, y el archivo CIE-10
(Catálogo Internacional de Enfermedades) contenían encabezados con una
pequeña descripción, información que no representa datos o valores de los
atributos o registros del archivo, por lo tanto, dichos encabezados fueron
eliminados.
Por último, para los datos geográficos, se encontraron 135 registros cuya
información no estaba completa, los registros correspondían a los estados de
Quintana Roo (8 registros), Campeche (11 registros) y Yucatán con 116 registros
incompletos. Para corregir la ausencia de valores identificada, fue necesario
recurrir a los Anuarios Estadísticos de los Estados (AEE) [57] para obtener la
información faltante en los registros. Se completó la información faltante de los
135 registros, después de completar la información de los registros no se
realizaron eliminaciones.

Capítulo 4 VALIDACIÓN DE LA METODOLOGÍA PROPUESTA Y RESULTADOS
61
4.2.3.1.2 Selección de datos.
Durante la fase de selección de datos, las acciones más importantes que se
realizaron son dos:
a) Seleccionar los datos horizontalmente, es decir aquellos registros que son
de interés.
b) Seleccionar los datos verticalmente, es decir, aquellos atributos que
representan información de interés.
Durante la selección horizontal (registros) se realizaron las siguientes acciones:
Originalmente, para los datos de población del año 2000 y 2010 se contaba
con 2475 registros, de éstos se seleccionaron aquellos registros de municipios con
un número de habitantes mayor a 100,000, los registros que no cumplían esta
condición fueron eliminados. Se eliminaron 2307 registros (el 93.22%)
conservando 168 registros para los datos el año 2000. Para los datos del año
2010, se eliminaron 2271 registros (91.76%) conservando 204 registros.
La selección de los registros en el archivo geográfico se hizo tomando como
referencia los municipios con más de 100,000 habitantes identificados para el año
2010, esto significa que se sumaron 34 nuevos en el año 2010, a los 168 que se
identificaron en el año 2000, obteniendo un total de 204 registros.
En el caso de los datos de mortalidad, dos condiciones importantes debían
cumplirse:
Que las defunciones hayan ocurrido durante los años 2000 o 2010.
Que los registros correspondieran a defunciones ocurridas en el territorio
Mexicano.

Capítulo 4 VALIDACIÓN DE LA METODOLOGÍA PROPUESTA Y RESULTADOS
62
A través del atributo ANODEF se verificó que los registros cumplieran con la
primer condición, se eliminaron un total de 8,297 registros (el 1.89% del total) que
no correspondían a defunciones ocurridas durante el año 2000 (condición
conocida como sub-registro [58]). En el caso de los datos de mortalidad del año
2010, 12,317 registros (el 2.08% del total) fueron eliminados.
Por último, el atributo ENTRES fue utilizado para verificar la segunda
condición, se eliminaron aquellos registros cuyos valores correspondían a 33, 34 o
35; estos códigos corresponden a defunciones que ocurrieron fuera del territorio
Mexicano, es por ello que esos registros son eliminados.
Del archivo CIE-10, que contiene la clasificación de las enfermedades, de
un total de 14,259 registros, se eliminaron 12,210 (el 85.63%) cuyo valor en el
atributo CAUSA excedía tres caracteres, esto, debido a que el cuarto dígito
representan la causa o ubicación explícita de la enfermedad y, en este caso, sólo
se requiere saber la causa general. El número final de registros fue de 2049.
Después de haber eliminado aquellos registros que no representaban
información de interés, se procedió a realizar la selección vertical (de atributos),
las acciones que se realizaron fueron:
Para el archivo de datos del CIE-10, de un total de 29 atributos, se
identificaron como atributos de interés los atributos CAUSA y NOMBRE, los 27
restantes (el 93.1%) fueron eliminados por no aportar información de interés para
lograr el objetivo de minería planteado.
Para la base de datos de mortalidad, se eliminaron los atributos nulos, es
decir, aquellos que tienen un valor constante en toda la columna, por ejemplo:
E_LETRA, PRES, LUGAR, TRABAJA, NECROP, NACION, CON_EMB y
REL_EMB; esta eliminación representa el 21.05% de un total de 38 atributos en el
año 2000, para el año 2010 representa el 20% de un total de 40 atributos.
También, para ambos años, se identificaron los atributos que tenían dependencia

Capítulo 4 VALIDACIÓN DE LA METODOLOGÍA PROPUESTA Y RESULTADOS
63
con otros atributos, por ejemplo, ENT_RES, MPO_RES y ENT_DEF, MPO_DEF,
éstos últimos se preservaron para su uso posterior en otras operaciones.
También, se eliminaron aquellos atributos que servían como identificadores
o llaves primarias, por ejemplo, el atributo CONTROL, presente en los datos de
mortalidad del año 2000, el número de atributos para el año 2000 se redujo a 29.
Por último, se eliminaron todos aquellos atributos que no representaban
información de interés, éstos son DIA_DEF, MES_DEF, DIA_NAC, MES_NAC y
TLOC; esta eliminación representa el 17.24% de un total de 29 atributos en el año
2000, para el año 2010 representa el 15.62% de un total de 32 atributos.
Por último, para los datos de mortalidad de ambos años, del conjunto
resultante se analizaron y seleccionaron un total de 10 atributos considerados de
interés, entre éstos están ENT_RES, MPO_RES, GÉNERO, CAUSA, E_CIVIL,
ENT_DEF, MUN_DEF, ESCO, OCUPA y EDAD; se conservaron el 41.66% de un
total de 24 atributos en el año 2000, para el año 2010, se conservaron el 37.03%
de un total de 27 atributos.
Para los datos geográficos, de un total de 11 atributos, se eliminaron 3
atributos (el 25.27%) MUNICIPIO, CABECERA y ALTITUD, se preservaron 8
atributos.
4.2.3.2 Preparación de Datos Específica.
En este nivel de Preparación de Datos se realizaron las tareas de formateo,
construcción e integración de datos. Estas tareas representan las operaciones que
están estrechamente ligadas al objetivo de Minería de Datos. Una vez que los
datos se han homogeneizado y se encuentran en condiciones óptimas son
utilizados para realizar cálculos durante éstas tres últimas sub-fases. Las
operaciones incluidas en este nivel, se realizaron sobre los datos de ambos años
2000 y 2010 indistintamente.

Capítulo 4 VALIDACIÓN DE LA METODOLOGÍA PROPUESTA Y RESULTADOS
64
4.2.3.2.1 Formateo de datos.
Es necesario homogeneizar el formato de los archivos de datos que se están
utilizando y los tipos de los atributos en cada archivo. En este punto, se realizaron
acciones para modificar el formato de los archivos y corregir errores en los tipos
de datos de los atributos.
Las acciones realizadas para el formateo de atributos fueron:
Se modificaron los tipos de datos de los atributos con el fin de que éstos
correspondieran a la información contenida en la columna. Podríamos mencionar,
por ejemplo: en el caso de los datos de mortalidad, en modificar los tipos de datos
en los atributos GÉNERO, E_CIVIL, ESCOLARIDAD, OCUPACION y EDAD; los
cuales estaban siendo manejados como tipo cadena o carácter, cuando la
información contenida en cada una de esas columnas representa información
numérica, el tipo de datos se convirtió a entero.
Otra modificación consistió en cambiar los nombres de los identificadores
de cada atributo, por otro que fuese más representativo o explicara mejor el
contenido de los datos, por ejemplo, los atributos ESCO y OCUPA; fueron
renombrados como ESCOLARIDAD y OCUPACIÓN respectivamente.
Una modificación más se realizó sobre los datos de mortalidad, ésta fue, la
reducción hecha al número de caracteres que utiliza el atributo CAUSA:
Figura 10. Formato de los valores de una clave de mortalidad.

Capítulo 4 VALIDACIÓN DE LA METODOLOGÍA PROPUESTA Y RESULTADOS
65
Este atributo contiene una sucesión de caracteres que representan una
clave, la cual identifica a una enfermedad determinada, la Figura 10 nos muestra
esta sucesión. El cuarto carácter indica la sub-localización de una enfermedad, sin
embargo, este carácter no representa información que sea relevante para el
objetivo de minería, ya que sólo se requiere saber la causa general, más no la
específica. Por lo tanto, una causa de muerte C34x puede ser manejada
simplemente como C34.
Para los datos geográficos, el número de decimales en los atributos
LAT_GRADOS, LAT_MIN, LONG_GRADOS y LONG_MIN; fue modificado, ya que
la herramienta de modelado que se utilizará, requiere una exactitud de catorce
decimales.
Posteriormente, se reordenaron los atributos contenidos en cada archivo de
datos, para el archivo de datos poblacionales el orden de los atributos es CLAVE,
MUNICIPIO y POBLACIÓN; para los datos geográficos CLAVE, LAT_GRADOS,
LAT_MIN, LONG_GRADOS y LONG_MIN. Por último, el orden de los atributos de
mortalidad es ENTRH, MUNRH, GÉNERO, CAUSA, E_CIVIL, ENT_OCU,
MUN_OCU, ESCOLARIDAD, OCUPACIÓN y EDAD.
Todos los archivos fueron convertidos a formato CVS, formato requerido por
el manejador de base de datos para que los datos se puedan cargar en las tablas.
4.2.3.2.2 Construcción de datos.
Durante esta etapa, se realiza una nueva revisión de los datos disponibles, con el
fin de verificar e identificar cuáles son los atributos que servirán para obtener
nuevos atributos necesarios para alcanzar el objetivo de Minería de Datos. Las
operaciones de construcción de datos incluyeron desde simples acciones para
concatenar dos cadenas hasta operaciones más complejas donde se requirieron
varios atributos para realizar cálculos matemáticos.

Capítulo 4 VALIDACIÓN DE LA METODOLOGÍA PROPUESTA Y RESULTADOS
66
Las acciones realizadas durante la construcción de datos son:
En el caso de los datos de mortalidad, se realizó la concatenación de los
atributos ENT_RES y MPO_RES para generar el atributo CLAVE. También se
concatenaron los atributos ENT_DEF y MPO_DEF para generar el atributo
LUG_DEFUNCIÓN.
Otras operaciones realizadas sobre los datos de mortalidad incluyeron el
cálculo de la incidencia y tasa de mortalidad. Las operaciones realizadas son:
(2)
La Expresión 2 anterior nos indica que para obtener la incidencia de
mortalidad, es necesario contabilizar el número de defunciones que se
presentaron en cada municipio para año determinado, en este caso 2000 o 2010,
relacionadas a una causa en particular. Como resultado se obtiene el atributo
adicional INCIDENCIA.
Los atributos CLAVE (clave del municipio) y CAUSA (causa de mortalidad)
fueron utilizados para realizar filtros sobre los datos, utilizando Excel, y contabilizar
el número de defunciones que se presentaron por municipio para una causa
determinada.
Para calcular la tasa de mortalidad, las operaciones realizadas son:
(3)
La Expresión 3 describe el cálculo de la tasa de mortalidad, esto requiere
de utilizar el atributo derivado INCIDENCIA y el atributo POBLACIÓN (presente en
los datos poblacionales) referente al número de habitantes en un municipio;
posteriormente calcular la tasa de mortalidad para cada municipio.

Capítulo 4 VALIDACIÓN DE LA METODOLOGÍA PROPUESTA Y RESULTADOS
67
Para los datos geográficos, se realizaron operaciones para convertir las
coordenadas de latitud y longitud, originalmente en grados sexagesimales, a
grados decimales:
(4)
La Expresión 4 nos muestra las operaciones requeridas para realizar esta
conversión. Es necesario cambiar el formato de las coordenadas geográficas de
latitud y longitud en grados sexagesimales a grados decimales con el fin de poder
representar estas coordenadas como puntos en el plano (x,y), esta información es
utilizada por los Sistemas de Información Geográfica (SIG) para representar
puntos sobre los mapas.
Por último, se realizó la normalización de los atributos derivados
LAT_DECIMAL y LONG_DECIMAL (presentes en los datos geográficos); y
TASAMORTALIDAD (presente en los datos de mortalidad). Este cálculo, llamado
normalización lineal, permite establecer los valores en un rango definido [59]:
(5)
En la Expresión 5, AV se refiere al valor actual que se desea normalizar,
mV es el valor mínimo presente en el atributo, MV es el valor máximo presente en
el atributo y valorN es el valor normalizado resultante.
Figura 11. Normalización de los atributos.

