Embed Size (px)
Citation preview

Análisis multivariado
-Las técnicas multivariadas permiten establecer relaciones
de similitud global (o fenéticas) entre unidades de estudio,
sobre la base de la evidencia que brindan sus caracteres
-A partir de los resultados de estas técnicas (e.g. un
fenograma), el especialista podrá adoptar decisiones
taxonómicas con respecto a las especies y las variaciones
infraespecíficas.

Análisis multivariado
Técnicas de Agrupamientos
Método del ligamiento promedio no ponderado
(UPGMA: Unweighted pair group method)
Técnicas de ordenación
Análisis de Componentes principales
Análisis de Coordenadas principales
Análisis Factorial Múltiple
Arboles de distancia
Árboles de Neighbor-Joining

MATRIZ DE DATOS
MATRIZ DE
SIMILITUD
DENDROGRAMAS
(UPGMA)
NEIGHBOR
JOINING TREEPCA

Pasos de Aplicación de Técnicas de Agrupamientos:
construcción de fenogramas
Elección de las OTU a estudiar
Selección y registro de caracteres
Construcción de una matriz de datos de OTU por caracteres.
Cálculo de un coeficiente de similitud (o disimilitud) entre cada par posible de OTU
Construcción de una matriz de similitud (o disimilitud) entre OTU
Obtención del dendrograma (=fenograma) entre OTU
Medida de la distorsión del dendrograma (=fenograma)
Descripción e interpretación de resultados

-Elección de OTU (Operational Taxonomic Units)

-Selección y registro de caracteres
-Construcción de una matriz de datos

-Selección y registro de caracteres
-Construcción de una matriz de datos

-Cálculo de un coeficiente de similitud entre cada para posible
de OTU

Coeficientes de correlación

Coeficientes de distancia

Aplicación de un coeficiente de similitud
n
Manhattan Distance Σ [ Xij-Xik]
i=1
Jaccard __a___
a+b+c
Simple Matching a + d
a+b +c +d

Construcción de una matriz de similitud

Matriz de similitud (Distancia)

Matriz de similitud (Distancia)
1 2 3 4 5 6
1 -
2 52 -
3 53 44 -
4 84 70 79 -
5 78 61 62 76 -
6 77 70 68 73 66 -

1 2 3 4 5 6
1 -
2 52 -
3 53 44 -
4 84 70 79 -
5 78 61 62 76 -
6 77 70 68 73 66 -
Matriz de similitud (Distancia)

