Embed Size (px)
Citation preview

ATHABASCA UNIVERSITY
KNOWLEDGE UNCERTAINTY IN INTELLIGENT SYSTEM
BY
SHIKHA SHARMA
An essay submitted in partial fulfillment
Of the requirements for the degree of
MASTER OF SCIENCE in INFORMATION SYSTEMS
Athabasca, Alberta
October, 2010
©Shikha Sharma, 2010
i

DEDICATION
I would like to dedicate this essay to my parents, and my siblings Rinki and Anshul, who have always been a source of encouragement and motivation to me. Without their continued love and support, this would not have been possible.
ii

ABSTRACT
One of the prominent questions in the field of artificial intelligence is “how to
deal with knowledge uncertainty?” Uncertainty is a fundamental and inevitable
feature of daily life; it is a central topic in many domains such as economics, artificial
intelligence, and logic. Management of uncertainty is an essentially important issue
in the design of an intelligent system. Various uncertainty models are available to
deal with uncertainty: Fuzzy logic, Rough set theory, Multi-valued logic, and
Bayesian network. Uncertainty can be found in many different Information
Technology applications such as semantic web services and data mining. These
applications are used in day to day lives where modeling and reasoning with
uncertainty is primordial; this makes it critical to have excellent measures in place to
deal with uncertainty. For intelligent system to deal with this uncertainty there has to
be a structured soft-computing framework in place, which will allow it to accomplish
this goal. The essence of designing an intelligent system lies in its ability to
effectively control an object in the dynamic environment under the influence of
uncertainty. Hybridization of soft computing techniques provides a cutting edge to
the hybrid intelligent systems. The design and architecture play a central role in the
success of intelligent system. At the design level, dealing with uncertainty at object,
environment and goal level help to deal with uncertainty at an architecture level.
Therefore, having a right design and architecture for intelligent system defines the
success of intelligent systems. ANFIS is an excellent example of an intelligent
system based upon hybridization of neural network and fuzzy logic useful in
suppressing maternal ECG from fetal ECG. An intelligent system that is
iii

implemented to handle uncertainty can handle real world situations accurately and
effectively than a system where uncertainty is fully ignored.
iv

ACKNOWLEDGEMENTS
I am heartily thankful to my supervisor, Larbi Esmahi whose encouragement, guidance and support from the initial to the final level enabled me to develop an understanding of the subject. Very special thanks to my Mom, Dad, Rinki and Anshul for providing me with the support during this journey. I would also like to thank wonderful friends for their continued support and encouragement.
v

TABLE OF CONTENTS
Table of Contents
INTRODUCTION ....................................................................................................... 1
1.1 Background................................................................................................... 1
1.2 Statement of Purpose ................................................................................... 3
1.3 Research Problem ........................................................................................ 3
1.4 Organization of Thesis .................................................................................. 4
REVIEW OF RELATED LITERATURE ..................................................................... 5
2.1 Classical Theory ........................................................................................... 5
2.2 Fuzzy Logic................................................................................................... 7
2.2.1 Characteristics of Fuzzy Logic ................................................................... 9
2.2.2 Features of Fuzzy Logic ............................................................................ 9
2.2.3 Deduction Process .................................................................................. 10
2.2.4 Membership Function .............................................................................. 11
2.2.5 Advantages ............................................................................................. 12
2.2.6 Disadvantages ......................................................................................... 12
2.2.7 Applications ............................................................................................. 12
2.2.8 Future Work ............................................................................................. 13
2.3 Rough Set ................................................................................................... 13
2.3.1 Basic Concept ......................................................................................... 15
vi

2.3.2 Advantages ............................................................................................. 19
2.3.3. Disadvantages ..................................................................................... 19
2.3.4 Future Work ............................................................................................. 19
2.4 Multi-Valued Logic ...................................................................................... 20
2.4.1 Approximate Reasoning with Linguistic Modifiers ................................... 24
2.4.2 Synthesis of Multi Valued Logic ............................................................... 25
2.4.3 Future Work ............................................................................................. 27
2.5 Bayesian Network ....................................................................................... 27
2.5.1 Independence Assumptions .................................................................... 28
2.5.2 Consistent Probabilities ........................................................................... 29
2.5.3 Constraints .............................................................................................. 30
2.5.5. Applications .......................................................................................... 32
2.5.6 Advantages ............................................................................................. 33
2.5.7 Disadvantages ......................................................................................... 33
UNCERTAINTY MODELS IN APPLICATIONS ....................................................... 34
3.1 Data Mining................................................................................................. 34
3.1.1 Background ............................................................................................. 34
3.1.2 Characteristics of Data Mining ................................................................. 36
3.1.3 Data Mining and Uncertainty ................................................................... 37
3.1.4 Fuzzy Logic Uncertainty Model ............................................................... 39
3.1.5 Applications ............................................................................................. 43
3.2 Semantic Web Services and Uncertainty .................................................... 44
vii

3.2.1 Background ............................................................................................. 44
3.2.2 Semantic Web Services .......................................................................... 45
3.2.3 Uncertainty in Semantic Web Services .................................................... 48
3.2.4 Fuzzy Logic Uncertainty Model ............................................................... 51
SOFT COMPUTING FOR INTELLIGENT SYSTEM: DESIGN AND
ARCHITECTURE ..................................................................................................... 57
4.1 Soft-computing for Intelligent Systems ....................................................... 57
4.1.1 Main Components of Soft Computing ...................................................... 58
4.1.2 Characteristics of Soft Computing ........................................................... 59
4.2 Design of Intelligent Systems with Uncertainty ........................................... 61
4.2.1 Main Aspects of Design ....................................................................... 62
1. Uncertainty in Objects .................................................................................... 62
2. Uncertainty in Surrounding Environment........................................................ 62
3. Uncertainty in Expected Functionality ............................................................ 63
4.2.2 Design Framework .................................................................................. 64
1. Fuzzy Logic .................................................................................................... 65
2. Evolutionary Artificial Neural Networks .......................................................... 66
1. Evolution introduced at weight training level .................................................. 67
2. Evolution introduced at the architecture level ................................................. 67
3. Evolution introduced at the learning level ...................................................... 68
4.2.3 Selection of Appropriate Design .............................................................. 69
4.3 Architecture of Intelligent System with Uncertainty ..................................... 70
viii

4.3.1 Architecture for Intelligent System ........................................................... 70
4.3.2 Architecture for Hybrid Intelligent System ................................................ 71
4.3.3 Evolutionary Algorithm Architecture......................................................... 75
4.3.4 Application: Suppression of Maternal ECG from Fetal ECG ................... 76
CONCLUSION AND RECOMMENDATIONS .......................................................... 84
5.1 Conclusion .................................................................................................. 84
5.2 Future Work ................................................................................................ 86
REFERENCES ........................................................................................................ 88
ix

LIST OF TABLES
Table 1: Candidate Data ......................................................................................... 15
Table 2: Buidling Phase [72] ................................................................................... 55
Table 3: Utilitization Phase [72]............................................................................... 56
x

xi
LIST OF FIGURES
Figure 1: D-connecting Paths [23] ........................................................................... 29
Figure 2: Connected Networks................................................................................ 31
Figure 3: Overview Steps in Knowledge Discovery of Databases [42] .................... 35
Figure 4: Data Mining [80] ....................................................................................... 38
Figure 5: Fuzzy Logic in Data Mining [70] ............................................................... 42
Figure 6: Web Services & Semantic Web Services [67] ......................................... 45
Figure 7: Semantic Web (Detailed) [66] .................................................................. 46
Figure 8: Web Services Framework [72] ................................................................. 51
Figure 9: Relation between soft computing and other fields [73] ............................ 60
Figure 10: Basic Architecture for Intelligent Systems .............................................. 71
Figure 11: Sequential Type of Architecture ............................................................. 72
Figure 12: Parallel Type of Architecture .................................................................. 73
Figure 13: Feedback Type of Architecture .............................................................. 74
Figure 14: Evolutionary Intelligent System Architecture [73] ................................... 76
Figure 15: Basic Configuration of a Fuzzy Logic System [89] ................................. 79
Figure 16: Maternal ECG Cancellation in Abdominal Signal using ANFIS [87] ....... 81

CHAPTER 1
INTRODUCTION
“As a general principle, the uncertainty of information in the knowledge base will induce some uncertainty in the validity of its conclusions. These systems possess nontrivial inferential capability and in particular, have the capability to infer from premises which are imprecise, incomplete or not totally reliable.”
- Prof. Lotfi A. Zadeh
1.1 Background One of the prominent questions in the field of artificial intelligence is “how to deal
with knowledge uncertainty?” Uncertainty is a fundamental and inevitable feature of
daily life; it is a central topic in many domains such as economics, artificial
intelligence, and logic. Its definition varies in a number of fields, including
philosophy, physics, statistics, economics, finance, insurance, psychology,
sociology, engineering, and information science [3]. More specific definition of
uncertainty by Doug Hubbard is: “the lack of certainty, a state of having limited
knowledge where it is impossible to exactly describe existing state or future
outcome, more than one possible outcome [3].”
When dealing with real-world problems, we can rarely avoid uncertainty. Klir
and Wierman describe uncertainty in [57]. “At the empirical level, uncertainty is an
inseparable companion of almost any measurement, resulting from a combination of
inevitable measurement errors and resolution limits of measuring instruments. At the
cognitive level, it emerges from the vagueness and ambiguity inherent in natural
language. At the social level, uncertainty has even strategic uses and it is often
1

created and maintained by people for different purposes (privacy, secrecy, propriety)
[57].” There are three main types of uncertainties:
1. Fuzziness (vagueness): uncertainty due to imprecise boundaries (fuzzy set
instead of crisp set).
2. Imprecision (non-specificity): uncertainty due to size of relevant sets of
alternatives.
3. Discord (strife): uncertainty due to conflicts among various sets of alternatives.
Management of uncertainty is an essentially important issue in the design of
an intelligent system. To define an intelligent system: it is an information system
which provides the user with a facility of posing and obtaining answers to questions
relating to information stored in its knowledge base. The knowledge base of an
intelligent system is a repository of human knowledge which is usually not very
precise in nature and is not a complete set of accurate facts and rules. Hence,
much of the information in the knowledge base is imprecise, incomplete, or not
totally reliable thereby making it imperative to deal with uncertainty.
There has been enormous effort undertaken to deal with uncertainty and lot of
literature has been generated during this time on “how to handle uncertainty.” The
most popular approach to dealing with uncertainty is the theory of probabilistic logic;
Judea Pearl’s classical book of “Probabilistic Reasoning in Intelligent Systems:
Networks of Plausible Inference [25]” provides a framework for this reasoning. Other
approaches were conditional planning, and decision theory. There has been a
revolution in the field of Artificial Intelligence on how to handle uncertainty; various
uncertainty models have been introduced based upon predicate logic, and
2

probability based method. Some of these models are:
• Fuzzy Logic
• Multi-valued Logic
• Bayesian Networks
• Rough Sets
Uncertainty can be found in many different Information Technology
applications such as semantic web services and data mining. These applications
are used in day to day lives, hence making it critical to have excellent measures in
place to deal with uncertainty. We will be identifying unique characteristics of each
domain and map them to the uncertainty model that best compliments them.
1.2 Statement of Purpose
Main goal of this essay is to identify main components of soft-computing framework
and discuss design and architecture for intelligent system. This will provide users
with much needed tools for developing intelligent systems that can handle
knowledge uncertainty in a diligent manner.
1.3 Research Problem Many theories have been developed to deal with knowledge uncertainty but neither
structured framework has been established nor have standard guidelines been
developed. This makes it imperative to find new measures to represent knowledge
uncertainty in intelligent systems. For these reasons, additional research is needed
to build frameworks and develop recommendations for managing uncertainty in
information systems. There has been extensive research done in the field,
3

identifying issues of uncertainty as well as uncertainty models of information
systems, but only limited interaction exists between these two areas.
1.4 Organization of Thesis This thesis contains 5 chapters:
Chapter 2 provides a literature review of five types of uncertainty models
highlighting underlying principles, their strengths and weaknesses. These models
are: Fuzzy logic; Multi-valued logic; Rough Set; and Bayesian network;
Chapter 3 deals with review of different domains of applications and mapping
uncertainty models to each type of application. Semantic web services and Data
mining will be two domains of interest for the purpose of this essay.
Chapter 4 presents a framework to represent knowledge uncertainty. The
design and architecture of the main components to be included in the framework will
be discussed. One application of intelligent system in the real world will be explored.
Chapter 5 concludes the thesis with conclusions, recommendations to work
around knowledge uncertainty, and future work to be conducted in this field.
4

CHAPTER 2
REVIEW OF RELATED LITERATURE “Uncertainty modeling is an area of artificial intelligence concerned with accurate
representation of uncertain information and with inference and decision-making
under conditions infused with uncertainty [4].” In an ideal world, agents would know
all the facts about the environment in which they operate. Unfortunately, reality is far
from idealism where agents do not have access to the whole truth, thereby making it
impossible to derive conclusions that are fully accurate. Hence these agents should
be well equipped to deal with uncertainty.
2.1 Classical Theory There are different methodologies to deal with uncertainty; few of them are
described below:
• Conditional Planning: one of the traditional approaches to dealing with
uncertainty is conditional planning. Conditional planning can deal with
uncertainty as long as it is a simple case where there are not too many
variables involved, i.e. ability to get its hand on required information and deal
with few contingencies. Due to very complex nature of our environment, it is
practically impossible to have a complete set of facts about the environment.
Three main reasons why first order logic fails to deal with uncertainty are [12]:
1. Laziness: it takes a lot of work to compile the complete set of rules for
the environment in which it operates.
5

2. Theoretical Ignorance: having incomplete knowledge of the complete
theory for the domain in question.
3. Practical Ignorance: each case is unique therefore all the generic rules
cannot be applied; hard to deal with exceptions.
• Probability Theory: Rational decision is another method where an agent has
a goal and will execute the plan that guarantees result (i.e., a goal is
achieved). This method is based upon “degree of belief.” In the world full of
uncertainty, it becomes tough to provide a yes or no answer. Therefore we
provide a number (ranging between 0 to 1) to the likelihood of event
happening or how true a statement is. This number represents degree of
belief and this theory is referred to as Probability Theory.
• Decision Theory: It is a combination of Probability Theory and Utility Theory.
o Probability Theory: as discussed above, is dependent upon degree of
belief.
o Utility Theory: is dependent upon making the decision based upon
highest utility (degree of usefulness).
These theories were competent in their own ways to deal with uncertainty; but
as the complexity grew, so did the demand for sophisticated models. These
conventional theories failed to provide an adequate model for modes of reasoning
which are approximate rather than exact, and most of human reasoning fall into this
category [15]. There were many different approaches introduced; we will take a look
at four different models: Fuzzy Logic, Multi-valued Logic, Bayesian Networks, and
Rough Sets.
6

2.2 Fuzzy Logic “Fuzzy logic provides a natural framework for the management of uncertainty in intelligent system because – in contrast to traditional logic systems – its main purpose is to provide a systematic basis for representing and inferring from imprecise rather than precise knowledge. In effect, in fuzzy logic everything is allowed to be – but need not be – a matter of degree.”
- Prof. Lotfi A. Zadeh
One of the main problems in dealing with uncertainty in information system is the
fuzziness associated with the knowledge base of an intelligent system; this lead to
the introduction of Fuzzy Logic, also referred to as fuzzy reasoning. Wikipedia
defines Fuzzy Logic as “a form of multi-valued logic derived from fuzzy set theory to
deal with reasoning that is approximate rather than precise [6].” Fuzzy logic contrary
to its name is not fuzzy rather precise. Fuzzy logic variables may have truth values
that range between 0 and 1 which corresponds to the degree of truth [6].
Prior to fuzzy logic being introduced in the world of uncertainty, probability
theory enjoyed the monopoly; but this traditional approach to dealing with
uncertainty failed to come to terms with the fact that uncertainty is possibilistic in
nature than probabilistic. As Asli and Burhan [5] claimed, in realm of uncertainty and
imprecision, fuzzy logic has much to offer. Fuzzy Logic is based upon both
predicate logic and probability theory providing the answer to the posed question
with an assessment of “how reliable the answer is.” This assessment of reliability is
also called a certainty factor. Fuzzy Logic has two main components:
1. Test-Score Semantics: represents the knowledge (Predicate Logic).
7

