Embed Size (px)
DESCRIPTION
Bab 30. Bias Butir. ------------------------------------------------------------------------------ Bias Butir ------------------------------------------------------------------------------. Bab 30 BIAS BUTIR A. Pendahuluan 1. Hakikat Bias Butir - PowerPoint PPT Presentation
Citation preview

Bab 30
Bias Butir

------------------------------------------------------------------------------Bias Butir
------------------------------------------------------------------------------
Bab 30
BIAS BUTIR
A. Pendahuluan
1. Hakikat Bias Butir
• Bias butir juga dikenal sebagai Differential Item Functioning (DIF)
• Butir adalah bias jika kelompok berbeda dengan kemampuan sama memperoleh sekor yang berbeda
• Misalnya, kelompok pria dan kelompok wanita berkemampuan sama memperoleh sekor berbeda (bias gender)

------------------------------------------------------------------------------Bias Butir
------------------------------------------------------------------------------
2. Kelompok Bias
• Perlu ada kelompok yang terkena dampak bias butir sehingga terdapat lebih dari satu kelompok
• Kelompok yang terkena bias bisa bermacam-macam
Kelamin pria atau wanita
Wilayah orang kota atau orang desa
Etnis orang kulit putih atau kulit hitam
3. Kelompok Fokus dan Referensi
• Apabila terjadi bias butir maka ada kelompok yang dianggap diuntungkan atau dirugikan
• Kelompok yang menjadi perhatian (diuntungkan atau dirugikan) dinamakan kelompok fokus
• Kelompok lainnya dinamakan kelompok referensi

------------------------------------------------------------------------------Bias Butir
------------------------------------------------------------------------------
4. Kriteria Bias
Kriteria adalah besaran yang menimbulkan bias butir terhadap kelompok
Misalkan, suatu butir ujian matematika menyebabkan bias terhadap wanita dibandingkan dengan pria
Dalam hal ini dikatakan bahwa
• Kriteria adalah ujian matematika
• Kelompok fokus adalah wanita
• Kelompok referensi adalah pria
Ada kalanya tidak dispesifikasi mana kelompok fokus dan mana kelompok referensi
Dalam banyak hal kelompok tersebut disebut juga sebagai subpopulasi

------------------------------------------------------------------------------Bias Butir
------------------------------------------------------------------------------
5. Indeks Bias Butir
• Bias butir dapat dinyatakan melalui indeks bias butir
• Ada bias butir ditentukan melalui pendekatan klasik melalui teori ujian klasik
• Ada bias butir pendekatan modern melalui teori responsi butir
6. Cara Pendeteksian Bias Butir
Ada sejumlah cara untuk melakukan pendeteksian butir yang bias. Di antaranya terdapat
Model Validitas Kelompok TunggalModel Validitas DiferensialModel Regresi atau ClearyProsedur Diskriminasi ButirMetoda Plot DeltaPendekatan Khi-kuadrat ScheunemanPendekatan Khi-kuadrat Camilli

------------------------------------------------------------------------------Bias Butir
------------------------------------------------------------------------------
B. Beberapa Model Korelasi dan Regresi
1. Model Validitas Kelompok Tunggal
• Populasi dibagi ke dalam sejumlah subpopulasi yang diduga terkena bias butir
• Sekor total adalah Y (kriteria) sedangkan sekor pada subpopulasi adalah masing-masing X1, X2, X3, dan seterusnya
• Dihitung koefisien korelasi di antara sekor Y dengan masing-masing sampel subpopulasi
YX1 , YX2, YX3, . . .
• Uji hipotesis statistika
bias jika YX = 0
tidak bias jika YX > 0

------------------------------------------------------------------------------Bias Butir
------------------------------------------------------------------------------
2. Model Validitas Diferensial
• Populasi dibagi ke dalam subpopulasi yang diduga terkena bias butir
• Misalkan populasi dibagi ke dalam dua subpopulasi dengan sekor X1 dan X2 (misal pria dan wantia)
• Sekor total Y adalah kriteria
• Koefisien korelasi di antara kriteria Y dengan masing-masing sampel subpopulasi adalah
YX1 dan YX2
• Uji hipotesis statistika
bias jika YX1 ≠ YX2
tidak bias jika YX1 = YX2

