Embed Size (px)
Citation preview

www.elsevier.com/locate/parco
Parallel Computing 31 (2005) 1013–1033
Performance prediction through simulationof a hybrid MPI/OpenMP application q
Rocco Aversa a, Beniamino Di Martino a, Massimiliano Rak a,Salvatore Venticinque a, Umberto Villano b,*
a Seconda Universita di Napoli, DII, via Roma 29, 81031 Aversa (CE), Italyb Universita del Sannio, Dipartimento di Ingegneria, C.so Garibaldi 107, 82100 Benevento, Italy
Received 11 October 2004; received in revised form 15 February 2005; accepted 5 March 2005Available online 10 October 2005
Abstract
This paper deals with the performance prediction of hybrid MPI/OpenMP code. The use ofHeSSE (Heterogeneous System Simulation Environment), along with an XML-based proto-type language, MetaPL, makes it possible to predict hybrid application performance in manydifferent working conditions, e.g., without the fully developed code or in an unavailable sys-tem. After a review of hybrid programming techniques and a brief overview of the HeSSE sim-ulation environment, the problems related to the simulation of hybrid code and to itsdescription through trace files are dealt with. The whole application modeling and analysiscycle is presented and validated, predicting the performance of a parallel N-body code on aSMP cluster and comparing it to the timings measured on the real system.� 2005 Elsevier B.V. All rights reserved.
Keywords: Simulation; Performance prediction; Hybrid; MPI; OpenMP
0167-8191/$ - see front matter � 2005 Elsevier B.V. All rights reserved.doi:10.1016/j.parco.2005.03.009
q This work was partially supported by ‘‘Centro di Competenza ICT Regione Campania’’. The authorswish to thank Eleonora Nazzaro and Roberto Torella for their technical support.* Corresponding author.E-mail addresses: [email protected] (R. Aversa), [email protected] (B. Di
Martino), [email protected] (M. Rak), [email protected] (S. Venticinque),[email protected] (U. Villano).

1014 R. Aversa et al. / Parallel Computing 31 (2005) 1013–1033
1. Introduction
Symmetrical multiprocessor (SMP) hardware currently is pervasive in high per-formance computing environments. The availability of relatively low-cost SMPnodes, originally targeted at the demanding high-end server market, has given aboost to the diffusion of networks of SMP workstations and clusters of SMPs(CLUMPS) networked by high-speed networks and switches or by inexpensive com-modity networks [1].
Now that computing nodes made up of multiple processors sharing a commonmemory are commonly available, it is natural to wonder if it is worth to switch tosoftware designs exploiting shared memory, given that most current software wasdeveloped with shared-nothing architectures in mind. ‘‘Pure’’ message-passing codesare obviously compatible with clusters of SMP nodes. The point is that communica-tion by message-passing inside an SMP node (i.e., in the presence of a shared mem-ory) is not necessarily the most efficient solution. The literature reports manyexperiences of adoption of a two-tier programming style, based on shared memoryfor communication between processes running in the same node, and on messagepassing for ‘‘outer-world’’communications. Special programming models have beenpurposely developed for such systems [2]. However, most of existing work is basedon the mixed use of shared and distributed memory codes.
In the wide spectrum of possible solutions for hybrid shared/distributed memorycode development, the joint use of MPI [3] and OpenMP [4] is emerging as a de factostandard. The majority of hybrid MPI/OpenMP code is based on a hierarchicalmodel, which makes it possible to exploit large- and medium-grain parallelism atMPI level, and fine-grain parallelism at OpenMP level. Hence, hierarchical hybridcode is structured in such a way that a single message-passing task, communicatingusing MPI primitives, is allocated to each SMP processing element, and the multipleprocessors with shared memory in a node are exploited by parallelizing loops usingOpenMP directives and run-time support. The objective is clearly to take advantagesof the best features of both programming styles.
Apart from applying two different standards and models of parallelism (which isannoying), the hybrid MPI/OpenMP model can be relatively easily understood andprogrammed. After all, both MPI and OpenMP are two well-established industrystandards, and solid documentation and tools are available to assist program devel-opment. The problem, as almost always in parallel programming, is to obtain satis-factory performance. There is a wide body of literature pointing out the drawbacksand pitfalls of SMP cluster codes, from the use of SMP nodes, which fail to obtainperformance comparable to traditional monoprocessor cluster with the same totalnumber of CPUs [5], to the adoption of hybrid programming, which may lead topoor CPU utilization.
As regards the issues linked to the hybrid programming model, it should bepointed out that the performance of a hybrid model exploiting coarse parallelismat task level and medium-grain parallelism at loop level depends heavily on architec-tural issues (type of CPUs, memory bandwidth, caches, etc.) and, above all, on struc-ture and code of the application. Depending on the latter, sometimes it may be

R. Aversa et al. / Parallel Computing 31 (2005) 1013–1033 1015
preferable to use a canonic single layer MPI decomposition, allocating to each nodea number of tasks equal to the number of CPUs [6,7].
The essence of the problem is that, even if a hybrid programming model stands asa viable and promising solution for the development of SMP cluster software, it ischaracterized by a higher architecture complexity and by the multiplicity of softwarelayers. In most cases, obtaining optimal performance from the system means to ex-plore a wide range of computational alternatives [8], and this is unpractical, if notimpossible. The most obvious and ‘‘natural’’ solution is to resort to software devel-opment tools making it possible to predict the performance of the target applicationeven at early development steps. These have proven to be effective for message-pass-ing parallel software development and tuning [9–11].
In previous papers, we have shown preliminary results regarding the performanceprediction of existing (i.e., fully developed) hybrid MPI/OpenMP applications [12],and of restructured (i.e., hybridized) traditional MPI code [13]. In this paper, we willthoroughly describe simulation-based techniques for performance prediction of hy-brid MPI/OpenMP code, in different working conditions.
The remainder of the paper is structured as follows. Section 2 will survey hybridprogramming techniques, pointing out performance problems and examining relatedwork. Section 3 will describe the simulation environment adopted and the simulationmodels developed in order to reproduce hybrid application behavior. Section 4 willshow how to apply a simulation-based methodology to development and perfor-mance analysis of hybrid applications, proposing a realistic case study and perfor-ming two types of performance analysis. Finally, the conclusions are drawn.
2. Hybrid MPI/OpenMP programming
As mentioned in Section 1, clusters of shared-memory nodes are becomingincreasingly popular in the parallel computing community. Hence, the programmingfocus is slowly but steadily moving from shared-nothing computing architectures tosystems where some form of shared memory is available. As is well known, these in-clude a great variety of system designs, from architectures where node interconnec-tion provides a single memory addressing space (e.g., ccNUMA and nccNUMAmachines), to systems with capability of remote direct memory access (RDMA),to hardware that supports no other-node memory access and relies only on messagepassing for node-to-node communication.
The hybrid MPI/OpenMP programming paradigm can be successfully exploitedon each of these systems. In practice, the only constraint is the availability of someshared memory. As a matter of fact, the principles of parallel code hybridization arefit for systems ranging from a single SMP node to large SMP clusters, or even toNUMA machines. However, hybrid code optimization (which, in essence, is the pri-mary concern of this paper) is fairly different on each class of systems. This is thereason why in the following we will consider only systems with no node-to-nodememory access capabilities. For a practical example of code hybridization in NUMAmachines the interested reader is referred to [14].