2
3
44 0

1 2 3 4 5 6
1 -
2 52 -
3 53 44 -
4 84 70 79 -
5 78 61 62 76 -
6 77 70 68 73 66 -

1 2 3 4 5 6
1 -
2
352.5
-
44 -
4 84 70 79 -
5 78 61 62 76 -
6 77 70 68 73 66 -

1 2 3 4 5 6
1 -
2
352.5 -
4 84 70 79 -
5 78 61 62 76 -
6 77 70 68 73 66 -

1 2 3 4 5 6
1 -
2
352.5 -
4 84 74.5 -
5 78 61 62 76 -
6 77 70 68 73 66 -

1 2 3 4 5 6
1 -
2
352.5 -
4 84 74.5 -
5 78 61.5 76 -
6 77 70 68 73 66 -

1 2 3 4 5 6
1 -
2
352.5 -
4 84 74.5 -
5 78 61.5 76 -
6 77 69 73 66 -

1 2 3 4 5 6
1 -
2
352.5 -
4 84 74.5 -
5 78 61.5 76 -
6 77 69 73 66 -

2
3
1
4452.5 0

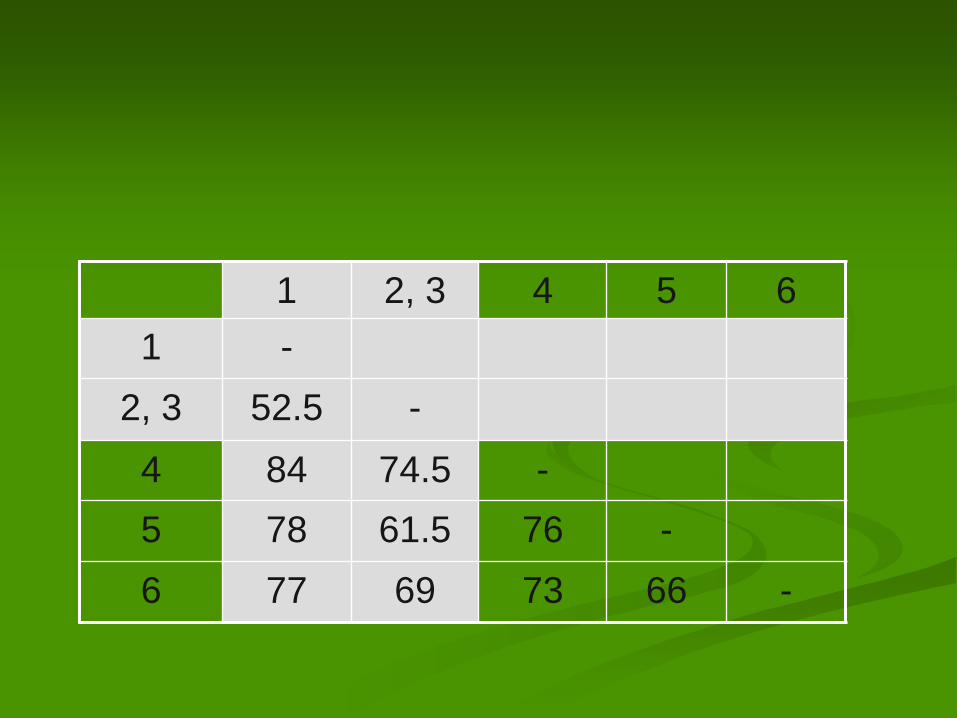
1 2, 3 4 5 6
1 -
2, 3 52.5 -
4 84 74.5 -
5 78 61.5 76 -
6 77 69 73 66 -
1 2, 3 4 5 6
1 -
2, 3 52.5 -
4 84 74.5 -
5 78 61.5 76 -
6 77 69 73 66 -

1, 2, 3 4 5 6
1, 2, 3-
52.5 -
4 84 74.5 -
5 78 61.5 76 -
6 77 69 73 66 -

1, 2, 3 4 5 6
1, 2, 3 -
4 84 74.5 -
5 78 61.5 76 -
6 77 69 73 66 -

1, 2, 3 4 5 6
1, 2, 3 -
4 79.25 -
5 78 61.5 76 -
6 77 69 73 66 -

1, 2, 3 4 5 6
1, 2, 3 -
4 79.25 -
5 69.75 76 -
6 77 69 73 66 -

1, 2, 3 4 5 6
1, 2, 3 -
4 79.25 -
5 69.75 76 -
6 73 73 66 -

1, 2, 3 4 5 6
1, 2, 3 -
4 79.25 -
5 69.75 76 -
6 73 73 66 -

2
3
1
6
5
4452.5 066

1, 2, 3 4 5, 6
1, 2, 3 -
4 79.25 -
5
6
69.75 76 -
73 73 66 -

1, 2, 3 4 5, 6
1, 2, 3 -
4 79.25 -
5, 6 71.325 76 -
73 66 -

1, 2, 3 4 5, 6
1, 2, 3 -
4 79.25 -
5, 6 71.325 74.5 -
66 -

1, 2, 3 4 5, 6
1, 2, 3 -
4 79.25 -
5, 6 71.325 74.5 -

1, 2, 3 4 5, 6
1, 2, 3 -
4 79.25 -
5, 6 71.325 74.5 -

2
3
1
6
5
4452.5 06671.3

4
2
3
1
6
5
4452.5 06671.376.3

1 2 3 4 5 6
1 -
2 52 -
3 53 44 -
4 84 70 79 -
5 78 61 62 76 -
6 77 70 68 73 66 -
1 2 3 4 5 6
1 -
2
3 52.5 -
4 84 74.5 -
5 78 61.5 76 -
6 77 69 73 66 -
1, 2, 3 4 5 6
1,
2, 3
-
4 79.25 -
5 69.75 76 -
6 73 73 66 -
Original
Derivada