2. Inferential Component: infer answers to posed questions and provide fuzzy
quantifier (Probability Theory).
The main difference between fuzzy logic and traditional approach is that the
objects of interest are allowed to be much more general and much more complex
than the objects in traditional logical systems and probability theory. Fuzzy Logic
further addressed issues that were hard to deal with using conventional techniques.
Here are few important issues [1] that can be handled through fuzzy logic:
1. Fuzzy rules where antecedent/consequent are of form:
a. If A is M then B is N
b. If A is M then B is N with CF = α
In the above forms, A is M and B is N are fuzzy propositions, and α is a
certainty factor.
2. Partial match between the users supplied fact and the rule in the knowledge
base: this is the case where fact may not be identical to antecedent of a rule
in the knowledge base.
3. Fuzzy Quantifiers: Antecedent/Consequent of a rule may contain explicit or
implicit fuzzy quantifiers. For example, consider the following proposition with
implicit fuzzy quantifier (disposition):
d = university students are between 18 and 24
This may be interpreted as the proposition:
p = most university students are between 18 and 24
Expressing this as a rule:
r = If x is a university student then it is likely that x is between 18 and 24.
8

2.2.1 Characteristics of Fuzzy Logic Main characteristics of Fuzzy Logic as outlined by Zadeh in [15]:
1. Matter of Degree concept: representing everything as a matter of degree.
“The unique property of fuzzy sets is that membership in a fuzzy set are not a
matter of acceptance or denial, but rather a matter of degree.”
2. Any logic system can be fuzzified: i.e., conversion of any system to a fuzzy
system. This is achieved by fuzzifying the inputs by applying membership
functions to the input.
3. Knowledge base consists of fuzzy constraint on collection of variables.
4. Reasoning is viewed as elastic constraint propagation.
2.2.2 Features of Fuzzy Logic Main features of Fuzzy logic as summarized by Zadeh in [15] are:
1. Truth values can range over the fuzzy subsets of a finite or infinite truth-
values set, usually assumed in the range of [0, 1]. This can be regarded as
providing some kind of characterization to intermediate truth values.
2. Predicate can be crisp or fuzzy: In contrast to bivalent systems where
predicates are only crisp for e.g., larger than, fuzzy logic lets predicates to be
fuzzy, for e.g., much larger than.
3. Allows typical quantifiers (all & some) and fuzzy quantifiers (e.g. most, few):
fuzzy logic allows quantifiers that are used in day to day lives, thereby making
it easier to relate to the real world.
9

4. Ability to represent non fuzzy and fuzzy-predicate modifiers: In contrast to
classical system where negation (not) is the main predicate modifier, fuzzy
logic utilizes fuzzy modifiers such as very, extremely.
5. Three models of qualification:
a. Truth Qualification: expressing fuzzy truth value.
b. Probability Qualification: expressing fuzzy probability.
c. Possibility Qualification: expressing fuzzy possibility.
2.2.3 Deduction Process Four main categories for Propositions:
1. An unconditional, unqualified proposition
X is F,
Where X = variable and F = Fuzzy predicate
2. An unconditional, qualified proposition
X is F is λ,
Where X = variable, F = Fuzzy predicate and λ = Fuzzy probability
3. Conditional, unqualified proposition
If X is F then Y is G,
Where X and Y = variable, and F and G = Fuzzy predicate
4. Conditional, qualified proposition
If X is F then Y is G is λ,
Where X and Y = variable, F and G = Fuzzy predicate and λ = Fuzzy
probability
10

All facts or propositions in knowledge base are stored in canonical form; this
is usually done through inspection or by applying test-score semantic application on
propositions. By applying canonical form, we get possibility distribution where each
proposition in knowledge base is converted into possibility distribution which
provides constraints on the variable. Applying conjunction will lead to the
construction of Global Possibility Distribution which is induced by the totality of
propositions in knowledge base.
2.2.4 Membership Function The key problem in application of fuzzy logic is the construction of the membership
function of a fuzzy set. Three principal approaches are used to address this
concern:
1. Declarative approach: membership functions are specified by the designer of
a system.
2. Computational approach: membership function is expressed as a function of
the membership functions of one or more fuzzy sets with specified
membership functions.
3. Modelization Elicitation approach: membership functions are computed
through the use of co-intension enhancement techniques.
The main challenge in development of fuzzy system models is to generate
fuzzy if –then rules. These rules are created by extracting knowledge from human
experts which might be incomplete or not organized. As oppose to traditional
approach, this challenge has lead to building automated algorithms for modeling
systems using fuzzy theories via machine learning and data mining techniques.
11

2.2.5 Advantages
• It is time-invariant and deterministic: this allows for the integration of stability
analysis methods to be used with fuzzy logic.
• Ability to handle real world situations since it goes beyond the restriction of
two-state model (yes/no): it is not constrained to the regular true/false or
yes/no and can handle any situation through truth values ranging from 0 -1.
• It provides computation framework for dealing with uncertainty through test-
score semantics which provides a higher level of expressing power to
represent meanings of more propositions in a natural language.
• It is easily blended with conventional control techniques and can be added on
top of the expert opinion/experience.
2.2.6 Disadvantages
• Hard to synthesize if-then rules: difficult to deduce membership functions.
• Defuzzification of output should be validated to ensure that output is being
translated in a right way as it was intended to.
2.2.7 Applications
• Anti-lock Braking Systems
• Data Mining
• E-services
• Quality Support
• Decision control system
12

2.2.8 Future Work
• More research is needed to create if-then rules more accurately.
• Compare if-then rules created by domain expert versus through machine
learning to see which one is more accurate and feasible.
2.3 Rough Set “Rough set theory is a new approach to decision making in the presence of uncertainty and vagueness.”
- Zdzislaw Pawlak
Rough set theory was introduced by Zdzislaw I. Pawlak in early 1980s; this theory is
based upon formal approximation of a crisp set – pair of sets which provide the
lower and the upper approximation of the original set [10]. Traditional use of rough
set was to deal with decision problems, since then it has become an area of
interests among researchers from different disciplines, most of which are related to
Artificial Intelligence. Recently, rough set theory has been extended to deal with
knowledge uncertainty. S. Wong demonstrated that rough sets provide a suitable
framework for managing uncertainty in intelligent system. It is one of many
techniques available in the area of artificial intelligence to deal with knowledge
uncertainty and for uncertainty management in relational database [11]. Rough set
theory is also used in different disciplines in computer technology such as,
knowledge acquisitions, data mining and many more.
13

Rough set theory is based on the fundamental principle of associating some
information with every object in the universe. The underlying principle for this
mathematical tool is based upon indiscernibility relation. Indiscernibility relation
exists between two objects when all their attribute values are identical with respect
to the attributes or information under consideration [14]. These attribute values
cannot be distinguish (discerned) with regards to the considered attribute. Generally
a knowledge base is composed of two different sets:
1. Crisp Set – is precise; union of elementary sets (collection of indiscernible
objects).
2. Rough Set – is imprecise or vague.
Usually, we hit a grey zone with boundary line objects which are hard to be
placed in either of these sets. As Pawlak said in [16] “knowledge base has a
granular structure; due to this, vague concepts cannot be characterized in terms of
information about their elements.” Rough set theory brings forth the approach of
replacing vague concepts with a pair of precise concepts; Indiscernibility relation is
used to divide universe into equivalence classes. Pair of precise sets consists of
lower approximation and upper approximation of the vague concept. The notion of
approximation (lower and upper) allows us to distinguish between certain and
possible or partial inclusion in a rough set.
• Lower Approximation Region – results that are certain and “surely” belong to
the concept, i.e., exact match.
• Upper Approximation Region – results that are likely but still uncertain and
“possibly” belong to the concept.
14

• Boundary Region – difference between the upper approximation and the
lower approximation constitutes the boundary region of the set.
2.3.1 Basic Concept Here is the basic concept of Rough Set theory: 1. Indiscernibility Relation
As mentioned earlier, it considers groups of indiscernible objects as
oppose to a single object. As in [16], indiscernibility relation can be
formulated in a table called information system or an attribute-value table.
Table 1: Candidate Data
Name Education Job Prospects
Mike Elementary No
Philip High School No
Shelly High School Yes
Melissa University Yes
Jeff University Yes
Looking at the above table, we can see that for each Candidate we
have three attributes:
A Name
B Education
C Job Prospects
15

Each person can be discerned (distinguished) from each other based
on all three attributes. But if we were to take a look at the attribute Education,
equivalence classes could be defined as:
R(B) = {{Mike}, {Philip, Shelly}, {Melissa,Jeff}}
These subsets also define a partition of objects into classes. Information
table is useful in determining classification patterns. Representing
Information table above into more formal way as in [16]:
Let U = universe consisting of finite set of objects;
Let A = finite set of attributes (for each object in Universe)
With every attribute a € A is associated a set of value Va
Every attribute a determines a function:
Fa: U Va
Let B be a subset of A, indiscernibility relation on Universe U will be
defined as:
I(b) = {(x,y) U X U: fa(x) = fa(y), a B}
2. Approximation
The method of approximation helps identify unique characteristics of
object in question by deducing information in knowledge base; in other words,
be able to identify attributes given the set. Using this process we define lower
and upper approximation.
From Table 1, we infer that candidate with Job Prospects are {Shelly,
Melissa, Jeff}. If we were to define attributes of candidates with Job
16

Prospects, we can easily deduce that if Candidate has good education, then
they have job prospects as well.
We define lower and upper approximation:
Lower Approximation: {Melissa, Jeff}
Upper Approximation: {Philip, Shelly, Melissa, Jeff}
Boundary Region = Upper Approximation – Lower Approximation
Hence, Boundary region is: {Philip, Shelly}
Transforming this in mathematical way as in [16] we get:
Let U = universe consisting of finite set of objects;
Let X = subset of U
B = Subset of attributes A
B*(x) = {x : B(x) X} (Lower approximation) U
B*(x) = {x U: B(x) X ≠ 0} (Upper approximation)
BNb(x) = B*(x) - B*(x) (Boundary region of x)
If BNb(x) = 0, then set (x) is called crisp set where have an exact match; and if
BNb(x) ≠ 0, then we have a rough set. Rough set is characterized
numerically.
3. Rough Membership
It identifies the boundary region member which does not belong to
crisp set. As Pawlak said in [16] “Rough membership identifies uncertainty
related to the membership of element to a set.” He described rough
membership function as:
μbx(x) = |x B(x) where μb
x(x) [0, 1] |B(x)|
17

This can be interpreted as a degree of certainty to which x belongs to X.
Using this to define approximations:
B*(x) = {x : μbx(x) = 1} Lower Approximation U
B*(x) = {x : μbx(x) > 0} Upper Approximation U
B*(x) = {x U: 0< μbx(x) < 1} Boundary Region
Pawlak said that above function confirms that “vagueness is related to set,
while uncertainty is related to elements of sets.”
4. Dependency of Attributes
It analyzes relationships between attributes to see if one can be
inferred from another; that is A B, if the value of B can be inferred uniquely
from the value of A. In formal way this can be defined as:
B depends totally on A, iff:
I(A) I(B)
Now to define partial dependency of attributes as in [16],
Let A and B be subset of C
B is dependent upon A to kth degree where 0 ≤ k ≤ 1 (A kB) if
K = |POSA(B)| |U| Where POSA (B) = U x U/B Ax(X)
POSA (B) represents a set of all elements of U that can be uniquely identified
to the partition U/B from A.
18

5. Reduction of Attributes
An attribute is superfluous if its appearance or no appearance does not
make any difference to the object in universe. Hence we can reduce the
attributes and be able to get the minimal set of attributes which delivers the
same classification as does the full set of attributes.
2.3.2 Advantages
• It only requires data and no additional information.
• Mathematical approach with fully structured model makes it easy to
understand and obtain straightforward interpretation.
• Generates minimal decision rules.
2.3.3. Disadvantages
• Hard to generate decision rules from data.
• Hard to optimize decision rules.
2.3.4 Future Work
• More research is needed to generate optimal decision rules from data.
19

2.4 Multi-Valued Logic “Uncertainty means that the atoms may be assigned logical values other than the conventional ones - true and false, in the semantics of the program. The use of multi-valued logics to express uncertainty in logic programs may be suitable.”
-Daniel Stamate
“Multi-valued logic is a ‘logical calculi’ in which there are more than two-truth values.
Traditionally, there were only two-possible values for any proposition. An obvious
extension to classical two-valued logic is an n-valued logic for n>2 [10]”. This
extension leads to a new set which may be finite or infinite and have same structure
in place. As Dubois and Prade said in [20], multi-valued logic is constructed on truth
function calculi: the degree of truth of a formula can be calculated from the degree
of truth of its constituents. Due to this, it has become an attractive model to be
applied in the field of uncertainty, where degree of truth was viewed as certainty
factors.
Multi-valued logic has been used in wide array of logic systems such as
memory, multi level data communication coding and various digital processors [28].
Its roots were originated from Lukasiewicz and Post in the twenties. In this logic,
fuzziness phenomenon can occur at metalogical level (the level of construction of
the calculus and its semantics) and set is considered to be fuzzy if it is the
actualization of a predicate symbol in a structure [21].
There are many instances in real world where we get different view from
different people on topics of interest, such as requirement gathering stage in a
20

software lifecycle. Different stakeholders are interested in different aspects and
have different expectations of functionalities accomplished from the software. This
usually results in information which might not be consistent with each others’ views
and opinions and might be even incomplete in nature. Inconsistent viewpoints might
be critical if they affect the main functionality of the software, otherwise
inconsistency can be easily ignored. These types of inconsistencies can be
overcome by adopting non-classical paraconsistent logic.
Multi valued logic is a type of paraconsistent logic which is not limited to
typical two truth values, rather it can represent different types of contradictions and
different levels of uncertainty. Belnap said in [27] that “paraconsistent logic (multi
valued logic) has been driven by the need for automated reasoning systems that are
done given spurious answers if their database becomes inconsistent.” The usual
choice of values in multi valued logic depends upon the nature of the problem or
system in hand and to what granularity do we want to sustain the information so we
do not lose much data.
Lattices are used to represent the information (truth values) of the system. In
multi-valued logic, we can calculate the product of lattices as the merging point for
different views for dealing with inconsistent data. Product of two lattices results in a
lattice where a pair of element (a, b) are composed of element a from the first
lattices and element b from the second lattice. These products sustain all the
information of individual logics. Products can be taken to n lattices, where the
number of values in the resulting product lattices grows exponentially as n
increases. To deal with this, we can use the technique of abstraction. Abstraction
21

results in discarding some information and only retaining information that is relatively
important. With the multi-valued logic the more values we have, the more detailed
information we hold about the system it represents, and more complex it becomes.
Hence depending upon the problem in hand, we make a tradeoff between complete
or abstract data.
Multi-logic is usually used to represent abstract and qualitative things such as
helpful, handsome. Fuzzy logic falls short to represent these descriptions through
the use of fuzzy set, and that is where multi-valued logic is used. As an example
given in [33]:
If X is A then Y is B
If X is A` then Y is B`
In here X and Y are variables, and A, B, A`, B` are predicates. In multi-valued
logic these predicates are expressed as multi-sets. Multi-valued logic can be viewed
as an extension of fuzzy logic, some of its features and principles can be extended
to multi-valued logic. Multi-set theory is used to formalize the notions of membership
degree and of a truth degree. Defining it further as in [34]:
“A membership degree is not an uncertainty degree on the membership of an
object to a multi-set; it is instead the degree to which an object belongs to a multi-set
regardless of any uncertainty.”
A truth degree (τα) is used to express the confidence of “how accurate the
predicate is”; this is associated with each multi-set which usually tells how true the
predicate is. As an example, “Student A is extremely smart,” here student A
satisfies the predicate smart with the degree extremely. The main difference
22

between multi-valued logic and fuzzy logic is that in multi-valued logic the
membership degree is a subset of natural language while in fuzzy logic the
membership degree belongs to set [0,1]. The condition of an “ordered list” is forced
upon the set of truth degree (symbolic) with λM = {τ0,…, τi, τm-1}2 with the total order
relation
τi ≤ τj such that i ≤ j
The truth degrees can be proposed by expert using multi-valued logic as long
as it satisfies the condition of being in order. An example described in [33]:
M =7; λ7 = {not-at-all, very-little, little, moderately, enough, very, completely}
In multi-valued logic, Lukasiewicz’s aggregation functions are generally used.
Here is the definition in [32] for M truth-degrees:
TL(τα, τβ) = τmax(0, α + β – M + 1)
SL(τα, τβ) = τmin(M-1, α + β)
IL(τα, τβ) = τ min(M-1, M+1, α + β)
Using General Modus Ponens we can infer that we can have a rule defined
by the same multi-set as the premise, but can modify the truth-degree associated
with it. Taking a look at two relations [32]:
A´ > A represents that A´ is a reinforcement of A
A´ < A represents that A´ is a weakening of A
The above relations are expressed through modifications of the truth degree
of the same multi-set. Reinforcement is represented through increase in its truth-
degree and weakening through reduction.
23