Capítulo 4 VALIDACIÓN DE LA METODOLOGÍA PROPUESTA Y RESULTADOS
68
La Figura 11 esquematiza la operación de normalización. La normalización
es necesaria cuando los valores de un atributo van a ser analizados por un
algoritmo de agrupamiento [23].
Los cálculos de construcción de datos se realizaron para diferentes causas
de mortalidad por ejemplo: C16 y C34 (correspondientes al mortalidad por cáncer);
y, E11 y E14 (correspondientes a mortalidad por diabetes).
Tabla 5. Número de registros y atributos después de la preparación de los datos.
Poblacionales Geográficos Mortalidad CIE-10
Registros
2000 168
204
2000 250,593
2049 2010 204 2010 355,091
Atributos 3 7 8 2
La Tabla 5 nos muestra el número de atributos y registros para cada una de
las fuentes de datos. Después de aplicar la Preparación de Datos General (PDG) y
el formateo y construcción de datos, el número de atributos y registros se redujo
en las fuentes de datos originales.
4.2.3.2.3 Integración de datos.
Se realizó un último análisis de los datos contenidos en las fuentes de datos.
Basados en este análisis, se seleccionó el atributo CLAVE con el fin de establecer
una relación entre los datos geográficos y los poblacionales. Por otro lado, el
atributo CAUSA se utilizó para establecer una relación entre los datos contenidos
en el Catalogo Internacional de Enfermedades (CIE-10) y los datos de mortalidad.
Adicionalmente se detectaron y resolvieron algunos conflictos de
integración, por ejemplo, se cambió el nombre al atributo CLAVECAUSA,

Capítulo 4 VALIDACIÓN DE LA METODOLOGÍA PROPUESTA Y RESULTADOS
69
contenido en los datos del CIE-10, se renombro como CAUSA para que hubiese
concordancia con el atributo, del mismo nombre, de los datos de mortalidad.
Otro conflicto que se presentó al intentar establecer la relación entre los
datos de mortalidad y los del CIE-10, fue un conflicto de contenido, es decir, en los
datos del año 2010 existen registros de defunciones ocurridas por una nueva
enfermedad conocida como AH1N1 o influenza porcina [60], fue necesario buscar
la clave y el nombre para esta causa de mortalidad y añadirla a los registros del
CIE-10 desde una versión más reciente, la 2009.
Una vez resueltos los conflictos de integración, se diseñó un esquema para
integrar los datos, el cual originalmente consistía en un Almacén de Datos tipo
estrella, ya que sólo contenía los datos de mortalidad del año 2000. Fue necesario
cambiar este esquema y rediseñarlo para poder incluir los datos de mortalidad del
año 2010.
Figura 12. Esquema del Almacén de Datos implementado.
El esquema de la Figura 12 conserva similitudes con el esquema propuesto
en [37]. Se manejan tres dimensiones relacionadas a causa de muerte o
defunción (círculo rojo), espacio o lugar de la defunción (circulo azul) y tiempo o
año de la defunción (recuadro verde). En [61] se considera que un país tiene como

Capítulo 4 VALIDACIÓN DE LA METODOLOGÍA PROPUESTA Y RESULTADOS
70
hecho básico, decesos, los cuales pueden tener atributos asociados como el
número de casos, la tasa de mortalidad, etcétera.
La implementación final se describe en el Anexo D, se hizo sobre un
esquema tipo copo de nieve (snowflake) utilizando el manejador MySQL, se
crearon las tablas MORTALIDAD (para los datos de mortalidad), CATALOGO
(para los datos del CIE-10), GEOGRÁFICA (para los datos geográficos) y
POBLACIONAL (para los datos de población).
Adicionalmente se creó una tabla de HECHOS en la cual se almacenan los
datos de los atributos derivados INCIDENCIA y TASAMORTALIDAD, entre otros.
En las tablas MORTALIDAD, POBLACIONAL y HECHOS, se agregó el atributo
AÑO para diferenciar los datos del año 2000, de los del año 2010.
Figura 13. Representación de la integración de los datos.
La Figura 13 representa la integración de los datos. El poblado de las tablas
se realizó utilizando una sentencia de MySQL que permite cargar los datos, desde
archivos CSV a tablas que tienen una estructura idéntica a la del archivo, incluidas
en el Anexo D.

Capítulo 4 VALIDACIÓN DE LA METODOLOGÍA PROPUESTA Y RESULTADOS
71
4.2.4 Preparación de Datos automatizada.
El proceso de Preparación de Datos se realizó de manera automática utilizando
los datos de mortalidad y poblacionales para los años 2000 y 2010. Se utilizó un
prototipo de Preparación de Datos que implementa tareas del nivel específico, de
las sub-fases de construcción e integración.
A continuación se describen las tareas de Preparación de Datos ejecutadas
durante el proceso automatizado:
4.2.4.1 Preparación de Datos Específica.
Las tareas automatizadas corresponden a tareas de la sub-fases de construcción
e integración de datos. Estas tareas constituyen las operaciones que representan
el mayor esfuerzo realizado durante el proceso de Preparación de Datos manual,
por otro lado, éstas son las operaciones donde es posible verificar la adaptabilidad
del proceso a cambios en los valores de las variables.
La implementación de las tareas se realizó con el lenguaje Java y se utilizó
SQL como método de acceso a los datos. Estas operaciones se automatizaron y
ejecutaron sobre los datos de los años 2000 y 2010.
4.2.4.1.1 Construcción de datos.
El prototipo implementa tres de las tareas de esta sub-fase. Las tareas
automatizadas son las siguientes:
Cálculo de la incidencia ( ).
Cálculo de la tasa de mortalidad (
).

Capítulo 4 VALIDACIÓN DE LA METODOLOGÍA PROPUESTA Y RESULTADOS
72
Cálculo de la tasa de mortalidad normalizada (
).
Figura 14. Operaciones realizadas por el prototipo de Preparación de Datos.
La Figura 14 representa las operaciones realizadas por el prototipo en la
sub-fase de construcción, para la ejecución de estas tareas únicamente se
requiere como entrada los valores de CAUSA y AÑO de mortalidad.
Figura 15. Ventana principal del prototipo de Preparación de Datos.
La Figura 15 muestra la ventana principal del prototipo de Preparación de
Datos, el cual tiene dos modos de ejecución:

Capítulo 4 VALIDACIÓN DE LA METODOLOGÍA PROPUESTA Y RESULTADOS
73
1. Desde XML.- Abre un cuadro de diálogo para buscar el archivo XML que
contiene la descripción de las tareas de Preparación de Datos (ejemplo:
Anexo B), lee el archivo XML y toma los valores de entrada.
2. Desde ventana.- Visualiza dos recuadros donde es posible introducir los
valores de entrada.
En ambos casos, el prototipo recibe los valores de CAUSA y AÑO,
posteriormente solicita al Almacén de Datos los registros relacionados a los
valores introducidos y realiza las operaciones para calcular los valores de
incidencia, tasa de mortalidad y tasa de mortalidad normalizada de manera
automática. Una vez que obtiene los resultados, éstos se almacenan en la tabla
HECHOS en los atributos: INCIDENCIA, TASAMORTALIDAD Y
TASAMORTALIDADNORMALIZADA.
Figura 16. Resultado de la ejecución del Prototipo de Preparación de Datos.
La Figura 16 muestra un ejemplo de los mensajes desplegados en pantalla
al término de la ejecución de las tareas, el prototipo despliega el tiempo que se
requirió para la ejecución de cada una de las tareas.

Capítulo 4 VALIDACIÓN DE LA METODOLOGÍA PROPUESTA Y RESULTADOS
74
La ejecución manual de estas tareas requiere realizar los cálculos uno a
uno para cada municipio con población mayor a 100,000 habitantes, lo cual
representa una tarea laboriosa. En contraste con la ejecución manual de las
tareas, el prototipo ejecuta de principio a fin la secuencia de tareas y realiza los
cálculos con sólo introducir los valores de CAUSA y AÑO de muerte, simplificando
la labor del experto minero.
4.2.4.1.2 Integración de datos.
Por último, el prototipo de Preparación de Datos, también automatiza la creación
del conjunto de datos final (data set). Este conjunto de datos está compuesto
únicamente de cuatro atributos, los cuales se describen a continuación:
Tabla 6. Atributos del conjunto de datos final.
CAUSA LATITUD_NORM LONGITUD_NORM TASAM_NORM
Causa de muerte
que se desea
analizar
Latitud del
municipio al cual
pertenecen las
defunciones
Longitud del
municipio al cual
pertenecen las
defunciones
Tasa de
mortalidad del
municipio
Este conjunto de datos contiene un máximo de 168 registros (cuando es
generado para los datos del 2000) o de 204 (cuando es generado para los datos
del año 2010). La Tabla 6 describe los cuatro atributos que integran el conjunto de
datos final que es utilizado como entrada por el visualizador cartográfico [17].
El conjunto de datos es almacenado en un archivo con extensión .TXT y
sirve como entrada para una herramienta de modelado que genera mapas donde
se visualizan grupos de municipios con alta incidencia de mortalidad para
diferentes causas.

Capítulo 4 VALIDACIÓN DE LA METODOLOGÍA PROPUESTA Y RESULTADOS
75
Figura 17. Interacción entre prototipo de Preparación de Datos y el de visualización
cartográfica.
La Figura 17 muestra la interacción que se da a través del conjunto de
datos final que genera como salida del prototipo de Preparación de Datos y, a su
vez, sirve como entrada al prototipo de visualización cartográfica.
4.3 ANÁLISIS DE LOS RESULTADOS.
En las secciones siguientes se describen los resultados obtenidos durante esta
investigación.
4.3.1 Comparativa de los resultados obtenidos contra los obtenidos en
investigaciones previas.
Parte de esta investigación está basada en la experiencia contenida en
investigaciones previas, realizadas dentro del dominio epidemiológico, enfocadas
específicamente a causas de mortalidad por cáncer. Por ejemplo, en los trabajos
[34] y [35] se analizaron causas de mortalidad por cáncer de estómago (C16) y
cáncer de pulmón (C34) respectivamente.
La primera fase de esta investigación consistió en repetir el proceso de
Preparación de Datos que se realizó en estas investigaciones, generar los
conjuntos de datos para cada enfermedad y visualizar los grupos de municipios

Capítulo 4 VALIDACIÓN DE LA METODOLOGÍA PROPUESTA Y RESULTADOS
76
para esas mismas causas de mortalidad. Es importante que los resultados
numéricos obtenidos concuerden para ambos casos.
Los resultados obtenidos para la causa de mortalidad por cáncer de
estómago (C16) fueron comparados con los resultados reportados en [17] y [35].
Se compararon los valores de incidencia y tasa de mortalidad obtenidos para los
grupos de municipios reportados como patrones de interés y los resultados
obtenidos fueron exactos.
Tabla 7. Valores de incidencia y tasa de mortalidad del primer grupo de interés para la causa
C16.
Municipio Incidencia Tasa de mortalidad
Minatitlán 14 9.15
Comalcalco 14 8.5
Tapachula 21 7.73
San Cristóbal de
las casas 9 6.8
Macuspana 9 6.72
Tuxtla Gutiérrez 28 6.45
Para el primero de los grupos, ubicado en la zona sur del país, entre los
estados de Chiapas, Tabasco y Veracruz, los valores obtenidos son los que se
muestran en la Tabla 7.
Tabla 8. Valores de incidencia y tasa de mortalidad del segundo grupo de interés para la
causa C16.
Municipio Incidencia Tasa de mortalidad
Guaymas 15 11.52
Hermosillo 48 7.87
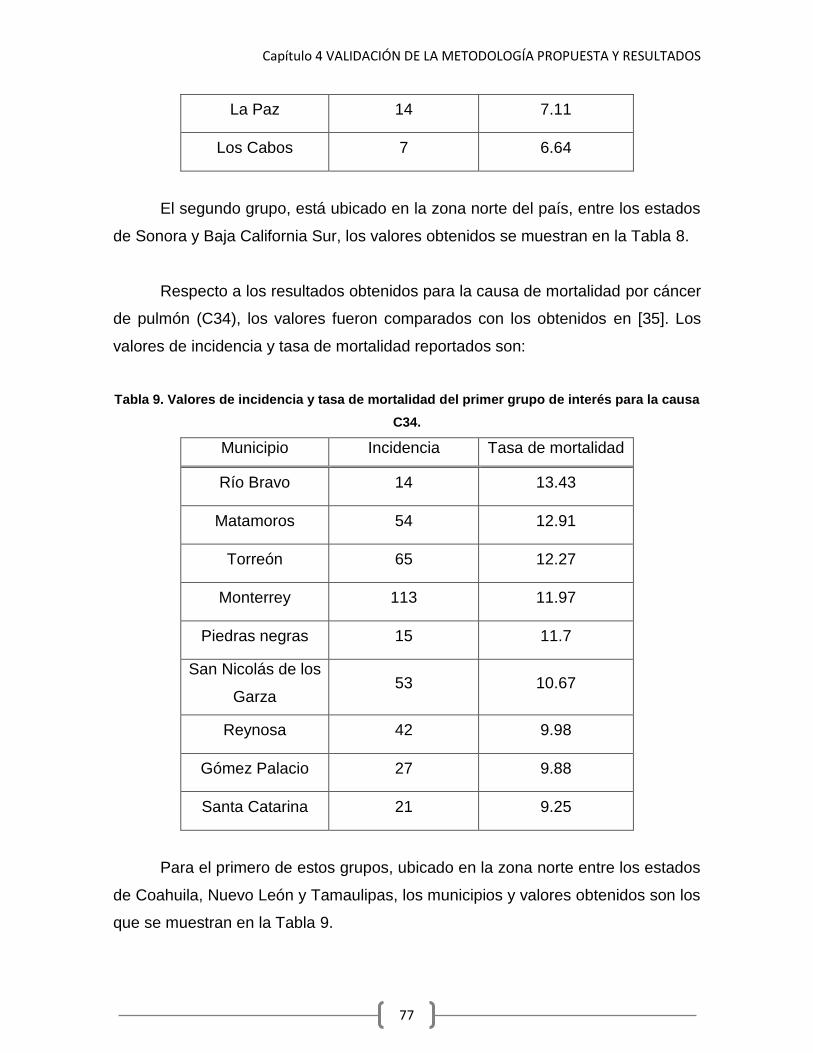
Capítulo 4 VALIDACIÓN DE LA METODOLOGÍA PROPUESTA Y RESULTADOS
77
La Paz 14 7.11
Los Cabos 7 6.64
El segundo grupo, está ubicado en la zona norte del país, entre los estados
de Sonora y Baja California Sur, los valores obtenidos se muestran en la Tabla 8.
Respecto a los resultados obtenidos para la causa de mortalidad por cáncer
de pulmón (C34), los valores fueron comparados con los obtenidos en [35]. Los
valores de incidencia y tasa de mortalidad reportados son:
Tabla 9. Valores de incidencia y tasa de mortalidad del primer grupo de interés para la causa
C34.
Municipio Incidencia Tasa de mortalidad
Río Bravo 14 13.43
Matamoros 54 12.91
Torreón 65 12.27
Monterrey 113 11.97
Piedras negras 15 11.7
San Nicolás de los
Garza 53 10.67
Reynosa 42 9.98
Gómez Palacio 27 9.88
Santa Catarina 21 9.25
Para el primero de estos grupos, ubicado en la zona norte entre los estados
de Coahuila, Nuevo León y Tamaulipas, los municipios y valores obtenidos son los
que se muestran en la Tabla 9.

