Embed Size (px)
Citation preview

Aurélio Moraes Figueiredo
Mapeamento Automático de Horizontes e Falhas em Dados Sísmicos 3D baseado no algoritmo de Gás Neural Evolutivo
Dissertação de Mestrado
Dissertação apresentada como requisito parcial para obtenção do título de Mestre pelo Programa de Pós-Graduação em Informática da PUC-Rio.
Orientador: Prof. Marcelo Gattass
Rio de Janeiro
29 de junho de 2007

Aurélio Moraes Figueiredo
Mapeamento Automático de Horizontes e Falhas em Dados Sísmicos 3D baseado no algoritmo de Gás Neural Evolutivo
Dissertação apresentada como requisito parcial para obtenção do título de Mestre pelo Programa de Pós-Graduação em Informática da PUC-Rio. Aprovada pela Comissão Examinadora abaixo assinada.
Prof. Marcelo Gattass Orientador
Departamento de Informática - PUC-Rio
Prof. Ruy Luiz Milidiú Departamento de Informática - PUC-Rio
Prof. Flavio Szenberg
Tecgraf - PUC-Rio
Prof. Paulo Marcos de Carvalho Petrobras
Prof. Waldemar Celes
Departamento de Informática - PUC-Rio
Rio de Janeiro 29 de junho de 2007

Todos os direitos reservados. É proibida a reprodução total
ou parcial do trabalho sem autorização da universidade, do
autor e do orientador.
Aurélio Moraes Figueiredo
Engenheiro de Computação graduado pela Pontifícia
Universidade Católica do Rio de Janeiro em dezembro de 2004.
Em março de 2006 entrou para o Programa de Pós-graduação em
Informática na mesma universidade.
Ficha Catalográfica
Figueiredo, Aurélio Moraes
Mapeamento Automático de Horizontes e
Falhas em Dados Sísmicos 3D baseados no Algoritmo
de Gás Neural Evolutivo / Aurélio Moraes Figueiredo;
orientador: Marcelo Gattass – Rio de Janeiro : PUC-
Rio, Departamento de Informática, 2007.
76f. : il. ; 30 cm
Dissertação (mestrado) – Pontifícia
Universidade Católica do Rio de Janeiro, Departamento
de Informática
Inclui referências bibliográficas.
1. Informática – Teses. 2. Computação Gráfica;
3. Volumes Sísmicos; 4. Horizontes Sísmicos; 5. Falhas
Sísmicas; 6. Growing Neural Gas
Gattass, Marcelo. III. Pontifícia Universidade Católica do
Rio de Janeiro. Departamento de Informática. IV. Título.

3

4
Agradecimentos
À minha família.
À Renata pelo apoio e pela paciência nos finais de semana perdidos enquanto
este trabalho era construído.
Ao meu orientador Marcelo Gattass por todas as idéias e conselhos que foram
indispensáveis na elaboração dessa dissertação.
Aos amigos Paulo Ivson Netto, Eduardo Teles Carlos, Rodrigo Toledo, Gustavo
Vagner, Thiago Bastos, Pedro Pereira, Carlos Eduardo Augusto e Maurício
Azevedo Ferreira pelas sugestões, e por ajudarem na revisão do texto.
Ao Tecgraf, por ser uma ótima fonte de problemas difíceis e interessantes e um
lugar único para trabalhar.
À PUC-Rio e aos seus professores que ensinam com o mesmo empenho nas
matérias mais simples e nos assuntos mais complexos.

5
Resumo
Figueiredo, Aurélio Moraes. Mapeamento Automático de Horizontes e Falhas em Dados Sísmicos 3D baseado no algoritmo de Gás Neural Evolutivo. Rio de Janeiro, 2007. 76p. Dissertação de Mestrado - Departamento de Informática, Pontifícia Universidade Católica do Rio de Janeiro.
Neste trabalho apresentamos um algoritmo baseado em agrupamento de
dados para o mapeamento automático de horizontes e de falhas sísmicas a partir
de dados sísmicos 3D. Apresentamos uma técnica para quantizar o volume
sísmico de entrada a partir dos neurônios do grafo resultante do processo de
treinamento de uma instância do algoritmo Growing Neural Gas (GNG). No
conjunto de amostras de entrada utilizadas pelo GNG, cada amostra representa
um voxel do volume de entrada, e retém informações da vizinhança vertical
desse voxel. Depois da etapa de treinamento, a partir do grafo gerado pelo GNG
um novo volume quantizado é gerado, e nesse volume possíveis ambigüidades e
imperfeições existentes no volume de entrada tendem a ser minimizadas. A partir
do volume quantizado descrevemos uma nova técnica de extração de horizontes,
desenvolvida com o objetivo de que seja possível mapear horizontes na presença
de estruturas geológicas complexas, como por exemplo horizontes que possuam
porções completamente desconectadas por uma ou mesmo diversas falhas
sísmicas. Também iniciamos o desenvolvimento de uma abordagem de
mapeamento de falhas sísmicas utilizando informações presentes no volume
quantizado. Os resultados obtidos pelo processo de mapeamento de horizontes,
testado em volumes diferentes, foram bastante promissores. Além disso, os
resultados iniciais obtidos pelo processo de extração de falhas sugerem que a
técnica pode vir a ser uma boa alternativa para a tarefa.
Palavras-chave
Computação Gráfica, Volumes Sísmicos, Horizontes Sísmicos, Falhas Sísmicas, Gás Neural Evolutivo

6
Abtract
Figueiredo, Aurélio Moraes. Mapping of Seismic Horizons and Faults based in the Growing Neural Gas Algorithm. Rio de Janeiro, 2007. 76p. MSc. Dissertation - Departamento de Informática, Pontifícia Universidade Católica do Rio de Janeiro.
In this work we present a clusterization-based method to map seismic
horizons and faults from 3D seismic data. We describe a method used to quantize
an initial seismic volume using a trained instance of the Growing Neural Gas
(GNG) algorithm. To accomplish this task we create a training set where each
sample corresponds to an entry volume voxel, retaining its vertical neighboring
information. After the training procedure, the resulting graph is used to create a
quantized version of the original volume. In this quantized volume both horizons
and faults are more evidenced in the data, and we present a method that uses the
created volume to map seismic horizons, even when they are completely
disconnected by seismic faults. We also present another method that uses the
quantized version of the volume to map the seismic faults. The horizon mapping
procedure, tested in different volume date, yields good results. The preliminary
results presented for the fault mapping procedure also yield good results, but
needs further testing.
Keywords
Computer Graphics, Seismic Volumes, Seismic Horizons, Growing Neural Gas

7
Sumário
AGRADECIMENTOS 4
RESUMO 4
PALAVRAS-CHAVE 5
ABTRACT 6
PALAVRAS-CHAVE 6
LISTA DE SÍMBOLOS 9
1 INTRODUÇÃO 11
1.1 Estrutura do documento da dissertação 13
1.2 Posicionamento da Instituição 14
1.3 Trabalhos Relacionados 14
2 AQUISIÇÃO DE DADOS SÍSMICOS 16
2.1 Método sísmico de reflexão 17
2.1.1 Aquisição 18
2.1.2 Processamento 20
2.1.3 Interpretação 23
3 AGRUPAMENTO DE DADOS E O ALGORITMO DE GNG 25
3.1 Processos de Agrupamento de Dados 26
3.1.1 Um exemplo simples 26
3.2 Definição do processo 27
3.3 Algoritmos difundidos 28

8
3.4 O algoritmo de Gás Neural Evolutivo (GNG) 29
3.4.1 Comentários adicionais sobre o funcionamento do algoritmo 33
3.4.1.1 O erro local acumulado 33
3.4.1.2 A movimentação dos nós 34
3.4.1.3 A inserção de novos nós no grafo 34
4 RASTREAMENTO DE HORIZONTES E FALHAS 36
4.1 Criação do conjunto de amostras de entrada 38
4.2 Funções de similaridade adotadas 39
4.3 A geração do novo volume quantizado 40
4.4 Uma interpretação geométrica do volume quantizado 41
4.4.1 Erro médio dos neurônios 41
4.5 O método de extração de horizontes sísmicos 43
4.6 Mapeamento de falhas sísmicas 47
5 RESULTADOS REPORTADOS 52
5.1 Mapeamento de Horizontes 54
5.2 Coeficiente de Correlação como Função de Similaridade 65
5.3 Mapeamento das falhas sísmicas 67
6 CONCLUSÕES E TRABALHOS FUTUROS 73
7 BIBLIOGRAFIA 75

9
Lista de símbolos
Número de amostras utilizadas até um novo neurônio ser incluído no
grafo GNG durante a fase de treinamento.
Taxa de decrescimento dos erros acumulados de todos os neurônios do
GNG.
Taxa de decrescimento dos erros acumulados dos vizinhos topológicos
do neurônio vencedor a cada treinamento do GNG.
amax Parâmetro de tempo de existência máximo de uma aresta no grafo do
GNG.
C Conjunto de vetores-amostra de entrada.
cx Vetor de código do neurônio nx.
D Função que mede a similaridade entre duas amostras do volume
quantizado.
dist Função de similaridade utilizada na fase de treinamento da instância de
GNG.
dmx Média das distâncias existentes entre um neurônio nx e seus vizinhos
topológicos.
dxy Critério de distância adotado entre os neurônios nx e ny, levando em
conta a distância média dmx.
errx Erro médio do neurônio nx em relação ao seu conjunto de amostras Sx.
F Conjunto de voxels contendo o melhor voxel candidato de cada traço
do volume sísmico ao mapear um horizonte.
fti Amostra obtida a partir do volume quantizado e que representa o voxel
de índice i no traço sísmico t do volume.
idx Identificador numérico que representa o neurônio nx no volume
quantizado.

10
k Número de identificadores utilizados acima e abaixo do voxel vti ao
criar a amostra sti.
nx Neurônio de índice x do grafo do GNG.
nx_error Taxa de erro acumulado do neurônio x.
q Número de identificadores utilizados acima e abaixo do voxel vti ao
criar a amostra fti.
r Coeficiente de correlação entre dois vetores.
sti Amostra obtida a partir do volume sísmico de entrada e que representa
o voxel de índice i no traço sísmico t do volume.
Sx Conjunto de amostras que são representadas pelo neurônio nx.
vti Voxel de índice i no traço sísmico t.
b Parâmetro do GNG que define a taxa de aprendizado do neurônio
vencedor.
t Parâmetro do GNG que define a taxa de aprendizado dos vizinhos
topológicos do neurônio vencedor.

11
1 Introdução
A descoberta de novas jazidas de petróleo envolve longa análise dos
dados geofísicos e geológicos da área sendo estudada. Somente depois
que boas estimativas do comportamento geológico das subcamadas do
subsolo, geólogos e geofísicos decidem propor a perfuração de poços.
Para conseguir boas estimativas da geologia da área sendo estudada, uma das
fontes de informação mais utilizadas atualmente são os volumes sísmicos obtidos
através de um método de aquisição de dados denominado método sísmico de
reflexão. Segundo Thomas, “o método sísmico de reflexão é o método de
prospecção mais utilizado na indústria de Petróleo atualmente, pois fornece alta
definição das feições geológicas em subsuperfície propícias a acumulação de
hidrocarbonetos, a um custo relativamente baixo” [Thomas 2001].
Uma vez adquiridos e processados, os dados sísmicos devem passar por uma
fase de interpretação. A interpretação das feições geológicas nesses conjuntos de
dados pode indicar situações favoráveis à acumulação de hidrocarbonetos.
Durante o processo é desejável a identificação de determinadas estruturas
geológicas, tais como horizontes e falhas sísmicas, entre outros.
Um volume sísmico tridimensional é resultante de um processo de aquisição
indireta dos dados sísmicos de uma determinada região geológica de interesse. Os
dados armazenados em um volume desse tipo, portanto, contêm características
particulares da região geológica na qual foram adquiridos, revelando informações
estruturais e estratigráficas das subcamadas geológicas existentes.
Na geologia, um horizonte sísmico é uma subsuperfície presente na região
geológica onde os dados foram adquiridos. Os horizontes se distinguem entre si
por apresentarem características geológicas bastante particulares, tais como a
espessura da camada de sedimentos que os define e características físicas do
material sedimentar que os compõe, além da sua vizinhança geológica. O
rastreamento de um horizonte sísmico consiste em identificar em quais dos voxels
do volume sísmico o horizonte desejado está representado, identificando quais são
as amostras que pertencem ao horizonte em questão.