1 2 3 4 5 6
1 -
2 52 -
3 53 44 -
4 84 70 79 -
5 78 61 62 76 -
6 77 70 68 73 66 -
Original
1 2 3 4 5 6
1 -
2
3 52.5 -
4 84 74.5 -
5 78 61.5 76 -
6 77 69 73 66 -
Derivada1, 2, 3 4 5 6
1,
2, 3
-
4 79.25 -
5 69.75 76 -
6 73 73 66 -
1, 2, 3 4 5 6
1,
2, 3
-
4 77.6 -
5 67.0 76 -
6 71.6 73 66 -
WPGMA UPGMA
Derivada Derivada

Desventajas de las técnicas de agrupamientos
Siempre aparecen grupos delimitados, aun cuando éstos no se
ajusten a la estructura de los datos.
Mediante estas técnicas no se puede evaluar la similitud
homóloga.
Sin embargo, dado que los algoritmos propuestos por la
Cladística operan sobre datos discretos, las técnicas de
agrupamientos, al igual que los árboles basados en distancias,
constituyen herramientas útiles para el análisis de datos
continuos frecuentemente utilizados para el estudio de la
variación infraespecífica mediante marcadores moleculares.

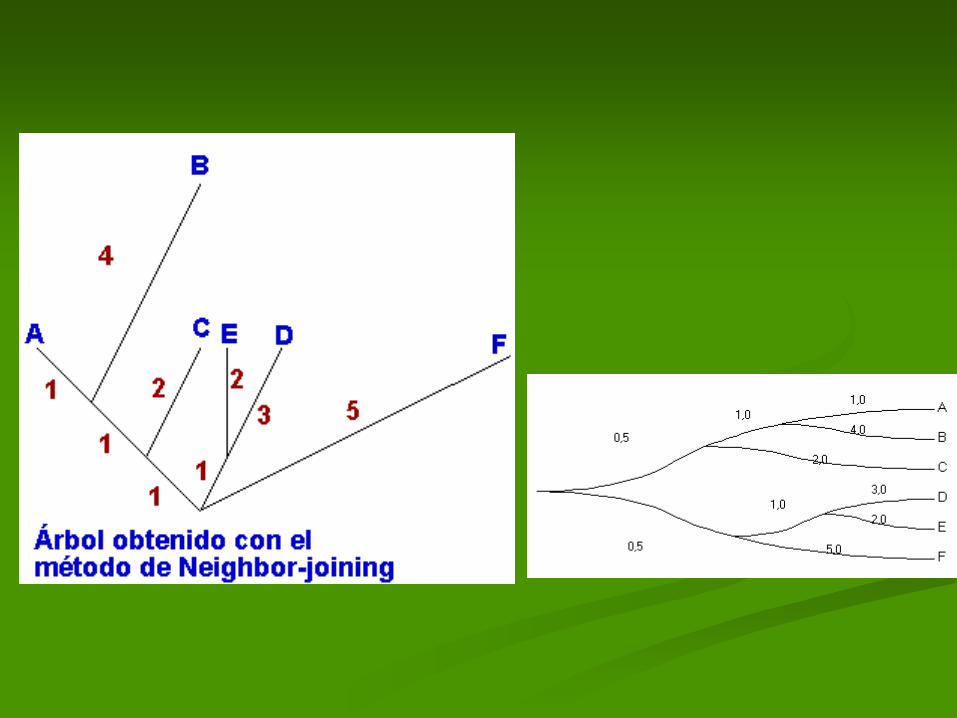
Método de Neighbor Joining
Saitou and Masatoshi Nei (1987),
Une los OTU's más cercanos
tratando de minimizar la longitud
total del árbol.
El método se inicia a partir de
una estrella en la cual todas los
OTU's están enlazados a un nodo
central.

Se calcula la divergencia de cada OTU a la red, denotada con la
letra r
r(i) = di1 + di2 + di3 + ... + dij. i es cualquier OTU, j es el
número total de OTU's.
Se calcula la nueva matriz de distancias:
Mij = Nueva distancia entre los OTU's i y j.
dij = Distancia actual entre los OTU's i y j.
r(i) = Divergencia del OTU i.
r(j) = Divergencia del OTU j.
N = Número de OTU's.