------------------------------------------------------------------------------Bias Butir
------------------------------------------------------------------------------
3. Model Regresi atau Model Cleary
• Populasi dibagi ke dalam subpopulasi yang diduga terkena bias butir
• Misalkan populasi itu dibagi ke dalam dua subpopulasi X1 dan X2 (misal pria dan wanita)
• Sekor total Y adalah sekor kriteria
• Regresi dari sekor kriteria terhadap sampel masing-masing sekor subpopulasi
Y = A1 + B1X1 dan Y = A2 + B2X2
• Uji hipotesis tentang kesamaan koefisien regresi
bias jika A1 ≠ A2 atau B1 ≠ B2
tidak bias jika A1 = A2 atau B1 = B2

------------------------------------------------------------------------------Bias Butir
------------------------------------------------------------------------------
Jika A1 ≠ A2 grafik menunjukkan
Jika B1 ≠ B2 grafik menunjukkan
Y
X
Y
X1 X2
X1
X2
Y
Y
X1 X2 X
X1
X2

------------------------------------------------------------------------------Bias Butir
------------------------------------------------------------------------------
4. Prosedur Diskriminasi Butir
• Populasi dibagi ke dalam subpopulasi yang diduga terkena bias butir
• Terhadap suatu kriteria, dihitung korelasi biserial butir sama di antara subpopulasi
• Uji statistika
bias jika koefisien korelasi biserial tidak sama
di antara subpopulasi
tidak bias jika koefisien korelasi biserial sama di antara subpopulasi

------------------------------------------------------------------------------Bias Butir
------------------------------------------------------------------------------
C. Metoda Plot Delta
1. Pendahuluan
• Delta adalah ukuran taraf sukar butir. Untuk z sebagai proporsi jawaban salah pada distribusi probabilitas normal baku, maka
= 13 + 4 z
• Populasi dibagi ke dalam subpopulasi yang diduga terkena bias butir, misalkan, subpopulasi 1 dan subpopulasi 2 (misal pria dan wanita)
• Untuk butir ke-i, taraf sukar butir adalah i1 dan i2
• Butir adalah bias jika i1 ≠ i2 dan tidak bias jika i1 = i2

------------------------------------------------------------------------------Bias Butir
------------------------------------------------------------------------------
2. Hubungan Linier Taraf Sukar Butir
• Rerata taraf sukar butir pada subpopulasi 1 dan 2 adalah
1 dan 2
• Kekeliruan baku taraf sukar butir pada subpopulasi 1 dan subpopulasi 2 adalah
1 dan 2
• Koefisien korelasi di antara taraf sukar butir pada subpopulasi 1 dan subpopulasi 2 adalah
• Hubungan linier di antara dua taraf sukar butir apabila tidak ada bias
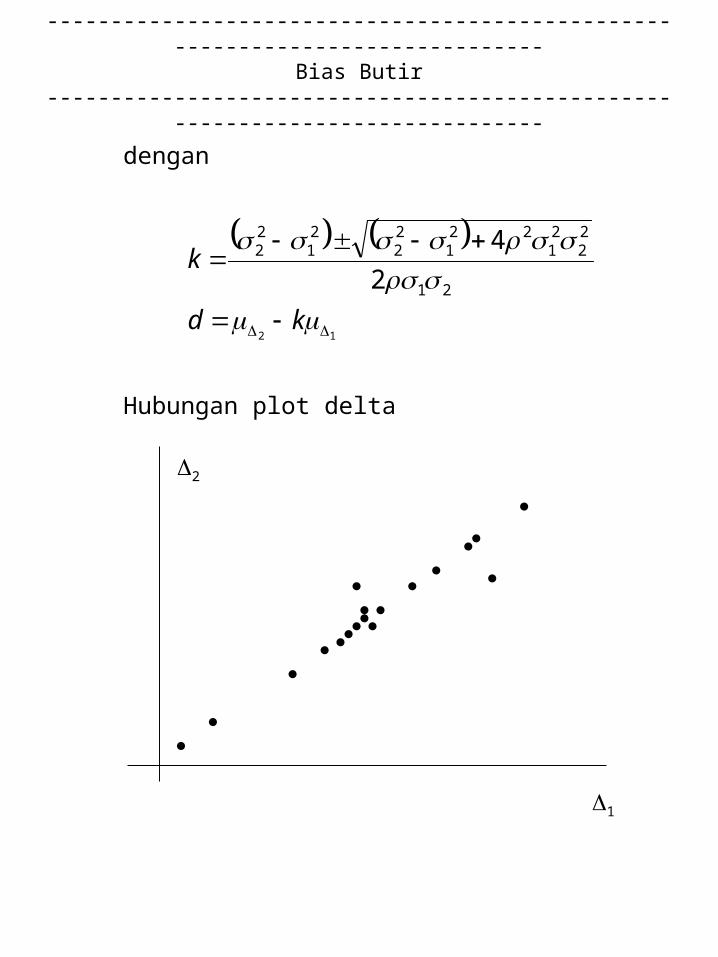
2 = k 1 + d
------------------------------------------------------------------------------Bias Butir
------------------------------------------------------------------------------
dengan
Hubungan plot delta
12
21
22
21
221
22
21
22
2
4
kd
k
1
2