1016 R. Aversa et al. / Parallel Computing 31 (2005) 1013–1033
In the rest of this section, we will consider the complementary features of MPIand OpenMP, describing the models that can be adopted for their joint use. Then,we will briefly survey the pros and cons of hybrid programming, stressing perfor-mance aspects. Finally, we will give several pointers to related work on hybridprogramming.
2.1. MPI
MPI is a specification of a library for message-passing programming [3]. Accord-ing to the MPI programming model, each processor runs one or more componenttasks of the parallel program. These tasks are written in a conventional sequentiallanguage (typically C or Fortran), have only private variables, and communicateamong them by calling functions of the MPI library. Synchronization among tasksmay be explicit (by means of suitable functions of the MPI library), or implicitly de-fined by the communication constructs.
It should be explicitly noted that the shared-nothing programming style matchesclosely only a load distribution where just one task is allocated per processor, andprocessors have no possibility to access the memory of all, or of a subset, of otherprocessors. In all other cases (multiple time-shared tasks per processor, and/or pres-ence of shared memory, such as in an SMP cluster), tasks have nevertheless only pri-vate data and communicate by message passing. However, shared memory, whereveravailable, is exploited to implement high-bandwidth message passing.
The MPI programming model is very simple, does not suffer from data placementproblems, and can lead to high performance. As a rule of thumb, this occurs when-ever code granularity is sufficiently large to hide communication overheads.
2.2. OpenMP
OpenMP is an industry standard [4] for shared memory programming. UnlikeMPI, which requires explicit program decomposition and task placement and com-munication, OpenMP supports an incremental approach to designing parallel pro-grams. In practice, a standard sequential program can be enriched with OpenMPcompilation directives, making it possible to exploit shared memory parallelismwhenever shared memory is available.
OpenMP supports data and control parallelism through three components:
• a set of compiler directives for creating teams of threads, sharing the work amongthreads, and synchronizing the threads;
• library routines for setting and querying thread attributes;• environment variables for controlling the run-time behavior of the parallelprogram.
OpenMP parallelism hinges on the parallel region construct, where a team ofthreads (typically, a number equal to the number of available CPUs) is created bya fork operation, and is joined at the end, as shown in Fig. 1. Parallel work can

Master thread
Parallel regions
Fig. 1. OpenMP parallel regions.
R. Aversa et al. / Parallel Computing 31 (2005) 1013–1033 1017
be explicitly coded through the use of parallel regions, or implicitly obtained bywork-sharing constructs, such as parallel loops. The latter is the most simple andtherefore preferred solution, and leads to the exploitation of fairly fine-grained par-allelism. Loop parallelization distributes the work among a team of threads, withoutexplicitly distributing the data. Scheduling assigns the iterations of a parallel loop tothe team of threads.
As far as address spaces are concerned, OpenMP threads are ordinary threads, inthat they have shared address space, but their stacks hold thread-private data.Threads in a parallel region may refer both private and shared data, with explicitsynchronization through suitable directives (critical, atomic, barrier, etc.).
Most of the times, OpenMP applications are relatively easy to implement startingfrom a sequential program, but the simple and most widely adopted parallelizationstyle is able to exploit only fine-grain parallelism. An additional problem is the place-ment policy of data, which may lead to performance losses.
2.3. Hybrid programming
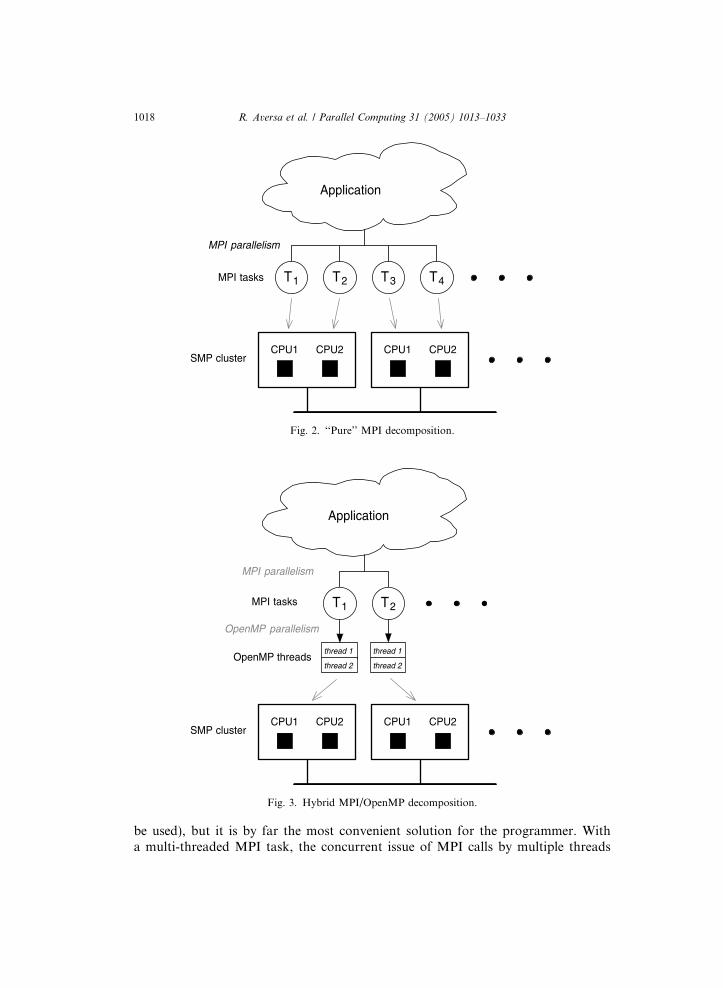
The rationale of hybrid MPI/OpenMP programming is to take advantage of thefeatures of both programming models, mixing the explicit decomposition and taskplacement of MPI with the simple and fine-grain parallelization of OpenMP. In lightof the above, it is not surprising that the majority of existing hybrid applications ex-ploits a hierarchical decomposition scheme. At high level, the program is explicitlystructured as a number of MPI tasks, whose sequential code in enriched withOpenMP directives in order to add multi-threading features and to take advantageof the presence of shared memory. This model matches closely the fairly commonsystems made up of clustered SMP nodes. Figs. 2 and 3 show how to exploit opti-mally the available hardware of a 2-CPUs SMP cluster by a ‘‘pure’’ MPI decompo-sition and by a hierarchical hybrid decomposition, respectively. It should beexplicitly noted that hierarchical decomposition is not the only way to mix MPIand OpenMP programming paradigms.
In fact, a more thorough examination of the interaction of the two programmingmodels is necessary. After all, the use of OpenMP adds multi-threading to traditionalMPI processes. It is not the only way to do so (for example, Posix threads could also
Application
T1 T2 T3 T4
CPU1 CPU2 CPU1 CPU2
MPI parallelism
MPI tasks
SMP cluster
Fig. 2. ‘‘Pure’’ MPI decomposition.
Application
T1 T2
CPU1 CPU2 CPU1 CPU2
MPI parallelism
MPI tasks
SMP cluster
thread 1
thread 2
thread 1
thread 2
OpenMP parallelism
OpenMP threads
Fig. 3. Hybrid MPI/OpenMP decomposition.
1018 R. Aversa et al. / Parallel Computing 31 (2005) 1013–1033
be used), but it is by far the most convenient solution for the programmer. Witha multi-threaded MPI task, the concurrent issue of MPI calls by multiple threads

