Embed Size (px)
Citation preview

02/10/2013 1
Lezione introduttiva (3 ore)
A cura di L. Palagi
Algoritmi di Classificazione
e Reti Neurali

02/10/2013 2
Struttura del corso
Il materiale del corso (6 cfu)
http://www.dis.uniroma1.it/~or/gestionale/svm/
Collaborano al corso
Dr. Ing Silvia Canale (Unservised Learning)
Ing. Umberto Dellepiane (Uso del software Weka)
Calendario delle lezioni dettagliato sul sito

02/10/2013 3
Contenuti del corso
Introduzione alla teoria dell’apprendimentostatistico (“imparare dai dati”)
Apprendimento supervisionato
Reti Neurali
Support Vector Machines
Apprendimento non supervisionato
Clustering
Uso di software standard
FOCUS: modelli di ottimizzazione, analisi di algoritmi, problemi aperti

Cosa significa «apprendimento automatico» (Machine Learning)
02/10/2013 6
Arthur Samuel (1901-1990)“ programming of a digital computer to behave in a way which, if done by human beings or animals, would be described as involving the process of learning”in Some Studies In Machine Learning Using the Game of Checkers ,1959
Tom Mitchell (1997) http://www.cs.cmu.edu/~tom/
“Machine Learning is the study of computer algorithms that improve automatically through experience”in Machine Learning, Tom Mitchell, McGraw Hill, 1997.

Cervello umano versus
apprendimento automatico
1. 10 miliardi neuroni
2. 60 trilione sinapsi
3. Processori Distribuiti
4. Processo Non lineare
5. Processo Parallelo
1. ??

Più precisamente (T. Mitchell)
02/10/2013 8
“we say that a machine learns with respect to a particular task T, performance metric P, and type of experience E, if the system reliably improves its performance P at task T, following experience E.”
http://www.cs.cmu.edu/~tom/pubs/MachineLearning.pdf

Un esempio di tutti i giorniSPAM detection
02/10/2013 9
Supponiamo che il vostro programma di e-mail
controlli quali mail sono classificate come spam o
non spam e debba imparare come migliorare il filtro
AntiSpam
T (task) classificare le mail come spam o non
spam
P (Performance misure) il numero (o %) di
mail che sono classificate correttamente
E (Experience) la vostra classificazione spam
o non spam

02/10/2013 10
Imparare da esempi
Le misure, sono dette “variabili di input” e si suppone che siano disponibili per tutti gli oggetti di interesse.
Le proprietà degli oggetti sono dette “variabili di output” e sono normalmente conosciute eventualmente solo per un sottoinsieme degli oggetti che rappresentano gli “esempi”
Stimare il tipo di dipendenza tra input-output serve per poter determinare il valore delle variabili di output su tuttii dati di interesse (non solo gli esempi)
Si tratta di trovare la descrizione analitica di una dipendenza sconosciuta tra la «misura» di alcuni “oggetti” e le proprietà di tali “oggetti”.

Un esempio di tutti i giorniSPAM detection
02/10/2013 11
Le misure, sono ad esempio mittente
oggetto
testo.
Le proprietà spam o non spam (1 o 0)
Un problema di questo tipo in cui le proprietà (cioè output) può assumere valori in un insieme di finito (discreto) si dice di
classificazione

02/10/2013 12
Diagnostica medica(esempio tratto da lezioni di T. Mitchell)
Vogliamo stabilire se una gravidanza terminerà con
un cesareo o con parto naturale
età
Parto cesareo
Parto naturale

02/10/2013 13
Diagnostica medica(esempio tratto da lezioni di T. Mitchell)
Vogliamo stabilire se una gravidanza terminerà con
un cesareo o con parto naturale
età
Parto cesareo Parto naturale
peso

02/10/2013 14
Diagnostica medica (esempio tratto da lezioni di T. Mitchell)

02/10/2013 15
Esempio: riconoscimento di caratteri manoscritti
Le “misure” (variabili di input) sono le immagini di
un carattere (disponibili per tutti gli esempi)

