Embed Size (px)
Citation preview

Bioinformatics: A perspective
Dr. Matthew L. Settles
Genome CenterUniversity of California, Davis

Outline
• TheWorldwearepresentedwith• AdvancesinDNASequencing• BioinformaticsasDataScience• Viewportintobioinformatics• Training• TheBottomLine

Cost per Megabase of Sequence
Year
Dollars
2005 2010 2015
$0.1
$1
$10
$100
$1000
Cost per Human Sized Genome @ 30x
Year
2005 2010 2015
$1000
$100000
$10000000
SequencingCosts
• Includes:labor,administration,management,utilities,reagents,consumables,instruments(amortizedover3years),informaticsrelatedtosequenceproductions,submission,indirectcosts.
• http://www.genome.gov/sequencingcosts/
$0.014/Mb $1245perHumansized(30x)genome
October2016

GrowthinPublicSequenceDatabase
• http://www.ncbi.nlm.nih.gov/genbank/statistics
WGS>1trillionbp
Year
Bases
1990 2000 2010
105
107
109
1011
1013
●
●
GenBankWGS
Year
Sequences
1990 2000 2010
102
104
106
108
●
●
GenBankWGS

ShortReadArchive(SRA)Growth of the Sequence Read Archive (SRA) over time
Year
2000 2005 2010 2015
1011
1012
1013
1014
1015
●
●
●
●
BasesBytesOpen Access BasesOpen Access Bytes
>1quadrillionbp
http://www.ncbi.nlm.nih.gov/Traces/sra/

IncreaseinGenomeSequencingProjects
• JGI– GenomesOnlineDatabase(GOLD)• 67,822genomesequencingprojects
Lists>3700uniquegenus

BriefHistory

SequencingPlatforms
• 1986- DyeterminatorSangersequencing,technologydominateduntil2005until“nextgenerationsequencers”,peakingatabout900kb/day

‘Next’Generation
• 2005– ‘NextGenerationSequencing’asMassivelyparallelsequencing,boththroughputandspeedadvances.ThefirstwastheGenomeSequencer(GS)instrumentdevelopedby454lifeSciences(lateracquiredbyRoche),Pyrosequencing 1.5Gb/day
Discontinued

Illumina
• 2006– Thesecond‘NextGenerationSequencing’platformwasSolexa (lateracquiredbyIllumina).Nowthedominantplatformwith75%marketshareofsequencerandandestimated>90%ofallbasessequencedarefromanIllumina machine,SequencingbySynthesis>200Gb/day.
NewNovaSeq

CompleteGenomics
• 2006– UsingDNAnanoball sequencing,hasbeenaleaderinHumangenomeresequencing,havingsequencedover20,000genomestodate.In2013purchasedbyBGIandisnowsettoreleasetheirfirstcommercialsequencer,theRevolocity.ThroughputonparwithHiSeq
Humangenome/exomes only.
10,000HumanGenomesperyear

BenchtopSequencers
• Roche454Junior
• LifeTechnologies• IonTorrent• IonProton
• Illumina MiSeq

The‘Next,Next’GenerationSequencers(3rd Generation)
• 2009– SingleMoleculeReadTimesequencingbyPacificBiosystems,mostsuccessfulthirdgenerationsequencingplatforms,RSII~2Gb/day,newerPacBioSequel~14Gb/day,near100Kbreads.
Iso-seq onPacBiopossible,transcriptomewithout‘assembly’
SMRTSequencing