R. Aversa et al. / Parallel Computing 31 (2005) 1013–1033 1019
becomes possible. A discussion on the threading models for hybrid MPI/OpenMPprogramming would be out of the scope of this paper. In the following, we will alwaysconsider only programs based on hierarchical decompositions and on the so-calledTHREAD_MASTERONLY model [15]. In this model, the MPI task can be multi-threaded, but theMPI functions may be called only by theMaster thread, and only out-side of parallel regions (i.e., outside of the shaded area in Fig. 1). Using this model,OpenMP cache coherence rules guarantee that the output of an MPI call is visible toall threads spawned in any subsequent parallel region, and, vice versa, that the out-come of all threads of the team spawned in a parallel region is visible to any subsequentMPI call. For this reason, the THREAD_MASTERONLYmodel, available in almostall programming environments, requires little care from the programmer.
2.4. Advantages and drawbacks of hybrid programming
At least in theory, the advantages of hybrid MPI/OpenMP programming areclear. The technique makes it possible to derive without great effort from a medium-or large-grain MPI decomposition (possibly, from a MPI program already available[13]) a code with greater parallelism, making the best use of shared memory of SMPnodes. However, as briefly mentioned in Section 1, often the resulting performanceresults are not satisfactory, in that a ‘‘pure’’ MPI decomposition outperforms the hy-brid one. The issue in this paper is to provide predictive tools to know beforehandwhich program design is likely to give the best performance results. By ‘‘beforehand’’we mean at the first steps of program development, before complete coding, if theprogram is to be developed from scratch, and before applying OpenMP paralleliza-tion, if an MPI code is already available.
Probably the best way to understand whether a hybrid code design can be fruitfulor not, is to review briefly the situations where a hybrid code is likely to be more effi-cient than its pure-MPI counterpart. These are extensively dealt with in Ref. [16], towhich the interested reader is referred for further detail. Situations with good poten-tial for hybrid code design include the following:
• codes which scale poorly with increasing MPI tasks;• MPI codes with poor load balancing (choosing the right schedule, OpenMPthreads can be very well balanced);
• fine-grain parallelism problems, more suitable for a OpenMP decomposition thanfor a MPI one;
• codes with replicated data (using OpenMP, it is possible to allocate a single copyof the data to each node, to be used by all local threads);
• MPI codes with constraints on the number of tasks (e.g., powers of two or maxi-mum number of tasks);
• target systems with poorly optimized intra-node communications (outperformedby the direct shared-memory access of OpenMP threads);
• target systems with high latency interconnect, with no concurrent sending/receiv-ing of messages, where sending a lower number of longer messages (due to theunification of the MPI tasks in each node) can be advantageous.

1020 R. Aversa et al. / Parallel Computing 31 (2005) 1013–1033
In all other cases, hybrid codes are likely to be equally or even less performingthan a pure-MPI solution. This is due to number of inefficiencies tied to the hybridapproach, and in particular to the adoption of the simple hierarchical decompositionmethod. In fact, in hierarchically decomposed programs, MPI calls are performedoutside of parallel regions. This means that whenever a MPI call is required, thereis only one active thread per node, and this is clearly a source of overhead. Addi-tional overhead is due to more subtle causes. Among these, it should be mentionedpossible higher communication costs, due to the inability of a single thread to satu-rate the node interconnection bandwidth. In practice, the hybrid approach is conve-nient whenever the advantages (due to one or more of the causes enumerated above)dwarf the ‘‘single-thread’’ overhead plus possible communication overhead.
2.5. Related work
At the state of the art, there is a fairly wide body of literature on hybridMPI/OpenMP programming. A first group of papers just presents case studies of hy-brid applications (see for example [8,17]). A second group includes papers dealingwith the basics of the approach and of its motivations [2,5,18]. In some cases, thereis also a discussion trying to give insight on measured performance figures [7,15,16].Finally, there are papers dealing almost solely with performance comparisonsbetween hybrid and traditional, ‘‘pure-MPI’’ code [6,9,19].
However, the totality of performance considerations in the literature stems frommeasurements taken on fully developed code running on the actual target executionenvironment. Hence, to the best of the Authors� knowledge, the approach followedhere, i.e., the use of a development environment to find if hybridization may be use-ful and to what extent, is completely new. Two companion papers [12,13] are focusedon the details of the hybrid MPI/OpenMP simulation and on the hybridization ofexisting, fully developed MPI code, respectively. Of course, performance-driven codedevelopment and performance prediction techniques [10,11] are not new, but theyhave been mainly applied for ‘‘traditional’’ high performance computing, not inthe context of code hybridization.
3. Hybrid application simulation
HeSSE (Heterogeneous System Simulation Environment) is a simulation tool thatcan reproduce or predict the performance behavior of a heterogeneous distributedsystem for a given application, under different computing and network load condi-tions [20,21].
HeSSE is capable of obtaining simulation models for distributed heterogeneoussystems (DHS) that can be even very complex, thanks to the use of component com-position. A HeSSE simulation component is basically a hard-coded object thatreproduces the performance behavior of a specific section of a real system. More de-tailed, each component reproduces both the functional and the temporal behavior ofthe subsystem it represents. In HeSSE, the functional behavior of a component is the

R. Aversa et al. / Parallel Computing 31 (2005) 1013–1033 1021
collection of the services that it exports to other components. On the other hand, thetemporal behavior of a component describes the time spent servicing. Componentbehavior is parameterized. In fact, most components are sufficiently general to beadapted to different working conditions. For example, a component modeling arun-time communication system or an O.S. service, has to be properly tuned tothe processing speed of the target machine. Component parameters are found, priorto final simulations, by tuning a base system model. This involves comparing the sim-ulated behavior to actually executed code [25].
While the behavior of the hardware/software objects making up a DHS is de-scribed by interconnecting simulation components, applications are described inHeSSE through traces. A trace is a file that records all the relevant actions of the pro-gram. Traces can be obtained by application instrumentation and execution on ahost system (e.g., a workstation used for software development), or through proto-type-oriented software description languages, such as MetaPL [22].
The behavioral analysis of a parallel application takes place as shown in Fig. 4. Atypical HeSSE trace file for a message-passing application (e.g., a PVM or MPIapplication) is a timed sequence of CPU bursts and of requests to the run-time envi-ronment. The simulator converts the length of the CPU bursts as measured in thetracing environment to their (expected) length in the actual execution environment,i.e., in the processing node where the code will be finally executed, taking into ac-count CPU availability and scheduling, as well as memory and cache effects. Thebasic mechanism used for conversion from trace times to simulated times is describedin [23]. On the other hand, the requests to the run-time environment, involving inter-actions with other processing nodes, are managed by simulating the data exchangeon the physical transmission medium under predicted network conditions, the trans-mission protocols, the actual run-time algorithm adopted, etc. Further details onHeSSE can be found in [20,21,24].
The simulation of multi-threaded OpenMP code requires additional informationto be recorded in the traces. In particular, it is necessary to know all the timing detailsof the parallel regions, in such a way that the activation/load sharing/synchroniza-tion/deactivation of threads can be suitably simulated by the OpenMP simulation
Fig. 4. HeSSE performance analysis process.