Capítulo 4 VALIDACIÓN DE LA METODOLOGÍA PROPUESTA Y RESULTADOS
78
Tabla 10. Valores de incidencia y tasa de mortalidad para el segundo grupo de interés para
la causa C34.
Municipio Incidencia Tasa de mortalidad
Cájeme 67 18.8
Hermosillo 104 17.05
Hidalgo del parral 16 15.86
Culiacán 113 15.15
Navojoa 21 14.93
Ahome 52 14.47
Guasave 39 14.05
Delicias 16 13.74
La Paz 27 13.71
Mazatlán 51 13.4
Guaymas 17 13.04
Cuauhtémoc 14 11.25
Chihuahua 75 11.16
Para el segundo de los grupos, ubicado en la zona Noroeste entre los
estados de Sinaloa, Chihuahua, Sonora y Baja California Sur, los resultados
obtenidos son mostrados en la Tabla 10.
Adicionalmente, los resultados obtenidos para cada uno de los 168
municipios registrados con número de habitantes mayor a 100,000 en el año 2000,
fueron comparados.
Como método de comprobación, era de importancia que los resultados
obtenidos por el prototipo de Preparación de Datos coincidieran con los valores

Capítulo 4 VALIDACIÓN DE LA METODOLOGÍA PROPUESTA Y RESULTADOS
79
reportados previamente, en especial para los grupos reportados como patrones de
interés, ya que los resultados previos fueron validados por expertos en el área de
epidemiología.
Figura 18. Grupos de municipios para la causa de mortalidad C34.
La Figura 18 muestra los grupos de municipios identificados como patrones
de interés, estos grupos fueron reportados en [35] para la causa de mortalidad
C34 (o cáncer de pulmón).
4.3.2 Otras causas analizadas.
La integración del Almacén de Datos también nos permitió observar el número de
defunciones ocurridas por otras causas de muerte, en los años 2000 y 2010. Las
tres primeras causas de muerte, en ambos años, están relacionados a: infarto
agudo de miocardio, diabetes mellitus no especificada y diabetes mellitus no
insulinodependiente. Actualmente, la diabetes representa un problema de salud

Capítulo 4 VALIDACIÓN DE LA METODOLOGÍA PROPUESTA Y RESULTADOS
80
importante, existen estudios que lo demuestran [62] y [63], por esta razón, estas
causas también fueron analizadas.
Se realizó la preparación de los datos de las causas de mortalidad
relacionadas a diabetes. Estas causas son la E11 (diabetes mellitus no
insulinodependiente) y E14 (diabetes mellitus no especificada).
Para la causa de mortalidad E11, se graficaron los mapas con los datos
obtenidos para las tasas de mortalidad de los años 2000 y 2010, adicionalmente,
se identificaron los diez municipios con las mayores tasas de mortalidad.
Tabla 11. Mayores tasas de mortalidad para la causa E11, año 2000.
Municipio Incidencia Tasa de mortalidad
Venustiano
Carranza 247 57.31
Orizaba 66 55.7
Iztacalco 177 46.05
Cuauhtémoc 236 45.71
Azcapotzalco 164 39.55
Piedras negras 49 38.24
Miguel Hidalgo 134 38
Gustavo A.
Madero 449 37.87
Nezahualcóyotl 417 37.55
Benito Juárez 128 35.51
La Tabla 11 muestra los municipios con las mayores tasas de mortalidad
para la causa de mortalidad E11 en el año 2000.

Capítulo 4 VALIDACIÓN DE LA METODOLOGÍA PROPUESTA Y RESULTADOS
81
Figura 19. Grupos de municipios para la causa de mortalidad E11, año 2000.
La Figura 19 muestra los grupos generados por el visualizador cartográfico
para los datos de mortalidad del año 2000 para la causa E11.
Tabla 12. Mayores tasas de mortalidad para la causa E11, año 2010.
Municipio Incidencia Tasa de mortalidad
Iztacalco 350 91.07
Cuauhtémoc 465 90.07
Poza Rica 136 88.98
Orizaba 105 88.54
Gustavo A.
Madero 1028 86.7
Venustiano
Carranza 373 86.55
Apatzingan 102 86.45

Capítulo 4 VALIDACIÓN DE LA METODOLOGÍA PROPUESTA Y RESULTADOS
82
San Martín
Texmelucan 104 85.9
Azcapotzalco 355 85.6
Macuspana 114 85.08
La Tabla 12 muestra los municipios con las mayores tasas de mortalidad
para la causa E11 en el año 2010.
Figura 20. Grupos de municipios para la causa de mortalidad E11, año 2010.
La Figura 20 muestra los grupos generados por el visualizador cartográfico
para los datos de mortalidad del año 2010 para la causa E11.
Los valores nos revelan un incremento en las tasas de mortalidad para la
causa E11. Adicionalmente, las imágenes generadas por el visualizador
cartográfico nos permiten observar un mayor número de municipios con una tasa
de mortalidad elevada para esta causa. Esta información representa un aporte
importante para la comunidad científica del dominio epidemiológico.
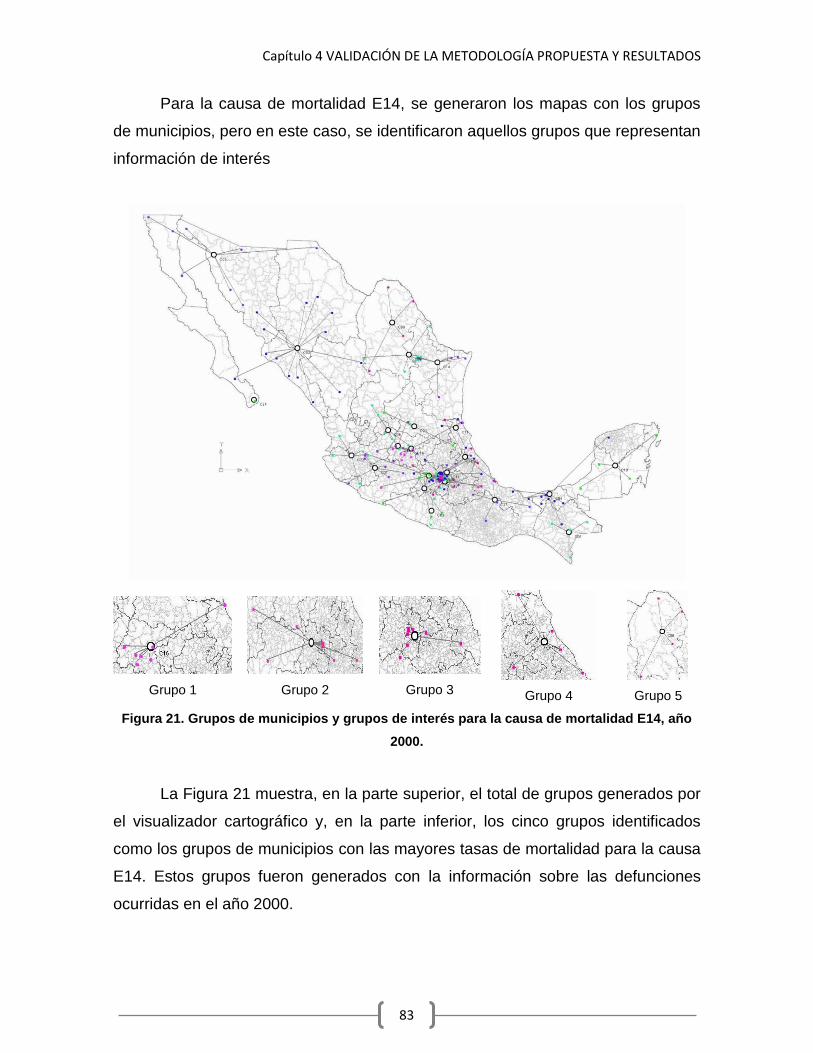
Capítulo 4 VALIDACIÓN DE LA METODOLOGÍA PROPUESTA Y RESULTADOS
83
Para la causa de mortalidad E14, se generaron los mapas con los grupos
de municipios, pero en este caso, se identificaron aquellos grupos que representan
información de interés
Grupo 1
Grupo 2
Grupo 3
Grupo 4
Grupo 5
Figura 21. Grupos de municipios y grupos de interés para la causa de mortalidad E14, año
2000.
La Figura 21 muestra, en la parte superior, el total de grupos generados por
el visualizador cartográfico y, en la parte inferior, los cinco grupos identificados
como los grupos de municipios con las mayores tasas de mortalidad para la causa
E14. Estos grupos fueron generados con la información sobre las defunciones
ocurridas en el año 2000.

Capítulo 4 VALIDACIÓN DE LA METODOLOGÍA PROPUESTA Y RESULTADOS
84
Grupo 1
Grupo 2
Grupo 3
Grupo 4
Figura 22. Grupos de municipios y grupos de interés para la causa de mortalidad E14, año
2010.
La Figura 22 muestra, en la parte superior, el total de grupos generados por
el visualizador cartográfico y, en la parte inferior, los cinco grupos identificados
como los grupos de municipios con las mayores tasas de mortalidad para la causa
E14. Estos grupos fueron generados con la información sobre las defunciones
ocurridas en el año 2010.

Capítulo 4 VALIDACIÓN DE LA METODOLOGÍA PROPUESTA Y RESULTADOS
85
4.3.3 Comparativa de los tiempos obtenidos durante la Preparación de Datos
realizada manual y automáticamente.
Durante el proceso de Preparación de Datos que se llevó a cabo de manera
manual, se registró el tiempo requerido en cada una de las tareas de preparación
realizadas. A su vez, el prototipo de Preparación de Datos es capaz de reportar el
tiempo que le llevó ejecutar las acciones de manera automatizada.
En este punto, realizamos una comparativa entre los tiempos requeridos al
realizar la Preparación de Datos de manera manual y automatizada.
Enfocándonos en dos de las tareas automatizadas por el prototipo de Preparación
de Datos. Esta comparativa tiene el objetivo de mostrar el porcentaje de tiempo
que se redujo en la ejecución de estas tareas.
Ambas tareas se realizaron de manera manual y automatizada, las causas
de mortalidad para las cuales se ejecutaron dichas tareas son: C16 (cáncer de
estómago), C34 (cáncer de pulmón), E11 (diabetes mellitus no
insulinodependiente) y E14 (diabetes mellitus no especificada), para los datos de
los años 2000 y 2010.
4.3.3.1 Tarea: Cálculo de la incidencia de mortalidad.
Los tiempos requeridos para calcular los valores de incidencia de mortalidad para
el año 2000 se muestran a continuación:
Tabla 13. Comparativa de tiempo manual y automático para el cálculo de la incidencia de
mortalidad con datos del año 2000.
Causa Tiempo manual Tiempo
automatizado % de reducción
C16 33.53 mins 0.058 mins 99.83%
C34 49.04 mins 0.034 mins 99.93%