2.4.1 Approximate Reasoning with Linguistic Modifiers Linguistic modifier is another dimension of approximate reasoning which is based
upon validating the “axiomatic of approximate reasoning.” Using the concept of
linguistic modifiers, El-Sayed and Pachlotczyk introduced new rules of General
Modus Ponens with free rules [32]. The primary difference between typical GMP
rules and new rules is that, in GMP observation and the premise correspond to the
same multi-set, where as in new rules they both are represented by different multi-
set (i.e., observed multi-set is different from conclusion multi-set).
Linguistic modifier is defined as an operator which builds terms from a
primary term; there exists two types of modifiers [32]:
• Reinforcing modifier: to reinforce the concept expressed such as “extremely”.
This modifier results in high precision.
• Weakening modifier: to weaken the concept expressed such as “rarely”. This
modifier results in low precision.
In multi-sets theory, these modifiers result in the same multi-set, but the truth
degree is modified, whereas in fuzzy logic, these modifiers result in a whole new
fuzzy set which is different from the original set. An example of an approximate
reasoning using linguistic modifier is:
If ‘X is A” then “Y is B” “Y is m(A)”________ then “Y is m(B)”
Inference conclusion is B´ = m´(B). This conclusion is drawn using the hypothesis
m´ = m, thereby giving the ability to infer this conclusion. A general principle is that,
24

a modification applied on the rule premise will be applied to rule conclusion as well.
For e.g.:
A B (Very A would imply Very B)
This would imply if A is reinforced, so is B and if A is weakened, then so is B.
To infer using linguistic modifiers, author of [32] proposed the approach of
using generalized linguistic modifiers in General Modus Ponens. Using this
approximation, we get as in [32]:
If “X is vαA” then “Y is vβB” “X is m(vαA)____________ “Y is m(vβB)” It is recommended to use modifiers which modify the truth-degree and not the actual
multi-set.
2.4.2 Synthesis of Multi Valued Logic Sarif and Barr defines n-variable multi-valued logic in mathematical terms as the
function f(x) with radix (r); f(x): Rn R where R = {0, 1, …, r-1} is a set of r logic
values where r ≥ 2 and X = {x1, x2,...,xn} is a set of n variables.
There are two main algorithms for synthesis of multi-valued logic:
Deterministic algorithm
This is based on direct cover approach and requires high computational time
[29]. Direct cover approach consist of the following important steps:
o Choose a minterm
o Identify a suitable implicant that covers the minterm
o Obtain a reduced function by removing the identified implicant
25

o Repeat steps 1-3, until all minterms are explored.
The steps to choose minterm and implicant that covers minterms are critical
in obtaining less expensive solutions (directly proportional to number of items
required). There are many different implementations in how to choose minterms and
implicants; these algorithms can be reviewed in [29, 30, 31].
Iterative heuristic based algorithm This is based on exploring large solution space and coming to near optimal
solutions. This is based on the concept of chromosome and genes, where solutions
are represented using string of chromosomes and each chromosome further
contains several genes. These genes consist of five attributes which represent the
product term as explained in [28]:
• First attribute: value of the constant of the corresponding product terms
• Second and third attribute: window’s boundary of product term for the first
variable X1
• Fourth and fifth attribute: window’s boundary of product term for second
variable X2
Length of chromosome plays a critical role in the solution; hence it is critical
for the length to be just right. If it is too short, it will not be able to reach best
solution, and if it is too large, it will take too long of a time. There are two proposed
approaches for selecting the length of chromosomes:
1. Static: length of chromosome is equal to the length of truth table
2. Reduced static: length of chromosome is equal to 75% of length of truth table
26

2.4.3 Future Work
As authors said in [32], it would be interesting to extend their proposal of new
rules to more complex strong rules, such as a set with multiple premises.
2.5 Bayesian Network “Bayesian networks are to a large segment of the AI-uncertainty community what resolution theorem proving is to the AI-logic community.”
-Eugene Charniak
Wikipedia defines Bayesian Network as a probabilistic graphical model that
represents a set of random variables and their conditional dependences via a
directed acyclic graph (DAG) [22]. Bayesian network can be used to represent
probabilistic relationship between two different variables, such as problem and
symptom. Given symptoms of a car, we can use the probabilistic relation to
calculate the probabilities of different problems that can occur. Bayesian network is
also referred to as a Belief network, directed acyclic graphical model or knowledge
maps probabilistic causal network.
Nodes represent random variable (RV), which can either have discrete values
(such as true/false) or continuous values (such as 1.0, 1.9). Directed Arcs between
pairs of nodes represent dependencies between the random variables. When
specifying probabilities in Bayesian networks, we should have probabilities of all root
nodes and the conditional probabilities of all non-root nodes. It allows us to
calculate conditional probabilities of a given node in the network if we have the
27

values of some of the nodes that have been observed. When new information
(evidence) is added to the network, it would result in recalculation of conditional
probabilities due to which they might change. When Bayesian network is referred as
Belief network, belief refers to the conditional probability given the evidence.
In the classic probability theory, probability distribution is complicated as the
complete distribution of n random variables will require 2n-1 joint probabilities. As
the random variable (n) grows in number, it becomes hard to depict all probabilities,
for e.g., if we have n = 5, then it will require 31 joint probabilities, where as if n = 10,
it will require 1023 joint probabilities. Bayesian network overcomes this complexity
through the use of “build in independence assumptions.”
2.5.1 Independence Assumptions
As Charniak explained in [23], in Bayesian network, a variable a is dependent on a
variable b given evidence E = {e1, e2,..} if there is a d-connecting path from a to b
given E. There are three types of d-connecting path as shown in figure 1.
28

Figure 1: D-connecting Paths [23] D-connecting path is a path from a to b with respect to the evidence nodes E
if every interior node n in the path has the property that either [23]:
1. It is linear or diverging and not a member of E or
2. It is converging and either n or one of it descendants is in E
To summarize, two nodes are d-connected it there exists a causal path between
them or there exists an evidence that renders the two nodes correlated with each
other.
2.5.2 Consistent Probabilities Another problem that comes with classical probabilistic theory is the problem of
inconsistent probabilities which usually requires some mechanism in place to ensure
we do not run in to this problem. Bayesian network handles this problem effectively
thereby ensuring consistent probabilities, which requires that probabilities of each
and every nodes in the network be specified (all possible combinations of its
parents). In fact, the network will calculate the joint distribution.
The joint distribution of a set of random variables r1,r2,…rn rn is defined as
p(r1,r2,…rn) for all values of r1,r2,…rn. This provides all the information associated
with the distribution. Also sum of all the joint distributions should equal 1. The joint
probability distribution of a set of variables {r1,r2,…rn} is calculated through the
following equation [25]:
P(r1,r2,…rn) = ∏ P[ri| parents(ri)]
29

It is important to understand how to number random variables 1, 2, n. There
are various techniques but for our interest we will look at topological sort where each
variable comes before its descendants.
Recent work in this field has lead to the invention of many new algorithms
which are both sophisticated and efficient in nature for computing and inferring
probabilities in Bayesian Network. As Boudali and Dugan said in [84], “during
inference, these new algorithms take advantage of the independence assumption
between the variable and proceed by local computations which makes the execution
times relatively short.” We mentioned earlier that Bayesian networks have the
feature of Independence Assumption; hence new algorithms make full use of this
feature offered by Bayesian Network. Using this, the number specified by the
Bayesian network formalism defines single joint distribution. Consistency at the
local level is used for insuring that global distribution is consistent as well.
2.5.3 Constraints
Underlying principle of Bayesian network is the calculation of conditional probability
of every single node in the network, as this computation is NP-hard (non
deterministic polynomial time) and usually takes exponential time to get the problem
solved. There are many factors that are taken into consideration during the
evaluation of the network, such as the type of network, the type of algorithm used,
and its implementation method. Option of having an exact solution or an
approximate solution provides different alternatives. We will briefly discuss here
exact solutions vs. approximate solutions.
30

Exact Solution
To find an exact solution is usually NP-hard, with the exception of single connected
network (also referred as polytree). It is an undirected graph with at most one
undirected path between any two nodes as shown in figure 2. These are usually
less complicated compared to multiple tree nodes (figure 2).
Figure 2: Connected Networks
We will not look at the algorithm in this paper, but it can be found in [25]. The
main difference between single connected networks (figure 2) and the multiple
connected networks is the way change in the connections is introduced. In polytree,
a change in one node will only have affect on its neighboring nodes, for e.g., in
figure 2, a change in d can not affect any other nodes except for node going through
b itself.
However in multiple connected networks, there can be more than one path
between any two nodes. Hence when a change is introduced, for e.g., in figure 2, if
a change is introduced in d, it will not only affect c, but also affect a through b.
31

Hence a will have double affects (through b and c). This ripple effect is what makes
multiple connected networks complicated. To deal with multiple connected
networks, we convert them into single connected networks through various
techniques such as clustering. This conversion works fine when dealing with
networks consisting of fewer nodes, but gets complicated when nodes created
through clustering has large values. Trade off is go from exact solution to
approximate solution.
Approximate Solution There are various techniques to calculate approximations of conditional probabilities
in Bayesian network and each technique fits well or not depending upon the nature
of network in question. Most of these techniques are based on the following
principles:
• Randomly picking (assuming) values of some nodes.
• Using values of some nodes to determine values of remaining nodes.
• Based on some values, use approximation to answer the questions.
2.5.5. Applications Bayesian networks have been applied in different domains. The most frequent
domains of application are:
• Diagnosis problems
• Speech recognition
• Data mining
• Determination of errors
32

2.5.6 Advantages
• Conclusions are made through probabilistic approach as oppose to logical
approach.
• Used for complex simulations since it does not rely on traditional approach of
specifying a set of all numbers that grows exponentially (independence
assumption).
• Knowledge is stored as collections of probabilities.
2.5.7 Disadvantages
• Time of evaluation: Bayesian networks require exponential time for
processing most cases.
33

CHAPTER 3
UNCERTAINTY MODELS IN APPLICATIONS
This chapter discusses two of the main applications where modeling and reasoning
with uncertainty is primordial; these applications are: Data Mining and E-services.
The chapter provides overview of these applications, discusses how uncertainty
comes into play and recommends model to deal with this uncertainty.
3.1 Data Mining “The fruits of knowledge growing on the tree of data are not easy to pick.”
- WJ Frawley, G. Piatetsky-Shapiro, CJ Matheus
3.1.1 Background Data mining is defined as “extracting or mining knowledge from large amounts of
data [45].” Data mining is also referred to as knowledge extraction, information
discovery, information harvesting, data archaeology, and data pattern processing. It
is a process of extracting patterns, associations, anomalies, changes and significant
structures from large database, data warehouses or other information repositories
[47]. A step in the knowledge discovery of databases that consists of applying data
analysis and discovery algorithm under acceptable computational efficiency
limitations, produce a particular enumeration of patterns over the data [42].
Knowledge discovery is a process which provides methodologies for extracting
knowledge from large data repositories. Computers have enabled humans to gather
more data than we can digest; it is only natural to turn to computational techniques
34

to help us unearth meaningful patterns and structures from the massive volumes of
data. Hence, knowledge discovery of databases is an attempt to address a problem
that the digital information era made a fact of life for all of us: data overload [42].
Knowledge discovery consists of following steps [45] as in figure 3 [42]:
1. Data Cleaning 2. Data Integration 3. Data Selection 4. Data Transformation 5. Data Mining 6. Pattern Evaluation 7. Knowledge Presentation
Figure 3: Overview Steps in Knowledge Discovery of Databases [42]
Across a wide variety of fields, data are being collected and accumulated at a
dramatic pace. Whether it is science, finance, telecommunication, retail, or
35

marketing, the classical approach to data analysis relied fundamentally on one of
more analysts becoming intimately familiar with the data and serving as an interface
between the data and the users and products [42]. Databases are increasing in size
by growing number of records and increasing files or attributes associated with each
record. To replace this manual and traditional approach which is slow and
expensive, and to deal with huge databases, demand for data mining has grown
proportionally to handle and utilize data efficiently. The unifying goal is extracting
high level knowledge from low-level data in the context of large data sets [42].
Organizations uses this data for various purposes such as understanding
customers’ behavior, increased efficiency, gain competitive advantage, predicting
future trend and be able to make knowledge driven decisions. Data is stored in data
warehouse; data warehouse is a repository of multiple heterogeneous data sources
organized under a unified schema at a single site in order to facilitate management
decision making. Data warehouse technology includes data cleaning, data
integration, and on-line analytical processing (OLAP), that is, analysis techniques
with functionalities such as summarization, consolidation, and aggregation as well as
the ability to view information from different angles [45]. It collects information about
subjects that span an entire organization. Data Mart is a department subset of a
data warehouse which focuses on selected subjects, and thus its scope is
department wide.
3.1.2 Characteristics of Data Mining
1. Scalability: designed to hold unlimited amounts of data
2. Complexity: very complex structure
36

3. Automated capability: ability to automatically discover hidden patterns or
useful information from a data set
4. Embedded learning capability: ability to learn from the past and to apply
its learning in the future
3.1.3 Data Mining and Uncertainty
Data mining has since evolved into an independent field of research in which
intelligent data analysis methods attempt to “unearth the buried treasures from the
mountains of raw data [48].” Data mining component of Knowledge discovery relies
heavily on techniques ranging from machine learning to pattern recognition and
statistics to find patterns. Data mining has functionalities such as outlier analysis,
association analysis, cluster, and evolution analysis. The main tasks involved in
data mining are: the definition/extraction of clusters that provide a classification
scheme, the classification of database values into the categories defined, and the
extraction of association rules or other knowledge artifacts [41]. Figure 4 [80]
highlights the steps involved in data mining.
37