12
Falhas sísmicas podem ser definidas como uma quebra na continuidade
original dos horizontes. São fraturas que causam um deslocamento relativo das
rochas, fazendo com que elas percam sua continuidade original. O mapeamento de
uma falha sísmica consiste em encontrar o conjunto de voxels do volume que
evidencia essa quebra de continuidade.
Considerando a quantidade de dados a serem interpretados, o mapeamento
manual dessas estruturas requer tempo e representa um esforço adicional a ser feito
pelo intérprete. Nesse sentido, algoritmos que possam automatizar ou mesmo
auxiliar nessa tarefa são de grande valia. No entanto, tais algoritmos são difíceis de
serem desenvolvidos, por diversas razões (baixa relação sinal/ruído devido a
interferências no processo de aquisição de dados, complexidade da geologia da
área onde o volume foi adquirido, etc.).
A maioria dos métodos desenvolvidos especificamente para a tarefa de
extração de horizontes possui algumas limitações indesejáveis. Por serem baseados
numa estratégia de crescimento de região, tais métodos utilizam medidas de
similaridade entre voxels vizinhos a partir dos voxels já descobertos do horizonte
(para o início do processo de extração, uma semente é selecionada externamente).
Em outras palavras, começando pela semente, seus vizinhos imediatos são
incluídos na superfície, depois os vizinhos dos seus vizinhos, seguindo esse
processo até que todos os voxels da superfície tenham sido descobertos. Métodos
dessa natureza apresentam bons resultados em volumes sísmicos onde não existam
falhas sísmicas ou onde, apesar da sua existência, o horizonte a ser descoberto
forma uma superfície conexa no volume sísmico. No entanto, é bastante comum
encontrar horizontes para os quais a porção conexa da superfície não está presente
nos dados sendo interpretados.

13
1.1 Estrutura da dissertação
Esta dissertação tem como foco principal analisar a viabilidade da aplicação de
algoritmos de agrupamento de dados (particularmente um dos vários desenvolvidos
nessa área, denominado Gás Neural Evolutivo ou simplesmente GNG – Growing
Neural Gas [Fritzke 1995]) à tarefa de mapeamento de horizontes e falhas sísmicas
a partir de dados sísmicos tridimensionais.
No capítulo 2 fazemos uma breve introdução dos componentes que formam o
que chamamos de dados sísmicos 3D. Apresentamos resumidamente o processo de
aquisição dos dados sísmicos através do método conhecido como método sísmico
de reflexão, mostrando algumas fases pelas quais passa um conjunto de dados
dessa natureza até a etapa de interpretação.
No capítulo 3 discutimos processos de agrupamento de dados, que formam a
base do processamento realizado nos dados sísmicos desta dissertação. Também
citamos alguns dos métodos destinados a essa tarefa difundidos na literatura da
área, e apresentamos o algoritmo de agrupamento particular que decidimos utilizar
ao longo de toda a dissertação, descrevendo em detalhes o processo de treinamento
do algoritmo, bem como a necessidade de cada um dos seus parâmetros de
treinamento.
No capítulo 4 descrevemos em detalhes todo o procedimento a ser realizado
nos dados sísmicos iniciais para que possamos gerar, partindo desses dados, um
novo volume de dados, a partir do qual tanto as falhas quanto os horizontes
sísmicos podem ser mapeados. Apresentamos a forma utilizada para criar o
conjunto das amostras de entrada, a ser utilizado como conjunto de amostras de
treinamento pelo algoritmo GNG. Depois de descrito o processo de criação do
novo volume de dados, quantizado a partir do volume original e levando em conta
o grafo criado pelo algoritmo GNG, é descrito o algoritmo de mapeamento de
horizontes sísmicos a partir do volume quantizado, obtido a partir de um novo
conjunto de amostras criadas já nesse novo volume. A última seção do capítulo
descreve a forma utilizada para extrair falhas sísmicas a partir desse mesmo
conjunto quantizado de dados.
No capítulo 5 fazemos as últimas considerações a respeito do trabalho,
apresentando o andamento atual da nossa pesquisa, bem como os resultados que

14
alcançamos até aqui. Finalmente, no capítulo 6 são também apresentadas as
conclusões e sugestões de trabalhos futuros que nos pareceram interessantes.
1.2 Posicionamento da instituição
Diversos trabalhos visando auxiliar a interpretação dos dados sísmicos têm
sido desenvolvidos no Tecgraf/PUC-Rio nos últimos anos, de tal forma que esta
dissertação é uma continuação dessa série de trabalhos. Em sua dissertação de
mestrado, Mauren Ruthner estudou a viabilidade de se utilizar a Transformada S
para, a partir dos dados sísmicos, encontrar componentes de freqüência desejados
no domínio do tempo [MRuthener, 2004]. Na dissertação de Mestrado de André
Gerhardt foi investigada e identificada a não adequação das técnicas de
visualização volumétrica tradicionais quando aplicadas ao problema de
iluminação de horizontes sísmicos [Gerhardt 1998]. A dissertação de Marcos
Machado experimentou a utilização de espaços de escala para segmentar esse
tipo de estrutura [Machado 2000]. Além desses, outros trabalhos relacionados a
dados sísmicos desenvolvidos no laboratório foram as teses de Doutorado de
Pedro Mário Cruz e Silva [Silva 2004], onde foram investigados algoritmos de
visualização volumétrica aplicados à sísmica e algoritmos de segmentação de
horizontes, e de Ernesto Fleck [Fleck 2004], onde foi proposto um novo método
de agrupamento de dados sísmicos para a visualização em mapas sísmicos.
1.3 Trabalhos relacionados
Ao extrair horizontes, a maioria dos métodos descritos na literatura utiliza
critérios de similaridade lateral entre os voxels como informação principal para
encontrar voxels vizinhos [Herron 2000] [Dorn 1998]. Já Alberts [Alberts 2000]
descreve um trabalho interessante baseado em redes neurais. No entanto, esse
método possui algumas limitações devido ao alto grau de distorção dos dados nas
regiões de falhas sísmicas. Admasu [Admasu 2004] descreve um algoritmo
desenvolvido somente com o intuito de correlacionar horizontes através das

15
falhas sísmicas existentes no volume sendo estudado. Em sua Tese de Doutorado,
Pedro Mário Cruz e Silva [Silva 2004] propôs um método que utilizava como
critério de similaridade entre as amostras o valor do coeficiente de correlação
entre elas.

16
2 Aquisição de dados sísmicos
O processo de aquisição de dados sísmicos visa modelar as
condições de formação e acumulação de hidrocarbonetos na região de
estudo.
O presente trabalho faz uso de especificidades que pertencem a áreas distintas
de conhecimento. Esse caráter interdisciplinar torna necessária uma introdução de
alguns dos conceitos básicos da área de exploração sísmica. Por isso nas próximas
seções faremos uma breve descrição do processo de obtenção de dados sísmicos
em três dimensões.
O subsolo é geralmente composto por diferentes camadas de sedimentos.
Diferentes camadas geológicas são caracterizadas por terem propriedades físicas
distintas, dentre elas diferentes impedâncias acústicas. Essa característica é a
base do processo de aquisição de dados conhecido como sísmica de reflexão.
O texto das próximas seções é fortemente baseado no capítulo correlato da
Tese de Doutorado de Pedro Mário Cruz e Silva [Silva 2004], e no trabalho de
Thomas [Thomas 2001].

17
2.1 Método sísmico de reflexão
O processo de aquisição de dados sísmicos tem como objetivo principal a
formação de modelos de dados que, depois de processados e organizados,
retenham informações relevantes a respeito da geologia da região onde foram
adquiridos. Dentre os modelos existentes, o método sísmico de reflexão,
classificado como um método indireto de exploração da subsuperfície, possui
várias vantagens tais como sua capacidade de produzir como resultado final
imagens sísmicas que forneçam alta definição das feições geológicas, além de
permitir a cobertura de grandes áreas de aquisição quando comparado com um
método de aquisição direto, como a perfuração de poços.
Neste texto, não temos a pretensão de apresentar detalhadamente o processo
de aquisição de dados sísmicos pela sísmica de reflexão. No entanto, é necessário
que seja feita uma introdução do assunto que permita ao leitor compreender o
processo de geração dos dados com algum grau de detalhe, uma vez que essa é a
massa de dados utilizada no nosso trabalho.
Segundo Robison e Treitel [Robison, Treitel 1980], a exploração de
hidrocarbonetos, óleo e gás baseada em sísmica pode ser dividida em três etapas
principais: aquisição, processamento e interpretação. A figura 2.1 ilustra essas
etapas.
Figura 2.1 - Etapas da exploração baseada na sísmica de reflexão (Adaptada de [Silva
2004]).
Nas subseções seguintes faremos uma breve descrição de cada uma das
etapas. Para uma visão mais aprofundada sugerimos consultar os trabalhos de

18
Gerhardt [Gerhardt 1998], Machado [Machado 2000], Robinson e Treitel
[Robison, Treitel 1980], e Thomas [Thomas 2001].
2.1.1 Aquisição
O modelo de aquisição dos dados é construído admitindo-se que a propagação
de ondas sísmicas (vibrações) através das rochas pode ser entendida fazendo uso
das mesmas leis físicas que regem a óptica geométrica [Thomas 2001].
Para a aquisição dos dados são geradas ondas elásticas artificiais (impulsos)
de duração relativamente pequena (em torno de 200 milisegundos) em pontos
específicos na superfície da área a ser mapeada. Essas perturbações mecânicas
são geradas através da utilização de dinamite quando em terra, ou canhões de ar
comprimido no caso de regiões marinhas.
Uma vez gerada, a onda sísmica se propaga através da terra, e ao atingir a
interface entre duas rochas de características físicas diferentes, parte da energia
incidente da onda é refletida e retorna à superfície, onde pode ser captada por
sensores. Uma outra parte da onda é refratada para o meio inferior. A porção de
energia refletida é proporcional à diferença de impedância acústica entre os dois
meios.
Os receptores que captam a porção refletida das ondas ficam situados em
pontos específicos na superfície, e podem ser de dois tipos: eletromagnéticos
para captação em terra (sendo comumente denominados geofones) ou de pressão
(chamados de hidrofones) para aquisição de dados em regiões oceânicas. Uma
vez captadas pelos sensores, as informações são gravadas em sismógrafos. O
sismógrafo armazena tanto o instante de tempo da chegada da informação quanto
a intensidade da onda medida nesse momento. A figura 2.2 ilustra os processos
de aquisição terrestre e marinha.