Capítulo 4 VALIDACIÓN DE LA METODOLOGÍA PROPUESTA Y RESULTADOS
86
E11 39.98 mins 0.13 mins 99.67%
E14 40.64 mins 0.042 mins 99.89%
La Tabla 13 nos muestra los tiempos registrados para realizar el cálculo de
la incidencia de mortalidad de manera manual y automatizada, adicionalmente, se
muestra el porcentaje de reducción entre una y otra.
Tabla 14. Comparativa de tiempo manual y automático para el cálculo de la incidencia de
mortalidad con datos del año 2010.
Causa Tiempo manual Tiempo
automatizado % de reducción
C16 40.69 mins 0.075 mins 99.81%
C34 59.54 mins 0.24 mins 99.59%
E11 64.26 mins 0.05 mins 99.92%
E14 48.53 mins 0.04 mins 99.91%
La Tabla 14 nos muestra los tiempos registrados para realizar el cálculo de
la incidencia de mortalidad de manera manual y automatizada, para los datos del
año 2010, y el porcentaje de reducción conseguido.
4.3.3.2 Tarea: Cálculo de la tasa de mortalidad.
Los tiempos requeridos para calcular los valores de la tasa de mortalidad para el
año 2000 se muestran a continuación:
Tabla 15. Comparativa de tiempo manual y automático para el cálculo de la tasa de
mortalidad con datos del año 2000.
Causa Tiempo manual Tiempo
automatizado % de reducción
C16 5.16 mins 0.33 mins 93.61%
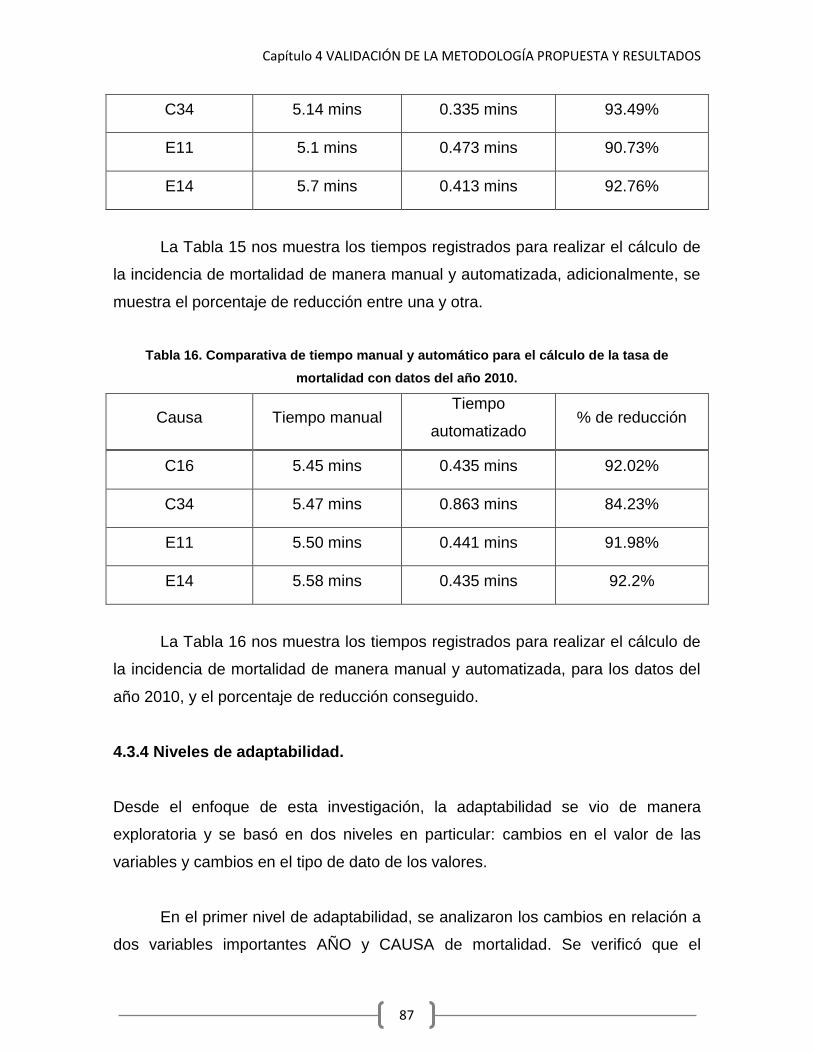
Capítulo 4 VALIDACIÓN DE LA METODOLOGÍA PROPUESTA Y RESULTADOS
87
C34 5.14 mins 0.335 mins 93.49%
E11 5.1 mins 0.473 mins 90.73%
E14 5.7 mins 0.413 mins 92.76%
La Tabla 15 nos muestra los tiempos registrados para realizar el cálculo de
la incidencia de mortalidad de manera manual y automatizada, adicionalmente, se
muestra el porcentaje de reducción entre una y otra.
Tabla 16. Comparativa de tiempo manual y automático para el cálculo de la tasa de
mortalidad con datos del año 2010.
Causa Tiempo manual Tiempo
automatizado % de reducción
C16 5.45 mins 0.435 mins 92.02%
C34 5.47 mins 0.863 mins 84.23%
E11 5.50 mins 0.441 mins 91.98%
E14 5.58 mins 0.435 mins 92.2%
La Tabla 16 nos muestra los tiempos registrados para realizar el cálculo de
la incidencia de mortalidad de manera manual y automatizada, para los datos del
año 2010, y el porcentaje de reducción conseguido.
4.3.4 Niveles de adaptabilidad.
Desde el enfoque de esta investigación, la adaptabilidad se vio de manera
exploratoria y se basó en dos niveles en particular: cambios en el valor de las
variables y cambios en el tipo de dato de los valores.
En el primer nivel de adaptabilidad, se analizaron los cambios en relación a
dos variables importantes AÑO y CAUSA de mortalidad. Se verificó que el

Capítulo 4 VALIDACIÓN DE LA METODOLOGÍA PROPUESTA Y RESULTADOS
88
prototipo de Preparación de Datos tuviera la flexibilidad para generar información
al variar los valores de estas variables.
Se consiguió que el prototipo fuese flexible a los cambios relacionados a
estas dos variables. En relación a la CAUSA de mortalidad tiene la capacidad de
adaptarse a 2049 diferentes causas de mortalidad y, en relación al AÑO, se
validaron los cambios para los años 2000 y 2010, pero es posible agregar
información al Almacén de Datos que corresponda a defunciones ocurridas en
otros años, siempre y cuando se respete el esquema de almacenamiento de datos
propuesto.
En relación a cambios en el tipo de dato de los atributos, no se presentaron
ocurrencias de este tipo adaptabilidad, pero fue posible identificar que en la sub-
fase de formateo de datos es donde se pueden resolver este tipo de conflictos.
Se pueden realizar cambios al tipo de dato de un atributo, para
homogeneizar los valores de los atributos, sin importar el momento en el que el
problema se presente, ya que por sí misma, la metodología CRISP-DM
proporciona una flexibilidad que nos permite volver entre las sub-fases.
4.3.5 Almacén de Datos.
Por último, se consiguió poblar un Almacén de Datos que contiene la información
oficial de las defunciones ocurridas en los años 2000 y 2010, para 204 municipios
diferentes cuya población es mayor de 100,000 habitantes, con el cual es posible
analizar 2049 causas de mortalidad, registradas en el Catalogo Internacional de
Enfermedades (CIE-10), incluida la AH1N1 de reciente aparición.

Capítulo 4 VALIDACIÓN DE LA METODOLOGÍA PROPUESTA Y RESULTADOS
89
Figura 23. Representación del cubo de datos.
La Figura 23 nos muestra la representación del cubo de datos generado por
la relación de los datos utilizados en esta investigación. Sus dimensiones LUGAR
y TIEMPO en relación a un HECHO que son las defunciones ocurridas por una
determinada CAUSA de muerte (ver detalle en Anexo D).
Todos los datos contenidos en el almacén provienen de fuentes oficiales y
censos como el de población y vivienda de los años 2000 y 2010. A diferencia de
las investigaciones previas, este almacén no sólo contiene información para las
causas de mortalidad por cáncer, sino para muchas otras causas de muerte
relacionadas a otras enfermedades como la diabetes, hipertensión, fallos
cardíacos, etcétera; o de hechos sociales como la muerte por violencia, aborto,
etcétera.


90
Capítulo 5 CONCLUSIONES Y TRABAJOS FUTUROS.
Este capítulo presenta las aportaciones de esta investigación y se sugieren tópicos
para trabajos futuros.

Capítulo 5 CONCLUSIONES Y TRABAJOS FUTUROS
91
5.1 CONCLUSIONES.
En este trabajo se mostró que es factible el desarrollo de una metodología para la
fase de Preparación de Datos, definida con un nivel de detalle mayor al propuesto
en la metodología CRISP-DM, para su aplicación directa a proyectos de Minería
de datos del dominio epidemiológico.
Para validar el enfoque de solución se usó un caso de estudio con datos
reales del dominio epidemiológico, con información de los censos oficiales de los
años 2000 y 2010; esto nos permitió validar la metodología de Preparación de
Datos propuesta y obtener resultados de interés, los cuales pueden ser utilizados
por el sector salud como apoyo para la toma de decisiones en sus procesos de
prevención y control de ciertas enfermedades.
Las principales aportaciones de esta tesis son las siguientes:
a) Se definió una metodología de Preparación de Datos con un nivel de detalle
mayor que el propuesto por otras metodologías como CRISP-DM, para su
aplicación directa a proyectos de Minería de Datos del dominio
epidemiológico. Dicha metodología se validó utilizando datos del censo
oficial del año 2000. Se realizaron pruebas para las causas de mortalidad
C16 y C34, los resultados obtenidos fueron equivalentes a los resultados
obtenidos por investigaciones previas en el 100% de los casos.
b) Se identificaron dos niveles dentro de la fase de Preparación de Datos:
Preparación de Datos General (PDG) y Preparación de Datos Específica
(PDE). Las tareas relacionadas a la Preparación de Datos General son un
conjunto de tareas “independientes” del objetivo de minería que se desea
alcanzar. Las tareas del nivel específico constituyen operaciones concretas,
estrechamente relacionadas con el objetivo de Minería de Datos que se
desea alcanzar y, en este caso, se repiten para cada causa de mortalidad
que se desee analizar.

Capítulo 5 CONCLUSIONES Y TRABAJOS FUTUROS
92
c) Se realizó la preparación de los datos del censo del año 2010 y fueron
anexados a los datos preparados del año 2000; se ejecutaron pruebas para
dos causas de muerte por cáncer (C16 y C34) y dos causas de muerte por
diabetes (E11 y E14) para ambos años. Con esto, comprobamos la
capacidad del prototipo de adaptarse a cambios en los valores de entrada
para las variables CAUSA y AÑO de mortalidad.
d) Se desarrolló un prototipo de un sistema de Minería de Datos que consta de
un almacén de datos y una herramienta de Preparación de Datos que
generan un data set que sirve como entrada al visualizador cartográfico.
e) Se implementó una herramienta de preparación de datos que automatiza
las tareas de cálculo de la incidencia, tasa de mortalidad, tasa de
mortalidad normalizada y la creación del data set; con esto pudimos
observar una reducción en el tiempo invertido en cada tarea, desde un 90%
o hasta un 99%, en comparación con su ejecución manual (ver sección
4.3.3).
f) Por último, un aporte importante es la integración de un almacén de datos
preparados que integra datos de mortalidad, extraídos de los censos
oficiales de los años 2000 y 2010, relacionados a 2049 causas de
mortalidad diferentes, para los municipios con un número de habitantes
mayor a los 100,000.
La metodología para la fase de Preparación de Datos propuesta, representan un
beneficio importante para los expertos en Minería de Datos, ya que permite reducir
la labor que el experto en minería invierte durante esta fase del proceso de
Minería.
Finalmente, como resultado de usar un caso de estudio con datos reales, se
obtuvieron hallazgos de posible interés para los organismos encargados de la
administración de los servicios públicos de salud en México, los cuales pueden ser
usados en sus procesos de toma de decisiones, dentro de programas para la
prevención y control de enfermedades como el cáncer y la diabetes. Estos
resultados se muestran en el Anexo E.

Capítulo 5 CONCLUSIONES Y TRABAJOS FUTUROS
93
5.2 TRABAJOS FUTUROS.
Como resultado de esta investigación, se han identificado otras áreas de
oportunidad para continuar esta investigación. A continuación se listan algunas de
las alternativas identificadas:
a) Extender el modelo de referencia CRISP-DM en la fase de preparación de
datos, particularmente en la tarea genérica de integración de datos.
b) Aprovechar la infraestructura creada para desarrollar metodologías de
preparación de datos para su aplicación en otros dominios.
c) Desarrollar un sistema de Minería de Datos mediante la integración de los
prototipos de Preparación de Datos y el prototipo de visualización
cartográfica.
5.3 PUBLICACIONES.
Como resultado de esta investigación, se realizaron las siguientes publicaciones:
a) “An Epidemiological Data Mining Application Based on Census Databases”,
International Conference on Advances in Databases, Knowledge and Data
Applications (DBKDA, Enero de 2013), Sevilla, España. Publicado en
ThinkMind (TM) Digital library.

94
REFERENCIAS.
[1] Instituto Nacional de Estadística y Geografía (INEGI). “Estadística a
propósito del día mundial contra el cáncer”. Fecha de consulta: Junio 2012.
Disponible en: http://www.inegi.org.mx/inegi/contenidos/espanol/prensa/cont
enidos/estadisticas/2011/cancer11.asp?s=inegi&c=2781&ep=51.
[2] L. M. Ruiz-Godoy, et al. “Lung cancer mortality in Mexico”. BioMed Central,
vol. 7. pp. 29, Febrero 2007.
[3] V. J. Tovar-Guzmán, et al. “Tendencias de la mortalidad por cáncer
pulmonar en México 1980-2000”. Panam Salud Pública, vol. 17, pp. 254-
262, Enero 2005.
[4] S. Zhang, et al., "Data preparation for data mining". International Journal of
Applied Artificial Intelligence, vol. 17, pp. 375-381, 2003.
[5] Q. Yang and X. Wu, "10 Challenging problems in data mining research",
International Journal of Information Technology & Decision Making, vol. 5,
pp. 597-604, 2006.
[6] W. Fraley et al. “Knowledge discovery in databases: an overview”. AI
Magazine, pp. 213 – 228, 1992.
[7] C. Pete, et al., "CRISP-DM 1.0 Step-by-step data mining guide," IBM SPSS,
2000.
[8] F. Gorunescu, Data mining: Concepts, Models and Techniques, vol. 12:
Springer-Verlag Berlin Heidelberg, 2011.
[9] A. Duhamel, et al., "A preprocessing method for improving data mining
techniques: Application to a large medical diabetes database". The new
navigators: from professionals to patients, vol. 95, pp. 269-274, 2003.
[10] T. Shin-Mu, et al., "A pre-processing method to deal with missing values by
integrating clustering and regression techniques", International Journal of
Applied Artificial Intelligence, vol. 7, pp. 535-544, 2003.
[11] N. M. Labib and M. N. Malek, "Data mining for cancer management in Egypt
case study: Childhood acute lymphoblastic lukemia", Transaction on
Engineering Computing and Technology, vol. 8, pp. 309-314, 2005.