------------------------------------------------------------------------------Bias Butir
------------------------------------------------------------------------------
3. Bias Butir
• Penyimpangan dari garis linier di antara dua taraf sukar adalah bias
• Bias butir membentuk jarak ke garis linier, dan untuk butir ke-i, jarak adalah
• Makin besar nilai D makin besar bias butir
• Diperlukan suatu ketentuan untuk memutuskan apakah suatu butir bias atau tidak bias terhadap kriteria
12
21
k
dkD iii

------------------------------------------------------------------------------Bias Butir
------------------------------------------------------------------------------
Contoh 1
Butir p1 z1 1 p2 z2 2
1 0,41 –0,228 12,088 0,45 –0,126 12,496
2 0,79 0,806 16,224 0,76 0,706 15,824
3 0,94 1,555 19,220 0,92 1,405 18,620
4 0,06 –1,555 6,780 0,07 –1,476 7,096
5 0,39 –0,279 11,884 0,37 –0,332 11,672
6 0,34 –0,412 11,352 0,35 –0,385 11,460
7 0,24 –0,706 10,176 0,19 –0,878 9,488
8 0,52 0,050 13,200 0,44 –0,151 12,396
9 0,54 0,100 13,400 0,54 0,100 13,400
10 0,44 –0,151 12,396 0,47 - 0,075 12,700
Statistik subpop 1 subpop 2 korelasi
Rerata 12,672 12,515
Variansi 10,003 8,940
Simp baku 3,163 2,990
Koef korelasi 0,992

------------------------------------------------------------------------------Bias Butir
------------------------------------------------------------------------------
Dari statistik ini ditemukan nilai
k = 0,946 dan d = 0,578
Selanjutnya nilai d untuk butir 1
Dengan cara sama d untuk butir 2 sampai 10 dapat dihitung, sehingga menghasilkan
Butir D Butir D
1 –0,3507 6 –0,1039
2 0,0740 7 0,5205
3 0,1018 8 0,4861
4 -0,0756 9 –0,1058
5 0,1077 10 –0,2872
3866,01)942,0(
581,0496,12)088,12)(942,0(21
D

------------------------------------------------------------------------------Bias Butir
------------------------------------------------------------------------------
D. Model Beda-P Terbakukan
1. Pendahuluan
• Populasi dibagi ke dalam dua subpopulasi yakni subpopulasi referensi dan subpopulasi fokus
• Pada satu sekor, dihitung proporsi jawaban betul pada subpopulasi referensi dan subpopulasi fokus
• Selisih proporsi mereka dijadikan patokan untuk menentukan bias tidaknya butir itu
• Pada sekor ke-Ai banyaknya responden pada subpopulasi referensi adalah mR dan pada subpopulasi fokus adalah mF
• Proporsi mereka adalah masing-masing pR = mR / MR dan pF = mF / MF