19
Figura 2.2 – Modelo representando a aquisição sísmica. Adaptada de [Gerhardt 1998].
A profundidade máxima a ser mapeada durante o processo de aquisição é
determinada pelo tempo de registro das reflexões pelos sensores e pela
velocidade de propagação dos sinais sísmicos através das camadas de rocha.
Para levantamentos terrestres, esse tempo de amostragem é tipicamente de 4
segundos a partir do instante de detonação (considera-se o instante da detonação
como sendo o instante de tempo t=0s) [Thomas 2001].
A velocidade de propagação das ondas nas rochas é variável segundo uma
grande diversidade de fatores, tais como a densidade e as constantes elásticas do
meio, que por sua vez são dadas em função de características intrínsecas da
rocha, tais como porosidade, temperatura, pressão, entre outros. No entanto, um
valor médio de velocidade de propagação tipicamente considerado é de 3000
metros por segundo. Dessa forma, pode-se considerar que as profundidades
mapeadas são próximas de 6000 metros (dois segundos para o sinal se propagar
na ida, mais 2 para refletir até ser registrado pelos sensores).
Ao realizar aquisições em áreas oceânicas o tempo de aquisição é ligeiramente
maior, uma vez que a velocidade típica de propagação das ondas através da
lâmina d’água é de aproximadamente 1500 metros por segundo, podendo chegar
a 12 segundos.
A imagem sísmica obtida por esse processo de captação dos sinais refletidos

20
será tão melhor quanto menor for o espaçamento lateral entre os sensores
localizados na superfície. Valores típicos para o número de sensores estão entre
128 e 1024, situados eqüidistantes a distâncias que variam de 20 a 50 metros
[Thomas 2001]. A freqüência de amostragem do sinal por cada um dos sensores
é o que determina o espaçamento vertical de medição dos sinais, sendo
igualmente importante. Equipamentos modernos tipicamente realizam
amostragem temporal das ondas refletidas a valores eqüidistantes de 2 ou 4
milisegundos.
2.1.2 Processamento
Para sísmica de petróleo, a fase posterior de processamento de dados visa
produzir imagens do interior que possuam a maior fidelidade possível,
procurando para isso atenuar as distorções geradas pelo processo de aquisição.
Nessa etapa, alguns erros inerentes ao levantamento sísmico são corrigidos.
Além disso, os dados são reorganizados para formarem uma grade tridimensional
com uma amostra de amplitude sísmica em cada vértice da grade (voxel). Duas
das dimensões do conjunto de dados são direções espaciais e estão relacionadas
com as posições das fontes e dos receptores. Uma das transformações realizadas
nos dados durante o processamento faz com que as posições da fonte e do
receptor sejam a mesma. Também graças a esta transformação podemos
considerar que a terceira dimensão do conjunto de dados é a temporal e que a
propagação da onda é feita apenas na direção vertical. Como podemos considerar
que a fonte e o receptor estão na mesma posição na superfície, o tempo de cada
amostra corresponde ao tempo que a onda leva para viajar até uma interface mais
o tempo da volta à superfície.
As chamadas correções primárias atenuam distorções causadas naturalmente
pelos receptores e pelos equipamentos de gravação. Uma vez que a fonte de
perturbação sísmica é admitida como sendo um impulso unitário mas é na
verdade uma fonte de pequena duração, existem reverberações presentes no sinal
adquirido que precisam ser posteriormente filtradas. Para esse fim os dados

21
passam por um processo de deconvolução. Como resultado da fase de
deconvolução, tem-se dados sísmicos de melhor resolução. Correções estáticas
visam principalmente corrigir variações topográficas e anomalias superficiais em
relação à superfície de referência (t=0s). Essas correções são feitas para que todo
o conjunto de tiros / receptores possa ser considerado como parte de uma mesma
superfície horizontal de referência. É essa superfície horizontal que vai
corresponder ao tempo t=0s de aquisição.
Para cada ponto de captação dos sensores na superfície, a imagem sísmica
obtida por esse processo será composta por um respectivo conjunto de valores
verticais de amplitudes. Essa coluna de amostras com as mesmas coordenadas
espaciais, variando apenas o tempo, é chamada de traço sísmico. Os máximos e
mínimos da função de amplitude sísmica do traço são chamados de eventos
sísmicos.
A organização das amostras em um dado sísmico é mostrada na figura 2.3. Do
lado esquerdo temos a função de amplitudes sísmicas do traço sísmico, na qual a
única dimensão é a temporal (1D). No centro temos uma seção vertical do
conjunto de dados formada por um conjunto de traços sísmicos, que é chamada
de linha sísmica (2D), com uma dimensão espacial e a outra temporal. No caso
dos dados sísmicos 3D (volume sísmico), formados por várias linhas sísmicas,
temos duas direções espaciais, que são chamadas de inline (direção das linhas
sísmicas) e crossline (direção perpendicular às linhas sísmicas), além de uma
direção temporal.

22
Figura 2.3: Traço sísmico (esquerda), linha sísmica (centro) e volume sísmico (direita).
Um modelo matemático interessante que descreve bem o efeito do
processamento sísmico realizado sobre o dado é o modelo de convolução,
ilustrado na figura 2.4.
Neste modelo consideramos a função de amplitude sísmica de cada traço do
conjunto de dados como sendo o resultado da convolução de um impulso sísmico
com uma função refletividade – a rigor, a função refletividade é uma distribuição
de coeficientes de reflexão. Os coeficientes de reflexão são proporcionais à
diferença de impedância acústica entre camadas geológicas adjacentes.
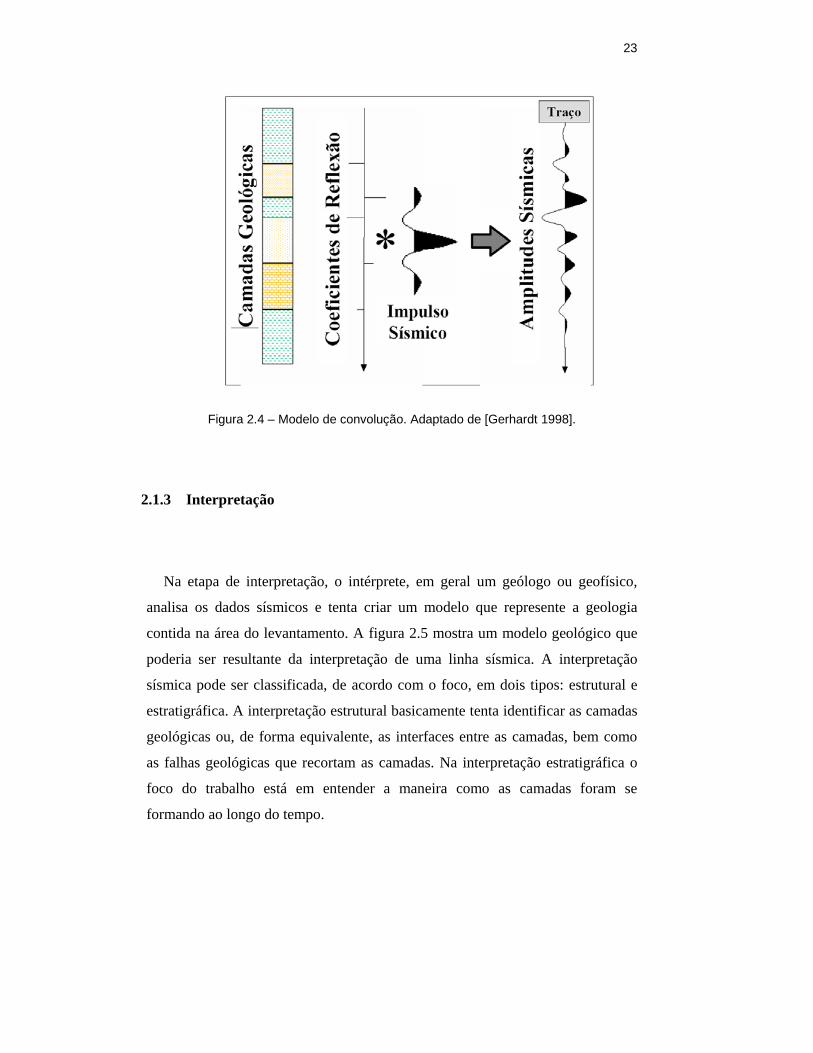
23
Figura 2.4 – Modelo de convolução. Adaptado de [Gerhardt 1998].
2.1.3 Interpretação
Na etapa de interpretação, o intérprete, em geral um geólogo ou geofísico,
analisa os dados sísmicos e tenta criar um modelo que represente a geologia
contida na área do levantamento. A figura 2.5 mostra um modelo geológico que
poderia ser resultante da interpretação de uma linha sísmica. A interpretação
sísmica pode ser classificada, de acordo com o foco, em dois tipos: estrutural e
estratigráfica. A interpretação estrutural basicamente tenta identificar as camadas
geológicas ou, de forma equivalente, as interfaces entre as camadas, bem como
as falhas geológicas que recortam as camadas. Na interpretação estratigráfica o
foco do trabalho está em entender a maneira como as camadas foram se
formando ao longo do tempo.

24
Figura 2.5 – Modelo geológico. Adaptada de [Robinson, Treitel 1980].
Um horizonte sísmico pode ser definido como uma série de reflexões
contínuas de intensidades similares encontradas através de vizinhanças laterais ao
longo do dado sísmico. Essas reflexões indicam a existência de uma interface
entre duas camadas de sedimentos. Sheriff [Sheriff 1991] define um horizonte
sísmico como sendo a superfície que separa duas camadas diferentes de rocha,
onde tal superfície (mesmo sem ter sido explicitamente identificada) está
associada com uma reflexão que se estende por uma grande área. Um horizonte
sísmico, portanto, se manifesta em um dado sísmico como uma série de eventos
(picos ou vales de amplitudes sísmicas) que aparecem de forma consistente traço
a traço. O mapeamento dos horizontes do conjunto de dados é uma das tarefas
mais importantes da interpretação sísmica. Os horizontes sísmicos também são
chamados de refletores.
Na etapa de interpretação, uma das tarefas mais dispendiosas em termos de
tempo de trabalho do intérprete é a de mapear manualmente determinados
horizontes de interesse para a interpretação. Sob esse ponto de vista, no presente
trabalho o objetivo final é desenvolver algoritmos que sejam capazes de, a partir
de uma semente pertencente a um horizonte particular do volume, mapear
automaticamente esse horizonte ao longo de todo o dado sísmico em questão,
permitindo que o processo de interpretação seja acelerado.

25
3 Agrupamento de dados e o algoritmo GNG
Processos de agrupamento de dados são utilizados para categorizar
uma massa de dados em um número desejado de grupos, com a restrição
de que os componentes de cada grupo compartilhem de características
semelhantes.
Tanto o procedimento de extração de horizontes sísmicos quanto o de extração
de falhas desenvolvidos neste trabalho se baseiam em uma fase de pré-
processamento a ser aplicada ao volume sísmico sendo interpretado. Esse
procedimento irá gerar um novo volume, obtido a partir dos dados existentes no
volume original, e faz uso de um procedimento pertencente a uma classe de
algoritmos denominados genericamente como processos de agrupamento de dados
(clusterization). Nosso trabalho utiliza um algoritmo de agrupamento de dados
particular, conhecido como Gás Neural Evolutivo ou GNG (Growing Neural Gas)
[Fritzke 1995]. Neste capítulo apresentamos as definições do que vêm a ser os
processos de agrupamento, assim como o algoritmo aqui adotado com um nível de
detalhe que julgamos ser suficiente para servir de introdução a um leitor pouco
familiarizado com métodos dessa natureza. O capítulo está organizado da seguinte
maneira: primeiramente, apresentamos uma definição do que vem a ser o
procedimento de agrupamento de dados, oferecendo um exemplo que ilustra o
processo, e definindo-o mais formalmente. Feito isso, citamos alguns dos
algoritmos mais difundidos na literatura, e em seguida apresentamos
detalhadamente o Gás Neural Evolutivo (GNG), algoritmo que utilizamos como
base da nossa proposta para identificação de horizontes e falhas em volumes
sísmicos.