Figure 4: Data Mining [80] A cluster consists of group of objects that are more similar to each other than
to other cluster. It is nothing but the subsets of the data set. In fact cluster analysis
has the virtue of strengthening the exposure of patterns and behavior as more and
more data becomes available [50]. Aim of cluster analysis is the classification of
objects according to similarities among them, and organizing objects into groups
[47]. Once the clustering task is executed, the product of categories could either be
fuzzy or crisp (hard) in nature. Hard clustering method is based upon a classical set
theory, where object either belong or does not belong to a cluster [47].
On the other hand, fuzzy clustering method is based upon the concept where
an object can belong to several clusters simultaneously with the degree of belief
associated with each object in the cluster. That is, during the clustering algorithm,
there could be some values that belong to the borderline, thereby not fully classifying
38

into one specific category or might belong to more than one category. In real world,
fuzzy clustering occurs more than hard clustering where objects in borderline are not
forcefully classified into one cluster. This is due to the fact that mostly real world
data suffers from following limitations [51]:
1. Not clearly known : Questionable; problematical
2. Vague : Not definite or determined
3. Doubtful : Not having certain information
4. Ambiguous : Many interpretations
5. Not steady : Varying
6. Liable to change : Not dependable or reliable
Another issue that exists in data mining is when data values are given equal
treatment during the classification process which is carried out in a crisp manner.
During this classification, some values belong more to the category as opposed to
other values in the same category. As an example, if employee X is working with a
company for 15 years, and another employee Y has been working with the same
company for 20 years. Theoretically, during classification they both belong to the
senior category. However an important fact is that an employee Y has more
seniority than X, but during the classification process, we lose this important
knowledge since it is not captured anywhere through the regular classification
technique.
3.1.4 Fuzzy Logic Uncertainty Model The conventional clustering algorithms have difficulties in handling the challenges
posed by the collection of natural data which is often vague and uncertain [51].
39

Traditionally, to deal with uncertainty in Data mining, several approaches have been
proposed, such as fuzzy decision trees, and fuzzy c-means. The underlying
principle with these approaches is to associate degree of belief to each value during
classification process where data value can be classified into more than one
category.
Fuzzy logic is a good model to deal with uncertainty in Data mining. Fuzzy
set theory is based upon membership function; users can use the given data to
define membership functions to characterize an element with a fuzzy subset [47].
Integration of fuzzy logic with data mining techniques has become one of the key
constituents of soft computing in handling the challenges posed by the massive
collection of natural data [52]. Rules can be designed to model the to-be-controlled
system given the input and output variables. Here are the basic steps of the
approach proposed as in [41, 47]:
1. Standardization: process of standardization is applied to the data where
some kind of calculation is performed on data to remove the influence of
dimension. As an example, each data value can be standardized by
subtracting a measure of central location (mean or median) and divided by
some measure of spread (standard deviation).
2. Clustering scheme extraction: defining or extracting clusters that correspond
to initial categories for the data set. Many clustering algorithms are available
for extraction. During this step, correlation coefficient is calculated to classify
data into clusters.
40

3. Evaluation of the clustering scheme: clustering method is used to find a
partition. Different parameters are applied to chosen clustering algorithm to
find the optimized clustering schema.
4. Definition of membership function: fuzzy logic is used to calculate degree of
belief (grade of membership) of each data value to the clusters. Uncertainty
features is assigned by an assignment of appropriate mapping functions to
the clusters. The membership value is in the range zero to one and indicates
the strength of its association in that cluster.
5. Fuzzy classification: data values (Ai) are classified into categories according
to a set of categories L = {li} available and clustering method chosen. This
results in a set of degree of belief (d.o.b.s) M = {µli(tk.Ai)} where tk is the tuple
identifier. This represents the confidence level with which tk.Ai belongs to the
category li.
6. Classification Value Space (CVS) construction: transforming the data into
classification beliefs and storing them in a cube, where the cell store the
degree of belief for the classification of attribute values. This cube is also
referred to as CVS.
7. Handling the information included in CVS: CVS contains knowledge about
our data set based on which sound decisions can be made. Fuzzy logic
concept is used for quality measurement of our dataset with regards to each
category.
8. Association rules extraction: extraction of rules between attributes depending
upon the classification method chosen.
41
9. Prediction and determination of samples to determine which cluster it will
belong to. This is usually done by calculating the average index of each
cluster and using proximal values to determine the sample’s cluster.
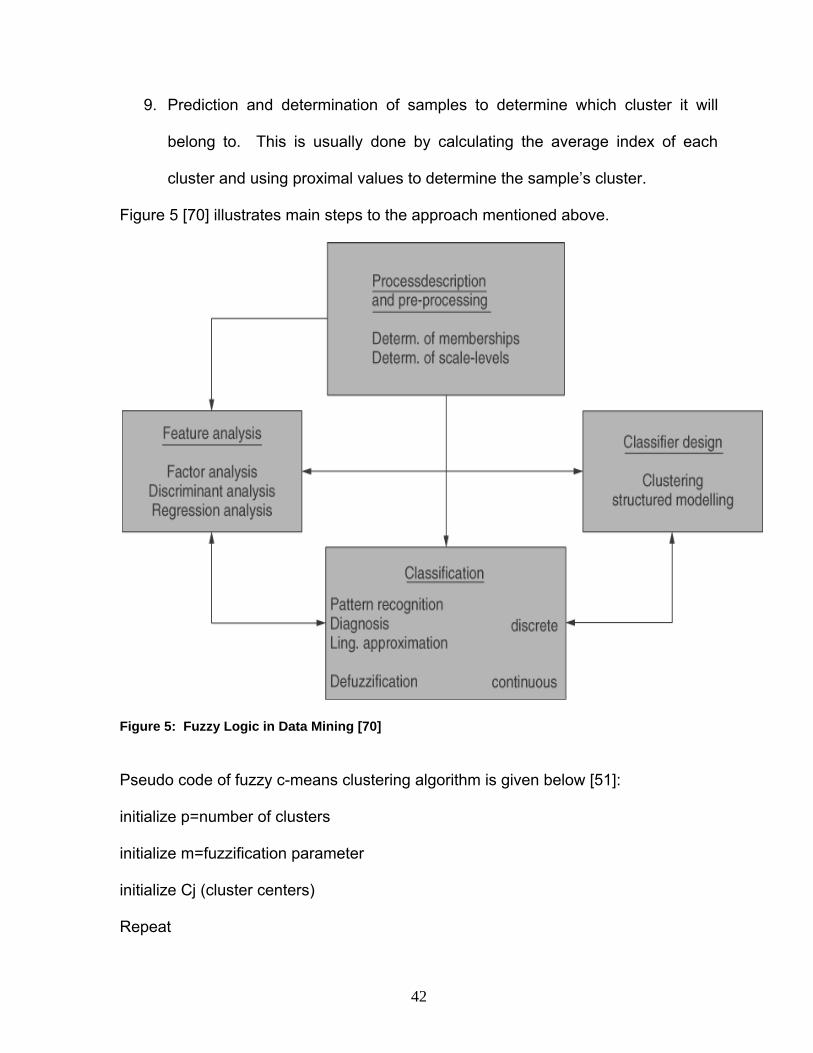
Figure 5 [70] illustrates main steps to the approach mentioned above.
Figure 5: Fuzzy Logic in Data Mining [70] Pseudo code of fuzzy c-means clustering algorithm is given below [51]: initialize p=number of clusters
initialize m=fuzzification parameter
initialize Cj (cluster centers)
Repeat
42

For i=1 to n :Update μj(xi) applying (3)
For j=1 to p :Update Ci with(4)with current μj(xi)
Until Cj estimate stabilize
This Fuzzy logic approach in data mining enables us to [41]:
1. Handle uncertainty based on degree of belief (membership function): ability to
transform crisp clustering method in fuzzy method to handle uncertainty.
2. Definition of a classification function to handle uncertainty: emphasis on
handling uncertainty during the classification phase through the framework
which is based on fuzzy logic.
3. Information measures for the classification scheme: checks for information
quantity included in fuzzy sets. Using these measures, we can check which
set best fits by checking the degree associate with the sets; this allow us to
make sound business decisions using the information measures.
3.1.5 Applications There are many applications of applying fuzzy logic to dealing with uncertainty in
data mining; here are few examples:
• Human Resource Management: Han Jing’s Application of Fuzzy Data Mining
Algorithm in Performance Evaluation of Human Resources provides the
application of applying fuzzy logic uncertainty model in data mining.
43

3.2 Semantic Web Services and Uncertainty “…deeds, efforts or performances whose delivery is mediated by information technology. Such e-service includes the service element of e-tailing, customer support, and service delivery”
- J. Rowley
3.2.1 Background
The spreading of network and business-to-business technologies has changed the
way business is performed. Companies are able to provide services as semantically
defined functionalities to vast number of customers by composing and integrating
these services over the Web [53]. Such services are referred to as E-services which
stand for electronic services, also known as web services.
Web has altered how businesses used to do its operation. The introduction of
e-business brought along a revolution and created a surge in technology-based-self-
service [56]. Enterprises look to business-to-business (B2B) solutions to improve
communications and provide a fast and efficient method of transacting with one
another [54]. E-services provide companies with the opportunity to conduct
electronic business with all other companies in the marketplace instead of traditional
approach of conducting business through collaborative business agreements only.
Services offers are described in such a way that they allow automated discovery to
take place and offer request matching on functional and non-functional service
capabilities [54].
E-services are available for different purposes, such as, banking, shopping,
health care, learning, and has high potential benefits in the areas of Enterprise
44

Application Integration and Business-to-Business Integration. The concept of e-
services plays a vital role in knowledge management applications through the ability
of exchanging functionality and information over the Internet. Web services provide a
service-oriented approach to system specification, enable the componentization,
wrapping and reuse of traditional applications, thereby allowing them to participate
as an integrated component to knowledge management activity [59]. It is important
to note that web services operate at a purely syntactic level [65] as shown in Figure
6 [67].
Figure 6: Web Services & Semantic Web Services [67]
3.2.2 Semantic Web Services
Semantic Web Services (SWS) is a combination of semantic web technology with
web services. Semantic Web Services are pieces of software advertised with a
formal description of what they do; composing services means to link them together
in a way satisfying a complex user requirement [63]. Discovery composition,
invocation, and interoperation are the core pillars of the deployment of semantic web
services [64]. SWS is taking web services to next level by adding the dimension of
45
semantically enhanced information processing in conjunction with logical inference
to provide development of high quality techniques for automated discovery,
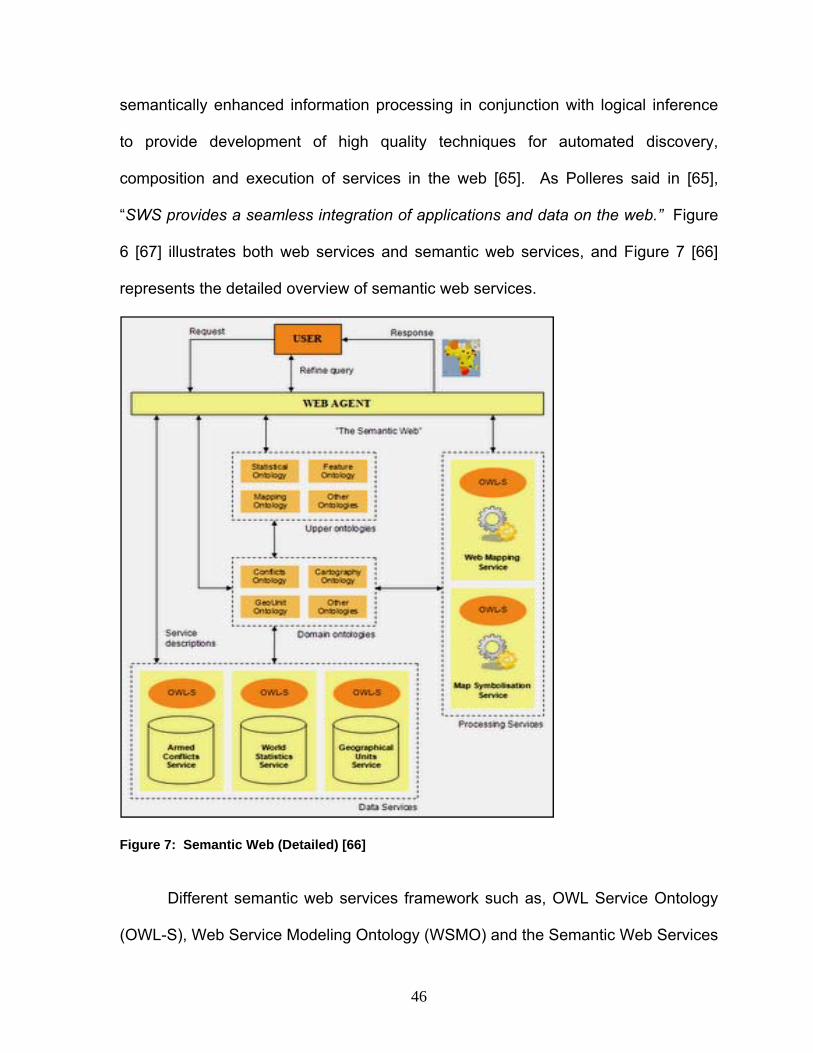
composition and execution of services in the web [65]. As Polleres said in [65],
“SWS provides a seamless integration of applications and data on the web.” Figure
6 [67] illustrates both web services and semantic web services, and Figure 7 [66]
represents the detailed overview of semantic web services.
Figure 7: Semantic Web (Detailed) [66] Different semantic web services framework such as, OWL Service Ontology
(OWL-S), Web Service Modeling Ontology (WSMO) and the Semantic Web Services
46