1022 R. Aversa et al. / Parallel Computing 31 (2005) 1013–1033
engine. The recording of this additional information required the use of a new tracingstandard, which is described in the following Section 3.1. The specialized componentsthat implement the OpenMP simulation engine, are dealt with in Section 3.2.
3.1. The Multitrace system
In trace-based simulation, every trace file contains information on the run-timebehavior of target processes/tasks. The simulation engine reproduces the simulatedsystem behavior, as a function of the system current state and of the events thatare progressively extracted from the trace file.
Even if the traces describe a single execution path, the performance simulation of ahybrid MPI/OpenMP decomposition is substantially more complex than that of apure message-passing one. The traces are collected for the actual number of tasks(i.e., time-slicing on a single workstation the number of tasks that will ideally allo-cated to the simulated system), but hardly ever for the actual number of threads thatwill be run in each node of the simulated system. It is likely that a monoprocessorworkstation is used for program development; hence, the simulation engine has tosimulate activation, scheduling, synchronization for a number of threads correspond-ing to the number of CPUs available per node in the target execution environment. Inorder to do so, the run-time behavior of the code produced by compilation of theOpenMP directives has to be suitably reproduced. taking into account the modalitiesof multi-threaded code execution, we have in each task two different types of code:
• sequential code sections (executed only by the master thread);• parallel code sections (executed by the master and by the secondary threads).
Inside each parallel code section, every simulated service can be requested, exceptOpenMP ones (which cannot be nested). Moreover, as we assume aTHREAD_MASTERONLY model for the hybrid code, no MPI primitive can ap-pear inside parallel sections.
The Multitrace system [12] describes each application by means of a set of tracepairs, one pair for each task. Each pair is composed of a main file (MF), which de-scribes the behavior of the master thread, and a OpenMP file (OMPF), which con-tains information about parallel sections. The MF is a typical HeSSE trace file,enriched with OpenMP event identification codes and construct identifiers. Theseare used as pointers within the OMPFs, which contain fine-grained informationon the parallel sections behavior. These files can be obtained by customary tracingtechniques, such as instrumentation and tracing or by prototype analysis. The lattertechnique, based on the use of the program description language MetaPL [22], willbe extensively dealt with in Section 4.
3.2. OpenMP simulation
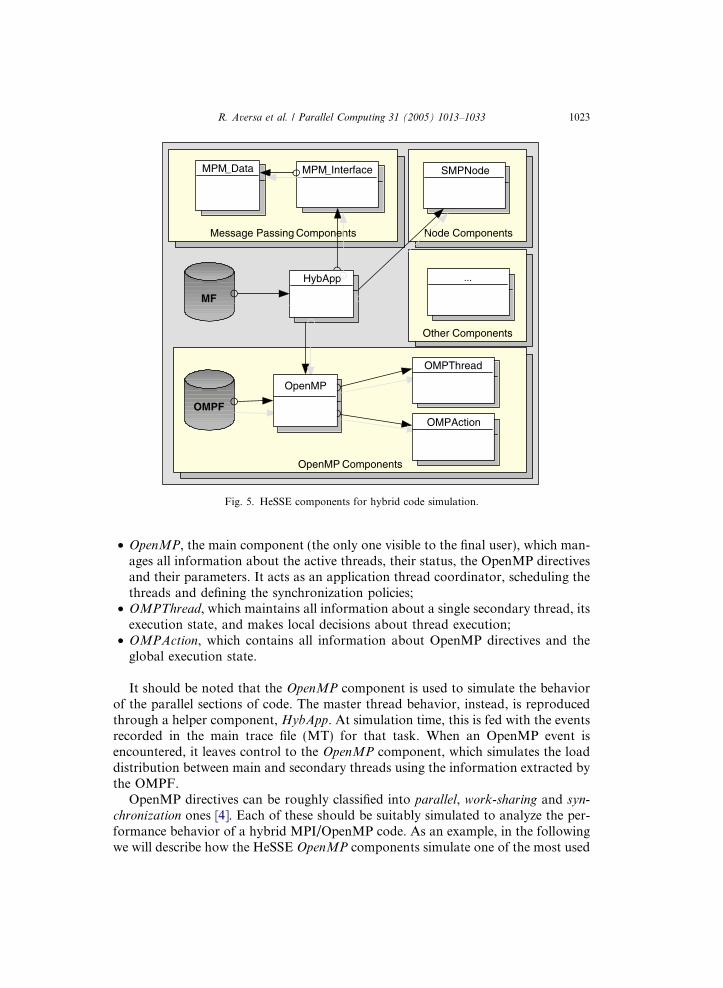
The existing implementation of the OpenMP simulation engine relies on threecomponents (see Fig. 5):
OpenMP Components
Other Components
Message Passing Components Node Components
OMPThread
OMPThread
......
SMPNodeSMPNodeMPM_DaemonMPM_InterfaceMPM_DataMPM_Data
HybAppHybApp
OMPAction
OMPThread
OMPF
MF
OpenMP
Fig. 5. HeSSE components for hybrid code simulation.
R. Aversa et al. / Parallel Computing 31 (2005) 1013–1033 1023
• OpenMP, the main component (the only one visible to the final user), which man-ages all information about the active threads, their status, the OpenMP directivesand their parameters. It acts as an application thread coordinator, scheduling thethreads and defining the synchronization policies;
• OMPThread, which maintains all information about a single secondary thread, itsexecution state, and makes local decisions about thread execution;
• OMPAction, which contains all information about OpenMP directives and theglobal execution state.
It should be noted that the OpenMP component is used to simulate the behaviorof the parallel sections of code. The master thread behavior, instead, is reproducedthrough a helper component, HybApp. At simulation time, this is fed with the eventsrecorded in the main trace file (MT) for that task. When an OpenMP event isencountered, it leaves control to the OpenMP component, which simulates the loaddistribution between main and secondary threads using the information extracted bythe OMPF.
OpenMP directives can be roughly classified into parallel, work-sharing and syn-chronization ones [4]. Each of these should be suitably simulated to analyze the per-formance behavior of a hybrid MPI/OpenMP code. As an example, in the followingwe will describe how the HeSSE OpenMP components simulate one of the most used