26
3.1 Processos de agrupamento de dados
Processos de agrupamento podem ser descritos informalmente como métodos
cujo objetivo principal é, dada uma massa de dados inicial, separar essa massa de
dados em um número desejado de grupos, com a restrição de que os
componentes de cada grupo compartilhem de características semelhantes. Isso
significa que o procedimento de separar os dados em conjuntos distintos faz uso
de um critério de medida utilizado para definir o quanto dois componentes
quaisquer da massa de dados são parecidos. Esse critério de medida geralmente é
traduzido pelo uso de uma função de similaridade particular, que varia de acordo
com a natureza dos dados sendo considerados.
3.1.1 Um exemplo simples
Como exemplo, podemos supor que nossa massa de dados inicial sejam todos
os pixels de um determinado arquivo de imagem, do tipo RGB. Essa imagem
possui um número de cores que conhecemos a priori. Foi-nos dada a tarefa de
diminuir o número de cores da imagem original, com a condição de que o
arquivo resultante seja o mais parecido possível com a imagem original. Nesse
caso a massa de dados a ser agrupada seria formada por um conjunto de vetores
tridimensionais, com cada pixel da imagem original sendo representando pelo
seu vetor de cores correspondente (3 componentes de cor, R, G e B).
Uma estratégia para diminuir o número total de cores poderia ser encontrar na
imagem original grupos de pixels cujas cores fossem bastante parecidas. Caso
um grupo de pixels tivesse cores parecidas entre si, uma cor única poderia ser
eleita para esse grupo (essa cor poderia ser a cor média entre todos os elementos
do grupo, por exemplo), e todos os pixels pertencentes ao grupo na imagem
original seriam substituídos por essa cor.
Como foi dito anteriormente, para que o procedimento funcione corretamente

27
é necessário estabelecer um critério que indique mais formalmente o quanto duas
cores se parecem. No caso da imagem, uma função para medir o quanto duas
cores são parecidas entre si poderia ser a distância euclidiana entre essas duas
cores no espaço RGB ( 3 ). Assim a nossa interpretação para essa tarefa seria de
que quanto menor for a distância euclidiana entre as duas cores mais elas se
parecem.
Dessa forma caso queiramos diminuir o número de cores de uma imagem, por
exemplo de 148.279 cores para 32 cores (um possível resultado pode ser visto na
figura 3.1), basta que encontremos 32 grupos de cores próximas segundo a
distância euclidiana a partir do conjunto de 148.279 cores inicial e substituir as
cores iniciais pelas cores representantes do seu grupo.
De posse desse exemplo, podemos descrever mais formalmente os processos
de agrupamento.
3.2 Definição do processo
Agrupamento de dados pode ser descrito como o processo de organizar uma
coleção de vetores k-dimensionais em um número n de grupos cujos membros
compartilham características similares segundo alguma função de medida.
Depois de formado, cada um desses n grupos é representado por somente um
vetor k-dimensional denominado vetor de código (codevector, outros nomes
utilizados seriam centre, ou simplesmente node).
O objetivo do processo é, portanto, reduzir a diversidade de grandes
quantidades de dados, para isso categorizando esses dados em n conjuntos de
itens similares.
Quantização vetorial (Vector Quantization – VQ) é o processo de quantizar
vetores de entrada k-dimensionais em vetores de saída também k-dimensionais,
denominados vetores de código. Ao conjunto de possíveis vetores de código dá-
se o nome de livro de código (codebook). O livro de código é geralmente obtido
através do agrupamento de um conjunto de vetores iniciais, denominado conjunto

28
de amostras (algumas vezes referido genericamente como training set).
Figura 3.1 – Ilustração do processo de quantização de cores de uma imagem através
de agrupamento de dados. A imagem original possui 148.279 cores. Já a segunda
imagem possui somente 32 cores (fonte: www.lenna.org).
3.3 Algoritmos difundidos
Ao longo das últimas décadas, vários algoritmos dessa classe têm sido
desenvolvidos. Dentre eles, podemos citar alguns que mais se destacam, como K-
means [MacQueen 1967], Mapas Auto-Organizáveis de Kohonen (Kohonen’s
Self Organizing Map – SOM) [Kohonen 1982] e o algoritmo Gás Neural (Neural
Gas algorithm).
Aqui vamos apresentar um algoritmo específico, o Gás Neural Evolutivo
(Growing Neural Gas), ou simplesmente GNG, desenvolvido por Bernd Fritzke
[Fritzke 1995], algoritmo esse no qual os grupos, também denominados nós ou
neurônios, são obtidos de forma incremental e evolutiva. Além do artigo original
de Fritzke, outros artigos (como [Holmström 2002]) descrevem com detalhes o
funcionamento do GNG.

29
3.4 O algoritmo Gás Neural Evolutivo (GNG)
O GNG é um algoritmo em que o processo de criação dos grupos (nós ou
neurônios) ocorre de forma evolutiva, no sentido de que esse número de grupos
aumenta à medida que o algoritmo de treinamento é executado, e não
supervisionada, uma vez que os nós são formados de maneira autônoma durante
o treinamento. O algoritmo recebe inicialmente um conjunto C de vetores de
entrada (as amostras) de dimensionalidade conhecida (Rk).
Seguindo o exemplo do arquivo de imagem, o conjunto de amostras C seria o
conjunto contendo as amostras de cada um dos pixels da imagem. Além disso,
cada amostra (ou seja, cada cor) possui três dimensões, R, G e B, nesse caso k=3
(R3).
Partindo de dois nós iniciais aleatoriamente posicionados, o algoritmo passa a
acrescentar novos nós à medida que é executado, segundo regras descritas a
seguir, e com isso cria um grafo no mesmo espaço vetorial das amostras de
entrada, onde cada um dos nós é o representante de um grupo de amostras,
possuindo uma posição nesse espaço dimensional das amostras. O algoritmo
pode, então, ser utilizado em processos de quantização, bastando para isso
substituir cada amostra pelo representante do grupo onde a amostra está
classificada.
O GNG alcança bons resultados no sentido de que a topologia do grafo
encontrado depois de inseridos todos os nós reflete fortemente a distribuição
probabilística do conjunto das amostras de entrada. Para isso, o algoritmo faz uso
de diversas heurísticas durante o processo de crescimento do grafo (que é
geralmente chamado de processo de treinamento), visando obter a melhor
distribuição possível das amostras entre os grupos.
Em resumo, dadas as amostras de entrada em Rk, cada nó np do grafo possui
as seguintes características (cada característica será analisada em detalhes
posteriormente):
a. um vetor de pesos de referência em Rk, que chamamos de cp;

30
b. uma variável que contém o erro acumulado do nó, que vamos chamar
de np_error;
c. uma lista de arestas contendo todas as ligações do nó np aos seus
vizinhos. Cada uma das arestas da lista possui uma característica
denominada sua idade.
O processo de criação (crescimento) do grafo se dá de forma incremental, e a
cada iteração do algoritmo durante o processo uma amostra é escolhida segundo
a distribuição de probabilidades do conjunto de amostras e utilizada no
treinamento. Vamos chamar essa amostra escolhida no passo atual genericamente
de amostra s.
Vetor de pesos: dado um nó na qualquer do grafo, seu vetor de
código (codevector) ca pode ser interpretado como a posição desse
nó no espaço vetorial das amostras. No caso de nosso exemplo, ele
seria simplesmente as coordenadas RGB do nó do grafo, ou seja, a
cor representante do grupo.
Variável de erro acumulado: durante o processo de criação do grafo
a cada iteração do algoritmo, é medido o nível de similaridade
(segundo a função de similaridade utilizada) entre a amostra s sendo
treinada e o nó na que a representa. O erro existente (ou seja, a
distância existente) entre a amostra s e o vetor ca do nó que
representa essa amostra é acumulado na variável de erro do nó
(na_error). É através desses erros acumulados que o algoritmo vai
decidir em qual posição serão incluídos os novos nós, à medida que
o grafo está sendo criado. A idéia aqui é que, depois de um certo
número de iterações, o nó do grafo que possui o maior erro
acumulado está sendo o representante de muitas amostras, e
portanto um novo nó a ser adicionado deveria ser incluído próximo
desse, dividindo o número de amostras representadas e com isso
melhorando a distribuição das amostras entre todos os nós do grafo.

31
Idade das arestas do grafo: a idade é utilizada para que o algoritmo
possa remover as arestas mais antigas, e essa é uma das
características que permitem ao algoritmo criar grafos cuja forma
vai sendo modificada ao longo do treinamento, obedecendo à
distribuição espacial das amostras de entrada.
Cada um dos passos do algoritmo é descrito abaixo. O algoritmo trabalha com
6 parâmetros: b, t, amax, , , . Cada um deles será apresentado à medida que
for utilizado na descrição do algoritmo, dada abaixo:
Passo 0: o primeiro passo consiste em criar um grafo inicial, composto por
somente dois nós situados inicialmente em posições aleatórias no espaço das
amostras e com valor de erro acumulado zero. Esses dois neurônios devem ser
ligados por uma aresta. A idade da aresta que liga os dois neurônios deve receber
valor zero.
Passo 1: obter aleatoriamente (segundo a distribuição de probabilidades do
conjunto de amostras de entrada) uma amostra de entrada qualquer s. A partir do
grafo, encontrar o primeiro e o segundo nós mais próximos da amostra s segundo
a função de similaridade sendo utilizada. Esses dois nós são denominados na e
nb, respectivamente.
Passo 2: o neurônio mais próximo da amostra s, na, é considerado o
vencedor (denominado BMU – Best Match Unit) e o seu valor de erro acumulado
deve ser atualizado:
na_error = na_error + dist(na, s)
Passo 3: mover a posição de na no espaço (ou seja, seu vetor de código ca)
e seus vizinhos topológicos (chamamos de vizinhos topológicos de na a todos os
outros nós do grafo ligados a ele através de uma aresta; chamaremos esses nós
genericamente de nt) em direção à amostra s. Essa movimentação é feita através
de médias ponderadas entre as posições dos neurônios no espaço e na amostra,
segundo os parâmetros b e t:

32
ca = ca + b . (s - ca)
ct = ct + t . (s - ct), nt Vizinhos(na)
Valores típicos para esses parâmetros são b = 0.05 e t =110-4.
Passo 4: a idade de todas as arestas que ligam na aos seus vizinhos
topológicos recebe o incremento de uma unidade;
Passo 5: inserir uma aresta ligando os nós na e nb. Caso essa aresta já
exista, sua idade deve ser reiniciada (receber valor zero);
Passo 6: remover do grafo todas as arestas cujo valor de idade for maior
que o valor estabelecido pelo parâmetro de entrada amax. Após essas arestas terem
sido removidas, caso existam nós desconexos (que não possuam pelo menos um
vizinho topológico) esses nós devem ser excluídos do grafo. Um valor exemplo
para amax é 88.
Passo 7: caso o número de amostras já treinadas no passo atual do
algoritmo seja múltiplo do parâmetro de entrada λ e a condição de parada do
treinamento não foi atingida, um novo nó (que vamos chamar de nó nr) será
inserido de acordo com o seguinte procedimento:
encontrar no grafo o nó nu que possua o maior erro acumulado
nu_error;
encontrar, dentre todos os vizinhos topológicos de nu, o nó nv que
possui o maior erro acumulado nv_error;
criar o novo nó nr no ponto médio da aresta que liga nu e nv, ou
seja:
cr = (cu + cv) / 2
criar duas novas arestas, uma ligando nr a nu e outra ligando nr a nv.
decrescer nu_error e nv_error de acordo com o parâmetro de entrada α.
Feito isso, o valor inicial do erro acumulado do novo neurônio nr
deve ser o mesmo valor de erro do neurônio nu:
nu_error = α . nu_error;