OxfordNanopore
• 2015– Another3rd generationsequencer,foundedin2005andcurrentlyinbetatesting.Thesequencerusesnanopore technologydevelopedinthe90’stosequencesinglemolecules.Throughputisabout500Mbperflowcell,capableofnear 200kbreads.
FYI:4th generationsequencingisbeingdescribedasIn-situsequencing
Funtoplaywithbutresultsarehighlyvariable
SmidgION:nanopore sensingforusewithmobiledevices
NanoporeSequencing
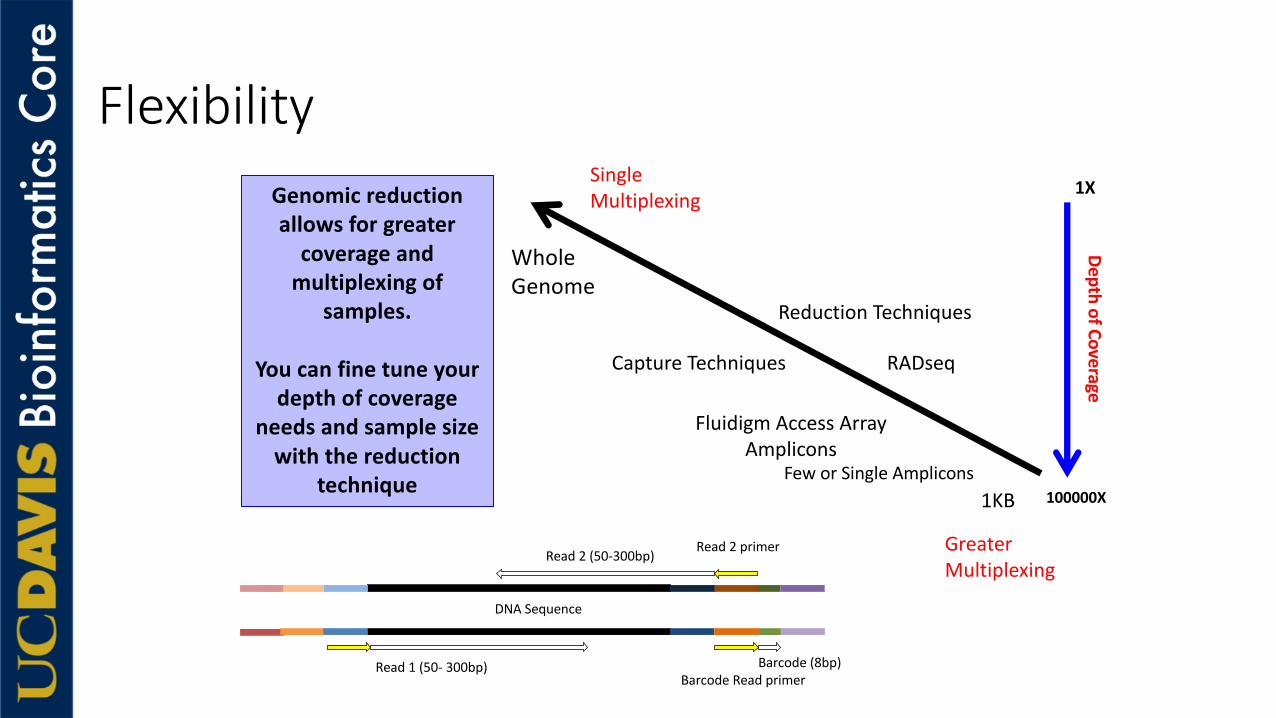
Flexibility
DNASequence
Read1(50- 300bp)
Read2(50-300bp) Read2primer
Barcode(8bp)BarcodeReadprimer
DepthofCoverage1X
100000X
WholeGenome
1KB
ReductionTechniques
CaptureTechniques
Fluidigm AccessArrayAmplicons
FeworSingleAmplicons
Genomicreductionallowsforgreatercoverageandmultiplexingof
samples.
Youcanfinetuneyourdepthofcoverage
needsandsamplesizewiththereduction
technique
RADseq
GreaterMultiplexing
SingleMultiplexing

SequencingLibraries• DNA-seq• RNA-seq• Amplicons• CHiP-seq• MeDiP-seq• RAD-seq• ddRAD-seq• Pool-seq• EnD-seq
DNase-seqATAC-seqMNase-seqFAIRE-seqRibose-seqsmRNA-seqmRNA-seqTn-seqQTL-seq
tagRNA-seqPAT-seqStructure-seqMPE-seqSTARR-seqMod-seqBrAD-seqSLAF-seqG&T-seq

omicsmaps.com

Thedatadeluge
• PluckingthebiologyfromtheNoise

Reality
• Itsmuchmoredifficultthanwemayfirstthink

Therealcostofsequencing
Pre-NGS(Approximately 2000)
Now(Approximately 2010)
Future(Approximately 2020)
0%20
4060
80
100%
Data reductionData management
Sample collection and experimental design
Sequencing Downstreamanalyses
Dat
a m
anag
emen
t
Sboner etal.GenomeBiology201112:125doi:10.1186/gb-2011-12-8-125

Bioinformatics
Biology
ComputerScience
MathStatistics
Biostatistics
ComputationalBiology
‘Thedatascientistrolehasbeendescribedas“partanalyst,partartist.”’Anjul Bhambhri,vicepresidentofbigdataproductsatIBM
BioinformaticsisDataScience