1024 R. Aversa et al. / Parallel Computing 31 (2005) 1013–1033
directives, the Parallel For, which starts secondary threads and, in combination withwork-sharing directives, distributes the work among them.
The OpenMP parallel for directive is a composition of the parallel directive, whichstarts the threads, and of the for work-sharing construct. Supported work-sharingclauses are [4]:
• private, firstprivate, lastprivate define the sharing policies for vari-ables inside the body loop (e.g., their scope, if in read- or in write-mode, etc.);
• ordered enforces that the following code section is executed in the order inwhich it would be executed in a sequential loop;
• schedule says how many loop iterations each thread should perform, and inwhich order;
• nowait defines if the master thread has to wait for the end of the secondarythreads when it finishes its workload.
The simulator will reproduce the synchronization between threads, the workloaddistribution, and, in general, the thread behavior defined by OpenMP directiveparameters. In the following, we assume static scheduling policy, with the nowaitclause being false, absence of ordered clause. Fig. 6 shows the time evolution ofthe proposed example.
Due to the nowait = false clause, the Parallel For has two synchronizationbarriers: at the start, due to the threads being started, and at the end of the loopfor each thread. The static scheduling imposes that the CPU time consumed by eachthread is fixed at startup time, and that it can be evaluated from the number of iter-ations that each thread will perform. The Parallel for event in the OMPF tracefile gives the time spent in each execution of loop body. This time can be equal foreach iteration, or can vary due to the type of computation that each iteration has to
Time
Master
Secondary
Active
Idle
… OpenMP 4 …
… 4 Parallel For static 4 16 const 5…
Fig. 6. An example of static schedule for a Parallel For.

R. Aversa et al. / Parallel Computing 31 (2005) 1013–1033 1025
perform. In the trace file, loop iteration timing is given by means of a timing model.At the state of the art, the hybrid HeSSE components support the following timingmodels:
• Const: the loop body has constant execution time;• Statistical: the loop body has a stochastic timing behavior. The timerequired for each iteration is represented by mean and variance, assuming normaldistribution;
• Linear: execution time increases with the iteration number (e.g., as in the pro-cessing of triangular matrices).
4. A case study
From here onwards, we will present as case study the performance analysis on afour-node biprocessor SMP cluster of an existing code solving the N-body problem,which simulates the motion of n particles under their mutual attraction. The objec-tive is to present several possible realistic analyses, and to validate the wholeprocedure.
The flexibility of the HeSSE/MetaPL simulation environment allows differenttypes of analyses to be performed, depending on whether code and/or system areavailable. As availability of code and target system are orthogonal issues, thereare four different classes of analysis. Even the most trivial of them all, i.e., the per-formance simulation of an existing code on an available machine is not completelyuseless: this is due to a number of reasons, among which are, for example, the pos-sibility to save expensive system cycles, or the friendliness of a simulation environ-ment as compared to execution and monitoring on a real distributed system.However, in the rest of this paper we will limit ourself to perform two‘‘less conven-tional’’ types of analyses: prediction of the effect of hybridization using the pure-MPIcode, i.e., in the absence of the hybrid code, and prediction of the scaling of the targetcomputing system configuration, namely an increase of the number of computingnodes. For simplicity�s sake, we will denote these two analyses by hybridization
and system scaling, respectively. In both cases, we will validate the predicted resultsby comparing them to the real ones. These are obtained by actual measurements,performed by developing the hybrid code starting from the pure-MPI one, and byadding more computing nodes, respectively. The system used as testbed is, in bothcases, the Cygnus cluster of the Parsec Laboratory, at the II University of Naples.This is a Linux cluster with SMP nodes equipped with two Pentium Xeon 1 GHz,512 MB RAM, and a dual-Pentium III 300 frontend.
4.1. Hybridization
In systems made up of SMP nodes, it is relatively common to ask whether the use ofthe hybrid programming paradigm and the exploitation of the shared memory avail-able in each node can lead to performance improvements. However, only in few cases

1026 R. Aversa et al. / Parallel Computing 31 (2005) 1013–1033
there is an actual advantage in doing so. The simulation of the behavior of the hybridcode using the readily available pure-MPI code can be an effective solution.
The steps required for obtaining performance predictions are essentially thoseoutlined in Fig. 4. Examining them in more detail, and introducing explicitly the tun-ing of customizable components, the whole procedure can be summarized as follows:
• modeling of application and system;• model timing and tuning;• prediction of the effect of hybridization.
At the end of these steps, on the basis of performance data obtained only by sim-ulation, it is possible to make the decision to adopt a hybrid code, or to use a pure-MPI code with multiple tasks per SMP node.
Even if the trace and the configuration files describing the model of applicationand system could be obtained in several alternative ways, the simplest way is to relyon a consolidated methodology that we have developed through the years, and thatis currently supported by suitable software tools. The whole methodology, whichintegrates in a single framework simulator, program description language (MetaPL)and software tools, is described in [24].
MetaPL is an extensible XML-based language [22]. It is composed of a core, aminimal set of language- and paradigm-independent commands for expressing highlevel prototypes of concurrent computations, plus language-, model- and paradigm-based extensions that can be added to the core notation. By exploiting suitablydefined extensions, MetaPL can not only describe most parallel and distributed pro-grams, but also to obtain views of the code. The views are synthetic descriptions ableto highlight specific aspects of the program.
The derivation of views is performed by filters, which formally are extensions tothe notation system. The filters are made up of a description of the target documentformat, and of a set of additional documents (translators). The translators formallyare XSLT (XSL Transformations) documents; they basically contain conversionrules from MetaPL to a new format and (possibly) vice versa. Traces and multitracesare just a special kind of views. The interfacing of MetaPL with the HeSSE simulatorengine is obtained through trace files generation. The MetaPL program description,annotated with information on the timing of elementary sequential blocks, is pro-cessed by a filter that feeds the simulation engine with input trace files.
The MetaPL model of a code can be produced by means of the Eclipse environ-ment with suitable plug-ins. Fig. 7 shows a screenshot of a high level MetaPLdescription of the N-body MPI code. Within the environment, it is possible to pro-duce an automatically instrumented version of the code that can be run on an exe-cution host to capture the program timing. The CPU burst measurements used forthis case study have been obtained by instrumenting the relevant sections of code(roughly speaking, the long computation sequences between two MPI communica-tions) by a simple library developed on the top of PAPI. This makes it possible toevaluate the (CPU) time spent in each region of the application code. The outputof the whole procedure is timed MetaPL code, such as the one presented in Fig. 8.