33
nv_error = α . nv_error;
nr_error = nu_error;
Valores para o parâmetro λ podem ser da ordem de 600 e do parâmetro α,
da ordem de ½.
Passo 8: decrescer os valores de erro de todos os nós do grafo de acordo
com o parâmetro de entrada β, multiplicando os valores de erro acumulado de
todos os neurônios do grafo por (1-β). Valores típicos de β são da ordem de
510-3
Passo 9: caso a condição de parada do algoritmo não tenha sido atingida
(essa condição pode ser, por exemplo, que o grafo possua um número pré-
definido de nós), retornar ao passo 1.
3.4.1 Comentários adicionais sobre o funcionamento do algoritmo
Neste tópico comentaremos os principais parâmetros do algoritmo,
procurando esclarecer sua função durante o processo de treinamento.
3.4.1.1 O erro local acumulado
No passo 2 a variável de erro local acumulado do nó vencedor é atualizada.
Essa variável mantém o valor do somatório das distâncias entre o nó e as
amostras para as quais ele é o nó vencedor (situadas à menor distância). Manter
esse somatório é a forma encontrada para identificar nós que estejam cobrindo
uma porção relativamente grande da distribuição das amostras. Dessa forma o
erro local de um nó serve como uma medida estatística no sentido em que nós
que estejam cobrindo uma porção relativamente grande da distribuição das
amostras de entrada terão, estatisticamente, seu erro total acumulado maior do
que os outros nós. Como o objetivo do algoritmo é minimizar o erro total do
grafo em relação às amostras, saber quais são os nós que têm maior erro

34
acumulado é um bom indicativo de em que áreas os novos nós devem ser
incluídos durante o processo de crescimento do grafo.
3.4.1.2 A movimentação dos nós
No passo 3 vemos que, uma vez encontrado o nó vencedor para cada amostra,
existe uma movimentação desse nó, bem como de seus vizinhos topológicos, na
direção da amostra segundo frações definidas por dois dos parâmetros fornecidos
ao algoritmo, b para o nó vencedor e t para seus vizinhos topológicos (ambos
parâmetros de valores variando entre 0 e 1). Isso é feito com o objetivo que, ao
longo do treinamento, o nó tenha a todo momento sua posição no espaço (seu
vetor de código) situada o mais próximo possível do centro do espaço
compreendido pelo conjunto de amostras para as quais esse nó é o representante.
Os deslocamentos são lineares em relação à distância entre o vetor de pesos do
nó e a amostra, sendo que o valor do parâmetro que define o deslocamento do
vencedor (b) é geralmente muito maior que o valor que define os deslocamentos
dos seus vizinhos (t).
Esses dois parâmetros variam caso a caso. Valores relativamente altos tendem
a favorecer a criação de grafos cuja posição dos nós é muito instável, variando
fortemente no decorrer do treinamento. Já valores excessivamente baixos irão
tornam a adaptação do grafo lenta e ineficaz.
3.4.1.3 A inserção de novos nós no grafo
No algoritmo GNG os nós são inseridos sempre após a execução de um
determinado número pré-definido de treinamentos (esse também é um dos
parâmetros do algoritmo, ). A cada treinamentos um novo nó é inserido no
grafo, sendo sua posição de inserção definida pelo nó que possui o maior erro
acumulado no momento. É dessa forma que se consegue manter uma boa
distribuição dos nós do grafo em relação à distribuição espacial das amostras de
treino.

35
Uma observação importante a ser feita diz respeito ao impacto que o valor
escolhido para tem no desempenho do algoritmo. Caso esse parâmetro tenha
seu valor excessivamente baixo, a distribuição inicial dos nós no grafo será mal
executada, pois ao se incluir um novo nó os nós existentes não terão seu vetor de
código situado em posições realmente representativas da distribuição amostral.
No entanto, escolhas de valores altos para farão com que o tempo de execução
do algoritmo seja demasiadamente aumentado, visto que serão necessários
treinamentos antes da inclusão de cada novo nó.

36
4 Rastreamento de horizontes e falhas
Os horizontes sísmicos e as falhas sísmicas são dois eventos
sísmicos importantes, sendo relevante encontrar sua localização ao
interpretar dados sísmicos.
Uma das técnicas mais importantes do processo de interpretação de dados
sísmicos consiste no rastreamento dos horizontes. Um horizonte sísmico é
definido na geologia como uma subsuperfície presente na região geológica onde
os dados foram adquiridos. O rastreamento de um horizonte sísmico consiste em
identificar em quais dos traços do volume o horizonte desejado está presente,
identificando as amostras que pertencem ao horizonte em questão.
As características dos horizontes retidas nos volumes sísmicos permitem que
um horizonte seja identificado nos traços por um padrão de amplitudes encontrado
na sua vizinhança vertical, padrão esse que se repete ao longo dos traços do
volume onde tal horizonte está definido.
Horizontes reais podem ser representados nos traços do volume por um
pequeno conjunto de voxels verticalmente contíguos. No entanto, na nossa
modelagem iremos considerar que um horizonte é representado por no máximo
um voxel por traço do volume. Essa consideração facilita bastante a modelagem
do problema.
A maioria dos métodos desenvolvidos para o mapeamento de horizontes
possui algumas limitações indesejáveis. Por serem métodos baseados em uma
estratégia de crescimento de região (Region Growing), esses métodos adicionam
novos voxels da superfície a partir dos voxels já descobertos do horizonte nos
traços vizinhos (para o início do processo de extração, uma semente é selecionada
externamente). Tais métodos conseguem bom desempenho em volumes onde não
existe a presença de falhas sísmicas ou onde, apesar da existência de tais falhas, o
horizonte a ser mapeado forma uma superfície conexa no volume. No entanto é
bastante comum encontrar horizontes para os quais a porção conexa da superfície
não está capturada nos dados, o que fará com que a procura por vizinhos aos

37
voxels descobertos cesse nas regiões delimitadas pelas falhas, comprometendo o
resultado final obtido.
Nos algoritmos de extração de horizontes a partir de dados sísmicos, a
informação de contexto espacial não pode ser descartada. Voxels de um mesmo
horizonte são fortemente caracterizados por sua similaridade considerando sua
própria amplitude em contraste com as intensidades da sua vizinhança no traço
sísmico. Desse modo, um método de agrupamento de dados em que os voxels de
um mesmo horizonte sejam representados no conjunto de amostras não somente
por sua amplitude, mas também pelas amplitudes da sua vizinhança vertical,
tenderia a situar voxels de um mesmo horizonte em um mesmo grupo ou em
grupos situados próximos entre si no espaço das amostras.
Além dos horizontes, outra estrutura geológica importante a ser identificada
durante o processo de interpretação dos dados são as falhas sísmicas. Essas
estruturas são quebras na continuidade original dos horizontes. São fraturas que
causam um deslocamento relativo das rochas, fazendo com que elas percam sua
continuidade original. Nos dados sísmicos, os voxels pertencentes às falhas são
caracterizados por sua baixa coerência em relação a sua vizinhança. O
mapeamento de uma falha sísmica consiste em encontrar o conjunto de voxels do
volume que evidencia essa quebra de continuidade. Ao interpretar um conjunto de
dados, o mapeamento das possíveis falhas sísmicas presentes no dado é
extremamente importante.
Neste capítulo são apresentados algoritmos para a extração de horizontes
sísmicos e para o mapeamento de falhas sísmicas, ambos baseados em uma
estratégia de agrupamento de dados na qual os voxels do volume são considerados
no contexto de sua vizinhança vertical. No início do processo, para cada voxel do
volume é criado um vetor de características que retém essa vizinhança. É esse
vetor que irá representar o voxel e sua vizinhança no conjunto de amostras de
entrada utilizado no processo de treinamento do algoritmo GNG. O capítulo está
organizado da seguinte maneira: na seção 4.1 é descrito em detalhes o processo de
criação do conjunto de dados de entrada a serem utilizados na etapa de
treinamento do algoritmo de GNG. Na seção 4.2 discutimos as funções de
similaridade testadas durante o processo de criação do grafo. Uma interpretação
geométrica do processo de agrupamento das amostras em relação à sua

38
classificação nos neurônios é apresentada na seção 4.3, ficando o processo de
extração dos horizontes a partir do volume quantizado descrito na seção 4.4. Na
seção 4.5 é discutido um método para extração de falhas sísmicas, que apesar de
ainda estar em fase inicial de pesquisa apresenta resultados que sugerem que a
técnica pode ser uma boa alternativa para o mapeamento automático desse tipo de
dados.
4.1 Criação do conjunto de amostras de entrada
Para reter a informação contextual vertical de cada voxel, ao criar as amostras
o i-ésimo voxel do traço t, vti (um escalar) é representado no conjunto de amostras
de entrada por um vetor sti contendo o valor da sua amplitude na posição central
da amostra, além das amplitudes dos seus k vizinhos acima e abaixo no traço
sísmico, fazendo com que cada uma das amostras seja formada por um total de
2k+1 voxels:
12
)()1()1()(},,...,,,,...,{
k
tikitittiitkitti svvvvvs
O número de voxels considerados acima e abaixo do voxel central vti varia
segundo as características do volume sísmico sendo considerado.
Durante o processo de criação do conjunto de amostras, para cada voxel vti do
volume é criada uma amostra sti correspondente, exceto para os k primeiros e
últimos voxels de cada traço, voxels de borda onde essa vizinhança não está
disponível.

39
Figura 4.1 – A amostra sti is é adicionada ao conjunto de amostras utilizado para criar o
grafo do algoritmo GNG. Os neurônios (nós) do grafo são utilizados para a criação do
volume quantizado.
Depois de criadas todas as amostras, o conjunto de dados de entrada está
completo. Esse conjunto de amostras é utilizado no processo de treinamento de
uma instância do algoritmo GNG. Espera-se que a localização dos neurônios do
grafo final obtido no espaço das amostras de entrada reflita fortemente a
distribuição das amostras ao longo desse espaço.
4.2 Funções de similaridade adotadas
Conforme descrito anteriormente, uma característica que define diretamente a
qualidade dos resultados obtidos pelo processo de agrupamento é o critério de
medida que utilizamos para definir o quanto duas amostras são similares. Para
dados sísmicos é necessário utilizar uma função que traduza adequadamente a
proximidade existente entre duas amostras produzidas a partir do volume sísmico
desejado. Duas funções de similaridade foram testadas. A primeira foi a distância

40
euclidiana, o critério de medida adotado no artigo original do GNG. Além dessa,
também foi utilizado nos testes o coeficiente de correlação.
O coeficiente de correlação (r) entre duas amostras assume somente valores
situados entre -1 e 1. O valor de r igual a 1 traduz a existência de uma correlação
positiva entre os dois vetores. Da mesma forma, caso r seja -1 tem-se uma
correlação negativa perfeita. Sejam duas amostras, st1a e st2b, respectivamente as
amostras representando o a-ésimo voxel do traço t1 e o b-ésimo voxel do traço
t2. O cálculo do coeficiente de correlação entre essas amostras é obtido segundo
a seguinte fórmula:
kj
kjbtjbt
kj
kjatjat
btjbt
kj
kjatjat
smvsmv
smvsmv
r2
2)(22
1)(1
2)(21)(1
))((.))((
))().()((
onde m(st1a) e m(st2b) são, respectivamente, os valores médios das amplitudes dos
voxels das amostras st1a e st2b. A variável vt1 faz referência aos voxels da amostra
st1a e vt2 faz referência aos voxels da amostra st2b.
4.3 A geração do novo volume quantizado
O algoritmo de treinamento do GNG será executado até que o número p
desejado de nós seja atingido. Uma vez finalizado o processo de treinamento, os
nós (neurônios) do grafo gerado resultam numa lista de p vetores de código
correspondentes, e recebem um identificador numérico inteiro entre 1 e p, sendo
utilizados para criar uma versão quantizada do volume de entrada. Nesse novo
volume cada voxel vti é substituído pelo vetor de código cx do nó nx do grafo,
onde sua amostra correspondente sti foi classificada. No novo volume, cada voxel
possui um valor numérico entre 1 e p.