------------------------------------------------------------------------------Bias Butir
------------------------------------------------------------------------------
MR dan MF adalah banyaknya responden pada tiap subpopulasi
2. Beda-P Terbakukan
Selisih proporsi adalah D = pF – pR dan
Jika beda-p terbakukan adalah PD maka
Makin besar D makin besar perbedaan di antara dua subpopulasi itu sehingga makin besar PD yakni makin bias butir
A
iiF
A
iiF
D
m
DmP
1
1

------------------------------------------------------------------------------Bias Butir
------------------------------------------------------------------------------
Contoh 2
Sekor mR pR mF pF D DmiF
1 10 0,3000 4 0,2500 –0,0500 –0,2000
2 30 0,4000 3 0,3333 –0,0667 –0,2000
3 85 0,4588 7 0,4286 –0,0303 –0,2118
4 110 0,4818 15 0,4667 –0,0152 –0,2273
5 150 0,5133 9 0,4444 –0,0689 –0,6200
6 140 0,7143 12 0,6667 –0,0476 –0,5714
7 130 0,8538 16 0,8125 –0,0413 –0,6615
8 100 0,8800 22 0,8182 –0,0618 –1,3600
9 45 0,9556 12 0,9167 –0,0389 –0,4667
100 –4,5187
Beda-p terbakukan menjadi
04520100
51874
1
1 ,,
A
iiF
A
iiF
D
m
DmP

------------------------------------------------------------------------------Bias Butir
------------------------------------------------------------------------------
E. Pendekatan Khi-kuadrat Scheuneman dan Camilli
1. Pendekatan Khi-kuadrat Scheuneman
• Populasi responden dibagi ke dalam subpopulasi yang diduga terkena bias butir, misalkan ke dalam subpopulasi 1 dan subpopulasi 2 (misal pria dan wanita)
• Sekor responden dibagi ke dalam interval, misalkan ke dalam K interval
• Ada K interval sekor pada subpopulasi 1 dan ada K interval sekor pada subpopulasi 2
• Butir tidak bias jika proporsi jawaban betul pada setiap interval adalah sama untuk dua subpopulasi itu

------------------------------------------------------------------------------Bias Butir
------------------------------------------------------------------------------
Langkah Pemeriksaan Bias Butir
• Pertama kita menentukan butir mana yang akan diperiksa bias atau tidak bias, misalkan butir ke-8
• Pada butir ke-8 urut sekor responden dari kecil ke besar, dan perhatikan salah satu sekor, misalkan sekor 12
• Perhatikan semua responden dengan sekor 12 dan mereka dipecah ke dalam dua subpopulasi yang diduga terkena bias butir
• Hitung proporsi jawaban betul pada setiap populasi
Subpopulasi 1 frekuensi betul dan salah
Subpopulasi 2 frekuensi betul dan salah
• Sekor lainnya dibagi ke dalam interval sehingga seluruhnya (termasuk sekor 12) menjadi 3 sampai 5 interval

------------------------------------------------------------------------------Bias Butir
------------------------------------------------------------------------------
• Menurut Scheuneman, setiap interval mengandung 10 sampai 20 sekor
• Karena Scheuneman menggunakan distribusi probabilitas khi-kuadrat maka setiap sel harapan jangan kurang dari 5 sekor (syarat pendekatan ke distribusi probabilitas khi-kuadrat)
• Perhatikan statistik setiap interval sekor pada setiap subpopulasi, misalnya, interval sekor ke-k
Subpo- interval banyaknya banyaknya
pulasi responden jawaban betul
1 k1 mk1 Ak1
2 k2 mk2 Ak2

------------------------------------------------------------------------------Bias Butir
------------------------------------------------------------------------------
Statistik Jawaban
• Proporsi jawaban betul P dan jawaban salah Q
Subpop 1 Pk1 = Ak1 / mk1 Qk1 = 1 – Pk1
Subpop 2 Pk2 = Ak2 / mk2 Qk2 = 1 – Pk2
Gabungan
subpop
• Harapan matematik jawaban betul dan salah
Subpop 1 EPk1 = Pkt mk1
EQk1 = Qkt mk1
Subpop 2 EPk2 = Pkt mk2
EQk2 = Qkt mk2
tit kkkk
kkk PQ
mm
AAP
1
21
21