Fig. 7. N-body MetaPL description in Eclipse.
Fig. 8. MetaPL description of the N-body MPI code, main loop.
R. Aversa et al. / Parallel Computing 31 (2005) 1013–1033 1027
The timed MetaPL model is used to generate the traces feeding the simulator forthe generation of the application performance predictions. The traces contain thetimed sequence of call for services issued by each application process (MPI primi-tives, OpenMP directives, O.S. calls, etc.) and of CPU bursts. They, similarly tothe MetaPL model, do not contain communication timing, which will be generatedat simulation time taking into account the actual communication workload.
As regards the computing system model, this can be obtained by means of anexisting visual tool, HeSSEGraphs [24]. HeSSEGraphs makes it possible to translateautomatically a visual system description into a HeSSE configuration file. Fig. 9shows the model of the Cygnus cluster for four nodes, as developed inHeSSEGraphs.

Fig. 9. The Cygnus model in the HeSSEGraphs environment.
1028 R. Aversa et al. / Parallel Computing 31 (2005) 1013–1033
After the modeling step, it is necessary to find the time parameters for all tunableHeSSE components. In this particular case, the only tunable component isMPM_Interface, which models MPI primitives behavior in terms of their loads onlocal CPU and the data sent on the network. Even if the detailed description ofthe tuning process is out of the scope of this paper, it is worth noting that carefulmeasurement and tuning make it possible to take (partially) into account the effecton performance of the memory system.
Examining once again Fig. 8, it is possible to see that the application is made upof three basic sequential computation steps, to be iterated a fixed number of times:ComputeTree, ComputeForces, Update. Before and after each of these steps,there is an MPI communication among the worker tasks. The main loop, repeatedthree times, starts with a barrier synchronization, followed by the first code region(ComputeTree). The second code region (ComputeForces), performs the compu-tation of the positions of the n bodies. Its actual response time is directly dependenton the problem dimension. It is followed by an MPI Reduce and by the last code re-gion (Update), which is composed of two steps (NewV and NewX), which updateparticle speed and position, respectively.
The objective of the final modeling step is to understand whether it is useful toinsert OpenMP directives in the MPI code and to resort to a hybrid MPI/OpenMPcode, or it is better to launch as many MPI tasks as the number of available CPUs in