41
4.4 Uma interpretação geométrica do volume quantizado
Como pode ser visto na figura 4.2, voxels de um mesmo horizonte, por terem
características parecidas entre si, são representados por vetores de amostras que
tendem a ser localizados em regiões similares do espaço R2k+1.
Na figura 4.2(a) vemos uma representação de sete vetores de amostras, todas
representando voxels de um mesmo horizonte (em azul). Na figura 4.2(b) vemos
sete curvas correspondendo às amplitudes dessas amostras. Todas essas 7
amplitudes foram classificadas em um mesmo nó, e na figura 4.2(c) é mostrado o
vetor de código desse nó. Apesar de, pelas características do algoritmo de
agrupamento, ser possível obter amostras referentes a voxels de um mesmo
horizonte representadas por nós diferentes, essas amostras tendem a ser
representadas por nós cujos vetores de código são próximos entre si.
4.4.1 Erro médio dos neurônios
A partir do grafo gerado, cada neurônio nx passa a representar seu conjunto de
amostras, Sx, todas amostras no espaço R2k+1 mais próximas desse neurônio do
que de qualquer outro. Cada uma dessas amostras passa a ser representada pelo
vetor de código do neurônio nx, cx. Dessa forma, cx representa um conjunto Sx de j
amostras. Esse processo de representação gera um erro.
O erro total de nx com respeito ao seu conjunto Sx de amostras poderia ser
computado simplesmente como a soma das distâncias entre cada uma das
amostras de Sx e cx. Contudo, pelo fato de o número de amostras representadas
pelos neurônios ser bastante variável, um critério mais adequado pode ser
computar o erro médio (distância média) de todas as amostras de Sx em relação a
cx. Ou seja:
j
csdisterr
j
ixxi
x
1
0
),(

42
onde sxi representa a i-ésima amostra do conjunto de amostra Sx do neurônio nx, e
dist representa a função de similaridade (ou distância) sendo utilizada.
Depois de executado o processo de criação do volume resultante da
quantização, é desejável que esse volume possa ser visualizado. No entanto, no
novo volume, o conjunto de amplitudes dos voxels foi substituído por um
conjunto de identificadores numéricos. Dessa forma, é necessário estabelecer uma
escala de cores, com uma cor específica correspondente a cada identificador, ou
seja, atribuir cores ao vetor de código de cada um dos neurônios da instância de
GNG. Simplesmente atribuir aleatoriamente uma cor a cada um dos neurônios não
é uma boa estratégia, uma vez que dessa forma as cores do padrão adotado não
refletem a possível similaridade entre neurônios.
Uma boa forma de estabelecer uma escala de cores é atribuir a cor do neurônio
segundo seu erro médio em relação às amostras que ele representa. Dessa forma,
neurônios vizinhos (espera-se que vizinhos topológicos estejam definidos em
áreas do espaço amostral onde a densidade das amostras é parecida) tenderão a ser
representados por cores próximas. A figura 4.3 mostra um exemplo da
visualização resultante desse processo. Na parte superior da figura, podemos ver
uma fatia extraída do volume de entrada. Na parte inferior vemos a mesma fatia,
obtida após o processo classificação das amostras e criação do volume quantizado.
Os horizontes, bem como as falhas sísmicas, ficam mais bem definidos e
pequenas ambigüidades existentes no dado original são minimizadas de maneira a
diminuir seu impacto.

43
(a) Amostras de um mesmo horizonte sísmico
(b) Amplitudes das amostras
(c) Vetor de código
correspondente
Figura 4.2 – Amostras de um mesmo horizonte e o vetor de código correspondente.
4.5 O método de extração de horizontes sísmicos
O algoritmo GNG é definido como um método não-supervisionado, e portanto
não existe um controle explicito do processo de treinamento. Como resultado, o
processo de quantização pode classificar amostras correspondentes a voxels de
horizontes diferentes em um mesmo neurônio, especialmente se durante o
processo de treinamento é escolhido um número reduzido de neurônios em

44
relação ao número de horizontes existentes no dado sísmico. Dois voxels não
contíguos de um mesmo traço que possuam amplitudes e vizinhanças verticais
semelhantes também podem ter o mesmo neurônio como representante. Por isso,
o processo de mapeamento dos horizontes não pode ser baseado em somente um
voxel do volume quantizado.
Figura 4.3 – Horizontes e falhas sísmicas no volume quantizado. Ilustração da mesma
fatia no volume de entrada e no volume quantizado.
Para suplantar essa limitação, propomos que cada voxel vti , o i-ésimo voxel
do traço t do volume quantizado, seja representado por uma amostra fti, formada
de maneira similar à criação das amostras sti, com a diferença de que agora os
componentes são obtidos a partir do volume quantizado. Podemos definir essas
novas amostras, vetores de inteiros, como:
12)()( ,,,
qTqixxiqixti ididid Zf

45
onde q é o número de identificadores de neurônios acima e abaixo de vti.
Para encontrar os voxels pertencentes ao horizonte a ser mapeado, uma nova
função de similaridade é definida no espaço das novas amostras. O processo de
extração inicialmente recebe um voxel vta (uma semente) do horizonte que se
deseja mapear e sua amostra correspondente fta, ambas definidas a partir de um
traço t qualquer do volume. O objetivo do procedimento é encontrar amostras
similares a fta, denominadas aqui genericamente como fb, ao longo dos demais
traços. Para isso, a função de similaridade utiliza uma função D que recebe fta e fb.
Essa função D poderia ser modelada de diversas formas. Uma primeira forma
D1 seria, uma vez recebidas fta e fb, simplesmente somar as distâncias dos vetores
de código correspondentes aos identificadores inteiros de cada uma de suas
componentes. No entanto, essa abordagem não leva em conta a densidade
amostral local do conjunto de amostras de entrada S.
A localização dos nós do grafo do GNG reflete a densidade local das amostras
de entrada no espaço de entrada inicial. Isso significa que neurônios localizados
no espaço R2k+1 em regiões de maior concentração de amostras por unidade de
volume são relativamente mais próximos dos seus vizinhos do que aqueles
situados em regiões do espaço onde a densidade amostral é mais baixa. Portanto,
para comparar distâncias entre neurônios precisamos dar maior ou menor peso de
acordo com sua posição espacial.
O grafo formado pelo algoritmo GNG inclui uma lista de arestas ligando
neurônios próximos (vizinhos topológicos). Caso uma aresta ligue dois vizinhos
topológicos (independentemente da densidade amostral dessa região), a função D
utiliza a média dmx das distâncias existentes entre um neurônio nx e seus vizinhos
topológicos. A média dmx é definida simplesmente como:
1
0
),(1 xm
ixi
xmx dist
md cc ,
onde mx é o número de vizinhos topológicos do neurônio nx e ci representa o vetor

46
de código do i-ésimo vizinho topológico de nx. Uma vez calculada essa média
para todos os neurônios do grafo, a distância do neurônio nx em relação a um
segundo neurônio ny pode ser dada por:
),(1
xymx
xy distd
d cc
A função D entre fta e fb utilizada pelo procedimento de extração leva em
conta ainda outra particularidade dos dados sísmicos, e não somente a soma das
distâncias dxy dos vetores de código correspondentes. Para cada componente j de
fta é permitida a comparação entre os componentes j-1, j, j+1 de fb, e somente a
menor das três distâncias é utilizada na soma dos componentes. Essa tolerância
pode ser maior em volumes sísmicos onde as camadas possuam inclinações
maiores. Na figura 4.4 tem-se uma ilustração do procedimento de tolerância. Na
figura o j-ésimo componente (j-ésimo vetor de código) de fta, idaj, é comparado
com as amostras idb(j-tol), idbj e idb(j+tol) da amostra fb. A menor distância, que no
caso da ilustração utiliza o identificador idx(j+tol), é a distância utilizada em D.
O procedimento D é executado para todos os traços exceto o próprio traço que
contém a semente fta, e para cada um dos traços a amostra mais próxima fb é
armazenada, passando a compor o conjunto F de voxels candidatos.
Figura 4.4 – O procedimento D de similaridade entre duas amostras. Tal procedimento
recebe duas amostras, fta e fb.

47
Depois de formado, o conjunto F possui o melhor candidato de cada um dos
traços do volume. A z-ésima amostra de F, fz, representa o seu voxel vz
correspondente e somente é considerado parte do horizonte definido a partir da
semente correspondente a vta caso a similaridade entre fta e fz, Daz, seja menor que
um valor de tolerância T1 e todos os outros voxels do mesmo traço (exceto
vizinhos imediatos) resultem em distâncias maiores que outro valor de tolerância
T2.
Com a adoção desse procedimento, desde que as tolerâncias e os
comprimentos das amostras sejam bem dimensionados, espera-se que os voxels
retornados realmente pertençam ao conjunto de voxels que formam o horizonte
sendo mapeado. No entanto, durante o processo de desenvolvimento do algoritmo
de extração, foi constatado que, apesar de o conjunto de voxels obtido pelo
algoritmo representar satisfatoriamente o horizonte, voxels situados
aleatoriamente dentro das regiões de falha presentes no volume eram
esporadicamente retornados. Tal possibilidade é explicada pela natureza caótica
das falhas sísmicas. Esses falsos positivos, no entanto, tendem a ser
completamente eliminados caso sejam comparados com seus vizinhos laterais.
Para isso, depois de encontrar cada um dos voxels do horizonte, é encontrada a
distância entre esse voxel e seus vizinhos laterais situados nos traços vizinhos.
Caso essa distância seja maior que um valor de tolerância T3, esse voxel é
descartado.
4.6 Mapeamento de falhas sísmicas
As falhas sísmicas são quebras na continuidade original dos horizontes,
causando um deslocamento relativo das rochas e fazendo com que elas percam
sua continuidade original. Na figura 4.5 apresentamos um exemplo de uma falha
desse tipo. Na parte superior da figura mostramos uma fatia do volume onde a
falha não está presente. Já na parte inferior mostramos uma outra fatia do mesmo
volume sísmico onde uma falha sísmica pode ser verificada. Os retângulos
vermelhos demarcam a região onde a presença da falha é constatada.

48
Figura 4.5 – Duas fatias de um mesmo volume sísmico. Na segunda uma falha sísmica
é evidenciada (retângulo vermelho).
Nos dados sísmicos, os voxels de um horizonte podem ser reconhecidos por
sua alta coerência espacial em relação aos seus vizinhos. Com relação às falhas
sísmicas, a quebra de continuidade é acompanhada de fenômenos como
compressão e erosão, aumentando a natureza caótica da região onde elas ocorrem
e fazendo com que essas regiões, ao contrário das regiões onde existem horizontes
definidos, sejam caracterizadas por um alto nível de distorção nos dados. Por isso
os voxels das regiões de falha são caracterizados pela sua pouca coerência
espacial em relação aos seus voxels vizinhos. Uma vez que a criação do volume
quantizado tende a diminuir o nível de ruído presente nos dados originais, nesses
volumes as características de coerência dos voxels de ambas as estruturas
geológicas (tanto horizontes quanto falhas) tendem a ser fortemente evidenciadas.
Isso pode ser verificado na figura 4.6, onde vemos duas fatias ortogonais cortando
um volume quantizado. Fica evidenciada a coerência dos voxels vizinhos dos
horizontes e a quebra da continuidade das superfícies nas regiões onde existe a
presença de falhas sísmicas.