02/10/2013 16
Riconoscimento di caratteri manoscritti
Ogni elemento di ingresso corrisponde a un immaginepxp (28x28, 256x256) pixel e quindi e` rappresentabileda un vettore a p2(=784, 65536) valori reali cherappresentano i livelli di grigio (0=bianco, 1=nero) rappresentabili ad es. con 8-bit
Le proprietà (variabili di uscita) mi indicano il “tipo” di carattere ovvero uno degli elementi dell’insieme{0,1,2….,9}
Gli esempi (E) sono i caratteri scritti da alcune persone.
Lo scopo (T) è riconoscere caratteri scritti da terzi
La difficoltà è l’alta variabilità delle forme e l’altonumero di diversi elementi (228 x28 x8 ,2256 x256 x8)

02/10/2013 17
Classificazione
La classificazione individua l’appartenenza di un elemento ad una classe.
Con la classificazione l’output predetto (la classe) è categorico ossia può assumere solo un numero finito di possibili valori come {Sì, No}, {Alto, Medio, Basso}, ecc.
Per esempio un modello di classificazione consiste nel predire se un potenziale cliente ‘X’ con determinate caratteristiche risponderà in modo positivo a negativo ad un’offerta di mercato.

02/10/2013 18
Approssimazione/regressione
Esistono modelli di apprendimento dai dati il cui output NON è l’appartenenza ad una classe ma un valore numerico. In questo caso si parla di approssimazione/regressione.
superficie
Prezzo

02/10/2013 19
Approssimazione/regressione
I dati di ingresso sono coppie di valori reali di (x,t) e si suppone cheesista una funzione t=f(x) incognita
I valori dei dati di input possono essere alterati da un (basso) valore di rumore. Si parla di “approssimazione” in assenza di rumore.
Le variabili in uscita possono assumere un numero illimitato di valori. Spesso queste variabili in uscita sono indicate come continue anche se talvolta non lo sono nel senso matematico del termine (ad esempio l’etàdi una persona)
Si vuole determinare la funzione che “meglio” approssima questi dati
Ad esempio un modello di regressione consiste nel predire il profitto “Y” in euro che uno specifico cliente “X” porterà nel corso di un determinato periodo di tempo.

02/10/2013 20
Approssimazione o Classificazione
Tipicamente classificazione e regressione vengono usate per lo sviluppo di modelli matematici per il supporto decisionale*
*Ricerca Operativa
regressione (statistica)
classificazione (statistica) o pattern recognition (ingegneria) riconoscimento di configurazioni
Reti neurali
SVM
clustering
…………
intelligenza artificiale (utilizzo logica simbolica) (computer science = (ingegneria) informatica)

02/10/2013 21
Apprendimento e statistica
Inferenza Statisticadata una collezione di dati empirici originati secondo
una qualche legge di dipendenza funzionale, inferire (dedurre) tale legge
Si distinguono due approcci principale
inferenza parametrica, che vuole individuare semplici metodi di inferenza per classi particolari di problemi reali
inferenza generale, che vuole individuare un metodo induttivo per qualunque problema di inferenza statistica

02/10/2013 22
Inferenza parametrica
Inizio 1930. Gli anni ‘30-’60 golden age
modelli basati su principi primi: si suppone di conoscere la legge fisica che regola le proprietà stocastiche dei dati e che tale funzione sia definita da un numero finito (basso) di parametri di tipo noto.
stimare i parametri (quelli non misurabili in modo diretto) utilizzando i dati e verificare la “veridicità” del modello individuato è l’essenza di un problema di inferenza statistica
I modelli parametrici utilizzati sono tipicamente lineari nei parametri; tali parametri sono determinati con il metodo della “massima verosimiglianza” (maximum likelihood method)

02/10/2013 23
La decadenza del modello di IP
La decadenza
Curse of dimensionality (R. Bellman) se la funzione non è abbastanza “contin. derivabile” per ottenere il grado di accuratezza desiderato sono necessari un numero esponenziale di termini del polinomio (ovvero di variabili)
molti problemi reali non possono essere descritti con le leggi classiche di distribuzione
il metodo della massima verosimiglianza non è un buon metodo anche in casi semplici
I modelli di inferenza parametrica sono semplici e ben si adattavano alle risorse di calcolo disponibili prima del 1960.
Si basano su tre risultati principali teorema di Weierstass per cui ogni funzione continua può essere
approssimata su un intervallo finito ad un qualunque grado di accuratezza da un polinomio (ovvero una funzione lineare nei parametri)
Il teorema del valore centrale per cui la somma di un gran numero di variabili random è approssimata dalla legge di distribuzione normale
il metodo della massima verosimiglianza è un buon strumento per la stima dei parametri