R. Aversa et al. / Parallel Computing 31 (2005) 1013–1033 1029
each node (two tasks per node, in our case). The most important point is that thiscomparative analysis is performed working only on simulated data. In other words,the development decisions will be taken by running only scaled-down code fragments(to obtain the model timing data). Neither the actual MPI code with multiple tasksper node, nor hybrid MPI/OpenMP code will be executed. To be precise, the latterdoes not even exist, since it can be developed after, if simulation data have proventhe validity of the hybrid approach.
It is clear that the three sequential sections of the program mentioned above havecompletion times that grow with the number of particles assigned to each task.Hence, the use of multiple tasks per node and the consequent reduction of the num-ber of particles per task will surely reduce the ‘‘sequential’’ response time (i.e., thepure computation time, not taking into account task communication). On the otherhand, communication time is likely to increase with increasing number of tasks.Hence, roughly speaking, the analysis performed through the simulator should pointout if it is better to have a lot of particles per node and to parallelize loops, or toreduce their number and to tolerate a higher degree of intra-node communications.
In order to pinpoint the effect of OpenMP parallelization, we will modify theapplication model (at MetaPL description level, not writing actual code), introdu-cing possible OpenMP parallelization in one code section at a time, and evaluatingby simulation the completion time of that code section. Table 1 shows the timesspent in the sequential code regions by the pure-MPI (4 and 8 tasks) and hybrid(4 tasks) versions. For brevity�s sake, we show only results for the largest inputdimension (32,768 bodies). All the times in the table were obtained by simulation.
Of course, the performance figures to be compared are those in column one (pure-MPI, 8 tasks) and three (hybrid, 4 tasks). These are the only configurations able toexploit all of the eight available processors. The pure-MPI, 4-tasks configuration,shown in column 2 for completeness� sake, uses only one half of the processors,and, in fact, has completion times which are about two times longer. The analysisof the figures in the table shows that the introduction of the OpenMP directives inComputeTree reduces the response time by about 10%. Considered that we can ex-pect a comparable measurement error (more on this later), the parallelization ofComputeTree does not appear particularly convenient by itself (it can be conve-nient if applied along with further OpenMP parallelization, of course). On the otherhand, both ComputeForces and Update attain approximately the same perfor-mance for both the MPI-8 and hybrid-4 versions.
The net result (adding all contributions to response time) would seem that the hy-brid model performance is roughly equivalent, or just slightly higher, than the one of
Table 1Completion time of seq. code sections, pure-MPI and hybrid code (simulated, ms)
Code region MPI-8 MPI-4 Hybrid-4
ComputeTree 301.81 342.00 274.75ComputeForces 83.01 153.80 81.92Update 1.23 2.14 1.12
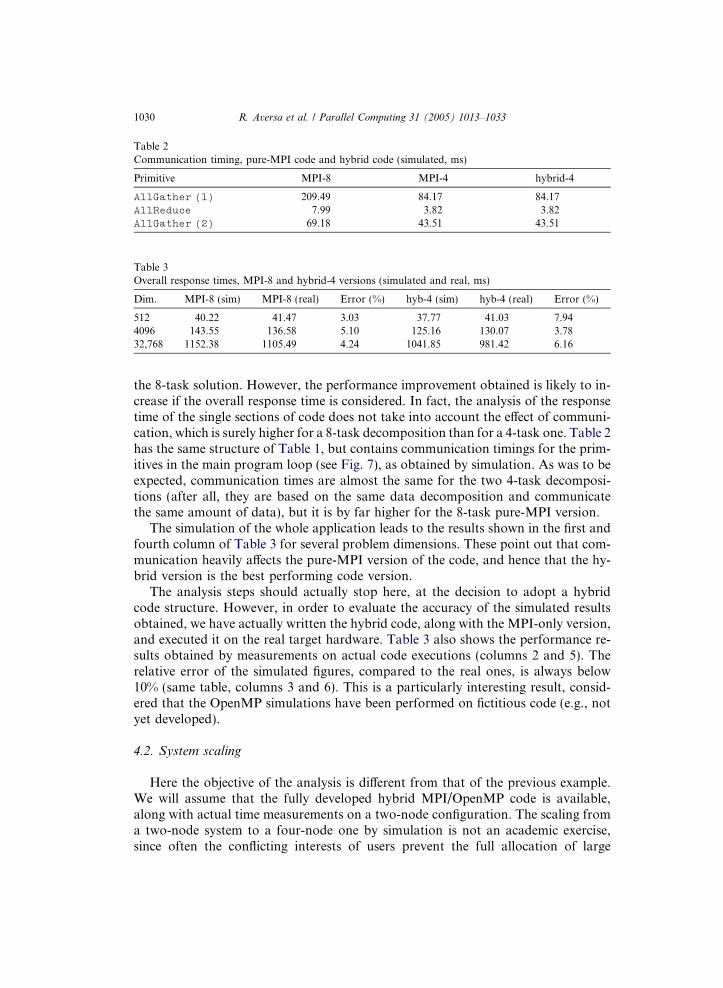
Table 2Communication timing, pure-MPI code and hybrid code (simulated, ms)
Primitive MPI-8 MPI-4 hybrid-4
AllGather (1) 209.49 84.17 84.17AllReduce 7.99 3.82 3.82AllGather (2) 69.18 43.51 43.51
Table 3Overall response times, MPI-8 and hybrid-4 versions (simulated and real, ms)
Dim. MPI-8 (sim) MPI-8 (real) Error (%) hyb-4 (sim) hyb-4 (real) Error (%)
512 40.22 41.47 3.03 37.77 41.03 7.944096 143.55 136.58 5.10 125.16 130.07 3.7832,768 1152.38 1105.49 4.24 1041.85 981.42 6.16
1030 R. Aversa et al. / Parallel Computing 31 (2005) 1013–1033
the 8-task solution. However, the performance improvement obtained is likely to in-crease if the overall response time is considered. In fact, the analysis of the responsetime of the single sections of code does not take into account the effect of communi-cation, which is surely higher for a 8-task decomposition than for a 4-task one. Table 2has the same structure of Table 1, but contains communication timings for the prim-itives in the main program loop (see Fig. 7), as obtained by simulation. As was to beexpected, communication times are almost the same for the two 4-task decomposi-tions (after all, they are based on the same data decomposition and communicatethe same amount of data), but it is by far higher for the 8-task pure-MPI version.
The simulation of the whole application leads to the results shown in the first andfourth column of Table 3 for several problem dimensions. These point out that com-munication heavily affects the pure-MPI version of the code, and hence that the hy-brid version is the best performing code version.
The analysis steps should actually stop here, at the decision to adopt a hybridcode structure. However, in order to evaluate the accuracy of the simulated resultsobtained, we have actually written the hybrid code, along with the MPI-only version,and executed it on the real target hardware. Table 3 also shows the performance re-sults obtained by measurements on actual code executions (columns 2 and 5). Therelative error of the simulated figures, compared to the real ones, is always below10% (same table, columns 3 and 6). This is a particularly interesting result, consid-ered that the OpenMP simulations have been performed on fictitious code (e.g., notyet developed).
4.2. System scaling
Here the objective of the analysis is different from that of the previous example.We will assume that the fully developed hybrid MPI/OpenMP code is available,along with actual time measurements on a two-node configuration. The scaling froma two-node system to a four-node one by simulation is not an academic exercise,since often the conflicting interests of users prevent the full allocation of large
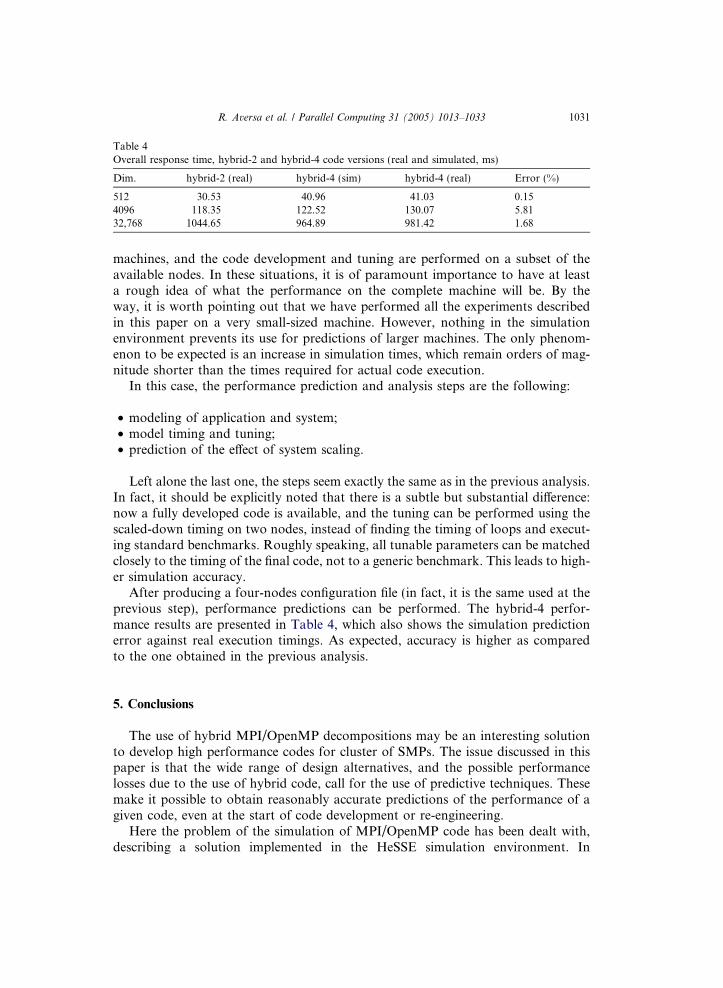
Table 4Overall response time, hybrid-2 and hybrid-4 code versions (real and simulated, ms)
Dim. hybrid-2 (real) hybrid-4 (sim) hybrid-4 (real) Error (%)
512 30.53 40.96 41.03 0.154096 118.35 122.52 130.07 5.8132,768 1044.65 964.89 981.42 1.68
R. Aversa et al. / Parallel Computing 31 (2005) 1013–1033 1031
machines, and the code development and tuning are performed on a subset of theavailable nodes. In these situations, it is of paramount importance to have at leasta rough idea of what the performance on the complete machine will be. By theway, it is worth pointing out that we have performed all the experiments describedin this paper on a very small-sized machine. However, nothing in the simulationenvironment prevents its use for predictions of larger machines. The only phenom-enon to be expected is an increase in simulation times, which remain orders of mag-nitude shorter than the times required for actual code execution.
In this case, the performance prediction and analysis steps are the following:
• modeling of application and system;• model timing and tuning;• prediction of the effect of system scaling.
Left alone the last one, the steps seem exactly the same as in the previous analysis.In fact, it should be explicitly noted that there is a subtle but substantial difference:now a fully developed code is available, and the tuning can be performed using thescaled-down timing on two nodes, instead of finding the timing of loops and execut-ing standard benchmarks. Roughly speaking, all tunable parameters can be matchedclosely to the timing of the final code, not to a generic benchmark. This leads to high-er simulation accuracy.
After producing a four-nodes configuration file (in fact, it is the same used at theprevious step), performance predictions can be performed. The hybrid-4 perfor-mance results are presented in Table 4, which also shows the simulation predictionerror against real execution timings. As expected, accuracy is higher as comparedto the one obtained in the previous analysis.
5. Conclusions
The use of hybrid MPI/OpenMP decompositions may be an interesting solutionto develop high performance codes for cluster of SMPs. The issue discussed in thispaper is that the wide range of design alternatives, and the possible performancelosses due to the use of hybrid code, call for the use of predictive techniques. Thesemake it possible to obtain reasonably accurate predictions of the performance of agiven code, even at the start of code development or re-engineering.
Here the problem of the simulation of MPI/OpenMP code has been dealt with,describing a solution implemented in the HeSSE simulation environment. In