95
[12] R. Amir, et al. (2005) “A data pre-processing method to increase efficiency
and accuracy in data mining”. Proceedings of the 10th Conference on
Artificial Intelligence in Medicine. Aberdeen, Escocia, pp.434-443.
[13] V. Bogorny, et al., “A reuse-based spatial data preparation framework for
data mining", Proceedings of the 17th International Conference on Software
Engineering and Knowledge Engineering, Taipei, Taiwan, pp. 649-652,
2005.
[14] V. Bogorny, et al., "Spatial data preparation for knowledge discovery".
Presentado en: IFIP Academy on the states of Software Theory and
Practices, Porto Alegre, Brazil, 2005.
[15] C. V. Bratu and R. Potolea, "Towards a unified strategy for the
preprocessing step in data mining". International Conference on Enterprise
Information systems (ICEIS), Milan, Italia, pp. 230-235, Mayo 2009.
[16] J. Pérez-Ortega, et al., "Spatial data mining of a population-based data
warehouse of cancer in Mexico" International Journal of Combinatorial
Optimization Problems and Informatics, vol. 1, pp. 61-67, Mayo 2010 2010.
[17] J. Pérez-Ortega, et al., "A data mining system for the generation of
geographical C16 cancer patterns" International Conference on Software
Engineering Advances (ICSEA), Nice, Francia, pp. 417-421, Agosto 2010.
[18] A. Silberschatz, et al., Fundamentos de bases de datos, 4a edición. Madrid:
McGraw-Hill, 2002.
[19] C. J. Date, Introducción a los sistemas de bases de datos, 7a edición.
México: Pearson Educación, 2001.
[20] Instituto Nacional de Estadística y Geografía (INEGI). “Población de
México”. Fecha de consulta: Mayo 2012. Disponible en:
http://cuentame.inegi.org.mx/poblacion/default.aspx?tema=P
[21] M. Gutiérrez, "El rol de las bases de datos espaciales en una infraestructura
de datos", Proceedings of the 9th Conference Global Spatial Data
Infrastructure, Santiago, Chile, 2006.
[22] J. M. Rubia. “Introducción a los almacenes de datos (Introduction to Data
Warehousing)”. Anales de mécanica y electricidad. 2009, pp. 42-47.

96
[23] J. H. Orallo, et al., Introducción a la Minería de Datos, 1a edición. España:
Pearson/Prentice Hall, 2004.
[24] Q. Luo, "Advancing knowledge discovery and data mining", Workshop on
Knowledge Discovery and Data Mining, Adelaide, Australia, 2008, pp. 3-5.
[25] J. Han, et al., Data mining: Concepts and Techniques, 3a edición. Waltham,
Ma. USA: Morgan Kaufman/Elsevier, 2012.
[26] A. B. Michael and S. L. Gordon, “Data mining techniques for marketing,
sales and customer relationship management, The role of Data
Warehousing”, 2a edición. Indiana, USA: Wiley Publishing, 2004.
[27] KDnuggets. “Data mining methodology”. Fecha de consulta: Mayo 2012.
Disponible en: http://www.kdnuggets.com/polls/2007/data_mining_methodo
logy.htm
[28] L. Gordis, Epidemiología, 3a edición. España: Elsevier, 2005.
[29] J. M. Last, A dictionary of epidemiology, 4a edición. New York: Oxford
University Press, 2000.
[30] M. Szklo and J. Nieto, Epidemiología intermedia: conceptos y aplicaciones.
España: Díaz de Santos, 2003.
[31] Organización Panamericana de la Salud (OPS). “Indicadores de salud:
Elementos básicos para el análisis de la situación de salud”. Fecha de
consulta: Mayo 2012. Disponible en: http://www.paho.org/spanish/sha/EB_
v22n4.pdf
[32] Instituto Nacional de Salud Pública (INSP). “Principales medidas en
epidemiología”. Fecha de consulta: Mayo 2012. Disponible en:
http://bvs.insp.mx/rsp/articulos/articulo.php?id=000641
[33] O. J. Holliday, “Guía para sistematizar experiencias”, pp. 1-15, 2006.
[34] A. Mexicano, "Desarrollo de una metodología para la selección de atributos
y generación de indicadores para la aplicación de Minería de Datos a una
base de datos real de registros de cáncer en base poblacional," Maestría,
Ciencias computacionales, CENIDET, Cuernavaca, México, 2007.
[35] J. Salinas, "Adecuación de una metodología de Minería de Datos para su
aplicación a una base de datos real de registros de cáncer de base

97
poblacional," Maestría, Ciencias computacionales, CENIDET, Cuernavaca,
México, 2007.
[36] M. A. Barrón, "Desarrollo de un prototipo para la aplicación de técnicas de
Minería de Datos sobre una base de datos real de base poblacional de
cáncer," Maestría, Ciencias computacionales, CENIDET, Cuernavaca,
México, 2008.
[37] R. Boone, "Identificación de regiones con altas tasas de incidencia de
cáncer mediante la integración y uso de técnicas de la Minería de Datos;
almacenes de datos, agrupamiento y sistemas de información geográficos"
Maestría, Ciencias computacionales, CENIDET, Cuernavaca, México, 2011.
[38] H. Oktaba, et al., "Modelo de procesos para la industria de software"
Secretaría de Economía, México, 2005.
[39] J. Rumbauh, et al., El lenguaje unificado de modelado: Manual de
referencia. Madrid, España: Pearson Educación, 2000.
[40] W. Sujansky, "Heterogeneous database integration in biomedicine"
Biomedical informatics, vol. 34, pp. 285-298, Enero 2002.
[41] M. P. Reddy, et al., "A methodology for integration of heterogeneus
databases" International Journal of Transactions on Knowledge and Data
Engineering, vol. 6, pp. 920-933, Diciembre 1994.
[42] L. Mong-Li and L. T. Wang, "Resolving structural conflicts in the integration
of entity-relationship schemas" Lecture Notes in Computer Science, vol.
1021, pp. 424-433, 1995.
[43] Universidad Nacional Autónoma de México (UNAM). “Computación
adaptativa”. Fecha de consulta: Julio 2011, Disponible en:
http://turing.iimas.unam.mx/SAAO/?q=node/1
[44] A. F. Quintero-Osorio, "Adaptatividad: Su conveniencia en el desarrollo de
software," Licenciatura, Universidad Tecnológica de Pereira, Pereira,
Colombia, 2009.
[45] A. K. Gupta and S. K. Arora, Industrial Automation and Robotics. 2a edición,
New Delhi, India: Ajit Press, Enero 2007.
[46] C. Calero, et al., Calidad del producto y proceso de software. 1a edición.
Madrid, España: Ra-Ma, 2010.

98
[47] I. H. Witten, et al., Data mining: practical machine learning tools and
techniques, 3a edición. Burlington, EU: Elsevier, 2011.
[48] M. Hidalgo, et al., "Definition of a metadata schema for describing data
preparation tasks" Proceedings of the 11th European Conference on
Machine Learning and Principles and Practice of Knowledge Discovery in
Databases, Bled, Eslovenia, 2009, pp. 64-75.
[49] MySQL. “MySQL in data Warehousing and Business Intelligence”. Fecha de
consulta: Agosto 2012. Disponible en: http://www.mysql.com/why-
mysql/data-warehouse.html
[50] Instituto Nacional de Salud Pública. Salud Pública de México. Fecha de
consulta: Mayo 2012. Disponible en: http://bvs.insp.mx/rsp/inicio/
[51] Instituto Nacional de Cancerología. Revista del Instituto Nacional de
Cancerología. Fecha de consulta: Mayo 2012. Disponible en:
http://www.incan.salud.gob.mx/
[52] Secretaría de Salud. Sistema Único de Información en Epidemiología.
Fecha de consulta: Mayo 2012. Disponible en: http://www.salud.gob.mx/
[53] Sistema Nacional de Información en Salud. “Bases de datos sobre
defunciones”. Fecha de consulta: Mayo 2012. Disponible en:
http://www.sinais.salud.gob.mx/basesdedatos/estandar.html
[54] Sistema Estatal y Municipal de Bases de Datos. (SIMBAD). “Área
geográfica”. Fecha de consulta: Enero 2012. Disponible en:
http://sc.inegi.org.mx/sistemas/cobdem/contenido-arbol.jsp
[55] Instituto Nacional de Estadística y Geografía (INEGI).“Censo de Población y
Vivienda”. Fecha de consulta: Enero 2012. Disponible en:
http://www.inegi.org.mx/sistemas/olap/Proyectos/bd/censos/cpv2010/PT.asp
?s=est&c=27770&proy=cpv10_pt
[56] Centro Colaborador para la Familia de Clasificadores Internacionales de la
OMS en México. ”Clasificación Estadística Internacional de Enfermedades y
Problemas Relacionados con la Salud, Décima Revisión (CIE-10)”. Fecha
de consulta: Mayo 2012. Disponible en: http://www.cemece.salud.gob.mx/fic
/cie/index.html

99
[57] Instituto Nacional de Estadística y Geografía. “Anuarios Estadísticos de los
Estados (AEE)”. Fecha de consulta: Enero 2012. Disponible en:
http://www.inegi.gob.mx/est/contenidos/espanol/sistemas/aee05/nacional/in
dex.htm
[58] Secretaría de salud (SS). “Causas y consecuencias del sub-registro de
defunciones”. Fecha de consulta: Mayo 2012. Disponible en:
http://www.clarciev.com/cms/wp-content/Secretar%C3%ADa_de_Salud_-
_M%C3%A9xico.pdf
[59] L. A. Shalabi, et al., "Data mining: A preprocessing engine" Journal of
Computer Science, vol. 2, pp. 735-739, 2006.
[60] Secretaría de salud (SS). “Influenza: preguntas frecuentes”. Fecha de
consulta: Mayo 2012. Disponible en: portal.salud.gob.mx/contenidos/notici
as/influenza/preguntas_frecuentes_ah1n1.html
[61] J. Pérez-Ortega, et al., "Data warehouse development to identify regions
with high rates of cancer incidence in Mexico through a spatial data mining
clustering task", Workshop on Semantic Web and New Technologies,
Puebla, México, 2010, pp. 37-47.
[62] C. González-Villalpando, et al. “The status of diabetes care in Mexican
population: Are we making a difference? Results of the National Health and
Nutrition Survey 2006”. Salud Pública de México, vol. 52, pp. 36-46, Abril
2010.
[63] S. Villalpando, et al. “Trends for type 2 diabetes and other cardiovascular
risk factors in Mexico from 1993-2006”. Salud Pública de México, vol. 52,
pp. 72-79, Abril 2010.

ANEXO A
100
Anexos.
Anexo A. Definición de procesos y diagramas de actividad.
Las tablas y los diagramas de actividad que se muestran a continuación
corresponden a aquellas tareas de Preparación de Datos seleccionadas para su
automatización.
Tabla A.1 Definición del proceso de “Construcción de datos”.
Tabla de definición de proceso. Fecha de creación: 30/10/2011
Nombre del proceso
Construcción de datos.
Responsable Minero de datos (MoD).
Descripción Incluye la ejecución de operaciones para construir nuevos atributos y/o transformar los valores de atributos existentes.
Objetivo Obtener atributos que son necesarios para alcanzar el objetivo de minería planteado.
Entradas Nombre Descripción
Datos de mortalidad, población Registros y valores numéricos.
Salidas
Nombre Descripción
Cálculo de la incidencia y tasa de mortalidad
Valores resultados de calcular la tasa de mortalidad e incidencia de mortalidad.
Actividades
Responsable Descripción
MoD
Verificación del conjunto de datos.- revisión del conjunto de datos con la finalidad de identificar la ausencia de valores o atributos que son necesarios para alcanzar el objetivo de minería planteado. Cálculo de la incidencia.- Esta operación es de importancia en el dominio epidemiológico, nos permite conocer el número de defunciones ocurridas en un determinado municipio, para un año especificado. Atributo derivado: INCIDENCIA. Cálculo de la tasa de mortalidad.- Esta operación es de importancia en el dominio epidemiológico, nos permite conocer la proporción de defunciones ocurridas para un año especificado en municipios con población mayor a los 100,000 habitantes. Atributo derivado: TASAMOR.
MoD
Identificación de atributos para calcular los atributos faltantes.- Se identifican cuales atributos del conjunto nos permiten calcular los atributos faltantes. Para el cálculo de la INCIDENCIA los atributos son: CLAVE (clave del municipio) y CAUSA (causa de muerte) Para el cálculo de la TASAMOR los atributos son: INCIDENCIA (atributo calculado) y POBLACION (número de habitantes por municipio).
MoD
Obtención de los atributos faltantes.- se realizan las operaciones necesarias para estimar los valores faltantes. Estas operaciones pueden ser la concatenación en el caso de atributos de tipo carácter u operaciones aritméticas, como las que se muestran a continuación:

ANEXO A
101
Para el cálculo de la Incidencia: 1. Leer la causa de muerte para la cual se calculara la
incidencia. 2. Leer la clave de cada municipio. 3. Generar consulta SELECT (count) para contabilizar el
número de casos. 4. Ejecutar SELECT. 5. Almacenar valor calculado de la incidencia. Para el cálculo de la Tasa de mortalidad:
1. Leer clave de cada municipio 2. Seleccionar los valores de INCIDENCIA 3. Seleccionar valores de POBLACIÓN (número de
habitantes por municipio). 4. Sustituir valores en la fórmula para el cálculo de la tasa
de mortalidad. 5. Guardar valores de las tasas de mortalidad calculadas.
Figura A.1 Definición del proceso de “Construcción de datos”.
act Construcción de datos
Identificar atributos
faltantes (INCIDENCIA y
TASAMORTALIDAD)
Identificar atributos para
realizar operaciones
Calcular INCIDENCIA
Leer CAUSA
de muerte
Leer CLAVE
del
municipio
Calcular
INCIDENCIA
Último municipio
Calcular
TASAMORTALIDAD Leer CLAVE
del
municipio
Seleccionar
INCIDENCIA
Seleccionar
POBLACION
Calcular
TASAMORTALIDAD
Último municipio
Leer AÑO de
muerte
Verificación del conjunto
de datos.