02/10/2013 24
Oltre il classico paradigma
modelli di inferenza generale: non si hannoinformazioni “a priori” sui principi primi cheregolano la legge statistica sottostante la distribuzione dei dati o della funzione che si vuoleapprossimare
si cerca un metodo (induttivo) in grado di inferire unafunzione approssimante dati gli esempi.
uso dei dati per derivare il modello stesso modelli non predefiniti e non lineari nei parametri
data analysis/data mining

02/10/2013 25
Storicamente Nel 1958 Rosenblatt (un fisiologo) propone una
macchina di apprendimento (ovvero un programma di calcolo) chiamato Perceptron per risolvere un semplice problema di calssificazione. Il Perceptron rifletteva alcuni modelli neurofisiologici di apprendimento. Il perceptron può generalizzare (ovvero impara). 1958-1992: Reti neurali
Successivamente sono state proposte molte altre macchine per apprendimento (programmi di calcolo) che non hanno analogia con il neurone biologico.
Esiste un principio di inferenza induttiva comune a queste macchine ?
(1992-oggi) ritorno alla teoria di inferenza statistica: principio generale di induzione

02/10/2013 26
Il data mining ha per oggetto l'estrazione di un sapere o di una conoscenza (implicita) a partire da grandi quantità di dati (attraverso metodi automatici o semi-automatici) e l'utilizzazione industriale o operativa di questo sapere.
Il termine data mining (letteralmente: estrazione di dati) è diventato popolare nei tardi anni '90 come versione abbreviata per “estrazione di informazione utile da insiemi di dati di dimensione cospicua”.Oggi il termine data mining ha una duplice valenza Estrazione, con tecniche analitiche, di informazione
implicita, nascosta, da dati già strutturati, per renderla disponibile e direttamente utilizzabile;
Esplorazione ed analisi, eseguita in modo automatico o semiautomatico, su grandi quantità di dati allo scopo di scoprire pattern (schemi/regole/configurazioni) caratterizzanti i dati e non evidenti.
Data Mining (DM)
(fonte: Wikipedia)

02/10/2013 27
Sviluppo del Data Mining
Crescita notevole degli strumenti e delle tecniche per generare e raccogliere dati (introduzione codici a barre, transazioni economiche tramite carta di credito, dati da satellite o da sensori remoti, servizi on line..)
Sviluppo delle tecnologie per l’immagazzinamento dei dati, tecniche di gestione di database e data warehouse, supporti più capaci più economici (dischi, CD) hanno consentito l’archiviazione di grosse quantità di dati
Simili volumi di dati superano di molto la capacità di analisi dei metodi manuali tradizionali, come le query ad hoc. Tali metodi possono creare report informativi sui dati ma non riescono ad analizzare il contenuto dei report per focalizzarsi sulla conoscenza utile.

Big Data
Report| McKinsey Global Institute
Big data: The next frontier for innovation, competition, and productivity
May 2011
“The amount of data in our world has been exploding, and analyzing large data sets—so-called big data—will become a key basis of competition, underpinning new waves of productivity growth, innovation, and consumer surplus, according to research by MGI and McKinsey's Business Technology Office………………….MGI studied big data in five domains—healthcare in the United States, the public sector in Europe, retail in the United States, and manufacturing and personal-location data globally. Big data can generate value in each.……………… Leading companies are using data collection and analysis to conduct controlled experiments to make better management decisions; others are using data for basic low-frequency forecasting to high-frequency nowcasting to adjust their business levers just in time. Third, big data allows ever-narrower segmentation of customers and therefore much more precisely tailored products or services. Fourth, sophisticated analytics can substantially improve decision-making…….”
http://www.mckinsey.com/insights/business_technology/big_data_the_next_frontier_for_innovation
02/10/2013 28

02/10/2013 29
Ambiti applicativi
Marketing segmentazione della clientela: Individuzione raggruppamenti omogenei in termini di
comportamento d’acquisto e di caratteristiche socio-demografiche identificazione dei target per promozioni di nuovi prodotti
Fraud detection (identificazione di frodi)Individuazione di comportamenti frudolenti
Analisi delle associazioni di prodotiindividuazione dei prodotti acquistati congiuntamente
Analisi di testi
Diagnostica medica