Framework (SWSF) are used to semantically describe necessary aspects of
services in a formal way for creating machine-readable annotations [65]. Matching
of a goal (client’s purpose of using web services) to the web services capabilities are
classified as follows as in [60]:
1. Exact-match: a goal exactly matches the matched web services capabilities
2. Plug-in-match: a goal is subsumed by matched web services capabilities
3. Subsume-match: matched web services capabilities are subsumed by a goal
4. Intersection-match: a goal and matched web services capabilities have some
common elements
5. Disjoint-match: a goal and matched web services capabilities do not belong
to any above classifications
During the matching process, it would be nice to identify a degree of matching
to each matched web services capabilities. This will tell us which result is closer to
the goal in comparison to all the results returned.
There are three forms of Semantics as defined in [71]:
1. Implicit Semantics: unstructured text, loosely defined and less formal
structure of data repositories. This is useful in processing data set to obtain
bootstrap semantics that can be used to represent through formal knowledge.
Machine learning utilizes implicit semantics.
2. Formal Semantics: well defined syntactic structure for knowledge
representation, more formal structure of data representation. Definite rules of
syntax in place which allows for automated reasoning thereby making
applications more intelligent. Since human language is ambiguous both
47

semantically and syntactically, it is tough for computers to use this language
as a means of communication with other machines. Semantics that are
represented in well formed syntactic form is referred to as formal semantic.
These are machine processable that does not allow for uncertainty due to
limited expressiveness. Two features of a formal language are:
• The Principle of Compositionality
• The notions of Model and Model Theoretic Semantics
3. Powerful Semantics: use of knowledge to its fullest; allows for vagueness,
imprecise or uncertain knowledge, and fuzzy form. Although it is ideal to
have a consistent knowledge base, but in practical, it is almost impossible. It
is usually impossible to gain local consistency but almost infeasible to
maintain global consistency. We should allow contradicting systems in
knowledge base, and have the ability to computationally evaluate these
contradicting statements to come to the right conclusion.
3.2.3 Uncertainty in Semantic Web Services The real power behind human reasoning however is the ability to do so in the face of
imprecision, uncertainty, inconsistency, partial truth and approximation. Powerful
semantics provide the benefit of utilizing a common language which allows for
abduction, induction and deduction. This will provide inference mechanism that is
complete with respect to the semantics.
Uncertainty exists in almost every life situation, and semantic web services
are no different. As authors of [63] said, one important issue with semantic web
services is the fact that they are embedded in background ontologies which
48

constraint the behavior of the involved entities. Semantic web provides a vision
where knowledge is being transferred by agents. This knowledge would be
imprecise or incomplete in nature, thereby introducing different aspects of
uncertainty. In semantic web services, when a user initiates a request through a
query, the request is not one hundred percent crisp. Semantic description contains
information that may be incomplete or imprecise in nature thereby making it critical
to have the ability to deal with uncertainty. In these cases, we cannot assume exact
matches of inputs provided by the users, as we might not be able to comprehend it.
Since both web content and user’s query are vague or uncertain in nature, we need
to foster the environment to deal with uncertainty in semantic web services.
Current semantic web services framework use first order logic and relies on
subsumption checking for matching process between goal and web services
capabilities. Authors of [71] said, “Overtime, many people have responded to the
need for increased rigor in knowledge representation by turning to first order logic as
a semantic criterion. This is distressing since it is already clear that first order logic
is insufficient to deal with many semantic problems inherent in understanding natural
language as well as the semantic requirements of a reasoning system for an
intelligent agent using knowledge to interact with the world.” In the real world,
concepts are not always subsumed by each other, and cannot always be classified
in crisp subsumption hierarchies [69]. This summarizes the foundational problem
with semantic web ontology which is based on the concept of crisp logic. Semantic
web frameworks such as OWL are not equipped to deal with this uncertainty. They
49

assume that the knowledge base is crisp in nature thereby entirely eliminating the
concept of uncertainty.
For most part, classical theories where used in semantic web services for
reasoning under uncertainty. Assumption was made of a closed world where
knowledge base was assumed to be complete and precise. Hence there was a
need to extend non-classical theories to deal with uncertainty (both qualitative and
quantitative).
In recent years, probabilistic and possibilistic logic has been extended into
semantic web services to deal with uncertainty. The underlying principles behind
these approaches were annotating the ontologies with some kind of uncertainty
information about its axioms and use this information to perform uncertainty
reasoning [68]. The main issue with this approach was that these uncertainties were
asserted by humans who are not good at either predicting or perceiving concepts
like probability [68].
The foundational problem with Semantic web ontology is that it is built upon
crisp logic. There is a need to represent partial subsumption in a quantified manner.
There are various models recommended to deal with this situation and handle
uncertainty. M. Holi and E. Hyvonen recommended Bayesian Network in [69], P.
Oliveria and P. Gomes recommended Markov Network in [68], and D. Parry
recommended Fuzz Logic in [61].
50
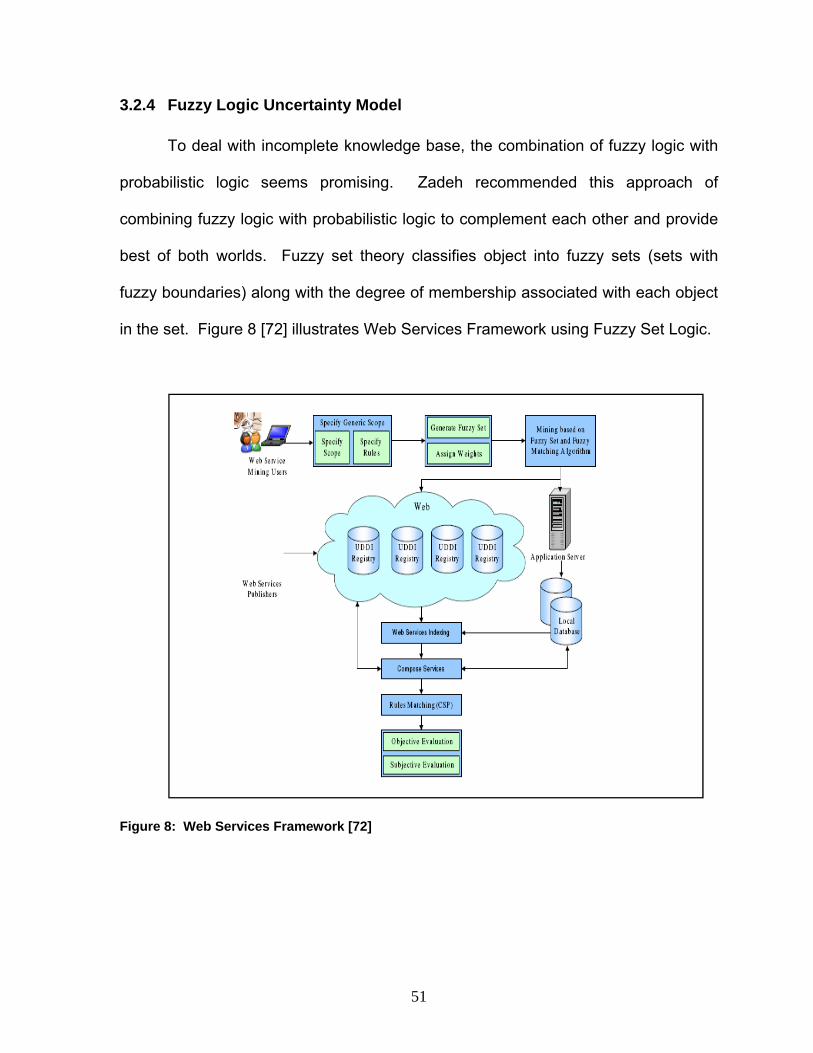
3.2.4 Fuzzy Logic Uncertainty Model To deal with incomplete knowledge base, the combination of fuzzy logic with
probabilistic logic seems promising. Zadeh recommended this approach of
combining fuzzy logic with probabilistic logic to complement each other and provide
best of both worlds. Fuzzy set theory classifies object into fuzzy sets (sets with
fuzzy boundaries) along with the degree of membership associated with each object
in the set. Figure 8 [72] illustrates Web Services Framework using Fuzzy Set Logic.
Figure 8: Web Services Framework [72]
51

The main steps involved in Semantic web services with integration of fuzzy logic are
[72]:
1. Scope and rules specification: Domain experts specify both the scope and
rules; these rules are matched in the rules matching phase with the web
service description
2. Fuzzy set generation: fuzzy set is then generated based on the scope
provided by the domain experts.
3. Weights calculation and assignment: weights are calculated using
probabilistic model; degree of truth is assigned to every fuzzy set based on
the history of how often it is used. This is then stored in a local database and
used for weights calculation.
4. Define fuzzy rules: Two fuzzy sets are defined; one is a fuzzy set of weights,
and the second is a fuzzy set of distance, which will be used in the matching
distance algorithm during the matching process. These fuzzy sets are used
in conjunction.
5. Model for fuzzy matching: all services that have been matched are stored in
database with associated weights, distance and matched values. Results are
sorted in indexed order based upon weights. The fuzzy matching algorithm
as stated in [72] is as follow:
Algorithm 1: FuzzyMatching Input: S[1..n], W[1..n] Output: services, composedServices 1. for i ¬ 1 to n do
2. initiate new thread
52

3. member ¬S[i]
4. weight ¬ W[i]
5. if weight is High then
6. distance ¬ Approximate
7. else if weight is Medium then
8. distance ¬ Close
9. else if weight is Short then
10. distance ¬ Exact
11. end if
12. service ¬ Fetch Web service
13. result ¬ call ApproximateMatchingAlgorithm(service, member, distance)
14. if result > 0 then
15. Store service in database
16. end if
17. Sort stored services
18. for each stored service
19. initiate new thread
20. O[1..n] ¬ service.outputParameters
21. service ¬ Fetch Web service
22. I[1..n] ¬ service.inputParameters
23. temp ¬ false
24. for i ¬ 1 to n do
25. if O[i] = I[i] then
26. temp ¬ true
27. else
28. temp ¬ false
29. break loop
30. end if
31. end for
32. if temp = true then
33. link services and store in database
53

34. end if
35. end for
36. end for
6. Constraint Satisfaction: the user’s request is matched with the constraints
specified by the service provider and rules specified in the first step are
satisfied with web services input parameters, output parameters and
operations.
7. Evaluation: the composition of various web services is conducted from the
pool of all web services. Final web service is selected by domain expert
depending upon their experience and knowledge.
Table 2 and 3 below show how fuzzy logic in integrated with Semantic web to deal
with uncertainty.
54

Bootstrapping Phase
(building phase)
Capabilities Implicit Semantics Formal Semantics
Possible use of Powerful (soft)
Semantics
Building ontologies either automatically or
semi-automatically
Analyzing word co-occurrence patterns in
text to learn taxonomies/ontologies
Using fuzzy or probabilistic clustering to
learn taxonomic structures or ontologies
Annotation of unstructured content with
respect to these ontologies
(resulting in semantic metadata)
Analyzing word occurrence patterns or hyperlink structures to
associate concept names from and
ontology with both resources and links
between them
Using fuzzy or probabilistic clustering to
learn taxonomic structures or
ontologies OR using fuzzy ontologies
Entity Disambiguation
Using clustering techniques or Support
Vector Machines (SVM) for Entity
Disambiguation
Using an ontology for
Entity Disambiguation
KR mechanisms to represent
ontologies that may be used for Disambiguation
Semantic Integration of
different schemas and
ontologies
Analyzing the extension of the ontologies to
integrate them
Schema based integration techniques
Semantic Metadata
Enrichment (further
enriching the existing
metadata)
Analyzing annotated resources in conjunction
with an ontology to enhance semantic
metadata
This enrichment could possibly
mean annotating with fuzzy ontologies.
Table 2: Building Phase [72]
55
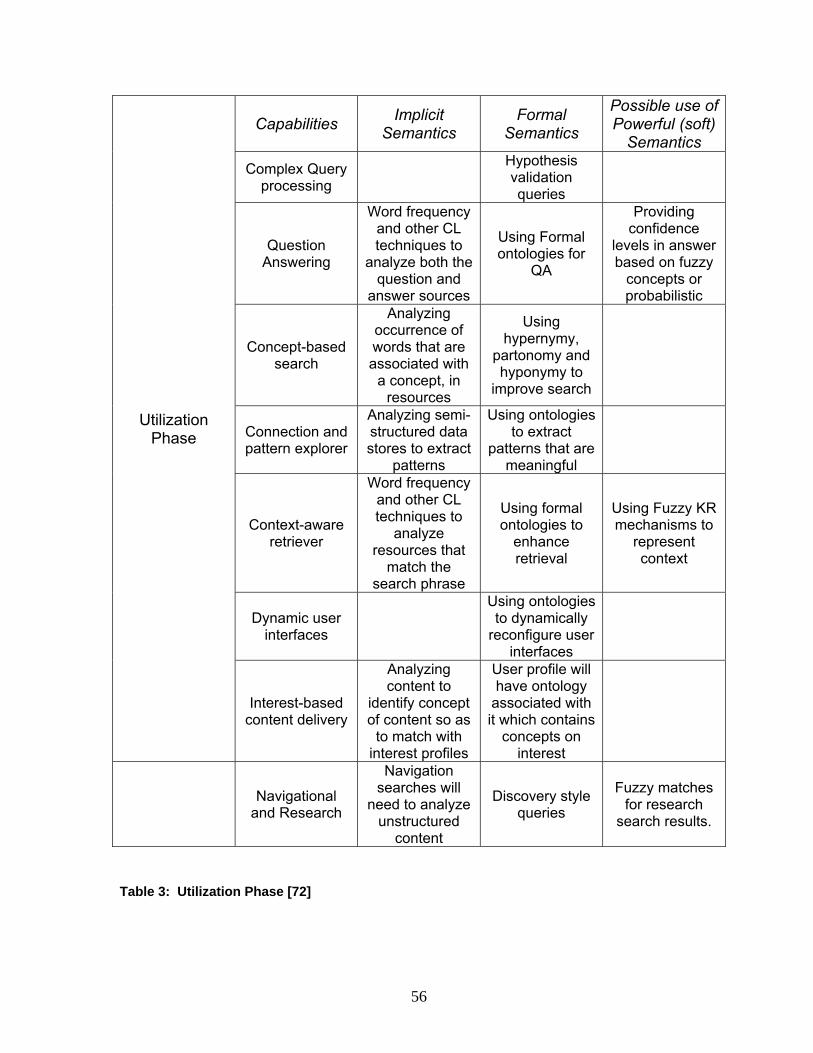
Utilization Phase
Capabilities Implicit Semantics
Formal Semantics
Possible use of Powerful (soft)
Semantics Complex Query
processing Hypothesis validation queries
Question Answering
Word frequency and other CL techniques to
analyze both the question and
answer sources
Using Formal ontologies for
QA
Providing confidence
levels in answer based on fuzzy
concepts or probabilistic
Concept-based search
Analyzing occurrence of words that are associated with
a concept, in resources
Using hypernymy,
partonomy and hyponymy to
improve search
Connection and pattern explorer
Analyzing semi-structured data stores to extract
patterns
Using ontologies to extract
patterns that are meaningful
Context-aware retriever
Word frequency and other CL techniques to
analyze resources that
match the search phrase
Using formal ontologies to
enhance retrieval
Using Fuzzy KR mechanisms to
represent context
Dynamic user interfaces
Using ontologies to dynamically
reconfigure user interfaces
Interest-based content delivery
Analyzing content to
identify concept of content so as
to match with interest profiles
User profile will have ontology
associated with it which contains
concepts on interest
Navigational and Research
Navigation searches will
need to analyze unstructured
content
Discovery style queries
Fuzzy matches for research
search results.
Table 3: Utilization Phase [72]
56