ANEXO B
102
Anexo B. Descripción de las tareas de Preparación de Datos con XML.
Con el fin de automatizar la fase de Preparación de Datos y así, conseguir reducir
el tiempo invertido en esta tarea, se utilizó el esquema de metadatos propuesto en
[48].
A continuación se muestra un ejemplo de la descripción, realizada con el esquema
XML, para la tarea de cálculo de la incidencia de mortalidad.
<metadataDictionary> <metadataSet setID="prep_01" setName="calculoIncidencia" processPhase="preparacionDatos"> <metadataItem itemID="prep_01_1" subPhase="construccionDatos" itemName="calculo" itemValue="true" itemDescription="Cálculo de la incidencia de mortalidad para una causa determinada"> <metadataSubject> <subjectID>1</subjectID> <subjectName>Task</subjectName> </metadataSubject> <metadataCategory> <categoryID>3</categoryID> <categoryName>definition</categoryName> </metadataCategory> <managementUnit> <unitID>01</unitID> <unitName>creationDate</unitName> <unitValue>15-13-2012</unitValue> <unitType>static</unitType> </managementUnit> </metadataItem> <metadataFlow> <flowID>1</flowID> </metadataFlow> <metadataItem itemID="prep_01_2" subPhase="construccionDatos" itemName="causa" itemValue="C34" itemDescription="Clave de la causa de mortalidad de la cual se calculara la incidencia"> <metadataSubject> <subjectID>2</subjectID> <subjectName>Activity</subjectName> </metadataSubject> <metadataCategory> <categoryID>5</categoryID> <categoryName>content</categoryName> </metadataCategory> <managementUnit> <unitID>01</unitID> <unitName>creationDate</unitName> <unitValue>15-13-2012</unitValue> <unitType>static</unitType> </managementUnit> </metadataItem> <metadataFlow> <flowID>2</flowID> </metadataFlow> <metadataItem itemID="prep_01_3" subPhase="construccionDatos" itemName="año" itemValue="2000" itemDescription="Año del cual se calculara la incidencia de mortalidad"> <metadataSubject> <subjectID>2</subjectID>

ANEXO B
103
<subjectName>Activity</subjectName> </metadataSubject> <metadataCategory> <categoryID>5</categoryID> <categoryName>content</categoryName> </metadataCategory> <managementUnit> <unitID>01</unitID> <unitName>creationDate</unitName> <unitValue>15-13-2012</unitValue> <unitType>static</unitType> </managementUnit> </metadataItem> <metadataFlow> <flowID>3</flowID> </metadataFlow> <metadataItem itemID="prep_01_4" subPhase="construccionDatos" itemName="tablaOrigen" itemValue="mortalidad" itemDescription="Tabla donde se encuentran los datos de mortalidad"> <metadataSubject> <subjectID>2</subjectID> <subjectName>Activity</subjectName> </metadataSubject> <metadataCategory> <categoryID>4</categoryID> <categoryName>control</categoryName> </metadataCategory> <managementUnit> <unitID>01</unitID> <unitName>creationDate</unitName> <unitValue>15-13-2012</unitValue> <unitType>static</unitType> </managementUnit> </metadataItem> <metadataFlow> <flowID>4</flowID> </metadataFlow> <metadataItem itemID="prep_01_5" subPhase="construccionDatos" itemName="tablaDestino" itemValue="hechos" itemDescription="Tabla donde se guardaran los resultados de los cálculos"> <metadataSubject> <subjectID>2</subjectID> <subjectName>Activity</subjectName> </metadataSubject> <metadataCategory> <categoryID>4</categoryID> <categoryName>control</categoryName> </metadataCategory> <managementUnit> <unitID>01</unitID> <unitName>creationDate</unitName> <unitValue>15-13-2012</unitValue> <unitType>static</unitType> </managementUnit> </metadataItem> <metadataFlow> <flowID>5</flowID> </metadataFlow> </metadataSet> </metadataDictionary>

ANEXO B
104
act Lectura del XML
Identificar
elemento
Identificar
v alor del
elemento
Guardar
v alor del
elemento
Fin XML
Leer
siguiente
elemento
Abrir archiv o
XML
Buscar
archiv o XML
Ejecutar calculo de
Incidencia y Tasa de
mortalidad
Pasar
v alores
obtenidos
del XML
Los valores que la herramienta de Preparación de Datos toma desde el archivo
XML corresponden a: CAUSA (para este ejemplo: C34), AÑO (para este ejemplo:
2000), la tabla de origen (desde donde se extraerá la información) y la tabla
destino (donde se almacenaran los resultados).
Figura B.1 Extracción de información desde archivo XML.
El prototipo de Preparación de Datos utiliza el archivo que contiene la descripción
del XML para leer los valores que requiere para su ejecución. La Figura B.1
describe brevemente la secuencia seguida, durante la ejecución, para la
extracción de dichos valores.

ANEXO C
105
Anexo C. Diagramas de clases.
Figura C.1 Diagrama de clases “Paquetes de Preparación de Datos General y Específica”.
Tabla C.1Descripción de paquetes “PDG y PDE”.
Paquete Responsabilidades
PDG PDG (Preparación de Datos General), agrupa los paquetes de limpieza y selección de datos. Son un conjunto de tareas “independientes” del objetivo de minería que se desea alcanzar.
PDE PDE (Preparación de Datos Específica), agrupa los paquetes de formateo, construcción e integración de datos. Son un conjunto de tareas que guardan una estrecha relación con el objetivo de minería que se desea alcanzar.
oO
pe
raci
on
es

ANEXO C
106
class generalMod
DLimpieza DSelección
Clases para limpieza
de datosClases para selección
de datos.
PDG
<<use>>
Figura C.2 Diagrama de clases del paquete de “Preparación de Datos General (PDG)”.
Tabla C.2Descripción de paquetes “Preparación de Datos General”.
Paquete Responsabilidades
DLimpieza Contiene las clases que permiten realizar acciones de identificación y limpieza de errores en los datos.
DSelección Contiene las clases que permiten realizar acciones para selección de atributos y registros de interés.
oOperaciones

ANEXO C
107
class DLimpieza
Operaciones
Identificación
+ ejecutarIdentificación() : void
Corrección
+ ejecutarCorrección() : void
correcciónValoresPerdidos
+ ejecutarCorrección() : void
correcciónValoresFueraRango
+ ejecutarCorrección() : void
identificaciónValoresPerdidos
+ ejecutarIdentificación() : void
deteccionValoresFueraRango
+ ejecutarIdentificación() : void
Figura C.3 Diagrama de clases del paquete de “Limpieza de datos”.
Tabla C.3Descripción de clase “Identificación”.
Clase Responsabilidades
Identificación Permite identificar errores en los datos, tales como, identificación de valores perdidos o valores fuera de rango. (No implementado)
Métodos Descripción Datos de entrada
Datos de salida
ejecutarIdentificación()
Llama a los métodos especializados en la identificación de valores perdidos o fuera de rango.
Ninguno. Ninguno.
Tabla C.4Descripción de clase “IdentificaciónValoresPerdidos”.
Clase Responsabilidades
IdentificaciónValoresPerdidos
Permite ejecutar métodos de identificación de valores perdidos. (No implementado)
Métodos Descripción Datos de entrada
Datos de salida
ejecutarIdentificación()
Ejecuta las acciones de identificación de valores perdidos.
Ninguno. Ninguno.

ANEXO C
108
Tabla C.5Descripción de clase “detecciónValoresFueraRango”.
Clase Responsabilidades
detecciónValoresFueraRango
Llama a las clases que ejecutan métodos de identificación de valores fuera de rango. (No implementado)
Métodos Descripción Datos de entrada
Datos de salida
ejecutarIdentificación()
Ejecuta las acciones de identificación de valores fuera de rango.
Ninguno. Ninguno.
Clases relacionadas
Responsabilidades
análisisMedia Ejecuta un análisis de media para identificar aquellos valores que se encuentran fuera de rango.
análisisModa Ejecuta un análisis de moda para identificar aquellos valores que se encuentran fuera de rango.
análisisMediana Ejecuta un análisis de mediana para identificar aquellos valores que se encuentran fuera de rango.
identificaciónBoxPlot Los datos son representados en una “caja” para identificar aquellos valores que se encuentran fuera de rango.
Histagramas Los datos son representados en una gráfica para identificar aquellos valores que se encuentran fuera de rango.
Tabla C.6Descripción de clase “Corrección”.
Clase Responsabilidades
Corrección Permite corregir errores en los datos, tales como valores perdidos o valores fuera de rango. (No implementado)
Métodos Descripción Datos de entrada
Datos de salida
ejecutarCorrección() Llama a los métodos especializados en la corrección de valores perdidos o fuera de rango.
Ninguno. Ninguno.
Tabla C.7Descripción de clase “CorrecciónValoresPerdidos”.
Clase Responsabilidades
correcciónValoresPerdidos
Permite ejecutar métodos de corrección de valores perdidos. (No implementado)
Métodos Descripción Datos de entrada
Datos de salida
ejecutarCorrección() Ejecuta las acciones de corrección de valores perdidos.
Ninguno. Ninguno.
Tabla C.8Descripción de clase “CorrecciónValoresFueraRango”.
Clase Responsabilidades
correcciónValoresFueraRango
Llama a las clases que ejecutan métodos de corrección de valores fuera de rango. (No implementado)
Métodos Descripción Datos de entrada
Datos de salida
ejecutarCorrección() Ejecuta las acciones de corrección de valores fuera de rango.
Ninguno. Ninguno.

ANEXO C
109
class DSelección
selecciónHorizontal
+ seleccionarRegistros() : void
+ eliminarRegistros() : void
selecciónVertical
+ eliminarAtributos() : void
+ crearTablaNueva() : void
Selección o
eliminación de
registros.
Selección o
eliminación de
atributos.
Operaciones
Figura C.4 Diagrama de clases del paquete de “Selección de datos”.
Tabla C.9Descripción de clase “selecciónHorizontal”.
Clase Responsabilidades
selecciónHorizontal
Permite ejecutar métodos para seleccionar atributos de interés. Esta selección se puede realizar generando nuevas tablas con una sentencia SELECT o alterando la tabla actual utilizando la sentencia ALTER TABLE. (No implementado)
Métodos Descripción Datos de entrada
Datos de salida
seleccionarRegistros
Ejecuta una sentencia para seleccionar únicamente aquellos registros que son de interés
Valores a seleccionar.
Registros seleccionados
eliminarRegistros Ejecuta una sentencia para eliminar todos aquellos registros que no son de interés.
Valores a eliminar.
Registros seleccionados

ANEXO C
110
Tabla C.10Descripción de clase “selecciónVertical”.
Clase Responsabilidades
selecciónVertical Permite ejecutar métodos para seleccionar atributos de interés. Esta selección se puede realizar generando nuevas tablas con una sentencia SELECT o alterando la tabla actual utilizando la sentencia ALTER TABLE. (No implementado)
Métodos Descripción Datos de entrada Datos de salida
eliminarAtributos Ejecuta las sentencias para eliminar atributos que no son de interés, la tabla de la cual se desean eliminar los atributos es alterada.
Nombre de los atributos
Tabla reducida
crearNuevaTabla Ejecuta las sentencias y mediante una selección de atributos, se genera una nueva tabla que contiene únicamente los atributos que son de interés.
Nombre tabla y atributos
Tabla nueva