02/10/2013 30
Altri esempi(esempio tratto da lezioni di T. Mitchell)
Individuazione clienti a rischio di abbandono
Previsione dei comportamenti di acquisto
Ottimizzazione di processo

02/10/2013 31
Credit risk detection(esempio tratto da lezioni di T. Mitchell) Individuazione di rischio per la concessione di credito

02/10/2013 32
Data Mining
Data Mining è solo una parte del processo di estrazione della conoscenza
Il termine knowledge discovery in databases, o KDD, indica l'intero processo di ricerca di nuova conoscenza dai dati, cioè l’insieme di tecniche e strumenti per assistere in modo intelligente e automatico gli utenti decisionali nell'estrazione di elementi di conoscenza dai dati. Il processo di KDD prevede
Formulazione del problema Generazione dei dati Cleaning dei dati e preprocessing Data mining Interpretazione del modello (analisi dei pattern)
Il termine di data mining (DM) si riferisce ad una fase fondamentale del processo KDD tanto che spesso è difficile distinguere il processo KDD dal DM che possono essere usati come sinonimi

TEORIA DEL CAOS
CAOS DETERMINISTICO in un sistema in evoluzione una minima perturbazione delle condizioni iniziali modifica la dinamica successiva su una curva che si allontana in modo radicale dalla curva che ha inizio nel punto non perturbato
Norme di “ buon uso ”
Non tutto è prevedibile o si può imparare:

sliding doors*
http://www.youtube.com/watch?v=0i-YOYD95dk
02/10/2013 * esempio dovuto a Marco Sciandrone 34
Helen è una giovane donna che lavora ed è fidanzata con GerryViene licenziata e si dirige in tutta fretta verso la metropolitanaLa sua vita si divide in due dimensioni parallele:
Helen riesce a prendere il metrò e rincasando primatrova il fidanzato a letto con la sua ex, così si rifà unavita con l'affascinante James che aveva conosciuto sulquel metrò
Helen perde il metrò e chiama un taxi, subisce un tentativo di scippo, per cui arriva a casa più tardi trovando il fidanzato solo. Trova un lavoro come cameriera, conduce una vita di sacrifici in cui Gerry la tradisce nuovamente
Una variazione “infinitesima” comporta una differenza radicale nella vita di Helen

Alcuni fenomeni sono “intrinsecamente caotici”: la modellistica matematica negli ultimi tempi si è occupata di fenomeni non fisici (biologici, sociali, economici) che sono caratterizzati dall’imprevedibilità, dalla scelta soggettiva
Il modello matematico “genera” il caos: un sistema può essere deterministico, tuttavia la determinazione numerica delle condizioni iniziali di un sistema può essere soggetta a una inevitabile approssimazione, che può essere fonte delle conclusioni più disparate

Il modello matematico “genera” il caos
nell’analisi di alcuni fenomeni, lo sviluppo di
modelli matematici più raffinati e/o l’aumento
della precisione degli strumenti può far
divenire prevedibili fenomeni che oggi non lo
sono;
in altri fenomeni, pur deterministici, nessun
raffinamento degli strumenti potrà permettere
una previsione del futuro

02/10/2013 37
Formulazione del problema di
apprendimento
Distribuzione degli esempi (Sampling distribution)
SistemaProduce un output con densità di probabilitàcondizionale sconosciutae fissata
Generatore daticon densità di probabilitàsconosciuta e fissata
fattori non osservabili che influenzano output
Il sistema di apprendimento NON ha controllo sul processodi generazione dei dati
Outliers presenza di dati “spuri” non consistenti con la maggior parte delle osservazioni (dovuti a errori di misuragrossolani, errori di codifica/memorizzazione, casiabnormali).

02/10/2013 38
Apprendimento automatico
Distinguiamo due fasi in un sistema di apprendimento automatico
fase di apprendimento si basa sulladisponibilità di un insieme di dati di esempio(training set)
fase di utilizzo/predizione capacità di dare la risposta corretta su esempi nuovi(generalizzazione).