CHAPTER 4
SOFT COMPUTING FOR INTELLIGENT SYSTEM: DESIGN AND ARCHITECTURE
“Role model for soft-computing is the human mind.”
-Prof. Lotfi A. Zadeh
Intelligent systems have to deal with knowledge uncertainty in practically every real
world situation as much of the knowledge base is based on human knowledge which
is usually imprecise and vague in nature. We have looked at different uncertainty
models such as fuzzy logic, rough set theory and so forth and mapped best fitted
uncertainty model to data mining and semantic web services application. For
intelligent systems to deal with this uncertainty there has to be a proper design and
architecture in place. The focus of this chapter is to discuss design and architecture
of intelligent system using soft computing techniques.
4.1 Soft-computing for Intelligent Systems “Soft computing is a term applied to a field within computer science which is
characterized by the use of inexact solutions to computationally-hard tasks such as
the solution of NP-complete problems, for which an exact solution cannot be derived
in polynomial time [74].” Soft computing techniques can work around knowledge
base which is incomplete, imprecise and uncertain in nature. Traditional approaches
of finding exact solutions cannot be applied anymore in today’s world which is highly
57

unpredictable. Hence the need for soft computing came about to deal with
uncertainty.
Guiding principle of soft computing as Zadeh said in [75] is to: “exploit the
tolerance for imprecision, uncertainty, partial truth, and approximation to achieve
tractability, robustness and low solution cost.” The main constituents of soft
computing are Neural Network (NN), Fuzzy Logic, Evolutionary Algorithm, and
Probability Theory. Soft computing is a fusion of various methodologies mentioned
above to create Intelligent Systems which can solve the problem in hand. Zadeh
defined soft computing as a “partnership in which each of the partners contributes a
distinct methodology for addressing problem in its domain; these methodologies are
complementary rather than competitive.” Combination and hybridization of these
methodologies provides soft computing with the cutting edge which is missing in
other techniques.
4.1.1 Main Components of Soft Computing
1. Neural Network: Inspired through field of biology, neural network is an
interconnected group of artificial neurons which can exhibit complex global
behavior. A neuron comprises of a significant information processing
elements [75]. It replicates a human central nervous system, where functions
are performed collectively by neurons and run in parallel.
2. Fuzzy Logic: It is discussed in great deal in Chapter 2 (Section 2.2)
3. Evolutionary Algorithms: Evolutionary algorithms also known as Genetic
algorithms have been used recently to program and engineer intelligent
systems. It is an adaptive heuristic search algorithm which is based upon
58

natural evolution and Darwin’s theory of “survival of the fittest.” Natural
evolution consists of selection, reproduction and mutation to reach solution to
a problem in hand. A standard process for generating new algorithms is [73]:
potential candidate solutions are initialized; through reproduction techniques,
new solutions are created; and suitable solution is selected depending upon
the “what fits best.”
These steps undergo series of iteration before the final solution is chosen.
In comparison to other popular techniques, evolutionary algorithms are easy
to implement and provide solutions to resolve issues in hand. It is different
from other methodologies as it aims for an optimized solution rather than just
a good solution and also makes use of historic data to gain better
performance during search.
Advantages of Evolutionary Algorithm:
a) More robust, hence a better option than typical AI.
b) Offers better performance while searching large space through heuristic
based approach and linear programming.
c) Ability to handle changes in input variables.
4. Probability Reasoning: used for approximate reasoning. This is based upon
probabilistic theory Discussed in Chapter 2 (Section 2.1).
4.1.2 Characteristics of Soft Computing
1. Human expertise represented through knowledge base which is a repository
of human knowledge.
59

2. Earlier soft computing would aim for good solutions versus optimal solution;
but now with introduction of new techniques such as evolutionary algorithms,
it can achieve optimization as well.
3. Neural Networks which is based upon biological system, more precisely
Central Nervous System.
4. Ability to handle real world applications by dealing with uncertainty rather than
ignoring it.
5. Support various applications for which mathematical models are not available
or inflexible.
6. Soft computing intersects with lot of other disciplines as in Figure 9 [73].
Figure 9: Relation between soft computing and other fields [73]
60

Next sections deal with design and architecture of intelligent systems with
uncertainty.
4.2 Design of Intelligent Systems with Uncertainty The essence of designing an intelligent system lies in its ability to effectively control
an object in the dynamic environment. In an ideal world, this object would be a
replica of a human expert making similar decision if they were placed in the situation
in which the intelligent system is operating. In the closed environment, where all
elements are accurately defined, and with minimal scope of change or introduction
of new or unknown elements, intelligent system can very precisely perform an action
for which they are designed. Design of such intelligent systems will be focused on
defining accurate and complete sets of rules for knowledge base.
Real world applications however cannot be described by complete set of facts
and rules. The variable which makes it harder to achieve this goal is “uncertainty”; it
plays a critical role in the design of an intelligent system. Therefore, instead of
ignoring this variable; it should be well considered during early stages of design
phase. While designing an intelligent system, it becomes vital to handle uncertainty
at three different levels: uncertainty in objects, uncertainty in surrounding
environment in which they operate, and uncertainty in expected functionalities. Here
are more details on these three aspects.
61

4.2.1 Main Aspects of Design
1. Uncertainty in Objects
Intelligent system is executed at the level of an object. An object is
usually operational with lot of sensors to record different measurements about
itself; these sensors help objects maintain their integrity with in parameters
defined during the design stage. If at any time, any measurement goes out of
range, these sensors send a signal to the object identifying something is
wrong. When uncertainty is factored in the situation, these sensors play a
critical role in signaling object of the uncertainty. If there is noise in the
measurements, then objects would filter the data to ensure it can ignore noise
in the data. In situations, where knowledge base is not fully equipped with
rules and facts to help objects, different soft computing techniques are used
in the design of these objects.
An example would be the use of rough set theory, which can help
identify the uncertain situation. Through the use of approximation and rough
membership concept of rough set theory, we can handle uncertainty to the
best of the ability; the success of handling uncertainty through rough set
theory is proportional to the data stored in knowledge base.
2. Uncertainty in Surrounding Environment
An object has to adapt itself to the surrounding environment in which it
operates. Environment is an open ended concept which constitute of many
different variables; it can never be described accurately and precisely through
facts in the knowledge base. Change is another factor which has to be dealt
62

with, since environment can change anytime. There could be many other
objects existing in the environment, and it would be critical to keep tabs on
them as well. An interaction of the main object with other objects in the
system is dependent upon the nature of other objects which could be very
uncertain in nature. Due to these reasons, this level is a little hard to deal
with where uncertainty plays a central role.
There could be various unknown factors that could be introduced in the
environment for which object has no account of; it is important to understand
if this is just a noise, an anomaly or a new factor. For example, in a retail
store, the sale of the store can go down steeply; for an intelligent system, it
becomes critical to understand if this was just one time thing due to bad
storm, or if there is a downward trend due to economic recession.
Because there are many different factors at this level, the best way to
deal with uncertainty is through multi-valued logic. Multi-valued logic provides
the flexibility to hold as much as information as needed depending upon the
problem in hand. Hence, if environment is not very complicated and pretty
well defined, then multi-valued logic can hold precisely almost all the
information, even if the information is conflicting with each other to determine
the behavior during uncertainty.
3. Uncertainty in Expected Functionality
An intelligent system is created to accomplish a given task at hand;
there is an expected functionality it has to perform. In earlier days, when
systems were less complicated, the scope of the problem would seldom
63

change; expansion of horizon. But recently, as systems have become more
complex and evolved to next level, change is the only thing that is constant.
Hence, scope of expected functionality can change anytime, depending upon
various variables. At this level, it is critical for the system to act intelligently
and be able to accept changes in the scope in a diligent manner.
Intelligent systems should be well equipped to deal with possible
modifications, contingency situations and be well aware of its safe mode of
operations. To accomplish these tasks, it should be able to perform analysis
of its current situation and predict future evolution when the modifications are
introduced. For contingency planning, it should be able to implement that
through decision making, learning and self learning. An example of this
would be the requirement engineering phase during the software
development cycle. The scope of software can change anytime which
requires requirements to be modified as per the new scope.
Rough set theory can be used at this level to help with decision making
and self learning. For optimization, we can use various hybrid soft-computing
techniques instead of the traditional ones.
4.2.2 Design Framework Traditional design frameworks are pretty effective and efficient in handling many real
world applications; main shortcoming is that they aim for a solution instead of an
optimized solution. Similar to field of agriculture, where hybrid seeds are created
through various techniques such as crossover; different hybrid frameworks have
64

been developed for optimization. Fuzzy logic and hybrid frameworks are two
different design frameworks discussed in this section.
1. Fuzzy Logic Fuzzy logic is a popular soft-computing technique being utilized in the design
of an intelligent system; this concept is known as fuzzy information
granulation [78]. Underlying principle of this concept involves partitioning a
class of objects into smaller granules in such a manner that the objects with in
granules are similar in nature, and objects amongst different granules are
distinct in nature.
State where granules can be easily distinguished from each other
could be referred to as black and white zone, which is crystal clear as to
which objects belong to which granule. In addition to typical black and white
zone, there is a grey zone, where granules cannot be easily discerned from
each other; the boundary line that divides one granule from another is fuzzy
instead of crisp in nature. This fuzziness is represented through words rather
than numbers which help bridge the gap between machine language and
human knowledge. These words act like labels of fuzzy granules; the ability
of these labels to use natural language is an added benefit which makes it
easily adaptable into the real world.
Advantage of using words helps us to handle imprecision and
uncertainty thereby making systems more robust and flexible in dealing with
reality. Since most knowledge bases are repository of human knowledge,
65

using words as labels for granules, can be practically used in every field
where soft computing techniques have been already explored.
2. Evolutionary Artificial Neural Networks
Recently, hybrid frameworks have gained a lot of popularity; this is
identical to creating hybrid seeds in the field of agriculture. Current soft-
computing techniques are inefficient when it comes to their computation
speed, due to the large search space. “Current state of Artificial Neural
Network is dependent upon human experts who have enough knowledge
about various aspects of the network and the problem domain [73]”. With the
growing complexity, this traditional design becomes insufficient to handle the
problem domain thereby, shifting the gear towards evolutionary algorithm in
Artificial Neural Networks.
Evolutionary algorithm is used for design and architecture of neural
networks which offer two main features: evolution and learning. These
qualities make them highly adaptable to dynamic environment making them
effective and efficient than classical approaches. The underlying algorithm is
based on Darwin’s theory of “survival for the fittest.” The selection process is
such that the desirable behaviors and features are passed on to the next
generation, whereas less desirable behaviors fade away. Evolution in this
hybrid network is introduced at three different layers, as highlighted in [73]:
66

1. Evolution introduced at weight training level
The training process at weights level is used for global search of a
connection weight to get an optimal set which is defined by evolutionary
algorithm. The evolutionary algorithm is a step ahead when compared to
other techniques such as gradient based techniques since it looks for a
global optimal solution rather than local optimum solutions. Here is the
algorithm for Evolutionary search of connection weights as in [73];
I. Initialize the population of N weight chromosomes
II. Fitness of each network is evaluated depending upon the problem in hand.
III. Based on results from step (II), selection method is executed to
create number of children for each individual (node) in the current generation. .
IV. Genetic operators are then applied to each child individual created
in step (III) to further reproduce next generation.
V. Check number of generations created versus the required target to evaluate next step. If target has not been achieved, then step (II) is executed again, else (VI).
VI. End
2. Evolution introduced at the architecture level
Evolutionary architecture is achieved through constructive and
destructive algorithm. Constructive algorithm refers to constructively
adding complexity by starting with a simple architecture, whereas
destructive algorithm refers to destructing the large architecture until
network cannot perform its task. Evolution is usually introduced at
architecture level when prior knowledge of architecture is known. Indirect
67

coding can be used in these cases to improve scalability such as,
Blueprint. Algorithm for Evolutionary search of architectures as in [73];
this algorithm is similar to the algorithm at the weight level, except this
initializes the population of architecture chromosomes.
I. Initialize the population of N architecture chromosomes
II. Fitness of each network is evaluated depending upon the problem in hand.
III. Based on results from step (II), selection method is executed to
create number of children for each individual (node) in the current generation. .
IV. Genetic operators are then applied to each child individual created
in step (III) to further reproduce next generation.
V. Check number of generations created versus the required target to evaluate next step. If target has not been achieved, then step (II) is executed again, else (VI).
VI. End
3. Evolution introduced at the learning level
Learning rules is critical to any intelligent system since learning rules
should be able to adapt itself to its dynamic environment in which it is
operating. The same learning rules are applied to the entire network and
the architecture is set up in such a manner, that for every learning rule
chromosome, several architecture chromosomes will evolve at a faster
rate. The algorithm for Evolutionary search for learning rules as in [73]:
this algorithm is very similar to previous two algorithms, with the exception
of learning rules are initialized in step (I).
I. Initialize the population of N learning chromosomes
68

II. Fitness of each network is evaluated depending upon the problem
in hand.
III. Based on results from step (II), selection method is executed to create number of children for each individual (node) in the current generation. .
IV. Genetic operators are then applied to each child individual created
in step (III) to further reproduce next generation.
V. Check number of generations created versus the required target to evaluate next step. If target has not been achieved, then step (II) is executed again, else (VI).
VI. End
The decision on which level to evolve is dependent upon the type of
knowledge available. If the knowledge is centered towards the architecture,
as oppose to learning rules, then it is better to implement evolution of
architecture at the highest level. Through this, we minimize the search space.
4.2.3 Selection of Appropriate Design
The question of selecting the proper configuration of design for intelligent
systems can take several combinations and permutations of various methodologies
available at our disposal. This can lead to an exhaust list of possible solutions, and
the best one has to be chosen depending upon the nature of the problem in hand.
Choice between soft-computing techniques and hybrid frameworks should be well
evaluated depending upon different criterions such as: speed vs. accuracy. Best
solution chosen to the problem could be the one which uses the least amount of
69

computational resources, or the one that provides more accuracy irrespective of the
computational speed.
4.3 Architecture of Intelligent System with Uncertainty Intelligence is defined as “the ability to act appropriately in an uncertain
environment, where appropriate action is that which increases the probability of
success, and success is the achievement of behavioral goals [33].” The success of
an intelligent system is directly dependent upon the efficiency of the system
architecture. An effective and efficient architecture provides a systematic framework
which can be used to implement intelligent systems that can deal with uncertainty.
These architectures at a higher level identify the main modules that are required
during the implementation.
There have been various architectures in place to implement intelligent
systems that can deal with uncertainty. In this section, few of these architectures
have been explored with the focus on how each of them deals with uncertainty.
4.3.1 Architecture for Intelligent System Basic Architecture
The basic architecture is a simple architecture which receives an input X; this input
represents the problem in hand. This could be the application being worked upon,
such as, data mining, or e-services. Function 1 can be implemented through any
soft-computing techniques such as fuzzy logic, or rough set theory whichever fits the
best depending upon the nature of the problem. Once it receives the input, it
processes the data to produce an output Y, as shown in figure 10.
70

Figure 10: Basic Architecture for Intelligent Systems As an example, in case of data mining, if this was the phase of clustering:
Function 1 can be implemented through Fuzzy logic. Fuzzy logic is used to
calculate degree of belief (grade of membership) of each data value to the clusters.
The output is the data clustered together along with the value of degree of belief.
Basic architecture as depicted in figure 10 could be implemented for various
set of applications. This is usually applied in cases where one soft computing
technique can solve the problem in hand. Intelligent systems based on this type of
architecture can be easily implemented, but may not be very efficient in solving
complex situations.
4.3.2 Architecture for Hybrid Intelligent System
Hybrid intelligent systems are becoming very popular due to their ability to be
implemented through hybridization of soft computing techniques. Hybridization of
different techniques offers the best of both worlds; they utilize the best of AI
techniques to implement intelligent systems that are more efficient and effective.
There are three general approaches to the architectures of the intelligent system
[79]:
71

1. Sequential Type
This is a type of architecture where different functions are performed in a
defined sequence. Function 1 receives an input X representing the problem
in hand. It processes the data and produces an output Y which is fed as an
input to function 2; function 2 further processes this data thereby producing
the final output Z. This is represented in of Fig 11.
Figure 11: Sequential Type of Architecture
In this type of architecture Function 1 and Function 2 could be
implemented using different algorithms. Function 1 can be implemented
through Fuzzy logic and Function 2 could be implemented using Neural
Network or vice versa. For example, in the case of e-services; uncertainty
exists at the level of user initiating the query. Originally when the user input
is received, Function 1 is implemented through Fuzzy logic algorithm. It
processes the data, and creates fuzzy sets. Function 2 can be implemented
using neural network; once function 2 receives an input Y, it calculates
weights thereby producing a final output of Z. In this case uncertainty is dealt
at the front level only while interpreting the user’s query.
72