49
Figura 4.6 – Duas fatias ortogonais demonstrando a coerência espacial entre voxels
vizinhos, exceto por aqueles que pertencem às falhas sísmicas.
Essa boa qualidade da classificação dos voxels obtida pela criação do volume
quantizado serviu de motivação para o desenvolvimento do algoritmo de extração
de falhas aqui descrito. Tal procedimento mostrou resultados iniciais bastante
promissores. O algoritmo se inicia a partir de um voxel semente recebido como
parâmetro, e utiliza como critério de similaridade o mesmo procedimento D
definido para o processo de mapeamento dos horizontes.
Para verificar se um determinado voxel vti pertence a uma falha,
primeiramente é necessário definir as dimensões de um paralelepípedo ao redor
desse voxel, que envolve todos os vizinhos de vti que serão considerados no
cálculo. Os vizinhos situados no mesmo traço sísmico do voxel candidato não são
levados em conta. Na figura 4.7 pode-se ver um exemplo de conjunto de voxels ao
redor do voxel vti candidato a falha (em vermelho) onde somente os vizinhos
imediatos (em cinza) estão sendo considerados.

50
Figura 4.7 – O voxel candidato a pertencer a uma falha (vermelho) e seus vizinhos
imediatos (em cinza).
Definidos os vizinhos, é calculado o valor da similaridade D da amostra fti que
representa o voxel vti em relação às amostras que representam seus voxels
vizinhos.
Depois de calculado esse conjunto de valores de similaridade, vários critérios
podem ser adotados para determinar se vti pertence ou não a uma falha sísmica.
Um exemplo possível seria encontrar a média dos valores de similaridade obtidos.
Um voxel pouco similar a seus vizinhos próximos tende a estar em uma região de
pouca coerência espacial, o que caracterizaria a falha. Segundo esse critério, o
voxel seria classificado como pertencente à falha caso a média obtida fosse maior
que um valor pré-estabelecido.
Caso um voxel pertença a um horizonte qualquer do volume, é esperado que
na sua lista de vizinhos laterais existam voxels pertencentes a esse mesmo
horizonte. Levando isso em conta, no procedimento que adotamos encontra-se, a
partir da lista de voxels vizinhos, aquele voxel que é o mais similar a vti. Caso
mesmo esse vizinho possua um valor de similaridade maior que um valor de
tolerância Tm estabelecido, considera-se que naquele ponto não existe um
horizonte definido, e vti é considerado um voxel de falha.
O procedimento se inicia a partir do voxel semente recebido. Caso esse voxel
seja considerado falha, é imediatamente adicionado à lista de voxels que
representam a falha em questão, e seus vizinhos são incluídos na lista de voxels
candidatos que serão testados posteriormente. O processo é repetido para cada um

51
dos voxels da lista de candidatos, até que essa lista esteja vazia.
Ao final, tem-se um conjunto de voxels formando uma nuvem de pontos
conexa onde a falha mapeada está definida, e espera-se que essa nuvem de pontos
defina a região de falha com precisão. Tal conjunto de pontos, apesar da boa
precisão obtida nos testes, não forma uma superfície simples, diferindo do
resultado obtido pelo procedimento de mapeamento manual das falhas, que
geralmente irá produzir somente uma superfície simples de falha. O processo de
obtenção de uma superfície a partir da nuvem de voxels de falha obtida não foi
desenvolvido durante a pesquisa para esta dissertação.

52
5 Resultados
Neste capítulo apresentamos os resultados obtidos pelos procedimentos
descritos ao longo desta dissertação, tanto o de mapeamento de horizontes quanto
o método de extração dos voxels pertencentes às falhas sísmicas. O capítulo
concentra os resultados no processo de mapeamento de horizontes, mas também
são apresentados resultados para o método de mapeamento automático das falhas.
No que diz respeito ao mapeamento de horizontes, reportamos vários
resultados obtidos com três dados de volume diferentes, informando o conjunto de
parâmetros correspondentes utilizados tanto na etapa de treinamento quanto na de
extração.
Uma observação a ser feita em relação aos resultados alcançados diz respeito
às funções de similaridade utilizadas durante a fase de treinamento dos grafos do
GNG. Duas delas foram testadas: o coeficiente de correlação e a distância
euclidiana. Nos testes aqui realizados, o desempenho alcançado pela utilização
desses dois critérios de medida foi bastante similar. No entanto, constatamos que
nos nossos dados o coeficiente de correlação é menos tolerante à presença de
ruído, o que faz com que a superfície resultante do mapeamento seja composta de
pequenas ranhuras, prejudicando a qualidade de visualização. Além disso, o
cálculo do coeficiente de correlação é computacionalmente mais caro quando
comparado ao cálculo da distância euclidiana. Dessa forma, ao longo de todo o
capítulo os resultados reportados utilizam distância euclidiana como função de
similaridade, e ao final da seção em que são reportados os resultados obtidos para
o mapeamento de horizontes apresentamos alguns resultados comparativos entre
as duas funções de similaridade testadas, sugerindo ser a distância euclidiana uma
melhor opção.
O capítulo está organizado da seguinte maneira: na seção 5.1 apresentamos os
resultados do processo de mapeamento automático de horizontes, obtidos para os
três volumes sísmicos de teste de que dispúnhamos. São também apresentados os
resultados para o volume onde inserimos ruído propositalmente no dado. Depois

53
dos resultados obtidos pelo mapeamento dos horizontes, na seção 5.2
apresentamos alguns resultados comparativos entre as duas funções de
similaridade testadas, a distância euclidiana e o coeficiente de correlação.
Na seção 5.3 apresentamos os resultados do procedimento de mapeamento das
falhas sísmicas acompanhado dos parâmetros de mapeamento desse algoritmo,
tanto de treinamento quanto o valor de tolerância utilizado na extração.
Não nos preocupamos em encontrar uma superfície simples a partir do
conjunto de voxels obtido pelo processo de mapeamento das falhas, de forma que
os resultados são apresentados apenas como o conjunto de voxels resultante, com
os voxels individualmente iluminados. A qualidade de visualização, no entanto,
permite avaliar corretamente o desempenho obtido pelo método.
Todos os testes foram realizados em um Pentium D 3.0GHz, com 2 GB de
memória RAM. A placa gráfica utilizada nos testes foi uma NVidia Quadro FX
3550. Entretanto nessa versão da implementação não foram utilizados recursos de
programação em placa gráfica.

54
5.1 Mapeamento de horizontes
O primeiro dado volumétrico era o de maior coerência espacial lateral entre os
voxels. Nesse primeiro volume, por mais que variássemos o conjunto de
parâmetros de treinamento, os resultados do processo de mapeamento eram
sempre satisfatórios. As dimensões são 171x371x111, e os voxels são do tipo
ponto flutuante de 32 bits.
Para esse dado sísmico, mostramos os resultados obtidos no mapeamento de
três horizontes. Para os três, os parâmetros de treinamento utilizados no GNG
foram: b = 0,06, t = 0,003, amax = 700, = 30000, = 0,5, = 0,005. As
amostras no volume de entrada têm 19 voxels (k=9), e as amostras no volume
quantizado têm 15 voxels (q=7).
A função de similaridade do treinamento foi a distância euclidiana, e o valor
da tolerância máxima para o voxel candidato em cada traço foi de 14 distâncias
médias para os três horizontes. Além disso, nesse treinamento foram gerados 88
neurônios, ou seja, no volume quantizado os voxels possuem somente 88
identificadores diferentes.
Nas figuras 5.1 e 5.2 apresentamos os dois primeiros resultados. Esses
horizontes são caracterizados no dado pelas altas amplitudes (em módulo) dos
seus voxels. Isso facilitou o procedimento de mapeamento automático.
Na figura 5.3 podemos ver outro resultado para o mesmo volume, situado em
uma região onde os voxels são caracterizados pelos baixos valores das suas
amplitudes, e o horizonte que eles representam não está bem caracterizado no
dado. Mesmo nesse caso pode-se considerar o resultado satisfatório. Na figura 5.4
apresentamos as três superfícies simultaneamente.

55
Figura 5.1: horizonte sísmico representado nos dados por voxels de alta amplitude e
numa região de traços bem definidos.

56
Figura 5.2: horizonte sísmico representado nos dados por voxels de alta amplitude.

57
Figura 5.3: horizonte sísmico representado nos dados por voxels de baixa amplitude.
Isso faz com que o horizonte seja mal caracterizado.

58
Figura 5.4: Última ilustração mostrando simultaneamente os três horizontes mapeados.
No segundo arquivo de dados sísmicos utilizado nos testes a taxa de ruído
existente nos dados já é bastante acentuada. Além disso, as superfícies que foram
mapeadas não estão representadas em vários dos traços sísmicos do dado, e a
vizinhança vertical dos voxels da superfície varia consideravelmente ao longo do
volume.
Dessa forma, para esse dado, apesar de os parâmetros de treinamento do
algoritmo de GNG não sofrerem variações em relação àqueles utilizados no
primeiro volume testado, o número de neurônios gerado e as dimensões das
amostras de treinamento e de extração foram aumentados. Neste caso as amostras
no volume de entrada têm 25 voxels (k=12), e as amostras no volume quantizado
têm 19 voxels (q=9). O número de neurônios do grafo resultante do treinamento
teve 120 neurônios. As dimensões do dado são 182x202x126, e os voxels são do
tipo ponto flutuante de 32 bits.
A função de distância do treinamento foi a distância euclidiana, e o valor da
tolerância máxima para o voxel candidato em cada traço foi aumentado para 30
distâncias médias. Mostramos os resultados obtidos para dois horizontes
mapeados. Nas figuras 5.5 e 5.6 temos os resultados das superfícies mapeadas.
Mostramos a mesma fatia com e sem a visualização dos horizontes, evidenciando
as dificuldades existentes.

59
Figura 5.5: O horizonte não está presente em vários dos traços do volume, o que
dificulta o mapeamento. O horizonte em contraste com algumas fatias.

60
Figura 5.6: A relação sinal/ruído e as características do dado dificultaram o procedimento
de mapeamento. Outro exemplo de horizonte mapeado.

61
O último volume de dados utilizado nos testes é, sem dúvida, aquele que tem a
pior relação sinal/ruído, o que fica claro quando observamos fatias contíguas do
volume. Esse foi o dado de teste em que os resultados foram mais difíceis de
serem obtidos, sendo o volume em que o conjunto de parâmetros adequado mais
influenciou o desempenho alcançado. As dimensões do dado são 100x70x126, e
os voxels são do tipo ponto flutuante de 32 bits.
Nesse caso mostramos os resultados do mapeamento de dois horizontes
sísmicos. Para ambos os parâmetros de treinamento utilizados no GNG foramb =
0,06, t = 0,003, amax = 900, = 35000, = 0,5, = 0,005. As amostras no
volume de entrada têm 25 voxels (k=12), e as amostras no volume quantizado têm
21 voxels (q=10).
Uma observação a ser feita é que, devido à qualidade do dado, a similaridade
existente entre voxels pertencentes a um mesmo horizonte tende a ser
relativamente baixa. Com isso o valor da tolerância máxima para o voxel
candidato em cada traço foi de 50 distâncias médias para os dois horizontes
mapeados. Além disso, visando minimizar o impacto do ruído, o número de
neurônios gerados pelo treinamento teve que ser aumentado, tendo sido gerados
140 neurônios.
Os resultados alcançados pelo procedimento de mapeamento para esse dado
sísmico podem ser visualizados nas figuras 5.7 e 5.8, onde são mostradas as
superfícies obtidas em contraste com três fatias volumétricas. Em cada caso na
porção esquerda da figura são apresentadas somente as fatias, e na porção direita
apresentamos também a superfície obtida. Na figura 5.9 vemos as mesmas
superfícies, porém com maior grau de detalhe.