02/10/2013 39
Apprendimento automatico
Distinguiamo due tipi di paradigmi di apprendimento
supervisionato “esiste un insegnante” (siconosce la risposta giusta sugli esempi)
Il training set è definito da coppie input - output
non supervisionato = “nessun insegnante” non sono noti a priori i valori di output. Si vuole determinare il numero di classi di
“similitudine” e la corrispondente classe di appartenenza. (Clustering)

02/10/2013 40
Apprendimento automatico
Possimao anche distinguere apprendimento
on-line Il training set è acquisito in modo incrementale
durante il processo di apprendimento
batch (fuori linea) Il training set è disponibile prima dell’inizio
processo di apprendimento

02/10/2013 41
ESEMPIO DI CLASSIFICAZIONE SUPERVISIONATA(riconoscimento di caratteri)
Datiun insieme di N elementi manoscritti rappresentati dalla matrice di pixel, ovvero dai vettorie la Categoria di appartenenza {0,1,2,3,4,5,6,7,8,9}
0
1
2
3
4
5
6
7
8
9
Dati di esempio o training set

02/10/2013 42
ESEMPIO DI CLASSIFICAZIONE NON SUPERVISIONATA(riconoscimento di caratteri)Dati: un insieme di N elementi manoscritti rappresentati dalla matrice di pixel, ovvero dai vettori
training set
0
1
2
3
4
5
6
7
8
9

02/10/2013 44
ESEMPIO DI APPROSSIMAZIONE
Input: vettore a valore reali a N componenti rappresentate
correnti elettriche che circolano in un dispositivo
magnetico
Output: valore del campo magnetico in un determinato punto
interno al dispositivo
Obiettivo: determinare una funzione analitica che approssimi
il legame funzionale tra il campo magnetico e il
valore delle correnti

02/10/2013 45
Apprendimento supervisionato
I dati sono coppie input-output generati in modo indipendente e identicamente distribuiti (i.i.d) secondo una funzione di probabilita (sconosciuta)
Il problema di apprendimento supervisionato: dato il valore di un vettore ottenere una “buona”predizione del vero output
Una macchina per apprendimento osserva i dati di training e costruisce una funzione in grado di fornire una predizione dell’output per un qualunque valore di input
LearningMachine

02/10/2013 46
Macchina per apprendimento
Più formalmente una macchina per apprendimento realizza una classe di funzioni , che dipende dalla struttura della macchina scelta, in cui α rappresenta un vettore di parametri che individua una particolare funzione nella classe.
La macchina è deterministica

02/10/2013 47
Macchina per apprendimento
La scelta ideale della funzione di approssimazionedovrebbe riflettere la conoscenza a priori sulsistema, ma in problemi di ML questa conoscenza è difficile o impossibile.
Metodi adattativi del ML utilizzano una classemolto ampia e flessibile di funzioni di approssimazione
Modelli non lineari nei parametri

Dal neurone biologico al
neurone artificiale
Dendrite corpo Assone
Input
pesi
Funzionesomma
Soglia (Bias)
α0
Funzione di
attivazione
Output
y
x1
x2
xl
w2
wl
w1
)(g

Esempi di funzioni di attivazione
b
a
b
a
Funzione gradino Funzione a rampa

02/10/2013 50
Il neurone formale
Il neurone formale (perceptron) è una semplice macchina per apprendimento che realizza la classe di funzioni
Gli ingressi sono moltiplicati per dei pesi, rappresentatividell’entità delle connessioni sinaptiche, e la loro sommmaalgebrica viene confrontata con una soglia. L’uscita è 1 se la somma pesata è > della soglia, -1 (o 0, funzione di Heaviside) altrimenti

02/10/2013 51
Processo di apprendimento
Fissata una macchina per apprendimento ovvero una classe di funzioni
Il processo di apprendimento consiste nello scegliere un particolare valore dei parametri α* che seleziona una funzione fα* nella classe scelta.
L’obiettivo è creare un modello del processo che sia in grado di dare risposte corrette e coerenti anche (e soprattutto) su dati mai analizzati (generalizzazione) e non di interpolare (=“riconoscere con certezza”) i dati di training (FUNZIONE PREDITTIVA)

02/10/2013 52
Misura di qualità
Si definisce la Loss function
una funzione che misura la discrepanza tra il valore previsto fα (x) e il valore
effettivo y. Per definizione la “perdita” è non negativa, quindi valori
positivi alti significano “cattiva” approssimazione.
Per scegliere tra tutte le possibili funzioni del parametro α è necessario definire un criterio di qualità da ottimizzare.
Assegnati i parametri α, il valore della loss function (intesa come funzione delle sole x, y) quantifica l’ERRORE risultante dalla realizzazione della coppia (x, y)