DataScience
Datascienceistheprocessofformulatingaquantitativequestionthatcanbeansweredwithdata,collectingandcleaningthedata,analyzingthedata,andcommunicatingtheanswertothequestiontoarelevantaudience.
FiveFundamentalConceptsofDataSciencestatisticsviews.com November11,2013byKirkBorne

7StagestoDataScience
1. Definethequestionofinterest
2. Getthedata3. Cleanthedata4. Explorethedata
5. Fitstatisticalmodels
6. Communicatetheresults7. Makeyouranalysisreproducible

1. Definethequestionofinterest
Beginwiththeendinmind!whatisthequestionhowarewetoknowwearesuccessfulwhatareourexpectations
dictatesthedatathatshouldbecollectedthefeaturesbeinganalyzedwhichalgorithmsshouldbeuse

2. Getthedata3. Cleanthedata4. Explorethedata
Knowyourdata!knowwhatthesourcewastechnicalprocessinginproducingdata(bias,artifacts,etc.)“DataProfiling”
Dataareneverperfectbutloveyourdataanyway!thecollectionofmassivedatasetsoftenleadstounusual,surprising,unexpectedandevenoutrageous.

5. FitstatisticalmodelsOverfittingisasinagainstdatascience!
Model’sshouldnotbeover-complicated
• Ifthedatascientisthasdonetheirjobcorrectlythestatisticalmodelsdon'tneedtobeincrediblycomplicatedtoidentifyimportantrelationships
• Infact,ifacomplicatedstatisticalmodelseemsnecessary,itoftenmeansthatyoudon'thavetherightdatatoanswerthequestionyoureallywanttoanswer.

6. Communicatetheresults7. Makeyouranalysisreproducible
Rememberthatthisis‘science’!Weareexperimentingwithdataselections,processing,algorithms,ensemblesofalgorithms,measurements,models.Atsomepointthesemustallbetestedforvalidityandapplicability totheproblemyouaretryingtosolve.

Datasciencedonewelllookseasy– andthat’sabigproblemfordatascientists
simplystatistics.orgMarch3,2015byJeffLeek

Training:DataScienceBias
DataScience(dataanalysis,bioinformatics)ismostoftentaughtthroughanapprenticemodel
Differentdisciplines/regionsdeveloptheirownsubcultures,anddecisionsarebasedonculturalconventionsratherthanempiricalevidence.• Programminglanguages• Statisticalmodels(Bayesvs.Frequentist)• Multipletestingcorrection• Applicationchoice,etc.These(andothers)decisionsmatteralot indataanalysis"Isawitinawidely-citedpaperinjournalXXfrommyfield"

TheDataScienceinBioinformatics
Bioinformaticsisnotsomethingyouaretaught,it’sawayoflife
MickWatson– Rosland Institute
“The best bioinformaticians I know are problem solvers – theystart the day not knowing something, and they enjoy finding out(themselves) how to do it. It’s a great skill to have, but for most,it’s not even a skill – it’s a passion, it’s a way of life, it’s a thrill. It’swhat these people would do at the weekend (if their families letthem).”

Training- Models
• Workshops• Oftenenrolledtoolate
• Collaborations• Moreexperiencepersons
• Apprenticeships• Previouslabpersonneltoyoungpersonnel
• FormalEducation• Mostprogramsaregraduatelevel• FewUndergraduate

Bioinformatics
• KnowandUnderstandtheexperiment• “TheQuestionofInterest”
• Buildasetofassumptions/expectations• Mixoftechnicalandbiological• Spendyourtimetestingyourassumptions/expectations• Don’tspendyourtimefindingthe“best”software
• Don’tunder-estimatethetimeBioinformaticsmaytake• Bepreparedtoaccept‘failed’experiments

BottomLine
TheBottomLine:Spendthetime(andmoney)planningandproducinggoodquality,accurateandsufficientdata foryourexperiment.
Gettoknowtoyourdata,developandtestexpectations
Result,you’llspendmuchlesstime(andlessmoney)extractingbiologicalsignificanceandresultsduringanalysis.

Substrate
ClusterComputing
CloudComputing
BASTM Laptop&DesktopLINUX

Environment
“CommandLine”and“ProgrammingLanguages”
VS
BioinformaticsSoftwareSuite

Prerequisites
• Accesstoamulti-core(24cpu orgreater),‘high’memory64GborgreaterLinuxserver.
• Familiaritywiththe’commandline’andatleastoneprogramminglanguage.
• Basicknowledgeofhowtoinstallsoftware• BasicknowledgeofR(orequivalent)andstatisticalprogramming• BasicknowledgeofStatisticsandmodelbuilding





