ANEXO C
111
class específicaMod
DConstrucción DIntegraciónDFormateo
PDE
Clases para
construcción de datos.
Clases para
integración de datos.
Clases para formateo
de datos.
<<use>>
Figura C.5 Diagrama de clases del paquete de “Preparación de Datos Específica (PDE)”.
Tabla C.11Descripción de paquetes “Preparación de Datos Específica”.
Paquete Responsabilidades
DFormateo Contiene las clases que permiten realizar acciones para cambiar el formato (extensión) del archivo u operaciones relacionadas al formateo de atributos.
DConstrucción Contiene las clases que permiten realizar acciones para construir nuevos atributos, desde los ya existentes, o modificar los que ya existen.
DIntegración Contiene las clases que permite realizar acciones de detección de conflictos de integración de datos y algunas operaciones adicionales que tienen que ver con la unificación de las fuentes de datos.
oOperaciones

ANEXO C
112
Figura C.6 Diagrama de clases del paquete de “Formateo de datos”.
Tabla C.12Descripción de clases “formatoArchivo”.
Clase Responsabilidades
formatoArchivo Llama a las clases que ejecutan métodos de para modificar la extensión del archivo de datos. (No implementado)
Métodos Descripción Datos de entrada
Datos de salida
cambiarFormato() Ejecuta las acciones para modificar el formato del archivo.
Ninguno. Ninguno.
Clases relacionadas Responsabilidades
aCSV Ejecuta la conversión de la extensión del archivo a formato CSV.
aBaseDatos Ejecuta la conversión de la extensión del archivo a una base de datos.
aXLS Ejecuta la conversión de la extensión del archivo a formato XLS (archivo de Excel).
aARFF Ejecuta la conversión de la extensión del archivo a formato ARFF (requerido por Weka).
aDBF Ejecuta la conversión de la extensión del archivo a formato DBF.
Tabla C.13Descripción de clase “formatoAtributos”.
Clase Responsabilidades
formatoAtributos Llama a las clases que ejecutan los métodos para realizar diversas modificaciones sobre los atributos. (No implementado)
class DFormateo
Operaciones
formatoArchiv o
+ cambiarFormato() : void
aCSV
+ cambiarFormato() : void
aBaseDatos
+ cambiarFormato() : void
aXLS
+ cambiarFormato() : void
aARFF
+ cambiarFormato() : void
aDBF
+ cambiarFormato() : void
formatoAtributos
cambiarTipoDato
+ cambiarTipoDato() : void
otrasModificaciones

ANEXO C
113
Tabla C.14 Descripción de clase “otrasModificaciones”.
Clase Responsabilidades
otrasModificaciones Realiza modificaciones sobre los atributos de una fuente de datos (ver sección de Formato de atributos). (No implementado)
Tabla C.15 Descripción de clases “cambiarTipoDato”.
Clase Responsabilidades
cambiarTipoDato Llama a las clases que ejecutan métodos de para modificar el tipo de dato de los atributos. (No implementado)
Métodos Descripción Datos de entrada Datos de salida
cambiarTipoDato() Ejecuta las acciones para modificar el tipo de dato de un atributo.
Atributo y tipo de dato.
Atributo modificado.
Clases relacionadas Responsabilidades
aEntero Ejecuta la conversión del tipo de dato de un atributo a tipo entero.
aCadena Ejecuta la conversión del tipo de dato de un atributo a tipo cadena de caracteres.
aCaracter Ejecuta la conversión del tipo de dato de un atributo a tipo caracter.
aFlotante Ejecuta la conversión del tipo de dato de un atributo a tipo flotante.
aDoble Ejecuta la conversión del tipo de dato de un atributo a tipo doble.

ANEXO C
114
Figura C.7 Diagrama de clases del paquete de “Construcción de datos”.
Tabla C.16 Descripción de clase “Incidencia”.
Clase Responsabilidades
Incidencia Ejecuta las operaciones para realizar el cálculo de la incidencia de mortalidad. (Implementado)
Métodos Descripción Datos de entrada
Datos de salida
calcularIncidencia() Ejecuta el cálculo de la incidencia de mortalidad.
causaMortalidad Año
Valor calculado de la incidencia
Atributos Tipo de dato Descripción
causaMortalidad Cadena de caracteres Valor que identifica una causa de muerte, el valor comprende un carácter y dos números (ej. C34).
Año Int Se refiere al año de defunción. Los valores corresponden a 2000 y 2010, ya que los datos contenidos en el almacén corresponden a censos de esos años.
class DConstrucción
Normalización
+ calcularNormalización() : void
minMaxNormalización
- valorMáximo: double
- valorMínimo: double
- valorActual: double
- rango: int
+ calcularNormalización() : void
zScoreNormalización
+ calcularNormalización() : void
escalaDecimalNormalización
+ calcularNormalización() : void
OperacionesIncidencia
- causaMortalidad: Varchar
- año: int
+ calcularIncidencia() : void
tasaMortalidad
- modificador: int
- incidencia: int
- población: int
- año: int
+ calcularTasaMortalidad() : void
cov ersiónDecimal
- valorGrados: int
- valorMinutos: int
- valorSegundos: int
+ carcularValorDecimal() : void

ANEXO C
115
Tabla C.17 Descripción de clase “tasaMortalidad”.
Clase Responsabilidades
tasaMortalidad Ejecuta las operaciones para realizar el cálculo de la tasa de mortalidad. (Implementado)
Métodos Descripción Datos de entrada
Datos de salida
calcularTasaMortalidad() Ejecuta el cálculo de la tasa de mortalidad.
Modificador Incidencia Población Año
Valor calculado de la tasa de mortalidad
Atributos Tipo de dato Descripción
Modificador Int Se refiere a un número potencia de 10 (10
n), en este
caso 100,000.
Incidencia Int Valor calculado.
Población Int Número de habitantes por municipio para un año determinado.
Año Int Se refiere al año de defunción 2000 o 2010.
Tabla C.18 Descripción de clase “conversiónDecimal”.
Clase Responsabilidades
conversiónDecimal Ejecuta las operaciones para realizar la conversión de los valores de latitud y longitud sexagesimales a un valor decimal. (No implementado)
Métodos Descripción Datos de entrada
Datos de salida
calcularValorDecimal() Ejecuta las operaciones para calcular el valor decimal de la latitud y longitud.
valorGrados valorMinutos valorSegundos
Valor decimal de la latitud y longitud
Atributos Tipo de dato Descripción
valorGrados Int Los valores sexagesimales de latitud y longitud presentan una triada, los grados corresponden al primer par de esta triada de valores.
valorMinutos Int Los minutos corresponden al segundo par de esta triada de valores.
valorSegundos Int Los segundos corresponden al tercer par de esta triada de valores.

ANEXO C
116
Tabla C.19 Descripción de clase “Normalización”.
Clase Responsabilidades
Normalización Ejecuta las operaciones para realizar la conversión de los valores de un atributo a un valor normalizado en un rango específico. Existen tres métodos de normalización que se pueden ejecutar: normalización por máximos y mínimos, normalización z-Score y normalización por escala decimal.
Métodos Descripción Datos de entrada
Datos de salida
calcularValorDecimal() Ejecuta los métodos de normalización (máximos y minimos, zScore o normalización por escala decimal).
Ninguno Ninguno
Tabla C.20 Descripción de clase “minMaxNormalización”.
Clase Responsabilidades
minMaxNormalización Ejecuta las operaciones para realizar la conversión de los valores de un atributo a un valor normalizado en un rango específico a través del método de máximos y mínimos. (Implementado)
Métodos Descripción Datos de entrada
Datos de salida
calcularValorDecimal() Ejecuta las operaciones para calcular el valor normalizado de un atributo.
valorMáximo valorMínimo valorActual rango
Valores normalizados
Atributos Tipo de dato Descripción
valorMáximo Double Valor máximo encontrado entre todos los valores del atributo que se desea normalizar.
valorMínimo Double Valor mínimo encontrado entre todos los valores del atributo que se desea normalizar.
valorActual Double Valor actual, se refiere al valor que se está normalizando.
Rango Int Valor entre los cuales estarán normalizados los valores del atributo, es decir, si rango es igual a 10, los valores estarán normalizados de cero a diez.

ANEXO C
117
Figura C.8 Diagrama de clases del paquete de “Integración de datos”.
Tabla C.21 Descripción de clase “detecciónConflictos”.
Clase Responsabilidades
detecciónConflictos Llama a las clases que ejecutan métodos de para identificar posibles conflictos de integración. (No implementado)
Clases relacionadas Responsabilidades
conflictosNombres Detectar el uso de términos diferentes para referirse a los mimos objetos.
conflictosEstructurales Identificar el uso indebido de las tablas, posibles errores como la mala normalización de tablas, atributos no atómicos, etc.
conflictosContenido Identificar posible ausencia de información.
class DIntegración
Operaciones
detecciónConflictos
correcciónConflictos
implementaciónEsquema
Integración
pobladoDatos
conflictosNombres conflictosEstructurales
conflictosContenido corConflictosNombres corConflictosEstructurales
corConflictosContenido
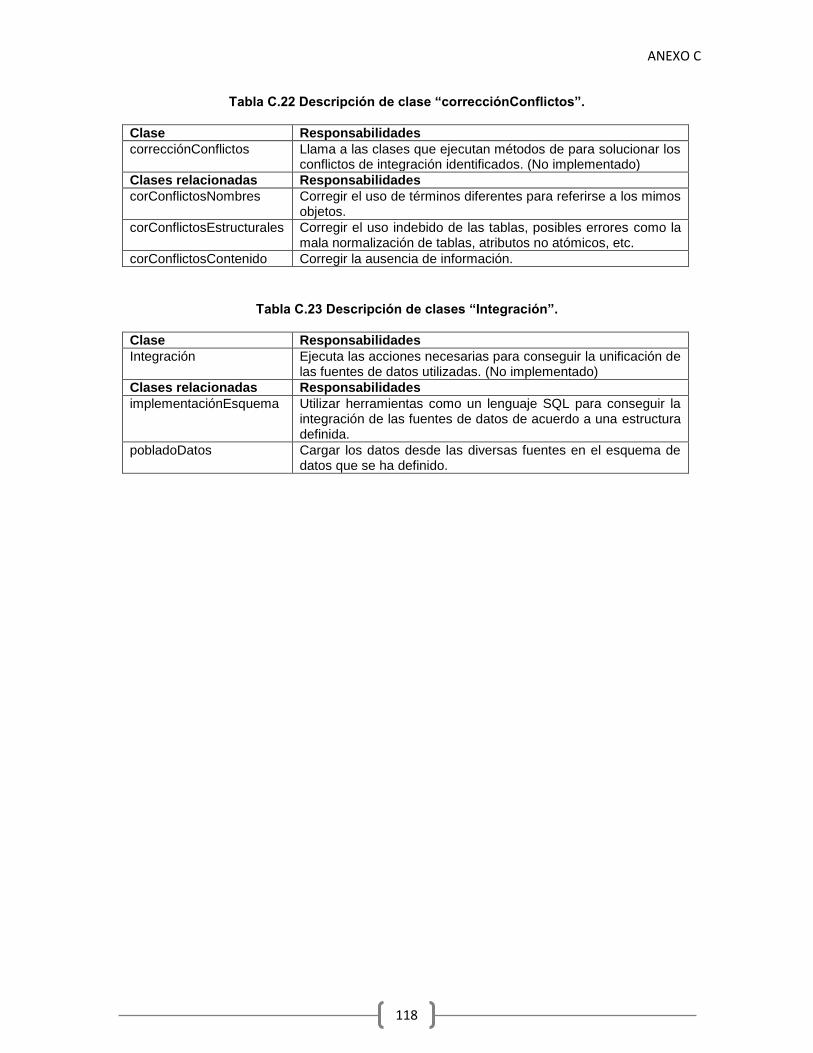
ANEXO C
118
Tabla C.22 Descripción de clase “correcciónConflictos”.
Clase Responsabilidades
correcciónConflictos Llama a las clases que ejecutan métodos de para solucionar los conflictos de integración identificados. (No implementado)
Clases relacionadas Responsabilidades
corConflictosNombres Corregir el uso de términos diferentes para referirse a los mimos objetos.
corConflictosEstructurales Corregir el uso indebido de las tablas, posibles errores como la mala normalización de tablas, atributos no atómicos, etc.
corConflictosContenido Corregir la ausencia de información.
Tabla C.23 Descripción de clases “Integración”.
Clase Responsabilidades
Integración Ejecuta las acciones necesarias para conseguir la unificación de las fuentes de datos utilizadas. (No implementado)
Clases relacionadas Responsabilidades
implementaciónEsquema Utilizar herramientas como un lenguaje SQL para conseguir la integración de las fuentes de datos de acuerdo a una estructura definida.
pobladoDatos Cargar los datos desde las diversas fuentes en el esquema de datos que se ha definido.

ANEXO D
119
Anexo D. Descripción del almacén de datos. Diseño del almacén de datos.
El almacén de datos implementado obedece a un esquema tipo ROLAP
(Relational OLAP). El almacén de datos está construido sobre una base de datos
relacional. La Figura D.1 muestra el esquema para el almacén de datos.
Figura D.1 Esquema del almacén de datos.