02/10/2013 53
Esempi di funzioni di perdita
(Loss functions)
classificazionecon

02/10/2013 54
Esempi di funzioni di perdita
(Loss functions)
regressione

02/10/2013 55
Minimizzazione del “rischio”
Il valore atteso della perdita dipende dalla distribuzione P
ed è dato dall’integrale
Il “criterio di qualità” per scegliere i parametri α è il valore atteso dell’errore dovuto alla scelta di una particolare funzione di perdita
La funzione è il rischio effettivo che vorremmo
minimizzare al variare di α (cioè al variare di )

02/10/2013 56
Apprendimento
determinare la funzione che minimizza il rischio effettivo nella classe di funzioni supportate dalla macchina per l’apprendimento, utilizzando un numero finito di dati di training è inerentemente mal posto
La difficoltà è scegliere la giusta complessità per “descrivere” i dati a disposizione
Principi induttiviminimizzazione del rischio empirico
structural risk minimization
early stopping rules

02/10/2013 57
Il rischio empirico
Il rischio effettivo non si può calcolare (né quindi minimizzare) perché la funzione di distribuzione di probabilità è sconosciuta
ma sono note solo ℓ osservazioni corrispondenti a
variabili random i.i.d
Cerchiamo una funzione che approssimi il rischio effettivo e richieda solo l’uso dei dati disponibili

02/10/2013 58
Il rischio empirico
si definisce rischio empirico
Il rischio empirico dipende SOLO dai dati e dalla funzione
La distribuzione di probabilità non interviene nella definizione del rischio empirico che fissatiè un valore preciso (errore di training).
Scelta una classe di funzioni
e definita una funzione di perdita (loss)

02/10/2013 60
Il rischio empirico:
regressione parametrica
Usiamo come approssimatori I polinomi di grado fissato M
Consideriamo dati generati “artificialmente” dalla funzionecorrotta da rumore

02/10/2013 61
Ancora l’esempio Regressione parametrica
Scelto un modello (ad esempio un polinomio di grado M)
Si può valutare l’errore quadratico; detti i valori noti si ha:
L’errore sui dati di training può idealmente diventare nullo, ma che succede su dati “nuovi” (dati di test)?

02/10/2013 62
Regressione parametrica
Aumento il grado del polinomio M da 3 a 9
Quale dei due è “meglio”?
Si può valutare l’errore quadratico; detti i valori noti si ha: L’errore sui dati di training può
idealmente diventare nullo, ma che succede su dati “nuovi” (dati di test)?

02/10/2013 63
Andamento errore
Graficando l’andamento dell’erroresui dati di training e di test
Ridurre errore di training può significare errori significativi
sui dati di test: fenomeno di Over-fitting
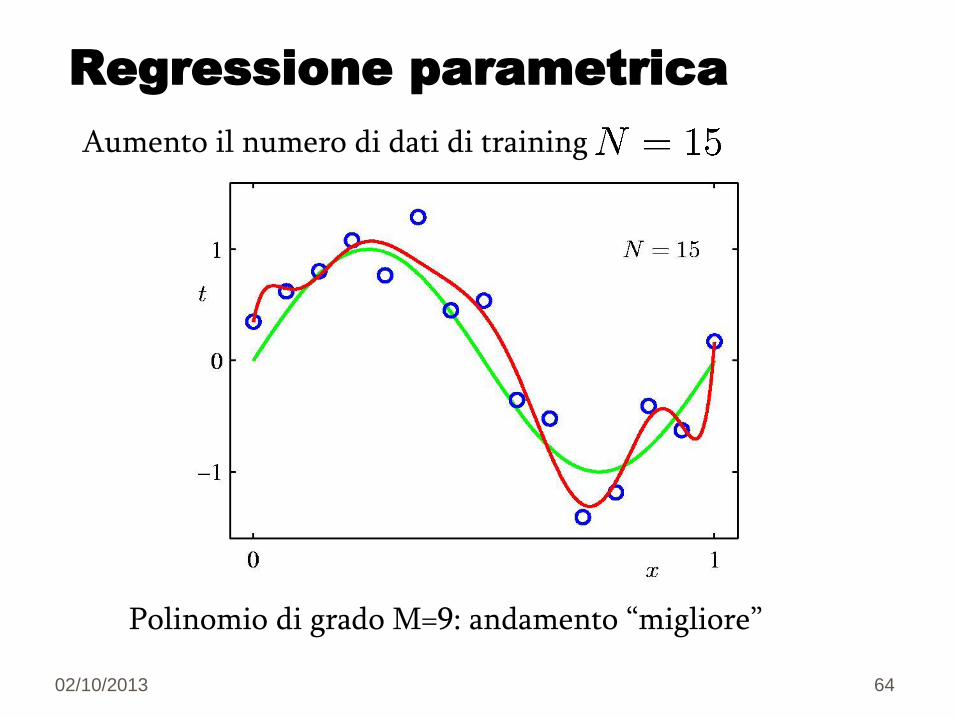
02/10/2013 64
Regressione parametrica
Polinomio di grado M=9: andamento “migliore”
Aumento il numero di dati di training