2. Parallel Type
This is a type where different functions are performed in parallel as shown in
Figure 12; there could be few variations to this. These two functions
(Function 1 & Function2) running in parallel could be working on the same
problem, and then Function 3, will choose the better solution and give that as
a final output. If this was the set up of the problem, then uncertainty needs to
be handled at the front level only when input X is received. Function 1 & 2
could be implemented using Fuzzy logic and Rough set theory. Function 3
will choose the better of two solutions which can be performed using neural
networks.
Figure 12: Parallel Type of Architecture
The other variation can be that these two functions could be
performing different functions (narrow & broad) and then function 3 will
aggregate their inputs to produce the final output. In this case, uncertainty
had to be dealt with at two levels; front level when input X is received and
secondly when the input Y is received by Function 3. During aggregation of
73

two solutions, if there was still some uncertainty, it could be dealt by Function
3 to produce the output Z.
3. Feedback Type
This is a type where function 1 performs the main function required, and
function 2 is there to fine tune the parameters of function 1 (figure 13), so that
the desired output is an optimal solution.
Figure 13: Feedback Type of Architecture
This type of architecture can be implemented in two ways:
• Selection of behavior before the fact – this is achieved by analyzing
goals provided to the system.
• Selection of behavior after the fact – achieved through the process of
subsumption.
74

Uncertainty can be dealt with at the level of receiving an input. In this
architecture, Function 1 and 2 could be implemented through various
algorithms such as, fuzzy logic, neural networks, Bayesian network or
Evolutionary algorithm.
Different types of architecture for hybrid system, is based upon mix and
match of different soft-computing techniques. This mix and match offer the best of
AI.
4.3.3 Evolutionary Algorithm Architecture
This is a specialized type of architecture for hybrid system, where one function is
evolutionary algorithm and other one can be chosen from a pool of soft-computing
techniques available.
Interactions between evolutionary algorithm and intelligent paradigms can
take many different variations. Intelligent paradigm refers to computational
intelligence techniques such as fuzzy logic, multi-valued logic. Abraham and Grosan
in [73] have discussed several architectures for evolutionary intelligent systems. For
instance, evolutionary algorithm can help optimize intelligent paradigm and
intelligent paradigm in return can help optimize evolutionary algorithm. Hence both
help each other to obtain the level of optimization. Figure 14 from [73] shows the
architecture of this evolutionary intelligent system; problem refers to real world
applications such as data mining, e-services.
75

Figure 14: Evolutionary Intelligent System Architecture [73] Design and architecture of intelligent system plays a crucial role in the
success of an intelligent system. With the recent hybridization of various soft-
computing techniques, hybrid systems have been developed which are fully capable
of handling real world applications. Next section provides us with an example of real
world application making use of Intelligent System. This will help us understand
design and architecture of intelligent system using soft computing techniques.
4.3.4 Application: Suppression of Maternal ECG from Fetal ECG Soft computing is clearly the emerging technique being used to build
intelligent systems. In this section, we will take a look at a real world application of
intelligent system called Adaptive Neuro Fuzzy Inference System (ANFIS) [86]. As
the name suggests, this Intelligent System is based upon combination of neural
networks and fuzzy logic. Neural networks enable recognition of patterns and
becoming adaptive to the changing environment the agent operates in. Similarly,
fuzzy logic provides the capability of inference and decision making through
knowledge base. ANFIS plays a critical role in the field of signal processing; we will
see how this intelligent system can help with noise cancellation in signal processing.
76

The application of noise cancellation can be applied to many real world applications
such as telecommunication, speech recognition, and medical field. For our
purposes we will take a look at one specific application in field of medicine where it
is being utilized to suppress maternal ECG from a fetal ECG.
Noise can be defined as an “unwanted energy, which interferes with the
desired signal [86].” The ultimate goal is to cancel or reduce the noise from the
signal so it does not distort the signals which can cause misinterpretation. The
underlying principle of noise cancellation is to “filter out an interference component
by identifying the non-linear model between a measureable noise source and the
corresponding immeasurable interference [86].” This is done by estimating the level
of noise in the system and then subtracting this from the signal. The effectiveness of
noise cancellation is directly dependent upon the accuracy of estimation of noise
level. It is a critical step in translating signals properly to what they truly represent;
this poses a challenge in the field of signal processing.
ANFIS is used to handle uncertainty by identifying unknown non linear
passage dynamics that transforms noise source into noise estimate in a detected
signal [86]. ANFIS architecture is composed of neural network and fuzzy logic; we
will briefly go over few details:
Neural Network
Neural Networks has already been mentioned in Section 4.2.2. ANFIS is based
upon Back Propagation from Neural Networks.
77

Back Propagation
This learning algorithm is based upon Widrow-Hoff learning rule which is used
to train multi layer feed forwards networks. Training of networks involve usage of
input and their corresponding output vectors until network is trained to approximate a
function, and is able to provide association between input and output vectors as
expected. Through this training, network learns to associate input with output.
Back propagation refers to the manner in which gradient is computed for non-
linear multi layer networks. When a back propagation is properly trained, they are
able to associate, infer and make precise decisions when presented with an
unknown input. Usually through similarity in inputs, it will lean towards the correct
output. This is based on two phases of data flow. First phase is where the input is
propagated from the input layer to the output layer, producing the output. Second
phase is where error signal is being propagated from the output layer to the previous
layer to update the weights [86].
Fuzzy Logic
Fuzzy logic has already been discussed in greater details in section 2.2. ANFIS is
based upon Fuzzy Inference System.
Fuzzy Inference System
“Fuzzy Inference system is the process of formulating the mapping from a
given input to an output using fuzzy logic [86].” Figure 15 [89] illustrates the
functional block of fuzzy inference system. This system takes an input which is a
crisp set, and returns the crisp output through weighed average.
78

Figure 15: Basic Configuration of a Fuzzy Logic System [89]
Suppressing Maternal ECG from Fetal ECG Noise cancellation application is used and implemented in various real world
problems; once such problem is to suppress maternal ECG from fetal ECG.
Pregnancy is a very critical stage where utmost precaution should be taken
by mother for safety of both the mother and the baby. Many health problems of a
new born baby can be reduced by monitoring fetus’s heart rate, since heart rate is
an important indicator of health [90]. ECG, which stands for electrocardiogram, can
be recorded and processed to derive this heart rate. Maternal ECG represents
mother’s ECG and Fetal ECG represents fetus’s ECG. While trying to get
measurements for fetal ECG, there is interference from maternal ECG. Hence it is
crucial to suppress maternal ECG from Fetal ECG while measuring abdominal signal
to get the accurate reading by cancelling noise.
79

ANFIS comes into play to deal with maternal ECG; we will look at details of
how maternal ECG is handled through ANFIS as discussed in [86]. Fetal ECG x(k)
is recorded through abdominal signal y(k) via a sensor in abdominal region. During
the process of recording y(k), this signal gets mixed (noisy) with mother’s heartbeat
n(k) which acts as a noise. n(K) can be easily measured in this case through
thoracic signal obtained via a sensor placed at thoracic region. Noise does not
appear directly in y(k), but only appears in bits and pieces which distorts the signal
y(k). This is represented as:
Y(K) = x(k) + d(k), where d(k) represents distorted noise (equation 1)
=x(k) + f(n(k), n(k-1)….)
Let B = f(n(k), n(k-1), …)
Function B represents the path that noise signal n(k) takes; if path was
known, then we would get the original signal through y(k) – d(k). Since, it is an
unknown factor and time variant due to changing environment, it is not simple
enough. Ď(k) is distorted noise signal which is an added component on top of y(k).
Learning rule of ANFIS which is implemented through neural networks aims at
minimizing the error:
E(k)2 = ( Y(k) - Ď(k))2
= ( x(k) + d(k) - Ď(k))2 (from equation 1)
Error is directly dependent upon d(k); hence by reducing d(k), we can
minimize error. The ANFIS approach to cancel noise cancellation works only when
[86]:
1. Noise signal n(k) is available and independent of information signal x(k)
80

2. Zero mean value for x(k)
3. Passage dynamic is known (path n(k) will take)
In our case of suppressing maternal ECG from fetal ECG; information signal
x(k) is of sinusoidal form and noise is a random signal. ANFIS performs calculation
and information signal is obtained. Overview of algorithm as discussed in [86]:
1. Abdominal signal is generated
2. Thoracic signal is generated
3. Interference signal is generated
4. Interference and abdominal is mixed to generate a measured signal
5. Ď(k) is calculated (distorted noise signal)
6. Subtract Ď(k) from the measured signal to get an estimated signal
7. Calculate the error signal through error calculation.
Figure 16 [87] is a high level overview of ANFIS cancelling maternal ECG
from the signal.
Figure 16: Maternal ECG Cancellation in Abdominal Signal using ANFIS [87]
81

In the real world, issue of accurately predicting Fetal ECG without the
implementation of uncertainty models would definitely provide us with a wrong
measurement. There will be lot of interference from Maternal ECG which could not
be cancelled or reduced since it is an unknown variable. While when the similar
issue is handled through an intelligent system which can handle uncertainty, we
were able to get a good estimation of fetal ECG. Even though this value contains
some error, but in comparison outperforms and gives a better prediction of fetal ECG
along with the measurement of error.
Intelligent system that was implemented through neural network only would
be a little complex to train the network, and the measurement of error in the
estimated signal will be higher. On the contrary, if fuzzy logic was used, then it will
be hard to create all if-then rules, since the environment is complex. While ANFIS is
dependent upon both neural network and fuzzy logic, it gets the best of both worlds.
Measurement of error obtained through ANFIS is not zero and does represent high
frequency noise, but the mean of error is zero.
ANFIS is just one of many examples of intelligent system that are being used
in real world applications to solve complex problems that involve uncertainty. ANFIS
architecture has been evolved through combination of various uncertainty models.
Lot of work has been conducted in this field; R. Swarnalath, and D.V. Prasad
incorporated ANFIS with wavelets for maternal ECG cancellation as in [87]; more
details can be found in [87].
Knowledge uncertainty plays a critical role in any intelligent system from
beginning to end; it preprocesses the input, so the input is accepted by the intelligent
82

system, transforms this input through various uncertainty models to effectively
handle uncertainty that exists in data and then finally produces the output. An
intelligent system that is implemented to handle uncertainty can handle real world
situations accurately and effectively than a situation where uncertainty is fully
ignored.
83

CHAPTER 5
CONCLUSION AND RECOMMENDATIONS
5.1 Conclusion Artificial intelligence is an ever growing field with a lot of scope for research and
advancement. It has recently gained a lot of popularity through its ability to handle
real world situations; since then, many new theories and methodologies have been
introduced. Knowledge uncertainty plays a crucial role in the field of AI because
uncertainty is a part of our day to day lives. For the invention of more robust
intelligent system, that can think and act like a human being, we have to apply
uncertainty models which can accept approximations instead of exactness.
Approximation is a reality of today’s world; hence it is important to use models for
intelligent systems which can handle this variable.
Several numbers of theories are in place to deal with uncertainty, ranging
from probabilistic and possibilistic theory to combination of these two. This essay
looked at four main uncertainty models: Fuzzy logic, Rough set theory, Multi-valued
logic, and Bayesian network.. These models share one common goal: to handle
uncertainty, impreciseness and incompleteness in the knowledge base. The
approach to handle uncertainty varies amongst these models, and some are more
effective in certain domain depending upon the nature of domain in question. Hence
we cannot claim that one model is better than another because the solution to be
implemented is very much dependent upon the type of application.
84

Hybridization of soft computing techniques provides a cutting edge to the
hybrid intelligent systems. These systems can handle complex system efficiently
and effectively if implemented accurately by understanding the needs of the task to
be solved. More and more research is conducted in hybridization and lot of work
has been conducted to start using this in our day to day lives.
Data mining and semantic web services are two different applications with the
need to handle uncertainty that exist at different levels. Different models have been
identified and used for these purpose; this essay recommends fuzzy logic for
handling different uncertainties that exist in these applications. For data mining,
fuzzy logic proves to be a good model to deal with uncertainty in Data mining. This
algorithm based on membership function and degree of belief, and can handle what
data mining needs. It’s ability to transform crisp sets into fuzzy sets along with the
value of degree of belief which signals which objects belongs more to the set in
comparison to other objects in the same set; It’s ability to search for hidden patterns
through huge amounts of data. These features make fuzzy logic suitable for data
mining.
Similar to Data mining, fuzzy logic is recommended for semantic web service
domain. Uncertainty exists in semantic web service at different levels, from user
initiating query to finding results that match the query. Fuzzy logic generates a fuzzy
set to understand user query and when they system retrieves the results against
user’s query; it creates two fuzzy sets which contains weights and distance
information to display the results in the order of most relevant to least relevant.
85

Concept of fuzzy sets in fuzzy logic sets itself apart from other soft-computing
techniques.
The design and architecture play a central role in the success of intelligent
system. More and more algorithms have been developed recently to achieve
success without compensating on speed and without using too much of
computational resources. Concept of natural selection is an interesting principle
which is applied in the field AI; this definitely helps to get rid of features that are not
very viable, thereby reducing the search space. At the design level, dealing with
uncertainty at object, environment and goal level help to deal with uncertainty at an
architecture level. Therefore, having a right design and architecture for intelligent
system defines the success of intelligent systems. As discussed in Section 4,
ANFIS is an excellent example of an intelligent system based upon hybridization of
neural network and fuzzy logic useful in suppressing maternal ECG from fetal ECG.
As more and more work is conducted in the field of Artificial Intelligence and
uncertainty, new architectures are being evolved which can handle any complex
problem with efficiency and accuracy. That day is not far away, when Artificial
Intelligent will provide solution to every real world problems.
5.2 Future Work Knowledge uncertainty in intelligent system has come a long way from the initial
state where intelligent systems were used for basic computation, to today’s era,
where intelligent systems have been practically evolved to handle complicated real
life situations. The success of these intelligent systems depends upon their abilities
86

to handle uncertainty. Future research should be conducted to create more hybrid
models which are generated through mix and match of available models. To handle
real world applications, we should be able to increase the speed of computation by
using algorithms which operate in the environment of lower search space by
compacting the environment which is smaller yet a true representation for the world
it represents.
87

REFERENCES [1] L.A. Zadeh, “The Role of Fuzzy Logic in the Management of Uncertainty in
Expert Systems,” Fuzzy Sets and Systems, Volume 11, Issues 1–3, pp. 199–227, 1983.
[2] J. Y. Halpern, Reasoning About Uncertainty, p. 434. Cambridge, MA: MIT
Press, 2003. [3] “Uncertainty,” http://en.wikipedia.org/wiki/Uncertainty, 3 July 2010.
[4] A. Motro, P. Smets, Uncertainty Management in Information Systems: from Need to Solutions, p. 459. Norwell, Massachusetts: Kluwer Academic Publisher, 1997.
[5] A. Celikyilmaz and I.B. Turksen, Modeling Uncertainty with Fuzzy Logic, p.
400. Heidelberg, Germany: Springer, 2009. [6] “Fuzzy Logic,” http://en.wikipedia.org/wiki/Fuzzy_logic, 24 July 2010.
[7] Y.Y. Yao, “A Comparative Study of Fuzzy Sets and Rough Sets,” Information Sciences, Volume 109, Issues 1-4, pp. 227–242, 1998.
[8] “Multi-valued Logic,” http://en.wikipedia.org/wiki/Multi-valued_logic, 5 August
2010. [9] S. Greco, B. Matarazzo and R. Slowinski, “Rough Sets theory for Multicriteria
Decision Analysis,” European Journal of Operational Research, Volume 129, Issue 1, pp. 1-47, 2001.
[10] “Rough Set,” http://en.wikipedia.org/wiki/Rough_set, 15 August 2010.
[11] M.Bit, T. Beaubouef, “Rough Set Uncertainty for Robotic Systems,” Journal of Computer Sciences in Colleges, Volume 23, Issue 6, pp. 126-132, 2008.
[12] Stuart Russell, and Peter Norvig, Artificial Intelligence: A Modern Approach,
Second Edition, p. 986. Upper Saddle River, N.J.: Prentice Hall, 2002. [13] Zdzislaw Pawlak, “Vagueness and Uncertainty: A Rough Set Perspective,”
Computation Intelligence, Volume 11, Issue 2, pp. 227-232, 1995. [14] H.G. Solheim, “Discerning Objects,” 15 August 2010,
http://www.pvv.ntnu.no/~hgs/project/report/node40.html
88