------------------------------------------------------------------------------Bias Butir
------------------------------------------------------------------------------
• Statistik khi-kuadrat tiap interval
• Khi-kuadrat Scheuneman pada K interval
SP = banyaknya subpopulasi
K = banyaknya interval
2
22
2
1
11
1
2
2
2
2
k
k
k
k
k
k
P
Pk
P
P
Pk
P
E
EA
E
EA
))(( 111
2
1
22
21
KSPs
K
kP
K
kPs kk

------------------------------------------------------------------------------Bias Butir
------------------------------------------------------------------------------
Contoh 3
Suatu data dibagi ke dalam dua subpopulasi berupa subpopulasi 1 dan subpopulasi 2 (misal pria dan wanita)
Sekor 12 dijadikan satu interval sebagai k = 3
Selanjutnya sekor 1 sampai 9 menjadi k =1
sekor 10 sampai 11 menjadi k =2
sekor 13 sampai 14 menjadi k = 4
Format statistik menjadi
statistik interval sekor k jumlah
1 2 3 4
sekor 1-9 10-11 12 13-14
agar isi tiap interval (harapan) tidak kurang dari 5 atau menurut Scheuneman di antara 10 sampai 20

------------------------------------------------------------------------------Bias Butir
------------------------------------------------------------------------------
Statistik data
statis- interval sekor ke-k jumlah
tik 1 2 3 4
sekor 1-9 10-11 12 13-14
mk1 25 24 48 65 162
mk2 315 110 118 92 635
mkt 340 134 166 157 797
Ak1 22 18 23 14 77
Ak2 300 99 93 33 525
Akt 322 117 116 47 602
mk1–Ak1 3 6 25 51 85
mk2–Ak2 15 11 25 59 110
Pk1 0,8800 0,7500 0,4792 0,2154
Pk2 0,9524 0,9000 0,7881 0,3587
Pkt 0,9471 0,8731 0,6988 0,2994
Qkt 0,0529 0,1269 0,3012 0,7006
EPk1 23,68 20,69 33,54 19,46 97,64
EPk2 298,32 96,04 82,46 27,54 504,36

------------------------------------------------------------------------------Bias Butir
------------------------------------------------------------------------------
statis- interval sekor ke-k jumlah
tik 1 2 3 4
sekor 1-9 10-11 12 13-14
EQk1 1,32 3,05 14,46 45,54 64,37
EQk2 16,66 13,96 35,54 64,46 130,62
2Pk1 0,1192 0,4180 3,3122 1,5319 5,3813
2Pk2 0,0095 0,0912 1,3472 1,0825 2,5304
2Qk1 2,1382 2,8533 7,6827 0,6546 13,3288
2Qk2 0,1654 0,6276 2,1258 0,4625 4,3813
Masukkan ke rumus khi-kuadrat
2s = 5,3813 + 2,5304 = 7,912
s = (2 – 1)(4 – 1) = 3
Dengan menentukan taraf signifikansi serta tabel fungsi distribusi 2
()() dapat diputuskan apakah
butir ini bias atau tidak

------------------------------------------------------------------------------Bias Butir
------------------------------------------------------------------------------
2. Pendekatan Khi-kuadrat Camilli
• Pada prinsipnya pendekatan khi-kuadrat Camilli sama dengan pendekatan khi-kuadrat Scheuneman
• Pendekatan khi-kuadrat Scheuneman hanya memperhatikan proporsi jawaban betul
• Pada pendekatan khi-kuadrat Camilli, selain memperhatikan proporsi jawaban betul, juga memperhatikan proporsi jawaban salah
• Semua rumus pada pendekatan khi-kuadrat Scheuneman digunakan di sini
• Perbedaan hanya terletak pada perhitungan akhir yakni pada khi-kuadrat