02/10/2013 65
Regressione parametrica
Aumento il numero di dati di training
Polinomio di grado M=9: l’andamento riesce quasi a “seguire” la funzione sottostante
La maggiore complessità della macchina (grado del polinomio) in relazione al miglior uso predittivo dipendono dal numero di dati disponibili

02/10/2013 66
Consistenza del rischio empirico
Interesse: trovare una relazione tra le soluzioni dei problemi
di ottimizzazione
In generale
imponderabile
calcolabile
La speranza è che l’errore sui dati di traning possa fornire delle indicazioni sulla probabilità di errore su una nuova istanza

02/10/2013 67
Minimizzazione del
rischio empirico
Quando ℓ è finito la minimizzazione del rischio empirico può non garantire una minimizzazione del rischio effettivo
La scelta della funzione in una classe che minimizza il rischio empirico non è unica
Entrambe le funzioni hanno Rischio empirico nullo
Il rischio effettivo su nuove istanze è diverso

02/10/2013 68
Complessità della classe
Un altro aspetto correlato alla minimizzazione del rischio empirico è la “complessità” della classe di funzioni
Una funzione molto complessa può descrivere molto bene i dati di training, ma può non generalizzare bene su nuovi dati
più semplice
più complessa

02/10/2013 69
Over and under fitting
Dati di training:2 classi
Aggiungo nuovidati
più semplice
più complessa
overfittingclasse fα “troppo complessa”
underfittingclasse fα “troppo semplice”

02/10/2013 70
Oltre il principio della (ERM)
è un parametro che che descrive una nuova proprietà generale della classe di funzioni scelta che si chiama capacità/complessità
È possibile dimostrare che con probabilità (1-η) con η in (0,1) risulta

02/10/2013 71
Teoria di Vapnik Chervonenkis (VC)
VC hanno sviluppato la teoria per determinare il valore di ε che compare nella disuguaglianza
ovvero per determinare un bound sull’errore di generalizzazione della classe di funzioni.
Questo bound è stato utilizzato per sviluppare un nuovo principio induttivo basato sul “trade-off” tra la complessità della classe di funzioni scelta e il valore del rischio empirico che si può ottenere utilizzando tale classe

02/10/2013 72
Complessità della classe di funzioni
Questa analisi ha portato alla definizione di un nuovo funzionale da minimizzare diverso dal rischio empirico. In particolare si introduce di un termine per il controllo della complessità
Termine di penalizzazione di complessità
Teoria di Vapnik Chervonenkis (VC)
VC dimension h
VC confidence

02/10/2013 73
VC dimension
La dimensione di Vapnik Chervonenkis (VC dimension) h>0 èuna misura della capacità di classificazione espressa dalla macchina rappresentata dall'insieme di funzioni
La VC dimension h misura il massimo numero di punti xi (di
training) che possono essere classificati per qualunqueassegnazione di etichette ±1 (shattered=“frammentati”) usandouna funzione nella classe
Insieme frammentabile
questi 3 punti in R2 possono essere separati con un iperpiano orientato
+1
-1