[15] L.A. Zadeh, "Knowledge Representation in Fuzzy Logic," 1989 IEEE Transactions on Knowledge and Data Engineering, Volume 1, Issue 1, pp. 89-100, March 1989.
[16] Zdzislaw Pawlak, “Rough Set Approach to Knowledge Based Decision
Support,” European Journal of Operational Research, Volume 99, Issue 1, pp. 48-57, May 1997.
[17] Pawlak, Z., and Skowron, A., “Rough membership functions,” Advances in the
Dempster Shafer Theory of Evidence, p. 251-271, New York, NY: John Wiley and Sons Inc., 1994.
[18] E. Orlowska, "Many-valuedness and uncertainty," Multiple-Valued Logic, 27th
International Symposium on Multiple-Valued Logic (ISMVL '97), pp. 153, 1997.
[19] M. Richardson, and P. Domingos, “Markov Logic Networks,” SpringerLink,
Volume 62, pp. 107-136, 2006. [20] D. Dubois, and H. Prade, “Possibility Theory, Probability Theory, and Multiple
Valued Logics,” Journal of Mathematics and Artificial Intelligence, Volume 32, Issues 1-4, pp. 35-66, August 2001.
[21] B.G. Buchanan and R.O. Duda, “Principles of Rule-Based Expert Systems,”
Advances in Computers, Volume 22, pp. 164-218, 1984. [22] “Bayesian Network,” http://en.wikipedia.org/wiki/Bayesian_network, 29 July
2010. [23] Eugene Charniak, “Bayesian Network Without Tears,” AI Magazine, Volume
12, Number 14, pp. 50-63, 1991.
[24] “NP-Hard,” http://en.wikipedia.org/wiki/NP-hard, 1 August 2010.
[25] J. Pearl, Probabilistic Reasoning in Intelligent Systems: Networks of Plausible Inference, p. 552. San Francisco, CA: Morgan Kaufmann Publishers Inc., 1988.
[26] S. Easterbrook and M. Chechik, “A Framework for Multi-valued Logic over
Inconsistent Viewpoints,” Proceedings of the 23rd International Conference on Software Engineering, pp. 411-420, 2001.
[27] N.D. Belnap. “A Useful Four-Valued Logic,” Modern Uses of Multiple-Valued
Logic, pp. 30-56, 1977.
89

[28] B. Sarif and M. Abd-El-Barr, “Synthesis of MVL Functions – Part I: The Genetic Algorithm Approach,” Proceedings of the International Conference on Microelectronics, pp. 154-157, 2006.
[29] G. Pomper and J. A. Armstrong, "Representation of Multivalued Functions
Using Direct Cover Method," 1981 IEEE Transactions on Computing, Volume C-30, Issue 9, pp. 674-779, Sept. 1981.
[30] P.W. Besslich, "Heuristic Minimization of MVL functions: A Direct Cover
Approach," 1986 IEEE Transactions on Computing, Volume C-35, Issue 2, pp. 134-144, Feb 1986.
[31] Dueck, G. W. and Miller, D. M., "A Direct Cover MVL Minimization: Using the
Truncated Sum," Proceeding of the 17th International Symposium on multi-valued logic, pp. 221-227, May 1987.
[32] A. Borgi, K. Ghedira, and S.B.H. Kacem, “Generalized Modus Ponens Based
on Linguistic Modifiers in a Symbolic Multi-valued Framework,” Multi Valued Logic, 38th International Symposium, pp. 150-155, 2008.
[33] J.S. Albus, “Outline for a Theory of Intelligence,” Proceedings of the 1991
IEEE International Conference on Systems, Man, and Cybernetics, Volume 21, Issue 3, pp. 473-509, 1991.
[34] C.J. Butz and J.Liu, “A Query Processing Algorithm for Hierarchical Markov
Networks,” 2003 IEEE/WIC International Conference on Web Intelligence (WI’03), pp. 588-592, 2003.
[35] C.Beeri, R. Fagin, D. Maier, and M. Yannakakis, “On the Desirability of
Acyclic Database Schemes,” Journal of the Association for Computing Machinery, Volume 30, Issue 3, pp. 479-513, 1983.
[36] L.R. Rabiner, B.H. Juang, “An Introduction to Hidden Markov Models,” IEEE
ASSP Magazine, Volume 3, Issue 1, pp. 4-16, 1986. [37] Ralph L. Wojtowicz, “Non-Classical Markov Logic and Network Analysis,” 12th
International Conference on Information Fusion, pp. 938-947, 2009. [38] M. Richardson, and P. Domingos, “Markov Logic Networks,” Machine
Learning, Spring Science Business Media, Volume 62, Issues 1-2, pp. 107-136, 2006.
[39] “Clique (graph theory),”
http://en.wikipedia.org/wiki/Clique_%28graph_theory%29, 6 September 2010.
90

[40] D. Hand, H. Mannila, and P. Smyth, Principles of Data Mining, p. 546. Cambridge, England: MIT Press, 2001.
[41] D. Gunopulos, M. Halkidi, and M. Vazirgiannis, Uncertainty Handling and
Quality Assessment in Data Mining, p. 421. London, England: Springer-Verlag London Limited, 2003.
[42] U. Fayyad, G. Piatelsky-Sharpio, and P. Smyth, “From Data Mining to
Knowledge Discovery in Databases,” AI Magazine, Volume 17, Number 3, pp. 37-54, 1996.
[43] T. Hastie, R. Tibshirani, J. Friedman, and J. Franklin, “The Elements of
Statistics Learning: Data Mining, Inference, and Prediction,” Springer, Volume 27, Number 2, pp. 83-85, 2001.
[44] Y. Xia, “Integrating Uncertainty in Data Mining,” Ph.D Dissertation. University
of California at Los Angeles, Los Angeles, CA. Advisor(s) Richard R. Muntz, pp. 1-185, 2005.
[45] J. Han, and M. Kamber, Data Mining: Concepts and Techniques, Second
Edition, p. 386. San Francisco, CA: Morgan Kaufmann Publishers, 2006. [46] “Data,” http://en.wikipedia.org/wiki/Data, 24 September 2010. [47] Han Jing, “Application of Fuzzy Data Mining Algorithm in Performance
Evaluation of Human Resources,” IEEE Transactions on Computing, Volume 1, pp. 343-346, 2009.
[48] N. Bissantsz, and J. Hagedorn, “Data Mining,” Business & Information
Systems Engineering, Volume 1, Issue 1, pp. 118-121, 2009. [49] W.J. Frawley, G.P. Shapiro, C.J. Matheus, “Knowledge Discovery in
Databases: an Overview,” AI Magazine, Volume 13, Number 3, pp. 57-70, 1992.
[50] Berkhin, P., “Survey of Clustering Data Mining Techniques,”
http://citeseer.ist.psu.edu/berkhin02survey.html, 20 September 2010. [51] G. Raju, B. Thomas, S. Kumar, and S. Thinley, “Integration of Fuzzy Logic in
Data Mining to Handle Vagueness and Uncertainty,” Advanced Intelligent Computing Theories and Applications, Volume 5227, pp. 880-887, 2008.
[52] S. Mitra, S.K. Pal, and P. Mitra, “Data Mining in Soft Computing Framework:
A Survey,” IEEE Transactions on Neural Networks 13, Volume 1, pp. 3–14, 2002.
91

[53] D. Berardi, D. Calvanese, G. Giacomo, M. Lenzerini, and M. Mecella, “A Foundational Vision of E-Services,” Web Services, E-Business, and the Semantic Web, Volume 3095, pp. 28-40, 2004.
[54] M. Aiello, M.P. Papazoglou, J. Yang, M. Carman, M. Pistore, L. Serafini, and
P. Traverso, “A Request Language for Web-Services Based on Planning and Constraint Satisfaction,” Proceedings of the Third International Workshop on Technologies for E-Services, Volume 2444/2002, pp. 9-38, 2002.
[55] J. Rowley, “An analysis of the e-service literature: towards a research
agenda,” Internet Research, Emerald Group Publishing Limited, Volume 16, Number 3, pp. 339-359, 2006.
[56] Z. Yang, “Consumer Perceptions of Service Quality in Internet-Based
Electronic Commerce,” Proceedings of the EMAC Conference, pp. 339-359, 2001.
[57] G.J. Klir and M.J. Wierman, Uncertainty-Based Information: Elements of
Generalized Information Theory, p. 165. Heidelberg, Germany: Springer, 1999.
[58] G. Yee, and L. Korba, “Negotiated Security Policies for E-Services and Web
Services,” Proceedings of the 2005 IEEE International Conference on Web Services, pp. 1-8, 2005.
[59] Z. Cob, and R. Abdullah, “Ontology-based Semantic Web Services
Framework for Knowledge Management System,” IEEE Transactions on Computing, Volume 2, pp. 1-8, 2008.
[60] F. Martin-Recuerda, and D. Robertson, “Discovery and Uncertainty in
Semantic Web Services,” URSW (LNCS Vol.) 2008, pp. 108-123, 2008. [61] D. Parry, “Tell Me the Important Stuff” - Fuzzy Ontologies And Personal
Assessments For Inter action With The Semantic Web,” Proceedings of the 2008 IEEE World Conference on Computational Intelligence, pp. 1295-1300, 2008.
[62] E. Sirin, and B. Parsia, “Planning for Semantic Web Services,” International
Workshop “Semantic Web Services” at ISWC, pp. 1-15, 2004. [63] J. Hoffmann, P. Bertoli, and M. Pistore, “Web Service Composition as
Planning, Revisited: In Between Background Theories and Initial State Uncertainty,” Proceedings of the 2007 National Conference on Artificial Intelligence, pp. 1013 – 1018, 2007.
92

[64] H. Haas and A. Brown (2004). Web Services Glossary, http://www.w3.org/TR/wsgloss/, 16 September 2010.
[65] A. Polleres, “Services as Application Areas for Answer Set Programming,”
Dagstuhl Seminar Proceedings 05171, pp. 1-6, 2005. [66] B. Sandvik, “Thematic Mapping on the Semantic Web,”
http://blog.thematicmapping.org/2008_07_01_archive.html, 19 September 2010.
[67] J. Carbonell, “Semantic Web Services o la Web Activa,”
http://www.lacofa.es/index.php/general/semantic-web-services-o-la-web-activa, 20 September 2010.
[68] P. Oliveira, and P. Gomes, “Instance-based Probabilistic Reasoning in the
Semantic Web,” Proceedings of the 18th International Conference on World Wide Web, pp. 1067-1068, 2009.
[69] M. Holi and E. Hyvonen, “A Method for Modeling Uncertainty in Semantic
Web Taxonomies,” Proceedings of the 13th International World Wide Conference, pp. 296-297, 2004.
[70] H. Zimmermann, “Fuzzy Set Theory,” Computational Statistics, Wiley
Interdisciplinary Reviews, Volume 2, Issue 3, pp. 317-332, 2010. [71] A. Sheth, C. Ramakrishnan, and C. Thomas, “Semantics for the Semantic
Web: the Implicit, the Formal, and the Powerful,” International Journal on Semantic Web and Information Systems, Volume 1, Issue 1, pp.1-18, 2005.
[72] K. Shehzad, and M. Javed, “Multithreaded Fuzzy Logic based Web Services
Mining Framework,” European Journal of Scientific Research, Volume 41, Iusse 4, pp.632-644, 2010.
[73] A. Abraham, C. Grosan J. Kacprzyk and W. Pedrycz, Studies in
Computational Intelligence, Volume 82, p. 441. Berlin, Germany: Springer, 2008.
[74] L.A. Zadeh, “Soft Computing and Fuzzy Logic,” IEEE Transactions on
Computing, Volume 11, Issue 6, pp. 48-56, 1994. [75] T. Ito, “Dealing with Uncertainty in Design and Decision Support
Applications,” International Journal of Soft Computing Applications, Issue 1, pp. 5-16, 2007.
[76] A. Korvin, H. Lin, and P. Simeonov, Knowledge Processing with Interval and
Soft Computing, p. 233. London, England: Springer, 2008.
93

[77] J. Jang, C. Sun, and E. Mizutani, Neuro-Fuzzy and Soft Computing: A
Computation Approach to Learning and Machine Intelligence, p. 614. Upper Saddle River, N.J.: Prentice Hall, 1996.
[78] L.A. Zadeh, “The Roles of Soft Computing and Fuzzy Logic in the
Conception, Design and Deployment of Intelligent System, Proceedings of IEEE Asia Pacific Conference on Circuits and Systems, pp. 3-4, 1996.
[79] V. Vasilyev, and B. Ilyasov, “Design of Intelligent Control Systems with Use of
Soft Computing: Conceptions and Methods,” Proceedings of the 15th IEEE International Symposium on Intelligent Control, pp. 103-108, 2000.
[80] E. Simoudis, “Reality Check for Data Mining,”
http://cs.salemstate.edu/hatfield/teaching/courses/DataMining/M.htm, 26 September 2010.
[81] Y. Fujiwara, Y. Sakurai, and M. Kitsuregawa, “Fast Likelihood Search for
Hidden Markov Models,” ACM Transaction on Knowledge Discovery from Data, Volume 3, Issue 4, pp. 1-37, 2009.
[82] S. Kok, and P. Domingos, “Learning Markov Logic Network Structure via
Hypergraph Lifting,” ACM Proceedings of the 26th Annual International Conference on Machine Learning, pp. 505-512, 2009.
[83] J.S. Albus, “A Reference Model Architecture for Intelligent System Design,”
Proceedings of the 1996 IEEE International Conference on Systems, Volume 1, Issue 1, pp. 15-30, 1996.
[84] H. Boudali, and J.B. Dugan, “A Discrete-Time Bayesian Network Reliability
Modeling and Analysis Framework,” Engineering and System Safety, Volume 87, Issue 3, pp. 337-349, March 2005.
[85] J. Lampinen, and A. Vehtari, “Bayesian Approach for Neural Networks –
Review and Case Studies,” Neural Networks, Volume 14, Issue 3, pp. 257-274, April 2001.
[86] C.K.S Vijila, S. Renganathan, and S. Johnson, “Suppression of Maternal ECG
from Fetal ECG using Neuro Fuzzy Logic Technique,” Proceedings of the International Joint Conference on Neural Networks, Volume 2, pp. 1007-1012, 2003.
[87] R. Swarnalath, and D.V. Prasad, “Maternal ECG Cancellation in Abdominal
Signal Using ANFIS and Wavelets,” Journal of Applied Sciences, Volume 10, Issue 11, pp. 868 – 877, 2010.
94

95
[88] B.B. Jovanovic, I.S. Reljin, and B.D. Reljin, “Modified ANFIS architecture – improving efficiency of ANFIS technique,” Neural Network Applications in Electrical Engineering, pp. 215-220, 2004.
[89] G. Luiz, C.Abreu, and J. Ribeiro, “On-line Control of a Flexible Beam Using
Adaptive Fuzzy Controller and Piezoelectric Actuators,” SBA Control and Automation, Volume 15, Issue 14, pp. 377-383, 2003.
[90] G. Clifford, “Fetal and Maternal ECG,” Biomedical Signal and Image
Processing, Volume 2, Issue 1, pp. 1-10, 2007.





