------------------------------------------------------------------------------Bias Butir
------------------------------------------------------------------------------
Statistik khi-kuadrat Camilli
2betul = 2
Pk1 + 2Pk2
2salah = 2
Qk1 + 2Qk2
sehingga khi-kuadrat Camilli menjadi
2C = 2
betul + 2salah
C = (SP – 1)K
SP = banyaknya subpopulasi K = banyaknya interval
Contoh 4
Dari contoh 3 diperoleh
2C = 5,3813 + 2,5304 + 13,3288 + 4,3813
= 25,622
C = (2 – 1)(4) = 4

------------------------------------------------------------------------------Bias Butir
------------------------------------------------------------------------------
F. Prosedur Mantel-Haenszel
1. Pendahuluan
• Populasi dibagi ke dalam subpopulasi yang diduga terkena bias butir dan dinamakan subpopulasi referensi (R) dan subpopulasi fokus (F)
• Sekor dibagi ke dalam K level
• Pada setiap level, banyaknya responden pada setiap subpopulasi berdasarkan jawaban betul dan salah
Subpop Betul Salah Jumlah
Referensi MRbk MRsk MRk
Fokus MFbk MFsk MFk
Jumlah Mbk Msk Mk

------------------------------------------------------------------------------Bias Butir
------------------------------------------------------------------------------
2. Statistik Mantel-Haenszel (MH)
Dari level k = 1 sampai k = K
• Ukuran bias butir delta dapat dihitung dari
bias-MH = – 2,35 ln MH
Makin negatif makin sukar butir itu bagi subpopulasi fokus
K
k k
FbkRsk
K
k k
FskRbk
MH
M
MMM
MM
1
1

------------------------------------------------------------------------------Bias Butir
------------------------------------------------------------------------------
3. Distribusi bias butir MH
Bias butir MH berdistribusi khi-kuadrat
Dengan distribusi khi-kuadrat dapat dilakukan pengujian selanjutnya
K
k k
FkRkskbk
K
k
K
k k
RkbkRbk
MH
MMMMM
MMM
M
1
2
1 12
50,||

------------------------------------------------------------------------------Bias Butir
------------------------------------------------------------------------------
G. Pendeteksian Modern denganTeori Responsi Butir
1. Pendeteksian Melalui Pencocokan Paramater
• Populasi dibagi ke dalam subpopulasi yang diduga terkena bias butir (misal pria wanita)
• Pada setiap subpopulasi dilakukan pencocokan di antara data dan model karakteristik butir yang digunakan
• Jika model cocok dengan data maka dicari penyetaraan skala di antara subpopulasi (skala b, a, dan c)
• Uji statistika terhadap kesamaan parameter butir di antara subpopulasi
• Terdapat bias butir jika mereka tidak sama dan tiada bias butir jika mereka sama

------------------------------------------------------------------------------Bias Butir
------------------------------------------------------------------------------
• Pencocokan model dengan data untuk model 1P menurut Wright dan Stone
M = banyaknya responden di dalam subpopulasi
• Statistik ini mendekati distribusi probabilitas khi-kuadrat
• Statistik uji untuk kesamaan parameter b (berdistribusi probabilitas normal)
11
2
M
QP
PXH
M
i ii
igii
)()(
)(
22
21
21
bibi
iii
ss
bbz

------------------------------------------------------------------------------Bias Butir
------------------------------------------------------------------------------
2. Pendekatan melalui Luas di antara Lengkungan
• Populasi dibagi ke dalam subpopulasi yang diduga terkena bias butir (misal pria wanita)
• Setiap subpopulasi membentuk karakteristik butir
• Jika karakteristik butir tidak sama maka di antara dua lengkungan karakteritik butir itu terdapat luas
• Makin besar luas itu makin bias butir itu
Pi()
Subpop 1
Subpop2
Luas

------------------------------------------------------------------------------Bias Butir
------------------------------------------------------------------------------
• Probabilitas jawaban betul pada supopulasi untuk butir ke-i
Subpopulasi 1 Pi1()
Subpopulasi 2 Pi2()
Selisih Pi1() – Pi2()
• Untuk nilai dari – 4,00 sampai 4,00 dengan interval 0,005
• Luas wilayah di antara lengkungan menjadi
004
004210050
,
,
||,
iii PPA





