02/10/2013 74
VC dimension
Se la VC dimension di una classe è h significa che esiste almeno un insieme di h punti che possono essere “frammentati”, ma in generale non è vero che un qualsiasi insieme di h punti può essere classificato da
Insieme di 3 punti in R2
non frammentabile Nessun insieme di 4 punti in R2 può essere frammentato da una funzione affine
La dimensione di VC della classe in R2 è h=3

02/10/2013 75
Un bound superiore per il rischio
VC Confidence termine di penalità sulla complessità
Il nuovo funzionale da minimizzare è
VC dimension è il parametro mancante
Si minimizza rispetto alla classe e non solo ai parametri

02/10/2013 76
Il principio di minimizzazione
In pratica l’andamento delle due funzioni è opposto, quindi lo scopo è cercare il miglior “trade-off” tra la minimizzazione del rischio effettivo, e la minimizzazione dell VC confidence
L’implicazione pratica dell’esistenza del bound è che la macchina per l’apprendimento dovrebbe essere costruita in modo tale minimizzare il valore empirico il termine di VC confidence
Complessità h
Mononicamente crescente in h

02/10/2013 77
Minimizzazione del rischio strutturale
La dimensione di VC è un valore intero.
Si definiscono classi di funzioni “annidate” con VC dimension NON decrescente
Osserviamo che la VC confidence dipende solo dalla classe di funzioni scelta, mentre il rischio empirico (e quindi il rischio effettivo) dipende dalla particolare funzione scelta durante la procedura di training
N.B. bisogna essere in grado di calcolare h per ogni classe
Procedura euristica per la minimizzazione

02/10/2013 78
Principio di
Minimizzazione del rischio strutturale
per ogni classe con dimensione di VC
si determina la soluzione ottima del problema
Si calcola il valore dell’upper bound
Si sceglie la classe di funzioni per cui è minimo il valore dell’upper bound

02/10/2013 79
Calcolo del termine di confidenza
Per calcolare il termine di “confidenza” è necessario conoscere il valore di h per una classe di funzioni.
e anche viceversa che macchine di apprendimento con pochi parametri hanno una dimensione di VC bassa
Non è vero che macchine di apprendimento con molti parametri hanno una dimensione di VC alta,
N.B. il numero di parametri non è un’indicazione utile,
infatti h non è proporzionale al # di parametri

02/10/2013 80
In questo caso otteniamo lo stesso valore del bound per entrambe le funzioni della classe
Tra i due c’è un “migliore” ?E qual è ?
sembra migliore“massimizza” la distanza della retta dai punti dei due insiemi
Calcolo della VC dimension

02/10/2013 81
Separatori lineari con margine
Semplici classificatori lineari sono poco utili come classe di funzioni (troppo flessibili)
Idea: restringere la scelta nell’ambito della classe deiclassificatori lineari può migliorare la dimensione di VC
Classificatore lineare con gap di tolleranza (≈margine)

02/10/2013 82
Mimimizzazione strutturale del rischio per
classificatori lineari con gap di tolleranza
Minimizzazione strutturale del rischioMinimizzare il bound sul rischio minimizzando rischio empirico massimizzando il margine (e quindi minimizzando la VC
confidence)
per ogni funzione f j nella classe calcola un bound su hj
minimizza il rischio empirico Rjemp
calcola il valore del bound
scegli la classe che minimizza il bound

02/10/2013 83
METODI
Minimizzazione rischio strutturale
Support Vector Machines si fissa il rischio empirico si minimizza la VC confidence
Reti Neurali fissata l’architettura della macchina e quindi la
complessità (e la VC confidence) minimizzazione rischio empirico

02/10/2013 84
Fonti bibliografiche e siti di interesse
Pattern Recognition and Machine Learning – C. Bishop, Springer (2006).
Learning from Data: Concepts, theory, and Methods - V. Cherkassky, F. Mulier, John Wiley and Sons, Inc. (1998).
Statistical Learning Theory – V. Vapnik, John Wiley and Sons, Inc., 1998
Machine Learning, T. Mitchell, Morgan Kaufmann, 1997. https://class.coursera.org/ http://research.google.com/pubs/papers.html#MachineLearning
Machine learning Group at Yahoo! Research Silicon Valleyhttp://research.yahoo.com/Machine_Learning
Cineca Consorzio Interuniversitario La Gestione delle Informazioni e della Conoscenza
http://www.cineca.it/gai/area/datamining.htm





