ANEXO D
120
Tabla D.1 Descripción de la tabla “Geográfica”.
Tabla Descripción
geográfica Contiene los registros de la posición (altitud, longitud) de los municipios de México con poblaciones mayores a los 100,000 habitantes.
Atributos Tipo de dato Descripción
Clave Int Clave del municipio (identificador)
Lat_decimal Decimal Valor decimal para la latitud del municipio.
Long_decimal Decimal Valor decimal para la longitud del municipio.
Lat_normalizada Decimal Valor normalizado para la latitud del municipio.
Long_ normalizada Decimal Valor normalizado para la longitud del municipio.
Lat_pixel Decimal Valor en pixeles para la latitud del municipio.
Long_pixel Decimal Valor pixeles para la longitud del municipio.
Tabla D.2 Descripción de la tabla “Poblacional”.
Tabla Descripción
Poblacional Contiene los registros relacionados al número de habitantes de los municipios de México con poblaciones mayores a los 100,000 habitantes.
Atributos Tipo de dato Descripción
Clave Int Clave del municipio (identificador)
Municipio Varchar Nombre del municipio.
Año Int Año al que pertenecen los datos, puede ser 2000 o 2010.
Población Int Número de habitantes para el municipio en determinado año.
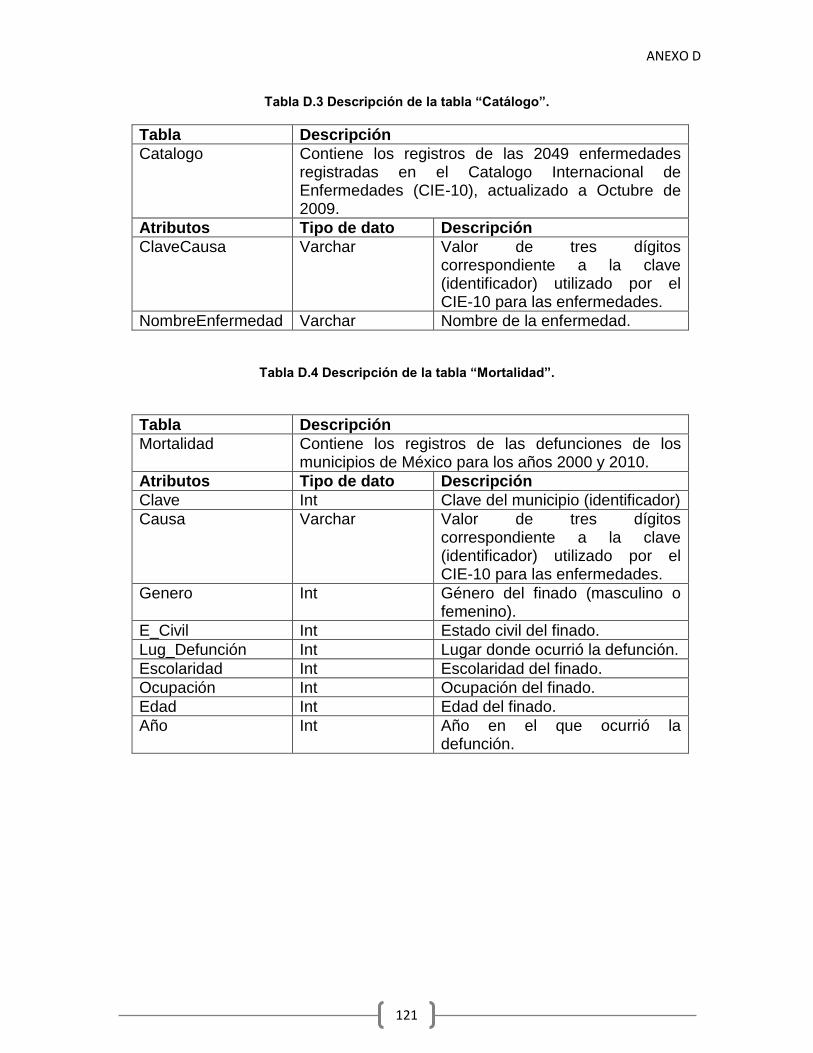
ANEXO D
121
Tabla D.3 Descripción de la tabla “Catálogo”.
Tabla Descripción
Catalogo Contiene los registros de las 2049 enfermedades registradas en el Catalogo Internacional de Enfermedades (CIE-10), actualizado a Octubre de 2009.
Atributos Tipo de dato Descripción
ClaveCausa Varchar Valor de tres dígitos correspondiente a la clave (identificador) utilizado por el CIE-10 para las enfermedades.
NombreEnfermedad Varchar Nombre de la enfermedad.
Tabla D.4 Descripción de la tabla “Mortalidad”.
Tabla Descripción
Mortalidad Contiene los registros de las defunciones de los municipios de México para los años 2000 y 2010.
Atributos Tipo de dato Descripción
Clave Int Clave del municipio (identificador)
Causa Varchar Valor de tres dígitos correspondiente a la clave (identificador) utilizado por el CIE-10 para las enfermedades.
Genero Int Género del finado (masculino o femenino).
E_Civil Int Estado civil del finado.
Lug_Defunción Int Lugar donde ocurrió la defunción.
Escolaridad Int Escolaridad del finado.
Ocupación Int Ocupación del finado.
Edad Int Edad del finado.
Año Int Año en el que ocurrió la defunción.

ANEXO D
122
Tabla D.4 Descripción de la tabla “Hechos”.
Tabla Descripción
Hechos La tabla de hechos almacena la información relacionada a los cálculos de la incidencia y tasa de mortalidad para cada municipio con población mayor a los 100,000 habitantes para un año, ya sea 2000 o 2010.
Atributos Tipo de dato Descripción
Clave Int Clave del municipio (identificador)
Causa Varchar Valor de tres dígitos correspondiente a la clave (identificador) utilizado por el CIE-10 para las enfermedades.
Incidencia Int Valor calculado. Número de muertes registradas en un municipio, para un año especificado.
Año Int Año para el que se realizaron los calculos.
TasaMortalidad Decimal Valor calculado. Relación entre el número de defunciones registradas y el total de la población para un municipio en un año determinado.
TasaMortalidadNormalizada
Decimal Valor normalizado de la tasa de mortalidad.

ANEXO D
123
Implementación del almacén de datos.
La implementación del almacén de datos se realizó utilizando MySQL, el almacén
de datos integrado contiene datos de mortalidad para los años 2000 y 2010
(censos oficiales).
Se crearon varias tablas para almacenamiento de las diferentes fuentes de datos:
geográfica, poblacional, catalogo, mortalidad y hechos. A continuación se describe
cada una de estas tablas y la sentencia SQL utilizada para su creación:
Tabla de datos geográficos.- contiene los registros relacionados a la posición de
los municipios de México con poblaciones mayores a 100,000 habitantes. Su
estructura es la siguiente:
CREATE TABLE geografica (clave INT NOT NULL, lat_decimal DECIMAL (18,14),
long_decimal DECIMAL (18,14), lat_normalizada DECIMAL (18,14),
long_normalizada DECIMAL (18,14), lat_pixel DECIMAL (18,14), long_pixel
DECIMAL (18,14), PRIMARY KEY(clave));
Tabla de datos poblacionales.- contiene los registros relacionados al número de
habitantes por municipio para los años 2000 y 2010, únicamente de aquellos
municipios con número de habitantes mayor a 100,000. Su estructura es la
siguiente:
CREATE TABLE poblacional (clave INT NOT NULL, municipio VARCHAR(50),
año INT, poblacion INT, FOREIGN KEY(clave) REFERENCES geografica(clave));
Tabla de datos catálogo de enfermedades (CIE-10).- contiene los registros de
las 2049 enfermedades contenidas en el Catalogo Internacional de Enfermedades
(CIE-10), actualizado al 2009. Su estructura es la siguiente:

ANEXO D
124
CREATE TABLE catalogo (claveCausa VARCHAR(3), nombreEnfermedad
VARCHAR(200), PRIMARY KEY(claveCausa));
Tabla de datos de mortalidad.- contiene los datos relacionados a las defunciones
ocurridas en municipios con número de habitantes mayor a 100,000 en los años
2000 y 2010. Su estructura es la siguiente:
CREATE TABLE mortalidad (clave INT NOT NULL, causa VARCHAR(3), genero
INT, e_civil INT, lug_defuncion INT, escolaridad INT, ocupacion INT, edad INT,
año INT, FOREIGN KEY(causa) REFERENCES catalogo(claveCausa));
Tabla de datos hechos.- En esta tabla se almacenan los valores arrojados para
los cálculos de los valores de incidencia y tasa de mortalidad. Su estructura es la
siguiente:
CREATE TABLE hechos (clave INT NOT NULL, causa VARCHAR(3), año INT,
incidencia INT, tasaMortalidad DECIMAL (18,14), tasaMortalidadNormalizada
DECIMAL (18,14), FOREIGN KEY(clave) REFERENCES geografica(clave),
FOREIGN KEY(causa) REFERENCES catalogo(claveCausa));

ANEXO D
125
Poblado del almacén de datos.
Para el poblado del almacén de datos, se realizó la conversión de los archivos de
datos a formato CSV, esto con el fin de facilitar la importación de los datos de
mortalidad, poblacionales y geográficos; mediante el uso de las sentencias
siguientes:
Tabla de datos de geográfica:
LOAD DATA INFILE 'C:/Users/Emmanuel/Desktop/OtrosTesis/1-
BDFinales/datos2000/Finales(mortalidad,poblacional,geografico)2000/CSVFiles/ge
ografica2000Final.csv' INTO TABLE geografica FIELDS TERMINATED BY ','
LINES TERMINATED BY '\n';
LOAD DATA INFILE 'C:/Users/Emmanuel/Desktop/OtrosTesis/1-
BDFinales/datos2010/Finales(mortalidad,poblacional,geografico)2010/CSVFiles/ge
ografica2010Adicionales.csv' INTO TABLE geografica FIELDS TERMINATED BY
',' LINES TERMINATED BY '\n';
Tabla de datos de poblacional:
LOAD DATA INFILE 'C:/Users/Emmanuel/Desktop/OtrosTesis/1-
BDFinales/datos2000/Finales(mortalidad,poblacional,geografico)2000/CSVFiles/po
blacional2000Final.csv' INTO TABLE poblacional FIELDS TERMINATED BY ','
LINES TERMINATED BY '\n';
LOAD DATA INFILE 'C:/Users/Emmanuel/Desktop/OtrosTesis/1-
BDFinales/datos2010/Finales(mortalidad,poblacional,geografico)2010/CSVFiles/po
blacional2010Final.csv' INTO TABLE poblacional FIELDS TERMINATED BY ','
LINES TERMINATED BY '\n';

ANEXO D
126
Tabla de datos catálogo:
LOAD DATA INFILE 'C:/Users/Emmanuel/Desktop/OtrosTesis/1-
BDFinales/datos2010/Finales(mortalidad,poblacional,geografico)2010/CSVFiles/ca
talogo2010Final.csv' INTO TABLE catalogo FIELDS TERMINATED BY ',' LINES
TERMINATED BY '\n';
Tabla de datos de mortalidad:
LOAD DATA INFILE 'C:/Users/Emmanuel/Desktop/OtrosTesis/1-
BDFinales/datos2000/Finales(mortalidad,poblacional,geografico)2000/CSVFiles/m
ortalidad2000Final.csv' INTO TABLE mortalidad FIELDS TERMINATED BY ','
LINES TERMINATED BY '\n';
LOAD DATA INFILE 'C:/Users/Emmanuel/Desktop/OtrosTesis/1-
BDFinales/datos2010/Finales(mortalidad,poblacional,geografico)2010/CSVFiles/m
ortalidad2010Final.csv' INTO TABLE mortalidad FIELDS TERMINATED BY ','
LINES TERMINATED BY '\n';

ANEXO E
127
Anexo E. Principales aportaciones al dominio epidemiológico.
a) Se generaron los mapas con los grupos de municipios con altas tasas de
mortalidad para las causas relacionadas a diabetes mellitus E11 y E14; y para
las causas C16 (cáncer de estómago), C34 (cáncer de pulmón), para los años
2000 y 2010.
b) Para la causa de mortalidad C16, se observó un decremento que va desde el
17.4% hasta el 87.48%, en la tasa de mortalidad del año 2010 respecto a la
del año 2000, para el grupo de interés ubicado en la zona norte del país,
integrado por los siguientes municipios:
Tabla E.1 Decremento registrado en las tasas de mortalidad.
Municipio Tasa (año
2000)
Tasa (año
2010)
% de reducción
respecto al año 2000
Guaymas 11.50 5.35 53.48
Hermosillo 7.87 6.5 17.4
La Paz 7.1 3.97 44.08
Los Cabos 6.63 0.83 87.48
c) Para la causa de mortalidad E11, se observó un incremento considerable en el
número de municipios con altas tasas de mortalidad y una mayor
concentración de éstos en la región centro de país (ver Figuras 18 y 19,
sección 4.3.2).:
Tabla E.2 Incremento registrado en las tasas de mortalidad
Delegación Tasa (año
2000)
Tasa (año
2010)
% de incremento
respecto al año 2000
Iztacalco 46.05 91.06 97.74
Cuauhtémoc 45.71 90.07 97.04
Azcapotzalco 39.54 85.6 114.97
Gustavo A. Madero 37.86 86.69 128.97

ANEXO E
128
Podemos observar varias delegaciones del Distrito Federal ubicadas dentro de
los diez primeros y los incrementos en las tasas de mortalidad que van desde
el 97.74% hasta el 128.97%.
d) Para la causa de mortalidad E14, se identificaron grupos de interés. Para el
año 2000, son cinco los grupos que se visualizan en la Figura 20. Para el año
2010, la Figura 21 muestra los cuatro grupos principales que fueron
identificados.





