Se escoge el par de OTU's que tenga el menor valor de
Mij (los más negativos), se calcula el nuevo nodo k y se
procede a estimar la longitud de las ramas que unen el
nodo interno K y los OTU's i y j.
Estas distancias se calculan con la siguiente formula:

Se estiman las distancias del resto de OTU's al nodo
interno k.
Estas distancias se calculan considerando los vecinos
OTU's i y j en el nodo k y sea n una OTU, entonces la
distancia de nodo interno k al OTU n es igual a:

A B C D E
B 5 . . . .
C 4 7 . . .
D 7 10 7 . .
E 6 9 6 5 .
F 8 11 8 9 8
Topología correcta del árbol
para los OTU's de la tabla 1.
Matriz de sustitución para
un grupo de seis OTU's

Reconstrucción del árbol aplicando el método de
Neighbor-joining.
Paso 1
Divergencia de la red.
r(A) = 5 + 4 + 7 + 6 + 8 = 30
r(B) = 5 + 7 + 10 +9 + 11 = 42
r(C) = 4 + 7 + 7 + 6 + 8 = 32
r(D) = 7 + 10 +7 + 5 + 9 = 38
r(E) = 6 + 9 + 6 + 5 + 8 = 34
r(F) = 8 + 11 + 8 + 9 + 8 = 44

Paso 2. Nueva matriz de distancias
MAB = 5 - [30 + 42]/ (6 - 2) .= 5 -72/4 = -13
MAC = 4 - [30 + 32]/4 = -11.5
MAD = 7 - [30 + 38]/4 = -10
MAE = 6 - [30 + 34]/4 = -10
MAF = 8 - [30 + 34]/4 = -10.5
MBC = 7 - [42 + 32]/ 4 = -11.5
MBD = 10 - [42 + 38]/4 = -10
MBE = 9 - [42 + 34]/4 = -10
MBF = 11 - [42 + 34]/4 = -10.5
MCD = 7 - [32 + 38]/ 4 = -10.5
MCE = 6 - [32 + 34]/4 = -10.5
MCF = 8 - [32 + 44]/4 = -11
MDE = 5 - [38 + 34]/ 4 = -13
MDF = 9 - [38 + 44]/4 = -11.5
MEF = 8 - [34 + 44]/4 = -11.5
A B C D E
B -13 . . . .
C -11.5 -11.5 . . .
D -10 -10 -10.5 . .
E -10 -10 -10.5 -13 .
F -10.5 -10.5 -11 -11.5 -11.5

Paso 3.
Se escogen los vecinos más cercanos. Se puede seleccionar el par AB
o el par DE. En este caso se ha seleccionado el par AB y se han
agrupado en el nodo interno U.
S(AU) = (5/2) + [30 - 42]/(2 (6 - 2)) = 5/2 - 3/2 = 1
S(BU) = 5 - 1 = 4

Paso 4.
Distancias de todos los OTU's al nodo U.
dCU = [4 + 7 - 5]/2 = 3
dDU = [7 + 10 - 5]/2 = 6
dEU = [6 + 9 - 5]/2 = 5
dFU = [8 + 11 - 5]/2 = 7
U C D E
C 3 . . .
D 6 7 . .
E 5 6 5 .
F 7 8 9 8
Paso 5. N = N - 1 = 6 - 1 = 5.
Se inicia el proceso de nuevo.

Árbol de Neighbor-joining de globinas
epsilon-human
alpha-human
myo-human
beta-humandelta-human
gamma-human

A
BC
D
E
a
b c
d
e
.;;
;3/)(
;3/)(
BXAXAB
BEBDBCBX
AEADACAX
dxbdxadba
dddd
dddd
X
•Unimos A y B a un nuevo nodo.•Juntamos en “X” todo lo demás.•Definimos dAX como el promedio de las distancias entre A y los elementos de X.•Ahora aplicamos el caso de tres nodos, a los nodos a, b y X.
x
Métodos de distancia: Neighbour Joining
A
B
C
D
E
a
b c
d
e
Empezamos con una estrella (es el peor caso!), y vamos uniendo.

dAN = a = ½ (dAB+dAX-dBX) dBN = b = ½ (dAB+dBX-dAX)
Para las distancias entre el nuevo y el resto, suponemos aditividad y promediamos lo que dan A y B:
dCN = ½(dCA-dAN) + ½(dCB-dBN)...etc
Métodos de distancia: Neighbour
Joining
A
BC
D
E
a
b c
d
e
X
x
•Se aplica esa idea repetidamente.•Para escoger cuáles unir, se aplica una estrategia, que escoge los que reduzcan más la suma de las ramas.





