1032 R. Aversa et al. / Parallel Computing 31 (2005) 1013–1033
addition, a methodology based on the use of the HeSSE simulator and of a proto-type description language (MetaPL) has been presented. This allows to performthe performance prediction of hybrid applications in different working conditions.
Finally, the proposed approach has been validated using a parallel N-body codeapplication. The N-body code was modeled with MetaPL, and simulated withHeSSE under two different working conditions: hybridization of an existing MPIcode, and scaling from a small cluster to a larger one. The comparison of the pre-dicted performance figures to those measured on the real system, prove the effective-ness of the approach adopted for the predictive analysis of hybrid MPI/OpenMPcode.
Currently, the proposed simulation model is able to deal only withTHREAD_MASTERONLY hybrid code, which contains no nested parallelism.OpenMP and MPI specifications define completely the target application behavioronly for this type of code. Other programming modes, characterized by nested par-allelism, are in fact implementation-dependent. Our simulation-based approach isable to manage these types of code as well, by minimal changes in the supportingHeSSE components. Our intention is to develop parameterized HeSSE components,able to reproduce also other hybrid programming modes. This will help us to com-pare application behavior under different types of hybrid-programming modes andcompilers.
References
[1] P.R. Woodward, Perspectives on supercomputing: three decades of change, IEEE Comput. 29 (1996)99–111.
[2] D.A. Bader, J. Jaja, Simple: a methodology for programming high performance algorithms onclusters of symmetric multiprocessors, J. Parallel Distr. Comput. 58 (1999) 92–108.
[3] MPI Committee, MPI: a message-passing interface standard. Available from: <http://www.-unix.mcs.anl.gov/mpi/>.
[4] OpenMP Architecture Review Board, OpenMP C and C++ Application Program Interface, version2.0. Available from: <www.openmp.org>.
[5] S.S. Lumetta, A.M. Mainwaring, D.E. Culler, Multi-protocol active messages on a cluster of SMPs,in: Proc. of the 1997 ACM/IEEE Conference on Supercomputing, 1997, pp. 1–22.
[6] F. Cappello, D. Etiemble, MPI versus MPI+Open MP on the IBM SP for the NAS Benchmarks,Proc. Supercomput. 2000 (2000) 51–62.
[7] E. Chow, D. Hysom, Assessing Performance of Hybrid MPI/OpenMP Programs on SMP Clusters, J.Par. Distr. Comput., submitted for publication. Available from: <http://www.llnl.gov/CASC/people/chow/pubs/hpaper.ps>.
[8] T. Boku, S. Yoshikawa, M. Sato, C.G. Hoover, W.G. Hoover, Implementation and performanceevaluation of SPAM particle code with OpenMP-MPI hybrid programming, in: Proc. EWOMP 2001,Barcelona, 2001.
[9] G. Jost, H. Jin, J. Labarta, J. Gimenez, J. Caubet, Performance analysis of multilevel parallelapplications on shared memory architectures, in: Proc. IPDPS�03, Nice, France, 2003, pp. 80–89.
[10] J. Labarta, S. Girona, V. Pillet, T. Cortes, L. Gregoris, DiP: a parallel program developmentenvironment, in: Proc. Euro-Par 96, Lyon, France, 1996, vol. II, pp. 665–674.
[11] R. Aversa, A. Mazzeo, N. Mazzocca, U. Villano, Developing applications for heterogeneouscomputing environments using simulation: a case study, Parallel Comput. 24 (1998) 741–761.

R. Aversa et al. / Parallel Computing 31 (2005) 1013–1033 1033
[12] R. Aversa, B. Di Martino, M. Rak, S. Venticinque, U. Villano, Performance simulation of a hybridOpenMP/MPI application with HeSSE, to be published in Proc. ParCo 2003, Dresden, DE, 2–5September 2003.
[13] E. Mancini, M. Rak, R. Torella, U. Villano, A performance-oriented technique for hybrid applicationdevelopment, in: Recent Advances in Parallel Virtual Machine and Message Passing Interface, LNCS,vol. 3241, 2004, pp. 378–387.
[14] M.F. Su, I. El-Kady, D.A. Bader, S. Lin, A novel FDTD application featuring OpenMP-MPI hybridparallelization, in: Proc. 33rd Int. Conf. Parallel Processing (ICPP), Montreal CA, 2004, pp. 373–379.
[15] R. Rabenseifner, G. Wellein, Communication and optimization aspects of parallel programmingmodels on hybrid architectures, Int. J. High Perform. Comput. Appl. 17 (2003) 49–62.
[16] L. Smith, M. Bull, Development of mixed mode MPI/OpenMP applications, Sci. Program. 9 (2001)83–98.
[17] K. Nakajima, H. Okuda, Parallel iterative solvers for unstructured grids using an OpenMP/MPIhybrid programming model for the GeoFEM platform on SMP cluster architectures, in: Proc.WOMPEI 2002, LNCS, vol. 2327, 2002, pp. 437–448.
[18] W.W. Gropp, E.L. Lusk, A taxonomy of programming models for symmetric multiprocessors andSMP clusters. Available from: <http://www-unix.mcs.anl.gov/gropp/bib/papers/1995/taxonomy.pdf>.
[19] G. Krawezik, F. Cappello, Performance comparison of MPI and three OpenMP programming styleson shared memory multiprocessors, in: Proc. 15th ACM Symp. on Par. Alg. and Arch., San DiegoUSA, 2003, pp. 118–127.
[20] N. Mazzocca, M. Rak, U. Villano, The transition from a PVM program simulator to a heterogeneoussystem simulator: the HeSSE project, in: J. Dongarra et al. (ed.), Recent Advances in Parallel VirtualMachine and Message Passing Interface, LNCS, vol. 1908, 2000, pp. 266–273.
[21] E. Mancini, N. Mazzocca, M. Rak, R. Torella, U. Villano, The HeSSE Simulation Environment, in:Proc. of the 2003 European Simulation and Modeling Conference EsMC03, Naples, Italy, 27–29October 2003, Eurosis-ETI, pp. 270–274.
[22] N. Mazzocca, M. Rak, U. Villano, The MetaPL approach to the performance analysis of distributedsoftware systems, in: Proc. WOSP 2002, Rome, Italy, ACM Press, 2002, pp. 142–149.
[23] R. Aversa, A. Mazzeo, N. Mazzocca, U. Villano, Heterogeneous system performance prediction andanalysis using PS, IEEE Concurr. 6 (1998) 20–29.
[24] N. Mazzocca, E. Mancini, M. Rak, U. Villano, Integrated tools for performance-oriented distributedsoftware developmentProc. Int. Conference on Software Engineering Research and Practice SERP03,Las Vegas, Nevada, USA, 23–26 June 2003, vol. I, CSREA Press, 2003.
[25] E. Mancini, N. Mazzocca, M. Rak, R. Torella, U. Villano, Off-line performance prediction ofmessage-passing applications on cluster systems, in: Recent Advances in Parallel Virtual Machine andMessage Passing Interface, LNCS, vol. 2840, 2003, pp. 45–54.





