62
Figura 5.7: Horizonte mapeado no volume de pior relação sinal/ruído.

63
Figura 5.8: Horizonte mapeado no volume de pior relação sinal/ruído.

64
Figura 5.9: Uma vista mais detalhada dos horizontes mapeados.

65
5.2 Coeficiente de correlação como função de similaridade
Nesta seção demonstramos alguns dos resultados obtidos pelo uso do
coeficiente de correlação como função de similaridade utilizada para a etapa de
treinamento do GNG.
Não constatamos diferença significativa na utilização desta função em relação
ao uso da distância euclidiana, exceto pelo fato de que ao utilizar o coeficiente de
correlação é bastante comum que a superfície mapeada apresente pequenos
deslocamentos relativos entre voxels vizinhos, o que causa pequenas ranhuras na
superfície mapeada, prejudicando a visualização.
Outra vantagem da utilização da distância euclidiana como critério de
similaridade diz respeito ao seu tempo de computação consideravelmente menor
quando relacionado ao tempo gasto pelo cálculo do coeficiente de correlação.
Essas vantagens foram as que nos motivaram a utilizar a distância euclidiana
como critério de similaridade ao longo dos demais testes reportados na
dissertação.
Na figura 5.10 são comparadas as superfícies resultantes do processo de
mapeamento de um mesmo horizonte utilizando como critério de similaridade a
distância euclidiana (porção superior da figura) e o coeficiente de correlação
(porção inferior). Apesar de os conjuntos de voxels retornados pelos
procedimentos serem similares, aqueles retornados pelo procedimento que utiliza
o coeficiente de correlação sofrem pequenos deslocamentos verticais em relação
aos seus vizinhos imediatos, o que prejudica a visualização.

66
Figura 5.10: Duas superfícies, indicando a maior uniformidade da superfície obtida a
partir do grafo gerado utilizando distância euclidiana.

67
5.3 Mapeamento das falhas sísmicas
O procedimento de mapeamento das falhas sísmicas foi realizado em apenas
um dado sísmico, o que não nos permitiu avaliar de maneira mais conclusiva seu
desempenho. No entanto, os resultados apresentados aqui sugerem que esse é um
procedimento que merece um estudo mais abrangente.
O mapeamento de cada falha presente no dado se inicia a partir de uma
semente. Uma vez definidos a semente e o valor de tolerância a ser utilizado, caso
o voxel semente seja considerado falha, é imediatamente adicionado à lista de
voxels que representam a falha em questão, e seus vizinhos são incluídos na lista
de voxels candidatos que serão testados posteriormente. O processo é repetido
para cada um dos voxels da lista de candidatos até que essa lista esteja vazia.
Ao final tem-se um conjunto de voxels formando uma nuvem de pontos
conexa onde a falha mapeada está definida, e espera-se que essa nuvem de pontos
defina a região de falha com precisão.
Nas próximas páginas são demonstrados os resultados obtidos pelo
procedimento de mapeamento das falhas sísmicas. Na figura 5.11 são mostradas
algumas fatias volumétricas, onde pode-se verificar a existência e a região de
ocorrência das falhas sísmicas. Nas figuras 5.12, 5.13, 5.14 e 5.15 as falhas
encontradas são mostradas em contraste com horizontes mapeados do volume,
ficando evidenciada sua existência.

68
Figura 5.11: Fatias indicando a presença de falhas sísmicas através do volume de dados
sísmicos.

69
Figura 5.12: As falhas sísmicas (em amarelo) obtidas pelo procedimento de mapeamento
automático em contraste com um horizonte.

70
Figura 5.13: As falhas sísmicas (em amarelo) obtidas vistas em maior detalhe.

71
Figura 5.14: As mesmas falhas sísmicas (em amarelo) em contraste com outro horizonte
sísmico.

72
Figura 5.15: As falhas sísmicas (em amarelo) vistas em maior detalhe.

73
6 Conclusões e trabalhos futuros
Neste trabalho foram descritos o processo de desenvolvimento e os primeiros
resultados alcançados por uma estratégia baseada em agrupamento de dados
aplicada ao mapeamento automático de dois eventos sísmicos importantes, os
horizontes sísmicos e as falhas sísmicas. Numa primeira etapa é realizado um pré-
processamento dos dados de entrada, o que permite a criação de um novo volume.
Os métodos de mapeamento utilizam o volume quantizado resultante desse
processo de agrupamento.
No que diz respeito ao procedimento de mapeamento dos voxels de um
determinado horizonte, a criação do volume quantizado permite que esses voxels
sejam encontrados através do volume independentemente da ordem em que os
traços são percorridos, e sem necessidade alguma de informações de vizinhança
lateral, pois tais informações tendem a ser implicitamente disponibilizadas pela
distribuição dos nós do grafo ao longo do espaço amostral. Tal fato permite que os
voxels dos horizontes sejam encontrados independentemente da existência e
através das possíveis falhas sísmicas presentes nos dados, o que representa um
avanço em relação aos métodos de mapeamento automático mais difundidos na
literatura, nos quais o processo pára na presença de descontinuidades que separem
completamente o horizonte sendo descoberto. Os resultados alcançados
apresentados ao longo do texto demonstraram um desempenho considerado
satisfatório para o método, mesmo quando aplicado a volumes sísmicos
caracterizados pelo alto nível de ruído presente nos dados.
Em relação ao processo de mapeamento automático das falhas, apesar de os
resultados alcançados serem preliminares (para os testes somente dispúnhamos de
um arquivo de volume onde existiam falhas sísmicas), o desempenho leva a crer
que essa estratégia merece um estudo mais aprofundado.
No que se refere à qualidade do código-fonte, a implementação pode ser
consideravelmente melhorada, principalmente no que diz respeito ao tempo
requerido pela implementação atual para a extração dos horizontes e ao tempo

74
gasto durante a fase de treinamento da instância do algoritmo GNG. Melhorar o
desempenho desse processo de treinamento (que resulta no grafo utilizado para
gerar o volume quantizado) é desejável, e para isso são necessárias melhorias na
estrutura de dados que armazena os neurônios à medida que vão sendo criados. Na
versão atual da implementação esses neurônios estão armazenados numa lista
simples, sem qualquer organização estrutural interna que reflita sua localização
espacial. Isso faz com que o processo de treinamento seja quadrático no número
de neurônios existentes, o que na prática impede a criação de grafos contendo um
grande número de neurônios.
Além disso, é desejável que sejam executados testes utilizando uma estratégia
híbrida entre o algoritmo utilizando GNG e as estratégias de crescimento de
região já difundidas na literatura. Isso supostamente vai gerar resultados
amplamente satisfatórios. Os voxels descobertos pelo algoritmo baseado em
agrupamento seriam considerados como parte do horizonte já descoberto, e
serviriam de sementes (através das falhas) para a descoberta dos demais voxels
utilizando os métodos de crescimento de região, garantido a qualidade do
processo final obtido.
É necessário testar o algoritmo de extração de falhas sísmicas em outros
volumes. Também deve ser levado em conta que o processo de extração das
falhas, aqui baseado numa estratégia simples, pode ser bastante melhorado. Uma
vez que o volume quantizado tende fortemente a minimizar a presença de ruído
existente nos dados iniciais, alguns dos métodos descritos na literatura para
encontrar falhas sísmicas em volumes sísmicos sem tratamento podem ser
reimplementados utilizando os dados do volume quantizado, o que possivelmente
irá melhorar o resultado final.
Outras funções de similaridade precisam ser implementadas e testadas, as
amostras podem ser criadas com os dados no domínio da freqüência, as amostras
podem ser criadas representando somente os picos de amplitude (supostamente
isso diminuiria ainda mais possíveis ambigüidades).... Enfim, existe uma vasta
quantidade de testes e melhorias a serem realizados.

75
7 Bibliografia
[Admasu 2004] Automatic method for correlating horizons across faults in 3D
seismic data. IEEE Conference on Computer Vision and Pattern Recognition,
Washington DC, June 2004.
[Alberts 2000] Artificial Neural Networks for Simultaneous Multi Horizon
Tracking across Discontinuities, 70th Annual International Meeting, SEG,
Houston, USA.
[Dorn 1998] Modern 3-D Seismic Interpretation, The Leading Edge, Vol. 17,
No. 9, pp. 1262-1273.
[Fleck 2004] Agrupamento e visualização de dados sísmicos através de
quantização vetorial, Tese de Doutorado, Pontifícia Universidade Católica do
Rio de Janeiro, Rio de Janeiro - RJ, 2005.
[Fritzke 1995] A growing neural gas network learns topologies. In G. Tesauro,
D. S. Touretzky, and T. K. Leen, editors, Advances in Neural Information
Processing Systems 7, MIT Press, Cambridge MA, pp. 625-632.
[Gerhardt 1998] Aspectos da Visualização Volumétrica de Dados Sísmicos.
[Haykin 1999] Neural Networks A Comprehensive Foundation 2nd ed.,
Prentice Hall Inc.
[Herron 2000] Horizon autopicking, The Leading Edge 19, 491.
[Holmström 2002] Experiments with GNG, GNG with Utility and Supervised
GNG, Master Thesis, Uppsala University.
[Kohonen 1982] Self-organized formation of topologically correct feature
maps. Biological Cybernetics, pp. 43:59 - 69.
[Loos 1998] DemoGNG v1.5.
[Lorensen, Cline 1987] Marching Cubes: A High Resolution 3D Surface
Construction Algorithm, International Conference on Computer Graphics and

76
Interactive Techniques (SIGGRAPH'87), 14th, v.21, n.4, August 1987, p. 163—
169.
[Machado 2000] Segmentação de Dados Sísmicos Via Hyperstack para
Visualização, Dissertação de Mestrado, Pontifícia Universidade Católica do Rio
de Janeiro, Rio de Janeiro - RJ, 2000.
[MacQueen 1967] Some methods for classification and analysis of
multivariate observations. In LeCam, L. and Neyman, J., editors, Proceedings of
the Fifth Berkeley Symposium on Mathematical statistics and probability, volume
1, Berkeley. University of California Press, pp. 281-297.
[MRuthener, 2004] Aplicação da Transformada S na decomposição espectral
de Dados Sísmicos, Dissertação de Mestrado, Pontifícia Universidade Católica
do Rio de Janeiro, Rio de Janeiro - RJ, 2004.
[Robison, Treitel 1980] Geophysical Signal Analysis, Prentice-Hall, 1980.
[Sheriff 1991] Encyclopedic Dictionary of Exploration Geophysics, 3. ed.,
[Silva 2004] Visualização Volumétrica de Horizontes em Dados Sísmicos 3D,
Tese de Doutorado, Pontifícia Universidade Católica do Rio de Janeiro, Rio de
Janeiro - RJ, 2004.
[Thomas 2001] Fundamentos da Engenharia de Petróleo, Editora Interciência.
Dissertação de Mestrado, Pontifícia Universidade Católica do Rio de Janeiro, Rio
de Janeiro - RJ, 1998.
Society of Exploration Geophysicists – SEG, Tulsa, OK, 1991.














![Um Estudo das Técnicas de Obtenção de Forma a …webserver2.tecgraf.puc-rio.br/~mgattass/teses/2005Dissertacao... · [28] Carihill [30] Tajima. Métodos de Codificação de Luz](https://img.dokumen.tips/doc/110x75/5ba9fb0609d3f221798b7613/um-estudo-das-tecnicas-de-obtencao-de-forma-a-mgattassteses2005dissertacao.jpg)














